DOI: 10.12928/TELKOMNIKA.v15i1.3546 421
Local Model Checking Algorithm Based on Mu-calculus
with Partial Orders
Hua Jiang*1, Qianli Li2, Rongde Lin3
1,2
Key Lab of Granular Computing, Minnan Normal University, Zhangzhou 363000, Fujian, China 3School of Mathematical Science, Huaqiao University, QuanZhou 362021, Fujian, China
*Corresponding author, e-mail: [email protected]
Abstract
The propositionalμ-calculus can be divided into two categories, global model checking algorithm and local model checking algorithm. Both of them aim at reducing time complexity and space complexity effectively. This paper analyzes the computing process of alternating fixpoint nested in detail and designs an efficient local model checking algorithm based on the propositional μ-calculus by a group of partial ordered relation, and its time complexity is O(d2(dn)d/2+2) (d is the depth of fixpoint nesting,
n
is the maximum of number of nodes), space complexity is O(d(dn)d/2). As far as we know, up till now, the best local model checking algorithm whose index of time complexity is d. In this paper, the index for time complexity of this algorithm is reduced from d to d/2. It is more efficient than algorithms of previous research.
Keywords: model checking, propositional mu-calculus, computational complexity, fixpoint, partitioned dependency graph
Copyright © 2017 Universitas Ahmad Dahlan. All rights reserved.
1. Introduction
Propositional
-calculus [1-4] model checking technique is widely used in the design and verification of the finite-control concurrent system. Model checking algorithms can be segmented into two categories. One is global model checking that obtains all the sets of states which satisfy a given logic expression in a finite-control concurrent system. The other is local model checking, which is not always necessary to examine all the states. As we know, the state space explosion problem is the main problem that the propositional
-calculus model checking algorithm faces with, so it is one of the hot topics to reduce time complexity and space complexity effectively.For global model checking, according to Tarski Fixpoint theory [5] and the fixpoint operator of formula, it can be computed by iteration. A number of global algorithms have been devised, for global propositionalμ-calculus, Emerson and Lei [6] presented a global algorithm that time complexity of the global algorithm was
O n
(
d1)
, then Andersen, Cleaveland and Steffen, et al., [7] improved the algorithm in [6], but the time complexity was stillO n
(
d1)
. In 1994, Long, Browne and Clarke, et al., [10] got a group of partial ordered relation by Tarski fixpoint theory and designed a global algorithm, both time complexity and space complexity wereO n
(
d/2 1)
. In 2010, Hua Jiang [11] got two groups of partial ordered relation by Tarski fixpoint theory and designed a global algorithm, the time complexity of the global algorithm was/2 1
((2
1)
d)
O
n
, and the space complexity isO dn
(
)
, at present, this is the best study result of global model checking algorithm. Because the global algorithms can not solve some practical problems perfectly, the local model checking was necessary.alternating fixpoints. Though reference [17] improved the complexity of the local algorithm, its efficiency did not achieve the desired results.
Related work can be found in [19] which presented global and local algorithms for computing fixpoint in linear time. In this way, the occurrence of the state exponential explosion problem is delayed, global algorithm is compared with local algorithm in [20], Jiang Hua [21] described an improved algorithm of global model checking for propositional μ-calculus. Modal μ -calculus are also important for studying probabilistic systems, Liu Wangwei, et al., [22] presented a natural and succinct probabilistic extension of μ-calculus, called PμTL, Castro Pablo, et al, [23] presented a probabilistic μ-calculus by using probabilistic quantification as an atomic operation and showed that PCTL and PCTL* can be captured in μ-calculus.
In this paper, we obtain a group of partial order relation by Tarski Fixpoint theory and the fixpoint operator of formula, then we present the bound algorithm which is based on the group of partial order relation. In this way, we can reduce the complexity and improve the computational efficiency. Our main result is a new efficient local algorithm that makes extensive use of monotonicity considerations to reduce the complexity of evaluation for evaluating partitioned dependency graphs [15] fixpoints. And the index for time complexity of this algorithm is reduced from
d
tod
/ 2
.The structure of the rest of this paper is organized as follows. In section 2, the equivalence between semantics of propositionalμ-calculus and Partitioned Dependency Graphs(PDGs) is introduced, and the basic algorithm for evaluating PDG fixpoint is analyzed in detail. Section 3 gives the partial order relation in the evaluating PDG fixpoint firstly, and then presents a new algorithm based on partial orders, shows the time and space complexity of the algorithm is
O d
(
2
(
dn
)
d/2 2)
andO d dn
(
(
)
d/2)
, and finally gives some experimental results. This paper ends with a detailed discussion of some conclusions and directions for future research in section 4.2. Partitioned Dependency Graphs and Fixpoint Evaluating Algorithm
The syntax of propositional μ-calculus formulas and the semantics under the transition system are refer to [24]. To guarantee the existence of the fixpoints, formulas with positive normal form (PNF) [1] are considered only, where each propositional variable is restricted to a fixpoint operator at most and the operator
only acts on the atomic proposition.2.1. Partitioned Dependency Graphs
Let transition system
M
( , , )
S T L
, whereS
is a non-empty set of states,L
is amapping each atomic proposition to a subset of
S
, andT
maps
a
{ , , ,
a b a a
1 2,...}
to a tuple of state,T a
:
( , )
S S
. For given a PNF fixpoint formula
R
.
or
R
.
, the semanticsdenotes as
.
( )
M
R
S
or.
( )
M
R
S
respectively, which is the least fixpoint or greatest fixpont of the predicate transformer respectively. So the mapping between two subset of states defined by predicate transformer is a dependency, and thus the computation sequences of fixpoint evaluatings is equivalent to a partitioned dependency graphs [15].Definition 1. A partitioned dependency graph ( PDG ) is a tuple
( , , ... , )
V E V V
1 n
, whereV
is a set of vertices,E
V
2
V is a set of hyper-edges,V V
1...
n is a finite sequence of subsets ofV
such that{ ,..., }
V
1V
n is a partition ofV
, and
:{ ,..., }
V
1V
n
{ , }
is a function that assigns
or
to each block of the partition [15]. Let
{ , }
. We shallsubsequently write
( )
x
ifx V
i and
( )
V
i
.G
is aPDG
,G
( , , ... , )
V E V V
1 n
. Xinxin Liu, et al., [15] regardedG
as a nested boolean equation system [13],
x V x
i,
( , )x SE
y Sy
. And
( )
V
i are nested inV V
1...
n,Example 1.
G
is aPDG
andG
( , ,
V E VV VV
1 2 3 4, )
, where1 2 3 4 5 6
{ , , , , , }
V
x x x x x x
,V
1
{ , }
x x
1 2 ,V
2
{ }
x
3 ,V
3
{ , }
x x
4 5 ,V
4
{ }
x
6 ,1 3 4 2 6 2 5 3 1 5 4 1 5 3 6 6 1
{( ,{ , }),( ,{ }),( ,{ }),( ,{ , }),( ,{ }),( ,{ , }), ( ,{ }),
E
x x x
x
x
x
x
x x x
x
x
x
x x
x
x
( ,{ })}
x x
6 4 ,1
( )
V
,
( )
V
2
,
( )
V
3
,
( )
V
4
. Thus, the corresponding nested boolean equation system consists of:1 3 4 2 5 6
=x
:
x
x
v
x
x
x
,
:{
x
3
x
1x
5,4 1 5 3 6
=x
:
x
v
x
x
x
,
:{
x
6
x
1x
42.2. Algorithm for PDG fixpoint Evaluatings
In reference [15] a local algorithm for evaluating PDG fixpoint, namely LAFP is proposed, where the search space is constructed as a subset of
V
which is divided into three blocks, and computes the fixpoints iteratively.Given a PDG, let
b
denote the out-to-in sequenceb b
1, ,...,
2b
d, whered
(
d
mod 2
0
) is fixpoint nesting depth. There aren
i nodes inb
i, and the fixpoint types are2k 1
(
V
2k 1)
,
2k(
V
2k)
,k
1, 2,...
, respectively. So all the sequences ofb
are asfollows:
0
1
( 1)
1 1 10 11 1 1 1
2 2 20 21 2 2 2
1 1 ( 1)0 ( 1)1 ( 1) 1 1 0 1
:
{
,
,...,
},
( )
:
{
,
,...,
},
( )
:
{
,
,...,
},
(
)
:
{
,
,...,
d n nd d d d d n d d
d d d d dn
b V
x
x
x
V
b V
x
x
x
V
b
V
x
x
x
V
b V
x
x
x
},
(
)
d
dV
d
(1)Let’s divides
V
i into three blocks, denoting' '' '''
i i i i
V
V
V
V
(1
i d
)
, whereV
i'saves nodes waiting for computing,
V
i''saves nodes which have been identified,V
i''' savesnodes which have not been identified. A assume that the initial value of state of each node of
V
i areTrue
orFalse
, thenV val
1(
)
True
,V val
2(
)
False
,V val
3(
)
True
,4
(
)
V val
False
, …,V
d1(
val
)
True
,V val
d(
)
False
respectively,V val
i(
)
means theinitial value of state of each node.
Let
g g
1,
2,...,
g
d1,
g
d be the computation function of the corresponding node ofb
in PDG, then the iteration formulas is as follows:1 1 1 1 1
1 2 1 1 2 1 2 1 2
1 2 1 1 1 2 1 2 1 1 2 1
1 2 1
1 ... ...
1 1 1 2 1
( 1) ... ..
2 2 1 2 1
...( 1) ... ...
1 1 1 2 1
... ( 1)
1
(
,
,...,
,
)
(
,
,...,
,
)
(
,
,...,
,
)
(
d d d
d d
k k k k k
d d k k k k k k k k k
d d
k k k k k k k k k k k k
d d d d
k k k k
d d
V
g V
V
V
V
V
g V
V
V
V
V
g
V
V
V
V
V
g V
1 1 2 1 2... 1 1 2... 12 1
,
,...,
k k kd,
k k kd kd)
k k k
d d
V
V
V
(2)
1
.
1V val
V
,V val
1.
means the iteration value of the nodes ofV
1. When 11
.
1k
V val
V
, then thecomputation sequence of
V
2 is 10 11 12 1( 1) 12
,
2,
2,...,
2,
2k k k k k
V
V
V
V
V
. When 11
.
1k
V val
V
,1 2
2
.
2k k
V val
V
, then the computation sequence ofV
3 is 1 20 1 21 1 22 1 2( 1) 1 22
,
2,
2,...,
2,
2k k k k k k k k k k
V
V
V
V
V
.When 1
1
.
1k
V val
V
, 1 22
.
2k k
V val
V
,…, 1 2... 11
.
1d k k k
d d
V
val
V
, then the computation sequence ofd
V
is k k1 2...kd10,
k k1 2...kd11,
k k1 2...kd12,...,
k k1 2...kd1( 1),
k k1 2...kd1d d d d d
V
V
V
V
V
.Therefore we can obtain k k1 2...k ki1i 'k k1 2...k ki1i ''k k1 2...k ki1i '''k k1 2...k ki1i
i i i i
V
V
V
V
.Thus, for given a PDG, the nesting computation sequence of Equation (1) descripted as:
00...00 00...01 00...02 00...0 00...1 00...10 00...11 00...12 00...1 00...2
1 1
,
,
,...,
,
,
,
,
,...,
,
,
d d d d d d d d d d
V
V
V
V
V
V
V
V
V
V
00...( 1)0 00...( 1)1 00...( 1)2 00...( 1) 00... 01
1 2
01...00 01...01 01...02 01...0 01...1 01...10 01...11 01...12 01...1 01...2
1 1
,
,
,...,
,
,...
,
,
,
,...,
,
,
,
,
,...,
,
,
d d d d d
d d d d d d d d d d
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
(3)
01...( 1)0 01...( 1)1 01...( 1)2 01...( 1) 01... 02 0 1
1 2 2 1
10...00 10...01 10...02 10...0 10...1 10...10 10...11 10...12 10...1 10..
1 1
,
,
,...,
,
,...
,...,
,
,
,
,
,...
,
,
,
,
,...
,
d d d d d
d d d d d d d d d d
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
.2
,
10...( 1)0 10...( 1)1 10...( 1)2 10...( 1) 10... 11 11...00 11...01 11...0
1 2
11...1 11...10 11...11 11...12 11...1 11...2 11...
1 1 1
,
,
,...,
,
,...
,
,
,...,
,
,
,
,
,...,
,
,...,
,
d d d d d d d d
d d d d d d d
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
...
V
212,...,
V
21,
V
12,...,
V
1
3. Local Model Checking Algorithm based on Partial Orders 3.1. Partial Ordering Relation of Computing Node Set
Let ( , , ) i
val i r
N
denotes data structure of computing nodes ofV
,r
i(1
r
in
i)
is free variable,val
{
True False
,
}
,
{ , }
,i
is nesting level. We will superscript relation nameswith vectors of iteration indices to show various approximations. We will let
k
i(0
k
in
)
andi
k
denote vectors of iteration indices. For example, ki0i
V
denotes k k1 2... 0ki iV
,k
i0
k k
1 2... 0
k
i . If0
00...00
i
k
, then ki0i
V
meansV
i00...00. The notationCas k
( )
t means thatk
t is the closestantecedent sequence. That is to say, if
k
th
t, and
h
ik
i1
, where1
i
t
, then we have( )=
t tCas h
k
.Let
A
andM
be node sets which consist of ( , , )(1
)
ival i r
N
i d
, and satisfy both of thefollowing criteria, (1)
| | = |
A
M
|
. (2) if ( , , ) iFalse i r
N
A
, then ( , , ) iTrue i r
N
A
. if ( , , ) iTrue i r
N
A
, then( , , )i
False i r
N
A
;M
is similar. where ( , , ) ival i r
N
is the data structure of computing nodes and(1
)
i i i
r
r
n
is free variable.Definition 2.
F(A,M ) = A M
is one-way, ifA
andM
satisfy both of the following criteria(1)
( , , ) ( , , ) ( , , )
i i i
False False True
i r i r i r
N
N
N
A
M
M
.(2)
( , , ) ( , , )
i i
True True i r i r
N
N
Clearly,
F
satisfies reflexive, antisymmetrical and transitive, that is to say,F
is a partial ordering relation of computing node set.For the iteration formulas (2), when 1
1
.
1k
V val
V
, 1 22
.
2k k
V val
V
,…, 1 2... 11
.
1d k k k
d d
V
val
V
, then the computation sequence of
V
dis1 2...d10
,
1 2...d11,
1 2...d12,...,
1 2... d1( 1),
1 2... d1k k k k k k k k k k k k k k k
d d d d d
V
V
V
V
V
;Because
d( )
V
d
, theval
of each node ofV
d isFalse
orTrue
. Ifval
is changed fromFalse
toTrue
, then storing the corresponding node ofval
inV
d''. If1 2...d10
,
1 2...d11,
1 2...d12,...,
1 2...d1( 1),
1 2...d1k k k k k k k k k k k k k k k
d d d d d
V
V
V
V
V
never change, by the Definition 4.2, the sequence satisfies the formulasF
, that is to say, the sequence is one-way, at the sametime,
g g
1,
2,...,
g
d1,
g
d is monotonous, then:1 2...d10 1 2...d11 1 2...d12
...
1 2...d1( 1) 1 2...d1k k k k k k k k k k k k k k k
d
V
dV
dV
dV
dV
d
F :
;For
d1(
V
d1)
, we have:1 2... 2 1 2... 2( 1) 1 2... 2( 2) 1 2... 21 1 2... 20
1 1 1 1
...
1 1d d d d d
k k k k k k k k k k k k k k k
d
V
dV
dV
dV
dV
d
F
:
; (4)For
2( )
V
2
, we have 10 11 12 1( 1) 12 2 2 2
...
2 2k k k k k
V
V
V
V
V
F :
;For
1( )
V
1
, we haveF :
1V
1V
1(1)V
1(2)...
V
11V
10.Definition 3.
k k
1 2...
k
t andh h h
1 2...
t are non-negative integer sequence, and both of them havet
integers.k k
1 2...
k
t is antecedent thanh h h
1 2...
t, if they satisfy both of the following criteria:(1) Exiting an odd (even) bit
j
ofk k
1 2...
k
t andh h h
1 2...
t, s.t.k
j
h
j, where1
j t j
, mod 2
0
.(2)
k
m
h
m, where1
m t
,m
j
;1 2
...
tk k
k
is antecedent thanh h h
1 2...
t, denotedk k
1 2...
k
th h h
1 2...
t;k k
1 2...
k
t 1 2...
th h h
denotes that k k1 2...kt iV
has been computed when h h1 2...ht iV
is computed.Definition 4.
k k
1 2...
k
t is the antecedent sequence ofh h h
1 2...
t, if they satisfy both of the following criteria:(1)
k k
1 2...
k
th h h
1 2...
t. (2)
h
ik
i1
, where1
i
t
;1 2
...
tk k
k
is the closest antecedent sequence ofh h h
1 2...
t, denotingCas h h h
(
1 2... )
t =1 2
...
tk k
k
.Lemma 1 If
i
,Cas h h h
(
1 2... )
t =k k
1 2...
k
t, then h h1 2...hi iV
and k k1 2...ki iV
satisfyF
,denoting h h1 2...hi i
V
k k1 2...ki iV
. Proof. (abbreviated)Definition 5.
k k
1 2,...,
k
t is an generalized antecedent sequence ofh h
1 2,...,
h
t, if they satisfy both of the following criteria:sequence of
h h
1 2,...,
h
t satisfy the lexicographic order, denoting1 2 1 2
( (
,..., ))
t( (
,..., ))
tlo os k k
k
lo os h h
h
.1 2
,...,
tk k
k
is an generalized antecedent sequence ofh h
1 2,...,
h
t, denoting( )
t tGas h
k
, wherek
t isk k
1 2,...,
k
t andh
t ish h
1 2,...,
h
t. Lemma 2. If
i
,Gas h
( )
t
k
t, then kii
V
and hii
V
satisfyF
, denoted hi kii i
V
V
.Proof. (abbreviated)
3.2. Local Model Checking Algorithm based on Partial Orders
As described above, LAFP presents an efficient local model checking algorithm, however, in the nested process, inner value of fixpoint is affected by outer value of fixpoint. If the value of outer iteration does not change, then the outer value of fixpoint starts computing with the value of inner iteration. When the value of outer iteration is changed, then all the inner value need to update, that is to say, a lot of computing processes is repeated.
For arbitrary sequence
k
i,i
mod 2 = 1, by Lemma 1 and Lemma 2, we only need to start the computing from the antecedent sequenceCas k
( )
i without affecting the correctness ofresult. Thus, let ki Cas k( )i
i i
V
V
instead of kii
V
True
, then the iteration time can be reduced and the computing efficiency can be improved. The Local Model Checking Algorithm based on Partial Orders is as follows:Algorithm 1 Local Model Checking Algorithm based on Partial Orders 1. for ( i = 1; i <= d; i ++ ) do
2.
V
i'
V
i,
V
i''
,
V
i'''
;
// initialize 3. end for4. i = d; // begin to compute from the innermost layer 5. while ( i > 0 ) do
6. if ( i == d ) then 7. Do
8. dequeue a node
V
i* fromV
i';9.
V
i'
V
i'V
i*; //removeV
i*10. 1 1 1 1 1 1
1 1 1
(
,...,
,
,
)
i i i i i i i
k k k k k k k n
i i i i i
V
g V
V
V
V
- -
-=
;11. if ( val of ki1ki 1
i
V
- changed ) then12.
V
i''
V
i''
V
i*;13. else
V
i''
V
i''
V
i*; 14. end if15. until
V
i'
; 16. i = i -1; 17. end if18. if ( i != d ) then 19. Do
20. dequeue a node
V
i* fromV
i';21.
V
i'
V
i'V
i*;22. 1 1 1 1 1 1
1 1 1
(
,...,
,
,
)
i i i i i i i
k k k k k k k n
i i i i i
V
g V
V
V
V
- -
-=
;23. if ( val of ki1ki 1
i
V
- changed ) then25. for ( t > i && t <= d ) do // update the value of all the inner layer 26. if ( t % 2 == 0 ) then
27. kt0
t
V
False
; // the initial value is False28. else if (
os k
( 0)
i
0
) then 29. kt0t
V
True
; // the initial value is True30. else kt0 Cas k( )t
t t
V
V
; //the initial value is Cas k( )tt
V
31. end if 32. end if 33. end for
34. else
V
i''
V
i''
V
i*; 35. end if36. until
V
i'
; 37. i = i – 1; 38. end if 39. end while3.3. Time Complexity Analysis
When
i
1
, according to 3.2, the computation sequence of the corresponding node is0 1 2 1
,
1,
1,...,
1V V V
V
in blockb
1,n
1 is the total number of computing node of blockb
1. The initialvalue of
val
isTrue
in each node by
1( )
V
1
. When the value ofval
turns intoFalse
fromTrue
, by the monotonicity of functiong
1, the value of the node no longer changes in thewhole computing process, so the node is deposited in
V
1''. The worst case is that the value ofval
turns intoFalse
fromTrue
after computing each node ofV
1', so the greatest computingtimes of corresponding node in block
b
1 are|
g
1| 1 2 ...
n
1n
12.When
i
2
,V val
1.
= 11
k
V
, the computation sequence of the corresponding node is10 11 12 1
2
,
2,
2,...,
2k k k k
V
V
V
V
in blockb
2, the computing times of the corresponding node are2
1 2 3 ...
n
in blockb
2, the number of different values ofV val
1.
isn
1, so the greatest computing times of corresponding node in blockb
2 are|
g
2|
n
1(1 2 3 ...
n
2)
n n
1 22.When
i
3
, according to Algorithm 1, ifk
1
0
,k
3
0
,V
3 starts to compute fromV
3'. In this case, the times aren
2 at most. The changing times of corresponding node value are2 3
n n
in blockb
3, and the computing times are not more thann n
2 32. Whenk
1
0
,k
3
0
,V
3starts to compute from 1 2 3
3
x x x
V
. In this case, the times aren n
1 2 at most, when it reaches the fixpoint, the computing times aren n n
1 2 3 at most, so the greatest computing times of corresponding node in blockb
3 are|
g
3|
n n
2 32n n n
1 2 3.Summarily, when
i
2
,|
g
2i|
n n n
2 4 6...
n
2i2 2 1 2n
in
2i,2
2 1 2 4 6 2 2 1 2 4 6 2 1 2 2 1
|
g
i|
n n n
...
n
i
n
i
n n n
...
n
i
n
i
n
i .Thus, we have 1 2
1
|
| |
| |
| ...|
|
d
i d
i
g
g
g
g
2 2 2 2 2
1 1 2
(
2 3 1 2 3)
2 3 4(
2 4 5 2 3 4 5) ...
n
n n
n n
n n n
n n n
n n n
n n n n
2 2 2 4 6 2 1 2 4 6 3 2 1 2 4 6 2 1
(
n n n
...
n
d
n
d
n n n
...
n
d
n
d
n
d)
n n n
...
n
dn n
d d2 2 4 6
...
d 2|
|
n n n
n
V
(2 (
/ 2) / )
d/2|
| = (
2 2 d/2+2)
n d
d
V
O d n
.Assume the alternative nesting depth
d
mod 2
0
, through the analysis of the above, then the time complexity analysis Algorithm 1 isO d n
(
2
d/2+2)
.3.4. Space Complexity Analysis
By Algorithm 1, if
i( )=
V
i
, x x1 2...(xi2+1)xi10=
x x1 2...xi2xi1i i
V
V
, then save intermediateresults,
V
i' andV
i''(1
i d
)
account for2
d
storage units. Wheni
3
, it accounts for2
n
2 storage units. Wheni
5
, it accounts for2
n n
2
4 storage units. Wheni
d
, it accounts for2 4 6
2
n n n
...
n
d storage units, therefore, the total numbers of storage units in Algorithm 1 are:
2
d
+2
n
2+2
n n
2
4+…+2
n n n
2
4 6...
n
d
2(
d n
2n n
2 4...
n n n
2 4 6...
n
d)
/2 /2 /2 /2 /2
2(
|
|
d|
|
d... |
|
d)
2(
/ 2(|
|
d))
(
(
)
d)
d
V
V
V
d d
V
O d d n
3.5. Comparison of Time Complexity
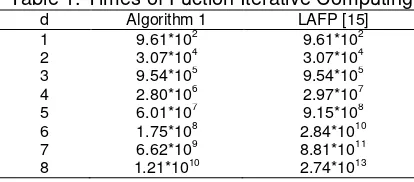
[image:8.595.192.399.413.504.2]According to Algorithm 1, we assume that the number of node of each layer is 30, then we can obtain the time of iterative computation of all functions by computing. When the alternation depth
d
takes a different value, the number of iteration is as Table 1. Table 1 shows that our algorithm is more efficient.Table 1. Times of Fuction Iterative Computing
d Algorithm 1 LAFP [15] 1 9.61*102
9.61*102
2 3.07*104
3.07*104
3 9.54*105 9.54*105 4 2.80*106 2.97*107 5 6.01*107
9.15*108
6 1.75*108
2.84*1010
7 6.62*109 8.81*1011 8 1.21*1010 2.74*1013
4. Conclusion
In this paper, we present a new efficient algorithm for evaluating PDG fixpoints. As we know, [26] presented a local model checker forμ-calculus, as a tableau system, but it did not analyze the computational complexity. Then [15] presented a new local algorithm for evaluating PDG fixpoints, and time complexity of the LAFP algorithm was exponential relationship with nesting depth. After a detailed analysis, we present a new algorithm by[11]. And our algorithm takes about
d n
2
d/2+2 steps. Clearly, the time required by our algori thm is only about the square root of the time required by LAFP algorithm. Furthermore, whend
mod 2 1
, we only need to design the algorithm in the same way asd
mod 2
0
. The nested bound algorithm reduces repetitive computation and improves the computational efficiency. The research in this paper is very important to theoretical research and practical application [25, 27], it can improve the efficiency for verifying hardware and software designs.Acknowledgements
This paper is supported by the National Natural Science Foundation of China under Grant No.61472406, the Natural Science Foundation of Fujian Province under Grant No.2015J01269 and No.2016J01304 and the Talent Introduction Foundation of Minnan Normal University.
References
[1] D Kozen. Results on the propositional μ-calculus. LNCS 140: Proc of the 9th Colloquium on Automata, Languages and Programming. Springer. 1982: 348-359.
[2] JW de Bakker. Mathematical theory of program correctness. Prentice-Hall, Inc. 1980.
[3] D Park. Fixpoint induction and proof of program semantics. In: B Meltzer, D Michie. Editors. Mach. Int, Edinburgh Univ. 1970: 59-78.
[4] C Stirling. Modal and temporal logics for processes. Springer. 1996: 149-237.
[5] A Tarski. A lattice-theoretical fixpoint theorem and its applications. Pacific Journal of Mathematics.
1955; 5(2): 285-309.
[6] EA Emerson, CL Lei. Efficient model checking in fragments of the propositional mu-calculus. Proc. 1st LICS. 1986.
[7] HR Andersen. Model checking and boolean graphs. ESOP 92. Springer. 1992: 1-19.
[8] R Cleaveland, M Klein, B Steen. Faster model checking for the modal mu-calculus. CAV 92, LNCS. 1992; 663: 410-422.
[9] R Cleaveland. Tableau-based model checking in the prepositional mucalculus. Acta Informatica. 1990; 27(8): 725-747.
[10] DE Long, A Browne, EM Clarke, et al. An improved algorithm for the evaluation of fixpoint expressions. Computer Aided Verification. 1994: 338-350.
[11] H Jiang. Efficient global model-checking for propositional μ-calculus. Journal of Computer Research and Development. 2010; 47(8): 1424-1433.
[12] HR Andersen. Model checking and boolean graphs. Theoretical Computer Science. 1994; 126(1). [13] B Vergauwen, J Lewi. Efficient local correctness checking for single and alternating boolean equation
systems. Proceedings of ICALP 94. Springer. 1994: 304-315.
[14] GS Bhat, R Cleaveland. Efficient model checking for fragments of the modal μ-calculus. Proceedings of the Second International Workshop on Tools and Algorithms for the Construction and Analysis of Systems (TACAS 96). Springer. 1996: 107-126.
[15] XX Liu, CR Ramakrishnan, SA Smolka. Fully local and efficient evaluation of alternating fixed points.
Tools and Algorithms for the Construction and Analysis of Systems. 1998: 5-19.
[16] R Mateescu. Local model-checking of modal mu-calculus on acyclic labeled transition systems. Tools and Algorithm for the Construction and Analysis of Systems. 2002: 281-295.
[17] JF Jensen, LK Østergaard. Local model checking of weighted CTL. 2012.
[18] D Latella, M Loreti, M Massink. On-the-fly fast mean-field modelchecking. Trustworthy Global Computing. Springer International Publishing, LNCS. 2014: 297-314.
[19] R Guerraoui, M Yabandeh. Local model checking. 2011.
[20] JF Jensen, KG Larsen, J Srba, et al. Local model checking of weighted CTL with upper-bound constraints. Model Checking Software. 2013: 178-195.
[21] Hua Jiang, Jianqing Xi. Improved algorithm of golbal model-checking for propositional mu-calculus.
Applied Mechanics and Materials. 2013; 263: 2314-2319.
[22] Liu Wanwei, et al. A Simple Probabilistic Extension of Modal Mu-calculus. 2015.
[23] Castro Pablo, Cecilia Kilmurray, Nir Piterman. Tractable Probabilistic μ-Calculus that Expresses Probabilistic Temporal Logics. 2015.
[24] EM Clarke, O Grumberg, D Peled. Model checking. MIT Press. 1999.
[25] N Piterman, MY Vardi. Global model-checking of infinite-state systems. Computer Aided Verification.
2004: 387-400.
[26] C Stirling, D Walker. Local model checking in the modal mu-calculus. Theoretical Computer Science.
1991; 89(1): 161-177.