CLUSTERING
KONSEP DOKUMEN BERBAHASA
INDONESIA MENGGUNAKAN
BISECTING
K-MEANS
HIZRY RAMDANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ii
CLUSTERING
KONSEP DOKUMEN BERBAHASA
INDONESIA MENGGUNAKAN
BISECTING
K-MEANS
HIZRY RAMDANI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iii
ABSTRACT
HIZRY RAMDANI. Clustering Indonesian Documents Concept Using Bisecting K-means. Supervised by TAUFIK DJATNA and MUSHTHOFA.
In recent years, we have seen a tremendous growth in the volume of text documents available on the Internet, digital libraries, news sources, and company-wide intranets. This has led to an increased interest in developing methods that can efficiently categorize and retrieve relevant information. Concept indexing (CI) is a dimensionality reduction algorithm. Recently, techniques based on dimensionality reduction have been explored for capturing the concepts present in a collection of documents. In this research we investigate concept indexing as interpretation concept in Indonesian documents for clustering documents using bisecting K-means. This research showed concept-based documents clustering was achievable and that it increased the F-measure up to 38% as compared to word-based clustering.
Judul Skripsi : Clustering Konsep Dokumen Berbahasa Indonesia Menggunakan Bisecting K-means
Nama : Hizry Ramdani
NIM : G64062226
Menyetujui
Pembimbing I Pembimbing II
Dr. Eng. Taufik Djatna, M.Si. Mushthofa, S.Kom M.Sc. NIP. 19700614 199512 1001 NIP. 19820325 2009121 003
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
ii
RIWAYATHIDUP
Penulis dilahirkan di Bogor, 11 Mei 1988 sebagai anak kedua dari tiga bersaudara. Penulis
merupakan putra dari Ayah M Rafe’i S. Pd dan Ibu Sopiah.
Tahun 2006 penulis lulus dari SMAN 1 Megamendung dan pada tahun yang sama melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB), diterima di Departemen Ilmu Komputer, Fakutas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
iii
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah SWT atas kemurahan dan izin-Nya sehingga tugas akhir ini berhasil diselesaikan. Tak lupa shalawat serta salam penulis curahkan kepada Nabi Besar Muhammad SAW. Topik yang dipilih dalam penelitian adalah pengelompokan dokumen, dengan judul Clustering Konsep Dokumen Berbahasa Indonesia Menggunakan Bisecting K-Means.
Penulis berterima kasih kepada Bapak Dr. Eng. Taufik Djatna M.Si dan Mushthofa S.Kom, M.Sc selaku dosen pembimbing yang telah membimbing penulis selama penelitian penelitian berlangsung. Selain itu kepada Bapak Ir. Julio Adisantoso M.Kom dan staf pengajar Departemen Ilmu Komputer terima kasih atas ilmu yang telah diberikan, serta tidak lupa kepada staf tata usaha yang membantu dalam administrasi selama kuliah di IPB.
Terima kasih setulus-tulusnya penulis sampaikan kepada Mama, Bapak, Aa, Teteh dan Ade yang telah memberikan kasih sayang, perhatian, semangat dan doa. Kepada seluruh keluarga yang telah mendukung baik moral atau materil penulis sampaikan terima kasih.
iv
DAFTAR ISI
Halaman
DAFTAR GAMBAR... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
Manfaat Penelitian... 1
TINJAUAN PUSTAKA ... 1
Clustering ... 1
Pemodelan Ruang Vektor ... 2
K-Means ... 2
Bisecting K-means... 2
Concept Indexing ... 3
Centroid Maksimum ... 3
Rand Index ... 3
F-Measure ... 4
METODE PENELITIAN ... 4
Koleksi Dokumen ... 4
Praproses... 4
Pemodelan Ruang Vektor ... 5
Concept Indexing ... 5
Clustering ... 5
Evaluasi ... 6
HASIL DAN PEMBAHASAN ... 6
Karakteristik Dokumen ... 6
Menghapus Stopwords dan Term dengan df < Treshold ... 6
Evaluasi Kinerja Sistem ... 6
Waktu Proses ... 9
Konsep dalam Koleksi ... 9
KESIMPULAN DAN SARAN ... 9
Kesimpulan ... 9
Saran ... 9
v
DAFTAR GAMBAR
Halaman
1 Metode penelitian. ... 4 2 Struktur dokumen teks. ... 6 3 Diagram nilai rand index pada jumlah dimensi berbeda untuk clustering dokumen menggunakan
bisecting K-means dengan concept indexing (centroid rata-rata)... 7 4 Diagram perbandingan nilai rand index antara bisecting K-means dan bisecting K-means dengan concept indexing (centroid rata-rata) dan (centroid maksimum) dengan jumlah dimensi 25. ... 7
DAFTAR LAMPIRAN
Halaman
1 Daftar kata buang (stopwords)... 12 2 Rand index pada dimensi yang berbeda untuk bisecting K-means dengan concept indexing (centroid maksimum). ... 13 3 Diagram nilai F-measure pada jumlah dimensi berbeda untuk clustering dokumen
menggu-nakan bisecting K-means dengan concept indexing (centroid rata-rata)... 13 4 Diagram nilai F-measure pada jumlah dimensi berbeda untuk clustering dokumen
1
PENDAHULUAN
Latar Belakang
Keakuratan dan kecepatan untuk memperoleh informasi menjadi salah satu aspek yang sangat diperhitungkan dalam temu kembali informasi. Keakuratan informasi berhubungan dengan kesesuaian informasi yang ditampilkan dengan keinginan pengguna. Pengguna menginginkan informasi yang sesuai dengan query yang dimasukan ke dalam sistem temu kembali. Sama halnya dengan keakuratan, waktu sangat mempengaruhi kepuasan pengguna. Setiap pengguna menginginkan waktu yang pendek dalam memperoleh informasi. Bila ditinjau dari volume dokumen teks yang berada di internet, perpustakaan digital, dan web intranet perusaan yang sangat besar, dibutuhkan suatu sistem yang efisien dalam mengekstraksi informasi sehingga waktu untuk mendapatkan informasi menjadi lebih pendek.
Salah satu cara untuk meningkatkan hasil temu kembali informasi adalah dengan menerapkan algoritme statistik, di antaranya clustering dan classification (Dhillon & Modha 2000). Clustering adalah proses pengelompokan sekumpulan objek ke dalam kelas yang objeknya mirip (Han & Kamber 2006). Clustering telah digunakan dalam menemukan
“konsep terpendam” dalam sekumpulan
dokumen teks yang tidak terstruktur dan proses pencarian teks dalam jumlah besar seperti Yahoo (Dhillon & Modha 2000).
Jumlah dokumen yang sangat besar menjadi tantangan tersendiri dalam temu kembali informasi. Semakin beragam dan besar jumlah dokumen maka semakin tinggi dimensi sebuah dokumen dalam koleksi. Jumlah dokumen dan dimensi sangat mempengaruhi waktu proses. Semakin besar dan tinggi dimensi dokumen maka waktu proses temu kembali informasi akan semakin bertambah. Salah satu cara untuk mengatasi masalah ini adalah dengan cara mengurangi dimensi suatu dokumen. Concept indexing adalah salah satu metode yang digunakan untuk mengurangi dimensi. Concept indexing memiliki keunggulan dibandingkan dengan metode pengurangan dimensi seperti Latent Semantic Index (LSI) karena memiliki waktu proses lebih rendah (Karypis G & Han E 2000). Maka dari itu, penelitian ini akan mencoba menerapkan concept indexing untuk koleksi dokumen berbahasa Indonesia dan mengetahui pengaruhnya terhadap clustering dokumen menggunakan bisecting K-means.
Tujuan Penelitian
Tujuan penelitian ini adalah melakukan clustering dokumen berbahasa Indonesia berdasarkan konsep dan mengukur pengaruh metode pengurangan dimensi menggunakan concept indexing terhadap bisecting K-means untuk pengelompokan dokumen berbahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah sebagai berikut:
1. Dokumen yang digunakan adalah dokumen berbahasa Indonesia.
2. Koleksi dokumen yang digunakan memiliki enam tema yaitu bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan.
3. Algoritme clustering yang digunakan untuk clustering konsep dokumen adalah bisecting K-means.
4. Jumlah cluster untuk
mengelompokkan konsep dokumen adalah 6 yang disesuaikan dengan jumlah tema dalam koleksi dokumen. 5. Algoritme clustering yang digunakan
dalam proses concept indexing adalah bisecting K-means.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengetahui pengaruh algoritme pengurangan dimensi concept indexing untuk pengelompokan dokumen berbahasa Indonesia menggunakan bisecting K-means.
TINJAUAN PUSTAKA
Clustering
Proses pengelompokan sekumpulan objek ke dalam kelas-kelas yang objek-objeknya serupa disebut clutering. Objek-objek dalam sebuah cluster mirip satu sama lain dan berbeda dengan objek-objek dalam cluster lain (Han & Kamber 2006).
2 secara simultan sebagai bagian data dan tidak
membentuk struktur hierarkikal (Jain. A. K 2009).
Berikut ini adalah definisi partitional clustering. Misalkan diberikan sekumpulan masukan data = 1,…, ,…, � , dengan
= 1,…, 2,…, ∈ ℜ , adalah
atribut, dimensi atau variabel. Partitional clustering berusaha membagi ke dalam jumlah atribut atau jumlah dimensi data (Riu X & D.C Wunsch 2009).
Pemodelan Ruang Vektor
Dalam sebuah koleksi, tiap dokumen d dianggap sebagai sebagai vektor dalam term-space. Masing-masing dokumen digambarkan ke dalam vektor = 1, 2,…, ,
dengan adalah frekuensi term i dalam koleksi dokumen dan adalah jumlah term dalam koleksi. Perbaikan model ini dilakukan pada pembobotan masing-masing term didasarkan pada inverse document frequency dalam koleksi dokumen. Tujuan pembobotan ini adalah term yang muncul di jumlah dokumen yang berbeda memiliki kekuatan yang berbeda. Hal ini dilakukan dengan melakukan perkalian tiap term i dengan log� , dengan � adalah
jumlah dokumen dalam koleksi dan adalah jumlah dokumen yang mengandung term i (document-frequency). Representasi tf-idf pada sebuah dokumen adalah = { 1log �
Dalam pemodelan ruang vektor, ukuran kesamaan antara 2 dokumen dan dihitung dengan fungsi cosine sebagai berikut
cos( , ) = ∙
∗
dengan “∙” adalah dot product antara dua vektor
dan panjang satuan vektor dokumen i.
Misalkan diberikan sekumpulan dokumen yang mana tiap dokumen direpresentasikan dalam bentuk vector, maka vektor centroid adalah
= 1
∈
yaitu vektor yang dihasilkan dari bobot rata-rata berbagai macam term dalam kumpulan dokumen S (Karypis G & Han E 2000).
K-Means
Misalkan = , i = 1, …, n adalah sekumpulan titik berjumlah n yang memiliki m-dimensi dikelompokkan ke dalam cluster,
= , = 1,…, . Algoritme K-means melakukan pembagian anggota cluster sehingga square error (jumlah jarak) antara centroid dan titik-titik dalam cluster menjadi minimum. � adalah centroid (rata-rata) pada cluster . Square error antara � dan objek dalam cluster
didefinisikan sebagai berikut
( ) = − � 2
∈
Tujuan utama dari K-means adalah meminimumkan jumlah square error secara keseluruhan pada cluster. Berikut ini adalah persamaan sum of square error.
( ) = − � 2
∈
=1
Algoritme K-means dimulai dengan inisialisasi pembagian menjadi cluster dengan meminimumkan square error. Karena square error selalu berkurang dengan bertambahnya jumlah cluster ( = 0 ketika
= ). dapat diperkecil dengan tujuan hanya untuk memperbaiki jumlah cluster. Tahapan utama algoritme K-means adalah sebagai berikut:
1. menginisialisasi pembagian cluster; ulangi tahap 2 dan 3 hingga keanggotaan cluster stabil.
2. menciptakan partisi baru dengan menempatkan titik ke pusat cluster terdekat
3. menghitung pusat cluster baru (Jain A. K 2009).
Bisecting K-means
Bisecting K-means menggunakan K-means untuk membagi sebuah cluster menjadi dua (Savaresi et.al 2007). Bisecting K-means dimulai dengan cluster tunggal yang berisi seluruh dokumen. Berikut ini adalah algoritme bisecting K-means untuk menemukan cluster pada sebuah koleksi dokumen yaitu:
3 2. menemukan 2 sub-clusters
menggu-nakan K-means tipe dasar (tahap bisecting).
3. mengulangi tahap 2, tahap membagi dua untuk ITER waktu dan ambil hasil split clustering yang memiliki overall similarity tertinggi.
4. mengulangi langkah 1, 2 dan 3 hingga jumlah cluster tercapai.
ITER adalah jumlah percobaan membagi dua (bisection) untuk masing-masing fase bisecting K-means sehingga pada tahap 3 dipilih hasil pembagian yang memiliki kerapatan yang tinggi atau memiliki overall similarity tertinggi.
Pemilihan cluster yang akan dibagi dua dilakukan dengan cara mencari cluster terluas atau memiliki overall similarity yang paling rendah dari beberapa kandidat cluster. Overall similarity dihitung menggunakan cohesiveness internal cluster. Berikut ini adalah rumus overall similarity
Concept indexing (CI) memproyeksikan koleksi dokumen ke dalam k dimensi dengan mengelompokkan dokumen-dokumen ke dalam k kelompok kemudian menggunakan vektor centroid pada cluster untuk memperoleh axes pada pengurangan ruang k dimensi.
Berikut ini proses pengurangan ruang dimensi pada unsupervised dimensionality reduction. Jika k adalah jumlah dimensi yang diinginkan. Tahap awal CI melakukan pengelompokan koleksi dokumen menjadi k cluster. Kemudian menggunakan vektor centroid pada cluster sebagai axes pada pengurangan ruang dimensi k. Misalkan, D adalah matriks document-term n×m (n adalah jumlah dokumen dan m adalah jumlah term dalam koleksi), baris ke-i pada D menyimpan ruang vektor yang menggambarkan dokumen ke-i (D[i, *] = ) dan kolom ke-j menggambarkan term ke-j. CI menggunakan algoritme clustering untuk membagi dokumen-dokumen ke dalam k kelompok yang disjoint,
1, 2, …, . Kemudian dihitung vektor
centroid untuk setiap sebagai berikut
= 1
∈
Masing-masing centroid membentuk sebuah axis pada pengurangan ruang dimensi k dan k dimensi merepresentasikan tiap dokumen yang diperoleh dari proyeksi ke dalam ruang ini. Proyeksi dapat ditulis dalam notasi matriks sebagai berikut. Misal matriks m×k yang mana kolom ke-i pada merupakan . Kemudian dimensi k merepresentasikan tiap vektor dokumen melalui persamaan dan dimensi k merepresentasikan koleksi diberikan dalam matriks = . Serupa dengan dimensi dokumen, dimensi k yang merepresentasikan query pada temu informasi ditunjukkan dengan persamaan . Pada akhirnya kesamaan antara dua dokumen dalam pengurangan ruang dimensi dihitung dengan perhitungan cosine antara vektor yang telah dikurangi dimensinya (Karypis & Han 2000).
Centroid Maksimum
Diberikan sekumpulan masukan dengan pola = 1,…, ,…, � , dengan =
1,…, 2,…, ∈ ℜ , adalah atribut
dimensi atau variabel. Centroid maksimum untuk adalah = { � { 11, 21,…, �1} , � { 12, 22,…, �2},…, � { 1 , 2 ,…,
� }}.
Rand Index
Alternatif untuk menerjemahkan informasi secara teoritik pada cluster adalah penggambaran sebagai rangkaian keputusan, satu untuk masing-masing N(N-1)/2 pasang dokumen dalam koleksi pada N cluster. Kita ingin menempatkan dua dokumen ke dalam cluster yang sama jika dan hanya jika kedua dokumen tersebut mirip. True positif (TP) adalah keputusan menempatkan dua dokumen yang mirip ke cluster yang sama, true negative (TN) adalah keputusan menempatkan dua dokumen yang tidak mirip ke cluster berbeda. Terdapat dua tipe kesalahan yang dapat terjadi pada clustering. False positif (FP) adalah keputusan menempatkan dua dokumen yang tidak mirip ke cluster yang sama. False negative (FN) adalah keputusan menempatkan dua dokumen yang mirip ke cluster yang berbeda. Rand index mengukur persentase terhadap keputusan yang sesuai. Berikut adalah persamaan rand index
= �+ �
4
F-Measure
F-measure mengombinasikan precision dan recall untuk temu kembali informasi. Nilai recall dan precision pada suatu keadaan dapat memiliki bobot (nilai keutamaan) yang berbeda. Ukuran yang menampilkan timbal balik antara recall dan precision adalah F-measure yang merupakan bobot harmonic mean pada recall dan precision. Berikut adalah persamaan F-measure keputusan menempatkan dua dokumen yang tidak mirip ke cluster berbeda. Terdapat dua tipe kesalahan yang dapat terjadi pada clustering. False positif (FP) keputusan menempatkan dua dokumen yang tidak mirip ke cluster yang sama. False negative (FN) keputusan menempatkan dua dokumen yang mirip ke cluster yang berbeda.
Kita dapat menggunakan F-measure dengan nilai false negative lebih kuat daripada false positive maka kita akan memberi nilai β> 1
sehingga memberikan bobot yang lebih untuk recall. F-measure yang seimbang memberikan bobot yang sama antara recall dan precision, dengan nilai = 1 2 atau β= 1. Hal ini dapat ditulis F1 atau �=1 sehingga persamaan
menjadi (Manning et.al 2009).
�=1 =
2 �
�+
METODE PENELITIAN
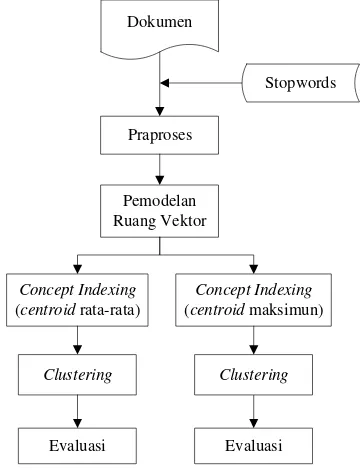
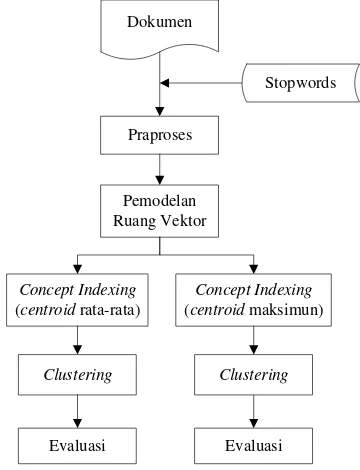
Secara garis besar metode penelitian yang digunakan dalam penelitian ini adalah seperti pada Gambar 1. Data yang akan diproses dalam sistem ini adalah koleksi dokumen. Masukan lain yang digunakan adalah stopwords yang merupakan daftar kata buang yang akan digunakan pada praproses. Setelah praproses, dilakukan pemodelan ruang vektor untuk melakukan pembobotan terhadap term dan merepresentasikan dokumen ke dalam bentuk vektor. Concept indexing dilakukan untuk mengurangi dimensi dokumen. Hasil dari
concept indexing adalah matriks document-concept yang kemudian akan dikelompokkan menjadi K cluster. Pada tahap akhir, dilakukan evaluasi menggunakan rand index terhadap hasil clustering.
Gambar 1 Metode penelitian.
Koleksi Dokumen
Penelitian ini menggunakan tiga koleksi dokumen yang berjumlah 400, 500, dan 600 dokumen. Koleksi dokumen yang digunakan telah diketahui jumlah kelasnya. Ketiga koleksi dokumen berasal dari sumber yang sama dan setiap koleksi memiliki 6 kelas yaitu dokumen yang bertemakan bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan. Tiap kelas dalam koleksi memiliki jumlah yang relatif sama.
Seluruh dokumen yang digunakan merupakan milik laboratorium Temu Kembali Informasi IPB yang diambil dari beberapa
5 Tokenisasi adalah suatu tahap pemrosesan
teks input yang dibagi menjadi unit-unit kecil yang disebut token atau term, yang dapat berupa suatu kata atau angka. Dalam penelitian ini tanda baca dihilangkan sehingga tidak dianggap sebagai token.
Stopwords adalah daftar kata-kata yang dianggap tidak memiliki makna. Kata yang tercantum dalam daftar ini dibuang dan tidak ikut diproses pada tahap selanjutnya. Pada umumnya kata-kata yang masuk ke dalam stopwords memiliki tingkat kemunculan yang tinggi ditiap dokumen sehingga kata tersebut tidak dapat digunakan sebagai penciri suatu dokumen. Daftar kata buang yang digunakan sama seperti (Ridha 2006). Selain pembuangan stopwords dilakukan juga pembuangan kata yang memiliki jumlah frekuensi (term frequency) yang kecil pada sebuah dokumen. Batas minimum yang digunakan dalam penelitian ini adalah 4 sehingga kata yang memiliki frekuensi di bawah 4 akan dibuang.
Pemodelan Ruang Vektor
Hasil dari tahap praproses adalah term terpilih yang akan digunakan pemodelan ruang vektor. Pertama, dilakukan perhitungan berapakali kemunculan term dalam sebuah dokumen atau sering biasa disebut term-frequency (tf). Selanjunya, dihitung document-frequency (df) yang menandakan banyaknya dokumen yang mengandung term tertentu. Tahap terakhir, dilakukan perkalian antara tf dan idf yang menghasilkan tf-idf dengan idf adalah invers document frequency dengan persamaan log2� (N jumlah dokumen dalam koleksi). Dengan kata lain tf-idft,d
memberikan bobot term t dalam dokumen d yang memiliki hubungan sebagai berikut:
1. bobot tinggi ketika kemunculan t dalam jumlah dokumen yang kecil
2. lebih rendah ketika kemunculan term sedikit dalam sebuah dokumen atau muncul dalam banyak dokumen
3. paling rendah ketika muncul di hampir seluruh dokumen (Manning et.al 2009).
Concept Indexing
Temu kembali berdasarkan konsep menunjukkan bahwa ide dalam dokumen lebih berhubungan pada konsep yang menggambarkan dokumen dari pada penggunaan kata-kata yang menggambarkan dokumen. Jadi, metode temu kembali harus mencocokkan konsep yang ditampilkan dalam
query ke konsep yang ditampilkan dalam dokumen (Karypis G & Han E 2000).
Concept indexing adalah metode pengurangan dimensi yang menggunakan algoritme clustering untuk mendapatkan konsep dalam koleksi. Algoritme clustering yang digunakan sangat mempengaruhi hasil dan waktu proses. Berbagai macam algoritme clustering untuk dokumen telah dikembangkan untuk mendapatkan waktu proses dan hasil clustering yang lebih baik. Algoritme clustering yang digunakan dalam concept indexing adalah algoritme bisecting K-means karena memiliki waktu kompleksitas yang liniar tehadap jumlah dokumen. Jumlah ITER dalam bisecting K-means yang digunakan dalam penelitian ini adalah 1 (Karypis G & Han E 2000).
Dalam penelitian ini, algoritme clustering yang digunakan dalam proses concept indexing adalah bisecting K-means karena memiliki hasil yang lebih baik dibandingkan K-means standar (Steinbach, Karypis & Kumar 2000).
Tahap concept indexing akan menghasilkan matriks document-concept dengan dimensi . Matriks document-concept dibentuk dengan mengelompokkan dokumen menjadi kelompok menggunakan bisecting K-Means sehingga tiap cluster menghasilkan centroid. Untuk mengetahui pengaruh jenis centroid terhadap concept indexing. Pembentukan matriks centroid dilakukan dengan dua cara yaitu menggunakan centroid rata-rata dan centroid maksimum.
Perkalian antara matriks centroid × dan
matriks koleksi dokumen × akan menghasilkan matriks × yang
menggambarkan matriks koleksi dokumen dengan jumlah dimensi . Matriks ×
memiliki dua jenis. Jenis pertama, matriks × yang dihasilkan dari perkalian matriks koleksi dokumen dengan centroid rata-rata. Jenis kedua, matriks × yang dihasilkan dari
perkalian matriks koleksi dokumen dengan centroid maksimum.
Untuk selanjutnya tiap matriks × disebut
matriks document-concept. Dalam penelitian ini dilakukan percobaan dengan jumlah dimensi 3, 6, 9, 15, dan 25.
Clustering
K-6 means. Metode ini merupakan penggabungan
antara divisive clustering dan partitional clustering.
Algoritme bisecting K-means akan membagi koleksi dokumen menjadi cluster. Pembagian diawali dengan membagi koleksi dokumen menjadi dua bagian. Pembagian ini dilakukan dengan menggunakan K-means. Jumlah ITER yang digunakan dalam penelitian ini adalah 1 sehingga pembagian menjadi dua (bisection) menggunakan K-means hanya dilakukan satu kali untuk setiap fase. Hasil dari pembagian ini akan menjadi kandidat untuk dilakukan pembagian kembali hingga jumlah cluster yang diinginkan tercapai. Cluster yang dipilih untuk dibagi dua adalah cluster yang memiliki overall similarity terendah dari keseluruhan kandidat cluster.
Penelitian ini melakukan percobaan menggunakan tiga koleksi dengan jumlah dokumen berbeda. Untuk tujuan mengukur akurasi, setiap matriks document-concept dikelompokkan menjadi enam cluster sesuai dengan pengelompokan secara manual. Hasil pengelompokan ini yang kemudian dievaluasi menggunakan rand index dan F-measure.
Evaluasi
Evaluasi hasil cluster menggunakan dua cara yaitu dengan menggunakan rand index dan F-measure seluruh cluster hasil clustering. Untuk menghitung rand index dan F-measure dibutuhkan pengetahuan mengenai pengelompokan dokumen yang telah dianggap benar. Dalam penelitian ini, pengelompokan dokumen yang telah dianggap benar adalah pengelompokan yang dilakukan dengan cara manual.
HASIL DAN PEMBAHASAN
Karakteristik Dokumen
Seluruh dokumen yang digunakan berbahasa Indonesia. Koleksi dokumen memiliki enam kelas dengan tiap kelas memiliki tema yang berbeda. Tema tiap kelompok dokumen bisa dianggap tidak memiliki keterhubungan atau memiliki hubungan yang jauh dengan kelas lain.
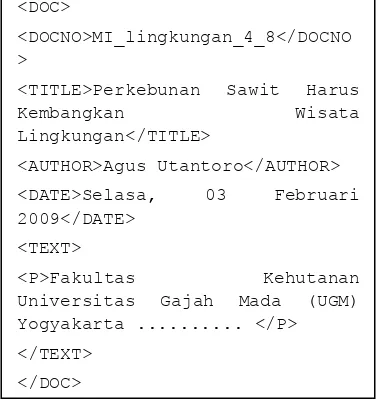
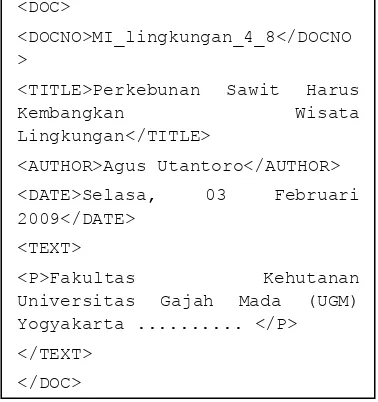
Digunakan 3 koleksi dokumen yang berasal dari sumber yang sama dengan jumlah setiap koleksi 400, 500, dan 600 dokumen. Seluruh dokumen berformat plain-text yang memiliki ekstensi *.txt. Struktur tulisan mirip dengan dokumen xml yang terdiri atas DOC, NODOC, AUTHOR, DATE, TEXT, dan P. Untuk lebih jelasnya dapat dilihat pada Gambar 2.
Gambar 2 Struktur dokumen teks.
Dalam penelitian ini, pemrosesan teks hanya dilakukan pada teks yang berada di antara tanda <TEXT> dan </TEXT> sehingga judul, tanggal, pengarang, dan nomor dokumen tidak ikut di proses.
Menghapus Stopwords dan Term dengan df < Treshold
Pada tahap praproses dilakukan penghapusan stopword dan term yang document-frequency kurang dari threshold. Jumlah term awal memiliki jumlah yang lebih besar dibandingkan setelah dilakukan pengurangan stopwords dan treshold. Hal tersebut dapat dilihat pada Tabel 1. Dari data ini dapat dihitung jumlah term (kata unik) berkurang sebesar 10948, 12201, 13531 term atau berkurang sebesar 90,2%, 89,9% dan 89,6% secara berurutan untuk koleksi dokumen dengan jumlah 400, 600, dan 500 dokumen.
Tabel 1 Jumlah term dalam koleksi.
Evaluasi Kinerja Sistem
Dimensi dokumen yang telah dikurangi dimensinya dapat disamakan dengan kecocokan dokumen ke konsep yang terbungkus dalam dengan df < treshold
1183 1363 1562
Jumlah kelas 6 6 6
<DOC>
<DOCNO>MI_lingkungan_4_8</DOCNO >
<TITLE>Perkebunan Sawit Harus
Kembangkan Wisata
Lingkungan</TITLE>
<AUTHOR>Agus Utantoro</AUTHOR>
<DATE>Selasa, 03 Februari
7 centroid (Karypis G & Han E 2000). Matriks
document-concept yang terbentuk pada tahap concept-indexing kemudian dilakukan pengelompokan menggunakan bisecting K-means (tahap clustering). Hasil dari pengelompokan ini merupakan hasil akhir dari sistem yang selanjutnya akan dievaluasi. Pengukuran keakuratan hasil clustering dilakukan dengan menggunakan rand index dan F-measure. Semakin besar nilai rand index dan F-measure maka hasil clustering semakin baik.
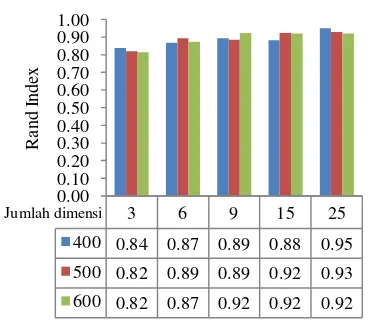
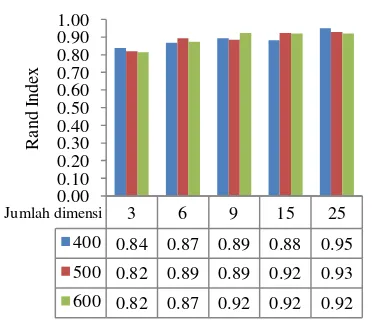
Gambar 3 Diagram nilai rand index pada jumlah dimensi berbeda untuk clustering dokumen menggunakan bisecting K-means dengan concept indexing (centroid rata-rata).
Untuk mengetahui pengaruh jumlah dimensi matriks document-concept yang dihasilkan pada tahap concept-indexing terhadap hasil clustering, dilakukan percobaan dengan menggunakan jumlah dimensi 3, 6, 9, 15, dan 25. Pengaruh perbedaan dimensi terhadap rand index untuk hasil clustering dokumen dengan menggunakan centroid rata-rata dapat dilihat pada Gambar 3 sedangkan yang menggunakan centroid maksimum dapat dilihat pada Lampiran 2. Jumlah dimensi matriks document-concept mempengaruhi hasil clustering. Ini ditunjukkan dengan perubahan nilai rand index pada dimensi document-concept yang berbeda. Pada Gambar 3 terlihat bahwa jumlah dimensi di atas jumlah kelas yaitu 6, nilai rand index lebih tinggi dibandingkan ketika dimensinya dibawah jumlah kelas. Pada percobaan ini rand index yang paling tinggi ketika jumlah dimensi 25 dengan jumlah dokumen 400 dan nilai rand index yang paling rendah dicapai ketika jumlah dimensi 3 dengan jumlah dokumen 600 yang mana jumlah dimensi kurang dari jumlah kelas koleksi dokumen.
Salah satu tujuan penelitian ini adalah mengukur pengaruh concept indexing terhadap clustering dokumen menggunakan bisecting K-means. Concept indexing memberi pengaruh positif terhadap bisecting K-means. Ini ditunjukkan dengan meningkatnya rand index. Dari tiga percobaan yang dilakukan yaitu menggunakan 400, 500, dan 600 dokumen. Perbandingan dilakukan antara clustering yang menggunakan bisecting K-means murni, bisecting K-means dengan concept indexing (centroid rata-rata) dan (centroid maksimum) dengan jumlah dimensi 25. Hasil perbandingan antara bisecting K-means murni dengan bisecting K-means menggunakan concept indexing (centroid rata-rata) menunjukkan bahwa rand index meningkat sebesar 0,07, 0,09, dan 0,02 secara berturut-turut untuk jumlah dokumen 400, 500, dan 600. Perbadingan rand index untuk clustering dokumen menggunakan bisecting K-means dengan concept indexing (centroid rata-rata) dan (centroid maksimum) tidak jauh berbeda. Untuk koleksi dengan jumlah 400 dokumen, nilai rand index sama yaitu 0,92 sedangkan untuk koleksi dokumen dengan jumlah 500 dan 600 dokumen nilai rand index menggunakan centroid maksimum bernilai 0,94 dan 0,96 yang mana lebih tinggi 0,01 dan 0,04 daripada yang menggunakan centroid rata-rata. Hal ini dapat dilihat pada Gambar 4.
Gambar 4 Diagram perbandingan nilai rand index antara bisecting K-means dan bisecting K-means dengan concept indexing (centroid rata-rata) dan (centroid maksimum) pada jumlah dimensi 25.
3 6 9 15 25
400 0.84 0.87 0.89 0.88 0.95
500 0.82 0.89 0.89 0.92 0.93
600 0.82 0.87 0.92 0.92 0.92
8
Tanpa CI 3 6 9 15 25
400 70.50 73.34 78.67 75.16 83.86 91.15
500 107.51 97.95 115.49 118.90 129.40 143.18
600 153.46 134.63 168.69 173.14 195.18 210.70
0.00 50.00 100.00 150.00 200.00 250.00
W
akt
u
pr
o
ses
(
det
ik)
Jumlah dimensi
Pada Gambar 4 terjadi fluktuasi rand index pada clustering dokumen menggunakan bisecting K-means. Ketika jumlah dokumen 400, rand index bernilai 0,88, ketika jumlah dokumen 500, rand index menurun menjadi 0,84 dan ketika jumlah dokumen 600 rand index meningkat menjadi 0,90. Perubahan ini karena inisialisasi centroid yang berdeda pada bisecting K-means, lebih tepatnya pada saat pembagian kelompok dokumen menjadi dua
sub-cluster yang dilakukan oleh means. K-means melakukan inisialisasi centroid secara acak. Pemilihan centroid awal yang berbeda akan mempengaruhi hasil clustering. Hal serupa terjadi ketika bisecting K-means dengan concept indexing, walaupun perubahan rand index tidak signifikan fruktuasi ini sama disebabkan inisialisasi centroid yang berbeda.
Pengukuran kualitas dan pemeringkatan algoritme clustering dapat berubah-ubah
Centroid (0-2)
Centroid 0 Centroid 1 Centroid 2
penelitian 15.31 pendidikan 32.28 antasari 8.44
tanaman 13.92 sekolah 23.74 tersangka 6.20
perlakuan 4.91 un 22.01 ganda 5.51
buah 4.35 siswa 15.74 kasus 5.06
percobaan 4.19 ujian 14.68 putra 5.03
produksi 3.28 nasional 14.59 pasangan 4.98
hama 2.98 pemerintah 8.52 pemain 4.81
insektisida 2.88 soal 7.95 jakarta 4.54
varietas 2.79 daerah 7.59 metro 4.28
jeruk 2.77 guru 7.28 pembunuhan 4.02
Centroid (3-5)
Centroid 3 Centroid 4 Centroid 5
indonesia 19.43 hutan 14.18 ekonomi 11.08
ekonomi 9.56 kawasan 11.79 harga 9.83
mahasiswa 6.59 masyarakat 8.17 2009 8.82
jakarta 6.44 ikan 6.31 indonesia 8.79
masyarakat 6.09 wilayah 6.13 pemerintah 8.28
presiden 5.89 air 6.08 negara 6.97
universitas 5.58 daerah 5.99 pertumbuhan 6.24
pasar 4.84 laut 5.93 bank 6.05
dunia 4.69 pemerintah 5.72 minyak 5.49
gubernur 4.61 lahan 5.10 triliun 5.44
Tabel 2 Sepuluh bobot terbesar term dalam centroid.
9 tergantung pada jenis pengukuran yang
digunakan (Steinbach M, Karypis & Kumar V, 2000). Dalam penelitian ini dilakukan pengukuran hasil clustering kembali menggunakan F-measure. Pengukuran kualitas hasil clustering menggunakan F-measure menunjukkan korelasi positif terhadap pengukuran menggunakan rand index. Hasil pengukuran menggunakan F-measure dapat di lihat pada Lampiran 3, Lampiran 4 dan Lampiran 5.
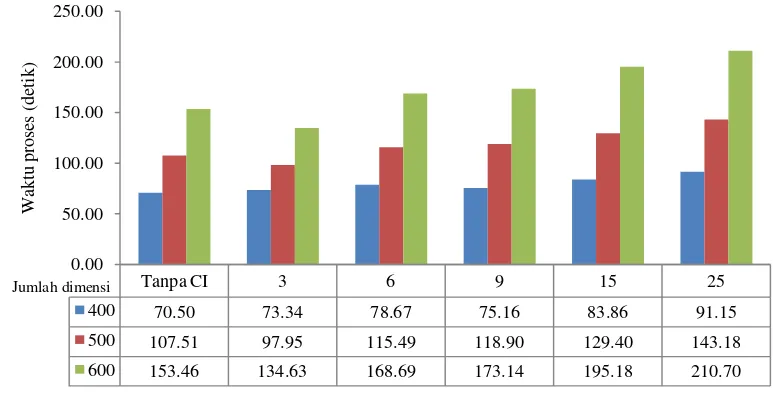
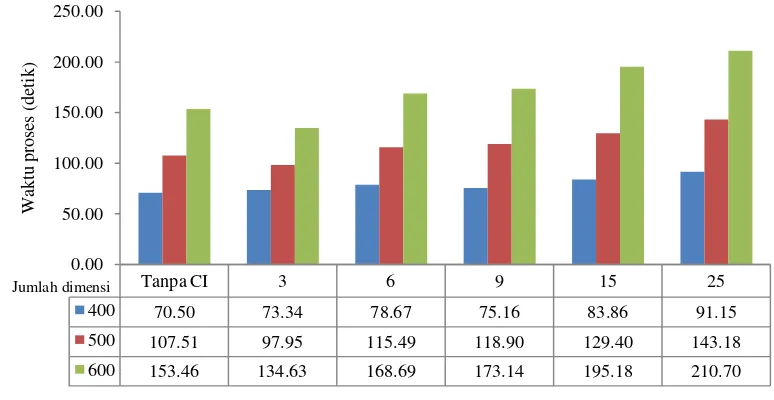
Waktu Proses
Jumlah dimensi dan banyaknya data akan mempengaruhi waktu proses. Semakin besar dimensi dan jumlah data maka waktu proses akan semakin lama. Hal tersebut dapat dilihat pada Gambar 5 dengan seiring meningkatnya jumlah dokumen dan term maka waktu proses akan meningkat. Peningkatan ini dapat diamati pada bisecting K-means selisih waktu antara koleksi dokumen yang berjumlah 400 dan 500 dengan jumlah term setelah dikurangi stopwords masing-masing 1183 dan 1363 adalah 37 detik. Selain dipengaruhi dua hal yaitu banyaknya data dan dimensi, metode yang digunakan juga dapat mempengaruhi waktu proses. Peningkatan waktu proses antara bisecting K-means murni dan bisecting K-means dengan concept indexing dapat dilihat pada Gambar 5. Peningkatan ini dipengaruhi oleh jumlah dimensi pada matriks document-concept semakin besar jumlah dimensi maka semakin lama waktu proses.
Konsep dalam Koleksi
Dalam proses pengurangan dimensi dalam concept indexing, dilakukan pengurangan dimensi dengan cara mengelompokkan koleksi dokumen ke dalam k kelompok/dimensi dan menghasilkan matriks centroid-term. Matrik centroid-term ini kemudian dikalikan dengan matrik document-term yang kemudian menghasilkan matrik document-concept yang memiliki dimensi sebayak k. Idealnya dengan jumlah kelompok/dimensi yang kecil sebuah centroid akan memperoleh konsep dari dokumen yang lebih banyak. Tabel 2 merupakan 10 bobot term tertinggi pada centroid yang diperoleh dengan mengelompokkan matriks document-term pada sebuah koleksi menjadi 6 kelompok/dimensi.
Kita berasumsi bahwa algorime clustering menghasilkan pengelompokan yang baik, yaitu dokumen-dokumen dalam sebuah cluster mirip satu sama lain dan tidak mirip dengan dukumen-dokumen dalam cluster yang berbeda.
Vektor centroid akan memberikan mekanisme peringkasan terhadap isi sekumpulan dokumen. Sebagai contoh, dari keenam tema bacaan tampak bahwa centroid 0 mewaliki dokumen yang bertemakan pernelitian di bidang pertanian. Ini ditunjukkan dengan term yang memiliki bobot tertinggi dalam centroid berhubungan dengan pertanian. Sebagai contoh terdapat term seperti “penelitian”, “tanaman”,
dan “hama” yang mana sering muncul dalam
dokumen yang bertemakan penelitian di bidang pertanian. Untuk centroid 1, 4, 5 secara berurutan lebih cenderung memiliki konsep pendidikan, lingkungan dan ekonomi. Akan tetapi untuk centroid 2 dan 3 kata-kata masih belum spesifik menuju konsep tertentu. Hal ini karena kesalahan pengelompokan.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan hasil yang diperoleh dapat disimpulkan bahwa clustering berdasarkan konsep dokumen dapat dilakukan. Ditinjau dari segi hasil, pengurangan dimensi menggunakan concept indexing dapat mengingkatkan nilai akurasi F-measure hingga mencapai 38%.
Saran
Sistem ini memiliki potensi untuk dikembangkan ke arah pruning cluster yang bertujuan untuk mengurangi dokumen yang dicari.
DAFTAR PUSTAKA
Dhillon S I & Modha D S. 2000. Concept Decompositions for Large Sparse Text Data using Clustering. Kluwer Academic Publishers.
Han J & Kamber M. 2006. Data Mining Concepts and Tehniques. Edisi Ke-2. Elsever Inc. San Francisco.
Jain A K. 2009. Data Clustering: 50 Years Beyond K-Means. Department of Computer Science & Engineering. Michigan State University. Michigan.
Karypis G & Han E. 2000. Concept Indexing: A Fast Dimensionally Reduction Algorithm with Applications to Document Retrieval & Categorization. Computer Science and Engineering. University of Minnesota. Minneapolis.
10 Rhida A. 2002. Pengindeksan Otomatis dengan
istilah tunggal untuk Dokumen Berbahasa Indonesia. Skripsi. Bogor: Departement Ilmu Komputer IPB.
Riu X & Wunsch D C. 2009. Clustering. John Wiley & Sons, Inc.
Savaresi et.al. Choosing the cluster to split in Bisecting Divisive Clustering Algorithms. Department of Electrical Engineering and Computer Science. University of Minnesota. Minneapolis.
12 Lampiran 1 Daftar kata buang (stopwords).
yang di dan itu dengan untuk penggunaan
tidak ini dari dalam akan pada juga
tersebut bisa ada mereka lebih kata tahun
oleh menjadi orang ia telah adalah seperti
para harus namun kita dua satu masih
kepada kami setelah melakukan lalu belum lain
banyak menurut anda hingga tak baru beberapa
sekitar secara dilakukan sementara tapi sangat hal
besar lagi selama antara waktu sebuah jika
tiga serta pun salah merupakan atas sejak
kembali selain tetapi pertama kedua memang pernah
tentang bukan agar semua sedang kali kemudian
persen sendiri katanya demikian masalah mungkin umum
bila lainnya terus luar cukup termasuk sebelumnya
perlu menggunakan memberikan rabu sedangkan kamis langsung
diri mencapai minggu aku berada tinggi ingin
the tahu bersama depan selasa begitu merasa
jumlah masuk katanya mengalami sering ujar kondisi
paling mendapatkan selalu lima meminta melihat sekarang
acara menyatakan masa proses tanpa selatan sempat
senin rasa maupun seluruh mantan lama jenis
bawah jangan meski terlihat akhirnya jumat punya
panjang badan juni of jelas jauh tentu
mampu posisi asal sekali sesuai sebesar berat
sabtu ternyata mencari sumber ruang menunjukkan biasanya
berlangsung barat kemungkinan yaitu berdasarkan sebenarnya cara
membawa kebutuhan suatu menerima penting tanggal bagaimana
sedikit nanti pasti muncul dekat lanjut ketiga
ribu akhir membantu terkait sebab menyebabkan khusus
mana ya kegiatan sebagian tampil hampir bertemu
pula digunakan justru padahal menyebutkan gedung apalagi
menjalani keputusan sumber a upaya mengetahui mempunyai
mengambil benar lewat belakang ikut barang meningkatkan
karena saat dapat mengatakan terjadi jalan bagi
sama juta bagian tempat melalui kini maka
datang mendapat kecil kurang pagi utara terlalu
diduga keluar teman b keterangan kehidupan memiliki
menghadapi ke atau bahwa hanya kalau saja
jadi baik mulai sejumlah bulan wib pihak
mengenai hubungan mau hidup misalnya terakhir tinggal
sebanyak pekan tingkat dulu ditemukan berarti milik
kesempatan yakni semakin dirinya nama utama terutama
masing-masing saya sudah sebagai hari dia ketika
sehingga sampai membuat apa hasil setiap bahkan
apakah sebelum berbagai akibat mengaku adanya segera
biasa bentuk usai program berjalan kejadian terhadap
13 Lampiran 2 Rand index pada dimensi yang berbeda untuk bisecting K-means dengan concept
indexing (centroid maksimum).
Lampiran 3 Diagram nilai F-measure pada jumlah dimensi berbeda untuk clustering dokumen menggunakan bisecting K-means dengan concept indexing (centroid rata-rata).
3 6 9 15 25
400 0.75 0.88 0.94 0.94 0.95
500 0.74 0.91 0.94 0.93 0.94
600 0.81 0.88 0.91 0.91 0.96
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
R
and
Inde
x
Jumlah dimensi
3 6 9 15 25
400 0.58 0.64 0.69 0.67 0.85
500 0.53 0.71 0.67 0.78 0.79
600 0.48 0.65 0.78 0.77 0.77
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
F
-m
ea
sur
e
14 Lampiran 4 Diagram nilai F-measure pada jumlah dimensi berbeda untuk clustering dokumen
menggunakan bisecting K-means dengan concept indexing(centroid maksimum).
Lampiran 5 Diagram perbandingan nilai F-measure antara bisecting K-means dan bisecting K-means dengan concept indexing (centroid rata-rata) dan (centroid maksimum) dengan jumlah dimensi 25.
3 6 9 15 25
400 0.47 0.66 0.83 0.83 0.85
500 0.46 0.74 0.82 0.79 0.82
600 0.48 0.68 0.75 0.75 0.87
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
F
-m
ea
sur
e
Jumlah dimensi
400 500 600
BSCKM 0.63 0.57 0.72
BSCKM+CI(means) 0.85 0.79 0.77
BSCKM+CI(Max) 0.85 0.82 0.87
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
F
-m
ea
sur
e
CLUSTERING
KONSEP DOKUMEN BERBAHASA
INDONESIA MENGGUNAKAN
BISECTING
K-MEANS
HIZRY RAMDANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ii
CLUSTERING
KONSEP DOKUMEN BERBAHASA
INDONESIA MENGGUNAKAN
BISECTING
K-MEANS
HIZRY RAMDANI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
1
PENDAHULUAN
Latar Belakang
Keakuratan dan kecepatan untuk memperoleh informasi menjadi salah satu aspek yang sangat diperhitungkan dalam temu kembali informasi. Keakuratan informasi berhubungan dengan kesesuaian informasi yang ditampilkan dengan keinginan pengguna. Pengguna menginginkan informasi yang sesuai dengan query yang dimasukan ke dalam sistem temu kembali. Sama halnya dengan keakuratan, waktu sangat mempengaruhi kepuasan pengguna. Setiap pengguna menginginkan waktu yang pendek dalam memperoleh informasi. Bila ditinjau dari volume dokumen teks yang berada di internet, perpustakaan digital, dan web intranet perusaan yang sangat besar, dibutuhkan suatu sistem yang efisien dalam mengekstraksi informasi sehingga waktu untuk mendapatkan informasi menjadi lebih pendek.
Salah satu cara untuk meningkatkan hasil temu kembali informasi adalah dengan menerapkan algoritme statistik, di antaranya clustering dan classification (Dhillon & Modha 2000). Clustering adalah proses pengelompokan sekumpulan objek ke dalam kelas yang objeknya mirip (Han & Kamber 2006). Clustering telah digunakan dalam menemukan
“konsep terpendam” dalam sekumpulan
dokumen teks yang tidak terstruktur dan proses pencarian teks dalam jumlah besar seperti Yahoo (Dhillon & Modha 2000).
Jumlah dokumen yang sangat besar menjadi tantangan tersendiri dalam temu kembali informasi. Semakin beragam dan besar jumlah dokumen maka semakin tinggi dimensi sebuah dokumen dalam koleksi. Jumlah dokumen dan dimensi sangat mempengaruhi waktu proses. Semakin besar dan tinggi dimensi dokumen maka waktu proses temu kembali informasi akan semakin bertambah. Salah satu cara untuk mengatasi masalah ini adalah dengan cara mengurangi dimensi suatu dokumen. Concept indexing adalah salah satu metode yang digunakan untuk mengurangi dimensi. Concept indexing memiliki keunggulan dibandingkan dengan metode pengurangan dimensi seperti Latent Semantic Index (LSI) karena memiliki waktu proses lebih rendah (Karypis G & Han E 2000). Maka dari itu, penelitian ini akan mencoba menerapkan concept indexing untuk koleksi dokumen berbahasa Indonesia dan mengetahui pengaruhnya terhadap clustering dokumen menggunakan bisecting K-means.
Tujuan Penelitian
Tujuan penelitian ini adalah melakukan clustering dokumen berbahasa Indonesia berdasarkan konsep dan mengukur pengaruh metode pengurangan dimensi menggunakan concept indexing terhadap bisecting K-means untuk pengelompokan dokumen berbahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah sebagai berikut:
1. Dokumen yang digunakan adalah dokumen berbahasa Indonesia.
2. Koleksi dokumen yang digunakan memiliki enam tema yaitu bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan.
3. Algoritme clustering yang digunakan untuk clustering konsep dokumen adalah bisecting K-means.
4. Jumlah cluster untuk
mengelompokkan konsep dokumen adalah 6 yang disesuaikan dengan jumlah tema dalam koleksi dokumen. 5. Algoritme clustering yang digunakan
dalam proses concept indexing adalah bisecting K-means.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengetahui pengaruh algoritme pengurangan dimensi concept indexing untuk pengelompokan dokumen berbahasa Indonesia menggunakan bisecting K-means.
TINJAUAN PUSTAKA
Clustering
Proses pengelompokan sekumpulan objek ke dalam kelas-kelas yang objek-objeknya serupa disebut clutering. Objek-objek dalam sebuah cluster mirip satu sama lain dan berbeda dengan objek-objek dalam cluster lain (Han & Kamber 2006).
1
PENDAHULUAN
Latar Belakang
Keakuratan dan kecepatan untuk memperoleh informasi menjadi salah satu aspek yang sangat diperhitungkan dalam temu kembali informasi. Keakuratan informasi berhubungan dengan kesesuaian informasi yang ditampilkan dengan keinginan pengguna. Pengguna menginginkan informasi yang sesuai dengan query yang dimasukan ke dalam sistem temu kembali. Sama halnya dengan keakuratan, waktu sangat mempengaruhi kepuasan pengguna. Setiap pengguna menginginkan waktu yang pendek dalam memperoleh informasi. Bila ditinjau dari volume dokumen teks yang berada di internet, perpustakaan digital, dan web intranet perusaan yang sangat besar, dibutuhkan suatu sistem yang efisien dalam mengekstraksi informasi sehingga waktu untuk mendapatkan informasi menjadi lebih pendek.
Salah satu cara untuk meningkatkan hasil temu kembali informasi adalah dengan menerapkan algoritme statistik, di antaranya clustering dan classification (Dhillon & Modha 2000). Clustering adalah proses pengelompokan sekumpulan objek ke dalam kelas yang objeknya mirip (Han & Kamber 2006). Clustering telah digunakan dalam menemukan
“konsep terpendam” dalam sekumpulan
dokumen teks yang tidak terstruktur dan proses pencarian teks dalam jumlah besar seperti Yahoo (Dhillon & Modha 2000).
Jumlah dokumen yang sangat besar menjadi tantangan tersendiri dalam temu kembali informasi. Semakin beragam dan besar jumlah dokumen maka semakin tinggi dimensi sebuah dokumen dalam koleksi. Jumlah dokumen dan dimensi sangat mempengaruhi waktu proses. Semakin besar dan tinggi dimensi dokumen maka waktu proses temu kembali informasi akan semakin bertambah. Salah satu cara untuk mengatasi masalah ini adalah dengan cara mengurangi dimensi suatu dokumen. Concept indexing adalah salah satu metode yang digunakan untuk mengurangi dimensi. Concept indexing memiliki keunggulan dibandingkan dengan metode pengurangan dimensi seperti Latent Semantic Index (LSI) karena memiliki waktu proses lebih rendah (Karypis G & Han E 2000). Maka dari itu, penelitian ini akan mencoba menerapkan concept indexing untuk koleksi dokumen berbahasa Indonesia dan mengetahui pengaruhnya terhadap clustering dokumen menggunakan bisecting K-means.
Tujuan Penelitian
Tujuan penelitian ini adalah melakukan clustering dokumen berbahasa Indonesia berdasarkan konsep dan mengukur pengaruh metode pengurangan dimensi menggunakan concept indexing terhadap bisecting K-means untuk pengelompokan dokumen berbahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah sebagai berikut:
1. Dokumen yang digunakan adalah dokumen berbahasa Indonesia.
2. Koleksi dokumen yang digunakan memiliki enam tema yaitu bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan.
3. Algoritme clustering yang digunakan untuk clustering konsep dokumen adalah bisecting K-means.
4. Jumlah cluster untuk
mengelompokkan konsep dokumen adalah 6 yang disesuaikan dengan jumlah tema dalam koleksi dokumen. 5. Algoritme clustering yang digunakan
dalam proses concept indexing adalah bisecting K-means.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengetahui pengaruh algoritme pengurangan dimensi concept indexing untuk pengelompokan dokumen berbahasa Indonesia menggunakan bisecting K-means.
TINJAUAN PUSTAKA
Clustering
Proses pengelompokan sekumpulan objek ke dalam kelas-kelas yang objek-objeknya serupa disebut clutering. Objek-objek dalam sebuah cluster mirip satu sama lain dan berbeda dengan objek-objek dalam cluster lain (Han & Kamber 2006).
2 secara simultan sebagai bagian data dan tidak
membentuk struktur hierarkikal (Jain. A. K 2009).
Berikut ini adalah definisi partitional clustering. Misalkan diberikan sekumpulan masukan data = 1,…, ,…, � , dengan
= 1,…, 2,…, ∈ ℜ , adalah
atribut, dimensi atau variabel. Partitional clustering berusaha membagi ke dalam jumlah atribut atau jumlah dimensi data (Riu X & D.C Wunsch 2009).
Pemodelan Ruang Vektor
Dalam sebuah koleksi, tiap dokumen d dianggap sebagai sebagai vektor dalam term-space. Masing-masing dokumen digambarkan ke dalam vektor = 1, 2,…, ,
dengan adalah frekuensi term i dalam koleksi dokumen dan adalah jumlah term dalam koleksi. Perbaikan model ini dilakukan pada pembobotan masing-masing term didasarkan pada inverse document frequency dalam koleksi dokumen. Tujuan pembobotan ini adalah term yang muncul di jumlah dokumen yang berbeda memiliki kekuatan yang berbeda. Hal ini dilakukan dengan melakukan perkalian tiap term i dengan log� , dengan � adalah
jumlah dokumen dalam koleksi dan adalah jumlah dokumen yang mengandung term i (document-frequency). Representasi tf-idf pada sebuah dokumen adalah = { 1log �
Dalam pemodelan ruang vektor, ukuran kesamaan antara 2 dokumen dan dihitung dengan fungsi cosine sebagai berikut
cos( , ) = ∙
∗
dengan “∙” adalah dot product antara dua vektor
dan panjang satuan vektor dokumen i.
Misalkan diberikan sekumpulan dokumen yang mana tiap dokumen direpresentasikan dalam bentuk vector, maka vektor centroid adalah
= 1
∈
yaitu vektor yang dihasilkan dari bobot rata-rata berbagai macam term dalam kumpulan dokumen S (Karypis G & Han E 2000).
K-Means
Misalkan = , i = 1, …, n adalah sekumpulan titik berjumlah n yang memiliki m-dimensi dikelompokkan ke dalam cluster,
= , = 1,…, . Algoritme K-means melakukan pembagian anggota cluster sehingga square error (jumlah jarak) antara centroid dan titik-titik dalam cluster menjadi minimum. � adalah centroid (rata-rata) pada cluster . Square error antara � dan objek dalam cluster
didefinisikan sebagai berikut
( ) = − � 2
∈
Tujuan utama dari K-means adalah meminimumkan jumlah square error secara keseluruhan pada cluster. Berikut ini adalah persamaan sum of square error.
( ) = − � 2
∈
=1
Algoritme K-means dimulai dengan inisialisasi pembagian menjadi cluster dengan meminimumkan square error. Karena square error selalu berkurang dengan bertambahnya jumlah cluster ( = 0 ketika
= ). dapat diperkecil dengan tujuan hanya untuk memperbaiki jumlah cluster. Tahapan utama algoritme K-means adalah sebagai berikut:
1. menginisialisasi pembagian cluster; ulangi tahap 2 dan 3 hingga keanggotaan cluster stabil.
2. menciptakan partisi baru dengan menempatkan titik ke pusat cluster terdekat
3. menghitung pusat cluster baru (Jain A. K 2009).
Bisecting K-means
Bisecting K-means menggunakan K-means untuk membagi sebuah cluster menjadi dua (Savaresi et.al 2007). Bisecting K-means dimulai dengan cluster tunggal yang berisi seluruh dokumen. Berikut ini adalah algoritme bisecting K-means untuk menemukan cluster pada sebuah koleksi dokumen yaitu:
3 2. menemukan 2 sub-clusters
menggu-nakan K-means tipe dasar (tahap bisecting).
3. mengulangi tahap 2, tahap membagi dua untuk ITER waktu dan ambil hasil split clustering yang memiliki overall similarity tertinggi.
4. mengulangi langkah 1, 2 dan 3 hingga jumlah cluster tercapai.
ITER adalah jumlah percobaan membagi dua (bisection) untuk masing-masing fase bisecting K-means sehingga pada tahap 3 dipilih hasil pembagian yang memiliki kerapatan yang tinggi atau memiliki overall similarity tertinggi.
Pemilihan cluster yang akan dibagi dua dilakukan dengan cara mencari cluster terluas atau memiliki overall similarity yang paling rendah dari beberapa kandidat cluster. Overall similarity dihitung menggunakan cohesiveness internal cluster. Berikut ini adalah rumus overall similarity
Concept indexing (CI) memproyeksikan koleksi dokumen ke dalam k dimensi dengan mengelompokkan dokumen-dokumen ke dalam k kelompok kemudian menggunakan vektor centroid pada cluster untuk memperoleh axes pada pengurangan ruang k dimensi.
Berikut ini proses pengurangan ruang dimensi pada unsupervised dimensionality reduction. Jika k adalah jumlah dimensi yang diinginkan. Tahap awal CI melakukan pengelompokan koleksi dokumen menjadi k cluster. Kemudian menggunakan vektor centroid pada cluster sebagai axes pada pengurangan ruang dimensi k. Misalkan, D adalah matriks document-term n×m (n adalah jumlah dokumen dan m adalah jumlah term dalam koleksi), baris ke-i pada D menyimpan ruang vektor yang menggambarkan dokumen ke-i (D[i, *] = ) dan kolom ke-j menggambarkan term ke-j. CI menggunakan algoritme clustering untuk membagi dokumen-dokumen ke dalam k kelompok yang disjoint,
1, 2, …, . Kemudian dihitung vektor
centroid untuk setiap sebagai berikut
= 1
∈
Masing-masing centroid membentuk sebuah axis pada pengurangan ruang dimensi k dan k dimensi merepresentasikan tiap dokumen yang diperoleh dari proyeksi ke dalam ruang ini. Proyeksi dapat ditulis dalam notasi matriks sebagai berikut. Misal matriks m×k yang mana kolom ke-i pada merupakan . Kemudian dimensi k merepresentasikan tiap vektor dokumen melalui persamaan dan dimensi k merepresentasikan koleksi diberikan dalam matriks = . Serupa dengan dimensi dokumen, dimensi k yang merepresentasikan query pada temu informasi ditunjukkan dengan persamaan . Pada akhirnya kesamaan antara dua dokumen dalam pengurangan ruang dimensi dihitung dengan perhitungan cosine antara vektor yang telah dikurangi dimensinya (Karypis & Han 2000).
Centroid Maksimum
Diberikan sekumpulan masukan dengan pola = 1,…, ,…, � , dengan =
1,…, 2,…, ∈ ℜ , adalah atribut
dimensi atau variabel. Centroid maksimum untuk adalah = { � { 11, 21,…, �1} , � { 12, 22,…, �2},…, � { 1 , 2 ,…,
� }}.
Rand Index
Alternatif untuk menerjemahkan informasi secara teoritik pada cluster adalah penggambaran sebagai rangkaian keputusan, satu untuk masing-masing N(N-1)/2 pasang dokumen dalam koleksi pada N cluster. Kita ingin menempatkan dua dokumen ke dalam cluster yang sama jika dan hanya jika kedua dokumen tersebut mirip. True positif (TP) adalah keputusan menempatkan dua dokumen yang mirip ke cluster yang sama, true negative (TN) adalah keputusan menempatkan dua dokumen yang tidak mirip ke cluster berbeda. Terdapat dua tipe kesalahan yang dapat terjadi pada clustering. False positif (FP) adalah keputusan menempatkan dua dokumen yang tidak mirip ke cluster yang sama. False negative (FN) adalah keputusan menempatkan dua dokumen yang mirip ke cluster yang berbeda. Rand index mengukur persentase terhadap keputusan yang sesuai. Berikut adalah persamaan rand index
= �+ �
4
F-Measure
F-measure mengombinasikan precision dan recall untuk temu kembali informasi. Nilai recall dan precision pada suatu keadaan dapat memiliki bobot (nilai keutamaan) yang berbeda. Ukuran yang menampilkan timbal balik antara recall dan precision adalah F-measure yang merupakan bobot harmonic mean pada recall dan precision. Berikut adalah persamaan F-measure keputusan menempatkan dua dokumen yang tidak mirip ke cluster berbeda. Terdapat dua tipe kesalahan yang dapat terjadi pada clustering. False positif (FP) keputusan menempatkan dua dokumen yang tidak mirip ke cluster yang sama. False negative (FN) keputusan menempatkan dua dokumen yang mirip ke cluster yang berbeda.
Kita dapat menggunakan F-measure dengan nilai false negative lebih kuat daripada false positive maka kita akan memberi nilai β> 1
sehingga memberikan bobot yang lebih untuk recall. F-measure yang seimbang memberikan bobot yang sama antara recall dan precision, dengan nilai = 1 2 atau β= 1. Hal ini dapat ditulis F1 atau �=1 sehingga persamaan
menjadi (Manning et.al 2009).
�=1 =
2 �
�+
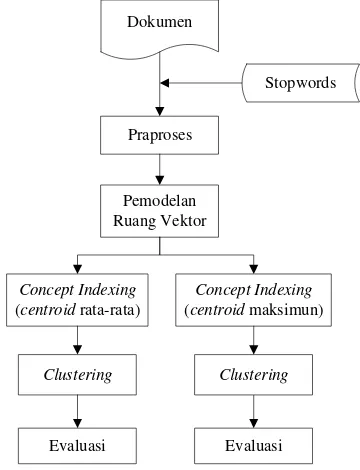
METODE PENELITIAN
Secara garis besar metode penelitian yang digunakan dalam penelitian ini adalah seperti pada Gambar 1. Data yang akan diproses dalam sistem ini adalah koleksi dokumen. Masukan lain yang digunakan adalah stopwords yang merupakan daftar kata buang yang akan digunakan pada praproses. Setelah praproses, dilakukan pemodelan ruang vektor untuk melakukan pembobotan terhadap term dan merepresentasikan dokumen ke dalam bentuk vektor. Concept indexing dilakukan untuk mengurangi dimensi dokumen. Hasil dari
concept indexing adalah matriks document-concept yang kemudian akan dikelompokkan menjadi K cluster. Pada tahap akhir, dilakukan evaluasi menggunakan rand index terhadap hasil clustering.
Gambar 1 Metode penelitian.
Koleksi Dokumen
Penelitian ini menggunakan tiga koleksi dokumen yang berjumlah 400, 500, dan 600 dokumen. Koleksi dokumen yang digunakan telah diketahui jumlah kelasnya. Ketiga koleksi dokumen berasal dari sumber yang sama dan setiap koleksi memiliki 6 kelas yaitu dokumen yang bertemakan bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan. Tiap kelas dalam koleksi memiliki jumlah yang relatif sama.
Seluruh dokumen yang digunakan merupakan milik laboratorium Temu Kembali Informasi IPB yang diambil dari beberapa
4
F-Measure
F-measure mengombinasikan precision dan recall untuk temu kembali informasi. Nilai recall dan precision pada suatu keadaan dapat memiliki bobot (nilai keutamaan) yang berbeda. Ukuran yang menampilkan timbal balik antara recall dan precision adalah F-measure yang merupakan bobot harmonic mean pada recall dan precision. Berikut adalah persamaan F-measure keputusan menempatkan dua dokumen yang tidak mirip ke cluster berbeda. Terdapat dua tipe kesalahan yang dapat terjadi pada clustering. False positif (FP) keputusan menempatkan dua dokumen yang tidak mirip ke cluster yang sama. False negative (FN) keputusan menempatkan dua dokumen yang mirip ke cluster yang berbeda.
Kita dapat menggunakan F-measure dengan nilai false negative lebih kuat daripada false positive maka kita akan memberi nilai β> 1
sehingga memberikan bobot yang lebih untuk recall. F-measure yang seimbang memberikan bobot yang sama antara recall dan precision, dengan nilai = 1 2 atau β= 1. Hal ini dapat ditulis F1 atau �=1 sehingga persamaan
menjadi (Manning et.al 2009).
�=1 =
2 �
�+
METODE PENELITIAN
Secara garis besar metode penelitian yang digunakan dalam penelitian ini adalah seperti pada Gambar 1. Data yang akan diproses dalam sistem ini adalah koleksi dokumen. Masukan lain yang digunakan adalah stopwords yang merupakan daftar kata buang yang akan digunakan pada praproses. Setelah praproses, dilakukan pemodelan ruang vektor untuk melakukan pembobotan terhadap term dan merepresentasikan dokumen ke dalam bentuk vektor. Concept indexing dilakukan untuk mengurangi dimensi dokumen. Hasil dari
concept indexing adalah matriks document-concept yang kemudian akan dikelompokkan menjadi K cluster. Pada tahap akhir, dilakukan evaluasi menggunakan rand index terhadap hasil clustering.
Gambar 1 Metode penelitian.
Koleksi Dokumen
Penelitian ini menggunakan tiga koleksi dokumen yang berjumlah 400, 500, dan 600 dokumen. Koleksi dokumen yang digunakan telah diketahui jumlah kelasnya. Ketiga koleksi dokumen berasal dari sumber yang sama dan setiap koleksi memiliki 6 kelas yaitu dokumen yang bertemakan bulu tangkis, ekonomi, jurnal pertanian, lingkungan, kriminal dan pendidikan. Tiap kelas dalam koleksi memiliki jumlah yang relatif sama.
Seluruh dokumen yang digunakan merupakan milik laboratorium Temu Kembali Informasi IPB yang diambil dari beberapa