KLASIFIKASI DEBITUR KARTU KREDIT DENGAN
PEMILIHAN FITUR MENGGUNAKAN
VOTING FEATURE INTERVALS
5
SRI RAHAYU NATASIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Debitur Kartu Kredit dengan Pemilihan Fitur Menggunakan Voting Feature Intervals 5 adalah benar karya saya dengan arahan dari pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2013
Sri Rahayu Natasia
ABSTRAK
SRI RAHAYU NATASIA. Klasifikasi Debitur Kartu Kredit dengan Pemilihan Fitur Menggunakan Voting Feature Intervals 5. Dibimbing oleh AZIZ KUSTIYO.
Penyediaan kartu kredit bagi nasabah merupakan salah satu cara untuk memperoleh keuntungan dalam kegiatan perbankan yang berisiko menimbulkan kerugian jika nasabah sering melakukan tunggakan pembayaran. Oleh karena itu penting untuk mengetahui riwayat perbankan nasabah yang akan mengajukan permohonan kartu kredit. Riwayat perbankan digunakan sebagai input algoritma Voting Feature Intervals 5 (VFI5) dalam pembangunan model klasifikasi yang bertujuan untuk mengelompokkan calon debitur berdasarkan status kelancaran membayar utang. Data debitur yang digunakan dalam penelitian ini tergolong imbalanced data, sehingga diperlukan metrik pengukuran selain akurasi untuk menilai keberhasilan model. Data ini terdiri atas 14 fitur, tetapi tidak semua fitur tersebut memiliki informasi yang penting dalam pengelompokan debitur, sehingga dalam pembuatan model dilakukan pemilihan fitur yang berpengaruh terhadap tingkat akurasi. Pemilihan fitur dilakukan melalui 2 pendekatan, yaitu berdasarkan akurasi masing-masing fitur dan pemilihan fitur secara bertahap. Model terbaik diperoleh dari pemilihan fitur berdasarkan akurasi dengan akurasi sebesar 67.74% serta recall dan precision untuk kelas debitur bad adalah 46.88% dan 24.69%.
Kata kunci: debitur kartu kredit, imbalanced data, klasifikasi, pemilihan fitur, Voting Feature Intervals 5
ABSTRACT
SRI RAHAYU NATASIA. The Classification of Credit Card Debtor by Feature Selection Using Voting Feature Intervals 5. Supervised by AZIZ KUSTIYO.
Provision of credit cards for customers is one of the ways to obtain profit in banking activities which cause risks of losses if the customer frequently delinquent the payments. Therefore, it is important to know the banking profile of the customer who will apply for a credit card. The banking profile data is used as input for Voting Feature Intervals 5 (VFI5) algorithm in the development of classification models that aim to classify potential debtor based on the payment status of the debtor. The debtor data used in this research is categorized as imbalanced data, hence it is necessary to have other performance measures beside accuracy; in this research we also used recall and precision. The input data consist of 14 features, however each features has different significance in classifying debtor. Therefore a feature selection process is conducted before the development of the model. The feature selection is conducted using two approaches: feature selection based on the accuracy of each feature and stepwise feature selection. The former method provides the better accuracy of 67.74%, and the values of recall and precision for the class of bad debtor are 46.88% and 24.69%, respectively.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DEBITUR KARTU KREDIT DENGAN
PEMILIHAN FITUR MENGGUNAKAN
VOTING FEATURE INTERVALS
5
SRI RAHAYU NATASIA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi Debitur Kartu Kredit dengan Pemilihan Fitur Menggunakan Voting Feature Intervals 5
Nama : Sri Rahayu Natasia
NIM : G64104034
Disetujui oleh
Aziz Kustiyo, S.Si, M.Kom Pembimbing
Diketahui oleh
Dr. Ir. Agus Buono, M.Si, M.Kom Ketua Departemen
PRAKATA
Segala puji bagi Allah subhanahu wata’ala atas segala limpahan rahmat dan karunia-Nya sehingga penulis mampu menyelesaikan skripsi yang berjudul
“Klasifikasi Debitur Kartu Kredit dengan Pemilihan Fitur Menggunakan Voting
Feature Intervals 5” ini. Shalawat dan salam senantiasa tercurah limpah kepada Rasulullah, Nabi Muhammad shalallahu ‘alaihi wasallam, serta keluarganya, sahabatnya, dan para pengikutnya yang tetap istiqomah hingga akhir zaman. Penulis juga menyampaikan terima kasih kepada seluruh pihak yang telah membantu dalam penelitian ini, yaitu:
1 Kedua orang tua penulis, Ayahanda Supriadi Anra, S.Pd, MM dan Ibunda Murniati S.Pd, serta saudara-saudara penulis, atas doa, kasih sayang, dan dukungan yang luar biasa.
2 Bapak Aziz Kustiyo, S.Si, M.Kom selaku dosen pembimbing yang telah banyak memberikan ide, saran, nasihat, dan dukungan, serta direpotkan dalam penyelesaian penelitian ini.
3 Bapak Dr. Irman Hermadi, S.Kom, MS dan Bapak Toto Haryanto, S.Kom, M.Si selaku dosen penguji.
4 Puspalia Ayudiar Setiawati yang telah berkenan memberikan data penelitian. 5 Revina Bayu Putri, Pebrya Narti, Sevriya Amban Suri, R.Putri Ayu
Pramesti, Silvia Rahmi, dan Dean A. Ramadhan, yang selalu memberikan semangat, dukungan dan tempat bertukar pikiran bagi penulis. Semoga ukhuwah kita selalu terajut.
6 Rekan-rekan satu bimbingan, Erni, Ilvi, kak Corry, Septy, mba Sri, kak Asep, dan Bangkit atas diskusi-diskusi dan suka-duka selama pembimbingan.
7 Sahabat Ilkomerz angkatan V atas persahabatan yang hangat.
8 Sahabat di lingkaran cahaya, sahabat DKM Alghifari, sahabat KAMUS IPB, sahabat INF 44, sahabat di kostan B14, terima kasih karena telah hadir dalam kehidupan penulis.
Penulis menyadari penelitian ini masih banyak kekurangan. Harapannya, semoga hasil penelitian ini dapat bermanfaat.
Bogor, Januari 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Klasifikasi 2
Imbalanced Data 2
Best Subset Regression 3
Stepwise Regression 3
Voting Feature Intervals 5 (VFI5) 3
Confusion Matrix 5
METODE 7
Data 7
Praproses 7
Pengambilan Sampel 50 Kali 8
Pembuatan Model VFI5 9
Evaluasi Kinerja 9
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Praproses 10
Pengambilan Sampel 50 Kali 11
Pemilihan Fitur berdasarkan Akurasi 11
Pemilihan Fitur secara Bertahap 12
Model 1 12
Model 2 15
Perbandingan dengan Penelitian Sebelumnya 21
SIMPULAN DAN SARAN 22
Simpulan 22
Saran 23
DAFTAR PUSTAKA 23
LAMPIRAN 24
DAFTAR TABEL
1 Confusion matrix dengan dua kelas data 6
2 Komposisi data latih dan uji di setiap kelas 11
3 Rata-rata akurasi untuk masing-masing fitur 11
4 Confusion matrix sampel ke-14 dan 24 13
5 Confusion matrix sampel ke-34 13
6 Nilai voting kesalahan prediksi instance uji ke-56 dan 132 14
7 Akurasi Model 2 15
8 Confusion matrix sampel ke-1 16
9 Confusion matrix sampel ke-39 17
10 Nilai voting kesalahan prediksi instance uji ke-6 dan ke-130 pada
sampel ke-39 17
11 Akurasi Model 3 18
12 Confusion matrix sampel ke-12 dan 22 19
13 Nilai voting kesalahan prediksi instance uji ke-4 dan 21 pada sampel 12 20
14 Confusion matrix sampel ke-30 20
15 Voting kesalahan prediksi pada sampel ke-30 untuk instance uji ke-30
dan 135 21
16 Perbandingan metrik pengukuran dengan penelitian lain 22
DAFTAR GAMBAR
1 Pseudocode tahap pelatihan algoritme VFI5 (Demiröz 1997) 4
2 Pseudocode tahap klasifikasi algoritme VFI5 (Güvenir et al. 1998) 5
3 Diagram alur penelitian 8
4 Akurasi pengujian Model 1 12
5 Perbandingan akurasi Model 1 dan 2 15
6 Perbandingan F-measure pada Model 1 dan 2 16
7 Perbandingan akurasi Model 1 dan 3 19
8 Perbandingan F-measure Model 1 dan 3 19
DAFTAR LAMPIRAN
1 Daftar fitur 24
2 Pemilihan fitur secara bertahap 25
3 Diagram metrik hasil pengukuran Model 1 26
4 Voting hasil pelatihan sampel ke-34 pada Model 1 27
5 Metrik pengukuran Model 2 29
6 Nilai voting hasil pelatihan sampel ke-39 Model 2 31
7 Metrik pengukuran Model 3 32
PENDAHULUAN
Latar Belakang
Penyediaan kartu kredit bagi nasabah merupakan salah satu cara untuk memperoleh keuntungan dalam kegiatan perbankan. Di sisi lain, kartu kredit dapat menimbulkan risiko kerugian jika nasabah sering melakukan tunggakan pembayaran. Oleh karena itu, perlu dilakukan penelusuran riwayat perbankan nasabah untuk mengetahui apakah calon debitur termasuk nasabah yang lancar (good) atau tidak (bad) dalam pembayaran kartu kredit. Riwayat perbankan nasabah ini dapat digunakan untuk membangun model klasifikasi dalam mengelompokkan calon debitur berdasarkan status kelancaran membayar utang.
Penelitian mengenai klasifikasi debitur kartu kredit dilakukan oleh Setiawati (2011) menggunakan algoritme jaringan saraf tiruan Backpropagation. Berdasarkan data penelitian Setiawati (2011), terdapat perbedaan yang cukup besar antara debitur good dan bad, yaitu sebesar 4:1 sehingga dapat dikatakan terjadi ketidakseimbangan (imbalanced) antara dua kelas tersebut. Akibatnya, suatu algoritme klasifikasi dapat mencapai akurasi tinggi hanya dengan mengelompokkan kelas debitur bad yang merupakan minoritas ke dalam kelas
good sehingga potensi kerugian tidak terdeteksi. Dari hasil penelitian tersebut diperoleh akurasi dari model terbaik sebesar 73.39% serta recall dan precision
kelas bad sebesar 56.26% dan 36.90%.
Data perbankan untuk mengetahui riwayat kredit nasabah memiliki banyak fitur. Kebanyakan dari fitur ini tidak memberikan informasi yang begitu penting dalam pengklasifikasian debitur sehingga dalam pembuatan model klasifikasi sebaiknya dipilih kembali. Berdasarkan information value fitur yang diperoleh dalam penelitian Setiawati (2011), secara umum keempat belas fitur yang digunakan memiliki tingkat prediksi yang rendah. Oleh karena itu, dalam penelitian ini akan dilakukan pemilihan fitur yang dapat mempengaruhi tingkat akurasi model.
Penelitian ini menggunakan algoritme Voting Feature Intervals 5 (VFI5) sebagai algoritme untuk klasifikasi. VFI5 memiliki beberapa kelebihan, di antaranya yaitu waktu pelatihan dan klasifikasi yang singkat serta prediksi yang dihasilkan sangat akurat.
Penelitian terkait imbalanced data dengan algoritme VFI5 sebagai metode klasifikasi dilakukan oleh Aritonang (2006). Pada penelitian ini dilakukan pendekatan dari level data untuk mengatasi masalah imbalanced data. Dataset
yang digunakan merupakan data penyakit Hypothyroid dan Euthyroid yang masing-masing terdiri atas dua kelas, yaitu positif dan negatif. Perbandingan komposisi data di kedua kelas untuk masing-masing dataset adalah 1:10 untuk
Euthyroid dan 1:20 untuk Hypothyroid. Akurasi yang dihasilkan oleh model terbaik pada data Euthyroid adalah 66.00% dengan recall dan precision kelas minoritas sebesar 69.57% dan 65.37%. Sementara untuk model terbaik pada data
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk melakukan pemilihan fitur dan menerapkan algoritme Voting Feature Intervals 5 (VFI5) pada klasifikasi debitur kartu kredit serta mengukur tingkat akurasinya.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengetahui tingkat akurasi algoritme
Voting Feature Intervals 5 (VFI5) dengan pemilihan fitur dalam permasalahan klasifikasi debitur kartu kredit. Serta diharapkan dapat terbangun suatu model untuk memprediksi calon debitur kartu kredit sehingga dapat meminimalkan potensi kerugian.
Ruang Lingkup Penelitian
Pada penelitian ini dilakukan pembatasan masalah pada:
1 Dataset yang digunakan adalah data penelitian Setiawati (2011), yaitu data debitur Bank X tahun 2008-2009. Dataset ini terdiri atas dua kelas yaitu debitur good dan bad.
2 Klasifikasi menggunakan algoritme VFI5.
3 Pembobotan fitur pada algoritme diseragamkan yaitu satu.
TINJAUAN PUSTAKA
Klasifikasi
Klasifikasi adalah proses menemukan sekumpulan model atau fungsi yang menggambarkan dan membedakan konsep atau kelas-kelas data, dengan tujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han dan Kamber 2001).
Pada klasifikasi dataset yang digunakan dibagi menjadi data latih dan data uji. Data latih digunakan untuk membangun model, sementara data uji digunakan untuk memvalidasi model yang telah dibangun. Akurasi model ditentukan oleh hasil pengujian terhadap data uji.
Imbalanced Data
3
besar, contohnya pada kasus deteksi penipuan kartu kredit, deteksi penyakit langka, dan manajemen resiko (Sun et al. 2009).
Pada masalah klasifikasi dengan dua kelas, tingkat imbalanced data dapat dilihat dari rasio distribusi jumlah instance pada kedua kelas. Rasio antara kedua kelas tersebut bisa sangat drastis, yaitu 1:100, 1:1000, bahkan lebih.
Beberapa solusi telah dikembangkan untuk mengatasi masalah imbalanced data, seperti pendekatan dari level data dan pendekatan dari level algoritme. Masing-masing pendekatan memiliki kekurangan dan kelebihan. Misalnya pada pendekatan dari level data, keuntungannya ialah dapat diterapkan pada metode pembelajaran apapun.
Best Subset Regression
Best subset adalah sebuah metode yang digunakan untuk membantu
memutuskan variabel prediktor yang akan dimasukkan ke dalam model regresi. Metode ini dilakukan dengan cara memeriksa semua kemungkinan model dari semua kombinasi prediktor yang mungkin. Misalnya, jika terdapat sejumlah p
kandidat prediktor, jumlah model dari kombinasi prediktor yang dapat dibentuk adalah 2p. Best subset menggunakan akurasi prediksi sebagai standar, harapannya adalah subset regression akan menghasilkan persamaan regresi yang lebih sederhana dan lebih akurat daripada persamaan berdasarkan semua variabel (Breiman 1995).
Stepwise Regression
Stepwise regression membentuk model dengan menambah atau mengurangi
prediktor individual secara otomatis, satu langkah pada satu waktu, berdasarkan pada signifikansi statistik prediktor tersebut. Detail proses dapat dikendalikan, termasuk level signifikansi, dan apakah proses hanya melibatkan penambahan/pengurangan prediktor, atau keduanya (Frost 2012). Terdapat dua metode yang dapat digunakan dalam stepwise regression, yaitu:
a Forward selection
Forward selection dimulai tanpa ada prediktor di dalam model. Selanjutnya ditambahkan prediktor yang paling signifikan di setiap langkah. Penambahan dilakukan hingga tidak ada kandidat prediktor yang memenuhi syarat untuk masuk ke dalam model.
b Backward selection
Pada backward selection, semua prediktor terdapat di dalam model. Setiap langkah dilakukan penghapusan prediktor yang paling tidak berpengaruh terhadap model. Penghapusan prediktor berhenti ketika tidak ada prediktor yang memenuhi syarat untuk dihapus.
Voting Feature Intervals 5 (VFI5)
4
ini yaitu prediksi yang dihasilkan sangat akurat, waktu pelatihan dan klasifikasinya singkat, robust terhadap data pelatihan yang memiliki noise dan tidak diketahui nilai fiturnya, dapat menggunakan bobot fitur, dan menghasilkan model yang dapat dibaca manusia dari pengetahuan klasifikasi (Güvenir et al. 1998).
Algoritme VFI5 terdiri atas dua tahap, yaitu tahap pelatihan dan klasifikasi. 1 Pelatihan
Tahap awal proses pelatihan adalah mencari nilai end point dari setiap
feature f pada setiap kelas c. End point pada feature linear, yaitu feature
yang nilainya kontinu adalah nilai minimum dan maksimum dari setiap kelasnya. End point untuk feature nominal adalah semua nilai yang berbeda pada feature tersebut untuk setiap kelas. Nilai end point feature dari setiap kelas c digabungkan dan diurutkan untuk dijadikan selang interval feature
tersebut. Ada dua jenis interval, yaitu point interval dan range interval.
Point interval dibentuk dari setiap nilai yang berbeda dari end point. Range interval merupakan nilai di antara dua point interval yang berdekatan tetapi tidak termasuk point interval tersebut.
Tahap selanjutnya menghitung jumlah instance pelatihan yang jatuh di interval i pada feature f di setiap kelas c yang direpresentasikan sebagai
interval_class_count[f,i,c]. Untuk setiap instance pelatihan, dicari interval i
tempat nilai feature f dari instance pelatihan ef tersebut jatuh. Jika ef jatuh
5
Berikutnya, setelah jumlah instance setiap interval i pada feature f dari setiap kelas diperoleh, jumlah instance setiap feature dijumlahkan kembali untuk masing-masing kelas.
Nilai vote diberikan kepada setiap feature f di kelas c, dengan nilai
vote merupakan hasil dari jumlah instance pada interval i dibagi dengan jumlah instance pada kelas c. Algoritme VFI5 melakukan normalisasi nilai
vote agar distribusi vote antar kelas tidak terlalu berbeda. Normalisasi ini dilakukan dengan membagi nilai vote interval i pada feature f dengan jumlah semua vote feature f di interval i untuk semua kelas c. Hasil normalisasi feature f pada semua kelas c berjumlah satu. Pseudocode untuk tahap pelatihan disajikan pada Gambar 1.
2 Klasifikasi
Proses klasifikasi diawali dengan memberi nilai vote 0 untuk setiap kelas c. Langkah berikutnya adalah mencari interval i dimana nilai ef dari
instance uji tersebut jatuh. Jika nilai feature dari instance uji tidak diketahui
vote feature tersebut bernilai 0 untuk semua kelas dan tidak diikutsertakan dalam proses voting. Jika nilai feature f instance e diketahui, akan dicari interval tempat nilai tersebut jatuh. Setelah diperoleh intervalnya, nilai vote feature f diisi dengan nilai vote feature yang diperoleh pada saat pelatihan.
Nilai vote yang diperoleh masing-masing kelas merupakan hasil penjumlahan setiap vote feature yang dikali dengan bobot feature. Kelas prediksi dari instance e merupakan kelas dengan nilai vote yang paling tinggi. Pseudocode algoritme untuk tahap klasifikasi disajikan pada Gambar 2.
Confusion Matrix
Pengukuran keberhasilan suatu algoritme klasifikasi dapat dilakukan dengan membuat confusion matrix dari setiap percobaan. Confusion matrix mengandung informasi tentang kelas data aktual dan kelas data hasil prediksi yang
classify(e) /* e: example to be classified*/ begin
6
direpresentasikan pada baris matriks. Kinerja algoritme klasifikasi biasanya dievaluasi berdasarkan data yang ada pada matriks. Tabel 1 menyajikan confusion matrix untuk data dengan dua kelas (Sun et al. 2009).
Evaluasi pada non-kelas independen gagal karena hasilnya hanya mencerminkan kinerja pembelajaran dari kelas mayoritas, dan semakin condong distribusi kelas efeknya akan semakin buruk. Oleh karena itu, dalam mengevaluasi imbalanced data fokus tertuju pada kelas individu (Weng dan Poon 2006). Beberapa pengukuran evaluasi untuk imbalanced data adalah precision,
recall, F-measure, kurva Receiver Operating Characteristic (ROC), dan lain lain. Metrik yang akan dihitung berdasarkan data confusion matrix adalah:
- Akurasi (AC)
AC= TP+TN
TP+FN+FP+TN
- Recall atau true positive rate (TP) menunjukkan persentase kelas data positif yang berhasil diprediksi benar dari keseluruhan instance kelas positif.
Recall= TP
TP+FN
- Precision (P) atau proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif.
P= TP TP + FP
Tabel 1 Confusion matrix dengan dua kelas data
Data berhasil diprediksi dengan benar karena masuk ke kelas negatif.
- FP adalah jumlah instance kelas negatif yang tidak berhasil diprediksi benar sebagai kelas negatif karena dikelompokkan ke kelas positif.
7
- F-measure yaitu evaluasi metrik umum yang menggabungkan precision dan
recall ke dalam satu nilai, biasanya dengan bobot yang sama pada kedua diprediksi benar dari keseluruhan instance kelas negatif.
TNrate
=
TN TN + FP- Negative predictive value merupakan proporsi kelas data negatif yang berhasil diprediksi benar dari keseluruhan hasil prediksi kelas negatif.
NPvalue
=
TN TN + FNMETODE
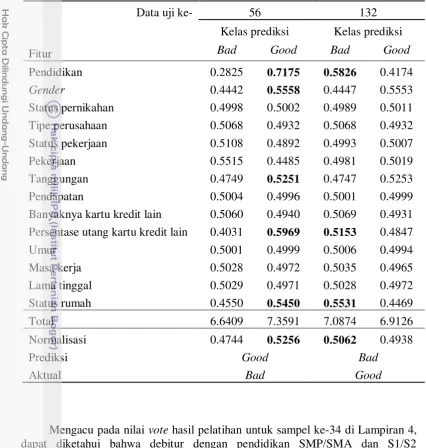
Ilustrasi tahapan proses penelitian disajikan dalam diagram alur pada Gambar 3.
Data
Data yang digunakan dalam penelitian ini adalah data sekunder debitur Bank X tahun 2008-2009 yang merupakan data penelitian Setiawati (2011) mengenai status kelancaran pembayaran utang kartu kredit. Dataset ini terdiri atas dua kelas, yaitu debitur good dan bad. Kelas good berarti debitur tersebut lancar dalam pembayaran, sedangkan bad berarti mengalami tunggakan lebih dari 90 hari (Setiawati 2011). Jumlah instance keseluruhan adalah 4413 dengan komposisi masing-masing kelas yaitu 3574 debitur good dan 839 debitur bad,
yang tergolong imbalanced data.
Terdapat 14 fitur pada dataset ini. Fitur-fitur tersebut ialah gender, usia, status pernikahan, pendidikan, tanggungan, status rumah, lama tinggal, pekerjaan, masa kerja, status pekerjaan, tipe perusahaan, pendapatan, banyaknya kartu kredit lain, dan persentase utang kartu kredit lain. Beberapa fitur memiliki missing value, contohnya fitur banyaknya kartu kredit lain dan persentase utang kartu kredit lain. Daftar fitur dan keterangannya disajikan dalam Lampiran 1.
Praproses
Pada tahap praproses, setiap kelas mengalami pengurangan jumlah instance.
8
pembuatan model. Selain itu, instance yang nilai fiturnya tidak valid juga tidak digunakan.
Pengambilan Sampel 50 Kali
Data yang telah dipraproses kemudian dipisahkan berdasarkan kelas debitur
good dan debitur bad. Pada masing-masing kelas dilakukan pengambilan sampel sebanyak 50 kali. Satu kali pengambilan sampel terdiri atas data latih dan data uji. Persentase pembagian data latih dan data uji adalah 80% data latih dan 20% data uji. Selanjutnya hasil pengambilan sampel tersebut digunakan untuk membuat model.
Gambar 3 Diagram alur penelitian Mulai
Data
Praproses
Pengambilan Sampel 50 Kali
Data Latih
Pelatihan VFI5 dengan Semua Fitur
Pemilihan Fitur berdasarkan Akurasi
Fitur Interval Model 1 Fitur Interval
Data Uji Data Uji
Model 2
Klasifikasi
Evaluasi Kinerja
Selesai
Pemilihan Fitur secara Bertahap
9
Pembuatan Model VFI5
Data latih dan data uji yang diperoleh dari pengambilan sampel sebanyak 50 kali, selanjutnya digunakan untuk membuat tiga model VFI5. Tiga model tersebut yaitu:
a Model 1
Model 1 merupakan model VFI5 yang menggunakan semua fitur. Tahapan pembuatan Model 1 yaitu sebagai berikut:
1 Melakukan pelatihan terhadap data latih yang menghasilkan fitur interval dan nilai vote untuk setiap fitur.
2 Proses klasifikasi terhadap data uji berdasarkan semua fitur. 3 Hitung akurasi Model 1.
b Model 2
Model 2 adalah model VFI5 dengan pemilihan fitur berdasarkan akurasi. Prosedur pemilihan fitur berdasarkan akurasi mengadopsi metode best subset regression, dengan langkah-langkah seperti di bawah ini:
1 Menggunakan fitur interval dan nilai vote dari Model 1 untuk setiap fitur. 2 Proses klasifikasi dilakukan berdasarkan masing-masing fitur.
3 Hitung akurasi klasifikasi masing-masing fitur. 4 Fitur diambil jika akurasi > 50%.
Setelah diperoleh fitur dengan akurasi > 50%, dilakukan klasifikasi terhadap data uji berdasarkan fitur-fitur tersebut. Terakhir, hitung akurasi Model 2. c Model 3
Model 3 yaitu model VFI5 dengan pemilihan fitur secara bertahap mengadopsi teknik stepwise regression, yaitu forward selection. Tahapan pembuatan Model 3 yaitu sebagai berikut:
1 Menggunakan fitur interval dan nilai vote dari Model 1 untuk setiap fitur. 2 Menentukan level signifikansi fitur untuk memasuki model, yaitu
akurasi bernilai 50%. Sementara level signifikansi fitur untuk meninggalkan model yaitu lebih kecil dari akurasi pada iterasi sebelumnya.
3 Tentukan fitur yang paling berpengaruh, yaitu fitur dengan akurasi tertinggi.
4 Uji cobakan model dengan setiap kandidat fitur yang tersisa. Fitur yang terpilih pada tahap sebelumnya tetap berada dalam model dan diikutsertakan pada proses pemilihan.
5 Ulangi tahap 3 dan 4. Iterasi berhenti ketika akurasi lebih kecil daripada level signifikansi, yang merupakan akurasi dari iterasi sebelumnya. Setelah diperoleh fitur melalui proses di atas, langkah terakhir adalah evaluasi kinerja Model 3.
Evaluasi Kinerja
Kinerja dari algoritme VFI5 dalam mengklasifikasikan debitur kartu kredit
10
model digunakan untuk membuat confusion matrix. Selanjutnya dihitung recall, precision, dan F-measure dari kelas positif, yaitu kelas debitur bad.
Lingkungan Pengembangan
Aplikasi yang dibangun pada penelitian ini menggunakan kode program yang dikembangkan oleh Aritonang (2006). Kode program tersebut kemudian dimodifikasi sesuai data yang digunakan. Selanjutnya diimplementasikan menggunakan spesifikasi perangkat keras dan perangkat lunak sebagai berikut:
Perangkat Keras:
- Processor Intel CoreTM i5 2.30 GHz - RAM kapasitas 2 GB
- Harddisk kapasitas 500 GB
Perangkat lunak:
- Sistem Operasi Windows 7 Ultimate - Matlab 7.7.0
- Microsoft Excel
HASIL DAN PEMBAHASAN
Data yang digunakan pada penelitian ini merupakan data debitur kartu kredit mengenai status kelancaran membayar utang, yang tergolong ke dalam kasus
imbalanced data. Terdapat dua kelas pada data ini, yaitu kelas debitur good dan
bad.
Praproses
Jumlah instance masing-masing kelas berkurang setelah dilakukan praproses. Instance yang salah satu nilai fiturnya tidak diketahui, misalnya banyaknya kartu kredit lain, tidak digunakan dalam pembuatan model. Selain itu,
instance yang nilai fiturnya tidak valid seperti 0 atau 1 pada fitur pendapatan, -1 pada fitur masa kerja dan lama tinggal juga tidak digunakan. Banyaknya instance
yang tidak digunakan dalam pembuatan model adalah 526, sehingga total data yang tersisa adalah 3887 instances. Dari hasil pemisahan ini diketahui bahwa
instance kelas debitur bad berkurang dari 839 menjadi 636 dan kelas debitur good
11
Pengambilan Sampel 50 Kali
Pengambilan sampel 50 kali dilakukan di setiap kelas sehingga terdapat 50 kombinasi data latih dan data uji dari masing-masing kelas. Setiap satu kali pengambilan diambil data latih dan data uji dengan persentase masing-masing 80% dan 20%. Komposisi data latih dan data uji ditampilkan pada Tabel 2.
Pemilihan Fitur berdasarkan Akurasi
Fitur interval dan nilai vote yang diperoleh pada Model 1, digunakan dalam proses klasifikasi data uji dari 50 sampel. Klasifikasi dilakukan berdasarkan masing-masing fitur. Rata-rata akurasi dari masing-masing fitur ditampilkan pada Tabel 3.
Berdasarkan akurasi rata-rata setiap fitur pada Tabel 3, diambil fitur dengan akurasi lebih besar dari 50%. Fitur yang terpilih yaitu pendidikan, gender, status pernikahan, tanggungan, dan status rumah. Fitur-fitur ini selanjutnya digunakan pada Model 2.
Tabel 2 Komposisi data latih dan uji di setiap kelas
Data Good Bad
Latih 2601 509
Uji 650 127
Tabel 3 Rata-rata akurasi untuk masing-masing fitur
Fitur Akurasi
Pendidikan 61.40%
Gender 52.62%
Status pernikahan 57.62%
Tipe perusahaan 19.67%
Status pekerjaan 35.95%
Pekerjaan 23.66%
Tanggungan 50.35%
Pendapatan 16.93%
Banyaknya kartu kredit lain 21.70% Persentase utang kartu kredit lain 29.80%
Umur 20.76%
Masa kerja 17.94%
Lama tinggal 22.01%
12
Pemilihan Fitur secara Bertahap
Pemilihan fitur secara bertahap dimulai dengan menentukan fitur yang paling berpengaruh terhadap akurasi. Berdasarkan akurasi fitur yang diperoleh pada tahap pemilihan fitur menggunakan akurasi > 50%, fitur yang memiliki
akurasi tertinggi adalah fitur pendidikan. Oleh karena itu, fitur ini digunakan sebagai fitur awal. Berikutnya fitur pendidikan dikombinasikan dengan 13 fitur lainnya dan diujikan terhadap 50 sampel Model 1.
Pada iterasi pertama diperoleh akurasi tertinggi sebesar 63.04% yaitu gabungan fitur pendidikan dengan banyaknya kartu kredit lain. Nilai ini lebih besar dibandingkan dengan akurasi fitur pendidikan saja sehingga kombinasi fitur ini diambil dan diteruskan ke iterasi selanjutnya. Untuk iterasi kedua fitur awal adalah gabungan fitur pendidikan dan banyaknya kartu kredit lain, sementara kandidat fitur adalah 12 fitur sisanya. Proses pemilihan fitur bertahap untuk Model 3 disajikan pada Lampiran 2.
Pada iterasi kedua, akurasi rata-rata dari kombinasi fitur pendidikan dan banyaknya kartu kredit lain dengan kandidat fitur lainnya tidak lebih besar daripada iterasi pertama, sehingga proses pemilihan fitur selesai di iterasi pertama. Fitur yang terpilih melalui proses ini hanya dua fitur yaitu pendidikan dan banyaknya kartu kredit lain.
Model 1
Model 1 merupakan model VFI5 tanpa pemilihan fitur. Hasil pengujian Model 1 untuk 50 sampel ditampilkan pada Gambar 4.
Dari Gambar 4 terlihat bahwa akurasi tertinggi diperoleh pada sampel ke-14 dan ke-24, masing-masing sebesar 68.25% dan terendah pada sampel 8 yaitu 21.11%. Pada metrik pengukuran lainnya, recall mencapai nilai tertinggi pada sampel 48, yaitu 93.70%. Ini artinya hampir keseluruhan instance uji kelas debitur bad dapat diprediksi dengan benar. Meskipun hasil pengukuran recall
13
cukup baik, tetapi ketepatan algoritme VFI5 dalam memprediksi kelas debitur bad masih sangat rendah. Hal ini dibuktikan oleh precision yang rendah di setiap sampel percobaan. Metrik precision untuk 50 sampel bernilai kurang dari 25%. Diagram pengukuran metrik recall, TNrate, precision, NPvalue, dan F-measure
untuk Model 1 dapat dilihat pada Lampiran 3.
Tabel 4 merupakan confusion matrix untuk sampel dengan akurasi tertinggi pada Model 1. Berdasarkan Tabel 4 diketahui bahwa jumlah instance uji kelas debitur bad yang diprediksi sebagai kelas debitur good lebih besar dibandingkan dengan jumlah instance bad yang diprediksi benar. Sementara pada instance uji debitur good, jumlah instance prediksi benar lebih besar dibandingkan dengan jumlah instance yang salah prediksi, sehingga nilai TNrate kelas good yang dihasilkan cukup tinggi yaitu 74.92%. Sebaliknya, recall dan precision pada kelas debitur bad jauh lebih kecil, masing-masing yaitu 34.38% dan 21.26%.
Berdasarkan confusion matrix di Tabel 5 diketahui bahwa jumlah instance
prediksi benar di kedua kelas cukup baik. Recall untuk kelas bad adalah 40.63% sedangkan TNrate untuk kelas good bernilai 70.15%. Sementara precision kelas
bad dan NPvalue kelas good terpaut cukup jauh. Hal ini disebabkan oleh jumlah
instance prediksi benar yang dibagi dengan jumlah instance keseluruhan di kelas tersebut mengalami ketidakseimbangan. Dari hasil pengukuran confusion matrix
ini dapat dikatakan bahwa sampel ke-34 cukup baik dalam memprediksi debitur yang berpotensi menjadi debitur good dan bad.
Kesalahan prediksi instance uji kelas debitur bad menjadi kelas debitur
good terjadi karena jumlah vote yang diberikan terhadap kelas debitur good lebih tinggi dibandingkan jumlah vote kelas debitur bad. Misalnya pada instance uji ke-56 di sampel 14, algoritme VFI5 memprediksi instance tersebut sebagai kelas debitur good, padahal kelas sebenarnya adalah bad. Sebaliknya, instance uji ke-132 di sampel 34 diprediksi sebagai kelas bad. Hal ini terjadi karena peluang
instance tersebut diprediksi sebagai kelas bad lebih tinggi dibandingkan dengan kelas good, sehingga instance uji tersebut diprediksi sebagai kelas bad. Nilai
voting kesalahan prediksi untuk instance uji ke-56 dan 132 disajikan pada Tabel 6. Tabel 4 Confusion matrix sampel ke-14 dan 24
Data Prediksi
Bad Good
Aktual Bad 44 84
Good 163 487
Tabel 5 Confusion matrix sampel ke-34
Data Prediksi
Bad Good
Aktual Bad 52 76
14
Mengacu pada nilai vote hasil pelatihan untuk sampel ke-34 di Lampiran 4, dapat diketahui bahwa debitur dengan pendidikan SMP/SMA dan S1/S2 cenderung diprediksi sebagai debitur good, sedangkan debitur dengan tingkat pendidikan akademi cenderung bad. Pada fitur gender, peluang wanita menjadi debitur good lebih tinggi dibandingkan dengan laki-laki. Sementara pada fitur status pernikahan, debitur yang berstatus lajang atau bercerai cenderung diprediksi sebagai debitur bad. Industri berat, jasa, dan transportasi merupakan tipe perusahaan yang cenderung dikelompokkan ke kelas bad. Begitupun dengan debitur yang bekerja sebagai wiraswasta yang juga cenderung diklasifikasikan sebagai debitur bad.
Pada fitur yang sifatnya kontinu seperti tanggungan, pendapatan, banyaknya kartu kredit lain, persentase utang kartu kredit lain, umur, masa kerja, dan lama tinggal, nilai vote fitur pada selang interval menunjukkan kecenderungan yang sama. Debitur cenderung good ketika nilai fitur berada pada ujung kanan dan kiri selang interval. Sementara ketika berada di bagian tengah selang interval, debitur akan cenderung diprediksi sebagai kelas bad.
Tabel 6 Nilai voting kesalahan prediksi instance uji ke-56 dan 132 Data uji ke-
Fitur
56 132
Kelas prediksi Kelas prediksi
Bad Good Bad Good
Pendidikan 0.2825 0.7175 0.5826 0.4174
Gender 0.4442 0.5558 0.4447 0.5553
Status pernikahan 0.4998 0.5002 0.4989 0.5011
Tipe perusahaan 0.5068 0.4932 0.5068 0.4932
Status pekerjaan 0.5108 0.4892 0.4993 0.5007
Pekerjaan 0.5515 0.4485 0.4981 0.5019
Tanggungan 0.4749 0.5251 0.4747 0.5253
Pendapatan 0.5004 0.4996 0.5001 0.4999
Banyaknya kartu kredit lain 0.5060 0.4940 0.5069 0.4931 Persentase utang kartu kredit lain 0.4031 0.5969 0.5153 0.4847
Umur 0.5001 0.4999 0.5006 0.4994
Masa kerja 0.5028 0.4972 0.5035 0.4965
Lama tinggal 0.5029 0.4971 0.5028 0.4972
Status rumah 0.4550 0.5450 0.5531 0.4469
Total 6.6409 7.3591 7.0874 6.9126
Normalisasi 0.4744 0.5256 0.5062 0.4938
Prediksi Good Bad
15
Model 2
Model 2 merupakan model VFI5 dengan pemilihan fitur berdasarkan akurasi. Hasil pengujian Model 2 dengan fitur berakurasi lebih besar dari 50% ditampilkan pada Tabel 7.
Berdasarkan hasil pengukuran akurasi pada Tabel 7, sampel yang awalnya memiliki akurasi lebih besar atau sama dengan 50% rata-rata mengalami kenaikan akurasi 5%-15%. Sementara sampel yang akurasi awalnya dibawah 40% rata-rata mengalami penurunan 0%-5%. Tetapi secara umum dapat dikatakan bahwa akurasi meningkat setelah dilakukan pemilihan fitur. Perbandingan akurasi Model 1 dan 2 diperlihatkan pada Gambar 5.
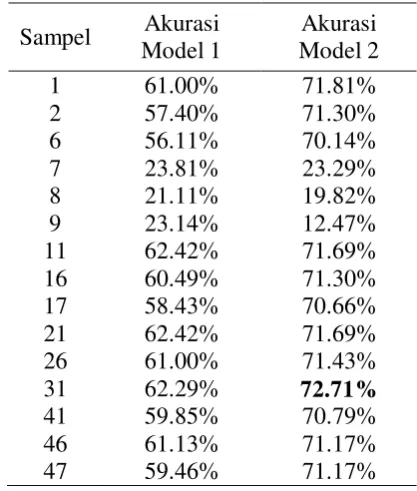
Akurasi tertinggi Model 2 adalah 72.71% pada sampel 31 dan terendah pada sampel ke-9 yaitu 12.47%. Pada metrik pengukuran lainnya, recall mencapai nilai
Tabel 7 Akurasi Model 2 Sampel Akurasi
Model 1
Akurasi Model 2
1 61.00% 71.81%
2 57.40% 71.30%
6 56.11% 70.14%
7 23.81% 23.29%
8 21.11% 19.82%
9 23.14% 12.47%
11 62.42% 71.69%
16 60.49% 71.30%
17 58.43% 70.66%
21 62.42% 71.69%
26 61.00% 71.43%
31 62.29% 72.71%
41 59.85% 70.79%
46 61.13% 71.17%
47 59.46% 71.17%
16
tertinggi pada sampel ke-28 yaitu 89.76%. Artinya pada sampel ini, hampir 90%
instance uji kelas bad dapat diprediksi dengan benar. Recall terendah terdapat pada sampel ke-5 yaitu 19.69%. Secara umum pengukuran terhadap recall
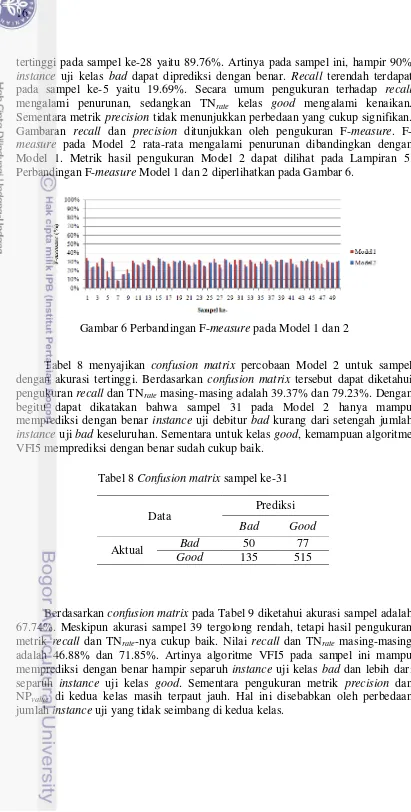
mengalami penurunan, sedangkan TNrate kelas good mengalami kenaikan. Sementara metrik precision tidak menunjukkan perbedaan yang cukup signifikan. Gambaran recall dan precision ditunjukkan oleh pengukuran F-measure.
F-measure pada Model 2 rata-rata mengalami penurunan dibandingkan dengan Model 1. Metrik hasil pengukuran Model 2 dapat dilihat pada Lampiran 5. Perbandingan F-measure Model 1 dan 2 diperlihatkan pada Gambar 6.
Tabel 8 menyajikan confusion matrix percobaan Model 2 untuk sampel dengan akurasi tertinggi. Berdasarkan confusion matrix tersebut dapat diketahui pengukuran recall dan TNrate masing-masing adalah 39.37% dan 79.23%. Dengan begitu dapat dikatakan bahwa sampel 31 pada Model 2 hanya mampu memprediksi dengan benar instance uji debitur bad kurang dari setengah jumlah
instance uji bad keseluruhan. Sementara untuk kelas good, kemampuan algoritme VFI5 memprediksi dengan benar sudah cukup baik.
Berdasarkan confusion matrix pada Tabel 9 diketahui akurasi sampel adalah 67.74%. Meskipun akurasi sampel 39 tergolong rendah, tetapi hasil pengukuran metrik recall dan TNrate-nya cukup baik. Nilai recall dan TNrate masing-masing adalah 46.88% dan 71.85%. Artinya algoritme VFI5 pada sampel ini mampu memprediksi dengan benar hampir separuh instance uji kelas bad dan lebih dari separuh instance uji kelas good. Sementara pengukuran metrik precision dan NPvalue di kedua kelas masih terpaut jauh. Hal ini disebabkan oleh perbedaan jumlah instance uji yang tidak seimbang di kedua kelas.
Gambar 6 Perbandingan F-measure pada Model 1 dan 2
Tabel 8 Confusion matrix sampel ke-31
Data Prediksi
Bad Good
Aktual Bad 50 77
17
Meskipun recall dan TNrate di kedua kelas dapat dikatakan cukup baik pada sampel 39, jumlah instance yang salah prediksi tergolong masih tinggi. Kesalahan prediksi ini terjadi karena adanya fitur-fitur yang memberikan nilai vote lebih tinggi meskipun bukan terhadap kelas targetnya. Nilai vote yang diberikan bergantung pada vote yang diperoleh ketika pelatihan. Nilai vote fitur hasil pelatihan untuk sampel ke-39 dapat dilihat pada Lampiran 6. Contohnya instance
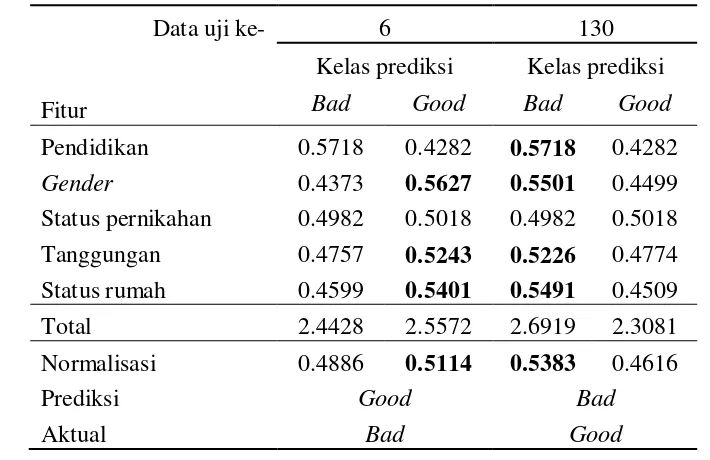
uji 6 dan 130. Pada instance uji 6 dan 130, tiga dari lima fitur memberikan vote
lebih tinggi kepada kelas bukan target. Jumlah vote kelas akhir yang diberikan lebih besar terhadap kelas bukan target sehingga kelas prediksi adalah kelas bukan target. Nilai voting kesalahan prediksi untuk instance uji ke-6 dan 130 ditampilkan pada Tabel 10.
Lampiran 6 menunjukan nilai vote fitur yang diperoleh ketika pelatihan untuk sampel ke-39. Berdasarkan hasil vote tersebut, diketahui bahwa debitur dengan pendidikan SMP/SMA dan S1/S2 cenderung dikategorikan ke kelas good. Pada fitur gender, peluang laki-laki dikelompokkan ke kelas debitur good lebih
Tabel 10 Nilai voting kesalahan prediksi instance uji ke-6 dan ke-130 pada sampel ke-39
Pendidikan 0.5718 0.4282 0.5718 0.4282
Gender 0.4373 0.5627 0.5501 0.4499
Status pernikahan 0.4982 0.5018 0.4982 0.5018 Tanggungan 0.4757 0.5243 0.5226 0.4774 Status rumah 0.4599 0.5401 0.5491 0.4509
Total 2.4428 2.5572 2.6919 2.3081
Normalisasi 0.4886 0.5114 0.5383 0.4616
Prediksi Good Bad
Aktual Bad Good
Tabel 9 Confusion matrix sampel ke-39
Data Prediksi
Bad Good
Aktual Bad 60 68
18
kecil dibandingkan dengan debitur bad, sehingga laki-laki cenderung temasuk kelas bad. Debitur yang telah menikah lebih cenderung dikelompokkan sebagai debitur good, sebaliknya lajang dan bercerai dikategorikan menjadi bad. Begitupun dengan jumlah tanggungan, debitur yang tidak memiliki tanggungan atau memiliki tanggungan lebih dari 5 orang lebih berpeluang sebagai debitur
good. Fitur status rumah juga menunjukkan kecenderungan yang jelas, yaitu debitur yang memiliki rumah sendiri cenderung dikelompokkan ke kelas good. Dari nilai vote ini terlihat bahwa kecenderungan kelas untuk semua fitur pada Model 2 sama dengan Model 1.
Hasil pengujian Model 2 menunjukkan peningkatan akurasi jika dibandingkan dengan Model 1. Hal ini dimungkinkan karena 5 fitur yang pengukuran akurasi untuk beberapa sampel Model 3 ditampilkan pada Tabel 11.
Pada percobaan Model 3, akurasi mengalami kenaikan cukup baik daripada model-model sebelumnya. Dari Tabel 11 terlihat bahwa umumnya sampel dengan akurasi lebih besar atau sama dengan 50% di Model 1 mengalami kenaikan hingga 34%. Sementara sampel dengan akurasi dibawah 45% lebih fluktuatif. Tetapi secara keseluruhan akurasi Model 3 mengalami kenaikan dibandingkan
19
dengan Model 1. Gambar 7 menunjukkan perbandingan akurasi pada Model 1 dan 3. Hasil metrik pengukuran Model 3 dapat dilihat pada Lampiran 7.
Akurasi tertinggi diperoleh pada sampel ke-12 dan 22 yaitu sebesar 85.59%. Sementara akurasi terendah berada di sampel ke-7 yaitu sebesar 5.92%.
Recall yang cukup baik di Model 1 mengalami penurunan 2%-61% pada model ini. Kenaikan recall hanya terjadi di beberapa sampel dengan kenaikan sebesar 1%-17%. Precision rata-rata mengalami penurunan 0%-24%. Beberapa sampel mengalami kenaikan precision yang cukup signifikan, yaitu hingga 83%. Meskipun recall menurun, metrik precision-nya justru mengalami peningkatan. Ini terjadi karena jumlah instance good yang salah prediksi hanya sedikit bahkan tidak ada, sehingga tidak terlalu mempengaruhi precision. Hasil recall dan
precision digunakan untuk mengukur metrik F-measure. Perbandingan F-measure
Model 3 dan Model 1 ditampilkan pada Gambar 8.
Tabel 12 menunjukkan confusion matrix untuk sampel dengan akurasi tertinggi. Dari confusion matrix tersebut dapat dilihat bahwa jumlah instance uji
bad yang berhasil diprediksi dengan benar hanya 15 instances. Hampir keseluruhan instance uji bad mengalami kesalahan prediksi, sehingga recall pada sampel ini hanya 11.81%. Sebaliknya, semua instance uji kelas good berhasil diprediksi benar sehingga TNrate bernilai 100%.
Gambar 8 Perbandingan F-measure Model 1 dan 3 Gambar 7 Perbandingan akurasi Model 1 dan 3
Tabel 12 Confusion matrix sampel ke-12 dan 22
Data Prediksi
Bad Good
Aktual Bad 15 112
20
Kesalahan prediksi pada sampel 12 terjadi karena adanya beberapa fitur yang memberikan nilai vote lebih besar ke kelas good. Hal ini menyebabkan jumlah vote kelas good lebih tinggi dibandingkan dengan kelas bad sehingga
instance uji diprediksi sebagai kelas good. Contoh nilai voting kesalahan prediksi untuk instance uji ke-4 dan 21 pada sampel 12 ditunjukkan pada Tabel 13. Pada Tabel 13 dapat dilihat bahwa untuk instance uji ke-4, kedua fitur mendapatkan nilai vote yang lebih besar di kelas good. Setelah nilai vote masing-masing fitur ini dijumlahkan dan dinormalisasi, diperoleh nilai tertinggi pada kelas good, sehingga instance uji ke-4 diprediksi sebagai kelas good. Begitupun dengan
recall dan TNrate cukup baik. Dari keseluruhan instance uji kelas bad, hampir 39% berhasil diprediksi dengan benar. Sementara di kelas good juga menunjukkan TNrate yang cukup baik, yaitu sebesar 76.62%. Akurasi dari sampel 30 ini adalah 70.40%.
Kesalahan prediksi pada sampel 30 terjadi di kedua kelas. Jumlah instance
yang salah prediksi ini bisa dikatakan cukup tinggi. Tetapi jika dibandingkan Tabel 13 Nilai voting kesalahan prediksi instance uji ke-4 dan 21 pada
sampel 12
Pendidikan 0.4682 0.5318 0.4682 0.5318
Banyaknya kartu kredit
lain 0.3457 0.6543 0.5088 0.4912
Total 0.8139 1.1861 0.9770 1.0230
Normalisasi 0.4070 0.5930 0.4885 0.5115
Prediksi Good Good
Aktual Bad Bad
Tabel 14 Confusion matrix sampel ke-30
Data Prediksi
Bad Good
Aktual Bad 49 78
21
dengan sampel lainnya pada Model 3, jumlah ini tergolong cukup baik. Kesalahan prediksi instance uji kelas bad terjadi karena adanya fitur yang mendapat nilai
vote lebih besar untuk kelas good. Hal ini menyebabkan jumlah vote dan hasil normalisasi kelas good lebih besar dibandingkan dengan kelas bad sehingga
instance uji bad diprediksi sebagai good. Begitupun sebaliknya pada instance uji
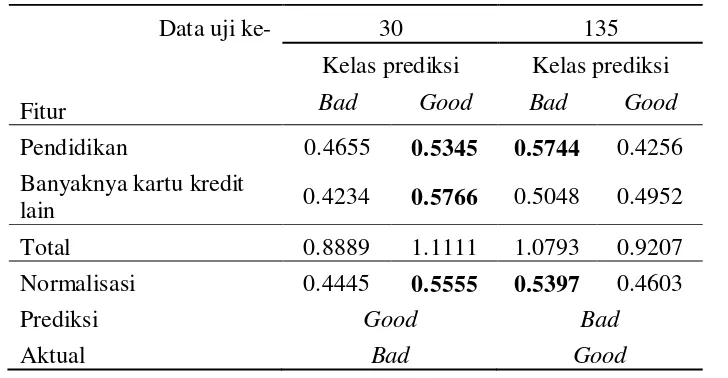
good, peluang instance tersebut masuk ke kelas bad lebih besar dibandingkan dengan kelasnya sendiri sehingga diprediksi sebagai kelas bad. Contoh kesalahan prediksi pada sampel 30 untuk instance uji ke-30 dan 135 dapat dilihat pada Tabel 15.
Hasil voting pelatihan untuk sampel ke-30 diperlihatkan pada Lampiran 8. Sama seperti Model 1 dan 2, debitur yang memiliki jenjang pendidikan SMP/SMA dan S1/S2 cenderung dikelompokkan sebagai debitur good. Pada fitur banyaknya kartu kredit lain, debitur yang memiliki 1 kartu kredit lain dikategorikan sebagai debitur bad, sementara debitur yang memiliki 2 atau 3 kartu kredit lain justru termasuk kelas good.
Berdasarkan pengujian yang telah dilakukan terhadap semua model, terlihat bahwa Model 3 menghasilkan akurasi yang lebih baik. Meskipun rata-rata akurasi semakin baik dengan pemilihan fitur, metrik pengukuran lainnya menunjukkan penurunan untuk kelas bad, sementara di kelas good menunjukkan peningkatan. Perbandingan metrik pengukuran pada ketiga model dilampirkan dalam Lampiran 9.
Perbandingan dengan Penelitian Sebelumnya
Akurasi yang diperoleh dari penelitian ini tidak memiliki perbedaan yang cukup besar dengan Setiawati (2011). Sementara jika dibandingkan dengan model terbaik untuk data Hypothyroid pada penelitian Aritonang (2006), terdapat
Tabel 15 Voting kesalahan prediksi pada sampel ke-30 untuk instance uji ke-30 dan 135
Pendidikan 0.4655 0.5345 0.5744 0.4256
Banyaknya kartu kredit
lain 0.4234 0.5766 0.5048 0.4952
Total 0.8889 1.1111 1.0793 0.9207
Normalisasi 0.4445 0.5555 0.5397 0.4603
Prediksi Good Bad
22
perbedaan yang cukup tinggi. Ini dikarenakan Aritonang (2006) menggunakan pendekatan dari level data untuk mengatasi masalah imbalanced data.
Metrik pengukuran lainnya untuk ketiga model tidak sebaik yang dihasilkan pada model terbaik di penelitian Setiawati (2011). Begitupun jika dibandingkan dengan penelitian Aritonang (2006), recall, precision, dan F-measure
menunjukkan perbedaan nilai yang cukup tinggi. Perbandingan metrik pengukuran pada penelitian Setiawati (2011), Aritonang (2006), dan penelitian ini diperlihatkan pada Tabel 16.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa: 1 Model VFI5 menggunakan keseluruhan fitur, menghasilkan model terbaik
dengan akurasi 65.30%, serta metrik recall, precision, dan F-measure-nya masing-masing adalah 40.63%, 21.14%, dan 27.81%.
2 Model VFI5 menggunakan pemilihan fitur berdasarkan akurasi, diperoleh model terbaik dengan akurasi 67.74%, serta metrik recall, precision, dan
F-measure masing-masing yaitu 46.88%, 24.69%, dan 32.25%.
3 Model VFI5 dengan pemilihan fitur bertahap menghasilkan model terbaik dengan pengukuran akurasi, recall, precision, dan F-measure masing-masingnya adalah 70.40%, 38.58%, 24.38%, dan 29.88%.
4 Model terbaik dari keseluruhan model yang dibangun terdapat pada Model VFI5 dengan pemilihan fitur berdasarkan akurasi fitur.
Tabel 16 Perbandingan metrik pengukuran dengan penelitian lain
Data Model Akurasi Recall Precision F-measure
Euthyroid1) VFI5 Model
undersampling 66.00% 69.57% 65.37% 67.40%
Hypothyroid2) VFI5 Model
undersampling 88.73% 79.17% 97.77% 87.49%
Debitur
Backpropagation3) 73.39% 56.26% 36.90% 44.57%
Model 14) 65.30% 40.63% 21.14% 27.81%
Model 1: model VFI5 menggunakan semua fitur
5)
Model 2: model VFI5 menggunakan fitur berakurasi > 50%
6)
23
Saran
Penelitian ini dapat dikembangkan lebih lanjut untuk mendapatkan hasil pengukuran akurasi dan metrik pengukuran lainnya yang lebih baik. Hal-hal yang dapat dilakukan misalnya:
1 Melakukan pendekatan dari level data (sampling technique) untuk mengatasi ketidakseimbangan di kedua kelas.
2 Mengujicobakan teknik pemilihan fitur terhadap dataset lain untuk mengetahui keberhasilan metode ini.
3 Menggunakan bobot yang berbeda untuk setiap fitur dengan algoritme genetika.
DAFTAR PUSTAKA
Aritonang R. 2006. Klasifikasi imbalanced data menggunakan algoritme klasifikasi voting feature intervals [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Breiman L. 1995. Better subset regression using the nonnegative garrote.
Tecnometrics. 37(4):373-384.
Demiröz G. 1997. Non-incremental classification learning algorithms based on voting feature intervals [tesis]. Ankara (TY): Bilkent University.
Frost J. 2012. Regression smackdown: stepwise versus best subset [internet]. [diacu 2012 Des 25]. Tersedia dari: http://blog.minitab.com/blog/
adventures-in-statistics/regression-smackdown-stepwise-versus-best-subsets Güvenir HA, Demiröz G, Ilter N. 1998. Learning differential diagnosis of
erythemato-squamous diseases using voting feature intervals. Artific Intelligen Medic. 13:147-165.
Han J, Kamber M. 2001. Data Mining Concepts & Technique. Champaign: Academic Press.
Setiawati PA. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Sun Y, Wong AKC, Kamel MS. 2009. Classification of imbalanced data: a review.
Internation J Pattern Recognition Artific Intelligen. 23(4):687-719.
24
Status pekerjaan 1 = Permanen
2 = Kontrak
Status rumah 0 = Bukan milik sendiri
1 = Milik sendiri
Kelas 0 = good
25
Lampiran 2 Pemilihan fitur secara bertahap
Fitur awal Kandidat Fitur Akurasi
-
Banyaknya kartu kredit lain 21.70% Persentase utang kartu kredit lain 29.80%
Umur 20.76%
Banyaknya kartu kredit lain 63.04% Persentase utang kartu kredit lain 61.68%
Umur 61.35%
Persentase utang kartu kredit lain 62.13%
Umur 62.99%
Masa kerja 61.34%
Lama tinggal 62.47%
26
27
28
Pendapatan
Good 1 1 0 0.4999 0.4945 1 1
Bad 0 0 1 0.5001 0.5055 0 0 3 5.2 6500 39000
Banyaknya Kartu Kredit Lain
Good 0.4931 0.6184 0.4772 0 1
Bad 0.5069 0.3816 0.5228 0 0 1 3 4
Persentase Utang Kartu Kredit Lain
Good 0.6159 0.4847 0.1636 1 1
Bad 0.3841 0.5153 0.8364 0 0 0 99 670
Umur
Good 0.3698 0.4994 0.3284 1 1
Bad 0.6302 0.5006 0.6716 0 0 21 62 68
Masa Kerja
Good 1 0 0.1636 0.4965 0 1 1
Bad 0 0 0.8364 0.5035 1 0 0 0 1 448 600
Lama Tinggal
Good 0.7688 0.4972 0.2812 1 1
Bad 0.2312 0.5028 0.7188 0 0
0 576 863
Status Rumah
Good 0.4469 0.5438
Bad 0.5531 0.4562 0 1
Keterangan:
29
Lampiran 5 Metrik pengukuran Model 2
Sampel Akurasi Recall Precision F-measure
30
Lampiran 5 Lanjutan
Sampel Akurasi Recall Precision F-measure
44 51.80% 72.66% 21.48% 33.15%
45 54.95% 61.42% 20.58% 30.83%
46 71.17% 33.86% 23.50% 27.74%
47 71.17% 26.77% 20.61% 23.29%
48 35.39% 84.25% 18.17% 29.89%
49 35.73% 79.69% 17.71% 28.98%
31
32
Lampiran 7 Metrik pengukuran Model 3
Sampel Akurasi Recall Precision F-measure
33
Lampiran 7 Lanjutan
Sampel Akurasi Recall Precision F-measure
44 21.59% 98.44% 17.17% 29.23%
45 67.05% 36.22% 20.81% 26.44%
46 83.66% 0.00% 0.00% 0.00%
47 83.66% 0.00% 0.00% 0.00%
48 37.84% 94.49% 20.13% 33.20%
49 21.21% 98.44% 17.10% 29.13%
34
Lampiran 8 Nilai vote hasil pelatihan sampel ke-30 Model 3 Pendidikan
Good 0.5401 0.4256 0.5345
Bad 0.4599 0.5744 0.4655 1 2 3
Banyaknya Kartu Kredit Lain
Good 0.4952 0.5766 0.5949
Bad 0.5048 0.4234 0.4051
1 3
35
36
RIWAYAT HIDUP
Penulis dilahirkan di kota Padang, Sumatera Barat, pada tanggal 8 Januari 1990 sebagai anak kedua dari pasangan Supriadi Anra dan Murniati. Penulis merupakan lulusan SMA Negeri 2 Painan (2004-2007), SMP Negeri 3 Bayang (2001-2004), dan SD Negeri 01 Asamkumbang (1995-2001).