KLASIFIKASI IMBALANCED DATA MENGGUNAKAN
WEIGHTED K-NEAREST NEIGHBOR PADA DATA DEBITUR
KARTU KREDIT BANK
AISYAH SYAHIDAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi ImbalancedData Menggunakan Weighted K-Nearest Neighbor pada Data Debitur Kartu
Kredit Bank adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Aisyah Syahidah
ABSTRAK
AISYAH SYAHIDAH. Klasifikasi Imbalanced Data Menggunakan Weighted
K-Nearest Neighbor pada Data Debitur Kartu Kredit Bank. Dibimbing oleh AZIZ
KUSTIYO.
Manajemen risiko kredit bertujuan untuk meminimalkan potensi kerugian dari kredit macet. Analisis data debitur bermasalah yang sudah ada dapat menjadi model dalam kualifikasi pemberian kredit selanjutnya. Data debitur bank termasuk kasus data tidak seimbang. Proses klasifikasi menjadi tidak optimal karena kelas dengan jumlah data lebih banyak memberikan pengaruh yang sangat besar dalam hasil klasifikasi. Penelitian ini bertujuan untuk mengembangkan model klasifikasi data debitur kartu kredit menggunakan algoritme weighted
k-nearest neighbor dan metode sampling yang bertujuan meningkatkan kualitas
klasifikasi pada data tidak seimbang. Metode sampling yang digunakan yaitu
oversampling dan undersampling. Metode oversampling acak menghasilkan nilai f-measure terbaik sebesar 86.51%. Metode oversampling duplikasi menghasilkan
nilai recall terbaik sebesar 100%.
Kata kunci: data tidak seimbang, oversampling, undersampling, weighted
k-nearest neigbor
ABSTRACT
AISYAH SYAHIDAH. Classification of Imbalanced Data Using Weighted K-Nearest Neighbor in Data Bank Credit Card Debtors. Supervised by AZIZ KUSTIYO.
Credit risk management aims to minimize potential losses of non-performing loans. The classification results of existing data debtors can be referred for credit qualifications. The debtors data, most likely, are imbalanced due to the good debtors dominated the bad one. Classification process could not be optimum because of the class with more data had tremendous influence in the classification result. This research aims to develop a data classification model based on credit card debtors using weighted k-nearest neighbor and sampling method which aimed to improve the quality of classification on the imbalanced data. The sampling methods used are the oversampling and undersampling. The random oversampling method obtains the best performance with F-measure of 86.51%. Moreover, the duplication oversampling can obtain 100% recall.
Keywords: imbalanced data, oversampling, undersampling, weighted k-nearest neighbor
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI IMBALANCED DATA MENGGUNAKAN
WEIGHTED K-NEAREST NEIGHBOR PADA DATA DEBITUR
KARTU KREDIT BANK
AISYAH SYAHIDAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji:
1 Toto Haryanto, SKom MSi 2 M Asyhar Agmalaro, SSi MKom
Judul Skripsi : Klasifikasi Imbalanced Data Menggunakan Weighted K-Nearest
Neighbor pada Data Debitur Kartu Kredit Bank
Nama : Aisyah Syahidah NIM : G64090036
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhaanahu wa ta’aala atas segala karunia dan hidayah-Nya sehingga karya ilmiah ini berhasil diselesaikan. Ungkapan terima kasih penulis sampaikan kepada Ayah Ir H Solichin, MMSI, Bunda Hj Bonita Anugrawati, adik Fatiya Nur Afifah, Rahma Fadhilah, dan Muhammad Labib Faishal atas segala bantuan, dukungan, doa, dan kasih sayang selama ini. Tema yang dipilih dalam penelitian ini ialah data tidak seimbang, dengan judul Klasifikasi Imbalanced Data Menggunakan Weighted K-Nearest
Neighbor pada Data Debitur Kartu Kredit Bank.
Terima kasih penulis ucapkan kepada Bapak Aziz Kustiyo, SSi, MKom selaku pembimbing, kepada Bapak Toto Haryanto, SKom, MSi dan Bapak M Asyhar Agmalaro, SSi, MKom selaku penguji. Terima kasih atas semua pengajaran, bimbingan, saran, dukungan, dan waktu yang telah diberikan selama masa studi dan penyelesaian penelitian tugas akhir ini. Tak lupa, penulis sampaikan terima kasih kepada seluruh staf Departemen Ilmu Komputer IPB atas layanan terbaik yang diberikan kepada penulis. Terima kasih juga penulis sampaikan kepada teman-teman ilkomerz 46 atas bantuan, dukungan, kasih sayang, dan doa selama ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2014
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN Latar Belakang 1 Perumusan Masalah 1 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE
Pengadaan Data 2
Praproses Data 2
Normalisasi Data 4
Strategi Sampling 4
Pembagian Data Uji dan Data Latih 5
Klasifikasi dengan WKNN 5
Confusion Matrix 7
Penerapan Model Terbaik 8
HASIL DAN PEMBAHASAN
Pengadaan Data 8
Praproses Data 8
Strategi Sampling 9
Klasifikasi dengan WKNN 9
Analisis Data Hasil Klasifikasi 9
Perbandingan dengan Penelitian Sebelumnya 12
SIMPULAN DAN SARAN
Simpulan 14
Saran 14
DAFTAR PUSTAKA 14
DAFTAR TABEL
1 Confusion matrix 7
2 Nilai rata-rata kinerja WKNN pada data asli 10 3 Confusion matrix pada data asli untuk pengujian ke-8 10 4 Nilai rata-rata kinerja WKNN pada data oversampling duplikasi 10 5 Nilai rata-rata kinerja WKNN pada data oversampling acak 11 6 Nilai rata-rata kinerja WKNN pada data undersampling acak 11 7 Nilai rata-rata kinerja WKNN pada data cluster undersampling 11
8 Perbandingan dengan penelitian sebelumnya 13
DAFTAR GAMBAR
1 Metode penelitian 3
2 Grafik f-measure setiap model data penelitian WKNN 13
DAFTAR LAMPIRAN
1 Keterangan lengkap atribut 16
2 Hasil klasifikasi data asli dalam % untuk data uji ke-8 dengan k
tetangga terdekat 16
3 Nilai precision data asli dengan 10 tetangga terdekat 17 4 Confusion matrix data asli untuk data uji ke-3 17 5 Nilai precision data oversampling duplikasi dengan 1 tetangga
terdekat 17
6 Confusion matrix data oversampling duplikasi untuk data uji ke-7 18 7 Nilai precision data oversampling acak dengan 1 tetangga terdekat 18 8 Confusion matrix data oversampling acak untuk data uji ke-6 18 9 Nilai precision data undersampling acak dengan 9 tetangga terdekat 18 10 Confusion matrix data undersampling acak untuk data uji ke-4 18 11 Nilai precision data cluster undersampling dengan 6 tetangga
terdekat 19
PENDAHULUAN
Latar Belakang
Layanan perkreditan adalah layanan bank yang sering digunakan oleh masyarakat. Ketika mengajukan kredit, masyarakat harus mengisi formulir yang membantu pihak bank menentukan penerimaan pengajuan kredit. Beberapa masyarakat yang memenuhi persyaratan pengajuan mengalami kendala dalam pelunasan kredit. Hal ini merugikan pihak bank karena berisiko menimbulkan kredit macet (bermasalah). Kredit bermasalah bukan hal yang dapat dihindari oleh pihak bank sehingga bank membutuhkan manajemen risiko kredit yang baik. Salah satu indikator manajemen risiko kredit yang baik adalah rendahnya persentase kredit bermasalah. Analisis data debitur bermasalah yang sudah ada dapat menjadi model dalam kualifikasi pemberian kredit.
Data debitur bank termasuk kasus data tidak seimbang. Proses klasifikasi menjadi tidak optimal karena kelas dengan jumlah data lebih banyak memberikan pengaruh yang sangat besar dalam hasil klasifikasi. Kelas dengan data yang sedikit (minoritas) difokuskan dalam kasus data tidak seimbang.
Berbagai penelitian menunjukkan bahwa klasifikasi weighted k-nearest
neighbor (WKNN) adalah modifikasi dari klasifikasi k-nearest neighbor (KNN).
Menurut Gou et al. (2012) permasalahan pada KNN terjadi ketika memilih k tetangga terdekat. Jika k yang dipilih sangat kecil, perkiraan klasifikasi cenderung menjadi tidak akurat karena data yang kurang, adanya noise, ambigu atau salah pelabelan. Nilai k yang terlalu besar dengan mudah membuat kinerja klasifikasi menurun karena adanya outlier dari kelas-kelas lain. Pemilihan k harus dioptimalkan untuk dapat meningkatkan akurasi. Menurut Pao et al. (2008) pemberian bobot pada klasifikasi KNN dapat memperbaiki tingkat kesalahan. Pao
et al. menyimpulkan hal ini dari hasil penelitian Dudani (1976) mengenai classifier WKNN. Gou et al. menggunakan dataset UCI yang juga digunakan
pada penelitian Dudani sehingga dapat membandingkan kinerja KNN dan WKNN. Dataset UCI merupakan data seimbang. Pao et al. menggunakan data rekaman menggunakan Bahasa Mandarin yang juga merupakan data seimbang. Dari kedua penelitian tersebut, dapat disimpulkan bahwa WKNN dapat mengatasi masalah sensitivitas KNN pada k tetangga terdekat.
Penelitian ini dilakukan untuk melihat kinerja WKNN pada data debitur kartu kredit bank yang tidak seimbang. Kemudian, dari hasil penelitian ini akan dibuat suatu model untuk mengklasifikasikan debitur ke dalam kelas baik atau buruk. Penelitian dengan menggunakan data yang sama telah dilakukan oleh Ulya (2013) menggunakan algoritme KNN. Dari hasil penelitian tersebut diperoleh akurasi dari model terbaik sebesar 96.24%, serta recall, precision, dan f-measure sebesar 99.23%, 95.21%, dan 96.30%.
Perumusan Masalah
Rumusan permasalahan pada penelitian ini adalah pengukuran kinerja WKNN terhadap data debitur kartu kredit bank yang tidak seimbang.
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan metode oversampling dan
undersampling serta WKNN pada data debitur kartu kredit yang tidak seimbang.
Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat menjadi pertimbangan dalam proses penerimaan calon debitur kartu kredit bank agar meminimumkan risiko terjadinya debitur bermasalah.
Ruang Lingkup Penelitian
Lingkup dari penelitian ini, yaitu:
1 Data yang digunakan adalah data penelitian Setiawati (2011) yaitu data sekunder nasabah kartu kredit pada bank X periode tahun 2008-2009.
2 Metode yang digunakan yaitu teknik oversampling dan undersampling dengan algoritme WKNN.
METODE
Penelitian ini melalui 8 tahapan yaitu pengadaan data, praproses data, normalisasi data, strategi sampling menggunakan metode oversampling dan
undersampling, 10-fold cross validation untuk membagi data latih dan data uji,
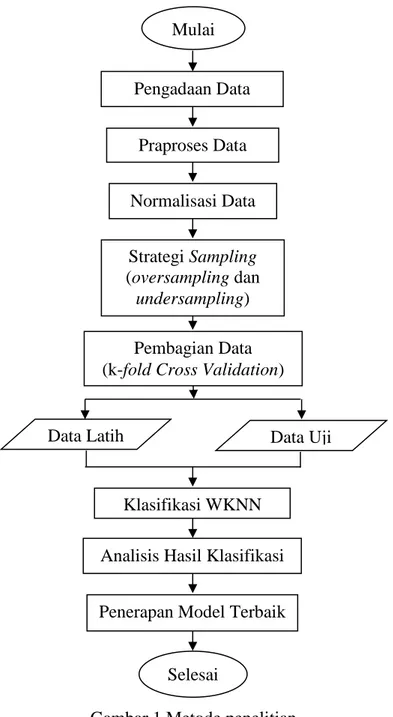
klasifikasi menggunakan WKNN, analisis hasil, dan penerapan model terbaik. Ilustrasinya dapat dilihat pada Gambar 1.
Pengadaan Data
Tahap pertama, data penelitian yang digunakan adalah data tidak seimbang yang juga digunakan pada penelitian Wijayanti (2013). Data berjumlah 4413
instances dengan 14 atribut yang terbagi menjadi 2 kelas yaitu kelas debitur baik
(good) dan kelas debitur buruk (bad). Peneliti sebelumnya membuat proposal penelitian dan menghubungi pihak bank yang bersedia untuk bekerja sama dalam penelitian yang sedang dilakukan.
Praproses Data
Tahap selanjutnya, data awal yang didapat berjumlah 4413 dengan 14 atribut yang terdiri atas 7 atribut bertipe data rasio, 6 atribut bertipe data nominal, dan 1 atribut bertipe data ordinal. Atribut pendapatan, jumlah tanggungan, umur, masa kerja, lama tinggal, banyaknya kartu kredit lain, dan persentase utang kartu kredit lain termasuk ke dalam tipe data rasio. Atribut jenis kelamin, status
3
pekerjaan, jenis pekerjaan, tipe perusahaan, status rumah, dan status pernikahan termasuk ke dalam tipe data nominal. Atribut pendidikan termasuk ke dalam atribut ordinal.
Terdapat 3 kategori teknik untuk menunjukkan kesalahan pengukuran sebagai wujud kehati-hatian dalam penggunaan data berskala besar (Dasu & Johnson 2003). Pertama, mendeteksi missing value. Pada penelitian ini, penghapusan instance dilakukan pada atribut data yang missing value, seperti pada atribut banyaknya kartu kredit lain. Kedua, mendeteksi incomplete data. Penghapusan instance juga dilakukan pada atribut yang incomplete. Pada kedua teknik ini terjadi pengurangan data. Ketiga, mendeteksi outliers. Data outliers pada penelitian ini dikoreksi secara manual, seperti data atribut pendapatan yang mengandung nilai yang tidak seharusnya antara 0 atau 1, dan nilai -1 pada atribut
Gambar 1 Metode penelitian Pengadaan Data Praproses Data Strategi Sampling (oversampling dan undersampling) Pembagian Data (k-fold Cross Validation)
Data Latih
Analisis Hasil Klasifikasi Penerapan Model Terbaik
Selesai Mulai
Normalisasi Data
Klasifikasi WKNN
4
masa kerja. Total data yang telah diproses dalam penelitian ini menjadi 3895 dengan 14 atribut, dengan 3259 termasuk ke dalam kategori kelas good dan 636 kelas bad.
Normalisasi Data
Variabel suatu data cenderung memiliki kisaran yang besar dan beragam. Tahapan selanjutnya yaitu melakukan normalisasi variabel untuk tipe data rasio untuk menstandardisasi skala setiap nilai variabel yang ada. Teknik normalisasi yang dilakukan dalam penelitian ini adalah min-max normalization.
Min-max normalization bekerja dengan cara melihat nilai suatu atribut
terhadap nilai minimum dan menskalakannya terhadap kisaran data. Nilai
min-max normalization akan berkisar antara 0.0 dan 1.0 (Larose 2005).
dengan adalah nilai hasil normalisasi, adalah nilai sebelum normalisasi, adalah nilai minimum dari atribut, dan adalah nilai maksimum dari atribut.
Strategi Sampling
Data yang telah dinormalisasi kemudian dilakukan strategi sampling untuk data tidak seimbang. Strategi sampling terdiri atas oversampling kelas minoritas atau undersampling kelas mayoritas (Garcia 2007). Strategi oversampling dapat mengurangi pengaruh data kelas mayoritas terhadap hasil pengujian keseluruhan data secara signifikan (Efendiev dan Hou 2008).
Ada 2 cara oversampling yang dilakukan pada penelitian ini yaitu
oversampling duplikasi dan oversampling acak. Oversampling duplikasi
merupakan proses duplikasi data kelas minoritas secara terurut hingga jumlah
instance sama atau mendekati jumlah instance data kelas mayoritas. Dalam
penelitian ini, 636 data kelas bad diduplikasi sebanyak 4 kali hingga mendekati jumlah kelas good sebanyak 3259 data. Proses duplikasi ini menyebabkan kelas
bad berjumlah 3180 data. Percobaan oversampling duplikasi menghasilkan 1 dataset.
Oversampling acak merupakan proses membangkitkan data kelas minoritas
secara acak hingga jumlah instance sama dengan data kelas mayoritas. Dalam penelitian ini, 636 data kelas bad dibangkitkan secara acak untuk setiap atribut independen hingga jumlah instance data kelas bad sebanyak kelas good yaitu 3259 data. 1 dataset dihasilkan pada percobaan oversampling acak.
Strategi undersampling dilakukan pada kelas mayoritas sehingga jumlah
instance data kelas mayoritas sama dengan data kelas minoritas. Ada 2 cara undersampling dalam penelitian ini yaitu undersampling acak dan undersampling
dengan clustering. Undersampling acak yaitu membangkitkan setiap atribut data kelas mayoritas (good) secara acak hingga jumlah instance sama dengan jumlah
5
instance data kelas minoritas (bad) sebanyak 636. Undersampling secara acak
dilakukan sebanyak 3 kali sehingga diperoleh 3 dataset.
Proses undersampling dengan clustering dimulai dengan mengolah data mayoritas (good) dengan metode k-means clustering menggunakan WEKA. Data dibagi menjadi 2 sampai 10 cluster, kemudian dilakukan pembangkitan data mayoritas (good) sesuai dengan perbandingan setiap cluster terhadap data minoritas (bad). Hal ini dilakukan supaya data tidak mengelompok pada cluster tertentu dan dapat merepresentasikan keseluruhan data. Jumlah data yang diambil untuk setiap cluster didapat menggunakan fungsi berikut (Yen dan Lee 2009):
lust
Percobaan cluster undersampling menghasilkan 9 dataset.
Pembagian Data Uji dan Data Latih
Data yang telah mengalami strategi sampling kemudian dibagi menjadi data latih dan data uji menggunakan metode k-fold cross-validation. Metode k-fold
cross validation membagi data secara acak sejumlah subset-k yang sama besar. Subset yang terbentuk kemudian dilakukan iterasi sebanyak k-kali untuk pelatihan
dan pengujian. Setiap proses pengujian menggunakan 1 subset sebagai data uji, sedangkan subset lainnya sebagai data latih. Penelitian ini menggunakan metode 10-fold cross validation (Kohavi 1995).
Klasifikasi dengan WKNN
Klasifikasi WKNN merupakan pengembangan dari klasifikasi KNN yang ada. WKNN termasuk salah satu aturan pemilihan di mana anggota berbeda dari kumpulan tetangga terdekat diberi bobot oleh fungsi jarak antara data latih dengan data uji (Zavrel 1997). WKNN memakai prinsip yang sama dengan KNN yaitu mencari jarak terdekat antara data yang akan diuji dengan sejumlah k tetangga terdekatnya dalam data latih. WKNN akan memberi bobot terberat pada tetangga terdekat dan terkecil pada tetangga terjauh sesuai fungsi jarak (Gou et al. 2012).
Langkah pertama dalam proses klasifikasi WKNN adalah perhitungan jarak antara data uji dengan data latih. Perhitungan jarak pada data rasio dan ordinal dapat menggunakan fungsi Euclidean seperti berikut:
( ) √∑
Berbeda dengan data rasio dan ordinal, untuk menghitung jarak data nominal tidak tepat menggunakan fungsi Euclidean. Data nominal hanya melambangkan makna sebagai angka dan tidak menunjukkan perbedaan nilai atau
6
tingkatan sehingga tidak dapat diperbandingkan besarnya. Dalam menghitung jarak nominal, fungsi yang digunakan yaitu:
{ dengan x adalah data uji dan y adalah data latih.
Kedua jarak tersebut kemudian digabungkan menggunakan fungsi agregat ketidaksamaan berat rata-rata yang diukur dari setiap atribut (Teknomo 2006). Fungsi yang digunakan adalah:
∑n w ∑n w
dengan:
Sij = jarak data uji dengan data latih
k = variabel fitur
Sijk = adalahnilai ketidaksamaan antarobjek i dan j untuk fitur k
wijk = bobot fitur, bernilai 1 untuk jarak rasio dan 0.5 untuk jarak nominal.
Langkah selanjutnya yaitu perhitungan menggunakan WKNN. Pemberian bobot terhadap k tetangga terdekat terhadap data uji mengikuti fungsi sebagai berikut (Dudani 1976 dalam Gou et al. 2012):
{
( ) ( )
( ) ( ) ( ) ( )
( ) ( )
kemudian, hasil klasifikasi data uji didapatkan dengan pemilihan bobot terbesar. ∑
( )
( )
dengan: {( )}
= kumpulan data latih = vektor data latih
= label kelas data latih yang berkorespondensi dengan vektor = data uji
( ) = jarak Euclidean antara dan (jarak terbesar) ( ) = jarak Euclidean antara dan (jarak data ke-i) ( ) = jarak Euclidean antara dan (jarak terkecil)
= label kelas data uji yang belum diketahui
= label kelas (good atau bad)
= label kelas untuk ke-i tetangga terdekat di antara k tetangga terdekatnya
7 ( ) = fungsi Dirac delta, bernilai 1 jika dan bernilai 0 jika
selainnya
Jarak tetangga terdekat mendapat bobot 1, jarak tetangga terjauh mendapat bobot 0, dan bobot jarak tetangga lain terskala secara linear terhadap selang antaranya.
Confusion Matrix
Langkah selanjutnya, hasil klasifikasi data uji dibandingkan dengan kelas aktual data uji. Jumlah dari kelas positif (kelas minoritas yaitu kelas bad) yang benar diklasifikasikan dilambangkan dengan TP. Jumlah kelas positif yang salah diklasifikasikan ke dalam kelas negatif dilambangkan dengan FN. FP adalah jumlah kelas negatif yang salah diklasifikasikan ke dalam kelas positif. TN adalah jumlah kelas negatif yang benar diklasifikasikan. TP, FN, FP, dan TN disajikan dalam bentuk tabel confusion matrix yang merupakan teknik untuk mengukur kemampuan dari classifier pada kasus data tidak seimbang. Confusion matrix untuk dua kelas (Han et al. 2005) dapat dilihat pada Tabel 1.
Tabel 1 Confusion matrix
Kelas aktual Kelas hasil klasifikasi Kelas positif Kelas negatif
Kelas positif TP FN
Kelas negatif FP TN
1 Akurasi
Akurasi adalah jumlah perbandingan data yang benar diklasifikasikan dengan jumlah keseluruhan data. Perhitungan akurasi menggunakan fungsi sebagai berikut:
2 Precision
Precision merupakan fungsi dari kelas data positif yang diklasifikasikan
dengan benar dibandingkan dengan keseluruhan hasil prediksi data ke dalam kelas positif. Perhitungan precision menggunakan fungsi sebagai berikut:
s n
3 Recall
Recall merupakan fungsi dari kelas data positif yang diklasifikasikan
dengan benar dibandingkan dengan keseluruhan data kelas aktual positif. Perhitungan recall menggunakan fungsi sebagai berikut:
8
all
4 F-measure
F-measure merupakan gabungan dari precision dan recall yang digunakan
untuk mengukur kemampuan classifier dalam mengklasifikasikan kelas minoritas.
F-measure bernilai tinggi jika nilai precision dan recall juga bernilai tinggi (Han et al. 2005). Perhitungan f-measure menggunakan fungsi sebagai berikut:
all s n all s n Penerapan Model Terbaik
Tahapan selanjutnya yaitu menganalisis hasil akurasi, f-measure, precision, dan recall setiap percobaan. Percobaan yang menghasilkan nilai f-measure tertinggi akan menjadi model sebagai acuan prediksi data baru.
HASIL DAN PEMBAHASAN
Pengadaan Data
Data yang didapat merupakan data penelitian Setiawati (2011) yang digunakan untuk mengklasifikasikan nasabah ke dalam kelas baik atau buruk menggunakan jaringan saraf tiruan. Data ini juga digunakan pada penelitian Ulya (2013) menggunakan klasifikasi KNN dan Wijayanti (2013) menggunakan klasifikasi FKNN. Data ini terdiri atas 4413 instance dengan 14 atribut. 6 atribut bertipe data nominal, 1 atribut bertipe data ordinal, dan 7 atribut bertipe data rasio. Atribut bertipe data nominal dan ordinal dilambangkan dengan angka untuk mempermudah pengklasifikasian data. Keterangan atribut dapat dilihat pada Lampiran 1.
Praproses Data
Data dengan missing value, outliers, dan tidak lengkap pada tahap ini dilakukan penghapusan instance. Beberapa instance seperti pada atribut banyaknya kartu kredit lain, pendapatan, dan masa kerja dihapus karena tidak lengkap dan tidak valid. Banyaknya data menjadi 3895 yang terbagi menjadi 3259 termasuk kelas good dan 636 termasuk kelas bad. Data kemudian dinormalisasi agar rentang antardata tidak terlalu besar. Atribut yang dinormalisasi adalah atribut bertipe data rasio dengan rentang nilai yang besar seperti atribut pendapatan per tahun, persentase utang kartu kredit maksimum, usia, masa kerja, dan lama tinggal.
9
Strategi Sampling
Metode oversampling yang diterapkan pada data minoritas, menjadikan data bertambah yang kemudian digabungkan dengan data mayoritas menjadi 6518 data. Metode undersampling yang diterapkan pada data mayoritas, menjadikan data berjumlah 1272 setelah digabungkan data minoritas.
Klasifikasi dengan WKNN
Prinsip kerja WKNN mengikuti prinsip kerja KNN yaitu mencari data uji dengan jarak terdekat terhadap data latih sesuai k tetangga terdekat yang dipilih. WKNN mengubah nilai jarak pada k tetangga terdekat menjadi nilai antara 0 dan 1. Jarak terdekat akan diberi nilai 1. Sebaliknya, jarak terjauh akan diberi nilai 0. Langkah pengklasifikasian menggunakan WKNN sebagai berikut:
1 Perhitungan jarak Euclidean untuk data bertipe data rasio setelah dilakukan normalisasi.
2 Perhitungan jarak data nominal dengan membandingkan data uji dan data latih. 3 Perhitungan kedua jarak yang digabung menggunakan fungsi agregrat
ketidaksamaan berat rata-rata.
4 Penentuan jarak terdekat sesuai k tetangga terdekat.
5 Pembobotan jarak terdekat antara data uji dan data latih. Hasil klasifikasi ditentukan oleh jarak dengan bobot terbesar untuk setiap kelas yang sama.
Analisis Data Hasil Klasifikasi
Data asli yang telah melalui praproses data dan normalisasi terdiri atas 636 data kelas minoritas dan 3259 data kelas mayoritas. Data kemudian diklasifikasikan menggunakan metode WKNN. Hasil akurasi, f-measure,
precision, dan recall pada data asli dengan k tetangga terdekat ditunjukkan pada
Tabel 2. Salah satu contoh hasil klasifikasi pengujian ke-8 pada data asli dapat dilihat pada Lampiran 2.
Hasil klasifikasi terbaik pada data asli yang tidak melalui proses sampling menghasilkan nilai akurasi sebesar 75.22%, nilai precision sebesar 0.81%, dan nilai recall sebesar 0.47%. Hasil precision terbaik pada data asli dengan 10 tetangga terdekat dapat dilihat pada Lampiran 3, sedangkan confusion matrix pada data asli dengan nilai precision terbaik dapat dilihat pada Lampiran 4. Data asli yang tidak seimbang ini menghasilkan nilai akurasi yang besar. Hal ini disebabkan oleh kinerja akurasi yang tidak dapat mewakili kelas minoritas. Bila kelas minoritas salah diklasifikasikan, nilai akurasi tetap besar karena didominasi oleh kelas mayoritas yang benar diklasifikasikan. Nilai f-measure pada data asli berupa NaN. Nilai ini didapatkan karena adanya nilai 0 pada precision dan recall untuk beberapa bagian data dari himpunan 10-fold cross validation. Adanya nilai 0 ini menunjukkan bahwa terdapat data uji yang keseluruhan kelas minoritasnya diklasifikasikan ke dalam kelas mayoritas. Salah satu contoh confusion matrix pada data asli dengan hasil precision dan recall adalah 0 dapat dilihat pada Tabel 3.
10
Data percobaan kedua yaitu data oversampling duplikasi. Data ini terdiri atas 636 data minoritas yang diduplikasi untuk setiap instance sebanyak 4 kali. Data kemudian digabungkan dengan data asli minoritas dan mayoritas sehingga 1
dataset berjumlah 6439. Hasil akurasi, f-measure, precision, dan recall dengan k
tetangga terdekat ditunjukkan pada Tabel 4. Hasil klasifikasi terbaik pada data
oversampling duplikasi memiliki nilai akurasi sebesar 84.51%, nilai f-measure
sebesar 86.44%, nilai precision sebesar 76.13%, dan nilai recall sebesar 100%. Hasil precision terbaik pada data oversampling duplikasi dengan 1 tetangga terdekat dapat dilihat pada Lampiran 5, sedangkan confusion matrix pada data
oversampling duplikasi dengan nilai precision terbaik dapat dilihat pada Lampiran
6. Hasil klasifikasi oversampling duplikasi lebih baik dibandingkan dengan hasil klasifikasi data asli.
Tabel 2 Nilai rata-rata kinerja WKNN pada data asli
Nilai k Akurasi (%) F-measure (%) Precision (%) Recall (%)
1 60.17 NaN 1.82 2.71 2 67.81 NaN 0.31 0.31 3 65.96 NaN 1.68 1.92 4 68.29 NaN 0.17 0.16 5 68.76 NaN 0.52 0.48 6 70.24 NaN 0.39 0.31 7 71.51 NaN 0.40 0.31 8 72.68 NaN 0.68 0.47 9 73.69 NaN 0.73 0.47 10 75.22 NaN 0.81 0.47
Tabel 3 Confusion matrix pada data asli untuk pengujian ke-8 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 0 64
Kelas negatif 33 295
Tabel 4 Nilai rata-rata kinerja WKNN pada data oversampling duplikasi Nilai k Akurasi (%) F-measure (%) Precision (%) Recall (%)
1 84.51 86.44 76.13 100.00 2 84.51 86.44 76.13 100.00 3 84.51 86.44 76.13 100.00 4 84.51 86.44 76.13 100.00 5 84.49 86.43 76.11 100.00 6 84.20 86.19 75.80 99.90 7 82.95 85.24 74.45 99.71 8 80.79 83.65 72.16 99.52 9 79.73 82.83 71.19 99.05 10 79.50 82.64 71.00 98.86
11
Data percobaan ketiga yaitu data oversampling acak. Data ini terdiri atas 636 data minoritas yang diduplikasi secara acak setiap atribut independen sehingga jumlahnya menjadi 3259. Data kemudian digabungkan dengan data asli mayoritas sehingga 1 dataset berjumlah 6518 data. Hasil akurasi, f-measure,
precision, dan recall dengan k tetangga terdekat ditunjukkan pada Tabel 5. Hasil
Tabel 5 Nilai rata-rata kinerja WKNN pada data oversampling acak Nilai k Akurasi (%) F-measure (%) Precision (%) Recall (%)
1 84.58 86.51 76.73 99.22 2 82.53 84.37 76.14 94.67 3 83.48 85.36 76.47 96.69 4 83.48 85.36 76.47 96.69 5 83.43 85.33 76.42 96.69 6 83.11 85.07 76.10 96.53 7 82.72 84.76 75.72 96.36 8 81.93 84.14 74.90 96.09 9 81.11 83.48 74.13 95.66 10 80.21 82.77 73.22 95.28
Tabel 6 Nilai rata-rata kinerja WKNN pada data undersampling acak Nilai k Akurasi (%) F-measure (%) Precision (%) Recall (%)
1 55.74 57.82 55.21 60.87 2 54.32 52.26 54.59 50.33 3 55.50 56.08 55.29 57.09 4 56.13 57.38 55.75 59.30 5 56.21 57.99 55.68 60.71 6 56.29 58.25 55.75 61.18 7 56.37 58.69 55.75 62.12 8 56.68 58.99 56.04 62.44 9 56.84 59.34 56.13 63.07 10 56.60 59.64 55.80 64.17
Tabel 7 Nilai rata-rata kinerja WKNN pada data cluster undersampling Nilai k Akurasi (%) F-measure (%) Precision (%) Recall (%)
1 75.01 74.42 75.92 73.28 2 75.01 74.42 75.92 73.28 3 75.01 74.42 75.92 73.28 4 75.24 75.00 75.70 74.54 5 75.31 75.03 76.00 74.38 6 74.53 74.15 75.34 73.28 7 75.08 74.84 75.68 74.38 8 74.69 74.55 74.99 74.39 9 73.67 73.36 74.23 72.81 10 73.67 73.26 74.40 72.50
12
klasifikasi terbaik pada data oversampling acak memiliki nilai akurasi sebesar 84.58%, nilai f-measure sebesar 86.51%, nilai precision sebesar 76.73%, dan nilai
recall sebesar 99.22%. Hasil precision terbaik pada data oversampling acak
dengan 1 tetangga terdekat dapat dilihat pada Lampiran 7, sedangkan confusion
matrix pada data oversampling acak dengan nilai precision terbaik dapat dilihat
pada Lampiran 8. Hasil recall oversampling acak tidak lebih baik dibandingkan dengan oversampling duplikasi. Metode oversampling acak menghasilkan nilai klasifikasi terbaik dibandingkan dengan metode sampling yang lain. Metode terbaik ini menjadi acuan dalam penentuan penerimaan nasabah kartu kredit yang baru.
Data percobaan keempat yaitu data undersampling acak. Pada percobaan ini, data mayoritas sebanyak 3259 dibangkitkan secara acak untuk setiap atribut independen sehingga jumlahnya menjadi 636. Data kemudian digabungkan dengan data asli minoritas sehingga 1 dataset berjumlah 1272 data. Percobaan
undersampling acak dilakukan sebanyak 3 kali kemudian diambil hasil terbaik.
Nilai akurasi, f-measure, precision, dan recall dengan k tetangga terdekat ditunjukkan pada Tabel 6. Hasil klasifikasi terbaik pada data undersampling acak memiliki nilai akurasi sebesar 56.84%, nilai f-measure sebesar 59.34%, nilai
precision sebesar 56.13%, dan nilai recall sebesar 63.07%. Hasil precision terbaik
pada data undersampling acak dengan 9 tetangga terdekat dapat dilihat pada Lampiran 9, sedangkan confusion matrix pada data undersampling acak dengan nilai precision terbaik dapat dilihat pada Lampiran 10. Hasil klasifikasi ini lebih baik dibandingkan dengan hasil klasifikasi pada data asli.
Data percobaan kelima yaitu data cluster undersampling. Pada percobaan ini, data mayoritas dibagi ke dalam 2 hingga 10 cluster. Setiap cluster kemudian dicari nilai proporsi terhadap data minoritas. Pembangkitan data mayoritas secara acak mengikuti nilai proporsinya pada data minoritas. Data ini kemudian digabungkan dengan data asli minoritas. Jumlah 1 dataset cluster undersampling yaitu 1272. Nilai akurasi, f-measure, precision, dan recall dengan k tetangga terdekat ditunjukkan pada Tabel 7. Hasil klasifikasi terbaik didapatkan saat 2
cluster dengan nilai akurasi sebesar 75.31%, nilai f-measure sebesar 75.03%, nilai precision sebesar 76.00%, dan nilai recall sebesar 74.38%. Hasil precision terbaik
pada data cluster undersampling dengan 5 tetangga terdekat dapat dilihat pada Lampiran 11, sedangkan confusion matrix pada data cluster undersampling dengan nilai precision terbaik dapat dilihat pada Lampiran 12.
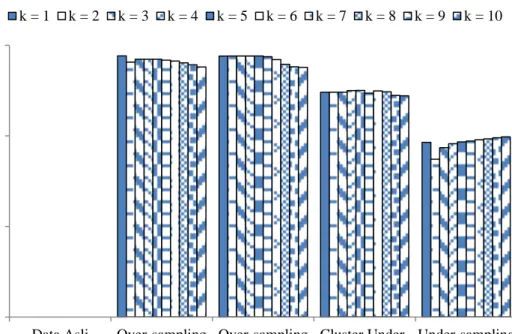
Data asli menghasilkan nilai f-measure yang tak terdefinisikan pada semua nilai k. Nilai f-measure pada data oversampling acak cenderung menurun ketika nilai k ditingkatkan. Hal ini juga berlaku pada data oversampling duplikasi. Nilai
f-measure pada data cluster undersampling cenderung meningkat ketika nilai k
tetangga terdekat ditingkatkan. Data undersampling acak menghasilkan nilai
f-measure yang stabil seiring peningkatan nilai k tetangga terdekat. Grafik
peningkatan f-measure untuk setiap data ditunjukkan pada Gambar 2.
Perbandingan dengan Penelitian Sebelumnya
Perbandingan hasil klasifikasi dari penelitian Ulya (2013) dan Wijayanti (2013) dengan penelitian ini dapat dilihat pada Tabel 8. Hasil klasifikasi data asli
13
yang tidak dilakukan sampling pada ketiga penelitian sangat rendah, setelah dilakukan sampling terjadi peningkatan hasil klasifikasi. Nilai recall pada
oversampling duplikasi dan oversampling acak pada penelitian ini lebih baik
dibandingkan dengan penelitian sebelumnya yaitu sebesar 100% dan 99.2%. Hal ini menunjukkan bahwa persentase data kelas minoritas yang bisa diklasifikasikan dengan benar menggunakan WKNN lebih besar dibandingkan dengan KNN dan
Gambar 2 Grafik f-measure setiap model data penelitian WKNN Tabel 8 Perbandingan dengan penelitian sebelumnya
Classifier Sampling Akurasi
(%) F-Measure (%) Precision (%) Recall (%) KNN Data asli 80.87 29.81 28.86 42.19 Oversampling duplikasi 96.24 99.23 95.21 96.30 Oversampling acak 84.27 83.91 86.23 90.40 Undersampling acak 77.28 75.99 82.86 83.60 Cluster undersampling 66.66 68.87 67.52 81.45 FKNN Data asli 79.05 22.64 25.68 15.59 Oversampling duplikasi 91.93 92.54 86.12 100.00 Oversampling acak 84.37 84.04 85.82 82.34 Undersampling acak 75.71 75.34 78.44 71.05 Cluster undersampling 76.33 72.43 78.27 72.80 WKNN
Data asli 75.22 NaN 0.81 0.47
Oversampling duplikasi 84.51 86.44 76.13 100.00 Oversampling acak 84.58 86.51 76.73 99.22 Undersampling acak 56.84 59.34 56.13 63.07 Cluster undersampling 75.31 75.03 76.00 74.38 0 30 60 90
Data Asli Over-sampling Acak Over-sampling Duplikasi Cluster Under-sampling Under-sampling Acak k = 1 k = 2 k = 3 k = 4 k = 5 k = 6 k = 7 k = 8 k = 9 k = 10
14
FKNN. Nilai f-measure oversampling acak pada penelitian ini sebesar 86.51% juga lebih baik dibandingkan dengan nilai f-measure oversampling acak pada penelitian sebelumnya. Hasil klasifikasi undersampling pada penelitian ini tidak lebih baik dibandingkan dengan penelitian sebelumnya.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, simpulan yang didapat yaitu: 1 Penelitian sebelumnya menggunakan KNN dan FKNN pada metode
oversampling duplikasi menghasilkan nilai akurasi yang lebih baik
dibandingkan dengan metode oversampling acak. Penelitian menggunakan WKNN pada metode oversampling duplikasi menghasilkan nilai akurasi yang hampir sama dengan oversampling acak.
2 Nilai akurasi pada metode oversampling duplikasi menggunakan KNN dan FKNN lebih baik dibandingkan dengan WKNN.
3 Pola nilai f-measure pada penelitian ini untuk metode oversampling duplikasi dan oversampling acak sama dengan pola nilai akurasi.
4 Nilai recall untuk metode oversampling duplikasi dan oversampling acak menggunakan WKNN lebih baik dibandingkan dengan KNN dan FKNN. 5 Klasifikasi pada metode undersampling acak menggunakan WKNN
menghasilkan nilai yang kurang baik dibandingkan dengan KNN dan FKNN.
Saran
Penelitian selanjutnya diharapkan dapat menerapkan metode classifier lain seperti distance weighted k-nearest neighbor (DWKNN) yang merupakan pengembangan dari WKNN dengan cara pembobotan berbeda. Hasil penelitian Gou et al. menunjukkan bahwa DWKNN menghasilkan nilai akurasi yang lebih baik dibandingkan dengan WKNN pada data seimbang.
DAFTAR PUSTAKA
Dasu T, Johnson T. 2003. Exploratory Data Mining and Data Cleaning. New Jersey (US). J Wiley.
Dudani SA. 1976. The distance-weighted k-nearest neighbor rule. IEEE
Transactions on System, Man, and Cybernetics. SMC-6(4): 325-327.
Efendiev Y, Hou TY. 2009. Multiscale Finite Element Methods: Theory and
Applications. New York (US). Springer.
Garcia V, Sanchez JS, Mollineda RA, Alejo R, Sotoca JM. 2007. The class imbalance problem in pattern classification and learning. DI dalam: II
15 Zaragoza. hlm 283-291; [diunduh 2014 Jan 20]. Tersedia pada: http://marmota.dlsi.uji.es/WebBIB/papers/2007/1GarciaTamida2007.pdf. Gou J, Du L, Zhang Y, Xiong T. 2012. A new distance-weighted k-nearest
neighbor classifier. Journal of Informational and Computational Science (9) [Internet]. [diunduh 2013 Okt 24]; 6(2012):1429-1436. Tersedia pada: http://www.joics.com/publishedpapers/2012_9_6_1429_1436.pdf.
Han H, Wang WY, Mao BH. 2005. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. Di dalam: Huang DS, Zhang XP, Huang GB, editor. International Conference in Intelligent Computing. ICIC; 2005 Agu 23-26; Hefei, China. Berlin (DE): Springer Berlin Heidelberg. hlm 878-887.
Kohavi R. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. International Joint Conference on Artificial Intelligence. 1995 Agu 20-25; Quebec, Kanada. Quebec (CA): Morgan Kauffman. hlm 1137-1145.
Larose DT. 2005. Discovering Knowledge in Data: An Introduction to Data
Mining. New Jersey (US). J Wiley.
Pao TL, Liao WY, Chen YT. 2008. A weighted discrete KNN method for mandarin speech and emotion recognition. Di dalam: Mihelic F, Zibert J, editor.
Speech Recognition Technologies and Applications. I-Tech; 2008 Nov 1;
Vienna, Austria. Vienna (AT): I-Tech. hlm 550-552.
Setiawati AP. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang (studi kasus debitur kartu kredit Bank Mandiri tahun 2008-2009) [skripsi]. Bogor (ID): Institut Pertanian Bogor. Teknomo K. 2006. Similarity measurement [internet]. [diunduh 2013 Nov 27].
Tersedia pada: http://people.revoledu.com/kardi/tutorial/Similarity/Aggregate Distances.html.
Ulya F. 2013. Klasifikasi debitur kartu kredit menggunakan algoritme k-nearest
neighbor untuk kasus imbalanced data [skripsi]. Bogor (ID): Institut Pertanian
Bogor.
Wijayanti R. 2013. Klasifikasi nasabah kartu kredit menggunakan algoritme fuzzy
k-nearest neighbor pada data tidak seimbang [skripsi]. Bogor (ID): Institut
Pertanian Bogor.
Yen SJ, Lee YS. 2009. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Systems with Applications. 36(3):5718-5727.doi: 10.1016/j.eswa.2008.06.108.
Zavrel J. 1997. An empirical re-examination of weighted voting for K-NN. Di dalam: Daelemans W, Flach P, van den Bosch A, editor. Proceedings of the 7th
Belgian-Dutch Conference on Machine Learning [Internet]. [Waktu dan tempat
pertemuan tidak diketahui]. Tilburg (NL): TILBURG. hlm 139-148. [diunduh 2014 Jan 20]. Tersedia pada: http://citeseerx.ist.psu.edu/viewdoc/download? doi=10.1.1.36.573&rep=rep1&type=pdf.
16
Lampiran 1 Keterangan lengkap atribut
Tipe Data Nama Atribut Keterangan
Nominal Jenis Kelamin 1 = Pria
2 = Wanita
Status Pernikahan 1 = Lajang
2 = Menikah 3 = Bercerai
Tipe Perusahaan 1 = Kontraktor
2 = Konversi 3 = Industri berat 4 = Pertambangan 5 = Jasa
6 = Transportasi
Status Pekerjaan 1 = Permanen
2 = Kontrak Pekerjaan 1 = Konversi 2 = PNS 3 = Profesional 4 = Wiraswasta 5 = Perusahaan swasta
Status Rumah 0 = Bukan milik sendiri
1 = Milik sendiri
Ordinal Pendidikan 1 = SMP/SMA
2 = Akademi 3 = S1/S2
Rasio Pendapatan Rupiah per tahun
Jumlah Tanggungan Satuan
Banyaknya Kartu Kredit Lain Satuan Persentase Utang Kartu Kredit
Lain Persen
Usia Tahun
Masa Kerja Bulan
Lama Tinggal Bulan
Lampiran 2 Hasil klasifikasi data asli dalam % untuk data uji ke-8 dengan k tetangga terdekat
Nilai k Akurasi F-Measure Precision Recall
1 60.46 6.06 4.95 7.81
2 68.11 NaN 0.00 0.00
17 Lampiran 2 Hasil klasifikasi data asli dalam % untuk data uji ke-8 dengan k
tetangga terdekat (lanjutan)
Nilai k Akurasi F-Measure Precision Recall
4 67.86 NaN 0.00 0.00 5 68.62 1.60 1.64 1.56 6 69.39 NaN 0.00 0.00 7 70.66 NaN 0.00 0.00 8 71.68 NaN 0.00 0.00 9 72.70 NaN 0.00 0.00 10 75.26 NaN 0.00 0.00
Lampiran 3 Nilai precision data asli dengan 10 tetangga terdekat Data Uji ke-k Precision (%)
1 0.00 2 0.00 3 2.94 4 2.70 5 0.00 6 0.00 7 2.50 8 0.00 9 0.00 10 0.00
Lampiran 4 Confusion matrix data asli untuk data uji ke-3 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 1 63
Kelas negatif 33 296
Lampiran 5 Nilai precision data oversampling duplikasi dengan 1 tetangga terdekat
Data Uji ke-k Precision (%)
1 75.90 2 77.02 3 75.90 4 74.64 5 75.36 6 76.64 7 78.82 8 75.18 9 77.40 10 74.41
18
Lampiran 6 Confusion matrix data oversampling duplikasi untuk data uji ke-7 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 346 0
Kelas negatif 115 211
Lampiran 7 Nilai precision data oversampling acak dengan 1 tetangga terdekat Data Uji ke-k Precision (%)
1 76.96 2 76.89 3 76.85 4 77.59 5 77.38 6 82.98 7 69.78 8 78.02 9 74.77 10 76.11
Lampiran 8 Confusion matrix data oversampling acak untuk data uji ke-6 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 334 23
Kelas negatif 83 212
Lampiran 9 Nilai precision data undersampling acak dengan 9 tetangga terdekat Data Uji ke-k Precision (%)
1 56.94 2 58.57 3 56.52 4 58.21 5 56.25 6 53.75 7 56.58 8 54.93 9 52.78 10 56.76
Lampiran 10 Confusion matrix data undersampling acak untuk data uji ke-2 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 42 21
19 Lampiran 11 Nilai precision data cluster undersampling dengan 5 tetangga
terdekat
Data Uji ke-k Precision (%)
1 81.48 2 76.12 3 76.81 4 79.66 5 83.02 6 73.02 7 77.94 8 68.85 9 73.44 10 69.70
Lampiran 12 Confusion matrix data cluster undersampling untuk data uji ke-5 Kelas aktual Kelas hasil klasifikasi
Kelas positif Kelas negatif
Kelas positif 37 27
20
RIWAYAT HIDUP
Penulis dilahirkan di Bekasi pada tanggal 6 April 1991. Penulis merupakan anak pertama pasangan Ir H Solichin, MMSI dan Hj Bonita Anugrawati. Penulis merupakan lulusan dari MAN 4 Model Jakarta (2006-2009), MTs Islam Ngruki Sukoharjo (2003-2006), dan MI Pembangunan UIN Jakarta (1997-2003).
Penulis diterima sebagai mahasiswa Ilmu Komputer Institut Pertanian Bogor pada tahun 2009 melalui jalur Undangan Seleksi Masuk IPB (USMI). Selama menjadi mahasiswa, penulis menjadi panitia dalam Masa Perkenalan Fakultas Matematika dan Ilmu Pengetahuan Alam (MPF-MIPA) dan Masa Perkenalan Departemen Ilmu Komputer (MPD-Ilkom) pada tahun 2011. Penulis menjalani praktik kerja lapang di Departemen Planning & Scheduling PT Rajawali Citra Televisi Indonesia, Jakarta Barat pada bulan Juni sampai Agustus 2012. Penulis juga aktif menjadi anggota Serambi Ruhiyah Mahasiswa FMIPA (SERUM-G) pada tahun yang sama.