KLASIFIKASI DEBITUR KARTU KREDIT MENGGUNAKAN
ALGORITME K-NEAREST NEIGHBOR UNTUK
KASUS IMBALANCED DATA
FIQROTUL ULYA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme K-Nearest Neighbor untuk Kasus
Imbalanced Data adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2013
Fiqrotul Ulya
ABSTRAK
FIQROTUL ULYA. Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme K-Nearest Neighbor untuk Kasus Imbalanced Data. Dibimbing oleh AZIZ KUSTIYO.
Data dikatakan tidak seimbang apabila terdapat distribusi jumlah data yang tidak merata, dengan suatu kelas memiliki jumlah data yang jauh lebih besar dari kelas lainnya. Dalam kasus ini, kelas minoritas lebih sulit diprediksi daripada kelas mayoritas. Padahal kelas minoritas inilah yang terkadang memiliki informasi penting. Pada penelitian ini dilakukan analisis klasifikasi debitur kartu kredit menggunakan k-nearest neighbor untuk kasus imbalanced data yang mampu mengklasifikasikan calon debitur ke dalam kategori baik atau buruk. Analisis kelayakan calon debitur sangat penting untuk meminimalisir terjadinya risiko kredit. Salah satu pendekatan yang dilakukan untuk menangani permasalahan pada kasus imbalanced data adalah dengan memodifikasi distribusi data menggunakan metode oversampling dan undersampling. Dalam penelitian ini dilakukan perbandingan nilai parameter k, akurasi, precision, recall serta F-measure dan diketahui bahwa teknik oversampling menunjukkan nilai terbaik dengan akurasi sebesar 96.24% ketika k = 3, recall 99.23% ketika k = 2, precision
95.21% ketika k = 1, dan F-measure sebesar 96.30% ketika k = 3.
Kata Kunci: imbalanced data, k-nearest neighbor, oversampling, undersampling
ABSTRACT
FIQROTUL ULYA. Credit Card Debtor Classification Based On K-Nearest Neighbor Algorithm for Imbalanced Data. Supervised by AZIZ KUSTIYO.
Data is said to suffer the class imbalanced problem when the class distribution are highly imbalance. In this case, minority class is more difficult to predict then the majority class. Though the minority class sometime has important information. In this paper, classification analysis of credit card debtors is conducted by using k-nearest neighbor that can classify debtors into two categories, good or bad. Analysis of a prospective debtor is essential to minimize credit risk. One approach taken to overcome imbalanced data problems is to modify instance distribution using oversampling and undersampling method. The evaluation is conducted by comparing the value of parameter k, accuracy, precision, recall, and F-measure. The evaluation results show that oversampling technique gives the best result of 96.24% with k = 3, 99.23% recall with k = 2, 95.21% precision with k = 1, and 96.30% F-measure with k = 3.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DEBITUR KARTU KREDIT MENGGUNAKAN
ALGORITME K-NEAREST NEIGHBOR UNTUK
KASUS IMBALANCED DATA
FIQROTUL ULYA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme K-Nearest Neighbor untuk Kasus Imbalanced Data
Nama : Fiqrotul Ulya NIM : G64090019
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji syukur kehadirat Allah Subhanahu Wa Taala yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan skripsi yang berjudul “Klasifikasi Debitur Kartu Kredit Menggunakan Algoritme K-Nearest Neighbor untuk Kasus Imbalanced Data”. Skripsi ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Departemen Ilmu Komputer, Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan dukungannya. Ungkapan terima kasih juga disampaikan kepada Bapak Aziz Kustiyo, SSi MKom selaku pembimbing yang telah memberikan arahan, bimbingan, saran dan motivasi dengan sabar dan membantu penulis dalam menyelesaikan skripsi ini. Penulis juga mengucapkan terima kasih kepada dosen penguji, Bapak Toto Haryanto, MKom dan Bapak M Asyhar Aglamaro, MKom atas saran dan bimbinganya, serta teman-teman satu bimbingan, Retno Wijayanti, Dhieta Anggraini serta Ilkomerz 46 atas bantuan, saran, kritik, dan dukungannya kepada penulis.
Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Risiko Kredit 2
Imbalanced Data 3
Sampling 3
K-Fold Cross Validation 3
K-Nearest Neighbor 3
Normalisasi 4
Confusion Matrix 5
METODE 6
Kerangka Penelitian 6
Pengadaan Data 7
Praproses Data 7
10-Fold Cross Validation 8
Proses Klasifikasi Metode KNN 8
Analisis Hasil Klasifikasi 8
HASIL DAN PEMBAHASAN 8
Praproses Data 8
Hasil Klasifikasi 9
Analisis Hasil Klasifikasi 12
Perbandingan dengan Penelitian Sebelumnya 14
Simpulan 15
Saran 16
DAFTAR PUSTAKA 16
LAMPIRAN 17
DAFTAR TABEL
1 Confusion matrix dua kelas 5
2 Karakteristik atribut 9
3 Hasil akurasi rata-rata 12
4 Hasil precision, recall dan F-measure 12
5 Perbandingan dengan penelitian lain 14
DAFTAR GAMBAR
1 Alur penelitian 6
2 Imbalanced data 7
3 Hasil percobaan data asli 9
4 Hasil percobaan oversampling replikasi 10
5 Hasil percobaan oversampling acak 10
6 Hasil percobaan undersampling acak 11
7 Hasil percobaan undersamplingcluster 11
DAFTAR LAMPIRAN
1 Daftar atribut 17
2 Nilai akurasi undersampling acak 18
3 Nilai precisionundersampling acak 18
4 Nilai recallundersampling acak 18
5 Nilai F-measureundersampling acak 18
1
PENDAHULUAN
Latar Belakang
Data Bank Indonesia (2013) menyebutkan bahwa daftar penerbit kartu kredit meningkat menjadi 20 penerbit. Banyaknya bank yang mengembangkan bisnis kartu kredit menandakan bahwa bisnis ini masih memiliki peluang yang baik bagi bank penerbit sebagai sumber keuntungan. Kartu kredit menawarkan kemudahan bagi nasabahnya untuk melakukan berbagai macam transaksi. Pemegang kartu kredit diwajibkan untuk melakukan pelunasan kewajiban pada waktu yang telah disepakati baik secara sekaligus ataupun angsuran (Sayono et al.
2009). Aturan dan sistem yang diterapkan terhadap analisis kelayakan calon debitur sangat penting untuk meminimalisir terjadinya risiko kredit. Debitur yang lancar dalam memenuhi kewajibannya mampu memberikan keuntungan kepada bank. Sementara itu, permasalahan dapat terjadi apabila debitur tidak mampu memenuhi kewajibannya dalam batas waktu yang telah disepakati sehingga dapat merugikan bank.
Data debitur kartu kredit merupakan salah satu data skala besar dengan distribusi kelas yang tidak merata antara debitur kategori baik dan buruk. Kumpulan data yang memiliki kelas tidak terdistribusi secara merata atau data yang jumlahnya didominasi oleh salah satu kelas disebut imbalanced data. Penggunaan metode sampling dalam imbalanced data dapat memberikan distribusi data yang seimbang untuk setiap kelas (He dan Edwardo 2009).
Salah satu metode yang digunakan untuk membangun model klasifikasi dalam mengidentifikasi debitur ke dalam kategori baik atau buruk adalah k -nearest neighbor (KNN). KNN merupakan teknik yang lebih fleksibel karena mampu mengklasifikasikan data uji ke dalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al. 2006).
Penelitian terkait tentang klasifikasi debitur kartu kredit dilakukan oleh Natasia (2013) menggunakan metode voting feature intervals 5 (VFI5) untuk melakukan pemilihan fitur serta mengukur tingkat akurasinya yang menghasilkan model terbaik dengan pengukuran akurasi, recall, precision, dan F-measure
sebesar 70.40%, 38.58%, 24.38%, dan 29.88%. Namun, penelitian tersebut tidak melakukan pendekatan dari sisi teknik sampling sebagai solusi mengatasi kasus
imbalanced data yang terjadi pada dua kelas debitur baik dan buruk. Penelitian terkait lainnya mengenai ekstraksi informasi untuk kasus imbalanced data
menyatakan bahwa KNN sensitif terhadap persentase jumlah data minoritas, dan bekerja secara baik pada distribusi data undersampling (Zhang dan Mani 2003).
2
Perumusan Masalah Masalah yang dianalisis dalam penelitian ini adalah :
1 Bagaimana metode KNN dapat mengklasifikasikan nasabah kartu kredit ke dalam kategori debitur baik atau debitur buruk?
2 Bagaimana akurasi, precision, recall, dan F-measure metode KNN dalam mengklasifikasikan debitur Bank X pada kasus imbalanced data?
Tujuan Penelitian
Penelitian ini bertujuan untuk menerapkan algoritme KNN untuk mengklasifikasikan debitur kartu kredit ke dalam kategori debitur baik atau debitur buruk pada kasus imbalanced data.
Manfaat Penelitian
Penelitian ini diharapkan dapat membantu pihak penerbit kartu kredit sebagai pertimbangan dalam mengidentifikasi debitur yang berpotensi tidak memenuhi kewajibannya tepat waktu sehingga dapat mengurangi tingkat risiko terjadinya kredit bermasalah.
Ruang Lingkup Penelitian
Data dalam penelitian ini merupakan data penelitian Setiawati (2011), yaitu data debitur Bank X mengenai status kelancaran pembayaran utang kartu kredit antara tahun 2008 dan 2009. Data yang diamati berjumlah 3895 dengan 14 atribut, 3259 termasuk ke dalam kategori debitur baik, yaitu debitur yang tepat membayar hutangnya dalam kurun waktu 90 hari serta 636 debitur buruk yang menunggak utang lebih dari 90 hari. Terdapat ketidakseimbangan data dengan jumlah data debitur yang termasuk ke dalam kategori baik mendominasi keseluruhan data.
TINJAUAN PUSTAKA
Risiko Kredit
3
diperlukan dalam melakukan pemantauan terhadap nasabah untuk menekan kerugian.
Imbalanced Data
Imbalanced data merupakan keadaan data dengan salah satu kelas memiliki porsi yang tidak sebanding dengan kelas yang lainnya. Bentuk ketidakseimbangan tersebut pada beberapa data menunjukkan perbandingan yang sangat signifikan jumlah antar kelasnya, yaitu 100:1, 1000:1, bahkan ada yang mencapai 10 000:1. Hal tersebut berpengaruh pada algoritme klasifikasi yang menghasilkan akurasi prediksi yang baik pada kelas data yang memiliki jumlah instance besar atau kelas mayoritas tetapi menghasilkan akurasi prediksi yang kurang baik terhadap kelas dengan jumlah instance lebih kecil atau kelas minoritas, sehingga dapat pula terjadi penyimpangan prediksi, yaitu kelas minoritas di prediksikan ke dalam kelas mayoritas. Salah satu solusi dari masalah imbalanced data adalah penggunaan metode sampling yang dapat memberikan distribusi data seimbang untuk setiap kelas (He dan Edwardo 2009).
Sampling
Metode sampling untuk menangani masalah pada imbalanced data
diantaranya adalah undersampling dan oversampling (He dan Edwardo 2009).
Undersampling adalah proses membuang sebagian data dari kelas minoritas agar diperoleh data yang seimbang, sedangkan oversampling adalah proses menduplikasi data dari kelas minoritas untuk mendapatkan data dengan kelas yang seimbang. Dalam kasus Undersampling, dapat menyebabkan classifier
melewatkan informasi penting karena sebagian data pada kelas mayoritas dihilangkan (He dan Edwardo 2009).
K-Fold Cross Validation
Data dalam metode k-fold cross validation akan dibagi menjadi k subset
dengan ukuran yang sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada iterasi pertama, subset 1 akan menjadi data uji, sedangkan subset 2, subset
3, ..., subsetk akan menjadi data latih. Proses selanjutnya, subset 2 akan menjadi data uji, subset 1, subset 3, ..., subset k menjadi data latih, dan seterusnya sebanyak k iterasi (Han dan Kamber 2006).
Metode evaluasi standar yang banyak digunakan adalah 10-fold cross validation. Menurut penelitian Kohavi (1995) dari berbagai percobaan menunjukkan bahwa 10-fold cross validation adalah pilihan terbaik untuk mendapatkan hasil validasi yang akurat.
K-Nearest Neighbor
4
Penggunaan rumus jarak Euclidean tidak tepat digunakan untuk atribut bertipe nominal. Berbeda dengan atribut pendidikan, yang termasuk atribut ordinal tetap dihitung dengan rumus perhitungan jarak Euclidean karena nilai tingkatan tinggi rendahnya pendidikan masih relevan dengan konsep perhitungan jarak Euclidean. Atribut yang bertipe nominal terlebih dahulu dilambangkan dengan nilai numerik untuk mempermudah perbandingan pengukuran jarak, kemudian digunakan fungsi sebagai berikut :
di= 1 selainnya 0 jika xi= yi
jika data latih sama dengan data uji jaraknya 0, selainnya berjarak 1 (Larose 2005).
Setelah itu dilakukan penggabungan atau agregate ketidaksamaan berat rata-rata dari jarak masing-masing atribut hasil perhitungan jarak Euclidean dan atribut nominal dengan rumus sebagai berikut :
S
ij=
∑
nk=1w
ijk×s
ijk∑
nw
ijkk=1
dengan k merupakan variabel fitur, ij merupakan selisih data latih dan data uji, Sij
merupakan kesamaan dan ketidaksamaan antara objek dengan Wijk bernilai 1
untuk nilai numerik dan 0.5 untuk nilai nominal (Teknomo 2006). Nilai pembobotan tersebut diberikan agar jarak atribut nominal tidak terlalu mendominasi hasil perhitungan.
Normalisasi
Atribut dengan nilai rentang yang cukup panjang dibandingkan dengan nilai atribut lainnya memiliki pengaruh besar terhadap atribut berskala pendek (Nurjayanti 2011). Oleh karena itu, untuk menghindari perbedaan rentang tersebut dilakukan tahap normalisasi data untuk atribut pendapatan, jumlah tanggungan, masa kerja, lama tinggal, dan umur, sehingga didapatkan range antara 0 sampai 1 menggunakan teknik min-max normalization, dengan rumus sebagai berikut (Larose 2005) :
X*= X - min(X)
5
Keterangan :
X*= nilai setelah normalisasi
X = nilai sebelum normalisasi min(X) = nilai minimum atribut
max(X) = nilai maksimum dari suatu atribut Confusion Matrix
Evaluasi hasil klasifikasi didapatkan dari confusion matrix pada Tabel 1 (Weng dan Poon 2008).
Kinerja metode klasifikasi yang dijelaskan lebih lanjut berdasarkan nilai akurasi, precision, recall, dan F-measure dengan rumus berikut (Weng dan Poon 2008) :
Akurasi (Ac)
Ac = TP+TN+FP+FNTP+TN × 100%
Precision (P)
P = TP+FPTP × 100%
Recall (R)
R = TP+FNTP × 100%
F-Measure (F)
F = 2 × RecallRecall + × PrecisionPrecision× 100% Tabel 1 Confusion matrix dua kelas
Kelas hasil prediksi
Kelas aktual Kelas positif Kelas negatif Kelas positif True Positive False Negative Kelas negatif False Positive True Negative Keterangan :
-True Positive (TP) adalah jumlah dari kelas positif, yaitu kelas yang mempunyai jumlah instance lebih sedikit yang benar diklasifikasikan. -False Negative (FN) adalah jumlah kelas positif yang salah
diklasifikasikan dalam kelas negatif.
-False Positive (FP) adalah jumlah kelas negatif yang diklasifikasikan ke dalam kelas positif.
6
METODE
Kerangka Penelitian
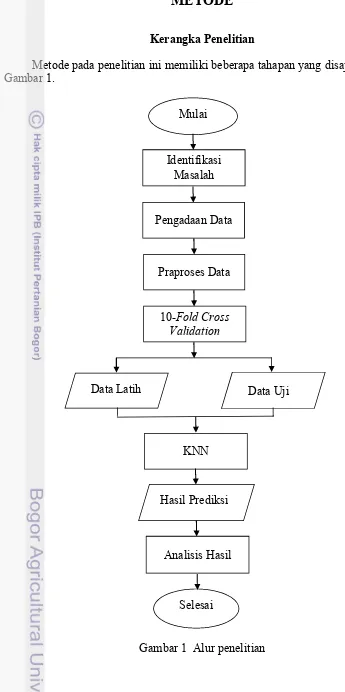
Metode pada penelitian ini memiliki beberapa tahapan yang disajikan dalam Gambar 1.
Gambar 1 Alur penelitian Mulai
Identifikasi Masalah
Pengadaan Data
Praproses Data
10-Fold Cross Validation
Hasil Prediksi
Data Latih Data Uji
KNN
7
Pengadaan Data
Penelitian ini menggunakan data sekunder debitur Bank X mengenai status kelancaran pembayaran utang kartu kredit tahun 2008 sampai dengan tahun 2009. Keseluruhan data asli yang belum mengalami praproses data berjumlah 4413 dengan 2 kelas, yaitu, 3574 data kelas debitur baik dan 839 data kelas debitur buruk. Terdapat ketidakseimbangan data dengan jumlah data debitur yang termasuk ke dalam kategori baik mendominasi sebesar 81% dari keseluruhan data, yang disajikan pada Gambar 2.
Gambar 2 Imbalanced data
Praproses Data
Eksplorasi data dilakukan untuk mengetahui karakteristik data serta permasalahan keberadaan missing value. Data awal berjumlah 4413 dengan 14 atribut, 7 atribut diantaranya termasuk ke dalam kategori atribut rasio, yaitu pendapatan, jumlah tanggungan, umur, masa kerja, lama tinggal, banyaknya kartu kredit lain, dan persentase utang kartu kredit lain, serta 6 atribut lainnya termasuk ke dalam kategori atribut bertipe nominal, yaitu jenis kelamin, status pekerjaan, jenis pekerjaan, tipe perusahaan, status rumah, dan status pernikahan, sedangkan pendidikan tergolong ke dalam atribut ordinal. Penghapusan data dilakukan terhadap record yang memiliki missingvalue dan nilai yang tidak relevan, seperti pada atribut pendapatan yang memiliki nilai minus, sehingga data yang diproses dalam penelitian ini berjumlah 3895 dengan 14 atribut, dengan 3259 termasuk ke dalam kategori debitur baik dan 636 debitur buruk.
Ketidakseimbangan yang terjadi pada masing-masing kelas dengan data pada kelas kategori debitur baik memiliki jumlah yang jauh lebih besar dibandingkan dengan kategori debitur buruk, sehingga harus dilakukan modifikasi distribusi data dengan teknik oversampling dan undersampling (He dan Edwardo 2009). Dalam penelitian ini, teknik oversampling dilakukan dengan 2 cara, yaitu dengan cara membangkitkan data kelas minoritas secara acak sehingga jumlahnya sama dengan kelas mayoritas dan teknik oversampling kedua dengan mereplikasi kelas minoritas sebanyak data pada kelas mayoritas. Modifikasi distribusi data teknik undersampling dilakukan dengan mengurangi jumlah kelas mayoritas sehingga jumlahnya sama dengan kelas minoritas. Dalam penelitian ini, dilakukan 2 cara teknik undersampling. Cara pertama, data mayoritas diambil secara acak sebanyak data minoritas yang dilakukan sebanyak 3 kali percobaan. Cara kedua,
81% 19%
8
dilakukan proses clustering untuk data mayoritas sebanyak 9 kali percobaan, mulai dari 2 cluster sampai 10 cluster. Percobaan dilakukan pada setiap cluster
dengan mengambil beberapa sampel dari setiap cluster yang banyaknya diperoleh dari rumus berikut :
=jumlah data kelas mayoritasjumlah data clusteri × jumlah data kelas minoritas
Jumlah total data yang digunakan untuk teknik oversampling adalah 6518, sedangkan untuk teknik undersampling adalah 1272 data.
10-Fold Cross Validation
Data dibagi menjadi data uji dan data latih secara acak dengan pemilihan 10
fold. Metode ini membagi data menjadi 10 bagian. Masing-masing bagian tersebut secara bergantian digunakan sebagai data latih dan data uji sampai dengan total 10 iterasi. Pemilihan jumlah 10 fold ini atas dasar pertimbangan jumlah data yang digunakan cukup besar, sehingga dibagi menjadi 10 bagian.
Proses Klasifikasi Metode KNN
Tahapan selanjutnya adalah proses klasifikasi menggunakan KNN dengan mencari jarak terdekat antara data uji dengan K tetangga terdekatnya dalam data latih. Langkah-langkah pada metode KNN adalah :
1. Menghitung jarak Euclidean untuk data numerik yang sebelumnya telah dilakukan normalisasi data.
2. Atribut nominal yang sudah dilambangkan dengan nilai numerik, dihitung jaraknya dengan membandingkan data latih dan data uji.
3. Penggabungan jarak dari hasil perhitungan jarak Euclidean dan perhitungan data atribut nominal.
4. Penentuan nilai k sebagai jumlah tetangga terdekat dalam metode KNN. Analisis Hasil Klasifikasi
Kinerja metode klasifikasi dievaluasi dari hasil perhitungan akurasi,
precision, recall, dan F-measure. Dalam penelitian ini, nilai akurasi, precision,
recall, dan F-measure dinyatakan dalam persen, semakin tinggi persentase akurasi, precision, recall, dan F-measure, maka semakin baik kinerja metode klasifikasi.
HASIL DAN PEMBAHASAN
Praproses Data
9
tidak relevan. Banyaknya instance yang tidak digunakan dalam proses klasifikasi adalah 518, sehingga sehingga data yang diproses dalam penelitian ini berjumlah 3895 dengan 14 atribut, dengan 3259 termasuk ke dalam kategori debitur baik dan 636 debitur buruk. Dari praproses data ini diketahui bahwa jumlah instance
debitur baik berkurang dari 3574 menjadi 3259, sedangkan kelas debitur buruk berkurang dari 839 menjadi 636. Pada tahap praproses data diketahui pula karakteristik dari atribut, selengkapnya dapat dilihat pada Tabel 2.
Tabel 2 Karakteristik atribut
Rasio Nominal Ordinal
1. Pendapatan 1. Jenis kelamin 1. Pendidikan 2. Jumlah tanggungan 2. Status pekerjaan
3. Umur 3. Jenis pekerjaan
4. Masa kerja 4. Tipe perusahaan 5. Lama tinggal 5. Status rumah
6. Banyaknya kartu kredit lain 6. Status pernikahan 7. Persentase utang kartu
kredit lain
Hasil Klasifikasi Percobaan Data Asli
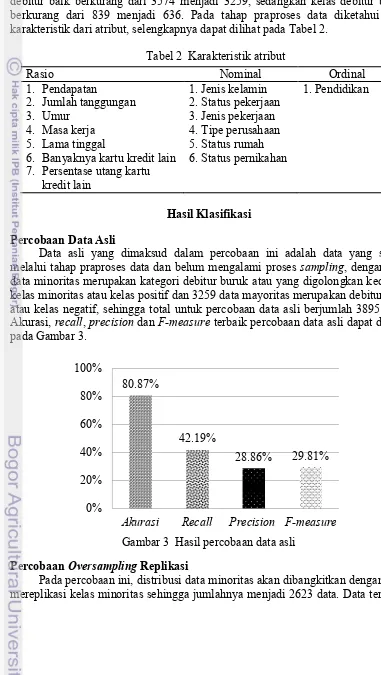
Data asli yang dimaksud dalam percobaan ini adalah data yang sudah melalui tahap praproses data dan belum mengalami proses sampling, dengan 636 data minoritas merupakan kategori debitur buruk atau yang digolongkan kedalam kelas minoritas atau kelas positif dan 3259 data mayoritas merupakan debitur baik atau kelas negatif, sehingga total untuk percobaan data asli berjumlah 3895 data. Akurasi, recall, precision dan F-measure terbaik percobaan data asli dapat dilihat pada Gambar 3.
Gambar 3 Hasil percobaan data asli Percobaan Oversampling Replikasi
Pada percobaan ini, distribusi data minoritas akan dibangkitkan dengan cara mereplikasi kelas minoritas sehingga jumlahnya menjadi 2623 data. Data tersebut
10
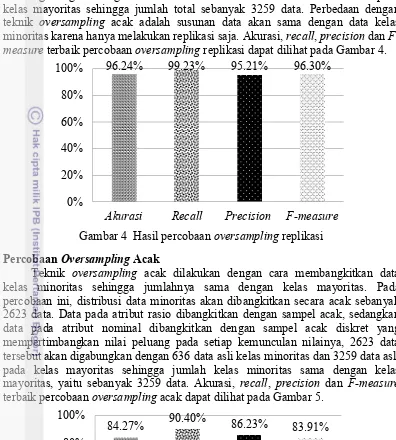
akan digabungkan dengan 636 data asli kelas minoritas dan 3259 data asli pada kelas mayoritas sehingga jumlah total sebanyak 3259 data. Perbedaan dengan teknik oversampling acak adalah susunan data akan sama dengan data kelas minoritas karena hanya melakukan replikasi saja. Akurasi, recall, precision dan F-measure terbaik percobaan oversampling replikasi dapat dilihat pada Gambar 4.
Gambar 4 Hasil percobaan oversampling replikasi Percobaan Oversampling Acak
Teknik oversampling acak dilakukan dengan cara membangkitkan data kelas minoritas sehingga jumlahnya sama dengan kelas mayoritas. Pada percobaan ini, distribusi data minoritas akan dibangkitkan secara acak sebanyak 2623 data. Data pada atribut rasio dibangkitkan dengan sampel acak, sedangkan data pada atribut nominal dibangkitkan dengan sampel acak diskret yang mempertimbangkan nilai peluang pada setiap kemunculan nilainya, 2623 data tersebut akan digabungkan dengan 636 data asli kelas minoritas dan 3259 data asli pada kelas mayoritas sehingga jumlah kelas minoritas sama dengan kelas mayoritas, yaitu sebanyak 3259 data. Akurasi, recall, precision dan F-measure
terbaik percobaan oversampling acak dapat dilihat pada Gambar 5.
Gambar 5 Hasil percobaan oversampling acak Percobaan Undersampling Acak
11
Pengurangan data dilakukan sebanyak 2623 data pada kelas mayoritas sehingga jumlahnya menjadi 636 data. Kemudian, 636 data pada kelas mayoritas tersebut digabung dengan 636 data kelas minoritas sehingga total data yang diproses adalah 1272. Akurasi, recall, precision dan F-measure terbaik percobaan
undersampling acak dapat dilihat pada Gambar 6.
Gambar 6 Hasil percobaan undersampling acak Percobaan Undersampling Cluster
Proses clustering pada percobaan ini dilakukan untuk 3259 data kelas mayoritasdengan 9 kali percobaan clustering, yaitu data tersebut dibagi menjadi 2
cluster, 3 cluster, 4 cluster dan seterusnya sampai 10 cluster. Untuk setiap cluster
tersebut akan diambil sejumlah data dari masing-masing cluster sehingga jumlahnya menjadi 636 data yang kemudian akan digabungkan dengan 636 data kelas minoritas sehingga total data adalah 1272. Akurasi, recall, precision dan F-measure terbaik percobaan undersamplingcluster dapat dilihat pada Gambar 7.
Gambar 7 Hasil percobaan undersamplingcluster
77.28% 83.60% 82.86% 75.99%
0% 20% 40% 60% 80% 100%
Akurasi Recall Precision F-measure
66.66%
81.45%
67.52% 68.87%
0% 20% 40% 60% 80% 100%
12
Analisis Hasil Klasifikasi
Evaluasi digunakan untuk mengukur kinerja metode klasifikasi, dalam penelitian ini digunakan untuk mengukur keakuratan metode klasifikasi yang diukur dengan akurasi, precision, recall, dan F-measure. Recall didefinisikan sebagai persentase antara data kelas debitur buruk yang dikelaskan dengan benar dan data kelas debitur buruk yang salah diprediksi ke kelas debitur baik. Precision
adalah persentase dari kelas debitur buruk yang dikelaskan dengan benar dan kelas yang seharusnya termasuk kelas debitur baik tetapi dikelaskan sebagai kelas debitur buruk, sedangkan untuk F-Measure yang memiliki nilai tinggi menyatakan bahwa nilai recall dan precision juga tinggi.
Berdasarkan hasil klasifikasi, diperoleh nilai akurasi percobaan pada data asli, oversampling replikasi, oversampling acak, undersampling acak dan
undersampling cluster yang diperlihatkan pada Tabel 3, untuk precision, recall, dan F-measure diperlihatkan pada Tabel 4. Nilai akurasi, precision, recall, dan F-measure dinyatakan dalam persen, semakin tinggi persentase nilainya, maka semakin baik kinerja metode klasifikasi.
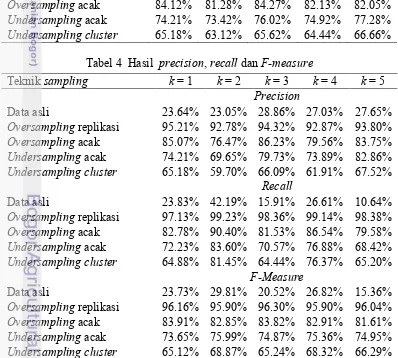
Tabel 3 Hasil akurasi rata-rata
Teknik sampling k = 1 k = 2 k = 3 k = 4 k = 5 Data asli 74.89% 67.76% 79.92% 76.46% 80.87%
Oversampling replikasi 96.13% 95.73% 96.24% 95.77% 95.93%
Oversampling acak 84.12% 81.28% 84.27% 82.13% 82.05%
Undersampling acak 74.21% 73.42% 76.02% 74.92% 77.28%
Undersampling cluster 65.18% 63.12% 65.62% 64.44% 66.66% Tabel 4 Hasil precision, recall dan F-measure
Undersamplingcluster 65.18% 59.70% 66.09% 61.91% 67.52%
Recall
Data asli 23.83% 42.19% 15.91% 26.61% 10.64%
Oversampling replikasi 97.13% 99.23% 98.36% 99.14% 98.38%
Oversampling acak 82.78% 90.40% 81.53% 86.54% 79.58%
Undersampling acak 72.23% 83.60% 70.57% 76.88% 68.42%
Undersamplingcluster 64.88% 81.45% 64.44% 76.37% 65.20%
F-Measure
Data asli 23.73% 29.81% 20.52% 26.82% 15.36%
Oversampling replikasi 96.16% 95.90% 96.30% 95.90% 96.04%
Oversampling acak 83.91% 82.85% 83.82% 82.91% 81.61%
Undersampling acak 73.65% 75.99% 74.87% 75.36% 74.95%
13
Berdasarkan Tabel 3 dan Tabel 4, dapat diketahui bahwa hasil klasifikasi pada data asli tidak lebih baik dari hasil klasifikasi pada data yang sudah mengalami modifikasi distribusi data. Akurasi pada percobaan data asli diperoleh sebesar 80.87% untuk k = 5. Namun, nilai precision, recall, dan F-measure yang dihasilkan dari percobaan data asli tidak sebaik hasil akurasinya. Precision
tertinggi diperoleh ketika nilai k =3 yaitu sebesar 28.86%, sementara itu recall dan
F-measure tertinggi diperoleh ketika nilai k = 2, yaitu sebesar 42.19% dan 29.81%. Hal tersebut terjadi karena distribusi data pada kelas mayoritas yang jumlahnya lima kali lebih besar dibandingkan kelas minoritas terlalu mendominasi keseluruhan data, padahal yang menjadi fokus penelitian ini adalah data minoritas, yaitu data debitur kategori buruk.
Ketika percobaan metode distribusi data undersampling dengan clustering
diterapkan pada data kelas debitur baik, jarak antara satu instance dengan instance
yang lain diukur kedekatannya pada saat proses clustering sehingga diperoleh akurasi yang cukup stabil untuk percobaan dengan nilai k = 1 sampai dengan k = 5. Hasil undersampling cluster pada Tabel 4 merupakan hasil rata-rata dari percobaan yang dilakukan pada data yang sudah melalui proses clustering 2
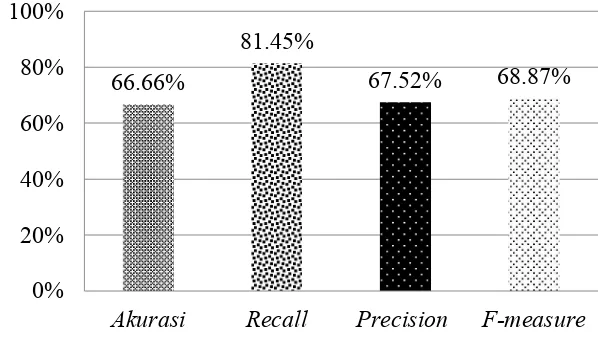
cluster sampai dengan 10 cluster. Akurasi tertinggi diperoleh ketika nilai k = 5 yaitu sebesr 66.66%, sedangkan untuk nilai precision tertinggi sebesar 67.52% ketika nilai k = 5, recall tertinggi sebesar 81.45% untuk nilai k = 2 serta F-measure tertinggi sebesar 68.87% untuk nilai k = 2.
Hasil undersampling acak yang diperoleh dari rata-rata 3 kali percobaan memiliki nilai akurasi, precision, recall, dan F-measure lebih baik jika dibandingkan dengan hasil pada undersampling cluster. Akurasi tertinggi diperoleh ketika nilai k = 5 yaitu sebesar 77.28%, sedangkan untuk nilai precision
tertinggi sebesar 82.86% ketika nilai k = 5, recall tertinggi sebesar 83.60% untuk nilai k = 2 serta F-measure tertinggi sebesar 75.99% untuk nilai k = 2.
Berdasarkan Tabel 3 dan Tabel 4, dapat diketahui untuk evaluasi nilai akurasi yang tertinggi diperoleh dari percobaan data oversampling replikasi dengan nilai k =1 yaitu sebesar 96,13%. Begitu juga dengan hasil akurasi
oversampling acak yang masih lebih unggul dibandingkan dengan modifikasi distribusi data undersampling yaitu sebesar 84.27% untuk nilai k = 3. Namun, akurasi dapat mengalami penurunan seiring bertambahnya nilai k. Keunggulan distribusi data dengan teknik oversampling dibuktikan pula dengan hasil
precision, recall, dan F-measure, yaitu sebesar 95.21% ketika nilai k = 1, 99.23% ketika nilai k = 2, 96.30% ketika nilai k =3 untuk oversampling replikasi dan 86.23% ketika nilai k = 3, 90.40% ketika nilai k = 2, 83.91% ketika nilai k = 1 untuk oversampling acak.
Dari beberapa teknik distribusi data yang diujikan, diketahui bahwa data yang didistribusikan melalui teknik oversampling memiliki nilai akurasi,
precision, recall, dan F-measure lebih baik. Jika dikaitkan dengan konsep algoritme KNN yang merepresentasikan data dalam k ruang dimensi serta mengklasifikasikan data berdasarkan ukuran kedekatan jarak, pada percobaan data
14
Perbandingan dengan Penelitian Sebelumnya
Jika dibandingkan dengan penelitian sebelumnya yang dilakukan oleh Natasia (2013), terjadi perbedaan yang cukup tinggi untuk tingkat akurasi,
precision, recall, dan F-measure yang perlihatkan dalam Tabel 5. Penelitian tersebut dilakukan pada data dan jumlah atribut yang sama, namun dengan pendekatan berbeda, yaitu dari sisi algoritme VFI5 tanpa melakukan modifikasi distribusi data kelas minoritas maupun kelas mayoritas dalam mengatasi kasus
imbalanced data.
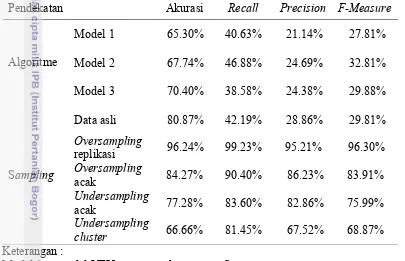
Tabel 5 Perbandingan dengan penelitian lain
Pendekatan Akurasi Recall Precision F-Measure
Algoritme
Model 1 : model VFI5 menggunakan semua fitur
Model 2 : model VFI5 menggunakan semua fitur berakurasi > 50% (best subset regression)
Model 3 : model VFI5 hasil pemilihan fitur bertahap (forward selection) Sampling : metode KNN
Dalam penelitian tersebut, dibuat 3 model VFI5, yaitu model 1 menggunakan semua fitur meghasilkan nilai akurasi, precision, recall, dan F-measure sebesar 65.30% , 40.63%, 21.14%, dan 27.81%. Sementara itu, untuk model 2 menggunakan fitur dengan akurasi kurang dari 50% menggunakan metode best subset regression, menghasilkan nilai masing-masing sebesar 67.74%, 46.88%, 24.69%, dan 32.35%, sedangkan model 3 merupakan hasil pemilihan fitur bertahap dengan hasil akurasi 70.40%, precision 38.58%, recall
24.38%, dan F-measure 29.88%. Hasil akurasi, precision, recall, dan F-measure
15
2 yaitu sebesar 29.81%. Dari hasil tersebut dapat diketahui bahwa percobaan pada data asli menggunakan metode KNN memiliki nilai akurasi, precision, recall, dan
F-measure yanglebih baik dari ketiga model menggunakan metode VFI5.
Jika hasil percobaan dengan metode VFI5 tersebut dibandingkan dengan hasil percobaan pada data yang sudah mengalami modifikasi dengan teknik
oversampling dan undersampling, hasil evaluasi memiliki perbedaan yang cukup besar. Perbedaan yang sangat sigifikan terlihat pada hasil percobaan oversampling
replikasi dengan nilai akurasi 96.24% ketika k = 3, nilai recall 99.23% ketika k = 2, nilai precision 95.21% ketika k = 1, dan nilai F-measure sebesar 96.30% ketika
k = 3. Teknik modifikasi distribusi data oversampling dan undersampling
menghasilkan nilai akurasi, precision, recall, dan F-measure yang lebih baik, tetapi jika dilihat dari sisi algoritme, VFI5 memiliki keunggulan untuk waktu pelatihan dan klasifikasi yang lebih singkat jika dibandingkan dengan metode KNN.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dengan metode KNN dapat diperoleh kesimpulan sebagai berikut :
1. Percobaan menggunakan data asli menghasilkan akurasi tertinggi ketika k = 5 yaitu sebesar 80.87% serta recall tertinggi sebesar 42.19% ketika k = 2,
precision tertinggi sebesar 28.86% ketika k = 3 dan F-measure tertinggi sebesar 29.81% ketika k = 2.
2. Percobaan menggunakan data oversampling replikasi menghasilkan nilai akurasi yang baik, yaitu sebesar 96.24% ketika k =3. Hasil yang baik ditunjukan pula pada recall, precision, dan F-measure dengan nilai masing-masing sebesar 99.23% ketika k = 2, 95.21% ketika k = 1, dan 96.30% ketika k
= 3.
3. Percobaan menggunakan data oversampling acak menghasilkan akurasi tertinggi ketika k = 3, yaitu sebesar 84.27%, untuk nilai recall, precision, dan
F-measure data minoritas diperoleh hasil sebesar 90.40% ketika k = 2, 86.23% ketika k = 3, dan 83.91% ketika k = 1.
4. Percobaan menggunakan data undersampling acak menghasilkan akurasi tertinggi sebesar 77.28% ketika k = 5, untuk recall, precision, dan F-measure
dengan nilai masing masing sebesar 83.60% ketika k = 2, 82.86% ketika k = 5, dan 75.99% ketika k = 1.
5. Percobaan menggunakan data undersampling cluster menghasilkan akurasi tertinggi sebesar 66.66% ketika k = 5, untuk recall, precision, dan F-measure
dengan nilai masing-masing sebesar 81.45% ketika k = 2, 68.87% ketika k = 5, dan 68.87% ketika k = 2.
Berdasarkan percobaan klasifikasi dengan KNN diketahui bahwa sampel yang sudah mengalami modifikasi distribusi data melalui teknik oversampling dan
16
sehingga dapat disimpulkan bahwa modifikasi distribusi data pada kasus
imbalance data dapat meningkatkan kinerja klasifikasi dengan metode KNN. Saran
Pada penelitian selanjutnya diharapkan dapat dilakukan percobaan dengan teknik sampling lain seperti SMOTE (synthetic minority oversampling technique) dalam mengatasi imbalanced data, serta algoritme modifikasi KNN, seperti
weighted KNN.
He H, Edwardo AG. 2009. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering. 21(9):1263-1284.
Kohavi R. 1995. A study of cross validation and bootstrap for accuracy estimation and model selection. Di dalam: Proceedings of the International Joint Conference on Articial Intelligence (IJCAI). 2:1137-1143.
Larose DT. 2005. Discovering Knowledge in Data : An Introduction to Data Mining. Canada (US) : John Wiley & Sons, Inc.
Natasia SR. 2013. Klasifikasi debitur kartu kredit dengan pemilihan fitur menggunakan Voting Feature Intervals 5 [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Nurjayanti B. 2011. Identifikasi shorea menggunakan K-Nearest Neighbour berdasarkan karakteristik morfologi daun [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Sayono JA, Sumarwan U, Achsani NA, Hartoyo. 2009. Analisis faktor-faktor yang mempengaruhi kepemilikan, penggunaan, pembayaran, dan peluang terjadinya gagal bayar dalam bisnis kartu kredit. Jurnal Ekonomi dan Bisnis. 3 (1):61-80.
Setiawati PA. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Tan PN, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Boston (US): Pearson Education.
Teknomo K. 2006. Similarity measurement. [diunduh 2012 Des 9]. Tersedia pada : http://people.revoledu.com/kardi/tutorial/Similarity/
Weng CG, Poon J. 2008. A new evaluation measure for imbalanced datasets. Di dalam: Proceedings of the 7th Australasian Data Mining Conference. 87:27-32.
17
Lampiran 1 Daftar atribut
Jenis Atribut Nama Atribut Keterangan
Rasio
Pendapatan Dalam rupiah per tahun
Masa Kerja Dalam bulan
Lama Tinggal Dalam bulan
Jumlah Tanggungan Jumlah orang
Umur Dalam tahun
Banyaknya Kartu Kredit Lain Persentase Utang Kartu
Kredit Lain Dalam persen
Nominal
Jenis Kelamin 1 = Pria
2 = Wanita Status Pekerjaan 1 = Permanen
2 = Kontrak
18
Lampiran 2 Nilai akurasi undersampling acak
k = 1 k = 2 k = 3 k = 4 k = 5
Undersampling acak 1 74.21 73.42 76.02 74.92 77.28
Undersampling acak 2 73.99 70.84 75.55 73.04 73.12
Undersampling acak 3 69.89 67.53 72.01 71.31 70.20 Lampiran 3 Nilai precisionundersampling acak
k = 1 k = 2 k = 3 k = 4 k = 5
Undersampling acak 1 69.65 69.65 79.73 73.89 82.86
Undersampling acak 2 66.93 66.93 77.27 70.74 75.68
Undersampling acak 3 63.45 63.45 73.78 68.37 72.75 Lampiran 4 Nilai recallundersampling acak
k = 1 k = 2 k = 3 k = 4 k = 5
Undersampling acak 1 72.23 83.60 70.57 74.92 77.28
Undersampling acak 2 73.14 83.13 72.49 73.04 73.12
Undersampling acak 3 67.96 82.31 68.53 71.31 70.20 Lampiran 5 Nilai F-measureundersampling acak
k = 1 k = 2 k = 3 k = 4 k = 5
Undersampling acak 1 73.65 75.99 74.87 75.36 74.95
Undersampling acak 2 73.81 74.15 74.80 74.46 71.40
19
Lampiran 6 Akurasi undersampling cluster 2 sampai cluster 10
k = 1 k = 2 k = 3 k = 4 k = 5
Lampiran 7 Precisionundersampling cluster 2 sampai cluster 10
k = 1 k = 2 k = 3 k = 4 k = 5
Lampiran 8 Recallundersampling cluster 2 sampai cluster 10
20
Lampiran 9 F-measureundersampling cluster 2 sampai cluster 10
k = 1 k = 2 k = 3 k = 4 k = 5
Undersamplingcluster 2 75.46 73.97 75.06 75.64 75.76
Undersamplingcluster 3 63.40 67.51 64.49 68.64 65.89
Undersamplingcluster 4 68.68 70.96 63.89 68.34 67.07
Undersamplingcluster 5 62.64 67.80 63.88 66.98 62.85
Undersamplingcluster 6 61.81 68.19 62.62 66.51 64.15
Undersamplingcluster 7 61.07 66.43 62.42 67.35 63.93
Undersamplingcluster 8 62.30 68.11 63.42 65.69 63.87
Undersamplingcluster 9 61.55 66.75 61.67 65.89 62.44
Undersamplingcluster 10 69.17 70.12 69.70 69.85 70.66
Rata-rata 65.12 68.87 65.24 68.32 66.29
21
RIWAYAT HIDUP
Penulis dilahir di Indramayu pada tanggal 27 Juli 1991 sebagai anak kedua dari pasangan Bapak Moh. Hariri dan Ibu Suparti.
Pada tahun 2009 penulis lulus dari SMA Negeri 1 Sindang Indramayu kemudian melanjutkan pendidikan jenjang S1 sebagai mahasiswa Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor pada tahun yang sama melalui jalur USMI.
Selama menjalani perkuliahan, penulis aktif dalam berbagai kepanitiaan, diantaranya kegiatan masa perkenalan mahasiswa baru angkatan 47 untuk divisi sponsorship, serta kepanitiaan IT TODAY divisi dekorasi dan dokumentasi yang diselenggarakan oleh Himalkom pada tahun 2011 dan 2012. Selain itu, penulis menjalani praktek kerja lapangan di Divisi Teknologi Perangkat Lunak PT Dirgantara Indonesia, Bandung pada bulan Juni sampai Agustus 2012. Dalam kompetisi Pekan Kreativitas Mahasiswa bidang Karsa Cipta, penulis bersama tim