iii ABSTRACT
FAZARIAH RACHMAWATI. Personality Analysis Based on Letter a and t using Voting Feature Intervals 5 Algorithm. Under direction of AZIZ KUSTIYO.
Graphology is a scientific method to identify, evaluate and understand human personality through the strokes and patterns revealed by handwriting. Handwriting will indicate the true personality including emotional, fear, honesty, defenses and many others. People who studied graphology called grapohologist. Graphologist has a subjective assessment in handwriting analyzing. Different graphologist can analyze the same handwriting but the result will shown in a different way. The accuracy of handwriting depends on the graphologist ability. Therefore, the computer technology will be needed to apply the science of graphology to help graphologist in analyzing handwriting. This research is concern to developed a model of handwriting analysis based on letter a and letter t using Voting Feature Intervals 5 algorithm. Image as an input for VFI5 algorithm and personality as an output. The result showed that letter a easier to be recognized than letter t.
ANALISIS GRAFOLOGI BERDASARKAN HURUF a DAN t
MENGGUNAKAN ALGORITME VOTING FEATURE INTERVALS 5
FAZARIAH RACHMAWATI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iii ABSTRACT
FAZARIAH RACHMAWATI. Personality Analysis Based on Letter a and t using Voting Feature Intervals 5 Algorithm. Under direction of AZIZ KUSTIYO.
Graphology is a scientific method to identify, evaluate and understand human personality through the strokes and patterns revealed by handwriting. Handwriting will indicate the true personality including emotional, fear, honesty, defenses and many others. People who studied graphology called grapohologist. Graphologist has a subjective assessment in handwriting analyzing. Different graphologist can analyze the same handwriting but the result will shown in a different way. The accuracy of handwriting depends on the graphologist ability. Therefore, the computer technology will be needed to apply the science of graphology to help graphologist in analyzing handwriting. This research is concern to developed a model of handwriting analysis based on letter a and letter t using Voting Feature Intervals 5 algorithm. Image as an input for VFI5 algorithm and personality as an output. The result showed that letter a easier to be recognized than letter t.
ii
ANALISIS GRAFOLOGI BERDASARKAN HURUF a DAN t
MENGGUNAKAN ALGORITME VOTING FEATURE INTERVALS 5
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
FAZARIAH RACHMAWATI
G64070120
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iv Judul : Analisis Grafologi Berdasarkan Huruf a dan t Menggunakan Algoritme Voting
Feature Intervals 5 Nama : Fazariah Rachmawati NRP : G64070120
Menyetujui:
Pembimbing,
Aziz Kustiyo, S.Si, M.Kom NIP. 19700719 199802 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Sri Nurdiati, MSc NIP. 19601126 198601 2 001
v PRAKATA
Segala puji bagi Allah SWT, atas limpahan rahmat dan karuniaNya dan semoga shalawat dan salam tetap tercurahkan kepada nabi Muhammad SAW. Penulis mengucapkan Alhamdulillahi rabbal ‘alamin, atas selesainya skripsi dengan judul Analisis Grafologi Berdasarkan Huruf a dan t Menggunakan Algoritme Voting Feature Intervals 5. Skripsi ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Penulis mengucapkan terima kasih kepada semua pihak sehingga terselesaikannya skripsi ini, diantaranya :
1. Orang tua tercinta yang selalu memberikan doa dan motivasi kepada penulis
2. Bapak Aziz Kustiyo, S.Si.,M.Kom selaku pembimbing yang telah memberikan arahan dan masukan sehingga selesainya skripsi ini.
3. Bapak Endang Purnama Giri, S.Kom, M.Kom. selaku penguji I dan moderator, terima kasih atas saran, kritikan dan bimbingannya kepada penulis.
4. Bapak Dr. Ir. Agus Buono, M.Si, M.Kom. selaku penguji II, terima kasih atas saran, kritikan dan bimbingannya kepada penulis.
5. Fitria Kusuma Dewi, S.Hut dan Mugi Rahayu, S.Psi selaku grafologis dan psikolog yang telah memberikan arahan dan masukan sehingga selesainya skripsi ini.
6. Seluruh dosen pengajar dan civitas akademika Departemen Ilmu Komputer FMIPA IPB
7. Teman-teman satu bimbingan Amanda K H, Jilly Pratiwi, Fauzan Ismara A, Supriyanti, Nurfitriana, dan Danar yang telah memberikan bantuan dan motivasi. 8. Serta teman-teman program studi Ilmu Komputer 44 atas motivasi dan
kebersamaannya selama ini.
Akhirnya penulis berharap semoga skripsi ini dapat bermanfaat bagi semua pihak yang membutuhkan. Amin
Bogor, Agustus 2011
vi RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 16 Desember 1989 sebagai anak pertama dari empat bersaudara dari ayah yang bernama Dedi Sutaryadi dan ibu yang bernama Atikah. Pada tahun 2007 penulis lulus dari Sekolah Menengah Atas Negeri 6 Bogor (SMAN 6). Penulis melanjutkan studi di Institut Pertanian Bogor Departemen Ilmu Komputer melalui jalur Seleksi Penerimaan Mahasiwa Baru (SPMB).
vii DAFTAR ISI
Halaman
DAFTAR TABEL ... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan... 1
Ruang Lingkup ... 1
Manfaat Penelitian... 1
TINJAUAN PUSTAKA ... 1
Grafologi... 1
Huruf a ... 2
Huruf t ... 2
Citra Digital ... 2
Pengolahan Citra ... 3
Klasifikasi ... 3
Voting Feature Intervals (VFI5) ... 3
Confusion Matrix ... 4
METODE PENELITIAN ... 4
Data Citra Tulisan Tangan ... 5
Praproses... 5
Data Latih dan Data Uji ... 5
Algoritme VFI5 ... 6
Analisis Hasil Klasifikasi... 6
Lingkungan Pengembangan ... 6
HASIL DAN PEMBAHASAN ... 6
Percobaan 1 Huruf a tanpa pertukaran ... 6
Percobaan 2 Huruf a dengan pertukaran data ... 7
Percobaan 3 Huruf t tanpa pergeseran ... 8
Percobaan 4 Huruf t dengan pergeseran ... 8
KESIMPULAN DAN SARAN ... 9
Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
viii DAFTAR TABEL
Halaman
1 Bentuk huruf a dan karakternya. ... 2
2 Bentuk huruf t dan karakternya... 2
3 Confusion matrix untuk data dua kelas ... 4
4 Kelas prediksi huruf a ... 5
5 Kelas prediksi huruf t ... 5
6 Hasil percobaan huruf a tanpa pertukaran ... 6
7 Jumlah vote data uji percobaan 1 yang salah klasifikasi... 6
8 Daftar kesalahan huruf a tanpa pertukaran data ... 7
9 Hasil percobaan huruf a dengan pertukaran data ... 7
10 Jumlah vote data uji percobaan 2 yang salah klasifikasi ... 7
11 Daftar huruf a dengan pertukaran data yang salah diklasifikasi... 7
12 Hasil percobaan huruf t ... 8
13 Beberapa contoh jumlah vote data uji percobaan 3 yang salah klasifikasi ... 8
14 Daftar huruf t tanpa pergeseran yang salah diklasifikasi. ... 8
15 Hasil percobaan huruf t setelah digeser. ... 8
16 Jumlah vote data uji percobaan 4 yang salah klasifikasi ... 9
17 Contoh huruf t dengan pergeseran yang salah diklasifikasi. ... 9
DAFTAR LAMPIRAN Halaman 1 Kalimat yang dituliskan responden ... 12
2 Citra data latih dan data uji huruf a ... 13
3 Citra data latih dan data uji huruf t... 15
4 Jumlah Vote Data yang Salah Klasifikasi pada Percobaan 3 ... 17
1 PENDAHULUAN
Latar Belakang
Pengenalan karakter dan potensi diri melalui tulisan tangan merupakan penelitian yang cukup penting. Ini disebabkan banyaknya tes psikologi yang ditawarkan dan disediakan untuk membantu mengenali potensi diri, tetapi tidak banyak yang menawarkan tes yang sederhana, dapat dilakukan di mana saja, waktu pengerjaan cepat, hasil instan tanpa harus bertatap muka, dan yang paling penting keakuratannya lebih dari 80%. Hanya grafologi yang menawarkan ini dan analisis tulisan tangan pun dapat menguak potensi dasar yang belum tergali secara optimal dan mencari tahu mengapa hal itu bisa terjadi (Rosette 2010).
Grafologi adalah ilmu yang mempelajari, mengidentifikasi, menganalisis, mengevaluasi dan mengetahui kepribadian sesorang melalui pola tulisan tangannya. Tulisan tangan mengungkapkan kepribadian sejati termasuk emosi, ketakutan, kejujuran, pertahanan dan banyak hal lainnya (Champa & Kumar 2010). Bentuk tulisan tangan seperti sidik jari dan DNA yang merupakan sesuatu yang unik dan berbeda di setiap orang. Tahun 1875, Jean Hyppolyte Michon memperkenalkan teori pengenalan karakter seseorang melalui tulisan ini yang dikenal dengan sebutan grafologi. Sejak tahun 1985 grafologi digunakan dalam ilmu kesehatan, pendidikan dan jurnalistik.
Bentuk tulisan tangan merupakan alat ukur yang tidak dapat berbohong karena berasal dari alam bawah sadar. Kecuali, proses syaraf-syaraf pusat dalam sistem tubuh dan pikiran bawah sadar dapat dikontrol. Bila seseorang berusaha untuk mengubah tulisan tangannya, hal tersebut dapat diidentifikasikan sebagai ketidakjujuran. Apabila seseorang mengubah bentuk tulisan secara permanen, format cara berpikir pun harus diubah. Jadi, yang dianalisis adalah bentuk, bukan isi tulisan karena isi tulisan cenderung dapat direkayasa. Grafologis dapat mempunyai penilaian yang subjektif dalam menganalisis tulisan tangan. Grafologis yang berbeda dapat menganalisis tulisan tangan yang sama tetapi memberikan hasil yang berbeda (Galbraith & Guest 1994 yang diacu dalam Sheilkholeslami et al). Keakuratan dari hasil analisis tulisan tangan bergantung pada kemampuan grafologis itu sendiri (Champa & Kumar 2010). Oleh karena itu, dibutuhkan suatu pemanfaatan teknologi komputer yang dapat
menerapkan ilmu grafologi untuk membantu grafologis dalam menganalisis tulisan tangan.
Penelitian ini mencoba mengembangkan metode analisis Grafologi dengan menguji data tulisan tangan. Algoritme VFI5 digunakan pada penelitian ini, karena selain merupakan algoritme klasifikasi algoritme ini juga cukup kokoh terhadap fitur yang tidak relevan tetapi memberikan hasil yang baik. Pada data analisis tulisan tangan fitur yang tidak relevan kemungkinan akan ada, dikarenakan data anilisis dari pakar akan berbeda-beda.
Penelitian sebelumnya tentang analisis tulisan tangan yaitu penelitian Grafologi yang pernah dilakukan yaitu tentang Artificial Neural Network for Human Behavior Prediction through Handwriting Analysis (Champa & Kumar 2010). Pada penelitian ini dilakukan analisis grafologi pada parameter huruf t menggunakan jaringan syaraf tiruan propagasi balik. Input berupa citra tulisan tangan huruf t dan output yang dihasilkan berupa karakter berdasarkan pada tekanan pena, baseline dan tanda bar t dan ketinggian huruf t orang tersebut.
Tujuan
Tujuan penelitian ini adalah melakukan pengenalan tulisan tangan dengan citra menggunakan algoritme VFI5.
Ruang Lingkup
Citra yang digunakan diperoleh dari 57 responden yang merupakan tulisan tangan tiap orang yang berukuran, yaitu 40x40 piksel. Penelitian ini juga dibatasi pada huruf yang digunakan yaitu huruf a dan huruf t. Output yang diperoleh dikelompokkan ke dalam tiga kelas pada masing-masing huruf a dan huruf t. Manfaat Penelitian
Manfaat dari penelitian ini adalah untuk membantu grafologis dalam menganalisis tulisan tangan.
TINJAUAN PUSTAKA
Grafologi
2 banyak hal lainnya. Analisis tulisan tangan
bukan dokumen periksaan, yang dapat mengidentifikasi siapa penulis dari contoh tulisan tangan tersebut (Champa & Kumar 2010).
Tulisan tangan sering disebut sebagai tulisan otak karena setiap ciri kepribadian diwakili oleh pola saraf otak. Setiap pola saraf otak menghasilkan gerakan neuromuskular yang unik untuk setiap orang yang memiliki ciri kepribadian tertentu. Saat menulis, terjadi gerakan-gerakan kecil secara tidak sadar. Setiap menulis gerakan atau goresan mengungkapkan ciri kepribadian tertentu. Dengan kata lain, grafologi adalah ilmu yang mengidentifikasikan pola yang muncul dalam tulisan tangan dan menggambarkannya sesuai sifat kepribadian. Orang yang mempelajari grafologi disebut grafologis. Akurasi grafologis dalam menganalisis tulisan tangan tergantung pada keterampilan grafologis itu sendiri (Champa & Kumar 2010).
Huruf a
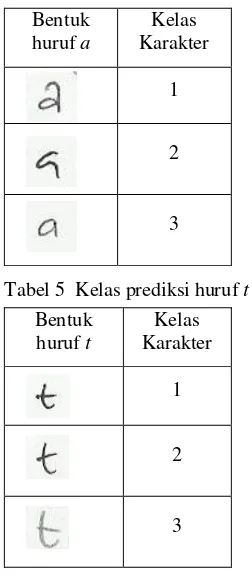
Dalam grafologi banyak huruf yang memberi petunjuk tentang ciri-ciri kepribadian. Salah satunya adalah huruf a. Huruf a dalam grafologi termasuk kedalam huruf kecil spesifik. Pada Tabel 1 akan dijelaskan beberapa bentuk huruf a beserta penggambaran karakternya (Amend & Ruiz 1980).
Tabel 1 Bentuk huruf a dan karakternya. Bentuk Huruf Karakter
a balok
cenderung tertarik pada kegiatan yang
berhubungan dengan seni, musik, budaya, dan sastra individu ini akan jujur dan terus terang jika ditanya mengenai pendapatnya, berbeda dengan huruf a terbuka di atas yang jujur dalam mengemukakan pendapat secara sukarela tanpa diminta.
Huruf t
Sejauh ini, banyak analisis tulisan tangan yang menganggap huruf t merupakan huruf
dari abjad yang secara grafologis paling penting. Dalam tulisan tangan seseorang, panjang, tekanan, penempatan, dan bentuk dari silangan huruf t memperlihatkan irama dan kekuatan kehendak yang ada di baliknya. Penempatan ruji t pada batangnya merupakan petunjuk utama terhadap sasaran-sasaran individual. Ada lebih dari 50 cara yang berbeda untuk menyilangkan huruf t dan seorang penulis akan sering mengubah atau memodifikasi gayanya seiring berubahnya kepribadian, atau karena kesehatanya yang berubah. Beberapa bentuk dan penggambaran karakter akan dijelaskan pada Tabel 2 (Amend & Ruiz 1980).
Tabel 2 Bentuk huruf t dan karakternya. Bentuk Huruf Karakter
Ruji t lurus
Ambisi: Balance, terkontrol
Ruji t yang horizontal menunjukkan putus asa dan pasrah. Citra Digital
Citra dapat didefinisikan sebagai fungsi dua dimensi, f(x,y), dimana x dan y adalah koordinat spasial dan amplitudo dari f pada setiap pasangan koordinat (x,y) yang disebut intensitas atau derajat keabuan sebuah citra. Ketika x,y dan nilai amplitudo f bernilai terbatas dan diskret, maka citra tersebut disebut citra digital (Gonzalez & Woods 2002).
3 ini disebut sebagai picture elements, image
elements, pels atau pixels. Pixel adalah istilah yang paling sering digunakan untuk menunjukkan elemen dari sebuah citra digital (Gonzalez & Woods 2002).
Pengolahan Citra
Pengolahan citra digital merupakan proses yang masukan dan keluaranya adalah citra dan meliputi proses pengekstrakan atribut dari citra dan pengenalan citra. Selain itu, yang dimaksud dengan pengolahan citra digital biasanya adalah pengolahan citra menggunakan komputer digital (Gonzalez & Woods 2002).
Klasifikasi
Klasifikasi merupakan serangkaian proses untuk menemukan sekumpulan model yang merepresentasikan dan membedakan kelas-kelas data. Klasifikasi ini bertujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu data yang label kelasnya tidak diketahui (Han & Kamber 2006).
Klasifikasi terdiri atas dua tahap, yaitu pelatihan dan klasifikasi. Tahap pelatihan, menggunakan beberapa algoritme, dan dibentuk sebuah model domain dari setiap data pelatihan yang label kelasnya sudah diketahui. Tahap klasifikasi, menggunakan model dan mencoba untuk memprediksi kelas yang baru dari label kelas yang sudah diketahui sebelumnya (Güvenir & Demiroz 1998)
Voting Feature Intervals (VFI5)
Algoritme Voting Feature Interval merupakan algoritme klasifikasi yang merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval nilai fitur. Klasifikasi sebuah instance baru didasarkan pada vote klasifikasi yang dibuat oleh nilai setiap fitur secara terpisah. VFI5 merupakan algoritme klasifikasi yang bersifat non-incremental, yaitu semua data training diproses secara bersamaan. Setiap contoh data training direpresentasikan sebagai nilai-nilai fitur sebuah vektor nominal (diskret) atau linear (kontinu) disertai sebuah label yang merepresentasikan kelas contoh data. Dari contoh pelatihan, algoritme VFI5 membentuk interval untuk masing-masing fitur (Güvenir, Demiroz & Ilter 1998).
Interval yang dibuat dapat berupa range interval atau point interval. Range interval didefinisikan sebagai nilai antara dua end
point yang berdekatan tetapi tidak termasuk kedua end point tersebut, sedangkan point interval didefinisikan sebagai seluruh end point secara berturut-turut. Untuk setiap interval, vote tiap kelas disimpan untuk tiap intervalnya. Dengan demikian, interval dapat mewakili beberapa kelas dengan menyimpang vote untuk setiap kelas. Algoritme VFI5 terdiri atas tahap pelatihan dan klasifikasi (Güvenir, Demiroz & Ilter 1998).
1. Pelatihan
Langkah pertama pada pelatihan adalah menemukan end point untuk setiap kelas c pada setiap fitur f. End point kelas c yang ditentukan merupakan nilai terendah dan tertinggi pada fitur linear f pada beberapa contoh kelas yang diamati. Pada end point dimensi fitur nominal f pada kelas c yang diberikan adalah semua nilai yang berbeda dari f pada beberapa instance yang diamati. End point dari masing-masing fitur f disimpan dalam array EndPoint[f]. Pada setiap fitur linear terdapat end point sebesar 2k, dimana k adalah jumlah kelas. End point pada setiap dimensi fitur diurutkan untuk menjadi fitur linear. Jika fitur adalah fitur linear, maka point interval terdiri dari setiap end point yang berbeda dan range interval dibentuk di antaranya. Jika fitur adalah fitur nominal, tiap end point yang berbeda merupakan point interval.
Selanjutnya jumlah instance pelatihan pada tiap interval dihitung dan jumlah instance kelas c dalam interval i dari fitur f
direpresentasikan sebagai
interval_class_count[f, i, c]. Untuk setiap instance pelatihan, dimana interval i yang merupakan nilai untuk fitur f dari instance pelatihan e (ef) tersebut berada. Jika interval i adalah point interval dan efsama dengan batas bawah (yang sama dengan batas atas pada point interval), jumlah kelas instance (ef) di interval i ditambah 1. Jika interval i adalah range interval dan ef berada pada batas bawah interval tersebut , maka jumlah kelas ef di interval i ditambah dengan 0.5. Tapi jika ef berada pada interval i, maka jumlah kelas ef dalam interval ditambah dengan 1.
Untuk menghilangkan efek perbedaan distribusi, jumlah instance kelas c untuk fitur f pada interval i dinormalisasi dengan membagi total jumlah instance dari kelas c dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai interval_class_vote[f, i,
c]. Selanjutnya nilai-nilai
4 fitur sama dengan 1. Tujuan normalisaso ini
adalah agar tiap fitur mempunyai kekuatan voting yang sama pada proses klasifikasi dan tidak dipengaruhi oleh ukuran fitur tersebut. Proses pelatihan dalam algoritme VFI5 dapat dilihat di bawah ini :
train(TrainingSet): begin
for each feature f for each class c
endPoints[f] = EndPoints[f] U find_end_points(TrainingSet, f, c); sort(EndPoints[f]);
if f is linear
for each end point p in EndPoints[f] form a point interval from end point p form a range interval between p and the next end point ≠ p
else /* f is nominal */
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f for each class c
interval_count[f, i, c] = 0 count_instances(f, TrainingSet);
for each interval i on feature dimension f for each class c
interval_vote[f, i, c] =
interval_count[f, i, c] / class_count[c] normalize interval_vote[f, i, c]; /* such that ∑c interval_vote[f, i, c] = 1 */ end.
2. Klasifikasi
Proses ini dimulai dengan menginisialisasi vote dari setiap kelas dengan nilai nol. Pada tiap fitur f dicari interval i dimana nilai ef jatuh, dimana efmerupakan nilai fitur f dari instance uji e. Jika nilai ef tidak diketahui (hilang), maka nilai ef tersebut akan diabaikan dengan memberikan vote nol pada tiap kelas. Jika ef diketahui maka interval i dapat ditemukan. Interval dapat berisi instance pelatihan beberapa kelas. Kelas dalam interval direpresentasikan oleh vote pada interval tersebut. Untuk setiap kelas c, fitur f memberikan vote yang sama dengan interval_class_vote[f, i, c]. Notasi ini dapat direpresentasikan sebagai kelas c yang diberikan vote fitur f.
Tiap fitur f mengumpulkan vote untuk kelas c yang disimpan dalam feature_vote[f, c], selanjutnya vote tersebut dinormalisasi sehingga nilai vote dari fitur f sama dengan 1.
Setiap fitur f mengumpulkan vote yang disimpan dalam sebuah vektor <votef,1, ...,
votef,k >, dimana votef,cdengan c adalah vote
fitur f untuk kelas c dan k yang merupakan jumlah kelas. Setelah sejumlah fitur vektor vote dijumlahkan untuk mendapatkan total vektor vote <vote1, ..., votek>. Kelas dengan
vote tertinggi dari total vektor vote akan menjadi kelas dari instance uji e. Klasifikasi dalam algoritme VFI5 dapat dilihat di bawah ini:
classify(e): /* e: example to be classified */ begin
for each class c vote [c] = 0 for each feature f
for each class c
feature_vote[f, c] = /* vote of feature f for class c */
if ef value is known i = find_interval(f, ef) for each class c
feature_vote[f, c] = interval_vote[f, i, c]
vote[c] = vote[c] + feature_vote[f, c] * weight[f];
return the class c with highest vote[c]; end.
Confusion Matrix
Confusion matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi. Tabel ini diperlukan untuk menentukan kinerja suatu model klasifikasi (Tan, Steinbach & Kumar 2005). Contoh confusion matrix dapat dilihat pada Tabel 3. Tabel 3 Confusion matrix untuk data dua kelas
Kelas Prediksi
Akurasi hasil klasifikasi dari confusion matrix dihitung dengan rumus :
Akurasi = a + d
a + b + c + d x 100%
METODE PENELITIAN
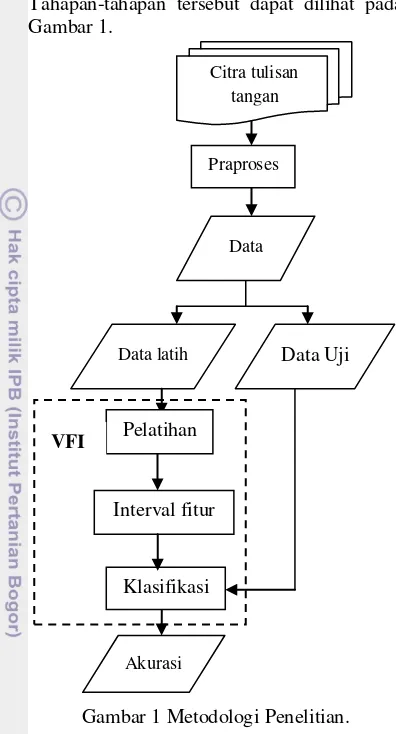
5 Tahapan-tahapan tersebut dapat dilihat pada
Gambar 1.
Gambar 1 Metodologi Penelitian. Data Citra Tulisan Tangan
Data yang digunakan dalam penelitian ini diperoleh dari 57 responden yang menuliskan sebuah kalimat yang sudah ditentukan pada selembar kertas. Kalimat yang ditulis oleh responden dapat dilihat pada Lampiran 1. Pada tahap awal kalimat tersebut dikonsultasikan terlebih dahulu dengan Grafologis dan Psikolog, hal ini dilakukan untuk mendapatkan informasi data citra tulisan tangan yang relevan untuk data penelitian. Konsultasi tersebut dilakukan dengan grafologis dan psikolog yaitu :
1. Fitri Kusuma Dewi, S.Hut 2. Mugi Rahayu, S.Psi
Dari hasil konsultasi, data tersebut kemudian dibagi menjadi 2 dengan 27 data responden untuk data citra huruf a dan 30 data responden untuk data citra huruf t. Dari kalimat yang sudah dituliskan hanya diambil huruf a dan t sebanyak lima citra, tiga citra untuk data latih dan 2 citra untuk data uji. Jadi, ada 81 citra yang digunakan sebagai data latih dan 54 citra untuk data uji pada huruf a.
Citra data latih dan data uji huruf a dapat dilihat pada Lampiran 2. Pada huruf t ada 90 data latih dan 60 data uji. Citra data latih dan data uji huruf t dapat dilihat pada lampiran 3. Citra tulisan tangan akan diklasifikasikan ke dalam 3 kelas untuk huruf a dan 3 kelas untuk huruf t. Definisi kelas tersebut dapat dilihat pada Tabel 4 dan 5.
Huruf a dan huruf t dipotong dari kalimat tersebut dengan ukuran 40 x 40 pixel. Agar mempercepat kinerja sistem dilakukan proses resizing pada citra sehingga ukurannya menjadi 24 x 12 pixel.
Tabel 4 Kelas prediksi huruf a Bentuk
Tabel 5 Kelas prediksi huruf t Bentuk
Sebelum citra diklasifikasi menggunakan algoritme VFI5, dilakukan praproses terlebih dahulu. Pada tahap praproses ini citra tulisan tangan yang merupakan citra RGB untuk mempermudah perhitungan citra akan diubah menjadi citra grayscale dan disederhanakan lagi menjadi citra biner. Selain itu juga dilakukan proses resizing citra dari ukuran awal 40 x 40 pixel menjadi 24 x 12 pixel. Setelah praproses tersebut seluruh data akan direpresentasikan dalam bentuk matriks yang merupakan input dalam VFI5.
Data Latih dan Data Uji
Matriks yang di dapat dari tahap praproses dipisahkan menjadi data latih dan data uji dengan perbandingan 3 : 2.
6 Algoritme VFI5
Tahap algoritme VFI5 ini akan dibagi menjadi tiga tahap, yaitu tahap pelatihan, tahap interval fitur dan tahap klasifikasi. Pada tahap pelatihan yang menjadi input adalah matriks yang didapat tahap praproses. Pada tahap ini akan dihitung vote tiap fitur untuk masing-masing kelas. Selanjutnya tiap nilai vote akan dijumlahkan pada masing-masing kelas. Jumlah nilai vote tersebut akan dinormalisasi untuk mendapatkan nilai vote masing-masing kelas pada tahap interval fitur.
Tahap klasifikasi dimulai dengan mencari interval yang sesuai dengan nilai tiap fitur dari data uji pada interval fitur data latih. Nilai vote pada interval tersebut kemudian dikumpulkan dan dijumlahkan untuk masing-masing kelasnya. Kelas yang memiliki total nilai vote terbesar menjadi kelas prediksi bagi data uji tersebut.
Analisis Hasil Klasifikasi
Analisis dilakukan menggunakan tabel confusion matrix, kemudian dihitung besaran akurasi yang berhasil dicapai, dan dapat diambil suatu kesimpulan. Tingkat akurasi diperoleh dengan rumus :
��� � �=Σ data uji benar klasifikasiΣ
data uji x 100%
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini ialah sistem operasi Microsoft Windows 7, Matlab 7.7 (R2008b). Perangkat keras yang digunakan adalah Prosesor AMD
Turion™ , Memori 2 GB RAM DDR2,
Harddisk, dan Monitor 11.6”.
HASIL DAN PEMBAHASAN
Pada penelitian ini dilakukan dua percobaan pada masing-masing huruf a dan huruf t. Pada huruf a selain menggunakan data latih yang asli juga dilakukan percobaan pertukaran data uji menjadi data latih. Pada huruf t dilakukan percobaan menggeser kolom utama huruf sehingga berada pada kolom yang sama dan percobaan tanpa menggeser huruf.
Percobaan 1 Huruf a tanpa pertukaran
Percobaan yang pertama adalah percobaan huruf a menggunakan data latih yang asli tanpa pertukaran. Pada percobaan huruf a ada
81 data latih dan 54 data uji. Dari data tersebut didapatkan hasil yang disajikan pada Tabel 6. salah diklasifikasi yaitu kelas 1 dikenali sebagai kelas 2 sebanyak 1 dengan selisih vote 2.362 dan dikenali sebagai kelas 3 sebanyak 2 dengan masing-masing selisih vote 0.396 dan 0.378, kelas 2 dikenali sebagai kelas 3 sebanyak 2 dengan masing-masing selisih vote 2.501 dan 2.270, dan kelas 3 dikenali sebagai kelas 1 dengan selisih vote 3.302, sehingga akurasinya adalah 88.89%. Jumlah vote dapat dilihat pada Tabel 7.
Tabel 7 Jumlah vote data uji percobaan 1 yang salah klasisifikasi
Data uji ke-
Jumlah vote kelas Kelas
1 2 3 Pre mengklasifikasi citra dengan baik. Hal tersebut terlihat pada Tabel 6 data uji yang diklasifikasikan dengan benar sebanyak 11 dari 14 data uji pada kelas 1, 18 dari 20 data uji pada kelas 2, dan 19 dari 20 data uji pada kelas 3. Dari ketiga kelas tersebut kelas 3 merupakan kelas yang paling mudah dikenali.
7
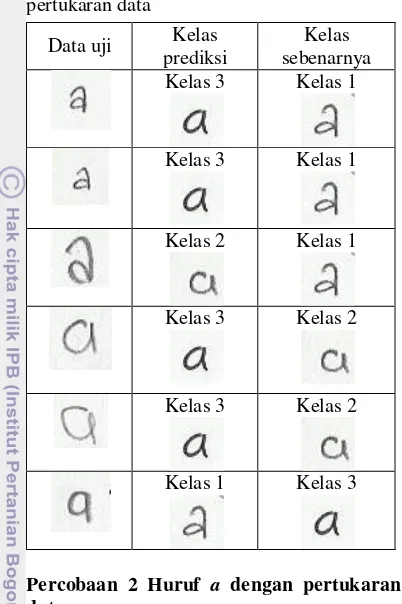
Percobaan ini masih menggunakan data latih dan data uji yang sama dengan percobaan sebelumnya tetapi pada percobaan kedua ini data latih pada percobaan sebelumnya akan ditukar menjadi data uji dan sebaliknya. Data latih sebelumnya berjumlah 21 untuk kelas 1, 30 untuk kelas 2, dan 30 untuk kelas 3. Setiap data latih diambil secara acak dari masing-masing kelas sebesar 7 dari kelas 1, 10 dari kelas 2 dan 10 dari kelas 3. Data latih yang sudah diambil secara acak tersebut ditambahkan dengan data uji sebelumnya pada masing-masing kelas dan data uji akan menjadi data latih yang baru. Hasil dari percobaan ini dapat dilihat pada Tabel 9.
Dilihat dari Tabel 9 data uji yang benar diklasifikasi pada kelas 1 sebanyak 10 dari 14 data uji dan kelas 2 sebanyak 11 dari 20 data uji, jumlah ini lebih kecil dibandingkan dengan percobaan pertama. Pada kelas 1 dan 2 pertukaran data menurunkan hasil klasifikasi. Pada kelas 3 data uji yang benar diklasifikasi sebanyak 20 dari 20 data uji, jumlah ini lebih besar dibandingkan dengan percobaan sebelumnya. salah diklasifikasi yaitu kelas 1 dikenali sebagai kelas 3 sebanyak 4 dengan masing-masing selisih vote 0.510, 2.981, 1.095, dan 2.275, kelas 2 dikenali sebagai kelas 1 sebanyak 1 dengan selisih vote 1.438, kelas 2 dikenali sebagai kelas 3 sebanyak 8 dengan masing-masing selisih nilai vote 1.816, 0.209, 5.320, 1.453, 1.517, 0.664, 2.566, dan 0.218, sehingga didapat akurasi sebesar 75.93%. Jumlah vote yang salah klasifikasi dapat dilihat pada Tabel 10.
Tabel 10 Jumlah vote data uji percobaan 2 yang salah klasifikasi
Data uji ke-
Jumlah vote kelas Kelas
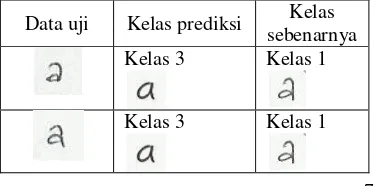
1 2 3 Pre meningkatkan akurasi. Akurasi yang didapat dari percobaan kedua ini sebesar 75.93%. Hal ini menunjukkan bahwa data latih percobaan pertama lebih baik dibandingkan akurasi pada percobaan kedua. Beberapa contoh huruf a yang salah diklasifikasi dapat dilihat pada Tabel 11.
Tabel 11 Daftar huruf a dengan pertukaran data yang salah diklasifikasi.
Data uji Kelas prediksi Kelas sebenarnya Kelas 3 Kelas 1
8
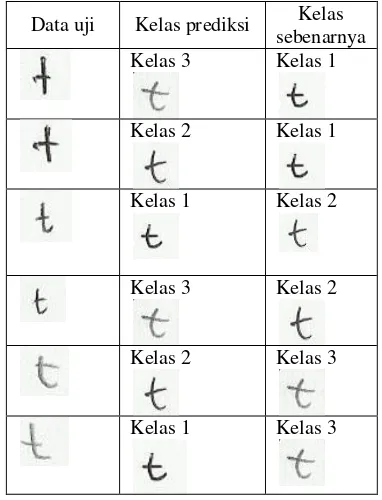
Percobaan 3 Huruf t tanpa pergeseran
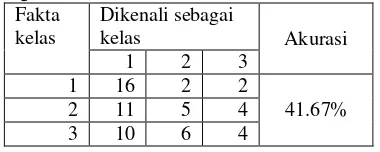
Pada percobaan ini data huruf t yang digunakan merupakan data latih asli. Percobaan ini memiliki 90 data latih yang berjumlah 30 untuk masing-masing kelas dan 60 data uji dengan jumlah 20 untuk masing-masing kelas. Hasil klasifikasi dari percobaan ini dapat dilihat pada Tabel 12.
Tabel 12 Hasil percobaan huruf t Fakta klasifikasi paling banyak dikenali sebagai kelas 1, dapat dilihat pada tabel 5 ada 10 data uji kelas 2 yang dikenali sebagai kelas 1 dan 8 data uji kelas 3 yang dikenali sebagai kelas 1. Hal tersebut dikarenakan pada analisis huruf t hanya dibedakan berdasarkan ruji huruf t. Pada Tabel 14 dapat dilihat beberapa contoh huruf t yang salah klasifikasi. Citra pada tabel tersebut memiliki posisi ruji t yang tidak jauh berbeda antara kelas 1, kelas 2, dan kelas 3. Hal tersebut menyebabkan banyaknya huruf t yang salah klasifikasi. Beberapa contoh jumlah vote data yang salah klasifikasi dapat dilihat pada Tabel 13. Seluruh jumlah vote data yang salah klasifikasi pada percobaan 3 dapat dilihat pada Lampiran 4.
Tabel 13 Beberapa contoh jumlah vote data uji percobaan 3 yang salah klasifikasi
Data
Pada Tabel 12 dapat dilihat bahwa data uji yang benar diklasifikasi pada kelas 1
sebanyak 8 dari 20 data uji, kelas 2 sebanyak 7 dari 20 data uji, dan kelas 3 sebanyak 9 dari 20 data uji. Dari ketiga kelas tersebut, kelas 3 lebih mudah dikenali dibandingkan kelas tersebut.
Tabel 14 Daftar huruf t tanpa pergeseran yang salah klasifikasi.
Data uji Kelas prediksi Kelas sebenarnya
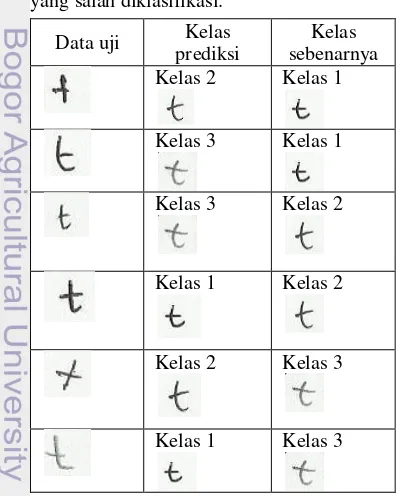
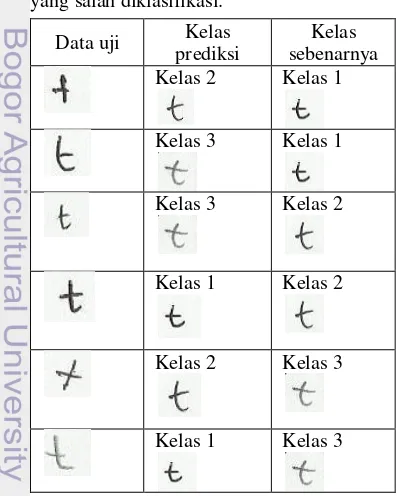
Percobaan 4 Huruf t dengan pergeseran Pada percobaan ini huruf t yang akan digunakan sebagai data latih dilakukan pergeseran terlebih dahulu. Pergeseran ini dilakukan agar kolom utama huruf t berada pada kolom yang sama. Hasil percobaan ini disajikan pada Tabel 15.
9 dengan benar lebih sedikit dibandingkan
percobaan sebelumnya. Jadi, pada kelas 2 dan kelas 3 pergeseran t tidak banyak berpengaruh dan jumlah data yang diklasifikasi dengan benar lebih sedikit dibandingkan dengan percobaan sebelumnya. Beberapa contoh jumlah vote data yang salah klasifikasi pada percobaan 4 dapat dilihat pada Tabel 16. Seluruh jumlah vote data yang salah klasifikasi pada percobaan 4 dapat dilihat pada Lampiran 5.
Jumlah vote kelas Kelas
1 2 3 Pre
Pada Tabel 15 juga terlihat bahwa data uji yang dikenali sebagai kelas 1 lebih banyak, baik untuk kelas yang diklasifikasi dengan benar ataupun kelas yang salah diklasifikasi. Kelas yang salah diklasifikasi sebagai kelas 1 sebanyak 11 dari 20 data uji pada kelas 2 dan 10 dari 20 data uji pada kelas 3. Hasil ini sama dengan percobaan sebelumnya. Contoh data uji yang salah diklasifikasi dapat dilihat pada Tabel 17. Selain posisi ruji t, kemiringan huruf t itu sendiri dan tebal tipisnya tulisan juga berpengaruh dalam klasifikasi.
Tabel 17 Contoh huruf t dengan pergeseran belum cukup meningkatkan akurasi agar lebih baik dari percobaan sebelumnya. Kemiringan huruf yang berbeda dapat menyebabkan huruf salah diklasifikasi baik klasifikasi pada huruf a maupun huruf t. Selain itu, ukuran dan bentuk huruf yang hampir sama antar kelas juga dapat menyebabkan citra salah diklasifikasi oleh sistem. Alat tulis juga berpengaruh dalam klasifikasi ini jika alat tulis yang dipakai memiliki ketebalan yang baik maka citra huruf akan semakin mudah dikenali.
KESIMPULAN DAN SARAN
Kesimpulan
Pada penelitian kali ini dapat disimpulkan bahwa algoritme VFI5 merupakan algoritme klasifikasi yang cukup baik dalam pengenalan pola huruf a. Akurasi yang didapat pada percobaan huruf a tanpa pertukaran sebesar 88.89%, percobaan huruf a dengan pertukaran sebesar 75.93%, percobaan huruf t tanpa pergeseran sebesar 40% dan percobaan huruf t dengan pergeseran sebesar 41.67% pada percobaan huruf t. Akurasi tertinggi pada percoban huruf a sebesar 88.89% sedangkan percobaan huruf t sebesar 41.67%. Dari akurasi tersebut dapat disimpulkan bahwa huruf a lebih mudah dikenali dibandingkan dengan huruf t.
Adanya pertukaran data latih menjadi data uji pada huruf a belum dapat meningkatkan akurasi percobaan sedangkan pergeseran kolom pada percobaan huruf t dapat meningkatkan sedikit akurasi pada penelitian ini.
Saran
Penelitian lebih lanjut dapat dilakukan yaitu dengan menambahkan proses ekstraksi ciri yang relevan terutama untuk huruf t. Pada proses resizing sebaiknya ukuran panjang dan lebar citra simetris agar didapatkan hasil yang lebih baik.
DAFTAR PUSTAKA
Amend KK, Ruiz MS. 1980. Handwriting Analysis, The Complete Basic Book. USA: Book Mart Press.
10 Mei 2010. India: SJB Institute of
Technology.
Galbraith D, Wilson W. 1964. Reliability of the Graphoanalytic Approach to Handwriting Analysis. Perceptual and Motor Skills, 19: 615-618.
Gonzales RC, Woods RE. 2002. Digital Image Processing. Massachussets : Addison Wasley.
Güvenir HA, Demiroz G, & Ilter N. 1998. Learning differential diagnosis of erythemato-squamous diseases using voting feature intervals. Artificial Intelligence in Medicine 13:147-165. Han J, Kamber M. 2006. Data Mining
Concepts and Techniques. Ed ke-2. San Fransisco: Elsevier Inc.
Rossete, Mita. Menganalisis Karakter dan Potensi Melalui Tulisan Tangan. Jakarta:Tangga Pustaka.2010.
Sheikholeslami G, Srihari SN & Govindaraju V. Computer Aided Graphology. USA: University of New York.
13 Lampiran 2 Citra data latih dan data uji huruf a
Huruf a orang ke Data latih Data uji
Orang ke 1
Orang ke 2
Orang ke 3
Orang ke 4
Orang ke 5
Orang ke 6
Orang ke 7
Orang ke 8
Orang ke 9
Orang ke 10
Orang ke 11
Orang ke 12
Orang ke 13
Orang ke 14
Orang ke 15
Orang ke 16
Orang ke 17
Orang ke 18
Orang ke 19
Orang ke 20
14 Lanjutan Lampiran 2 Citra Data Latih dan Data Uji Huruf a
Huruf a orang ke Data latih Data uji
Orang ke 21
Orang ke 22
Orang ke 23
Orang ke 24
Orang ke 25
Orag ke 26
Orang ke 27
15 Lampiran 3 Citra data latih dan data uji huruf t
Huruf t orang ke Data latih Data uji
Orang ke 1
Orang ke 2
Orang ke 3
Orang ke 4
Orang ke 5
Orang ke 6
Orang ke 7
Orang ke 8
Orang ke 9
Orang ke 10
Orang ke 11
Orang ke 12
Orang ke 13
Orang ke 14
Orang ke 15
Orang ke 16
Orang ke 17
Orang ke 18
Orang ke 19
Orang ke 20
16 Lanjutan Lampiran 3 Citra Data Latih dan Data Uji Huruf t
Huruf t orang ke Data latih Data uji
Orang ke 21
Orang ke 22
Orang ke 23
Orang ke 24
Orang ke 25
Orang ke 26
Orang ke 27
Orang ke 28
Orang ke 29
Orang ke 30
17 Lampiran 4 Jumlah Vote Data yang Salah Klasifikasi pada Percobaan 3
Data uji ke-
Jumlah vote Kelas
Kelas 1 Kelas 2 Kelas 3 Prediksi Aktual
1 33,06 33,40 33,55 3 1
2 33,65 33,67 32,68 2 1
3 33,03 33,83 33,14 2 1
4 32,69 32,96 34,35 3 1
5 33,44 33,60 32,96 3 1
8 33,21 33,05 33,74 3 1
9 32,43 33,37 34,20 3 1
10 33,19 33,87 32,94 2 1
12 33,39 33,13 33,48 3 1
14 33,22 33,33 33,45 3 1
18 33,31 33,22 33,47 3 1
20 33,31 33,27 33,42 3 1
21 33,89 33,04 33,07 1 2
22 33,34 33,19 33,47 3 2
23 33,89 33,04 33,07 1 2
24 33,34 33,19 33,47 3 2
27 34,01 33,45 32,54 1 2
28 33,63 33,61 32,76 3 2
29 33,00 33,44 33,56 3 2
31 33,37 33,36 33,27 1 2
34 32,71 33,64 33,65 3 2
35 33,57 33,24 33,19 1 2
36 33,77 33,61 32,62 1 2
37 33,72 33,48 32,80 1 2
38 32,93 33,25 33,82 3 2
41 33,06 33,96 32,98 2 3
42 33,95 32,92 33,13 1 3
43 32,65 33,97 33,38 2 3
44 33,93 32,81 33,26 1 3
45 34,14 33,16 32,70 1 3
47 33,57 33,22 33,21 1 3
49 33,46 33,27 33,27 1 3
51 33,54 33,17 33,28 1 3
53 33,49 33,68 32,83 2 3
55 33,89 32,91 33,20 1 3
18 Lampiran 5 Jumlah Vote Data yang Salah Klasifikasi pada Percobaan 4
Data uji ke-
Jumlah vote Kelas
Kelas 1 Kelas 2 Kelas 3 Prediksi Aktual
1 33,42 33,84 32,73 2 1
3 32,60 33,11 34,29 3 1
15 33,39 33,42 33,19 2 1
20 33,70 32,46 33,84 3 1
21 33,13 33,21 33,65 3 2
23 33,06 33,16 33,77 3 2
26 34,00 32,70 33,30 1 2
27 33,98 32,63 33,40 1 2
29 34,00 32,17 33,84 1 2
30 34,03 31,89 34,08 3 2
31 33,77 32,92 33,31 1 2
32 34,26 32,60 33,15 1 2
33 34,21 32,85 32,94 1 2
34 34,21 32,85 32,94 1 2
36 32,89 33,26 33,85 3 2
37 33,89 32,60 33,51 1 2
38 33,50 33,36 33,14 1 2
39 33,65 33,15 33,20 1 2
40 34,42 32,10 33,48 1 2
42 32,81 34,03 33,16 2 3
44 31,88 34,46 33,66 2 3
45 33,22 33,47 33,31 2 3
46 34,00 32,70 33,30 1 3
47 33,98 32,63 33,40 1 3
48 32,95 34,19 32,86 2 3
49 34,00 32,17 33,84 1 3
51 33,77 32,92 33,31 2 3
52 34,26 32,60 33,15 1 3
53 34,21 32,85 32,94 1 3
54 34,21 32,85 32,94 1 3
55 33,28 33,54 33,17 2 3
57 33,89 32,60 33,51 1 3
58 33,22 33,55 33,23 2 3
59 33,65 33,15 33,20 1 3
1 PENDAHULUAN
Latar Belakang
Pengenalan karakter dan potensi diri melalui tulisan tangan merupakan penelitian yang cukup penting. Ini disebabkan banyaknya tes psikologi yang ditawarkan dan disediakan untuk membantu mengenali potensi diri, tetapi tidak banyak yang menawarkan tes yang sederhana, dapat dilakukan di mana saja, waktu pengerjaan cepat, hasil instan tanpa harus bertatap muka, dan yang paling penting keakuratannya lebih dari 80%. Hanya grafologi yang menawarkan ini dan analisis tulisan tangan pun dapat menguak potensi dasar yang belum tergali secara optimal dan mencari tahu mengapa hal itu bisa terjadi (Rosette 2010).
Grafologi adalah ilmu yang mempelajari, mengidentifikasi, menganalisis, mengevaluasi dan mengetahui kepribadian sesorang melalui pola tulisan tangannya. Tulisan tangan mengungkapkan kepribadian sejati termasuk emosi, ketakutan, kejujuran, pertahanan dan banyak hal lainnya (Champa & Kumar 2010). Bentuk tulisan tangan seperti sidik jari dan DNA yang merupakan sesuatu yang unik dan berbeda di setiap orang. Tahun 1875, Jean Hyppolyte Michon memperkenalkan teori pengenalan karakter seseorang melalui tulisan ini yang dikenal dengan sebutan grafologi. Sejak tahun 1985 grafologi digunakan dalam ilmu kesehatan, pendidikan dan jurnalistik.
Bentuk tulisan tangan merupakan alat ukur yang tidak dapat berbohong karena berasal dari alam bawah sadar. Kecuali, proses syaraf-syaraf pusat dalam sistem tubuh dan pikiran bawah sadar dapat dikontrol. Bila seseorang berusaha untuk mengubah tulisan tangannya, hal tersebut dapat diidentifikasikan sebagai ketidakjujuran. Apabila seseorang mengubah bentuk tulisan secara permanen, format cara berpikir pun harus diubah. Jadi, yang dianalisis adalah bentuk, bukan isi tulisan karena isi tulisan cenderung dapat direkayasa. Grafologis dapat mempunyai penilaian yang subjektif dalam menganalisis tulisan tangan. Grafologis yang berbeda dapat menganalisis tulisan tangan yang sama tetapi memberikan hasil yang berbeda (Galbraith & Guest 1994 yang diacu dalam Sheilkholeslami et al). Keakuratan dari hasil analisis tulisan tangan bergantung pada kemampuan grafologis itu sendiri (Champa & Kumar 2010). Oleh karena itu, dibutuhkan suatu pemanfaatan teknologi komputer yang dapat
menerapkan ilmu grafologi untuk membantu grafologis dalam menganalisis tulisan tangan.
Penelitian ini mencoba mengembangkan metode analisis Grafologi dengan menguji data tulisan tangan. Algoritme VFI5 digunakan pada penelitian ini, karena selain merupakan algoritme klasifikasi algoritme ini juga cukup kokoh terhadap fitur yang tidak relevan tetapi memberikan hasil yang baik. Pada data analisis tulisan tangan fitur yang tidak relevan kemungkinan akan ada, dikarenakan data anilisis dari pakar akan berbeda-beda.
Penelitian sebelumnya tentang analisis tulisan tangan yaitu penelitian Grafologi yang pernah dilakukan yaitu tentang Artificial Neural Network for Human Behavior Prediction through Handwriting Analysis (Champa & Kumar 2010). Pada penelitian ini dilakukan analisis grafologi pada parameter huruf t menggunakan jaringan syaraf tiruan propagasi balik. Input berupa citra tulisan tangan huruf t dan output yang dihasilkan berupa karakter berdasarkan pada tekanan pena, baseline dan tanda bar t dan ketinggian huruf t orang tersebut.
Tujuan
Tujuan penelitian ini adalah melakukan pengenalan tulisan tangan dengan citra menggunakan algoritme VFI5.
Ruang Lingkup
Citra yang digunakan diperoleh dari 57 responden yang merupakan tulisan tangan tiap orang yang berukuran, yaitu 40x40 piksel. Penelitian ini juga dibatasi pada huruf yang digunakan yaitu huruf a dan huruf t. Output yang diperoleh dikelompokkan ke dalam tiga kelas pada masing-masing huruf a dan huruf t. Manfaat Penelitian
Manfaat dari penelitian ini adalah untuk membantu grafologis dalam menganalisis tulisan tangan.
TINJAUAN PUSTAKA
Grafologi
4 fitur sama dengan 1. Tujuan normalisaso ini
adalah agar tiap fitur mempunyai kekuatan voting yang sama pada proses klasifikasi dan tidak dipengaruhi oleh ukuran fitur tersebut. Proses pelatihan dalam algoritme VFI5 dapat dilihat di bawah ini :
train(TrainingSet): begin
for each feature f for each class c
endPoints[f] = EndPoints[f] U find_end_points(TrainingSet, f, c); sort(EndPoints[f]);
if f is linear
for each end point p in EndPoints[f] form a point interval from end point p form a range interval between p and the next end point ≠ p
else /* f is nominal */
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f for each class c
interval_count[f, i, c] = 0 count_instances(f, TrainingSet);
for each interval i on feature dimension f for each class c
interval_vote[f, i, c] =
interval_count[f, i, c] / class_count[c] normalize interval_vote[f, i, c]; /* such that ∑c interval_vote[f, i, c] = 1 */ end.
2. Klasifikasi
Proses ini dimulai dengan menginisialisasi vote dari setiap kelas dengan nilai nol. Pada tiap fitur f dicari interval i dimana nilai ef jatuh, dimana efmerupakan nilai fitur f dari instance uji e. Jika nilai ef tidak diketahui (hilang), maka nilai ef tersebut akan diabaikan dengan memberikan vote nol pada tiap kelas. Jika ef diketahui maka interval i dapat ditemukan. Interval dapat berisi instance pelatihan beberapa kelas. Kelas dalam interval direpresentasikan oleh vote pada interval tersebut. Untuk setiap kelas c, fitur f memberikan vote yang sama dengan interval_class_vote[f, i, c]. Notasi ini dapat direpresentasikan sebagai kelas c yang diberikan vote fitur f.
Tiap fitur f mengumpulkan vote untuk kelas c yang disimpan dalam feature_vote[f, c], selanjutnya vote tersebut dinormalisasi sehingga nilai vote dari fitur f sama dengan 1.
Setiap fitur f mengumpulkan vote yang disimpan dalam sebuah vektor <votef,1, ...,
votef,k >, dimana votef,cdengan c adalah vote
fitur f untuk kelas c dan k yang merupakan jumlah kelas. Setelah sejumlah fitur vektor vote dijumlahkan untuk mendapatkan total vektor vote <vote1, ..., votek>. Kelas dengan
vote tertinggi dari total vektor vote akan menjadi kelas dari instance uji e. Klasifikasi dalam algoritme VFI5 dapat dilihat di bawah ini:
classify(e): /* e: example to be classified */ begin
for each class c vote [c] = 0 for each feature f
for each class c
feature_vote[f, c] = /* vote of feature f for class c */
if ef value is known i = find_interval(f, ef) for each class c
feature_vote[f, c] = interval_vote[f, i, c]
vote[c] = vote[c] + feature_vote[f, c] * weight[f];
return the class c with highest vote[c]; end.
Confusion Matrix
Confusion matrix merupakan sebuah tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi. Tabel ini diperlukan untuk menentukan kinerja suatu model klasifikasi (Tan, Steinbach & Kumar 2005). Contoh confusion matrix dapat dilihat pada Tabel 3. Tabel 3 Confusion matrix untuk data dua kelas
Kelas Prediksi
Akurasi hasil klasifikasi dari confusion matrix dihitung dengan rumus :
Akurasi = a + d
a + b + c + d x 100%
METODE PENELITIAN
5 Tahapan-tahapan tersebut dapat dilihat pada
Gambar 1.
Gambar 1 Metodologi Penelitian. Data Citra Tulisan Tangan
Data yang digunakan dalam penelitian ini diperoleh dari 57 responden yang menuliskan sebuah kalimat yang sudah ditentukan pada selembar kertas. Kalimat yang ditulis oleh responden dapat dilihat pada Lampiran 1. Pada tahap awal kalimat tersebut dikonsultasikan terlebih dahulu dengan Grafologis dan Psikolog, hal ini dilakukan untuk mendapatkan informasi data citra tulisan tangan yang relevan untuk data penelitian. Konsultasi tersebut dilakukan dengan grafologis dan psikolog yaitu :
1. Fitri Kusuma Dewi, S.Hut 2. Mugi Rahayu, S.Psi
Dari hasil konsultasi, data tersebut kemudian dibagi menjadi 2 dengan 27 data responden untuk data citra huruf a dan 30 data responden untuk data citra huruf t. Dari kalimat yang sudah dituliskan hanya diambil huruf a dan t sebanyak lima citra, tiga citra untuk data latih dan 2 citra untuk data uji. Jadi, ada 81 citra yang digunakan sebagai data latih dan 54 citra untuk data uji pada huruf a.
Citra data latih dan data uji huruf a dapat dilihat pada Lampiran 2. Pada huruf t ada 90 data latih dan 60 data uji. Citra data latih dan data uji huruf t dapat dilihat pada lampiran 3. Citra tulisan tangan akan diklasifikasikan ke dalam 3 kelas untuk huruf a dan 3 kelas untuk huruf t. Definisi kelas tersebut dapat dilihat pada Tabel 4 dan 5.
Huruf a dan huruf t dipotong dari kalimat tersebut dengan ukuran 40 x 40 pixel. Agar mempercepat kinerja sistem dilakukan proses resizing pada citra sehingga ukurannya menjadi 24 x 12 pixel.
Tabel 4 Kelas prediksi huruf a Bentuk
Tabel 5 Kelas prediksi huruf t Bentuk
Sebelum citra diklasifikasi menggunakan algoritme VFI5, dilakukan praproses terlebih dahulu. Pada tahap praproses ini citra tulisan tangan yang merupakan citra RGB untuk mempermudah perhitungan citra akan diubah menjadi citra grayscale dan disederhanakan lagi menjadi citra biner. Selain itu juga dilakukan proses resizing citra dari ukuran awal 40 x 40 pixel menjadi 24 x 12 pixel. Setelah praproses tersebut seluruh data akan direpresentasikan dalam bentuk matriks yang merupakan input dalam VFI5.
Data Latih dan Data Uji
Matriks yang di dapat dari tahap praproses dipisahkan menjadi data latih dan data uji dengan perbandingan 3 : 2.
6 Algoritme VFI5
Tahap algoritme VFI5 ini akan dibagi menjadi tiga tahap, yaitu tahap pelatihan, tahap interval fitur dan tahap klasifikasi. Pada tahap pelatihan yang menjadi input adalah matriks yang didapat tahap praproses. Pada tahap ini akan dihitung vote tiap fitur untuk masing-masing kelas. Selanjutnya tiap nilai vote akan dijumlahkan pada masing-masing kelas. Jumlah nilai vote tersebut akan dinormalisasi untuk mendapatkan nilai vote masing-masing kelas pada tahap interval fitur.
Tahap klasifikasi dimulai dengan mencari interval yang sesuai dengan nilai tiap fitur dari data uji pada interval fitur data latih. Nilai vote pada interval tersebut kemudian dikumpulkan dan dijumlahkan untuk masing-masing kelasnya. Kelas yang memiliki total nilai vote terbesar menjadi kelas prediksi bagi data uji tersebut.
Analisis Hasil Klasifikasi
Analisis dilakukan menggunakan tabel confusion matrix, kemudian dihitung besaran akurasi yang berhasil dicapai, dan dapat diambil suatu kesimpulan. Tingkat akurasi diperoleh dengan rumus :
��� � �=Σ data uji benar klasifikasiΣ
data uji x 100%
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini ialah sistem operasi Microsoft Windows 7, Matlab 7.7 (R2008b). Perangkat keras yang digunakan adalah Prosesor AMD
Turion™ , Memori 2 GB RAM DDR2,
Harddisk, dan Monitor 11.6”.
HASIL DAN PEMBAHASAN
Pada penelitian ini dilakukan dua percobaan pada masing-masing huruf a dan huruf t. Pada huruf a selain menggunakan data latih yang asli juga dilakukan percobaan pertukaran data uji menjadi data latih. Pada huruf t dilakukan percobaan menggeser kolom utama huruf sehingga berada pada kolom yang sama dan percobaan tanpa menggeser huruf.
Percobaan 1 Huruf a tanpa pertukaran
Percobaan yang pertama adalah percobaan huruf a menggunakan data latih yang asli tanpa pertukaran. Pada percobaan huruf a ada
81 data latih dan 54 data uji. Dari data tersebut didapatkan hasil yang disajikan pada Tabel 6. salah diklasifikasi yaitu kelas 1 dikenali sebagai kelas 2 sebanyak 1 dengan selisih vote 2.362 dan dikenali sebagai kelas 3 sebanyak 2 dengan masing-masing selisih vote 0.396 dan 0.378, kelas 2 dikenali sebagai kelas 3 sebanyak 2 dengan masing-masing selisih vote 2.501 dan 2.270, dan kelas 3 dikenali sebagai kelas 1 dengan selisih vote 3.302, sehingga akurasinya adalah 88.89%. Jumlah vote dapat dilihat pada Tabel 7.
Tabel 7 Jumlah vote data uji percobaan 1 yang salah klasisifikasi
Data uji ke-
Jumlah vote kelas Kelas
1 2 3 Pre mengklasifikasi citra dengan baik. Hal tersebut terlihat pada Tabel 6 data uji yang diklasifikasikan dengan benar sebanyak 11 dari 14 data uji pada kelas 1, 18 dari 20 data uji pada kelas 2, dan 19 dari 20 data uji pada kelas 3. Dari ketiga kelas tersebut kelas 3 merupakan kelas yang paling mudah dikenali.
1 PENDAHULUAN
Latar Belakang
Pengenalan karakter dan potensi diri melalui tulisan tangan merupakan penelitian yang cukup penting. Ini disebabkan banyaknya tes psikologi yang ditawarkan dan disediakan untuk membantu mengenali potensi diri, tetapi tidak banyak yang menawarkan tes yang sederhana, dapat dilakukan di mana saja, waktu pengerjaan cepat, hasil instan tanpa harus bertatap muka, dan yang paling penting keakuratannya lebih dari 80%. Hanya grafologi yang menawarkan ini dan analisis tulisan tangan pun dapat menguak potensi dasar yang belum tergali secara optimal dan mencari tahu mengapa hal itu bisa terjadi (Rosette 2010).
Grafologi adalah ilmu yang mempelajari, mengidentifikasi, menganalisis, mengevaluasi dan mengetahui kepribadian sesorang melalui pola tulisan tangannya. Tulisan tangan mengungkapkan kepribadian sejati termasuk emosi, ketakutan, kejujuran, pertahanan dan banyak hal lainnya (Champa & Kumar 2010). Bentuk tulisan tangan seperti sidik jari dan DNA yang merupakan sesuatu yang unik dan berbeda di setiap orang. Tahun 1875, Jean Hyppolyte Michon memperkenalkan teori pengenalan karakter seseorang melalui tulisan ini yang dikenal dengan sebutan grafologi. Sejak tahun 1985 grafologi digunakan dalam ilmu kesehatan, pendidikan dan jurnalistik.
Bentuk tulisan tangan merupakan alat ukur yang tidak dapat berbohong karena berasal dari alam bawah sadar. Kecuali, proses syaraf-syaraf pusat dalam sistem tubuh dan pikiran bawah sadar dapat dikontrol. Bila seseorang berusaha untuk mengubah tulisan tangannya, hal tersebut dapat diidentifikasikan sebagai ketidakjujuran. Apabila seseorang mengubah bentuk tulisan secara permanen, format cara berpikir pun harus diubah. Jadi, yang dianalisis adalah bentuk, bukan isi tulisan karena isi tulisan cenderung dapat direkayasa. Grafologis dapat mempunyai penilaian yang subjektif dalam menganalisis tulisan tangan. Grafologis yang berbeda dapat menganalisis tulisan tangan yang sama tetapi memberikan hasil yang berbeda (Galbraith & Guest 1994 yang diacu dalam Sheilkholeslami et al). Keakuratan dari hasil analisis tulisan tangan bergantung pada kemampuan grafologis itu sendiri (Champa & Kumar 2010). Oleh karena itu, dibutuhkan suatu pemanfaatan teknologi komputer yang dapat
menerapkan ilmu grafologi untuk membantu grafologis dalam menganalisis tulisan tangan.
Penelitian ini mencoba mengembangkan metode analisis Grafologi dengan menguji data tulisan tangan. Algoritme VFI5 digunakan pada penelitian ini, karena selain merupakan algoritme klasifikasi algoritme ini juga cukup kokoh terhadap fitur yang tidak relevan tetapi memberikan hasil yang baik. Pada data analisis tulisan tangan fitur yang tidak relevan kemungkinan akan ada, dikarenakan data anilisis dari pakar akan berbeda-beda.
Penelitian sebelumnya tentang analisis tulisan tangan yaitu penelitian Grafologi yang pernah dilakukan yaitu tentang Artificial Neural Network for Human Behavior Prediction through Handwriting Analysis (Champa & Kumar 2010). Pada penelitian ini dilakukan analisis grafologi pada parameter huruf t menggunakan jaringan syaraf tiruan propagasi balik. Input berupa citra tulisan tangan huruf t dan output yang dihasilkan berupa karakter berdasarkan pada tekanan pena, baseline dan tanda bar t dan ketinggian huruf t orang tersebut.
Tujuan
Tujuan penelitian ini adalah melakukan pengenalan tulisan tangan dengan citra menggunakan algoritme VFI5.
Ruang Lingkup
Citra yang digunakan diperoleh dari 57 responden yang merupakan tulisan tangan tiap orang yang berukuran, yaitu 40x40 piksel. Penelitian ini juga dibatasi pada huruf yang digunakan yaitu huruf a dan huruf t. Output yang diperoleh dikelompokkan ke dalam tiga kelas pada masing-masing huruf a dan huruf t. Manfaat Penelitian
Manfaat dari penelitian ini adalah untuk membantu grafologis dalam menganalisis tulisan tangan.
TINJAUAN PUSTAKA
Grafologi
2 banyak hal lainnya. Analisis tulisan tangan
bukan dokumen periksaan, yang dapat mengidentifikasi siapa penulis dari contoh tulisan tangan tersebut (Champa & Kumar 2010).
Tulisan tangan sering disebut sebagai tulisan otak karena setiap ciri kepribadian diwakili oleh pola saraf otak. Setiap pola saraf otak menghasilkan gerakan neuromuskular yang unik untuk setiap orang yang memiliki ciri kepribadian tertentu. Saat menulis, terjadi gerakan-gerakan kecil secara tidak sadar. Setiap menulis gerakan atau goresan mengungkapkan ciri kepribadian tertentu. Dengan kata lain, grafologi adalah ilmu yang mengidentifikasikan pola yang muncul dalam tulisan tangan dan menggambarkannya sesuai sifat kepribadian. Orang yang mempelajari grafologi disebut grafologis. Akurasi grafologis dalam menganalisis tulisan tangan tergantung pada keterampilan grafologis itu sendiri (Champa & Kumar 2010).
Huruf a
Dalam grafologi banyak huruf yang memberi petunjuk tentang ciri-ciri kepribadian. Salah satunya adalah huruf a. Huruf a dalam grafologi termasuk kedalam huruf kecil spesifik. Pada Tabel 1 akan dijelaskan beberapa bentuk huruf a beserta penggambaran karakternya (Amend & Ruiz 1980).
Tabel 1 Bentuk huruf a dan karakternya. Bentuk Huruf Karakter
a balok
cenderung tertarik pada kegiatan yang
berhubungan dengan seni, musik, budaya, dan sastra individu ini akan jujur dan terus terang jika ditanya mengenai pendapatnya, berbeda dengan huruf a terbuka di atas yang jujur dalam mengemukakan pendapat secara sukarela tanpa diminta.
Huruf t
Sejauh ini, banyak analisis tulisan tangan yang menganggap huruf t merupakan huruf
dari abjad yang secara grafologis paling penting. Dalam tulisan tangan seseorang, panjang, tekanan, penempatan, dan bentuk dari silangan huruf t memperlihatkan irama dan kekuatan kehendak yang ada di baliknya. Penempatan ruji t pada batangnya merupakan petunjuk utama terhadap sasaran-sasaran individual. Ada lebih dari 50 cara yang berbeda untuk menyilangkan huruf t dan seorang penulis akan sering mengubah atau memodifikasi gayanya seiring berubahnya kepribadian, atau karena kesehatanya yang berubah. Beberapa bentuk dan penggambaran karakter akan dijelaskan pada Tabel 2 (Amend & Ruiz 1980).
Tabel 2 Bentuk huruf t dan karakternya. Bentuk Huruf Karakter
Ruji t lurus
Ambisi: Balance, terkontrol
Ruji t yang horizontal menunjukkan putus asa dan pasrah. Citra Digital
Citra dapat didefinisikan sebagai fungsi dua dimensi, f(x,y), dimana x dan y adalah koordinat spasial dan amplitudo dari f pada setiap pasangan koordinat (x,y) yang disebut intensitas atau derajat keabuan sebuah citra. Ketika x,y dan nilai amplitudo f bernilai terbatas dan diskret, maka citra tersebut disebut citra digital (Gonzalez & Woods 2002).
3 ini disebut sebagai picture elements, image
elements, pels atau pixels. Pixel adalah istilah yang paling sering digunakan untuk menunjukkan elemen dari sebuah citra digital (Gonzalez & Woods 2002).
Pengolahan Citra
Pengolahan citra digital merupakan proses yang masukan dan keluaranya adalah citra dan meliputi proses pengekstrakan atribut dari citra dan pengenalan citra. Selain itu, yang dimaksud dengan pengolahan citra digital biasanya adalah pengolahan citra menggunakan komputer digital (Gonzalez & Woods 2002).
Klasifikasi
Klasifikasi merupakan serangkaian proses untuk menemukan sekumpulan model yang merepresentasikan dan membedakan kelas-kelas data. Klasifikasi ini bertujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu data yang label kelasnya tidak diketahui (Han & Kamber 2006).
Klasifikasi terdiri atas dua tahap, yaitu pelatihan dan klasifikasi. Tahap pelatihan, menggunakan beberapa algoritme, dan dibentuk sebuah model domain dari setiap data pelatihan yang label kelasnya sudah diketahui. Tahap klasifikasi, menggunakan model dan mencoba untuk memprediksi kelas yang baru dari label kelas yang sudah diketahui sebelumnya (Güvenir & Demiroz 1998)
Voting Feature Intervals (VFI5)
Algoritme Voting Feature Interval merupakan algoritme klasifikasi yang merepresentasikan deskripsi sebuah konsep dengan sekumpulan interval nilai fitur. Klasifikasi sebuah instance baru didasarkan pada vote klasifikasi yang dibuat oleh nilai setiap fitur secara terpisah. VFI5 merupakan algoritme klasifikasi yang bersifat non-incremental, yaitu semua data training diproses secara bersamaan. Setiap contoh data training direpresentasikan sebagai nilai-nilai fitur sebuah vektor nominal (diskret) atau linear (kontinu) disertai sebuah label yang merepresentasikan kelas contoh data. Dari contoh pelatihan, algoritme VFI5 membentuk interval untuk masing-masing fitur (Güvenir, Demiroz & Ilter 1998).
Interval yang dibuat dapat berupa range interval atau point interval. Range interval didefinisikan sebagai nilai antara dua end
point yang berdekatan tetapi tidak termasuk kedua end point tersebut, sedangkan point interval didefinisikan sebagai seluruh end point secara berturut-turut. Untuk setiap interval, vote tiap kelas disimpan untuk tiap intervalnya. Dengan demikian, interval dapat mewakili beberapa kelas dengan menyimpang vote untuk setiap kelas. Algoritme VFI5 terdiri atas tahap pelatihan dan klasifikasi (Güvenir, Demiroz & Ilter 1998).
1. Pelatihan
Langkah pertama pada pelatihan adalah menemukan end point untuk setiap kelas c pada setiap fitur f. End point kelas c yang ditentukan merupakan nilai terendah dan tertinggi pada fitur linear f pada beberapa contoh kelas yang diamati. Pada end point dimensi fitur nominal f pada kelas c yang diberikan adalah semua nilai yang berbeda dari f pada beberapa instance yang diamati. End point dari masing-masing fitur f disimpan dalam array EndPoint[f]. Pada setiap fitur linear terdapat end point sebesar 2k, dimana k adalah jumlah kelas. End point pada setiap dimensi fitur diurutkan untuk menjadi fitur linear. Jika fitur adalah fitur linear, maka point interval terdiri dari setiap end point yang berbeda dan range interval dibentuk di antaranya. Jika fitur adalah fitur nominal, tiap end point yang berbeda merupakan point interval.
Selanjutnya jumlah instance pelatihan pada tiap interval dihitung dan jumlah instance kelas c dalam interval i dari fitur f
direpresentasikan sebagai
interval_class_count[f, i, c]. Untuk setiap instance pelatihan, dimana interval i yang merupakan nilai untuk fitur f dari instance pelatihan e (ef) tersebut berada. Jika interval i adalah point interval dan efsama dengan batas bawah (yang sama dengan batas atas pada point interval), jumlah kelas instance (ef) di interval i ditambah 1. Jika interval i adalah range interval dan ef berada pada batas bawah interval tersebut , maka jumlah kelas ef di interval i ditambah dengan 0.5. Tapi jika ef berada pada interval i, maka jumlah kelas ef dalam interval ditambah dengan 1.
Untuk menghilangkan efek perbedaan distribusi, jumlah instance kelas c untuk fitur f pada interval i dinormalisasi dengan membagi total jumlah instance dari kelas c dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai interval_class_vote[f, i,
c]. Selanjutnya nilai-nilai