PENDETEKSIAN PENJIPLAKAN KODE PROGRAM C
DENGAN
BISECTING K-MEANS
ARIZAL NOTYASA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pendeteksian Penjiplakan Kode Program C dengan Bisecting K-means adalah benar karya saya denganarahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Arizal Notyasa
ABSTRAK
ARIZAL NOTYASA. Pendeteksian Penjiplakan Kode Program C dengan
Bisecting K-means. Dibimbing oleh AHMAD RIDHA.
Penjiplakan tugas berupa kode program merupakan masalah yang sering dihadapi oleh berbagai institusi akademik. Pendeteksian penjiplakan secara manual memakan banyak waktu dan tenaga. Oleh sebab itu, sebuah sistem yang dapat membantu pendektesian penjiplakan kode program dibutuhkan. Pendeteksian dapat dilakukan dengan mengelompokkan kode-kode program yang mirip berdasarkan struktur kodenya. Cara ini dilakukan pada penelitian sebelumnya dengan menggunakan iterasi K-means otomatis. Iterasi K-means
otomatis ini, walau dapat menghasilkan clusters yang cukup baik, tapi membutuhkan waktu eksekusi yang lama. Tujuan penelitian ini adalah meningkatkan efisiensi waktu dan clusters hasil pendeteksian dengan menggunakan algoritme bisecting K-means. Hasil penelitian ini menunjukkan bahwa ada peningkatan efisiensi waktu yang cukup signifikan dari 11.68 detik menjadi 6.64 detik. Algoritme bisecting K-means juga menghasilkan jumlah
clusters yang lebih sedikit dengan nilai Rand Index yang lebih baik daripada iterasi K-means. Selain itu, percobaan dengan 2-gram hingga 6-gram
menunjukkan bahwa 4-gram memiliki kinerja yang paling baik.
Kata kunci: bisecting k-means, hierarchical clustering, pendeteksi penjiplakan
ABSTRACT
ARIZAL NOTYASA. C Source Code Plagiarism Detection Using Bisecting K-means. Supervised by AHMAD RIDHA.
Plagiarism of source codes assignments is a widespread problem in academic institutions. Manual plagiarism detection is time and energy consuming. Therefore, a system that can help detecting this plagiarism is needed. The detection can be done by grouping similar source codes based on their structure. This method is used in previous research by using automatic K-means iterations algorithm. That algorithm, although produced decent clusters, had a long execution time. The purpose of this research is to improve the time efficiency and clusters result quality by using bisecting K-means algorithm. The results showed a significant improvement in execution time from 11.68 seconds to 6.64 seconds. Bisecting K-means also produced fewer clusters with slightly better Rand Index than K-means iterations. Furthermore, experiments using 2-gram to 6-gram showed that 4-gram resulted in the best performance.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENDETEKSIAN PENJIPLAKAN KODE PROGRAM C
DENGAN
BISECTING K-MEANS
ARIZAL NOTYASA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pendeteksian Penjiplakan Kode Program C dengan Bisecting K-means
Nama : Arizal Notyasa NIM : G64070038
Disetujui oleh
Ahmad Ridha, SKom MS Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wa-ta’ala
atas rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir ini. Shalawat serta salam juga penulis sampaikan pada junjungan Nabi besar Muhammad shallallahu ‘alaihi wa sallam beserta keluarga dan sahabatnya.
Banyak pihak yang telah membantu penulis hingga terselesaikannya tugas akhir ini. Oleh sebab itu, penulis ingin mengucapkan rasa terima kasih kepada: 1 Ayahanda Listyo Sumitro dan ibunda Diah Aryati serta kakak penulis Arfika
Nurhudatiana dan Yulianto yang senantiasa mendoakan, memotivasi, dan memberikan kasih sayangnya kepada penulis.
2 Bapak Ahmad Ridha, SKom MS selaku dosen pembimbing yang telah membimbing dan mengarahkan penulis selama penelitian tugas akhir ini. 3 Bapak Sony Hartono Wijaya, SKom MKom dan Bapak Mushthofa, SKom
MSc selaku dosen penguji.
4 Seluruh teman-teman Ilkomerz 44 atas ilmu, semangat, dan dukungannya selama penulis melakukan penelitian.
5 Sahabat-sahabat di T3S: Trijaya, Wahyu, Putri, Nadea, Nina, Ikhwan, dan Adi atas segala suka dan duka yang dialami bersama.
Akhir kata, penulis mohon maaf apabila dalam tulisan ini masih terdapat banyak kekurangan. Penulis berharap semoga tulisan ini dapat bermanfaat bagi para pembaca.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL v
DAFTAR GAMBAR v
DAFTAR LAMPIRAN v
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
METODE 3
Pengambilan dan Pemilihan Data 3
Pengelompokan Manual 3
Praproses Data 4
Bisecting K-means 6
Validasi Hasil Clustering 8
Perbandingan dengan Penelitian Sebelumnya 9
HASIL DAN PEMBAHASAN 10
Pengambilan dan Pemilihan Data 10
Pengelompokan Manual 10
Praproses Data 11
Bisecting K-means 12
Validasi Hasil Clustering 16
Perbandingan dengan Penelitian Sebelumnya 17
Rentang Nilai i Terbaik 19
Pengaruh Ukuran N-gram terhadap Hasil Clustering 19
SIMPULAN DAN SARAN 20
Simpulan 20
Saran 21
DAFTAR PUSTAKA 21
DAFTAR TABEL
1 Contoh aturan konversi kode program 5
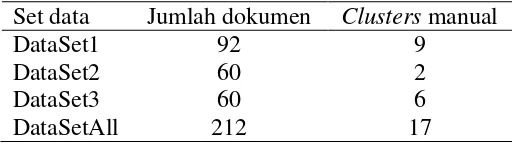
2 Set data awal 10
3 Set data setelah pengelompokan manual 10
4 Term frequency 12
5 Hasil percobaan clustering untuk DataSet1 13
6 Hasil percobaan clustering untuk DataSet2 13
7 Hasil percobaan clustering untuk DataSet3 14
8 Hasil percobaan clustering untuk DataSetAll 15
9 Nilai RI, jumlah clusters, jumlah dokumen, dan waktu eksekusi
clustering setiap set data 15 10 Perbandingan hasil clustering bisecting K-means dengan iterasi
K-means pada saat nilai i=0.97 17 11 Perbandingan hasil clustering bisecting K-means dengan iterasi
K-means pada saat nilai i terbaik 18
12 Nilai i terbaik untuk setiap set data 19
13 Hasil percobaan clustering dengan 2-gram hingga 6-gram untuk setiap
set data 20
DAFTAR GAMBAR
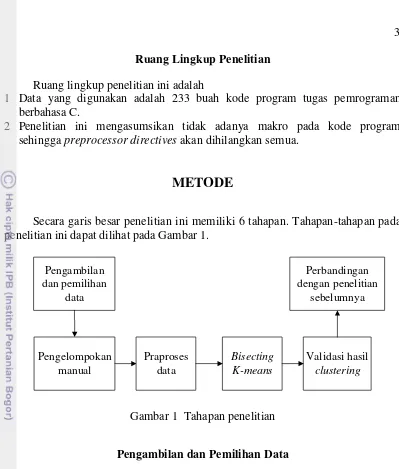
1 Tahapan penelitian 3
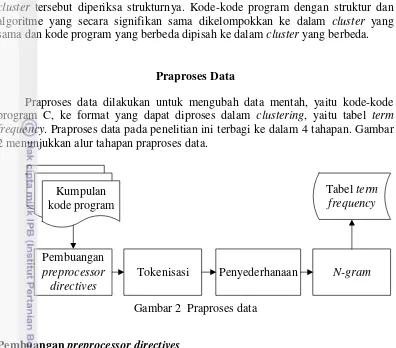
2 Praproses data 4
3 Ilustrasi kesamaan kosinus 7
4 False negative dokumen D42 dan D44 pada DataSet1 16 5 False positive dokumen D25 dan D59 pada DataSet1 17
DAFTAR LAMPIRAN
1 Contoh kode program dari masing-masing set data yang digunakan
dalam penelitian 22
2 Hasil pengelompokan manual untuk DataSet1 23
3 Hasil pengelompokan manual untuk DataSet2 24
4 Hasil pengelompokan manual untuk DataSet3 25
PENDAHULUAN
Latar Belakang
Penjiplakan atau plagiarisme merupakan suatu masalah yang sering dihadapi oleh institut-institut akademik. Penjiplakan pada kode program adalah penggunaan kembali struktur dan syntax bahasa pemrograman yang berasal baik dari mahasiswa ataupun sumber lainnya (Burrows 2004). Tugas akademik berupa kode program umumnya dikumpulkan dalam bentuk berkas digital. Hal ini menyebabkan tugas kode program rentan terhadap aksi penjiplakan.
Saat ini pendeteksian penjiplakan semakin sulit dilakukan. Hal ini disebabkan oleh bertambahnya jumlah mahasiswa dan semakin mudahnya mahasiswa untuk saling berbagi hasil perkerjaan mereka baik melalui internet maupun media lainnya. Pendeteksian juga semakin dipersulit dengan adanya modifikasi kode program yang dilakukan oleh mahasiswa untuk mengelabui pendeteksian. Modifikasi yang dilakukan antara lain penambahan atau penghapusan baris komentar atau pengubahan nama variabel atau fungsi. Pendeteksian penjiplakan dengan menggunakan tenaga manusia akan memakan banyak waktu dan tenaga. Oleh sebab itu, dibutuhkan suatu sistem yang dapat membantu pendeteksian penjiplakan kode program secara otomatis.
Burrows (2004) telah melakukan pendeteksian penjiplakan untuk
repositories kode program berskala besar. Pendeteksian yang dilakukan Burrows ialah dengan mengindeks semua kode program yang terkumpul kemudian melakukan query terhadap hasil indexing tersebut untuk mendapatkan kode-kode program yang mirip. Burrows menggunakan cara pendeteksian penjiplakan
structure-oriented code-based system. Sistem berorientasi struktur kode program ini membuat representasi sederhana dari kode program. Sistem ini sengaja mengabaikan elemen yang mudah dimodifikasi seperti komentar, whitespace dan nama variabel. Sistem berorientasi struktur ini juga tidak rentan terhadap penambahan kode program yang bersifat redundant. Mahasiswa harus memodifikasi sebagian besar kode program apabila ingin mengelabui pendeteksian (Bowyer dan Hall 1999, Gitchel dan Tran 1999, Prechelt et al. 2002 dalam Burrows 2004).
Gumilang (2013) menggunakan structure-oriented code-based system untuk pendeteksian penjiplakan kode program C dengan clustering. Pendeteksian yang dilakukan Gumilang ialah dengan mengelompokkan kode-kode program berdasarkan kemiripan strukturnya. Proses pengelompokan pada penelitian Gumilang dilakukan dengan menggunakan algoritme flat clustering K-means.
Flat clustering memiliki kelemahan, yaitu harus ditentukannya jumlah clusters
keluaran yang diinginkan secara manual. Hal ini pada penelitian Gumilang diatasi dengan melakukan iterasi K-means otomatis. Iterasi K-means otomatis yaitu melakukan clustering menggunakan K-means dengan nilai K bertambah secara otomatis pada setiap iterasinya. Iterasi berhenti apabila anggota-anggota clusters
hasil sudah cukup dekat dengan centroid-nya. Iterasi K-means otomatis ini membutuhkan waktu eksekusi yang lama. Hal ini dikarenakan pada setiap iterasi dilakukan proses clustering dengan jumlah dokumen yang sama dan jumlah
2
Pengelompokan tanpa perlu menentukan terlebih dahulu jumlah cluster-nya dapat dilakukan dengan menggunakan hierarchical clustering. Hierarchical clustering terbagi menjadi 2 jenis, yaitu hierarchical agglomerative clustering
(HAC) dan hierarchical divisive clustering (HDC). HAC menggunakan pendekatan bottom-up, sedangkan HDC menggunakan pendekatan top-down. HDC, dalam beberapa kasus, terbukti dapat menghasilkan hierarki clusters yang lebih akurat dibandingkan dengan HAC. Hal ini dikarenakan HDC menggunakan pendekatan top-down dan memiliki informasi penyebaran seluruh dokumen sejak awal clustering (Manning et al. 2008). HDC juga dapat berjalan lebih cepat dibandingkan dengan HAC apabila dikombinasikan dengan algoritme flat clustering efisien seperti K-means.
Pendeteksian penjiplakan pada penelitian ini dilakukan dengan menerapkan
structure-oriented code-based system dan kode-kode program yang mirip kemudian dikelompokkan dengan HDC. Algoritme HDC yang digunakan adalah
bisecting K-means. Bisecting K-means adalah algoritme HDC yang menggunakan
K-means untuk pemisahan setiap cluster-nya.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah
1 Bagaimana mengimplementasikan structure-oriented code-based system dan algoritme HDC bisecting K-means dalam pendeteksian penjiplakan kode program C.
2 Apakah pengelompokan kode-kode program dengan menggunakan bisecting K-means membutuhkan waktu eksekusi yang lebih singkat dibandingkan dengan iterasi K-means otomatis.
3 Apakah bisecting K-means dapat menghasilkan clusters yang lebih baik dibandingkan denganiterasi K-means otomatis.
Tujuan Penelitian
Tujuan dari penelitian ini ialah mengimplementasikan structure-oriented code-based system dan algoritme HDC bisecting K-means untuk membantu pendeteksian penjiplakan pada kode program C secara otomatis, cepat, dan akurat.
Manfaat Penelitian
3 Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah
1 Data yang digunakan adalah 233 buah kode program tugas pemrograman berbahasa C.
2 Penelitian ini mengasumsikan tidak adanya makro pada kode program sehingga preprocessor directives akan dihilangkan semua.
METODE
Secara garis besar penelitian ini memiliki 6 tahapan. Tahapan-tahapan pada penelitian ini dapat dilihat pada Gambar 1.
Pengambilan diperoleh dari Bagian Komputasi Terapan, Departemen Ilmu Komputer. Data pada penelitian ini berupa berkas digital kode program bahasa C. Kode program yang dipilih berasal dari tugas-tugas pemrograman yang memiliki tingkat kesulitan tidak terlalu mudah dan tidak terlalu susah. Hal ini dikarenakan tugas yang terlalu mudah akan memiliki variasi algoritme pemecahan yang sedikit, sedangkan tugas yang terlalu susah cenderung memiliki jumlah kode program yang sedikit karena banyak mahasiswa yang tidak mengumpulkan tugas.
Pengelompokan Manual
4
cluster tersebut diperiksa strukturnya. Kode-kode program dengan struktur dan algoritme yang secara signifikan sama dikelompokkan ke dalam cluster yang sama dan kode program yang berbeda dipisah ke dalam cluster yang berbeda.
Praproses Data
Praproses data dilakukan untuk mengubah data mentah, yaitu kode-kode program C, ke format yang dapat diproses dalam clustering, yaitu tabel term frequency. Praproses data pada penelitian ini terbagi ke dalam 4 tahapan. Gambar 2 menunjukkan alur tahapan praproses data.
Kumpulan
Tahap pertama adalah pembuangan preprocessor directives. Preprocessor directives adalah sejumlah baris di awal kode program yang diawali dengan karakter “#”. Pembuangan ini dilakukan karena pada penelitian ini diasumsikan tidak adanya penggunaan makro pada kode program.
Tokenisasi
Proses Tokenisasi dilakukan untuk mendapatkan keywords dan special characters dari kode program. Pada proses tokenisasi, karakter whitespace
dibuang semua sehingga didapat term atau string uniknya saja (Manning et al. 2008). Baris komentar pada kode program dibuang karena tidak berpengaruh terhadap output program. Karakter “;” juga dibuang karena merupakan karakter umum yang selalu digunakan di setiap akhir baris kode program C.
Penyederhanaan
Selanjutnya pada proses penyederhanaan, keywords dan special characters
kode program diubah menjadi token sederhana agar lebih ringkas dan mudah dalam pembentukan term. Kode program yang telah diubah menjadi sebuah string
5 Tabel 1 Contoh aturan konversi kode program
Keywords Token sederhana
Tabel 1 memperlihatkan contoh aturan konversi beberapa keywords dan
special characters kode program C menjadi token sederhana. ALPHANUM
adalah nama fungsi, nama variabel, atau nilai variabel. STRING adalah sederetan karakter yang diapit oleh tanda "" (kutip ganda). Berikut adalah contoh kode
program yang diubah menjadi token stream:
1 #include <stdio.h>
Tahap selanjutnya adalah proses N-gram. N-gram adalah potongan sejumlah
N karakter dari sebuah string. N-gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Pada penelitian ini metode
N-gram digunakan untuk mengambil potongan-potongan karakter huruf sejumlah
N dari suatu token stream.
6
quad-grams : _TEX, TEXT, EXT_
quint-grams : _TEXT, TEXT_
Penggunaan N-gram adalah metode yang sesuai untuk pendeteksian penjiplakan. Hal ini dikarenakan modifikasi atau perubahan pada kode program akan mempengaruhi beberapa N-gram yang berdekatan saja. Oleh sebab itu, kode program yang dimodifikasi akan tetap memiliki sebagian besar N-gram yang sama dengan kode program aslinya dan pendeteksian penjiplakan menjadi semakin mudah dilakukan (Burrows 2004). Lebih jelasnya berikut contoh 2-gram dari kata “Text” dan “Teext”:
Text : _T Te ex xt t_ Teext : _T Te ee ex xt t_
Modifikasi hanya menyebabkan perbedaan munculnya N-gram “ee” pada string
“Teext”, sedangkan N-gram sisanya sama dengan N-gram pada string“Text”.
Pada penelitian ini, proses N-gram dilakukan pada token stream dengan ukuran N=4. N dipilih 4 karena merupakan nilai N terbaik untuk pendeteksian penjiplakan kode program (Chawla 2003 dalam Burrows 2004). Pada bagian akhir penelitian ini juga akan dilakukan percobaan pendeteksian dengan menggunakan nilai N yang berbeda. Hal ini dilakukan untuk melihat pengaruh nilai N yang lebih kecil dan lebih besar terhadap hasil pendeteksian pada penelitian ini.
Selanjutnya kemunculan setiap N-gram pada masing-masing dokumen dihitung untuk memperoleh tabel term frequency. Tabel term frequency
merupakan tabel yangmenyimpan statistik kemunculan seluruh term atau N-gram
suatu koleksi dokumen. Tabel inikemudian digunakan untuk membentuk vektor-vektordokumen pada proses clustering dengan bisecting K-means.
Bisecting K-means
Bisecting K-means merupakan algoritme HDC oleh karena itu dilakukan dengan pendekatan top-down. Pertama-tama seluruh kode program dimasukkan ke dalam satu cluster besar. Kemudian algoritme bisecting K-means dilanjutkan mengikuti langkah-langkah berikut (Steinbach et al. 2000):
1 Pilih cluster yang akan dipisah.
2 Temukan 2 sub-clusters dengan menggunakan algoritme K-means. (Tahap pemisahan)
3 Ulangi langkah 2 sebanyak ITER kali dan ambil pemisahan yang menghasilkan 2 sub-clusters terbaik.
4 Ulangi langkah 1, 2, dan 3 hingga didapat jumlah clusters yang diinginkan. Pemilihan cluster
Pemilihan cluster yang akan dipisah dilakukan dengan melihat ukuran
cluster. Cluster dengan anggota terbanyak akan menjadi kandidat utama cluster
yang akan dipisah. Hal ini dikarenakan cluster dengan anggota terbanyak umumnya memiliki tingkat kemiripan anggota yang masih rendah. Apabila cluster
kandidat utama ternyata telah memiliki anggota-anggota yang sama persis, dipilih
7 K-means
Tahap pemisahan pada algoritme bisecting K-means dilakukan dengan algoritme flat clustering K-means dengan K=2. Algoritme K-means yang digunakan pada penelitian ini adalah sebagai berikut:
1 Pilih K dokumen sebagai centroid awal.
2 Tempatkan setiap dokumen ke centroid yang terdekat.
3 Hitung ulang nilai centroid setiap cluster.
4 Ulangi langkah 2 dan 3 sampai nilai centroid-nya tidak berubah.
Pemilihan 2 centroids awal pada penelitian ini dilakukan dengan cara pemilihan acak dan perhitungan jarak terjauh. Satu dokumen dipilih secara acak sebagai centroid pertama, kemudian jarak setiap dokumen ke centroid tersebut dihitung. Centroid kedua adalah dokumen dengan jarak terjauh dari centroid
pertama.
Penelitian ini menggunakan ukuran kesamaan kosinus sebagai pengukur jarak antar vektor dokumen. Kesamaan kosinus memiliki sifat semakin besar nilai persamaan kosinusnya, semakin dekat jarak kedua vektor, dan berarti semakin mirip kedua dokumen tersebut. Gambar 3 adalah ilustrasi dari ukuran kesamaan kosinus.
Gambar 3 Ilustrasi kesamaan kosinus
Perhitungan jarak antara 2 dokumen d1 dan d2 adalah dengan menghitung kesamaan kosinus dari representasi vektor dokumen � (d1) dan � (d2). Vektor dokumen merupakan term frequency yang merepresentasikan jumlah term pada tiap dokumen. Kesamaan kosinus diformulasikan sebagai berikut:
sim(d1,d2) = V d1 ∙V d2 V
d1 V d2
8
Perulangan pemisahan
Tahap pemisahan pada bisecting K-means diulang sebanyak ITER kali. Hal ini bertujuan untuk mendapatkan clusters hasil K-means yang terbaik. Penelitian ini menggunakan nilai ITER=5 (Steinbach et al. 2000). Clusters hasil pemisahan terbaik ditentukan berdasakan nilai I-nya.
Nilai I adalah rata-rata jarak setiap anggota clusters ke centroidcluster-nya. Nilai kesamaan kosinus antara centroid dan setiap dokumennya pada satu cluster
dijumlahkan semua kemudian dibagi dengan banyaknya anggota pada cluster
tersebut sehingga didapat nilai rata-rata internal cluster (� a). Selanjutnya, nilai � a
dari masing-masing cluster dijumlahkan semua dan dibagi dengan banyaknya
cluster yang dihasilkan sehingga didapat nilai rata-rata akhir (I). Semakin besar nilai I, semakin dekat rata-rata jarak dokumen di masing-masing cluster dengan
centroid cluster-nya dan berarti semakin baik hasil pemisahannya. Nilai I juga digunakan untuk menentukan kapan looping algoritme bisecting K-means akan berhenti.
Penghentian looping
Algoritme bisecting K-means akan melakukan looping terus menerus sampai tiap cluster hanya berisi satu dokumen atau tidak ada lagi cluster yang dapat dipisah. Pada pendeteksian penjiplakan hal ini tidak diharapkan. Cluster
hasil yang hanya berisi satu atau sejumlah dokumen yang sama persis tidak dapat digunakan untuk mendeteksi penjiplakan kode program yang dimodifikasi. Oleh sebab itu diperlukan suatu parameter untuk menghentikan looping pada algoritme
bisecting K-means saat clusters yang dihasilkan sudah cukup baik.
Penelitian ini menggunakan nilai i sebagai parameter pemberhenti looping
algoritme bisecting K-means. Apabila I > i maka looping dihentikan. I adalah rata-rata jarak setiap anggota clusters ke centroid cluster-nya. Nilai i adalah bilangan desimal antara 0 sampai 1. Semakin besar nilai i, semakin dekat rata-rata jarak setiap dokumen dengan centroid-nya sebelum looping dihentikan. Secara umum, semakin besar nilai i maka semakin banyak looping yang dilakukan dan berarti semakin banyak jumlah clusters yang dihasilkan.
Penentuan nilai i terbaik dilakukan dengan melakukan percobaan. Percobaan dilakukan dari nilai i=0.85 sampai i=1.00 dengan increment sebesar 0.01. Pada masing-masing nilai i tersebut dilakukan percobaan sebanyak 5 kali. Setiap percobaan i dicatat jumlah clusters, nilai akurasi Rand Index, nilai I, dan lama waktu eksekusinya.
Validasi Hasil Clustering
Validasi hasil clustering dilakukan untuk mengukur seberapa baik hasil
clustering yang didapat. Validasi dilakukan dengan membandingkan clusters hasil
9 dalam cluster yang sama dan 2 dokumen yang berbeda dipisahkan ke cluster yang berbeda. Formula RI dituliskan sebagai berikut:
RI = TP +TN TP +FP+FN+TN dengan
RI : Rand index
TP : true positive / keputusan 2 dokumen mirip berada di cluster yang sama FP : false positive / keputusan 2 dokumen berbeda berada di cluster yang sama TN : true negative / keputusan 2 dokumen berbeda berada di cluster yang berbeda FN : false negative / keputusan 2 dokumen mirip berada di cluster yang berbeda
Perbandingan dengan Penelitian Sebelumnya
Hasil dari penelitian ini kemudian dibandingkan dengan hasil penelitian sebelumnya. Variabel yang dibandingkan antara lain jumlah clusters yang dihasilkan, ukuran akurasi hasil clustering-nya, dan lama waktu clustering. Selanjutnya berdasarkan hasil perbandingan tersebut, dapat dianalisis kelebihan dan kekurangan pendeteksian penjiplakan pada penelitian ini dibandingkan dengan penelitian sebelumnya.
Alat
Perangkat keras:
Processor Intel Core i3-2328M 2.20 GHz, Read Access Memory 2 GB, dan
Hard disk 500 GB. Perangkat lunak:
Operating system Microsoft Windows 7 Professional 64-bit, Programming language PHP 5.3.8,
PHP Integrated Development Environment Netbeans for PHP 7.1.2, Server control panel XAMPP 1.7.7,
Database management system MySQL,
10
HASIL DAN PEMBAHASAN
Pengambilan dan Pemilihan Data
Data yang digunakan pada penelitian ini adalah kode-kode program tugas pemrograman berbahasa C. Jumlah data sebanyak 233 kode program yang dipilih dari 3 tugas dengan kesulitan menengah. Masing-masing tugas tersebut kemudian dijadikan set data pada penelitian ini. Tabel 2 menunjukkan komposisi set data yang digunakan pada penelitian ini. Contoh kode program dari masing-masing set data penelitian ini dapat dilihat pada Lampiran 1.
Tabel 2 Set data awal
Pengelompokan manual dilakukan dengan memeriksa nilai output program dan struktur kode programnya. Khusus untuk DatSet1, penelitian ini menggunakan hasil pengelompokan manual yang sudah dilakukan oleh Gumilang (2013). Hasil pengelompokan manual untuk DatSet1 dapat dilihat pada Lampiran 2. Pemeriksaan nilai output kode program pada DataSet2 menghasilkan 5 clusters,
sedangkan pada pemeriksaan DataSet3 menghasilkan 1 cluster. Setiap kode program pada masing-masing clusters tersebut kemudian dibandingkan strukturnya. Setelah dibandingkan, didapat DatSet2 menghasilkan 14 clusters
kode program dan DataSet3 menghasilkan 12 clusters. Namun, dari semua
clusters yang dihasilkan tersebut, terdapat clusters yang hanya berisi 1 atau 2 kode program. Clusters yang berisi terlalu sedikit dokumen tersebut kemudian dihilangkan. Tabel 3 menunjukkan set data setelah dilakukan pengelompokan manual. Hasil pengelompokan manual untuk DataSet2 dan DataSet3 dapat dilihat pada Lampiran 3 dan 4. Hasil pengelompokan manual untuk DataSetAll adalah 17
clusters gabungan hasil pengelompokan manual set data lainnya. Tabel 3 Set data setelah pengelompokan manual Set data Jumlah dokumen Clusters manual
DataSet1 92 9
DataSet2 60 2
DataSet3 60 6
11 Praproses Data
Praproses data terbagi dalam beberapa tahapan, yaitu: pembuangan
preprocessor directives, tokenisasi, penyederhanaan, dan N-gram. Pembuangan
preprocessor directives dilakukan karena pada penelitian ini diasumsikan tidak adanya penggunaan makro pada kode program. Berikut contoh kode program dari DataSet1 yang telah dihilangkan preprocessor directives-nya:
1
9 printf("%lu\n", b); //cetak hasil
10 return 0;
11 }
Proses tokenisasi dilakukan untuk mendapatkan keywords dan special characters kode program. Pada tahap ini dilakukan pembuangan whitespace, baris
comments, karakter “;”, dan pengubahan huruf uppercase menjadi lowercase
semua. Berikut contoh kode program setelah melalui proses tokenisasi: 1
Selanjutnya dilakukan proses penyederhanaan dengan mengubah keywords
dan special characters kode program menjadi deretan token sederhana yang merepresentasikan struktur kode program. Sebelum dilakukan pengubahan, dilakukan pengecekan dan penambahan spasi di awal dan akhir keywords atau
special characters. Hal ini dilakukan untuk memastikan tidak terjadi kesalahan konversi karena adanya keywords atau special characters yang berhimpitan. Pengubahan yang dilakukan pada penelitian ini mengikuti tabel aturan konversi yang dapat dilihat pada Lampiran 5. Hasil dari proses penyederhanaan adalah
string panjang token sederhana yang disebut token stream. Berikut contoh token stream hasil penyederhanaan kode program di atas:
12
Setelah token stream didapat, kemudian dilakukan proses N-gram. Proses N-gram merupakan proses pembangkitan term dengan mengambil sejumlah N huruf dari suatu string panjang. Pada penelitian ini digunakan N=4. Berikut contoh N-gram yang dihasilkan dari token stream di atas:
_Nhi NjNo oNNh iKhh Naai iNao jNiR
Selanjutnya dihitung jumlah kemunculan setiap N-gram pada masing-masing dokumen. Perhitungan jumlah kemunculan N-gram atau term dari masing-masing dokumen ini menghasilkan tabel term frequency. Tabel 4 merupakan contoh tabel term frequency dari N-gram di atas. Tabel term frequency kemudian digunakan untuk membentuk vektor-vektor dokumen pada proses clustering.
Tabel 4 Term frequency
Proses clustering pada penelitian ini menggunakan algoritme bisecting K-means. Bisecting K-means merupakan algoritme hierarchical divisive clustering. Seluruh dokumen dimasukkan ke dalam satu cluster awal kemudian dipisah-pisah berdasarkan kemiripannya. Setiap pemisahan dilakukan dengan menggunakan K-means. Nilai i digunakan untuk menghentikan pemisahan pada saat clusters yang dihasilkan sudah cukup baik.
Nilai i terbaik ditentukan dengan melakukan serangkaian percobaan
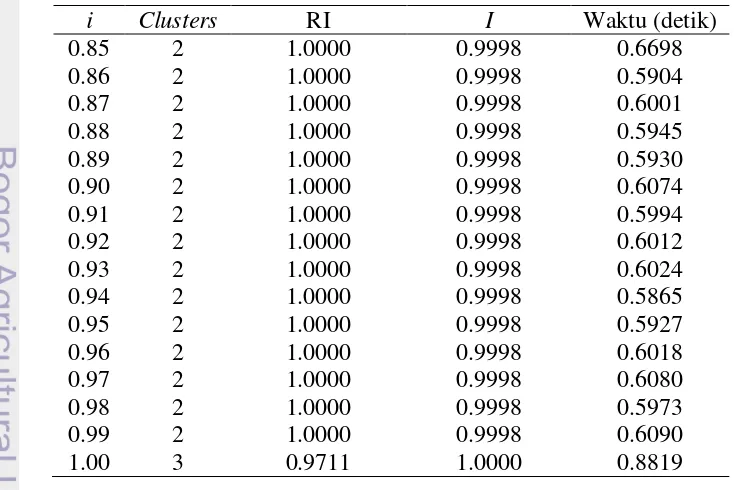
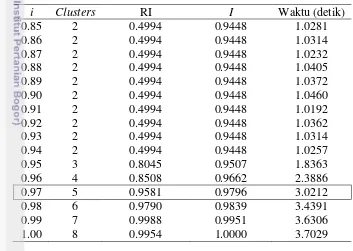
13 Tabel 5 Hasil percobaan clustering untuk DataSet1
i Clusters RI I Waktu (detik)
Tabel 5 menunjukkan hasil percobaan clustering pada DataSet1. Berdasarkan hasil percobaan tersebut, dipilih nilai i=0.94. Nilai tersebut dipilih karena memiliki rata-rata RI yang sudah cukup baik, yaitu 0.9288, dan jumlah
clusters yang tidak terlalu banyak, yaitu 10. Nilai i lebih besar dari 0.94 memiliki rata-rata RI yang sedikit lebih baik tetapi menghasilkan jumlah clusters yang lebih banyak. Jumlah clusters yang terlalu banyak memungkinkan adanya kode-kode program hasil penjiplakan yang awalnya sudah terkumpul dalam satu cluster,
terpisah ke clusters yang berbeda.
Tabel 6 Hasil percobaan clustering untuk DataSet2
14
Tabel 6 menunjukkan hasil percobaan clustering pada DataSet2. Berdasarkan hasil percobaan tersebut, dapat dilihat bahwa saat clustering baru menghasilkan 2 clusters, nilai I dan RI yang didapat sudah sangat tinggi. Hal ini menandakan bahwa DataSet2 hanya terdiri atas 2 variasi kode program dengan tiap variasinya terdiri atas kode-kode program yang hampir sama persis. Dengan demikian, nilai i terbaik dipilih saat didapat RI=1.00 yaitu saat i kurang dari 1.00.
Saat i=1.00, rata-rata RI yang dihasilkan, seperti yang terlihat pada Tabel 6, justru menurun. Hal ini mungkin terjadi karena adanya kode program hasil penjiplakan yang dimodifikasi sehingga memiliki struktur yang sedikit berbeda dari kode program aslinya. Semakin tinggi nilai i, semakin peka clustering
terhadap perbedaan-perbedaan kecil pada struktur kode program. Hal ini yang menyebabkan dipisahkannya kembali kode-kode program yang sudah mirip sehingga jumlah clusters yang dihasilkan bertambah banyak dan ukuran RI yang didapat menurun.
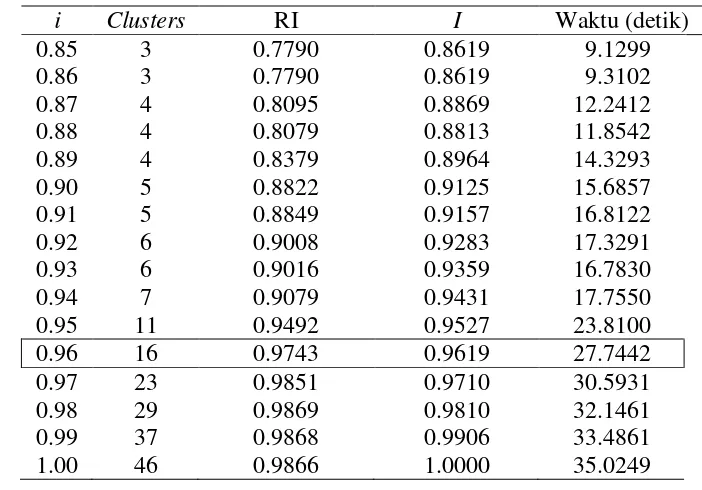
Tabel 7 Hasil percobaan clustering untuk DataSet3
i Clusters RI I Waktu (detik)
Tabel 7 menunjukkan hasil percobaan clustering pada DataSet3. Berdasarkan hasil percobaan tersebut dipilih nilai i=0.97. Nilai tersebut dipilih karena memiliki jumlah clusters yang tidak terlalu banyak, yaitu 5, dan rata-rata RI yang sudah cukup baik, yaitu 0.9581.
15 Tabel 8 Hasil percobaan clustering untuk DataSetAll
i Clusters RI I Waktu (detik)
Tabel 9 menunjukkan nilai RI, jumlah clusters, jumlah dokumen, dan waktu eksekusi clustering masing-masing set data pada saat i terbaiknya. Berdasarkan Tabel 9, rata-rata nilai RI untuk setiap set data pada penelitian ini sudah cukup baik, yaitu lebih dari 90%.
Tabel 9 Nilai RI, jumlah clusters, jumlah dokumen, dan waktu eksekusi clustering setiap set data
Set Data RI Clusters Dokumen Waktu (detik)
Hasil clustering DataSet2 memiliki nilai RI=1.00 yang berarti clusters hasil pengelompokan bisecting K-means sama persis dengan clusters hasil pengelompokan manualnya. Waktu yang dibutuhkan untuk mendapatkan nilai RI tersebut juga sangat singkat. Hal ini dikarenakan DataSet2 hanya terdiri atas 2
clusters kode program yang masing-masing anggotanya hampir sama persis. Dengan demikian, proses clustering menjadi mudah dan cepat dilakukan.
16
Validasi Hasil Clustering
Validasi hasil clustering pada penelititan ini dilakukan dengan menggunakan ukuran akurasi RI. Hasil clustering untuk set data selain DataSet2 menghasilkan nilai RI kurang dari 1.00. Hal ini menunjukkan bahwa masih terdapat kesalahan pada hasil pendeteksian dengan menggunakan sistem. Kesalahan yang mungkin terjadi adalah dipisahkannya 2 kode program yang mirip ke clusters yang berbeda (false negative) dan dikelompokkannya 2 kode program yang berbeda ke cluster yang sama (false positive). Contoh pasangan dokumen
false negative dan false positive pada DataSet1 saat i=0.94 ditunjukkan pada Gambar 4 dan 5.
Gambar 4 menunjukkan contoh kesalahan false negative antara dokumen D42 dan D44. Kesalahan ini disebabkan oleh adanya perbedaan pada beberapa bagian kode program sehingga mempengaruhi token stream yang dihasilkan. Perbedaan-perbedaan ini, antara lain adanya tipe data long pada baris ke-5 dokumen D44 dan adanya perbedaan antara penggunaan operator increment ++b
pada baris ke-7 dokumen D42 dengan b+=1 pada baris ke-8 dokumen D44.
1 #include <stdio.h> 1 #include <stdio.h>
2 main() { 2 main()
3 unsigned long int a,n=0; 3 {
4 int b=0; 4 unsigned long int a,n=0;
5 scanf("%lu", &a); 5 long int b=0;
6 while ((pow(10,n++))<=a) 6 scanf("%lu", &a);
7 ++b; 7 while ((pow(10,n++))<=a)
8 printf("%d\n", b); 8 b+=1;
9 return 0; 9 printf("%lu\n", b);
10 } 10 return 0; Gambar 4 False negative dokumen D42 dan D44 pada DataSet1
Gambar 5 menunjukkan false positive antara dokumen D25 dan D44. Kedua kode program ini memiliki sejumlah perbedaan, antara lain adanya 2 tipe data yaitu int dan unsigned long int pada dokumen D59 dan adanya penggunaan operator kondisi if() pada dokumen D25. Namun, kedua kode program tersebut dikelompokkan ke dalam cluster yang sama oleh sistem. Hal ini dapat disebabkan oleh adanya beberapa bagian kode program yang mirip sehingga
token stream yang dihasilkan juga masih memiliki banyak kemiripan. Kemiripan kedua kode program ini di antaranya sama-sama menggunakan fungsi while()
17
11 printf("%d", x); 11 printf("%d", digit);
12 return 0; 12 return 0;
Gambar 5 False positive dokumen D25 dan D59 pada DataSet1
Perbandingan dengan Penelitian Sebelumnya
Hasil penelitian ini dibandingkan dengan hasil pendeteksian penjiplakan kode program yang telah dilakukan oleh Gumilang (2013). Algoritme yang digunakan pada penelitian Gumilang adalah algoritme flat clustering K-means. Gumilang menggunakan iterasi K-means otomatis agar banyaknya clusters yang diinginkan tidak perlu ditentukan terlebih dahulu. Set data yang digunakan adalah DataSet1 yang berjumlah 92 kode progam. Variabel yang dibandingkan adalah rata-rata jumlah clusters, nilai RI, dan lama waktu eksekusi.
Pertama-tama dilakukan perbandingan hasil clustering saat nilai i terbaik pada penelitian Gumilang. Hasil clustering terbaik pada penelitian Gumliang didapat saat nilai i=0.97. Tabel 10 menunjukkan perbandingan hasil clustering bisecting K-means dengan iterasi K-means pada saat nilai i=0.97.
Tabel 10 Perbandingan hasil clustering bisecting K-means
dengan iterasi K-means pada saat nilai i=0.97 Variabel Bisecting K-means Iterasi K-means
Jumlah clusters 19 12
Nilai RI 0.9420 0.9063
Waktu eksekusi (detik) 8.2308 11.6826
18
manual oleh staf akademik dengan berpedoman pada hasil pendeteksian penjiplakan ini. Tabel 10 juga menunjukkan waktu eksekusi clustering yang dibutuhkan bisectingK-means lebih singkat dibandingkan dengan iterasi K-means
walau jumlah clusters yang dihasilkannya lebih banyak. Hal ini menunjukkan bahwa algoritme bisecting K-means lebih efisien dibandingkan dengan iterasi K-means.
Selanjutnya, hasil clustering saat nilai i terbaik pada penelitian ini dibandingkan dengan hasil clustering saat nilai i terbaik pada penelitian Gumilang. Pada penelitian Gumilang didapat hasil iterasi K-means terbaik adalah saat i=0.97, sedangkan pada penelitian ini, hasil clustering terbaik adalah saat i=0.94. Tabel 11 menunjukkan perbandingan hasil clustering bisecting K-means dengan iterasi K-means pada saat nilai i terbaik.
Tabel 11 Perbandingan hasil clustering bisecting K-means
dengan iterasi K-means pada saat nilai i terbaik Variabel Bisecting K-means Iterasi K-means
Nilai i terbaik 0.94 0.97
Jumlah clusters 10 12
Nilai RI 0.9288 0.9063
Waktu eksekusi (detik) 6.6439 11.6826
Berdasarkan Tabel 11 dapat dilihat bahwa bisecting K-means menghasilkan jumlah clusters yang lebih sedikit dan nilai RI yang lebih tinggi. Hal ini disebabkan oleh adanya pengulangan pemisahan sebanyak ITER kali pada algoritme bisecting K-means. Pengulangan pemisahan ini bertujuan untuk memperoleh clusters hasil pemisahan terbaik dari setiap looping algoritme
bisecting K-means. Semakin baik clusters hasil pemisahan yang didapat maka semakin sedikit looping yang perlu dilakukan dan clusters yang dihasilkan menjadi lebih optimal baik jumlah maupun kualitasnya.
Tabel 11 juga menunjukkan bahwa waktu eksekusi yang dibutuhkan oleh
bisecting K-means lebih singkat dibandingkan dengan iterasi K-means. Hal ini disebabkan oleh adanya proses pemisahan clusters menjadi 2 sub-clusters pada setiap looping algoritme bisecting K-means. Proses pemisahan pada looping
berikutnya selalu dilakukan pada sub-clusters hasil pemisahan sebelumnya. Hal ini menyebabkan jumlah dokumen yang dipisah pada suatu looping selalu lebih sedikit dibandingkan dengan jumlah dokumen pada looping sebelumnya. Semakin banyak looping yang dilakukan pada algoritme bisecting K-means, jumlah dokumen yang dipisah juga semakin sedikit. Selain itu, proses pemisahan pada setiap looping dilakukan menggunakan K-means dengan nilai K selalu 2. Pengelompokan K-means dengan nilai K yang kecil cenderung lebih mudah dan cepat dilakukan dibandingkan dengan pengelompokan K-means dengan nilai K
19 Rentang Nilai i Terbaik
Pada penelitian ini, pengelompokan secara manual telah dilakukan sebelum proses clustering dengan bisecting K-means. Dengan demikian, validasi hasil
clustering untuk mengukur sudah seberapa baik clusters yang dihasilkan dapat dilakukan dan nilai i terbaik untuk suatu set data dapat dengan mudah ditentukan. Namun, pada penggunaan sistem pendeteksian ini nantinya, pengguna tidak diharapkan untuk melakukan pengelompokan manual terlebih dahulu sehingga validasi hasil clustering tidak mungkin dilakukan. Hal ini menyebabkan penentuan nilai i terbaik akan lebih sulit dilakukan. Oleh sebab itu, pada bagian ini akan diusulkan rentang nilai i terbaik berdasarkan hasil percobaan-percobaan yang telah dilakukan. Tabel 12 menunjukkan nilai i terbaik untuk keempat set data yang digunakan pada penelitian ini.
Tabel 12 menunjukkan bahwa hasil clustering terbaik pada penelitian ini didapat saat i 0.94 hingga 0.97. Dengan demikian, rentang nilai i tersebut dapat digunakan dalam pendeteksian suatu set data baru dengan harapan dapat memberikan hasil clustering yang baik. Namun, Tabel 7 menunjukkan bahwa hasil percobaan clustering pada DataSet3 saat i=0.94 memiliki nilai RI yang masih terlalu rendah, yaitu 0.4994. Oleh sebab itu, nilai i=0.94 merupakan nilai yang belum aman untuk selalu menghasilkan clusters yang baik pada penelitian ini. Dengan demikian, pendeteksian terhadap set data baru yang belum diketahui hasil pengelompokan manualnya dapat dilakukan dengan menggunakan nilai i
antara 0.95 sampai 0.97.
Pengaruh Ukuran N-gram terhadap Hasil Clustering
Ukuran N-gram yang digunakan pada penelitian ini mengacu pada ukuran
N-gram terbaik menurut Chawla (2003), yaitu N=4. Pada bagian akhir penelitian ini dilakukan percobaan clustering dengan menggunakan ukuran N-gram kurang dan lebih dari 4 untuk melihat pengaruhnya terhadap hasil pendeteksian pada penelitian ini. Tabel 13 menunjukkan hasil percobaan clustering dengan ukuran
2-gram hingga 6-gram pada setiap set data saat i=0.95.
Tabel 13 menunjukkan bahwa ukuran N-gram yang terlalu kecil menghasilkan nilai RI yang rendah. Semakin besar nilai N, maka clusters yang dihasilkan cenderung semakin baik. Namun, semakin besar nilai N, jumlah
20
Tabel 13 Hasil percobaan clustering dengan 2-gram hingga 6-gram
untuk setiap set data
Waktu (detik) 0.66538 3.31638 7.29670 9.64294 13.69878 DataSet2
Clusters 2 2 2 2 2
RI 1.00000 1.00000 1.00000 1.00000 1.00000
Waktu (detik) 0.45738 0.61758 0.62552 0.70988 0.77162 DataSet3
Clusters 2 2 3 5 4
RI 0.65898 0.49943 0.80452 0.98022 0.82429
Waktu (detik) 0.52038 0.82234 1.97462 4.13240 4.20660 DataSetAll
Clusters 3 6 11 20 21
RI 0.77908 0.89953 0.95568 0.98388 0.98577
Waktu (detik) 2.91646 8.88326 23.89546 41.72346 60.54178 Terdapat beberapa pengecualian yang juga ditunjukkan pada Tabel 13. Hasil
clustering DataSet2 yang hanya terdiri atas 2 jenis kode program yang homogen tidak terpengaruh dengan berbagai ukuran N-gram yang dicobakan. Selain itu, DataSet3 memiliki nilai RI lebih rendah saat N=6 dibandingkan saat N=5. Hal ini menunjukkan peningkatan nilai N tidak selalu menghasilkan kualitas clusters
yang lebih baik. Dengan demikian, N=4 merupakan ukuran N-gram yang paling sesuai pada penelitian ini karena memberikan hasil clustering yang baik dan waktu eksekusi yang tidak terlalu lama.
SIMPULAN DAN SARAN
Simpulan
Algoritme HDC bisecting K-means dan structure-oriented code-based system dapat diimplementasikan untuk mendeteksi penjiplakan kode program C. Hasil dari pendeteksian ini cukup baik dengan clusters yang dihasilkan memiliki rata-rata akurasi RI lebih dari 90%. Pendeteksian dengan bisectingK-means dapat melakukan pengelompokan kode program dalam waktu yang secara signifikan lebih cepat dibandingkan pendeteksian dengan iterasi K-means otomatis.
Pendeteksian pada penelitian ini juga dapat menghasilkan jumlah clusters yang lebih sedikit dengan akurasi RI yang lebih tinggi dibandingkan dengan hasil pendeteksian dengan iterasi K-means otomatis. N=4 merupakan ukuran N-gram
21 Saran
Pendeteksian penjiplakan pada penelitian ini dilakukan hanya berorientasikan pada struktur kode program. Hal ini dapat menyebabkan terjadinya kesalahan pada pendeteksian apabila dilakukan modifikasi yang mengubah struktur kode program tanpa mengubah nilai keluarannya. Hal ini dapat diatasi pada penelitian selanjutnya dengan juga memperhatikan faktor semantik kode program pada saat pendeteksian. Pemeriksaan faktor semantik ini dapat dilakukan dengan mengecek nilai keluaran kode program terlebih dahulu sebelum dilakukan proses clustering. Saran lainnya adalah menggunakan algoritme
hierarchical agglomerative clustering dalam pendeteksian untuk mengakomodasi adanya kode program baru yang ingin dimasukkan dalam hasil clustering tanpa perlu melakukan clustering ulang kode-kode program lainnya. Selain itu, disarankan untuk menambah korpus kode program sehingga pendeteksian dapat diujikan pada berbagai macam kompleksitas kode program.
DAFTAR PUSTAKA
Bowyer K, Hall L. Experience using MOSS to detect cheating on programming assignments. Di dalam: 29th ASEE/IEEE Frontiers in Education Conference: 1999 Nov 10-13; San Juan, Puerto Rico. Champaign (US): Stipes Publishing LLC. hlm 18-22.
Burrow S. 2004. Efficient and effective plagiarism detection for large code repositories [tesis]. Melbourne (AU): RMIT University.
Cavnar WB, Trenkle JM. 1994. N-Gram-Based Text Categorization. Ann Arbor (US): Environmental Research Institute of Michigan.
Chawla M. 2003. An indexing technique for efficiently detecting plagiarism in large volume of source code [tesis]. Melbourne (AU): RMIT University.
Gitchel D, Tran N. Sim. A utility for detecting similarity in computer programs. Di dalam: 30th SIGCSE Technical Symposium: 1999 Mar 14-28; New Orleans, Louisiana. New York (US): ACM. hlm 266-270.
Gumilang AP. 2013. Pendeteksian penjiplakan kode program C dengan K-means [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information
Retrieval. Cambridge (UK): Cambridge University Press.
Prechelt L, Malpohl G, Philippsen M. 2002. Finding plagiarisms among a set of programs with JPlag. Universal Computer Science. 8(11):1016–1038.
22
9 printf("%lu\n", b); //cetak hasil
23 Lampiran 2 Hasil pengelompokan manual untuk DataSet1
1 2 3 4 5 6 7 8 9
D13 D1 D2 D3 D6 D9 D19 D25 D20
D16 D60 D4 D5 D18 D12 D41 D50 D59
D17 D68 D11 D7 D28 D34 D54 D66
D22 D86 D14 D8 D39 D38 D63 D71
D23 D87 D15 D10 D58 D40 D75
D24 D90 D21 D47 D64 D76
D26 D91 D29 D53 D69 D77
D27 D31 D56 D72 D88
D30 D35 D78 D92
D32 D43 D84
D33 D49
D36 D52
D37 D55
D42 D57
D44 D67
D45 D73
D46 D83
24
Lampiran 3 Hasil pengelompokan manual untuk DataSet2
1 2
D1 D32 D5
D2 D33 D25
D3 D34 D31
D4 D35 D36
D6 D37 D40
D7 D38 D52
D8 D39 D56
D9 D41 D60
D10 D42
D11 D43
D12 D44
D13 D45
D14 D46
D15 D47
D16 D48
D17 D49
D18 D50
D19 D51
D20 D53
D21 D54
D22 D55
D23 D57
D24 D58
D26 D59
25 Lampiran 4 Hasil pengelompokan manual untuk DataSet3
26
Lampiran 5 Tabel aturan konversi kode program menjadi token sederhana
Keyword / special character
Token
sederhana
Keyword / special character
Token
sederhana
+ a short E
- b long F
* c signed G
/ d unsigned H
% e if I
& f else J
| g while K
( h do L
) i for M
, j ALPHANUM N
{ k goto O
} l case P
< m break Q
> n return R
= o switch S
. p const T
! q continue U
: r sizeof W
int A struct X
float B enum Y
char C typedef Z
27