PARTIAL LEAST SQUARE STRUCTURAL EQUATION
MODELING (PLS-SEM) PADA DATA BINER
(Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi
Susu di Indonesia)
RIWI DYAH PANGESTI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI DISERTASI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Partial Least Square Structural Equation Modeling (PLS-SEM) pada Data Biner (Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi Susu di Indonesia) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2016
Riwi Dyah Pangesti
RINGKASAN
RIWI DYAH PANGESTI. Partial Least Square Structural Equation Modeling
(PLS-SEM) pada Data Biner (Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi Susu di Indonesia). Dibimbing oleh I MADE SUMERTAJAYA dan ANGGRAINI SUKMAWATI.
Peubah laten merupakan peubah yang tidak dapat diukur secara langsung. Peubah laten dapat diukur berdasarkan indikator-indikator yang dapat mencerminkan peubah laten tersebut. Nilai tiap indikator untuk mengukur peubah laten biasanya didapatkan melalui kuesioner yang disebarkan kepada responden. Kuesioner ini kebanyakan menggunakan skala likert. Kelemahan skala likert menurut Garland (1991) adalah sering terjadinya bias sosial. Satu hal lagi, menurut Mattjik dan Sumertajaya (2011), ketika sebuah peubah diukur berdasarkan indikatornya akan terdapat dua permasalahan besar, yaitu masalah pengukuran dan masalah hubungan kausalitas. Teknik statistika yang dapat digunakan untuk mengukur atau menganalisis pola hubungan dan pola pengaruh (baik langsung maupun tidak langsung) secara simultan serta untuk mengetahui indikator-indikator yang dapat mengukur peubah laten tersebut valid dan reliabel adalah Model Persamaan Struktural (MPS) atau Structural Equation Modeling
(SEM).
Structural Equation Modeling (SEM) pada awalnya dikembangkan berdasarkan matriks peragam yang disebut dengan Covariance-Based SEM (CB-SEM). Covariance-Based SEM (CB-SEM) ini mensyaratkan terpenuhinya asumsi normalitas ganda dan ukuran contoh yang besar, setidaknya 5 kali parameternya atau 10 kali indikatornya. Pada kenyataannya tidak semua kasus memenuhi keadaan tersebut. Pendekatan yang powerfull dalam mengatasi hal tersebut adalah menggunakan Partial Least Square Structural Equation Modeling (PLS-SEM).
Koperasi Susu Indonesia yang tergabung dalam Gabungan Koperasi Susu Indonesia (GKSI) merupakan organisasi modern yang dalam menjalankan fungsinya, koperasi-koperasi ini telah menerapkan prinsip-prinsip manajemen. Koperasi susu di Indonesia menampung hasil perahan susu dari peternak dan langsung mendistribusikannya ke Industri Pengolahan Susu (IPS). Koperasi ini menjadi jembatan antara peternak dan IPS. Sukmawati et. al. (2009) menerangkan pada tahun 2004-2006 impor Indonesia untuk susu dan produk turunannya mencapai 92%. Hal ini mengindikasikan kurangnya kualitas koperasi persusuan Indonesia dalam memenuhi kebutuhan susu segar di Indonesia. Oleh karena itu peningkatan kualitas Sumber Daya Manusia dan pemberdayaan masyarakat serta daya saing berbasis pengetahuan di dalam koperasi ini harus terus ditingkatkan untuk menciptakan inovasi yang semakin baik. Faktor-faktor pendorong tercapainya pengetahuan di suatu organisasi yang dikutip Purwanto (2010) antara lain adalah visi bersama, penyebaran pengetahuan internal, dan proses penciptaan pengetahuan.
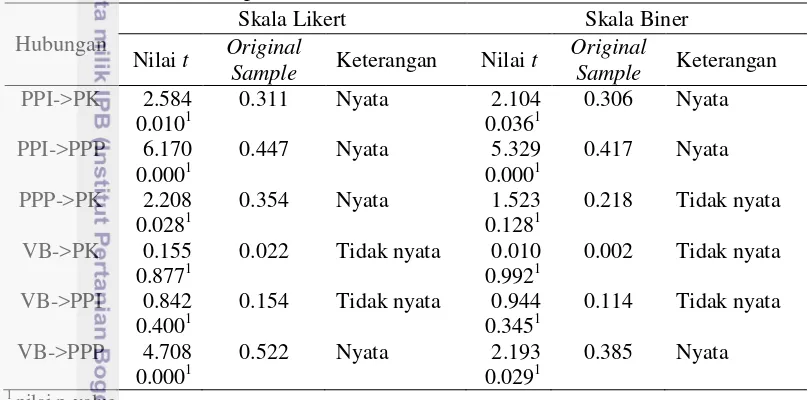
yang meliputi R-square, f-square, , , RMSEA, SRMR, Khi-Kuadrat, dan GoF. Uji statistik t melalui prosedur bootstrapping juga dilakukan untuk lebih menegaskan kesimpulan terkait model terbaik yang diperoleh.
Berdasarkan nilai validitas konvergen, validitas diskriminan, dan reliabilitas dapat disimpulkan bahwa data skala likert memberikan hasil yang lebih baik daripada skala biner. Hal ini disebabkan bahwa skala likert merupakan ukuran yang lebih tinggi daripada skala biner. Berdasarkan uji R-square, f-square, ,
dan GoF, memperlihatkan juga bahwa skala likert lebih baik daripada skala biner. Sedangkan berdasarkan nilai Khi-Kuadrat, RMSEA, dan SRMR, kedua model ini tidak mengindikasikan model yang baik. Hal ini dikarenakan, ketiga kriteria ini mensyaratkan data berdistribusi normal ganda, sedangkan skala likert dan skala biner tidak mengikuti sebaran normal ganda. Dengan demikian, model terbaik berdasarkan kriteria tersebut adalah model pengetahuan koperasi yang dibangun berdasarkan skala likert. Model pengetahuan koperasi yang dibangun berdasarkan skala biner dapat diselesaikan dengan pendekatan PLS-SEM yang lainnya.
SUMMARY
RIWI DYAH PANGESTI. Structural Equation Modeling Using Partial Least Squares-PLS SEM on Binary Data, Case Study: Supporting Factors Increased Knowledge possessed by Indonesian Dairy Cooperative. Supervised by I MADE SUMERTAJAYA dan ANGGRAINI SUKMAWATI.
Latent variables are variables that are not directly observed. Latent variables are measured from other indicators which are reflecting them. The value of each indicator to measure latent variables are usually obtained by the questionnaires. The questionnaires commonly use Likert scale. According to Garland (1991), the occurrence of social bias is the weakness of Likert scale. One more thing, according to Mattjik and Sumertajaya (2011), when a variable is measured by the indicators, there are two major problems, namely the problem of measurement and causality relationship. Statistical techniques that can be used to measure or analyze patterns of relationships and patterns of influence (directly or indirectly) simultaneously and to know the indicators that can measure the validity and reliability of latent variable is Structural Equation Modeling ( SEM).
Structural Equation Modeling (SEM) is firstly developed based on the covariance matrix called Covariance-Based SEM (CB-SEM). Covariance-Based SEM (CB-SEM) requires the fulfillment of the assumptions of multivariate normality distribution of the data and large sample sizes, at least 5 times parameters or 10 times indicators. In reality, not all cases meet this condition. A powerful approach to overcome this problem is to use the Partial Least Square Structural Equation Modeling (PLS-SEM).
Indonesian Milk Cooperation (Koperasi Susu Indonesia) which joined in Gabungan Koperasi Susu Indonesia (GKSI) is a modern organization that implemented management principles in carrying out its functions. Each milk cooperation in Indonesia collects the cow milk from farmers and directly distribute it to the Milk Processing Industry (IPS). The cooperative is a bridge between farmers and IPS. Sukmawati et. al. (2009) described that the 2004-2006 Indonesian imports for milk and its derivative products reached 92%. This indicates a lack of Indonesian dairy cooperative quality in meeting the needs of fresh milk in Indonesia. Therefore, improving the quality of human resources, community development and knowledge-based competitiveness in the cooperative to be further enhanced to create the better innovations. Factors which drive the achievement of knowledge in an organization quoted by Purwanto (2010), were a shared vision, internal knowledge sharing and knowledge creation process.
The purpose of this study is to get a model PLS-SEM best of cooperative systems increased knowledge on the binary data and compare it with the Likert scale. The best model is viewed based on the goodness of fit measurement model that includes convergent validity, discriminant validity, and reliability. The best model is also seen by the goodness test of structural models which include the R-square, f-R-square, Q2, , RMSEA, SRMR, Chi-Square, and GoF. The statistical t-test through bootstrapping procedure was also performed to further confirm the conclusions of best model obtained.
binary scale. It is due to that the Likert scale is a measure that is higher than the binary scale. Based on the R-square test, f-square, , and GoF, shows also that the Likert scale is better than the binary scale. While based on the value of Chi-Square, RMSEA, and SRMR, both models do not indicate a good model. This is because, these three criteria, it requires double the normal distribution of data, whereas the Likert scale and binary scale does not follow the normal distribution doubles. Thus, the best model based on these criteria is the model of cooperative knowledge that builds on the Likert scale. Model of cooperative knowledge built on a binary scale can be completed with PLS-SEM approach others.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
PARTIAL LEAST SQUARE STRUCTURAL EQUATION
MODELING (PLS-SEM) PADA DATA BINER
(Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi
Susu di Indonesia)
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Judul Tesis : Partial Least Square Structural Equation Modeling (PLS-SEM) pada Data Biner. Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi Susu di Indonesia
Nama : Riwi Dyah Pangesti
NIM : G152140121
Disetujui oleh Komisi Pembimbing
Dr Ir I Made Sumertajaya, M.Si Ketua
Dr Ir Anggraini Sukmawati, MM Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Indahwati, M.Si
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Februari 2016 ini ialah Model Persamaan Struktural, dengan judul “Partial Least Square Structural Equation Modeling (PLS-SEM) pada Data Biner (Kasus: Faktor Pendorong Peningkatan Pengetahuan Koperasi Susu di Indonesia)”.
Keberhasilan penulisan karya ilmiah ini tidak terlepas dari bantuan, bimbingan dan arahan dari berbagai pihak. Dengan demikian penulis menyampaikan terimakasih yang sebesar-besarnya khususnya kepada:
1. Bapak Dr Ir I Made Sumertajaya, M.Si selaku pembimbing I dan Ibu Dr Ir Anggraini Sukmawati, MM selaku pembimbing II yang dengan kesabaran dan tanggungjawabnya telah memberikan arahan dan masukan kepada penulis selama penulisan karya ilmiah ini.
2. Ibu Dr Utami Dyah Syafitri, M.Si selaku penguji dalam ujian tertutup yang telah banyak memberikan kritikan, masukan, dan saran untuk kebaikan karya ilmiah ini.
3. Seluruh staf pengajar Departemen Statistika IPB yang telah banyak memberikan ilmu dan pengajaran selama perkuliahan sampai dengan penyusunan karya ilmiah ini.
4. Kedua orang tua dan kedua adik (Alvi dan Rofi) serta seluruh keluarga besar yang telah memberikan cinta, dukungan, do’a, semangat, motivasi, kasih sayang, dan semuanya yang tidak dapat penulis tuliskan.
5. Teman-teman statistika angkatan 2014 atas kekompakannya, kebersamaannya, bantuan, dan masukan selama menempuh perkuliahan bersama-sama.
6. Semua pihak yang namanya tidak dapat ditulis satu per satu, terimakasih atas bantuan dan dukungannya.
Atas segala bantuan yang telah diberikan, penulis hanya bisa berdo’a
semuga semua kebaikan yang penuh keikhlasan tersebut dicatat sebagai amal baik di sisi Allah SWT. Semoga karya ilmiah ini bermanfaat dan dapat menambah wawasan bagi para pembaca. Kritikan dan saran yang membangun sangat penulis harapan untuk kebaikan karya ilmiah ini di masa yang akan datang.
Bogor, November 2016
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 3
2 TINJAUAN PUSTAKA 3 Faktor-faktor Penciptaan Pengetahuan dalam Organisasi 3
Model Persamaan Struktural (SEM- Struktural Equation Modeling) 4
Kuadrat Terkecil Parsial(Partial Least Square-PLS) 5
Model Rekursif dan Nonrekursif 6
Spesifikasi Model 7
Evaluasi Model 9
Resampling Bootstrapping 9
3 METODE 11 Data 11
Metode penarikan Contoh 12
Analisis Data 12
4 HASIL DAN PEMBAHASAN 19 Koperasi Susu Indonesia 19
Profil beberapa Koperasi Susu Indonesia 19
Analisis Deskriptif 20
Pendugaan Data Hilang 21
Analisis PLS-SEM 22
5 SIMPULAN DAN SARAN 33 Simpulan 33
Saran 33
DAFTAR PUSTAKA 34
LAMPIRAN 37
DAFTAR TABEL
1 Peubah-peubah endogen dan eksogen beserta indikator-indikatornya 11
2 Kriteria R-square dan f-square 16
3 Responden berdasarkan jenis kelamin 20
4 Sebaran jawaban responden 21
5 Penerapan analisis regresi sederhana antar indikator untuk
menduga data tidak lengkap 22
6 Nilai AVE untuk Skala Likert dan Skala Biner 25
7 Nilai cross loading skala likert 26
8 Nilai cross loading skala biner 26
9 Nilai akar kuadrat AVE Skala Likert 27
10 Nilai akar kuadrat AVE Skala Biner 27
11 Ukuran kesesuaian model pengukuran 28
12 Nilai R-square pada data skala likert dan data skala biner 28 13 Nilai f-square untuk data skala Likert dan data skala biner 29
14 Nilai Goodness of Fit Model 31
15 Nilai statistik t pada model struktural 32
DAFTAR GAMBAR
1 Model indikator refleksif 5
2 Model indikator formatif 6
3 Hubungan antara peubah dan indikator dalam model PLS-SEM 6 4 Teknik penarikan contoh (Multistage random sampling) 12
5 Kerangka teoritis model pengetahuan koperasi 13
6 Tahapan Analisis 18
7 Diagram jalur model lengkap untuk skala likert 23
8 Diagram jalur model lengkap untuk skala biner 23
DAFTAR LAMPIRAN
1 Nilai Korelasi Antar Indikator 37
2 Nilai Cross Loading Skala Likert 38
3 Nilai Cross Loading Skala Biner 39
4 Nilai statistik t pada model pengukuran 40
5 Skor peubah laten skala likert 41
6 Skor peubah laten skala biner 44
7 Rumus ragam-peragam implied model skor laten 47
8 Perhitungan manual pada skala likert 48
1
PENDAHULUAN
Latar Belakang
Peubah laten (unobserved variables) merupakan peubah yang tidak dapat diukur secara langsung. Peubah laten dapat diukur berdasarkan indikator (observed variables) yang mencerminkan peubah laten tersebut. Indikator haruslah dapat dipertanggungjawabkan secara teori, mempunyai nilai logis yang dapat diterima, serta memiliki tingkat validitas dan reliabilitas yang baik.
Peubah laten diukur dalam format kuesioner yang indikatornya merupakan item-item pertanyaan dari setiap peubah laten. Kebanyakan kuesioner menggunakan skala likert. Kelemahan skala likert menurut Garland (1991) adalah responden harus memilih satu dari banyak pilihan jawaban. Pilihan jawaban yang banyak akan menyebabkan responden bingung dan malas mengisi (human error), responden menghindari jawaban yang ekstrim dan cenderung ingin memuaskan peneliti (tidak tegas), terjadi bias sosial karena jawaban responden mementingkan nilai-nilai yang berlaku di masyarakat daripada kondisi responden itu sendiri. Skala likert pertama kali dikembangkan menggunakan 5 titik pilihan, yaitu sangat setuju, setuju, netral, tidak setuju, dan sangat tidak setuju (Likert 1932). Kuesioner dalam skala biner hanya menyatakan dua jawaban ya/tidak, setuju/tidak setuju, benar/salah atau yang lainnya. Skala biner akan sangat memudahkan responden dalam mengisi kuesioner, karena responden hanya memilih satu dari dua pilihan sehingga menghasilkan jawaban yang tegas dan efektif. Terdapat juga kelemahan skala yang memiliki jumlah titik kurang dari 5 seperti dikemukakan oleh Preston dan Colman (2000) yaitu memiliki nilai reliabilitas, validitas, kekuatan diskriminasi dan stabilitas yang kurang bagus.
Mattjik dan Sumertajaya (2011) menerangkan bahwa ketika indikator-indikator digunakan untuk mengukur suatu peubah laten, akan ada dua permasalahan besar, yaitu masalah pengukuran dan masalah hubungan kausal antar peubah. Teknik statistika yang dapat digunakan untuk mengukur atau menganalisis pola hubungan dan pola pengaruh (baik langsung maupun tidak langsung) secara simultan serta untuk mengetahui indikator-indikator yang dapat mengukur peubah laten tersebut valid dan reliabel adalah Model Persamaan Struktural (MPS) atau Structural Equation Modeling (SEM).
Terdapat dua jenis SEM, yaitu Covariance-Based-SEM (CB-SEM) dan
Partial Least Square-SEM (PLS-SEM) atau sering disebut SEM berbasis ragam (Hair et. al. 2014). Covariance-Based-SEM pertama kali dikembangkan oleh Joreskog (1973), Keesling (1972), dan Wiley (1973). Prinsip dari CB-SEM ini adalah meminimumkan perbedaan antara matriks peragam contoh dan matriks peragam model ( ) dengan menggunakan fungsi Maximum Likelihood
(ML) (Henseler dan Sarstedt 2013, Hair et. al. 2011). Pemodelan menggunakan SEM mensyaratkan ukuran contoh sebanyak 10 kali banyaknya indikator atau lebih dari 100 unit pengamatan dan data harus menyebar normal ganda (Mattjik dan Sumertajaya 2011).
2
normal ganda, ukuran contoh tidak harus besar, ada banyak perangkat lunak yang mudah digunakan untuk mengestimasi parameternya, dan dapat digunakan pada peubah laten dan indikator yang besar. Tetapi ada kelemahan PLS-SEM, yaitu sulitnya menentukan kebaikan model menggunakan nilai Khi-Kuadrat (Henseler dan Sarstedt 2013).
Jaya dan Sumertajaya (2008) telah mengkaji PLS-SEM serta menyimpulkan bahwa pemodelan struktural dengan sampel relatif kecil dan asumsi normalitas ganda tidak terpenuhi mendapatkan estimasi yang baik menggunakan PLS-SEM, sedangkan pengujian model dengan ukuran sampel relatif besar dan data mengikuti sebaran normal ganda, pendekatan CB-SEM merupakan pendekatan yang terbaik. Monecke dan Leisch (2012) juga menerapkan PLS-SEM menggunakan package dalam perangkat lunak R. Henseler dan Sarstedt (2013) mengkaji PLS-SEM dengan melihat kebaikan model menggunakan Goodness of Fit Index (GoF) dan Relatives Goodness of Fit Index (GoFrel) pada data simulasi. Simulasi ini menerangkan bahwa GoF dapat digunakan untuk menduga seberapa baik model PLS-SEM yang dapat dijelaskan oleh kumpulan data.
Penelitian ini menggunakan data pengetahuan koperasi di Indonesia. Pengetahuan dalam setiap organisasi seperti koperasi susu Indonesia merupakan aset yang sangat penting untuk kemajuan organisasi tersebut. Koperasi susu di Indonesia merupakan organisasi modern yang dalam menjalankan fungsinya, koperasi mengikuti prinsip-prinsip manajemen. Koperasi-koperasi ini tergabung dalam Gabungan Koperasi Susu Indonesia (GKSI). Berdasarkan data GKSI (2005) yang dikutip Sukmawati et. al. (2008), terdapat 192 koperasi persusuan yang tersebar di pulau Jawa. Jawa Barat dan DKI Jakarta berjumlah 96 koperasi, Jawa Tengah dan DIY berjumlah 34 koperasi, dan Jawa Timur berjumlah 38 koperasi. Koperasi susu di Indonesia menampung hasil perahan susu dari peternak dan langsung mendistribusikannya ke Industri Pengolahan Susu (IPS). Koperasi ini menjadi jembatan antara peternak dan IPS.
Tahun 2009 produksi susu segar Indonesia hanya mampu memenuhi 25% kebutuhan susu nasional, yaitu sekitar 1.3 juta liter per hari atau setara dengan 56000 ton. Kontribusi pembangunan ekonomi Indonesia tidak terlepas dari peranan agroindustri susu di Indonesia. Agroindustri susu akan membantu dalam penciptaan lapangan kerja, peningkatan kesejahteraan petani, dan penghematan devisa negara (Sukmawati et. al. 2008). Sukmawati et. al. (2009) menerangkan pada tahun 2004-2006 impor Indonesia untuk susu dan produk turunannya mencapai 92%. Hal ini mengindikasikan kurangnya kualitas koperasi persusuan Indonesia dalam memenuhi kebutuhan susu segar di Indonesia. Oleh karena itu peningkatan kualitas Sumber Daya Manusia dan pemberdayaan masyarakat serta daya saing berbasis pengetahuan di dalam koperasi ini harus terus ditingkatkan untuk menciptakan inovasi yang semakin baik.
3 Penelitian ini menggunakan data yang kecil (98 responden) dan data tidak menyebar normal ganda. Oleh karena itu, penelitian ini menerapkan PLS-SEM untuk memodelkan pengetahuan koperasi pada koperasi susu di Indonesia. Penelitian mengenai PLS-SEM banyak menggunakan data skala likert yang terdiri dari lima titik pilihan jawaban dari sangat tidak penting sampai sangat penting. Karakteristik responden biasanya akan memilih antara dua jawaban penting atau tidak penting, bahkan beberapa responden akan memilih netral. Responden cenderung tidak memilih jawaban yang ekstrim (sangat tidak penting atau sangat penting). Berbeda dengan apabila kuesioner dibuat dalam skala biner yang hanya memiliki dua titik pilihan jawaban seperti 0 menunjukkan tidak penting dan 1 menunjukkan penting. Skala biner diharapkan akan memudahkan responden untuk menentukan pilihan jawabannya dengan lebih tegas. Oleh karena itu, penelitian ini akan memfokuskan analisis PLS-SEM pada data biner. Kajian menggunakan data biner ini diharapkan penyusunan kuesioner untuk mengukur skala sikap tidak perlu harus menggunakan skala likert lagi, melainkan menggunakan skala biner. Penyusunan kuesioner yang simpel ini diharapkan akan lebih mudah dan efektif.
Tujuan Penelitian
Tujuan dari penelitian ini adalah mendapatkan model PLS-SEM terbaik dari sistem peningkatan pengetahuan koperasi pada data biner dan membandingkannya dengan data skala likert.
2
TINJAUAN PUSTAKA
Faktor-faktor Penciptaan Pengetahuan dalam Organisasi
Berdasarkan teori Von Krogh et al. (2000) yang dikutip Irsan (2005) dan disitasi oleh Purwanto (2010) menyatakan bahwa terdapat lima faktor dalam penciptaan pengetahuan enabler di sebuah perusahaan atau organisasi:
1. Visi bersama (instill a knowledge vision).
Visi bersama dalam kaitannya dengan penciptaan pengetahuan merupakan tujuan bersama terkait apa yang diinginkan di masa depan, komitmen setiap individu untuk suatu organisasi.
2. Pengelolaan percakapan (manage conversation).
Merupakan suasana pembangun dialog agar tercipta kreasi pengetahuan. Adanya proses saling berbagi pengetahuan yang dilakukan melalui percakapan/interaksi antara orang-orang yang berada di dalam suatu organisasi.
3. Mobilisasi penggerak pengetahuan (mobilize knowledge activists).
Manajer atau pimpinan organisasi bergerak sebagai pemimpin yang melakukan peran sebagai katalis, koordinator, dan visioner untuk menghasilkan pengetahuan perusahaan.
4. Penyediaan lingkungan yang kondusif (create the right context).
4
space, dan mental space, yaitu tempat saling berbagi pengalaman, ide, dan emosi.
5. Penyebaran pengetahuan internal (globalize local knowledge).
Merupakan aktivitas mentransfer pengetahuan lokal yang mencakup
triggering, packaging, dan recreating. Penyerapan pengetahuan oleh para individu dan interaksi sosial yang saling berbagi pengetahuan dalam komunitas pembelajarannya.
Enabler penciptaan pengetahuan dapat meningkatkan kemampuan organisasi dalam menghasilkan inovasi yang kemudian inovasi tersebut dibutuhkan untuk menjaga eksistensi sebuah organisasi.
Model Persamaan Struktural (SEM-Struktural Equation Modeling)
Menurut Roykov dan Marcoulides (2006) SEM adalah metode analisis yang bersifat komprehensif (lengkap) untuk perhitungan dan pengujian teori yang berhubungan dengan pengaruh antar peubah. Analisis SEM dikatakan lengkap karena terdiri atas Analisis Faktor (CFA dan EFA) untuk mengetahui layak atau tidak suatu indikator yang digunakan dalam mengukur suatu peubah laten tertentu berdasarkan teori baku yang sudah ada ataupun yang akan dikembangkan, Regresi Linier Berganda (OLS-ordinary least square) untuk mengetahui seberapa besar hubungan dan seberapa kuat pengaruh antar peubah dengan masing-masing indikatornya, dan Analisis Jalur (path analysis) untuk mengetahui seberapa besar pengaruh langsung dan tidak langsung antar peubah.
Garson (2012) yang dikutip Latan (2013) menyebutkan bahwa SEM adalah teknik analisis multivariat generasi kedua yang menggabungkan analisis faktor dan analisis jalur sehingga memungkinkan peneliti menganalisis dan menguji suatu peubah bebas laten (peubah eksogen) dan peubah terikat laten (peubah endogen) beserta indikator-indikator yang menyertainya secara serentak.
Covariance Based-SEM (CB-SEM) dengan menggunakan fungsi Maximum Likelihood (ML), berusaha meminimumkan perbedaan antara peragam contoh yang diprediksi dengan model teoritis ( ) sehingga proses estimasi menghasilkan matriks peragam dari data yang diestimasi (Ghozali 2008).
Mattjik dan Sumertajaya (2011) mengungkapkan asumsi yang tidak boleh dilanggar ketika menggunakan CB-SEM adalah sebagai berikut:
1. Ukuran contoh yang digunakan minimal 100 contoh atau 5-10 kali parameternya.
2. Sebaran data harus memenuhi asumsi sebaran normal ganda dan hubungan parameter yang diestimasi bersifat linear.
3. Tidak boleh terdapat outlier, yaitu observasi yang muncul dengan nilai-nilai ekstrim dan terlihat sangat jauh berbeda dari observasi-observasi lainnya. 4. Tidak boleh terdapat multikolinieritas dan singularitas antar peubah. Peubah
5
Kuadrat Terkecil Parsial (PLS-Partial Least Square)
Partial Least Squares-Structural Equation Modeling (PLS-SEM) dapat digunakan sebagai konfirmasi teori (theoritical testing) dan merekomendasikan hubungan yang belum ada dasar teorinya (exploratory). Partial Least Squares
menurut Jaya dan Sumertajaya (2008) dapat mengatasi masalah serius diantaranya:
1. Solusi yang tidak dapat diterima (inadmissible solution), yaitu masalah matriks singular tidak akan pernah terjadi. Masalah un-identified, under-identified atau over-identified juga tidak akan pernah terjadi karena PLS bekerja pada model struktural yang bersifat rekursif. Model rekursif adalah model persamaan struktural yang hanya memiliki satu arah hubungan kausal. 2. Masalah faktor yang tidak dapat ditentukan (factor indeterminacy), karena
peubah laten merupakan kombinasi linier dari indikator-indikatornya sehingga selalu akan diperoleh peubah laten yang bersifat komposit.
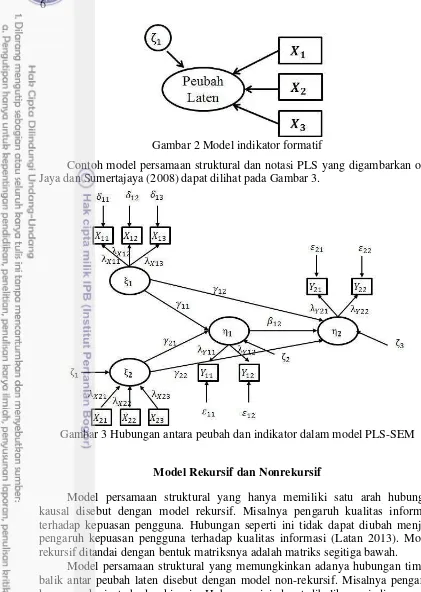
Selain bebas asumsi terkait sebaran data dan tidak memerlukan contoh yang relatif besar yaitu minimal diatas 30, keunggulan PLS-SEM dibandingkan CB-SEM yang lain adalah indikator dari peubah laten dapat berupa model indikator refleksifatau formatif. Model indikator refleksif dan formatif berturut-turut dapat dilihat pada Gambar 1 dan Gambar 2.
Ciri-ciri model indikator refleksif seperti dikemukakan oleh MacKenzie, et al. (2005) adalah:
1. Peubah laten merupakan hasil pencerminan dari indikatornya. 2. Arah hubungan kausalitas dari peubah laten ke indikator.
3. Antar indikator diharapkan saling berkorelasi (memiliki internal consitency reliability).
4. Perubahan pada indikator tidak menyebabkan perubahan pada peubah laten. 5. Menghitung adanya kesalahan pengukuran (error) pada tingkat indikator.
Gambar 1 Model indikator refleksif
Ciri-ciri model indikator formatif seperti dikemukakan oleh MacKenzie, et al. (2005) adalah:
1. Peubah laten dibentuk (disusun) dari indikatornya.
2. Arah hubungan kausalitas seolah olah dari indikator ke peubah laten.
3. Antar indikator diasumsikan tidak berkorelasi (tidak diperlukan uji konsistensi internal atau (Cronbach’s Alpha).
6
Gambar 2 Model indikator formatif
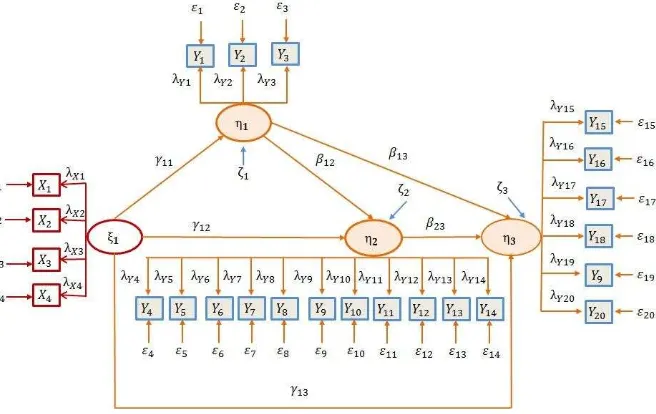
Contoh model persamaan struktural dan notasi PLS yang digambarkan oleh Jaya dan Sumertajaya (2008) dapat dilihat pada Gambar 3.
Gambar 3 Hubungan antara peubah dan indikator dalam model PLS-SEM
Model Rekursif dan Nonrekursif
Model persamaan struktural yang hanya memiliki satu arah hubungan kausal disebut dengan model rekursif. Misalnya pengaruh kualitas informasi terhadap kepuasan pengguna. Hubungan seperti ini tidak dapat diubah menjadi pengaruh kepuasan pengguna terhadap kualitas informasi (Latan 2013). Model rekursif ditandai dengan bentuk matriksnya adalah matriks segitiga bawah.
Model persamaan struktural yang memungkinkan adanya hubungan timbal balik antar peubah laten disebut dengan model non-rekursif. Misalnya pengaruh kepuasan kerja terhadap kinerja. Hubungan ini dapat dibalik menjadi pengaruh kinerja terhadap kepuasan kerja (Latan 2013).
Spesifikasi Model
7 1. Model Struktural (inner model/ inner relation)
Menggambarkan hubungan antar peubah laten berdasarkan teori yang sesungguhnya (substantive theory). Bollen (1989), Ghozali (2008), Dijkstra (2010) menuliskan model persamaan struktural sebagai berikut:
(1)
Keterangan:
: Vektor peubah laten endogen : Vektor peubah laten eksogen
: Vektor residual (unexplained variance)
Ghozali (2008) menerangkan PLS dirancang untuk model rekursif (model persamaan struktural yang hanya mempunyai satu arah kausalitas) sehingga hubungan antar peubah laten endogen ( ) atau yang disebut sebagai causal chain system dari peubah laten dapat didefinisikan sebagai berikut:
Sebagai contoh, spesifikasi model struktural dari Gambar 3 dapat dituliskan sebagai berikut:
atau dapat juga disajikan dalam bentuk matriks
( ) ( ) ( )
Persamaan tersebut menunjukkan contoh sederhana dari causal chain system karena peubah laten endogen hanya memiliki hubungan satu arah. Hal ini dibuktikan dari koefisien peubah laten endogen, yaitu matriks yang membentuk matriks segitiga bawah dengan elemen diagonalnya nol. Model seperti ini disebut dengan model rekursif.
2. Model Pengukuran (outer model/ outer relation)
Model pengukuran menerangkan hubungan antara peubah laten dengan indikatornya. Ghozali (2008) menuliskan persamaan untuk model indikator refleksif sebagai berikut:
(3)
Keterangan:
: Indikator untuk peubah laten eksogen : Indikator untuk peubah laten endogen : Peubah laten eksogen
: Peubah laten endogen
, : Matriks loading sebagai koefisien regresi sederhana yang menghubungkan antara peubah laten dengan indikatornya
8
Sebagai contoh model pengukuran pada Gambar 3 dapat dituliskan sebagai berikut:
: Lambda (kecil), faktor loading peubah laten eksogen : Lambda (kecil), faktor loading peubah laten endogen : Lambda (besar), matriks loading peubah laten eksogen : Lambda (besar), matriks loading peubah laten endogen
: Beta (kecil), koefisien pengaruh peubah endogen terhadap peubah endogen
: Gamma (kecil), koefisien pengaruh peubah eksogen terhadap peubah endogen
: Zeta (kecil), galat model
: Delta (kecil), galat pengukuran pada peubah manifes untuk peubah laten eksogen
: Epsilon (kecil), galat pengukuran pada peubah manifes untuk peubah laten endogen
Persamaan untuk model indikator formatif yang dituliskan Ghozali (2008) adalah sebagai berikut:
(4)
dengan dan adalah seperti koefisien regresi berganda dari peubah laten terhadap indikator. dan merupakan vektor residual dari regresi. 3. Weight Relation
Ghozali (2008) weight relation memungkinkan nilai kasus dari peubah laten dapat diestimasi. Diasumsikan bahwa peubah laten dan indikator diskala zero means dan unit variance (nilai standardize) tanpa kehilangan generalisasinya. Nilai kasus pada setiap peubah laten diestimasi dalam PLS sebagai berikut:
∑
9
Bobot ke-k yang membentuk estimasi peubah laten Bobot ke-k yang membentuk estimasi peubah laten
Evaluasi Model
PLS-SEM dapat digunakan untuk jenis indikator refleksif maupun formatif. Model pengukuran untuk indikator refleksif dapat dievaluasi dengan validitas konvergen, validitas diskriminan, dan reliabilitas. Validitas konvergen dapat dilihat berdasarkan nilai loading factor dan Average Variance Extracted (AVE). Nilai loading factor lebih dari 0.7 dianggap bagus, namun demikian untuk pengembangan model nilai loading factor diatas 0.5 sudah dianggap cukup. Peniliaian konvergen validitas berdasarkan nilai AVE, memiliki nilai cut off 0.5. Nilai AVE diatas 0.5 menyatakan bahwa validitas konvergen dari indikator baik. Validitas diskriminan dapat dilihat dengan membandingkan loading factor dengan
cross loading-nya. Loading factor diharapkan lebih besar daripada cross loading -nya. Validitas diskriminan juga dapat dinilai dengan cara membandingkan nilai akar kuadrat AVE dengan korelasi antar peubah laten. Nilai akar kuadrat AVE juga diharapkan lebih besar dari korelasi antar peubah latennya. Hal ini menandakan bahwa indikator dalam suatu peubah laten baik untuk mengukur peubah laten tersebut daripada untuk mengukur peubah laten lainnya (Ghozali 2008). Reliabilitas diukur berdasarkan nilai Composite Reliablity dan Cronbach’s
Alpha. Keduanya memiliki nilai cut off sama, yaitu diatas 0.7 (Ghozali 2008). Chin (1998) yang disitasi oleh Ghozali (2008), Model pengukuran formatif, dievaluasi berdasarkan substantive content-nya yaitu dengan membandingkan besarnya relatif weight dan melihat signifikansi dari ukuran weight tersebut.
Model struktural dievaluasi dengan menggunakan nilai R-square untuk peubah laten endogen dan dengan melihat nilai Stone-Geisser Q-square Test. Selain itu juga dapat dilihat berdasarkan signifikansi dari koefisien jalurnya. Signifikansi koefisien jalur diuji dengan statistik uji t yang diperoleh dari metode
Resampling Bootstrapping (Ghozali 2008).
Resampling Bootstrapping
Pengujian hipotesis pada PLS-SEM dilakukan dengan statistik uji t yang diperoleh melalui prosedur resampling bootsrapping. Bootstrap pertama kali diperkenalkan oleh Bradley Efron (1979). Bootstrap merupakan teknik
resampling nonparametrik yang digunakan untuk memperkirakan standar error dan selang kepercayaan dari parameter seperti rata-rata, median, proprsi, koefisien regresi dan koefisien korelasi tanpa menggunakan asumsi distribusi (Efron dan Tibshirani 1993). Prosedur Bootstrap dilakukan dengan mengambil contoh dari contoh asli yang ukurannnya sama dengan contoh asli tersebut dengan pengembalian. Contoh asli ini dianggap sebagai populasi dalam prosedur
10
Partial Least Square-SEM tidak mengasumsikan data menyebar normal ganda sehingga pengujian hipotesis secara parametrik tidak dapat dilakukan. Prosedur resampling bootsrapping yang merupakan teknik resampling
nonparametrik, menjadi alternatif dalam melakukan pengujian hipotesisnya (Hair
et. al. 2011).
11
3
METODE
Data
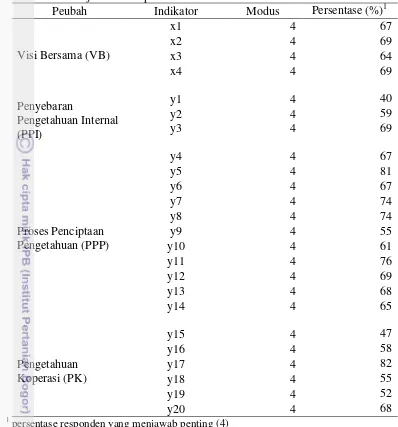
Data yang digunakan merupakan data sekunder yang diperoleh dari laporan tim riset Departemen Ekonomi dan Manajemen (FEM) IPB. Data diperoleh melalui wawancara terstruktur yang ditujukan kepada peternak sapi, karyawan koperasi dan pengurus koperasi di beberapa koperasi susu yang tergabung dalam Gabungan Koperasi Susu Indonesia (GKSI) dan sebagai pemasok di Industri Pengolahan Susu (IPS). Kuesioner adalah skala likert terdiri dari 24 pertanyaan yang merupakan indikator dari visi bersama, penyebaran pengetahuan internal, pengetahuan koperasi, dan proses penciptaan pengetahuan. Kuesioner dibuat menggunakan skala likert dimana 1 menunjukkan Sangat Tidak Penting (STP), 2 Tidak Penting (TP), 3 Ragu-ragu (R), 4 Penting (P) dan 5 Sangat Penting (SP). Daftar peubah dapat dilihat pada Tabel 1. Kuesioner penelitian dapat dilihat pada Lampiran 1.
Tabel 1 Peubah-peubah endogen dan eksogen beserta indikator-indikatornya
Peubah Laten Indikator
: Membangun komunikasi dengan bidang dipihak pelanggan
: Saling berbagi pengetahuan : Kerjasama antar karyawan
: Memberi informasi yang dibutuhkan kepada teman dari koperasi lain
: Memberi informasi yang dibutuhkan kepada pakar
Pengetahuan Koperasi
: Berteknologi tinggi : Lebih baik dari pesaing
: Keunggulan berdasarkan pengetahuan : Jarang dimiliki koperasi lain
: Sulit ditiru pesaing
12
Metode Penarika Contoh
Metode penarikan contoh yang digunakan oleh tim riset Departemen Ekonomi dan Manajemen (FEM) IPB adalah multi stage random sampling. Pertama memilih koperasi yang merupakan anggota GKSI, sebagai pemasok susu ke IPS, dan kesediaan koperasi untuk dilakukan penelitian. Pengambilan data dilakukan pada enam koperasi yang tersebar di wilayah Jawa Barat, Jawa Tengah, Yogyakarta, dan Jawa Timur dengan jumlah responden sebanyak 102 responden. Selanjutnya, pemilihan responden pada masing-masing koperasi dilakukan melalui teknik penarikan contoh acak sederhana (Simple Random Sampling). Metode penarikan contoh acak sederhana ini diharapkan akan memperoleh contoh yang representatif.
Gambar 4 Teknik penarikan contoh (Multistage random sampling)
Analisis Data
1. Mendeskripsikan data untuk memperoleh gambaran umum tentang responden yang meliputi deskripsi responden berdasarkan jenis kelamin dan deskripsi terkait sebaran jawaban responden.
2. Mengatasi data tidak lengkap dengan menggunakan metode imputasi, yaitu proses pengisian data-data yang hilang dengan nilai yang memungkinkan berdasarkan informasi yang ada. Berdasarkan Malahayati (2008) metode imputasi ganda regresi menghasilkan penduga data hilang yang lebih baik daripada metode Predictive Mean Matching (PMM). Oleh karena itu, penelitian ini akan menggunakan metode imputasi ganda regresi.
3. Mengubah skala data likert menjadi biner. Jawaban 1, 2 dan 3 menjadi 0 yang menyatakan tidak penting sedangkan jawaban 4 dan 5 diubah menjadi 1 yang menyatakan penting. Transformasi skala data ini dilakukan berdasarkan kebijakan peneliti.
4. Melakukan Pemodelan PLS-SEM pada skala likert dan biner dengan tahapan sebagai berikut:
a. Konseptualisasi model meliputi merancang model struktural dan model pengukuran.
13 pengetahuan , dan pengetahuan koperasi . Berdasarkan teori diketahui bahwa: dipengaruhi oleh ; dipengaruhi oleh dan
; dan dipengaruhi oleh , , dan .
Perancangan model pengukuran menjadi sangat penting dalam pemodelan PLS-SEM. Hal ini bertujuan untuk mengetahui apakah indikator bersifat refleksif atau formatif. Dalam penelitian ini semua indikator diasumsikan bersifat refleksif.
b. Mengkonstruksi diagram jalur.
Ketika perancangan model struktural dan model pengukuran sudah dilakukan, maka selanjutnya dinyatakan dalam bentuk diagram jalur seperti Gambar 5. Mengkonstruksi ke dalam diagram jalur ini dimaksudkan agar hasilnya lebih mudah dipahami.
Gambar 5 Kerangka teoritis model pengetahuan koperasi c. Konversi diagram jalur ke dalam sistem persamaan.
Model pengukuran d. Estimasi: weight, loading, dan rata-rata dan konstanta.
Tahap 1 estimasi bobot (weight estimate)
14
dan (6), yang digunakan untuk menciptakan skor peubah laten. Peubah laten adalah linear agregat dari indikator yang nilai bobotnya diperoleh dari metode PLS.
Afifah dan Sunaryo (2010) mengemukakan bahwa peubah eksogen pada tipe indikator refleksif, bobot merupakan koefisien regresi dari dan adalah peubah yang distandarkan dari persamaan berikut:
(7) Proses iterasi, akan selesai ketika sudah konvergen, yaitu dengan batas:
Tahap 2 estimasi rata-rata dan lokasi parameter (konstanta).
Lokasi parameter adalah konstanta untuk peubah laten endogen sedangkan rata-rata ̂ untuk peubah laten eksogen.
e. Evaluasi model (Goodness of fit).
Proses pendugaan yang dilakukan pada penelitian ini menggunakan pendekatan untuk data kontinu, yaitu Ordinary Least Square (OLS) sehingga kriteria kebaikan model yang digunakan mengikuti proses pendugaan parameter pada data kontinu. Pendekatan ini mengandung kelemahan, yaitu kriteria kebaikan model yang meliputi nilai Khi-Kuadrat, RMSEA, dan SRMR tidak dapat digunakan karena asumsi yang digunakan untuk membangun kriteria kebaikan model tersebut tidak terpenuhi. Namun demikian, dalam penelitian ini tetap menggunakan pendekatan tersebut, karena dalam beberapa kasus skala likert dan biner bisa juga diperlakukan sebagai data numerik, dimana jika kategori yang satu lebih tinggi dibanding kategori lainnya. Skala likert pada penelitian ini terdapat lima titik pilihan jawaban, dimana kategori 5 lebih tinggi dibanding 4, 3, 2, dan 1. Skala biner juga demikian bahwa kategori 1 lebih tinggi daripada kategori 0.
Model Pengukuran
Model pengukuran menggambarkan bagaimana indikator merepresentasikan peubah latennya. Hal ini dapat diukur dengan menguji validitas dan reliabilitasnya.
Validitas Konvergen
15 peubah laten seharusnya berkorelasi tinggi. Validitas Konvergen dapat ditentukan melalui nilai loading factor. Nilai loading factor
0.5 dianggap cukup pada jumlah indikator per peubah laten tidak besar antara 3 sampai 7 indikator (Jaya dan Sumertajaya 2008). Validitas Konvergen juga dapat dilihat dari nilai Average Variance Extracted (AVE). Nilai AVE diatas 0.5 menandakan indikator memiliki nilai Validitas Konvergen yang baik.
Validitas Diskriminan
Latan (2013) mengungkapkan Validitas Diskriminan berhubungan dengan prinsip bahwa indikator dari peubah laten yang berbeda tidak memiliki korelasi yang tinggi. Validitas Diskriminan digunakan untuk mengukur keragaman peubah laten yang dapat dijelaskan oleh model. Nilai Validitas Diskriminan yang tinggi mengindikasikan bahwa suatu peubah laten itu unik. Cara mengukur Validitas Diskriminan adalah dengan membandingkan akar kuadrat AVE untuk setiap peubah laten dengan korelasi antar peubah laten dalam model. Latan (2013), Ghozali (2008), serta Jaya dan Sumertajaya (2008) nilai akar kuadrat AVE yang lebih besar dari korelasi antar peubah laten dalam model, mengindikasikan bahwa indikator memiliki Validitas Diskriminan yang baik. Formula AVE adalah
∑
∑ ∑ (11)
Reliabilitas
Ukuran reliabilitas dapat dilihat berdasarkan nilai Composite Reliability. Composite Reliability merupakan reliability
gabungan untuk mengukur reliabilitas setiap peubah laten dan menunjukkan stabilitas serta kekonsistenan dari suatu pengukuran. Nilai sudah dianggap cukup baik. Latan (2013), Ghozali (2008), serta Jaya dan Sumertajaya (2008) menuliskan formula adalah
∑ ∑ ∑ (12)
Pengujian reliabilitas juga dapat dilakukan dengan melihat nilai Cronbach’s Alpha . Nilai dianggap bahwa indikator memiliki reliabilitas yang baik. Cronbach (1951) menuliskan rumus Cronbach’s Alpha sebagai berikut:
∑ ( )
∑ ( )
(13)
dengan adalah jumlah indikator dan adalah blok indikator. Model Struktural
R-Square
16
Nilai koefisien determinasi yang mendekati 1 mengindikasikan semakin banyaknya keragaman yang dapat dijelaskan oleh peubah endogen untuk menjelaskan peubah eksogen. Bollen (1989) merumuskan nilai sebagai berikut:
̂ (14)
̂ merupakan nilai varian yang dapat diprediksi oleh model. f-Square
Berdasarkan Ghozali (2008) f-Square merupakan effect size
yang digunakan untuk menilai pengaruh peubah laten eksogen tertentu terhadap peubah laten endogen apakah mempunyai pengaruh yang substantif. Formula f-square dituliskan sebagai berikut:
(15)
dan adalah dari peubah laten endogen ketika indikator dari peubah laten tersebut digunakan atau dikeluarkan dari persamaan struktural.
Cohen (1988) yang disitasi oleh Akter et al. (2011) dan Götz
et al. (2010) memberikan tiga kategori nilai koefisien determinasi dan f-square yang dapat dilihat pada Tabel 2.
Tabel 2 Kriteria R-square dan f-square
R-square f-square Keterangan
0.26 0.35 Kuat
0.13 0.15 Medium
0.02 0.02 Lemah
Q-Square Predictive Relevance
Uji kabaikan pada model struktural diukur menggunakan nilai R-square yang interpretasinya sama dengan regresi. Kemudian untuk menguji kebaikan model struktural secara keseluruhan diukur menggunakan nilai Q-square predictive relevance.
( ) (16)
dengan merupakan nilai R-square pada peubah endogen. Nilai berkisar antara 0 sampai 1. Nilai yang semakin mendekati 1 berarti model semakin prediktif (Jaya dan Sumertajaya 2008). Chin (2010) menerangkan bahwa nilai
sudah dapat dikatakan model memiliki tingkat predictive relevance yang baik.
Khi-kuadrat
Nilai Khi-Kuadrat menunjukkan adanya penyimpangan antara matriks peragam contoh dengan matriks peragam model,
17 matriks peragam yang diobservasi dengan model yang diprediksi. Nilai Khi-Kuadrat diharapkan tidak signifikan agar model yang diperoleh sesuai. Nilai Khi-Kuadrat dapat dihitung melalui rumus
, dimana adalah jumlah contoh dan adalah
minimum of the fit function. Hal ini seperti yang dikemukaan oleh Latan (2013), Hooper et al. (2008) dan Bollen (1989). Nilai F akan berbeda-beda tergantung pada metode pendugaannya.
| | ( ) | | (17) Rumus 16 diatas adalah nilai F untuk metode pendugaan
Maximum Likelihood (ML). adalah jumlah indikator peubah laten endogen dan adalah jumlah indikator peubah laten eksogen . Σ(θ) adalah matrik peragam model yang merupakan fungsi
dari parameter model bebas dalam θ.
Root Mean Square Error of Approximation (RMSEA)
Latan (2013) dan Hooper et al. (2008) mengemukakan bahwa RMSEA merupakan ukuran fit model yang sering digunakan pada penelitian SEM. Hal ini disebabkan karena RMSEA tidak tergantung dari besarnya jumlah contoh dan tidak overestimate atau
underestimate. RMSEA dapat mengukur penyimpangan nilai parameter suatu model dengan matriks peragam populasinya. Nilai RMSEA mengindikasikan model cukup baik. Engel et al. (2003) menuliskan RMSEA secara matematis sebagai berikut:
{( ) } (18)
(derajat bebas), diperoleh dari dengan adalah jumlah parameter yang diestimasi.
Standardise Root Mean square Residual (SRMR)
SRMR merupakan akar kuadrat dari selisih residual matriks peragam contoh dengan matriks peragam model. Nilai SRMR berkisar antara 0 sampai 1. Nilai SRMR sama dengan 0 mengindikasikan model sempurna. Model dianggap cukup baik jika nilai SRMR . Nilai SRMR cenderung kecil apabila model dibangun berdasarkan sejumlah contoh yang besar (Hooper et. al. 2008).
Goodness of Fit Index
Tenenhaus et. al. (2004), Akter et. al. (2011), Henseler and Sarstedt (2013), serta Hussein (2015) menyarankan menggunakan
Goodness of Fit Index (GoF). Berbeda dengan CB-SEM, nilai GoF
pada PLS-SEM harus dihitung manual berdasarkan rumus berikut.
18
Hipotesis statistik untuk model struktural, pengaruh peubah eksogen terhadap peubah endogen.
: lawan :
Hipotesis statistik untuk model struktural, pengaruh peubah endogen terhadap peubah endogen lainnya.
: lawan :
5. Membandingkan model terbaik dari data likert dan biner berdasarkan kriteria kebaikan model pengukuran dan model struktural yaitu: Validitas Konvergen, Validitas Diskriminan, reliabilitas, R-square, f-square, Q-square, RMSEA, Khi-Kuadrat, SRMR, dan Goodness of Fit index .
Gambar 6 adalah diagram alir untuk tahapan analisis yang telah dilakukan.
19
4
HASIL DAN PEMBAHASAN
Koperasi Susu Indonesia
Koperasi susu di Indonesia merupakan jenis koperasi produksi yang anggotanya adalah para peternak sapi perah di suatu wilayah tertentu. Penelitian ini melibatkan beberapa koperasi diantaranya Koperasi Peternak Sapi Bandung Utara (KPSBU), KUD Jatinom Klaten, KUD Cepogo Boyolali, KUD Warga Mulya Sleman, KUD Musuk Boyolali dan Koperasi SAE Pujon Malang. Koperasi-koperasi tersebut tergabung dalam Gabunagn Koperasi Susu Indonesia (GKSI). Koperasi Susu Indonesia berperan sebagai penampung hasil susu perah dari peternak, pemberi layanan input produksi, dan langsung mendistribusikan susu tersebut ke Industri pengolahan Susu (IPS). Sistem kerjasama seperti ini di Indonesia disebut dengan sistem cluster. Daerah penghasil sapi perah dan susu murni di Indonesia terpusat di Pulau Jawa. Ada 25 Koperasi dan KUD Persusuan yang menjadi anggota GKSI Wilayah Jawa Barat yang tersebar di beberapa Kabupaten/Kota, diantaranya (GKSI Jawa Barat 2007).
Daerah penghasil susu lainnya di pulau Jawa yang tidak kalah besarnya adalah Kabupaten Boyolali, Jawa Tengah. Boyolali yang dikenal sebagai kota susu merupakan sentra susu di Provinsi Jawa Tengah. Sentra peternak sapi di Boyolali berpusat di Kecamatan Cepogo dan mampu menghasilkan total produksi susu sapi sebanyak 30500 juta liter per tahun (Berita Daerah Jawa 2014). Badan Pusat Statistik Jawa Tengah (2015) menyatakan banyaknya koperasi susu di Jawa Tengah sampai Maret 2016 adalah sebanyak 22 koperasi dengan populasi ternak sebanyak 140410 ekor.
Profil Beberapa Koperasi Susu Indonesia
Koperasi Peternak Sapi Bandung Utara (KPSBU)
Koperasi Peternak Sapi Bandung Utara (KPSBU) berdiri pada tahun 1971. Pada tahun 2013, KPSBU memiliki jumlah anggota sebanyak 7264 (7015 peternak dan 249 karyawan koperasi). Peternak laki-laki berjumlah 5993 orang dan peternak perempuan sebanyak 1022 orang serta memiliki jumlah sapi sampai pada tahun 2015 adalah sebanyak 18583 ekor dengan total produksi susu 48821568 ton liter (GKSI Jawa Barat 2016). Koperasi Peternak Sapi Bandung Utara terletak di Komplek Pasar panorama Lembang, Kecamatan Lembang, Kabupaten Bandung Barat, Jawa Barat 40391.
Koperasi Unit Desa (KUD) Musuk Boyolali
20
Koperasi Unit Desa (KUD) Cepogo Boyolali
Pada tahun 2007 dan 2008 anggota KUD Cepogo ada sebanyak 4074 orang. Produksi susu KUD Cepogo dari tahun ke tahun mengalami kemunduran. Hal ini terlihat dari tahun 2004, KUD ini mampu menghasilkan susu sebanyak 3201318 liter, tahun 2005 sebanyak 2645536 liter, tahun 2006 ada sebanyak 2345953 liter, pada tahun 2007 menghasilkan susu sebanyak 2204000 liter. Namun pada tahun 2008 mengalami sedikit peningkatan produksi susu dengan susu yang dihasilkan pada tahun ini ada sebanyak 3076560 liter.
Koperasi Unit Desa (KUD) Warga Mulya Sleman
Koperasi Warga Mulya berdiri pada tanggal 30 Januari 1979 dan bergerak dibidang Agroindustri, salah satunya adalah usaha pembuatan produk susu. Koperasi Warga Mulya beralamat di Jalan Palagan Tentara Pelajar, Bunder, Purwobinangun, Pakem, Sleman, Yogyakarta. Anggota koperasi pada tahun 2006 ada sebanyak 1285 orang dan 1275 pada tahun 2007.
Koperasi SAE (Sinau Andandani Ekonomi) Pujon Malang
Koperasi SAE berdiri pada tanggal 30 Oktober 1962 dengan 22 anggota, 35 sapi perah dan produksi susu 50 liter pada awal berdirinya. Pada saat ini Koperasi SAE memiliki jumlah anggota 7967 dengan 24218 sapi perah dan mampu memproduksi 36284145 liter susu. Alamat koperasi SAE Pujon adalah di Jalan Brigjen Abdul Manan Wijaya No. 16, Ngroto, Pujon, Malang, Jawa Timur.
Koperasi Unit Desa (KUD) Jatinom Klaten
Koperasi Unit Desa (KUD) Jatinom berdiri pada tanggal 1974 di Desa Krajan, kecamatan tulung, Kabupaten Klaten, Jawa Tengah. Tahun 2007 jumlah anggota KUD Jatinom Klaten ada sebanyak 6594 orang dan pada tahun 2008 jumlah anggotanya berkurang sebanyak 34 orang. Pada tahun 2008 KUD Jatinom mampu memproduksi susu sebanyak 2281321 liter.
Analisis Deskriptif
Analisis deskriptif yang dilakukan meliputi deskripsi responden berdasarkan jenis kelamin dan sebaran jawaban responden.
Tabel 3 Responden berdasarkan jenis kelamin
Frekuensi Persentasi (%) Presentase Komulatif (%)
Laki-laki 63 62.76 62.76
Perempuan 39 38.24 100
Total 102 100
21 Tabel 4 Sebaran jawaban responden
Peubah Indikator Modus Persentase (%)1
Visi Bersama (VB)
Berdasarkan Tabel 4 dapat disimpulkan bahwa hampir seluruh responden menjawab penting (4) untuk semua indikator pada tiap peubah. Hal ini dilihat dari nilai persentase responden yang menjawab 4. Hampir semua persentase responden yang menjawab 4 diatas 50%.
Pendugaan Data Hilang
Secara keseluruhan, responden yang mengisi kuesioner dibawah ada sebanyak 4 responden. Responden yang mengisi kurang dari akan dihapus dari penelitian karena akan mengganggu proses pendugaan data tidak lengkap. Jumlah responden pada awalnya adalah 102, setelah dikurangi 4 menjadi 98 responden. Ke-98 responden ini akan digunakan sebagai analisis PLS-SEM dengan terlebih dahulu menduga data yang tidak lengkap.
22
untuk menduga data hilang dengan meregresikan kedua indikator tersebut. Indikator yang lengkap akan dijadikan peubah bebas pada analisis regresi sederhana. Berdasarkan korelasi tertinggi dan indikator yang lengkap pendugaan data hilang diterapkan pada indikator-indikator yang dapat dilihat pada Tabel 5. Tabel 5 Penerapan analisis regresi sederhana antar indikator untuk menduga data
tidak lengkap
Peubah Analisis Regresi Sederhana Korelasi
Visi bersama X1 vs X3
Proses penciptaan pengetahuan Y4 vs Y5
Y4 vs Y6 Indikator Y19 diduga dengan menggunkan indikator Y16 karena korelasi Y19 lebih tinggi terhadap Y16 daripada terhadap Y15. Indikator Y4 diduga menggunakan indikator Y6 dan indikator Y11 diduga dengan indikator Y12. Nilai korelasi antar indikator selengkapnya dapat dilihat pada Lampiran 1.
Analisis PLS-SEM
Analisis PLS-SEM dilakukan dengan menggunakan perangkat lunak
SmartPLS 3. Hasil analisis yang disajikan adalah berupa diagram jalur dengan nilai loading factor, persamaan model pengukuran dan model struktural, dan perbandingan model skala likert dan biner.
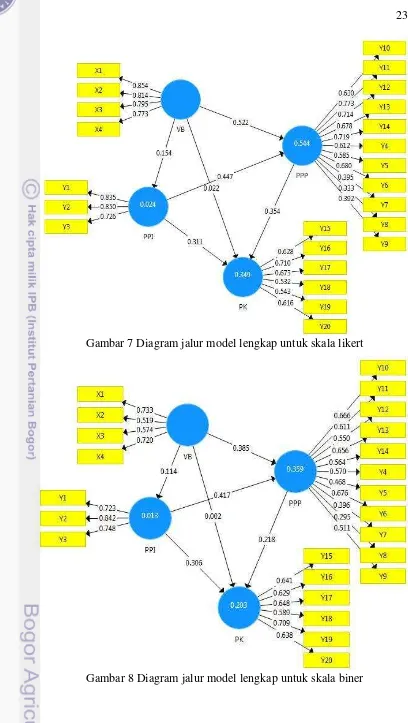
Gambar 7 dan 8 memberikan informasi berupa nilai loading factor. Nilai
loading factor yang tinggi mengindikasikan bahwa tiap indikator dalam sebuah peubah laten konvergen pada satu titik. Nilai loading factor diatas 0.6 dianggap bahwa indikator cukup baik digunakan untuk mengukur peubah latennya. Berdasarkan Gambar 7, terdapat 4 indikator pada peubah proses penciptaan pengetahuan yang tidak valid, yaitu Y5, Y7, Y8, dan Y9. Terdapat 2 indikator yang tidak valid pada peubah pengetahuan koperasi, yaitu Y18 dan Y19. Peubah visi bersama dan penyebaran pengetahuan internal semua indikatornya valid.
23
Gambar 7 Diagram jalur model lengkap untuk skala likert
24
Model pengukuran dan model struktural untuk Gambar 7 dapat dibentuk dengan memanfaatkan nilai loading factor. Berikut ini akan dituliskan persamaan model pengukuran dan model struktural untuk Gambar 7.
Model pengukuran
Model pengukuran dan model struktural untuk Gambar 8 dapat dituliskan sebagai berikut.
Perbandingan PLS-SEM Skala Likert dan PLS-SEM data Biner
25
Model Pengukuran
1. Validitas Konvergen
Validitas konvergen berprinsip bahwa indikator-indikator dalam satu peubah laten haruslah memiliki korelasi yang lebih tinggi. Pada penelitian ini akan dinilai validitas konvergen melalui nilai loading factor dan AVE. Loading factor
Nilai loading factor skala likert dan biner disajikan dalam Gambar 7 dan Gambar 8. Pada skala likert terdapat 6 indikator yang tidak valid (nilai loading factor kurang dari 0.6). Indikator yang tidak valid ini adalah sebanyak 4 dari peubah PPP dan 2 dari peubah PK. Data biner memiliki 11 indikator yang tidak valid (2 indikator dari peubah VB, 7 indikator dari peubah PPP, dan 2 dari peubah PK). Skala likert memberikan ukuran validitas yang lebih baik daripada data biner berdasarkan nilai loading factor. Hal ini terlihat dari banyaknya indikator pada skala likert yang valid daripada indikator pada data biner. Nilai AVE
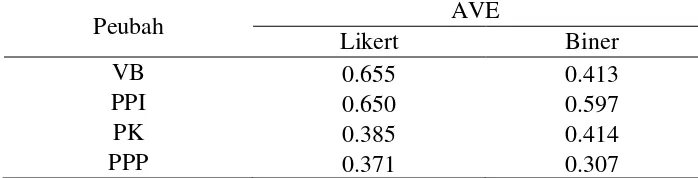
Nilai AVE menggambarkan seberapa besar keragaman peubah laten yang dapat dijelaskan oleh model pengukuran. Nilai AVE sebesar 0.5 menerangkan bahwa model cukup baik. Skala Likert memberikan nilai AVE pada masing-masing peubah laten yang lebih baik daripada data biner. Hal ini ditunjukkan dari nilai AVE yang berada dibawah standar data biner lebih banyak daripada skala likert. Besarnya nilai AVE dapat dilihat pada Tabel 7 berikut:
Tabel 6 Nilai AVE untuk Skala Likert dan Skala Biner
26
Berdasarkan kedua kriteria (loading factor dan nilai AVE) dalam mengukur validitas konvergen diperoleh kesimpulan yang berbanding lurus. Indikator yang tidak valid berdasarkan kriteria loading factor
terdapat pada peubah-peubah yang nilai AVE-nya kurang dari 0.5 baik untuk skala likert maupun biner.
2. Validitas Diskriminan
Validitas diskriminan berprinsip bahwa korelasi antara indikator-indikator yang berada pada peubah laten yang berbeda tidak boleh tinggi. Pada penelitian ini pengukuran validitas diskriminan dilakukan berdasarkan nilai cross loading dan akar kuadrat AVE.
Nilai cross loading
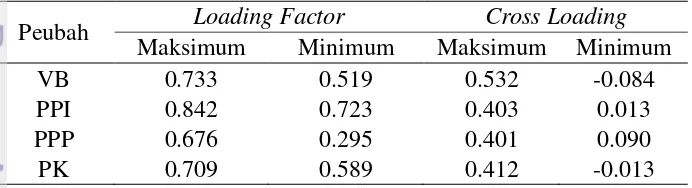
Menilai validitas diskriminan menggunakan cross loading
dilakukan dengan cara membandingkan loading factor tiap indikator dengan nilai cross loading-nya. Indikator memiliki nilai validitas konvergen yang baik jika loading factor lebih besar nilainya dibanding
cross loading-nya. Tabel 7 dan 8 adalah nilai maksimum dan minimum
cross loading dan loading factor pada data skala likert dan biner. Tabel 7 Nilai cross loading skala likert
Peubah Loading Factor Cross Loading
Maksimum Minimum Maksimum Minimum
VB 0.854 0.773 0.625 0.000 yang masih lebih besar dibandingkan nilai maksimum cross
loading-nya. Peubah laten memprediksi indikator pada blok mereka lebih baik dibandingkan dengan indikator di blok yang lain.
Terdapat tiga indikator pada peubah PPP yang nilai loading factor-nya lebih kecil dari nilai cross loading-nya yaitu; Y13, Y14, dan Y15 (nilai cross loading skala likert selengkapnya dapat dilihat pada Lampiran 2). Hal ini berarti bahwa peubah laten tidak baik untuk memprediksi indikator-indikator tersebut. Indikator-indikator ini juga merupakan indikator yang tidak valid berdasarkan kriteria validitas konvergen.
Tabel 8 Nilai cross loading skala biner
Peubah Loading Factor Cross Loading
Maksimum Minimum Maksimum Minimum
VB 0.733 0.519 0.532 -0.084
PPI 0.842 0.723 0.403 0.013
PPP 0.676 0.295 0.401 0.090
27 Y12. Peubah PPP memiliki dua indikator yang nilai loading factor-nya lebih kecil daripada cross loading-nya, yaitu Y7 dan Y8. Nilai cross loading untuk skala biner selengkapnya dapat dilihat pada Lampiran 3. Nilai akar kuadrat AVE
Membandingkan nilai akar kuadrat AVE dengan korelasi antar peubah laten juga dapat digunakan dalam penilaian validitas diskriminan. Kriterianya adalah, apabila nilai akar kuadrat dari AVE lebih besar daripada korelasi antar peubah laten, berarti indikator-indikator tersebut memiliki validitas konvergen yang baik. Nilai akar AVE pada Tabel 9 dan Tabel 10 adalah angka yang dicetak tebal pada tiap diagonalnya. Selain angka yang dicetak tebal adalah nilai korelasi antar peubah laten.
Tabel 9 Nilai akar kuadrat AVE Skala Likert
PK PPI PPP VB
PK 0.620
PPI 0.501 0.806
PPP 0.531 0.528 0.609
VB 0.279 0.154 0.591 0.809
Berdasarkan Tabel 9 dapat disimpulkan bahwa indikator-indikator pada skala likert semuanya memiliki ukuran validitas diskriminan yang baik. Hal ini dapat dilihat berdasarkan nilai akar kuadrat AVE yang semuanya lebih besar nilainya daripada korelasi antar peubah laten. Tabel 10 Nilai akar kuadrat AVE Skala Biner
PK PPI PPP VB
PK 0.643
PPI 0.406 0.773
PPP 0.359 0.460 0.554
VB 0.131 0.114 0.433 0.643
Tabel 10 menjelaskan bahwa indikator-indikator pada data biner semuanya memiliki ukuran validitas diskriminan yang baik. Hal ini dapat dilihat berdasarkan nilai akar kuadrat AVE yang semuanya lebih besar nilainya daripada korelasi antar peubah laten.
3. Ukuran Reliabilitas
Reliabilitas menunjukkan kekonsistenan suatu indikator untuk mengukur peubah laten. Pada penelitian ini ukuran reliabilitas dilakukan berdasarkan Composite Reliability dan Cronbach’s Alpha. Nilai Composite Reliability dan Cronbach’s Alpha yang lebih besar dari 0.7 menunjukkan bahwa indikator tersebut andal untuk mengukur peubah latennya.
Akar kuadrat AVE
28
Tabel 11 Ukuran kesesuaian model pengukuran
Peubah Laten Composit Reliability Cronbach's Alpha
Likert Biner Likert Biner
VB 0.884 0.734 0.824 0.543
PPI 0.847 0.816 0.734 0.669
PK 0.777 0.809 0.703 0.726
PPP 0.860 0.823 0.823 0.770
Secara keseluruhan, baik data skala Likert maupun biner semuanya menunjukkan nilai Composit reliability yang baik, begitu juga dengan nilai
Cronbach's Alpha. Hanya saja, nilai Composit Reliability dan Cronbach's Alpha pada skala biner menunjukkan nilai yang lebih kecil daripada skala likert.
Model Struktural
Uji kebaikan model pada model struktural adalah berdasarkan nilai R-square, f-square, Q-square, dan Goodness of Fit index (GoF), Khi-Kuadrat, RMSEA, dan SRMR. Perangkat lunak smartPLS hanya menampilkan uji kebaikan model pada model struktural yaitu nilai R-square, f-square, dan SRMR. Nilai Q-square, GoF, Khi-kuadrat, dan RMSEA harus menghitung secara manual berdasarkan informasi yang ada. Nilai R-square, f-square, dan Q-square yang mendekati 1 mengindikasikan model semakin baik.
1. R-square
Nilai R-square digunakan untuk mengukur keeratan hubungan antar peubah endogen. Tabel 12 berikut ini adalah nilai R-square keluaran dari perangkat lunak smartPLS 3.
Tabel 12 Nilai R-square pada data skala likert dan data skala biner
Likert Keterangan Biner Keterangan
PPI 0.025 Lemah 0.013 Lemah
PK 0.306 Kuat 0.203 Kuat
PPP 0.544 Kuat 0.359 Kuat
Berdasarkan Tabel 12, dapat diinterpretasikan bahwa hanya sebesar 2.5% keragaman peubah laten eksogen yang mampu menjelaskan peubah PPI pada skala likert dan 1.3% pada skala biner. Keragaman yang dapat dijelaskan oleh peubah laten eksogen untuk peubah PK adalah sebesar 30.6% pada skala likert dan 20.3% pada skala biner. Selanjutnya sebersar 54.4% keragaman yang dapat dijelaskan oleh peubah laten eksogen untuk peubah PPP pada skala likert dan 35.9% untuk skala biner.
29 2. Effect sizef-square ( )
f-square digunakan untuk mengukur keeratan hubungan peubah laten eksogen terhadap peubah laten endogennya. Tabel 13 berikut ini adalah nilai
f-square berdasarkan output dari perangkat lunak smartPLS 3. Tabel 13 Nilai f-square untuk data skala Likert dan data skala biner
Hubungan Likert Keterangan Biner Keterangan
VB->PK 0 Lemah 0 Lemah mengindikasikan bahwa efek peubah laten eksogen terhadap peubah laten eksogen lemah, medium, dan kuat. Kriteria kebaikan model menggunakan nilai f-square menunjukkan bahwa tidak banyak perbedaan kesimpulan antara data skala likert dan data skala biner. Kedua model yang dibangun menggunakan skala likert dan biner menunjukkan model yang kurang baik. 3. Nilai predictive relevanceQ-square ( )
Evaluasi model menggunakan predictive relevance diperoleh melalui perhitungan sebagai berikut lebih besar dari 0.5 yang berarti bahwa model memiliki predictive relevance
yang baik. Skala data biner hanya memiliki nilai sebesar 0.496, yang berarti bahwa data skala biner kurang memiliki predictive relevance. Jika dilihat dari besaran nilainya, hal ini menunjukkan data skala likert lebih baik dari pada data skala biner.
4. Goodness of Fit Index (GoF)
Evaluasi model struktural pada PLS-SEM digunakan nilai Goodness of Fit Index (GoF) yang diperoleh melalui perhitungan sebagai berikut: