TUNING PARAMETER
DALAM FUNGSI OKAPI BM25 PADA
MESIN PENCARI TEKS BAHASA INDONESIA
TEDY SAPUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
TEDY SAPUTRA. Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia. Dibimbing oleh JULIO ADISANTOSO.
Sistem temu-kembali informasi dikembangkan dalam beragam model, seperti model peluang, model bahasa, model boolean,model ruang vektor dan lainnya. Meskipun demikian, masih sulit menetukan model manakah yang paling baik dan efisien dalam setiap kondisi pencarian. Dalam penelitian ini, akan dibandingkan dua mesin pencari yang dibuat dengan menggunakan model peluang dan model ruang vektor sebagai pembandingnya. Pada model peluang, digunakan fungsi kesamaan Okapi BM25 yang memiliki suatu variabel yang dapat diubah-ubah nilainya, yang disebut dengan tuning parameter. Modifikasi nilai dari tuning parameter ini bertujuan untuk meningkatkan kinerja dari model peluang dan juga sekaligus membandingkan kinerjanya dengan model lain, seperti model ruang vektor. Modifikasi nilai dari tuning parameter meningkatkan nilai rata-rata presisi dari sistem, yang pada awalnya sebesar 0.5885 menjadi 0.5901. Selanjutnya, model peluang juga mengungguli model ruang vektor yang memiliki nilai rata-rata presisi sebesar 0.5327.
Kata kunci: model peluang, model ruang vektor, Okapi BM25, tuning parameter
ABSTRACT
TEDY SAPUTRA. Tuning Parameters in Okapi BM25 Function on Indonesian Text Search Engine. Supervised by JULIO ADISANTOSO.
Information retrieval system was developed using various models, such as probabilistic models, language models, boolean models, vector-space models and many more. Thus, it’s problematic to determine which models is the best and the most efficient in every search condition. In this study, two models were developed and compared: probabilistic model and vector-space model. The probabilistic model has Okapi BM25 similarity function with parameters that are subject to fine tuning to seek for better performance. Fine tuning the parameters has made the probabilistic model’s average precision increases from 0.5885 to 0.5901. Further, this model also outperformed the vector-space model with average precision 0.5327.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
TUNING PARAMETER
DALAM FUNGSI OKAPI BM25 PADA
MESIN PENCARI TEKS BAHASA INDONESIA
TEDY SAPUTRA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia
Nama : Tedy Saputra NIM : G64090054
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan November 2012 ini ialah temu-kembali informasi, dengan judul Tuning Parameter dalam Fungsi Okapi BM25 pada Mesin Pencari Teks Bahasa Indonesia.
Terima kasih penulis ucapkan kepada ayah, ibu, serta seluruh keluarga atas segala doa dan kasih sayangnya. Terima Kasih kepada Bapak Ir Julio Adisantoso MKom selaku pembimbing, Bapak Ahmad Ridha SKom MS dan Bapak Dr Irman Hermadi SKom MSc selaku penguji, juga teman-teman seperjuangan Edo Apriyadi, Achmad Manshur Zuhdi, Rahmatika Dewi, Fitria Rahmadina, Arini Daribti Putri, dan Damayanti Elisabeth Sibarani atas kebersamaannya selama ini. Ungkapan terima kasih juga disampaikan kepada Widya Retno Utami beserta keluarga atas semangat, doa, dan motivasinya selama ini.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
METODE 3
Pengumpulan Dokumen 4
Tokenisasi 4
Pembuangan Stopwords 5
Pemilihan Fitur 5
Pembobotan 6
Similarity 7
Evaluasi 9
HASIL DAN PEMBAHASAN 10
Pemrosesan Dokumen 10
Praproses 11
Similarity 12
Evaluasi 14
Perbandingan Kinerja Model Peluang dengan Model Ruang Vektor 16
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 18
DAFTAR PUSTAKA 18
DAFTAR TABEL
1 Confusion Matrix 9
2 Nilai AVP BM25 sebelum dan sesudah tuning 15
3 Nilai AVP pada BM25 dan VSM 17
DAFTAR GAMBAR
1 Diagram metodologi 3
2 Contoh dokumen 4
3 Tabel document pada database 10
4 Tabel words pada database 11
5 Implementasi fungsi kesamaan Okapi BM25 13
6 Algoritme pada fungsi kesamaan Okapi BM25 13
7 Algoritme pada fungsi kesamaan cosine 14
8 Perbandingan grafik recall-precision BM25 15 9 Grafik recall-precision dari BM25 dan VSM 17
DAFTAR LAMPIRAN
1 Antarmuka implementasi 21
2 Gugus query dan jawaban 22
PENDAHULUAN
Latar Belakang
Penggunaan internet yang semakin populer saat ini mempengaruhi jumlah informasi yang semakin lama semakin besar keragamannya. Informasi dapat dicari dengan mudah apabila jumlahnya sedikit, akan tetapi sangat sulit untuk mencari banyak informasi yang dibutuhkan dengan waktu yang singkat secara manual. Oleh sebab itu dibutuhkan suatu sistem yang dapat membantu user untuk mendapatkan informasi yang dibutuhkan secara cepat dan mudah yang kemudian disebut dengan sistem temu-kembali informasi (information retrieval system).
Sistem temu-kembali informasi (information retrieval system) adalah sistem pencarian informasi pada dokumen, pencarian untuk meta data di dalam database, baik relasi database yang stand-alone atau hypertext database yang terdapat pada jaringan seperti internet (Buckley et al. 1994). Sistem temu-kembali informasi berhubungan dengan pencarian dari informasi yang isinya tidak memiliki struktur. Begitu juga dengan dengan ekspresi dari kebutuhan pengguna yang disebut dengan query, juga tidak memiliki struktur. Hal inilah yang membedakan antara sistem temu-kembali informasi dengan sistem basis data.
Penerapan aplikasi dari sistem temu-kembali informasi adalah search engine atau mesin pencari yang terdapat pada jaringan internet (Harman 1992). Mesin pencari (search engine) adalah salah satu sistem temu-kembali informasi yang mengolah informasi dan mengambil daftar, peringkat maupun urutan dari dokumen berdasarkan relevansi antara query dengan dokumen yang dibutuhkan dalam rangka memenuhi pencarian yang dilakukan oleh user. Suatu mesin pencarian harus mampu menggunakan kesamaan (similarity) antara kata pencarian yang diinputkan oleh user dengan setiap dokumen yang ada.
Saat ini banyak model-model yang digunakan untuk suatu sistem temu-kembali informasi, salah satunya adalah model peluang. Sesuai dengan namanya, model peluang bertujuan untuk mengevaluasi setiap kata pencarian (query), berdasarkan peluang suatu dokumen relevan dengan kata pencarian yang diberikan. Model peluang pada sistem temu-kembali informasi menghitung koefisien kesamaan antara sebuah query dengan sebuah dokumen sebagai sebuah peluang bahwa dokumen tersebut akan relevan dengan suatu query. Model peluang akan memberikan nilai peluang pada setiap kata yang menjadi komponen dalam suatu query, dan kemudian menggunakan nilai-nilai tersebut untuk menghitung peluang akhir bahwa suatu dokumen relevan dengan suatu query.
2
Penelitian ini akan difokuskan menggunakan model peluang yang menggunakan fungsi kesamaan OKAPI BM25 dengan melakukan modifikasi pada nilai tuning parameter. Tuning parameter adalah suatu variabel yang dapat diubah-ubah nilainya sesuai dengan kebutuhan dengan tujuan untuk mendapatkan hasil pencarian yang lebih baik. Penelitian ini dilakukan untuk menguji apakah pencarian dengan model peluang dapat menghasilkan banyak dokumen yang relevan terutama untuk dokumen yang menggunakan Bahasa Indonesia. Selain itu akan dibuktikan juga pengaruh dari perubahan tuning parameter yang akan dimodifikasi sedemikian rupa untuk mendapatkan hasil pencarian dengan nilai yang lebih baik. Kemudian akan dibandingkan kinerja dari sistem yang menggunakan model peluang dengan sistem yang menggunakan model lain yaitu model ruang vektor.
Perumusan Masalah
Penelitian ini dilakukan untuk menjawab masalah-masalah sebagai berikut: 1 Apakah model peluang dapat mengukur relevansi secara akurat antara query
masukan dengan dokumen yang dibutuhkan sehingga hasil pencarian sesuai dengan apa yang user inginkan?
2 Apakah modifikasi dari nilai tuning parameters dalam fungsi kesamaan OKAPI BM25 dapat menghasilkan pencarian dengan hasil evaluasi yang lebih baik?
3 Apakah model peluang lebih baik apabila dibandingkan dengan model ruang vektor?
4 Apakah model peluang cocok digunakan untuk melakukan pencarian pada dokumen yang menggunakan Bahasa Indonesia?
Tujuan Penelitian
Penelitian ini bertujuan untuk menguji seberapa besar pengaruh modifikasi nilai dari tuning parameter yang ada dalam fungsi kesamaan OKAPI BM25 terhadap evaluasi dari hasil pencarian. Selain itu juga akan dibandingkan kinerja antara model peluang dengan model lain yaitu model ruang vektor dalam pencarian dokumen yang menggunakan Bahasa Indonesia.
Manfaat Penelitian
3
Ruang Lingkup Penelitian
Fokus dari penelitian ini adalah menguji dua model sistem temu-kembali informasi, yaitu model peluang dan model ruang vektor. Fungsi kesamaan yang digunakan pada model peluang adalah fungsi kesamaan OKAPI BM25 dengan modifikasi nilai pada tuning parameter. Dokumen yang digunakan dalam penelitian ini adalah dokumen yang menggunakan Bahasa Indonesia.
METODE
Sistem temu-kembali informasi pada prinsipnya merupakan suatu sistem yang sederhana. Misalkan terdapat sekumpulan dokumen dan seorang user yang memformulasikan sebuah pertanyaan (query). Jawaban dari pertanyaan atau query tersebut adalah sekumpulan dokumen yang relevan dengan query dari user. Sistem temu-kembali informasi pada dasarnya dibagi menjadi dua komponen utama, yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temu-kembali yang merupakan gabungan dari user interface dan look-up-table (Sudirman dan Kodar 2012).
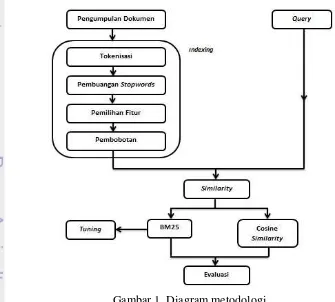
Metode pada penelitian ini menggunakan model peluang yang merupakan salah satu model pada temu-kembali informasi. Model peluang tersebut akan dibandingkan dengan model lain yaitu model ruang vektor. Metode yang akan dilakukan pada penelitian ini dicantumkan pada Gambar 1.
4
Tahapan dari metode diawali dengan pengumpulan dokumen, kemudian dilanjutkan dengan proses indexing. Indexing adalah sebuah proses dimana dilakukan pengindeksan pada sekumpulan dokumen yang nantinya akan menjadi informasi yang ditujukan untuk user. Indexing dapat dilakukan secara manual maupun secara otomatis. Adapun tahapan dari indexing terdiri dari tokenisasi, pembuangan stopwords, pemilihan fitur, dan pembobotan (term weighting). Selanjutnya adalah melihat similarity, yaitu kesamaan hasil yang didapatkan dari dokumen dengan query yang dimasukkan. Tahap akhir yang dilakuan adalah melakukan evaluasi dari kedua model tersebut.
Pengumpulan Dokumen
Tahapan awal yang dilakukan adalah melakukan pengumpulan dokumen yang akan dijadikan sebagai data uji dari penelitian ini. Dokumen yang digunakan adalah kumpulan dokumen (korpus) yang tersedia di Laboratorium Temu-Kembali Informasi hasil penelitian Adisantoso dan Ridha (2004). Di dalam korpus tersebut tersedia 1000 dokumen pertanian berbahasa Indonesia berikut dengan sejumlah query dan gugusan jawaban yang relevan dengan query tersebut. Query dan gugus jawaban yang relevan dicantumkan pada Lampiran 2.
Selain itu ditambahkan juga dokumen lain yang didapatkan dari berbagai portal berita secara online yang berjumlah 300 dokumen. Total dokumen yang digunakan adalah 1300 dokumen yang memiliki format plain teks dengan struktur XML (Extensible Markup Language). Contoh dokumen yang digunakan dapat dilihat pada Gambar 2.
Tokenisasi
Tokenisasi adalah proses memotong teks input menjadi unit-unit terkecil yang disebut token dan pada saat yang sama dimungkinkan untuk membuang karakter tertentu, seperti tanda baca (Manning et al. 2008). Token tersebut dapat berupa suatu kata, angka, atau suatu tanda baca. Proses ini bertujuan untuk mempermudah dalam mengetahui frekuensi kemunculan tiap token pada suatu dokumen. Pada umumnya token yang dipakai pada suatu teks input adalah kata
5 (term). Kata adalah sekumpulan karakter alfanumerik yang saling terhubung dan dipisahkan oleh whitespace, di antaranya adalah spasi, tab, dan newline.
Proses tokenisasi dilakukan dengan bantuan Sphinx Search karena tokenisasi dengan Sphinx tergolong mudah dan cepat dalam prosesnya. Selain itu Sphinx juga mendukung pemrosesan dokumen yang berasal dari database. Sphinx Search digunakan hanya pada saat proses tokenisasi dan pada proses pembobotan yaitu mencari nilai dari Term Frequency (TF).
Pembuangan Stopwords
Proses tokenisasi merupakan proses yang sangat penting dalam indexing. Setiap token didaftar dan dihitung frekuensi kemunculannya pada suatu dokumen. Dalam proses tokenisasi akan terlihat kata mana saja yang sering muncul dan kata mana saja yang jarang muncul dalam dokumen yang di tokenisasi. Untuk stopwords pada dokumen Bahasa Indonesia seperti dan, yang, tetapi, sedangkan, sebagaimana, selanjutnya dan lainnya dapat dipastikan bahwa kemunculan kata-kata tersebut akan banyak sekali ditemukan. Kata-kata-kata tersebut juga bukanlah merupakan kata yang penting. Oleh sebab itu proses indexing selanjutnya adalah proses pembuangan kata-kata yang tidak dapat dijadikan sebagai penciri dari suatu dokumen yang disebut dengan stopwords.
Stopwords yang terdapat di dalam Bahasa Indonesia sangat banyak jumlahnya. Stopwords tersebut bisa berasal dari kata hubung, kata awalan, kata penegasan dan lain sebagainya. Stopwords yang digunakan pada penelitian ini sudah merupakan satu package dengan korpus yang tersedia pada Laboratorium Temu Kembali Informasi Ilmu Komputer IPB. Stopwords yang digunakan tersebut berjumlah sekitar 732 kata.
Pemilihan Fitur
Berdasarkan pernyataan dari Luhn (1958) atau yang biasa dikenal sebagai Luhn Ideas, bahwa kata-kata yang paling umum dan paling tidak umum adalah tidak signifikan untuk indexing. Kata-kata yang tidak dapat dijadikan sebagai penciri dari suatu dokumen adalah kata-kata yang kemunculannya sangat sering dan juga kata-kata yang kemunculannya sangat jarang pada sebuah dokumen. Oleh sebab itu kata-kata dengan frekuensi kemunculan yang cukup merupakan kata-kata yang paling baik digunakan sebagai penciri dari suatu dokumen.
Pemilihan fitur (feature selection) adalah tahapan dimana term yang didapatkan dari hasil tokenisasi dan telah melalui proses pembuangan stopwords diseleksi kembali berdasarkan frekuensi kemunculan dari kata-kata tersebut. Selain stopwords yang sudah jelas bukan merupakan kata yang penting, masih ada kata-kata lain yang bisa diseleksi kembali. Kata-kata tersebut adalah kata-kata yang bukan merupakan kata yang penting dan tidak dapat dijadikan sebagai ciri pada sebuah dokumen.
6
pembobotan kata. Berkurangnya jumlah indeks juga mempengaruhi kecepatan dari proses information retrieval itu sendiri.
Pembobotan
Pembobotan merupakan proses pemberian bobot/nilai pada term yang ada pada dokumen. Tujuan dari pembobotan adalah untuk memberikan suatu nilai pada suatu term dimana nilai tersebut nantinya akan merepresentasikan kemiripan (similarity) dari suatu query dengan suatu dokumen. Metode pembobotan yang digunakan pada sistem temu-kembali informasi berbeda-beda dan sangat beragam. Metode pembobotan yang umum dan paling sering digunakan adalah metode pembobotan berdasarkan term frequency (TF) dan inverse document frequency (IDF).
TF adalah teknik pembobotan dimana kemunculan dari suatu term diperhitungkan dalam suatu dokumen d. Dengan kata lain, bobot dari term tersebut adalah bergantung dari seberapa banyak term tersebut muncul dalam suatu dokumen d (Manning et al. 2008).
Teknik pembobotan term frequency menjadi tidak konsisten ketika suatu dokumen memiliki panjang dokumen yang berbeda-beda. Dokumen dengan panjang dokumen yang lebih besar otomatis akan memiliki frekuensi kemunculan term yang lebih banyak dibandingkan dengan dokumen yang panjangnya lebih sedikit. Padahal belum tentu term yang sering muncul itu merupakan kata penciri dari dokumen tersebut.
IDF merupakan suatu teknik pembobotan dengan memperhitungkan jumlah dokumen yang memiliki term t serta membandingkannya dengan jumlah dokumen yang ada secara keseluruhan. IDF dicari dengan menggunakan rumus sebagai berikut:
Idft = log N
�t
dengan Idft adalah nilai IDF untuk term t, N adalah jumlah dokumen dalam koleksi, dan nt adalah jumlah dokumen yang memiliki termt.
Dari kedua pembobotan tersebut, terbentuklah sistem pembobotan gabungan yang dikenal dengan pembobotan tf.idf, yaitu penggabungan antara TF dan IDF dengan mengalikan kedua rumusnnya sebagai berikut:
(tf.idf)t,d = fd,t × idft
dengan (tf.idf)t,d adalah nilai tf.idf dari term t pada dokumen d, fd,t adalah jumlah
term t pada dokumen d, dan idft adalah nilai idf dari term t.
Dengan kata lain, (tf.idf)t,d menandakan bahwa term t pada dokumen d adalah :
1 Tertinggi ketika t muncul berkali-kali dalam sejumlah kecil dokumen.
2 Rendah ketika t muncul lebih sedikit dalam suatu dokumen atau muncul pada banyak dokumen.
7
(1)
Similarity
Proses selanjutnya setelah dilakukan pembobotan adalah similarity. Nilai-nilai yang didapatkan dari proses pembobotan akan digunakan kembali pada perhitungan dari similarity. Nilai-nilai dari perhitungan similarity tersebut akan membentuk suatu sistem ranking, yang akan mengurutkan dokumen-dokumen berdasarkan tingkat kemiripan tertinggi ke tingkat kemiripan terendah.
Ranking adalah mekanisme pengurutan dokumen-dokumen berdasarkan tingkat relevansi antara dokumen dengan query yang diberikan oleh pengguna. Adanya proses similarity dan sistem ranking menyebabkan adanya kecenderungan dari sistem temu-kembali informasi untuk mengarah kepada suatu model information retrieval (IR).
Penentuan ataupun perhitungan similarity dari suatu mesin pencari didasarkan pada suatu model IR tertentu. Model dari IR beragam jenisnya seperti model peluang, model ruang vektor, model boolean, model bahasa, dan model-model lainnya. Penelitian ini hanya akan membahas pada model-model peluang dan model ruang vektor.
Model Ruang Vektor
Model yang sering digunakan dalam temu-kembali informasi adalah model ruang vektor (vector space model). Model ruang vektor adalah model yang berbasis token. Pada model ruang vektor dimungkinkan adanya partial matching sehingga model ini juga dapat mengenali dokumen yang agak relevan dengan query. Selain itu, pada model ruang vektor juga telah mendukung adanya pemeringkatan dokumen berdasarkan kemiripannya. Model pemeringkatan yang dilakukan adalah dengan melakukan scoring pada dokumen. Dokumen diurutkan berdasarkan kerelevanannya dari yang paling relevan ke yang paling tidak relevan. Untuk dokumen yang memiliki score paling tinggi, dokumen itulah yang paling relevan dengan query yang diberikan, begitupun sebaliknya.
Model ruang vektor menentukan kemiripan (similarity) antara dokumen dengan query dengan cara merepresentasikannya ke dalam bentuk vektor. Tiap kata yang ditemukan pada dokumen dan query diberi bobot dan disimpan sebagai elemen dari sebuah vektor. Model ruang vektor menggunakan ukuran kesamaan cosine (cosine similarity) yang digunakan untuk menghitung kemiripan antara dokumen dan query masukan yang terdiri atas beberapa term. Sebagai contoh terdapat query q dan dokumen d, maka ukuran kesamaan cosine antara query dan dokumen adalah:
sim(q,d) = V��⃗q∙ V��⃗d
�V��⃗q� × �V��⃗d�
dengan V��⃗q adalah nilai tf.idf untuk query, V��⃗d adalah nilai tf.idf untuk dokumen,
8
(2)
(3) dokumen. Nilai terbesar dari perhitungan kesamaan cosine diatas menandakan bahwa query dekat dengan dokumen tersebut.
Model Peluang
Model peluang, sesuai dengan namanya bertujuan untuk mengevaluasi dari setiap kata pencarian (query), berapakah kemungkinan dokumen tersebut relevan dengan query yang diberikan. Model peluang menghitung kesamaan antara sebuah query dengan sebuah dokumen sebagai sebuah peluang bahwa dokumen tersebut akan relevan dengan query tersebut. Nilai peluang akan diberikan pada setiap kata yang menjadi komponen suatu query, kemudian menyatukan setiap nilai-nilai tersebut untuk menghitung suatu nilai peluang akhir yang akan menunjukkan besar atau kecilnya relevansi antara query dengan suatu dokumen. Semakin besar nilai peluang yang dihasilkan, semakin besar pula peluang dari query tersebut relevan dengan suatu dokumen.
Penelitian ini difokuskan menggunakan model peluang yang menggunakan fungsi kesamaan OKAPI BM25 dengan melakukan modifikasi pada nilai Tuning parameter. Tuning parameter adalah suatu variabel yang dapat diubah-ubah nilainya sesuai dengan kebutuhan dengan tujuan untuk mendapatkan hasil pencarian yang lebih baik. Fungsi kesamaan OKAPI BM25 adalah sebagai berikut:
Seperti terlihat dalam rumus OKAPI BM25 terdapat variabel yang disebut tuning parameter, yaitu k1, k3, dan b. Adapun nilai tuning parameter yang direkomendasikan oleh Robertson dan Walker (1999) yang telah terbukti efektif dan memberikan keakuratan yang baik yaitu: k1 = 1,2; k3 = 1000; b = 0,75. Nilai tersebut akan diubah-ubah sesuai dengan kebutuhan sehingga dapat menghasilkan pencarian dengan skor kesamaan yang lebih baik.
Menurut Robertson dan Walker (1999), nilai k1 dan b masing-masing di set
9 Sementara itu, nilai k3 untuk query yang panjang, Robertson dan Walker (1999) menyarankan dengan nilai 1000 atau 7. Oleh karena pencarian yang dilakukan dihitung berdasarkan dari jumlah kata dari query yang dimasukkan dan query yang digunakan merupakan query pendek, maka query masukkan tidak memungkinkan adanya kata yang berulang. Maka, nilai dari k3 relatif konstan apabila di set dengan nilai 1000 maupun 7. Oleh karena hal tersebut, nilai dari k3 dibiarkan menjadi 1000 tanpa dilakukan perubahan. Proses tuning yang akan dilakukan sebanyak 30 kali dan dicantumkan pada Lampiran 3.
Evaluasi
Terdapat dua hal mendasar yang paling sering digunakan untuk mengukur kinerja temu-kembali secara efektif, yaitu recall dan precision (Manning et al. 2008). Precision (P) adalah bagian dari dokumen yang di retrieve adalah relevan, sedangkan recall (R) adalah bagian dari dokumen relevan yang di retrieve. Perhitungan dari recall (R) dan precision (P) ditunjukkan dalam Tabel 1.
Tabel 1 Confusion Matrix
Relevant Not Relevant
Retrieved tp fp
Not Retrieved fn tn
Sehingga perhitungan dari Precision dan Recall adalah sebagai berikut: Precision
=
tp(tp + fp) Recall
=
tp
(tp + fn)
dengan tp adalah jumlah dokumen relevan yang di retrieve, fp adalah jumlah dokumen tidak relevan yang di retrieve, dan fn adalah jumlah dokumen relevan yang tidak di retrieve.
Menurut Baeza-Yates dan Ribeiro-Neto (1999), temu-kembali yang dievaluasi menggunakan beberapa kueri berbeda akan menghasilkan nilai Recall dan Precision yang berbeda untuk masing-masing query. Average Precision (AVP) dengan interpolasi maksimum diperlukan untuk menghitung rata-rata precision pada berbagai 11 tingkat recall, yaitu dari tingkat recall 0 sampai dengan 1. Perhitungan AVP ditunjukkan oleh rumus sebagai berikut:
P�(rj)=�Pi(r)
10
AVP. Dengan didapatkannya nilai AVP pada setiap nilai tuning, dapat diketahui berapakah nilai yang menghasilkan evaluasi dengan nilai AVP paling tinggi.
HASIL DAN PEMBAHASAN
Pemrosesan Dokumen
Dokumen yang digunakan untuk pengujian berjumlah 1300 dokumen. Sebanyak 1000 dokumen pertanian berasal dari korpus yang tersedia di Laboratorium Temu-Kembali Informasi dan 300 dokumen lainnya yang ditambahkan berasal dari portal berita online. Dokumen yang digunakan berformat plain text dengan struktur XML (Extensible Markup Language). Dokumen dikelompokkan menjadi tag-tag sebagai berikut:
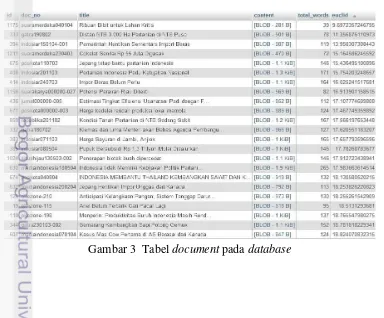
• <document_id=’1’></document_id>, menunjukkan ID dari dokumen. • <doc-no></doc-no>, menunjukkan nama file.
• <title></title>, menunjukkan judul dari dokumen. • <content></content>, menunjukkan isi dari dokumen.
Dokumen-dokumen tersebut kemudian dimasukkan ke dalam database MySql sehingga akan terbentuk sebuah tabel yang bernama document. Tabel document tersebut memiliki field sesuai dengan tag-tag yang ada pada dokumen, seperti terlihat pada Gambar 3. Pada tabel document terdapat field tambahan yaitu total_words dan euclid. Angka-angka tersebut akan digunakan selanjutnya pada proses similarity model peluang dan model ruang vektor.
11 Selain dokumen yang telah disiapkan, pada 1000 dokumen pertanian tersebut juga telah tersedia 30 query yang akan digunakan dalam pencarian, berikut dengan daftar dokumen yang relevan dari query-query tersebut. Query-query tersebut akan digunakan untuk melakukan pada proses similarity pada model peluang maupun model ruang vektor.
Praproses
Tokenisasi
Setelah dokumen dimasukkan ke dalam database, kemudian dilakukan tokenisasi. Proses tokenisasi dilakukan dengan bantuan Sphinx Search karena tokenisasi dengan Sphinx tergolong mudah dan cepat dalam prosesnya. Selain itu, Sphinx juga mendukung pemrosesan dokumen yang berasal dari database.
Sebelum dilakukan proses indexing, terlebih dahulu dilakukan konfigurasi pada Sphinx. File konfigurasi untuk Sphinx yang digunakan adalah file sphinx-min.conf.in. Pada file konfigurasi ini terdapat pengaturan koneksi database dan pengaturan lainnya termasuk jumlah minimal huruf pada kata yang akan diindeks. Kata yang diindeks adalah kata yang memiliki jumlah minimal 3 huruf, sehingga untuk kata yang kurang dari 3 huruf tidak akan ikut terindeks.
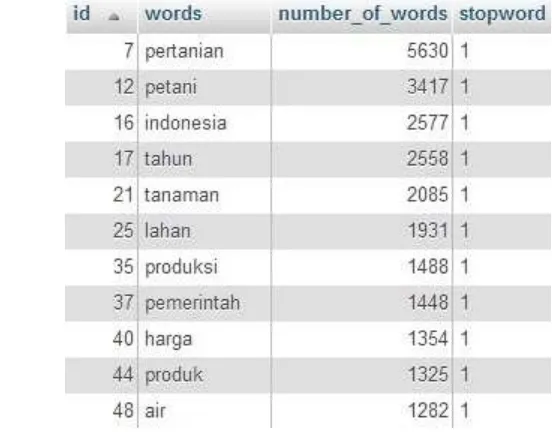
Setelah service dari Sphinx dibuat dan koneksi ke database untuk tabel document telah dibuat pada file konfigurasi Sphinx, proses indexing dapat dilakukan. Pada akhirnya didapatkan indeks kata yang berasal dari 1300 dokumen yang berada pada tabel document di dalam database. Setiap term yang telah diindeks akan dimasukkan ke dalam tabel words pada database. Pada tabel words terdapat seluruh kata yang terindeks, berikut id dan jumlah kemunculan term tersebut pada seluruh dokumen yang ada. Tabel words pada database dapat dilihat pada Gambar 4.
12
Pembuangan Stopwords
File yang berisi stopwords telah tersedia sebelumnya dan berjumlah 732 kata stopwords. Setiap kata stopwords tersebut dimasukkan ke dalam tabel bernama stopwords. Kemudian pada tabel words, akan dibuat 1 field baru dengan nama stopwords yang akan berisi angka 0 dan 1. Angka 0 menunjukkan bahwa kata tersebut merupakan kata stopwords yang terdapat pada tabel stopwords sedangkan angka 1 menunjukkan bahwa kata tersebut bukanlah suatu stopwords. Untuk kata yang memiliki angka 0 pada field stopwords akan dihapus sehingga kata yang tersisa sudah tidak ada lagi kata stopwords.
Akan tetapi, masih terdapat kata-kata yang mengandung angka, seperti tahun, tanggal lahir, dan kata yang mengandung angka lainnya. Kata yang mengandung angka tersebut tidak diperlukan karena pada query yang digunakan, tidak ada query yang mengadung angka. Angka-angka yang ikut terindeks tersebut dihilangkan secara manual (di delete) dari dalam database satu per satu sehingga tidak ditemukan lagi kata yang memiliki unsur angka di dalam database.
Pemilihan Fitur
Pada penelitian ini, metode pemilihan fitur yang digunakan adalah dengan menggunakan Inverse Document Frequency (IDF). Nilai IDF dari sekumpulan indeks kata akan dicari, sehingga akan terlihat kata mana saja yang memiliki nilai IDF yang besar dan yang kecil. Dari nilai tersebut, akan ditentukan nilai batas (threshold) untuk kata yang memiliki nilai IDF yang kecil.
Nilai threshold yang digunakan adalah 0.15. Untuk kata dengan nilai IDF < 0.15 akan dibuang. Untuk nilai IDF yang melebihi nilai threshold akan dipertahankan untuk selanjutnya dilakukan proses pembobotan dan similarity.
Pembobotan
Pembobotan yang dilakukan adalah dengan menghitung tf, idf, dan tf.idf. untuk nilai dari tf dan idf dihitung dengan menggunakan bantuan Sphinx Search. Nilai dari tf dan idf tersebut selanjutnya digunakan untuk mencari nilai dari tf.idf. Nilai-nilai tersebut dimasukkan ke dalam database MySql untuk selanjutnya digunakan pada perhitungan berikutnya. Nilai dari tf dimasukkan ke dalam tabel bernama tf dan nilai idf dimasukkan ke dalam tabel dengan nama idf, sedangkan untuk nilai dari tf.idf ikut dimasukkan ke dalam tabel tf.
Nilai yang didapatkan pada proses pembobotan ini selanjutnya akan digunakan pada proses similarity, baik pada model peluang maupun model ruang vektor. Nilai pembobotan sudah tersedia untuk semua term yang ada pada seluruh dokumen yang terindeks, oleh sebab itu, proses perhitungan pada bagian similarity dapat langsung dilakukan dengan query pengujian yang telah tersedia.
Similarity
13
Similarity Model Peluang
Implementasi dari fungsi kesamaan Okapi BM25 dilakukan dengan bantuan nilai-nilai yang telah ada pada database sebelumnya. Seperti dapat dilihat pada fungsi (2) tersebut terbagi atas 3 bagian. Bagian pertama sebenarnya merupakan rumus dari idf yang mengalami sedikit modifikasi. Nilai dari bagian pertama tersebut dihitung terlebih dahulu untuk setiap term, dan kemudian dimasukkan ke dalam database dengan field bernama idf_modif. Sementara itu, bagian kedua merupakan perhitungan yang berhubungan dengan dokumen, dan bagian ketiga merupakan perhitungan yang berhubungan dengan query.
Nilai dari avl atau panjang rata-rata seluruh dokumen dalam korpus dapat dicari dengan menghitung keseluruhan jumlah kata pada korpus, kemudian membaginya dengan jumlah dari seluruh dokumen. Sedangkan untuk dld atau jumlah term dalam dokumen dapat dicari terlebih dahulu. Pada tabel document akan ditambahkan field yang berisi jumlah kata dalam dokumen tersebut. Kemudian, fungsi kesamaan Okapi BM25 dapat dihitung dengan persamaan pada Gambar 5.
Gambar 5 Implementasi fungsi kesamaan Okapi BM25
Pada saat dimasukkan query yang tersedia, akan didapatkan skor kesamaan dari perhitungan tersebut untuk tiap-tiap dokumen yang dianggap relevan dengan query oleh sistem. Hasil pencarian pada setiap query ini akan dilakukan evaluasi pada tahap selanjutnya. Algoritme dari fungsi kesamaan Okapi BM25 secara garis besar ditunjukkan pada Gambar 6.
Gambar 6 Algoritme pada fungsi kesamaan Okapi BM25
1 Input query q.
2 Pisahkan query q menjadi satu kata query q1, q2, q3, dst.
3 Proses q1 dengan mencari nilai IDF, TF dokumen, dan TF query
nya sesuai dengan fungsi Okapi BM25.
4 Kalikan IDF, DF, dan TF yang didapatkan pada q1 tersebut
sehingga didapatkan skor kesamaan untuk satu kata query.
5 Ulangi langkah 3 sampai 4 untuk q2, q3, dst.
6 Jumlahkan setiap hasil yang didapatkan dari q1, q2, q3 dst
tergantung banyaknya jumlah kata pada query, sehingga didapatkan skor keseluruhan untuk 1 query pencarian.
7 Didapatkan skor kesamaan untuk suatu query, sehingga dapat
ditentukan dokumen hasil pencarian yang dianggap relevan dengan query tersebut.
8 Urutkan dokumen hasil pencarian berdasarkan skor tertinggi
ke skor terendah.
9 Dokumen yang telah diurutkan dapat ditampilkan pada sistem.
$K = $k1*((1-$b)+$b*$total_document_words->total_words/$avl); $part1 = $idf_modif->idf;
$part2 = (($k1+1)*$t->tf)/($K+$t->tf); $part3 = (($k3+1)*1)/($k3+1);
14
Algoritme pada Gambar 6 adalah algoritme untuk satu query. Proses tersebut harus dilakukan untuk ke 30 query yang diujikan, sehingga dapat dilakukan evaluasi untuk seluruh query berdasarkan hasil dari skor kesamaan yang didapatkan tersebut.
Similarity Model Ruang Vektor
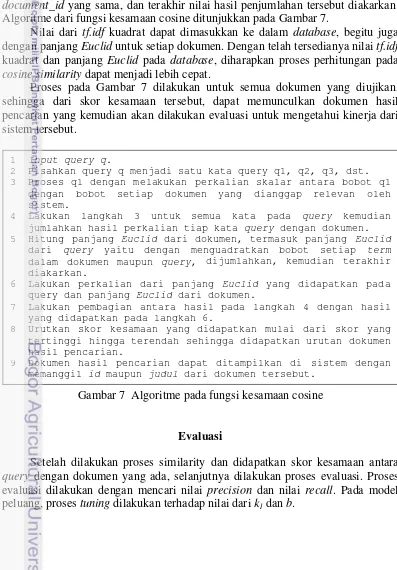
Sesuai dengan fungsi (1), terlebih dahulu dilakukan perkalian antara nilai tf.idf dari query dengan tf.idf dari dokumen yang relevan dengan query masukan. Kemudian hitung panjang Euclid setiap dokumen yang relevan dan panjang Euclid dari query. Panjang Euclid dihitung dengan mengkuadratkan bobot (tf.idf) setiap term dalam setiap dokumen, kemudian dijumlahkan sesuai dengan document_id yang sama, dan terakhir nilai hasil penjumlahan tersebut diakarkan. Algoritme dari fungsi kesamaan cosine ditunjukkan pada Gambar 7.
Nilai dari tf.idf kuadrat dapat dimasukkan ke dalam database, begitu juga dengan panjang Euclid untuk setiap dokumen. Dengan telah tersedianya nilai tf.idf kuadrat dan panjang Euclid pada database, diharapkan proses perhitungan pada cosine similarity dapat menjadi lebih cepat.
Proses pada Gambar 7 dilakukan untuk semua dokumen yang diujikan, sehingga dari skor kesamaan tersebut, dapat memunculkan dokumen hasil pencarian yang kemudian akan dilakukan evaluasi untuk mengetahui kinerja dari sistem tersebut.
Gambar 7 Algoritme pada fungsi kesamaan cosine
Evaluasi
Setelah dilakukan proses similarity dan didapatkan skor kesamaan antara query dengan dokumen yang ada, selanjutnya dilakukan proses evaluasi. Proses evaluasi dilakukan dengan mencari nilai precision dan nilai recall. Pada model peluang, proses tuning dilakukan terhadap nilai dari k1 dan b.
1 Input query q.
2 Pisahkan query q menjadi satu kata query q1, q2, q3, dst.
3 Proses q1 dengan melakukan perkalian skalar antara bobot q1
dengan bobot setiap dokumen yang dianggap relevan oleh sistem.
4 Lakukan langkah 3 untuk semua kata pada query kemudian
jumlahkan hasil perkalian tiap kata query dengan dokumen.
5 Hitung panjang Euclid dari dokumen, termasuk panjang Euclid
dari query yaitu dengan menguadratkan bobot setiap term
dalam dokumen maupun query, dijumlahkan, kemudian terakhir diakarkan.
6 Lakukan perkalian dari panjang Euclid yang didapatkan pada
query dan panjang Euclid dari dokumen.
7 Lakukan pembagian antara hasil pada langkah 4 dengan hasil
yang didapatkan pada langkah 6.
8 Urutkan skor kesamaan yang didapatkan mulai dari skor yang
tertinggi hingga terendah sehingga didapatkan urutan dokumen hasil pencarian.
9 Dokumen hasil pencarian dapat ditampilkan di sistem dengan
15 Setiap perubahan nilai dari k1 dan b dilakukan proses evaluasi terhadap 30
query yang diujikan. Untuk setiap query, dihitung nilai precision pada setiap nilai recall standar (eleven standard recall), yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Setelah didapatkan nilai precision pada sebelas nilai recall standar dengan interpolasi masksimum untuk setiap query, dilanjutkan dengan mencari nilai average precision (AVP). Nilai inilah yang digunakan untuk mengetahui kinerja dari setiap perubahan nilai k1 dan b yang diujikan. Nilai AVP dari setiap pengujian nilai k1 dan b akan dibandingkan untuk mencari nilai k1 dan b yang manakah yang menghasilkan nilai yang paling tinggi.
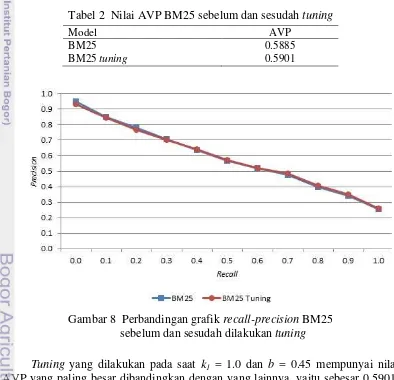
Untuk hasil evaluasi pada fungsi BM25 tanpa tuning yaitu dengan nilai k1 = 1.2 dan b = 0.75 didapatkan nilai average precision (AVP) sebesar 0.5885. Nilai AVP untuk BM25 sebelum dan sesudah dilakukan tuning dicantumkan pada Tabel 2. BM25 Tuning tersebut adalah nilai tuningparameter yang menghasilkan nilai AVP paling besar dari yang lainnya. Nilai AVP dari seluruh tuning parameter yang diujikan dicantumkan pada Lampiran 4. Grafik perbandingan evaluasi BM25 sebelum dan sesudah dilakukan perubahan tuning parameter ditunjukkan pada Gambar 8.
Tabel 2 Nilai AVP BM25 sebelum dan sesudah tuning
Model AVP
BM25 0.5885
BM25 tuning 0.5901
Tuning yang dilakukan pada saat k1 = 1.0 dan b = 0.45 mempunyai nilai AVP yang paling besar dibandingkan dengan yang lainnya, yaitu sebesar 0.5901. Tuning yang dilakukan meningkatkan nilai sebesar 0.0016 dari nilai AVP semula. Nilai ini menunjukkan angka yang tidak terlalu jauh dari nilai AVP pada BM25
16
sebelum dilakukan tuning. Hal ini disebabkan oleh perubahan dari nilai k1 dan b yang sangat berpengaruh terhadap panjang dokumen yang digunakan pada korpus.
Seperti dapat dilihat pada rumus (2) dan rumus (3), nilai dari k1 berhubungan langsung dengan fungsi dari frekuensi kemunculan suatu kata dalam dokumen sedangkan nilai dari b berhubungan langsung dengan rumus (2), yaitu fungsi normalisasi dari panjang dokumen. Nilai tuning terbesar adalah pada saat k1 = 1.0 dan b = 0.45 yang mengartikan bahwa fungsi tersebut hanya menggunakan 0.45 atau sekitar setengah dari panjang dokumen yang ada pada korpus sebagai pengaruh terhadap hasil perhitungan. Apabila b mempunyai nilai 1, maka menandakan fungsi akan menggunakan keseluruhan pengaruh panjang dokumen yang ada pada korpus sebagai hasil perhitungan. Nilai k1 = 1.0 menandakan fungsi tidak menambahkan pengaruh porsi term dalam suatu dokumen. Untuk nilai dari k3 tidak diperhitungkan karena penelitian ini menggunakan query pendek yang tidak memungkinkan adanya kata yang berulang.
Seperti diketahui, dokumen yang digunakan pada penelitian ini berjumlah 1300 dokumen yang seluruhnya merupakan dokumen berita yang ada di koran maupun yang ada di internet. Ini berarti dokumen dalam korpus memiliki jumlah kata untuk tiap dokumen yang tidak terlalu berbeda jauh, karena dokumen berita biasanya tidak akan terlalu panjang dan tidak juga terlalu pendek. Oleh karena dokumen yang digunakan relatif sama dalam hal panjang dokumennya, maka tuning yang dilakukan tidak akan memberikan peningkatan nilai AVP yang terlalu jauh dari nilai AVP awal. Perlu dilakukan tuning dengan menggunakan korpus yang lebih bervariasi untuk membuktikan pengaruh panjang dokumen terhadap hasil perubahan tuning parameter.
Selain dari hal tersebut, tidak dapat dipungkiri bahwa nilai tuning parameter yang disarankan oleh Robertson dan Walker (1999) merupakan nilai tuning parameter yang sudah terbukti efektif pada beberapa kondisi pencarian, seperti panjang dokumen dan panjang query yang berbeda-beda. Oleh karena itu, tuning yang dilakukan pun memang semestinya tidak diubah terlalu jauh dari nilai yang disarankan tersebut.
Meskipun demikian, proses modifikasi dari tuning parameter yang dilakukan sudah berhasil dilakukan karena terbukti mampu meningkatkan nilai AVP dari model peluang yang menggunakan fungsi kesamaan Okapi BM25. Nilai precision dari tiap query pada eleven standard recall untuk model peluang sebelum dan sesudah dilakukan tuning dapat dilihat pada Lampiran 6 dan Lampiran 7.
Perbandingan Kinerja Model Peluang dengan Model Ruang Vektor
17 Tabel 3 Nilai AVP pada BM25 dan VSM
Model AVP
BM25 0.5885
VSM 0.5327
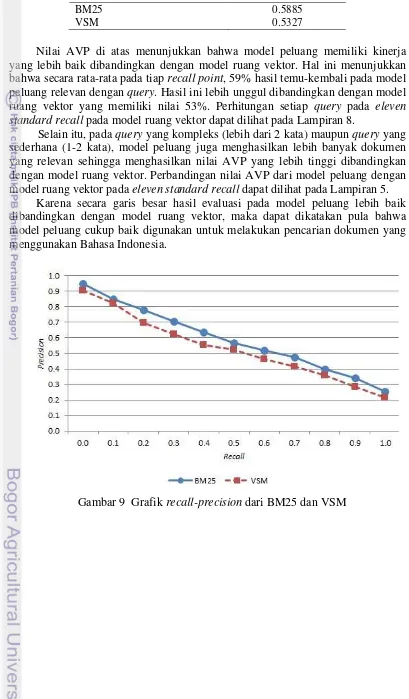
Nilai AVP di atas menunjukkan bahwa model peluang memiliki kinerja yang lebih baik dibandingkan dengan model ruang vektor. Hal ini menunjukkan bahwa secara rata-rata pada tiap recall point, 59% hasil temu-kembali pada model peluang relevan dengan query. Hasil ini lebih unggul dibandingkan dengan model ruang vektor yang memiliki nilai 53%. Perhitungan setiap query pada eleven standard recall pada model ruang vektor dapat dilihat pada Lampiran 8.
Selain itu, pada query yang kompleks (lebih dari 2 kata) maupun query yang sederhana (1-2 kata), model peluang juga menghasilkan lebih banyak dokumen yang relevan sehingga menghasilkan nilai AVP yang lebih tinggi dibandingkan dengan model ruang vektor. Perbandingan nilai AVP dari model peluang dengan model ruang vektor pada eleven standard recall dapat dilihat pada Lampiran 5.
Karena secara garis besar hasil evaluasi pada model peluang lebih baik dibandingkan dengan model ruang vektor, maka dapat dikatakan pula bahwa model peluang cukup baik digunakan untuk melakukan pencarian dokumen yang menggunakan Bahasa Indonesia.
18
SIMPULAN DAN SARAN
Simpulan
Hasil penelitian ini menunjukkan bahwa:
1 Telah dilakukannya proses modifikasi nilai dari tuning parameter yang ada pada fungsi kesamaan Okapi BM25 yang terdapat pada model peluang. Nilai AVP dari model peluang sebelum dilakukan tuning yaitu 0.5885, sedangkan setelah dilakukan tuning nilai AVP yang terbesar yaitu 0.5901.
2 Telah dilakukan perbandingan kinerja antara model peluang dengan model ruang vektor. Perbandingan kedua model ini ditunjukkan oleh nilai AVP dari model peluang standar adalah sebesar 0.5885, sedangkan untuk model ruang vektor, nilai AVP yang didapat adalah sebesar 0.5327. Dari perbandingan nilai AVP tersebut, dapat disimpulkan bahwa model peluang memiliki kinerja yang lebih baik dibandingkan dengan model ruang vektor untuk pencarian dokumen yang menggunakan Bahasa Indonesia.
Saran
Terdapat beberapa hal yang dapat ditambahkan ataupun diperbaiki untuk penelitian-penelitian selanjutnya, diantaranya:
1 Mengembangkan sistem dengan menggunakan dokumen yang lebih beragam, contohnya seperti menggunakan korpus dengan dokumen yang memiliki panjang dokumen yang berbeda-beda.
2 Melakukan pengujian dengan query yang berbeda, lebih beragam, dan terdiri dari banyak kata.
3 Melakukan modifikasi dari tuning parameter dengan nilai k1, k3, dan b yang lebih beragam sehingga memungkinkan didapatkannya nilai AVP yang lebih baik.
DAFTAR PUSTAKA
Adisantoso J, Ridha A. 2004. Korpus dokumen teks bahasa Indonesia untuk pengujian efektivitas temu-kembali informasi. Di dalam: Laporan Akhir Hibah Penelitian SP4. Bogor (ID): Institut Pertanian Bogor.
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. England: Addison Wesley.
Buckley C, Salton G, Allan J. 1994. The effect of adding relevance information in a relevance feedback environment. Di dalam: Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval; 1994 Jul 3-6; Dublin, Irlandia. New York (US):
Springer-Verlag. hlm 292-300.
Chen B. 2011. Modeling in Information Retrieval. Department of Computer Science and Information Engineering, National Taiwan Normal University.
19 in Information Retrieval; 1992 Jun 21-24; Copenhagen, Denmark. New York (US): ACM. hlm 1-10.
Luhn HP. 1958. The automatic of literature abstracts. IBM Journal of Research and Development. 2(2):159-165.
Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information Retrieval. Cambridge (UK): Cambridge Univ Pr.
Robertson SE, Walker S. 1999. Okapi/Keenbow at TREC-8. Di dalam:
Proceedings of TREC-8; 1999 Nov 16-19; Maryland, United States of America. Maryland (US): NIST. hlm 151-162.
21
LAMPIRAN
22
Lampiran 2 Gugus query dan jawaban
Kueri Gugus Jawaban
Bencana kekeringan
gatra070203, gatra161002, gatra210704, gatra301002,
indosiar010903, indosiar170603, indosiar220503, indosiar260803-003, indosiar310504, kompas210504, kompas250803,
mediaindonesia050604-001, mediaindonesia110703,
kompas050303, kompas060503, kompas071100, kompas150201, kompas200802, kompas300402, mediaindonesia130204, Flu burung gatra220604, gatra270104-001, gatra270104-002, gatra300104,
indosiar020304, indosiar240204, mediaindonesia090204,
23 Lampiran 2 Lanjutan
Kueri Gugus Jawaban
Gagal panen gatra070203, gatra190802, gatra190902-02, gatra301002,
indosiar010504, indosiar031203, indosiar040903, indosiar050704-002, indosiar070504, indosiar130504, indosiar140204,
indosiar160304, indosiar170603, indosiar180304, indosiar240703, indosiar260803-001, indosiar260803-003, kompas030704,
kompas031003, kompas170504, mediaindonesia030603, mediaindonesia050604-001, mediaindonesia110703, mediaindonesia140203, mediaindonesia160603,
mediaindonesia240503, mediaindonesia310503, republika030903-002, republika060804-001, republika080703, republika090804-01, republika120804-04, republika130704-001, republika130804-02,
gatra180103, gatra220802, indosiar180603, indosiar180703, indosiar200304, indosiar300703-002, kompas 170402, kompas 170402, kompas050602, kompas101002, kompas101004,
kompas160704, kompas180504, kompas270401, kompas270502-002, kompas310702, mediaindonesia050104,
mediaindonesia060803, mediaindonesia100203, mediaindonesia131003, mediaindonesia160603,
mediaindonesia250304, republika020604-001, republika060804-001, republika090902, republika100703, republika100704-003, republika180504-002, republika210704-001, republika230704-001,
Industri gula gatra200103, kompas031003, kompas250901,
24
Lampiran 2 Lanjutan
Kueri Gugus Jawaban
Institut pertanian bogor
gatra020804, gatra180304, gatra180702, gatra220704, gatra290903, gatra300404, kompas100399, kompas111099, kompas121099, kompas150304-001, kompas200704, kompas200799,
25 Lampiran 2 Lanjutan
Kueri Gugus Jawaban Musim
panen
gatra190902-02, gatra230103-001, gatra240203, indosiar010504, indosiar021203-002, indosiar060204, indosiar071103,
indosiar110304, indosiar240604, indosiar300304, kompas030502-001, kompas041103, kompas220901-kompas030502-001, kompas240103,
kompas300502-001, mediaindonesia131203-001,
gatra180304, jurnal000000-002, kompas020803, kompas031003, kompas060203, kompas060503, kompas100399, kompas101004, kompas110201, kompas111099, kompas121099, kompas150304-002, kompas190802, kompas191099, kompas200799,
kompas210502, kompas220901-002, kompas230603,
kompas240803, kompas260203, kompas270204, kompas280602, kompas290404, mediaindonesia050604-002, 003, republika150903, republika190803, republika251002-003, republika290704-003, republika300604-001, situshijau091203-002, situshijau270703-005, situshijau300403, situshijau310303, situshijau310303-No, suarakarya000000-001-02,
26
Lampiran 2 Lanjutan
27 Lampiran 2 Lanjutan
Kueri Gugus Jawaban
Penyuluhan pertanian bitraindonesia000000-001, gatra190902-02, indosiar310504, jurnal000000-005, jurnal000000-014, kompas050802, 002, jurnal000000-027, kompas031003, kompas041102, kompas101002, kompas140802, kompas160304, Petani tebu indosiar190504-002, indosiar290604, kompas031003,
28
Lampiran 2 Lanjutan
Kueri Gugus Jawaban
Peternak ayam gatra270104-001, gatra270104-002, gatra300104, indosiar020304, indosiar161203, indosiar240204,
Pupuk organik balaipenelitian000000-001, kompas270502-002,
kompas280502, kompas300502-001, republika050804-007, Riset pertanian balaipenelitian000000-012, gatra270104-002,
29
Swasembada pangan indosiar021203-002, kompas060503, kompas100901, kompas110201, kompas150304-002, kompas170104, Tadah hujan gatra210704, gatra301002, indosiar260803-001,
indosiar310504, jurnal000000-001, kompas270502-002,
30
Lampiran 2 Lanjutan
Kueri Gugus Jawaban
31
Lampiran 3 Nilai tuning parameter yang akan diujikan
Nama k1 b
Tuning1 1.0 0.75
Tuning2 1.0 0.60
Tuning3 1.0 0.45
Tuning4 1.0 0.30
Tuning5 1.0 0.15
Tuning6 (BM25) 1.2 0.75
Tuning7 1.2 0.60
Tuning8 1.2 0.45
Tuning9 1.2 0.30
Tuning10 1.2 0.15
Tuning11 1.4 0.75
Tuning12 1.4 0.60
Tuning13 1.4 0.45
Tuning14 1.4 0.30
Tuning15 1.4 0.15
Tuning16 1.6 0.75
Tuning17 1.6 0.60
Tuning18 1.6 0.45
Tuning19 1.6 0.30
Tuning20 1.6 0.15
Tuning21 1.8 0.75
Tuning22 1.8 0.60
Tuning23 1.8 0.45
Tuning24 1.8 0.30
Tuning25 1.8 0.15
Tuning26 2.0 0.75
Tuning27 2.0 0.60
Tuning28 2.0 0.45
Tuning29 2.0 0.30
32
Lampiran 4 Hasil tuning parameter yang diujikan beserta nilai AVP nya
Nama k1 b AVP
Selisih dengan BM25
Tuning1 1.0 0.75 0.5895 0.0010
Tuning2 1.0 0.60 0.5897 0.0012
Tuning3 (Best) 1.0 0.45 0.5901 0.0016
Tuning4 1.0 0.30 0.5822 -0.0063
Tuning5 1.0 0.15 0.5806 -0.0079
Tuning6 (BM25) 1.2 0.75 0.5885 0.0000
Tuning7 1.2 0.60 0.5896 0.0011
Tuning8 1.2 0.45 0.5887 0.0002
Tuning9 1.2 0.30 0.5822 -0.0063
Tuning10 1.2 0.15 0.5802 -0.0083
Tuning11 1.4 0.75 0.5875 -0.0010
Tuning12 1.4 0.60 0.5883 -0.0002
Tuning13 1.4 0.45 0.5871 -0.0014
Tuning14 1.4 0.30 0.5836 -0.0049
Tuning15 1.4 0.15 0.5783 -0.0102
Tuning16 1.6 0.75 0.5847 -0.0038
Tuning17 1.6 0.60 0.5860 -0.0025
Tuning18 1.6 0.45 0.5861 -0.0024
Tuning19 1.6 0.30 0.5832 -0.0053
Tuning20 1.6 0.15 0.5779 -0.0106
Tuning21 1.8 0.75 0.5844 -0.0041
Tuning22 1.8 0.60 0.5842 -0.0043
Tuning23 1.8 0.45 0.5865 -0.0020
Tuning24 1.8 0.30 0.5822 -0.0063
Tuning25 1.8 0.15 0.5766 -0.0119
Tuning26 2.0 0.75 0.5821 -0.0064
Tuning27 2.0 0.60 0.5852 -0.0033
Tuning28 2.0 0.45 0.5851 -0.0034
Tuning29 2.0 0.30 0.5802 -0.0083
33 Lampiran 5 Hasil perhitungan precision pada eleven standard recall
Recall
Precision
BM25 BM25 Tuning VSM
0 0.9483 0.9307 0.9070
0.1 0.8491 0.8463 0.8217
0.2 0.7801 0.7690 0.6958
0.3 0.7048 0.7031 0.6219
0.4 0.6346 0.6430 0.5541
0.5 0.5659 0.5718 0.5229
0.6 0.5180 0.5214 0.4615
0.7 0.4765 0.4864 0.4173
0.8 0.3996 0.4084 0.3583
0.9 0.3410 0.3506 0.2842
1 0.2556 0.2606 0.2154
34
Lampiran 6 Precision setiap query pada BM25
Query Nilai precision pada eleven standard recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
bencana kekeringan 1.0000 1.0000 1.0000 1.0000 1.0000 0.7241 0.7143 0.6512 0.6275 0.5217 0.5217 dukungan pemerintah pada
pertanian 1.0000 0.4615 0.4615 0.3636 0.3636 0.2909 0.2647 0.2308 0.1579 0.0495 0.0495 flu burung 1.0000 1.0000 1.0000 1.0000 0.9231 0.9231 0.8889 0.8889 0.8696 0.8696 0.8696 gabah kering giling 1.0000 1.0000 1.0000 0.6190 0.6190 0.6190 0.5357 0.5152 0.4651 0.4182 0.4182 gagal panen/puso 1.0000 1.0000 1.0000 0.9048 0.8800 0.7813 0.6531 0.6140 0.2000 0.2000 0.2000 impor beras Indonesia 1.0000 1.0000 1.0000 1.0000 1.0000 0.8148 0.6735 0.6735 0.6034 0.5063 0.2756 industri gula 1.0000 1.0000 1.0000 1.0000 1.0000 0.8571 0.8571 0.7000 0.4706 0.2571 0.2436 institut pertanian bogor 1.0000 1.0000 1.0000 1.0000 0.8182 0.7419 0.7105 0.6444 0.5500 0.4111 0.0506 kelangkaan pupuk 1.0000 1.0000 1.0000 1.0000 1.0000 0.9091 0.8947 0.8947 0.8947 0.7917 0.6250 kelompok masyarakat
tani/kelompok tani 1.0000 0.5714 0.4348 0.4348 0.2281 0.2250 0.2247 0.1923 0.1923 0.1923 0.1923 laboratorium pertanian 1.0000 0.8750 0.8750 0.8750 0.6250 0.5789 0.5200 0.4000 0.3469 0.3443 0.3443 musim panen 1.0000 1.0000 0.6000 0.5833 0.5000 0.4375 0.4308 0.4308 0.3367 0.3158 0.1504 pembangunan untuk sektor
pertanian 0.5000 0.5000 0.4167 0.2917 0.2037 0.1870 0.1867 0.1771 0.1653 0.1631 0.1631 penerapan bioteknologi di
35
Lampiran 6 Lanjutan
petani tebu 1.0000 1.0000 0.8000 0.6000 0.6000 0.6000 0.6000 0.5600 0.5333 0.5294 0.5294 peternak ayam 1.0000 1.0000 1.0000 0.9500 0.9500 0.9500 0.9500 0.9500 0.9500 0.9500 0.8696 produk usaha peternakan
rakyat 1.0000 1.0000 0.6667 0.4375 0.2571 0.1967 0.1967 0.1687 0.1053 0.0833 0.0623 pupuk organik 1.0000 1.0000 0.8182 0.8182 0.8182 0.7143 0.6190 0.5833 0.5161 0.4500 0.3279 riset pertanian 1.0000 0.5294 0.5250 0.5250 0.2240 0.1273 0.0948 0.0846 0.0749 0.0749 0.0749 swasembada pangan 1.0000 0.7727 0.7727 0.7727 0.7727 0.7727 0.7500 0.6000 0.5106 0.1875 0.0893 tadah ujan 1.0000 1.0000 1.0000 0.9091 0.9091 0.9091 0.7857 0.6818 0.6818 0.6296 0.1579 tanaman obat 1.0000 1.0000 1.0000 1.0000 0.8571 0.6522 0.5455 0.5349 0.4815 0.4091 0.1576 tanaman pangan 1.0000 0.6875 0.6875 0.5909 0.3291 0.3291 0.3291 0.2857 0.2500 0.2381 0.2381 upaya peningkatan pendapatan
36
Lampiran 7 Precision setiap query pada BM25 dengan tuning tertinggi
Query Nilai precision pada eleven standard recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
bencana kekeringan 1.0000 1.0000 1.0000 1.0000 1.0000 0.7419 0.7143 0.6364 0.6275 0.5143 0.5143 dukungan pemerintah pada
pertanian 1.0000 0.3333 0.3333 0.3333 0.3333 0.3148 0.2727 0.2258 0.1538 0.0493 0.0493 flu burung 1.0000 1.0000 1.0000 0.9231 0.9231 0.9231 0.8947 0.8947 0.8947 0.8696 0.8696 gabah kering giling 1.0000 1.0000 1.0000 0.5652 0.5652 0.5652 0.5000 0.5000 0.4694 0.4694 0.4694 gagal panen/puso 1.0000 1.0000 0.9286 0.8889 0.8750 0.8333 0.7632 0.6182 0.1875 0.1875 0.1875 impor beras Indonesia 1.0000 1.0000 1.0000 1.0000 1.0000 0.7586 0.7222 0.6471 0.5645 0.5000 0.2575 industri gula 1.0000 1.0000 1.0000 1.0000 1.0000 0.7333 0.6842 0.6364 0.4722 0.2769 0.2262 institut pertanian bogor 1.0000 1.0000 1.0000 1.0000 0.9444 0.7333 0.7143 0.6596 0.5238 0.5000 0.0473 kelangkaan pupuk 1.0000 1.0000 1.0000 1.0000 1.0000 0.9091 0.8947 0.8947 0.8947 0.8261 0.5882 kelompok masyarakat
tani/kelompok tani 1.0000 0.7143 0.4706 0.4545 0.2727 0.2286 0.2083 0.1923 0.1923 0.1923 0.1923 laboratorium pertanian 1.0000 0.8750 0.8750 0.8750 0.6250 0.5789 0.4545 0.4545 0.3462 0.3443 0.3443 musim panen 1.0000 0.8000 0.7273 0.5909 0.5000 0.4118 0.3704 0.3704 0.3303 0.3303 0.1413 pembangunan untuk sektor
pertanian 0.5000 0.4118 0.2979 0.2979 0.2346 0.2045 0.1847 0.1777 0.1729 0.1713 0.1631 penerapan bioteknologi di
37
Lampiran 7 Lanjutan
petani tebu 1.0000 1.0000 1.0000 0.6000 0.6000 0.6000 0.6000 0.6000 0.5714 0.5294 0.5294 peternak ayam 1.0000 1.0000 1.0000 1.0000 1.0000 0.9500 0.9500 0.9500 0.9500 0.9500 0.9091 produk usaha peternakan
rakyat 1.0000 1.0000 0.5714 0.5455 0.3077 0.1961 0.1935 0.1443 0.1322 0.0833 0.0569 pupuk organik 1.0000 1.0000 0.7500 0.6875 0.6875 0.6875 0.6000 0.6000 0.5517 0.5143 0.3774 riset pertanian 1.0000 0.5333 0.5263 0.5250 0.2188 0.1071 0.0870 0.0825 0.0719 0.0719 0.0719 swasembada pangan 1.0000 0.8000 0.8000 0.8000 0.8000 0.8000 0.7917 0.6875 0.5333 0.2250 0.0890 tadah ujan 1.0000 1.0000 1.0000 1.0000 0.9091 0.9091 0.7143 0.7143 0.7143 0.6071 0.1856 tanaman obat 1.0000 1.0000 1.0000 0.9091 0.8125 0.7500 0.6429 0.5676 0.5333 0.4058 0.1429 tanaman pangan 0.6000 0.6000 0.6000 0.5909 0.3281 0.3056 0.2826 0.2627 0.2569 0.2386 0.2386 upaya peningkatan pendapatan
38
Lampiran 8 Precision setiap query pada vector space model
Query Nilai precision pada eleven standard recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
bencana kekeringan 1.0000 1.0000 0.8667 0.8667 0.8421 0.8000 0.7429 0.7179 0.6809 0.5373 0.5373 dukungan pemerintah pada
pertanian 1.0000 0.3750 0.3750 0.3462 0.2745 0.2698 0.2000 0.1750 0.1622 0.0508 0.0508 flu burung 1.0000 1.0000 1.0000 0.9167 0.9167 0.9167 0.8750 0.8500 0.8500 0.8261 0.8261 gabah kering giling 1.0000 0.8333 0.8333 0.6667 0.5556 0.5000 0.4000 0.3953 0.3846 0.3143 0.3143 gagal panen/puso 1.0000 1.0000 0.7692 0.6296 0.5263 0.4561 0.3947 0.3211 0.2074 0.2074 0.2074 impor beras Indonesia 1.0000 1.0000 1.0000 1.0000 0.9000 0.8462 0.6364 0.6078 0.4235 0.3083 0.2216 industri gula 1.0000 1.0000 0.8000 0.8000 0.8000 0.7692 0.6667 0.6087 0.5714 0.1782 0.1234 institut pertanian bogor 1.0000 1.0000 0.8000 0.7368 0.6800 0.6667 0.6667 0.6250 0.6000 0.5441 0.2398 kelangkaan pupuk 1.0000 1.0000 1.0000 1.0000 1.0000 0.9167 0.8571 0.8235 0.6957 0.6667 0.3774 kelompok masyarakat
tani/kelompok tani 1.0000 0.8000 0.4375 0.4000 0.2468 0.2468 0.2360 0.2190 0.1955 0.1921 0.1921 laboratorium pertanian 1.0000 0.7500 0.7273 0.7273 0.6111 0.6111 0.5909 0.5769 0.4595 0.3800 0.3088 musim panen 0.8182 0.8182 0.8182 0.5417 0.4706 0.4348 0.3636 0.2887 0.2520 0.2346 0.1826 pembangunan untuk sektor
pertanian 1.0000 0.5625 0.4194 0.3125 0.2333 0.2121 0.2121 0.2121 0.2114 0.1811 0.1756 penerapan bioteknologi di
39
Lampiran 8 Lanjutan
petani tebu 1.0000 0.7500 0.6667 0.6250 0.6250 0.6250 0.5417 0.5333 0.5333 0.3830 0.3830 peternak ayam 1.0000 1.0000 1.0000 1.0000 0.9167 0.9167 0.8571 0.7778 0.7619 0.7500 0.4255 produk usaha peternakan
rakyat 1.0000 1.0000 0.5556 0.3529 0.1714 0.1714 0.1714 0.1386 0.1039 0.0695 0.0579 pupuk organik 1.0000 1.0000 0.5000 0.5000 0.5000 0.5000 0.4000 0.2414 0.1954 0.1856 0.1695 riset pertanian 1.0000 0.7500 0.6250 0.5652 0.2314 0.1289 0.0971 0.0921 0.0766 0.0766 0.0766 swasembada pangan 0.5714 0.5714 0.5714 0.5714 0.5714 0.5714 0.5455 0.4375 0.3582 0.2276 0.0929 tadah ujan 0.8333 0.8333 0.8333 0.5294 0.5294 0.5294 0.4615 0.4412 0.4412 0.3333 0.1915 tanaman obat 1.0000 1.0000 1.0000 1.0000 0.8000 0.6522 0.3830 0.2414 0.1805 0.1436 0.1336 tanaman pangan 0.5000 0.2857 0.2564 0.2500 0.1606 0.1606 0.1606 0.1606 0.1333 0.1320 0.1320 upaya peningkatan pendapatan
40