KLASIFIKASI NASABAH KARTU KREDIT MENGGUNAKAN
ALGORITME
FUZZY K-NEAREST NEIGHBOR
PADA DATA TIDAK SEIMBANG
RETNO WIJAYANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Nasabah Kartu Kredit Menggunakan Algoritme Fuzzy K-Nearest Neighbor pada Data Tidak Seimbang adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
RETNO WIJAYANTI. Klasifikasi Nasabah Kartu Kredit Menggunakan Algoritme Fuzzy K-Nearest Neighbor pada Data Tidak Seimbang. Dibimbing oleh AZIZ KUSTIYO.
Klasifikasi debitur diperlukan untuk mengurangi kemungkinan kerugian yang akan diderita oleh bank akibat menerima aplikasi kredit yang berpotensi menimbulkan masalah. Penelitian ini mengusulkan sebuah model klasifikasi nasabah kartu kredit menggunakan algoritme fuzzy k-nearest neighbor. Data yang digunakan tidak seimbang ketika data dari satu kelas mendominasi data yang lain. Algoritme klasifikasi umumnya memberikan kinerja yang buruk pada data tidak seimbang, terutama untuk kelas minoritas. Penelitian ini bertujuan meningkatkan kualitas klasifikasi pada data tidak seimbang menggunakan oversampling dan undersampling. Oversampling duplikasi menghasilkan akurasi, precision, recall, dan f-measure terbaik pada saat tetangga terdekat adalah 1, yaitu 91.93%, 86.12%, 100%, dan 92.54%. Namun, menurun drastis pada saat jumlah tetangga terdekat adalah 5. Oversampling acak menghasilkan akurasi, precision, recall, dan f-measure yang cukup bagus dan stabil pada saat jumlah tetangga terdekat ditingkatkan. Undersampling menghasilkan akurasi, precision, recall, dan f-measure yang stabil pada saat jumlah tetangga terdekat 1 sampai 5.
Kata kunci: fuzzy k-nearest neigbor, data tidak seimbang, oversampling, undersampling
ABSTRACT
RETNO WIJAYANTI. Credit Card Debtor Classification using Fuzzy K-Nearest Neighbor Algorithm in Imbalanced Data. Supervised by AZIZ KUSTIYO.
Debtor classification is a crucial banking process in order to identify potential problematic credit card applicant. This information is to support decision making in accepting or rejecting the application. The classification method makes use of fuzzy k-nearest neighbor method. Due to the nature of credit card business, most likely, the data collected is imbalanced. In this case, the good debtors always significantly outnumber the bad one. Most of the existing classification systems work well on balanced data, which is not the case in this research. Thus, in order to improve the system, the data composition must be banced using oversampling and undersampling technique. The performance indicator used are accuracy, precision, recall, and f-measure. Replication oversampling improved the algorithm best at the number of nearest neighbors 1. The accuration, precision, recall, and f-measure is 91.93%, 86.12%, 100%, and 92.54%, while the least performance was achieved at the number of nearest neighbors 5. Random oversampling performed better as the number of the nearest neighbors increases. Undersampling performed more stable with the number of the nearest neighbors between 1 and 5.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI NASABAH KARTU KREDIT MENGGUNAKAN
ALGORITME
FUZZY K-NEAREST NEIGHBOR
PADA DATA TIDAK SEIMBANG
RETNO WIJAYANTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Klasifikasi Nasabah Kartu Kredit Menggunakan Algoritme Fuzzy K-Nearest Neighbor pada Data Tidak Seimbang
Nama : Retno Wijayanti NIM : G64090070
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Ungkapan terima kasih penulis sampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Terima kasih penulis ucapkan kepada Bapak Aziz Kustiyo, MKom selaku pembimbing, kepada Ibu Dr Imas S Sitanggang, MKom dan Bapak Toto Haryanto, MSi selaku penguji. Terima kasih atas semua bimbingan dan saran yang diberikan dalam menyelesaikan karya ilmiah ini. Terima kasih juga penulis sampaikan kepada Nanang Wahyu Hariyadi, Munjiati, Leni Mariana, Rina Oktaviana, Listia Hesti, dan Ilkomerz 46 khususnya Dhieta Anggraini dan Fiqrotul Ulya atas kerja samanya. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Kartu Kredit 2
Klasifikasi 2
Data Tidak Seimbang 3
Algoritme K-Means 3
Metode K-Fold Cross Validation 3
Fuzzy K-Nearest Neighbor 3
Normalisasi 5
Confusion Matrix 5
METODE 6
Pengadaan Data 6
Praproses Data 6
Pembagian Data 7
Klasifikasi dengan FKNN 8
Analisis Hasil Klasifikasi 8
Penerapan Model Terbaik 8
Lingkungan Pengembangan 8
HASIL DAN PEMBAHASAN 8
Pengadaan Data 8
Praproses Data 9
Analisa Hasil Klasifikasi 10
Penerapan Model Terbaik 14
Perbandingan dengan Penelitian Sebelumnya 14
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 16
DAFTAR PUSTAKA 16
DAFTAR TABEL
1 Confusion matrix 5
2 Atribut data 9
3 Nilai akurasi setiap model data percobaan 11
4 Nilai precision setiap proses uji oversampling duplikasi saat tetangga
terdekat 1 11
5 Confusion matrix proses pengujian ke-6 11
6 Nilai precision setiap model data percobaan 12
7 Nilai recall setiap model data percobaan 12
8 Nilai f-measure setiap model data percobaan 12 9 Atribut data baru yang diuji beserta hasil prediksi 15
10 Hasil prediksi data uji 15
11 Perbandingan metrik pengukuran dengan penelitian lain 15
DAFTAR GAMBAR
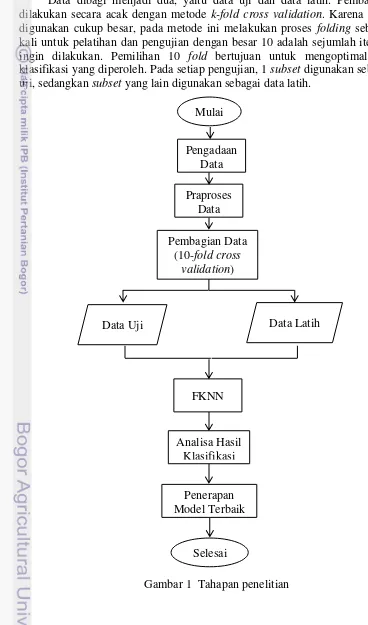
1 Tahapan penelitian 7
2 Ilustrasi perhitungan FKNN 9
3 Grafik akurasi setiap model data percobaan 13
4 Grafik f-measure setiap model data percobaan 14
DAFTAR LAMPIRAN
1 Keterangan atribut 18
2 Nilai akurasi dalam % pada saat jumlah tetangga adalah 1 sampai 5 19 3 Nilai precision dalam % pada saat jumlah tetangga 1 sampai 5 19 4 Nilai recall dalam % pada saat jumlah tetangga adalah 1 sampai 5 20 5 Nilai f-measure dalam % pada saat jumlah tatangga 1 sampai 5 20 6 Contoh hasil klasifikasi data oversampling duplikasi saat k = 1 21 7 Contoh hasil klasifikasi data oversampling duplikasi saat k = 2 21 8 Contoh hasil klasifikasi data oversampling duplikasi saat k = 3 22 9 Contoh hasil klasifikasi data oversampling duplikasi saat k = 4 22 10 Contoh hasil klasifikasi data oversampling duplikasi saat k = 5 23
11 Tampilan sistem 23
PENDAHULUAN
Latar Belakang
Usaha perbankan tidak hanya melayani penyimpanan dana nasabah, namun terdapat berbagai macam bentuk usaha bank. Salah satu usaha bank tersebut adalah memberikan fasilitas kartu kredit. Setiap bank mempunyai standar yang khusus dalam menentukan diterima atau tidaknya suatu pengajuan kredit. Hal ini sangat penting untuk mengurangi peluang kerugian bank akibat menerima nasabah kartu kredit yang mempunyai potensi bermasalah. Diperlukan manajemen risiko untuk meminimalkan kerugian yang akan diderita oleh pihak bank yang diakibatkan oleh kredit bermasalah. Salah satu bentuk manajemen risiko adalah menganalisis nasabah bermasalah yang sudah ada yang kemudian digunakan sebagai acuan penerimaan nasabah baru. Keputusan pemberian kredit kepada calon nasabah atau calon debitur melewati proses pengajuan kredit dan melalui tahap analisis terhadap kredit yang diajukan. Tahap analisis ini merupakan tahap yang paling penting dalam kualifikasi pemberian kredit.
Data nasabah yang akan digunakan untuk pembuatan model klasifikasi merupakan salah satu data yang termasuk kasus data tidak seimbang. Hal ini menyebabkan proses klasifikasi menjadi tidak optimal karena kelas yang mempunyai jumlah data lebih banyak mendominasi hasil klasifikasi daripada kelas yang memiliki jumlah data lebih sedikit. Pada sebagian besar kasus data tidak seimbang, kelas yang menjadi target klasifikasi adalah kelas yang jumlah datalebih sedikit atau minoritas.
Berbagai penelitian dilakukan untuk mencari solusi dari permasalahan klasifikasi data tidak seimbang. Salah satu penelitian tersebut adalah Liao (2008) yang mencoba berbagai teknik sampling untuk mengklasifikasikan kegagalan pengelasan menggunakan jarak minimum, k-nearest neighbor (KNN), dan fuzzy k-nearest neighbor (FKNN). Dari penelitian tersebut dapat disimpulkan bahwa FKNN memiliki perhitungan yang sederhana dan mudah diaplikasikan pada data berukuran besar. Selain itu, akurasi yang dihasilkan FKNN lebih tinggi daripada KNN dan mampu memberikan derajat keanggotaan pada kelas prediksi.
Pada penelitian ini akan dibuat suatu model untuk mengklasifikasikan nasabah dengan kategori baik atau buruk. Pembuatan model dilakukan dengan menggunakan algoritme FKNN. Sebelumnya, penelitian dengan menggunakan data yang sama dilakukan oleh Setiawati (2011) menggunakan algoritme jaringan saraf tiruan backpropagation. Berdasarkan penelitian tersebut, diketahui bahwa perbandingan jumlah debitur pada kelas baik dan burukmemiliki perbedaan yang cukup besar, yaitu 4:1. Dari hasil penelitian tersebut diperoleh akurasi dari model terbaik sebesar 73.39%, serta recall dan precision kelas buruk sebesar 56.26% dan 36.90%.
Perumusan Masalah
2
Dengan mengambil sampel data sekunder dari Bank X akan dibuat model untuk mengklasifikasikan nasabah kredit yang diterima baik atau buruk.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun suatu model untuk mengklasifikasikan nasabah kredit yang baik atau buruk menggunakan algoritme FKNN.
Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat menjadi alternatif model untuk menganalisis proses penerimaan kredit, khususnya nasabah kartu kredit. Dengan demikian, jumlah kredit yang bermasalah dapat berkurang.
Ruang Lingkup Penelitian
Data yang dipakai pada penelitian ini adalah data sekunder nasabah kartu kredit Bank X pada periode waktu 2008 2009. Atribut atau feature yang digunakan adalah atribut yang mempengaruhi proses analisis. Algoritme yang digunakan adalah FKNN.
TINJAUAN PUSTAKA
Kartu Kredit
Kartu kredit adalah alat pembayaran dengan menggunakan kartu yang dapat digunakan untuk melakukan pembayaran atas kewajiban yang timbul dari suatu kegiatan ekonomi, termasuk transaksi pembelanjaan dan/atau untuk melakukan penarikan tunai, dimana kewajiban pembayaran pemegang kartu dipenuhi terlebih dahulu oleh acquirer atau penerbit, dan pemegang kartu berkewajiban untuk melakukan pembayaran pada waktu yang disepakati baik dengan pelunasan secara sekaligus (charge card) ataupun dengan pembayaran secara angsuran (BI 2012).
Klasifikasi
Klasifikasi merupakan proses menemukan sekumpulan model atau fungsi yang menggambarkan dan membedakan konsep atau kelas-kelas data. Tujuan dari klasifikasi adalah membentuk model yang dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han dan Kamber 2001).
3 Data Tidak Seimbang
Data tidak seimbangmerupakan suatu kondisi ketika sebuah himpunan data terdapat satu kelas yang memiliki jumlah data yang kecil dibandingkan jumlah data dari kelas yang lain. Kondisi tersebut dapat menimbulkan proses klasifikasi pada kelas minoritas menjadi kurang optimal, sedangkan kelas minoritas dianggap lebih penting dari kelas mayoritas. Sebagai contoh pada proses klasifikasi teks, pengenalan citra satelit untuk mendeteksi titik-titik tertentu, kecurangan transaksi, dan sebagainya (Kotsiantis et al. 2006).
Sebagai upaya untuk mengatasi permasalahan yang ada pada proses klasifikasi data tidak seimbang, dapat dilakukan perubahan pada level algoritme dan level data. Perubahan pada level algoritme dilakukan dengan mengubah algoritme yang sudah ada atau dengan membuat algoritme baru. Perubahan pada level data dilakukan dengan resampling. Ada 2 cara teknik resampling, yaitu oversampling kelas minoritas dan undersampling kelas mayoritas. Oversampling dilakukan dengan cara memperbanyak kelas minoritas sehingga jumlahnya sama dengan kelas mayoritas. Teknik undersampling dilakukan dengan mengurangi jumlah kelas mayoritas sehingga jumlahnya sama dengan kelas minoritas (Kotsiantis et al. 2006). Undersampling dapat dilakukan dengan mengambil data mayoritas secara acak atau dengan memakai teknik tertentu, misalnya dengan clustering.
Algoritme K-Means
Algoritme k-means merupakan salah satu algoritme data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam beberapa cluster. Hal pertama yang dilakukan adalah memilih k obyek secara acak, yang masing-masing merupakan nilai rata-rata cluster atau centroid. Untuk masing-masing obyek yang tersisa, dihitung kemiripannya berdasarkan jarak antara obyek tersebut dengan centroid pada masing-masing cluster. Kemudian menghitung rata-rata baru untuk setiap cluster. Proses ini dilakukan sampai fungsi kriteria konvergen (Han dan Kamber 2001).
Metode K-Fold Cross Validation
Metode k-fold cross validation membagi data secara acak sejumlah k subset yang saling bebas dengan ukuran yang kira-kira sama. Setelah subset terbentuk, dilakukan pengulangan sebanyak k-kali untuk pelatihan dan pengujian. Pada masing-masing proses pengujian, digunakan 1 subset sebagai data uji, sedangkan subset lainnya sebagai data latih (Kohavi 1995).
Fuzzy K-Nearest Neighbor
4
Pada data yang digunakan terdapat 2 jenis tipe atribut, yaitu atribut rasio dan nominal. Pengukuran jarak pada data rasio dapat digunakan fungsi Euclidean yang ada pada persamaan berikut.
√∑
Namun, penggunaan fungsi Euclidean untuk mengukur jarak data nominal tidak tepat karena meskipun dapat dinyatakan dalam bentuk angka, data nominal tidak memiliki urutan atau makna secara matematika sehingga tidak dapat dibandingkan besarnya. Untuk menghitung jarak nominal, fungsi yang digunakan adalah:
{
dengan: x = data uji
y = data latih (Larose 2005)
Untuk menggabungkan kedua jarak tersebut, diperlukan fungsi aggregate ketidaksamaan berat rata-rata yang diukur dari masing-masing fitur (Teknomo 2006). Fungsi yang digunakan sebagai berikut:
∑ ∑
Sijk = nilai ketidaksamaan antarobjek
wijk = bobot fitur, bernilai 1 untuk jarak rasio dan 0.5 untuk jarak nominal.
Besarnya nilai pembobotan ini diberikan agar jarak nominal tidak terlalu mendominasi hasil perhitungan (Nurjayanti 2011).
Setelah didapatkan nilai agregasi kedua jarak, perhitungan menurut konsep FKNN mulai dilakukan. Untuk mendapatkan derajat keanggotaan suatu data uji, digunakan fungsi:
k = jumlah tetangga terdekat yang digunakan
m = bobot yang diberikan (pada penelitian ini nilai m adalah 2) u(xk,cn) = derajat keanggotaan data dalam k tetangga terdekat pada kelas cn
Bernilai 1 jika data latih xk merupakan anggota dari kelas cn atau 0 jika
5 Normalisasi
Pada perhitungan untuk jarak rasio, atribut yang mempunyai rentang nilai besar akan mempengaruhi hasil dari perhitungan jarak Euclidean. Solusi yang dapat digunakan untuk mengatasi permasalahan tersebut adalah dilakukannya normalisasi (Larose 2005). Metode normalisasi yang dapat diterapkan adalah min-max normalization dengan mengikuti persamaan berikut:
dengan X* adalah nilai hasil normalisasi, X nilai sebelum normalisasi, min(X) nilai minimun dari fitur, dan max(X) nilai maksimum dari fitur.
Confusion Matrix
Salah satu teknik untuk mengukur kemampuan dari algoritme klasifikasi pada kasus data tidak seimbang adalah dengan menggunakan confusion matrix. Confusion matrix berisi informasi mengenai klasifikasi aktual dengan hasil prediksi yang disajikan dalam bentuk tabel. Confusion matrix untuk dua kelas dapat dilihat pada Tabel 1.
Tabel 1 Confusion matrix
Kelas aktual Kelas hasil klasifikasi Kelas positif Kelas negatif
Kelas positif TP FN
Kelas negatif FP TN
TP adalah jumlah dari kelas positif (kelas yang mempunyai jumlah data lebih sedikit) yang benar diklasifikasikan. FN adalah jumlah kelas positif yang salah diklasifikasikan ke dalam kelas negatif. FP adalah jumlah kelas negatif yang salah diklasifikasikan ke dalam kelas positif. TN adalah jumlah kelas negatif yang benar diklasifikasikan. Berdasarkan data yang didapatkan dari confusion matrix, akan dihitung (Weng dan Poon 2008):
1Akurasi
Akurasi adalah jumlah perbandingan data yang benar dengan jumlah keseluruhan data. Untuk menghitung akurasi, digunakan fungsi sebagai berikut:
2 Precision
Precision digunakan untuk mengukur seberapa besar proporsi dari kelas data positif yang berhasil diprediksi dengan benar dari keseluruhan hasil prediksi kelas positif. Untuk menghitung precision, digunakan fungsi sebagai berikut:
6 3 Recall
Recall digunakan untuk menunjukkan persentase kelas data positif yang berhasil diprediksi benar dari keseluruhan data kelas positif. Untuk menghitung recall, digunakan fungsi sebagai berikut:
all
4 F-measure
F-measure merupakan gabungan dari precision dan recall yang digunakan untuk mengukur kemampuan algoritme dalam mengklasifikasikan kelas minoritas. Untuk menghitung f-measure, digunakan fungsi sebagai berikut:
all all
METODE
Penelitian ini dilakukan dalam beberapa tahapan. Alur tahapan penelitian yang dilakukan dapat dilihat pada Gambar 1.
Pengadaan Data
Pada tahap ini, dilakukan pembuatan proposal penelitian dan menghubungi pihak bank yang bersedia untuk bekerja sama dalam penelitian yang sedang dilakukan.
Praproses Data
7
l
Pembagian Data
Data dibagi menjadi dua, yaitu data uji dan data latih. Pembagian data dilakukan secara acak dengan metode k-fold cross validation. Karena data yang digunakan cukup besar, pada metode ini melakukan proses folding sebanyak 10 kali untuk pelatihan dan pengujian dengan besar 10 adalah sejumlah iterasi yang ingin dilakukan. Pemilihan 10 fold bertujuan untuk mengoptimalkan hasil klasifikasi yang diperoleh. Pada setiap pengujian, 1 subset digunakan sebagai data uji, sedangkan subset yang lain digunakan sebagai data latih.
Analisa Hasil Klasifikasi
Selesai FKNN
Mulai
Pengadaan Data Praproses
Data Pembagian Data
(10-fold cross validation)
)
Data Uji Data Latih
Penerapan Model Terbaik
8
Klasifikasi dengan FKNN
Teknik klasifikasi menggunakan FKNN berbasis sama dengan KNN, yaitu mencari jarak terdekat antara data yang akan dievaluasi dengan sejumlah k tetangga terdekatnya dalam data latih. Langkah-langkah untuk memodelkan prediksi menggunakan FKNN pada penelitian ini adalah sebagai berikut:
1 Perhitungan jarak Euclidean untuk data rasio. Perhitungan jarak dilakukan setelah data dinormalisasi.
2 Perhitungan jarak nominal dengan membandingkan data latih dengan data uji. Fitur nominal dilambangkan dengan angka agar mempermudah proses perbandingan.
3 Agregasi jarak yang telah didapatkan, yaitu dengan menggabungkan perolehan jarak rasio dan nominal.
4 Penentuan nilai k untuk menunjukkan berapa jumlah tetangga terdekat yang diinginkan.
5 Perhitungan derajat keanggotaan data pada masing-masing kelas. Kelas hasil klasifikasi ditentukan oleh derajat keanggotaan terbesar di antara 2 kelas yang dituju.
Ilustrasi perhitungan FKNN selengkapnya dapat dilihat pada Gambar 2. Analisis Hasil Klasifikasi
Untuk mengetahui keefektifan suatu algoritme dalam mengklasifiikasikan data, dilakukan perhitungan akurasi, precision, recall, dan f-measure. Semakin tinggi tingkat akurasi, precision, recall dan f-measure, maka algoritme semakin baik dalam melakukan klasifikasi.
Penerapan Model Terbaik
Setelah analisis hasil dilakukan, akan dibuat sistem yang mampu memprediksi kelas dari data baru. Berdasarkan hasil analisis akan didapatkan model data terbaik. Model data tersebut digunakan sebagai dasar pada proses prediksi data baru.
Lingkungan Pengembangan
Aplikasi yang dibangun pada penelitian ini menggunakan kode program yang ditulis dalam buku Prasetyo (2012). Kode program tersebut kemudian dimodifikasi sesuai keperluan. Program diimplementasikan menggunakan spesifikasi perangkat processor Intel Core i3 2.30 GHz, RAM kapasitas 2 GB, dan harddisk kapasitas 500 GB. Perangkat lunak yang digunakan ialah sistem operasi Windows 7 Professional, Matlab 7.7.0, dan Microsoft Excel.
HASIL DAN PEMBAHASAN
Pengadaan Data
9
seimbang (Setiawati 2011). Terdapat 4413 datadan 14 atribut yang terkait dengan nasabah. Ada 3 jenis atribut, yaitu atribut rasio sebanyak 7 atribut, ordinal sebanyak 1 atribut, dan nominal sebanyak 6 atribut. Atribut data selengkapnya dapat dilihat pada Tabel 2. Untuk mempermudah proses klasifikasi, atribut ordinal dan nominal dikategorisasikan dalam bentuk angka. Keterangan lengkap atribut tersebut dapat dilihat pada Lampiran 1.
Praproses Data
Jumlah datasetiap kelas berubah setelah dilakukan praproses data. Sebelum praproses, jumlah data sebesar 4413 dengan 839 datauntuk kelas burukdan 3574 data kelas baik. Data yang terdapat missing value tidak digunakan dalam proses klasifikasi. Selain itu, datayang mempunyai nilai fitur tidak valid seperti 0 atau 1 pada fitur pendapatan, -1 pada fitur masa kerja dan lama tinggal juga tidak digunakan. Banyaknya data setelah mengalami praproses data berkurang menjadi 3895 data. Dari hasil praproses didapatkan 636 data dengan kelas buruk dan 3259 datadengan kelas baik.
Tabel 2 Atribut data
Rasio Ordinal Nominal
Usia
Jumlah tanggungan Penghasilan
Jumlah kartu kredit lain Presentase utang kartu kredit lain
Lama kerja Lama tinggal
Pendidikan Gender
10
Resampling
Pada saat teknik oversampling diterapkan, jumlah data bertambah menjadi 6518 data. Pada saat teknik undersampling diterapkan, jumlah data berkurang menjadi 1272 data.
Analisa Hasil Klasifikasi
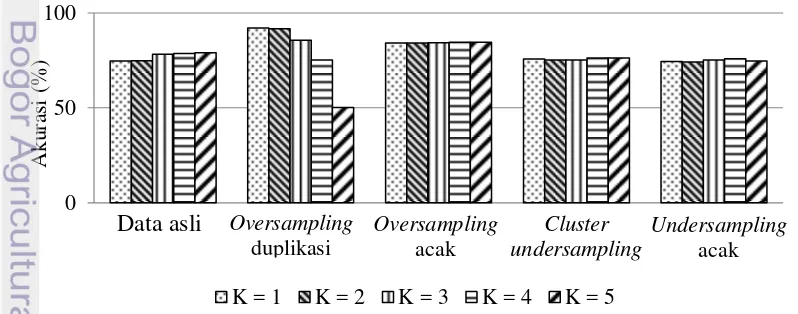
Pada penelitian ini, hasil yang diperoleh adalah akurasi, precision, recall, dan f-measure yang merupakan rata-rata dari 10-fold cross validation. Hasil dari cluster undersampling dan undersampling acak merupakan yang terbesar dari hasil 9 data cluster undersampling dan 3 undersampling acak. Akurasi yang paling besar didapatkan dari teknik oversampling duplikasi pada saat nilai tetangga terdekat adalah 1, yaitu sebesar 91.93%. Namun, nilai ini menurun saat jumlah tetangga terdekat ditingkatkan. Akurasi yang didapatkan dari data oversampling acak paling besar adalah 84.37% pada saat jumlah tetangga terdekat 4. Jumlah tetangga terdekat tidak begitu berpengaruh terhadap akurasi yang diperoleh. Akurasi yang didapatkan dari data aslipaling besar adalah 79.05% pada saat jumlah tetangga terdekat adalah 5. Nilai ini naik meskipun tidak signifikan saat jumlah tetangga terdekat ditingkatkan. Akurasi yang didapatkan dari data cluster undersampling paling besar adalah 76.33% pada saat jumlah tetangga terdekat 5. Akurasi yang didapatkan dari data undersampling acak paling besar adalah 75.71% pada saat jumlah tetangga terdekat 4. Hasil akurasi keduanya tidak berbeda jauh pada saat jumlah tetangga terdekat adalah 1 sampai 5. Perbandingan hasil akurasi pada saat jumlah tetangga terdekat 1 sampai 5 untuk masing-masing data hasil resampling dan data asli dapat dilihat pada Tabel 3. Nilai selengkapnya dapat dilihat pada Lampiran 2.
Namun, hasil akurasi tersebut belum dapat mengukur kemampuan algoritme dalam melakukan proses klasifikasi pada data minoritas. Sehingga, dihitung precision dan recall yang didapatkan dari hasil confusion matrix. Precision tertinggi dihasilkan oleh data hasil oversampling duplikasi, yaitu sebesar 86.12% pada saat jumlah tetangga terdekat 1. Namun, hasil tersebut menurun seiring dengan meningkatnya jumlah tetangga terdekat. Penurunan sangat drastis terjadi pada saat jumlah tetangga terdekat adalah 5, yaitu menjadi sebesar 50.36%. Berdasarkan Tabel 4, precision terbaik diperoleh pada proses uji ke-6 yaitu sebesar 88.23%. Confusion matrix untuk proses pengujian ke-6 dapat dilihat pada Tabel 5.
Precision yang didapatkan dari data oversampling acak paling besar adalah 85.82% pada saat jumlah tetangga terdekat adalah 4. Precision yang didapatkan dari data asli paling besar adalah 27.17% pada saat jumlah tetangga terdekat adalah 4. Precision yang didapatkan dari data cluster undersampling paling besar adalah 78.27% pada saat jumlah tetangga terdekat adalah 5. Precision yang didapatkan dari data undersampling acak paling besar adalah 78.44% pada saat jumlah tetangga terdekat adalah 4. Hasil precision ini tidak berbeda jauh pada saat nilai K adalah 1 sampai 5. Perbandingan hasil precision pada jumlah tetangga terdekat 1 sampai 5 untuk masing-masing data hasil resampling dan data asli dapat dilihat pada Tabel 6. Nilai selengkapnya dapat dilihat pada Lampiran 3.
11 meningkatnya jumlah tetangga terdekat. Penurunan sangat drastis terjadi pada saat jumlah tetangga terdekat adalah 5, yaitu menjadi sebesar 32.49%. Recall yang didapatkan dari data oversampling acak paling besar adalah 83.17% pada saat jumlah tetangga terdekat adalah 2. Recall yang didapatkan dari data asli paling besar adalah 22.75% pada saat jumlah tetangga terdekat adalah 1. Recall yang didapatkan dari data cluster undersampling paling besar adalah 75.85% pada saat jumlah tetangga terdekat adalah 4. Recall yang didapatkan dari data undersampling acak paling besar adalah 72.35% pada saat jumlah tetangga terdekat adalah 1. Hasil recall ini tidak berbeda jauh pada saat jumlah tetangga terdekat adalah 1 sampai 5. Perbandingan hasil recall pada jumlah tetangga terdekat adalah 1 sampai 5 untuk masing-masing data hasil resampling dan data asli dapat dilihat pada Tabel 7. Nilai recall selengkapnya dapat dilihat pada Lampiran 4.
Dari hasil precision dan recall yang didapatkan, kemudian dihitung nilai f-measure untuk mengetahui kemampuan algoritme dalam mengklasifikasikan data minoritas secara keseluruhan. F-measure tertinggi masih dihasilkan oleh data
Tabel 3 Nilai akurasi setiap model data percobaan Model data Akurasi tiap jumlah tetangga (k) (%)
1 2 3 4 5
Data asli 74.48 74.69 78.08 78.56 79.05
Oversampling duplikasi 91.93 91.60 85.44 75.22 50.24 Oversampling acak 83.94 84.00 84.17 84.37 84.35 Cluster undersampling 75.63 75.16 75.24 76.18 76.33 Undersampling acak 74.30 74.21 75.16 75.71 74.60
Tabel 4 Nilai precision setiap proses uji oversampling duplikasi saat tetangga terdekat 1
Tabel 5 Confusion matrix proses pengujian ke-6 Kelas aktual Kelas hasil klasifikasi
Bad Good
Bad 322 0
12
Tabel 6 Nilai precision setiap model data percobaan
Model data Precision tiap jumlah tetangga (k) (%)
1 2 3 4 5
Data asli 22.53 22.25 26.56 27.17 25.68
Oversampling duplikasi 86.12 85.85 79.24 74.06 50.36 Oversampling acak 84.52 84.56 85.71 85.82 85.80 Clusterundersampling 75.62 74.84 76.31 77.74 78.27 Undersampling acak 75.43 75.03 77.02 78.44 77.53
Tabel 7 Nilai recall setiap model data percobaan
Model data Recall tiap jumlah tetangga (k) (%)
1 2 3 4 5
Data asli 22.75 22.47 19.50 18.54 15.59
Oversampling duplikasi 100.00 99.64 95.99 77.58 32.49 Oversampling acak 83.10 83.17 82.01 82.34 82.35 Clusterundersampling 75.38 75.85 73.61 73.84 72.80 Undersampling acak 72.35 72.34 71.64 71.05 69.27 hasil oversampling duplikasi, yaitu mencapai 92.54%. Namun, hasil tersebut menurun seiring dengan meningkatnya jumlah tetangga terdekat. Penurunan sangat drastis terjadi pada saat jumlah tetangga terdekat adalah 5, yaitu menjadi sebesar 39.50%. F-measure yang didapatkan dari data oversampling acak paling besar adalah 84.04% pada saat jumlah tetangga terdekat adalah 4 dan 5. Hasil f -measure paling besar yang didapatkan dari data asliadalah 22.64% pada saat nilai jumlah tetangga terdekat adalah 1. F-measure yang didapatkan dari data cluster undersampling paling besar adalah 75.74% pada saat jumlah tetangga terdekat adalah 4. F-measure yang didapatkan dari data undersampling acak paling besar adalah 74.56% pada saat jumlah tetangga terdekat adalah 4. Perbandingan hasil f-measure pada jumlah tetangga terdekat adalah 1 sampai 5 untuk masing-masing data hasil resampling dan data asli dapat dilihat pada Tabel 8. Nilai f-measure selengkapnya dapat dilihat pada Lampiran 5.
Selain menghasilkan akurasi, precision, recall, dan f-measure, algoritme FKNN mampu memberikan derajat keanggotaan pada masing-masing kelas. Derajat keanggotaan tersebut menjadi dasar algoritme untuk menentukan kelas hasil prediksi. Sebagai contoh pada Lampiran 6 hingga Lampiran 10 dapat dilihat derajat keanggotaan yang dihasilkan pada masing-masing nilai k saat
Tabel 8 Nilai f-measure setiap model data percobaan Model data F-measure tiap jumlah tetangga (k) (%)
1 2 3 4 5
Data asli 22.64 22.36 22.49 22.04 19.40
13 menggunakan data oversampling duplikasi. Pada saat tetangga terdekat 1, derajat keanggotaan masing-masing kelas hanya berupa angka 0 dan 1 karena hanya membandingkan 1 jarak tetangga. Pada saat jumlah tetangga lebih dari 1, mulai terlihat bahwa derajat keanggotaan yang dihasilkan semakin beragam.
Dari hasil penjabaran di atas, dapat dilihat bahwa akurasi dari data asli cukup tinggi. Namun, hasil tersebut lebih didominasi oleh hasil klasifikasi data mayoritas. Hal tersebut dibuktikan dengan hasil f-measure yang rendah. Pada penelitian ini secara umum teknik resampling mampu meningkatkan nilai F-measure.Hasil yang diperoleh dari teknik oversampling acak lebih stabil daripada hasil yang diperoleh dari teknik oversampling duplikasi. Pada saat jumlah tetangga terdekat adalah 4 dan 5, hasil akurasi dan f-measure oversampling acak lebih bagus daripada teknik yang lain. Pada saat undersampling baik secara acak maupun berdasarkan cluster, hasil f-measure dan akurasi cenderung stabil pada saat jumlah tetangga terdekat ditingkatkan. Untuk lebih jelasnya, digambarkan dengan grafik pada Gambar 3 untuk akurasi dan Gambar 4 untuk f-measure.
Pada saat digunakan teknik oversampling acak, hasil yang didapatkan lebih bagus dibandingkan hasil dari undersampling dan oversampling duplikasi pada jumlah tetangga terdekat adalah 4 dan 5. Hal ini disebabkan data yang dibangkitkan merupakan data yang diacak dari data minoritas. Hasil yang didapat dari oversampling, baik secara duplikasi maupun acak lebih bagus daripada teknik yang lain. Hal ini disebabkan konsep jarak yang ada pada algoritme KNN. Pada saat oversampling duplikasi, data minoritas diduplikasi sehingga jumlahnya sama dengan data mayoritas. Saat pengujian terdapat kemungkinan data yang diuji membandingkan jarak dengan dirinya sendiri yang ada pada data latih, sehingga hasil klasifikasi yang didapatkan lebih bagus.
Undersampling terbukti berhasil meningkatkan f-measure dari data asli. Ketika menggunakan undersampling, perbandingan data buruk dengan baik seimbang. Dari hasil penelitian didapatkan bahwa teknik undersampling acak menghasilkan akurasi, precision, recall dan f-measure yang lebih rendah daripada undersampling yang dilakukan secara clustering. Pada saat teknik clustering diterapkan untuk pengambilan sampel data baik, jarak antara satu data dengan data yang lain sudah diukur kedekatannya. Oleh karena itu, pada saat proses klasifikasi diperoleh hasil yang stabil pada saat jumlah tetangga terdekat adalah 1 sampai 5.
14
Penerapan Model Terbaik
Berdasarkan penelitian ini, didapatkan model terbaik berasal dari data hasil oversampling acak karena menghasilkan akurasi, precision, recall, dan f-measure yang stabil. F-measure terbaik dihasilkan pada saat jumlah tetangga adalah 4. Model terbaik tersebut digunakan sebagai dasar untuk pengujian data baru. Tampilan sistem untuk menguji data baru ada pada Lampiran 11. Pada saat dimasukkan data baru untuk diprediksi, sistem berhasil menampilkan kelas prediksi dan derajat keanggotaan untuk setiap kelas. Pada saat data pertama dimasukkan, sistem memprediksi data tersebut adalah kelas 1 dengan derajat keanggotaan sebesar 0.64. Kemudian pada saat data kedua dimasukkan, sistem memprediksi data tersebut adalah kelas 2 dengan derajat keanggotaan sebesar 0.66. Tampilan sistem pada saat menamplikan hasil prediksi ada pada Lampiran 12. Data baru yang diujikan dapat dilihat pada Tabel 9. Hasil prediksi sistem dapat dilihat pada Tabel 10.
Perbandingan dengan Penelitian Sebelumnya
Perbandingan metrik pengukuran pada penelitian Natasia (2013), Setiawati (2011), Aritonang (2006), dan penelitian ini diperlihatkan pada Tabel 11. Hasil penelitian yang dilakukan oleh Natasia (2013) dan Setiawati (2011) menunjukkan hasil f-measure yang rendah. Hal ini kemungkinan disebabkan pada kedua penelitian tersebut tidak mengubah data yang digunakan. Pada penelitian yang dilakukan oleh Aritonang (2006) yang menggunakan pendekatan pada level data, hasil yang didapatkan cukup bagus. Aritonang (2006) menggunakan algoritme VFI5 untuk mengklasifikasikan data hypothyroid yang merupakan data tidak seimbang.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa: 1 Teknik resampling dengan oversampling dan undersampling dapat
meningkatkan f-measure.
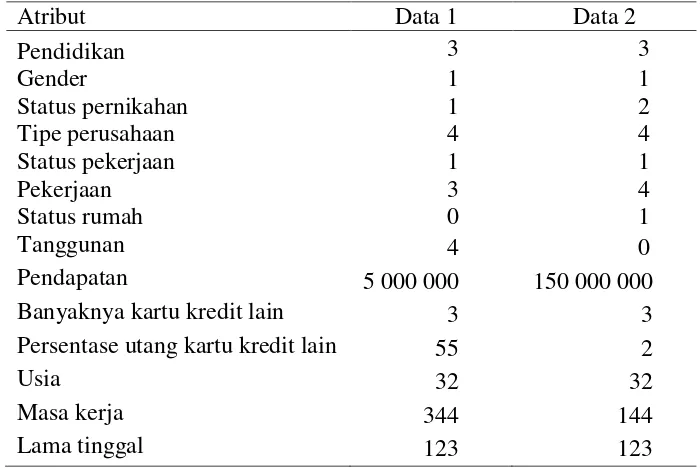
15 Tabel 9 Atribut data baru yang diuji beserta hasil prediksi
Atribut Data 1 Data 2
Persentase utang kartu kredit lain 55 2
Usia 32 32
Masa kerja 344 144
Lama tinggal 123 123
Penjelasan atribut ada pada Lampiran 1.
Tabel 10 Hasil prediksi data uji
Hasil prediksi Data 1 Data 2
Tabel 11 Perbandingan metrik pengukuran dengan penelitian lain
Data Model Akurasi Precision Recall F
-measure Hypothyroida VFI5 model
Undersampling
88.73 97.77 79.17 87.49
Debitur Backpropagationb 73.39 36.90 56.26 44.57 VFI5 dengan semua
16
2 Besarnya jumlah tetangga terdekat mempunyai pengaruh berbeda pada masing-masing data percobaan. Pada percobaan menggunakan data asli, meningkatnya jumlah tetangga terdekat meningkatkan nilai akurasi. Akurasi tertinggi terjadi pada saat jumlah tetangga terdekat adalah 5, yaitu sebesar 79.05%. Nilai ini lebih tinggi daripada akurasi yang dihasilkan pada saat menggunakan undersampling, tapi lebih rendah jika dibandingkan dengan akurasi yang dihasilkan oleh oversampling secara umum. Pada saat menggunakan oversampling duplikasi, meningkatnya jumlah tetangga terdekat menurunkan nilai akurasi, precision, recall, dan f-measure. Jumlah tetangga terdekat tidak berpengaruh signifikan pada saat digunakan oversampling acak dan undersampling.
3 F-measure paling tinggi dihasilkan saat menggunakan oversampling duplikasi, yaitu 92.54% pada saat jumlah tetangga terdekat 1.
4 Pada percobaan menggunakan data oversampling duplikasi menghasilkan f -measure untuk data minoritas cukup besar, yaitu 92.54%. Hasil ini lebih tinggi jika dibandingkan dengan percobaan menggunakan data oversampling acak yang menghasilkan f-measure 84.04%.
5 Pada percobaan menggunakan data cluster undersampling menghasilkan f -measure untuk data minoritas cukup besar, yaitu 75.74%. Hasil ini lebih tinggi jika dibandingkan dengan percobaan menggunakan data undersampling acak yang menghasilkan f-measure 74.56%.
6 Sistem berhasil memprediksi data baru dengan menggunakan model terbaik, yaitu oversampling acak dengan tetangga terdekat 4.
Saran
Pada penelitian selanjutnya diharapkan dapat membandingkan hasil klasifikasi FKNN yang didapatkan pada penelitian ini dengan teknik sampling yang lain, seperti synthetic minority oversampling technique dan bootstrap undersampling dengan memperhatikan keterkaitan antar-atribut. Selain itu, diharapkan juga untuk mencoba algoritme klasifikasi yang lain, seperti weighted KNN.
DAFTAR PUSTAKA
Aritonang R. 2006. Klasifikasi imbalanced data menggunakan algoritme klasifikasi voting feature intervals [skripsi]. Bogor (ID): Institut Pertanian Bogor.
[BI] Bank Indonesia. 2012. Peraturan Bank Indonesia nomor 14/2/PBI/2012 tentang Perubahan Atas Peraturan Bank Indonesia nomor 11/11/PBI/2009 Tentang Penyelenggaraan Kegiatan Alat Pembayaran Dengan Menggunakan Kartu. Bank Indonesia. Jakarta.
Han J, Kamber M. 2001. Data Mining Concepts & Techniques. San Fansisco (US): Morgan Kaufmann.
Keller JM, Gray MR, Givens JA. 1985. A fuzzy k-nearest neigbor algorithm. IEEE Trans System Man Cybernet. 15(4):580-585. doi:10.1109/TSMC.198
17 Kohavi R. 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. International Joint Conference on Artificial Intelligence [Internet]; 1995 Agu 20-25. Quebec, Kanada. Quebec (CA). [diunduh 2013 Juli 16]. Tersedia pada: http://frostiebek.free.fr/docs/Machine %20Learning/validation-1.pdf
Kotsiantis S, Kanellopoulos D, Pintelas P. 2006. Handling imbalanced datasets: a review. GESTS International Transactions on Computer Science and Engineering. 30(1):25-36. doi:10.1.1.96.9248.
Larose DT. 2005. Discovering Knowledge in Data: An Introduction to Data Mining. New Jersey (US). J Wiley.
Liao TW. Classification of weld flaws with imbalanced class data. Expert System with Application. 35(3):1041-1052. doi:10.1016/j.eswa.207.08.044.
Natasia SR. 2013. Klasifikasi debitur kartu kredit dengan pemilihan fitur menggunakan voting feature intervals 5 [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Nurjayanti B. 2011. Identifikasi Shorea menggunakan k-nearest neighbor berdasarkan karakteristik morfologi daun [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Prasetyo E. 2012. Data Mining: Konsep dan Aplikasi Menggunakan Matlab. Nikodemus WK, editor. Yogyakarta (ID): Andi Offset.
Setiawati PA. 2011. Penelusuran banyaknya unit dan lapisan tersembunyi jaringan saraf tiruan pada data tidak seimbang [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Teknomo K. 2006. Similarity measurement [internet]. [diunduh 2013 Apr 3]. Tersedia pada: http://people.revoledu.com/kardi/ tutorial/Similarity/.
Weng GC, Poon J. 2008. A new evaluation measure for imbalanced datasets. Di dalam: Roddick FJ, Li J, Christen P, Kennedy P, editor. Seventh Australian Data Mining Conference (AusDM 2008) [Internet]; 2008 Nov 27; Glenelg, Australia. Adelaide (AU). [diunduh 2013 Mei 21]. Tersedia pada: http://crpit.com/confpapers/CRPITV87Weng.pdf.
Yen SJ, Lee YS. 2009. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Systems with Applications. 36(3):5718-5727. doi:10.1016/j.eswa.2008.06.108.
18
Lampiran 1 Keterangan atribut
Tipe atribut Atribut Keterangan
Ordinal Pendidikan 1 = SMP/SMA
2 = Akademi 3= S1/S2
Nominal Gender 1 = Pria
2 = Wanita Status pernikahan 1 = Lajang 2 = Menikah 3 = Bercerai Tipe perusahaan 1 = Kontraktor
2 = Conversion 3 = Industri berat 4 = Pertambangan 5 = Jasa
6 = Transportasi
Status pekerjaan 1 = Permanen
2 = Kontrak
Pekerjaan 1 = Conversion
2 = PNS 3 = Profesional 4 = Wiraswasta 5 = Perusahaan swasta Status rumah 0 = Bukan milik sendiri
1 = Milik sendiri
Rasio Tanggunan Orang
Pendapatan Rupiah per tahun
Banyaknya kartu kredit lain Persentase utang kartu kredit lain
Usia Dalam bulan
Masa kerja Dalam bulan
Lama tinggal Dalam bulan
Kelas 1 = buruk
19 Lampiran 2 Nilai akurasi dalam % pada saat jumlah tetangga adalah 1 sampai 5
Model data Akurasi tiap jumlah tetangga (k)
1 2 3 4 5
Data asli 74.48 74.69 78.08 78.56 79.05
Oversampling duplikasi 91.93 91.84 85.44 75.22 50.24 Oversampling acak 83.94 84.00 84.17 84.37 84.35 2-cluster undersampling 75.63 75.16 75.24 76.18 76.33 3-cluster undersampling 63.83 63.68 63.92 65.64 65.57 4-cluster undersampling 67.68 69.11 69.97 69.73 70.35
Lampiran 3 Nilai precision dalam % pada saat jumlah tetangga 1 sampai 5 Model data Precision tiap jumlah tetangga (k)
1 2 3 4 5
Data asli 22.53 22.25 26.56 27.17 25.68
20
Lampiran 4 Nilai recall dalam % pada saat jumlah tetangga adalah 1 sampai 5
Model data Recall tiap jumlah tetangga (k)
1 2 3 4 5
Data asli 22.75 22.47 19.50 18.54 15.59
Oversampling duplikasi 100.00 99.76 95.99 77.58 32.49 Oversampling acak 83.10 83.17 82.01 82.34 82.35 2-cluster undersampling 75.38 75.85 73.61 73.84 72.80 3-cluster undersampling 63.21 62.56 61.94 64.93 63.74 4-cluster undersampling 66.14 69.75 69.55 68.12 69.57
Lampiran 5 Nilai f-measure dalam % pada saat jumlah tetangga 1 sampai 5 Model data F-measure tiap jumlah tetangga (k)
1 2 3 4 5
Data asli 22.64 22.36 22.49 22.04 19.40
21
Lampiran 6 Contoh hasil klasifikasi data oversampling duplikasi saat k = 1 Kelas asli Kelas
22
Lampiran 8 Contoh hasil klasifikasi data oversampling duplikasi saat k = 3 Kelas asli Kelas
23 Lampiran 10 Contoh hasil klasifikasi data oversampling duplikasi saat k = 5
Kelas asli Kelas hasil uji
Membership kelas 1
Membership kelas 2
2 1 0.79 0.21
1 2 0.35 0.65
2 1 0.53 0.47
2 2 0.00 1.00
2 1 1.00 0.00
1 2 0.35 0.65
1 2 0.02 0.98
2 2 0.25 0.75
2 1 1.00 0.00
2 2 0.48 0.52
2 2 0.00 1.00
1 1 1.00 0.00
1 1 1.00 0.00
2 2 0.18 0.82
2 1 0.58 0.42
24
RIWAYAT HIDUP
Penulis dilahirkan di Kediri, Jawa Timur, pada tanggal 29 Juni 1991 sebagai anak pertama dari pasangan Selam dan Sri Mardiari. Penulis merupakan lulusan SMA Negeri 1 Kediri (2006-2009), SMP Negeri 1 Kepung (2003-2006), dan SD Negeri Kepung 6 (1997-2003).