SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana Program Strata Satu Jurusan Teknik Informatika
Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia
JAJANG MACHPUDIN SURYANA
10107277
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
BANDUNG
i
ABSTRAK
IMPLEMENTASI SUFFIX TREE CLUSTERING UNTUK
PENGELOMPOKAN DOKUMEN HASIL PENCARIAN ONLINE
PADA MESIN PENCARI DAN JEJARING SOSIAL
Oleh:
JAJANG MACHPUDIN SURYANA 10107277
Pencarian terhadap suatu dokumen merupakan hal yang sering dilakukan. Namun seringkali pencarian yang dilakukan tidak menghasilkan hasil yang optimal. Pengguna kadangkala harus menelusuri beberapa halaman untuk mendapatkan hasil pencarian yang diinginkan, terlebih untuk beberapa hal yang spesifik dan jarang ditemukan. Tentu saja hal tersebut akan memakan waktu yang tidak sedikit.
Clustering merupakan salah satu cara yang dapat digunakan untuk mengelompokan hasil pencarian ke dalam kelas-kelas tersendiri, tanpa harus ditentukan terlebih dahulu kelas-kelas apa saja yang harus ada sebagai penampungnya. Salah satu algoritma yang dapat digunakan untuk proses mengelompokan dokumen adalah algoritma Suffix Tree Clustering, yang nantinya akan digunakan untuk mengelompokan hasil pencarian yang dilakukan seorang pengguna. Algoritma ini dapat diterapkan secara langsung ke dalam hasil pencarian yang diberikan oleh mesin pencari ataupun jejaring sosial. Masukan untuk pengelompokan dokumen menggunakan algoritma Suffix Tree Clustering
ini adalah snippet yang didapat dari hasil pencarian. Snippet ini akan diproses untuk didapatkan topik yang dikandungnya. Suatu snippet dapat memiliki lebih dari satu topik, oleh karena itu, kemampuan algoritma Suffix Tree Clustering
untuk mengelola dokumen yang memiliki lebih dari satu topik cocok digunakan untuk mengelompokan dokumen hasil pencarian.
Dengan adanya algoritma ini, diharapkan proses pencarian informasi yang dilakukan oleh seorang pengguna dapat dilakukan dengan lebih cepat, sehingga dapat mengoptimalkan waktu yang digunakan untuk melakukan pencarian.
ii
ABSTRACT
THE IMPLEMENTATION OF SUFFIX TREE CLUSTERING FOR GROUPING DOCUMENT OF THE ONLINE SEARCH RESULTS
IN SEARCH ENGINE AND SOCIAL NETWORK
By:
JAJANG MACHPUDIN SURYANA 10107277
Searching of documents are things that often doing by users. But sometimes the searching didnât give the optimal result. Users often should browse some page before he/she gets the result he/she wants, especially for things that is specific and hard to find. This will use so much time.
Clustering is a way to grouping search result to its own class, without having to predefine what class that should be there. One of many algorithms that can be use for grouping document is Suffix Tree Clustering algorithm, which will be used to grouping some search results that is done by users. This algorithm can be implemented directly into search results from search engine and social network. The input for this Suffix Tree Clustering algorithm is the snippet from the search results. This snippet will be processed to get known what topic it is about. One snippet can have many topics, therefore the ability of Suffix Tree Clustering algorithm is very useful for grouping the search result documents.
With this algorithm, it is expected that the process of searching information that is done by users can be done in a much faster time, so that the time for it can be optimalized.
iii
KATA PENGANTAR
Assalamualaikum Wr.Wb.
Puji dan syukur penulis panjatkan ke hadirat Allah SWT, atas karunia, nikmat, berkah serta hidayah yang tercurah kepada seluruh alam.
Shalawat serta salam semoga selalu untuk nabi dan kekasih tercinta Muhammad SAW, beserta seluruh keluarga, sahabat, dan para pengikutnya hingga akhir zaman.
Penyusunan skripsi dengan judul âImplementasi Suffix Tree Clustering untuk
Pengelompokan Dokumen Hasil Pencarian Online pada Mesin Pencari dan
Jejaring Sosialâ ini adalah salah satu syarat untuk memperoleh gelar Strata Satu
(S1) di Jurusan Teknik Informatika Universitas Komputer Indonesia.
Telah banyak pihak yang membantu dalam penyusunan skripsi ini, baik secara moril maupun materil. Oleh karena itu, pada kesempatan ini penulis ingin menyampaikan ucapan dan rasa terima kasih yang sebesar-besarnya kepada : 1. Empah dan Ibu, atas kasih sayang, doâa, dukungan serta semangat yang selalu
diberikan kepada penulis setiap saat. Semoga seluruh amal kebaikan penulis selalu tercurah kepada Empah dan Ibu tercinta.
2. Alm. Mamah Ageung, atas kenangan terindah dari seorang nenek untuk cucunya. Semoga seluruh amal kebaikan penulis selalu tercurah kepada nenek tersayang.
iv
6. Bapak Adam Mukharil Bachtiar, S.Kom., selaku dosen pembimbing yang telah memberi perhatian dan bimbingan kepada penulis selama proses penyusunan skripsi.
7. Ibu Ednawati Rainarli S.Si., M.Si., selaku dosen reviewer yang telah memberi saran dan bimbingan kepada penulis.
8. Ibu Dian Dharmayanti, S.T., selaku dosen penguji atas segala koreksinya terhadap tugas akhir penulis.
9. Teman-teman kelas dan seperjuangan, atas semangat dan motivasinya.
10.Novia Ermawathi, akhir tapi bukan yang terakhir, atas semangat, cinta, perhatian, dan seluruh warna-warni kehidupan selama ini.
Akhir kata, penulis menyadari bahwa skripsi ini masih jauh dari kesempurnaan, maka saran dan kritik yang membangun dari semua pihak sangat penulis harapkan untuk penyempurnaan karya tulis selanjutnya.
Kebenaran datangnya dari Allah Tuhan semesta alam, kesalahan datangnya hanyalah dari penulis semata.
Wassalamualaikum Wr. Wb.
Bandung, Juli 2012
v
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... xi
DAFTAR TABEL ... xiii
DAFTAR SIMBOL ... xv
DAFTAR LAMPIRAN ... xvi
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang Masalah ... 1
I.2 Perumusan Masalah ... 4
I.3 Maksud dan Tujuan ... 4
I.4 Batasan Masalah ... 5
I.5 Metodologi Penelitian ... 5
I.6 Sistematika Penulisan ... 8
BAB II TINJAUAN PUSTAKA ... 10
II.1 Data Mining ... 10
II.1.1 Tahapan Data Mining ... 11
vi
II.1.2.3 Clustering ... 15
II.2 Suffix Tree Clustering ... 16
II.2.1 Document preprocessing ... 17
II.2.1.1 Pembersihan stop word ... 18
II.2.1.2 Stemming kata ... 18
II.2.2 Identifikasi Cluster Dasar Pembangun ... 18
II.2.3 Pengkombinasian Cluster Dasar ... 19
II.3 Jejaring Sosial ... 20
II.4 Mesin Pencari ... 21
II.4.1 Google ... 22
II.4.2 Manfaat Mesin Pencari ... 22
II.4.3 Cara Kerja Mesin Pencari ... 23
II.4.4 Prinsip Umum Mesin Pencari ... 25
II.4.4.1 Spider ... 25
II.4.4.2 Crawler ... 25
II.4.4.3 Indexer ... 25
II.4.4.4 Database ... 26
vii
II.6 Data Flow Diagram (DFD) ... 29
II.6.1 Komponen Data Flow Diagram (DFD) ... 30
II.6.1.1 Komponen Terminator atau Entitas Luar ... 30
II.6.1.2 Komponen Proses ... 30
II.6.1.3 Komponen Data Store ... 30
II.6.1.4 Komponen Alur Data ... 31
II.6.1.5 Bentuk Data Flow Diagram (DFD) ... 31
II.6.1.6 Pembuatan DFD ... 32
II.7 Entity Relationship Diagram ... 33
II.7.1 Entitas (Entity) ... 33
II.8 Aplikasi Pembangun ... 36
II.8.1 PHP ... 36
II.8.1.1 Kelebihan PHP ... 36
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 38
III.1 Analisis Sistem ... 38
III.1.1 Analisis Masalah ... 38
III.1.2 Analisis Sumber Data ... 39
viii
III.1.3.1.2 Stemming kata ... 44
III.1.3.2 Identifikasi Cluster Dasar Pembangun ... 53
III.1.3.3 Pengkombinasian Cluster Dasar ... 55
III.1.4 Analisis Data ... 58
III.1.5 Spesifikasi Kebutuhan Perangkat Lunak ... 60
III.1.6 Analisis Kebutuhan Non-Fungsional ... 61
III.1.6.1 Analisis Kebutuhan Perangkat Keras ... 62
III.1.6.2 Analisis Kebutuhan Perangkat Lunak ... 62
III.1.6.3 Analisis Kebutuhan Perangkat Pikir ... 62
III.1.7 Analisis Kebutuhan Fungsional ... 62
III.1.7.1 Diagram Konteks ... 63
III.1.7.2 DFD Level 1 ... 63
III.1.7.3 DFD Level 2 Proses 1 ... 64
III.1.7.4 DFD Level 2 Proses 2 ... 65
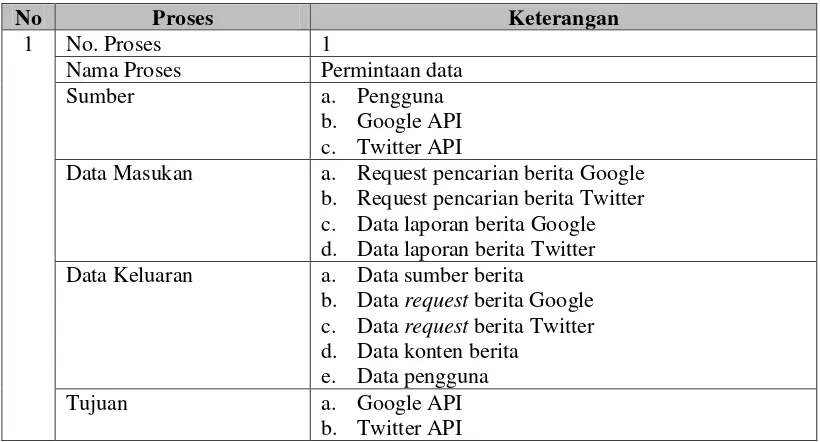
III.1.8 Spesifikasi Proses ... 66
III.1.9 Kamus Data... 70
III.2 Perancangan Sistem ... 71
ix
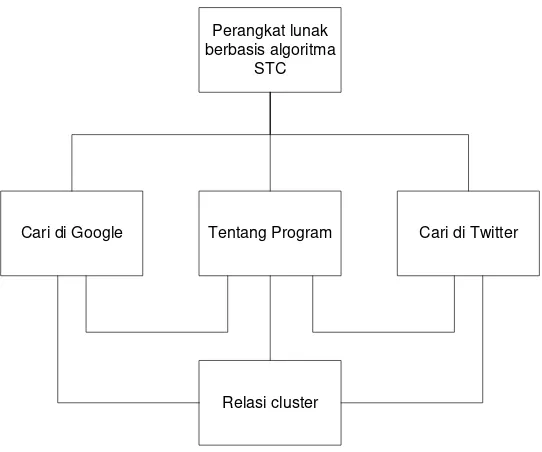
III.2.2 Perancangan Arsitektur Perangkat Lunak... 74
III.2.2.1 Perancangan Struktur Menu ... 74
III.2.3 Perancangan Antarmuka ... 75
III.2.3.1 Perancangan Antarmuka Halaman Utama ... 75
III.2.3.2 Perancangan Antarmuka Hasil Pencarian Google ... 76
III.2.3.3 Perancangan Antarmuka Hasil Pencarian Twitter ... 77
III.2.3.4 Perancangan Antarmuka Hasil Clustering ... 77
III.2.3.5 Perancangan Antarmuka Relasi Cluster ... 77
III.2.3.6 Perancangan Antarmuka Tentang Program ... 78
III.2.3.7 Perancangan Antarmuka Pesan Kesalahan ... 80
III.2.4 Jaringan Semantik ... 80
III.2.5 Perancangan Prosedural ... 81
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 85
IV.1 Implementasi Sistem ... 85
IV.1.1 Kebutuhan Perangkat Keras (Hardware) ... 85
IV.1.2 Kebutuhan Perangkat Lunak (Software) ... 85
IV.1.3 Implementasi Data ... 86
x
IV.2.2 Pengujian White Box ... 92
IV.2.2.1 Pengujian Penghapusan Stop Word ... 92
IV.2.2.2 Pengujian Stemming Kata ... 94
IV.2.2.3 Pengujian Identifikasi Cluster ... 100
IV.2.3 Pengujian Black Box ... 102
IV.2.4 Pengujian Beta ... 103
IV.2.5 Kesimpulan Pengujian Beta ... 111
BAB V KESIMPULAN DAN SARAN ... 112
V.1 Kesimpulan ... 112
V.2 Saran ... 112
1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
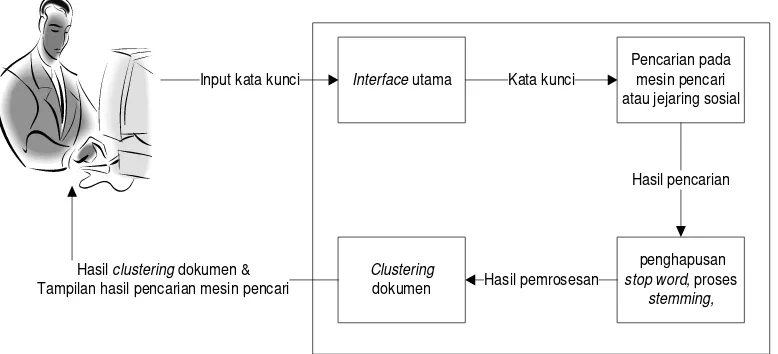
Perkembangan teknologi dewasa ini semakin memudahkan pengguna mendapatkan informasi yang diinginkan. Salah satu sumber yang mudah digunakan untuk mendapatkan informasi tersebut adalah search engine (mesin pencari) dan social network (jejaring sosial). Mesin pencari adalah salah satu tempat di mana pengguna dapat mencari informasi apapun dengan mudah. Pengguna hanya tinggal mengetikan kata kunci yang ingin dicari dan beberapa saat kemudian hasil pencarian berdasarkan kata kunci tersebut dapat terlihat. Jejaring sosial adalah tempat dimana seseorang dapat saling berinteraksi dengan orang lain secara tidak langsung. Dengan adanya mesin pencari dan jejaring sosial, maka pengguna dapat meng-update informasi kapan pun dan dimanapun. Mesin pencari dan jejaring sosial sendiri bukanlah hal yang asing di Indonesia, karena berdasarkan hasil survei yang dilakukan oleh internetworldstats.com [7], sebelum 31 Desember 2011, pengguna internet di Indonesia sudah mencapai angka 55.000.000 orang. Sedangkan semiostat.com [8], merilis angka akun pengguna Twitter di Indonesia yang dibuat sebelum tanggal 1 Januari 2012 mencapai angka 19.500.000 akun. Angka ini menempatkan Indonesia sebagai negara ke-5 pengguna Twitter terbanyak di dunia.
terhadap topik yang ingin diketahui. Pencarian tersebut biasanya akan menghasilkan hasil penelusuran yang tidak sedikit, mulai dari ratusan sampai jutaan hasil akan ditampilkan. Namun, hasil teratas pencarian tersebut tidak selamanya relevan dengan informasi yang benar-benar diinginkan. Tidak jarang, informasi yang benar-benar sesuai justru tersimpan di bagian bawah dari halaman hasil pencarian, yang kemungkinan besar tidak akan ditelusuri pengguna. Hal ini berlaku untuk mesin pencari sekelas Google sekalipun yang pada tahun 2010
menempati urutan pertama sebagai âtop most search engine for 2010â [9], seperti
dikemukakan dalam [10]. Walaupun Google sendiri telah memiliki solusi terhadap masalah ini, yaitu dengan adanya algoritma pencarian baru yang bernama Google Panda, tetap saja algoritma tidak memperbaiki hasil pencarian seratus persen akurat [12].
Salah satu solusi untuk permasalahan di atas adalah dengan mengorganisasikan hasil pencarian yang didapat ke dalam kelompok-kelompok bahasan berdasarkan topik yang dimiliki. Pengguna dapat melihat dan menelusuri ringkasan dari hasil pencarian tersebut secara lebih cepat. Solusi ini diharapkan dapat membuat waktu yang digunakan pengguna lebih efektif dan efisien saat melakukan penelusuran dari hasil pencarian terhadap suatu informasi tertentu. Penerapan solusi ini dapat dilakukan dengan metode clustering.
karena dapat mengekstrak topik dari dokumen secara otomatis dan tanpa perlu ditentukan terlebih dahulu cluster apa saja yang harus ada untuk menampungnya.
Clustering sangat berguna untuk pengelompokan dokumen hasil pencarian online
karena hasil pencarian yang ditampilkan bisa sangat bermacam-macam walaupun dalam satu kata kunci. Diharapkan pengguna dapat melakukan seleksi dan menemukan informasi lebih cepat dari hasil penelusuran yang telah dikelompokan.
merupakan mesin pencari terpopuler [9], sedangkan Twitter dipilih karena dinilai lebih informatif berdasarkan batasan karakter yang dapat ditulis dalam tweet.
I.2 Perumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah yang dikaji dalam penelitian ini adalah bagaimana menerapkan metode Suffix Tree Clustering untuk pengelompokan dokumen hasil pencarian secara online pada mesin pencari dan jejaring sosial.
I.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan penelitian ini adalah untuk mengimplementasikan metode Suffix Tree Clustering
untuk pengelompokan dokumen hasil pencarian secara online. Sedangkan tujuan yang akan dicapai dalam penelitian ini adalah :
1. Untuk menganalisis metode Suffix Tree Clustering pada pengelompokan dokumen secara umum.
2. Untuk mengimplementasikan metode Suffix Tree Clustering pada pengelompokan dokumen hasil pencarian online.
I.4 Batasan Masalah
Untuk memberikan suatu pandangan dan arah yang jelas dalam penelitian ini, maka penulis membatasi masalah sebagai berikut :
1. Studi kasus dilakukan di mesin pencari Google dan jejaring sosial Twitter. 2. Sumber data berasal dari hasil pencarian dokumen berdasarkan suatu kata
kunci.
3. Metode yang digunakan adalah metode Suffix Tree Clustering.
4. Clustering data dilakukan pada halaman hasil yang telah ditelusuri oleh mesin pencari Google dan Twitter.. Hasil clustering akan berada di samping isi halaman hasil pencarian.
5. Semua tanda kutip ( â ) dan petik ( â ) yang terdapat dalam hasil pencarian akan dirubah menjadi garis bawah ( _ ) setelah proses clustering dilakukan. 6. Metode analisis dan pembangunan perangkat lunak yang digunakan adalah
metode analisis terstruktur.
I.5 Metodologi Penelitian
Metodologi yang digunakan dalam penulisan penelitian ini adalah metode analisis deskriptif, dengan metode-metode sebagai berikut :
1. Metode pengumpulan data
a. Studi Literatur.
Suatu metode pengumpulan data dengan cara mengumpulkan literatur, jurnal,
paper, dan bacaan-bacaan yang ada kaitannya dengan penelitian. b. Observasi.
Suatu teknik pengumpulan data dengan melakukan penelitian dan peninjauan langsung terhadap permasalahan yang diambil.
2. Metode pembangunan perangkat lunak.
Teknik analisis data dalam pembuatan perangkat lunak menggunakan paradigma perangkat lunak secara waterfall [13] (Gambar I.1), yang meliputi beberapa proses diantaranya :
Requirements definition
System and software design
Implementation and unit testing
Integration and system testing
Operation and maintenance
Gambar I-1 Metode Waterfall
a. Requirements Definitions
Informasi tersebut dianalisis untuk mendapatkan dokumentasi kebutuhan pengguna untuk digunakan pada tahap selanjutnya.
b. System and Software Design
Tahap ini dilakukan sebelum melakukan coding. Tahap ini bertujuan untuk memberikan gambaran apa yang seharusnya dikerjakan dan bagaimana tampilannya. Tahap ini membantu dalam menspesifikasi kebutuhan hardware dan sistem serta mendefinisikan arsitektur sistem secara keseluruhan.
c. Implementation and Unit Testing
Dalam tahap ini dilakukan pemrograman. Pembuatan software dipecah menjadi modul-modul kecil yang nantinya akan digabungkan dalam tahap berikutnya. Selain itu dalam tahap ini juga dilakukan pemeriksaan terhadap modul yang dibuat, apakah sudah memenuhi fungsi atau belum.
d. Integration and System Testing
Di tahap ini dilakukan penggabungan modul-modul yang sudah dibuat dan dilakukan pengujian. Ini dilakukan untuk mengetahui apakah software yang dibuat telah sesuai dengan desainnya dan masih terdapat kesalahan atau tidak.
e. Operation and Maintenance
I.6 Sistematika Penulisan
Sistematika penulisan proposal penelitian ini disusun untuk memberikan gambaran umum untuk memudahkan dalam menganalisa dan memahami tentang penelitian yang dilakukan. Sistematika penulisan penelitian ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini menguraikan tentang latar belakang permasalahan, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian yang digunakan, serta sistematika penulisan dalam penelitian ini.
BAB II TINJAUAN PUSTAKA
Bab ini membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan. Teori-teori yang dibahas mengenai perangkat lunak, data flow diagram, entity relationship diagram, data mining, clustering, text mining,
suffix tree clustering, dan aplikasi pembangun perangkat lunak. BAB III ANALISIS DAN PERANCANGAN SISTEM
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini membahas dua bagian utama, yaitu implementasi dan pengujian. Pada bagian implementasi terdapat empat bagian yang akan dijelaskan, yaitu penjelasan mengenai perangkat keras, perangkat lunak, basis data serta antarmuka. Sedangkan pada bagian pengujian akan dijelaskan mengenai pengujian yang berupa pengujian alpha dengan menggunakan metode blackbox serta pengujian
beta dengan menggunakan kuesioner. BAB V KESIMPULAN DAN SARAN
10
BAB II
TINJAUAN PUSTAKA
II.1 Data Mining
Data mining merupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan jumlah yang besar. Beberapa definisi data mining yang diantaranya adalah sebagai berikut :
1. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual.
2. Data mining adalah analisa otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak didasari keberadaannya.
3. Data mining atau Knowledge Discovery in Database (KDD) adalah pengambilan informasi yang tersembunyi, dimana informasi tersebut sebelumnya tidak dikenal dan berpotensi bermanfaat. Proses ini meliputi sejumlah pendekatan teknis yang berbeda, seperti clustering, data summarization, learning classification rules.
karena dalam banyak teknik data mining ada beberapa parameter yang masih harus ditentukan secara manual atau semi manual. Data mining juga dapat memanfaatkan pengalaman atau bahkan kesalahan di masa lalu untuk meningkatkan kualitas dari model maupun hasil analisanya, salah satunya dengan kemampuan pembelajaran yang dimiliki beberapa teknik data mining seperti klasifikasi.
II.1.1 Tahapan Data Mining
Salah satu tuntutan dari data mining ketika diterapkan pada data berskala besar adalah diperlukan metodologi sistematis tidak hanya ketika melakukan analisa saja tetapi juga ketika mempersiapkan data dan juga melakukan interpretasi dari hasilnya sehingga dapat menjadi aksi ataupun keputusan yang bermanfaat.
Data mining seharusnya dipahami sebagai suatu proses, yang memiliki tahapan-tahapan tertentu dan juga ada umpan balik dari setiap tahapan ke tahapan sebelumnya. Pada umumnya proses data mining berjalan interaktif karena tidak jarang hasil data mining pada awalnya tidak sesuai dengan harapan analisnya sehingga perlu dilakukan desain ulang prosesnya.
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yang diilustrasikan di Gambar II-1. Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base. Adapun untuk tahap-tahap data mining tersebut adalah sebagai berikut :
1. Pembersihan data
Pembersihan dilakukan untuk membuang data yang tidak konsisten dan berupa noise.
2. Integrasi Data
Data yang diperlukan untuk data mining tidak hanya berasal dari satu
database tetapi juga berasal dari beberapa database atau file teks. Hasil integrasi data sering diwujudkan dalam sebuah data warehouse karena dengan data warehouse, data dikonsolidasikan dengan struktur khusus yang efisien. Selain itu
data warehouse juga memungkinkan tipe analisa seperti OLAP. 3. Transformasi data
Transformasi dan pemilihan data ini untuk menentukan kualitas dari hasil data mining, sehingga data diubah menjadi bentuk sesuai untuk di-mining.
4. Aplikasi Teknik Data Mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining.
5. Evaluasi pola yang ditemukan
6. Presentasi Pengetahuan
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat.
II.1.2 Teknik Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa kata mining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar data dasar. Karena itu data mining
sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan basis data. Beberapa teknik yang sering disebut-sebut dalam literatur data mining antara lain yaitu
association rule mining, clustering, klasifikasi, neural network, genetic algorithm
dan lain-lain.
II.1.2.1 Classification
metode klasifikasi yang paling populer karena mudah untuk diinterpretasi. Decision tree adalah model prediksi menggunakan struktur pohon atau struktur berhirarki.
Decision tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiap simpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri dari simpul akar ke simpul daun yang memegang prediksi kelas untuk contoh tersebut. Decision tree mudah untuk dikonversi ke aturan klasifikasi (classification rules).
Gambar II-2 Contoh decision tree
II.1.2.2 Association
dengan susu. Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu.
Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter,
support yaitu prosentasi kombinasi atribut tersebut dalam basis data dan
confidence yaitu kuatnya hubungan antar atribut dalam aturan asosiatif. Motivasi awal pencarian association rule berasal dari keinginan untuk menganalisa data transaksi supermarket, ditinjau dari perilaku customer dalam membeli produk.
Association rule ini menjelaskan seberapa sering suatu produk dibeli secara bersamaan. Sebagai contoh, association rule âbeer => diaper (80%)â
menunjukkan bahwa empat dari lima customer yang membeli beer juga membeli
diaper. Dalam suatu association rule X => Y, X disebut dengan antecedent dan Y
disebut dengan consequent.
II.1.2.3 Clustering
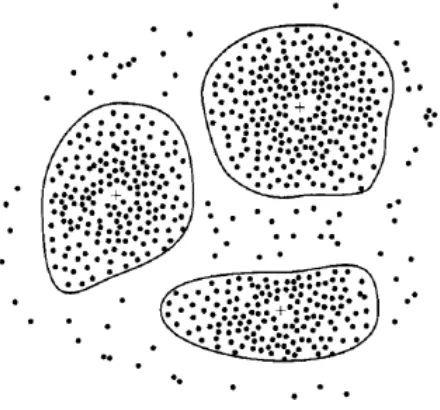
Clustering digunakan untuk menganalisis pengelompokkan berbeda terhadap data, mirip dengan klasifikasi, namun pengelompokkan belum didefinisikan sebelum dijalankannya tool data mining. Biasanya menggunakan metode neural network atau statistik. Clustering membagi item menjadi kelompok-kelompok yang ditemukan tool data mining.
lokasi, dinyatakan dengan bidang dua dimensi, dari pelanggan suatu toko dapat dikelompokkan menjadi beberapa cluster dengan pusat cluster ditunjukkan oleh tanda positif (+). Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data, diperlukan juga metoda untuk normalisasi bermacam atribut yang dimiliki data.
Gambar II-3 Contoh clustering
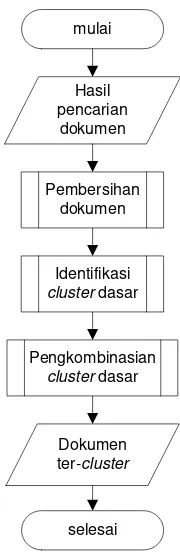
II.2 Suffix Tree Clustering
Algoritma STC memiliki tiga proses utama, yaitu document preprocessing,
mulai
Hasil pencarian
dokumen
selesai Pembersihan
dokumen
Identifikasi cluster dasar
Pengkombinasian cluster dasar
[image:31.595.274.364.110.388.2]Dokumen ter-cluster
Gambar II-4 Langkah-langkah dalam algoritma STC
Penjelasan untuk langkah-langkah dalam algoritma STC adalah sebagai berikut :
II.2.1 Document preprocessing
Pembersihan dokumen merupakan langkah awal dalam algoritma STC. Dalam proses ini dokumen yang didapat berdasarkan pencarian suatu kata kunci dibersihkan dari karakter-karakter yang tidak diperlukan, proses penghapusan
II.2.1.1 Pembersihan stop word
Stop word adalah kata-kata yang muncul dalam suatu pencarian, namun bukan merupakan kata-kata yang menjadi inti dari hasil pencarian tersebut. Stop word dapat berbeda satu sama lain, misalnya stop word untuk menyeleksi kata-kata yang muncul dalam e-mail akan berbeda dengan stop word yang digunakan untuk menyeleksi dokumen secara umum.
II.2.1.2 Stemming kata
Stemming adalah pengubahan suatu kata ke dalam bentuk dasarnya. Umumnya algoritma ini dibuat untuk kata-kata dalam bahasa Inggris. Namun beberapa algoritma stemming saat ini telah dibuat oleh para peneliti untuk mencakup beberapa bahasa lain di dunia selain bahasa Inggris. Contoh algoritma stemming
untuk selain bahasa Inggris adalah algoritma Nazief dan Andriani, yang dikembangkan khusus untuk bahasa Indonesia.
II.2.2 Identifikasi Cluster Dasar Pembangun
Tahap kedua dari algoritma STC adalah tahap identifikasi pembentukan
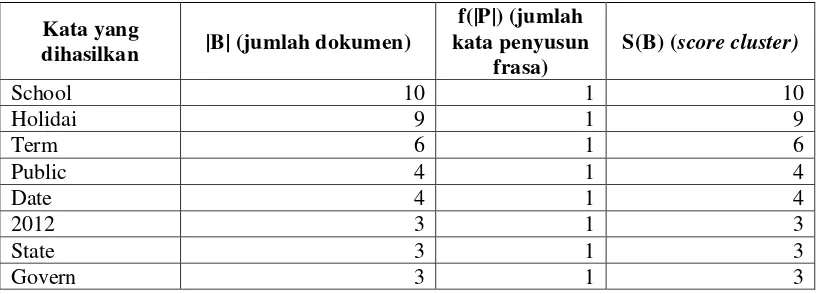
� � = � .�( � ) (2.1)
Dimana
S(B) = score cluster,
|B| = jumlah dokumen yang memiliki frasa yang muncul di dalam cluster dasar, dan
f(|P|) = jumlah kata yang menyusun frasa tersebut.
Tidak semua cluster yang didapat akan diberikan score, cluster yang diberi
score dan ditampilkan hanyalah cluster yang memiliki jumlah kemunculan kata yang lebih banyak daripada tiga. Nilai tiga dipilih karena jika cluster memiliki jumlah score yang lebih sedikit maka akan dianggap sebagai outlier yang tidak mencerminkan cluster dasar secara umum.
II.2.3 Pengkombinasian Cluster Dasar
Tahap ini dilakukan unutk menangani cluster-cluster yang overlap. Pengkombinasian dapat dilakukan dengan menghitung nilai similarity antar
cluster dasar yang didasarkan pada jumlah dokumen yang overlap. Overlapping
dokumen didasarkan karena dokumen dapat memiliki lebih dari satu topik.
Penghitungan nilai similarity menggunakan nilai biner. Rumus untuk menghitung nilai similarity antar cluster dasar dapat dilihat pada persamaan di bawah ini.
� ⩠�
|� | > 0,5
(2.2)
� ⩠�
|� | > 0,5
Dimana :
|Bm â© Bn| = jumlah dokumen yang mengandung kedua kata <Bm> dan <Bn>. |Bm| = jumlah dokumen yang mengandung kata <Bm>.
|Bn| = jumlah dokumen yang mengandung kata <Bn>.
Dalam penggunaan di atas, penggunaan nilai ambang 0,5 digunakan karena nilai tersebut merupakan nilai tengah antara 0 sampai 1. Jika nilai dari kedua persamaan di atas bernilai benar (lebih dari 0,5) maka similarity antar dua cluster
dasar akan bernilai satu sehingga kedua cluster tersebut akan terhubung. Jika hanya salah satu yang bernilai benar atau keduanya salah maka nilai similarity
akan dianggap bernilai 0 dan kedua cluster dasar tersebut tidak terhubung.
II.3 Jejaring Sosial
Jejaring sosial adalah struktur sosial yang terdiri dari elemen-elemen individual atau organisasi. Jejaring ini menunjukan jalan dimana mereka berhubungan karena kesamaan sosialitas, mulai dari mereka yang dikenal sehari-hari sampai dengan keluarga. Istilah ini diperkenalkan oleh profesor J.A. Barnes di tahun 1954.
Jejaring sosial adalah suatu struktur sosial yang dibentuk dari simpul-simpul (yang umumnya adalah individu atau organisasi) yang diikat dengan satu atau lebih tipe relasi spesifik seperti nilai, visi, ide, teman, keturunan, dan lain-lain.
dan ruang secara fisik. Dari sekian banyak penyedia jejaring sosial, ada sebagian menghilang begitu saja, adapula yang sukses, tergantung dari pengelolaannya baik secara teknikal maupun manajemen (pemasaran/promosi, keuangan, legalitas,
business intelegent).
II.4 Mesin Pencari
Mesin pencari adalah program komputer yang dirancang untuk melakukan pencarian atas berkas-berkas yang tersimpan dalam layanan www, ftp, publikasi milis, ataupun news group dalam sebuah ataupun sejumlah komputer peladen dalam suatu jaringan. Hasil pencarian umumnya ditampilkan dalam bentuk daftar yang seringkali diurutkan menurut tingkat akurasi ataupun rasio pengunjung atas suatu berkas yang disebut sebagai hits. Informasi yang menjadi target pencarian bisa terdapat dalam berbagai macam jenis berkas seperti halaman situs web, gambar, ataupun jenis-jenis berkas lainnya. Beberapa mesin pencari juga diketahui melakukan pengumpulan informasi atas data yang tersimpan dalam suatu basis data ataupun direktori web.
II.4.1 Google
Google muncul di akhir tahun 1997, dimana Google memasuki pasar yang telah diisi oleh para pesaing lain dalam penyediaan layanan mesin pencari, seperti Yahoo, Altavista, HotBot, Excite, InfoSeek dan Lycos, dimana perusahaan-perusahaan tersebut mengklaim sebagian perusahaan-perusahaan yang bergerak dalam bidang layanan pencarian di internet, hingga akhirnya Google mampu menjadi sebagai penyedia mesin pencari yang cukup diperhitungkan di dunia.
Tingginya persaingan antar mesin pencari yang ada tidak mampu menghentikan kesuksesan Google. Setelah Yahoo mampu pada posisi puncak di sekitar tahun 2000, Google mampu menerobos liga besar tersebut. sehingga Google dipandang sebagai mesin pencari yang utama seperti yang kita ketahui pada hari ini.
II.4.2 Manfaat Mesin Pencari
Adapun manfaat dari mesin pencari antara lain adalah sebagai berikut :
1. Mesin pencari merupakan tempat kebanyakan orang mencari sesuatu via internet. Menurut survei hampir 90% pengguna internet memakai mesin pencari untuk mencari lokasi tertentu di internet, dan di antara mesin pencari yang ada, Google merupakan mesin pencari yang paling banyak digunakan. 2. Sebagian besar pengguna mesin pencari tidak pernah melewatkan dua
halaman pertama dari mesin pencari.
(secara alami) akan membuat suatu website memperoleh posisi strategis dalam dunia internet.
4. Di negara-negara maju, porsi penjualan yang dilakukan melalui internet sudah hampir mencapai 20% dari keseluruhan transaksi tahunan.
5. Sebuah informasi yang mudah di akses oleh semua orang baik dalam maupun luar negeri.
II.4.3 Cara Kerja Mesin Pencari
Mesin pencari web bekerja dengan cara menyimpan informasi tentang banyak halaman web. Halaman-halaman ini diambil dengan web crawler - browser yang secara otomatis yang mengikuti setiap pranala yang dilihatnya. Isi setiap halaman lalu dianalisis untuk menentukan indeksnya (misalnya, kata-kata diambil dari judul, subjudul, atau field khusus yang disebut meta tag). Data tentang halaman web disimpan dalam sebuah database indeks untuk digunakan dalam pencarian selanjutnya. Sebagian mesin pencari menyimpan seluruh atau sebagian halaman sumber (yang disebut cache) maupun informasi tentang halaman web itu sendiri.
Selain halaman web, Mesin pencari juga menyimpan dan memberikan informasi hasil pencarian berupa pranala yang merujuk pada file, seperti file audio, file video, gambar, foto dan sebagainya, serta informasi tentang seseorang, suatu produk, layanan, dan informasi beragam lainnya yang semakin terus berkembang sesuai dengan perkembangan teknologi informasi.
daftar halaman web yang paling sesuai dengan kriterianya, biasanya disertai ringkasan singkat mengenai judul dokumen dan kadang-kadang sebagian teksnya.
Ada jenis mesin pencari lain: mesin pencari real-time, seperti Orase. Mesin seperti ini tidak menggunakan indeks. Informasi yang diperlukan mesin tersebut hanya dikumpulkan jika ada pencarian baru. Jika dibandingkan dengan sistem berbasis indeks yang digunakan mesin-mesin seperti Google, sistem real-time ini unggul dalam beberapa hal: informasi selalu mutakhir, (hampir) tak ada pranala mati, dan lebih sedikit sumber daya sistem yang diperlukan. (Google menggunakan hampir 100.000 komputer, Orase hanya satu.) Tetapi, ada juga kelemahannya, yaitu pencarian lebih lama rampungnya.
Manfaat mesin pencari bergantung pada relevansi hasil-hasil yang diberikannya. Meskipun mungkin ada jutaan halaman web yang mengandung suatu kata atau frasa, sebagian halaman mungkin lebih relevan, populer, atau autoritatif daripada yang lain. Kebanyakan mesin pencari menggunakan berbagai metode untuk menentukan peringkat hasil pencarian agar mampu memberikan hasil "terbaik" lebih dahulu. Cara mesin menentukan halaman mana yang paling sesuai, dan urutan halaman-halaman itu diperlihatkan, sangat bervariasi. Metode-metode yang digunakan pun berubah seiring waktu dengan berubahnya penggunaan internet dan berevolusinya teknik-teknik baru.
II.4.4 Prinsip Umum Mesin Pencari
Sistem kinerja mesin ini ada beberapa hal yang perlu di perhatikan terutama keterkaitannya dengan masalah arsitekrut dan mekanismenya.
II.4.4.1 Spider
Spider merupakan program yang men-download halaman-halaman yang mereka temukan, mirip dengan browser. Perbedannya adalah bahwa browser
menampilkan secara langsung informasi yang ada (baik tekas, gambar, dll). Untuk kepentingan manusia yang menggunakannya pada saat itu, sedangkan spider tidak melakukan untuk menampulkan dalam bentuk yang terlihat seperti itu, karena kepentingannya adalah untuk mesin, bukan untuk manusia, spider pun dijalankan oleh mesin secara otomatis. Kepentingannya adalah untuk mengambil halaman-halaman yang dikunjunginya untuk disimpan kedalam database yang dimiliki oleh search engine.
II.4.4.2 Crawler
Crawler merupakan program yang dimiliki search engine untuk melacak dan menemukan link yang terdapat dari setiap halaman yang ditemuinya. Tugasnya adalah untuk menentukan spider harus pergi kemana dan mengevaluasi link berdasarkan alamat yang ditentukan dari awal. Crawler mengikuti link dan mencoba menemukan dokumen yang belum dikenal oleh search engine.
II.4.4.3 Indexer
II.4.4.4 Database
Merupakan tempat standar untuk menyimpan data-data dari halaman yang telah dikunjungi, di-download dan sudah dianalisis. kadang kala disebut juga dengan index dari suatu search engine.
II.4.4.5 Result Engine
Mesin yang melakukan penggolongan dan penentuan peringkat dari hasil pencarian pada search engine. Mesin ini menentukan halaman mana yang menemui kriteria terbaik dari hasil pencarian berdasarkan permintaan penggunanya, dan bagaimana bentuk penampilan yang akan ditampilkan.
Proses ini dilaksanakan berdasarkan algoritma pe-ranking-an yang dimiliki oleh search engine tersebut, mengikuti kaidah pe-rangking-an halaman yang dipergunakan oleh mereka adalah hak mereka, para peneliti mempelajari sifat-sifat yang mereka gunakan, terutama untuk meningkatkan pencarian yang dihasilkan oleh search engine tersebut.
II.4.4.6 WebServer
II.5 Application Programming Interface (API)
API adalah serangkaian instruksi dan standar pemrograman untuk mengakses aplikasi atau layanan berbasis web. Sebuah perusahaan software atau penyedia layanan berbasis web seringkali merilis API mereka kepada publik. Dengannya, pengembang lain dapat mendesain aplikasi yang memanfaatkan layanan mereka. Sebagai contoh, Amazon.com merilis API sehingga para pengembang web dapat lebih mudah mengakses informasi produk-produk Amazon dari website mereka. Menggunakan API dari Amazon, website pihak ketiga dapat mem-posting link
langsung ke produk-produk Amazon dengan harga aktual dan opsi âbuy nowâ. API adalah software-to-software interface, bukan user interface. Dengan API, aplikasi-aplikasi saling berkomunikasi tanpa ada intervensi dari pengguna. Misalnya ketika Anda memasukkan nomor kartu kredit untuk berbelanja, toko
online tersebut akan menggunakan API untuk mengirimkan informasi kartu kredit kepada aplikasi dari perusahaan lain yang memverifikasi kartu kredit. Bila aplikasi verifikasi kartu kredit menyatakan bahwa informasi yang Anda masukkan benar, aplikasi tersebut akan mengirimkan respons kembali ke toko online tempat Anda berbelanja, dan menyatakan bahwa proses pembayaran bisa dilakukan. Proses komunikasi antara aplikasi toko online dengan aplikasi verifikasi kartu kredit sepenuhnya dilakukan tanpa campur tangan manusia. Anda hanya melihat satu interface: toko online. Tapi di belakang layar, terdapat beberapa aplikasi yang bekerja sama menggunakan API. Jenis integrasi ini dikenal dengan istilah
API serupa dengan konsep Software as a Service (SaaS), karena pengembang aplikasi tidak perlu memulai segala sesuatu dari kertas kosong (from scratch) setiap kali mereka menulis sebuah program. Alih-alih membangun aplikasi inti yang menangani semua pekerjaan (semisal e-mail, billing, tracking, dll) sendiri, pekerjaan-pekerjaan tersebut dapat diserahkan kepada penyedia layanan atau perusahaan software lain.
API memungkinkan sebuah aplikasi berkomunikasi dengan aplikasi lain di Internet melalui serangkaian panggilan (call). Sebuah API, berdasarkan definisinya, adalah sesuatu yang mendefinisikan cara dua entitas untuk berkomunikasi. Entitas di sini adalah sebuah software yang nyata berbeda (dalam layanan) dengan software lain. Dengan API, panggilan-panggilan yang bolak-balik antar aplikasi diatur melalui web service. Web service adalah kumpulan standar teknis dan protokol, termasuk XML (Extensible Markup Language), bahasa umum yang digunakan oleh aplikasi-aplikasi tersebut selama berkomunikasi di Internet.
API sendiri merupakan sekumpulan kode software yang ditulis sebagai serangkaian pesan XML. Setiap pesan XML berhubungan dengan fungsi spesifik dari aplikasi yang akan diajak berkomunikasi. Sebagai contoh, pada API Facebook, terdapat pesan XML yang berhubungan dengan fungsi spesifik wall post, wall comment, wall like. Pengembang aplikasi pihak ketiga menggunakan pesan-pesan XML yang berhubungan dengan fungsi-fungsi spesifik dari layanan
rancangannya. Sebagai contoh, Anda bisa membuat Facebook client yang hanya menampilkan update status teman-teman Anda.
API dan web service sepenuhnya bekerja di belakang layar. Para peselancar
web dan pengguna software sama sekali tidak melihatnya. Keduanya bekerja diam-diam, menyediakan jalan bagi beberapa aplikasi untuk bekerja sama untuk memberikan informasi atau fungsionalitas yang dibutuhkan oleh pengguna aplikasi. Dengan demikian, API adalah standar komunikasi yang dibuka oleh perusahaan software, agar dapat dimanfaatkan oleh pengembang pihak ketiga untuk mendesain aplikasi yang memanfaatkan layanan mereka dengan mudah [15].
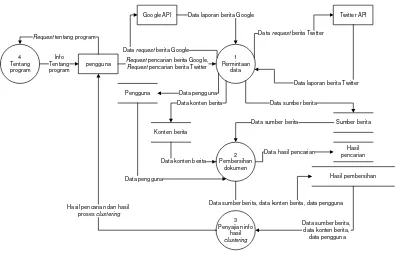
II.6 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) adalah alat pembuatan model yang memungkinkan profesional untuk menggambarkan sistem sebagai suatu jaringan proses fungsional yang dihubungkan satu sama lain dengan alur data, baik secara manual maupun komputerisasi. DFD ini sering disebut juga dengan Bubble Chart,
Bubble Diagram, model proses, diagram alur kerja, atau model fungsi.
DFD ini merupakan alat perancangan sistem yang berorientasi pada alur data dengan konsep dekomposisi dapat digunakan untuk penggambaran analisa maupun rancangan sistem yang mudah dikombinasikan oleh profesional sistem kepada pemakai maupun pembuat program.
II.6.1 Komponen Data Flow Diagram (DFD)
Data Flow Diagram memiliki beberapa komponen utama sebagai berikut :
II.6.1.1 Komponen Terminator atau Entitas Luar
Terminator mewakili entitas eksternal yang berkomunikasi dengan sistem yang sedang dikembangkan. Biasanya terminator dikenal dengan nama entitas luar (external entity).
Terdapat dua jenis terminator yaitu :
1. Terminator Sumber (source), merupakan terminator yang menjadi sumber 2. Terminator Tujuan (sink), merupakan terminator yang menjadi tujuan data
atau informasi sistem.
II.6.1.2 Komponen Proses
Komponen proses menggambarkan bagian dari sistem yang mentransformasikan input menjadi output. Proses dilambangkan dengan lingkaran. Nama proses dituliskan dengan satu kata, singkatan atau kalimat sederhana.
II.6.1.3 Komponen Data Store
file/database yang tersimpan dalam harddisk atau bersifat manual seperti buku alamat.
II.6.1.4 Komponen Alur Data
Alur data digunakan untuk menerangkan perpindahan data atau paket data dari satu bagian ke bagian lainnya. Alur data dapat berupa kata, pesan, atau informasi. Ada empat konsep tentang alur data yaitu :
1. Packets of data
Apabila ada dua data atau lebih yang mengalir dari satu sumber yang sama menuju pada tujuan yang sama dan mempunyai hubungan, maka digambarkan dengan satu alur data.
2. Diverging data flow
Apabila ada sejumlah paket data yang berasal dari sumber yang sama menuju pada tujuan yang berbeda atau paket data yang kompleks dibagi menjadi beberapa elemen data yang dikirim ke tujuan berbeda.
3. Converging data flow
Apabila ada beberapa alur data yang berbeda sumber menuju ke tujuan yang sama.
4. Sumber dan tujuan
Semua alur data harus minimal mengandung satu proses.
II.6.1.5 Bentuk Data Flow Diagram (DFD)
dari sistem diterapkan, sedangkan diagram alur data logika lebih menekankan proses-proses apa yang terdapat di dalam sistem.
1. Diagram Alur Data Fisik (DADF)
Diagram alur data fisik lebih tepat digunakan untuk menggambarkan sistem yang ada (sistem yang lama). Penekanan dari diagram alur data fisik adalah bagaimana proses-proses dari sistem yang diterapkan (dengan cara apa, oleh siapa dan dimana), termasuk proses-proses manual.
2. Diagram Alur Data Logika (DADL)
Diagram alur data logika lebih tepat digunakan untuk menggambarkan sistem yang akan diusulkan (sistem yang baru). untuk sistem komputerisasi, penggambaran diagram alur data logika hanya menunjukkan kebutuhan proses dari sistem yang diusulkan secara logika, biasanya proses-proses yang digambarkan hanya merupakan proses-proses secara komputer saja.
II.6.1.6 Pembuatan DFD
Tidak ada aturan baku untuk membuat DFD, tetapi dari berbagai referensi yang ada adalah sebagai berikut :
1. Diagram Context
Diagram ini adalah diagram level tertinggi dari DFD yang menggambarkan keterkaitan aliran-aliran data antar sistem dengan bagian luar (kesatuan luar). Kesatuan luar ini merupakan sumber arus data atau tujuan data yang berhubungan dengan sistem informasi tersebut.
2. Diagram Level Nol
3. Diagram Level Satu
Diagram ini merupakan dekomposisi dari diagram level nol.
II.7 Entity Relationship Diagram
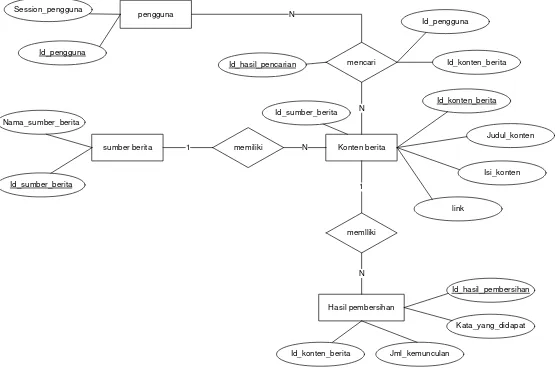
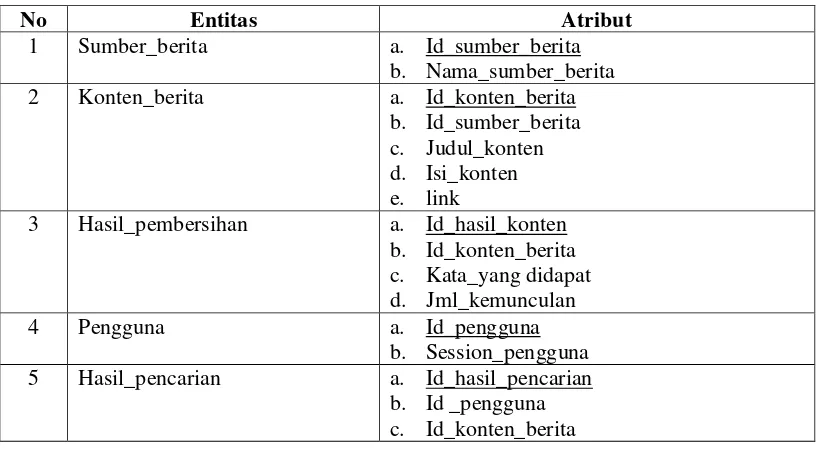
Entity Relationship Diagram (ERD) merupakan suatu model untuk menjelaskan hubungan antar data dalam basis data, berdasarkan objek-objek dasar data yang mempunyai hubungan antar relasi.
ERD digunakan untuk memodelkan struktur data dan hubungan antar data, dan untuk menggambarkannya digunakan beberapa notasi dan simbol. Pada dasarnya ada tiga simbol yang digunakan yaitu :
II.7.1 Entitas (Entity)
Entitas merupakan objek yang mewakili sesuatu yang nyata dan dapat dibedakan dari sesuatu yang lain. Simbol dari entitas ini biasanya digambarkan dengan persegi panjang. Entitas memiliki dua tipe yaitu :
a. Entitas Kuat
b. Entitas Lemah
Entitas yang tidak mempunyai atribut kunci. Entitas lemah diidentifikasikan dengan menghubungkan entitas tertentu dari tipe entitas yang lain ditambah atribut dari entitas lemah. Tipe entitas lain yang dipakai untuk mengidentifikasikan suatu entitas lemah disebut identifying owner dan identifying relationship.
c. Atribut
Setiap entitas pasti mempunyai elemen yang disebut atribut yang berfungsi untuk mendeskripsikan karakteristik dari entitas tersebut. Isi dari atribut mempunyai sesuatu yang dapat mengidentifikasi isi elemen satu dengan yang lain.
Atribut memiliki beberapa tipe yaitu : a. Atribut Sederhana (Simple Attribute)
Merupakan atribut atomik yang tidak dapat dipilah lagi. b. Atribut Komposit (Composite Attribute)
Merupakan atribut yang masih dapat diuraikan lagi menjadi subsub atribut yang masing-masing memiliki makna
c. Atribut Bernilai Banyak (Multivalued Attribute)
Ditunjukkan pada atribut-atribut yang dapat kita isi dengan lebih dari 1 nilai, tetapi jenisnya sama. Contohnya nomor telepon, hobi, dan lain-lain.
d. Atribut Bernilai Tunggal (Single-Valued Attribute)
e. Atribut Turunan
Adalah atribut yang nilai-nilainya diperoleh dari pengolahan atau dapat diturunkan dari atribut atau tabel lain yang berhubungan. Contoh atribut umur yang dapat dikalkulasi dari atribut tanggal lahir.
f. Atribut Harus Bernilai (Mandatory Attribute)
Adalah atribut yang harus berisi nilai. Contoh pada tabel mahasiswa, nomor induk mahasiswa dan nama mahasiswa harus diketahui.
g. Atribut Tidak Harus Bernilai (Non Mandatory Attribute) Adalah atribut yang nilainya boleh dikosongkan.
d. Hubungan atau Relasi
Hubungan antara sejumlah entitas yang berasal dari himpunan entitas yang berbeda.
Relasi yang terjadi diantara dua himpunan entitas (misalnya A dan B) dalam satu basis data yaitu :
1. Satu ke satu (One to One)
Hubungan relasi satu ke satu yaitu setiap entitas pada himpunan entitas A berhubungan paling banyak dengan satu entitas pada himpunan entitas B.
2. Satu ke banyak (One to Many)
3. Banyak ke satu (Many to One)
Setiap entitas A hanya dapat mempunyai satu hubungan dengan himpunan entitas B.
4. Banyak ke banyak (Many to Many)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B.
II.8 Aplikasi Pembangun
Aplikasi pembangun yang digunakan dalam pembangunan perangkat lunak ini adalah sebagai berikut :
II.8.1 PHP
PHP adalah bahasa pemrograman script yang paling banyak dipakai saat ini. PHP banyak dipakai untuk memprogram situs web dinamis, walaupun tidak tertutup kemungkinan digunakan untuk pemakaian lain.
II.8.1.1 Kelebihan PHP
Kelebihan PHP bila dibandingkan dengan program bahasa lainnya adalah sebagai berikut :
1. Bahasa pemrograman PHP adalah sebuah script yang tidak melakukan sebuah kompilasi dalam penggunaannya.
2. Web server yang mendukung PHP dapat ditemukan dimana-mana dari mulai
Apache, IIS, Lighttpd, hingga Xitami dengan konfigurasi yang relatif mudah. 3. Dalam sisi pengembangan lebih mudah dan developer yang siap membantu
4. Dalam sisi pemahaman, PHP adalah bahasa scripting yang paling mudah karena memiliki referensi yang banyak.
PHP adalah bahasa open source yang dapat digunakan di berbagai mesin (Linux, Unix, Macintosh, Windows) dan dapat dijalankan secara runtime melalui
38
BAB III
ANALISIS DAN PERANCANGAN SISTEM
III.1 Analisis Sistem
Analisis sistem didefinisikan sebagai penguraian dari sistem utama ke dalam sub-sub sistem dengan tujuan untuk mengidentifikasi permasalahan-permasalahan yang ada dan kebutuhan-kebutuhan yang diperlukan agar dapat diusulkan dan diciptakan sistem baru yang lebih baik. Analisis terhadap sistem lama yang sedang berjalan perlu dilakukan sebagai dasar dari perancangan sistem baru, agar dapat dibuat sistem yang lebih efektif dan efisien.
III.1.1 Analisis Masalah
Tahapan analisis masalah dilakukan terlebih dahulu sebelum tahapan perancangan sistem. Hal ini dilakukan agar masalah-masalah yang dihadapi dapat diketahui dengan jelas, bagaimana penggunaan sistem yang sedang berjalan oleh pengguna, sampai solusi yang diajukan untuk permasalahan tersebut. Berdasarkan hasil penelitian, masalah-masalah yang dibahas dalam penelitian ini adalah sebagai berikut :
1. Studi kasus dilakukan di mesin pencari Google dan jejaring sosial Twitter. 2. Sumber data berasal dari hasil pencarian dokumen berdasarkan suatu kata
kunci.
3. Metode yang digunakan adalah metode Suffix Tree Clustering (STC).
III.1.2 Analisis Sumber Data
Sumber data yang digunakan dalam penelitian ini adalah data-data yang berasal dari hasil pencarian terhadap suatu kata kunci dalam mesin pencari atau jejaring sosial. Cara-cara utama untuk melakukan pencarian terhadap suatu kata kunci dalam mesin pencari Google adalah sebagai berikut :
1. Pengguna memasukkan kata kunci pencarian ke dalam antarmuka sistem. 2. Sistem kemudian akan meneruskan pencarian berdasarkan kata kunci tersebut.
Sebelum pencarian dilakukan, aturan-aturan khusus untuk pencarian berdasarkan sistem yang dipilih akan diterapkan terhadap kata kunci tersebut. 3. Hasil pencarian yang didapat kemudian dikembalikan kepada pengguna.
Sedangkan dalam Twitter berlaku hal-hal sebagai berikut :
1. Pengguna memasukkan kata kunci pencarian ke dalam antarmuka sistem. 2. Sistem kemudian akan meneruskan pencarian berdasarkan kata kunci tersebut.
Sebelum pencarian dilakukan, aturan-aturan khusus untuk pencarian berdasarkan sistem yang dipilih akan diterapkan terhadap kata kunci tersebut. Twitter memberikan beberapa fungsi khusus pencarian, seperti format #<kata kunci> untuk mencari tweet yang tergabung dalam bahasan kata kunci tersebut.
3. Hasil pencarian yang didapat kemudian dikembalikan kepada pengguna. Hasil pencarian yang diberikan dalam berupa tweet ataupun orang yang mengandung kata yang dicari.
diolah berdasarkan algoritma STC. Pengolahan data hasil pencarian dilakukan dengan melalui beberapa langkah dalam sub-bab 3.1.3. Keluaran dari algoritma ini adalah data hasil pencarian dan topik-topik utama yang terdapat dalam hasil pencarian tersebut. Topik-topik ini diekstrak dari dokumen-dokumen hasil pencarian.
III.1.3 Analisis Algoritma
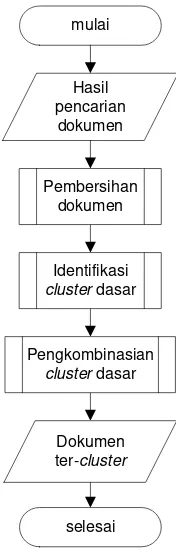
Algoritma STC memiliki tiga proses utama, yaitu document preprocessing,
identifikasi cluster dasar pembangun menggunakan suffix tree, dan pengkombinasian cluster-cluster dasar ke dalam cluster yang lebih umum.
mulai
Hasil pencarian
dokumen
selesai Pembersihan
dokumen
Identifikasi cluster dasar
Pengkombinasian cluster dasar
[image:54.595.275.363.360.636.2]Dokumen ter-cluster
Gambar III-1 Langkah-langkah dalam algoritma STC
III.1.3.1 Document preprocessing
Pembersihan dokumen merupakan langkah awal dalam algoritma STC. Dalam proses ini dokumen yang didapat berdasarkan pencarian suatu kata kunci dibersihkan dari karakter-karakter yang tidak diperlukan, proses penghapusan
stop-word, dan proses stemming. Penghapusan karakter-karakter yang tidak diperlukan meliputi pembersihan tanda baca jika tanda tersebut bukan kata kunci yang dicari pengguna, penghapusan stop-word meliputi penghapusan kata-kata umum yang tidak mengacu kepada suatu hal, seperti kata depan, kata gabung, dan sebagainya. Sedangkan proses stemming adalah proses pengembalian suatu kata ke dalam bentuk awalnya, misalnya penghilangan imbuhan. Proses-proses pada langkah ini meliputi pembersihan stop word dan stemming kata. Penjelasan untuk tiap-tiap langkah di atas adalah sebagai berikut :
III.1.3.1.1Pembersihan stop word
Berikut ini adalah pseudocode dari prosedur penghapusan stop word function hapus_stopWord(Input kata : String) â String
{I. S : masukan untuk pembanding antara daftar stop word terdefinisi}
{F. S : stop word tereliminasi} Deklarasi :
Kumpulan_stopWord : array [1..100] of String {berisi dari kumpulan daftar stop word terdefinisi dengan jumlah anggota 100}
Algoritma :
If kata != Kumpulan_stopWord then Return kata
Endif
III.1.3.1.2Stemming kata
Stemming dalam perangkat lunak ini mengikuti langkah-langkah dalam algoritma Porter Stemming. Dalam algoritma Porter Stemming, konsonan didefinisikan sebagai huruf selain A, E, I, O, atau U dan Y yang didahului oleh huruf selain yang disebutkan. Misalkan dalam kata TOY, konsonannya adalah T dan Y, dan dalam kata SYZYGY konsonannya adalah S, Z dan G. Dalam algoritma ini kumpulan dari konsonan dengan panjang lebih dari 0 dinotasikan dengan C, sedangkan kumpulan vokal dengan panjang lebih dari 0 dinotasikan dengan V. Oleh karena itu, setiap kata akan mengandung satu dari bentuk di bawah :
Bentuk di atas dapat dipresentasikan dengan : [C] VCVC .. [V].
Dengan menggunakan komposisi (VC) {m} untuk menggambarkan VC yang diulang sebanyak m kali, maka rumus di atas dapat ditulis ulang menjadi :
[C] (VC) {m} [V]
Contoh kata dengan m yang berbeda adalah sebagai berikut : m = 0 TR, EE, TREE, Y, BY
m = 1 TROUBLE, OATS, TREES, IVY
m = 2 TROUBLES, PRIVATE, OATEN, ORRERY Kondisi untuk setiap kata dapat juga mengandung : *S â kata berakhiran dengan S
*v* - kata mengandung satu huruf vokal
*d â kata berakhiran dengan konsonan ganda (misalkan âTT, -SS)
*o â kata berakhiran dengan pola cvc, dimana konsonan kedua bukan W, X, atau Y (misalkan âWIL, -HOP)
Selanjutnya untuk langkah-langkah dalam algoritma Porter Stemming adalah sebagai berikut :
Langkah 1a :
a. Jika kata berakhir dengan akhiran SSES, maka ubah akhiran tersebut menjadi SS. Contohnya caresses menjadi caress.
c. Jika kata berakhir dengan akhiran SS, maka jangan ubah kata tersebut. Contohnya caress menjadi caress.
d. Jika kata berakhir dengan akhiran S, maka hilangkan akhiran S. Contohnya
cats menjadi cat. Langkah 1b :
a. Jika kata berakhiran EED, maka ubah akhiran tersebut menjadi EE. Contohnya agreed menjadi agree.
b. Jika kata berakhiran ED, maka hilangkan akhiran tersebut. Contohnya
plastered menjadi plaster.
c. Jika kata berakhiran ING, maka hilangkan akhiran tersebut. Contohnya
motoring menjadi motor.
Jika aturan kedua atau ketiga dalam langkah 1b terpenuhi, maka aturan berikut ini akan diterapkan :
a. Jika kata berakhiran AT, maka ubah akhiran tersebut menjadi ATE. Contohnya conflat(ed) menjadi conflate.
b. Jika kata berakhiran BL, maka ubah akhiran tersebut menjadi BLE. Contohnya troubl(ed) menjadi trouble.
c. Jika kata berakhiran IZ, maka ubah akhiran tersebut menjadi IZE. Contohnya
siz(ed) menjadi size.
d. Jika kata berakhiran dengan konsonan ganda (misalnya âNN) dan bukan berakhiran L, S, atau Z, maka ubah konsonan ganda tersebut menjadi 1 karakter saja. Contohnya hopp(ing) menjadi hop, tann(ed) menjadi tan,
e. Jika kata berakhiran dengan pola konsonan â vokal â konsonan (misalnya â WIL, -HOP), dan konsonan kedua bukan W, X, atau Y, maka ubah akhiran tersebut menjadi E. Contohnya fil(ing) menjadi file.
Langkah 1c :
a. Jika kata hanya memiliki 1 huruf vokal dan berakhiran Y, maka ubah akhiran tersebut menjadi I. Contohnya happy menjadi happi.
Langkah 2 :
a. Jika kata berakhiran dengan ATIONAL, maka ubah akhiran tersebut menjadi ATE. Contohnya relational menjadi relate.
b. Jika kata berakhiran dengan TIONAL, maka ubah akhiran tersebut menjadi TION. Contohnya conditional menjadi condition.
c. Jika kata berakhiran dengan ENCI, maka ubah akhiran tersebut menjadi ENCE. Contohnya valenci menjadi valence.
d. Jika kata berakhiran dengan ANCI, maka ubah akhiran tersebut menjadi ANCE. Contohnya hesitanci menjadi hesitance.
e. Jika kata berakhiran dengan IZER, maka ubah akhiran tersebut menjadi IZE. Contohnya digitizer menjadi digitize.
f. Jika kata berakhiran dengan ABLI, maka ubah akhiran tersebut menjadi ABLE. Contohnya conformabli menjadi conformable.
g. Jika kata berakhiran dengan ALLI, maka ubah akhiran tersebut menjadi AL. Contohnya radicalli menjadi radical.
i. Jika kata berakhiran dengan ELI, maka ubah akhiran tersebut menjadi E. Contohnya vileli menjadi vile.
j. Jika kata berakhiran dengan OUSLI, maka ubah akhiran tersebut menjadi OUS. Contohnya analogousli menjadi analogous.
k. Jika kata berakhiran dengan IZATION, maka ubah akhiran tersebut menjadi IZE. Contohnya vietnamization menjadi vietnamize.
l. Jika kata berakhiran dengan ATION, maka ubah akhiran tersebut menjadi ATE. Contohnya predication menjadi predicate.
m. Jika kata berakhiran dengan ATOR, maka ubah akhiran tersebut menjadi ATE. Contohnya operator menjadi operate.
n. Jika kata berakhiran dengan ALISM, maka ubah akhiran tersebut menjadi AL. Contohnya feudalism menjadi feudal.
o. Jika kata berakhiran dengan IVENESS, maka ubah akhiran tersebut menjadi IVE. Contohnya decisiveness menjadi decisive.
p. Jika kata berakhiran dengan FULNESS, maka ubah akhiran tersebut menjadi FUL. Contohnya hopefulness menjadi hopeful.
q. Jika kata berakhiran dengan OUSNES, maka ubah akhiran tersebut menjadi OUS. Contohnya callousness menjadi callous.
r. Jika kata berakhiran dengan ALITI, maka ubah akhiran tersebut menjadi AL. Contohnya formaliti menjadi formal.
t. Jika kata berakhiran dengan BILITI, maka ubah akhiran tersebut menjadi BLE. Contohnya sensibiliti menjadi sensible.
Langkah 3 :
a. Jika kata berakhiran dengan ICATE, maka ubah akhiran tersebut menjadi IC. Contohnya triplicate menjadi triplic.
b. Jika kata berakhiran dengan ATIVE, maka hapus akhiran tersebut. Contohnya
formative menjadi form.
c. Jika kata berakhiran dengan ALIZE, maka ubah akhiran tersebut menjadi AL. Contohnya formalize menjadi formal.
d. Jika kata berakhiran dengan ICITI, maka ubah akhiran tersebut menjadi IC. Contohnya electriciti menjadi electric.
e. Jika kata berakhiran dengan ICAL, maka ubah akhiran tersebut menjadi IC. Contohnya electrical menjadi electric.
f. Jika kata berakhiran dengan FUL, maka hapus akhiran tersebut. Contohnya
hopeful menjadi hope.
g. Jika kata berakhiran dengan NESS, maka hapus akhiran tersebut. Contohnya
goodness menjadi good. Langkah 4 :
a. Jika kata berakhiran dengan AL, maka hapus akhiran tersebut. Contohnya
revival menjadi reviv.
b. Jika kata berakhiran dengan ANCE, maka hapus akhiran tersebut. Contohnya
c. Jika kata berakhiran dengan ENCE, maka hapus akhiran tersebut. Contohnya
inference menjadi infer.
d. Jika kata berakhiran dengan ER, maka hapus akhiran tersebut. Contohnya
airliner menjadi airlin.
e. Jika kata berakhiran dengan IC, maka hapus akhiran tersebut. Contohnya
gyroscopic menjadi gyroscop.
f. Jika kata berakhiran dengan ABLE, maka hapus akhiran tersebut. Contohnya
adjustable menjadi adjust.
g. Jika kata berakhiran dengan IBLE, maka hapus akhiran tersebut. Contohnya
defensible menjadi defens.
h. Jika kata berakhiran dengan ANT, maka hapus akhiran tersebut. Contohnya
irritant menjadi irrit.
i. Jika kata berakhiran dengan EMENT, maka hapus akhiran tersebut. Contohnya replacement menjadi replac.
j. Jika kata berakhiran dengan MENT, maka hapus akhiran tersebut. Contohnya
adjustment menjadi adjust.
k. Jika kata berakhiran dengan ENT, maka hapus akhiran tersebut. Contohnya
dependent menjadi depend.
l. Jika kata berakhiran dengan S atau T lalu diikuti ION, maka hapus akhiran tersebut. Contohnya adoption menjadi adopt.
m. Jika kata berakhiran dengan OU, maka hapus akhiran tersebut. Contohnya
n. Jika kata berakhiran dengan ISM, maka hapus akhiran tersebut. Contohnya
communism menjadi commun.
o. Jika kata berakhiran dengan ATE, maka hapus akhiran tersebut. Contohnya
activate menjadi activ.
p. Jika kata berakhiran dengan ITI, maka hapus akhiran tersebut. Contohnya
angulariti menjadi angular.
q. Jika kata berakhiran dengan OUS, maka hapus akhiran tersebut. Contohnya
homologous menjadi homolog.
r. Jika kata berakhiran dengan IVE, maka hapus akhiran tersebut. Contohnya
effective menjadi effect.
s. Jika kata berakhiran dengan IZE, maka hapus akhiran tersebut. Contohnya
bowdlerize menjadi bowdler. Langkah 5a :
a. Jika kata berakhiran dengan E, maka hapus akhiran tersebut. Contohnya
probate menjadi probat.
b. Jika kata berakhiran dengan pola konsonan - vokal â konsonan dan diikuti E, maka hapus akhiran tersebut. Contohnya cease menjadi ceas.
Langkah 5b :
Berikut ini adalah pseudocode dari prosedur stemming kata.
function stemming(Input kata : String) â String
{I.S : kata sebagai masukan merupakan hasil dari proses penghapusan stop word}
{F. S : kata kembali dalam bentuk dasar} Deklarasi:
{langkah 1-5 dalam proses stemming menggunakan algoritma porter stemming terdefinisi}
Algoritma :
If length(kata) <= 2 then
{length digunakan untuk mengetahui jumlah huruf dari kata} Return kata
Endif
If kata mengandung tanda baca then Hapus tanda baca dari kata Return kata
Endif
If kata mengandung bagian dari langkah 1a then Hapus tiap bagian langkah 1a dari kata Return kata
endif
If kata mengandung bagian dari langkah 1b then Hapus tiap bagian langkah 1b dari kata Return kata
endif
If kata mengandung bagian dari langkah 1c then Hapus tiap bagian langkah 1c dari kata Return kata
endif
If kata mengandung bagian dari langkah 2 then Hapus tiap bagian langkah 2 dari kata Return kata
endif
If kata mengandung bagian dari langkah 3 then Hapus tiap bagian langkah 3 dari kata Return kata
endif
If kata mengandung bagian dari langkah 4 then Hapus tiap bagian langkah 4 dari kata Return kata
endif
If kata mengandung bagian dari langkah 5a then Hapus tiap bagian langkah 5a dari kata Return kata
If kata mengandung bagian dari langkah 5b then Hapus tiap bagian langkah 5a dari kata Return kata
III.1.3.2 Identifikasi Cluster Dasar Pembangun
Tahap kedua dari algoritma STC adalah tahap identifikasi pembentukan
cluster dasar. Pembentukan cluster dasar dilakukan dengan cara menemukan kesamaan frasa-frasa yang ditemukan dalam dokumen-dokumen yang diteliti dengan menggunakan struktur data suffix tree. Dengan c