ABSTRACT
FATHONI ARIEF MUSYAFFA. Signature Recognition using VFI5 Algorithm and Wavelet Preprocess. Under the Direction of AZIZ KUSTIYO.
Biometric is a science in recognizing the identity of a person based on their physical or behavioral traits. Today, one of the most widely applied biometric object is hand-written signature. In this research, we tried to identify offline handwritten signature using VFI5 (Voting Feature Intervals 5) classification algorithm. The VFI5 classification algorithm has been used previously on non-image objects with promising result. The feature used in the classification is the grayscale value of the image and the signature image dimension used in this research is 40×60 pixels which means originally there are 2400 features that relatively large to compute. Thus, Haar wavelet transform is used to reduce the dimension. This is done by taking only the approximation image of the transformation result, and leave the horizontal, vertical, diagonal details. The wavelet decomposition is applied until the fifth level, creating new low level images with 20×30, 10×15, 5×8, 3×4, 2×2 dimension respectively for the first, second, third, fourth, and fifth decomposition levels. The approximation images then classified using VFI5 algorithm, with 97.5%, 95%, 90%, 65%, and 62.5% accuracy respectively for the first, second, third, fourth, and fifth decomposition levels. It turned out that VFI5 algorithm can be used to identify images with wavelet transform to reduce the image dimension with good result, and the higher decomposition level applied, the more accuracy dropped.
PENGENALA
ALGORITME
F
DEP
FAKULTAS MATEM
INSTI
LAN TANDA TANGAN MENGGUNA
E VFI5 MELALUI PRAPROSES WA
FATHONI ARIEF MUSYAFFA
EPARTEMEN ILMU KOMPUTER
TEMATIKA DAN ILMU PENGETAHU
INSTITUT PERTANIAN BOGOR
BOGOR
2009
NAKAN
AVELET
PENGENALA
ALGORITME
F
DEP
FAKULTAS MATEM
INSTI
LAN TANDA TANGAN MENGGUNA
E VFI5 MELALUI PRAPROSES WA
FATHONI ARIEF MUSYAFFA
EPARTEMEN ILMU KOMPUTER
TEMATIKA DAN ILMU PENGETAHU
INSTITUT PERTANIAN BOGOR
BOGOR
2009
NAKAN
AVELET
PENGENALAN TANDA TANGAN MENGGUNAKAN
ALGORITME VFI5 MELALUI PRAPROSES WAVELET
FATHONI ARIEF MUSYAFFA
Skripsi
Sebagai salah satu syarat untuk memperoleh
Gelar Sarjana Komputer
pada Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
FATHONI ARIEF MUSYAFFA. Signature Recognition using VFI5 Algorithm and Wavelet Preprocess. Under the Direction of AZIZ KUSTIYO.
Biometric is a science in recognizing the identity of a person based on their physical or behavioral traits. Today, one of the most widely applied biometric object is hand-written signature. In this research, we tried to identify offline handwritten signature using VFI5 (Voting Feature Intervals 5) classification algorithm. The VFI5 classification algorithm has been used previously on non-image objects with promising result. The feature used in the classification is the grayscale value of the image and the signature image dimension used in this research is 40×60 pixels which means originally there are 2400 features that relatively large to compute. Thus, Haar wavelet transform is used to reduce the dimension. This is done by taking only the approximation image of the transformation result, and leave the horizontal, vertical, diagonal details. The wavelet decomposition is applied until the fifth level, creating new low level images with 20×30, 10×15, 5×8, 3×4, 2×2 dimension respectively for the first, second, third, fourth, and fifth decomposition levels. The approximation images then classified using VFI5 algorithm, with 97.5%, 95%, 90%, 65%, and 62.5% accuracy respectively for the first, second, third, fourth, and fifth decomposition levels. It turned out that VFI5 algorithm can be used to identify images with wavelet transform to reduce the image dimension with good result, and the higher decomposition level applied, the more accuracy dropped.
Judul : Pengenalan Tanda Tangan Menggunakan Algoritme VFI5 Melalui Praproses Wavelet
Nama : Fathoni Arief Musyaffa
NRP : G64053198
Menyetujui:
Pembimbing
Aziz Kustiyo, S.Si., M.Kom. NIP 19700719 199802 1 001
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. drh. Hasim, DEA NIP 19610328 198601 1 002
RIWAYAT HIDUP
Penulis dilahirkan di Kediri, Jawa Timur pada tanggal 14 Juli 1987 dari ayah Moh. Sjahid Has dan ibu Istianah. Penulis adalah anak kedua dari empat bersaudara.
Tahun 2005, penulis lulus dari SMAN 2 Pare dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur SPMB (Seleksi Penerimaan Mahasiswa Baru). Pada Tahun 2006, penulis masuk Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga penulis bisa menyelesaikan makalah skripsi ini. Penulis mengucapkan banyak terima kasih kepada Bapak Aziz Kustiyo, S.Si., M.Kom. selaku pembimbing yang tidak hanya memberikan saran, masukan, dan ide-ide, namun juga nasihat dan pelajaran hidup kepada penulis. Penulis juga mengucapkan terima kasih kepada Bapak Dr. Ir Agus Buono, M.Si.,M.Kom. dan Bapak Hari Agung Adrianto, S.Kom., M.Si.yang telah memberikan saran dan masukan. Selanjutnya, penulis ingin mengucapkan terima kasih kepada:
1 Bapak, Ibu, kakak, dan adik-adik serta seluruh keluarga yang telah memberikan bimbingan, doa dan kasih sayangnya,
2 Kakak tingkat dan teman-teman sebimbingan yang selalu memberikan semangat, motivasi dan bantuannya terutama Mas Ganang, Novi, Esti, Furqon, Rifki, Putra dan Abdul. 3 Teman-teman kontrakan, Wawan, Mizan, Fahmilu, Desca, Furqon, Haryanto dan Hengky,
atas kebersamaan yang telah dijalin dalam satu atap.
4 Teman-teman Ilkomerz 42 yang telah membantu penulis semasa perkuliahan baik dalam mempelajari teori dalam mata kuliah hingga mempelajari pemrograman. Ilkomerz 42, khususnya Wisnu, Gaos, Fakhri, Freddy, Bang Fuad, Mega, Windy, Dhani, Tanto dan Rifki.
5 Teman-teman yang tak henti memberikan nasihat: Pak Yusfan, Mas Ikhsan, Mas Slamet, Mas Dekri, Jarot, Saiful, Wikhdal, Fahmi, Mas Igma, Mas Dedi, dan Mas Yanuar.
6 Pembahas yang telah memberikan saran kepada penulis: Freddy, Mizan dan Haryanto. 7 Seluruh dosen dan staf Departemen Ilmu Komputer IPB.
Penulis menyadari banyak kekurangan dalam penelitian ini, oleh karena itu, penulis sangat mengharapkan kritik dan saran untuk perbaikan penelitian selanjutnya. Penulis berharap agar hasil penelitian ini dapat menjadi acuan bagi pembaca, khususnya untuk para peneliti yang berminat melanjutkan dan menyempurnakan penelitian ini.
Bogor, Agustus 2009
iv
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... v
DAFTAR TABEL ... v
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 2
Ruang Lingkup ... 2
TINJAUAN PUSTAKA Pengolahan Citra Digital ... 2
Tanda Tangan ... 2
Klasifikasi ... 2
Wavelet... 2
Transformasi Haar ... 3
VFI5 ... 3
Penelitian Sebelumnya ... 5
METODE PENELITIAN Data ... 6
Praproses ... 6
Transformasi Wavelet ... 6
Data Latih dan Data Uji ... 6
Algoritme VFI5 ... 6
Pelatihan ... 6
Klasifikasi ... 7
Akurasi ... 7
Lingkungan Pengembangan ... 7
HASIL DAN PEMBAHASAN Percobaan 1: Dekomposisi wavelet level 1 ... 7
Percobaan 2: Dekomposisi wavelet level 2 ... 7
Percobaan 3: Dekomposisi wavelet level 3 ... 8
Percobaan 4: Dekomposisi wavelet level 4 ... 8
Percobaan 5: Dekomposisi wavelet level 5 ... 8
Algoritme VFI5 Pada Tiap Kelas ... 9
Algoritme VFI5 Tanpa Kelas p, s, atau q di Level 3 ... 10
Algoritme VFI5 Tanpa Kelas p atau q di Level 2 ... 10
Algoritme VFI5 Tanpa Kelas p atau y di Level 1 ... 11
Algoritme VFI5 dengan menggunakan data latih yang berbeda ... 12
Waktu Pemrosesan ... 12
KESIMPULAN DAN SARAN Kesimpulan ... 12
Saran ... 12
v
DAFTAR GAMBAR
Halaman
1 Bank Filter Haar ... 3
2 Algoritme pelatihan VFI5 (Güvenir 1998). ... 5
3 Algoritma klasifikasi VFI5 (Güvenir 1998). ... 5
4 Tahapan klasifikasi. ... 6
5 Ilustrasi pengolahan fitur. ... 6
6 Persentase rata-rata akurasi pada tiap level. ... 8
7 Akurasi pada tiap level untuk tiap kelas. ... 9
DAFTAR TABEL Halaman 1 Ukuran dimensi dan banyak fitur pada dekomposisi wavelet... 7
2 Akurasi tiap-tiap kelas pada level 1 ... 7
3 Akurasi tiap-tiap kelas pada level 2 ... 7
4 Akurasi tiap-tiap kelas pada level 3 ... 8
5 Akurasi tiap-tiap kelas pada level 4 ... 8
6 Akurasi tiap-tiap kelas pada level 5 ... 8
7 Akurasi pada tiap level untuk tiap kelas ... 9
8 Akurasi tiap kelas pada level 3 tanpa kelas p ... 10
9 Akurasi tiap kelas pada level 3 tanpa kelas s ... 10
10 Akurasi tiap kelas pada level 3 tanpa kelas q ... 10
11 Akurasi tiap kelas pada level 2 tanpa kelas p ... 11
12 Akurasi tiap kelas pada level 2 tanpa kelas q ... 11
13 Akurasi tiap kelas pada level 1 tanpa kelas p ... 11
14 Akurasi tiap kelas pada level 1 tanpa kelas y ... 11
15 Akurasi tiap-tiap level dengan menggunakan data latih dan data uji yang berbeda ... 12
vi
DAFTAR LAMPIRAN
Halaman
1 Ilustrasi pelatihan VFI5 ... 15
2 Ilustrasi klasifikasi VFI5 ... 17
3 Citra yang digunakan ... 18
4 Citra hasil dekomposisi ... 20
1
PENDAHULUAN Latar Belakang
Biometrik merupakan ilmu pengetahuan yang membangun identitas seseorang berdasarkan sifat-sifat fisik, kimiawi, ataupun kebiasaan seseorang. Sistem biometrik dapat menggunakan ciri fisik (physical traits) maupun tingkah laku (behavioral traits). Contoh ciri fisik antara lain sidik jari, iris, wajah dan bentuk geometris tangan, sedangkan contoh ciri tingkah laku misalnya tanda tangan, pola penekanan
keyboard, dan gaya berjalan (Ross et al. 2006). Objek biometrik hendaknya memenuhi beberapa kriteria untuk digunakan sebagai objek. Kriteria biometrik tersebut antara lain
universality (setiap orang memiliki biometrik tersebut), distinctiveness (biometrik tersebut berbeda pada setiap orang), permanence (tidak berubah-ubah dalam jangka waktu yang lama), dan collectability (dapat diukur secara kuantitatif) (Maltoni et al. 2003).
Tanda tangan merupakan salah satu objek biometrik yang mudah diperoleh, baik melalui kertas maupun peralatan elektronik seperti PC tablet, layar sentuh dan PDA. Meskipun demikian, biometrik tanda tangan masih menjadi topik riset yang menantang. Tantangan dalam biometrik tanda tangan ini antara lain karena variasi dalam kelas yang besar, tingkat
universality dan permanence yang rendah, serta adanya kemungkinan serangan pemalsuan tanda tangan (Jain et al. 2008).
Metode pengenalan tanda tangan dapat diklasifikasikan berdasarkan informasi masukan tanda tangan menjadi dua kategori, online dan
offline. Metode pengenalan tanda tangan online
merujuk pada penggunaan fungsi-fungsi waktu dalam proses penandatanganan secara dinamis (misalnya lintasan posisi atau penekanan). Metode pengenalan tanda tangan offline
merujuk pada penggunaan gambar statis dari tanda tangan (Jain et al. 2008).
Penelitian ini menggunakan metode pengenalan tanda tangan secara offline.
Pengenalan tanda tangan dilakukan dengan menggunakan algoritme klasifikasi VFI5. Pada percobaan dengan penambahan fitur yang tidak relevan, algoritme VFI5 memiliki akurasi yang lebih tinggi dibandingkan dengan algoritme
nearest neighbor (Güvenir 1998).
Penelitian dengan menggunakan algoritme VFI5 sebelumnya telah banyak dilakukan untuk
klasifikasi berbasis teks, di antaranya diagnosis penyakit demam berdarah dengue, diagnosis gangguan sistem urinari pada anjing dan kucing, hingga klasifikasi pasien suspect parvo
dan distemper pada data rekam medik rumah sakit hewan IPB. Pada penelitian pertama, diagnosis penyakit demam berdarah dengue
dengan menggunakan algoritme VFI5 memiliki akurasi sebesar 100%, sedangkan ketika diklasifikasikan menggunakan ANFIS akurasi yang diperoleh adalah 86.67% (Apniasari 2007). Selanjutnya, diagnosis gangguan sistem urinari pada anjing dan kucing memberikan akurasi sebesar 77.38% ketika klasifikasi dilakukan tanpa menggunakan fitur pemeriksaan laboratorium, sedangkan ketika klasifikasi dilakukan dengan menggunakan fitur pemeriksaan laboratorium, diperoleh akurasi sebesar 86.31% (Ramdhany 2007). Pada klasifikasi pasien suspect parvo dan distemper, diperoleh rata-rata akurasi sebesar 90% (Iqbal 2007). Karena pada klasifikasi berbasis teks algoritme VFI5 mampu menglasifikasikan dengan akurasi yang tinggi, maka muncul dugaan bahwa algoritme klasifikasi VFI5 juga baik digunakan untuk identifikasi citra.
Sebelum melakukan klasifikasi citra, dilakukan praproses untuk mereduksi ukuran citra. Citra yang memiliki ukuran m×n piksel misalnya, akan memiliki m×n fitur pada algoritme VFI5 sehingga komputasi yang dilakukan menjadi lebih banyak. Untuk itu, diperlukan proses reduksi. Reduksi yang digunakan dalam penelitian ini adalah reduksi dimensi melalui transformasi wavelet. Dibandingkan dengan metode reduksi PCA, reduksi dimensi menggunakan wavelet memiliki efisiensi komputasi yang lebih baik (Agarwal et al. 2005).
Transformasi wavelet untuk reduksi dimensi sebelumnya telah dilakukan pada pengenalan citra wajah oleh Anjum & Javed (2006). Pada penelitian tersebut, hanya low pass filter yang digunakan karena diasumsikan low frequency
yang memberikan kontribusi lebih banyak dalam merepresentasikan informasi citra wajah.
2 hasil dekomposisi detail, dan energi terendah
berada pada citra Hi-Hi atau citra diagonal, yakni 0.4%. Oleh karena itu, hanya citra pendekatan saja yang digunakan sebagai input untuk klasifikasi menggunakan algoritme VFI5.
Tujuan Penelitian
Tujuan dari penelitian ini adalah melakukan pengenalan tanda tangan dengan menggunakan algoritme VFI5 setelah dilakukan reduksi dimensi melalui transformasi wavelet. Selanjutnya dilakukan analisis kinerja pengenalan tanda tangan menggunakan algoritme VFI5 dan pengaruh dekomposisi wavelet terhadap akurasi yang diperoleh.
Ruang Lingkup
Terdapat beberapa batasan dari penelitian ini, yaitu:
1 Citra yang digunakan adalah citra tanda tangan yang diperoleh dari data skripsi (Setia 2007) sejumlah 10 tanda tangan, dan tiap-tiap tanda tangan terdiri dari 10 citra berukuran 40×60 piksel.
2 Reduksi fitur yang digunakan adalah menggunakan transformasi wavelet Haar. 3 Algoritme klasifikasi yang digunakan yaitu
algoritme VFI5 dengan bobot yang seragam untuk tiap fiturnya.
TINJAUAN PUSTAKA Pengolahan Citra Digital
Sebuah citra dapat didefinisikan sebagai fungsi dua dimensi, f(x, y) dimana x dan y
merupakan koordinat spasial (bidang) dan amplitudo dari f pada semua pasang koordinat
(x,y) disebut sebagai intensitas atau gray level
dari sebuah citra pada titik tertentu. Ketika x,y
dan nilai amplitudo dari f bernilai diskret dan terbatas, kita menyebut citra tersebut sebagai citra digital. Bidang pengolahan citra digital mengacu pada pengolahan gambar digital dengan menggunakan komputer digital. Citra digital terbentuk dari elemen bilangan terbatas, dimana tiap-tiap elemen memiliki lokasi dan nilai tertentu. Elemen-elemen ini disebut dengan elemen gambar (picture elements), elemen citra (imageelements), pels, atau pixel.
Pixel merupakan istilah yang paling sering digunakan untuk menyebutkan elemen dari citra digital (Gonzalez & Woods 2002).
Tanda Tangan
Tanda tangan merupakan salah satu bentuk biometrik behavioral yang berubah-ubah tergantung dari kondisi fisik dan emosional
seseorang. Meskipun tanda tangan memerlukan kontak dengan alat tulis dan usaha dari sisi pengguna, tanda tangan banyak digunakan pada instansi pemerintahan hingga transaksi komersial yang sah sebagai salah satu bentuk otentikasi. Dengan adanya PDA dan PC tablet, tanda-tangan online bisa menjadi salah satu alat biometrik untuk digunakan pada perangkat-perangkat ini (Ross et al. 2006).
Klasifikasi
Klasifikasi merupakan salah satu bentuk analisis data yang digunakan untuk melakukan ekstraksi model yang mendeskripsikan kelas data yang penting atau memperkirakan kecenderungan selanjutnya dari suatu data. Analisis seperti demikian dapat membantu pihak yang berkepentingan dalam memahami data yang besar. Klasifikasi memperkirakan label kategorik yang bersifat diskret dan tak memiliki urutan. Misalnya, seorang ahli dapat mengembangkan model klasifikasi untuk memberikan kategori pada aplikasi peminjaman bank, apakah termasuk aman, atau berisiko. Metode klasifikasi banyak menerapkan pembelajaran mesin, pengenalan pola, dan statistik (Han & Kamber 2006).
Wavelet
Wavelet merupakan fungsi matematis yang memisahkan data menjadi beberapa komponen frekuensi yang berbeda dan mempelajari tiap-tiap komponen sesuai dengan resolusi yang tepat dengan skalanya masing-masing. Wavelet memiliki kelebihan dibandingkan dengan transformasi Fourier dalam menganalisis keadaan fisik yang memiliki sinyal tak kontinu dan memiliki variasi yang tajam. Wavelet dikembangkan secara bebas dalam bidang matematika, fisika kuantum, teknik elektro, dan geologi seismik (Graps 1995).
Wavelet ditunjukkan pertama kali sebagai dasar pendekatan baru untuk pemrosesan sinyal dan analisis yang disebut teori multiresolusi. Teori multiresolusi berkaitan dengan analisis dan representasi sinyal atau citra pada lebih dari satu resolusi. Hasil pendekatan teori multiresolusi yakni fitur yang tidak terdeteksi pada suatu resolusi dapat terdeteksi pada resolusi lain (Gonzalez & Woods 2002).
Dalam analisis multiresolusi (AMR), scaling function digunakan untuk menciptakan satu rangkaian pendekatan pada suatu fungsi atau citra, scaling function ini dinyatakan dalam persamaan berikut:
3 dimana koefisien dalam persamaan
rekursif ini merupakan scaling function
(Gonzalez & Woods 2002).
Transformasi wavelet bekerja dengan mengambil rata-rata dari nilai masukan dan mempertahankan informasi yang diperlukan untuk mengembalikan ke nilai semula (McAndrew 2004). Secara umum, jika a dan b
adalah dua bilangan, dapat dihitung rata-rata s
dan selisih d melalui persamaan:
s = (a + b) / 2 , d = a – s ,
selanjutnya, nilai a dan b dapat diperoleh kembali melalui:
a = s + d , b = s – d . Transformasi Haar
Transformasi Haar merupakan transformasi wavelet yang paling sederhana dan telah banyak digunakan pada citra (McAndrew 2004). Wavelet Haar dapat dituliskan sebagai pulse function:
1 0 0 1
dengan menggunakan relasi:
ψ 2 2 1 ,
nilai 2 sama dengan 1 jika 0 1/2 dan nilai 2 1 sama dengan 1 untuk
1/2 1. Pulse function ini juga dapat dituliskan sebagai:
2 2 1 .
Dalam teori wavelet, fungsi ψ disebut
mother wavelet dan fungsi disebut scaling function (McAndrew 2004).
Dekomposisi menggunakan transformasi Haar dilakukan dengan menggunakan bank filter dengan koefisien h0 = 1/ √2 h1 = 1/√2 dan g0 = 1/√2 serta g1 = 1/ √2. Bank filter Haar ditunjukkan pada Gambar 1.
h" h# 0 0 $
g" g# 0 0 $
0 0 h" h# $
0 0 g" g# $
& & & &
Gambar 1 Bank Filter Haar.
VFI5
VFI5 merupakan algoritme klasifikasi yang memberikan deskripsi melalui sekumpulan interval fitur. Klasifikasi dari sebuah instance
baru didasarkan pada vote di antara klasifikasi yang dibuat oleh nilai dari tiap fitur secara terpisah. VFI5 merupakan algoritme supervised learning yang bersifat non-incremental, sehingga, seluruh contoh dalam data training
diproses sekali dalam satu waktu. Tiap-tiap contoh training direpresentasikan sebagai nilai-nilai fitur vektor nominal (diskret) atau linear (kontinu), disertai dengan label yang menunjukkan kelas contoh.
Dari data training, algoritme VFI5 membentuk interval untuk tiap fitur. Suatu interval bisa berupa interval titik atau selang (range). Interval selang didefinisikan sebagai sekumpulan nilai yang berurutan dari fitur yang diberikan, sedangkan interval titik didefinisikan sebagai fitur bernilai tunggal. Untuk interval titik, hanya sebuah nilai yang digunakan untuk mendefinisikan sebuah interval.
Untuk tiap interval, diambil sebuah nilai tunggal yang merupakan vote dari tiap-tiap kelas dalam interval tersebut. Oleh karena itu, sebuah interval dapat merepresentasikan beberapa kelas dengan menyimpan vote dari tiap-tiap kelas (Güvenir 1998).
VFI5 merupakan versi terakhir yang dikembangkan dari algoritme VFI1. Pada tahap pelatihan dalam algoritme VFI1, jika fitur bersifat linear (kontinu), maka hanya dibentuk
range interval. Dalam perhitungan count instance sebagai vote dari data latih, jika nilai fitur terletak tepat di dalam satu interval i, maka nilai count interval i ditambah 1, namun jika nilai fitur terletak pada batas bawah interval, nilai count untuk interval ke-i dan ke-(i-1) ditambah 0.5. Proses klasifikasi pada algoritme VFI1 dilakukan dengan melihat letak nilai fitur dari instance pengujian ef dalam interval pelatihan. Jika i merupakan point interval dan nilai ef sama dengan nilai pada point interval, maka fitur f memberikan vote untuk tiap kelas c
sebesar nilai vote kelas pada interval pelatihan. Namun jika i merupakan range interval dan nilai ef sama dengan nilai batas bawah dari interval tersebut, maka vote yang diberikan oleh fitur f adalah rata-rata vote pelatihan dari interval ke-i dan ke-(i-1).
4 klasifikasi pada algoritme VFI2 sama dengan
tahapan klasifikasi pada algoritme VFI1. Algoritme VFI3 tidak berkaitan dengan algoritme VFI2 dan dikembangkan dari algoritme VFI1. Ada penambahan beberapa kondisi untuk pembentukan interval dan klasifikasi. Kondisi ini mempertimbangkan apakah nilai instance terletak pada titik tertinggi, titik terendah, atau titik lain pada end points. Kondisi-kondisi dan ilustrasi lebih lengkap dapat dilihat pada Demiröz (1997).
Algoritme VFI4 dikembangkan dari algoritme VFI3. Pada algoritme VFI4, jika fitur merupakan fitur linear dan ada kelas yang memiliki nilai titik tertinggi sama dengan nilai titik terendah, maka selain dibentuk range interval, juga dibentuk point interval pada fitur nominal. Hal ini dilakukan untuk menghindari kesalahan pemberian vote pada kelas yang memiliki nilai titik tertinggi sama dengan nilai terendah. Pada tahap klasifikasi, jika nilai fitur pada instance pengujian terletak pada point interval, maka nilai vote yang diambil hanya dari nilai vote pada point interval hasil pelatihan.
Versi selanjutnya dari algoritme VFI4 adalah VFI5. Pada algoritme VFI5, dilakukan generalisasi pembentukan point interval pada fitur linear, tanpa memperhatikan apakah ada kelas dalam suatu fitur yang memiliki nilai titik tertinggi sama dengan nilai titik terendah. Algoritme dan ilustrasi untuk tiap versi VFI dapat dilihat di Demiröz (1997). Kelebihan algoritme VFI5 adalah prediksi yang akurat, pelatihan dan waktu yang dibutuhkan untuk melakukan klasifikasi cukup singkat, bersifat
robust terhadap training dengan data yang memiliki noise dan nilai fitur yang hilang, dapat menggunakan bobot fitur, serta dapat memberikan model yang mudah dipahami manusia (Güvenir 1998).
1 Pelatihan
Hal pertama yang harus dilakukan dalam tahap pelatihan adalah menemukan titik-titik akhir (end points) dari tiap kelas c pada tiap fitur f. Titik akhir dari kelas c yang diberikan merupakan nilai yang terkecil dan terbesar pada dimensi fitur linear (kontinu) f untuk beberapa
instance pelatihan dari kelas c yang sedang diamati. Namun demikian, titik akhir dari dimensi fitur nominal (diskret) f, merupakan nilai-nilai yang berbeda satu sama lain, untuk beberapa instance pelatihan dari kelas c yang sedang diamati. Titik akhir dari fitur f kemudian disimpan dalam arrayEndPoints[f].
Batas bawah pada interval selang adalah -∞, sedangkan batas atas interval selang adalah +∞.
List dari titik akhir pada tiap dimensi fitur linear diurutkan. Jika fitur tersebut merupakan fitur linear, terdapat dua jenis interval, interval titik dan interval selang. Jika fitur tersebut merupakan fitur nominal, hanya ada satu jenis interval, yaitu interval titik.
Selanjutnya, banyak instance pelatihan setiap kelas c dengan fitur f untuk setiap interval
i dihitung dan direpresentasikan sebagai
interval_class_count[f,i,c]. Pada setiap instance
pelatihan, dicari interval i, yang merupakan interval nilai fitur f dari instance pelatihan e (ef) tersebut berada. Apabila interval i adalah interval titik dan ef sama dengan batas bawah interval tersebut (yang sama dengan batas atas untuk interval titik), jumlah kelas instance
tersebut (ef) pada interval i ditambah 1. Apabila interval i merupakan interval selang dan ef
berada pada interval tersebut maka jumlah kelas
instance ef pada interval i ditambah 1. Proses inilah yang menjadi vote pelatihan untuk kelas c
pada interval i.
Agar tidak mengalami efek perbedaan distribusi setiap kelas, vote kelas c untuk fitur f
pada interval i harus dinormalisasi dengan membagi vote tersebut dengan hasil penjumlahan tiap-tiap instance kelas c yang direpresentasikan dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai
5
train(TrainingSet): begin
for each feature f
for each class c
EndPoints[f] = EndPoints[f] ∪ find_end_points(TrainingSet, f, c);
sort(EndPoints[f]);
if f is linear
for each end point p in EndPoints[f] form a point interval from end point p
form a range interval between p and the next endpoint ≠ p
else /* f is nominal*/
each distinct point in EndPoints[f] forms a point interval
for each interval i on feature dimension f
for each class c
interval_class_count[f,i,c]=0
count_instances(f,TrainingSet);
for each interval i on feature dimension f
for each class c
t[c] class_coun c] i, [f, lass_count interval_c c] i, f, lass_vote[ interval_c = normalize interval_class_vote[f,i,c]
* such that ∑c interval_class_vote[f,i,c] = 1 * End
Gambar 2 Algoritme pelatihan VFI5 (Güvenir 1998).
2 Klasifikasi
Tahap klasifikasi dimulai dengan inisialisasi
vote dengan nilai nol pada tiap-tiap kelas. Pada tiap-tiap fitur f, dicari interval i yang sesuai dengan nilai ef, dimana ef merupakan nilai fitur f
dari instance pengujian e. Jika ef hilang atau tidak diketahui, fitur tersebut tidak diikutsertakan dalam voting dengan memberikan vote nol pada setiap kelas yang hilang. Tiap-tiap fitur f mengumpulkan vote-vote-nya dalam sebuah vektor
〈feature_vote[f,C1], ..., feature_vote[f,Cj], ...
,feature_vote[f,Ck]〉, dimana feature_vote[f,Cj] adalah vote fitur f untuk kelas Cj dan k adalah banyak kelas. Sebanyak d vektor feature vote
dijumlahkan sesuai dengan fitur dan kelasnya masing-masing untuk memperoleh total vektor
vote〈vote[C1], ..., vote[Ck]〉. Kelas dari instance
pengujian e adalah kelas yang memiliki jumlah
vote terbesar. Ilustrasi klasifikasi pada algoritme VFI5 dapat dilihat pada Lampiran 2, sedangkan cara kerja algoritme VFI5 terdapat pada Gambar 3.
classify(e):
/* e: example to be classified */ begin
for each class c
vote[c] = 0
for each feature f
for each class c
feature_vote[f,c] = 0 /* vote of feature f for class c */ if ef value is known
i = find_interval( f, ef )
feature_vote[f,c] = interval_class_vote[f,i,c]
for each class c
vote[c] = vote[c] + feature_vote[f,c]
return class c with highest vote[c] end
Gambar 3 Algoritma klasifikasi VFI5 (Güvenir 1998).
Penelitian Sebelumnya
Data yang digunakan dalam penelitian ini berasal dari data pada penelitian Setia (2007). Pada penelitian tersebut, data tanda tangan dikumpulkan di atas kertas dan proses digitalisasi dilakukan dengan menggunakan
scanner menjadi file citra 300 dpi format BMP dan mode RGB. Citra tanda tangan ini selanjutnya dikonversi menjadi citra 8 bit dengan format PCX berukuran 40×60 piksel.
6 Pengenalan tanda tangan menggunakan
Hidden Markov Model (HMM) memperoleh akurasi rata-rata 75% untuk 8 state, 73% untuk 6 state, dan 53% untuk 4 state (Setia 2007). Pengenalan tanda tangan sebelumnya menggunakan Jaringan Syaraf Tiruan (JST) propagasi balik mampu mengenali pola yang diberikan dengan akurasi tertinggi sebesar 99%, tergantung dari metode yang digunakan dari output JST (metode nilai maksimum atau metode threshold), representasi pola input yang digunakan sebagai representasi input JST, nilai toleransi galat, laju pembelajaran dan jumlah
neuron lapisan tersembunyi (Riadi 2001).
METODE PENELITIAN
Ada beberapa tahap yang dilakukan dalam proses klasifikasi citra tanda tangan dengan menggunakan praproses wavelet. Tahapan ini ditunjukkan pada Gambar 4.
Gambar 4 Tahapan klasifikasi.
Data
Semua citra tanda tangan yang digunakan dalam penelitian ini melalui praproses transformasi wavelet. Selanjutnya, citra latih dan citra uji diklasifikasikan menggunakan algoritme VFI5.
Praproses
Citra tanda tangan yang akan diproses dengan algoritme VFI5 direduksi terlebih dahulu menggunakan transformasi wavelet. Hal
ini dilakukan agar fitur yang dihitung tidak terlalu banyak sehingga proses komputasi lebih mudah dan cepat.
Transformasi Wavelet
Citra tanda tangan yang diproses menggunakan transformasi wavelet akan mengalami penurunan banyak fitur hingga 75% dari banyak fitur semula. Dalam penelitian ini, dilakukan transformasi wavelet hingga lima level. Setelah melalui transformasi wavelet, diperoleh empat citra yang memiliki dimensi baru, yakni citra pendekatan, citra detail horizontal, citra detail vertikal, dan citra detail diagonal. Ilustrasi citra hasil dekomposisi wavelet dapat dilihat pada Lampiran 4.
Data Latih dan Data Uji
Data dibagi ke dalam dua bagian, yaitu data latih dan data uji. Data latih digunakan untuk memberikan supervised learning pada algoritme VFI5, sedangkan data uji digunakan untuk menguji ketepatan hasil klasifikasi yang dilakukan oleh algoritme VFI5. Perbandingan antara data latih dan data uji yang digunakan dalam percobaan ini adalah 3:2. Hal ini berarti terdapat 6 citra latih dan 4 citra uji untuk tiap-tiap kelas.
Algoritme VFI5
Terdapat dua proses dalam algoritme VFI5. Kedua tahapan ini yaitu pelatihan dan klasifikasi.
Pelatihan
Tiap-tiap matriks citra yang digunakan dibentuk menjadi matriks baris tunggal. Misalnya, matriks citra berukuran 3×4 piksel yang diilustrasikan pada Gambar 5.
f1 f2 f3 f4
f5 f6 f7 f8
f9 f10 f11 f12
Citra ke-1
&
f1 f2 f3 f4
f5 f6 f7 f8
f9 f10 f11 f12
Citra ke-n
f1 f2 … f11 f12
Citra ke-1 ⋮
f1 f2 … f11 f12
Citra ke-n
7 Fitur yang digunakan untuk pelatihan pada
algoritme VFI5 diperoleh dari tiap-tiap piksel pada citra tanda tangan. Fitur pada pelatihan yang semula berupa matriks berukuran 3×4
piksel disusun menjadi matriks berukuran 1×12
piksel.
Klasifikasi
Setiap nilai fitur dari instance citra uji diperiksa letak interval nilai fitur tersebut pada hasil vote yang telah dinormalisasi. Vote-vote
setiap kelas untuk setiap fitur pada setiap interval yang bersesuaian diambil dan kemudian dijumlahkan. Kelas yang memiliki nilai total
vote tertinggi menjadi kelas prediksi instance
tersebut.
Akurasi
Hasil yang diamati pada penelitian ini yaitu tingkat akurasi yang dicapai algoritme klasifikasi VFI5 dalam menglasifikasikan data pengujian setelah dilakukan pelatihan. Tingkat akurasi diperoleh dengan perhitungan:
%. 100 uji data total asi diklasifik benar uji data akurasi tingkat × ∑ ∑ = Lingkungan Pengembangan
Penelitian dilakukan dengan menggunakan perangkat lunak MATLAB 7.0.1 dan Microsoft Office Excel 2007 yang berjalan pada sistem operasi Microsoft Windows XP SP3. Adapun perangkat keras yang digunakan memiliki spesifikasi Prosesor AMD Athlon XP 3200+, DDRAM 1470 MB, VGA GeForce 6100 nForce 405, dan HDD 160 GB.
HASIL DAN PEMBAHASAN
Dalam penelitian ini, data diproses menggunakan wavelet Haar hingga level ke-5. Adapun ukuran dimensi dan banyak fitur yang diperoleh dari hasil praproses menggunakan transformasi wavelet Haar tercantum pada Tabel 1.
Tabel 1 Ukuran dimensi dan banyak fitur pada dekomposisi wavelet Level Transformasi Ukuran Dimensi Banyak Fitur
1 20x30 600
2 10x15 150
3 5x8 40
4 3x4 12
5 2x2 4
Klasifikasi yang dilakukan tanpa melalui reduksi dimensi menghasilkan akurasi
sebesar 97.5%. Hasil ini kemudian dibandingkan dengan klasifikasi dengan menggunakan reduksi.
Percobaan 1: Dekomposisi wavelet level 1
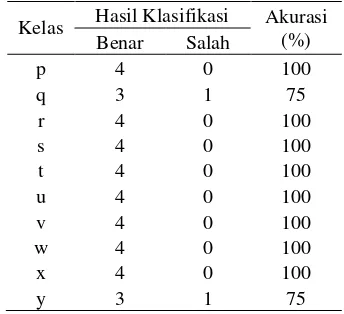
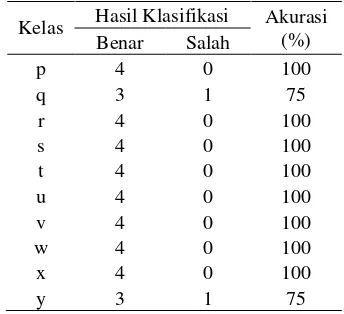
Percobaan pertama merupakan percobaan dengan dekomposisi wavelet paling rendah. Hasil percobaan secara rinci untuk tiap kelas pada percobaan kelima dicantumkan pada Tabel 2.
Tabel 2 Akurasi tiap-tiap kelas pada level 1
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 4 0 100
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 3 1 75
Dari Tabel 2 dapat dilihat bahwa kelas y memiliki akurasi terendah, yakni 75%. Kelas lainnya memiliki akurasi 100%. Adapun rata-rata akurasi yang diperoleh secara keseluruhan mencapai 97.5%.
Percobaan 2: Dekomposisi wavelet level 2
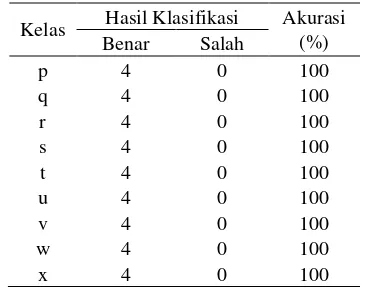
Hasil percobaan untuk dekomposisi wavelet level 2 ditunjukkan pada Tabel 3. Dibandingkan percobaan sebelumnya pada level 1, kelas q mengalami penurunan akurasi sebesar 25%. Kelas selain q dan y memiliki akurasi 100%. Pada percobaan ini, akurasi rata-rata mencapai 95%.
Tabel 3 Akurasi tiap-tiap kelas pada level 2
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
8
Percobaan 3: Dekomposisi wavelet level 3
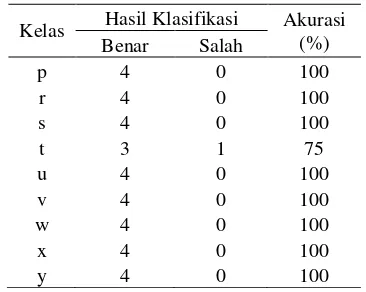
Pada level 3, akurasi rata-rata mengalami penurunan dibandingkan level 2. Perolehan akurasi ini ditunjukkan pada Tabel 4.
Tabel 4 Akurasi tiap-tiap kelas pada level 3
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 2 2 50
r 4 0 100
s 3 1 75
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 3 1 75
Kelas q memiliki akurasi paling kecil, yakni sebesar 50%. Kelas s dan y memiliki akurasi 75%, sedangkan kelas sisanya memiliki akurasi sebesar 100%. Rata–rata akurasi untuk keseluruhan kelas pada wavelet dekomposisi level 3 turun menjadi 90%.
Percobaan 4: Dekomposisi wavelet level 4
Rata-rata akurasi yang diperoleh pada tiap kelas di level 4 dapat dilihat pada Tabel 5. Kelas p masih memiliki akurasi klasifikasi sebesar 100%, namun kelas u mengalami penurunan akurasi sebesar 50% dibandingkan hasil klasifikasi pada level 3. Akurasi sebesar 100% juga diperoleh untuk klasifikasi kelas w. Akurasi terkecil dimiliki oleh kelas r, yang mengalami penurunan akurasi hingga 75% dibandingkan hasil klasifikasi pada level 3. Secara rata-rata, akurasi pada level 4 ini adalah 65%, mengalami penurunan akurasi rata-rata hingga 25% dibandingkan hasil klasifikasi pada level 3.
Tabel 5 Akurasi tiap-tiap kelas pada level 4
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 1 3 25
s 2 2 50
t 3 1 75
u 2 2 50
v 2 2 50
w 4 0 100
x 3 1 75
y 2 2 50
Percobaan 5: Dekomposisi wavelet level 5
Rata-rata persentase akurasi yang diperoleh pada tiap kelas di level 5 dapat dilihat pada Tabel 6. Dari Tabel 6, kelas p dan u memiliki akurasi 100%. Pada kelas v dan r, hanya diperoleh akurasi sebesar 25%. Kelas s, w, dan y memiliki akurasi sebesar 50% dan sisanya memiliki akurasi sebesar 75%. Persentase akurasi rata-rata dari tiap-tiap kelas pada dekomposisi wavelet level 5 ini mencapai 62.5%.
Tabel 6 Akurasi tiap-tiap kelas pada level 5
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 1 3 25
s 2 2 50
t 3 1 75
u 4 0 100
v 1 3 25
w 2 2 50
x 3 1 75
y 2 2 50
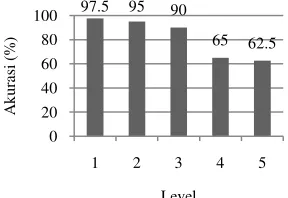
Secara umum, terjadi penurunan akurasi pada setiap peningkatan level dekomposisi wavelet. Semakin rendah level dekomposisi wavelet, semakin tinggi rata-rata akurasinya. Pada dekomposisi wavelet level 4 dan 5, akurasi turun drastis dibandingkan dekomposisi level 1, 2 dan 3. Penurunan akurasi paling besar terjadi pada dekomposisi wavelet dari level 3 ke dekomposisi wavelet level 4, yakni dari 90% menjadi 65%, atau turun sebesar 25%. Penurunan akurasi yang cukup besar dibanding percobaan sebelumnya dimungkinkan karena dengan 12 fitur, penciri pada tiap-tiap kelas mulai tidak dapat dikenali. Hubungan antara level dekomposisi dengan akurasi ditunjukkan pada Gambar 6.
Gambar 6 Persentase rata-rata akurasi pada tiap level.
97.5 95 90
65 62.5 0 20 40 60 80 100
1 2 3 4 5
9 Penelitian Riadi (2001) yang menggunakan
keseluruhan 2400 fitur sebagai input dalam JST menghasilkan akurasi tertinggi sebesar 99%. Sementara pada penelitian Setia (2007), citra tanda tangan yang berukuran 40×60 piksel
di-resize menjadi citra 30×45 piksel. Hasil resize
tersebut selanjutnya disegmentasi sebanyak 45 segmen dimana setiap segmen terdiri atas vektor observasi berukuran 30. Dengan menggunakan 8 hidden state, diperoleh rata-rata akurasi sebesar 75%. Dalam penelitian ini, setelah dilakukan dekomposisi wavelet level 1, terdapat 600 fitur sebagai input dalam algoritme VFI5 dan diperoleh akurasi sebesar 97.5%.
Jika dibandingkan antara hasil percobaan tanpa reduksi yang memiliki 2400 fitur dengan hasil percobaan melalui reduksi wavelet level 1 yang memiliki 600 fitur, diperoleh kesamaan akurasi, yakni 97.5%. Meskipun demikian, banyak fitur pada percobaan yang telah melalui reduksi telah berkurang hingga 75%.
Algoritme VFI5 Pada Tiap Kelas
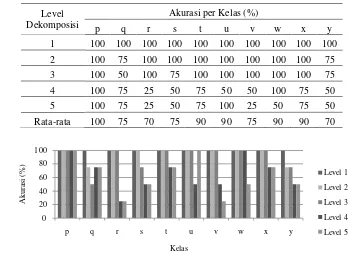
Hasil perhitungan akurasi pada tiap kelas per level dapat dilihat pada Tabel 7. Representasi grafis dari Tabel 7 dapat dilihat pada Gambar 7, sedangkan hasil penyesuaian antara kelas dugaan hasil klasifikasi dengan kelas sebenarnya terdapat dalam Lampiran 5.
Tabel 7 Akurasi pada tiap level untuk tiap kelas
Level Dekomposisi
Akurasi per Kelas (%)
p q r s t u v w x y
1 100 100 100 100 100 100 100 100 100 100 2 100 75 100 100 100 100 100 100 100 75 3 100 50 100 75 100 100 100 100 100 75
4 100 75 25 50 75 50 50 100 75 50
5 100 75 25 50 75 100 25 50 75 50
Rata-rata 100 75 70 75 90 90 75 90 90 70
Gambar 7 Akurasi pada tiap level untuk tiap kelas.
Pada kelas p, seluruh citra pada tiap level dapat diklasifikasikan dengan benar. Pada kelas q, akurasi sebesar 100% hanya diperoleh pada level 1. Akurasi paling rendah terdapat pada level 3 sebesar 50%. Adapun akurasi sisanya pada kelas q sebesar 75%,
Klasifikasi level 1, 2 dan 3 pada kelas r memiliki akurasi sebesar 100%, namun pada level 4 dan 5 akurasi turun menjadi 25%. Klasifikasi kelas s pada level 1 dan 2 memiliki akurasi sebesar 100%, dan menurun pada level 3 menjadi 75%. Pada level 4 dan 5, akurasi kembali turun menjadi 50%.
Pada kelas t, citra pada level 1, 2 dan 3 dapat diklasifikasikan dengan benar, sedangkan pada level 4 dan 5, akurasi turun menjadi 75%. Pada kelas u, akurasi terendah sebesar 50% berada pada level 4, sisanya memiliki akurasi 100%.
Nilai akurasi 100% di kelas v terjadi pada klasifikasi level 1, 2 dan 3. Nilai akurasi ini kemudian turun menjadi 50% pada level 4 dan 25% pada level 5. Klasifikasi pada kelas w memiliki akurasi sebesar 50% untuk level 5, namun untuk level lainnya, seluruh citra dapat diklasifikasikan dengan benar.
0 20 40 60 80 100
p q r s t u v w x y
A
k
u
ra
si
(
%
)
Kelas
Level 1
Level 2
Level 3
Level 4
10 Pada kelas x, diperoleh nilai akurasi 100%
untuk level 1, 2 dan 3. Nilai akurasi ini turun menjadi 75% pada level 4 dan 5. Pada kelas y, nilai akurasi 100% hanya diperoleh pada klasifikasi level 1. Nilai ini turun menjadi sebesar 75% pada level 2 dan 3, kemudian kembali turun menjadi 50% pada level 4 dan 5.
Kelas p memiliki akurasi paling tinggi dibandingkan kelas lainnya. Seluruh citra pada kelas p dapat diklasifikasikan dengan benar. Kelas r dan y memiliki akurasi terendah, dengan rata-rata akurasi sebesar 70%.
Algoritme VFI5 Tanpa Kelas p, s, atau q di Level 3
Pada percobaan selanjutnya, dilakukan eliminasi pada kelas-kelas yang berturut-turut memiliki nilai rata-rata akurasi tertinggi, sedang dan terendah pada level 3. Kelas-kelas yang dihilangkan yaitu kelas p yang memiliki rata-rata akurasi tertinggi (100%), kelas s yang memiliki nilai rata-rata akurasi sedang (75%), dan kelas q yang memiliki nilai rata-rata akurasi terendah (50%). Nilai rata-rata akurasi yang diperoleh dengan menghilangkan kelas p, kelas s dan kelas q berturut-turut sebesar 86.11%, 86.11% dan 97.22%. Hasil percobaan secara rinci untuk kelas p, s, dan q berturut-turut dapat dilihat pada Tabel 8, Tabel 9, dan Tabel 10. Tabel 8 Akurasi tiap kelas pada level 3 tanpa
kelas p
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
q 2 2 50
r 3 1 75
s 3 1 75
t 3 1 75
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 8 menunjukkan penurunan rata-rata akurasi ketika terjadi eliminasi kelas yang memiliki nilai akurasi yang besar. Terlihat kelas r dan kelas t mengalami penurunan akurasi menjadi 75%, berkurang 25% dari akurasi percobaan sebelumnya dengan menggunakan data pelatihan seluruh kelas di level 3. Meskipun demikian, kelas y justru mengalami kenaikan nilai akurasi sebesar 25% dibandingkan percobaan sebelumnya di level 3 yang menggunakan keseluruhan kelas.
Tabel 9 Akurasi tiap kelas pada level 3 tanpa kelas s
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 2 2 50
r 2 2 50
t 3 1 75
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 9 menunjukkan penurunan rata-rata akurasi ketika terjadi eliminasi kelas yang memiliki nilai akurasi sedang. Terlihat kelas r mengalami penurunan akurasi sebesar 50%, begitu juga dengan kelas t yang mengalami penurunan akurasi sebesar 25%. Kelas y mengalami kenaikan akurasi sebesar 25%, sama seperti percobaan di level 3 dengan menghilangkan kelas p.
Tabel 10 Akurasi tiap kelas pada level 3 tanpa kelas q
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
r 4 0 100
s 4 0 100
t 3 1 75
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 10 menunjukkan peningkatan akurasi ketika kelas q yang memiliki akurasi rendah dihilangkan. Kelas s dan kelas y mengalami kenaikan akurasi sebesar 25% dibandingkan percobaan di level 3 sebelumnya. Ketika kelas dengan akurasi rendah dihilangkan, nilai rata-rata akurasi untuk keseluruhan kelas meningkat.
Algoritme VFI5 Tanpa Kelas p atau q di Level 2
11 akurasi terbesar dan kelas q untuk akurasi
terendah. Akurasi rata-rata yang diperoleh dengan menghilangkan kelas p adalah 94.44%, sedangkan akurasi rata-rata yang diperoleh dengan menghilangkan kelas q adalah 97.22%. Tabel 11 dan Tabel 12 berturut-turut menunjukkan rincian akurasi dengan menghilangkan kelas p dan kelas q.
Tabel 11 Akurasi tiap kelas pada level 2 tanpa kelas p
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
q 3 1 75
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 3 1 75
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 11 menunjukkan penurunan akurasi untuk kelas v sebesar 25% menjadi 75% dan peningkatan akurasi sebesar 25% untuk kelas y menjadi 100% jika dibandingkan dengan percobaan level 2 sebelumnya yang menggunakan keseluruhan kelas. Dari percobaan ini, diperoleh rata-rata akurasi sebesar 94.44%, atau turun 0.56% jika dibandingkan percobaan level 2 yang menggunakan keseluruhan kelas.
Tabel 12 Akurasi tiap kelas pada level 2 tanpa kelas q
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 3 1 75
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 12 menunjukkan peningkatan akurasi pada kelas y sebesar 25%, dan penurunan akurasi pada kelas v sebesar 25%. Dari percobaan ini, diperoleh rata-rata akurasi sebesar 97.22% atau meningkat 2.22% dari percobaan sebelumnya yang menggunakan keseluruhan kelas.
Algoritme VFI5 Tanpa Kelas p atau y di Level 1
Pada percobaan sebelumnya untuk level 1 dengan menggunakan keseluruhan kelas, hanya terdapat dua nilai akurasi, yakni 75% dan 100%. Akurasi 75% dimiliki oleh kelas y, kelas lainnya memiliki akurasi 100%. Pada percobaan ini, kelas p dan kelas y dihilangkan. Rata-rata akurasi yang diperoleh dengan menghilangkan kelas p mencapai 100%, begitu juga dengan rata-rata akurasi dengan menghilangkan kelas y. Tabel 13 dan Tabel 14 berturut-turut menunjukkan rincian hasil percobaan dengan menghilangkan kelas p dan kelas y.
Tabel 13 Akurasi tiap kelas pada level 1 tanpa kelas p
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
q 4 0 100
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 4 0 100
Tabel 13 menunjukkan peningkatan akurasi untuk kelas y sebesar 25% menjadi 100%. Rata-rata akurasi yang diperoleh dengan menghilangkan kelas p menjadi 100%, atau meningkat 2.5% jika dibandingkan dengan percobaan level 1 sebelumnya yang menggunakan keseluruhan kelas.
Tabel 14 Akurasi tiap kelas pada level 1 tanpa kelas y
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 4 0 100
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
12 sebelumnya yang menggunakan keseluruhan
kelas.
Algoritme VFI5 dengan menggunakan data latih yang berbeda
Pada percobaan selanjutnya, dilakukan pergantian data latih dan data uji. Jika pada awal percobaan dilakukan pelatihan dengan menggunakan data ke-1, 2, 3, 4, 5, dan 6, percobaan kedua menggunakan data latih ke-5, 6, 7, 8, 9 dan 10. Data Uji pada data percobaan ini menggunakan data ke-1, 2, 3 dan 4. Hasil percobaan dapat dilihat pada Tabel 15.
Tabel 15 Akurasi tiap-tiap level dengan menggunakan data latih dan data uji yang berbeda
Level Akurasi (%)
1 95
2 90
3 87.5
4 67.5
5 52.5
Pada level 1, 2, 3 dan 5 akurasi menurun menjadi berturut-turut 95%, 90%, 87.5% dan 52.5%. Penurunan akurasi paling besar terjadi pada level 5 yakni sebesar 10%. Pada level 4, justru terjadi kenaikan akurasi sebesar 2.5% dibandingkan percobaan dengan kombinasi data ke-1, 2, 3, 4, 5, 6 sebagai data latih dan data ke-7, 8, 9, 10 sebagai data uji.
Waktu Pemrosesan
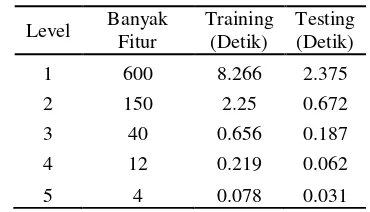
Perhitungan waktu yang diperlukan untuk menglasifikasikan citra tanda tangan selanjutnya dilakukan, dan hasil perhitungan ini ditunjukkan pada Tabel 16.
Tabel 16 Waktu pemrosesan untuk tiap-tiap level dekomposisi
Level Banyak Fitur
Training (Detik)
Testing (Detik)
1 600 8.266 2.375
2 150 2.25 0.672
3 40 0.656 0.187
4 12 0.219 0.062
5 4 0.078 0.031
Dari Tabel 16, dapat dilihat bahwa level 1 yang memiliki 600 fitur memerlukan waktu paling lama, sedangkan level 5 dengan empat fitur memiliki waktu klasifikasi yang paling singkat. Dari Tabel 16 terlihat kecenderungan
menurunnya waktu pelatihan dan pengujian sekitar seperempat hingga sepertiga dari level dekomposisi sebelumnya. Terlihat juga bahwa semakin besar level dekomposisi, semakin sedikit fitur, semakin singkat waktu yang diperlukan dalam proses klasifikasi.
KESIMPULAN DAN SARAN Kesimpulan
Dari penelitian ini dapat disimpulkan bahwa kinerja penggabungan antar reduksi dimensi wavelet dengan algoritme klasifikasi VFI5 cukup baik untuk digunakan dalam pengenalan citra tanda tangan. Jika dibandingkan antara klasifikasi tanpa melalui reduksi dimensi menggunakan wavelet dengan klasifikasi melalui reduksi dimensi menggunakan wavelet untuk dekomposisi level 1, diperoleh rata-rata akurasi yang sama dengan pengurangan dimensi sebanyak 75% dari dimensi yang tanpa melalui reduksi dimensi. Akurasi bernilai di atas 90% jika dekomposisi wavelet yang digunakan berada pada level 1 dan 2. Selain itu, seiring meningkatnya level dekomposisi wavelet, fitur semakin berkurang dan akurasi yang diperoleh semakin rendah.
Saran
Penelitian selanjutnya dapat dilakukan dengan menambahkan noise pada citra tanda tangan yang digunakan. Selain itu, dapat dilakukan verifikasi tanda tangan dengan menggunakan metode reduksi dimensi transformasi wavelet dan algoritme klasifikasi VFI5 dan menganalisis kemiripan fitur menggunakan multidimensional scaling (MDS).
DAFTAR PUSTAKA
Agarwal A, El-Ghazawi T, Moigne LE, Joiner J. 2005. An Application of Wavelet Based Dimension Reduction to AIRS Data. Earth-Sun System Technology Conference, ESTC’05; Adelphi, 27-30 Juni 2005. Maryland: NASA.
Anjum, MA, Javed, MY. Face Images Dimension Reduction Using Wavelets and Decimation Algorithm. Proceedings of the 2006 International Conference on Image Processing, Computer Vision and Pattern Recognition (IPCV 2006); Las Vegas: 26-29 Juni 2006. hlm 397- 402.
13 Fakultas Matematika dan Ilmu Pengetahuan
Alam, Institut Pertanian Bogor.
Demiröz G. 2007. Non-incremental
classification learning algorithms based on voting feature intervals. [Tesis]. The Institute of Engineering and Science, Bilkent University.
Gonzalez RC, Woods RE. 2002. Digital Image Processing, Second Edition. New Jersey: Prentice Hall.
Graps A. 1995. An Introduction to Wavelets. IEEE Computational Science and Engineering. Vol.2, No. 2. 1995.
Güvenir HA. 1998. A Classification Learning Algorithm Robust to Irrelevant Features. Di Dalam: Giunchiglia F, editor. Artificial Intelligence: Methodology, Systems Applications. Proceeding of AIMSA ‘98; Sozopol, 21-23 September 1998. Sozopol: Springer-Verlag. hlm 281-290.
Han J, Kamber M. 2006. Data Mining Concepts & Technique, Second Edition. USA : Academic Press.
Iqbal M. 2007. Klasifikasi pasien suspect parvo dan distemper pada data rekam medik rumah sakit hewan IPB menggunakan Voting Feature Intervals. [Skripsi]. Bogor:
Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Jain AK, Flynn P, Ross AA. 2008. Handbook of Biometrics. New York: Springer.
Kingsburry N. 2005. The Haar Transform.
[terhubung berkala],
http://cnx.org/content/m11087/2.6/ [13 Agustus 2009].
McAndrew A. 2004. An Introduction to Digital Image Processing with MATLAB. USA: Thomson Course Technology.
Ramdhany DN. 2007. Diagnosis gangguan sistem urinari pada anjing dan kucing menggunakan VFI5. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Riadi. 2001. Jaringan syaraf tiruan untuk pengenalan tanda tangan. [Skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Ross AA, Nandakumar A, Jain AK. 2006.
Handbook of Multibiometrics. New York: Springer Science.
15 Lampiran 1 Ilustrasi pelatihan VFI5
1. Misalnya kelas untuk pelatihan terdiri dari dua kelas, A dan B. Masing-masing kelas terdiri dari tiga instance, instance 1, 2, 3 pada kelas A dan instance 4, 5, dan 6 pada kelas B. Tiap kelas memiliki tiga fitur, f1, f2 dan f3.
f1 f2 f3
instance 1 8 7 5 A
instance 2 9 8 5
instance 3 7 7 8
instance 4 4 4 3 B
instance 5 0 2 1
instance 6 4 1 2
2. Tiap fitur dari tiap kelas diambil, kemudian diurutkan dari kecil ke besar untuk membentuk
end points.
A B
f1 f2 f3 f1 f2 f3
7 7 5 0 1 1
8 7 5 4 2 2
9 8 8 4 4 3
3. Nilai minimum dan maksimum dari tiap fitur dari tiap kelas dimasukkan ke dalam satu tabel
end points, selanjutnya, tabel end points tersebut diurutkan berdasarkan kolom (berdasarkan fitur)
f1 f2 f3 7 7 5 9 8 8 0 1 1 4 4 3
f1 f2 f3 0 1 1 4 4 3 7 7 5 9 8 8
Sebelum pengurutan Setelah Pengurutan
4. Tiap-tiap kolom (fitur) pada tabel end points kemudian diambil sebagai interval, selanjutnya diinisialisasikan 0 sebagai vote pada tiap interval vote pelatihan.
F1
A 0 0 0 0 0 0 0 0 0 B 0 0 0 0 0 0 0 0 0
0 4 7 9
F2
A 0 0 0 0 0 0 0 0 0 B 0 0 0 0 0 0 0 0 0
1 4 7 8
F3
A 0 0 0 0 0 0 0 0 0 B 0 0 0 0 0 0 0 0 0
16 Lampiran 1 Lanjutan
5. Dilakukan pembentukan interval dan perhitungan count nilai pada tiap data latih.
f1 f2 f3
instance 1 8 7 5 A
instance 2 9 8 5
instance 3 7 7 8
instance 4 4 4 3 B
instance 5 0 2 1
instance 6 4 1 2 Data Latih
F1
A 0 0 0 0 0 1 1 1 0 B 0 1 0 2 0 0 0 0 0
0 4 7 9
F2
A 0 0 0 0 0 2 1 0 0 B 0 1 1 1 0 0 0 0 0
1 4 7 8
F3
A 0 0 0 0 0 2 1 0 0 B 0 1 1 1 0 0 0 0 0
1 3 5 8
Hasil perhitungan count.
6. Hasil count pada vote interval pelatihan selanjutnya dinormalisasi dengan melakukan pembagian antara vote interval pada suatu kelas dan interval dalam suatu fitur dengan nilai total vote yang ada pada suatu interval pada vote tersebut, sehingga jumlah maksimal dalam suatu kolom dari tiap interval untuk tiap fitur adalah satu.
F1
A 0 0 0 0 0 1 1 1 0 B 0 1 0 1 0 0 0 0 0
0 4 7 9
F2
A 0 0 0 0 0 1 1 0 0 B 0 1 0 1 0 0 0 0 0
1 4 7 8
F3
A 0 0 0 0 0 1 1 0 0 B 0 1 1 1 0 0 0 0 0
17 Lampiran 2 Ilustrasi klasifikasi VFI5
1. Dalam tahap klasifikasi, digunakan hasil vote interval pelatihan ternormalisasi. Dalam contoh ini, terdapat dua kelas, A dan B, dengan banyak fitur tiap kelas adalah 3 (f1, f2 dan f3) serta banyak instance tiap kelas sebanyak dua instance.
f1 f2 f3
instance 1 6 7 8
A
instance 2 8 9 7
instance 3 3 2 1
B
instance 4 1 1 3
Data Uji
F1
A 0 0 0 0 0 1 1 1 0 B 0 1 0 1 0 0 0 0 0
0 4 7 9
F2
A 0 0 0 0 0 1 1 0 0 B 0 1 0 1 0 0 0 0 0
1 4 7 8
F3
A 0 0 0 0 0 1 1 0 0 B 0 1 1 1 0 0 0 0 0
1 3 5 8
Vote interval pelatihan ternormalisasi
2. Selanjutnya dilakukan pencocokan nilai vote dengan interval yang sesuai, dengan hasil untuk tiap-tiap instance adalah sebagai berikut:
Instance 1
A B
F1 0 0
F2 1 0
F3 0 0
Jumlah 1 0
Instance 2
A B
F1 1 0
F2 0 0
F3 1 0
Jumlah 2 0
Instance 3
A B
F1 0 0
F2 0 0
F3 0 1
Jumlah 0 1
Instance 4
A B
F1 0 1
F2 0 1
F3 0 1
Jumlah 0 3
18 Lampiran 3 Citra yang digunakan
P1 P2 P3 P4 P5
P6 P7 P8 P9 P10
Q1 Q2 Q3 Q4 Q5
Q6 Q7 Q8 Q9 Q10
R1 R2 R3 R4 R5
R6 R7 R8 R9 R10
S1 S2 S3 S4 S5
S6 S7 S8 S9 S10
T1 T2 T3 T4 T5
19 Lampiran 3 Lanjutan
U1 U2 U3 U4 U5
U6 U7 U8 U9 U10
V1 V2 V3 V4 V5
V6 V7 V8 V9 V10
W1 W2 W3 W4 W5
W6 W7 W8 W9 W10
X1 X2 X3 X4 X5
X6 X7 X8 X9 X10
Y1 Y2 Y3 Y4 Y5
20 Lampiran 4 Citra hasil dekomposisi
Citra Asli:
Level 1:
Pendekatan Detail Horizontal Detail Vertikal Detail Diagonal
Level 2
Pendekatan Detail Horizontal Detail Vertikal Detail Diagonal
Level 3
Pendekatan Detail Horizontal Detail Vertikal Detail Diagonal
Level 4
Pendekatan Detail Horizontal Detail Vertikal Detail Diagonal
Level 5
21 Lampiran 5 Pencocokan kelas dugaan hasil klasifikasi dengan kelas aktual
1 Level 1
Kelas Aktual Jumlah
P Q R S T U V W X Y
K
el
as
D
u
g
aa
n
P 4 4
Q 4 4
R 4 4
S 4 1 5
T 4 4
U 4 4
V 4 4
W 4 4
X 4 4
Y 3 3
Jumlah Total 40
2 Level 2
Kelas Aktual Jumlah
P Q R S T U V W X Y
K
el
as
D
u
g
aa
n
P 4 4
Q 3 3
R 4 4
S 4 1 5
T 4 4
U 4 4
V 4 4
W 4 4
X 4 4
Y 1 3 4
Jumlah Total 40
3 Level 3
Kelas Aktual Jumlah
P Q R S T U V W X Y
K
el
as
D
u
g
aa
n
P 4 1 5
Q 2 2
R 1 4 5
S 3 3
T 4 4
U 4 1 5
V 4 4
W 4 4
X 4 4
Y 1 3 4
22 Lampiran 5 Lanjutan
4 Level 4
Kelas Aktual Jumlah
P Q R S T U V W X Y
K
el
as
D
u
g
aa
n
P 4 1 1 6
Q 3 1 1 5
R 1 1
S 2 1 3
T 1 3 4
U 2 2 1 1 6
V 1 2 3
W 4 4
X 3 1 4
Y 1 1 2 4
Jumlah Total 40
5 Level 5
Kelas Aktual Jumlah
P Q R S T U V W X Y
K
el
as
D
u
g
aa
n
P 4 2 2 1 1 10
Q 3 3
R 1 1 1 3
S 2 1 3
T 3 1 1 5
U 1 4 5
V 1 1 2
W 2 2
X 3 3
Y 2 2 4
7 Fitur yang digunakan untuk pelatihan pada
algoritme VFI5 diperoleh dari tiap-tiap piksel pada citra tanda tangan. Fitur pada pelatihan yang semula berupa matriks berukuran 3×4
piksel disusun menjadi matriks berukuran 1×12
piksel.
Klasifikasi
Setiap nilai fitur dari instance citra uji diperiksa letak interval nilai fitur tersebut pada hasil vote yang telah dinormalisasi. Vote-vote
setiap kelas untuk setiap fitur pada setiap interval yang bersesuaian diambil dan kemudian dijumlahkan. Kelas yang memiliki nilai total
vote tertinggi menjadi kelas prediksi instance
tersebut.
Akurasi
Hasil yang diamati pada penelitian ini yaitu tingkat akurasi yang dicapai algoritme klasifikasi VFI5 dalam menglasifikasikan data pengujian setelah dilakukan pelatihan. Tingkat akurasi diperoleh dengan perhitungan:
%. 100 uji data total asi diklasifik benar uji data akurasi tingkat × ∑ ∑ = Lingkungan Pengembangan
Penelitian dilakukan dengan menggunakan perangkat lunak MATLAB 7.0.1 dan Microsoft Office Excel 2007 yang berjalan pada sistem operasi Microsoft Windows XP SP3. Adapun perangkat keras yang digunakan memiliki spesifikasi Prosesor AMD Athlon XP 3200+, DDRAM 1470 MB, VGA GeForce 6100 nForce 405, dan HDD 160 GB.
HASIL DAN PEMBAHASAN
Dalam penelitian ini, data diproses menggunakan wavelet Haar hingga level ke-5. Adapun ukuran dimensi dan banyak fitur yang diperoleh dari hasil praproses menggunakan transformasi wavelet Haar tercantum pada Tabel 1.
Tabel 1 Ukuran dimensi dan banyak fitur pada dekomposisi wavelet Level Transformasi Ukuran Dimensi Banyak Fitur
1 20x30 600
2 10x15 150
3 5x8 40
4 3x4 12
5 2x2 4
Klasifikasi yang dilakukan tanpa melalui reduksi dimensi menghasilkan akurasi
sebesar 97.5%. Hasil ini kemudian dibandingkan dengan klasifikasi dengan menggunakan reduksi.
Percobaan 1: Dekomposisi wavelet level 1
[image:34.595.324.501.226.383.2]Percobaan pertama merupakan percobaan dengan dekomposisi wavelet paling rendah. Hasil percobaan secara rinci untuk tiap kelas pada percobaan kelima dicantumkan pada Tabel 2.
Tabel 2 Akurasi tiap-tiap kelas pada level 1
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 4 0 100
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 3 1 75
Dari Tabel 2 dapat dilihat bahwa kelas y memiliki akurasi terendah, yakni 75%. Kelas lainnya memiliki akurasi 100%. Adapun rata-rata akurasi yang diperoleh secara keseluruhan mencapai 97.5%.
Percobaan 2: Dekomposisi wavelet level 2
Hasil percobaan untuk dekomposisi wavelet level 2 ditunjukkan pada Tabel 3. Dibandingkan percobaan sebelumnya pada level 1, kelas q mengalami penurunan akurasi sebesar 25%. Kelas selain q dan y memiliki akurasi 100%. Pada percobaan ini, akurasi rata-rata mencapai 95%.
Tabel 3 Akurasi tiap-tiap kelas pada level 2
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 4 0 100
s 4 0 100
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
[image:34.595.326.498.572.729.2]8
Percobaan 3: Dekomposisi wavelet level 3
[image:35.595.108.281.163.319.2]Pada level 3, akurasi rata-rata mengalami penurunan dibandingkan level 2. Perolehan akurasi ini ditunjukkan pada Tabel 4.
Tabel 4 Akurasi tiap-tiap kelas pada level 3
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 2 2 50
r 4 0 100
s 3 1 75
t 4 0 100
u 4 0 100
v 4 0 100
w 4 0 100
x 4 0 100
y 3 1 75
Kelas q memiliki akurasi paling kecil, yakni sebesar 50%. Kelas s dan y memiliki akurasi 75%, sedangkan kelas sisanya memiliki akurasi sebesar 100%. Rata–rata akurasi untuk keseluruhan kelas pada wavelet dekomposisi level 3 turun menjadi 90%.
Percobaan 4: Dekomposisi wavelet level 4
[image:35.595.323.502.242.404.2]Rata-rata akurasi yang diperoleh pada tiap kelas di level 4 dapat dilihat pada Tabel 5. Kelas p masih memiliki akurasi klasifikasi sebesar 100%, namun kelas u mengalami penurunan akurasi sebesar 50% dibandingkan hasil klasifikasi pada level 3. Akurasi sebesar 100% juga diperoleh untuk klasifikasi kelas w. Akurasi terkecil dimiliki oleh kelas r, yang mengalami penurunan akurasi hingga 75% dibandingkan hasil klasifikasi pada level 3. Secara rata-rata, akurasi pada level 4 ini adalah 65%, mengalami penurunan akurasi rata-rata hingga 25% dibandingkan hasil klasifikasi pada level 3.
Tabel 5 Akurasi tiap-tiap kelas pada level 4
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 1 3 25
s 2 2 50
t 3 1 75
u 2 2 50
v 2 2 50
w 4 0 100
x 3 1 75
y 2 2 50
Percobaan 5: Dekomposisi wavelet level 5
Rata-rata persentase akurasi yang diperoleh pada tiap kelas di level 5 dapat dilihat pada Tabel 6. Dari Tabel 6, kelas p dan u memiliki akurasi 100%. Pada kelas v dan r, hanya diperoleh akurasi sebesar 25%. Kelas s, w, dan y memiliki akurasi sebesar 50% dan sisanya memiliki akurasi sebesar 75%. Persentase akurasi rata-rata dari tiap-tiap kelas pada dekomposisi wavelet level 5 ini mencapai 62.5%.
Tabel 6 Akurasi tiap-tiap kelas pada level 5
Kelas Hasil Klasifikasi Akurasi (%) Benar Salah
p 4 0 100
q 3 1 75
r 1 3 25
s 2 2 50
t 3 1 75
u 4 0 100
v 1 3 25
w 2 2 50
x 3 1 75
y 2 2 50
Secara umum, terjadi penurunan akurasi pada setiap peningkatan level dekomposisi wavelet. Semakin rendah level dekomposisi wavelet, semakin tinggi rata-rata akurasinya. Pada dekomposisi wavelet level 4 dan 5, akurasi turun drastis dibandingkan dekomposisi level 1, 2 dan 3. Penurunan akurasi paling besar terjadi pada dekomp