CLUSTERING
DOKUMEN RINGKASAN TESIS MAHASISWA
PASCASARJANA IPB BERBASIS
FREQUENT ITEMSETS
MENGGUNAKAN ALGORITME
BISECTING K-MEANS
ARI SETIAWAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Clustering Dokumen Ringkasan Tesis Mahasiswa Pascasarjana IPB berbasis Frequent Itemsets menggunakan Algoritme Bisecting K-Means adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Mei 2016
RINGKASAN
ARI SETIAWAN. ClusteringDokumen Ringkasan Tesis Mahasiswa Pascasarjana IPB berbasis Frequent Itemsets menggunakan Algoritme Bisecting K-Means. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan IRMAN HERMADI.
Proses pencarian dokumen tesis mahasiswa Pascasarjana IPB pada repository IPB dapat dipercepat dengan cara mengelompokkan dokumen tersebut berdasarkan kata kunci dan kombinasi kata kunci yang sering muncul dalam dokumen tersebut. Metode frequent itemsets dapat memunculkan term-term yang frekuensi kemunculannya tinggi terhadap kumpulan dokumen. Term-term yang sering muncul dalam dokumen dapat mewakili sebuah dokumen. Dalam proses temu kembali dokumen, pada umumnya kata kunci dimasukkan oleh pengguna. Pengelompokkan dokumen berdasarkan frequent term (dalam hal ini kata kunci) dapat mempercepat pengembalian dokumen yang dicari.
Penelitian ini dilakukan untuk menggali frequent itemsets dari kumpulan dokumen ringkasan tesis mahasiswa Pascasarjana IPB menggunakan algoritme Apriori. Proses clustering terhadap frequent itemsets yang terbentuk menggunakan algoritme Bisecting K-Means, untuk kemudian digunakan dalam proses clustering dokumen. Proses pencarian dokumen akan dilakukan terhadap dokumen yang telah dikelompokkan.
Metode dalam penelitian ini diawali dengan mengumpulkan data ringkasan tesis mahasiswa Pascasarjana pada repositori IPB. Kemudian dilakukan praposes data yang meliputi tonization, remove number, stopword removal, stemming, remove punctuation, dan remove sparse term. Selanjutnya proses menggali frequent itemsets menggunakan algoritme Apriori dan pengelompokkan dokumen berbasis frequent itemsets menggunakan algoritme Bisecting K-Means. Tahap terakhir adalah melakukan analisis dan evaluasi hasil cluster. Pada tahap ini akan diuji pencarian dokumen terhadap kata kunci yang dimasukkan berdarakan itemsets yang dihasilkan.
Hasil penelitian menunjukkan bahwa pengelompokan dokumen menggunakan algoritme Bisecting K-Means dapat pengelompokkan itemsets yang mempunyai nilai support tinggi. Pengujian dengan nilai k=3 sampai dengan k=10, pada pengujian k=10 dapat memperoleh hasil cluster yang baik, dengan nilai Sum of Squared Error yaitu 132.15. Pengujian dengan nilai k=10, cluster dua dapat mengelompokkan beberapa itemsets yang mempunyai nilai support tertinggi, yaitu itemsets {base,method}, {base,develop}, {analysi,base}, dan {base,product}. Akurasi hasil clustering berbasis frequent itemsets sangat dipengaruhi oleh term-term yang dihasilkan pada tahap praproses data, yaitu pada tahap penghapusan term berdasarkan tabel stopword, remove sparse term dan nilai minimum support (minsup) karena berdampak terhadap banyaknya jumlah frequent itemsets yang dihasilkan. Term-term yang dihasilkan dengan pendekatan frequent itemsets masih bersifat umum sehingga tidak dapat digunakan untuk pencarian dokumen dengan topik penelitian yang spesifik.
SUMMARY
ARI SETIAWAN. Clustering IPB Graduate Student Thesis Summary based on Frequent Itemsets using Bisecting K-Means Algorithm. Supervised by IMAS SUKAESIH SITANGGANG and IRMAN HERMADI.
The searching documents of IPB graduate student’s thesis in IPB repository can be accelerated by grouping these documents based on keywords and its combinations that often appear in the document. Frequent itemsets approach can discover terms that are frequently occurred in the documents. These frequent terms may represent content of the documents. In the document retrieval process, keywords are commonly entered by users. Grouping documents based on frequent term including keywords can accelerate the document retrieval.
This research was conducted to explore the frequent itemsets of document summaries IPB graduate student’s thesis using Apriori algorithm. Clustering frequent itemsets was performed using the bisecting K-Means algorithm. The searching documents will be done on clusters of documents.
The research steps in this research begin by collecting of IPB Graduate student thesis’s summaries. Data preprocessing consists of several tasks including tokenization, stopword removal, stemming, removing numbers, removing punctuation and removing spare terms. Furthermore, frequent terms were discovered using Apriori algorithm. Based on the frequent terms, documents were clustered using bisecting K-Means algorithm. The last step is analyzing and evaluating the clustering results. At this stage clusters of documents were evaluated based on keywords that were selected from the frequent terms.
The results show that the best clustering result was obtained at number of clusters of 10 with the Sum of Squared Error is 132.15. These clusters contain documents that have frequent terms {base, method}, {base, develop}, {analysi, base}, and {base, product}. This study show that data preprocessing task including removing stopwords and removing sparse terms have high influence on frequent terms generation. This study discovers frequents terms related to the common topics in the summaries of IPB graduate student’s thesis therefore the terms cannot be used to discover thesis related to specific topics.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
ARI SETIAWAN
CLUSTERING
DOKUMEN RINGKASAN TESIS MAHASISWA
PASCASARJANA IPB BERBASIS
FREQUENT ITEMSETS
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan April 2014 ini ialah text minning, dengan judul Clustering Dokumen Ringkasan Tesis Mahasiswa Pascasarjana IPB berbasis Frequent Itemsets menggunakan Algoritme Bisecting K-Means.
Terima kasih penulis ucapkan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi MKom dan Bapak Irman Hermadi, SKom MS PhD selaku pembimbing, serta Bapak DrEng Wisnu Ananta Kusuma, ST MT selaku penguji yang telah banyak memberikan saran untuk penelitan ini. Ungkapan terima kasih juga disampaikan kepada ayahanda, ibunda, isteriku tersayang Dewi Tirta Ayu, Anak-anakku tersayang Devan, Abel, Nadine, Reynand, dan keluarga Bapak Haji Saefulloh. Tak lupa pula saya ucapkan terima kasih kepada Priyo Puji Nugroho yang telah membantu pengumpulan data serta teman-teman Andri Hidayat, Mulyani yang telah membantu dan menemani saya saat menempuh masa-masa sulit penelitian.
Ungkapan terima kasih juga penulis sampaikan pada pengelola Pascasarjana, seluruh Dosen dan Staf Akademik Departemen Ilmu Komputer Institut Pertanian Bogor, teman-teman MKom Angkatan 14. Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Rumusan Masalah 2
Tujuan Penelitian 3
Ruang Lingkup Penelitian 3
Manfaat Penelitian 3
2 TINJAUAN PUSTAKA 3
Document Clustering 3
Partitional Clustering 4
Algoritme Bisecting K-Means 4
Representasi Dokumen Menggunakan Vector Space Model (VSM) 5 Clustering Dokumen Berbasis Frequent Itemset 5
Algoritme Apriori 6
Term Frequency – Invers Document Frequency 6
3 METODE 7
Data Penelitian 7
Metode Penelitian 7
Praproses Data 8
Penggalian frequent itemsets dengan algoritme Apriori 10 Clustering Frequent Term Menggunakan Algoritme Bisecting K-Means 10
Evaluasi Cluster Dokumen 11
4 HASIL DAN PEMBAHASAN 11
Data Penelitian 11
Praproses Data 12
Penggalian frequent itemsets dengan algoritme Apriori 18 Clustering Frequent Term Menggunakan algoritme Bisecting K-Means 21
Evaluasi Cluster Dokumen 22
4 SIMPULAN DAN SARAN 28
Simpulan 28
Saran 29
DAFTAR PUSTAKA 29
LAMPIRAN 31
DAFTAR TABEL
1 Frequent Itemsets 19
2 Dokumen yang mengandung frequent itemsets 21
3 Nilai SSE cluster dokumen menggunakan algoritme Bisecting
K-Means 21
4 Cluster frequent itemsets menggunakan algoritme Bisecting
K-Means berdasarkan frequent itemsets dengan nilai k 10 22 5 Jum;ah dokumen yang mengandung frequent itemsets 24 6 Daftar tabel stopword tambahan untuk memunculkan term yang
lebih spesifik 25
7 Pembentukan frequent itemsets terhadap pengujian nilai sparsity,
minsup dan mincof 26
8 Pembentukan frequent itemsets terhadap pengujian nilai sparsity 0.90,
minsup 0.08, dan mincof 0.8 27
DAFTAR GAMBAR
1 Diagram alir penelitian 8
2 Dokumen ringkasan tesis mahasiswa Pascasarjana IPB 11 3 Document term matrix 17 4 Wordcloud untuk dokumen ringkasan tesis mahasiswa
Pascasarjana IPB 18
5 Korelasi antar items (term) 20
6 Wordcloud perubahan pembentukan itemsets akibat
penambahan tabel stopword 26
7 Korelasi antar items setelah penambahan tabel stopword 28
DAFTAR LAMPIRAN
1 Source code praposes data 31
2 Source code Source code Penggalian Frequent Itemsets 33 3 Source code clustering menggunakan algoritme Bisecting K-Means 34
1
PENDAHULUAN
Latar Belakang
Pengelompokan dokumen atau pengelompokan teks adalah salah satu tema utama dalam text mining. Hal ini mengacu pada proses pengelompokan dokumen dengan isi atau topik yang sama ke dalam kelompok untuk meningkatkan ketersediaan dan keandalan aplikasi text mining seperti pencarian informasi (Zamir et al. 1997), klasifikasi teks (Aggarwal et al. 1999), dan peringkasan dokumen (Larson et al. 1999). Ada tiga jenis masalah dalam pengelompokan dokumen. Masalah pertama adalah bagaimana mendefinisikan kesamaan dua dokumen. Masalah kedua adalah bagaimana menentukan jumlah yang tepat dari cluster dokumen koleksi teks dan yang ketiga adalah bagaimana mengelompokkan dokumen secara tepat sesuai dengan cluster. Document clustering adalah proses pengelompokkan dokumen secara otomatis ke dalam suatu cluster, sehingga dokumen-dokumen yang berada dalam sebuah cluster akan memiliki kemiripan yang tinggi dibandingkan dokumen pada cluster yang berbeda (Steinbach et al. 2000).
Dalam beberapa tahun terakhir, clustering dokumen web telah menjadi area penelitian yang sangat menarik di antara komunitas akademis dan ilmiah yang terlibat dalam temu kembali informasi (information retrieval) dan pencarian web (Carpineto et al. 2009). Sistem klasifikasi dokumen web berusaha untuk meningkatkan cakupan (jumlah) dokumen yang disajikan bagi pengguna untuk meninjau, sekaligus mengurangi waktu yang dihabiskan dalam pencarian dokumen (Yates et al. 1999). Dalam information retrieval, sistem klasifikasi dokumen web disebut mesin pengelompokan web. Sistem tersebut biasanya terdiri atas empat komponen utama yaitu hasil akuisisi pencarian, pre-prosesing input, konstruksi dan pelabelan cluster, serta visualisasi yang dihasilkan cluster (Carpineto et al. 2009).
Konsep frequent itemsets berasal dari association rule mining yang digunakan untuk menemukan hubungan aturan item dalam basis data transaksional yang besar (Agrawal et al. 1993). Sebuah frequent itemsets adalah sekumpulan frequent item, yang sering terjadi pada transaksi yang melebihi nilai ambang batas tertentu yang disebut minimum support (minsup). Penambangan frequent itemsets lebih sering mengarah ke penemuan asosiasi dan korelasi antara item dalam jumlah data yang besar yang telah dikumpulkan dan disimpan secara terus menerus ke dalam data transaksional. Frequent itemsets dalam pengelompokan dokumen dapat dikaitkan dengan permintaan pengurangan dimensi untuk representasi. Dalam Vector Space Model (VSM), keterbatasan tempat penyimpanan sementara dari kata-kata individu menyebabkan dimensi ruang yang besar. Tidak semua dokumen dalam koleksi berisi semua indeks istilah yang digunakan dalam representasi dan sebagai akibat kekurangan ruang terjadi pada vektor dokumen sangat besar. Sebuah frequent itemsets adalah satu set kata-kata individu yang mencakup makna konseptual dan kontekstual dari kata individu (Wen et al. 2010).
dokumen. Pengguna dapat mencari dokumen berdasarkan jenis dokumen karya ilmiah, tahun penerbitan, nama penulis, judul, dan subjek. Responses time dalam proses informasi retrieval juga terbilang cepat. Namun dalam beberapa kasus tingkat efektifitas pengembalian dokumen tidak relevan dengan kata kunci yang dimaksukkan. Hal ini dapat disebabkan beberapa faktor, salah satu di antaranya mengenai pengelompokkan dokumen. Dengan mengelompokkan dokumen dalam suatu cluster dengan tingkat kemiripan dokumen yang sama, maka proses pencarian tersebut tertuju pada suatu cluster tertentu, dokumen yang akan dikembalikan akan berisi dokumen yang ada pada cluster tersebut, sehingga tingkat relevansi dokumen bisa dikatakan efektif. Clustering selain dapat mengelompokkan dokumen dengan tingkat kemiripan yang tinggi dalam suatu cluster, dapat juga digunakan dalam hal peringkasan dokumen dan proses information retrieval.
Dalam penelitian ini digunakan data repositori IPB, khususnya pada kumpulan dokumen ringkasan tesis mahasiswa Pascasarjana IPB. Clustering dokumen diperlukan untuk mengelompokkan dokumen berdasarkan kemiripan dokumen ke dalam satu cluster, dan akan dilakukan pengujian terhadap tingkat efektifitas dalam proses temu kembali dokumen. Teknik data mining yang digunakan dalam penelitian ini adalah Frequent Pattern Mining dan Clustering. Frequent Pattern Mining akan menentukan terms dalam kumpulan dokumen berbasis frequent itemsets dari kumpulan dokumen. Clustering frequent term menggunakan algoritme Bisecting K-Means digunakan untuk proses pengelompokkan kemiripan dokumen ke dalam masing–masing cluster. Clustering dokumen berbasis frequent itemsets merupakan salah satu metode clustering dokumen yang dapat digunakan untuk mengatasi masalah tingginya ruang dimensi dari dokumen yang akan dikelompokkan. Namun waktu komputasi yang dibutuhkan pada proses clustering terhadap database yang besar akan terasa lama. Oleh sebab itu akan dipadukan dengan metode clustering menggunakan algoritme Bisecting K-Means. Dalam beberapa penelitian sebelumnya, algoritme Bisecting K-Means mampu mempercepat proses kumputasi terhadap database yang besar karena dapat melakukan pengulangan fungsi yang kompleksitasnya tinggi. Pengulangan tersebut mampu mengelompokkan suatu objek atau dokumen dalam suatu cluster dengan tingkat kemiripan yang tinggi.
Rumusan Masalah
Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut:
1. Menentukan frequent term dari kumpulan dokumen ringkasan tesis mahasiswa Pascasarjana IPB menggunakan algoritme Apriori.
2. Pengelompokkan dokumen berbasis frequent itemset menggunakan algoritme Bisecting K-Means.
Ruang Lingkup Penelitian
Adapun ruang lingkup dalam penelitian ini adalah data dokumen berupa ringkasan tesis mahasiswa Pascasarjana IPB dalam Bahasa Inggris sebanyak 295 dokumen yang diambil secara acak dari berbagai disiplin ilmu.
Manfaat Penelitian
Hasil penelitian ini diharapkan dapat mempercepat proses pencarian dokumen berdasarkan kata kunci yang dimasukkan pengguna terhadap hasil clustering dokumen dan bukan terhadap keseluruhan kumpulan dokumen.
2
TINJAUAN PUSTAKA
Document Clustering
Secara umum clustering dokumen adalah proses mengelompokkan dokumen berdasarkan kemiripan antara satu dengan yang lain dalam satu cluster. Tujuannya adalah untuk memisahkan dokumen yang relevan dari dokumen yang tidak relevan (Zhang et al. 2001). Pengelompokan ini didasarkan pada hipotesa yang dikemukakan oleh Van Rijsbergen bahwa dokumen-dokumen yang berkaitan erat cenderung sesuai dengan permintaan informasi yang sama. Atau dengan kata lain, dokumen-dokumen yang relevan dengan suatu query cenderung memiliki kemiripan satu sama lain dari pada dokumen yang tidak relevan, sehingga dapat dikelompokkan ke dalam suatu cluster. Oleh karena itu, suatu cluster berisi kelompok dokumen homogen yang saling berkaitan antara satu dengan yang lain.
mempermudah pencari informasi untuk memberikan interpretasi terhadap hasil penelusuran sesuai dengan kebutuhannya.
Menurut Rijbergen (1979), clustering dokumen telah lama diterapkan untuk meningkatkan efekifitas temu kembali informasi. Penerapan clustering ini didasarkan pada suatu hipotesis (cluster-hypothesis) bahwa dokumen yang relevan akan cenderung berada pada cluster yang sama jika pada koleksi dokumen dilakukan clustering. Beberapa penelitian untuk dokumen berbahasa Inggris menerapkan clustering dokumen untuk memperbaiki kinerja dalam proses pencarian (Tombros 2002). Satu hal menarik adalah tidak ada algoritma clustering terbaik yang dapat diaplikasikan terhadap semua bentuk data (Achtert et al. 2005).
Partitional Clustering
Dalam partitional clustering, algoritme awal melakukan pembagian data dalam cluster dan kemudian memindahkannya dari satu kelompok ke yang lain didasarkan pada optimisasi dari kriteria yang telah ditentukan atau fungsi tujuan (Jain et al. 1999). Algoritme yang paling representatif menggunakan teknik ini adalah K-Means dan K-Medoids.
Metode partisi akan memindahkan dokumen dari satu cluster ke cluster yang lain, mulai dari partisi awal. Metode tersebut berdasarkan pada jumlah cluster yang ditetapkan oleh pengguna. Untuk mencapai optimalitas global dalam pengelompokkan berbasis partisi, proses pembagian lengkap dari semua partisi yang mungkin diperlukan. Karena proses tersebut tidak layak, maka metode greedy digunakan dalam bentuk optimasi iteratif dengan menggunakan metode relokasi iteratif untuk merelokasi poin antara k-cluster. Ada dua cara untuk komputasi clustering dokumen dalam metode partitional clustering, baik secara langsung atau melalui urutan bisecting atau perpecahan berulang (Zhao dan Karypis 2002).
Metode partisi pertama menciptakan set awal partisi k, di mana k adalah parameter jumlah partisi untuk membangun cluster, kemudian menggunakan teknik relokasi berulang yang mencoba untuk meningkatkan partisi dengan benda bergerak dari satu kelompok ke kelompok lain. Metode partisi khas termasuk K-Means, K-Medoids, dan CLARANS (Han et al. 2012).
Pada tahun 2000 (Steinbach et al. 2000), sebuah penelitian menghasilkan algoritme Bisecting K-means dengan menggabungkan metode Divisive Hierarchical Clustering dan Partitional Clustering memberikan hasil yang lebih baik mengenai akurasi dan efisiensi dibandingkan dengan metode Unweighted Pair Group Method with Arithmetic Mean (UPGMA) dan algoritme K-Means (Steinbach et al. 2000).
Algoritme Bisecting K-Means
dokumen dibagi dua dengan cara K-Means (bisecting-step). Selanjutnya cara itu dikenakan pada tiap-tiap cluster sampai diperoleh k buah cluster. Algoritme Bisecting K-Means dimulai dengan satu cluster dan kemudian membagi cluster menjadi dua. Cluster perpecahan ditentukan dengan meminimalkan Sum of Squared Error (SSE). Dasar algoritme Bisecting K-Means (Steinbach et al. 2000) adalah:
1. Inisialisasi satu cluster yang akan di split (dibagi).
2. Split dua cluster dengan mencari 2 sub cluster menggunakan algoritme K-Mean.
3. Ulangi langkah 2, untuk nilai tetap sebanyak iterasi yg dilakukan dan mengambil perpecahan yang menghasilkan clustering dengan keseluruhan kesamaan tertinggi, ambil hasil clustering yang terbaik yaitu rata-rata nilai document similarity yang terbaik.
4. Ulangi langkah 1, 2, dan 3 sampai jumlah cluster yang diinginkan tercapai (memilih split gugus yang memberikan nilai SSE terkecil).
Untuk menentukan perpecahan atau membagi cluster sesuai nilai k ditentukan dengan menggunakan nilai SSE terkecil. Persamaan 1 digunakan untuk mencari SSE (Steinbach et al. 2000).
dengan :
pci : setiap data titik pada cluster i ci : center cluster i
mi : centroid pada cluster i
d : jarak pada masing-masing cluster i
Representasi Dokumen Menggunakan Vector Space Model (VSM)
Vector Space Model (VSM) adalah metode untuk melihat tingkat kedekatan atau kesamaan (similarity) term dengan cara pembobotan term. Dokumen dipandang sebagi sebuah vektor yang memiliki magnitude (jarak) dan direction (arah). Pada VSM, sebuah istilah direpresentasikan dengan sebuah dimensi dari ruang vektor. Relevansi sebuah dokumen ke sebuah query didasarkan pada similaritas diantara vektor dokumen dan vektor query (Yates 1999).
VSM digunakan untuk representasi dokumen. Dalam model vektor setiap dokumen secara konseptual direpresentasikan sebagai vektor dari kata kunci yang diambil dari dokumen dengan bobot terkait mewakili pentingnya istilah kunci dalam dokumen maupun dalam keseluruhan dokumen corpus. Pada model ini, query dan dokumen dianggap sebagai vektor-vektor pada ruang n-dimensi, dimana n adalah jumlah dari seluruh term yang ada dalam leksikon (Ian et al. 1999). Leksikon adalah daftar semua term yang ada dalam indeks.
Clustering Dokumen Berbasis Frequent Itemsets
Konsep frequent itemsets sebenarnya berasal dari penggalian kaidah asosiasi (association rule mining). Frequent itemsets untuk text mining dapat dibagi menjadi dua kategori yaitu: penggunaan frequent itemsets untuk kategorisasi dokumen dan penggunaan frequent itemsets dalam clustering
dokumen. Motivasi dalam mengadaptasi frequent itemsets pada proses clustering dokumen berkaitan dengan permintaan untuk mengurangi dimensi dari representasi suatu dokumen. Dalam VSM, sekumpulan kata-kata akan mengakibatkan tingginya dimensi. Padahal tidak semua dokumen dalam koleksi berisi semua indeks istilah atau term yang digunakan dalam representasi.
Algoritme Apriori
Sebuah kaidah dalam analisis asosiasi dituliskan dalam bentuk AB, dimana A dan B adalah dua item yang berbeda. Kekuatan relasi antara A dan B dapat diukur dengan nilai support dan confidence. Support menunjukkan seberapa sering sebuah itemsets diaplikasikan dalam sebuah basis data transaksi atau dataset. Confidence adalah seberapa sering item B muncul pada transaksi yang melibatkan item A. Untuk menemukan kaidah asosiasi dari sebuah daftar transaksi, dibutuhkan nilai batasan yaitu minimum support (minsup) dan minimum confidence (minconf). Persamaan untuk mencari Support diberikan pada persamaan 2 dan confidence diberikan pada persamaan 3 (Han et al. 2012).
dengan :
A : Antecendent aturan (bagian jika) B : Consequent aturan (bagian maka) D : Dataset (transaction)
Prosedur umum yang banyak dipakai dalam menemukan kaidah asosiasi adalah sebagai berikut (Han et al. 2012):
a. Pembentukan frequent itemsets bertujuan untuk menemukan semua itemsets yang memiliki nilai support lebih besar atau sama dengan nilai minsup.
b. Pembentukan kaidah (rule generation) bertujuan untuk membentuk kaidah yang kuat (strong rule) yaitu kaidah dengan tingkat kepercayaan (confidence) yang tinggi dari frequent itemsets yang dihasilkan pada tahap sebelumnya.
Term Frequency – Invers Document Frequency
Term Frequency-Inverse Document Frequency (TF-IDF) merupakan pembobotan klasik berbasis frekuensi dan IDF kemudian menjadi inspirasi untuk mengkombinasikan kedua metode pembobotan tersebut, dengan mempertimbangkan frekuensi inter-dokumen dan frekuensi intra-dokumen dari suatu term. Dengan menggunakan frekuensi term pada suatu dokumen dan distribusinya pada keseluruhan dokumen, yakni kemunculannya pada dokumen-dokumen lain (IDF).
menggabungkan konsep frekuensi intra-dokumen dan inter-dokumen ini kemudian dikenal sebagai metode TF-IDF, yang dinyatakan pada persamaan 4.
dengan:
Wij = bobot term j pada dokumen i tfij = frekuensi term j pada dokumen i N = jumlah total dokumen yang diproses
idij = jumlah dokumen yang memiliki term j didalamnya
3
METODE
Data Penelitian
Data yang digunakan dalam penelitian ini adalah kumpulan ringkasan tesis mahasiswa Pascasarjana IPB dalam bahasa Inggris sebanyak 295 dokumen yang bersumber dari Direktorat Integritas Data dan Sistem Informasi (DIDSI) IPB.
Metode Penelitian
Bagian metode penelitian akan menjelaskan secara sistematis tahapan-tahapan dan metode yang dilakukan dalam penelitian. Tahapan ini dibuat
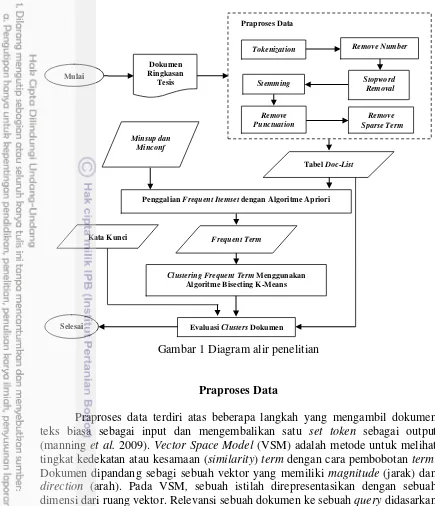
agar penelitian menjadi lebih terarah. Ilustrasi tahapan kegiatan penelitian dapat dilihat pada Gambar 1. Penelitian dimulai mengumpulkan data ringkasan tesis mahasiswa pascasarjana pada repositori IPB sebanyak 295 dokumen. Tahap kedua dilakukan praposes data terhadap kumpulan dokumen ringkasan tesis. Tahap ketiga adalah menggali frequent itemsets menggunakan algoritme Apriori. Tahap keempat adalah mengelompokkan dokumen berbasis frequent itemsets menggunakan algoritme Bisecting K-means. Tahap kelima adalah evaluasi hasil cluster dokumen yang terbentuk. Pada tahap ini juga akan diuji seberapa relevan dokumen yang ditemukan terhadap kata kunci yang dimasukkan. Penjelasan lebih lanjut setiap tahapan yang dilakukan pada metode penelitian akan dibahas pada sub bahasan berikutnya.
j df
N tf ij
ij *id ij tf ij W
log *
Gambar 1 Diagram alir penelitian
Praproses Data
Praproses data terdiri atas beberapa langkah yang mengambil dokumen teks biasa sebagai input dan mengembalikan satu set token sebagai output (manning et al. 2009). Vector Space Model (VSM) adalah metode untuk melihat tingkat kedekatan atau kesamaan (similarity) term dengan cara pembobotan term. Dokumen dipandang sebagi sebuah vektor yang memiliki magnitude (jarak) dan direction (arah). Pada VSM, sebuah istilah direpresentasikan dengan sebuah dimensi dari ruang vektor. Relevansi sebuah dokumen ke sebuah query didasarkan pada similaritas antar vektor dokumen dan vektor query (Yates 1999). Dalam model ruang vektor (vector space model), sekumpulan kata-kata akan mengakibatkan tingginya dimensi.
Langkah awal dari penelitian ini adalah praproses data yang meliputi tonization, remove number, stopword removal, stemming, remove punctuation, dan menghilangkan term yang kemunculannya kurang dari nilai remove sparse term yang ditentukan, sehingga kumpulan dokumen terdiri dari kumpulan term. Hasil dari praproses data dipresentasikan ke dalam document term matrix, yaitu sebuah matriks yang berisikan semua dokumen dari kumpulan dokumen yang terdiri atas term yang telah bersifat individu. Setiap sel dalam matriks bersesuaian dengan bobot yang diberikan dari suatu term dalam dokumen yaitu 1 dan 0, dengan nilai nol berarti bahwa term tersebut tidak hadir di dalam dokumen.
Clustering Frequent Term Menggunakan
Algoritme Bisecting K-Means
Evaluasi Clusters Dokumen Dokumen
Ringkasan Tesis
Mulai Stopword
Removal Tokenization
Praproses Data
Remove Sparse Term
Tabel Doc-List
Penggalian Frequent Itemset dengan Algoritme Apriori
Selesai
Frequent Term
Remove Number
Remove Punctuation
Minsup dan Minconf
Kata Kunci
Tokenization
Tokenisasi merupakan proses pemisahan suatu rangkaian karakter berdasarkan karakter spasi, dan mungkin pada waktu yang bersamaan dilakukan juga proses penghapusan karakter tertentu, seperti simbol. Token seringkali disebut sebagai istilah (term) atau kata, sebagai contoh sebuah token merupakan suatu urutan karakter dari dokumen tertentu yang dikelompokkan sebagai unit semantik yang berguna untuk diproses (Salton dan Christopher 1988).
Remove number
Remove number merupakan proses penghilangan karakter angka yang terdapat dalam suatu dokumen. Penghilangan karakter angka bertujuan agar dokumen tidak mengandung karakter angka sehingga memudahkan dalam hal representasi dokumen dalam sebuah term matrix.
Stopword removal
Stopword removal akan menghilangkan sebagian besar kata yang tidak signifikan, yang tidak menyampaikan makna apapun sebagai dimensi dalam model vektor. Oleh karena itu kata-kata dari daftar membentuk set kata-kata yang unik. Strategi yang paling umum untuk menghilangkan stopword adalah untuk membandingkan setiap istilah dengan daftar stopword. Proses stopword removal merupakan proses penghapusan term yang tidak memiliki arti atau tidak relevan (Tala 2003).
Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari query dan istilah-istilah dokumen (Porter 1997). Stemming dilakukan atas dasar asumsi bahwa kata-kata yang memiliki stem yang sama memiliki makna yang serupa sehingga memperoleh dokumen-dokumen yang di dalamnya terdapat kata-kata dengan stem yang sama dengan query. Proses clustering dapat dipercepat dengan menggunakan algoritme Porter (Tala 2003) untuk mereduksi jumlah kata melalui penghilangan imbuhan (stemming).
Remove punctuation
Remove punctuation merupakan proses menghilangkan karakter tanda baca seperti koma, titik, dan lain lain.
Remove sparse term
lebih kecil dari jumlah dokumen yang dikalikan dengan hasil 1 dikurangi nilai sparse, maka term tersebut akan dihilangkan, namum apabila nilai jumlah frekuensi lebih besar, maka term tersebut akan digunakan. Setiap term akan dilakukan proses tersebut, sehingga hanya tersisa term yang mempunyai nilai lebih besar dari nilai sparsity yang akan dipertahankan.
Penggalian frequent itemsets dengan Algoritme Apriori
Algoritme Apriori (Han et al. 2012) diaplikasikan dalam penggalian frequent itemsets dari sekumpulan dokumen dengan menentukan nilai minimal support dan minimum confidence. Algoritme Apriori pada umumnya digunakan pada basis data transaksional. Oleh karena itu, dalam penelitian ini terdapat beberapa proses yang dilakukan pada algoritme Apriori tersebut agar dapat digunakan dalam proses clustering dokumen. Algoritme Apriori digunakan untuk menentukan himpunan data yang paling sering muncul (frequent itemsets) dalam sebuah kumpulan data (David 2008). Sebuah frequent itemsets adalah seperangkat individu kata-kata yang mencakup makna konseptual dan kontekstual daripada kata yang berdiri sendiri.
Dalam sebuah transaksi, I={i1, i2, i3, ... , id} adalah himpunan barang-barang (item) yang dapat ditransaksikan dan T={t1, t2, t3,..., tN} adalah suatu himpunan transaksi. Setiap transaksi ti terdiri dari item yang merupakan subset dari I. Itemsets adalah himpunan dari 0 atau banyak item. Bila terdiri dari k item, maka dapat disebut dengan k-itemsets. Itemsets juga disebut sebagai suatu pola. Support count menunjukkan jumlah transaksi yang mengandung itemsets tertentu. Dalam penelitian ini penggalian frequent itemsets dilakukan menggunakan algoritme Apriori, dengan pengujian nilai minimum support 0.10 dan minimum confidence 0.8. Hasil penggalian frequent itemsets inilah yang akan dilakukan proses clustering menggunakan algoritme Bisecting K-means.
Clustering Frequent Itemsets Menggunakan Algoritme Bisecting K-Means Metode Bisecting K-Means (Steinbach et al. 2000) menggabungkan pendekatan partitional dengan divisive hierarchical, yaitu mula-mula seluruh dokumen dibagi dua dengan cara K-Means (bisecting-step). Selanjutnya cara itu dikenakan pada tiap-tiap cluster sampai diperoleh k buah cluster. Algoritme Bisecting K-Means dimulai dengan satu cluster dan kemudian membagi cluster menjadi dua. Cluster perpecahan ditentukan dengan meminimalkan Sum of Squared Error (SSE). Pemisahan ini didasarkan pada nilai SSE terkecil dan akan diulang sampai jumlah cluster yang ditetapkan pengguna tercapai.
Evaluasi Cluster Dokumen
Evaluasi cluster dokumen dilakukan terhadap clustering dokumen yang terbentuk menggunakan algoritme Bisecting K-Means. Evaluasi dilakukan pada hasil pengelompokkan frequen itemset dan dokumen mana yang masuk dalam satu cluster. Pembentukkan cluster dilakukan dengan memberikan nilai k 3 sampai dengan k 10, dan menganalisa cluster mana yang terbaik berdasarkan nilai SSE terkecil. Tahap pengujian pencarian dokumen yang mengandung frequent itemset dilakukan dengan memasukkan kata kunci berdasarkan term yang terkandung dalam frequent itemsets. Proses pencarian dilakukan terhadap cluster dan kumpulan dokumen ringkasan tesis. Pada tahap ini akan diujikan apakah dokumen yang dikembalikan relevan dengan kata kunci yang dimasukkan.
4
HASIL DAN PEMBAHASAN
Data Penelitian
Data yang digunakan dalam penelitian ini adalah dokumen ringkasan tesis mahasiswa Pascasarjana IPB dalam bahasa Inggris yaitu sebanyak 295 dokumen yang bersumber dari Direktorat Integritas Data dan Sistem Informasi (DIDSI) IPB. Gambar 2 adalah contoh dokumen ringkasan tesis mahasiswa pascasarjana IPB yang dapat diunduh pada halaman website repository IPB pada laman http://repository.ipb.ac.id.
Gambar 2 Dokumen ringkasan tesis mahasiswa Pascasarjana IPB
Header yang berisi nama penulis, judul tesis dan komisi pembimbing.
Isi ringkasan tesis yang berisi latar belakang masalah, tujuan penelitian, metode yang digunakan serta hasil penelitian.
Praposes Data
Tahap yang dilakukan sebelum tahap praproses data adalah mengumpulkan sebanyak 295 dokumen yang diambil secara acak dari berbagai disiplin ilmu pascasarjana IPB dan semua dokumen tersebut disimpan dalam sebuah file teks dengan format csv (comma delimited). Tahap praproses data adalah untuk menjadikan data kumpulan dokumen sebanyak 295 dokumen menjadi kumpulan term. Tahapan-tahapan praproses yang dilakukan adalah proses tokenisasi yaitu proses pemisahan suatu rangkaian kalimat menjadi rangkaian kata berdasarkan karakter dan dipisahkan dengan sehingga setiap istilah (term) bersifat individu dan bersifat konseptual. Stopword removal menghilangkan term berdasarkan daftar stopword, penghapusan angka, stemming menghilangkan imbuhan dan akhiran sehingga hanya menjadi kata dasar dari setiap istilah dan penghapusan tanda baca.
Pada sub-bab ini juga dijelaskan perintah-perintah dalam bahasa pemrograman R pada tahap praposes data sehingga menghasilkan sebuah document term matrix. Pada tahap praproses data menggunakan bahasa pemrograman R, setiap fungsi yang akan dijalankan menggunakan library yang telah disediakan. Dalam hal ini library yang digunakan adalah library(tm).
Sebagai ilustrasi akan dipaparkan tahapan praproses data dengan menggunakan dokumen asli, namun dalam bentuk satu paragraf untuk menjelaskan perubahan dokumen dari setiap tahapan dalam tahap praproses data dapat dijelaskan sebagai berikut:
Following the global spike in food prices in 2008, there is renewed interest in Indonesia in self-sufficiency as a means of achieving food security. Restrictive trade policies, including specific tariffs on rice and sugar, and quantitative restrictions on imports and exports, have been used in an attempt to meet conflicting objectives of assisting both producers and consumers.
Tokenizaion
Tokenisasi merupakan proses pemisahan suatu rangkaian kata sehingga setiap kata besifat individu dan berdiri sendiri, dan pada waktu yang bersamaan dilakukan juga proses penghapusan karakter tertentu, seperti simbol dan mengubah semua huruf kapital menjadi huruf kecil. Untuk proses tokenisasi dan transformasi dokumen dilakukan dengan menjalankan perintah-perintah dalam Bahasa R berikut:
1 for (j in seq(my.corpus)) 2 {
3 my.corpus[[j]] <- gsub("ƒ", " ", my.corpus[[j]]) 4 my.corpus[[j]] <- gsub("@", " ", my.corpus[[j]]) 5 my.corpus[[j]] <- gsub("-", " ", my.corpus[[j]]) 6 my.corpus[[j]] <- gsub("\\|", " ", my.corpus[[j]]) 7 }
8 my.corpus <- tm_map(my.corpus, tolower)
kumpulan dokumen. Sementara itu, baris kedelapan menyatakan proses tolower, yaitu merubah huruf kapital menjadi huruf kecil, sehingga dokumen sudah terdiri dari kata-kata yang terpisah satu dengan lainnya tanpa huruf kapital pada semua kumpulan dokumen. Hasil dokumen yang terbentuk sebagai berikut:
following the global spike in food prices in 2008, there is renewed interest in indonesia in self sufficiency as a means of achieving food security. restrictive trade policies, including specific tariffs on rice and sugar, and quantitative restrictions on imports and exports, have been used in an attempt to meet conflicting objectives of assisting both producers and consumers.
Remove Number
Remove number merupakan proses penghilangan karakter angka yang terdapat dalam kumpulan dokumen, sehingga tidak terdapat karakter angka. Perintah dalam Bahasa R berikut digunakan dalam proses remove number.
my.corpus <- tm_map(my.corpus, removeNumbers)
Hasil dari proses remove number berikut sudah tidak terdapat karakter angka. Penghilangan karakter angka dilakukan terhadap semua dokumen.
follow global spike food price in , renew interest indonesia self suffici mean achiev food security. restrict trade policies, includ specif tariff rice sugar, quantit
restrict import exports, use attempt meet conflict object assist produc consumers.
Stopword Removal
Stopword removal akan menghilangkan sebagian besar kata yang tidak signifikan, yang tidak menyampaikan makna apapun sebagai dimensi dalam model vektor berdasarkan tabel stopword bahasa Inggris dengan menjalankan perintah-perintah dalam Bahasa R berikut:
my.corpus<- tm_map(my.corpus,removeWords,stopwords("english"))
Hasil dari proses stopword removal tersebut menghilangkan beberapa term misalkan kata the, in, there dan lain-lain sesuai dengan tabel stopword dalam bahasa Inggris. Hasil dokumen yang terbentuk sebagai berikut:
following global spike food prices , renewed interest indonesia self sufficiency means achieving food security. restrictive trade policies, including specific tariffs rice sugar, quantitative restrictions imports exports, used attempt meet conflicting objectives assisting producers consumers.
Stemming
Proses stemming bertujuan untuk menghilangkan awalan dan akhiran dari setiap kata, sehingga terbentuk kata dasar. Perintah dalam Bahasa R berikut digunakan dalam proses stemming.
Hasil dari proses stemming tersebut adalah sebagai berikut, dimana telah dihilangkannya awalan dan akhiran, sehingga setiap term bermakna kata dasar. follow global spike food price , renew interest indonesia self suffici mean achiev food security. restrict trade
policies, includ specif tariff rice sugar, quantit restrict import exports, use attempt meet conflict object assist produc consumers.
Remove Punctuation
Remove punctuation merupakan proses menghilangkan karakter tanda baca seperti koma, titik, dan lain lain. Perintah yang digunakan menghilangkan tanda baca dalam Bahasa R adalah sebagai berikut:
my.corpus <- tm_map(my.corpus, removePunctuation)
Hasil dari proses remove punctuation tersebut adalah kalimat yang terbentuk sudah tidak dipisahkan dengan suatu tanda baca seperti titik, koma dan lain-lain, sehingga sudah tidak terdapat karakter tanda baca dalam kumpulan dokumen.
follow global spike food price renew interest indonesia self suffici mean achiev food secur restrict trade polici includ specif tariff rice sugar quantit restrict import export use attempt meet conflict object assist produc consumer
Strip White Space
Strip white space merupakan proses menghilangkan karakter spasi. Hal ini perlu dilakukan karena pada tahap proses sebelumnya, jarak antara term masih tidak beraturan, tiap term dipisahkan dengan satu atau lebih karakter spasi. Oleh karena itu perlu penghapusan karakter spasi agar setiap kata hanya dipisahkan dengan satu karakter spasi. Perintah dalam Bahasa R berikut yang digunakan untuk memisahkan jarak antara term dengan satu karakter spasi.
tm_map(my.corpus, stripWhitespace)
Hasil dari proses strip white space tersebut adalah kalimat yang terbentuk sudah tidak dipisahkan dengan beberapa karakter spasi, melainkan setiap kata hanya dipisahkan dengan satu karakter spasi.
follow global spike food price renew interest indonesia self suffici mean achiev food security restrict trade policies includ specif tariff rice sugar quantit restrict import exports use attempt meet conflict object assist produc consumers
Pembuangan stopword
misalkan can, use, result, research, studi dan lain-lain. Term tersebut muncul hampir disetiap dokumen, namun sebenarnya term tersebut tidak bermakna atau mempresentasikan isi dokumen. Perintah-perintah dalam Bahasa R berikut yang dijalankan dalam pembuatan tabel dan penghapusan stopword.
1 mystopwords
<-2 my.corpus <- tm_map(my.corpus, removeWords, mystopwords)
menggunakan ejaan dalam bahasa Indonesia maka perlu dimasukkan dalam tabel stopword sehingga dapat dihilangkan. Baris kedua menyatakan tentang pembuangan term berdasarkan tabel stopword yang dibuat. Hasil penghilangan term berdasarkan stopword adalah sebagai berikut:
follow global spike food price renew indonesia self suffici mean achiev food security restrict trade policies includ specif tariff rice sugar quantit restrict import exports attempt meet conflict object assist produc consumers
Remove sparse term
Remove sparse term adalah proses menghilangankan term yang frekuensi kemunculannya rendah. Nilai sparsity adalah nilai yang dipakai untuk menentukan seberapa banyak term yang akan dihilangkan dari document term matrix. Rentang nilai sparsity berkisar antara 0 sampai dengan 1. Pemberian nilai sparsity yang besar akan mengakibatkan jumlah term yang dihasilkan semakin banyak.
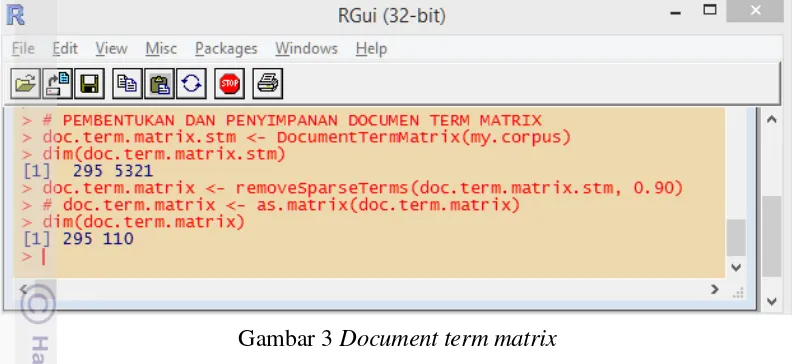
Perintah-perintah dalam Bahasa R berikut digunakan untuk mempresentasikan dokumen dalam document term matrix. Proses yang dilakukan pada tahap ini adalah menghitung frekuensi kemunculan tiap-tiap term pada document term matrix, dan menghilangkan term yang jumlah frekuensi kemunculannya lebih kecil dari nilai remove sparse time yang diberikan yaitu sebesar 0.90. Nilai remove sparse term 0.90 akan menghilangkan term yang jumlah frekuensi kemunculanya dari seluruh dokumen yang lebih kecil dari hasil perhitungan jumlah dokumen keseluruhan yang dikalikan dengan hasil 1 0.90. Sebagai contoh apabila jumlah frekuensi kemuncuan term j dari seluruh dokumen sebanyak 34, sedangkan jika nilai N * (1 0.90) adalah 40, N adalah jumlah dokumen keseluruhan, maka term j tersebut akan dihilangkan, karena jumlah frekuensi kemunculan term j yaitu 34 lebih kecil dari dari 40. Begitu juga sebaliknya, apabila jumlah frekuensi kemunculan term j dari keseluruhan dokumen lebih besar dari nilai sparse maka term j tersebut tidak akan dihilangkan. Proses ini dilakukan terhadap semua term, sehingga isi dari document term matrix berisi term-term yang frekuensi kemunculannya lebih besar dari nilai sparse yang ditentukan.
1 # PEMBENTUKAN DOCUMENT TERM MATRIX
2 term.doc.matrix.stm <- TermDocumentMatrix(my.corpus) 3 dim(doc.term.matrix.stm)
4 doc.term.matrix <- removeSparseTerms(doc.term.matrix.stm, 0.90)
5 dim(doc.term.matrix)
Gambar 3 Document term matrix
Gambar 3 menunjukkan hasil akhir pada tahap proposes data. Document term matrix yang dihasilkan dari dari kumpulan dokumen memiliki sebanyak 5321 term. Kemudian dilakukan penghapusan term yang kemunculannya kurang dari nilai sparsity yang ditentukan yaitu 0.90, sehingga dihasilkan sebanyak 110 term. Document term matrix sebanyak 110 term inilah yang akan dilakukan proses penggalian frequent itemsets dan proses clustering.
Visualiasi Wordcloud dokumen berdasarkan frekuensi term yang dihasilkan dapat dilihat pada Gambar 4. Perintah-perintah dalam Bahasa R berikut digunakan untuk menggambarkan visualisasi wordcloud.
1 #EXPLORING AND DISTRIBUTION OF TERM FREQUENCIES
2 freq <- sort(colSums(as.matrix(dtm)), decreasing=TRUE) 3 #VISUALISASI WORD CLOUDS
4 library(wordcloud) 5 set.seed(142)
6 wordcloud(names(freq), freq, min.freq=30, scale=c(2, .1), colors=brewer.pal(6, "Dark2"))
Gambar 4 Wordcloud untuk dokumen ringkasan tesis mahasiswa Pascasarjana IPB
Dari visualisasi wordcloud pada Gambar 4, dapat dijelaskan bahwa ukuran huruf term yang lebih besar menandakan bahwa frekuensi kemunculan term tersebut lebih tinggi dibandingkan dengan term yang lain dari kumpulan dokumen. Term product, develop, method, data, increase dan base mempunyai frekuensi kemunculan yang tinggi pada kumpulan dokumen. Frekuensi kemunculan term product sebanyak 207, develop sebanyak 195, method sebanyak 188, data sebanyak 185, increase sebanyak 185, dan base sebanyak 184. Perintah-perintah dalam tahap proposes data secara lengkap dapat dilihat pada lampiran 1.
Penggalian Frequent Itemset dengan Algoritme Apriori
Tahap penggalian frequent itemsets dilakukan berdasarkan data document terms matrix dengan menggunakan algoritme Apriori. Proses penggalian frequent itemsets dilakukan dengan memberikan nilai support 0.10 dan nilai confidence 0.8. Nilai support menunjukkan persentasi jumlah transaksi yang mengandung {term1, term2, term3} dan nilai confidence menunjukkan persentasi {term3} yang terdapat pada transaksi yang mengandung {term1, term2}. Frequent itemsets adalah set term yang dihasilkan dari algoritme Apriori yang melakukan proses transaksi terhadap semua term. Algoritme Apriori akan memproses keterkaitan kemunculan suatu term terhadap term yang lain yang muncul secara bersamaan dalam suatu dokumen yang mempunyai nilai support ≥ minimum support. Sebuah frequent itemsets adalah seperangkat individu kata-kata yang mencakup makna konseptual dan kontekstual daripada kata yang berdiri sendiri. Perintah-perintah dalam Bahasa R berikut digunakan untuk menggali frequent itemsets.
1 # PEMBENTUKAN TRANSAKSI TERM 2 library(arules)
3 trans <- as(doc.term.matrix, "transactions") 4 # GENERATE FREQUENT ITEMSET USING APRIORI
5 frequent <- apriori(trans, parameter = list(sup=0.10, conf = 0.8, target="frequent itemsets", minlen=2, maxlen=4))
7 frequent <- as(items(frequent), "matrix")
Baris pertama pada pernyataan di atas menyatakan tentang judul pembentukan transaksi term. Baris kedua menjelaskan pemanggilan library(arules) yang mempunyai fungsi menentukan frequent itemsets. Baris ketiga menjelaskan transaksi terhadap semua term dari document term matrix yang nantinya akan digunakan dalam proses penggalian frequent itemsets. Baris keempat menjelaskan judul menggali frequent itemsets menggunakan algoritme Apriori. Baris kelima menjelaskan pembentukan frequent itemsets menggunakan algoritma Apriori dengan batasan nilai minimum support 0.10 dan minimum confidence 0.80, target adalah menentukan kaidah frequent itemsets, dengan minimal itemsets (minlen) sebanyak dua term dan maksimal itemset (maxlen) sebanyak empat term. Baris keenam menjelaskan mengenai judul transformasi frequent itemsets dalam sebuah matriks, dan baris ketujuh menjelaskan representasi frequent itemsets dalam sebuah matriks. Matriks frequent itemset inilah yang akan digunakan dalam proses clustering.
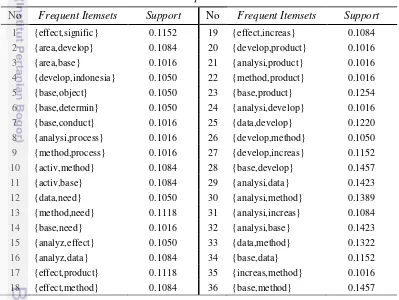
Frequent itemsets yang dihasilkan dengan nilai minimum support 0.10 dan minimum confidence 0.8 dihasilkan sebanyak 36 frequent itemsets yang diberikan pada Tabel 1. Kemudian frequent itemsets yang dihasilkan akan dikelompokkan menggunakan algoritme Bisecting K-Means.
Tabel 1 Frequent Itemsets
No Frequent Itemsets Support No Frequent Itemsets Support 1 {effect,signific} 0.1152 19 {effect,increas} 0.1084 2 {area,develop} 0.1084 20 {develop,product} 0.1016 3 {area,base} 0.1016 21 {analysi,product} 0.1016 4 {develop,indonesia} 0.1050 22 {method,product} 0.1016 5 {base,object} 0.1050 23 {base,product} 0.1254 6 {base,determin} 0.1050 24 {analysi,develop} 0.1016 7 {base,conduct} 0.1016 25 {data,develop} 0.1220 8 {analysi,process} 0.1016 26 {develop,method} 0.1050 9 {method,process} 0.1016 27 {develop,increas} 0.1152 10 {activ,method} 0.1084 28 {base,develop} 0.1457 11 {activ,base} 0.1084 29 {analysi,data} 0.1423 12 {data,need} 0.1050 30 {analysi,method} 0.1389 13 {method,need} 0.1118 31 {analysi,increas} 0.1084 14 {base,need} 0.1016 32 {analysi,base} 0.1423 15 {analyz,effect} 0.1050 33 {data,method} 0.1322 16 {analyz,data} 0.1084 34 {base,data} 0.1152 17 {effect,product} 0.1118 35 {increas,method} 0.1016 18 {effect,method} 0.1084 36 {base,method} 0.1457
digunakan. Setiap bahasa peprograman mempunyai cara yang berbeda ketika proses stemming dijalankan walaupun algoritme stemming yang digunakan sama. Untuk itu perlu diadakan kajian mendalam mengenai proses stemming¸ sehingga ada persamaan persepsi tentang hal tersebut. Namun hal ini bukanlah suatu kendala disebabkan merupakan bentuk representasi term pada VSM. Representasi tersebut tidak mempengaruhi keutuhan dokumen asli.
Itemsets {base,develop} dan itemsets {base,method} mempunyai nilai support tertinggi, yaitu 0.1457. Nilai support adalah nilai atau persentase dari frekuensi transaksi kombinasi term yang muncul secara bersamaan pada suatu dokumen terhadap semua transaksi. Kemunculan term base terhadap term develop, dan term base terhadap term method sangatlah dominan dalam kumpulan dokumen. Hal ini dikarenakan kedua itemsets tersebut mempunyai frekuensi kemunculan secara bersamaan pada setiap dokumen sangat tinggi. Frequent itemsets yang terbentuk adalah hasil korelasi antara suatu term dengan term yang lain yang akan muncul secara bersamaan dengan batasan nilai minsup dan mincof. Korelasi menggambarkan hubungan term satu dengan term yang lain yang terkandung dalam suatu itemsets berdasarkan nilai support. Berikut perintah dalam Bahasa R untuk menggambarkan korelasi antar term dalam penggalian itemsets pada Gambar 5.
plot(frequent, method="graph")
Pernyataan di atas menyatakan pemanggilan fungsi untuk memvisualisasikan hubungan antara term berdasarkan nilai minsup dan mincof. Visualisasi korelasi antar term ditampilkan pada Gambar 5 menggunakan metode graph.
Gambar 5 Korelasi antar items (term)
tinggi. Itemsets {base,develop}, itemsets {base,method}, itemsets {analysi,data}, dan itemsets {analysi,data}. Nilai support {base,develop} dan {base,method} adalah 0.1457, sedangkan {analysi,data} dan {analysi,base} adalah 0.1423.
Itemsets yang dihasilkan tidak semua terdapat pada tiap-tiap dokumen, hal ini dikarenakan algoritme Apriori menggali itemsets yang nilai support-nya di atas atau sama dengan minimum support. Dalam beberapa dokumen hanya terdapat beberapa term yang dapat dijadikan kandidat dalam pembentukan itemsets. Tabel 2 menyatakan dokumen yang mengandung itemsets pada kumpulan dokumen terhadap empat itemsets yang mempunyai nilai support tertinggi. Itemset dengan nilai support tertinggi akan berisi kumpulan dokumen yang lebih banyak dibandingkan dengan itemsets dengan nilai terendah. Perintah-perintah dalam Bahasa R pada tahap penggalian frequent itemsets secara lengkap dapat dilihat pada lampiran 2.
Tabel 2 Dokumen yang mengandung frequent itemsets No Frequent
Itemsets Support Dokumen Mengandung Frequent Itemsets
1 {base,develop} 0.1457
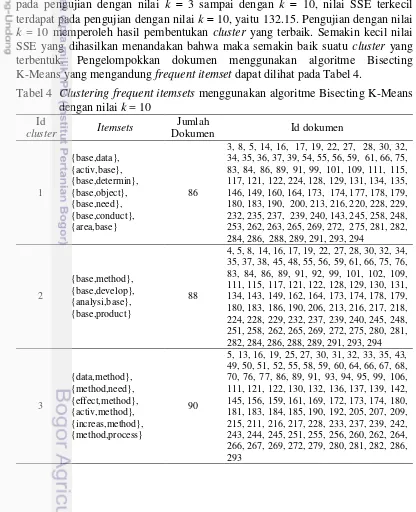
Clustering Frequent Itemset Menggunakan AlgoritmeBisecting K-Means Pembentukan cluster yang digunakan adalah algoritme Bisecting Kmeans, dengan jumlah cluster yang diujikan adalah k 3 sampai dengan k 10. Hal ini dilakukan untuk melihat perbandingan hasil cluster yang terbentuk. Pembentukan cluster dilakukan menggunakan data matrix frequent itemsets. Matrix frequent itemsets adalah sebuah matriks yang berisi frequent itemsets. Tabel 3 berisi hasil pembentukan cluster dokumen berdasarkan nilai Sum of Squared Error (SSE) tiap-tiap pembentukan jumlah cluster yang diujikan. Perintah-perintah dalam Bahasa R pada tahap pembentukan cluster menggunakan algoritme Bisecting K-Means secara lengkap dapat dilihat pada lampiran 3.
Tabel 3 Nilai SSE cluster dokumen menggunakan algoritme Bisecting K-Means Jumlah Cluster (k) Nilai SSE
Jumlah Cluster (k) Nilai SSE
Dengan menggunakan algoritme Bisecting K-Means, pembentukan cluster pada pengujian dengan nilai k 3 sampai dengan k 10, nilai SSE terkecil terdapat pada pengujian dengan nilai k 10, yaitu 132.15. Pengujian dengan nilai k = 10 memperoleh hasil pembentukan cluster yang terbaik. Semakin kecil nilai SSE yang dihasilkan menandakan bahwa maka semakin baik suatu cluster yang
terbentuk. Pengelompokkan dokumen menggunakan algoritme Bisecting K-Means yang mengandung frequent itemset dapat dilihat pada Tabel 4.
Id
Dari hasil pengelompokkan menggunakan algoritme Bisecting K-Means terhadap itemsets, terlihat bahwa pada cluster dua menunjukkan pengelompokan yang berisi empat itemsets yang mempunyai nilai support yang tinggi. Dari empat itemsets tersebut, itemsets {base,method} dan {base,develop} dengan nilai support 0.1457, itemsets{analysi,base} dengan nilai support 0.1423, dan itemsets {base,product} dengan nilai support 0.1254.
rentetan teks (truncation and text string searching), pembatasan penelusuran (stop list or common word list), thesaurus atau pendukung perbendaharaan kosa kata (thesaurus/vocabulary support), kedekatan penelusuran (proximity searching), pembatasan penelusuran dengan ruas (limiting searching by field), dan penelusuran kawasan numerik (numeric range searching).
Boolean query formulation atau yang lebih dikenal dengan operator Boolean logic merupakan hubungan dari istilah-istilah yang ditelusuri. Boolean logic terdiri dari 3 operator logis, yaitu operator AND, operator OR dan operator NOT. Operator boolean berfungsi sebagai instruksi atas informasi yang diinginkan pengguna. Operator boolean berperan sebagai pembentuk konsep dari apa yang hendak dipakai terhadap sistem temu kembali informasi, misalkan mengunakan salah satu operator atau memadukan beberapa operator sesuai dengan kebutuhan informasi yang akan ditampilkan.
Pada penelitian ini metode yang digunakan untuk proses temu kembali dokumen yang digunakan adalah menggunakan operator boolean AND. Operator Boolean AND digunakan untuk menghadirkan dokumen-dokumen dimana kedua istilah yang ditelusur sama-sama disebutkan dalam satu dokumen. Penelusuran dengan menggunakan operator AND akan memperkecil hasil informasi yang ditemukan. Sebagai contoh kata kunci yang dimasukkan berdasarkan term base AND method maka akan menghadirkan dokumen yang mengandung term base dan term method saja, dokumen yang hanya berisi salah satu dari istilah tersebut tidak akan muncul. Maka, semakin banyak jumlah term dalam suatu itemsets yang terbentuk, semakin sedikit persentase perolehan dokumen. Contoh penggunaan operator AND dalam penelusuran dokumen dalam sistem menggunakan bahasa pemrograman R adalah sebagai berikut:
query <- base&&method
Dari perintah tersebut dapat dijelaskan bahwa query dipresentasikan dengan term base dan method. Penelusuran akan dilakukan terhadap kedua term tersebut yang muncul secara bersamaan dalam sebuah dokumen. Dokumen yang mengandung kedua term tersebut akan dikembalikan dalam proses penelusuran, sedangkan dokumen yang hanya mengandung salah satu term tersebut akan diabaikan. Pengujian terhadap inputan dari kata kunci menggunakan frequent itemsets terhadap dokumen ringkasan tesis mahasiswa Pascasarjana IPB berdasarkan cluster yang terbentuk dapat dilihat pada Tabel 5.
Tabel 5 Jumlah dokumen yang mengandung frequent itemsets
Frequent itemsets Jumlah dokumen
hasil query {base,data}, {activ,base}, {base,determin}, {base,object},
{base,need}, {base,conduct}, {area,base} 86 {base,method}, {base,develop}, (analysi,base}, {base,product} 88
88 dokumen yang ada pada cluster tersebut. Namun apabila pencarian dilakukan terhadap kumpulan dokumen, maka pencarian akan dilakukan terhadap 295 dokumen secara keseluruhan, dan mengembalian dokumen berdasarkan kata kunci itemsets {base,method} sebanyak 42 dokumen. Oleh karena itu proses pencarian dokumen akan lebih cepat apabila tertuju pada cluster yang berisi dokumen yang telah dikelompokkan dibandingkan apabila pencarian dokumen dilakukan terhadap keseluruhan kumpulan dokumen.
Hal yang perlu diperhatikan bahwa, penggalian itemsets berdasarkan frekuensi kemunculan istilah akan mendapatkan term-term yang masih bersifat umum. Hal ini dapat disebabkan oleh beberapa faktor. Pertama, tabel stopword pada tahap praproses data belum mencakup istilah-istilah umum yang perlu dihapus dan untuk menghapus term yang masih bersifat umum, perlu dibuat sebuah tabel stopword tambahan.
Dari hasil pengujian terhadap term yang terbentuk, ternyata masih banyak mengandung term yang masih bersifat umum dan tidak mempunyai makna. Term yang muncul juga masih bersifat umum, dan hampir semua dokumen memuat term tersebut. Hal ini dikarenakan format penulisan setiap dokumen ringkasan tesis mengacu pada aturan yang berlaku, sehingga term-term tersebut banyak muncul hampir pada setiap dokumen. Oleh sebab itu akan dilakukan pengujian terhadap penambahan stopword yang dapat memunculkan term-term yang lebik spesifik dan lebih bermakna. Tabel 6 berisi term-term yang akan dihilangkan, sehingga dapat memunculkan term yang mengandung makna atau yang bersifat unik.
Tabel 6 Daftar tabel stopword tambahan untuk memunculkan term yang lebih spesifik
manag analysi
active analyz
develop need
method signific
increase process
result produc
product determin
effect group
level
(a)Hasil awal (b) Hasil penambahan stopword
Gambar 6 perubahan pembentukan itemsets akibat penambahan tabel stopword Dari visualisasi wordcloud pada Gambar 6, dapat dilihat bahwa term-term yang frekuensi kemunculannya tinggi dan tidak bermakna sudah dihilangkan, seperti term method, develop, increase, product, dan lain-lain. Sedangkan hasil document term matrix akibat penambahan stopword juga masih terdapat beberapa term yang sebenarnya masih dapat dihilangkan, karena pada hakekatnya tidak mengandung makna. Hal ini mengacu dari hasil pembentukan freguent itemsets yang diperlihatkan pada Tabel 7, bahwa sejumlah itemsets yang terbentuk berisi term-term yang sebenarnya masih bersifat umum. Oleh sebab itu, untuk membuat tabel stopword harus mempertimbangkan kaidah dan kajian yang mendalam terhadap istilah-istilah yang sering muncul namun tidak mempunyai makna, dan juga terhadap istilah yang jarang muncul namun mempunyai makna yang sifatnya unik. Penambahan tabel stopword dapat mempengaruhi hasil dari proses pembentukan frequent itemsets, clustering dan information retrieval.
Kedua, pemberian nilai sparsity, minsup dan mincof pada tahap penentuan frequent itemsets. Pemberian nilai sparsity, minsup dan mincof juga sangat berpengaruh dalam menentukan frequent itemset yang terbentuk. Semakin besar nilai sparsity dan semakin kecil nilai minsup yang diberikan maka akan semakin banyak frequent itemsets yang terbentuk, dan dapat menampilan itemsets dengan jumlah term lebih dari dua. Oleh sebab itu, kedua faktor tersebut memerlukan perhatian khusus karena akan mempengaruhi hasil pada tahap penggalian frequent itemsets, clustering, dan information retrieval.
Tabel 7 memperlihatkan hasil pembentukkan frequent itemsets yang diakibatkan perubahan daftar stopword menggunakan nilai remove sparse term (sparsity) yaitu 0.70 s/d 0.99, nilai minsup 0.005 s/d 0.11, dan nilai mincof 0.08. Tabel 7 Pembentukan frequent itemsets terhadap pengujian nilai sparsity, minsup
dan mincof
Nilai
Sparsity
Jumlah
term
Jumlah Frequent itemsets yang terbentuk berdasarkan nilai
minsup
Nilai
Sparsity
Jumlah
term
Jumlah Frequent itemsets yang terbentuk berdasarkan nilai
minsup
0.05 0.06 0.07 0.08 0.90 0.10 0.11 0.90 94 185 80 33 18 9 4 1 0.95 257 202 83 33 18 9 4 1 0.99 1407 202 83 33 18 9 4 1
Dari tabel di atas dapat disimpulkan bahwa semakin besar nilai sparsity dan semakin kecil nilai minsup yang diberikan, maka makin banyak itemsets yang terbentuk. Namun pemberian nilai minsup yang lebih besar dari 0.11, maka tidak akan terbentuk suatu itemsets, walaupun nilai sparsity yang diberikan besar. Pemberian nilai sparsity 0.70 pada semua pengujian dengan nilai minsup yang diberikan tidak menghasilkan itemsets. Hal ini dikarenakan term yang dihasilkan dari nilai tersebut hanya sebanyak satu term. Nilai mincof tidak berpengaruh terhadap hasil pembentukan frequent itemsets walaupun diujikan dengan merubah nilainya pada semua pengujian. Pada tahap praproses data pada dasarnya tidak menghilangkan makna dari setiap dokumen. Document term matrix yang dihasilkan merupakan representasi dokumen dalam vector space model, sehingga memudahkan untuk melakukan transaksi pembentukan frequent itemsets.
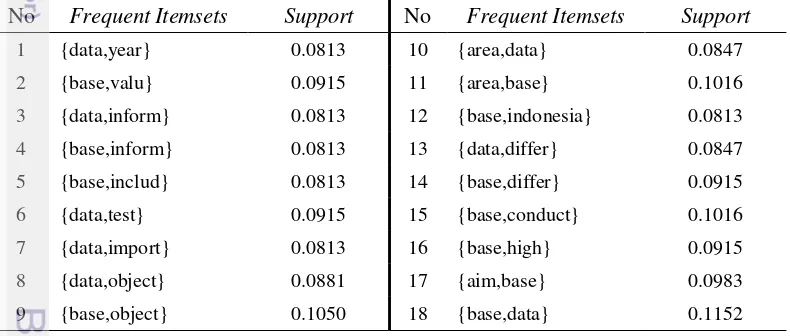
Pada pengujian berdasarkan nilai sparsity 0.90, nilai minsup 0.10 dan nilai mincof 0.8, hasil yang didapat adalah sebanyak 36 itemsets. Namun setelah ada penambahan stopword maka pengujian dengan nilai yang sama diperoleh hanya sebanyak 4 itemsets yang terbentuk. Dengan demikian dapat dikatakan bahwa penambahan tabel stopword mempengaruhi hasil pembentukan frequent itemsets. Selanjutnya dilakukan pengujian dengan nilai sparsity 0.90, nilai minsup 0.08 dan nilai mincof 0.8. Hal ini dilakukan untuk menggali dan melihat hasil pembentukan itemsets dari penambahan stopword. Tabel 8 memperlihatkan hasil pembentukan frequent itemsets berdasarkan nilai sparsity 0.90, nilai minsup 0.08 dan nilai mincof 0.8.
Tabel 8 Pembentukan frequent itemsets terhadap pengujian nilai sparsity 0.90, minsup 0.08, dan mincof 0.8
No Frequent Itemsets Support No Frequent Itemsets Support 1 {data,year} 0.0813 10 {area,data} 0.0847 2 {base,valu} 0.0915 11 {area,base} 0.1016 3 {data,inform} 0.0813 12 {base,indonesia} 0.0813 4 {base,inform} 0.0813 13 {data,differ} 0.0847
stopword. Perbedaan itemsets yang terbentuk sebelum dan sesudah adanya penambahan tabel stopword dapat dilihat dari visualisasi Gambar 5 dan Gambar 7. Dari kedua gambar tersebut menunjukkan bahwa itemsets dengan nilai support yang tinggi terkadang dapat dihilangkan karena term yang membentuk itemsets tersebut diasumsikan tidak mengandung makna.
Gambar 7 Korelasi antar items setelah penambahan tabel stopword
Dari pengujian yang dilakukan, term-term yang membentuk itemsets dipengaruhi pada saat praproses data. Pada proses inilah diharapkan data yang akan dioleh sudah tidak mengandung term-term yang masih bersifat umum dan tidak bermakna. Pembuatan tabel stopword dan pemberian nilai sparsity hendaknya dapat memunculkan term-term yang membentuk itemsets lebih spesifik dan bersifat unik, sehingga dapat mewakili sebuah dokumen secara keseluruhan. Pembentukan itemsets dapat mempengaruhi hasil clustering maupun proses temu kembali dokumen. Dalam temu kembali dokumen, pada umumnya penguna akan memasukkan keyword atau kata kunci dengan suatu istilah yang sifatnya unik dan lebih spesifik.
SIMPULAN DAN SARAN
Simpulan