PERBANDINGAN ALGORITME C4.5 DAN CART PADA
DATA TIDAK SEIMBANG UNTUK KASUS PREDIKSI
RISIKO KREDIT DEBITUR KARTU KREDIT
DHIETA ANGGRAINI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Algoritme C4.5 dan CART pada Data Tidak Seimbang untuk Kasus Prediksi Risiko Kredit Debitur Kartu Kredit adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2013 Dhieta Anggraini NIM G64090104
ABSTRAK
DHIETA ANGGRAINI. Perbandingan Algoritme C4.5 dan CART pada Data Tidak Seimbang untuk Kasus Prediksi Risiko Kredit Debitur Kartu Kredit. Dibimbing oleh AZIZ KUSTIYO.
Risiko kredit merupakan risiko ketidakmampuan nasabah atas kewajiban pembayaran utangnya. Risiko kredit dapat menyebabkan kredit bermasalah sehingga mengurangi pendapatan bank. Beberapa teknik dapat membantu dalam pemodelan penerimaan debitur, salah satunya adalah pohon keputusan. Beberapa algoritme pohon keputusan seperti C4.5 dan CART dapat digunakan sebagai classifier. Namun, hasil klasifikasi menjadi tidak akurat disebabkan data yang digunakan tidak seimbang. Salah satu cara yang dapat digunakan untuk menangani permasalahan ini adalah dengan strategi sampling diantaranya metode over-sampling dan under-sampling. Penelitian ini menunjukkan bahwa penerapan strategi sampling pada pohon keputusan C4.5 dan CART dapat meningkatkan performa yaitu akurasi, precision, recall, dan F-measure.
Kata kunci: C4.5, CART, data tidak seimbang, pohon keputusan, risiko kredit, strategi sampling
ABSTRACT
DHIETA ANGGRAINI. Comparison of C4.5 and CART Algorithms in Imbalanced Dataset to Predicting Credit Risk. Supervised by AZIZ KUSTIYO.
Credit risk is the risk of customers inability regarding their debt payment obligations. Credit risk can lead to non-performing loans, thereby reducing bank earnings. Various techniques can model the revenue of a debtor. One of them is the decision tree. There are several decision tree algorithms that can be used as classifiers, for example: C4.5 and CART. However, the classification results may be inaccurate due to the imbalanced in the used data. One way that can be used to address this problem is to include methods of sampling strategies: for examples over-sampling and under-sampling. This research found that the implementation of sampling strategy on the use of C4.5 and CART can improve the average accuracy, precision, recall, and F-measure.
Keywords: C4.5, CART, credit risk, decision tree, imbalance data, sampling strategy
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PERBANDINGAN ALGORITME C4.5 DAN CART PADA
DATA TIDAK SEIMBANG UNTUK KASUS PREDIKSI
RISIKO KREDIT DEBITUR KARTU KREDIT
DHIETA ANGGRAINI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
Penguji : 1. Toto Haryanto, SKom MSi
Judul Skripsi : Perbandingan Algoritme C4.5 dan CART pada Data Tidak Seimbang untuk Kasus Prediksi Risiko Kredit Debitur Kartu
Kredit
Nama : Dhieta Anggraini
NIM : G64090104
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Oktober 2012 ini ialah klasifikasi, dengan judul Perbandingan Algoritme C4.5 dan CART pada Data Tidak Seimbang untuk Kasus Prediksi Risiko Kredit Debitur Kartu Kredit.
Terima kasih penulis ucapkan kepada kedua orangtua penulis, saudara-saudara penulis yaitu Anggun dan Angga, serta seluruh anggota keluarga atas segala doa dan kasih sayangnya, Bapak Aziz Kustiyo, SSi MKom selaku pembimbing yang telah banyak memberi ide, saran, nasihat dan dukungan. Bapak Toto Haryanto, SKom MSi dan Bapak Muhammad Ashyar Agmalaro, SSi MKom selaku penguji yang telah memberi saran dan nasihat. Di samping itu, penulis juga mengucapkan terima kasih kepada rekan-rekan satu bimbingan atas diskusi-diskusi selama bimbingan, Maulita, Nadya, Srividola, Putri Mushandri, Wara, Intan, Retno Wijayanti dan Fiqrotul Ulya atas semangat, bantuan, kritik dan saran yang diberikan kepada penulis, Ilkomerz 46 atas segala suka duka dalam kebersamaan.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2013 Dhieta Anggraini
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Klasifikasi 2
Data Tidak Seimbang 3
K-fold cross validation 3
Strategi Sampling 3
Pohon Keputusan 4
Algoritme C4.5 4
Algoritme CART 5
Akurasi, Precision, Recall, dan F-measure 6
METODE 6
Pengumpulan Data 7
Praproses Data 8
Strategi Sampling 8
Pembagian Data Latih dan Uji 9
Pembangunan Pohon Keputusan C4.5 dan CART 9
Analisis Hasil 10
Pembangunan Decision Support System (DSS) 10
HASIL DAN PEMBAHASAN 10
Praproses Data 10
Analisis Hasil 11
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 16
DAFTAR PUSTAKA 16
DAFTAR TABEL
1 Confusion matrix untuk 2 kelas 6
2 Keterangan atribut independen penentuan risiko kredit 8 3 Keterangan set data yang digunakan pada penelitian 9
4 Perfomansi akurasi (%) 12
5 Perfomansi precision (%) 12
6 Perfomansi recall (%) 12
7 Perfomansi F-measure (%) 12
8 Jumlah node pohon keputusan 12
9 Perbandingan analisis hasil dengan penelitian sebelumnya 15
DAFTAR GAMBAR
1 Metode penelitian 7
2 Sebaran data 11
DAFTAR LAMPIRAN
1 Daftar atribut 18
2 Akurasi hasil seluruh percobaan 19
3 Precision hasil seluruh percobaan 19
4 Recall hasil seluruh percobaan 20
5 F-measure hasil seluruh percobaan 20
6 Pohon keputusan algoritme C4.5 menggunakan strategi under-sampling
cluster 21
7 Aturan yang terbentuk berdasarkan pohon keputusan algoritme C4.5
menggunakan strategi under-sampling cluster 22
8 Pohon keputusan algoritme CART menggunakan strategi
under-sampling cluster 25
9 Aturan yang terbentuk berdasarkan pohon keputusan algoritme CART
menggunakan strategi under-sampling cluster 25
10 Ilustrasi pohon keputusan algoritme CART 27
11 Ilustrasi pohon keputusan algoritme C4.5 28
12 Antarmuka decision support system prediksi risiko kredit 29 13 Hasil decision support system prediksi risiko kredit 29
1
PENDAHULUAN
Latar Belakang
Salah satu sumber pendapatan dalam kegiatan perbankan adalah memberikan kredit pada debitur. Salah satu kredit yang diberikan bank berupa kartu kredit. Pemberian kredit kepada debitur bisa menimbulkan risiko ketidakmampuan debitur atas kewajiban pembayaran utangnya, baik utang pokok maupun bunganya atau keduanya yang disebut risiko kredit (Rahayu 2008). Debitur dengan risiko kredit tinggi disebut debitur bad. Secara umum, jumlah debitur bad lebih sedikit dibanding jumlah debitur good. Risiko kredit tinggi dapat menyebabkan ketidaklancaran pembayaran utang oleh debitur sehingga dapat memunculkan kredit bermasalah. Hal ini bisa menyebabkan pengurangan pendapatan bank.
Perkembangan teknologi informasi dapat digunakan dalam klasifikasi risiko kredit. Penelitian mengenai klasifikasi debitur kartu kredit dilakukan oleh Setiawati (2011). Setiawati mengklasifikasikan debitur menjadi 2 kelas, yaitu kelas debitur bad dan debitur good. Debitur bad merupakan debitur yang mengalami keterlambatan dalam pembayaran utangnya sedangkan debitur good merupakan debitur yang lancar pembayaran utangnya. Penelitian ini menggunakan data yang tidak seimbang. Untuk mengatasi ketidakseimbangan data ini dilakukan pengambilan sampel sebanyak 50 kali. Metode klasifikasi yang digunakan ialah jaringan saraf tiruan propagasi balik. Akurasi terbaik yang diperoleh sebesar 73.39%, recall, precision, dan F-measure kelas bad sebesar 56.26%, 36.90%, dan 44.57%.
Pohon keputusan merupakan salah satu teknik yang populer dalam data mining. Hal ini dikarenakan pohon keputusan terbukti menghasilkan akurasi yang baik pada beberapa penelitian sebelumnya dalam hal klasifikasi. Yusuf (2007) melakukan klasifikasi risiko kredit dengan pohon keputusan algoritme C5.0, CART dan CHAID. Algoritme C5.0 memberikan rata-rata tingkat keakuratan sebesar 87.72%, CART 87.27% , dan CHAID 87.15%. Ada beberapa algoritme pohon keputusan di antaranya ID3, C4.5, CART, CHAID, SPRINT dan SLIQ.
Ada dua kondisi pada himpunan data yaitu data seimbang dan data tidak seimbang. Data seimbang merupakan kondisi distribusi data pada dua kelas mendekati sama dan data tidak seimbang merupakan kondisi sebuah himpunan data terdapat satu kelas yang memiliki jumlah instance yang lebih kecil dibandingkan kelas lainnya (Chawla 2003). Penelitian yang dilakukan Chawla menggunakan 5 set data dengan distribusi data minority sebagai berikut pima 35%, phoneme 29%, satimage 10%, mammography 2%, dan krkopt 1%. Untuk mengatasi ketidakseimbangan data ini, Chawla melakukan strategi sampling yaitu Synthetic Minority Over-sampling Technique (SMOTE), over-sampling, dan under-sampling. Pada SMOTE membangkitkan data dengan memperhitungkan jarak tetangga data minority, over-sampling dilakukan duplikasi pada data minority, dan under-sampling dilakukan pemilihan instance pada data majority sehingga jumlahnya sama dengan data minority. Pohon keputusan C4.5 merupakan model klasifikasi yang digunakan pada penelitian ini dan AUC
2
merupakan analisis hasil. Penelitian ini menyimpulkan bahwa SMOTE paling baik, dan under-sampling lebih baik dari over-sampling.
Dengan latar belakang ini, pengembangan model pada penelitian ini menggunakan pohon keputusan dengan algoritme C4.5 dan CART untuk mengklasifikasikan calon debitur ke dalam kategori good atau bad. Data pada penelitian ini merupakan data tidak seimbang sehingga dilakukan strategi sampling yaitu over-sampling dan under-sampling untuk mengatasinya.
.
Perumusan Masalah
Bank memiliki kemungkinan menerima debitur dengan risiko kredit tinggi. Jumlah debitur yang memiliki risiko kredit tinggi biasanya jauh lebih sedikit dibanding debitur dengan risiko kredit yang rendah. Namun, hal ini bisa menyebabkan pengurangan pendapatan bank.
Tujuan Penelitian
Tujuan penelitian ini ialah menerapkan over-sampling dan under-sampling pada data tidak seimbang dengan metode klasifikasi pohon keputusan algoritme C4.5 dan CART. Penelitian ini juga membandingkan nilai akurasi, precision, recall, F-measure dan jumlah node yang terbentuk pada pohon keputusan algoritme C4.5 dan CART serta pembuatan decision support sistem (DSS).
Manfaat Penelitian
Manfaat penelitian ini ialah membuat suatu model serta decision support system (DSS) yang dapat memprediksi risiko kredit pada penerimaan debitur kartu kredit sehingga dapat meminimalkan potensi kerugian.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini ialah set data yang digunakan merupakan data pada penelitian Setiawati (2011) yaitu data debitur kartu kredit Bank X tahun 2008-2009. Data ini juga digunakan pada penelitian Natasia (2013). Metode yang digunakan pada penelitian ini ialah pohon keputusan dengan algoritme C4.5 dan CART.
TINJAUAN PUSTAKA
Klasifikasi
Menurut Tan et al. (2006) teknik klasifikasi merupakan pendekatan sistematik untuk membentuk model klasifikasi dari set data. Contoh teknik klasifikasi di antaranya pohon keputusan, neural network, support vector machines, naïve Bayes, dan lainnya. Model klasifikasi digunakan untuk mengetahui label kelas dari instance yang belum diketahui.
3 Set data yang digunakan pada klasifikasi tediri atas data latih dan data uji. Data latih merupakan instance yang diketahui kelasnya. Data latih digunakan untuk pembuatan model, sedangkan data uji digunakan untuk mengevaluasi model. Evaluasi dari model klasifikasi didasarkan perhitungan prediksi yang benar dan prediksi yang salah oleh model klasifikasi.
Data Tidak Seimbang
Data tidak simbang merupakan kondisi sebuah himpunan data terdapat satu kelas yang memiliki jumlah instance yang kecil bila dibandingkan dengan kelas lainnya. Kelas yang memiliki jumlah instance yang kecil disebut minority dan kelas yang memiliki jumlah instance besar disebut majority (Chawla 2003). Permasalahannya hal yang ingin diamati ialah kelas minority sehingga sering terjadi kesalahan klasifikasi pada kelas minority. Ketidakseimbangan data ini dapat diatasi dengan beberapa cara, di antaranya dengan pengambilan sampel pada tiap kelas dan strategi sampling seperti over-sampling dan under-sampling.
K-fold cross validation
Dalam membagi data latih dan data uji, K-fold cross validation ialah metode yang umum digunakan. Metode ini membagi data menjadi k bagian yang berukuran sama, kemudian sebanyak k-1 bagian akan digunakan sebagai data latih dan 1 bagian akan digunakan sebagai data uji. Proses ini diulangi sebanyak k kali sehingga setiap bagian pernah dijadikan data uji sebanyak 1 kali. Akurasi ditentukan dengan menjumlahkan akurasi untuk semua k proses tersebut (Tan et al. 2006).
Strategi Sampling
Strategi sampling merupakan salah satu teknik yang populer dalam mengatasi ketidakseimbangan data. Strategi sampling akan mendistribusikan data pada 2 kelas mendekati sama. Teknik strategi sampling di antaranya over-sampling kelas minority atau under-over-sampling kelas majority (Chawla 2003).
Strategi over-sampling dilakukan pada data kelas minority sehingga jumlah kelas minority mendekati jumlah kelas majority. Strategi ini dapat dilakukan dengan menduplikasi kelas minority. Strategi over-sampling dengan duplikasi memiliki beberapa instance yang sama sehingga tidak memiliki variasi data. Oleh karena itu, strategi over-sampling juga dilakukan dengan pembangkitan data acak untuk masing-masing atribut independen. Hal ini menghasilkan instance dengan kombinasi nilai atribut berbeda dengan data aslinya.
Strategi under-sampling dilakukan pada kelas majority sehingga jumlah instance kelas majority sama dengan jumlah kelas minority. Strategi ini dapat dilakukan dengan memilih secara acak kelas majority. Strategi under-sampling dengan pemilihan acak dapat menyebabkan pemilihan instance tidak mewakili populasi. Oleh karena itu, dilakukan cluster pada data majority sebelum dilakukan pemilihan data.
4
Pohon Keputusan
Pohon keputusan merupakan salah satu teknik yang populer dan banyak digunakan dalam data mining. Pohon keputusan merupakan model prediksi menggunakan struktur pohon atau berhirarki. Konsep dari pohon keputusan ialah mengubah data menjadi pohon keputusan dan aturan-aturan keputusan. Pohon keputusan digunakan untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon atribut input dengan satu atribut target.
Pohon keputusan terdiri atas root node, internal node, dan leaf node. Root node merupakan atribut yang paling atas pada pohon keputusan, internal node menggambarkan atribut data yang akan diuji, dan leaf node merupakan kelas dari data yang dinginkan.
Proses pembentukan pohon keputusan memiliki 2 tahap, yaitu pembentukan pohon keputusan dan pemangkasan pohon. Pada pembentukan pohon keputusan, diawali dengan pembentukan root node, kemudian dicari internal node berdasar atribut-atribut yang sesuai sehingga diperoleh atribut target yaitu leaf node. Setelah pohon keputusan terbentuk, dilakukan pemangkasan pohon. Hal ini dilakukan untuk meningkatkan nilai akurasi dari proses klasifikasi data.
Algoritme C4.5
Algoritme C4.5 merupakan perkembangan dari algoritme ID3, dikembangkan oleh Quinlan Ross pada tahun 1993. Algoritme C4.5 merupakan penerapan dari algoritme Hunt yang juga diterapkan pada ID3 dan CART. Kelebihan algoritme C4.5 dibandingkan algoritme ID3 yaitu, dapat mengolah nilai data kategorik dan data numerik. Algoritme C4.5 juga dapat menangani nilai atribut yang hilang. Algoritme dari pohon keputusan C4.5 dimulai dengan pemilihan node tunggal sebagai akar/root dari pohon keputusan. Setelah node akar dibentuk, maka data pada node akar diukur dengan information gain untuk dipilih atribut mana yang dijadikan atribut pemecahannya. Sebuah cabang dibentuk dari atribut yang dipilih menjadi pembagi kemudian data didistribusikan ke dalam cabang masing-masing. Algoritme ini menggunakan proses rekursif dalam membentuk sebuah pohon keputusan. Ketika sebuah atribut dipilih menjadi node pemecahan atau cabang, maka atribut tersebut tidak diikutkan lagi dalam perhitungan nilai information gain. Proses rekursif berhenti ketika atribut memiliki cabang berupa kelas atau tidak ada lagi atribut yang bisa dipecah untuk menjadi cabang pohon keputusan.
Jika dalam satu cabang anggotanya berasal dari satu kelas maka cabang ini disebut pure. Semakin pure suatu cabang semakin baik. Ukuran purity dinyatakan dengan tingkat impurity. Algoritme C4.5 menggunakan information gain dan entrophy untuk kriteria impurity penggunaan atribut sebagai node dari pohon keputusan (Kantardzic 2003). Persamaan entrophy dapat dilihat pada persamaan di bawah ini.
( ) - ∑ ( 1 )
dengan :
T = Himpunan Kasus
5
Jika kandidat pemecahan A terdiri atas beberapa kandidat. Pada data latih T terdiri atas beberapa bagian, yaitu T1, T2, T3, ….Tk maka informasi dapat dihitung dengan bobot entrophy dari masing-masing bagian tersebut dan information gain (A) dapat dihitung dengan persamaan 2.
Gain , A ( )- ∑ |Ti| |T|* i n i ) ( 2 ) dengan: T = Himpunan Kasus A = Atribut
n = Jumlah Partisi atribut A |Ti| = Jumlah kasus pada partisi ke i |T| = Jumlah Kasus dalam T
Nilai Gain merupakan nilai kesamaan dari partisi data. Semakin besar nilai Gain dari sebuah data maka, nilai keanekaragaman data semakin kecil. Pemecahan terbaik merupakan pemecahan yang menghasilkan nilai Gain terbesar.
Algoritme CART
Algoritme Classification And Regression Tree (CART) merupakan algoritme pohon keputusan yang dikembangkan oleh Breiman et al. (1984). Algoritme CART Pada klasifikasi pohon keputusan menghasilkan pohon keputusan berupa binary tree (Larose 2005).
Hal pertama yang dilakukan pada pembentukan pohon keputusan algoritme CART ialah menentukan atribut independen yang menjadi pemecahan terbaik. Pemecahan terbaik merupakan pemecahan yang menurunkan keanekaragaman set data dengan penurunan terbesar. Pemecahan awal akan menghasilkan dua node. Pada tiap node, akan dicari pemecahan terbaik berikutnya. Proses pemecahan ini dilakukan secara rekursif sampai semua leaf node berupa kelas. Algoritme CART menentukan pemecahan yang paling optimal menggunakan ukuran kesamaan nilai Gini yang dapat dilihat pada persamaan di bawah ini.
Gini ∑i iGini( i) ( 3 ) Gini( i) - ∑ i ( 4 ) dengan :
Gini(Di) = nilai Gini dari data jika dipartisi dengan parameter A. k = jumlah pembagian data pada CART k = 2
i = nilai perbandingan jumlah data D dengan jumlah data pertisi ke-i m = jumlah kelas yang ada
i = nilai perbandingan jumlah data Di dengan jumlah data kelas ke-j Nilai Gini merupakan nilai keanekaragaman dari partisi data. Semakin kecil nilai Gini dari sebuah data, nilai keanekaragaman data semakin kecil. Pemecahan terbaik merupakan pemecahan yang menghasilkan nilai Gini terkecil.
6
Akurasi, Precision, Recall, dan F-measure
Pengukuran kemampuan algoritme dilakukan dengan confusion matrix yang dapat dilihat pada Tabel 1. Confusion matrix mengandung informasi tentang data kelas aktual dan hasil prediksi. Confusion matrix digunakan sebagai dasar dari variasi ukuran penilaian seperti precision dan recall. Kombinasi precision dan recall merepresentasikan nilai F-measure yang biasanya menggunakan bobot yang sama pada keduanya. Persamaan precision, recall dan F-measure dapat dilihat pada persamaan 5, persamaan 6, persamaan 7, dan persamaan 8 (Weng dan Poon 2006).
Recall merupakan persentase kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan instance di kelas positif. Precision merupakan proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Nilai F-measure yang tinggi menunjukkan bahwa recall dan precision juga tinggi.
METODE
Pada penelitian ini hal utama yang dilakukan yaitu identifikasi masalah, pengumpulan data, praproses data, strategi sampling, 10-fold cross validation untuk menentukan data latih dan data uji, pembangunan model dengan pohon keputusan C4.5 dan CART, analisis hasil, pembuatan decision support system dan pengujian. Ilustrasinya dapat dilihat pada Gambar 1.
n a a i T T T T ( 5 )
n a i i n T
T ( 6 )
Tabel 1 Confusion matrix untuk 2 kelas
Kelas hasil prediksi Kelas aktual Kelas positif Kelas negatif
Kelas positif TP FN
Kelas negatif FP TN
Keterangan :
TP = jumlah instance kelas positif yang diprediksi benar sebagai
kelas positif
FN = jumlah instance kelas positif yang diprediksi salah sebagai
kelas negatif
FP = jumlah instance kelas negatif yang diprediksi salah sebagai
kelas positif
TN = jumlah instance kelas negatif yang diprediksi benar sebagai
7 n a a T T ( 7 ) n a - a ( 8 ) Pengumpulan Data
Data yang digunakan pada penelitian ini ialah data sekunder yang digunakan juga pada penelitian Setiawati (2011) dan Natasia (2013). Data penelitian ini merupakan data dari Bank X yaitu data debitur kartu kredit tahun 2008-2009. Identifikasi masalah pada penelitian ialah pengklasifikasian risiko kredit penerimaan debitur kartu kredit pada Bank X. Pada data ini debitur dikategorikan menjadi dua yaitu good berarti debitur tersebut lancar dalam memenuhi kewajibannya, dan debitur bad mengalami tunggakan lebih dari 90 hari. Data yang digunakan merupakan data debitur yang sudah selesai kewajibannya.
Gambar 1 Metode penelitian Mulai
Pengumpulan Data Praproses Data
Strategi Sampling Data Asli
Over-sampling
Under-sampling
Pembagian Data 10-fold
cross validation
Data Latih Data Uji
Pembangunan Pohon Keputusan C4.5 dan CART Pengujian Model Analisis Hasil Pembangunan decision support system Pengujian Sistem Selesai
8
Penelitian ini menggunakan 14 atribut independen. Atribut tersebut ialah pendidikan, jenis kelamin, status pernikahan, tipe perusahaan, status pekerjaan, pekerjaan, masa kerja, lama tinggal, status pemilikan rumah, banyaknya tanggungan, pendapatan, banyaknya kartu kredit lain, persentase utang kartu kredit, umur dan 1 atribut kelas yaitu debitur bad atau debitur good. Atribut tersebut bertipe ordinal, nominal, atau rasio riciannya ditunjukkan pada Tabel 2.
Praproses Data
Beberapa atribut memiliki missing value, contohnya pada atribut persentase utang kartu kredit, banyaknya kartu kredit lain, dan lainnya. Untuk mengatasi missing value dilakukan penghapusan instance yang memiliki missing value dan nilai yang tidak valid sehingga terjadi pengurangan jumlah instance. Setelah dilakukan praproses data diperoleh 1 set data asli.
Strategi Sampling
Pada penelitian ini, strategi sampling digunakan karena data pada kedua kelas tidak seimbang. Strategi sampling yang digunakan ialah over-sampling dan under-sampling.
Pada strategi over-sampling jumlah instance pada data minority ditambah sehingga jumlahnya mendekati data majority. Strategi ini dilakukan dua cara yaitu dengan menduplikasi data minority dan pembangkitan data acak sebanyak 2600. Pada strategi over-sampling diperoleh 2 set data, yaitu 1 set data over-sampling duplikasi dan 1 set data over-sampling acak.
Pada strategi under-sampling, jumlah instance pada data majority dikurangi sehingga jumlahnya sama dengan data minority. Strategi ini dilakukan dua cara, yaitu dengan memilih secara acak data majority dan pemilihan dilakukan berdasar hasil cluster data majority. Pada pemilihan acak data majority, dilakukan
Tabel 2 Keterangan atribut independen penentuan risiko kredit
Atribut Keterangan Pendidikan Jenis Kelamin Status Pernikahan Tipe Perusahaan Status Pekerjaan Pekerjaan Masa Kerja Lama Tinggal
Status Pemilikan Rumah Banyaknya Tanggungan Pendapatan
Banyaknya Kartu Kredit Lain Persentase Utang Kartu Kredit Umur Kelas Ordinal Nominal Nominal Nominal Nominal Nominal Rasio Rasio Rasio Rasio Rasio Rasio Rasio Rasio Nominal
9 percobaan sebanyak 3 kali sehingga diperoleh 3 set data. Pemilihan yang dilakukan berdasar hasil cluster dilakukan beberapa percobaan untuk mencari jumlah cluster yang paling maksimal. Percobaan cluster dilakukan mulai dari 2 cluster sampai 11 cluster. Setelah itu, dilakukan pemilihan data secara acak pada tiap cluster sesuai dengan proporsi instance pada tiap cluster. Setelah diperoleh jumlah cluster yang menghasilkan akurasi tertinggi, maka dilakukan percobaan sebanyak 3 kali dengan jumlah cluster tersebut. Pada strategi under-sampling diperoleh 15 set data yaitu 10 set data hasil cluster 2 sampai 11, 2 set data lain setelah diperoleh jumlah cluster paling maksimal, 3 set data under-sampling acak. Rincian set data pada penelitian ini dapat dilihat pada Tabel 3.
Pembagian Data Latih dan Uji
Teknik yang digunakan untuk membagi data latih dan data uji ialah 10-fold cross validation. Teknik ini membagi data menjadi 10 bagian terpisah. Data pelatihan menggunakan 9 bagian dan data pengujian menggunakan 1 bagian. Hal ini dilakukan berulang-ulang sampai semua subsampel pernah menjadi data uji.
Pembangunan Pohon Keputusan C4.5 dan CART
Data latih yang diperoleh dengan 10-fold cross validation selanjutnya digunakan untuk pembuatan model pohon keputusan C4.5 dan CART. Penelitian ini memiliki 18 set data. Data asli 1 set data, data under-sampling 15 set data, over-sampling 2 set data. Pada tiap set data dilakukan percobaan terhadap pohon
Tabel 3 Keterangan set data yang digunakan pada penelitian
Set Data Keterangan
Asli Asli
Over-sampling Duplikasi
Pembangkitan Acak
Under-sampling Pemilihan Acak 1
Pemilihan Acak 2 Pemilihan Acak 3 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Cluster 9 Cluster 10-1 Cluster 10-2 Cluster 10-3 Cluster 11
10
keputusan algoritme C4.5 dan CART yang dilakukan pruning dan unpruning.
Analisis Hasil
Analisis hasil dilakukan dengan membandingkan hasil dari pohon keputusan yang dihasilkan oleh algoritme C4.5 dan CART yang menerapkan metode over-sampling dan under-over-sampling. Penilaian yang digunakan dalam menganalisis model yaitu akurasi untuk melihat secara keseluruhan. Pada data asli yang merupakan data tidak seimbang, akurasi dapat didominasi oleh kelas majority sehingga dilakukan juga perhitungan precision, recall, dan F-measure untuk kelas bad. Pohon keputusan dengan algoritme C4.5 dan CART merupakan classifier yang digunakan pada penelitian ini sehingga jumlah node yang terbentuk pada pohon keputusan juga dijadikan ukuran penilaian.
Pembangunan Decision Support System (DSS)
Setelah analisis terhadap pohon keputusan yang dihasilkan, dipilih 1 pohon yang menerapkan algoritma C4.5 dan 1 pohon yang menerapkan algoritme CART untuk diambil aturannya dan dibangun decision support system. Pemilihan pohon dilakukan berdasar nilai F-measure dan jumlah node yang dihasilkan pada pohon keputusan.
HASIL DAN PEMBAHASAN
Praproses Data
Dari hasil analisis data, diketahui bahwa tidak semua atribut memiliki nilai yang lengkap, dimana kelengkapan atribut ini menentukan seberapa baik hasil dari klasifikasi. Jumlah instance pada kedua kelas berkurang setelah praproses data. Jumlah data yang diperoleh sebanyak 4413 dengan 518 data yang memiliki nilai tidak lengkap pada atributnya. Untuk mengatasi nilai yang tidak lengkap pada data maka dilakukan penghapusan terhadap data yang tidak lengkap. Setelah penghapusan data, jumlah data yang digunakan pada penelitian ini sebanyak 3895 data. Data kelas bad sebanyak 636 data dan data kelas good sebanyak 3259 data. Sebaran datanya dapat dilihat pada Gambar 2.
Pada strategi over-sampling dilakukan 2 cara, yaitu duplikasi dan pembangkitan data secara acak. Metode over-sampling duplikasi menduplikasi data dari kelas bad sebanyak 4 kali sehingga jumlah data kelas bad yang semula sebanyak 636 data menjadi 3180 data. Metode over-sampling membangkitkan data secara acak untuk setiap atribut berdasarkan nilai data yang sudah ada sebanyak 2600 sehingga data bad yang semula 636 menjadi 3236.
Strategi under-sampling juga menggunakan dua cara pemilihan instance sampling, yaitu menggunakan cluster dan secara acak. Pada pemilihan under-sampling acak data kelas good dipilih secara acak sehingga jumlah data kelas good yang semula 3259 menjadi 636. Strategi under-sampling acak dapat menyebabkan pemilihan instance tidak mewakili populasi. Oleh karena itu, strategi under-sampling cluster dilakukan dengan mengelompokkan data kelas
11 good menjadi beberapa cluster. Pada tiap cluster tersebut diambil sampel secara acak sesuai proporsi jumlahnya sehingga data kelas good menjadi 636. Pada percobaan pemilihan cluster terbaik dilakukan percobaan dari 2 cluster sampai 11 cluster. Hasil yang diperoleh menunjukkan bahwa cluster 10 menghasilkan akurasi paling maksimal baik menggunakan algoritme C4.5 maupun CART. Setelah cluster 10 diperoleh sebagai cluster terbaik, percobaan dengan cluster 10 dilakukan lagi sebanyak 2 kali. Hal ini dilakukan agar set data yang diperoleh merupakan set data yang menghasilkan akurasi dan F-measure paling maksimal.
Analisis Hasil
Analisis hasil percobaan dengan membandingkan pohon keputusan yang menggunakan strategi over-sampling duplikasi, over-sampling acak, under-sampling acak, under-under-sampling cluster dan data asli dengan algoritme C4.5 dan CART baik dilakukan pruning maupun unpruning. Dari hasil pengolahan dan uji coba menggunakan WEKA 3.6.9 dalam menerapkan algoritme C4.5 dan CART dihasilkan dihasilkan kinerja berupa nilai akurasi, precision, recall, F-measure, dan banyaknya jumlah node pada pohon keputusan.
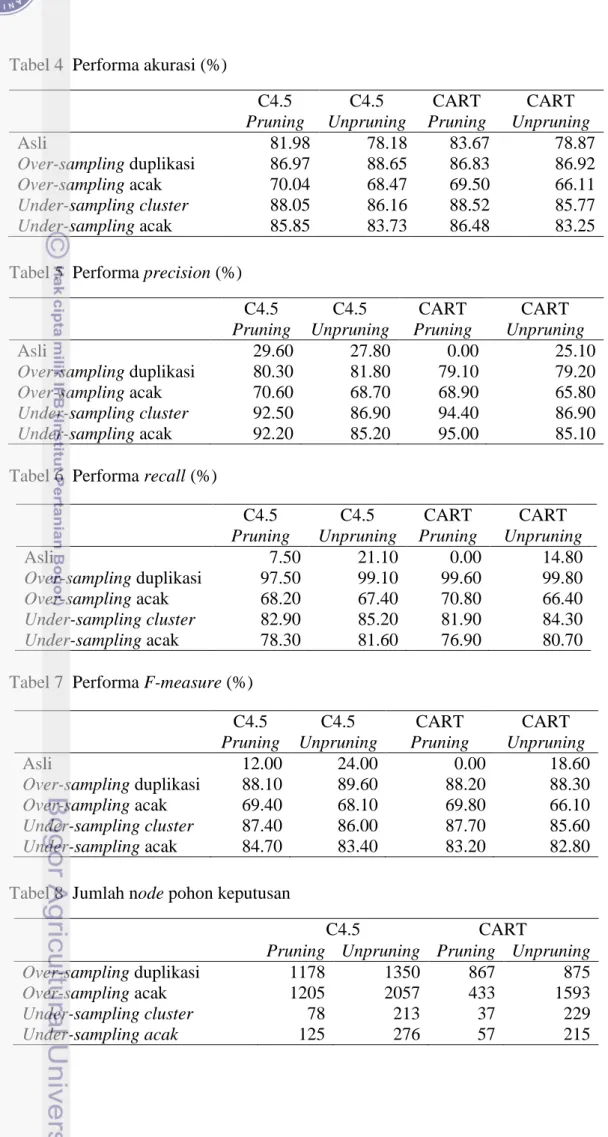
Berdasarkan akurasi yang diperoleh pada Tabel 4 terlihat bahwa akurasi antara data asli dan data yang sudah dilakukan strategi sampling tidak memiliki perbedaan yang signifikan. Algoritme C4.5 memiliki akurasi tertinggi pada pohon keputusan yang dihasilkan unpruning dan dilakukan strategi over-sampling duplikasi yaitu sebesar 88.65%. Algoritme CART memiliki akurasi tertinggi pada pohon keputusan yang dihasilkan pruning dan dilakukan strategi under-sampling cluster yaitu sebesar 88.52%. Pada strategi under-sampling yang ditampilkan merupakan hasil terbaik, baik under-sampling cluster maupun under-sampling acak. Secara global akurasi tertingi diperoleh pada saat dilakukan strategi over-sampling duplikasi dan under-over-sampling cluster walaupun hasil akurasi dengan metode lain juga cukup tinggi rata-rata di atas 80%. Akurasi saat dilakukan strategi over-sampling acak merupakan akurasi yang paling kecil hal ini dikarenakan data yang diperoleh merupakan data yang dibangkitkan secara acak pada masing-masing atribut sehingga mempengaruhi kombinasi antara atribut independen dan atribut dependen yang juga mempengaruhi purity pada saat membangun pohon keputusan.
12
Tabel 4 Performa akurasi (%)
C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 81.98 78.18 83.67 78.87 Over-sampling duplikasi 86.97 88.65 86.83 86.92 Over-sampling acak 70.04 68.47 69.50 66.11 Under-sampling cluster 88.05 86.16 88.52 85.77 Under-sampling acak 85.85 83.73 86.48 83.25
Tabel 5 Performa precision (%) C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 29.60 27.80 0.00 25.10 Over-sampling duplikasi 80.30 81.80 79.10 79.20 Over-sampling acak 70.60 68.70 68.90 65.80 Under-sampling cluster 92.50 86.90 94.40 86.90 Under-sampling acak 92.20 85.20 95.00 85.10
Tabel 6 Performa recall (%)
C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 7.50 21.10 0.00 14.80 Over-sampling duplikasi 97.50 99.10 99.60 99.80 Over-sampling acak 68.20 67.40 70.80 66.40 Under-sampling cluster 82.90 85.20 81.90 84.30 Under-sampling acak 78.30 81.60 76.90 80.70
Tabel 7 Performa F-measure (%) C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 12.00 24.00 0.00 18.60 Over-sampling duplikasi 88.10 89.60 88.20 88.30 Over-sampling acak 69.40 68.10 69.80 66.10 Under-sampling cluster 87.40 86.00 87.70 85.60 Under-sampling acak 84.70 83.40 83.20 82.80
Tabel 8 Jumlah node pohon keputusan
C4.5 CART
Pruning Unpruning Pruning Unpruning
Over-sampling duplikasi 1178 1350 867 875
Over-sampling acak 1205 2057 433 1593
Under-sampling cluster 78 213 37 229
13 Precision yang diperoleh pada Tabel 5 menunjukkan perbedaan yang cukup signifikan antara data asli dan data yang dilakukan strategi sampling. Hal ini berbeda dengan akurasi yang tidak memiliki perbedaan signifikan. Precision merupakan proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Precision yang diperoleh menunjukkan bahwa kesalahan prediksi pada kelas good kecil. Hal ini dikarenakan nilai precision besar berarti salah prediksi kelas good pun kecil. Hasil precision menunjukkan bahwa pada saat menghitung akurasi diperoleh akurasi yang tinggi pada data asli dikarenakan data good yang jauh lebih besar dari data bad mempengaruhi hasil akurasi tersebut. Setelah dilakukan over-sampling, dan under-sampling nilai precision mengalami peningkatan yang cukup signifikan. Precision tertinggi pada algoritme C4.5 diperoleh pada pohon keputusan yang dilakukan pruning dan menggunakan strategi under-sampling cluster, yaitu sebesar 92.50%. Precision tertinggi pada algoritme CART diperoleh pada pohon keputusan yang dilakukan pruning dan mengunakan strategi under-sampling acak, yaitu sebesar 95.00%. Secara global, nilai precision tertinggi diperoleh pada saat dilakukan strategi under-sampling walaupun hasil akurasi dengan metode lain juga cukup tinggi. Seperti akurasi, precision yang dihasilkan pada saat menggunakan strategi over-sampling acak merupakan nilai precision yang paling kecil diantara yang lainnya.
Recall merupakan merupakan persentase kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan instance di kelas positif. Bedasarkan hasil recall yang diperoleh terlihat bahwa jumlah data bad yang dikelaskan dengan benar sangat kecil, baik menggunakan algoritme C4.5 maupun CART. Hasil recall yang diperoleh dapat dilihat pada Tabel 6. Nilai recall yang dihasilkan juga memiliki perbedaan yang signifikan antara data asli dan data yang dilakukan strategi sampling. Nilai recall menunjukkan bahwa data bad pada data asli yang dikelaskan dengan benar sangat kecil, baik menggunakan algoritme C4.5 maupun CART. Nilai recall tertinggi menggunakan algoritme C4.5 diperoleh pada pohon keputusan yang dihasilkan tanpa dilakukan pruning dan menggunakan strategi over-sampling duplikasi, yaitu sebesar 99.10%. Algoritme CART menghasilkan nilai recall tertinggi pada pohon keputusan yang dihasilkan tanpa dilakukan pruning dan menggunakan strategi over-sampling duplikasi, yaitu sebesar 99.80. Secara global, nilai recall tertinggi diperoleh pada saat dilakukan stategi over-sampling duplikasi.
F-measure merupakan perbandingan antara nilai precision dan recall. Nilai F-measure dapat dilihat pada Tabel 7. Perhitungan F-measure menggunakan nilai precision dan recall, sehingga nilai F-measure juga memiliki perbedaan yang signifikan antara data asli dan data yang dilakukan strategi sampling. Nilai F-measure tinggi merepresentasikan bahwa nilai precision dan recall juga tinggi. Nilai F-measure tertinggi menggunakan algoritme C4.5 diproleh pada pohon keputusan yang dihasilkan tanpa dilakukan pruning dan menggunakan strategi over-sampling duplikasi, yaitu sebesar 89.60. Algoritme CART menghasilkan nilai F-measure tertinggi pada pohon keputusan yang dihasilkan tanpa dilakukan pruning dan menggunakan strategi over-sampling duplikasi, yaitu sebesar 88.30. Secara global, nilai F-measure tertinggi diperoleh pada saat dilakukan stategi over-sampling duplikasi.
14
Secara global diperoleh bahwa nilai akurasi, recall dan F-measure tertinggi diperoleh pada saat dilakukan strategi over-sampling duplikasi sedangkan nilai precision tertinggi diperoleh pada saat dilakukan strategi under-sampling. Hasil akurasi, precision, recall, maupun F-measure yang dilakukan strategi sampling cukup tinggi dan tidak memiliki perbedaan yang cukup signifikan. Oleh karena itu, pada penelitian ini dapat disimpulkan bahwa strategi sampling, yaitu over-sampling dan under-over-sampling dapat meningkatkan perfomansi dalam mengklasifikasikan data tidak seimbang pada kasus prediksi risiko kredit. Dengan dilakukan pruning pada pohon keputusan, rata-rata akurasi, precision, recall, dan F-measure mengalami sedikit peningkatan pada strategi over-sampling acak dan under-sampling. Namun, pada strategi over-sampling duplikasi dengan dilakukan pruning pada pohon keputusan menurunkan akurasi, precision, recall, dan F-measure.
Jumlah node yang dihasilkan pada pohon keputusan dapat dilihat pada Tabel 8. Jumlah node paling sedikit menggunakan algoritme C4.5 diperoleh pada pohon keputusan yang dihasilkan dilakukan pruning dan menggunakan under-sampling cluster, yaitu sebanyak 78 node dengan jumlah rules sebanyak 42. Jumlah node paling sedikit pada algoritme CART diperoleh pada pohon keputusan yang dihasilkan dilakukan pruning dan menggunakan under-sampling cluster, yaitu sebanyak 37 node dengan jumlah rules sebanyak 12. Berdasarkan jumlah node pada Tabel 8, dapat disimpulkan bahwa rata-rata jumlah node yang dihasilkan oleh algoritme CART lebih kecil dibandingkan dengan C4.5. Hal ini dikarenakan pohon keputusan yang dihasilkan merupakan binary tree.
Setelah dilakukan analisis terhadap akurasi, precision, recall, dan F-measure dilanjutkan dengan pembuatan decision support system. Berdasarkan nilai F-measure, strategi over-sampling duplikasi merupakan nilai F-measure tertinggi dibandingkan yang lainnya. Namun, jumlah node yang dihasilkan sangat besar. Nilai F-measure menggunakan strategi under-sampling cluster cukup tinggi bahkan mendekati nilai F-measure yang dihasilkan menggunakan strategi over-sampling duplikasi dan jumlah node yang dihasilkan jauh lebih kecil dibandingkan over-sampling duplikasi. Oleh karena itu, aturan yang digunakan pada pembuatan decision support system merupakan aturan yang dihasilkan oleh pohon keputusan menggunakan strategi under-sampling cluster.
Perbandingan dengan Penelitian Sebelumnya
Setiawati (2011) dan Natasia (2013) melakukan penelitian menggunakan data yang sama dengan penelitian ini. Pada penelitian yang dilakukan Setiawati, jaringan saraf tiruan propagasi balik merupakan classifier. Pengambilan sampel sebanyak 50 kali dilakukan untuk mengatasi data yang tidak seimbang. Model terbaik dari penelitian ini menghasilkan akurasi sebesar 73.4%, precision kelas bad sebesar 36.90, recall kelas bad sebesar 56.26% dan F-measure sebesar 44.57%. Pada penelitian yang dilakukan Natasia, voting feature intervals 5 merupakan classifier. Pengambilan sampel sebanyak 50 kali dilakukan untuk mengatasi data tidak seimbang. Penelitian Natasia menggunakan 3 model. Model 1 merupakan model VFI5 tanpa pemilihan fitur. Model 2 merupakan model VFI5 dengan pemilihan fitur berdasarkan akurasi. Pemilihan fitur yang dipilih pada saat fitur memiliki akurasi lebih besar dari 50%. Model 3 merupakan model VFI5
15
dengan pemilihan fitur secara bertahap dan hanya menggunakan 2 fitur. Akurasi tertinggi diperoleh pada model 3 yaitu sebesar 70.40%. Nilai recall tertinggi diperoleh pada model 2 yaitu sebesar 46.88%. Nilai precision tertinggi diperoleh pada model 2 24.69% dan nilai F-measure tertinggi diperoleh pada model 2 sebesar 32.35%. Perbandingan akurasi, precision, recall, dan F-measure pada penelitian ini terhadap penelitian yang sudah dilakukan sebelumnya dapat dilihat pada Tabel 9.
Berdasarkan Tabel 9 terlihat bahwa secara global akurasi, precision, recall dan F-measure yang dihasilkan menggunakan over-sampling dan under-sampling lebih baik dibandingkan penelitian yang dilakukan sebelumnya.
SIMPULAN DAN SARAN
Simpulan
Penelitian yang menerapkan algoritme C4.5 dan CART dalam mengklasifikasikan calon debitur ke dalam kategori good atau bad telah dilakukan. Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan bahwa pemodelan yang menggunakan data tidak seimbang dengan strategi sampling yaitu under-sampling dan over-sampling mampu meningkatkan precision, recall, dan F-measure pada kelas bad. Nilai precision, recall, dan F-measure yang diperoleh setelah dilakukan strategi sampling rata-rata lebih dari 80%. Pohon keputusan yang dilakukan pruning menggunakan strategi over-sampling acak dan under-sampling rata-rata mengalami peningkatan pada akurasi, precision, recall, dan F-measure dibandingkan yang tidak dilakukan pruning. Namun, pohon keputusan yang dilakukan pruning menggunakan strategi over-sampling duplikasi mengalami penurunan pada akurasi, precision, recall, dan F-measure.
Decision support system menggunakan pohon keputusan C4.5 dan CART dengan strategi under-sampling cluster telah berhasil dibuat. Sistem menerima inputan berupa 14 atribut seperti pendidikan, jenis kelamin, status pernikahan, tipe perusahaan, status pekerjaan, pekerjaan, masa kerja, lama tinggal, status Tabel 9 Perbandingan analisis hasil dengan penelitian sebelumnya
Metode Akurasi Precison Recall F-measure
JST propagasi balik 1) 73.39 36.90 56.26 44.57
VFI5 model 1 2) 65.30 21.14 40.63 27.81
VFI5 model 2 2) 67.74 24.69 46.88 32.35
VFI5 model 3 2) 70.40 24.38 38.58 29.88
C4.5 over-sampling duplikasi 86.97 80.30 97.5 88.10 CART over-sampling duplikasi 86.83 79.10 99.60 88.20 C4.5 under-sampling cluster 88.05 92.50 82.90 87.40 CART under-sampling cluster 88.52 94.40 81.90 87.70 Keterangan:
1) Penelitian Setiawati (2011) 2) Penelitian Natasia (2013)
16
pemilikan rumah, banyaknya tanggungan, pendapatan, banyaknya kartu kredit lain, persentase utang kartu kredit, dan umur. Decision support system akan memberikan output risiko kredit calon debitur yaitu tinggi atau rendah. Risiko kredit tinggi merupakan debitur bad.
Perbandingan dengan penelitian sebelumnya menunjukkan bahwa akurasi, precision, recall, dan F-measure yang dihasilkan menggunakan over-sampling dan under-sampling dengan pohon keputusan sebagai classifier paling baik. Hal ini dikarenakan akurasi, precision, recall, dan F-measure yang dihasilkan lebih tinggi dibandingkan penelitian yang dilakukan Setiawati (2011) dan Natasia (2013) menggunakan data yang sama.
Saran
Penelitian ini dapat dikembangkan lebih lanjut untuk mendapatkan hasil akurasi, precision, recall, dan F-measure yang lebih baik. Hal-hal yang dapat dilakukan di antaranya ialah melakukan strategi sampling yang lain untuk mengatasi ketidakseimbangan data misal SMOTE atau melakukan perbandingan pada pohon keputusan dengan algoritme lain seperti supervised learning in quest (SLIQ) atau scalable parallelizable induction of decision tree (SPRINT).
DAFTAR PUSTAKA
Chawla VN. 2003. C4.5 and Imbalance Data sets: Investigating the effect of sampling method, probabilistic estimate, and decision tree structure. Di dalam: Workshop on Learning from Imbalanced Datasets II [Internet]; 2003 Aug 21; Washington DC, Amerika Serikat. Washington DC(US). [diunduh 2013 Mar
27]. Tersedia pada: http://www.site.uottawa.ca/
~nat/Workshop2003/chawla.pdf
Kantardzic M. 2003. Data Mining Concepts, Models, Methods, and Algorithms. Kartalopoulos VS, editor. New Jersey(US):IEEE Press Wiley-Interscience Larose TD. 2005. Discovering Knowledge in Data an Introduction to Data
Mining. New Jersey (US): John Wiley & Sons, Inc
Natasia RS. 2013. Klasifikasi debitur kartu kredit dengan pemilihan fitur mengunakan voting feature intervals5 [skripsi]. Bogor (ID). Institut Pertanian Bogor
Rahayu U. 2008. Klasifikasi Nasabah Kredit dengan Regresi Logistik [skripsi]. Bogor (ID). Institut Pertanian Bogor
Setiawati AP. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang (Studi kasus debitur kartu kredit Bank Mandiri tahun 2008-2009) [skripsi].Bogor (ID). Institut Pertanian Bogor
Tan NP, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Goldstein M, editor. London (UK) : Pearson Education, Inc
Weng GC, Poon J. 2008. A New Evaluation Measure for Imbalanced Datasets. Dalam :Roddick FJ, Li J, Christen P, Kennedy P, editor. Data Mining and Analytics 2008. Volume 87. Conference Seventh Australian Data Mining Conference (AusDM 2008) [Internet]; 2008 Nov 27; Glenelg Australia.
17 Adelaide (AU). [diunduh 2013 Mar 21]. Tersedia pada: http://crpit.com/confpapers/CRPITV87Weng.pdf
Yusuf Y. 2007. Perbandingan Perfomansi Algoritma Decision Tree C5.0, CART, dan CHAID : Kasus Prediksi Status Risiko Kredit di Bank X. Seminar Nasional Aplikasi Teknologi Informasi 2007 (SNATI 2007) [Internet]; 2007 Jun 16; Yogyakarta. Indonesia. Yogyakarta(ID). ;[diunduh 2013 Mar 27]. Tersedia pada:http://journal.uii.ac.id/index.php/Snati/article/viewFile/ 1628/1403
18
Lampiran 1 Daftar atribut
Atribut Keterangan
Pendidikan 1 = SMP/SMA
2 = Akademi 3 = S1/S2
Jenis Kelamin 1 = Pria
2 = Wanita
Status Pernikahan 1 = Lajang
2 = Menikah 3 = Bercerai
Tipe Perusahaan 1 = Kontraktor
2 = Conversion 3 = Industri Berat 4 = Pertambangan 5 = Jasa
6 = Transportasi
Status Pekerjaan 1 = Permanen
2 = Kontrak Pekerjaan 1 = Conversion 2 = PNS 3 = Professional 4 = Wiraswasta 5 = Perusahaan Swasta
Masa Kerja Dalam bulan
Lama Tinggal Dalam bulan
Status Pemilikan Rumah 0 = Bukan Milik Sendiri 1 = Milik Sendiri
Banyaknya Tanggungan
Pendapatan Rupiah
Banyaknya Kartu Kredit Lain Persentase Utang Kartu Kredit
Umur Dalam tahun
Kelas 1 = Debitur bad
19 Lampiran 2 Akurasi hasil seluruh percobaan
C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 81.98 78.18 83.67 78.87 Over-sampling duplikasi 86.97 88.65 86.83 86.92 Over-sampling acak 70.04 68.47 69.50 66.11 Under-sampling cluster2 82.63 80.03 85.22 80.66 Under-sampling cluster3 72.88 71.38 73.03 73.43 Under-sampling cluster4 82.63 79.87 84.43 81.68 Under-sampling cluster5 70.05 68.95 69.34 69.18 Under-sampling cluster6 65.72 65.57 68.08 66.67 Under-sampling cluster7 64.07 64.07 65.49 64.54 Under-sampling cluster8 71.23 69.58 70.60 69.50 Under-sampling cluster9 86.95 85.61 87.50 86.87 Under-sampling cluster10_1 79.64 77.04 80.27 79.01 Under-sampling cluster10_2 88.05 86.16 88.52 85.77 Under-sampling cluster10_3 74.53 72.80 75.31 72.72 Under-sampling cluster11 76.57 75.00 74.61 73.90 Under-sampling acak1 84.20 81.45 85.14 82.39 Under-sampling acak2 84.20 80.50 86.48 82.47 Under-sampling acak3 85.85 83.73 86.48 83.25
Lampiran 3 Precision hasil seluruh percobaan C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 29.60 27.80 0.00 25.10 Over-sampling duplikasi 80.30 81.80 79.10 79.20 Over-sampling acak 70.60 68.70 68.90 65.80 Under-sampling cluster2 89.10 82.60 100.00 81.70 Under-sampling cluster3 75.00 71.30 78.30 74.30 Under-sampling cluster4 86.60 80.10 92.40 83.30 Under-sampling cluster5 68.90 68.20 70.90 69.40 Under-sampling cluster6 66.30 65.70 68.50 66.30 Under-sampling cluster7 64.60 64.10 66.20 63.80 Under-sampling cluster8 73.00 69.90 72.10 69.70 Under-sampling cluster9 91.50 87.10 93.00 88.90 Under-sampling cluster10_1 83.70 78.00 89.70 79.70 Under-sampling cluster10_2 92.50 86.90 94.40 86.90 Under-sampling cluster10_3 76.40 73.20 86.30 73.20 Under-sampling cluster11 78.90 75.20 75.90 73.80 Under-sampling acak1 89.80 82.70 93.60 84.40 Under-sampling acak2 91.60 81.40 95.00 81.40 Under-sampling acak3 92.20 85.20 95.00 85.10
20
Lampiran 4 Recall hasil seluruh percobaan C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 7.50 21.10 0.00 14.80 Over-sampling duplikasi 97.50 99.10 99.60 99.80 Over-sampling acak 68.20 67.40 70.80 66.40 Under-sampling cluster2 74.40 76.10 70.40 79.10 Under-sampling cluster3 68.60 71.70 63.70 71.50 Under-sampling cluster4 77.20 79.60 75.00 79.20 Under-sampling cluster5 70.60 71.10 65.60 68.70 Under-sampling cluster6 64.00 65.30 66.80 67.80 Under-sampling cluster7 62.30 64.00 63.40 67.10 Under-sampling cluster8 67.30 68.90 67.10 69.00 Under-sampling cluster9 81.40 83.60 81.10 84.30 Under-sampling cluster10_1 73.60 75.30 68.40 77.80 Under-sampling cluster10_2 82.90 85.20 81.90 84.30 Under-sampling cluster10_3 70.90 72.00 60.20 71.70 Under-sampling cluster11 72.50 74.50 72.20 74.10 Under-sampling acak1 77.20 79.60 75.50 79.40 Under-sampling acak2 75.30 79.10 77.00 80.80 Under-sampling acak3 78.30 81.60 77.00 80.70
Lampiran 5 F-measure hasil seluruh percobaan C4.5 Pruning C4.5 Unpruning CART Pruning CART Unpruning Asli 12.00 24.00 0.00 18.60 Over-sampling duplikasi 88.10 89.60 88.20 88.30 Over-sampling acak 69.40 68.10 69.80 66.10 Under-sampling cluster2 81.10 79.20 82.70 80.40 Under-sampling cluster3 71.70 71.50 70.30 72.90 Under-sampling cluster4 81.60 79.80 82.80 81.20 Under-sampling cluster5 70.20 69.60 68.10 69.00 Under-sampling cluster6 65.10 65.50 67.70 67.00 Under-sampling cluster7 63.40 64.00 64.70 65.40 Under-sampling cluster8 70.00 69.40 69.50 69.40 Under-sampling cluster9 86.20 85.30 86.60 86.50 Under-sampling cluster10_1 78.30 76.60 77.60 78.80 Under-sampling cluster10_2 87.40 86.00 87.70 85.60 Under-sampling cluster10_3 73.60 72.60 70.90 72.40 Under-sampling cluster11 75.60 74.90 74.00 73.90 Under-sampling acak1 83.00 81.10 83.60 81.80 Under-sampling acak2 82.70 80.20 85.10 82.20 Under-sampling acak3 84.70 83.40 83.20 82.80
21 Lampiran 6 Pohon keputusan algoritme C4.5 menggunakan strategi
under-sampling cluster pendidikan = 1: 1 pendidikan = 2: 1 pendidikan = 3 | lama tinggal <= 59
| persentase utang kartu kredit <= 49.8: 2 | | persentase utang kartu kredit > 49.8 | | | pekerjaan = 1: 2 | | | pekerjaan = 2: 2 | | | pekerjaan = 3: 1 | | | pekerjaan = 4 | | | | status pernikahan = 1: 1 | | | | status pernikahan = 2 | | | | | status pekerjaan = 1
| | | | | | status pemilikan rumah = 0
| | | | | | | persentase utang kartu kredit <= 72: 2 | | | | | | | persentase utang kartu kredit > 72: 1 | | | | | | status pemilikan rumah = 1
| | | | | | | masa kerja <= 49
| | | | | | | | persentase utang kartu kredit <= 73.33: 2 | | | | | | | | persentase utang kartu kredit > 73.33: 1 | | | | | | | masa kerja > 49: 2
| | | | | status pekerjaan = 2
| | | | | | status pemilikan rumah = 0
| | | | | | | persentase utang kartu kredit <= 77.89: 2 | | | | | | | persentase utang kartu kredit > 77.89: 1 | | | | | | status pemilikan rumah = 1
| | | | | | | jenis kelamin = 1: 1 | | | | | | | jenis kelamin = 2
| | | | | | | | persentase utang kartu kredit <= 82: 1 | | | | | | | | persentase utang kartu kredit > 82: 2 | | | | status pernikahan = 3: 2 | | | pekerjaan = 5 | | | | pendapatan <= 100000000 | | | | | lama tinggal <= 11: 2 | | | | | lama tinggal > 11 | | | | | | banyaknya tanggungan <= 1 | | | | | | | banyaknya tanggungan <= 0
| | | | | | | | persentase utang kartu kredit <= 68.57 | | | | | | | | | jenis kelamin = 1: 1 (4.0)
| | | | | | | | | jenis kelamin = 2
| | | | | | | | | | pendapatan <= 48750000: 1 | | | | | | | | | | pendapatan > 48750000: 2
| | | | | | | | persentase utang kartu kredit > 68.57: 2 | | | | | | | banyaknya tanggungan > 0
22 | | | | | | | | lama tinggal > 25: 1 | | | | | | banyaknya tanggungan > 1: 2 | | | | pendapatan > 100000000: 2 | lama tinggal > 59 | | umur <= 39 | | | lama tinggal <= 84 | | | | umur <= 29: 1 (16.0) | | | | umur > 29 | | | | | banyaknya tanggungan <= 0 | | | | | | status pekerjaan = 1 | | | | | | | masa kerja <= 59: 2 | | | | | | | masa kerja > 59 | | | | | | | | masa kerja <= 109: 1 | | | | | | | | masa kerja > 109: 2 | | | | | | status pekerjaan = 2: 2 | | | | | banyaknya tanggungan > 0 | | | | | | umur <= 38: 1 | | | | | | umur > 38: 2 | | | lama tinggal > 84: 1 | | umur > 39 | | | lama tinggal <= 120 | | | | pendapatan <= 37700000: 1 | | | | pendapatan > 37700000: 2 | | | lama tinggal > 120 | | | | umur <= 47: 1 | | | | umur > 47 | | | | | masa kerja <= 49: 1 | | | | | masa kerja > 49 | | | | | | lama tinggal <= 240 | | | | | | | pendapatan <= 3250000000: 2 | | | | | | | pendapatan > 3250000000: 1 | | | | | | lama tinggal > 240: 1
Lampiran 7 Aturan yang terbentuk berdasarkan pohon keputusan algoritme C4.5 menggunakan strategi under-sampling cluster
1. If pendidikan = 1 then kelas = 1 2. If pendidikan = 2 then kelas = 1
3. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit <= 49.8 then kelas = 2
4. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 1 then kelas = 2
5. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 2 then kelas = 2
6. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 3 then kelas = 1
7. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 1 then kelas = 1
23 8. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 4 and status pernikahan = 3 then kelas = 2
9. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 1 and status pemilikan rumah = 0 and persentase utang kartu kredit <= 72 then kelas = 2
10. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 1 and status pemilikan rumah = 0 and persentase utang kartu kredit > 72 then kelas = 1
11. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 1 and status pemilikan rumah = 1 and masa kerja > 49 then kelas = 2 12. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 1 and status pemilikan rumah = 1 and masa kerja < 49 and persentase utang kartu kredit <= 73.33 then kelas = 2
13. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 1 and status pemilikan rumah = 1 and masa kerja < 49 and persentase utang kartu kredit > 73.33 then kelas = 1
14. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 2 and status pemilikan rumah = 0 and persentase utang kartu kredit <= 77.89 then kelas = 2
15. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 2 and status pemilikan rumah = 0 and persentase utang kartu kredit > 77.89 then kelas = 1
16. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 2 and status pemilikan rumah = 1 and jenis kelamin = 1 then kelas = 1 17. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 2 and status pemilikan rumah = 1 and jenis kelamin = 2 and persentase utang kartu kredit <= 82 then kelas = 1
18. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 4 and status pernikahan = 2 and status pekerjaan = 2 and status pemilikan rumah = 1 and jenis kelamin = 2 and persentase utang kartu kredit > 82 then kelas = 2
19. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan > 100000000 then kelas = 2 20. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal <= 11 then kelas = 2
21. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan > 1 then kelas = 2
24
22. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 0 and persentase utang kartu kredit > 68.57 then kelas = 2
23. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 0 and persentase utang kartu kredit <= 68.57 and jenis kelamin = 1 then kelas = 1
24. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 0 and persentase utang kartu kredit <= 68.57 and jenis kelamin = 2 and pendapatan > 48750000 then kelas = 2 25. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 0 and persentase utang kartu kredit <= 68.57 and jenis kelamin = 2 and pendapatan <= 48750000 then kelas = 1 26. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit
> 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 1 and lama tinggal <= 25 then kelas = 2 27. If pendidikan = 3 and lama tinggal <= 59 and persentase utang kartu kredit > 49.8 and pekerjaan = 5 and pendapatan <= 100000000 and lama tinggal > 11 and banyaknya tanggungan = 1 and lama tinggal > 25 then kelas = 1 28. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal
> 84 then kelas = 1
29. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur <= 29 then kelas = 1
30. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan = 0 and status pekerjaan = 2 then kelas = 2
31. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan = 0 and status pekerjaan = 1 and masa kerja <= 59 then kelas = 2
32. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan = 0 and status pekerjaan = 1 and masa kerja > 59 and masa kerja > 109 then kelas = 2
33. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan = 0 and status pekerjaan = 1 and masa kerja > 59 and masa kerja <= 109 then kelas = 1
34. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan > 0 and umur > 38 then kelas = 2
35. If pendidikan = 3 and lama tinggal > 59 and umur <= 39 and lama tinggal <= 84 and umur > 29 and banyaknya tanggungan > 0 and umur <= 38 then kelas = 1
36. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal <= 120 and pendapatan > 37700000 then kelas = 2
37. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal <= 120 and pendapatan <= 37700000 then kelas = 1
25 38. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal >
120 and umur <= 47 then kelas = 1
39. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal > 120 and umur > 47 and masa kerja <= 49 then kelas = 1
40. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal > 120 and umur > 47 and masa kerja > 49 and lama tinggal > 240 then kelas = 1
41. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal > 120 and umur > 47 and masa kerja > 49 and lama tinggal <= 240 and pendapatan > 3250000000 then kelas = 1
42. If pendidikan = 3 and lama tinggal > 59 and umur > 39 and lama tinggal > 120 and umur > 47 and masa kerja > 49 and lama tinggal <= 240 and pendapatan <= 3250000000 then kelas = 2
Lampiran 8 Pohon keputusan algoritme CART menggunakan strategi under-sampling cluster pendidikan=(3) | lama tinggal < 59.5: 2 | lama tinggal >= 59.5 | | umur < 39.5 | | | lama tinggal < 77.5 | | | | umur < 29.5: 1 | | | | umur >= 29.5 | | | | | banyaknya tanggungan < 1: 2 | | | | | banyaknya tanggungan >= 1 | | | | | | umur < 38.5: 1 | | | | | | umur >= 38.5: 2 | | | lama tinggal >= 77.5: 1 | | umur >= 39.5 | | | lama tinggal < 131.5 | | | | pendapatan < 37500000: 1 | | | | pendapatan >= 37500000: 2 | | | lama tinggal >= 131.5 | | | | umur < 47.5: 1 | | | | umur >= 47.5 | | | | | masa kerja < 54.0: 1 | | | | | masa kerja >= 54.0 | | | | | | lama tinggal < 245.0: 2 | | | | | | lama tinggal >= 245.0: 1 pendidikan!=(3): 1
Lampiran 9 Aturan yang terbentuk berdasarkan pohon keputusan algoritme CART menggunakan strategi under-sampling cluster
1. If pendidikan != 3 then kelas 1
2. If pendidikan = 3 and lama tinggal < 59.5 then kelas = 2
3. If pendidikan = 3 and lama tinggal >= 59.5 and umur < 39.5 and lama tinggal >= 77.5 then kelas = 1
26
4. If pendidikan = 3 and lama tinggal >= 59.5 and umur < 39.5 and lama tinggal < 77.5 and umur < 29.5 then kelas = 1
5. If pendidikan = 3 and lama tinggal >= 59.5 and umur < 39.5 and lama tinggal < 77.5 and umur >= 29.5 and tanggungan < 1 then kelas = 2
6. If pendidikan = 3 and lama tinggal >= 59.5 and umur < 39.5 and lama tinggal < 77.5 and umur >= 29.5 and tanggungan >= 1 and umur < 38.5 then kelas = 1
7. If pendidikan = 3 and lama tinggal >= 59.5 and umur < 39.5 and lama tinggal < 77.5 and umur >= 29.5 and tanggungan >= 1 and umur >= 38.5 then kelas = 2
8. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama tinggal < 131.5 and pendapatan < 37500000 then kelas = 1
9. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama tinggal < 131.5 and pendapatan >= 37500000 then kelas = 2
10. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama tinggal >= 131.5 and umur < 47.5 then kelas = 1
11. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama tinggal >= 131.5 and umur >= 47.5 and masa kerja < 54 then kelas = 1 12. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama
tinggal >= 131.5 and umur >= 47.5 and masa kerja >= 54 and lama tinggal < 245 then kelas = 2
13. If pendidikan = 3 and lama tinggal >= 59.5 and umur >= 39.5 and lama tinggal >= 131.5 and umur >= 47.5 and masa kerja >= 54 and lama tinggal >= 245 then kelas = 1
27