iii ABSTRACT
WINDU PURNOMO. Fingerprint Classification Using Support Vector Machine with Minutiae-Based Features and Region Method. Under the direction of AHMAD RIDHA and DWI HANDOKO.
Manual fingerprint classification proceeds by carefully inspecting the geometric characteristics of major ridge curves in a fingerprint image. This research proposed an automatic approach of identifying the geometric characteristics of ridges based on minutiae position and angle. Position and angle of minutiae are analyzed using region method. Region was used to discretize the number of minutiae. Positions of minutiae in a region give information about its relation to another region. Angles of minutiae indicate the ridge flow direction. Support vector machine, a binary classifier, is used to classify the fingerprint based on those characteristics. In this research, the classes are left loop, right loop, whorl, arch and tented arch. This research used 2695 fingerprint images from NIST. Classification performance is measured using 3-fold cross validation method. This research achieved 79.7 % accuracy. As we only used local features in this research, further research needs to be conducted especially to investigate global features.
1 PENDAHULUAN
Latar Belakang
Setiap manusia memiliki sesuatu yang unik/khas dan hanya dimiliki oleh dirinya sendiri. Hal ini menimbulkan gagasan untuk menjadikan keunikan tersebut sebagai identitas diri. Gagasan tersebut kemudian didukung oleh teknologi yang secara otomatis dapat mengidentifikasi atau mengenali seseorang, yang disebut biometrik. Teknik identifikasi biometrik didasarkan pada karakteristik alami manusia, yaitu karakteristik fisiologis atau karakteristik perilaku seperti wajah, sidik jari, suara, telapak tangan, iris, retina mata, DNA, dan tanda tangan.
Identifikasi biometrik memiliki keunggulan dibanding dengan metode konvensional. Pada teknik konvensional, identifikasi dilakukan dengan menggunakan password atau kartu, namun ini tidak cukup handal, karena sistem keamanan dapat ditembus ketika password dan kartu tersebut digunakan oleh pengguna yang tidak berwenang. Oleh karena itu, teknik identifikasi biometrik dalam hal ini sidik jari lebih sering digunakan dan telah terbukti unik, akurat, aman, mudah, dan nyaman untuk dipakai sebagai identifikasi jika dibandingkan dengan metode konvensional.
Proses identifikasi dilakukan dengan cara membandingkan antara citra sidik jari masukan dengan citra sidik jari yang terdapat dalam database. Pemanfaatan citra sidik jari untuk identifikasi dalam cakupan yang luas seperti kartu identitas nasional akan menghasilkan database yang berukuran sangat besar. Dalam kasus seperti ini, proses identifikasi akan berlangsung lama, karena banyaknya proses pembandingan antara citra input dengan citra dalam database. Peningkatan kinerja dapat dilakukan dengan cara mengurangi jumlah perbandingan antara citra sidik jari masukan dengan citra sidik jari dalam database. Salah satu tekniknya adalah citra sidik jari diklasifikasikan ke kelas-kelas tertentu. Kemudian, sidik jari masukan akan dianalisis menggunakan model klasifikasi yang sudah dibuat dan hanya dicocokkan dengan sidik jari database pada kelas yang sesuai dengannya.
Penelitian ini menggunakan data yang telah diklasifikasikan oleh National Institute of Standards and Technology (NIST) dengan hasil akurasi 100%. Akan tetapi, sistem yang digunakan oleh NIST bersifat tertutup, sehingga penelitian ini bertujuan melakukan
eksplorasi klasifikasi citra sidik jari dengan menggunakan support vector machine (SVM).
Jain dan Pankanti (2000) melakukan penelitian tentang klasifikasi citra sidik jari menggunakan metode rule-based. Feature yang digunakan adalah singular point, yaitu titik delta dan titik core.
Penelitian yang serupa dilakukan oleh Dass dan Jain (2004) dengan menggunakan metode dan feature yang berbeda. Mereka melakukan klasifikasi dengan menggunakan metode hybrid, yang menggabungkan antara tiga metode dasar, yaitu metode struktur, sintaksis, dan matematis. Feature yang digunakan adalah Orientation Field Flow Curves. Lu et al. (2009) menggunakan data yang sama dan klasifikasi feature Gabor, dengan SVM.
Beberapa penelitian yang telah dilakukan, feature yang sering digunakan adalah orientation image, singularities, ridge flow dan gabor filter. Metode klasifikasinya dapat digolongkan menjadi enam classifier sebagai berikut: rule-based, syntactic, structural, statistical, neural network, dan multiple classifier. Dalam penelitian ini dibuat sebuah model klasifikasi menggunakan metode klasifikasi SVM, dengan feature singular point. Pemilihan metode SVM berdasarkan kelebihan yang dimilikinya yaitu robustness, theoritical analysis, dan feasibility (Nugroho et al. 2005).
Tujuan Penelitian
Tujuan dari penelitian ini adalah melakukan eksplorasi untuk:
1. Pemilihan feature sidik jari
2. Pembuatan model klasifikasi dari citra sidik jari dengan menggunakan SVM
3. Penentuan parameter dari SVM
4. Analisis kinerja SVM dalam melakukan proses klasifikasi
Ruang Lingkup
Batasan masalah dalam penelitian ini adalah:
1. Citra sidik jari yang akan digunakan adalah citra sidik jari yang terdapat dalam database NIST, yang terdiri atas 2695 citra 2. Citra sidik jari dalam format wsq
Manfaat Penelitian
2 pencocokan sidik jari juga akan meningkat
sehingga memungkinkan pemanfaatan sidik jari dalam cakupan yag luas.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra digital merupakan fungsi identitas cahaya f(x,y), dengan x dan y merupakan koordinat spasial. Harga fungsi tersebut pada setiap titik (x,y) merupakan tingkat kecemerlangan citra pada titik tersebut. Citra digital adalah citra f(x,y) yang telah dilakukan diskretisasi koordinat spasial (sampling) dan diskretisasi tingkat kecemerlangannya/keabuan (kuantisasi). Citra digital merupakan suatu matriks yang indeks baris dan kolomnya menyatakan suatu titik pada citra tersebut. Elemen matriks (yang disebut sebagai elemen gambar/piksel) menyatakan tingkat keabuan pada titik tersebut.
Fungsi f(x,y) direpresentasikan dalam suatu fungsi koordinat berukuran . Variabel M adalah baris dan variabel N adalah kolom sebagaimana ditunjukkan pada matriks berikut.
[
]
Citra dengan skala keabuan berformat 8-bit memiliki 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling gelap (hitam) dan 255 menunjukkan nilai paling cerah/putih (Gonzales & Woods 2002).
Representasi Sidik Jari
Sebuah sidik jari dihasilkan dari tampilan eksterior epidermis. Struktur dari sidik jari adalah pola dari ridge (bukit) dan valley (lembah). Citra sidik jari memiliki ridge berwarna gelap dan valley berwarna terang.
Detail dari ridge umumnya dijelaskan dalam urutan berhierarki yang terdiri dari tiga level (Gambar 1):
1. Level 1, pola aliran ridge secara global 2. Level 2, titik-titik minutiae
3. Level 3, pori-pori, bentuk lokal dari garis-garis ridge
Klasifikasi
Klasifikasi adalah fungsi pembelajaran f yang memetakan setiap atribut himpunan x ke salah satu label kelas yang sudah ditetapkan y
(Tan et al. 2006). Fungsi pembelajaran f juga sering disebut sebagai model klasifikasi (classification model). Model klasifikasi digunakan dalam descriptive modeling dan predictive modeling.
Descriptive Modelling: Model klasifikasi dapat menjelaskan perbedaan objek-objek yang terdapat dalam kelas berbeda. Contohnya adalah klasifikasi dalam bidang biologi. Hasil klasifikasi dapat menjelaskan feature-feature yang mengakibatkan sebuah binatang digolongkan ke dalam kelas mamalia, reptil, burung, ikan dan amfibi.
Gambar 1 Ridge (bukit) dan valley (lembah) pada citra sidik jari.
Predictive Modelling: Model klasifikasi juga dapat digunakan untuk memprediksi objek yang belum diketahui kelasnya. Model klasifikasi seperti kotak hitam yang akan memberikan label kelas kepada objek berdasarkan atribut-atribut yang dimilikinya.
Klasifikasi terdiri dari dua tahap, yaitu pelatihan dan prediksi. Pada tahap pelatihan, dibentuk sebuah model domain permasalahan dari setiap instance yang ada. Penentuan model tersebut berdasarkan analisis pada sekumpulan data pelatihan, yaitu data yang label kelasnya sudah diketahui. Pada tahap klasifikasi, dilakukan prediksi kelas dari instance baru dengan menggunakan model yang telah dibuat pada tahap pelatihan (Guvenir et al. 1998). Pattern Recognition
3 recognition adalah Support Vector Machine
(SVM) (Nugroho et al. 2005). Kelas Target Sidik Jari
Aturan klasifikasi sidik jari pertama kali diperkenalkan oleh Purkinje pada tahun 1823 yang mengklasifikasikan sidik jari ke dalam sembilan kategori (transverse curve, central longitudinal stria, oblique stripe, oblique loop, almond whorl, spiral whorl, ellipse, circle, dan double whorl) berdasarkan konfigurasi ridge. Penelitian berikutnya dilakukan oleh Francis Galton pada tahun 1892 yang membagi sidik jari ke dalam tiga kelas utama (arch, loop dan whorl). Selanjutnya setiap kelas utama tersebut dibagi menjadi subkelas. Sepuluh tahun kemudian Edward Henry memperbaiki sistem klasifikasi Francis Galton dengan menambahkan jumlah kelas. Klasifikasi Galton-Henry ini membagi sidik jari ke dalam lima kelas yaitu: arch, tented arch, left loop, right loop, dan whorl (Gambar 2). Klasifikasi Galton-Henry inilah yang banyak digunakan di beberapa negara (Maltoni & Maio 2009).
Gambar 2 Kelas target sidik jari. Teknik Klasifikasi (Classifier)
Teknik klasifikasi atau classifier adalah pendekatan sistematik untuk membangun model klasifikasi dari input data set (Tan et al. 2006). Beberapa Classifier yang sering digunakan dalam proses klasifikasi sidik jari adalah sebagai berikut (Maltoni & Maio 2009): 1. Rule Based Approach
2. Syntactic Approaches 3. Structural Approaches 4. Statistical
5. Neural Network 6. Multiple Classifier
7. Support Vector Machine (SVM) Support Vector Machine (SVM)
Support Vector Machine (SVM) bertujuan untuk menemukan fungsi pemisah (classifier/ hyperplane) terbaik untuk memisahkan dua buah class pada input space. Hyperplane terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Hyperplane dalam ruang berdimensi d adalah affine
subspace berdimensi d-1 yang membagi ruang vector tersebut ke dalam dua bagian yang masing-masing berkorespondensi pada class yang berbeda (Cristianini dan Taylor, 2000). Margin adalah jarak antara hyperplane dengan pattern terdekat dari masing-masing class. Pattern yang paling dekat disebut sebagai support vector.
Dua kondisi yang dapat diselesaikan oleh SVM yaitu kondisi yang dapat dipisahkan secara linear (linearly separable data) dan kondisi yang tidak dapat dipisahkan secara linear.
Linearly Separable Data
Gambar 3 SVM berusaha menemukan hyperplane terbaik yang memisahkan kedua class -1 dan +1.
Linearly separable data merupakan data yang dapat dipisahkan secara linear. Misalkan {x1,…,xn} adalah dataset dan
adalah label kelas dari data xi. Pada Gambar 3 garis tebal menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class. Titik yang berada dalam lingkaran adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran (training) pada SVM. Penentuan bidang pembatas terbaik dapat dirumuskan seperti persamaan 1 (Osuna et al. 1997):
| | (1) w adalah vektor tegak lurus terhadap hyperplane dan b adalah jarak antar tidik pusat dengan hyperplane. Penyelesaian persamaan 1 dapat dipermudah dengan mengubah persamaan ke dalam bentuk dual problem menggunakan teknik pengali Lagrange menjadi seperti persamaan 2 (Osuna et al. 1997).
‖ ‖ ∑ [ ]
4 α = adalah vektor non-negatif dari
koesifien Lagrange. Dengan meminimumkan L terhadap w dan b, maka diperoleh persamaan 3 dan 4. persamaan 2 sehingga diperoleh persamaan 5. yang nantinya digunakan untuk menemukan w. Terdapat αi untuk setiap data pelatihan. Data pelatihan yang memiliki nilai αi ≥ 0 adalah support vector sedangkan sisanya memiliki nilai αi = 0. Dengan demikian, fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector.
Formula pencarian bidang terbaik ini adalah permasalahan quadratic programming sehingga nilai maksimum global dari αi selalu dapat ditemukan. Setelah solusi permasalahan quadratic programming ditemukan (αi), maka kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan pada persamaan 6: diklasifikasikan (Osuna et al. 1997).
Soft Margin Hyperplane
Formulasi SVM harus dimodifikasi untuk mengklasifikasikan data yang tidak dapat dipisahkan secara sempurna karena tidak akan ada solusi yang ditemukan. Pencarian bidang
pemisah terbaik dengan penambahan variabel sering juga disebut soft margin hyperplane. Dengan demikian, formula pencarian bidang pemisah terbaik pada persamaan 1 berubah menjadi seperti persamaan 7.
| | (∑ penalti akibat kesalahan dalam klasifikasi data dan nilainya ditentukan oleh pengguna. Pada kasus soft margin hyperplane tidak hanya meminimalkan w tetapi meminimalkan juga parameter penalti C.
Kernel Trick
Pada kenyataannya tidak semua data bersifat linearly separable, sehingga sulit dicari bidang pemisah secara linear. Permasalahan ini dapat diselesaikan dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) yang lebih tinggi sehingga dapat dipisahkan secara linear pada feature space yang baru. Pemisahan feature space dilakukan dengan cara memetakan data menggunakan fungsi pemetaan (transformasi) dalam feature space sehingga terdapat bidang pemisah yang dapat memisahkan data sesuai dengan kelasnya. Dengan menggunakan fungsi tranformasi , fungsi hasil pembelajaran yang dihasilkan seperti pada persamaan 5 (Osuna et al. 1997).
(∑
)
5 Fungsi kernel yang umum digunakan adalah
sebagai berikut: 1. Linear kernel
2. Polynomial kernel
3. Radial basis function (RBF)
| | 4. Sigmoid kernel
parameter C, γ, r, dan d adalah parameter-parameter pada kernel.
Image Processing
Pengolahan citra merupakan proses pengolahan dan analisis citra yang banyak melibatkan persepsi visual. Proses ini mempunyai ciri data masukan dan informasi keluaran yang berbentuk citra. Istilah pengolahan citra digital secara umum didefinisikan sebagai pemrosesan citra dua dimensi dengan komputer. Pengolahan citra digital juga mencakup semua data dua dimensi dalam definisi yang lebih luas. Citra digital adalah barisan bilangan nyata maupun kompleks yang diwakili oleh bit-bit tertentu (Gonzales & Woods 2002).
METODE PENELITIAN
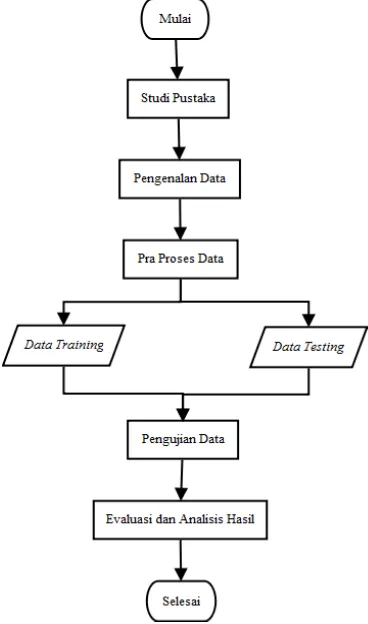
Penelitian ini dilakukan dengan tahapan sebagai berikut: studi pustaka, pengenalan data, pra proses data, pengujian data, dan evaluasi dan analisis hasil. Gambar 4 memperlihatkan alur penelitian yang dilakukan.
Studi Pustaka
Pada tahapan ini, proses yang dilakukan adalah mengumpulkan informasi atau literatur yang terkait dengan penelitian. Informasi didapatkan dari jurnal, buku dan artikel yang membahas tentang metode klasifikasi, SVM, proses pengenalan citra, dan manual NIST serta weka.
Perumusan Masalah
Proses utama dari penelitian ini ada tiga tahapan yaitu: praproses data, ekstraksi feature, proses klasifikasi, dan analisis hasil.
Pembentukan Data
Data citra sidik jari yang digunakan berasal dari NIST yang berjumlah 2700 citra berformat wsq. Dari jumlah tersebut, 5 citra (tipe scar)
tidak digunakan karena jumlah tipe ini lebih sedikit dibandingkan dengan tipe sidik jari yang lain. Sehingga dalam penelitian ini hanya digunakan 2695 citra. Citra diperoleh dari proses scanning sidik jari pada kertas (laten). Gambar 5 adalah contoh data sidik jari yang digunakan dalam penelitian. Data tersebut sudah diklasifikasikan ke dalam lima kelas yaitu whorl (W), left loop (L), right loop (R), arch (A), dan tented arch (T).
Gambar 4 Alur penelitian.
Gambar 5 Contoh data citra sidik jari. Praproses
5 Fungsi kernel yang umum digunakan adalah
sebagai berikut: 1. Linear kernel
2. Polynomial kernel
3. Radial basis function (RBF)
| | 4. Sigmoid kernel
parameter C, γ, r, dan d adalah parameter-parameter pada kernel.
Image Processing
Pengolahan citra merupakan proses pengolahan dan analisis citra yang banyak melibatkan persepsi visual. Proses ini mempunyai ciri data masukan dan informasi keluaran yang berbentuk citra. Istilah pengolahan citra digital secara umum didefinisikan sebagai pemrosesan citra dua dimensi dengan komputer. Pengolahan citra digital juga mencakup semua data dua dimensi dalam definisi yang lebih luas. Citra digital adalah barisan bilangan nyata maupun kompleks yang diwakili oleh bit-bit tertentu (Gonzales & Woods 2002).
METODE PENELITIAN
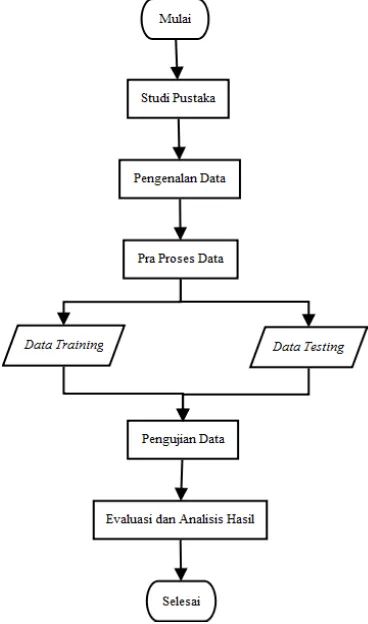
Penelitian ini dilakukan dengan tahapan sebagai berikut: studi pustaka, pengenalan data, pra proses data, pengujian data, dan evaluasi dan analisis hasil. Gambar 4 memperlihatkan alur penelitian yang dilakukan.
Studi Pustaka
Pada tahapan ini, proses yang dilakukan adalah mengumpulkan informasi atau literatur yang terkait dengan penelitian. Informasi didapatkan dari jurnal, buku dan artikel yang membahas tentang metode klasifikasi, SVM, proses pengenalan citra, dan manual NIST serta weka.
Perumusan Masalah
Proses utama dari penelitian ini ada tiga tahapan yaitu: praproses data, ekstraksi feature, proses klasifikasi, dan analisis hasil.
Pembentukan Data
Data citra sidik jari yang digunakan berasal dari NIST yang berjumlah 2700 citra berformat wsq. Dari jumlah tersebut, 5 citra (tipe scar)
tidak digunakan karena jumlah tipe ini lebih sedikit dibandingkan dengan tipe sidik jari yang lain. Sehingga dalam penelitian ini hanya digunakan 2695 citra. Citra diperoleh dari proses scanning sidik jari pada kertas (laten). Gambar 5 adalah contoh data sidik jari yang digunakan dalam penelitian. Data tersebut sudah diklasifikasikan ke dalam lima kelas yaitu whorl (W), left loop (L), right loop (R), arch (A), dan tented arch (T).
Gambar 4 Alur penelitian.
Gambar 5 Contoh data citra sidik jari. Praproses
6 Tented Arch dalam jumlah yang proporsional.
Tabel 1 memberikan informasi jumlah data dalam setiap fold.
Tabel 1 Jumlah data setiap fold
Kelas F1 F2 F3 Jumlah
L 268 268 268 804
R 245 245 245 735
W 341 341 341 1023
A 16 16 17 49
T 28 28 28 84
Keterangan: F1 : Fold 1 F2 : Fold 2 F3 : Fold 3 Ekstraksi Feature
Feature yang akan diekstrak dari citra sidik jari berasal dari level ke dua, yaitu titik-titik minutiae. Minutiae terdiri dari dua jenis yaitu Ridge ending (RIG) dan Bifurcation (BIF). Ridge ending adalah lokasi pada citra, di mana ridge berakhir. Sedangkan, bifurcation adalah lokasi pada citra di mana ridge bercabang. Gambar 6 menampilkan ridge ending dan bifurcation pada citra sidik jari. Sudut minutiae dihitung berdasarkan garis horizontal (axis). Sudut minutiae diharapkan akan memberikan informasi arah pergerakan ridge. Gambar 7 memberikan ilustrasi untuk menentukan theta.
Gambar 6 Ridge ending dan bifurcation.
Gambar 7 Penentuan theta pada ridge ending dan bifurcation.
Feature diperoleh dengan membagi citra ke dalam beberapa region. Gambar 8 memberikan ilustrasi pembagian citra sidik jari ke dalam region berukuran 5x5. Region yang digunakan dalam penelitian ini berukuran 5x5. Hal ini ditentukan berdasarkan beberapa percobaan
yang telah dilakukan dengan menggunakan region yang berbeda-beda, seperti yang ditunjukkan pada Tabel 2. Hasil dari percobaan tersebut menunjukkan region 5x5 memberikan akurasi yang terbaik.
Tabel 2 Penelitian jumlah region dalam pemilihan feature
Region Akurasi(%)
3x3 41.0
4x4 41.0
5x5 42.8
6x6 42.7
Masing-masing region kemudian dihitung feature-feature sebagai berikut:
1. Jumlah jenis BIF/RIG 2. Jumlah jenis theta 3. Kelas target
Gambar 8 Citra sidik jari yang sudah dibagi ke dalam region berukuran 5x5.
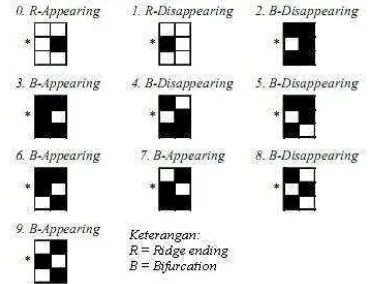
BIF dan RIG dikelompokkan ke dalam sepuluh jenis. Pengelompokan ditentukan pada sumber dan arah penampakan BIF dan RIG. Gambar 9 mengilustrasikan pengelompokan BIF dan RIG. Dalam Gambar 9, titik-titik yang berwarna hitam mewakili ridge dan tanda bintang merupakan titik pengamatan.
Gambar 9 Sepuluh jenis bifurcation dan ridge ending.
7 sampai 31. Nilai 0 artinya minutiae memiliki
sudut antara 0o sampai 11.25o. Nilai 1 artinya minutiae memiliki sudut antara 11.25o sampai 22.50o, dan seterusnya sampai nilai 31. Masing-masing jenis memiliki rentang yang selisihnya 11.25o.
Klasifikasi
Klasifikasi dilakukan dengan menggunakan classifier SVM dengan menggunakan kernel RBF. Sebagai perbandingan akan dilakukan juga klasifikasi menggunakan classifier K-Nearest Neighbour (KNN) dan Naïve Bayes. Pengujian
Data diuji menggunakan metode pengujian 3-fold cross validation. Total data set akan dibagi ke dalam 3 kelompok (fold). Kemudian dilakukan proses training secara berulang. Pada setiap pengulangan, 2 fold akan menjadi data training, dan 1 lainnya menjadi data testing. Proses ini dilakukan sebanyak 3 kali sehingga semua fold pernah berperan sebagai data training atau pun data testing. Dalam setiap pengulangan akan dihitung nilai akurasi sehingga akurasi akhir adalah rata-rata nilai akurasi dari tiga kali pengulangan yang Evaluasi dan Analisis Hasil
Evaluasi dilakukan dengan melakukan penghitungan nilai akurasi. Nilai akurasi diperoleh dengan melakukan prediksi terhadap data menggunakan model klasifikasi. Dari hasil prediksi ini kemudian dihitung jumlah data yang diklasifikasikan secara benar dan salah. Evaluasi juga dilakukan dengan melihat kinerja SVM dalam mengklasifikasikan citra sidik jari, ketika dibandingkan dengan classifier yang lain, seperti Naïve Bayes dan KNN.
HASIL DAN PEMBAHASAN
Pemilihan Feature
Eksperimen pertama yaitu pemilihan feature, menggunakan classifier SVM dengan menggunakan kernel polynomial (poly kernel), dan C = 1. Dalam eksperimen ini dilakukan beberapa percobaan dengan menggunakan feature yang berbeda. Berikut ini adalah
feature-feature yang dicobakan dengan hasil yang ditampilkan pada Tabel 3.
1. Feature 1, Jumlah BIF dan RIG setiap region
Feature 1 mengambil karakterisitik dari citra sidik jari, yaitu lokasi bifurcation dan ridge ending. Untuk setiap region, dihitung jumlah bifurcation dan ridge ending. Sehingga feature 1 memiliki format:
Keterangan: region + jumlah jenis theta setiap region Jenis BIF/RIG dikodekan dengan angka 0 sampai dengan 9. Jenis theta dikodekan dengan angka 0 sampai dengan 31. Contoh pengambilan data untuk feature ke 2 ditampilkan pada Gambar 10. Format penulisan feature adalah sebagai berikut:
Keterangan:
k : Region,
brgk : Jumlah jenis BIF/RIG pada region k,
θjk : Jumlah jenis theta h pada region k,
C : Kelas target citra sidik jari
Gambar 10 Contoh pengambilan feature jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region pada region 21. br01,br02,…,br025,br11,br12,…br125,
…br91,br92,…br925,
θ01, θ02,…,θ025, θ11, θ12,…,
7 sampai 31. Nilai 0 artinya minutiae memiliki
sudut antara 0o sampai 11.25o. Nilai 1 artinya minutiae memiliki sudut antara 11.25o sampai 22.50o, dan seterusnya sampai nilai 31. Masing-masing jenis memiliki rentang yang selisihnya 11.25o.
Klasifikasi
Klasifikasi dilakukan dengan menggunakan classifier SVM dengan menggunakan kernel RBF. Sebagai perbandingan akan dilakukan juga klasifikasi menggunakan classifier K-Nearest Neighbour (KNN) dan Naïve Bayes. Pengujian
Data diuji menggunakan metode pengujian 3-fold cross validation. Total data set akan dibagi ke dalam 3 kelompok (fold). Kemudian dilakukan proses training secara berulang. Pada setiap pengulangan, 2 fold akan menjadi data training, dan 1 lainnya menjadi data testing. Proses ini dilakukan sebanyak 3 kali sehingga semua fold pernah berperan sebagai data training atau pun data testing. Dalam setiap pengulangan akan dihitung nilai akurasi sehingga akurasi akhir adalah rata-rata nilai akurasi dari tiga kali pengulangan yang Evaluasi dan Analisis Hasil
Evaluasi dilakukan dengan melakukan penghitungan nilai akurasi. Nilai akurasi diperoleh dengan melakukan prediksi terhadap data menggunakan model klasifikasi. Dari hasil prediksi ini kemudian dihitung jumlah data yang diklasifikasikan secara benar dan salah. Evaluasi juga dilakukan dengan melihat kinerja SVM dalam mengklasifikasikan citra sidik jari, ketika dibandingkan dengan classifier yang lain, seperti Naïve Bayes dan KNN.
HASIL DAN PEMBAHASAN
Pemilihan Feature
Eksperimen pertama yaitu pemilihan feature, menggunakan classifier SVM dengan menggunakan kernel polynomial (poly kernel), dan C = 1. Dalam eksperimen ini dilakukan beberapa percobaan dengan menggunakan feature yang berbeda. Berikut ini adalah
feature-feature yang dicobakan dengan hasil yang ditampilkan pada Tabel 3.
1. Feature 1, Jumlah BIF dan RIG setiap region
Feature 1 mengambil karakterisitik dari citra sidik jari, yaitu lokasi bifurcation dan ridge ending. Untuk setiap region, dihitung jumlah bifurcation dan ridge ending. Sehingga feature 1 memiliki format:
Keterangan: region + jumlah jenis theta setiap region Jenis BIF/RIG dikodekan dengan angka 0 sampai dengan 9. Jenis theta dikodekan dengan angka 0 sampai dengan 31. Contoh pengambilan data untuk feature ke 2 ditampilkan pada Gambar 10. Format penulisan feature adalah sebagai berikut:
Keterangan:
k : Region,
brgk : Jumlah jenis BIF/RIG pada region k,
θjk : Jumlah jenis theta h pada region k,
C : Kelas target citra sidik jari
Gambar 10 Contoh pengambilan feature jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region pada region 21. br01,br02,…,br025,br11,br12,…br125,
…br91,br92,…br925,
θ01, θ02,…,θ025, θ11, θ12,…,
8 Tabel 3 Hasil eksperimen pemilihan feature
Feature Akurasi (%)
Feature 1 40.7
Feature 2 74.0
Keterangan:
Feature 1 : Jumlah BIF dan RIG setiap region Feature 2 : Jumlah jenis BIF/RIG + Jumlah
jenis theta setiap region
Program yang Digunakan
Penelitian ini menggunakan program-program sebagai berikut:
1. Mindtct (eksternal) 2. Wsq2Min
3. Min2Arff
4. Weka 3.6.2 (eksternal)
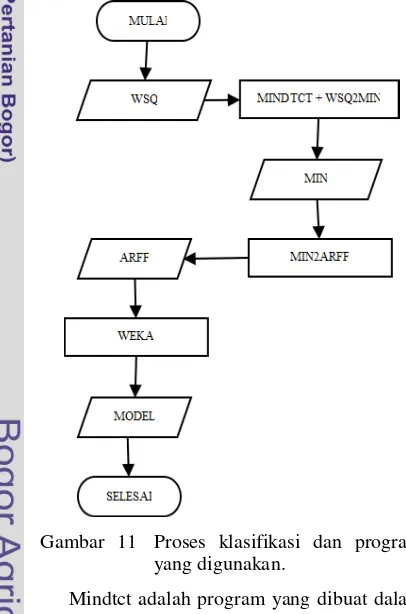
Program-program tersebut digunakan dalam proses yang berbeda dalam klasifikasi. Gambar 11 mengilustrasikan tentang proses klasifikasi dan program yang digunakan.
Gambar 11 Proses klasifikasi dan program yang digunakan.
Mindtct adalah program yang dibuat dalam bahasa C oleh NBIS. Mindtct berperan dalam proses ekstraksi citra sidik jari. Masukan dari program mindtct adalah file citra berformat wsq. Sedangkan keluarannya berupa file plain text berekstensi min. File min memberikan informasi jumlah minutiae, lokasi minutiae,
jenis minutiae, kemiringan minutiae, dan ketetanggaan antara minutiae satu dengan yang lain.
Wsq2Min adalah program yang dikembangkan dalam penelitian ini dengan bahasa Java. Program ini digunakan bersama dengan program mindtct. Pada siklus hidupnya, mindtct hanya dapat memroses satu file, sehingga untuk memroses file wsq yang jumlahnya lebih dari satu harus dilakukan pemanggilan ulang terhadap program mindtct. Agar proses ekstraksi dapat berjalan lebih cepat dan cukup satu pemanggilan, mindtct perlu dikombinasikan dengan Wsq2Min. Masukan dari program Wsq2Min adalah directory tempat file wsq berada, dan keluarannya adalah file min.
Program Min2Arff adalah program yang dikembangkan dalam penelitian ini juga menggunakan bahasa Java. Program ini berperan dalam proses pemilihan feature untuk proses klasifikasi. Masukan untuk program Min2Arff adalah file min, dan keluarannya adalah file arff. File arff adalah standar file yang digunakan oleh program weka. File arff berisi informasi hasil ekstraksi feature.
Weka adalah program dalam bahasa Java, yang dibuat oleh Universitas Waikato. Weka adalah program machine learning, yang digunakan untuk melakukan teknik-teknik data mining seperti klasifikasi dan clustering. Masukan untuk program Weka adalah file arff, dan keluarannya adalah model klasifikasi. Model klasifikasi yang diperoleh akan digunakan untuk memprediksi data ke dalam kelas yang sudah ditentukan.
Pemilihan Classifier dan Konfigurasi Parameter
9
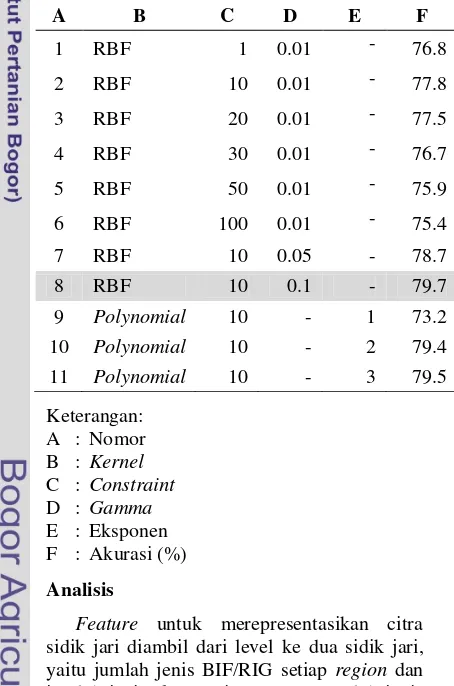
Dari eksperimen pemilihan classifier, diperoleh kesimpulan bahwa classifier SVM memberikan akurasi yang lebih baik dibandingkan dengan classifier Naïve Bayes dan KNN. Selanjutnya akan dilakukan beberapa eksperimen dengan menggunakan parameter pada SVM yang berbeda. Hasil eksperimen konfigurasi parameter SVM ditampilkan pada Tabel 5. Nilai akurasi terbaik yaitu 79.7% diperoleh dengan menggunakan kernel RBF (Gamma = 0.1) dan C = 10.
Tabel 5 Hasil eksperimen pemilihan parameter pada SVM
Feature untuk merepresentasikan citra sidik jari diambil dari level ke dua sidik jari, yaitu jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region. Jumlah jenis BIF/RIG mampu memberikan model atau pola lokasi jenis minutiae dan hubungan minutiae satu dengan yang lain. Jumlah jenis theta akan
memberikan informasi pergerakan lengkungan sudut minutiae.
Feature jenis BIF/RIG dan theta akan diekstrak dalam bentuk region. Dari percobaan yang telah dilakukan region berukuran 5x5 memberikah akurasi yang lebih baik. Tabel 2, menampilkan hasil percobaan dengan menggunakan variasi beberapa ukuran region. Pemilihan ukuran region yang terlalu kecil (sedikit), memberikan variasi yang kecil sehingga arah pergerakan ridge tidak dapat diidentifikasi lebih detail, sebaliknya region yang lebih besar (banyak), akan menghasilkan atribut pada instance menjadi banyak, sehingga komputasi menjadi lebih berat.
Classifier yang digunakan adalah SVM dengan menggunakan kernel RBF (gamma = 1.0) dan C = 10. Berdasarkan literatur yang dipelajari, pada banyak kasus SVM memberikan hasil yang lebih baik dibandingkan dengan classifier yang lain (Nugroho et al. 2005). Dalam penelitian ini terbukti bahwa untuk seluruh data yang dicobakan, SVM mampu mengklasifikasikan secara benar lebih banyak jika dibandingkan dengan Naïve Bayes dan KNN. Hasil klasifikasi dan sebaran citra sidik jari setiap kelas dapat dilihat dengan memperhatikan confusion matrix dalam Tabel 6.
Tabel 6 Confusion matrix dari klasifikasi citra sidik jari dengan menggunakan feature jumlah jenis BIF/RIG +
10 sebagai Whorl, 0 sebagai Arch, dan 1 yang
diidentifikasi sebagai Tented arch.
Dari confusion matrix pada Tabel 6 kita mendapatkan informasi sebaran hasil klasifikasi untuk setiap kelas. Tabel 7 menunjukkan jumlah instance dan akurasi untuk setiap kelas.
Tabel 7 Jumlah instance dan akurasi setiap kelas
Kelas Jumlah instance Akurasi (%)
L 804 85.7
R 735 83.7
W 1023 82.5
A 49 0.0
T 84 1.2
Tabel 7 menunjukkan bahwa akurasi untuk kelas Arch dan Tented Arch lebih kecil dibanding dengan tiga kelas lainnya. Hal ini berbanding lurus dengan jumlah instance kelas tersebut yang jumlahnya relatif sedikit dibanding kelas yang lain. Sehingga dapat disimpulkan bahwa jumlah data training berpengaruh terhadap tingkat akurasi.
KESIMPULAN DAN SARAN Kesimpulan
Feature yang digunakan berasal dari feature lokal sidik jari, yaitu feature berbasis minutiae. Pada penelitian ini, feature yang dapat memberikan representasi sidik jari paling baik adalah dengan menggunakan jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region. Jumlah jenis BIF/RIG akan memberikan model sebaran minutiae, sedangkan theta akan memberikan model arah pergerakan minutiae.
Dari literatur yang dipelajari, pada banyak kasus SVM mampu memberikan model klasifikasi yang lebih baik dibandingkan dengan classifier yang lain (Nugroho et al. 2005). Berhubungan dengan hal ini, SVM digunakan untuk inisialisasi classifier pada proses pemilihan feature. Setelah dilakukan perbandingan dengan Naïve Bayes dan KNN, SVM dapat mengklasifikasikan lebih baik di antara yang lain. Beberapa parameter dipilih dan ditentukan untuk mendapatkan model yang lebih baik. Ada dua parameter yang harus ditentukan, yaitu nilai C dan kernel. Dengan menggunakan metode coba-coba, model terbaik diperoleh dengan menggunakan nilai C = 10 dan kernel RBF, dengan gamma = 0.1.
Klasifikasi citra sidik jari menggunakan SVM dengan feature berbasis minutiae, memberikan akurasi 79.7%. Dalam penelitian ini SVM memberikan model klasifikasi yang lebih baik daripada classifier yang lain (KNN dan Naïve Bayes).
Saran
Penelitian ini menghasilkan akurasi 79.7% . Nilai tersebut masih dapat ditingkatkan dengan mengevaluasi hal-hal berikut:
1. Model klasifikasi yang lebih baik dapat diperoleh dengan mengoptimalkan praproses pada citra.
2. Feature yang digunakan dapat dipilih dari feature global pada citra sidik jari dengan menggunakan gabor filter (Munir & Javed 2004).
3. Untuk mendapatkan model yang robust pada setiap kelas, jumlah data training setiap kelas harus sama.
4. Optimasi parameter SVM dengan mengevaluasi fungsi algoritme genetika atau particle swam optimization.
DAFTAR PUSTAKA
Cristianini N, Taylor JS. 2000. An Introduction to Support Vector Machines and Other Kernel Based Learning Methods. Cambridge University Press.
Dass SC, Jain AK. 2004. Fingerprint Classification Using Orientation Field Flow Curves. Michigan State University: Proc. Indian Conference on Computer Vision, Graphics and Image Processing; Kolkata 16-18 Desember 2004. Kolkata: Allied Publishers. hlm 650-655.
Gonzales RC, RE Woods. 2002. Digital Image Processing. Ed. ke-2. New Jersey: Prentice Hall.
Guvenir HA, Demiroz G, Ilter N. 1998. Learning Differential Diagnosis of Erythemato-squamous Diseases Using Voting Feature Intervals. [tesis]. Ankara: Departemen of Computer Engeneering and Information Science, Bilkent University. Jain AK, Pankanti, S 2000. Fingerprint
Classification and Matching. Di dalam: Bovik AC, editor. Handbook of Image and Video Processing. Austin: Academic Press.
10 sebagai Whorl, 0 sebagai Arch, dan 1 yang
diidentifikasi sebagai Tented arch.
Dari confusion matrix pada Tabel 6 kita mendapatkan informasi sebaran hasil klasifikasi untuk setiap kelas. Tabel 7 menunjukkan jumlah instance dan akurasi untuk setiap kelas.
Tabel 7 Jumlah instance dan akurasi setiap kelas
Kelas Jumlah instance Akurasi (%)
L 804 85.7
R 735 83.7
W 1023 82.5
A 49 0.0
T 84 1.2
Tabel 7 menunjukkan bahwa akurasi untuk kelas Arch dan Tented Arch lebih kecil dibanding dengan tiga kelas lainnya. Hal ini berbanding lurus dengan jumlah instance kelas tersebut yang jumlahnya relatif sedikit dibanding kelas yang lain. Sehingga dapat disimpulkan bahwa jumlah data training berpengaruh terhadap tingkat akurasi.
KESIMPULAN DAN SARAN Kesimpulan
Feature yang digunakan berasal dari feature lokal sidik jari, yaitu feature berbasis minutiae. Pada penelitian ini, feature yang dapat memberikan representasi sidik jari paling baik adalah dengan menggunakan jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region. Jumlah jenis BIF/RIG akan memberikan model sebaran minutiae, sedangkan theta akan memberikan model arah pergerakan minutiae.
Dari literatur yang dipelajari, pada banyak kasus SVM mampu memberikan model klasifikasi yang lebih baik dibandingkan dengan classifier yang lain (Nugroho et al. 2005). Berhubungan dengan hal ini, SVM digunakan untuk inisialisasi classifier pada proses pemilihan feature. Setelah dilakukan perbandingan dengan Naïve Bayes dan KNN, SVM dapat mengklasifikasikan lebih baik di antara yang lain. Beberapa parameter dipilih dan ditentukan untuk mendapatkan model yang lebih baik. Ada dua parameter yang harus ditentukan, yaitu nilai C dan kernel. Dengan menggunakan metode coba-coba, model terbaik diperoleh dengan menggunakan nilai C = 10 dan kernel RBF, dengan gamma = 0.1.
Klasifikasi citra sidik jari menggunakan SVM dengan feature berbasis minutiae, memberikan akurasi 79.7%. Dalam penelitian ini SVM memberikan model klasifikasi yang lebih baik daripada classifier yang lain (KNN dan Naïve Bayes).
Saran
Penelitian ini menghasilkan akurasi 79.7% . Nilai tersebut masih dapat ditingkatkan dengan mengevaluasi hal-hal berikut:
1. Model klasifikasi yang lebih baik dapat diperoleh dengan mengoptimalkan praproses pada citra.
2. Feature yang digunakan dapat dipilih dari feature global pada citra sidik jari dengan menggunakan gabor filter (Munir & Javed 2004).
3. Untuk mendapatkan model yang robust pada setiap kelas, jumlah data training setiap kelas harus sama.
4. Optimasi parameter SVM dengan mengevaluasi fungsi algoritme genetika atau particle swam optimization.
DAFTAR PUSTAKA
Cristianini N, Taylor JS. 2000. An Introduction to Support Vector Machines and Other Kernel Based Learning Methods. Cambridge University Press.
Dass SC, Jain AK. 2004. Fingerprint Classification Using Orientation Field Flow Curves. Michigan State University: Proc. Indian Conference on Computer Vision, Graphics and Image Processing; Kolkata 16-18 Desember 2004. Kolkata: Allied Publishers. hlm 650-655.
Gonzales RC, RE Woods. 2002. Digital Image Processing. Ed. ke-2. New Jersey: Prentice Hall.
Guvenir HA, Demiroz G, Ilter N. 1998. Learning Differential Diagnosis of Erythemato-squamous Diseases Using Voting Feature Intervals. [tesis]. Ankara: Departemen of Computer Engeneering and Information Science, Bilkent University. Jain AK, Pankanti, S 2000. Fingerprint
Classification and Matching. Di dalam: Bovik AC, editor. Handbook of Image and Video Processing. Austin: Academic Press.
i
KLASIFIKASI SIDIK JARI MENGGUNAKAN
SUPPORT VECTOR
MACHINE
DENGAN
FEATURE
BERBASIS
MINUTIAE
MENGGUNAKAN METODE
REGION
WINDU PURNOMO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
10 sebagai Whorl, 0 sebagai Arch, dan 1 yang
diidentifikasi sebagai Tented arch.
Dari confusion matrix pada Tabel 6 kita mendapatkan informasi sebaran hasil klasifikasi untuk setiap kelas. Tabel 7 menunjukkan jumlah instance dan akurasi untuk setiap kelas.
Tabel 7 Jumlah instance dan akurasi setiap kelas
Kelas Jumlah instance Akurasi (%)
L 804 85.7
R 735 83.7
W 1023 82.5
A 49 0.0
T 84 1.2
Tabel 7 menunjukkan bahwa akurasi untuk kelas Arch dan Tented Arch lebih kecil dibanding dengan tiga kelas lainnya. Hal ini berbanding lurus dengan jumlah instance kelas tersebut yang jumlahnya relatif sedikit dibanding kelas yang lain. Sehingga dapat disimpulkan bahwa jumlah data training berpengaruh terhadap tingkat akurasi.
KESIMPULAN DAN SARAN Kesimpulan
Feature yang digunakan berasal dari feature lokal sidik jari, yaitu feature berbasis minutiae. Pada penelitian ini, feature yang dapat memberikan representasi sidik jari paling baik adalah dengan menggunakan jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region. Jumlah jenis BIF/RIG akan memberikan model sebaran minutiae, sedangkan theta akan memberikan model arah pergerakan minutiae.
Dari literatur yang dipelajari, pada banyak kasus SVM mampu memberikan model klasifikasi yang lebih baik dibandingkan dengan classifier yang lain (Nugroho et al. 2005). Berhubungan dengan hal ini, SVM digunakan untuk inisialisasi classifier pada proses pemilihan feature. Setelah dilakukan perbandingan dengan Naïve Bayes dan KNN, SVM dapat mengklasifikasikan lebih baik di antara yang lain. Beberapa parameter dipilih dan ditentukan untuk mendapatkan model yang lebih baik. Ada dua parameter yang harus ditentukan, yaitu nilai C dan kernel. Dengan menggunakan metode coba-coba, model terbaik diperoleh dengan menggunakan nilai C = 10 dan kernel RBF, dengan gamma = 0.1.
Klasifikasi citra sidik jari menggunakan SVM dengan feature berbasis minutiae, memberikan akurasi 79.7%. Dalam penelitian ini SVM memberikan model klasifikasi yang lebih baik daripada classifier yang lain (KNN dan Naïve Bayes).
Saran
Penelitian ini menghasilkan akurasi 79.7% . Nilai tersebut masih dapat ditingkatkan dengan mengevaluasi hal-hal berikut:
1. Model klasifikasi yang lebih baik dapat diperoleh dengan mengoptimalkan praproses pada citra.
2. Feature yang digunakan dapat dipilih dari feature global pada citra sidik jari dengan menggunakan gabor filter (Munir & Javed 2004).
3. Untuk mendapatkan model yang robust pada setiap kelas, jumlah data training setiap kelas harus sama.
4. Optimasi parameter SVM dengan mengevaluasi fungsi algoritme genetika atau particle swam optimization.
DAFTAR PUSTAKA
Cristianini N, Taylor JS. 2000. An Introduction to Support Vector Machines and Other Kernel Based Learning Methods. Cambridge University Press.
Dass SC, Jain AK. 2004. Fingerprint Classification Using Orientation Field Flow Curves. Michigan State University: Proc. Indian Conference on Computer Vision, Graphics and Image Processing; Kolkata 16-18 Desember 2004. Kolkata: Allied Publishers. hlm 650-655.
Gonzales RC, RE Woods. 2002. Digital Image Processing. Ed. ke-2. New Jersey: Prentice Hall.
Guvenir HA, Demiroz G, Ilter N. 1998. Learning Differential Diagnosis of Erythemato-squamous Diseases Using Voting Feature Intervals. [tesis]. Ankara: Departemen of Computer Engeneering and Information Science, Bilkent University. Jain AK, Pankanti, S 2000. Fingerprint
Classification and Matching. Di dalam: Bovik AC, editor. Handbook of Image and Video Processing. Austin: Academic Press.
11 Lu C, Wang H, Liu Y. 2009. Fingerprint
Classification Based on Support Vector Machine. International Joint Conference on Computational Science and Optimization; Hainan, 24-26 April 2009. Hainan: IEEE Computer Society. Vol. 1:859-862.
Maltoni D, Maio D. 2009. Handbook of Fingerprint Recognition. New York: Springer.
Munir MU, Javed MY. 2004. Fingerprint Matching using Gabor Filters. National Conference on Emerging Technologies; Karachi, 18-19 Desember 2004. Karachi: IEEE Computer Society. hlm 147-151. NIST. 2010. NIST Biometric Open Source
Server. http://www.nist.gov/itl/iad/ig/ nigos.cfm. [5 Maret 2010].
Nugroho AS, Witarto AB, Handoko D. 2005. Analisa Informasi Dimensi Tinggi pada Bioinformatika Memakai Support Vector Machine. Badan Pengkajian dan Penerapan Teknologi: Proc. of National Conference on Information and Communication Technology (ICT) for Indonesia / e-Indonesia Initiatives-II; Bandung, 19-20 April 2005. Bandung: ITB. hlm. 427-435. Osuna E, Freund R, Girosi F. 1997. An
Improved Training Algorithm for Support Vector Machines. Proc. of the 1997 IEEE Workshop Neural Networks for Signal
Processing VII ; Amelia Island, 24-26
September 1997. Amelia Island: IEEE Computer Society. hlm 276-285.
i
KLASIFIKASI SIDIK JARI MENGGUNAKAN
SUPPORT VECTOR
MACHINE
DENGAN
FEATURE
BERBASIS
MINUTIAE
MENGGUNAKAN METODE
REGION
WINDU PURNOMO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iii ABSTRACT
WINDU PURNOMO. Fingerprint Classification Using Support Vector Machine with Minutiae-Based Features and Region Method. Under the direction of AHMAD RIDHA and DWI HANDOKO.
Manual fingerprint classification proceeds by carefully inspecting the geometric characteristics of major ridge curves in a fingerprint image. This research proposed an automatic approach of identifying the geometric characteristics of ridges based on minutiae position and angle. Position and angle of minutiae are analyzed using region method. Region was used to discretize the number of minutiae. Positions of minutiae in a region give information about its relation to another region. Angles of minutiae indicate the ridge flow direction. Support vector machine, a binary classifier, is used to classify the fingerprint based on those characteristics. In this research, the classes are left loop, right loop, whorl, arch and tented arch. This research used 2695 fingerprint images from NIST. Classification performance is measured using 3-fold cross validation method. This research achieved 79.7 % accuracy. As we only used local features in this research, further research needs to be conducted especially to investigate global features.
ii
KLASIFIKASI SIDIK JARI MENGGUNAKAN
SUPPORT VECTOR
MACHINE
DENGAN
FEATURE
BERBASIS
MINUTIAE
MENGGUNAKAN METODE
REGION
WINDU PURNOMO
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar sarjana komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DANILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
i Judul : Klasifikasi Sidik Jari Menggunakan Support Vector Machine dengan Feature Berbasis
Minutiae Menggunakan Metode Region
Nama : Windu Purnomo NIM : G64061132
Menyetujui: Pembimbing I,
Ahmad Ridha, S.Kom, MS NIP 19800507 200501 1 001
Pembimbing II,
Dr. Dwi Handoko
NIP 19700425 198812 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer, Institut Pertanian Bogor
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
ii PRAKATA
Puji syukur kehadirat Allah subhanahu wa ta’ala yang telah memberi kekuatan dan rahmat-Nya sehingga penulisan skripsi berjudul “Klasifikasi Sidik Jari Menggunakan Support Vector Machine dengan Feature Berbasis Minutiae Menggunakan Metode Region” dapat diselesaikan dengan baik. Penulisan skripsi ini dilakukan sebagai salah satu syarat untuk memperoleh gelar sarjana di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan, Institut Pertanian Bogor.
Penelitian ini merupakan salah satu rangkaian penelitian yang dilakukan oleh Badan Pengkajian dan Penerapan Teknologi (BPPT) Jakarta. Penelitian ini diharapkan mampu memberikan solusi dalam peningkatan kecepatan dalam proses pengenalan citra sidik jari.
Pada kesempatan ini penulis ingin menyampaikan ucapan terima kasih kepada :
1. Ahmad Ridha S.Kom, MS selaku pembimbing I, yang telah mencurahkan waktu dan tenaga untuk membimbing selama melaksanakan skripsi.
2. Dr. Dwi Handoko selaku pembimbing II, yang telah memberikan kesempatan untuk bergabung dalam penelitian di BPPT dan memberikan bimbingan dalam penyelesaian skripsi.
3. Dr. Anto Satriyo Nugroho selaku supervisor dan dosen selama penelitian di BPPT, yang telah mengajarkan penulis untuk menjadi seorang engineer.
4. Mamah, Mimih, Teteh dan Ade Ito untuk semua cinta, motivasi, dan kasih sayang yang tulus diberikan.
5. Siti Hapshoh istriku, atas cinta dan kasih sayang yang diberikan serta bantuan selama penelitian ini berlangsung.
6. Muhammad Irawan, Sandy Cahya Gumilar, M. Awet Samana, Rina Trisminingsih, dan Kartina. 7. Teman-teman Ilkom 43.
8. Adik-adik Ilkom 44 dan 45.
9. Teman-teman di lantai 4 BPPT, Agas, Mas Agung, Mbak Ninon, dan Mbak Yuni. 10.Teman-teman di RDS BPPT Mas Yusuf, Mas Deni, Mas Nope.
Penulis berharap semoga karya ilmiah ini bermanfaat bagi penulis dan semua pihak yang membutuhkan. Semoga karya ini dapat menjadi amal saleh bagi penulis.
Bogor, Januari 2011
iii RIWAYAT HIDUP
iv DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 2
Representasi Citra Digital... 2
Representasi Sidik Jari ... 2
Klasifikasi ... 2
Pattern Recognition ... 2
Kelas Target Sidik Jari ... 3
Teknik Klasifikasi (Classifier) ... 3
Support Vector Machine (SVM)... 3
Image Processing ... 5
METODE PENELITIAN ... 5
Studi Pustaka ... 5
Perumusan Masalah ... 5
Pembentukan Data ... 5
Praproses ... 5
Ekstraksi Feature ... 6
Klasifikasi ... 7
HASIL DAN PEMBAHASAN... 7
Pemilihan Feature ... 7
Program yang Digunakan ... 8
Pemilihan Classifier dan Konfigurasi Parameter... 8
Analisis ... 9
KESIMPULAN DAN SARAN... 10
Kesimpulan ... 10
Saran ... 10
v
DAFTAR TABEL
Halaman
1 Jumlah data setiap fold ... 6
2 Penelitian jumlah region dalam pemilihan feature ... 6
3 Hasil eksperimen pemilihan feature ... 8
4 Hasil klasifikasi dari beberapa classifier ... 9
5 Hasil eksperimen pemilihan parameter pada SVM ... 9
6 Confusion matrix dari klasifikasi citra sidik jari dengan menggunakan feature jumlah jenis BIF/RIG + jumlah jenis theta dan classifier SVM (gamma = 0.1) dan C=10 ... 9
7 Jumlah instance dan akurasi setiap kelas ... 10
DAFTAR GAMBAR
Halaman 1 Ridge (bukit) dan valley (lembah) pada citra sidik jari. ... 22 Kelas target sidik jari. ... 3
3 SVM berusaha menemukan hyperplane terbaik yang memisahkan kedua class -1 dan +1. ... 3
4 Alur penelitian. ... 5
5 Contoh data citra sidik jari. ... 5
6 Ridge ending dan bifurcation. ... 6
7 Penentuan theta pada ridge ending dan bifurcation. ... 6
8 Citra sidik jari yang sudah dibagi ke dalam region berukuran 5x5. ... 6
9 Sepuluh jenis bifurcation dan ridge ending. ... 6
10 Contoh pengambilan feature jumlah jenis BIF/RIG setiap region dan jumlah jenis theta setiap region pada region 21. ... 7
1 PENDAHULUAN
Latar Belakang
Setiap manusia memiliki sesuatu yang unik/khas dan hanya dimiliki oleh dirinya sendiri. Hal ini menimbulkan gagasan untuk menjadikan keunikan tersebut sebagai identitas diri. Gagasan tersebut kemudian didukung oleh teknologi yang secara otomatis dapat mengidentifikasi atau mengenali seseorang, yang disebut biometrik. Teknik identifikasi biometrik didasarkan pada karakteristik alami manusia, yaitu karakteristik fisiologis atau karakteristik perilaku seperti wajah, sidik jari, suara, telapak tangan, iris, retina mata, DNA, dan tanda tangan.
Identifikasi biometrik memiliki keunggulan dibanding dengan metode konvensional. Pada teknik konvensional, identifikasi dilakukan dengan menggunakan password atau kartu, namun ini tidak cukup handal, karena sistem keamanan dapat ditembus ketika password dan kartu tersebut digunakan oleh pengguna yang tidak berwenang. Oleh karena itu, teknik identifikasi biometrik dalam hal ini sidik jari lebih sering digunakan dan telah terbukti unik, akurat, aman, mudah, dan nyaman untuk dipakai sebagai identifikasi jika dibandingkan dengan metode konvensional.
Proses identifikasi dilakukan dengan cara membandingkan antara citra sidik jari masukan dengan citra sidik jari yang terdapat dalam database. Pemanfaatan citra sidik jari untuk identifikasi dalam cakupan yang luas seperti kartu identitas nasional akan menghasilkan database yang berukuran sangat besar. Dalam kasus seperti ini, proses identifikasi akan berlangsung lama, karena banyaknya proses pembandingan antara citra input dengan citra dalam database. Peningkatan kinerja dapat dilakukan dengan cara mengurangi jumlah perbandingan antara citra sidik jari masukan dengan citra sidik jari dalam database. Salah satu tekniknya adalah citra sidik jari diklasifikasikan ke kelas-kelas tertentu. Kemudian, sidik jari masukan akan dianalisis menggunakan model klasifikasi yang sudah dibuat dan hanya dicocokkan dengan sidik jari database pada kelas yang sesuai dengannya.
Penelitian ini menggunakan data yang telah diklasifikasikan oleh National Institute of Standards and Technology (NIST) dengan hasil akurasi 100%. Akan tetapi, sistem yang digunakan oleh NIST bersifat tertutup, sehingga penelitian ini bertujuan melakukan
eksplorasi klasifikasi citra sidik jari dengan menggunakan support vector machine (SVM).
Jain dan Pankanti (2000) melakukan penelitian tentang klasifikasi citra sidik jari menggunakan metode rule-based. Feature yang digunakan adalah singular point, yaitu titik delta dan titik core.
Penelitian yang serupa dilakukan oleh Dass dan Jain (2004) dengan menggunakan metode dan feature yang berbeda. Mereka melakukan klasifikasi dengan menggunakan metode hybrid, yang menggabungkan antara tiga metode dasar, yaitu metode struktur, sintaksis, dan matematis. Feature yang digunakan adalah Orientation Field Flow Curves. Lu et al. (2009) menggunakan data yang sama dan klasifikasi feature Gabor, dengan SVM.
Beberapa penelitian yang telah dilakukan, feature yang sering digunakan adalah orientation image, singularities, ridge flow dan gabor filter. Metode klasifikasinya dapat digolongkan menjadi enam classifier sebagai berikut: rule-based, syntactic, structural, statistical, neural network, dan multiple classifier. Dalam penelitian ini dibuat sebuah model klasifikasi menggunakan metode klasifikasi SVM, dengan feature singular point. Pemilihan metode SVM berdasarkan kelebihan yang dimilikinya yaitu robustness, theoritical analysis, dan feasibility (Nugroho et al. 2005).
Tujuan Penelitian
Tujuan dari penelitian ini adalah melakukan eksplorasi untuk:
1. Pemilihan feature sidik jari
2. Pembuatan model klasifikasi dari citra sidik jari dengan menggunakan SVM
3. Penentuan parameter dari SVM
4. Analisis kinerja SVM dalam melakukan proses klasifikasi
Ruang Lingkup
Batasan masalah dalam penelitian ini adalah:
1. Citra sidik jari yang akan digunakan adalah citra sidik jari yang terdapat dalam database NIST, yang terdiri atas 2695 citra 2. Citra sidik jari dalam format wsq
Manfaat Penelitian
2 pencocokan sidik jari juga akan meningkat
sehingga memungkinkan pemanfaatan sidik jari dalam cakupan yag luas.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra digital merupakan fungsi identitas cahaya f(x,y), dengan x dan y merupakan koordinat spasial. Harga fungsi tersebut pada setiap titik (x,y) merupakan tingkat kecemerlangan citra pada titik tersebut. Citra digital adalah citra f(x,y) yang telah dilakukan diskretisasi koordinat spasial (sampling) dan diskretisasi tingkat kecemerlangannya/keabuan (kuantisasi). Citra digital merupakan suatu matriks yang indeks baris dan kolomnya menyatakan suatu titik pada citra tersebut. Elemen matriks (yang disebut sebagai elemen gambar/piksel) menyatakan tingkat keabuan pada titik tersebut.
Fungsi f(x,y) direpresentasikan dalam suatu fungsi koordinat berukuran . Variabel M adalah baris dan variabel N adalah kolom sebagaimana ditunjukkan pada matriks berikut.
[
]
Citra dengan skala keabuan berformat 8-bit memiliki 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling gelap (hitam) dan 255 menunjukkan nilai paling cerah/putih (Gonzales & Woods 2002).
Representasi Sidik Jari
Sebuah sidik jari dihasilkan dari tampilan eksterior epidermis. Struktur dari sidik jari adalah pola dari ridge (bukit) dan valley (lembah). Citra sidik jari memiliki ridge berwarna gelap dan valley berwarna terang.
Detail dari ridge umumnya dijelaskan dalam urutan berhierarki yang terdiri dari tiga level (Gambar 1):
1. Level 1, pola aliran ridge secara global 2. Level 2, titik-titik minutiae
3. Level 3, pori-pori, bentuk lokal dari garis-garis ridge
Klasifikasi
Klasifikasi adalah fungsi pembelajaran f yang memetakan setiap atribut himpunan x ke salah satu label kelas yang sudah ditetapkan y
(Tan et al. 2006). Fungsi pembelajaran f juga sering disebut sebagai model klasifikasi (classification model). Model klasifikasi digunakan dalam descriptive modeling dan predictive modeling.
Descriptive Modelling: Model klasifikasi dapat menjelaskan perbedaan objek-objek yang terdapat dalam kelas berbeda. Contohnya adalah klasifikasi dalam bidang biologi. Hasil klasifikasi dapat menjelaskan feature-feature yang mengakibatkan sebuah binatang digolongkan ke dalam kelas mamalia, reptil, burung, ikan dan amfibi.
Gambar 1 Ridge (bukit) dan valley (lembah) pada citra sidik jari.
Predictive Modelling: Model klasifikasi juga dapat digunakan untuk memprediksi objek yang belum diketahui kelasnya. Model klasifikasi seperti kotak hitam yang akan memberikan label kelas kepada objek berdasarkan atribut-atribut yang dimilikinya.
Klasifikasi terdiri dari dua tahap, yaitu pelatihan dan prediksi. Pada tahap pelatihan, dibentuk sebuah model domain permasalahan dari setiap instance yang ada. Penentuan model tersebut berdasarkan analisis pada sekumpulan data pelatihan, yaitu data yang label kelasnya sudah diketahui. Pada tahap klasifikasi, dilakukan prediksi kelas dari instance baru dengan menggunakan model yang telah dibuat pada tahap pelatihan (Guvenir et al. 1998). Pattern Recognition
3 recognition adalah Support Vector Machine
(SVM) (Nugroho et al. 2005). Kelas Target Sidik Jari
Aturan klasifikasi sidik jari pertama kali diperkenalkan oleh Purkinje pada tahun 1823 yang mengklasifikasikan sidik jari ke dalam sembilan kategori (transverse curve, central longitudinal stria, oblique stripe, oblique loop, almond whorl, spiral whorl, ellipse, circle, dan double whorl) berdasarkan konfigurasi ridge. Penelitian berikutnya dilakukan oleh Francis Galton pada tahun 1892 yang membagi sidik jari ke dalam tiga kelas utama (arch, loop dan whorl). Selanjutnya setiap kelas utama tersebut dibagi menjadi subkelas. Sepuluh tahun kemudian Edward Henry memperbaiki sistem klasifikasi Francis Galton dengan menambahkan jumlah kelas. Klasifikasi Galton-Henry ini membagi sidik jari ke dalam lima kelas yaitu: arch, tented arch, left loop, right loop, dan whorl (Gambar 2). Klasifikasi Galton-Henry inilah yang banyak digunakan di beberapa negara (Maltoni & Maio 2009).
Gambar 2 Kelas target sidik jari. Teknik Klasifikasi (Classifier)
Teknik klasifikasi atau classifier adalah pendekatan sistematik untuk membangun model klasifikasi dari input data set (Tan et al. 2006). Beberapa Classifier yang sering digunakan dalam proses klasifikasi sidik jari adalah sebagai berikut (Maltoni & Maio 2009): 1. Rule Based Approach
2. Syntactic Approaches 3. Structural Approaches 4. Statistical
5. Neural Network 6. Multiple Classifier
7. Support Vector Machine (SVM) Support Vector Machine (SVM)
Support Vector Machine (SVM) bertujuan untuk menemukan fungsi pemisah (classifier/ hyperplane) terbaik untuk memisahkan dua buah class pada input space. Hyperplane terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Hyperplane dalam ruang berdimensi d adalah affine
subspace berdimensi d-1 yang membagi ruang vector tersebut ke dalam dua bagian yang masing-masing berkorespondensi pada class yang berbeda (Cristianini dan Taylor, 2000). Margin adalah jarak antara hyperplane dengan pattern terdekat dari masing-masing class. Pattern yang paling dekat disebut sebagai support vector.
Dua kondisi yang dapat diselesaikan oleh SVM yaitu kondisi yang dapat dipisahkan secara linear (linearly separable data) dan kondisi yang tidak dapat dipisahkan secara linear.
Linearly Separable Data
Gambar 3 SVM berusaha menemukan hyperplane terbaik yang memisahkan kedua class -1 dan +1.
Linearly separable data merupakan data yang dapat dipisahkan secara linear. Misalkan {x1,…,xn} adalah dataset dan
adalah label kelas dari data xi. Pada Gambar 3 garis tebal menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class. Titik yang berada dalam lingkaran adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran (training) pada SVM. Penentuan bidang pembatas terbaik dapat dirumuskan seperti persamaan 1 (Osuna et al. 1997):
| | (1) w adalah vektor tegak lurus terhadap hyperplane dan b adalah jarak antar tidik pusat dengan hyperplane. Penyelesaian persamaan 1 dapat dipermudah dengan mengubah persamaan ke dalam bentuk dual problem menggunakan teknik pengali Lagrange menjadi seperti persamaan 2 (Osuna et al. 1997).
‖ ‖ ∑ [ ]
4 α = adalah vektor non-negatif dari
koesifien Lagrange. Dengan meminimumkan L terhadap w dan b, maka diperoleh persamaan 3 dan 4. persamaan 2 sehingga diperoleh persamaan 5. yang nantinya digunakan untuk menemukan w. Terdapat αi untuk setiap data pelatihan. Data pelatihan yang memiliki nilai αi ≥ 0 adalah support vector sedangkan sisanya memiliki nilai αi = 0. Dengan demikian, fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector.
Formula pencarian bidang terbaik ini adalah permasalahan quadratic programming sehingga nilai maksimum global dari αi selalu dapat ditemukan. Setelah solusi permasalahan quadratic programming ditemukan (αi), maka kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan pada persamaan 6: diklasifikasikan (Osuna et al. 1997).
Soft Margin Hyperplane
Formulasi SVM harus dimodifikasi untuk mengklasifikasikan data yang tidak dapat dipisahkan secara sempurna karena tidak akan ada solusi yang ditemukan. Pencarian bidang
pemisah terbaik dengan penambahan variabel sering juga disebut soft margin hyperplane. Dengan demikian, formula pencarian bidang pemisah terbaik pada persamaan 1 berubah menjadi seperti persamaan 7.
| | (∑ penalti akibat kesalahan dalam klasifikasi data dan nilainya ditentukan oleh pengguna. Pada kasus soft margin hyperplane tidak hanya meminimalkan w tetapi meminimalkan juga parameter penalti C.
Kernel Trick
Pada kenyataannya tidak semua data bersifat linearly separable, sehingga sulit dicari bidang pemisah secara linear. Permasalahan ini dapat diselesaikan dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) yang lebih tinggi sehingga dapat dipisahkan secara linear pada feature space yang baru. Pemisahan feature space dilakukan dengan cara memetakan data menggunakan fungsi pemetaan (transformasi) dalam feature space sehingga terdapat bidang pemisah yang dapat memisahkan data sesuai dengan kelasnya. Dengan menggunakan fungsi tranformasi , fungsi hasil pembelajaran yang dihasilkan seperti pada persamaan 5 (Osuna et al. 1997).
(∑
)