Nama
: Heri Yulianto Sugandi
TTL
: Subang, 16 Juli 1992
Alamat
: Kp. Mayasuta RT. 12 RW. 06
Ds. Rancamulya
Kec. Patokbeusi
Subang, Jawa Barat
No. Handphone
: 087718641777
:
RIWAYAT PEDIDIKAN
1998-2004
: SDN Pundong Subang
2004-2007
: SMPN 2 Pabuaran Subang
2007-2010
: SMAN 1 Patokbeusi Subang
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
HERI YULIANTO SUGANDI
10110493
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... xii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah... 3
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 4
1.5.2 Metode Pembangunan Perangkat Lunak ... 4
1.6 Sistematika Penulisan... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Kecerdasan Buatan ... 7
2.2 Pola ... 7
2.3 Pengenalan Pola ... 8
2.4 Pengolahan Citra ... 11
2.5 Operasi-operasi Pengolahan Citra ... 12
2.6 Tekstur... 14
2.6.1 Analisis Tekstur ... 15
2.7 Metode Run Length... 15
2.8 Klasifikasi Naïve Bayes ... 18
2.9 Pengujian Black Box ... 20
2.10 Pengujian Confusion Matrix ... 20
vi
2.11.1 Konsep Dasar Berorientasi Objek ... 23
2.11.2 UML (Unified Modelling Language)... 24
2.11.3 Database ... 26
2.11.4 Bahasa Pemograman C# ... 28
BAB 3 ANALISIS DAN KEBUTUHAN ALGORITMA ... 31
3.1 Analisis Masalah ... 31
3.2 Analisis Proses ... 31
3.2.1 Analisis Masukan Citra Sidik Jari ... 33
3.2.2 Analisis Pengolahan Citra ... 33
3.2.3 Analisis Pelatihan Naïve Bayes ... 39
3.2.4 Analisis Pengujian Naïve Bayes ... 41
3.3 Analisis Data ... 42
3.3.1 Analisis Data Masukan ... 42
3.3.2 Analisis Data Keluaran ... 43
3.4 Analisis Metode / Algoritma ... 44
3.4.1 Analisis Tahapan Pengolahan Citra ... 44
3.4.2 Analisis pelatihan ... 54
3.4.3 Analisis Pengujian ... 56
3.4.4 Analisis data keluaran ... 59
3.5 Analisis Kebutuhan Basis Data ... 59
3.5.1 Entity Relationship Diagram(ERD) ... 59
3.6 Analisis Kebutuhan Perangkat Lunak ... 60
3.6.1 Analisis Kebutuhan Non Fungsional ... 61
3.6.2 Analisis Kebutuhan Fungsional ... 63
3.6.3 Perancangan Basis Data ... 73
3.6.4 Perancangan Simulasi ... 76
3.6 Jaringan Semantik ... 81
BAB 4 IMPLEMETASI DAN PENGUJIAN SISTEM ... 83
4.1 Implementasi ... 83
4.1.1 Implementasi Perangkat Keras ... 83
4.1.2 Implementasi Perangkat Lunak ... 83
4.1.3 Implementasi Basis Data ... 84
vii
4.1.5 Implementasi Antarmuka ... 86
4.2 Rencana Pengujian ... 88
4.2.1 Pengujian Fungsionalitas ... 89
4.2.2 Pengujian Algoritma ... 90
4.2.3 Rencana Pengujian Algoritma... 91
4.3 Kesimpulan Pengujian ... 92
BAB 5 KESIMPULAN DAN SARAN... 95
5.1 Kesimpulan ... 95
5.2 Saran ... 95
92
1.
Ahmad, U., 2005.
Pengolahan Citra Digital & Teknik Pemrogramanya.
Yogyakarta: Graha Ilmu.
2.
Achmad, S., 2010. MySql dari Pemula Hingga Mahir. Jakarta: Achmatim.
3.
Asbaugh, R., 1999. Ridgeology.
Journal of Forensic Identification
, Royal
Canadian Mounted Police, Canada.
4.
Eko, S., Nataliani Y., 2009. Klasifikasi Sidik Jari dengan Menggunakan
Metode Wavelet Symlet.
Jurnal Informatika Volume 5 No 2
, Universitas
Kristen Satya Wacana, Diponegoro.
5.
Galloway, M., “Texture analysis using gray level run length”, Computer
Graphics Image Process., vol. 4, pp.172-179, juni 1975.
6.
Hartanto, B., 2008.
Memahami Visual C#.Net Secara Mudah.
Pertama
penyunt. Yogyakarta: Andi.
7.
Mita, I., Santoso, I., Christyono, Y., 2007. Analisis Tekstur Menggunakan
Metode Run Length.
Tugas Akhir Teknik Elektro
, Universitas Diponegoro,
Semarang.
8.
Munir, R., 2002. Pengolahan Citra Digital. Bandung: Informatika.
9.
Nugroho, A., 2005. Pemodelan Berorientasi Objek, Bandung: Informatika.
10.
Pressman, S. R., 2010. Rekayasa Perangkat Lunak. Yogyakarta: Andi.
11.
Prasetyo, E., 2012. Pengenalan Pola Naive Bayes, Universitas
Pembangunan Nasional, Jawa Timur.
12.
Sri, K., 2009. Klasifikasi Status Gizi Menggunakan Naïve Bayesian
Clasification.
Tugas Akhir Teknik Informatika
, Universitas Islam Indonesia,
Yogyakarta.
13. Anik, A., 2013. Sistem Pedukung Keputusan Berbasis Decision Tree Dalam
Pemberian Beasiswa Studi Kasus:AMIK BSI YOGYAKARTA, Amik BSI
Jakarta, Jakarta Selatan.
14.
Sutopo, A. H & Masya, F
.,
2005
. Pemograman Berorientasi Objek dengan
PENERAPAN METODE RUN-LENGTH DAN ALGORITMA SIMPLE
NAIVE BAYES UNTUK IDENTIFIKASI SIDIK JARI
Heri Yulianto Sugandi
11
Teknik Informatika – Univesitas Komputer Indonesia
Jl. Dipatiukur 112 - 114 Bandung
E-mail : [email protected]
1ABSTRAK
Salah satu cara untuk mengenali citra adalah dengan membedakan tekstur citra tersebut. Citra dikatakan memiliki tekstur apabila pola citra terjadi secara berulang-ulang memenuhi semua bidang citra. Citra yang berbeda memiliki ciri-ciri yang berbeda. Ciri-ciri inilah yang menjadi dasar dalam klasifikasi citra berdasarkan tekstur. Terdapat beberapa metode untuk memperoleh ciri-ciri tekstur dalam suatu citra, Salah satu metode untuk memperoleh ciri-ciri citra tekstur adalah matriks run-length. Ciri-ciri tekstur yang didapat dari metode matriks run-length diantaranya adalah SRE(short run emphasis), LRE(long run emphasis), GLU(grey level uniformity), RLU(run length uniformity) dan RPC(run percentage). Dari hasil ciri-ciri tersebut kemudian digunakan untuk klasifikasi dengan menggunakan Naïve Bayes yang menentukan hasil klasifikasi berdasarkan nilai probabilitas terbesar. Objek yang diuji adalah citra sidik jari.
Dari penelitian yang telah dilakukan, dapat ditarik kesimpulan sebagai berikut : naïve bayes dapat melakukan klasifikasi citra berdasarkan tekstur yang diekstraksi dengan metode matriks run-length. Dikarenakan data hasil ekstraksi ciri matriks run-length adalah berupa data continue, atau biasa disebut data nominal, sehingga saat proses klasifikasi data hasil ekstraksi ciri tersebut dapat langsung digunakan sebagai inputan dalam klasifikasi naïve bayes.
Berdasarkan hasil pengujian, kesimpulan yang didapatkan adalah Algoritma naïve bayes dapat mengklasifikasikan citra digital sidik jari berdasarkan hasil ekstraksi citra digital metode run-length dan menghasilkan tingkat keakurasian 99,8%. , dikarenakan data hasil ekstraksi ciri tekstur sidik jari dengan metode matriks run-length memiliki interval jarak yang berjauhan antar kelasnya. Sehingga klasifikasi naïve bayes dapat berjalan dengan baik saat melakukan klasifikasi.
Kata kunci : tekstur citra, ekstraksi ciri, run-length matriks, klasifikasi naïve bayes
1.
PENDAHULUAN
Sidik jari (fingerprint) adalah hasil reproduksi tapak jari baik yang sengaja diambil, dicapkan dengan tinta, maupun bekas yang ditinggalkan pada benda karena pernah tersentuh kulit telapak tangan atau kaki. Identifikasi sidik jari dikenal dengan ilmu daktiloskopi yang mempelajari sidik jari untuk keperluan pengenalan kembali identitas seseorang dengan cara mengamati garis yang terdapat pada guratan garis jari tangan dan telapak kaki (Ashbaugh R, 1991). Karena tekstur sidik jari pada setiap orang memiliki ciri khas yang berbeda antara satu orang dengan orang lain, perbedaan pola dari sidik jari tersebut digunakan sebagai alat identifikasi.
parameter dari metode run-length adalah short run emphasis (SRE), long run emphasis (LRE), grey level uniformity (GLU), run length uniformity (RLU), run percentage (RPC) (Mita I, 2007). Metode run-length dapat menghasilkan suatu ciri-ciri berupa keseragaman, kerapatan, kekasaran, keteraturan, kelinieran, frekuensi, fase, keterarahan, ketidakteraturan, kehalusan, dan lain-lain. Hasil dari ekstraksi ciri digunakan untuk pengklasifikasian. Oleh karena itu proses ektraksi ciri yang dihasilkan dari metode run-length akan menghasilkan data kontinu yang akan di proses pada tahap selanjutnya yaitu tahap klasifikasi citra dengan menggunakan metode naïve bayes. Pada penelitian yang dilakukan Sri Kusumadewi (2009), naïve bayes dapat digunakan untuk proses klasifikasi data kontinu dan menghasilkan total kinerja pengujian sebesar 93%. Naïve bayes adalah salah satu metode klasifikasi yang menggunakan konsep probabilitas. Metode naïve bayes merupakan algoritma klasifikasi yang sangat efektif dan efisien.
Dari permasalahan dan solusi yang telah dijelaskan, penelitian skripsi ini akan mengklasifikasikan sidik jari berdasarkan tekstur sidik jari dengan menerapkan metode run length untuk proses ekstraksi citra dan metode naïve bayes untuk klasifikasi citra, diharapkan metode naïve bayes dapat mengklasifikasikan sidik jari berdasarkan tekstur dan mengukur tingkat keakuratan klasifikasinya.
1.1 Rumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan, maka penelitian ini merumuskan masalah yang akan dibahas yaitu bagaimana menerapkan metode run length untuk ekstraksi citra dan algoritma naïve bayes untuk klasifikasi citra.
1.2 Maksud dan Tujuan
Maksud dari penelitian skripsi ini adalah untuk mengimplementasikan metode naïve bayes untuk mengklasifikasikan citra sidik jari berdasarkan hasil ekstraksi citra digital.
Adapun tujuan yang akan dicapai pada penelitian skripsi ini adalah
1. Dapat mengklasifikasikan citra digital sidik jari berdasarkan tekstur sidik jari 2. Untuk mengetahui tingkat akurasinya.
2.
ISI PENELITIAN
2.1 Kecerdasan buatanKecerdasan buatan (Artificial inteligence) adalah salah satu cabang ilmu pengetahuan yang berhubungan dengan pemanfaatan mesin untuk memecahkan persoalan yang rumit dengan cara yang lebih manusiawi. Hal ini biasanya dilakukan dengan mengikuti/mencontoh karakteristik dan analogi
berpikir dari kecerdasan manusia, dan menerapkannya sebagai algoritma yang dikenal oleh komputer.
Kecerdasan buatan dapat digunakan untuk menganalisis pemandangan dalam citra dengan perhitungan simbol-simbol yang mewakili isi pemandangan tersebut setelah citra diolah untuk memperoleh ciri khas. Kecerdasan buatan bisa dilihat sebagai tiga kesatuan yang terpadu yaitu persepsi, pengertian dan aksi. Persepsi menerjemahkan sinyal dari dunia nyata dalam citra menjadi simbol-simbol yang lebih sederhana, pengertian memanipulasi simbol-simbol tadi untuk memudahkan penggalian suatu informasi tertentu, dan aksi menerjemahkan simbol-simbol yang telah dimanipulasi menjadi sinyal lain yang dapat merupakan hasil akhir atau hasil antara sesuai dengan keperluan (Ahmad U, 2005).
2.2 Tekstur
Secara umum tekstur mengacu pada repetisi elemen-elemen tekstur dasar yang sering disebut primitif atau texel (texture element). Suatu texel terdiri dari beberapa pixel dengan aturan posisi bersifat periodik, kuasiperiodik, atau acak (Ahmad U. , 2005).
Syarat-syarat terbentuknya tekstur setidaknya ada dua, yaitu :
1. Adanya pola-pola primitif yang terdiri dari satu atau lebih pixel. Bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus, garis lengkung, luasan dan lain-lain yang merupakan elemen dasar dari sebuah bentuk. 2. Pola-pola primitif tadi muncul
berulang-ulang dengan interval jarak dan arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik pengulangannya.
Gambar 1 Contoh tekstur dari VisTex Database
Suatu citra memberikan interpretasi tekstur yang berbeda apabila dilihat dengan jarak dan sudut yang berbeda. Manusia memandang tekstur berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur, tidak teratur, dan sebagainya. Hal ini merupakan deskripsi yang tidak tepat dan non-kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantitatif (matematis) untuk memudahkan analisis (Ahmad U. , 2005).
2.3 Analisis Tekstur
Analisis tekstur merupakan dasar dari berbagai macam aplikasi, aplikasi dari analisis tekstur antara lain: penginderaan jarak jauh, pencitraan medis, identifikasi kualitas suatu bahan (kayu, kulit, tekstil, dan lain-lain), dan juga berbagai macam aplikasi
lainnya. Pada analisis citra, pengukuran tekstur dikategorikan menjadi lima kategori utama yaitu: statistis, struktural, geometri, model dasar, dan pengolahan sinyal. Pendekatan statistis mempertimbangkan bahwa intensitas dibangkitkan oleh medan acak dua dimensi, metode ini berdasar pada frekuensi frekuensi ruang. Contoh metode statistis adalah fungsi autokorelasi, cooccurence Matrix, transformasi Fourier, frekuensi tepi, run length dan lainya. Teknik struktural berkaitan dengan penyusunan bagian bagian terkecil suatu citra. Contoh metode struktural adalah model fraktal. Metode geometri berdasar atas perangkat geometri yang ada pada elemen tekstur. Contoh metode model dasar adalah medan acak. Sedangkan metode pengolahan sinyal adalah metode yang berdasarkan analisis frekuensi seperti transformasi Gabor dan transformasi wavelet (Ahmad U. , 2005).
2.3.1 Metode Run-lenth
Grey level run length matrix yang biasa disingkat dengan GLRLM merupakan salah satu metode yang populer untuk mengekstrak tekstur sehingga diperoleh ciri statistik atau atribut yang terdapat dalam tekstur dengan mengestimasi piksel-piksel yang memiliki derajat keabuan yang sama. Ekstraksi tekstur dengan metode run-length dilakukan dengan membuat rangkaian pasangan nilai (i,j) pada setiap baris piksel. Perlu diketahui maksud dari run-length itu sendiri adalah jumlah piksel berurutan dalam arah tertentu yang memiliki derajat keabuan/nilai intensitas yang sama. Jika diketahui sebuah matriks run-length dengan elemen matriks q ( i, j | θ) dimana i adalah derajat keabuan pada masing-masing piksel, j adalah nilai run-length, dan
θ adalah orientasi arah pergeseran tertentu yang
dinyatakan dalam derajat. Orientasi dibentuk dengan empat arah pergeseran dengan interval 450, yaitu 00, 450, 900 , dan 1350.
Berdasarkan penelitian yang dilakukan oleh Galloway (1975), terdapat beberapa jenis ciri tekstural yang dapat diekstraksi dari matriks run-length. Berikut variabel-variabel yang terdapat di dari ekstraksi citra dengan menggunakan metode statistikal Grey Level Run Length Matrix :
i = nilai derajat keabuan j = piksel yang berurutan (run)
M = Jumlah derajat keabuan pada sebuah gambar N = Jumlah piksel berurutan pada sebuah gambar r(j) = Jumlah piksel berurutan berdasarkan banyak urutannya (run length)
g(i) = Jumlah piksel berurutan berdasarkan nilai derajat keabuannya
s = Jumlah total nilai run yang dihasilkan pada arah tertentu
p(i,j) = himpunan matrik i dan j n = jumlah baris * jumlah kolom.
Dimana varibel-variabel tersebut akan digunakan untuk mencari nilai dari atribut-atribut tekstur sebagai berikut:
1. Short Run Emphasis (SRE)
SRE mengukur distribusi short run. SRE sangat tergantung pada banyaknya short run dan diharapkan bernilai besar pada tekstur halus.
2. Long Run Emphasis (LRE)
LRE mengukur distribusi long run. LRE sangat bergantung pada banyaknya long run dan diharapkan bernilai besar pada tekstur kasar.
3. Grey Level Uniformity (GLU)
GLU mengukur persamaan nilai derajat keabuan seluruh citra dan diharapkan bernilai kecil jika nilai derajat keabuan serupa diseluruh citra.
4. Run Length Uniformity (RLU)
RLU mengukur persamaan panjangnya run diseluruh citra dan diharapkan bernilai kecil jika panjangnya run serupa diseluruh citra.
5. Run Percentage (RPC)
RPC mengukur kebersamaan dan distribusi run dari sebuah citra pada arah tertentu. RPC bernilai paling besar jika panjangnya run adalah 1 untuk semua derajat keabuan pada arah tertentu.
2.4 Klasifikasi
Klasifikasi merupakan suatu pekerjaan yang melakukan penilaian terhadap suatu obyek data untuk masuk dalam suatu kelas tertentu dari sejumlah kelas yang tersedia. (Prasetyo, 2012). Ada dua pekerjaan utama:
1. Pembangunan model sebagai prototype untuk disimpan sebagai memori
2. Menggunakan model tersebut untuk melakukan pengenalan/klasifikasi/prediksi pada suatu obyek data lain masuk pada kelas mana
2.4.1 Klasifikasi naïve bayes
Naïve bayes adalah Teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes (Prasetyo, 2012)
1. Asumsi independensi (ketidaktergantungan) yang kuat (naif).
2. Model yang digunakan adalah “model fitur
independen”
Independensi yang kuat pada fitur adalah bahwa sebuah fitur pada sebuah data tidak ada kaitannya dengan adanya atau tidak adanya fitur yang lain dalam data yang sama
Naïve bayes adalah suatu metode pengklasifikasian paling sederhana dengan menggunakan peluang yang ada, dimana diasumsikan bahwa setiap variable X bersifat bebas (independence). Karena asumsi variabel tidak saling terikat, maka didapatkan persamaan (7).
Data yang digunakan dapat bersifat kategorial (diskrit) maupun kontinyu. Namun, pada tugas akhir ini akan digunakan data kontinyu, karena hasil ekstraksi ciri citra merupakan data kontinyu berupa angka angka hasil pengukuran tingkat kontras, homogenitas, entropy, energy, dan dissimilarity pada ekstraksi ciri. Maka dari itu Untuk data kontinyu dapat diselesaikan dengan menggunakan langkah-langkah berikut.
Training :
Hitung rata-rata (mean) tiap fitur dalam dataset training dengan persamaan
� = ∑ ��
�
Dimana:
� = mean
= banyaknya data
∑ �� = jumlah nilai data
Kemudian hitung nilai varian dari diat dataset training tersebut seperti pada persamaan
� = �− ∑��= ��− µ
Dimana:
� = varians µ= mean
�� = nilai data
= banyaknya data
Testing :
1. Hitung probabilitas (Prior) tiap kelas yang ada dengan cara menghitung jumlah data tiap kelas dibagi jumlah total data secara keseluruhan. 2. Selanjutnya menghitung densitas
probabilitasnya menggunakan persamaan (10). Fungsi densitas mengekspresikan probabilitas relatif. Data dengan mean μ dan standar deviasi
σ, fungsi densitas probabilitasnya adalah :
��� � =√ ��2
−�−� 22�2
Dimana :
� = data masukan
π = 3,14
� = standar deviasi µ = mean
3. Setelah didapatkan nilai densitas probabilitasnya, selanjutnya menghitung posterior masing-masing kelas dengan menggunakan persamaan � � = � �� � �(� … … … � |��) �(� … … … � |��) � � � � = � � � ℎ�
4. Nilai posterior terbesar adalah kelas yang sesuai.
2.5 Metode pengujian keakurasian
Pada penelitian ini, rencana pengujian dilakukan dengan beberapa skenario, berikut adalah skenario yang telah dipersiapkan :
1. Menguji citra yang dijadikan data latih. 2. Menguji citra yang tidak termasuk data
latih.
3. Menguji pengaruh jumlah data latih terhadap akurasi dan waktu.
1. Menguji citra yang dijadikan data latih.
qi
P
X
iY
y
y
Y
X
Metode pengujian ini menggunakan data yang telah di training, dengan kata lain, data training dan data uji adalah data yang sama
2. Supplied set test
Metode pengujian ini menggunakan data yang berbeda, dengan kata lain, data training berbeda dengan data yang akan diujikan
3. Pengaruh jumlah data latih terhadap akurasi Pengujian skenario 3 dilakukan untuk menguji pengaruh jumlah data latih terhadap akurasi, pengujian ini dilakukan dengan mengubah perbandingan antara data latih dan data uji
a) Perbandingan data uji 3:5
Pada pengujian ini dilakukan dengan menggunakan perbandingan data latih dan data uji 3:5 untuk data pada setiap kelasnya yang berarti menggunakan 3 citra latih dan 5 citra uji
b) Perbandingan data uji 4:5
Pada pengujian ini dilakukan dengan menggunakan perbandingan data latih dan data uji 4:5 untuk data pada setiap kelasnya yang berarti menggunakan 4 citra latih dan 5 citra uji.
2.6 Analisis Proses
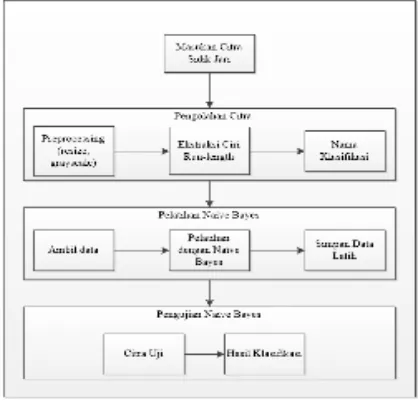
Analisis proses yang akan dilakukan pada penelitian ini adalah analisis dalam melakukan klasifikasi citra berdasarkan tekstur. Tahapan-tahapan proses kerja dalam melakukan klasifikasi mulai dari data masukan sampai data keluaran. Berikut adalah tahapan analisis proses yang akan dilakukan dan untuk alur analisis proses dapat dilihat pada gambar 2 :
[image:12.595.72.281.479.680.2]
Gambar 2 Diagram alur analisis proses
Berikut penjelasan dari tiap tahapannya adalah sebagai berikut :
1. Masukan citra sidik jari
Merupakan langkah pengambilan data citra pada media masukan ke dalam sistem. Citra
masukan berupa file gambar yang didalamnya mengandung objek sidik jari yang diambil menggunakan tinta stempel yang ditempelkan pada kertas lalu kemudian di scan.
2. Pengolahan citra
Pada tahap ini citra yang dimasukan akan diresize menjadi 32x32 piksel, di grayscale menjadi keabu-abuan untuk mendapatkan nilai matriks grayscale. Setelah didapat matriks grayscale kemudian dilakukan proses ekstraksi ciri run-length dan memberi nama klasifikasi setelah didapat nilai fitur rata-rata run-length. 3. Pelatihan naïve bayes
Tahap pelatihan pada naïve bayes yaitu mengambil data yang telah diberi nama klasifikasi dan memiliki nilai rata-rata fitur run-length untuk dihitung dan mencari nilai mean dan varian. Setelah didapat nilai mean dan varian data latih disimpan ke database.
4. Pengujian naïve bayes
Pada proses pengujian naïve bayes, masukan citra yang akan diujikan. Citra yang dimasukan akan diproses untuk mencari nilai densitas probabilitas dan mencari nilai posterior terbesar. Setelah didapat nilai posterior terbesar maka diketahui hasil klasifikasi dari citra uji.
2.6.1 Analisis Data masukan
Dalam penelitian ini, yang pertama akan dilakukan adalah analisis data masukan. Analisis data masukan dilakukan untuk mendapatkan sebuah nilai inputan yang nantinya dapat digunakan untuk proses klasifikasi dalam metode naïve bayes. Dalam penelitian ini, data masukan merupakan sebuah citra, yang akan dicari kandungan nilainya dengan menggunakan metode ekstraksi ciri Run-length matrix, nilai keluaran yang akan didapatkan adalah SRE, LRE, GLU, RLU, dan RPC. Nilai-nilai tersebut akan dijadikan sebagai data awal yang akan digunakan sebagai inputan dalam metode naïve bayes. Tahapan-tahapan yang akan dilakukan pada analisis data masukan adalah preprocessing yaitu dengan melakukan resize dan grayscale citra. Setelah melakukan preprocessing, maka dilakukan ekstraksi ciri dengan metode matriks run-lrngth untuk mendapatkan nilai fitur dari citra tersebut.
2.6.1.1 Preprocessing
Gambar 4. Alur preprocessing
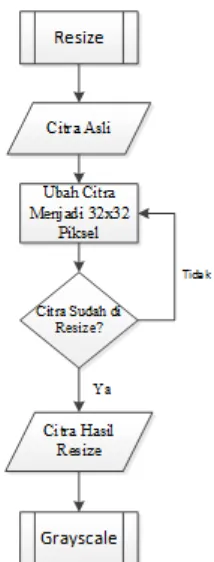
2.6.1.1.1 Resize
[image:13.595.129.236.183.462.2]Resize adalah tahap pertama dari preprocessing. Resize dilakukan untuk mempercepat dan memudahkan proses perhitungan. Berikut alur proses dari resizeing :
Gambar 3 alur proses resize
2.6.1.1.2 Grayscale
Grayscale merupakan proses untuk mengubah warna menjadi keabu-abuan. Dengan mengubah nilai RGB setiap piksel gambar menjadi satu nilai yang sama sehingga setiap piksel memiliki nilai yang sama untuk ketiga unsur warna serta didapatkan nilai matriks grayscale. Berikut alur dari proses grayscale :
Gambar 4 alur proses greyscale
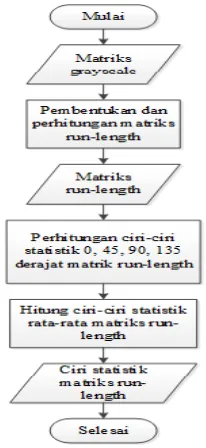
2.6.1.2 Ekstraksi Ciri
Ekstraksi ciri adalah proses untuk mendaptkan ciri utama yang terdapat pada citra, citra yang telah di grayscale akan menghasilkan matriks grayscale ynag telah di kuantisasi, matriks tersebutlah yang akan digunakan pada tahap ini. Tahap ini akan menghitung 5 nilai statistik dari run length yaitu SRE, LRE, GLU, RLU dan RPC dengan sudut simetri 0, 45, 90 dan 135 . Setelah didapatkan semua nilai dari sudut akan dirata-ratakan. Berikut alur proses dari ekstrak
si ciri :
[image:13.595.365.468.504.728.2]
2.6.1.3 Nama klasifikasi
[image:14.595.114.204.150.417.2]Nama klasifikasi digunakan untuk menentukan nama klasifikasi yang telah didapatkan nilai rata-rata statistik dari ekstraksi ciri run-length. Berikut alur proses dari nama klasifikasi:
Gambar 6 alur proses nama klasifikasi
2.6.2 Analisis Pelatihan Naïve Bayes
Pelatihan naïve bayes dilakukan untuk mendapatkan data latih, proses ini dilakukan menjadi 3 tahap yaitu ambil data, latih data dan simpan data. Tahapan-tahapan tersebut akan dijelaskan sebagai berikut :
2.6.2.1 Ambil Data
Ambil data berfungsi sebagai pengambilan data yang telah disimpan sebelumnya. Berikut alur proses dari ambil data:
[image:14.595.371.462.162.439.2]
Gambar 7 proses ambil data
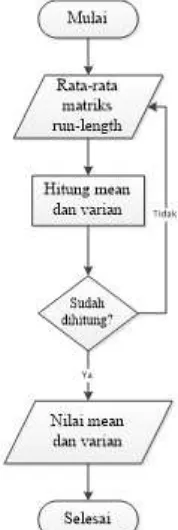
2.6.2.2 Pelatihan naïve bayes
Proses pelatihan dengan naïve bayes dilakukan dengan melakukan perhitungan nilai mean dan varians. Berikut adalah alur proses pelatihan dengan naïve bayes:
Gambar 8 alur proses pelatihan
2.6.3 Pengujian Naïve Bayes
[image:14.595.131.216.573.753.2]2.7 Pengujian
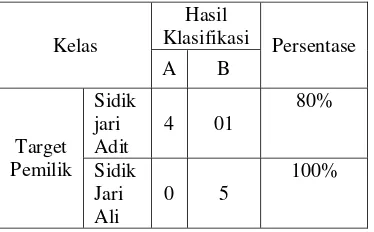
Pengujian algoritma ini bertujuan untuk mengetahui performansi dari metode run-length dan naïve bayes untuk klasifikasi citra. Pengujian pada penelitian ini adalah untuk mengukur tingkat keakuratan dan waktu yang dibutuhkaan untuk proses klasifikasi citra dengan beberapa skenario yang telah dipersiapkan, untuk mengukur tingkat keakuratan menggunakan metode confusion matrix.
Kelas
Hasil
Klasifikasi Persentase
A B
Target Pemilik
Sidik jari Adit
4 01
80%
Sidik Jari Ali
0 5
[image:15.595.311.528.89.223.2]100%
Tabel 1 Confusion matrix
Untuk menghitung akurasinya digunakan formula :
5
5 � = %
2.7.1 Rencana Pengujian
Pada penelitian ini, rencana pengujian dilakukan dengan beberapa skenario, berikut adalah skenario yang telah dipersiapkan :
1. Menguji citra yang dijadikan data latih. 2. Menguji citra yang tidak termasuk data
latih.
3. Menguji pengaruh jumlah data latih terhadap akurasi dan waktu.
2.7.1.1 Pengujian Skenario 1
[image:15.595.71.258.212.328.2]Skenario 1 dilakukan dilakukan untuk mengetahui keakurasian dalam mengenali pola-pola yang telah dilatihkan kepadanya. Jika naïve bayes dapat mengenali masing-masing citra secara sempurna, maka naive bayes berfungsi secara baik. Pada pengujian skenario 1 didapat kesimpulan yaitu pengujian klasifikasi citra berdasarkan tekstur dengan menggunakan data citra yang telah dilatih memiliki rata-rata tingkat akurasi 99,88%. Berikut adalah hasil pengujian skenario 1
Gambar 9 pengujian scenario 1
2.7.1.2 Pengujian scenario 2
[image:15.595.324.538.347.471.2]Pengujian skenario 2 dilakukan dengan menguji citra yang tidak termasuk dalam data latih, pengujian ini bertujuan untuk mengetahui tingkat pengenalan citra diluar data latih. Pada pengujian skenario 2 didapat kesimpulan yaitu untuk citra yang belum dilatih rata-rata tingkat akurasinya adalah 78,63%. Berikut adalah hasil pengujian skenario 2
Gambar 9 pengujian scenario 2
2.7.1.3 Pengujian Skenario 3
Pengujian skenario 3 dilakukan untuk menguji pengaruh jumlah data latih terhadapa akurasi, pengujian ini dilakukan dengan mengubah perbandingan antara data latih dan data uji. Perbandingan data latih dan data uji yang akan digunakan adalah perbandingan 3:5 dan 4:5.
2.7.1.3.1 Pengaruh data uji 3:5
Gambar 10 pengujian pengaruh data latih 3:5
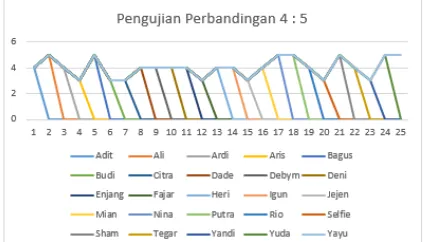
2.7.1.3.2 Pengaruh data uji 4:5
Pada pengujian ini dilakukan dengan menggunakan perbandingan data latih dan data uji 4:5 untuk data pada setiap kelasnya yang berarti menggunakan 4 citra latih dan 5 citra uji. Pada pengujian skenario 4:5 didapat kesimpulan yaitu tingkat akurasi menggunakan 4 data latih adalah 62,45%, Berikut adalah hasil pengujian perbandingan 4 : 5
Gambar 11 pengujian pengaruh data latih 4:5
2.8 Kesimpulan Pengujian
Berdasarkan Dari pengujian yang telah dilakukan maka didapatkanlah kesimpulan bahwa metode naïve bayes dapat mengklasifikasikan citra dengan masukan data statistik yang langsung membandingkan jarak terdekat dengan pelatihannya, pengujian klasifikasi citra berdasarkan tekstur dengan menggunakan data citra yang telah dilatih memiliki rata-rata tingkat akurasi 99,88% dan untuk citra yang belum dilatih rata-rata tingkat akurasi 78,63% dan tingkat akurasi menggunakan 3 data latih adalah 57,07% dan menggunakan 4 data latih adalah 62,45%. Maka semakin banyak data latih semakin besar tingkat akurasinya dan begitu pun sebaliknya.
3.
PENUTUP
3.1 KesimpulanDari hasil penelitian, analisis pengolahan citra, pelatihan dan pengujian metode run-length dan
naïve bayes untuk klasifikasi citra berdasarkan tekstur ini didapatkan kesimpulan sebagai berikut:
1. Algoritma naïve bayes dapat mengklasifikasikan citra digital sidik jari berdasarkan hasil ekstraksi citra digital metode run-length
2. Algoritma naïve bayes menghasilkan tingkat keakurasian 99,8%.
3.2 Saran
Dari hasil penelitian, analisis, pengolahan citra, pelatihan dan pengujian terdapat saran-saran yang mungkin akan bermanfaat jika ada yang akan melakukan penelitian yang sejenis, yaitu :
1. Dari hasil penelitian ini, maka disarankan untuk mengembangkan penelitian ini kearah identifikasi citra sidik jari milik kepolisian yang datanya lebih kompleks, sehingga dapat membantu pihak penegak hukum dalam mengungkap berbagai kasus
kejahatan.
[image:16.595.72.284.364.487.2]DAFTAR PUSTAKA
1. Ahmad, U., 2005. Pengolahan Citra
Digital & Teknik Pemrogramanya.
Yogyakarta: Graha Ilmu.
2. Achmad, S., 2010. MySql dari Pemula Hingga Mahir. Jakarta: Achmatim.
3. Asbaugh, R., 1999. Ridgeology. Journal of Forensic Identification, Royal Canadian Mounted Police, Canada.
4. Eko, S., Nataliani Y., 2009. Klasifikasi Sidik Jari dengan Menggunakan Metode Wavelet Symlet. Jurnal Informatika Volume 5 No 2, Universitas Kristen Satya Wacana, Diponegoro.
5. Galloway, M., “Texture analysis using gray
level run length”, Computer Graphics
Image Process., vol. 4, pp.172-179, juni 1975.
6. Hartanto, B., 2008. Memahami Visual
C#.Net Secara Mudah. Pertama penyunt.
Yogyakarta: Andi.
7. Mita, I., Santoso, I., Christyono, Y., 2007. Analisis Tekstur Menggunakan Metode Run Length. Tugas Akhir Teknik Elektro, Universitas Diponegoro, Semarang. 8. Munir, R., 2002. Pengolahan Citra Digital.
Bandung: Informatika.
9. Nugroho, A., 2005. Pemodelan Berorientasi Objek, Bandung: Informatika.
10. Pressman, S. R., 2010. Rekayasa Perangkat Lunak. Yogyakarta: Andi.
11. Prasetyo, E., 2012. Pengenalan Pola Naive Bayes, Universitas Pembangunan Nasional, Jawa Timur.
12. Sri, K., 2009. Klasifikasi Status Gizi Menggunakan Naïve Bayesian Clasification. Tugas Akhir Teknik Informatika, Universitas Islam Indonesia, Yogyakarta.
13. Anik, A., 2013. Sistem Pedukung Keputusan Berbasis Decision Tree Dalam Pemberian Beasiswa Studi Kasus:AMIK BSI YOGYAKARTA, Amik BSI Jakarta, Jakarta Selatan.
14. Sutopo, A. H & Masya, F., 2005.
Pemograman Berorientasi Objek dengan
Java. Yogyakarta: Graha Ilmu.
PENERAPAN METODE RUN-LENGTH DAN ALGORITMA SIMPLE
NAIVE BAYES UNTUK IDENTIFIKASI SIDIK JARI
Heri Yulianto Sugandi
11
Teknik Informatika – Univesitas Komputer Indonesia
Jl. Dipatiukur 112 - 114 Bandung
E-mail : [email protected]
1ABSTRACT
The fingerprint is a medium that could be used to recognize a person's identity. Fingerprints have a which distinguishes characteristics of fingerprint with others. The way to differentiate these characteristics is a way to recognize the difference in the texture of the fingerprint image. Which has a texture image is the image that has a pattern, the pattern of the image occurs repeatedly meet all field image. Different image having different characteristics. The characteristics are the basis for the image classification based on texture. There are several methods to obtain the characteristics of texture in an image, one method to obtain the characteristics of the texture image is the run length matrix. The characteristics of the texture obtained from the run-length matrix method include SRE(short run emphasis), LRE(long run emphasis), GLU(grey level uniformity), RLU(run length uniformity) dan RPC(run percentage). From the results of these characteristics are then used for classification using Naïve Bayes which determines the classification results based on the value of the largest probability. The object being tested is the image of fingerprint.
From the research that has been done, it can be deduced as follows: naïve Bayes can perform image classification based on texture are extracted by the method of run length matrix. Due to the characteristics of the data extracted run length matrix is in the form of data continuously, or so-called nominal data, so that the process of data classification feature extraction results can be directly used as an input in the naïve Bayes classification.
Based on test results, obtained conclusion is naïve Bayes algorithm can classify digital fingerprint image based on the digital image extraction of run-length method and generates 95.8% accuracy rate. because of data from fingerprint feature extraction of textures with run-length matrix method has the advantage of distinguishing among smooth textures and rough textures, so naïve Bayes classification could run most leverage when performing fingerprint image classification.
Keywords: texture images, feature extraction, the run length matrix, classification, Naïve Bayes.
1.
INTRODUCTION
Fingerprint (fingerprint) is a reproduction finger palm either intentionally taken, stamped with ink, as well as scars left on objects because never touched leather palms of the hands or feet. Fingerprint identification known to science that studies dactyloscopy fingerprint for recognition purposes back a person's identity by observation the lines contained in line strokes fingers and soles of the feet (Ashbaugh R, 1991). Because the texture fingerprints on every person has a characteristic that is different from one person to another person, differences in the pattern of the fingerprint is used as a means of identification.
In classifying and detecting an object-level accuracy is crucial, because to produce a classification system and object detection required a good accuracy. Previous research by Eko Sediyono (2009), to process the fingerprint image classification using wavelet feature extraction method symlet capable of producing up to 80% accuracy. Wavelet transform is used as a texture analysis which is input to the classification system. The occurrence of errors in the classification of characteristics may occur due to several reasons, among them are, thumb prints were taken using ink stamp affixed on the paper and then scanned to give effect to the sketch of the fingerprint formed, among others, the thickness of the ink stick is too thick or thin, the size of the fingerprint image that is diverse and positions fingerprints are not upright.
emphasis (SRE), long run emphasis (LRE), gray level uniformity (GLU), run length uniformity (RLU), run percentage (RPC) (Mita I 2007 ). Run-length method can produce a characteristic form of diversity, density, roughness, regularity, linearity, frequency, phase, keterarahan, irregularity, smoothness, and others. Results of feature extraction is used for classification. Therefore the extraction process characteristics resulting from the run-length method will generate continuous data which will be processed on the next stage of image classification stages by using naïve Bayes methods. In the study conducted Sri Kusumadewi (2009), naïve Bayes classification process can be used for continuous data and generate a total of 93% of performance testing. Naïve Bayes classification method is one that uses the concept of probability. Methods naïve Bayes classification algorithm is a highly effective and efficient.
Of problems and solutions that have been described, this thesis research will classify fingerprint based texture fingerprints by applying run length for the extraction process the image and methods naïve Bayes for image classification, the expected method of naïve Bayes can classify fingerprints by texture and measure the level of accuracy classification.
1.1 Formulation of the Problem
Based on the background described, this research is to formulate the problem to be discussed is how to implement the run length method for extracting images and naïve Bayes algorithm for image classification.
1.2 Purpose and Objectives
The point of the study of this thesis is for implementing naïve Bayes method to classify the fingerprint image based on the extraction of digital imagery.
The objectives to be achieved in this thesis research is
1. Can be classifying digital image of a fingerprint by fingerprint texture 2. To determine the level of accuracy.
2.
CONTENTS RESEARCH
2.1 Artificial IntelligenceArtificial intelligence is a branch of science which deals with the use of machines to solve complex problems in a more humane way. This is usually done by following / copying the characteristics and analogy to think of human intelligence, and apply it as an algorithm known by the computer.
Artificial intelligence can be used to analyze the image of the scenery in the calculation of the symbols that represent the content of the scene after the image is processed to obtain characteristic.
Artificial intelligence could be seen as three integrated entity that is the perception, understanding and action. Perception translate signals from the real world in the image become symbols of a more simple, the notion of manipulating the symbols was to facilitate extracting certain information, and acts to translate the symbols that have been manipulated into other signals that can be the end result or outcome between appropriate with the purpose of (Ahmad U, 2005).
2.2 Texture
Generally texture refers to the repetition of elements of basic textures are often called primitive or texel (texture element). A texel is composed of several pixels with the rules of periodic position, kuasiperiodik, or random (U. Ahmad, 2005).
The terms of the formation of the texture of at least two, namely:
1. The existence of primitive patterns consisting of one or more pixels. The forms of these primitive patterns can be a point, a straight line, curved line, area and others which are the basic elements of a form.
2. Primitive patterns had appeared repeatedly at intervals of a certain distance and direction so it can be predicted or found characteristics of repetition.
Figure 1 Example texture of VisTex Database
An image of an interpretation different texture when viewed at different distances and angles. Humans look at the texture based on the description that is random, such as smooth, rough, regular, irregular, and so on. This is a description of improper and non-quantitative, so it needed a quantitative description (mathematical) to facilitate analysis (U. Ahmad, 2005).
2.3 Tekstur Analisys
Texture analysis is the basis of a wide range of applications, application of texture analysis, among others: remote sensing, medical imaging, identification of quality of materials (wood, leather, textiles, etc.), and also a wide range of other applications. In the image analysis, texture measurement is categorized into five main categories: statistical, structural, geometry, basic model, and signal processing. Statistical approach considering that the intensity generated by random two-dimensional field, the method is based on the frequency of the frequency space. Examples of statistical methods is the autocorrelation function, cooccurence Matrix, Fourier transform, frequency edge, run length and others. Structural engineering
related to developing the smallest part of an image. Examples of structural method is the fractal models. The method is based on the geometry of existing geometry in the texture elements. Examples of the method is the basic model of a random field. While the signal processing method is a method that is based on the analysis of the frequency of such transformation, and Gabor wavelet transform (U. Ahmad, 2005).
2.3.1 Method Run-lenth
Gray level run length matrix commonly abbreviated to GLRLM is one popular method to extract the texture in order to obtain statistical characteristics or attributes contained in texture to estimate the pixels that have the same degree of gray. Extraction texture with run-length method is done by making a series of value pairs (i, j) in each row of pixels. Keep in mind the purpose of the run-length itself is the number of pixels in sequence in a particular direction which has a degree of gray / value of the same intensity. If it is known a run-length matrix with matrix elements q (i, j | θ) where i is the degree of gray at each pixel, j is the value run-length, and θ is the orientation towards certain shifts are expressed in degrees. Orientation formed with a four-way shift at intervals of 450, 00, 450, 900, and 1350. Based on research conducted by Galloway (1975), there are several types of textural characteristics that can be extracted from the run-length matrix. Here are the variables contained in the extraction of the image by using statistical methods Grey Level Run Length Matrix:
i = the value of degrees of gray j = successive pixels (run)
M = The number of degrees of gray in an image N = The number of pixels in an image sequence r(j) = The number of pixels in sequence by many order (run length)
g(i) = The number of pixels in sequence based on the degree of grayed.
s = The amount of the total value of the resulting run in a certain direction
p(i,j) = The set of matrices i and j
n = The number of rows * number of columns. Where the variable-the variable will be used to find the value of the texture attributes as follows:
1. Short Run Emphasis (SRE)
SRE measuring the distribution of short-run. SRE is highly dependent on the number of short-run and is expected to be greater in fine texture.
2. Long Run Emphasis (LRE)
LRE distribution measure long run. LRE is highly dependent on the number of long run and is expected to be large on a rough texture.
3. Grey Level Uniformity (GLU)
GLU measure the degree of gray value equation entire image and is expected to be small if the value of a similar degree of gray around the image.
4. Run Length Uniformity (RLU)
RLU equation measure the length of the run throughout the image and is expected to be small if a similar run length across the image.
5. Run Percentage (RPC)
RPC run measure of togetherness and distribution of an image in a particular direction. RPC-value is greatest when the run length is 1 for all degrees of gray in a particular direction.
2.4 Classification
Classification is a job that assessment of an object's data to fit in a particular class of a number of classes available. (Prasad, 2012).
There are two main jobs:
2. Using the model to perform recognition / classification / projection on an object other data entry in which the class.
2.4.1 Classification naïve bayes
Naïve Bayes is a simple probabilistic-based prediction technique that is based on the application of Bayes theorem (Prasad, 2012)
1. The assumption of independence (independence) is strong (naive).
2. The model used is the "model of the independent feature"
Strong independence of the features is that a feature on a Data has nothing to do with the presence or absence of other features that are in the same data
Naïve Bayes is an simplest method of classification by using existing opportunities, where it is assumed that every variable X is free (independence). Because the assumptions are not mutually dependent variable, then obtained the equation (7).
The data used can be categorical or continuous. However, in this final project will use continuous data, as a result of the image feature extraction is a continuous data measurement results in the form of figures on the level of contrast, homogeneity, entropy, energy, and dissimilarity in feature extraction. Therefore For continuous data can be completed using the following steps.
Training :
Calculate the average (mean) of each feature in the training dataset by the equation
� = ∑ ��
�
Where :
� = mean
= The number of data
∑ �� = The number of data Values
Then calculate the variance of the training dataset blood money as in equatio.
� = �− ∑��= ��− µ
Where:
� = varians µ= mean
�� = value data
= The number of data
Testing :
1. Calculate the probability (Prior) for each class that is by counting the number of data for each class divided by the total number of overall data.
2. Next calculate the probability density using equation (10). Expressing the relative probability density function. Data with mean μ and standard deviation σ, the probability density function is:
��� � =√ ��2
−�−� 22�2
Where :
� = input of data
π = 3,14
� = standard deviation µ = mean
3. Having obtained the probability density value, then calculate the posterior of each class using the equation � � = � �� � �(� … … … � |��) �(� … … … � |��) � � = � � � ℎ�
4. The greatest posterior is the corresponding class.
2.5 Method of testing accuracy
In this study, plan testing is done with a few scenarios, here is a scenario that has been prepared :
1. Test image used as training data.
2. Examine the image that does not include training data.
3. Test the effect of the amount of training data on the accuracy and time.
1. Test image used as training data.
This test method uses the data already in training, in other words, the training data and test data is the same data.
2. Supplied set test
This test method uses different data, in other words, the training data different from the data that will be tested
3. The influence of the amount of training data for accuracy
The 3 scenario testing conducted to test the effect of the amount of training data for accuracy, this test is done by changing the ratio between training data and test data.
a) Comparison of test data The 3: 5 In this test done using training data comparison and test data The 3: 5 for the
qi
P
X
iY
y
y
Y
X
data in each class, which means using The 3 images trained and 5 test images
b) Comparison of test data in 4: 5 In this test done using training data comparison and test data 4: 5 for the data in each class, which means using the image of train 4 and 5 test images.
2.6 Process Analysis
Analysis of the process to be conducted in this study is the analysis of the image based on texture classification. The stages of work processes within the classification from the input data to the output data. Here are the stages of the process of analysis to be performed and to the flow of process analysis can be seen in figure 2 :
Ficture 2 flow chart analysis process
The following by explanations of each stage is as follows :
1. Put the fingerprint image
An image data acquisition step on the media input into the system. Image input in the form of image files that contain objects fingerprints taken using the ink stamp affixed on the paper and then scanned.
2. Image processing
At this stage, the image will be resized entered into 32x32 pixels, in grayscale becomes grayish to obtain value matrix grayscale. Having obtained matrix grayscale feature extraction process is then performed run-length and give the name of the classification after the obtained value of the average feature-length run.
3. Training naïve bayes
Training on naive Bayes stage which takes the data that has been named classification and has an average value run-length feature to be calculated and the search for the mean and
variance. Having obtained the mean and variance training data is saved to the database.
4. Testing naïve bayes
In the testing process naïve Bayes, the input image to be tested. Input image to be processed to find the probability density values and seek the greatest posterior value. Having obtained posterior greatest value then known classification results of the test images.
2.6.1 Analysis Data Input
In this study, the first to be done is the analysis of the input data. Analysis of the input data is done to obtain an input value that can later be used to process naïve Bayes classification methods. In this study, the data input is an image, which will be searchable content value using Run-length feature extraction matrix, the output value to be obtained is SRE, LRE, GLU, RLU, and RPC. These values will serve as baseline data which will be used as input in the naïve Bayes method. Stages that will be performed on the input data analysis is preprocessing is to resize and grayscale images. After performing preprocessing, feature extraction is carried out with a run-lrngth matrix method to get the value of the image feature.
2.6.1.1 Preprocessing
[image:22.595.74.282.271.478.2]In the present study, preprocessing done to make it easier to get the value of feature extraction. Preprocessing will do is resize, grayscale and image quantization. The following by process flow of preprocessing :
2.6.1.1.1 Resize
[image:23.595.130.237.144.425.2]Resize is the first stage of the preprocessing. Resize done to accelerate and facilitate the process of calculation. The following by process flow of resizeing :
Figure 3 process flow resize
2.6.1.1.2 Grayscale
Grayscale is a process to change the color to greyish. By changing the RGB value of each pixel of the image into the same value so that each pixel has the same value for all three elements of color and grayscale matrix values obtained. The following by the flow of the process grayscale:
Figure 4 greyscale process flow
2.6.1.2 Feature extraction
Feature extraction is a process for mendaptkan main characteristics contained in the image, which has been in the grayscale image will produce a grayscale matrix ynag been in quantitation, matrix is exactly what will be used at this stage. This stage will calculate the 5 statistical values of run length that SRE, LRE, GLU, RLU and RPC with symmetry angles of 0, 45, 90 and 135. Having obtained all the value of the angle will be averaged. The following by process flow of extract the characteristics:
Figure 5 process flow feature extraction
2.6.1.3 Name of Classification
[image:23.595.356.448.525.749.2]Name of classification used to determine the classification of names that have obtained an average statistical value from run-length feature extraction. The following by process flow of the classification name:
[image:23.595.128.233.539.754.2]2.6.2 Analysis of Training Naïve Bayes
Training naïve Bayes made to obtain training data, the process is carried out into 3 stages: data capture, training data and store data. These stages are described as follows:
2.6.2.1 Take Data
Retrieve data functions as retrieval of data that have been stored previously. The following by process flow of data capture:
[image:24.595.129.215.216.398.2]
Figure 7 process data capture
2.6.2.2 The Training naïve bayes
The training process with naïve Bayes is done by calculating the mean and variance. Here is the training process flow with naïve Bayes:
Ficture 8 flow process training
2.6.3 Pengujian Naïve Bayes
Figure 8 testing naïve bayes
2.7 The Testing
The aim of this algorithm testing to determine the performance of the run-length method and naïve Bayes for image classification. Tests on this study was to measure the level of accuracy and time dibutuhkaan for image classification process with several scenarios have been prepared, to measure the degree of accuracy using the confusion matrix.
Class
Classification
results Persentase
A B
Target Owner
Finger print Adit
4 01
80%
Finger Print Ali
0 5
[image:24.595.133.222.473.738.2]100%
Table 1 Confusion matrix
Use a formula to calculate accuracy :
5
5 � = %
2.7.1 Testing Plan
In this study, plan testing is done with a few scenarios, here is a scenario that has been prepared:
1. Test image used as training data.
[image:24.595.316.513.494.617.2]3. Test the effect of the amount of training data on the accuracy and time.
2.7.1.1 Testing Scenario 1
[image:25.595.312.525.134.260.2]Scenario 1 was conducted to determine the accuracy in identifying patterns that have trained him. If naïve Bayes can identify each image is perfect, then Naive Bayes function properly. In the test scenario 1 could be concluded that the test image classification based on the texture using image data that has been trained to have an average of 99.88% accuracy rate. Here are the results of testing scenario 1
Figure 9 Testing scenario 1
2.7.1.2 Testing scenario 2
[image:25.595.71.286.218.352.2]Testing of scenario 2 was conducted by examining the image that are not included in the training data, this test aims to determine level of image recognition beyond the training data. In the second scenario testing can be concluded that the image has not been trained for the average accuracy rate is 78.63%. Here are the results of testing scenario 2
Figure 9 testing scenario 2
2.7.1.3 Testing Scenario 3
The 3 scenario testing conducted to test the effect of the amount of training data terhadapa accuracy, this test is done by changing the ratio between training data and test data. Comparison of training data and test data will be used is the ratio of 3: 5 and 4: 5.
2.7.1.3.1 Effect of test data The 3: 5
In this test done using training data comparison and test data The 3: 5 for the data in each class, which means using The 3 images trained and 5
[image:25.595.312.524.388.509.2]test images. In the test scenario The 3: 5 could be concluded that the level of accuracy using The 3 training data is 57.07%, Here are the results of testing ratio of 3: 5
Figure 10 testing the effect of training data The 3: 5
2.7.1.3.2 Effect o the Test data The 4:5
In this test done using training data comparison and test data 4: 5 for the data in each class, which means using the image of train 4 and 5 test images. In the test scenario 4: 5 can be concluded that the level of accuracy using the 4 training data is 62.45%, Here are the test results a ratio of 4: 5
Figure 11 testing the effect of training data 4: 5
2.8 Conclusion Testing
Based From the testing that has been done so didapatkanlah conclusion that naïve Bayes method can classifying the input image with statistical data directly comparing the closest distance to the training, testing of image classification based on the texture using image data that has been trained to have an average accuracy rate of 99.88% and the image has not been trained for an average of 78.63% accuracy rate and level of accuracy using the The 3 training data is 57.07% and the use of 4 training data is 62.45%. The more training data the greater the degree of accuracy and vice versa.
3.
CLOSING
3.1 Conclusion [image:25.595.77.297.471.604.2]and naïve Bayes for classification based on the texture image is obtained the following conclusion:
1. Naïve Bayes algorithm can classify digital image of a fingerprint based digital image extracted run-length method 2. Naïve Bayes algorithm generates 99.8%
accuracy rate.
3.2 Suggestion
From the research, analysis, image processing, training and testing there were suggestions that it might be beneficial if there were going to conduct similar research, namely:
1. From these results, it is advisable to develop this research towards identifying the fingerprint image data belonging to the police were more complex, so it can assist law enforcement authorities in uncovering various crimes.
2. To be able to classify the input image should
DAFTAR PUSTAKA
1. Ahmad, U., 2005. Pengolahan Citra Digital & Teknik Pemrogramanya. Yogyakarta: Graha Ilmu.
2. Achmad, S., 2010. MySql dari Pemula Hingga Mahir. Jakarta: Achmatim.
3. Asbaugh, R., 1999. Ridgeology. Journal of Forensic Identification, Royal Canadian Mounted Police, Canada.
4. Eko, S., Nataliani Y., 2009. Klasifikasi Sidik Jari dengan Menggunakan Metode Wavelet Symlet. Jurnal Informatika Volume 5 No 2, Universitas Kristen Satya Wacana, Diponegoro.
5. Galloway, M., “Texture analysis using gray
level run length”, Computer Graphics Image
Process., vol. 4, pp.172-179, juni 1975. 6. Hartanto, B., 2008. Memahami Visual
C#.Net Secara Mudah. Pertama penyunt.
Yogyakarta: Andi.
7. Mita, I., Santoso, I., Christyono, Y., 2007. Analisis Tekstur Menggunakan Metode Run Length. Tugas Akhir Teknik Elektro, Universitas Diponegoro, Semarang. 8. Munir, R., 2002. Pengolahan Citra Digital.
Bandung: Informatika.
9. Nugroho, A., 2005. Pemodelan Berorientasi Objek, Bandung: Informatika.
10. Pressman, S. R., 2010. Rekayasa Perangkat Lunak. Yogyakarta: Andi.
11. Prasetyo, E., 2012. Pengenalan Pola Naive Bayes, Universitas Pembangunan Nasional, Jawa Timur.
12. Sri, K., 2009. Klasifikasi Status Gizi Menggunakan Naïve Bayesian Clasification. Tugas Akhir Teknik Informatika, Universitas Islam Indonesia, Yogyakarta.
13. Anik, A., 2013. Sistem Pedukung Keputusan Berbasis Decision Tree Dalam Pemberian Beasiswa Studi Kasus:AMIK BSI YOGYAKARTA, Amik BSI Jakarta, Jakarta Selatan.
14. Sutopo, A. H & Masya, F., 2005.
Pemograman Berorientasi Objek dengan
Java. Yogyakarta: Graha Ilmu.
iii
Alhamdulillah,
Segala puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah
memberikan iman, kekuatan, kecerdasan, kesehatan, semangat yang tinggi, serta
semua kekayaan yang dilimpahkan kepada penulis, karena dengan izin dan
berkah-Nya lah penelitian ini dapat diselesaikan dengan baik sesuai dengan waktu yang
direncanakan.
Skripsi yang berjudul “
PENERAPAN METODE RUN-LENGTH DAN
ALGORITMA SIMPLE NAÏVE BAYES UNTUK IDENTIFIKASI SIDIK JARI”
disusun untuk memperoleh gelar Sarjana Teknik Informatika, Fakultas Teknik dan
Ilmu Komputer Universitas Komputer Indonesia.
Pada kesempatan ini penulis hendak menyampaikan terima kasih kepada :
1.
Allah SWT atas berkah dan karunia-Nya sehingga penulis dapat menyelesaikan
tugas akhir ini.
2.
Ayah, Ibu, Arim Sugandi, Dede Sri Mulyani Sugandi, Nurma Nugraha, Hendra
Wijaya dan Kaila Yona tak lupa pada keponakan ku tercinta terima kasih yang
tak terhingga atas segala dukungan serta doanya sehingga penulis memiliki
semangat yang menggebu-gebu untuk dapat menyelesaikan tugas akhir ini.
3.
Bapak Galih Hermawan, S.Kom, M.T. selaku dosen pembimbing tugas akhir
yang telah memberikan segenap waktu, kekuatan dan inspirasi pembuatan
tugas akhir serta banyak memberikan bimbingan dan saran-saran kepada
penulis sampai akhirnya penulis dapat menyelesaikan tugas akhir ini.
4.
Ibu Ednawati Rainarli, S.Si., M.Si. selaku penguji yang telah memberikan
masukan dan saran-saran dalam penyusunan tugas akhir ini.
5.
Ibu Utami Dewi, S.Kom,. M.T selaku dosen wali yang telah memberikan
masukan dan juga arahan-arahan dari awal masuk perkuliahan sampai akhir
iv
19 dan semua teman-teman yang selalu ke kosan untuk memberi dukungan
pada penulis
7.
Seluruh teman-teman khususnya IF-11 angkatan 2010 yang telah menjadi
teman seperjuangan terbaik (maaf jika tidak disebutkan namanya).
8.
Seluruh pihak yang telah memberikan kontribusi dan bantuannya dalam
penyelesaian tugas akhir ini, namun tidak sempat dicantumkan namanya satu
per satu.
Penulis telah berupaya dengan semaksimal mungkin dalam penyelesaian
tugas akhir ini, namun penulis menyadari masih banyak kelemahan baik dari segi
isi maupuntata bahasa, untuk itu penulis mengharapkan kritik dan saran yang
bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Tak lupa
penulis mohon maaf apabila dalam penulisan atau penyusunan tugas akhir ini, telah
menyinggung perasaan atau bahkan telah menyakiti pihak tertentu baik yang
disengaja maupun tidak disengaja. Kiranya isi tugas akhir ini bermanfaat dalam
memperkaya khasanah ilmu pendidikan dan juga dapat dijadikan sebagai salah satu
sumber referensi bagi peneliti selanjutnya yang berminat meneliti hal yang sama.
Bandung, 6 Agustus 2015