KLASIFIKASI DEBITUR KARTU KREDIT MENGGUNAKAN
ALGORITME SUPPORT VECTOR MACHINE LINEAR KERNEL
UNTUK KASUS IMBALANCED DATA
AVITA UNAIYA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme Support Vector Machine Linear Kernel
untuk Kasus Imbalanced Data adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, April 2014
Avita Unaiya
ABSTRAK
AVITA UNAIYA. Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme
Support Vector Machine Linear Kernel untuk Kasus Imbalanced Data. Dibimbing oleh AZIZ KUSTIYO.
Pada penelitian ini dilakukan analisis klasifikasi debitur kartu kredit menggunakan algoritme support vector machine linear kernel yang mampu mengklasifikasikan calon debitur ke dalam kategori baik dan buruk. Data yang digunakan merupakan imbalanced data karena data dari satu kelas mendominasi data yang lain. Algoritme klasifikasi umumnya memberikan kinerja buruk pada
imbalanced data karena kelas minoritas lebih sulit diprediksi dibanding kelas mayoritas. Salah satu cara yang dapat digunakan untuk menangani permasalahan ini adalah dengan strategi sampling menggunakan teknik oversampling dan
undersampling. Penelitian ini membandingkan nilai akurasi, recall, precision, serta F-measure Hasil penelitian menunjukkan nilai akurasi yang cukup tinggi pada data asli sebesar 83.59% namun, nilai recall, precision, dan F-measure yang dihasilkan sebesar 0%. Teknik oversampling acak menunjukkan kinerja terbaik dengan akurasi sebesar 54.14%, recall sebesar 53.47%, precision sebesar 61.30%, dan F-measure sebesar 54.51%.
Kata kunci: imbalanced data, oversampling, support vector machine, undersampling
ABSTRACT
AVITA UNAIYA. Credit Card Debtor Classification using Support Vector Machine Linear Kernel Algotihm for Imbalanced Data. Supervised by AZIZ KUSTIYO.
In this research, classification analysis of credit card debtors is conducted by using support vector machine linear kernel that can classify debtors into two categories good or bad. The data used in this research is imbalanced because most data are from one class. Classification algorithms generally result in poor performance on imbalanced data because the minority class is more difficult to predict than the majority class. One way that can be used to solve this problem is by using a sampling method with oversampling and undersampling technique. This research compares the value of accuracy, recall, precision, and F-measure. The evaluation result shows a fairly high accuracy values in the original data is 83.59% but, the value of recall, precision, and F-measure are 0%. Random oversampling technique gives the best performance with 54.14% accuracy, 53.47% recall, 61.30% precision, and 54.51% F-measure.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DEBITUR KARTU KREDIT MENGGUNAKAN
ALGORITME SUPPORT VECTOR MACHINE LINEAR KERNEL
UNTUK KASUS IMBALANCED DATA
AVITA UNAIYA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme Support Vector Machine Linear Kernel untuk Kasus Imbalanced Data
Nama : Avita Unaiya
NIM : G64100029
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Ungkapan terima kasih penulis sampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Terima kasih penulis ucapkan kepada Bapak Aziz Kustiyo, MKom selaku pembimbing, kepada Ibu Karlina Khiyarin Nisa, MT dan Bapak Wisnu Ananta Kusuma, MT selaku penguji. Terima kasih atas semua bimbingan dan saran yang diberikan dalam menyelesaikan karya ilmiah ini. Terima kasih juga penulis sampaikan kepada Dewi Sri Rahayu, Aisyah Syahidah, Pristi Sukmasetya, Annisa Amalia, Riska Effirokh, dan Ilkomerz 47 atas kerja samanya. Semoga karya ilmiah ini bermanfaat.
Bogor, April 2014
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengadaan Data 2
Praproses Data 4
Normalisasi Data 4
Strategi Sampling 4
10-Fold Cross Validation 5
Klasifikasi Support Vector Machine 5
Analisis Hasil Klasifikasi 7
HASIL DAN PEMBAHASAN 8
Praproses Data 8
Strategi Sampling 9
Hasil Klasifikasi 9
Analisis Hasil Klasifikasi 12
Perbandingan dengan Penelitian Sebelumnya 14
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 16
DAFTAR PUSTAKA 16
RIWAYAT HIDUP 26
DAFTAR TABEL
1 Atribut data 4
2 Confussion matrix dua kelas 7 3 Confussion matrix data asli 12 4 Confussion matrix oversampling acak 13 5 Confussion matrix oversampling duplikasi 13 6 Confussion matrix undersamplingcluster 14 7 Confussion matrix undersampling acak 14
8 Perbandingan dengan penelitian sebelumnya 15
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Konsep dasar SVM 6
3 Hasil percobaan data asli 9
4 Hasil percobaan oversampling duplikasi 10
5 Hasil percobaan oversampling acak 10
6 Hasil percobaan undersampling acak 11
7 Hasil percobaan undersampling cluster 11
DAFTAR LAMPIRAN
1 Keterangan atribut 18
PENDAHULUAN
Latar Belakang
Banyak layanan yang diberikan oleh usaha perbankan salah satunya yaitu layanan kredit. Layanan kredit yang diberikan bank kepada debitur di antaranya kredit pemilikan rumah (KPR), kredit kendaraan, kredit usaha mikro, dan kartu kredit. Berdasarkan data penerbit kartu kredit yang dirilis Bank Indonesia (2013), jumlah penerbit kartu kredit mencapai 22 penerbit. Pemberian kredit kepada debitur bisa menimbulkan risiko ketidakmampuan debitur atas kewajiban pembayaran utangnya, baik utang pokok maupun bunganya atau keduanya. Oleh sebab itu, setiap bank melakukan proses analisis dalam menentukan penerimaan pengajuan kredit. Hal ini dilakukan dengan tujuan untuk mengurangi peluang kerugian bank akibat menerima pengajuan kredit yang berpotensi bermasalah.
Berbagai penelitian terkait proses analisis terhadap kredit yang diajukan telah dilakukan. Penelitian-penelitian tersebut dilakukan oleh Anggraini (2013), Wijayanti (2013), dan Ulya (2013) dengan membuat model klasifikasi menggunakan data debitur kartu kredit. Data debitur kartu kredit merupakan data skala besar dengan distribusi kelas tidak merata antara debitur kategori good dan
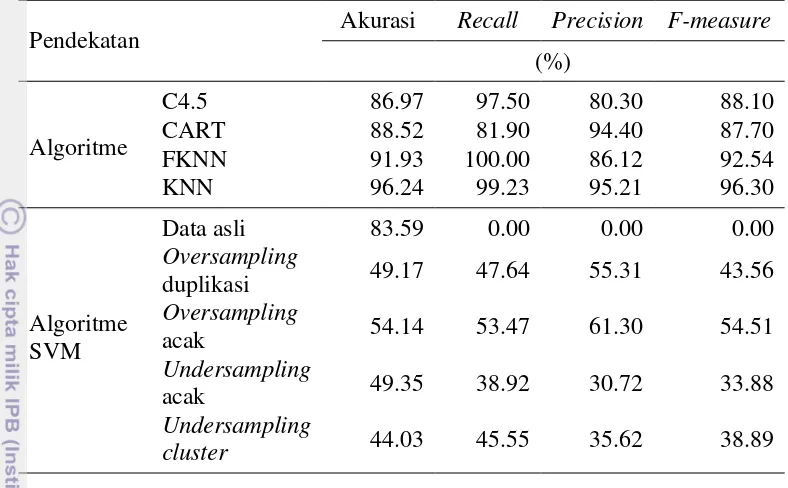
bad. Anggraini (2013) melakukan klasifikasi dengan pohon keputusan menggunakan algoritme C4.5 dan CART. Algoritme C4.5 memberikan nilai akurasi sebesar 88.65% dan algoritme CART memberikan nilai akurasi sebesar 88.52%. Wijayanti (2013) melakukan klasifikasi menggunakan algoritme FKNN dan menghasilkan akurasi sebesar 91.93%, sedangkan Ulya (2013) melakukan klasifikasi menggunakan algoritme KNN dan didapat nilai akurasi sebesar 96.24%. Kasus klasifikasi data tidak seimbang juga diteliti oleh Japkowicz dan Stephen (2002) menggunakan data kerang abalone dan algoritme SVM dengan metode undersampling yang menghasilkan akurasi sebesar 64.36%.
Data umumnya memiliki dua kondisi yaitu data seimbang dan data tidak seimbang. Data seimbang merupakan kondisi distribusi data pada dua kelas mendekati sama dan data tidak seimbang merupakan kondisi sebuah himpunan data terdapat satu kelas yang memiliki jumlah instance yang lebih kecil dibandingkan kelas lainnya (Chawla 2003). Untuk mengatasi ketidakseimbangan data dilakukan strategi sampling yaitu oversampling dan undersampling. Pada
oversampling dilakukan duplikasi pada data minoritas, dan pada undersampling
dilakukan pemilihan instance pada data mayoritas sehingga jumlahnya sama dengan data minoritas.
Penelitian ini akan membuat suatu model untuk mengklasifikasikan debitur ke dalam kategori good atau bad menggunakan algoritme support vector machine
(SVM) linear kernel. Karena data yang digunakan pada penelitian ini merupakan data tidak seimbang maka dilakukan strategi sampling yaitu oversampling dan
undersampling untuk mengatasinya.
Perumusan Masalah
2
proses analisis yaitu mengklasifikasikan debitur kartu kredit ke dalam kategori
good atau kategori bad. Penelitian ini akan menganalisis bagaimana algoritme SVM dapat mengklasifikasikan debitur kartu kredit ke dalam kategori debitur
good atau debitur bad.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan oversampling dan
undersampling untuk mengklasifikasikan debitur kartu kredit ke dalam kategori debitur good atau debitur bad pada data tidak seimbang menggunakan algoritme SVM.
Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat menjadi salah satu alternatif model bagi pihak penerbit kartu kredit dalam menganalisis proses penerimaan kredit, sehingga dapat mengurangi jumlah potensi kerugian bank akibat menerima pengajuan kredit yang berpotensi bermasalah. Selain itu, hasil dari penelitian ini juga diharapkan dapat memberi gambaran mengenai kinerja support vector machine classifier pada data tidak seimbang.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini adalah set data yang digunakan merupakan data pada penelitian Anggraini (2013) yaitu data debitur kartu kredit Bank X tahun 2008 dan 2009. Strategi sampling yang digunakan dalam penelitian ini adalah oversampling dan undersampling. Algoritme yang digunakan dalam penelitian ini adalah SVM.
METODE
Penelitian ini dilakukan dalam beberapa tahapan. Alur tahapan penelitian yang dilakukan dapat dilihat pada Gambar 1.
Pengadaan Data
3
.
Gambar 1 Tahapan penelitian
Oversampling
Strategi Sampling
Undersampling
Mulai
Praproses Data Pengadaan Data
Normalisasi Data
10-Fold Cross Validation
Data Uji Data Latih
Klasifikasi SVM
Hasil Klasifikasi
Analisis Hasil Klasifikasi
4
Praproses Data
Praproses data dilakukan untuk membantu dalam pengenalan atribut dan data segmen yang relevan. Data asli memiliki 14 atribut yang terdiri dari 3 kategori, yaitu rasio, nominal, dan ordinal. Atribut disajikan pada Tabel 1:
Tabel 1 Atribut data
Ordinal Nominal Rasio
Pendidikan Jenis kelamin Pendapatan
Status pekerjaan Jumlah tanggungan Jenis pekerjaan Umur
Tipe perusahaan Masa kerja Status rumah Lama tinggal
Status pernikahan Banyaknya kartu kredit lain Presentase utang kartu kredit lain Keterangan lengkap atribut tersebut dapat dilihat pada Lampiran 1. Ada 5 atribut yang memiliki missing value, yaitu tipe perusahaan, status pekerjaan, jenis pekerjaan, presentase utang kartu kredit lain, dan banyaknya kartu kredit lain. Untuk mengatasi missing value dilakukan penghapusan data terhadap record yang memiliki missing value.
Normalisasi Data
Atribut dengan nilai rentang yang cukup panjang dibandingkan dengan nilai atribut lainnya memiliki pengaruh besar terhadap atribut berskala pendek (Nurjayanti 2011). Untuk menghindari perbedaan rentang tersebut dilakukan normalisasi data pada atribut pendapatan, jumlah tanggungan, masa kerja, lama tinggal, dan umur, sehingga didapatkan range antara 0 sampai 1 mengunakan teknik min-max normalization, dengan rumus sebagai berikut (Larose 2005):
X*= X-min(X) max X -min(X)
Keterangan:
X*= nilai setelah normalisasi X = nilai sebelum normalisasi min(X) = nilai minimum atribut
max(X) = nilai maksimum dari suatu atribut Strategi Sampling
5 yang dapat memberi distribusi data seimbang untuk setiap kelas (He dan Edwardo 2009). Strategi sampling yang digunakan yaitu oversampling dan undersampling.
Oversampling dilakukan dengan 2 cara yaitu dengan menduplikasi data minoritas sebanyak data mayoritas dan pembangkitan data minoritas secara acak sebanyak data mayoritas. Strategi undersampling juga dilakukan dengan 2 cara yaitu,
undersampling acak dan undersampling clustering. Undersampling acak dilakukan dengan cara mengambil secara acak data mayoritassehingga jumlahnya sama dengan dengan data minoritas. Undersampling clustering dilakukan dengan proses clustering pada data majority menggunakan metode k-means sebanyak 10
cluster dan menggunakan WEKA. Agar data yang diambil tidak mengelompok pada suatu cluster, jumlah data yang diambil pada masing-masing cluster
menggunakan rumus berikut (Yen dan Lee 2009):
Ci=jumlah data kelas mayoritasjumlah data cluster i ×jumlah data kelas minoritas
10-Fold Cross Validation
Teknik yang digunakan untuk membagi data uji dan data latih adalah k-fold cross validation. Teknik ini membagi data menjadi k subset dengan ukuran yang sama. Setelah subset terbentuk, dilakukan pengulangan sebanyak k-kali untuk pelatihan dan pengujian. Pada iterasi pertama, subset 1 akan menjadi data uji, sedangakan subset 2 sampai subset k akan menjadi data latih. Iterasi selanjutnya,
subset 2 akan menjadi data uji, maka subset 1, subset 3 sampai subset k menjadi data latih, dan seterusnya sebanyak k iterasi (Han dan Kamber 2006). Pada penelitian ini k yang digunakan adalah 10. Data dibagi menjadi 10 bagian terpisah dengan ukuran yang sama. Masing-masing bagian data secara bergantian digunakan sebagai data uji sebanyak 10 kali dan sebagai data latih sebanyak 10 kali. Data uji menggunakan 1 subset dan data latih menggunakan 9 subset. Hal ini dilakukan berulang kali sampai semua subsample pernah menjadi data uji.
Klasifikasi Support Vector Machine
Support vector machine (SVM) merupakan metode klasifikasi jenis
supervised, karena ketika proses pelatihan diperlukan target pembelajaran tertentu (Widodo dan Handayanto 2013). Prinsip dasar support vector machine adalah
linear classifier yang berusaha menemukan fungsi pemisah (hyperplane) optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda.
6
Gambar 2 Konsep dasar SVM
Kelas -1 dan kelas +1 diasumsikan dapat terpisah secara sempurna oleh
hyperplane yang didefinisikan sebagai berikut: (w . �) + b = 0 dengan:
� = nilai data
= vektor bobot � = bias
Margin terbesar dapat ditemukan dengan memaksimalkan jarak antara
hyperplane dan titik terdekatnya, yaitu 1/‖w‖. Hal ini dapat dirumuskan sebagai masalah quadratic programming (QP), yaitu mencaari titik minimal pada persamaan:
min τ w =12‖w‖2
dengan memperhatikan constraint pada persamaan: yi xi.w+b ≥1
Masalah ini dapat dipecahkan dengan Lagrange Multiplier.
� w,b,a =12‖w‖2-∑∝
i(yi((xi.
l
i=1
w+b)-1))
∝i adalah pengganda lagrange yang bernilai nol atau positif. Nilai optimal hyperplane dapat dihitung denga memaksimalkan nilai L terhadap w dan b, dan memaksimalkan L terhadap ∝i.
Algoritme SVM memiliki beberapa macam fungsi kernel. Menurut Santosa (2010), fungsi kernel yangumum digunakan adalah:
-1 +1
vektor kelas +1 vektor kelas -1
Support Vectors
7 1 linear kernel
K(xi,x)=xTxi
2 polynomial kernel
K(xi,x)=(xTxi+1)d
3 radial basis function (RBF) kernel
K xi,x = exp - ‖xi-x‖2 , dengan = 1
2σ2
4 tangent hyperbolic (sigmoid)
K xi,x = tanh( xTxi+ 1), dengan , 1∈ R
Dari keempat fungi kernel tersebut xi merepresentasikan vektor dari setiap data, d merepresentasikan jumlah derajat dari fungsi polinomial, dan γ merepresentasikan ukuran rentangan pada kurva gaussian. SVM menerapkan
kernel yang digunakan untuk merepresentasikan data ke dimensi lebih tinggi.
Kernel yang digunakan pada penelitian ini adalah linear kernel. Dari hasil percobaan akan didapatkan model SVM dengan linear kernel yang memiliki akurasi pelatihan 10-cross fold validation.
Analisis Hasil Klasifikasi
Untuk mengetahui keefektifan suatu algoritme dalam mengklasifikasikan data, dilakukan perhitungan akurasi, precision, recall, dan f-measure yang didapatkan dari confusion matrix pada Tabel 2 (Weng dan Poon 2008).
Tabel 2 Confusion matrix dua kelas Kelas aktual Kelas hasil prediksi
Kelas positif Kelas negatif
Kelas positif TP FN
Kelas negatif FP TN
Keterangan:
- True Positive (TP) adalah jumlah instance kelas positif yang diprediksi benar sebagai kelas positif
- False Negative (FN) adalah jumlah instance kelas positif yang diprediksi salah sebagai kelas negatif
- False Positive (FP) adalah jumlah instance kelas negatif yang diprediksi salah sebagai kelas positif
8
Semakin tinggi akurasi, precision, recall, dan f-measure, maka algoritme semakin baik dalam melakukan klasifikasi. Akurasi, precision, recall, dan f-measure dapat dihitung menggunakan rumus berikut (Weng dan Poon 2008) : 1 Akurasi
Akurasi adalah jumlah perbandingan data yang benar dengan jumlah keseluruhan data. Akurasi dapat dihitung menggunakan rumus berikut:
Akurasi = TP+TPTN++TNFP+FN × %
2 Precision
Precision digunakan untuk mengukur seberapa besar proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Precision dapat dihitung menggunakan rumus berikut:
Precision= TPTP+FP × %
3 Recall
Recall digunakan untuk menunjukkan persentase kelas data positif yang berhasil diprediksi benar dari keseluruhan data kelas positif. Recall dapat dihitung menggunakan rumus berikut:
Recall= TPTP+FN × %
4 F-measure
F-measure merupakan gabungan dari precision dan recall yang digunakan untuk mengukur kemampuan algoritme dalam mengklasifikasikan kelas minoritas.
F-measure dapat dihitung menggunakan rumus berikut: F = 2 × RecallRecall+ × PrecisionPrecision
Berdasarkan hasil analisis akan didapatkan model data terbaik. Model data tersebut digunakan sebagai dasar pada proses prediksi data baru.
HASIL DAN PEMBAHASAN
Praproses Data
9 Strategi Sampling
Saat teknik oversampling diterapkan, jumlah data bertambah menjadi 6518 data. Saat teknik undersampling diterapkan, jumlah data berkurang menjadi 1272 data.
Hasil Klasifikasi
Penelitian ini menggunakan teknik k-fold cross validation untuk membagi data uji dan data latih dengan k yang digunakan adalah 10, sehingga dilakukan 10 kali proses klasifikasi untuk masing-masing teknik sampling. Hasil yang ditampilkan merupakan rata-rata dari 10 kali proses klasifikasi. Untuk linear kernel perlu dicari nilai C optimal. Pencarian nilai C yang optimal dilakukan dengan percobaan menggunakan 10-cross fold validation terhadap data dengan rentang nilai C dari 1 sampai 10. Dari hasil pencarian didapatkan nilai C dengan akurasi tertinggi yaitu sebesar 1.
Percobaan Data Asli
Data asli dalam percobaan ini adalah data yang belum mengalami proses
sampling tetapi sudah mengalami tahap praproses data. Data ini terdiri dari 636
record data minoritas yang merupakan kategori debitur buruk atau kelas positif dan 3259 record data mayoritas yang merupakan debitur kategori baik atau kelas negatif, sehingga total untuk percobaan data asli berjumlah 3895 record data. Kemudian dilakukan 10-fold cross validation pada masing-masing data bad dan data good untuk memperoleh data uji dan data latih.Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi, recall, precision, dan F-measure
data asli dapat dilihat pada Gambar 3.
Gambar 3 Hasil percobaan data asli Percobaan Oversampling Duplikasi
Pada percobaan ini, data minoritas yaitu 636 record data bad akan dibangkitkan dengan cara duplikasi sehingga jumlahnya menjadi 2623 record data, lalu digabungkan dengan 636 record data asli kelas minoritas sehingga jumlah kelas minoritas sama dengan kelas mayoritas yaitu sebanyak 3259 record data. Data tersebut akan digabungkan dengan 3259 record data asli kelas mayoritas atau kelas good sehingga jumlah total data yang digunakan pada percobaan ini adalah 6518 record data. Kemudian dilakukan 10-fold cross validation pada
10
masing data bad dan data good untuk memperoleh data uji dan data latih. Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi, recall,
precision, dan F-measure pada percobaan oversampling duplikasi dapat dilihat pada Gambar 4.
Gambar 4 Hasil percobaan oversampling duplikasi Percobaan Oversampling Acak
Pada percobaan ini, data minoritas yaitu 636 record data bad akan dibangkitkan dengan cara acak menggunakan software Minitab sehingga jumlahnya menjadi 2623 record data, lalu digabungkan dengan 636 record data asli kelas minoritas sehingga jumlah kelas minoritas sama dengan kelas mayoritas yaitu sebanyak 3259 record data. Data tersebut akan digabungkan dengan 3259
record data asli kelas mayoritas atau kelas good sehingga jumlah total data yang digunakan pada percobaan ini adalah 6518 record data. Kemudian dilakukan 10-fold cross validation pada masing-masing data bad dan data good untuk memperoleh data uji dan data latih. Setelah itu, data diproses agar dapat diolah pada software WEKA. Akurasi, recall, precision, dan F-measure pada percobaan
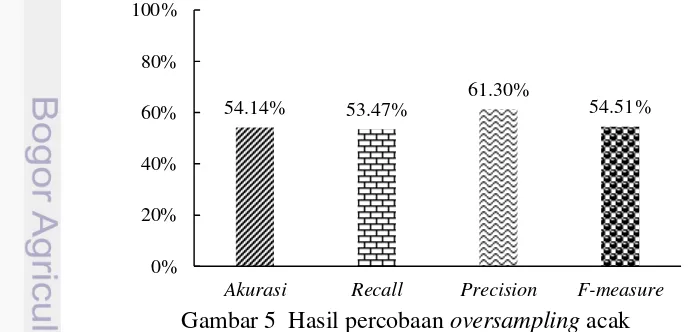
oversampling acak dapat dilihat pada Gambar 5.
Gambar 5 Hasil percobaan oversampling acak Percobaan Undersampling Acak
Pada percobaan ini, data mayoritas yaitu 3259 record akan dikurangi jumlahnya dengan cara acak sehingga jumlahnya menjadi 636 record data. 636
49.17% 47.64% 55.31%
43.56%
0% 20% 40% 60% 80% 100%
Akurasi Recall Precision F-measure
54.14% 53.47%
61.30%
54.51%
0% 20% 40% 60% 80% 100%
11
record data tersebut diambil secara acak menggunakan software Minitab. Data tersebut akan digabungkan dengan 636 record data asli kelas minoritas atau kelas
bad sehingga jumlah total data yang digunakan pada percobaan ini adalah 1272
record data. Kemudian dilakukan 10-fold cross validation pada masing-masing data bad dan data good untuk memperoleh data uji dan data latih. Akurasi, recall,
precision, dan F-measure pada percobaan undersampling acak dapat dilihat pada Gambar 6.
Gambar 6 Hasil percobaan undersampling acak Percobaan Undersampling Cluster
Pada percobaan ini, akan dilakukan proses clustering dengan metode k-means yang dibagi sebanyak 10 cluster untuk data mayoritas yaitu 3259 record
data good menggunakan software WEKA. Masing-masing cluster akan diambil sejumlah data menggunakan rumus Yen dan Lee (2009) sehingga jumlahnya menjadi 636 record data. Data tersebut akan digabungkan dengan 636 record data asli kelas minoritas atau kelas bad sehingga jumlah total data yang digunakan pada percobaan ini adalah 1272 record data. Kemudian dilakukan 10-fold cross validation pada masing-masing data bad dan data good untuk memperoleh data uji dan data latih. Akurasi, recall, precision, dan F-measure pada percobaan
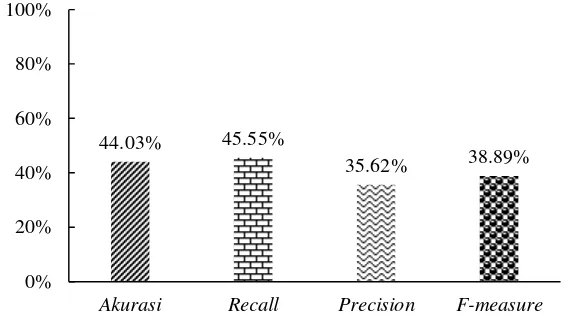
undersampling cluster dapat dilihat pada Gambar 7.
Gambar 7 Hasil percobaan undersampling cluster
49.35%
38.92%
30.72% 33.88%
0% 20% 40% 60% 80% 100%
Akurasi Recall Precision F-measure
44.03% 45.55%
35.62% 38.89%
0% 20% 40% 60% 80% 100%
12
Analisis Hasil Klasifikasi
Berdasarkan hasil klasifikasi pada percobaan data asli, oversampling
duplikasi, oversampling acak, undersampling acak, dan undersampling cluster
dapat diketahui bahwa hasil klasifikasi pada data yang sudah mengalami sampling
lebih baik dibanding hasil klasifikasi pada data asli. Percobaan data asli menghasilkan rata-rata nilai akurasi yang cukup tinggi jika dibandingkan dengan percobaan lain yaitu sebesar 83.59% namun, pada data asli semua data kelas positif diprediksi ke dalam kelas negatif. Pada percobaan ini nilai recall, precision, dan F-measure yang dihasilkan sebesar 0%, nilai ini tidak sebaik dengan nilai akurasinya. Hal ini disebabkan karena jumlah instance kelas positif atau debitur kategori bad yang diprediksi benar sebagai kelas positif yang diperlihatkan pada Tabel 3 bernilai 0, dengan kata lain semua debitur kategori bad diprediksi ke dalam debitur kategori good.
Tabel 3 Confusion matrix data asli Kelas aktual Kelas hasil prediksi
Kelas bad Kelas good
Kelas bad 0 636
Kelas good 0 3259
Klasifikasi dengan teknik oversampling memiliki hasil yang lebih baik dibanding klasifikasi dengan teknik undersampling. Hal ini disebabkan karena jumlah data yang digunakan pada teknik oversampling lebih banyak dibanding teknik undersampling. Pada teknik oversampling semua data kelas negatif atau data debitur kategori good digunakan, sedangkan pada teknik undersampling
hanya menggunakan data kelas negatif sebanyak 636 record data.
Akurasi tertinggi yang diperoleh melalui percobaan menggunakan teknik
oversampling acak sebesar 77.30% dengan nilai recall sebesar 59.51%, precision
sebesar 92.38%, dan F-measure sebesar 72.39%, sedangkan nilai akurasi terendah yang diperoleh sebesar 0.61% dengan nilai recall, precision¸ dan F-measure
sebesar 0%. Akurasi tertinggi yang diperoleh melalui percobaan dengan teknik
oversampling duplikasi sebesar 84.82% dengan nilai recall sebesar 69.63%,
precision sebesar 100%, dan F-measure sebesar 82.09%, sedangkan nlai akurasi terendah yang diperoleh sebesar 0.77% dengan nilai recall, precision, dan F-measure sebesar 0%. Berdasarkan hasil tersebut terlihat bahwa hasil percobaan
oversampling duplikasi lebih baik dibanding hasil percobaan oversampling acak. Namun, jika dilihat dari hasil rata-rata 10 kali percobaan, teknik oversampling
acak memiliki hasil yang lebih baik dibanding teknik oversampling duplikasi. Hal ini disebabkan karena jumlah instance kelas positif atau debitur kategori bad yang diprediksi benar sebagai kelas positif pada teknik oversampling acak lebih besar dibanding jumlah instance kelas positifyang diprediksi benar sebagai kelas positif pada teknik oversampling duplikasi yang ditunjukan pada Tabel 4 dan Tabel 5.
13 Tabel 4 Confusion matrix oversampling acak
Kelas aktual Kelas hasil prediksi Kelas bad Kelas good
Kelas bad 1743 1516
Kelas good 1468 1791
Tabel 5 Confusion matrix oversampling duplikasi Kelas aktual Kelas hasil prediksi
Kelas bad Kelas good
Kelas bad 1540 1719
Kelas good 1593 1666
Dari 10 kali percobaan menggunakan teknik oversampling acak diperoleh rata-rata nilai akurasi sebesar 54.14%. Nilai ini lebih baik jika dibandingkan dengan rata-rata nilai akurasi yang diperoleh dari 10 kali percobaan pada teknik
oversampling duplikasi yaitu sebesar 49.17%. Hal ini juga terjadi pada nilai recall,
precision, dan F-measure. Rata-rata nilai recall, precision, dan F-measure yang diperoleh dari 10 kali percobaan teknik oversampling acak masing-masing sebesar 53.47%, 61.30%, dan 54.51%, sementara rata-rata nilai recall, precision, dan F-measure yang diperoleh dari 10 kali percobaan teknik oversampling duplikasi masing-masing sebesar 47.64%, 55.31%, dan 43.56%.
Nilai akurasi tertinggi yang diperoleh pada percobaan teknik undersampling
acak sebesar 73.44% dengan nilai recall sebesar 90.62%, precision sebesar 67.44%, dan F-measure sebesar 77.33%, sedangkan nilai akurasi terendah yang diperoleh sebesar 34.17% dengan nilai recall 1.67%, precision sebesar 4.76%, dan
F-measure sebesar 2.47%. Nilai akurasi tertinggi yang diperoleh pada percobaan teknik undersampling cluster sebesar 64.06% dengan nilai recall sebesar 81.25%,
precision sebesar 60.46%, dan F-measure sebesar 69.33%, sedangkan nilai akurasi terendah yang dihasilkan sebesar 31.25% dengan nilai recall, precision, dan F-measure sebesar 0%. Berdasarkan hasil tersebut terlihat bahwa hasil percobaan undersampling acak lebih baik dibanding hasil percobaan
undersampling cluster. Namun, jika dilihat dari hasil rata-rata 10 kali percobaan, teknik undersampling cluster memiliki hasil yang lebih baik dibanding teknik
undersampling acak. Hal ini disebabkan karena jumlah instance kelas positif atau debitur kategori bad yang diprediksi benar sebagai kelas positif pada teknik
14
Tabel 6 Confusion matrix undersamplingcluster
Kelas aktual Kelas hasil prediksi Kelas bad Kelas good
Kelas bad 292 344
Kelas good 367 269
Tabel 7 Confusion matrix undersampling acak Kelas aktual Kelas hasil prediksi
Kelas bad Kelas good
Kelas bad 249 387
Kelas good 256 380
Nilai akurasi dari 10 kali percobaan dengan teknik undersampling acak sebesar 49.35%. Nilai ini lebih besar jika dibanding dengan rata-rata nilai akurasi yang diperoleh dari 10 kali percobaan pada teknik undersampling cluster yaitu sebesar 44.03%, namun hal ini tidak berlaku untuk nilai recall, precision, dan F-measure. Rata-rata nilai recall, precision, dan F-measure yang diperoleh dari 10 kali percobaan teknik undersampling acak masing-masing sebesar 38.92%, 30.72%, dan 33.88%, hasil ini lebih kecil dibanding hasil yang diperoleh dari 10 kali percobaan dengan teknik undersampling cluster yaitu masing-masing sebesar 45.55%, 35.62%, dan 38.89%.
Secara keseluruhan, dapat diketahui bahwa hasil tertinggi diperoleh pada teknik oversampling acak. Hal ini disebabkan karena instance kelas positif yang diprediksi benar sebagai kelas positif pada teknik oversampling acak memiliki jumlah tertinggi dibanding instance kelas positif yang diprediksi benar sebagai kelas positif pada teknik yang lain.
Perbandingan dengan Penelitian Sebelumnya
15 Tabel 8 Perbandingan dengan penelitian sebelumnya
Pendekatan Akurasi Recall Precision F-measure
(%)
Hasil pada penelitian ini menunjukkan nilai F-measure yang rendah jika dibanding hasil penelitian yang lain. Hal ini membuktikan bahwa algoritme SVM kurang optimal dalam mengklasifikasikan debitur ke dalam kategori bad dan kategori good.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa: 1 Percobaan data dengan teknik sampling menghasilkan nilai F-measure yang
lebih baik dibanding percobaan data asli.
2 Percobaan data dengan teknik oversampling memiliki hasil yang lebih baik dari percobaan dengan teknik undersampling.
3 Percobaan data asli dengan 10-fold cross validation menghasilkan rata-rata akurasi sebesar 83.59% serta nilai rata-rata untuk recall, precision, dan F-measure sebesar 0% karena algoritme SVM memiliki tingkat kecenderungan untuk mengklasifikasikan data ke dalam kelas negatif, sehingga semua data debitur kategori bad diprediksi ke dalam kategori good.
4 F-measure paling tinggi diperoleh saat percobaan data dengan teknik
oversampling acak sebesar 54.51%.
5 Pada percobaan dengan teknik oversampling acak menghasilkan nilai F-measure sebesar 54.51%. Nilai ini lebih tinggi jika dibandingkan dengan percobaan menggunakan teknik oversampling duplikasi yang menghasilkan nilai F-measure sebesar 43.56%.
16
percobaan menggunakan teknik undersampling acak yang menghasilkan nilai
F-measure sebesar 33.88%.
7 Hasil percobaan terbaik diperoleh dari percobaan dengan teknik oversampling
acak.
Saran
Pada penelitian selanjutnya diharapkan dapat membandingkan hasil klasifikasi SVM yang didapatkan pada penelitian ini dengan teknik sampling yang lain, seperti synthetic minority oversampling technique dan diharapkan untuk mencoba dengan fungsi kernel yang lain, seperti kernel RBF. Selain itu, diharapkan juga untuk mencoba algoritme klasifikasi yang lain, seperti weighted
SVM.
DAFTAR PUSTAKA
Anggraini D. 2013. Perbandingan algoritme C4.5 dan CART pada data tidak
seimbang untuk kasus prediksi risiko kredit debitur kartu kredit [skripsi].
Bogor (ID): Institut Pertanian Bogor.
Bank Indonesia. 2013. Daftar penerbit kartu kredit. [diunduh 2013 Des 2]. Tersedia pada: http://bi.go.id/ Statistik/Statistik+Sistem+Pembayaran/APMK/ Chawla VN. 2003. C4.5 and imbalance datasets: investigating the effect of sampling method, probabilistic estimate, and decision tree structure. Di
dalam: Workshop on Learning from Imbalanced Datasets II [Internet]; 2003
Aug 21; Washington DC, Amerika Serikat. [diunduh 2013 Sep 9]. Tersedia pada: http://arxiv.org/pdf/1106.1813.pdf.
Han J, Kamber M. 2001. Data Mining Concepts & Techniques. San Fransisco
(US): Morgan Kaufmann.
He H, Edwardo AG. 2009. Learning from imbalanced data. Knowledge and Data
Engineering IEEE Transactions. 21(9):1263-1284.
Japkowicz N, Stephen K. 2004. Applying support vector machine to imbalanced datasets. Di dalam: Boulicaut JF, Esposito F, Giannotti F, Pedreschi D
(editor). Proc. 15th European Conference on Machine Learning. Berlin (DE):
Springer Berlin Heidelberg. pp 39-50.
Kawakibi T. 2009. Steganalisis pada media audio menggunakan metode support
vector machine radial basis function classifier [skripsi]. Bogor (ID): Institut
Pertanian Bogor.
Larose DT. 2005. Discovering Knowledge in Data: An Introduction to Data
Mining. New Jersey (US). J Wiley.
Nurjayanti B. 2011. Identifikasi shorea menggunakan k-nearest neighbor
berdasarkan karakteristik morfologi daun [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Santosa B. 2010. Tutorial support vector machine. Surabaya (ID): Institut
Teknologi Sepuluh Nopember.
Ulya F. 2013. Klasifikasi debitur kartu kredit menggunakan algoritme k-nearest
neighbor untuk kasus imbalanced data [skripsi]. Bogor (ID): Institut
17
Weng GC, Poon J. 2008. A new evaluation measure for imbalanced datasets. Di
dalam: Roddick FJ, Li J, Christen P, Kennedy P, editor. Data Mining and
Analytics 2008. Volume 87. Conference Seventh Australian Data Mining
Conference (AusDM 2008) [Internet]; 2008 Nov 27; Glenelg Australia.
[diunduh 2013 Des 16]. Tersedia pada:
http://crpit.com/confpapers/CRPITV87Weng.pdf.
Widodo PP, Handayanto RT. 2013. Penerapan data mining. Bandung (ID):
Rekayasa Sains.
Wijayanti R. 2013. Klasifikasi nasabah kartu kredit menggunakan algoritme fuzzy
k-nearest neighbor pada data tidak seimbang [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Yen SJ, Lee YS. 2009. Cluster-based under-sampling approaches for imbalanced
data distributions. Expert System with Applications. 36(3):5718-5727.
18
Lampiran 1 Keterangan atribut
Tipe atribut Atribut Keterangan
Ordinal Pendidikan 1 = SMP/SMA
2 = Akademi 3= S1/S2
Nominal Gender 1 = Pria
2 = Wanita Status pernikahan 1 = Lajang 2 = Menikah 3 = Bercerai Tipe perusahaan 1 = Kontraktor
2 = Conversion 3 = Industri berat 4 = Pertambangan 5 = Jasa
6 = Transportasi
Status pekerjaan 1 = Permanen
2 = Kontrak
Pekerjaan 1 = Conversion
2 = PNS 3 = Profesional 4 = Wiraswasta 5 = Perusahaan swasta Status rumah 0 = Bukan milik sendiri
1 = Milik sendiri
Rasio Tanggungan Orang
Pendapatan Rupiah per tahun
Banyaknya kartu kredit lain Persentase utang kartu kredit lain
Usia Dalam bulan
Masa kerja Dalam bulan
Lama tinggal Dalam bulan
Kelas 1 = buruk
19 Lampiran 2 Nilai akurasi dalam % pada data asli dan setiap teknik sampling
Fold
Lampiran 3 Nilai recall dalam % pada data asli dan setiap teknik sampling
20
Lampiran 4 Nilai precision dalam % pada data asli dan setiap teknik sampling
Fold
21 Lampiran 6 Confussion matrix data asli
Fold
ke- Confusion matrix
Fold
ke- Confusion matrix
22
Lampiran 7 Confusion matrix oversampling acak
Fold
ke- Confusion matrix
Fold
ke- Confusion matrix
23 Lampiran 8 Confusion matrix oversampling duplikasi
Fold
ke- Confusion matrix
Fold
ke- Confusion matrix
24
Lampiran 9 Confusion matrix undersampling acak
Fold
ke- Confusion matrix
Fold
ke- Confusion matrix
25 Lampiran 10 Confusion matrix undersampling cluster
Fold
ke- Confusion matrix
Fold
ke- Confusion matrix
26
RIWAYAT HIDUP
Penulis dilahirkan di Tangerang, Banten, Jawa Barat, pada tanggal 25 Mei 1992 sebagai anak pertama dari pasangan Ropingi Suwito dan Dwi Ilmiah. Penulis merupakan lulusan SMA Negeri 34 Jakarta (2007-2010), SMP Negeri 85 Jakarta (2004-2007), dan SD Negeri 01 Jakarta (2004).