PENDETEKSIAN PENJIPLAKAN KODE PROGRAM C
DENGAN
K-MEANS
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2013
PENDETEKSIAN PENJIPLAKAN KODE PROGRAM C
DENGAN
K-MEANS
ABI PANCA GUMILANG
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABI PANCA GUMILANG. C Code Plagiarism Detection Using K-Means. Supervised by AHMAD RIDHA.
The practice of plagiarism in programming assignments can be easily done by students. Thus, a system that can detect this practice, i.e., by grouping similar programs into a cluster, is needed. K-Means clustering is a method of flat clustering that has been used to determine similar codes based on the structure of the source codes. The objective of this research is to make the checking process automatic. This research uses a sample of 92 source codes in C comprising 9 groups based on the source code structure similarity. In this study we conducted two experiments, i.e., by determining the number of clusters (manual) and without determining the number of clusters (automatic). The results indicate that the manual experiment resulted in a higher Rand Index (91.35%) and a faster execution time. The system is able to perform automatic clustering process with a Rand Index of 90.63%. The automated clustering does not have significant difference of Rand index, implying the performance is good enough for the clustering without determining the K value first.
Judul Skripsi : Pendeteksian Penjiplakan Kode Program C dengan K-Means Nama : Abi Panca Gumilang
NRP : G64070042
Menyetujui:
Pembimbing
Ahmad Ridha, SKom MS NIP. 19800507 200501 001
Mengetahui: Ketua Departemen
Dr Ir Agus Buono, MSi MKom NIP. 19660702 199302 1 001
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah Subhanahu wa Ta’ala atas rahmat, hidayah, dan nikmat-Nya sehingga penulis dapat menyelesaikan penelitian ini sebagai tugas akhir untuk memperoleh gelar Sarjana Komputer. Banyak pihak yang telah memberikan bantuan baik yang bersifat materi maupun moral kepada penulis dalam penyelesaian tugas akhir ini. Oleh karena itu, penulis ingin menyampaikan rasa terima kasih yang sebesar-besarnya kepada:
1 Ayahanda Sutopo dan Ibunda Emma Kurniasari serta Kakak-kakak Manggar Purwa Setiawan, Dwinanto Mulyo Satriotomo dan Danu Darmoyuwono yang senantiasa mendoakan, mendukung, serta memberikan motivasi dan kesabarannya dalam mengingatkan penulis untuk menyelesaikan tugas akhir. Keluarga besar Natawidjaya yang selalu mendukung dan mendoakan penulis.
2 Bapak Ahmad Ridha, SKom MS selaku dosen pembimbing yang senantiasa membimbing dan mengarahkan dengan sabar serta memberi saran dan motivasi yang membangun.
3 Bapak Sony Hartono Wijaya, SKom MKom dan Bapak Musthofa, SKom MSc selaku dosen penguji yang telah memberikan kritik dan saran yang membangun.
4 Teman-teman Ilmu Komputer 44 yang selalu sabar berbagi ilmu, membantu, dan mengajarkan penulis dalam proses menyelesaikan tugas akhir.
5 Sahabat-sahabat penulis: Arizal Notyasa, Remarchtito Heyziputra, Nur Nissa A. D., Ade Fruandta, Teguh Cipta Pramudia, Huswantoro Anggit P. M., Inne Larasati, Ni Made F., Ria Astriratma, Rani Dwijayanti, Windy Widowati, serta Risa Nurul Fitra yang selalu ada menemani, mendukung, mengingatkan, membantu, dan memberi semangat serta motivasi kepada penulis.
6 Teman-teman satu Ilmu Komputer, serta semua pihak yang telah memberikan dorongan, semangat, doa, bantuan dan kerja samanya selama pengerjaan tugas akhir ini.
Semoga tulisan ini dapat bermanfaat bagi para pembaca. Terima kasih.
Bogor, November 2012
RIWAYAT HIDUP
v
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
Manfaat ... 1
METODE PENELITIAN Studi Literatur dan Pengambilan Data Penelitian ... 2
Pemilihan Sampel Tugas dan Pengelompokan Awal ... 2
Clustering ... 2
Validasi Hasil Clustering ... 4
Otomatisasi Pengelompokan ... 4
Lingkungan Implementasi ... 5
HASIL DAN PEMBAHASAN Pemilihan Sampel Tugas dan Pengelompokan Awal ... 5
Clustering ... 5
Otomatisasi Pengelompokan ... 7
Validasi Hasil Clustering dan Analisis Hasil ... 9
KESIMPULAN DAN SARAN Kesimpulan... 11
Saran ... 11
DAFTAR PUSTAKA ... 11
vi
DAFTAR TABEL
Halaman
1 Konversi kode program ... 2
2 Hasil pengelompokan awal ... 6
3 Term frequency ... 7
4 Hasil looping dengan iterasi maksimum 25 ... 7
5 Hasil pengelompokan iterasi pertama percobaan pertama ... 8
6 Hasil pengelompokan iterasi pertama percobaan kedua ... 8
7 Contoh cluster hasil pengelompokan dengan K = 9 ... 9
8 Contoh cluster hasil pengelompokan otomatis ... 10
DAFTAR GAMBAR
Halaman 1 Tahapan penelitian. ... 12 Tahapan praproses sebelum clustering. ... 2
3 Ilustrasi kesamaan kosinus dengan query T1 dan T2. ... 3
4 Alur otomatisasi pengelompokan. ... 4
DAFTAR LAMPIRAN
1 Daftar konversi kode program ... 13PENDAHULUAN
Latar Belakang
Tugas pemrograman biasanya dikumpulkan berupa berkas elektronik. Hal ini sangat memungkinkan terjadinya penjiplakan yang dapat dilakukan mahasiswa. Untuk mengetahui terjadinya plagiat, dibutuhkan pemeriksaan kemiripan program. Pemeriksaan dengan tenaga manusia akan memakan banyak waktu dan menguras tenaga yang dapat mengurangi efisiensi kerja. Pemeriksaan kemiripan juga dipersulit oleh keahlian mahasiswa dalam melakukan plagiat misalnya mengubah nama variabel dan menambahkan blok komentar pada tugasnya. Oleh sebab itu, dibutuhkan sistem yang dapat memeriksa kemiripan tugas-tugas pemrograman secara otomatis.
Pemeriksaan kemiripan kode program yang dilakukan oleh Burrows (2004) ialah dengan cara mencari kode program dari query yang diberikan dan menghitung kemiripannya. Sistem yang digunakan oleh Burrows adalah structure-oriented code-based system. Sistem berbasis kode dengan berorientasikan pada struktur kode program ini membuat representasi yang lebih ringkas dari kode program. Sistem ini sengaja mengabaikan elemen yang mudah dimodifikasi seperti blok komentar, white space dan nama variabel. Sistem berorientasi struktur tidak terlalu rentan terhadap penambahan pernyataan yang berlebihan. Untuk menghindari pendeteksian, mahasiswa harus memodifikasi semua bagian program secara signifikan (Bowyer dan Hall 1999, Gitchel dan Tran 1999, Prechelt et al. 2002 diacu dalam Burrows 2004).
Pendekatan Burrows (2004) ini digunakan untuk pendeteksian penjiplakan kode program dengan cara mengelompokkan kode program yang serupa. Salah satu teknik pengelompokan yang termasuk dalam kategori flat clustering
adalah K-Means. Pemodelan K-Means dapat digunakan untuk mengelompokkan dokumen yang menerapkan pengukuran jarak kedekatan suatu dokumen dengan titik centroid-nya (Manning et al. 2008).
Penelitian ini mengelompokkan kode program secara otomatis yang memiliki kemiripan struktural. Pengelompokan kode program dilakukan dengan pemodelan K-Means
berdasarkan jarak terdekat yang didapat dari pengukuran kesamaan kosinus dokumen dengan
centroid-nya.
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Membentuk korpus kode program untuk pengujian plagiarisme program C.
2 Mengotomatiskan pendeteksian plagiat pada program bahasa C dengan sistem pengelompokan dokumen-dokumen yang mirip menggunakan pemodelan K-Means. Ruang Lingkup
Ruang lingkup penelitian ini meliputi: 1 Contoh kasus yang digunakan merupakan
kode program bahasa pemrograman C sebanyak 92 tugas.
2 Nilai masukan berupa path folder yang berisi kumpulan tugas dan jumlah cluster
ditentukan sebanyak sembilan cluster.
Banyaknya cluster yang digunakan berdasarkan hasil pengelompokan yang telah dilakukan secara manual.
3 Penelitian ini mengasumsikan tidak adanya makro sehingga bagian preprocessor directives dibuang semua.
Manfaat
Pengotomatisan pendeteksian plagiat ini memudahkan dalam pemeriksaan kode program yang dapat meningkatkan efisiensi kerja.
METODE PENELITIAN
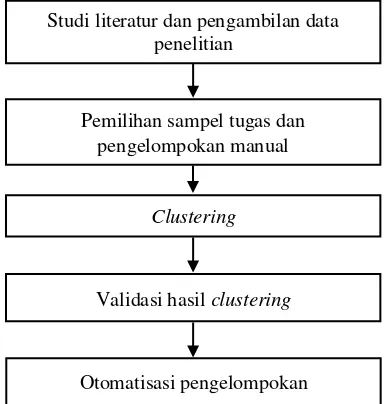
Secara umum terdapat 5 tahapan penelitian, yaitu studi literatur dan pengambilan data penelitian, pemilihan sampel tugas dan pengelompokan manual, clustering, validasi hasil
clustering dan otomatisasi pengelompokan. Tahapan penelitian dapat dilihat pada Gambar 1.
Gambar 1 Tahapan penelitian. Validasi hasil clustering
Clustering
Studi literatur dan pengambilan data penelitian
Pemilihan sampel tugas dan pengelompokan manual
Studi Literatur dan Pengambilan Data Penelitian
Tahap awal penelitian dimulai dengan pengumpulan bahan pustaka yang berkaitan dengan pendeteksian praktik plagiat pada kode program. Salah satunya adalah tesis dengan judul
“Efficient And Effective Plagiarism Detection For Large Code Repositories” (Burrows 2004) dan artikel “Otomatisasi Pengelompokan Koleksi Perpustakaan dengan Pengukuran
Cosine Similarity dan Euclidean Distance”
(Kurniawan dan Aji 2006). Selain itu, studi literatur mengenai clustering dan K-Means
termasuk dalam tahapan ini.
Data yang digunakan sebagai korpus kode program yang diambil dari lab Temu Kembali Informasi Ilmu Komputer. Data penelitian ini adalah kumpulan berkas elektronik tugas pemrograman yang berisi kode program dengan bahasa pemrograman C.
Pemilihan Sampel Tugas dan Pengelompokan Awal
Pada tahap ini dilakukan pemilihan sampel tugas dan pengelompokan tugas secara manual. Sampel yang dipilih pada penelitian ini memiliki tingkat kesulitan tidak terlalu mudah dan tidak terlalu sulit. Sampel yang dipilih sebanyak 92 kode program. Sampel diperiksa satu per satu dan dikelompokkan berdasarkan kemiripan algoritme dan struktur kode programnya.
Clustering
Proses clustering pada tahap ini menggunakan pemodelan K-Means terhadap dokumen. Alur proses clustering dapat dilihat pada Gambar 2.
Gambar 2 Tahapan praproses sebelum
clustering.
Pembuangan preprocessor directives
dilakukan karena diasumsikan tidak adanya
makro pada kode program. Selanjutnya Tokenisasi dilakukan untuk memilah keyword
dan special character dari kode program bahasa C. Pada proses tokenisasi, karakter white space
dibuang sehingga didapat term atau string
uniknya saja (Manning et al. 2008). Komentar pada kode program dibuang karena tidak berpengaruh ketika program dijalankan. Setelah pembuangan komentar, dilakukan perubahan
uppercase menjadi lowercase semua.
Selanjutnya kode program diubah menjadi
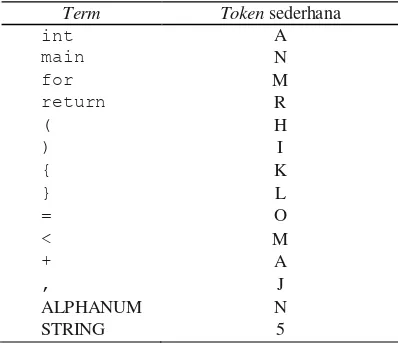
token sederhana agar lebih ringkas dan mudah untuk perhitungan. Perubahan kode program menjadi sebuah string panjang dari token yang telah dikonversi disebut token stream (Burrows 2004). Konversi kode program ke token sederhana dilakukan berdasarkan aturan pada Tabel 1.
Tabel 1 Konversi kode program
Term Token sederhana
int A
Tabel 1 memperlihatkan perubahan penulisan kode menjadi token sederhana. ALPHANUM adalah nama fungsi nama variabel atau nilai variabel. STRING adalah sederetan karakter yang diapit oleh tanda "" (doublequote). Berikut adalah contoh kode program yang diubah menjadi token stream:
1 #include <stdio.h>
2 int main (){
3 int var;
4 for (var=0; var<5; var++){
5 printf("%d\n", var);
6 }
7 return 0;
8 }
Tokenstream:
ANhikANMhNoNNmNNaaikNh5jNilRNl
Selanjutnya token stream ini dilakukan proses
sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Metode
N-Gram ini digunakan untuk mengambil potongan-potongan karakter huruf sejumlah n dari suatu token stream.
Menurut Cavnar dan Trenkle (1994), N-Gram
dibedakan berdasarkan jumlah potongan karakter sebesar n. Untuk membantu dalam mengambil potongan-potongan kata berupa karakter huruf tersebut, dilakukan padding dengan blank
karakter di awal dan di akhir suatu kata. Sebagai
contoh kata ”TEXT” dapat diuraikan ke dalam beberapa N-Gram berikut (penggunaan karakter
„_‟ merepresentasikan blank):
uni-grams : T, E, X, T
bi-grams : _T, TE, EX, XT, T_
tri-grams : _TE, TEX, EXT, XT_
quad-grams : _TEX, TEXT, EXT_
quint-grams : _TEXT, TEXT_
Salah-satu keunggulan menggunakan
N-Gram dalam pencocokan string adalah karena semua string dipecah menjadi beberapa
substring, kesalahan yang terjadi pada suatu
string cenderung hanya berpengaruh pada bagian
substring-nya, sedangkan sisanya tidak terpengaruh. Berikut contoh string dengan 2-Gram:
Text : _T Te ex xt t_ Teext : _T Te ee ex xt t_
Kesalahan hanya terdapat pada substring “ee”
pada string “Teext”, sedangkan sisa substring -nya sama dengan substring pada string “Text”. Token stream diproses N-Gram dengan N = 4. Kemudian kemunculan tiap substring dihitung sehingga didapat tabel term frequency. Tabel ini digunakan sebagai vektor dokumen untuk proses pengelompokan pada algoritme pemodelan
K-Means. Berikut adalah pseudocode dari
K-Means yang digunakan dalam penelitian ini.
1 K-Means({� 1,...,� n},K)
2 (� 1 ,� 2, …,� K)
SelectRandomSeed({� 1,...,� n},K)
3 for 1 k to K
4 do µ k � k
5 while stopping criterion has
not been met akan dikelompokkan sebanyak K. Kemudian vektor dokumen yang telah dipilih secara acak dengan anggota cluster yang lama.
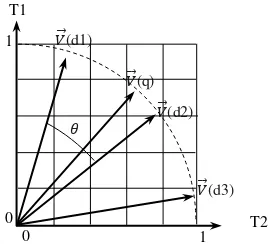
Gambar 3 Ilustrasi kesamaan kosinus dengan
query T1 dan T2.
Dalam algoritme pemodelan K-Means
terdapat pengukuran kemiripan dokumen dalam ruang vektor pada saat looping. Penelitian ini menggunakan ukuran kesamaan kosinus sebagai pengukur kemiripan dokumen. Kesamaan kosinus memiliki sifat makin besar nilai kesamaan kosinusnya semakin dekat jarak kedua vektor tersebut. Gambar 3 adalah ilustrasi dari ukuran kesamaan kosinus.
Perhitungan standar kesamaan antara dua dokumen d1 dan d2 adalah dengan menghitung kesamaan kosinus dari representasi vektor dokumen � (d1) dan � (d2). Vektor dokumen merupakan term frequency yang merepresentasikan jumlah term pada tiap dokumen. Kesamaan kosinus diformulasikan sebagai berikut:
���(�1,�2) = � �1.� �2
� �1 � �2 , (1)
� (d2). Penyebut menunjukkan perkalian panjang jarak Euclid masing-masing vektor (Manning et al. 2008).
Validasi Hasil Clustering
Validasi dari hasil clustering dilakukan pada tahap ini. Validasi clustering dilakukan dengan menggunakan perhitungan akurasi Rand Index
(RI). RI menghitung persentase keputusan yang benar. Tujuannya adalah memasukkan dua dokumen ke dalam satu cluster yang sama jika dokumen mirip dengan cluster yang sama FP : false positive memberikan keputusan dua dokumen berbeda dalam cluster yang sama
TN : true negative memberikan keputusan dua dokumen berbeda di cluster yang berbeda FN : false negative memberikan keputusan dua
dokumen mirip di cluster yang berbeda Setelah mendapatkan hasil akurasi, selanjutnya kekurangan dan kelebihan dari hasil pengelompokan juga dianalisis pada tahap ini. Otomatisasi Pengelompokan
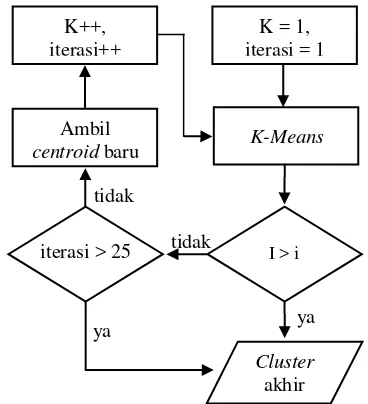
Pengotomatisan pengelompokan dilakukan pada tahap ini dengan mengubah metode pengelompokan, yaitu dengan tanpa memasukkan banyaknya cluster pada awal menu. Alur proses otomatisasi dapat dilihat pada Gambar 4.
Proses otomasi ini bermula dari pengelompokan K-Means dengan K = 1 pada iterasi pertama. Proses K-Means menghasilkan kumpulan nama kode program sebagai anggota
cluster yang telah terkelompokkan. Tiap anggota
cluster memiliki nilai kesamaan kosinus dokumen-centroid. Setelah itu, dilakukan perhitungan rata-rata jarak kesamaan kosinus internal tiap cluster dengan menjumlahkan semua nilai kesamaan kosinus pada satu cluster
yang dibagi dengan banyaknya anggota dari
cluster tersebut sehingga didapat nilai rata-rata internal (� a). Setelah didapat � a, kemudian nilai-nilai � a tersebut dirata-rata kembali dengan menjumlahkan tiap � a kemudian dibagi dengan banyaknya K sehingga didapat nilai rata-rata
akhir (I). Salah satu permasalahan dari otomatisasi pengelompokan adalah pemberhenti dari proses otomasi ini. Oleh sebab itu, suatu nilai variabel dibutuhkan sebagai pemberhenti proses ini. Penelitian ini menggunakan nilai i sebagai pemberhenti dalam kondisi I > i. Pada tahap ini, nilai i yang digunakan sebagai batasan minimal untuk pemberhentian proses pengelompokan ditentukan.
Gambar 4 Alur otomatisasi pengelompokan. Ada kondisi saat I > i terpenuhi atau tidak. Jika kondisi terpenuhi, proses berhenti. Jika kondisi tidak terpenuhi, proses selanjutnya adalah pengambilan centroid baru. Setelah terpilih centroid, kemudian K ditambah 1 untuk iterasi ke dua, K = K+1, kemudian dilakukan
K-Means kembali, dan begitu seterusnya. Untuk menghindari adanya anggota yang memiliki nilai kemiripan rendah berada dalam satu cluster, dilakukan pemilihan centroid dari anggota
cluster yang memiliki jarak terjauh dari yang paling jauh dari centroid pada tiap cluster-nya.
Ada variabel lain selain i yang digunakan sebagai pemberhenti apabila kondisi I > i tidak kunjung terpenuhi, yaitu batas maksimum iterasi. Apabila I tidak dapat mencapai nilai i pada maksimum 25 iterasi, maka proses pengelompokan berhenti. Hal ini dilakukan untuk menghindari terjadinya looping tanpa batas yang terlampau lama.
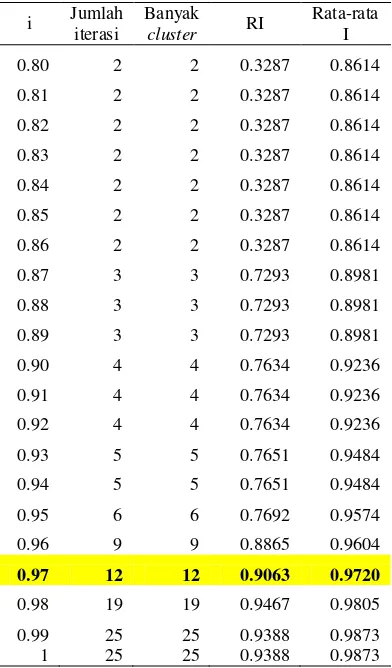
Percobaan penentuan variabel i dilakukan dengan 20 kali looping mulai dari i = 0.80 hingga i = 1 dengan increment = 0.01 dan maksimum iterasi 25. Proses K-Means dilakukan tiap iterasi, kemudian dihitung nilai I-nya dan dibandingkan apakah nilai I > i. Jika I telah melebihi i, proses berhenti dan berlanjut ke looping i+0.01 dan
centroid baru K-Means
seterusnya. Tiap percobaan i dicatat jumlah iterasi, banyak cluster, nilai RI dan nilai I. Lingkungan Implementasi
Lingkungan implementasi perangkat keras yang digunakan pada penelitian ini berupa
desktop dengan spesifikasi sebagai berikut:
Processor : Pentium(R) Dual-Core CPU T4400 @2.20GHz
Memory : 3.00 GB
Harddisk : 250GB
Perangkat lunak yang termasuk lingkungan implementasi pada penelitian ini adalah sebagai berikut:
Windows 7 Professional sebagai sistem operasi
PHP 5.3.0 sebagai bahasa pemrograman
Netbeans 6.8 sebagai Integrated Development Environment
XAMPP 2.5 sebagai server control panel
MySQL sebagai database management system
Notepad++ sebagai editor
HASIL DAN PEMBAHASAN
Pemilihan Sampel Tugas dan Pengelompokan Awal
Pemilihan sampel tugas dilakukan berdasarkan tingkat kesulitan tugas. Sampel ini dipilih dengan tujuan mendapat beberapa kelompok dengan anggota yang memiliki kemiripan sehingga kemiripan kode program dapat dianalisis. Berikut adalah salah satu kode program yang digunakan sebagai sampel. Contoh kode program yang digunakan sebagai sampel:
1 #include <stdio.h>
2 main()
Tugas dengan tingkat kesulitan rendah sebagian besar memiliki algoritme yang sama, sedangkan tugas dengan tingkat kesulitan tinggi memiliki algoritme yang cenderung berbeda. Oleh sebab itu, pemilihan tugas dengan tingkat
kesulitan menengah dianggap tepat untuk pengelompokan awal.
Pengelompokan 92 kode program secara manual menghasilkan 9 cluster dengan struktur kode program yang berbeda. Hasil pengelompokan manual dapat dilihat pada Tabel 2. Cluster 1 memiliki anggota sebanyak 30 kode program karena sebagian besar sampel kode program sama strukturnya pada cluster ini.
Cluster 3 merupakan kelompok dengan anggota terbanyak kedua setelah cluster 1. Berikut masing-masing contoh kode program pada
cluster 1 dan cluster 3. Kode program M80:
1 #include <stdio.h>
2 main()
Proses clustering memiliki beberapa tahap praproses data, yaitu pembuangan preprocessor directives, tokenisasi, simplification, serta
N-Gram. Setelah tahap praproses selesai, kemudian dihitung term tiap dokumen sehingga didapat tabel term frequency yang digunakan sebagai vektor dokumen pada algoritme pemodelan K-Means. Ukuran kesamaan kosinus digunakan dalam pemodelan K-means sebagai pengukur kemiripan dokumen-centroid.
Preprocessor directives dibuang setelah proses parsing selesai, yaitu proses pembacaan dan pengenalan kode program mulai dari tanda
„#‟ pada awal kode program hingga tanda „}‟
preprocessor directives dilakukan karena diasumsikan tidak adanya makro dalam tugas-tugas tersebut. Oleh sebab itu,
preprocessor directives tersebut tidak dibutuhkan.
Proses selanjutnya adalah tokenisasi. Pemilahan keyword dan special character pada kode program dilakukan dalam proses tokenisasi.
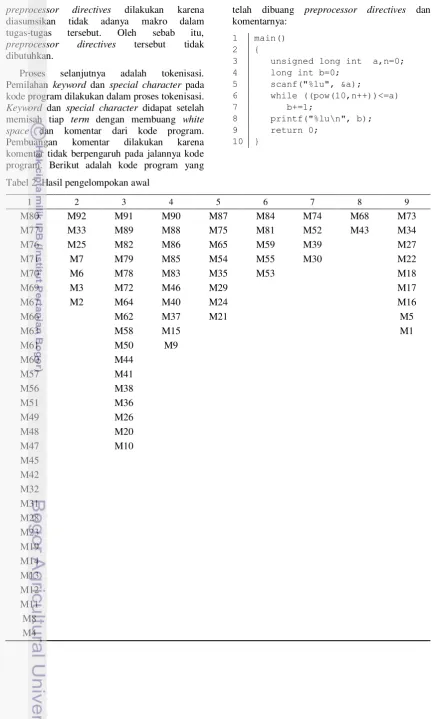
Keyword dan special character didapat setelah memisah tiap term dengan membuang white space dan komentar dari kode program. Pembuangan komentar dilakukan karena komentar tidak berpengaruh pada jalannya kode program. Berikut adalah kode program yang
telah dibuang preprocessor directives dan komentarnya:
1 main()
2 {
3 unsigned long int a,n=0;
4 long int b=0;
5 scanf("%lu", &a);
6 while ((pow(10,n++))<=a)
7 b+=1;
8 printf("%lu\n", b);
9 return 0;
10 }
Tabel 2 Hasil pengelompokan awal
1 2 3 4 5 6 7 8 9
M80 M92 M91 M90 M87 M84 M74 M68 M73
M77 M33 M89 M88 M75 M81 M52 M43 M34
M76 M25 M82 M86 M65 M59 M39 M27
M71 M7 M79 M85 M54 M55 M30 M22
M70 M6 M78 M83 M35 M53 M18
M69 M3 M72 M46 M29 M17
M67 M2 M64 M40 M24 M16
M66 M62 M37 M21 M5
M63 M58 M15 M1
M61 M50 M9
M60 M44
M57 M41
M56 M38
M51 M36
M49 M26
M48 M20
M47 M10
Setelah keyword dan special character
dipilah, masing-masing term diubah dari
uppercase menjadi lowercase. Sebagai contoh: Int diubah menjadi int. Tujuan dilakukannya perubahan tersebut agar mempermudah konversi selanjutnya karena kedua keyword ini dianggap sebagai dua term
yang berbeda walaupun memiliki arti yang sama, yaitu mendeklarasikan tipe integer.
Selanjutnya, keyword dan special character
dikonversi menjadi sebuah token sederhana dan diurutkan berdasarkan struktur program. Setelah diurutkan, kode program tersebut berubah bentuk menjadi sebuah string panjang sederhana yang merepresentasikan struktur kode program. Aturan perubahan term menjadi
token sederhana dapat dilihat pada Lampiran 1. Berikut adalah hasil pengurutan berupa token stream dari sampel kode program yang digunakan:
“NhikHFANjNoNFANoNNh5jfNiKhhNhNjNa aiimoNiNaoNNh5jNiRNl”.
Setelah string panjang didapat, dilakukan proses
N-Gram pada string tersebut. Hasil proses
N-Gram dapat dilihat pada Tabel 3. Tabel 3 Term frequency
N-Gram yang dilakukan dengan menggunakan N = 4. Selanjutnya, dilakukan penghitungan frekuensi tiap term dari hasil proses N-Gram. Hasil term frekuensi ini kemudian disimpan ke dalam berkas XML. Tabel term frequency ini digunakan pada pemodelan K-Means sebagai vektor dokumen kode program. Vektor dokumen pada pemodelan K-Means digunakan untuk perhitungan kemiripan dengan menggunakan ukuran kesamaan kosinus. Semakin besar nilai kesamaan kosinusnya, maka semakin dekat jarak dokumen dengan
centroid.
Otomatisasi Pengelompokan
Pengotomatisan pengelompokan dilakukan
dengan mengubah mekanisme
pengelompokannya yang sebelumnya harus memasukkan banyaknya cluster menjadi hanya memasukkan path direktori dan nama tugas.
Tahapan ini dapat dilihat pada Gambar 4. Langkah pengelompokan pada pengotomatisan ini dilakukan sama seperti pengelompokan
K-Means sebelumnya hanya saja berbeda pada saat pemilihan seed di awal.
Sebuah percobaan dilakukan untuk menentukan nilai i yang cocok sebagai pemberhenti proses clustering otomatis. Nilai I harus dihitung terlebih dahulu untuk menentukan nilai i yang akan digunakan. Misalnya, terdapat 3 cluster, tiap cluster
memiliki anggota yang sudah dihitung jarak kesamaan kosinusnya antara dokumen dan
centroid. Nilai-nilai jarak tersebut kemudian dirata-ratakan untuk mendapatkan nilai � a pada tiap cluster. Setelah didapat nilai rata-rata jarak dari ketiga cluster tersebut, yaitu � 1,� 2 dan� 3, ketiga nilai rataan tersebut kemudian dirata-ratakan kembali ([� 1+� 2+� 3]/3) sehingga didapat nilai I. Nilai I digunakan untuk dibandingkan dengan nilai i pada tiap looping
seperti kondisi pada Gambar 4. Hasil percobaan ini dapat dilihat pada Tabel 4.
Nilai tersebut diambil karena memiliki RI yang cukup baik, yaitu 0.906 dan memiliki banyak
cluster yang mendekati hasil pengelompokan manual seperti pada Tabel 2. Pada i = 0.96, banyak cluster yang terbentuk pada Tabel 2.
Proses yang berhenti karena sudah tercapainya I > i adalah looping dari i = 0.80 hingga i = 0.98, sedangkan proses yang berhenti karena sudah tercapainya iterasi maksimum 25 adalah looping dengan i = 0.99 dan i = 1. Perbedaan pengelompokan manual dan pengelompokan otomatis adalah terjadinya beberapa kali proses pengelompokan yang mengakibatkan lamanya waktu komputasi.
Setelah nilai i ditentukan, dilakukan pengujian otomatisasi pengelompokan. Iterasi pertama proses pengotomatisan pengelompokan dengan K-Means dimulai dengan inisialisasi K = 1. Kemudian, seed diambil secara acak yang digunakan sebagai centroid awal pada iterasi pertama proses K-Means. Setelah proses
K-Means selesai, dilakukan pengecekan apakah I > 0.97.
Penelitian ini memanfaatkan nilai hasil perhitungan kesamaan kosinus sebagai faktor dalam memilih centroid baru untuk iterasi berikutnya. Dokumen dengan jarak terjauh dari
centroid yang ditandai dengan nilai kesamaan kosinus terkecil, akan dijadikan kandidat untuk pemilihan centroid berikutnya. Dari semua kandidat yang didapat pada tiap cluster,
centroid diambil dari anggota yang memiliki jarak paling jauh, yaitu yang memiliki nilai kesamaan kosinus paling kecil. Hal ini dilakukan dengan tujuan meningkatkan fungsi objektif dari pengelompokan, yaitu kemiripan
dokumen pada satu cluster (intra-cluster similarity) yang tinggi dan
kemiripan dokumen pada beda cluster (inter-cluster similarity) yang rendah. Proses pengelompokan otomatis berhenti ketika rata-rata keseluruhan jarak dokumen-centroid I pada tiap cluster melebihi nilai 0.97.
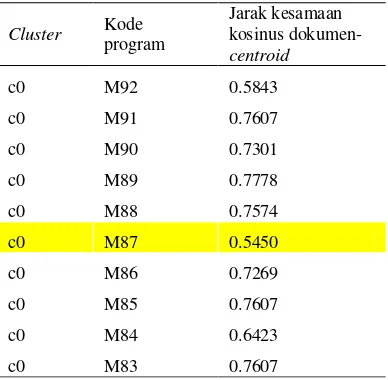
Pengujian pengotomatisan pengelompokan dilakukan dengan beberapa kali percobaan yaitu dengan mengulang pengelompokan sebanyak lima kali. Hasil pengelompokan untuk iterasi pertama proses pengelompokan otomatis pada percobaan pertama dapat dilihat pada Tabel 5.
Tabel 5 Hasil pengelompokan iterasi pertama percobaan pertama
Tabel 5 menunjukkan sepuluh anggota pertama iterasi pertama pada proses pengotomatisan pengelompokan dengan K = 1. Kode program M92 terpilih secara acak sebagai
centroid awal. Setelah proses K-Means selesai, pemillihan centroid berikutnya untuk iterasi kedua pengotomatisan pengelompokan diambil dari anggota cluster dengan jarak terjauh dari
centroid, yaitu kode program M87 dengan jarak kesamaan kosinus dokumen-centroid sebesar 0.5450 yang ditandai dengan arsiran kuning pada Tabel 5.
Percobaan kedua dilakukan dengan mengulang pengelompokan yang sama. Hasil untuk iterasi pertama proses pengelompokan otomatis pada percobaan kedua dapat dilihat pada Tabel 6.
Tabel 6 menunjukkan sepuluh anggota pertama pada iterasi pertama proses pengotomatisan pengelompokan dengan K = 1. Kode program M16 terpilih sebagai centroid
awal. Setelah terbentuk kelompok pada iterasi pertama pengelompokan otomatis, pemillihan
centroid berikutnya untuk iterasi kedua proses pengelompokan otomatis, centroid diambil dari anggota cluster dengan jarak terjauh dari
centroid, yaitu kode program M87 dengan jarak kesamaan kosinus dokumen-centroid sebesar 0.5450 yang ditandai dengan arsiran kuning pada Tabel 6.
Pengulangan percobaan sebanyak lima kali memberikan hasil pada iterasi pertama dengan K = 1 yang sama pada tiap percobaan. Hal ini mengakibatkan hasil akhir yang terbentuk sama untuk semua perulangan percobaan dengan RI sebesar 0.9027. Centroid yang terpilih pada lima kali percobaan dapat dilihat pada Lampiran 2. Centroid pada iterasi pertama dipilih secara acak, selanjutnya pemilihan
centroid dilakukan berdasarkan jarak kesamaan kosinusnya pada tiap iterasi.
Dengan hasil yang demikian, maka tidak diperlukan pengelompokan berulang karena hasil pengelompokan akan sama pada tiap perulangan pengotomatisan pengelompokan sehingga untuk mendapatkan terkelompoknya kode program hanya diperlukan satu kali perulangan pengelompokan. Hal ini tentu memiliki kelebihan, yaitu penghematan dalam penggunaan waktu untuk pengelompokan kode program.
Validasi Hasil Clustering dan Analisis Hasil
Validasi hasil clustering dilakukan dengan dua kali percobaan menggunakan RI. Percobaan pertama adalah pengujian pengelompokan dengan memasukkan K = 9. Pada percobaan pertama, pengujian pengelompokan dilakukan sebanyak lima kali dengan rata-rata hasil RI 91.35%. Rata-rata lama waktu eksekusi pada percobaan pertama adalah 4.3025 detik. Percobaan kedua adalah pengujian pengelompokan yang dilakukan tanpa memasukkan banyaknya cluster. Pada percobaan ke dua pengujian dilakukan sebanyak lima kali pengelompokan otomatis. Percobaan kedua didapat hasil RI sebesar 90.63%. Rata-rata lama waktu eksekusi pada percobaan kedua adalah 20.9882 detik. Contoh hasil percobaan pertama dapat dilihat pada Tabel 7.
Bagian yang ditandai dengan arsiran hijau pada Tabel 7 adalah anggota yang merupakan satu kelompok berdasarkan pada Tabel 2.
Karena banyak cluster sudah ditentukan, pengelompokan pada percobaan ini memberikan rata-rata hasil yang lebih baik dibanding dengan pengelompokan tanpa memasukkan banyaknya cluster. Rata-rata RI yang dihasilkan sebesar 0.9135. Waktu komputasi yang dibutuhkan juga lebih sedikit. Akan tetapi, dengan hasil demikian masih terdapat kekurangan, yaitu ada cluster kosong pada hasil saat percobaan. Kesalahan lain juga terdapat pada hasil pengelompokan seperti pada Tabel 7.
Tabel 7 Contoh cluster hasil pengelompokan dengan K = 9 merah merupakan dua anggota beda kelas yang sekelompok pada cluster ini. Anggota yang ditandai dengan arsiran hijau adalah anggota yang dominan pada cluster tersebut. Masing-masing kode program M30 dan M85 adalah sebagai berikut.
Kode program M30:
1 #include <stdio.h>
Kode program M85:
1 #include <stdio.h>
2 main (){ kelompok yang berbeda berdasarkan Tabel 2, tetapi masuk dalam cluster yang sama pada hasil percobaan pertama. Terdapat perbedaan pada kode program M30 dan M85, yaitu struktur looping dan hasil keluarannya. Pada kode program M30 baris 5 sampai 9 menggunakan struktur do while dan untuk kode program M85 pada baris 6 sampai 9 menggunakan struktur while. Jika diberi masukan 0, keduanya memberikan hasil keluaran yang berbeda. M30 memberikan keluaran 1 sedangkan M85 memberikan keluaran 0. Percobaan kedua menghasilkan 12
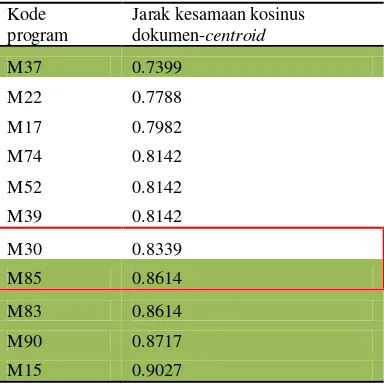
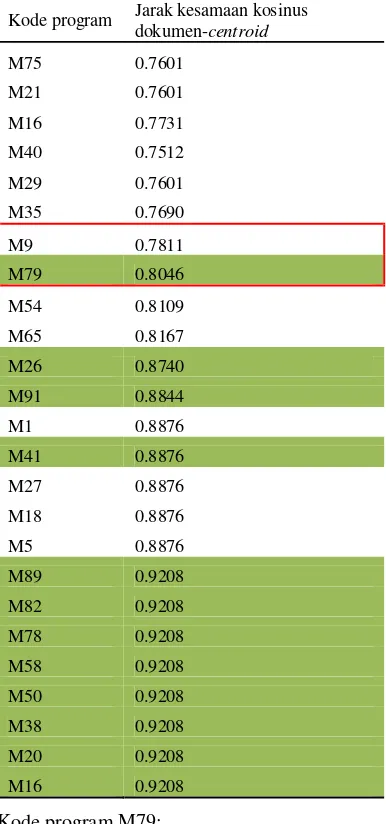
cluster untuk 5 kali pengelompokan. Masih terdapat kekurangan pada hasil pengelompokan secara otomatis. Contoh hasil untuk percobaan kedua dapat dilihat pada Tabel 8.
Tabel 8 merupakan contoh cluster hasil percobaan pengelompokan tanpa memasukkan banyaknya cluster. Bagian yang ditandai dengan arsiran hijau adalah anggota yang satu kelompok berdasarkan Tabel 2. Bagian yang ditandai dengan kotak garis merah merupakan anggota yang tidak sekelompok pada Tabel 2, tetapi sekelompok pada percobaan ini seperti kode program M9 dan kode program M79 yang berada pada satu cluster berdasarkan hasil percobaan. Masing-masing kode program M9 dan M79 adalah sebagai berikut.
Kode program M9:
Kode program Jarak kesamaan kosinus
dokumen-centroid
1 #include <stdio.h>
Hasil keluaran pada kode program M9 dan M79 memberikan keluaran yang sama. Misalnya, masukan 1231252 memberikan keluaran 7 pada kedua program tersebut. Akan tetapi, struktur kode program berbeda pada kondisi while pada kode program M9 dan kode program M79. Kode program M9 menggunakan kondisi while(n)pada baris 5, sedangkan kode program M79 menggunakan kondisi while (n!=0)pada baris 7.
Secara keseluruhan, hasil yang demikian disebabkan oleh belum mengertinya sistem terhadap semantik kode program. Secara sintaksis, sistem sudah cukup mampu untuk mengelompokkan kode program berdasarkan struktur kodenya.
Kekurangan dari hasil juga dipengaruhi oleh pemilihan seed pertama kali pada percobaan pertama yang memasukkan banyaknya cluster
dan percobaan kedua yang mengelompokkan secara otomatis. Hal ini mempengaruhi hasil akhir pengelompokan dan besar kecilnya nilai RI. Faktor lainnya adalah adanya kemungkinan kekeliruan pengelompok karena cukup sulitnya membandingkan tugas dan menentukan apakah tugas satu dengan tugas yang lain cocok untuk dikelompokkan.
KESIMPULAN DAN SARAN
Kesimpulan
Pengelompokan telah membentuk suatu korpus kode program C yang dapat digunakan untuk pengujian pengelompokan. Korpus tersebut telah digunakan dalam penelitian ini untuk pengelompokan berdasarkan struktur kode program menggunakan K-Means. Untuk mengatasi masalah penentuan banyaknya K dalam pengelompokan, telah dilakukan otomatisasi pengelompokan dengan hasil RI yang selisihnya kurang dari 1%. Dengan demikian, pengelompokan dapat dilakukan tanpa menentukan banyaknya K. Akan tetapi, waktu yang dibutuhkan menjadi jauh lebih lama.
Saran
Penelitian selanjutnya dapat mengembangkan aspek semantik kode program agar pengelompokan lebih optimal. Salah satunya dengan cara mengecek kesamaan keluaran sebelum dikelompokkan. Selain itu, dapat dicoba metode clustering yang tidak perlu menentukan banyaknya K seperti hierarchical clustering agar pengelompokan lebih cepat. Korpus kode program C perlu dikembangkan agar mencakup kompleksitas kode program yang beragam.
DAFTAR PUSTAKA
Bowyer K, Hall L. Experience using MOSS to detect cheating on programming assignments. Di dalam 29th ASEE/IEEE Frontiers in Education Conference: San Juan, 10-13 Nov 1999. Hlm 18-22.
Burrows S. 2004. Effecient and effective plagiarism detection for large code repositories [tesis]. Melbourne: RMIT University, Australia.
Cavnar WB, Trenkle JM. 1994. N-Gram-Based Text Categorization. Ann Arbor: Environmental Research Institute of Michigan.
Gitchel D, Tran N. Sim: A utility for detecting similarity in computer programs. Di dalam 30th SIGCSE Technical Symposium: New Orleans, 14-28 Mar 1999. Hlm 266-270.
Kurniawan H, Aji RF. Otomatisasi pengelompokan koleksi perpustakaan dengan pengukuran cosine similarity dan euclidean distance. Di dalam SNATI: Yogyakarta, 17 Jun 2006. Hlm 19-22.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Lampiran 1 Daftar konversi kode program
Keyword / special character Pemetaan
+ a
Keyword / special character Pemetaan
short E
abjad atau angka dan nama
fungsi N
Lampiran 2 Centroid yang terpilih pada lima kali percobaan
Percobaan 1 Percobaan 2 Percobaan 3 Percobaan 4 Percobaan 5