PERBANDINGAN
OVERSAMPLING
DUPLIKASI TERHADAP
OVERSAMPLING
ACAK PADA ALGORITME
K-NEAREST
NEIGHBOUR
UNTUK KASUS
IMBALANCED DATA
MEITANISYAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Oversampling Duplikasi Terhadap Oversampling Acak pada Algoritme K-Nearest Neighbour untuk Kasus Imbalanced Data adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Oktober 2014
ABSTRAK
MEITANISYAH. Perbandingan Oversampling Duplikasi terhadap Oversampling Acak pada Algoritme K-Nearest Neighbour untuk Kasus Imbalanced Data. Dibimbing oleh AZIZ KUSTIYO.
Imbalanced class dapat memberikan dampak yang buruk terutama kecenderungan kelas data menjadi tidak merata. Hal ini menyebabkan data akan lebih condong ke bagian data yang memiliki komposisi data yang lebih besar dan mengabaikan kelas data yang kecil. Padahal kelas data kecil inilah yang terkadang memiliki informasi penting walaupun lebih sulit diprediksi dari pada kelas data yang besar. Selain itu, imbalanced class juga dapat menyebabkan kinerja classifier yang semakin menurun. Penyelesaian imbalanced data akan dilakukan dengan memodifikasi dataset dengan cara menduplikasi dan mengacak data secara oversampling. Pada penelitian, ini akan dibuat suatu perbandingan antara oversampling acak terhadap oversampling duplikasi. Perbandingan oversampling ini dilakukan menggunakan klasifikasi k-nearest neighbour. Hasil penelitian menunjukkan bahwa oversampling duplikasi memiliki kinerja lebih baik daripada oversampling acak, tetapi oversampling acak memiliki selisih nilai f-measure yang tidak berbeda jauh dibandingkan dengan oversampling duplikasi.
Kata Kunci:F-measure, Imbalanced data, K-Nearest Neighbour,Oversampling.
ABSTRACT
MEITANISYAH. Comparison of Random Oversampling and Duplication Oversampling in K-Nearest Neighbour for Imbalanced Case. Supervised by AZIZ KUSTIYO .
Imbalanced class can give negative effect, especially the tendency of the data classes becomes imbalanced. It causes the data will be more inclined to the majority class composition and ignore the minority class. But, minority class sometimes has important information even more difficult to predict than the majority class. In addition, it can also decrease the classifier performance of imbalanced class. The solution will be done by modifying the dataset using duplication oversampling and random oversampling. In this study, a comparison will be made between the random oversampling and duplication oversampling. In this study, we use k-nearest neighbour as the clasifier. The results show that duplication oversampling has better performance than random oversampling, but random oversampling. However, the f-measure of random oversampling is slightly different compared to that of the duplication oversampling.
PERBANDINGAN
OVERSAMPLING
DUPLIKASI TERHADAP
OVERSAMPLING
ACAK PADA ALGORITME
K-NEAREST
NEIGHBOUR
UNTUK KASUS
IMBALANCED DATA
MEITANISYAH
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji : 1. Toto Haryanto, SKom MSi
Judul Skripsi : Perbandingan Oversampling Duplikasi Terhadap Oversampling Acak pada Algoritme K-Nearest Neighbour untuk Kasus Imbalanced Data Nama : Meitanisyah
NIM : G64090021
Disetujui oleh
Aziz Kustiyo, SSi, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji syukur kehadirat Allah subhanahu wa ta'ala yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan skripsi yang
berjudul “Perbandingan Oversampling Duplikasi Terhadap Oversampling Acak pada Algoritme K-Nearest Neighbour untuk Kasus Imbalanced Data”. Skripsi ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Departemen Ilmu Komputer, Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan dukungannya. Ungkapan terima kasih juga disampaikan kepada Bapak Aziz Kustiyo SSi MKom selaku pembimbing yang telah memberikan arahan, bimbingan, saran dan motivasi dengan sabar dan membantu penulis dalam menyelesaikan skripsi ini, teman-teman satu bimbingan, serta Ilkomerz 46 atas bantuan, saran, kritik, dan dukungannya kepada penulis. Semoga karya ilmiah ini bermanfaat.
Bogor, Oktober 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 1 Manfaat Penelitian 1 Ruang Lingkup Penelitian 2 TINJAUAN PUSTAKA 2 Klasifikasi 2 Imbalanced Data 2 Teknik Sampling 2 METODE PENELITIAN 3
Kerangka Penelitian 3 Pengadaan Data 4 Praproses Data 4 Normalisasi data 4 Oversampling 5 Pembagian Data Uji dan Data Latih 5 Algoritme K-Nearest Neighbour 6 Confusion Matrix 6 Analisis Hasil Klasifikasi 7 HASIL DAN PEMBAHASAN 8 Kinerja KNN 8 Kinerja Terbaik KNN 13
Perbandingan Grafik dan Tabel Kinerja KNN 14
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 15
DAFTAR PUSTAKA 15
LAMPIRAN 16
DAFTAR TABEL
1 Spesifikasi data 4 2 Confusion matrix dua kelas 6
3 Hasil akurasi rata-rata (%) data prediksi gaji 8 4 Hasil precision rata-rata (%) data prediksi gaji 8 5 Hasil recall rata-rata (%) data prediksi gaji 9 6 Hasil f-measure rata-rata (%) data prediksi gaji 9 7 Hasil akurasi rata-rata (%) data pemasaran kredit lancar/tidak 10 8 Hasil precision rata-rata (%) data pemasaran kredit lancar/tidak 10 9 Hasil recall rata-rata (%) data pemasaran kredit lancar/tidak 10 10 Hasil f-measure rata-rata (%) data pemasaran kredit lancar/tidak 11 11 Hasil akurasi rata-rata (%) data kreditur bank baik/buruk 11 12 Hasil precision rata-rata (%) data kreditur bank baik/buruk 12 13 Hasil recall rata-rata (%) data kreditur bank baik/buruk 12 14 Hasil f-measure rata-rata (%) data kreditur bank baik/buruk 12
DAFTAR GAMBAR
1 Kerangka penelitian 3
2 Rata-rata setiap crossvalidation grafik akurasi, precision, recall dan f-measure pada data prediksi gaji
13
3 Rata-rata setiap cross validation grafik akurasi, precision, recall dan f-measure pada data pemasaran kredit lancar / macet
13
4 Rata-rata setiap crossvalidation grafik akurasi, precision, recall dan f-measure pada data kreditur bank baik / buruk
14
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Ada dua kondisi pada himpunan data yaitu data seimbang dan data tidak seimbang. Data seimbang merupakan kondisi distribusi data pada dua kelas mendekati sama dan data tidak seimbang merupakan kondisi sebuah himpunan data yang terdapat satu kelas memiliki jumlah instance yang lebih kecil dibandingkan kelas lainnya (Chawla 2003). Imbalanced class dapat memberikan dampak yang buruk terutama kecenderungan kelas data menjadi tidak merata. Hal ini terjadi karena data akan lebih condong ke bagian data yang memiliki komposisi data yang lebih besar dan mengabaikan kelas data yang kecil. Padahal kelas data kecil inilah yang terkadang memiliki informasi penting walaupun lebih sulit diprediksi dari pada kelas data yang besar. Penyelesaian imbalanced data akan dilakukan dengan memodifikasi dataset dengan cara menduplikasi dan mengacak data secara oversampling.
Dengan adanya penerapan sampling pada data yang imbalanced, tingkat imbalanced semakin kecil dan klasifikasi dapat dilakukan dengan tepat (Laurikkala 2001). Adapun, teknik oversampling dilakukan agar dapat menyeimbangkan distribusi data melalui peningkatan jumlah data kelas minor. Berbagai penelitian dilakukan untuk mengatasi permasalahan klasifikasi data tidak seimbang. Salah satu penelitian yang dilakukan oleh Wijayanti (2013) yang menggunakan metode fuzzy k-nearest neighbor dan penelitian oleh Anggraini (2013) menggunakan algoritme C. 45 dan CART serta penelitian oleh Ulya (2013) menggunakan k-nearest neighbour. Jika dilihat dari beberapa penelitian-penelitian sebelumnya terdapat perbedaan cukup besar antara nilai oversampling duplikasi terhadap oversampling acak. Pada penelitian ini akan dibuat suatu perbandingan antara oversampling acak terhadap oversampling duplikasi. Perbandingan oversampling ini dilakukan menggunakan klasifikasi k-nearest neighbour. Sebelumnya, penelitian ini menggunakan data yang sama dilakukan oleh Anggraini (2013) menggunakan algoritme C. 45 dan CART ditambah dengan data kasus imbalanced class lainnya. Penelitian ini diharapkan dapat membantu berbagai pihak sebagai pertimbangan dalam meminimalisir data imbalanced agar menjadi lebih balance. Hasil akhirnya adalah mengetahui bagaimana pengaruh metode oversampling duplikasi dan oversampling acak dari beberapa imbalanced data.
Tujuan Penelitian
Penelitian ini bertujuan untuk membandingkan hasil akurasi, precision, recall, f-measure pada oversampling duplikasi dan oversampling acak terhadap algoritme k-nearest neighbour pada kasus imbalanced data.
Manfaat Penelitian
Ruang Lingkup Penelitian
Ada tiga jenis data yang digunakan antara lain data penelitian UCI Machine Learning Database , data Ronny Kohavi dan Barry Becker 5 Jan 1996 pada situs http://archive. ics. uci. edu/ml/datasets/Adult tentang prediksi pendapatan yang melebihi $50K/yr, penelitian S. Moro, Laureano dan Cortez tentang pemasaran bank pada situs http://archive. ics. uci. edu/ml/datasets/Bank+Marketing
dan penelitian Anggraini (2013), yaitu data debitur Bank X mengenai status kelancaran pembayaran utang kartu kredit tahun 2008-2009.
TINJAUAN PUSTAKA
Klasifikasi
Klasifikasi adalah proses penemuan model (fungsi) yang menggambarkan dan membedakan kelas data atau konsep yang bertujuan agar bisa digunakan untuk memprediksi kelas dari objek yang label kelasnya tidak diketahui (Han dan Kamber 2006). Klasifikasi data terdiri dari 2 langkah proses. Pertama adalah learning (fase training), algoritme klasifikasi dibuat untuk menganalisa data training lalu direpresentasikan dalam bentuk rule klasifikasi. Proses kedua adalah klasifikasi data testing digunakan untuk memperkirakan akurasi dari rule klasifikasi (Han dan Kamber 2006). Proses klasifikasi didasarkan pada empat komponen (Gorunescu 2011). Pertama, kelas merupakan variabel dependen yang
berupa kategorikal yang merepresentasikan „label‟ yang terdapat pada objek. Kedua, predictor merupakan variabel independen yang direpresentasikan oleh karakteristik (atribut) data. Ketiga, training dataset adalah satu set data yang berisi nilai dari kedua komponen di atas yang digunakan untuk menentukan kelas yang cocok berdasarkan predictor. Keempat, testing dataset terdapat data baru yang akan diklasifikasikan oleh model yang telah dibuat dan akurasi klasifikasi dievaluasi Klasifikasi merupakan proses menemukan sekumpulan model (fungsi) yang menggambarkan dan membedakan konsep atau kelas-kelas data, dengan tujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han dan Kamber 2006).
Imbalanced Data
Sebuah himpunan data dikatakan menjadi tidak seimbang (imbalanced) jika terdapat satu kelas yang direpresentasikan dalam jumlah instance yang kecil bila dibandingkan dengan jumlah instance kelas yang lainnya. Pengaruh penggunaan data tidak seimbang untuk membuat model sangat besar pada hasil model yang diperoleh. Pengolahan algoritme yang tidak menghiraukan ketidakseimbangan data akan cenderung diliputi oleh kelas mayor dan mengacuhkan kelas minor (Chawla 2003).
Teknik Sampling
Representatif Oversampling seringkali lebih baik daripada undersampling karena pada oversampling semua informasi yang ada di training set disimpan sedangkan pada undersampling ada banyak informasi yang dibuang (Margono 2004). Pada oversampling acak data minoritas dibangkitkan secara acak per fitur-nya dari total keseluruhan data menggunakan minitab yang jumlah instances-nya sebanyak data mayoritas. Oversampling duplikasi dilakukan dengan mereplikasi secara langsung semua instance kelas minoritas sebanyak data mayoritas.
METODOLOGI
Kerangka Penelitian
Alur tahapan metode penelitian yang dilakukan dapat dilihat pada Gambar 1.
Gambar 1 Kerangka penelitian Pengadaan Data
Normalisasi Data
Oversampling
Pembagian Data 10- fold dan 5-fold cross validation Data Uji
Klasifikasi k-nearest neighbour
Analisis Hasil Klasifikasi Penerapan Model Terbaik
Selesai Data Latih
Mulai
Oversampling Acak Oversampling duplikasi
Praproses Data
Prediksi Gaji
Pemasaran Kredit
Pengadaan Data
Penelitian ini menggunakan data penelitian UCI Machine Learning Database yaitu data Ronny Kohavi dan Barry Becker 5 januari 1996 pada situs http://archive. ics. uci. edu/ml/datasets/Adult tentang prediksi pendapatan yang melebihi $50K/yr yang berdasarkan data sensus. Juga dikenal sebagai "Sensus Penghasilan" dataset. Data yang diamati berjumlah 32 561 dengan 9 atribut.
Penelitian S. Moro, R. Laureano dan P. Cortez tentang pemasaran bank pada situs http://archive.ics.uci.edu/ml/datasets/Bank+Marketing. Data yang diamati berjumlah 4 521 dengan 16 atribut.
Selanjutnya data hasil penelitian Anggraini (2013), yaitu data debitur Bank X mengenai status kelancaran pembayaran utang kartu kredit tahun 2008-2009. Data yang diamati berjumlah 3 895 dengan 14 atribut, untuk 3 259 termasuk kedalam kategori debitur baik, yaitu debitur yang tepat membayar hutangnya dalam kurun waktu 90 hari serta 636 debitur buruk yang menunggak utang lebih dari 90 hari.
Praproses Data
Ketidakseimbangan yang terjadi pada masing-masing kelas negative memiliki jumlah yang jauh lebih besar dibandingkan dengan kelas positive, sehingga harus dilakukan modifikasi distribusi data dengan teknik oversampling Dalam penelitian ini, teknik oversampling dilakukan dengan 3 data. Adapun tahapan praproses yaitu ketiga data mengalami pengurangan jumlah instance. Setiap instance yang nilai feature pdays, previous, campaign, duration, day, balance, previous dan stay yang tidak lengkap (tidak diketahui) tidak digunakan. Nilai feature tsb tidak digunakan karena nilainya banyak yang tidak diketahui. Dari hasil analisis data yang dilakukan, tidak semua atribut memiliki nilai yang lengkap, data yang terdapat missing value tidak digunakan dalam proses klasifikasi. Selain itu, data yang mengdanung nilai fitur tidak valid seperti 0 atau 1 pada fitur pendapatan, -1 pada fitur misalnya masa kerja dan lama tinggal juga tidak digunakan. Kelengkapan atribut ini menentukan seberapa baik hasil dari klasifikasi. Jumlah instance kedua kelas berkurang setelah praproses data. Setelah penghapusan data, jumlah data yang digunakan penelitian ini disajikan pada Tabel 1.
Normalisasi Data
Normalisasi dilakukan pada atribut data numerik yang memiliki pengaruh terhadap atribut berskala kecil dengan skala nilai antara 0.0 sampai 1.0. Normalisasi dapat mengatasi atribut yang memilki nilai rentang yang cukup besar (misalnya atribut pendapatan). Adapun atribut-atribut yang digunakan pada data kreditur bank baik / buruk terdapat pada Lampiran 1. Banyak metode digunakan untuk normalisasi data antara lain min-max normalization yang digunakan pada penelitian ini (Han dan Kamber 2006). Min-maxnormalization melakukan transformasi linear
data asli. Untuk melakukan normalisasi, perlu mengetahui minimum (Xmin) dan maksimum (Xmax) dari data (Chipman et al. 1998):
Xnorm=
Dengan Xnorm adalah nilai hasil normalisasi, X nilai sebelum normalisasi, Xmin nilai minimun dari fitur, dan Xmax nilai maksimum dari fitur.
Oversampling
Setelah itu dilakukan pendekatan sampling technique pada ketiga data tersebut yaitu oversampling duplikasi dan oversampling acak. Oversampling duplikasi yang dilakukan dengan mereplikasi secara langsung semua instance kelas positive sehingga mendekati jumlah instances pada kelas negative. Misalnya pada data prediksi gaji jumlah instances kelas positive yang awalnya 7 841 direplikasi tiga kali sehingga menjadi 23 523 dan jumlah instances negative-nya 24 720. Begitu juga dengan pemasaran kredit jumlah instances kelas positive yang awalnya 521 direplikasi sebanyak tujuh kali sehingga menjadi 3 647 dan jumlah instancesnegative-nya 4 000. Pada oversampling acak data dibangkitkan per fitur dari total keseluruhan data menggunakan Minitab yang jumlah instances-nya sama dengan jumlah pada kelas negative (mayoritas). Kemudian menggabungkan nilai yang telah dibangkitkan tersebut dengan kelas positive (minoritas). Misalnya pada data prediksi gaji total data 32 561 diacak, dan dibangkitkan menjadi berjumlah 24 720 dengan menggunakan Minitab lalu digabungkan dengan data minoritas yang berjumlah 7 841 sehingga data keseluruhan tetap berjumlah 32 561. Lalu data tersebut diproses dengan softwere Weka untuk memperoleh hasil akurasi, precision, recall, dan f-measure.
Pembagian Data Uji dan Data Latih
Algoritme K-Nearest Neighbour
Algoritme KNN merupakan teknik yang lebih fleksibel karena mampu mengklasifikasikan data uji kedalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al. 2006). KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing (Wu dan Kumar 2009). Tujuan dari algoritme KNN adalah untuk mengklasifikasi objek baru berdasarkan atribut dan training sampel (Larose 2005). Pada proses pengklasifikasian, jarak yang digunakan adalah jarak euclidean distance. Jarak euclidean adalah jarak yang paling umum digunakan pada data (Goujon et al. 2007). Euclidean distance didefinisikan sebagai berikut (Han dan Kamber 2006):
d (xi , xj) = √∑ 2
Penggunaan rumus jarak euclidean tidak tepat digunakan untuk atribut bertipe nominal. Berbeda dengan atribut misalnya pendidikan termasuk atribut ordinal tetap dihitung dengan rumus perhitungan jarak euclidean karena nilai tingkatan tinggi rendahnya pendidikan masih relevan dengan konsep perhitungan jarak euclidean (Goujon et al. 2007)
Confusion Matrix
Evaluasi dengan confusion matrix menghasilkan nilai accuracy, precision, recall, dan f-measure (Han dan Kamber 2006). Tabel confusion matrix dapat dilihat pada Tabel 2 dibawah ini.
Tabel 2 Model confusion matrix (Han dan Kamber 2006)
Confusion matrix pada tabel 2 biasanya terbentuk dari tabel 2x2 untuk baris pertama adalah nilai true positive (TP) dan false positive (FP) , kemudian berisi false negative (FP) dan true negative (TN). Untuk perhitungannya digunakan persamaan di bawah ini (Han dan Kamber 2006).
1 Akurasi dalam klasifikasi
Akurasi adalah presentase ketepatan record data yang diklasifikasikan secara benar setelah dilakukan pengujian pada hasil klasifikasi ( Han dan Kamber 2006). Untuk menghitung akurasi, digunakan fungsi sebagai berikut:
Akurasi (Ac) yang seharusnya termasuk kelas positive tetapi dikelaskan sebagai kelas negative Precision digunakan untuk mengukur seberapa besar proporsi dari kelas data positive yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positive. Untuk menghitung precision, digunakan fungsi sebagai berikut:
Precision (P)
Persentase antara data kelas negative yang dikelaskan dengan benar dan data kelas positive yang sudah diprediksi ke kelas positive. Recall digunakan untuk menunjukkan persentase kelas data positive yang berhasil diprediksi benar dari keseluruhan data kelas positive. Untuk menghitung recall, digunakan fungsi sebagai berikut: mengukur kemampuan algoritme dalam mengklasifikasikan kelas minoritas yang memiliki nilai tinggi jika nilai recall dan precision juga tinggi. Untuk menghitung f-measure, digunakan fungsi sebagai berikut:
F-measure (F)
F = 2 .
× 100%
Analisis Hasil Klasifikasi
HASIL DAN PEMBAHASAN
Evaluasi digunakan untuk mengukur kinerja metode klasifikasi, dalam penelitian ini digunakan untuk mengukur keakuratan metode klasifikasi yang diukur dengan akurasi, precision, recall, dan f-measure. Sebagai persentase antara data kelas negative yang dikelaskan dengan benar dan data kelas positive yang sudah diprediksi ke kelas mayoritas tersebut. Berdasarkan hasil klasifikasi, diperoleh nilai akurasi, precision, recall, dan f-measure pada data oversampling duplikasi lebih besar daripada data oversampling acak seperti yang telihat pada tabel di bawah ini.
Kinerja KNN
Nilai akurasi, precision, recall, dan f-measure dinyatakan dalam persen, semakin tinggi persentase nilainya, maka semakin baik kinerja metode klasifikasi.
Pada Tabel 3 data prediksi gaji dapat dilihat bahwa hasil akurasi algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Akurasi tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 90.84% sedangkan pada data oversampling acak memiliki nilai 88.98% Terlihat bahwa oversampling duplikasi lebih tinggi nilainya daripada oversampling acak. Sementara itu, akurasi tertinggi pada oversampling duplikasi 5-fold saat k=1 sebesar 90.54% sedangkan pada oversampling acak memiliki nilai 88.22% Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai akurasinya daripada oversampling acak. Adapun, untuk nilai akurasi pada data prediksi gaji 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 2.
Pada Tabel 4 data prediksi gaji dapat dilihat bahwa hasil precision algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh
Tabel 3 Hasil akurasi rata-rata (%) data prediksi gaji Pembagian
sekitar 2%. Precision tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 86.37% sedangkan pada data oversampling acak memiliki nilai 83.69% Sementara itu, precision tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 85.86% sedangkan pada oversampling acak memiliki nilai 83.28% Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai precision-nya daripada oversampling acak. Adapun, untuk nilai
precision pada data prediksi gaji 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 3.
Pada Tabel 5 data prediksi gaji dapat dilihat bahwa hasil recall algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 3%. Recall tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 99. 27% sedangkan pada data oversampling acak memiliki nilai 96.58% Recall tertinggi pada oversampling duplikasi 5-fold saat k=1 sebesar 99.42% sedangkan pada data oversampling acak memiliki nilai 95.74% Terlihat bahwa oversampling duplikasi lebih tinggi nilainya daripada oversampling acak Adapun, untuk nilai recall pada data prediksi gaji 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 4.
Pada Tabel 6 data prediksi gaji dapat dilihat bahwa hasil f-measure
algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. F-measure tertinggi pada oversampling duplikasi 10-fold saat k=1 sebesar 92.37% sedangkan pada data oversampling acak memiliki nilai 89.68% Sementara itu, f-measure tertinggi pada oversampling duplikasi 5-fold saat k=1 sebesar 92.14% sedangkan pada oversampling acak memiliki nilai 89.06% Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai f-measure nya daripada oversampling acak. Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai
Tabel 5 Hasil recall rata-rata (%) data prediksi gaji Pembagian
Tabel 6 Hasil f-measure rata-rata(%) data prediksi gaji Pembagian Oversampling duplikasi 92.37 90.07 88.56 87.49 86.86 Oversampling acak 89.68 87.25 84.77 84.41 83.49
5-fold
f-measure-nya daripada oversampling acak. Adapun, untuk nilai f-measure pada data prediksi gaji 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 5.
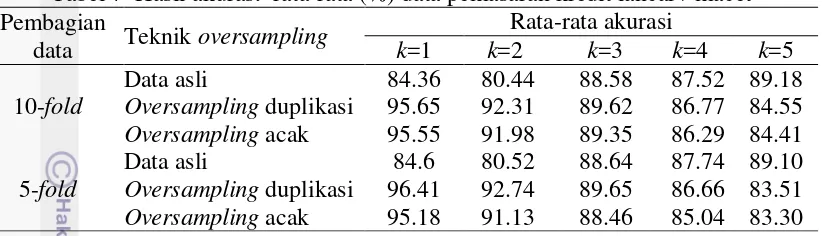
Pada Tabel 7 data pemasaran kredit lancar / macet dapat dilihat bahwa hasil akurasi algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Akurasitertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 95.65% sedangkan pada data oversampling acak bernilai 95.55% Sementara itu, akurasi tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 96.41% sedangkan pada oversampling acak memiliki nilai 95.18%.
Pada Tabel 8 data pemasaran kredit lancar / macet dapat dilihat bahwa hasil
precision algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Precision tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 100.0% sedangkan pada data oversampling acak memiliki nilai 99.97%. Sementara itu, precision tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 99.90% sedangkan pada oversampling acak memiliki nilai 93.00%. Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai precision-nya daripada oversampling acak.
Tabel 7 Hasil akurasi rata-rata (%) data pemasaran kredit lancar / macet Pembagian
Tabel 8 Hasil precision rata-rata(%) data pemasaran kredit lancar / macet Pembagian Oversampling duplikasi 100.00 100.00 100.00 100.00 100.00 Oversampling acak 99.97 99.50 99.63 98.07 98.10
5-fold
Data asli 31.18 26.60 52.14 44.86 61.60 Oversampling duplikasi 99.90 98.82 94.56 91.20 91.10 Oversampling acak 93.00 86.82 82.18 78.16 74.34
Tabel 9 Hasil recall rata-rata (%) data pemasaran kredit lancar / macet Pembagian Oversampling duplikasi 100.00 100.00 100.00 100.00 100.00 Oversampling acak 99.97 99.50 99.63 98.07 98.10
5-fold
Pada Tabel 9 data pemasaran kredit lancar / macet dapat dilihat bahwa hasil
recall algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 4%. Recall tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 100.0% sedangkan pada data oversampling acak memiliki nilai 99.97% Sementara itu, recall tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 99.90% sedangkan pada oversampling acak memiliki nilai 93.00% Terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai recall-nya daripada oversampling acak.
Pada Tabel 10 data pemasaran kredit lancar / macet dapat dilihat bahwa hasil f-measure algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. F-measure tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 95.36% sedangkan pada data oversampling acak memiliki nilai 95.34%. Sementara itu, f-measure tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 96.4% sedangkan pada oversampling acak memiliki nilai 94.94%. Terlihat oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai recall-nya daripada oversampling acak.
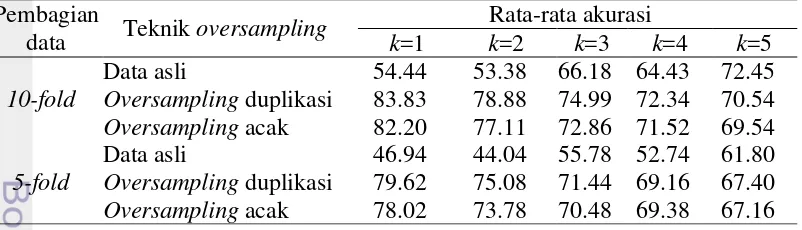
Pada Tabel 11 data kreditur bank baik / buruk dapat dilihat bahwa hasil
akurasialgoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Akurasi tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 83.83% sedangkan pada data oversampling acak memiliki nilai 82.2% Sementara itu, akurasi tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 79.62% sedangkan pada oversampling acak memiliki nilai 78.02% . Adapun, untuk nilai akurasipada data kreditur bank baik /buruk 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 6.
Tabel 10 Hasil f-measure rata-rata (%) data pemasaran kredit lancar / macet Pembagian
Pada Tabel 12 data kreditur bank baik / buruk dapat dilihat bahwa hasil
precision algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Precision tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 80.17% sedangkan pada data oversampling acak memiliki nilai 78.09% . Sementara itu, precisiontertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 75.56% sedangkan pada oversampling acak memiliki nilai 73.9% . Adapun, untuk nilai precision pada data kreditur bank baik / buruk 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 7.
Pada Tabel 13 data kreditur bank baik / buruk dapat dilihat bahwa hasil recall
algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. Recall tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 100% sedangkan pada data oversampling acak memiliki nilai 99.03%. Sementara itu, recall tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 100% sedangkan pada oversampling acak memiliki nilai 98.94% . Adapun, untuk nilai recall pada data kreditur bank baik / buruk 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 8.
Tabel 12 Hasil precision rata-rata (%) data kreditur bank baik / buruk
Pembagian
Tabel 13 Hasil recall rata-rata (%) data kreditur bank baik / buruk Pembagian Oversampling duplikasi 100.00 100.00 100.00 100.00 100.00 Oversampling acak 99.03 99.43 97.23 98.17 93.91
5-fold
Data asli 0.00 0.00 0.00 0.00 0.00 Oversampling duplikasi 100.00 100.00 100.00 100.00 100.00 Oversampling acak 98.94 99.34 96.86 97.88 92.92
Pada Tabel 14 data kreditur bank baik / buruk dapat dilihat bahwa hasil f-measure algoritme k-nearest neighbour pada oversampling duplikasi memiliki nilai lebih tinggi daripada nilai oversampling acak namun memiliki selisih yang tidak terlalu jauh sekitar 2%. F-measure tertinggi pada oversampling duplikasi 10-fold yaitu saat k=1 sebesar 90.15% sedangkan pada data oversampling acak memiliki nilai 89.41%. Sementara itu, f-measure tertinggi pada oversampling duplikasi 5-fold yaitu saat k=1 sebesar 85.2% sedangkan pada oversampling acak memiliki nilai 78.54%. Adapun, untuk nilai f-measure pada data kreditur bank baik / buruk 10-fold dan 5-fold selengkapnya dapat dilihat pada Lampiran 9.
Kinerja Terbaik KNN
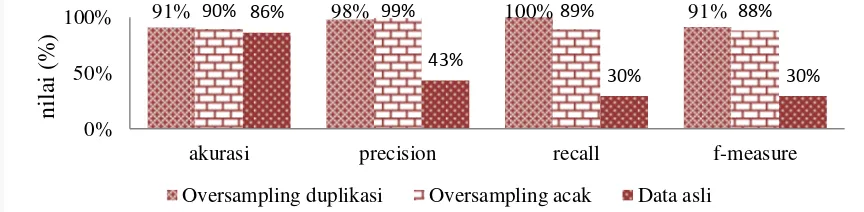
Pada data prediksi gaji, data asli dalam percobaan ini merupakan data yang sudah melalui tahap praproses yang telah mengalami proses. Rata-rata parameter 10-fold dan 5-fold pada data prediksi gaji percobaan oversampling duplikasi dan oversampling acak dan dapat dilihat Gambar 2.
Gambar 2 Rata-rata setiap cross validation grafik akurasi, precision, recall dan f-measure pada data prediksi gaji
Dari Gambar 2 dapat dilihat bahwa oversampling duplikasi pada setiap cross validation 10-fold dan 5-fold memiliki nilai rata-rata akurasi, precision, recall dan f-measure lebih tinggi dari pada oversampling acak. Rata-rata parameter 10 fold dan 5 fold pada data data pemasaran kredit lancar / macet percobaan oversampling duplikasi dan oversampling acak dan dapat dilihat pada Gambar 3.
Gambar 3 Rata-rata setiap cross validation grafik akurasi, precision, recall dan f-measure pada data pemasaran kredit lancar / macet.
Dari Gambar 3 dapat dilihat bahwa oversampling duplikasi pada setiap cross validation 10-fold dan 5-fold memiliki nilai rata-rata akurasi, precision, recall dan f-measure lebih tinggi dari pada oversampling acak. Rata-rata parameter 10-fold dan 5-fold data kreditur bank baik / buruk percobaan oversampling duplikasi dan oversampling acak dan dapat dilihat pada Gambar 4.
Gambar 4 Rata-rata setiap cross validation grafik akurasi, precision, recall dan f-measure pada data kreditur bank baik / buruk
Dari Gambar 4 dapat dilihat bahwa oversampling duplikasi pada setiap cross validation 10-fold dan 5-fold memiliki nilai rata-rata akurasi, precision, recall dan f-measure lebih tinggi dari pada oversampling acak. Hasil klasifikasi pada data asli tidak lebih baik dari hasil klasifikasi pada data yang sudah mengalami modifikasi distribusi data.
Perbandingan Grafik dan Tabel Kinerja KNN
Terlihat pada tabel dan grafik bahwa nilai akurasi, precision , recall dan f-measure lebih tinggi dan lebih baik daripada oversampling acak. Berdasarkan Tabel 3, 4, 5, dan 6 algoritme k-nearest neighbour data prediksi gaji dapat diketahui untuk evaluasi nilai akurasi yang paling tinggi diperoleh dari percobaan oversampling duplikasi untuk akurasi, precision, recall dan f-measure parameter 10-fold dan k=1 yaitu sebesar 90.84 %, 86.37%, 99.27%, dan 92.37% sedangkan nilai oversampling acak yaitu sebesar 88.98, % 83.69%, 96.58%, 89.68%. Begitu juga untuk cross-validation 5-fold nilai oversampling duplikasi seluruhnya lebih besar daripada nilai oversampling acak. Berdasarkan Tabel 7, 8, 9, dan 10 algoritme k-nearest neighbour data pemasaran kredit lancar / macet. Dapat diketahui untuk evaluasi nilai akurasi yang paling tinggi diperoleh dari percobaan oversampling duplikasi untuk akurasi, precision, recall dan f-measure parameter 10-fold dan k=1 yaitu sebesar 95.65%, 100%, 100%, dan 95,36% untuk nilai oversampling acak yaitu 95.6 %, 99.97%, 99.97%, 95,34%. Berdasarkan Tabel 11, 12, 13, dan 14 algoritme k-nearest neighbor data kreditur bank baik / buruk dapat diketahui untuk evaluasi nilai akurasi yang paling tinggi diperoleh dari percobaan data oversampling duplikasi. Untuk akurasi, precision, recall dan f-measure parameter 10-fold dan k=1 yaitu sebesar 83.83%, 80.17%, 100%, dan 90.15% sedangkan nilai oversampling acak yaitu sebesar 78.88%, 78.09%, 99.03%, 89.41%. Begitu juga untuk 5-fold oversampling duplikasi seluruhnya memiliki nilai lebih besar dari pada nilai oversampling acak.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dengan metode k-nearest neighbour dapat diperoleh kesimpulan bahwa secara umum terlihat bahwa oversampling duplikasi untuk algoritme k-nearest neighbour lebih tinggi nilai
f-measure nya daripada oversampling acak, namun memiliki selisih yang tidak terlalu jauh. Nilai akurasi, precision, recall, dan f-measure pada setiap percobaan ini rata-rata menurun pada saat nilai k ditingkatkan. Dengan demikian, dapat disimpulkan bahwa sampel yang sudah mengalami modifikasi distribusi data melalui teknik oversampling duplikasi memiliki kinerja lebih baik dibandingkan dengan data oversampling acak.
Saran
Pada penelitian selanjutnya diharapkan dapat mengggunakan jarak selain jarak euclide untuk variabel yang bertipe nominal. Percobaan dapat dilakukan untuk algoritme klasifikasi yang lainnya seperti jaringan saraf tiruan (JST) dan SVM dalam mengatasi imbalanced data. Selain itu, penelitian ini juga diharapkan dapat dilakukan dengan menambahkan data set yang berjumlah lebih banyak dengan menggunakan banyak data.
DAFTAR PUSTAKA
Anggraini D. 2013. Perbandingan algoritme C4.5 dan CART pada data tidak seimbang untuk kasus prediksi risiko kredit debitur kartu kredit [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Chawla VN. 2003. K-nearest neighbour and imbalance data sets: investigating the effect of sampling method, probabilistic estimate, and decision tree structure.Di dalam: Workshop on Learning from Imbalanced Datasets [Internet]; 2003 Agu 21; Washington DC, Amerika Serikat. Washington DC (US). [diunduh 2013 Mar 27]. Tersedia pada: www.site.uottawa.ca/ ~nat/Workshop2003/chawla.pdf
Chipman H, George EI, McCulloch RE. 1998. Bayesian CART model search. Journal of the American Statistical Association. 93 (443): 935-948.
Gorunescu F. 2011. Data Mining Concepts, Models dan Tehniques. Intelligent Systems Reference Library. Berlin Heidelberg (DE): Springer-Verlag.
Goujon G, Chaoqun, Jianhong W. 2007. Data Clustering: Theory, Algorithms dan Applications. Virginia (US): ASA.
Han J, Kamber M. 2006. Data Mining: Concepts and Techniques, 2nd ed. San Fransisco (US): Morgan Kaufmann.
Larose DT. 2005. Discovering Knowledge in Data : An Introduction to Data Mining. New Jersey (US) : John Wiley.
Laurikkala. 2001. Improving Identification of Difficult Small Classes by Balancing Class Distribution. Tampere (FI): University of Tampere.
Margono. 2004. Metodologi Penelitian Pendidikan. Jakarta (ID): Rineka Cipta. Tan PN, Steinbach M, Kumar V.2006.Introduction to Data Mining. Boston (US):
Pearson Education.
Ulya F. 2013. Klasifikasi debitur kartu kredit menggunakan algoritme k-nearest neighbor untuk kasus imbalanced data [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Wijayanti R. 2013. Klasifikasi nasabah kartu kredit menggunakan algoritme fuzzy k-nearest neighbor pada data tidak seimbang [skripsi]. Bogor (ID): Institut Pertanian Bogor.
LAMPIRAN
Lampiran 1 Atribut-atribut data kreditur bank baik buruk Atribut Keterangan
Pendidikan 1 = SMP/SMA 2 = Akademi 3 = S1/S2 Jenis Kelamin 1 = Pria
2 = Wanita Status Pernikahan 1 = Lajang 2 = Menikah 3 = Bercerai Tipe Perusahaan 1 = Kontraktor
2 = Conversion 3 = Industri Berat 4 = Pertambangan 5 = Jasa
6 = Transportasi Status Pekerjaan 1 = Permanen
2 = Kontrak Pekerjaan 1 = Conversion
2 = PNS
3 = Professional 4 = Wiraswasta
5 = Perusahaan Swasta Masa Kerja Dalam bulan
Lama Tinggal Dalam bulan
Status Pemilikan Rumah 0 = Bukan Milik Sendiri 1 = Milik Sendiri
Banyaknya Tanggungan
Pendapatan Rupiah Banyaknya Kartu Kredit Lain
Persentase Utang Kartu Kredit
Umur Dalam tahun
Lampiran 8 Hasil recall (%) data kreditur bank baik / buruk
Rata-rata 98.94 99.34 96.86 97.88 92.9
RIWAYAT HIDUP
Penulis dilahirkan di Palembang pada tanggal 29 Mei 1991 sebagai anak kedua dari pasangan Bapak Ir Yulius ibrahim dan Ibu Wenni andriani.