IMPLEMENTASI METODE MAXIMUM MARGINAL
RELEVANCE (MMR) DAN ALGORITMA STEINER TREE
UNTUK MENENTUKAN STORYLINE DOKUMEN BERITA
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
AJI TEJA HARTANTO
10111301
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Bismillahirahmaanirahiim
Dengan memanjatkan puji syukur kehadirat Allah SWT, atas rahmat dan karunianya penulis dapat menyelesaikan skripsi ini, yang merupakan syarat untuk menyelesaikan program studi Strata I Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer pada Universitas Komputer Indonesia.
Selama pelaksanaan dan penyusunan laporan Skripsi ini banyak menemui hambatan dan kesulitan. Namun berkat dorongan, bantuan dan bimbingan baik secara moril ataupun material dari berbagai pihak penulis dapat mengatasinya. Untuk itu penulis ingin mengucapkan terima kasih kepada :
1. Allah SWT yang senantiasa memberikan hidayah serta inayah-Nya sehingga penulis dapat menyelesaikan laporan tugas akhir ini dengan penuh sadar akan kewajiban fardhu kifayah.
2. Kedua orang tua dan kedua adik yang dengan penuh syukur Allah memberikan kesempatan hidup bagi mereka sehingga dapat memberikan dorongan moriil maupun materiil sehingga penulis terus berupaya untuk menuntaskan laporan tugas akhir ini.
3. Keluarga Besar Dakwah Kampus UNIKOM yang senantiasa menyebarkan dakwah ditengah-tengah civitas kampus unikom dan mendorong bersinerginya antara kuliah dan menggapai mardhatillah sehingga mengarahkan penulis dalam menuntaskan laporan ini tanpa kesia-siaan namun demi menggapai tujuan yang hakiki.
4. Keluarga Besar Asrama Revolt Camp & Umar bin Khattab yang senantiasa sangat membantu penulis dalam menyelesaikan TA ini.
iv
6. Ibu Kania Evita Dewi, S.Pd., M.Si. selaku Dosen Pembimbing II di Universitas Komputer Indonesia yang sangat membantu penulis dalam menyelesaikan skripsi ini.
7. Seluruh Dosen dan Staff pengajar jurusan Teknik Informatika Universitas Komputer Indonesia.
8. Saudara-saudara yang selalu memberikan dukungannya kepada penulis. 9. Teman-teman HIMA & UKM dalam rentang angkatan 2012-2015 yang
telah memberikan pelajaran hidup sehingga mampu mendorong penulis dalam kemandirian untuk menuntaskan laporan ini
10. Teman-teman IF-7 angkatan 2011 yang telah banyak membantu dan memberikan dorongan kepada penulis.
11. Semua pihak yang terlibat yang telah ikut membatu dalam penulisan laporan ini baik secara langsung maupun tidak langsung.
Dengan keterbatasan ilmu dan pengetahuan yang penulis miliki, penulis menyadari bahwa penyusunan skripsi ini masih jauh dari kesempurnaan dan masih terdapat kekurangan dan kelemahan, walaupun demikian penulis telah berusaha semaksimal mungkin untuk mendapat hasil yang optimal.
Bertolak dari inilah, penulis mengharapkan adanya koreksi, kritik dan saran yang membangun dari berbagai pihak sehingga menjadi bahan masukan bagi penulis untuk peningkatan di masa yang akan datang
Akhirnya penulis mengucapkan syukur alhamdullilah kehadirat ilahirobi yang tiada hentinya atas selesainya proses penulisan laporan Tugas Akhir ini Amin.
Bandung, Maret 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... ix
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... xv
PENDAHULUAN ... 1
Latar Belakang Masalah ... 1
Rumusan Masalah ... 2
Maksud dan Tujuan ... 2
1.3.1. Maksud ... 2
1.3.2. Tujuan... 3
Batasan Masalah ... 3
Metodologi Penelitian ... 4
1.5.1. Metode Pengumpulan Data ... 4
1.5.2. Metode Pembangunan Perangkat Lunak ... 4
1.5.3. Metode Pengujian ... 6
Sistematika Penulisan ... 7
LANDASAN TEORI ... 9
Maximum Marginal Relevance ... 9
Text Processing ... 9
2.2.1. Case Folding ... 9
2.2.2. Tokenizing ... 9
2.2.3. Filtering dan Eliminasi Stopwords ... 10
2.2.4. Stemming ... 10
Cosine Similiarity ... 12
Pembobotan MMR ... 14
Pembobotan TF-IDF ... 15
Teori Graf ... 16
vi
Tree... 19
2.8.1. Multi-view Graph ... 21
2.8.2. Himpunan Dominasi ... 21
2.8.3. Steiner tree... 21
2.8.4. Aproksimasi Steiner tree ... 22
Alur Kronologis... 22
2.9.1. Menentukan Alur Kronologis ... 23
2.9.2. Alur Kronologis yang Baik ... 24
Tingkat Komulatif Kejadian (Tingkat Insidensi Komulatif)... 24
OOP (Object Oriented Programming)... 25
2.11.1. Konsep Dasar Berorientasi Objek ... 25
UML (Unified Modeling Language) ... 28
2.12.1. Use Case Diagram ... 29
2.12.2. Activity Diagram ... 30
2.12.3. Class Diagram ... 30
2.12.4. Sequence Diagram... 31
Pengujian Perangkat Lunak ... 32
2.13.1. Pengujian Whitebox ... 32
2.13.2. Pengujian Ketergunaan (Usability Testing) ... 33
2.13.3. Notasi Big O ... 35
Perangkat Lunak Pendukung ... 37
2.14.1. Apache ... 37
2.14.2. MySQL ... 38
2.14.3. PHP... 38
2.14.4. PHPMyAdmin ... 39
2.14.5. XAMPP ... 39
2.14.6. Adobe Dreamwever CC ... 40
ANALISIS DAN PERANCANGAN SISTEM ... 41
Analisis masalah ... 41
Analisis Sistem ... 42
vii
3.2.2. Analisis Algoritma Steiner Tree ... 61
Analisis Kebutuhan Non Fungsional ... 78
3.3.1. Analisis Perangkat Keras ... 78
3.3.2. Analisis Perangkat Lunak... 79
3.3.3. Analisis Kebutuhan Pengguna ... 79
Analisis Basis Data... 80
3.4.1. Struktur Tabel ... 80
Analisis Kebutuhan Fungsional ... 81
3.5.1. Use Case Diagram ... 81
3.5.2. Activity Diagram ... 96
3.5.3. Class Diagram ... 107
3.5.4. Sequence Diagram... 107
3.5.5. Perancangan Arsitektur ... 114
IMPLEMENTASI DAN PENGUJIAN SISTEM ... 119
Implementasi Sistem ... 119
4.1.1. Implementasi Perangkat Lunak ... 119
4.1.2. Implementasi Perangkat Keras ... 120
4.1.3. Implementasi Antar Muka ... 121
Pengujian Sistem ... 122
4.2.1. Rencana Pengujian ... 123
4.2.2. Pengujian White Box ... 123
4.2.3. Pengujian Ketergunaan (Usability Testing) ... 134
4.2.4. Sekenario Pengujian Performansi ... 141
KESIMPULAN DAN SARAN ... 145
KESIMPULAN ... 145
SARAN ... 145
136
DAFTAR PUSTAKA
[1] E. Lukman, "Laporan: Inilah Yang Dilakukan 74,6 Juta Pengguna Internet Indonesia Ketika Online," Techinasia, 31 Oktober 2013. [Online]. Available: Https://Id.Techinasia.Com/Tingkah-Laku-Pengguna-Internet-Indonesia/. [Accessed 7 10 2015].
[2] J. Ahmad, L. A. Abdillah And S. , "Penerapan Teknik Web Scraping Pada Mesin Pencari Artikel Ilmiah," Sistem Informasi (Sisfo), Vol. 5, P. 6, 2014.
[3] M. Mustaqhfiri, Z. Abidin And R. Kusumawati, "Peringkasan Teks Otomatis Berita Berbahasa Indonesia Menggunakan Metode Maximum Marginal Relevance," Matics,
Vol. Iv, No. 4, Pp. 1-14, 2011.
[4] S. Simon, "Studi Pohon Steiner Dan Penggunaannya Dalam Perancangan Chip Dan Jaringan," 2008.
[5] A. Baihaqi, "Penerapan Algoritma Steiner Tree Dalam Konstruksi Jaringan Pipa Gas,"
Makalah If2091 Struktur Diskrit, Pp. 1-7, 2009.
[6] M. N. Hidayatullah, "Penerapan Metodologi Waterfall Dalam Pengembangan Sistem Informasi Akademik Universitas Negeri Surabaya (Studi Kasus Pt Sentra Vidya Utama Surabaya)".
[7] R. Jeff And D. Chisnell, Handbook Of Usability Testing, Canada: Wiley Publishing, Inc., 2008.
[8] D. Nopiyanti And K. A. Sekarwati, "Aplikasi Pencarian Kata Dasar Dokumen Berbahasa Indonesia Dengan Metode Stemming Porter Menggunakan Php & Mysql," In Seminar Ilmiah Nasional Komputer Dan Sistem Intelijen (Kommit 2014) , Depok, 2014.
[9] A. D. Tahitoe And D. Purwitasari, "Implementasi Modifikasi Enhanced Confix Stripping Stemmer Untuk Bahasa Indonesia Dengan Metode Corpus Based Stemming," 2010. [10] R. V. Imbar, A. M. Ayub And A. Rehatta, "Implementasi Cosine Similarity Dan
Algoritma Smith-Waterman Untuk Mendeteksi Kemiripan Teks," Informatika, Vol. 10, No. 1, Pp. 1-12, 2014.
[11] R. Nicholas, "Aplikasi Graf Berbobot Dalam Menentukan Jalur Angkot (Angkutan Kota) Tercepat," Itb, Bandung, 2010/2011.
[12] Z. Fathoni, "Algoritma Penentuan Graf Bipartit," Makalah If2091, P. 2, 2009. [13] H. Kusniyati, "Teori Graf," In Matematika Diskrit, Pusat Bahan Ajar Dan Elearning. [14] E. N. Hayati And A. Yohanes, "Pencarian Rute Terpendek Menggunakan Algoritma
Greedy," In Seminar Nasional Ienaco, Semarang, 2014.
[15] C. Lin, C. Lin And J. Li, "Generating Event Storylines From Microblogs," In Cikm '12 Proceedings Of The 21st Acm International Conference On Information And Knowledge Management, New York, 2012 .
[16] K. Kesehatan, "Kamus Kesehatan," [Online]. Available: Http://Kamuskesehatan.Com/Arti/Tingkat-Insiden/.
[17] M. Danuri, "Object Oriented Programming (Oop)," Infokam, Vol. V, No. 1, Pp. 1-8, 2009.
[18] "Pengertian Uml ( Unified Modelling Language ) & Sejarah Uml," Abstrakpengetahuan,
10 2014. [Online]. Available:
137
[20] S. "Efisiensi Algoritma Dan Notasi O-Besar," Comtech, Vol. 2, No. 2, P. 857, 2011. [21] K. T. Martono, "Tracer Alumni Berbasis Website (Kasus: Sistem Komputer Falkutas
Teknik Undip)," Sistem Komputer, Vol. 3, No. 1, P. 33, 2013.
[22] "Phpmyadmin," Wikipedia, 6 April 2013. [Online]. Available: Https://Id.Wikipedia.Org/Wiki/Phpmyadmin. [Accessed 7 10 2015].
[23] "Xampp," Wikipedia, 5 Mei 2015. [Online]. Available: Https://Id.Wikipedia.Org/Wiki/Xampp.
[24] "Dreamweaver," Wikipedia, 6 April 2014. [Online]. Available: Https://Id.Wikipedia.Org/Wiki/Adobe_Dreamweaver.
[25] E. Saputra, Z. Mazalisa And R. Andryani, "Usability Testing Untuk Mengukur Penggunaan Website," Jurnal Teknik Informatika, Pp. 1-9, 2014.
[26] L. Marlinda And H. Rianto, "Pembelajaran Bahasa Indonesia Berbasis Web Menggunakan Metode Maximum Marginal Relevance," In Seminar Nasional Sistem Informasi Indonesia, Jakarta, 2013.
[27] A. Solihin, F. Solihin And F. H. Rachman, "Penerapan Modifikasi Metode Enhaced Confix Stripping Stemmer Pada Teks Berbahasa Madura," Sarjana Teknik Informatika,
Vol. Ii, No. 1, Pp. 1-18, 2013.
[28] D. Wang, T. Li And M. Ogihara, "Generating Pictorial Storylines Via Minimum-Weight Connected Dominating Set Approximation In Multi-View Graphs," In Twenty-Sixth Aaai Conference On Artificial Intelligence, Toronto, 2012.
[29] Andri, Heuristik Sebagaimana Secara Bahasa Dapat Diartikan Sebagai Seni Untuk Menemukan Strategi Dalam Menyelesaikan Persoalan., Jakarta: Uin Syarif Hidayatullah, 2008.
[30] S. And M. Fathoni, "Pengantar Analisa Perancangan Sistem," Jurnal Saintikom, Vol. 9, No. 2, P. 5, 2010.
[31] A. Srivastava, "Generating Storylines".
1
PENDAHULUAN
Latar Belakang Masalah
Seiring diterbitkannya data survei yang dikeluarkan Markplus Insight dan Majalah Online Marketeers 2013, terdapat 98% dari 2015 responden menjadikan sumber informasi utama adalah internet. Sebanyak 54,2% dari persentase responden tersebut, konten yang dijadikan rujukan sumber informasi adalah berita [1]. Namun, survei yang dilakukan terhadap sampel 41 pembaca menunjukan sekitar 58,84% menganggap bahwa pencarian berita untuk mendapatkan kronologis peristiwa membutuhkan waktu yang lama. Padahal, sebanyak 95% pembaca memiliki tujuan dalam aktivitas pencarian berita adalah untuk mendapatkan alur kronologis suatu peristiwa. Disamping itu, hasil pencarian yang diperoleh melalui media online, terutama pada mesin pencari tidak memahami pola semantik atau tren dari sejumlah data yang telah diperoleh [2]. Sehingga, hasil pencarian tidak terstruktur dan tidak memiliki hubungan sebab akibat antara teks dokumen satu dengan yang lainnya.
Teks representatif terhadap suatu dokumen, secara umum diterapkan sebagai fitur dalam mesin pencari. Namun, teks representatif tersebut masih berdasarkan kata kunci saja. Sehingga secara kualitas belum memenuhi representasi dokumen. Untuk mendapatkan teks representatif, penelitian yang dilakukan oleh Mustaqhfiri [3], teks representatif berupa ringkasan dihasilkan oleh metode MMR
merupakan hasil ekstraksi kalimat. Metode ini digunakan untuk mengurangi redudansi dalam perangkingan kalimat pada multi dokumen. Kualitas ringkasan yang dihasilkan dari metode MMR ini ditunjukan dengan hasil berupa recall,
precission dan kombinasi keduanya berupa f-measure. Dari data uji coba yang diambil dari surat kabar berbahasa Indonesia online sejumlah 30, menunjukan hasil rata-rata berupa recall 60%, precision 77% dan f-measure 66%.
dapat dilakukan dengan memahami keterkaitan antar dokumen teks tersebut. Untuk menentukan sebuah jaringan tanpa sirkuit (struktur pohon tanpa cabang) yang menghubungkan seluruh node dapat digunakan Steiner Tree [4]. Penerapan steiner tree dalam penelitian yang dilakukan oleh Achmad Baihaqi [5], bertujuan untuk menentukan konstruksi suatu jaringan. Dalam penerapannya digunakan dalam jaringan pipa gas dari suatu graf. Implementasi algoritma heuristic yang didasarkan pada kecepatan waktu komputasi dalam algoritma steiner tree menghasilkan konstruksi pendistribusian gas yang lebih optimal dalam pertimbangan waktu dan biaya. Hal ini dikarenakan bobot steiner tree yang dihasilkan oleh algoritma
heuristic ini belum tentu merupakan bobot yang minimum, akan tetapi bobot tersebut tidak akan melebihi suatu nilai batas atas.
Oleh karena itu, pada penelitian ini akan disusun sebuah penelitian berjudul
“Implementasi Metode Maximum Marginal Relevance (MMR) dan Algoritma Steiner Tree Untuk Menentukan Storyline Dokumen Berita”
Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, maka rumusan masalah yang diperoleh adalah bagaimana meningkatkan efektivitas dan efesiensi dalam melakukan pencarian berita oleh pembaca media online dengan implementasi metode maximum marginal relevance dan algoritma steiner tree
untuk menentukan Storyline (alur kronologis) dari dokumen berita tekstual.
Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dan tujuan dari penelitian adalah sebagai berikut:
1.3.1. Maksud
Maksud dari penelitian ini adalah untuk melakukan implementasi metode
3
1.3.2. Tujuan
Adapun tujuan dari penelitian ini adalah mempermudah dan mempercepat proses pencarian yang dilakukan oleh pembaca media berita online dalam mencari alur kronologis sebuah peristiwa dengan penerapan metode maximum marginal relevance dan algoritma Steiner Tree.
Batasan Masalah
Batasan masalah dilakukan untuk membatasi penelitian ini agar dalam implementasi metode maximum marginal relevance dan algoritma steiner tree
dapat dilakukan secara lebih mendalam sehingga pembahasan tidak terlalu umum. Adapun batasan masalah yang dapat dijelaskan adalah sebagai berikut:
1. Dokumen teks artikel diperoleh dari a. detik.com/internasional, b. internasional.kompas.com, c. news.okezone.com/internasional, d. internasional.sindonews.com, e. dunia.news.viva.co.id dan
f. voa-indonesia.com
g. unisosdem
2. Dokumen teks artikel berita diambil dalam satu kategori rubrik politik internasional.
3. Peringkasan teks dilakukan dengan proses peringkasan dokumen tunggal untuk masing-masing dokumen.
4. Batasan cakupan setiap teks hasil dari ringkasan kurang sama dengan 2 kalimat.
5. Cakupan sejumlah teks berita yang menjadi alur kronologis dibatasi oleh penentuan waktu peristiwa pada teks berita itu terjadi.
6. Alur kronologis dibentuk dari berita peristiwa.
10. Sistem query yang digunakan adalah MySQL.
11. Software yang digunakan dalam penelitian ini adalah Dreamwever. 12. Proses pencarian steiner tree dari ringkasan banyak teks artikel berita
dilakukan secara offline.
13. Representasi Graph menggunakan Adjacency Matrix.
14. Segmentasi kalimat dilakukan berdasarkan simbol titik untuk membagi artikel kedalam beberapa kaliamt.
Metodologi Penelitian
Metode penelitian yang akan dilakukan dalam penelitian ini adalah dengan melakukan penelitian deskriptif, yakni metode penelitian yag sistematika dan akurat mengenai keadaan fakta penelitian. Gambaran tersebut diperoleh dengan cara mengumpulkan, mengklasifikasikan, menyajikan seta menganalisis data sehingga dapat ditaring suatu kesimpulan. Metode ini dibagi menjadi dua, yaitu pengumpulan data dan pembangunan perangkat lunak.
1.5.1. Metode Pengumpulan Data
Metode pengumpulan data yang digunakan adalah dengan melakukan studi literatur. Pada tahap ini, penggunaan metode pengumpulan studi literatur adalah untuk mencari informasi yang berkaitan dengan permasalahan sekaligus berkaitan erat dengan teknik peringkasan maximum marginal relevance dan penggunaan algoritma steiner tree dalam beberapa penelitian. Tahap ini dilakukan dengan mengumpulkan literatur, jurnal, paper, buku-buku dan bacaan-bacaan yang dapat membantu menyelesaikan penelitian ini.
1.5.2. Metode Pembangunan Perangkat Lunak
Metode yang digunakan dalam pembangunan perangkat lunak pada penelitian ini adalah metode waterfall. Secara garis besar, metode Waterfall
5
Pada tahap ini dilakukan analisa terhadap kebutuhan sistem. Pengumpulan data dalam tahap ini dilakukan dengan studi literatur. Kemudian, dilakukan analisis terhadap algoritma yang akan diimplementasikan yakni terdiri dari penggunaan metode maximum marginal relevance dan algoritma steiner tree. Selain itu, analisis yang dilakukan antara lain analisis non-fungsional (kebutuhan hardware dan
software), serta analisis fungsional meliputi usecase diagram, class diagram,
Activity Diagram dan squencediagram.
2. System Design (Perancangan Sistem)
Proses desain akan menerjemahkan syarat kebutuhan kesebuah perancangan perangkat lunak yang dapat diperkirakan sebelum dilakukan coding. Tahap ini memiliki tujuan dalam memberikan gambaran apa yang haris dikerjakan dan bagamana tampilannya. Tahap ini serupa dengan perancangan storyboard pra implementasi.
3. Implementation/Coding
Tahap implementasi yakni berupa penerapan hasil rancangan kepada program merupakan penerjemahan desain dalam bahasa yang bisa dikenali oleh komputer. Pada tahap ini dilakukan pemrograman pada sistem yang dibangun, sekaligus melakukan implementasi algoritma didalamnya. Selain itu, pada tahap ini pula dilakukan pemeriksaan, apakah sistem yang sudah dibuat sudah memenuhi fungsi yang diinginkan atau belum.
4. Integration & Testing
Analisys Design Code Test System Information
Engineering
Gambar 1.1 Pemodelan Waterfall [6]
1.5.3. Metode Pengujian
Metode pengujian yang digunakan untuk melakukan evaluasi terhadap perangkat lunak atau sistem pencariann alur kronologis adalah teknik pengujian ketergunaan (Usability Testing). Dengan teknik ini, dilakukan pengujian perangkat lunak dengan langsung kepada pengguna. Usability memiliki lima komponen diantaranya learnability, effeciency, memorability, Errors dan Satisfaction.
Tujuan dari metode pengujian Usability Testing ini adalah menginformasikan desain dengan mengumpulkan data untuk mengidentifikasi dan memperbaiki kekurangan kegunaan yang ada dalam produk dan bahan pendukung sebelum rilis, mengeliminasi problem desain dan meminimalisir kesalahan serta menunjukan keuntungan yang diperolah dari sistem [7].
Ada beberapa langkah dalam proses melakukan pengujian ketergunaan
(usability testing) diantaranya [7]:
1. Mengembangkan perencanaan pengujian 2. Mengatur lingkundan pengujian
3. Mencari dan memilih partisipan 4. Menyiapkan bahan pengujian 5. Melakukan sesi pengujian
6. Mengadakan wawancara terhadap partisipan dan pengamat 7. Analisa data dan observasi
7
Gambar 1.2 Langkah-Langkah Pengujian Usability Testing
Sistematika Penulisan
Sistematika penulisan skripsi ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini menjelaskan tentang latar belakang masalah mengenai hal-hal yang menjadi kajian penelitian, merumuskan masalah, menentukan batasan masalah, mengutarakan maksud dan tujuan serta menjelaskan mengenai metode penelitian dan sistematika penulisan yang dimaksudkan untuk memberikan gambaran tentang penyajian laporan ini.
BAB II LANDASAN TEORI
Bab ini menjelaskan tentang metode maximum marginal relevance, teori graf, approximation steiner tree algorithm dan Storyline (alur kronologis) serta bahasa pemograman yang digunakan berikut konsep dasar dan teori-teori yang berhubungan dengan topik penelitian yang akan dilakukan.
BAB III ANALISIS DAN PERANCANGAN
Bab ini menjelaskan tentang analisis masalah berkaitan dengan tahapan dalam penggunan metode MMR dan algoritma steiner tree dalam menentukan
Storyline dokumen berita analisis kebutuhan fungsional dan perancangan antarmuka yang menggambarkan bagaimana sistem dapat menentukan Storyline
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan implementasi, kebutuhan perangkat lunak, kebutuhan perangkat lunak yang digunakan, implementasi pada sistem yang dibangun, implementasi antarmuka dan pengujian sistem dari penerapan metode maximum marginal relevance juga algoritma steiner tree yang digunakan.
BAB V KESIMPULAN DAN SARAN
9
LANDASAN TEORI
Maximum Marginal Relevance
Algoritma mazimum marginal relevance (MMR) merupakan salah satu metode ekstraksi ringkasan (extractive summary) yang digunakan untuk meringkas dokumen tunggal atau multi dokumen [3]. MMR meringkas dokumen dengan menghitung kesamaan (similiarity) antara bagian teks.
Pada peringkasan dokumen dengan metode MMR dilakuakn proses segmentasi dokumen menjadi kalimat dan dilakukan pengelompokan sesuai dengan gendeer kalimat tersebut. MMR digunakan dengan mengkombinasikan matrik cosine similiaritu untuk merangking kalimat-kalimat sebagai tanggapan pada query yang diberikan oleh user.
Text Processing
Dalam melakukan pemrosesan teks terdapat beberapa tahap, yakni masing-masing dapat dijelaskan sebagai berikut:
2.2.1. Case Folding
Case folding merupakan proses penyamaan case dalam sebuah dokumen teks [3]. Case folding dilakukan karena total semua dokumen teks konsisten dalam menggunakan huruf kapital. Untuk itu peran case-folding dibutuhkan dalam merubah kseluruhan teks dalam dokumen menjadi bentuk standar yang secara umum diubah kedalam bentuk huruf kecil.
2.2.2. Tokenizing
Kata
Hapus Kata yang masuk dalam
kamus
Kata filter
Kamus Stopwords
Gambar 2.1 Activity Diagram Filtering
2.2.3. Filtering dan Eliminasi Stopwords
Eliminasi Stopwords dilakukan dengan mengambil kata-kata penting dari hasil token. Dalam proses ini dapat dilakukan pembuangan kata yang kurang penting (stop list) atau penyimpanan kata yang dianggap penting (word list).
Penggunaan eliminasi stopwords berfungsi untuk menghilangkan kata-kata yang dianggap tidak penting, secara umum kandidat stopwords seperti article, preposisi, dan konjungsi. Beberapa kata kerja, kata sifat dan kata keterangan lainnya dapat juga dimasukan kedalam daftar stopwords.
2.2.4. Stemming
11
dasar) dari sebuah kata. Pada umumnya kata dasar pada bahasa indonesia terdiri dari kombinasi [8] :
Prefiks 1 + Prefiks 2 + Kata dasar + Sufiks 3 + Sufiks 2 + Sufiks 1
Start Input
Data Cek kamus
Kata Ada di Kamus
Cek Rule Precedence
Rule Precedence Hapus Deriv ation
Prefix
Hapus Possecive Pronoun
Recording
Hapus Possecive Pronoun
Hapus Deriv ation Suffix
Ya Tidak
Hapus Derivatio n Suffix
Hapus Deriv ation Prefix
Recording Hapus Sisipan
Cek Kamus
Kata ada di Kamus Hapus Pengulangan
Dwipurwa
Loop Pengambilan Akhiran
Hasil Stemming
End
Tidak
Tidak
Ya
Ya
Gambar 2.2 Algoritma ECS [9]
Cosine Similiarity
Cosine similiarity digunakan untuk menghitung pendekatan relevansi query
terhadap dokumen [10]. Penentuan relevansi sebuah query terhadap suatu dokumen dipandang sebagai pengukuran kesamaan vektor query dengan vektor dokumen. Semakin besar nilai kesamaan vektor query dengan vektor dokumen maka query
tersebut dipandang semakin relevan dengan dokumen. Saat mesin menerima query,
13
pada query dan sebuah vektor D (Di1,Di2, Dit) berukuran t untuk setiap dokumen.
Pada umumnya cosine similiarity dihitung dengan rumus cosine measure
(Grossman, 1998). Berikut ini adalah gambaran bagaimana query dan dokumen dibentuk menjadi model vektor.
è1
è2
Q
D
t
D1
t
t
Gambar 2.1 Vektor Skalar [3]
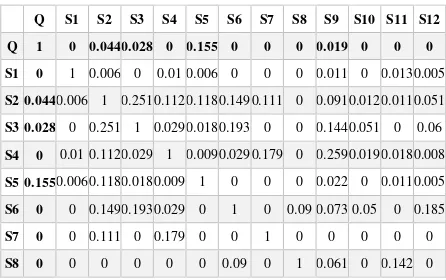
Penggunaan cosine similiarity adalah tindak lanjut dari proses pembobotan TF-IDF. Dari hasil pembobotan maka dicarilah kemiripan daintara dokumen yang ada. Namun penerapannya dalam MMR adalah kemiripan kalimat-kalimat dalam sebuah dokumen tekstual. Persamaannya dapat digambarkan sebagai berikut:
�� Θ = ∑ � �
√∑ d2 √∑ d2 2.1
Database dari semua dokumen direpresntasikan oleh matriks term-document (atau matriks term-frequency). Dimana setiap sel pada matriks
[
�
� � �� …… � �
⋮ ⋮ �⋮ …⋱
��
��
��
⋮ �� � � � � … ���]
2.2
Pembobotan MMR
MMR (maximum marginal relevance) adalah metode peringkasan yang menggunakan dokumen tunggal ataupun multi-dokumen [3]. Teknik ini menerapkan penghitungan kesamaan (similiarity) antara segmentasi teks. Segmentasi ini dilakukan terhadap kalimat-kalimat dan dilakukan pengelompokan sesuai jenis kalimat tersebut. MMR digunakan dengan mengkombinasikan matrik
cosine similiarity untuk merangking kalimat-kalimat sebagai tanggapan pada query
yang diberikan oleh user.
Pembobotan maximum marginal relevance pada kalimat menggunakan algoritma MMR. Kelimat dirangking sebagai tanggapan terhadap query yang telah dimasukan oleh user. Perhitungan MMR dilakukan dengan perhitungan iterasi antara kombinasi dua matrik cosine similiarity yakni query releance dan similiarity
kalimat.
Pengguna yang menginginkan ruang sampel informasi disekitar query, maka harus menetapkan pada nilai yang lebih rendah. Sedangkan bagi pengguna yang ingin fokus untuk memperkuat dokumen-dokumen lebih relevan, maka harus menetapkan pada nilai yang lebih dekat dengan . Kalimat dengan nilai MMR
15
Start
Stop Input dokumen dan
kalimat Query
Text Processing
Pembobotan TF-IDF
Pembobotan Query relevance similiaritu kalimat
Pembobotan MMR
Ekstraksi Ringkasan
Gambar 2.5 Proses Peringkasan Dengan Menggunakan MMR[3]
Pembobotan TF-IDF
Term Frequency (tf)factor, yaitu faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculannya dalam dokumen tersebut [3]. Nilai jumlah kemunculan suatu kata (term frequency) diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar jumlah kemunculan suatu term (tf tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuian yang semakin besar.
Menurut Mandala (dalam Witten, 1999) ‘Kata yang muncul pada sedikit dokumen
harus dipandang sebagai kata yang lebih penting (uncommon tems) daripada kata yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor kebalikan frekuensi dokumen yang mengandung suatu kata (inverse document frequency). Hal ini merupakan usulan dari George Zipf. Zipf mengamati bahwa frekuensi dari sesuatu cenderung kebalikan secara proposional dengan urutannya.
Nilai idf sebuah sistem term (kata) dapat dihitung menggunakan persamaan sebagai berkut:
� � = �� (� �) 2.3
D adalah jumlah dokumen yang berisi term (t) dan dfi adalah jumlah kemunculan
term terhadap D. adapun algoritma yang digunakan untuk menghitung bobot (W)
masing-masing dokumen kata kunci (query), yaitu:
�
�,� = � �,�∗ � �� 2.4
Keterangan: d = dokumen ke-d
t = term ke-t dari kata kunci tf = term frekuensi/frekuensi kata
W = bobot dokumen ke-d terhadap term ke-t
Teori Graf
17
Kemudian, berdasarkan orientasi arah pada sisi, ada 2 jenis graf secara umum (Rio, 2010/2011) :
1. Graf tidak bearah, yaitu sisinya (edge) tidak memiliki orientasi arah 2. Graf berarah, yaitu sisinya (edge) memiliki orientasi arah.
Adapun yang disebut graf unik atau graf berbobot, yaitu suatu graf yang setiap sisinya memiliki bobot/nilai tersendiri.
2.6.1. Bipartit Graf
Graf Bipartit adalah graf yang simpulnya dapat dipisah menjadi dua himpunan, misalnya bagian U dan V, sedemikian sehingga setiap sisi pada grad tersebut menghubungkan sebuah simpul di U dengan sebuah simpul di V, grad tersebut dapat dinyatakan sebagai G(U,V). pula dengan simpul-simpul di V [12].
Kedua himpunan U dan V tersebut juga dapat dianggap sebagai suatu pewarnaan graf dengan dua warna. Apabila semua simpul di U diberi warna biru, dan semua simpul di V diberi warna hijau, masing-masing sisi akan mempunyai ujung yang berbeda warna, sama halnya dengan ketentuan pada masalah perwarnaan graf. Namun demikian, pewarnaan demikian (dua warna). Tidak mungkin dilakukan pada graf non-bipartit. Berikut ini adalah contoh dari graf bipartit.
2.6.2. Graf Basis Data
Graph Database merupakan sebuah teknologi penyimpanan dalam database sebagaimana graph pada umumnya yang terdiri dari kumpulan edge dan vertex
sehingga dapat diakses secara langsung melalui aplikasi dan mendukung OLTP. Graph database ini oleh para ahli digolongkan pada database jenis NoSQL. NoSQL adalah istilah umum yang merujuk pada penyimpanan data yang tidak mengikuti aturan dari Relational Database. NoSQL ini sangat cocok digunakan untuk pemrosesan Big Data dimana data mempunyai ukuran yang sangat besar serta data itu akan terus berkembang.
Lintasan
Dimisalkan G adalah suatu graf. Dan v dan w adalah 2 titik dalam G. Walk
didefinisikan sebagai barisan titik-titik berhubungan dan sisi (garis/edge) secara berselang-seling, diawali dari titik v diakhiri pada titik w. Lintasan (path) dengan asumsi n dari v ke w adalah walk dari v ke w yang semua garisnya berbeda. Dengan demikian dapat dituliskan sebagai v = v0 e1 v1 e2 v2 ... vn-1 en vn = w dengan ei ej
untuk i j. Lintasan sederhana dengan panjang n dari v ke w adalah path dari v ke w yang semua titiknya berbeda. Sehingga dapat ditulis dalam bentuk v = v0 e1 v1 e2
v2 ... vn-1 en vn = w dengan ei ej untuk i j dan vk vm untuk k m [13].
V6 V5
V4 V3
V2
V1
Gambar 2.2 Graf Lintasan (Path) [13]
Tree
Pohon (atau tree) didefinisikan sebagai graf terhubung yang tidak memuat lingkaran [1]. Dengan demikian, suatu lintasan merupakan salah satu contoh dari
19
node (verteks) dalam graf bersifat sama untuk kedua arah, maka graf tersebut dikatakan graf berarah. Sedangkan jika hubungan tersebut berbeda, maka graf tersebut dikatakan graf tidak berarah. Di dalam teori graf, dikenal juga istilah graf terhubung dan sirkuit. Graf terhubung adalah graf yang setiap titiknya dapat dicapai oleh semua titik lain dalam graf tersebut, sedangkan yang dimaksud dengan sirkuit adalah lintasan/jalur yang berawal dan berakhir pada titik yang sama.
Gambar 2.3 Graf Terhubung[4]
Gambar 2.4 Graf tidak terhubung[4]
Gambar 2.5 Sirkuit[4]
1. Pertama, dipilih sebuah sirkuit dalam graf
2. Kedua, hapus salah satu garis/sisi atau path dari sirkuit itu
3. Ketiga, Graf tersebut akan tetap terhubung, namun jumlah sirkuitnya berkurang Satu.
4. Keempat, Jika proses penghapusan tersebut dilakukan berulang-ulang hingga tidak ada lagi sirkuit tersisa, maka graf tersebut menjadi sebuah pohon.
Pohon itulah yang dapat disebut sebagai spanning tree (pohon merentang). Adapun pohon steiner memiliki kesamaan dengan pohon merentang. Namun,
steiner tree memiliki aturan tambahan.
Karena tidak ada dua bintang pengganti (star-replacement) melibatkan tepi yang sama, ini membuktikan bahwa solusi dikembalikan oleh algoritma
TerminalSteiner memiliki panjang di sebagian besar kali 2ρ panjang solusi optimal.
Perhatikan bahwa waktu berjalan dari garis 2, 4, 5, dan 6 dari algoritma TerminalSteiner adalah linier. Oleh karena itu total waktu menjalankan algoritma
ini didominasi oleh algoritma ρ-pendekatan yang digunakan untuk masalah pohon
Steiner.
2.8.1. Multi-view Graph
Multi-view graph merupakan G = (V,E,A) yakni graf yang terdiri dari
verteks, edge tidak berarah dan seperangkat edge terarah (arcs).Multi-view graph
dibentuk dari kumpulan summary dokumen berita tekstual sebagai V, perhitungan
E yang tidak terarah berdasarkan tingkat kemiripan dari dua buah summary text (V).
Sedangkan, perhitungan pada variabel A (edge berarah) berdasarkan perbedaan waktu dimana berita tersebut dipublikasikan yang merepresentasikan waktu kejadian itu berlangsung atau bisa dikatakan sebagai temestamp.
2.8.2. Himpunan Dominasi
21
sederhana yang tidak memiliki loop dan sisi ganda. Himpunan ini merupakan himpunan bagian V’ dari himpunan V(G) dimana titik-titik yang tidak berada pada
V’ terhubung langsung dengan minimal satu titik pada V’.
2.8.3. Steiner tree
Algoritma Steiner tree adalah sekumpulan subset atau bagian tertentu dari
vertices pohon rentang (spanning tree). Tree adalah graf terhubung yang tidak memuat lingkaran (sirkuit). Dengan demikian, suatu lintasan merupakan salah satu contoh dari tree. Bobot dari tree didefinisikan sebagai jumlah seluruh bobot sisi
(edge) pada tree. Pada vertices yang merupakan bagian dari tree dibagi dua bagian yakni terminal dan simpul non terminal. Terminal adalah pemberian node yang harus mengandung solusi atau nilai. Cost dari pohon steiner didefinisikan sebagai
edge total weight. Pohon steiner dapat mengandung beberapa simpul nonterminal untuk mengurangi cost. Algoritma ini dihasilkan dari algoritma heuristik, yakni sebuah aproksimasi. Akibatnya, bobot steiner yang dihasilkan itu belum tentu merupakan bobot yang minimum. Walau demikian terdapat batasan dalam pembobotan Steiner tree heuristic.
2.8.4. Aproksimasi Steiner tree
Secara khusus, penggunaan algoritma aproksimasi steiner tree akan memberikan waktu perhitungan yang lebih cepat dibandingkan dengan algoritma
steiner tree yang eksak [5]. Walaupun hasilnya tidak seakurat algoritma eksak, metode aproksiamsi steiner tree dapat menentukan tree hampiran untuk graf dengan banyak titik sekitar 100 buah dalam waktu kurang dari 1 detik.
Penggunaan greedy sebagai algoritma heuristik untuk melakukan solusi aproksimasi dapat dilakukan untuk menentukan pohon steiner. Hanya saja, penggunaan algoritma greedy tidak selalu memberikan solusi yang optimal, namun algoritma greedy pasti memberikan solusi mendekati optimum (approximation)
Alur Kronologis
Alur adalah urutan kejadian (peristiwa) yang mempunyai hubungan kausalitas (sebab-akibat) untuk menghantarkan runtunan kejadian tersebut kepada pembaca. Pada dasarnya alur dan plot memiliki perbedaan. Plot adalah suatu cerita yang saling berkaitan secara kronologis untuk menunjukan suatu maksud jalan cerita. Sedangkan alur hanya menunjukan urutan kejadian berdasarkan waktu kejadian tersebut terjadi. Dengan kata lain, urutan peristiwa yang membentuk alur bila ditampilkan berdasarkan pertimbangan struktur hubungan satu sama lain dan keterkaitan kausalitasnya maka dapat membentuk sebuah plot.
Alur kronologis adalah nama lain dari alur maju, alur lurus atau alur progresif. Peristiwa-peristiwa ditampilkan secara kronologis, maju, secara runtut dari awal tahap tengah hingga akhir. Dalam alur ini terdapat hitungan jam, menit, detik, hari dan sebagainya.
Gambar 2.6 Contoh Alur Kronologis “Revolusi Mesir”[15]
Demonstran bentrok dengan
polisi
Tidak ada pernyataan
Mubarak
Pengumuman
Api meluas ke musium
Pelindung manusia lindungi
Musium
Harapan antiquitis ok
Looters hancurkan mumi
Revolusi diikuti Eritrea
Rakyat diundang untuk mendukung
23
2.9.1. Menentukan Alur Kronologis
Sebagaimana telah dibahas berkaitan dengan alur kronologis dari berita tekstual, alur kronologis ini dihasilkan dari kumpulan hasil ringkasan yang relevan. Secara intuitif, dapat diambil ringkasan terbaik untuk merepresebtasujab ringkasan yang duplikat. Represetatif dari artikel tekstual berupa ringkasan menghasilkan plot dasar untuk setiap fase. Kemudian dari setiap representatif berita tekstual yakni ringkasan tersebut dikoneksikan atau dihubungkan sesuai untuk menggambarkan pengembangan struktur dari peristiwa (event). Secara berurut, untuk mengeliminasikan noisy dari ringkasan artikel, hanya teks terpublikasi setelah waktu tertentu yang dapat dianggap sebagai fase berikutnya. Terakhir, ada yang boleh dalam cara yang berbeda untuk menghubungkan representatif artikel dengan dan sebuah hubungan optimal seharusnya menjadi satu yang menghubungkan titik-titik tersebut lebih halus.
Berikut ini adalah arsitektur sistem untuk menghasilkan alur kronologis
Titik dominan Steiner Tree
Kumpulan Artikel
Ringkasan berita tekstual MMR
Query Alur Kronologis
Gambar 2.7 Arsitektur Sistem [15]
2.9.2. Alur Kronologis yang Baik
Dalam menggenerasikan alur kronologis atau Storyline tentu pembahasan yang paling pokok adalah bagaimana hasil yang diberikan oleh sistem memiliki unsur-unsur berikut (Anunaya Srivastava):
2. Relevan : memiliki keterkaitan antara dokumen berita yang satu dengan yang
lainnya.
3. Redudansi kecil atau sedikit: tidak ada pengulangan terhadap berita atau sedikit.
4. Keterkaitan : Keterhubungan antar dokumen. 5. Coverage : mewakili sebuah ulasan.
Tingkat Komulatif Kejadian (Tingkat Insidensi Komulatif)
Dalam pembahasan berkaitan dengan ilmu kesehatan sering di istilahkan sebagai Tingkat Insidensi Komulatif. Tingkat insiden (incident rate) adalah proporsi penduduk yang memiliki kondisi tertentu yang dimulai selama periode waktu. Angka ini diukur dengan salah satu dari tiga cara, yaitu tingkat serangan, tingkat kepadatan kejadian, atau risiko kejadian kumulatif [16].
Namun, dalam hal ini, Tingkat Kumulatif Kejadian menunjukan sejumlah atau banyaknya kejadian maupun peristiwa yang terjadi dalam kurun waktu tertentu.
OOP (Object Oriented Programming)
25
Gambar 2.8 Skema OOP [17]
2.11.1. Konsep Dasar Berorientasi Objek
Pemrograman borientasi objek menekankan pada konsep-konsep berikut yang merupakan ciri khasnya, yaitu :
1. Kelas
Kelas adalah kumpulan atas definisi data dan fungsi-fungsi dalam suatu unit untuk suatu tujuan tertentu. Sebagai contoh 'class of dog' adalah suatu unit yang terdiri atas definisi-definisi data dan fungsi-fungsi yang menunjuk pada berbagai macam perilaku/turunan dari anjing. Sebuah class adalah dasar dari modularitas dan struktur dalam pemrograman berorientasi
object. Sebuah class secara tipikal sebaiknya dapat dikenali oleh seorang non-programmer sekalipun terkait dengan domain permasalahan yang ada, dan kode yang terdapat dalam sebuah class sebaiknya (relatif) bersifat mandiri dan independen (sebagaimana kode tersebut digunakan jika tidak menggunakan OOP). Dengan modularitas, struktur dari sebuah program akan terkait dengan aspek-aspek dalam masalah yang akan diselesaikan melalui program tersebut. Cara seperti ini akan menyederhanakan pemetaan dari masalah ke sebuah program ataupun sebaliknya. Objek Objek membungkus data dan fungsi bersama menjadi suatu unit dalam sebuah program komputer; objek merupakan dasar dari modularitas dan struktur dalam sebuah program komputer berorientasi objek.
Properties Pengatur
Obyek
OBJECT PROGRAM /
TOOLBOX REPORT
FORM
DATABAS OTHERS
2. Abstraksi
Abstraksi merupakan kemampuan sebuah program untuk melewati aspek informasi yang diproses olehnya, yaitu kemampuan untuk memfokus pada inti. Setiap objek dalam sistem melayani sebagai model dari "pelaku" abstrak yang dapat melakukan kerja, laporan dan perubahan keadaannya, dan berkomunikasi dengan objek lainnya dalam sistem, tanpa mengungkapkan bagaimana kelebihan ini diterapkan. Proses, fungsi atau metode dapat juga dibuat abstrak, dan beberapa teknik digunakan untuk mengembangkan sebuah pengabstrakan.
3. Enkapsulasi
Enkapsulasi memastikan pengguna sebuah objek tidak dapat mengganti keadaan dalam dari sebuah objek dengan cara yang tidak layak; hanya metode dalam objek tersebut yang diberi ijin untuk mengakses keadaannya. Setiap objek mengakses interface yang menyebutkan bagaimana objek lainnya dapat berinteraksi dengannya. Objek lainnya tidak akan mengetahui dan tergantung kepada representasi dalam objek tersebut.
4. Polimorfisme
27
meningkat, tapi bagaiman proses peningkatan kecepatan ini dapat berbeda-beda untuk setiap jenis mobil.
5. Inheritas
Inheritas mengatur polimorfisme dan enkapsulasi dengan mengijinkan objek didefinisikan dan diciptakan dengan jenis khusus dari objek yang sudah ada - objek-objek ini dapat membagi (dan memperluas) perilaku mereka tanpa haru mengimplementasi ulang perilaku tersebut ( bahasa berbasis objek tidak selalu memiliki inheritas.) Dengan menggunakan OOP maka dalam melakukan pemecahan suatu masalah kita tidak melihat bagaimana cara menyelesaikan suatu masalah tersebut (terstruktur) tetapi objek-objek apa yang dapat melakukan pemecahan masalah tersebut. Sebagai contoh anggap kita memiliki sebuah departemen yang memiliki manager, sekretaris, petugas administrasi data dan lainnya. Misal manager tersebut ingin memperoleh data dari bag administrasi maka manager tersebut tidak harus mengambilnya langsung tetapi dapat menyuruh petugas bag administrasi untuk mengambilnya. Pada kasus tersebut seorang manager tidak harus mengetahui bagaimana cara mengambil data tersebut tetapi manager bisa mendapatkan data tersebut melalui objek petugas adminiistrasi. Jadi untuk menyelesaikan suatu masalah dengan kolaborasi antar objek-objek yang ada karena setiap objek memiliki deskripsi tugasnya sendiri.
UML (Unified Modeling Language)
Unified Modeling Language (UML) merupakan salah satu alat bantu yang
dapat digunakan dalam bahasa pemograman yang berorientasi objek, saat ini UML
Unified Modeling Language merupakan metode pengembangan perangkat lunak (sistem informasi) dengan menggunakan metode grafis serta merupakan bahasa untuk visualisasi, spesifikasi, konstruksi serta dokumentasi.
1. Unified Modeling Language (UML) adalah bahasa yang telah menjadi standard untuk visualisasi, menetapkan, membangun dan mendokumentasikan arti suatu sistem perangkat lunak.
2. Unified Modeling Language (UML) dapat didefinisikan sebagai sebuah bahasa yang telah menjadi standar dalam industri untuk visualisasi, merancang dan mendokumentasikan sistem perangkat lunak.
3. Unified Modeling Language (UML) merupakan standard modeling
language yang terdiri dari kumpulan-kumpulan diagram, dikembangkan untuk membantu para pengembang sistem dan software agar bisa menyelesaikan tugas-tugas seperti :
a. Spesifikasi b. Visualisasi c. Desain arsitektur d. Konstruksi
e. Simulasi dan testing f. Dokumentasi
Berdasarkan beberapa pendapat yang dikemukakan diatas dapat ditarik
kesimpulan bahwa “Unified Modeling Language (UML) adalah sebuah bahasa yang
berdasarkan grafik atau gambar untuk menvisualisasikan, menspesifikasikan, membangun dan pendokumentasian dari sebuah sistem pengembangan perangkat lunak berbasis Objek (OOP) (Object Oriented programming)”.
29
2.12.1. Use Case Diagram
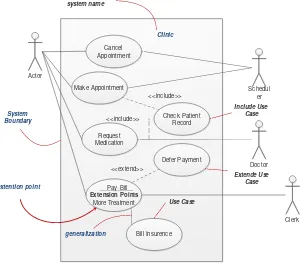
Diagram Use Case menggambarkan apa saja aktifitas yang dilakukan oleh suatu sistem dari sudut pandang pengamatan luar. yang menjadi persoalan itu apa yang dilakukan bukan bagaimana melakukannya. Diagram Use Case dekat kaitannya dengan kejadian-kejadian. Kejadian (scenario) merupakan contoh apa yang terjadi ketika seseorang berinteraksi dengan sistem.
Gambar 2.2 Use Case Diagram
2.12.2. Activity Diagram
Pada dasarnya diagram Activity sering digunakan oleh flowchart. Diagram ini berhubungan dengan diagram Statechart. Diagram Statechart berfokus pada obyek yang dalam suatu proses (atau proses menjadi suatu obyek), diagram Activity berfokus pada aktifitas-aktifitas yang terjadi yang terkait dalam suatu proses tunggal. Jadi dengan kata lain, diagram ini menunjukkan bagaimana aktifitas-aktifitas tersebut bergantung satu sama lain.
Actor
Cancel Appointment
Make Appointment
Check Patient Record
Request Medication
Pay Bill
Extension Points
More Treatment
Bill Insurence
Schedul er
Doctor
Clerk Defer Payment
<<include>>
<<include>>
<<extend>>
system name
System Boundary
Include Use Case
Extende Use Case
extention point
generalization
Use Case
2.12.3. Class Diagram
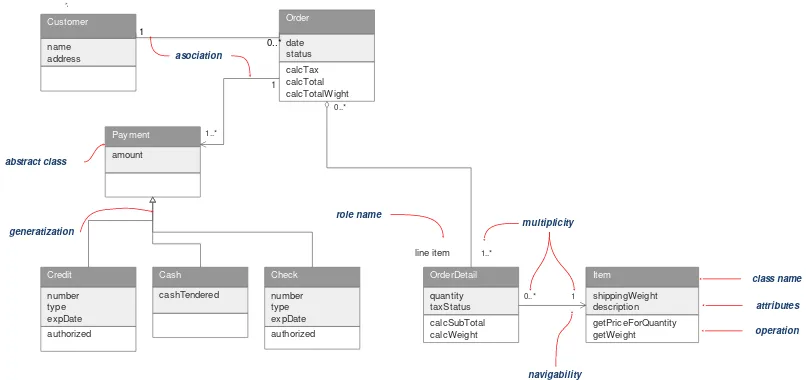
Diagram Class memberikan pandangan secara luas dari suatu sistem dengan menunjukan kelas-kelasnya dan hubungan mereka. Diagram Class bersifat statis; menggambarkan hubungan apa yang terjadi bukan apa yang terjadi jika mereka berhubungan.
Gambar 2.3 Class Diagram
2.12.4. Sequence Diagram
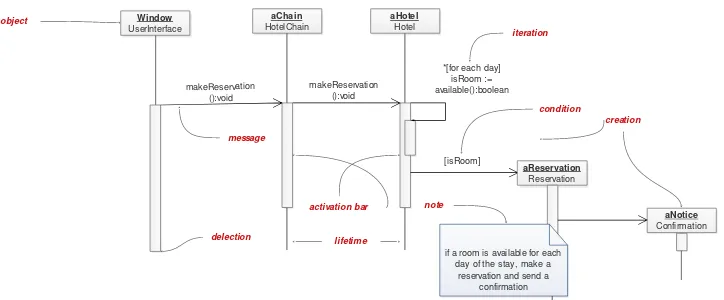
Diagram Class dan diagram Object merupakan suatu gambaran model statis. Namun ada juga yang bersifat dinamis, seperti Diagram Interaction. Diagram sequence merupakan salah satu diagram Interaction yang menjelaskan bagaimana suatu operasi itu dilakukan; message (pesan) apa yang dikirim dan kapan pelaksanaannya. Diagram ini diatur berdasarkan waktu. Obyek-obyek yang berkaitan dengan proses berjalannya operasi diurutkan dari kiri ke kanan berdasarkan waktu terjadinya dalam pesan yang terurut.
31
Gambar 2.4 Sequence Diagram
Pengujian Perangkat Lunak
Ujicoba perangkat lunak merupakan elemen yang kritis dan perepresentasikan tinjauan ulan yang menyeluruh terhadap spesifikasi, desain dan pengkodean. Ujicoba merepresentasikan ketidanormalan yang terjadi pada pengembangan perangkat lunak [19]. Dari teknik yang dapat diterapkan dalam menguji suatu perangkat lunak dapat menggunakan dua jenis pengujian yang umum digunakan, yakni:
2.13.1. Pengujian Whitebox
Metode ujicoba blackbox memfokuskan pada keperluan fungsional dari software [19]. Karna itu ujicoba blackbox memungkinkan pengembang software untuk membuat himpunan kondisi input yang akan melatih seluruh syarat-syarat fungsional suatu program. Ujicoba blackbox bukan merupakan alternatif dari ujicoba whitebox, tetapi merupakan pendekatan yang melengkapi untuk menemukan kesalahan lainnya, selain menggunakan metode whitebox. Ujicoba blackbox berusaha untuk menemukan kesalahan dalam beberapa kategori, diantaranya (Ayuliana, 2009):
1. Fungsi-fungsi yang salah atau hilang
Window
UserInterface
aChain
HotelChain
aHotel
Hotel
makeReservation ():void
makeReservation ():void
*[for each day] isRoom := available():boolean
[isRoom]
aReservation
Reservation
aNotice
Confirmation
if a room is available for each day of the stay, make a
reservation and send a confirmation
note
creation condition iteration
activation bar message
2. Kesalahan interface
3. Kesalahan dalam struktur data atau akses database eksternal 4. Kesalahan performa
5. kesalahan inisialisasi dan terminasi
2.13.2. Pengujian Ketergunaan (Usability Testing)
Ketergunaan atau Usability adalah ketika suatu produk memiliki kegunaan yakni seorang pengguna dapat melakukan apa yang dia ingin lakukan dengan cara yang ia harapkan untuk dapat melakukannya, tanpa halangan, ragu-ragu atau pertanyaan [7]. Dalam konsep usability ada beberapa atribut yang menunjukan bahwa suatu produk atau sistem memiliki ketergunaan yakni suatu produk harus melingkupi beberapa hal [7]:
1. Usefulness
Atribut ini menyangkut sejauh mana suatu produk memungkinkan pengguna dalam mencapai tujuan-tujuannya dan penilaian pengguna terhadap kesediannya untuk menggunakan produk tersebut. Namun, dorongan untuk menggunakan sistem atau produk tersebut akan tidak masuk akal bilamana produk hanya dibiarkan tanpa ada ketergunaan. Jika sistem mudah digunakan, mudah untuk dipelajari dan memuaskan untuk digunakan tapi tidak mencapai tujuan yang spesifik dari pengguna tertentu, hal itu pun tidak akan berguna meskipun diberikan secara gratis.
Artinya, pada tahap awal pengembangan produk, harus memastikan produk atau fitur apa yang diperlukan dalam sistem sebagai unsur-unsur kegunaan.
2. Efficiency
Efesiensi adalah kecepatan yang dapat dicapai untuk merealisasikan tujuan pengguna dengan akurasi tertentu dan ukuran waktu yang normal. Misalnya, menetapkan pengujian ketergunaan yang mengatakan “95% dari semua pengguna akan dapat memuat (menjalankan) perangkat
33
3. Effectiveness
Efektivitas mengacu pada sejauh mana produk berperilaku dimana pengguna berharap akan kemudahan. Selain itu, pengguna padat menggunakannya untuk melakukan apa yang mereka inginkan. Hal ini biasanya diukur secara kuantitatif dengan tingkat kesalahan. Kegunaan dalam pengujian berdasarkan ukuran efektivitas sekaligus untuk efesiensi harus diikat kedalam beberapa persentase dari total pengguna. Memperluas contoh dari efisiensi yang mungkin dinyatakan sebagai 95% dari semua pengguna akan dapat memuat atau menjalankan perangkat lunak dengan benar pada usaha yang pertama.
4. Satisfying
Mengacu pada persepsi pengguna, perasaan maupun pendapat dari pada produk tersebut. Biaranya diperoleh dari kedua pertanyaan baik tertulis maupun lisan. Pengguna lebih mungkin untuk melakukan dengan baik pada produk yang memenuhi kebutuhan mereka sehingga memberikan kepuasan. Biasanya, pengguna diminta untuk menilai produk atau sistem yang mereka coba dan ini sering dapat mengungkapkan penyebab dan alasan bagaimana suatu masalah dapat terjadi.
5. Learnable
Learnable merupakan bagian dari efektivitas dan memiliki kaitan erat dengan kemampuan pengguna dalam mengoperasikan sistem untuk beberapa tingkat yang ditetapkan secara kompetensi yang telah ditentukan setelah beberapa jumlah dan periode pelatihan. Hal ini juga dapat mengacu pada kemampuan pengguna yang jarang mempelajari kembali sistem setelah periode tidak aktif.
6. Accessible
pembahasan ini, aksesibilitas mempertimbangkan bagi penyandang cacat dapat memperjelas dan menyederhanakan desain untuk orang-orang yang menghadapi keterbatasan sementara (misal, cedera) atau situasional (misalnya kondisi lingkungan perhatian atau buruk dibagi seperti cahaya terang atau tidak cukup cahaya). Ada banyak perangkat pedoman yang tersedia dalam membuat desain aksesabel.
Membuat hal-hal yang lebih bermanfaat dan dapat diakses adalah bagian dari disiplin yang lebih besar dari desain yang berpusat pada pengguna.
2.13.3. Notasi Big O
Berikut ini merupakan beberapa contoh nilai Big-O yang bisa ditemukan dalam beberapa literatur [20] :
1. O(1): konstan. Algoritma dengan O-Besar O(1) dieksekusi di kecepatan yang sama tidak tergantung pada data masukannya. Sebagai contoh, algoritma yang selalu menghasilkan nilai yang sama apapun nilai masukannya dapat dipandang sebagai algoritma dengan efisiensi O(1). Contoh lain adalah algoritma untuk menentukan suatu bilangan genap atau ganjil, look table atau hash table adalah konstan ukuran tabel tetap. O(log n): logaritmik. Algoritma yang didasarkan pada pohon biner kerap mempunyai efisiensi O(log n). Hal ini disebabkan karena BST (binary search tree) yang sangat seimbang mempunyai banyak lapisan log dan untuk mencari sembarang elemen di BST memerlukan penelusuran satu simpul di setiap lapisan. Algoritma untuk mencari suatu item di array terurut menggunakan pencarian biner atau balanced search tree serta semua operasi di binomial heap adalah O(log n).
35
algoritma harus menelusuri seluruh array untuk mencek setiap elemen dalam array yang berarti O(n). Keadaan rerata berdasarkan pada asumsi bahwa elemen yang dicari ada dalam array dan setiap elemen mempunyai peluang yang sama untuk ditemukan. Pencarian hanya perlu mengunjungi n/2. Contoh lain adalah link-list. Akses elemen pada link-list adalah O(n) karena link-list tidak mendukung akses acak. Menambahkan dua integer n-bit menggunakan ripple carry adalah O(n).
3. O(n log n): loglinear, quasilinear atau linearithmik. Algoritma pengurutan yang baik kerap mempunyai order O(n log n). Contoh algoritma dengan efisiensi ini adalah algoritma yang tergabung dalam kelompok devide and conquer (DAC) seperti quick sort (best dan average case) dan merge sort. Algoritma merge sort membagi array menjadi dua bagian, urutkan kedua subarray secara rekursif dengan memanggil dirinya sendiri dan kemudian gabung kembali hasilnya kedalam array tunggal. Karena setiap kali membagi array menjadi dua bagian maka perulangan luar mempunyai
efisiensi log n, dan untuk setiap “level” array yang dibagi menjadi dua
bagian maka harus menggabungkan kembali semua elemen ke dalam satu array, operasinya membutuhkan order n. Algoritma pengurutan paling popular quick sort mempunyai kinerja terbaik O(n log n) yang membuatnya menjadi algoritma pengurutan yang sangat cepat didasarkan pada asumsi bahwa semua nilai berbeda dan dalam keadaan acak. Tetapi data masukan yang paling jelek akan membuat kinerjanya menjadi O(n2
). Contoh lain algoritma loglinear adalah Fast Fourier Transform (FFT) dan heapsort.
Dengan demikian algoritma membandingkan secara rerata elemen ke j+1 yang akan disisipkan separuh sub-array yang telah urut, sehingga tj = j/2. Hasil akhirnya waktu eksekusi kasus rerata adalah fungsi kuadratik dari ukuran masukan; sama dengan waktu eksekusi kasus terjelek. Contoh lain algoritma kuadratik adalah mengalikan dua bilangan n-digit menggunakan algoritma sederhana.
5. O(2n): eksponensial. Efisiensi non-polinomial yang paling penting adalah exponential time. Banyak masalah penting yang hanya dapat diselesaikan oleh algoritma dengan efisiensi seperti ini.
Perangkat Lunak Pendukung
2.14.1. Apache
Apache adalah sebuah nama web server yang bertanggung jawab pada request-response HTTP dan logging informasi secara detail (kegunaan basicnya) [21]. Selain itu, Apache juga diartikan sebagai suatu web server yang kompak, modular, mengikuti standar protokol HTTP, dan tentu saja sangat digemari.
Kesimpulan ini bisa didapatkan dari jumlah pengguna yang jauh melebihi para pesaingnya. Sesuai hasil survai yang dilakukan oleh Netcraft, bulan Januari 2005 saja jumlahnya tidak kurang dari 68% pangsa web server yang berjalan di Internet. Ini berarti jika semua web server selain Apache digabung, masih belum bisa mengalahkan jumlah Apache.
Saat ini ada dua versi Apache yang bisa dipakai untuk server produksi, yaitu versi mayor 2.0 dan versi mayor 1.3. Apache merupakan webserver yang paling banyak digunakan saat ini. Hal ini disebabkan oleh beberapa sebab, di antaranya adalah karena sifatnya yang opensource dan mudahnya mengkostumisasikannya. diantaranya dengan menambahkan support secure protocol melalui ssl dan konektifitasnya dengan database server melalui bahasa scripting PHP.
2.14.2. MySQL
37
seluruh dunia, diantaranya Silicon Graphics (http://www.sgi.com), Siemens Nixdorf (http://www.siemens.com), Alesis Digital Studio Electronics (http://www.alesis.com) dan masih banyak perusahaan-perusahaan terkemuka lainnya yang menggunakan MySQL. Perusahaan-perusahaan tersebut dapat dilihat
pada MySQL user’s list di http://www.mysql.com/information/userlist.htm.
MySQL adalah sebuah text based database server, artinya MySQL tidak dibuat dalam bentuk aplikasi yang memiliki Graphical User Interface
2.14.3. PHP
PHP (Personal Home Page) dahulunya merupakan objek pribadi dari Rasmus Lerdorf (PHP versi 1) yang digunakan untuk membuat homepage pribadinya. PHP merupakan scripting yang menyatu dalam HTML dan berada di server (server side HTML – embeded scripting) yang digunakan untuk membuat halaman web yang dinamis.
Dinamis berarti halaman yang akan ditampilkan dibuat saat halaman itu diminta oleh client. Mekanisme ini menyebabkan informasi yang diterima client
selalu yang terbaru. Semua script PHP dieksekusi pada server dimana script tersebut dijalankan.
Style standar PHP selalu diawali dengan <?php dan diakhiri dengan tanda ?> dan style PHP ini sangat mirip dengan program XML atau seperti pada C atau Perl. Selain itu PHP juga mendukung komentar C, C++, dan Unix shell-style.
2.14.4. PHPMyAdmin
satunya adalah phpMyAdmin. Dengan phpMyAdmin kita dapat membuat tabel, mengisi data dan lain-lain dengan mudah tanpa harus hafal perintahnya.
2.14.5. XAMPP
Fungsinya adalah sebagai server yang berdiri sendiri (localhost), yang terdiri atas program Apache HTTP Server, MySQL database, dan penerjemah bahasa yang ditulis dengan bahasa pemrograman PHP dan Perl. Nama XAMPP merupakan singkatan dari X (empat sistem operasi apapun), Apache, MySQL, PHP dan Perl [23]. Program ini tersedia dalam GNU General Public License dan bebas, merupakan web server yang mudah digunakan yang dapat melayani tampilan halaman web yang dinamis. Untuk mendapatkanya dapat mendownload langsung dari web resminya.
2.14.6. Adobe Dreamwever CC
Dreamweaver memiliki fitur browser yang terintegrasi untuk melihat halaman web yang dikembangkan di jendela pratinjau program sendiri agar konten memungkinkan untuk terbuka di web browser yang telah terinstal [24]. Aplikasi ini menyediakan transfer dan fitur sinkronisasi, kemampuan untuk mencari dan mengganti baris teks atau kode untuk mencari kata atau kalimat biasa di seluruh situs, dan templating feature yang memungkinkan untuk berbagi satu sumber kode atau memperbarui tata letak di seluruh situs tanpa server side includes atau scripting. Behavior Panel juga memungkinkan penggunaan JavaScript dasar tanpa pengetahuan coding, dan integrasi dengan Adobe Spry Ajax framework
193
KESIMPULAN DAN SARAN
KESIMPULAN
Berdasarkan hasil implementasi dan pengujian dari metode MMR dan algoritma Steiner Tree, maka diperoleh kesimbulan bahwa pencarian alur kronologis memberikan kemudahan secara efesien kepada pengguna dalam mencari berita-berita secara runut dalam bentuk alur kronologis.
SARAN
Pembanguna aplikasi pencari alur kronologis berita bertujuan untuk menyelesaikan persoalan efektivitas dan efesiensi dalam proses pencarian berita yang dilakukan oleh kebanyakan para pembaca media online. Hanya saja, penelitian ini dibatasi hanya pada aspek penerapan metode saja sehingga dapat menghasilkan sebuah alur kronologis dengan mengacu pada berita internasioanl. Maka dari itu, perlu ada pengembangan yang lebih luas untuk bisa mewadahi semua pembaca media online. Adapun saran-saran terhadap pengembang adalah sebagai berikut:
1. Memberikan fitur tambahan berupa RSS sehingga sistem dapat menerima berita secara otomatis sehingga perbendaharaan peristiwa yang terjadi akan memberikan alur yang mengarah pada sifat komprehensif.
2. Melakukan perbaikan pada tahap textprocessing terutama pada tahap
stemming sehingga tidak memakan waktu yang lama dalam melakukan eksekusi. Selain itu, secara kualitas mampu membersihkan kata dari berbagai bentuk imbuhan dengan efesien.
F-1
DAFTAR RIWAYAT HIDUP
Nama Lengkap : Aji Teja Hartanto
Nama Panggilan : Aji
Tempat/Tanggal Lahir : Bandung , 10 Januari 1994 Jenis Kelamin : Laki-laki
Agama : Islam
Status : Belum Menikah
Kewarganegaraan : Indonesia
Alamat Tetap : Jl. Sedap Malam VI No 6 Rancaekek Kencana No Telepon : Rumah : -
Handphone : 085777511087
Email : [email protected]
F-2
1. Studi Tour Musium Geologi Bandung, SMPN 1 Paseh. 2. Studi Tour Indosat M2, Jakarta. SMK Medikacom 2009.
3. Seminar Islamic Civilization Forum LDK UMMI UNIKOM 2012/2015 4. TDOK LDK UMMI UNIKOM 2012, 2013, 2014, 2015.
5. Simposium Nasional BKLDK 7-9 2012 6. Kuliah Bersama Teknik Informatika 2011 7. Kongres Mahasiswa Indonesia 2014. 8. LKMM BEM UNIKOM 2013 9. LKMM HMIF UNIKOM 2014
10. Seminar IoT & SMARCITY 2016 Teknik Informatika UNIKOM. 11. Seminar WISE Smart City Widyatama 2016
12. Be:Logix: Building App for Android Mobile Device, 2015.
2011 – 2016 : Universitas Komputer Indonesia, Fakultas Teknik dan ilmu komputer, Program Studi Teknik Informatika. Program Srata-1
2008 – 2011 : SMK Medikacom Bandung 2005 – 2008 : SLTP Negeri 1 Paseh 1999 – 2005 : SD Negeri Babakan Loa
PENDIDIKAN FORMAL
1999 – 2005 : Anggota Pramuka SDN 1 Babakan Loa 2005 - 2008 : Anggota Paskibra SMP N 1 Paseh
2006 : Delegasi Olimpiade Fisika SMPN 1 Paseh, Kecamatan Paseh. 2009 : Menggagas Komunitas Animasi Spiegel Anivers.
2011 : Anggota Syiar LDK UMMI UNIKOM
2012 : Panitia Acara Islamic Civilization Forum 2012, 2013, 2014 : Panitia Qurban LDK UMMI UNIKOM
2012-2013 : Ketua Divisi Opini & Propaganda GEMA Pembebasan Komisariat
2013 : Pemred. Pers Mahasiswa “Catatan Aktivis Pembebasan”. 2013 : Anggota Pers Birama UNIKOM (Redaktur Politik)
2013 - 2015 : Ketua Organisasi Ekstra Kampus GEMA Pembebasan Komisariat 2016 : Kepala Divisi Kajian Strategis GEMA Pembebasan Kota
Bandung
2013, 2014, 2015 : Koor. Treatikal LDK UMMI UNIKOM 2015 : Panitia Acara Islamic Civilization Fest
F-4
Spesifikasi Keterangan
Adobe Flash Animasi, AS2.
Adope Photoshop Desain
Adobe Dreamwever Pemrograman Web: PHP, CSS, Javascript, HTML Mic. Visual Studio Pemrograman Desktop: C#
Eclips Pemrograman Mobile: Android
Corel Desain Vektor
Adobe After Effect Video Intro editing Adobe Priemere Video editing 3D Max Studio Modelling
![Gambar 2.6 Contoh Alur Kronologis “Revolusi Mesir” [15]](https://thumb-ap.123doks.com/thumbv2/123dok/1291767.790594/31.595.197.461.421.681/gambar-contoh-alur-kronologis-revolusi-mesir.webp)
![Gambar 2.8 Skema OOP [17]](https://thumb-ap.123doks.com/thumbv2/123dok/1291767.790594/34.595.142.479.113.298/gambar-skema-oop.webp)