1. Data Pribadi
Nama : David Erwinson
NIM : 10112350
Tempat/Tanggal Lahir : Bandung, 20 Oktober 1994 Jenis Kelamin : Laki-Laki
Agama : Kristen Protestan
Alamat : Komp. Manglayang Sari Blok A 9
A No 17 Cibiru
No. Telp : 089667808121
Email : [email protected]
2. Riwayat Pendidikan
2000-2006 : SDN Pelita 02 Cibiru
2006-2009 : SMPN 46 Bandung
2009-2012 : SMAN 24 Bandung
2012-2016 : Universitas Komputer Indonesia (Unikom)
Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar tanpa paksaan.
Bandung, 29 Juli 2016
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
DAVID ERWINSON
10112350
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
iii
dan anugrah yang berlimpah kepada penulis sehingga penulis dapat menyelesaikan penulisan ini dengan baik, yang merupakan salah satu syarat untuk memperoleh gelar
Sarjana pada Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Tujuan dari penulisan skripsi yang berjudul “Pembangunan Aplikasi Pendeteksi Plagiarisme Suatu Dokumen Berupa Paper Menggunakan Metode Vector Space Model (VSM)” ini adalah untuk memberikan kemudahan bagi para pembaca dalam penggunan aplikasi yang dapat memudahkan dalam mendeteksi
plagiarisme suatu dokumen.
Penulis menyadari bahwa skripsi ini masih jauh dari kata sempurna karena keterbatasan pengetahuan, pengalaman, dan waktu yang penulis miliki. Oleh karena itu, dengan kerendahan hati penulis menerima kritik dan saran yang bersifat membangun demi penyempurnaan penulisan ini.
Pada kesempatan ini juga penulis ingin menyampaikan terima kasih dan penghargaan yang setinggi-tingginya kepada semua pihak yang terkait dan ikut membantu dalam penulisan skripsi ini. Secara khusus penulis ingin menyampaikan ucapan terima kasih ini kepada :
1. Dr. Ir. Eddy Soeryanto Soegoto selaku Rektor Universitas Komputer
Indonesia.
2. Irawan Afrianto, S.T., M.T selaku Ketua Program Studi Teknik Informatika,
Universitas Komputer Indonesia.
3. Ken Kinanti Purnamasari, S.Kom., M.T selaku Dosen Pembimbing Utama yang
telah memberikan bimbingan dan pengarahan selama penulisan penelitian ini. 4. Ednawati Rainarli, S.Si., M.Si selaku Dosen Pendamping yang juga selalu
memberikan bimbingan dan pengarahan kepada penulis.
5. Bapak, Ibu dosen dan staff yang ada di Universitas Komputer Indonesia yang
iv terselesaikannya penulisan skripsi ini.
7. Seluruh keluarga besar dari Sihombing maupun Manurung yang telah
membantu, memberikan dukungan dan semangat dalam penyusunan skripsi ini.
8. Sahabat-sahabat IF9 dan teman-teman di kampus yang telah membantu
memberikan semangat dan motivasi agar terselesaikannya penulisan skripsi ini. 9. Bang Christian dan rekan-rekan PA untuk dukungan doa, waktu, tenaga, dan
bantuan moril dalam penyusunan skripsi ini.
10. Keluarga Besar dari Pram Squad yang sudah memberikan dukungan doa dan
motivasi dalam penyusunan skripsi ini.
11. Ezra, Angga, Kaleb, Mas Prapto, Putra Sitanggang, Yesyurun, Abraham,
Joshua, Sheba, Marlaokta, Eunike, Cilla, Bang Obin, Bang Yustian, Bang Saut, Bang Paulus, Ko Hernawan, Ka Rina, Ka Oan, abang/kakak ,rekan-rekan dan adik-adik di Pelajar Unstoppable Bandung Timur.
Akhir kata penulis mengucapkan terimakasih banyak kepada semua pihak yang telah membantu dalam menyelesaikan penulisan skripsi ini, semoga skripsi ini dapat bermanfaat bagi semua pihak.
Bandung, Agustus 2016
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... ix
DAFTAR SIMBOL ... x
DAFTAR LAMPIRAN ... xii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 2
1.3 Maksud dan Tujuan ... 3
1.4 Batasan Masalah... 3
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Perangkat Lunak ... 4
1.6 Sistematika Penulisan... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Plagiarisme ... 7
2.2 Preprocessing ... 8
vi
2.4 Vector Space Model ... 11
2.5 Data Flow Diagram (DFD) ... 13
2.6 Kamus Data ... 14
2.7 ERD (Entity Relationship Diagram) ... 14
2.8 PHP (Personal Home Page) ... 15
2.9 HTML (Hyper Text Markup Language) ... 17
2.10 MySQL ... 17
BAB 3 ANALISIS DAN PERANCANGAN ... 19
3.1 Analisis Masalah ... 19
3.2 Analisis Sistem ... 19
3.2.1 Analisis Metode ... 19
3.2.2 Analisis Masukan ... 21
3.2.3 Proses ... 21
3.2.4 Keluaran ... 33
3.3 Analisis Pengguna ... 33
3.4 Perancangan Sistem ... 34
3.4.1 Entity Relationship Diagram (ERD) ... 34
3.4.2 Diagram Konteks ... 35
3.4.3 Data Flow Diagram (DFD) ... 35
vii
3.4.8 Perancangan Antarmuka Sistem ... 45
3.4.9 Perancangan Semantik ... 48
3.4.10 Perancangan Prosedural ... 48
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 53
4.1 Implementasi ... 53
4.1.1 Implementasi Perangkat Keras ... 53
4.1.2 Implementasi Perangkat Lunak ... 53
4.1.3 Implementasi Basis Data (Sintak SQL) ... 54
4.1.4 Implementasi Antarmuka ... 56
4.2 Pengujian ... 59
4.2.1 Rencana Pengujian ... 60
4.2.2 Kasus dan Hasil Pengujian ... 64
4.2.3 Kesimpulan Hasil Pengujian Black Box ... 67
4.2.4 Pengujian Penghitungan Tingkat Similaritas ... 67
4.2.5 Hasil Pengujian Similarity dan Waktu Eksekusi ... 68
4.2.6 Analisis Hasil Pengujian ... 69
BAB 5 KESIMPULAN DAN SARAN ... 71
5.1 Kesimpulan ... 71
5.2 Saran ... 71
72 Offset, Yogyakarta
Baeza R.Y., Neto R., 1999. Modern Information Retrieval, Addison Wesley-Pearson international edition, Boston. USA.
Depdikbud. 2014. Kamus Besar Bahasa Indonesia. Jakarta . Balai Pustaka. Harjono, K. D. Perluasan Vektor Pada Metode Search Vector Space.
Integral Vol. 10 No.2, Juli 2005 Jurusan Ilmu Komputer, Universitas Katolik Parahyangan, Bandung.
Herqutanto. 2013. Plagiarisme, runtuhnya tembok akademik, 1(1), 1-2.Diunduh dari http://journal.ui.ac.id/index.php/eJKI/article/viewFile/1589/1335
Jogiyanto, HM, 2005, “Analisis dan Desain Sistem Informasi : Pendekatan Terstruktur Teori dan Praktik Aplikasi Bisnis”, Penerbit Andi, Yogyakarta
K. S. Jones, 2004, ”A Statistical Interpretation of Term Specify and Its
Application in Retrieval”, Journal of Documentation, vol 60 (2), pp. 493-502. Peraturan Mentri Pendidikan Nasional Republik Indonesia. (2010). Pencegahan dan penanggulangan plagiat di perguruan tinggi, 1-2. Diunduh
dari http://unnes.ac.id/wp-content/uploads/Permen-Nomor-17-Thn-2010- tentang-pencegahan-dan-penanggulangan-plagiat.pdf.
Robertson, S., 2004. “Understanding Inverse Document Frequency: On theoretical
arguments for IDF”, Journal of Documentation, Vol.60, no.5, pp. 503-520. Salton, G., 1989, Automatic Text Processing, The Transformation, Analysis, and
Retrieval of information by computer. Addison – Wesly Publishing Company, Inc. USA
S.Pressman, Roger.2001. Software Engineering. New York. Americas, McGraw-Hill.
Sudigdo, Sastroasmoro 2007, Beberapa Catatan Tentang Plagiarisme, Majalah Kedokteran Indonesia; Vol. 57, No. 8, Agustus 2007, 239-244.
Tala, F.Z., 2003, A Study of Stemming Effects on Information Retrieval in bahasa Indonesia. Master Thesis, Institut for logic, Language and Computation
Universiteit van Amsterdam The Netherlands
Triwati, Candra. 2009. Metode Pembobotan Statistical Concept Based untuk
Klastering dan Kategorisasi Dokumen Berbahasa Indonesia. IT TELKOM
Bandung
1
Plagiarisme adalah perbuatan yang mengambil tulisan, karangan, atau pendapat dari orang lain tanpa adanya rujukan dan menjadikannya seolah-olah kutipan atau tulisan tersebut sebagai tulisan milik sendiri. Kemajuan teknologi saat ini ada yang berdampak negatif, yaitu dengan mudah mendapat dokumen secara online. Kemudahan itu disalahgunakan dengan seringnya mengutip tulisan dari orang lain tanpa menuliskan rujukan terhadap tulisan yang diambil.
Penelitian yang berkaitan dengan plagiarisme sudah pernah dilakukan sebelumnya. Penelitian yang dilakukan oleh Taufiq M Isa, dkk (Isa dkk, 2013)
dengan judul ”Mengukur Tingkat Kesamaan Paragraf Menggunakan Vector Space
Model untuk Mendeteksi Plagiarisme” menunjukkan bahwa algoritma yang diusulkan dapat mendeteksi dengan baik kesamaan antar dua dokumen. Proses yang dilakukan penelitian tersebut memasukkan data berupa dokumen PDF lalu di konversi kedalam bentuk XML dan nantinya dokumen dirangking dengan cara mengambil paragraf-paragraf yang kemudian dipecah-pecah, setelah didapatkan nilai IDF, TF-IDF dan VSM nya, didapatkan hasil akhir yaitu nilai similaritas antar paragraf. Dalam penelitian tersebut pada tahap preprocessing tidak digunakan stemming danhasil pengujian tersebut peneliti menggunakan beberapa jenis query, yaitu query satu kata dimana hasilnya menunjukkan pasangan paragraf dalam
kelompok similaritas tinggi lebih banyak dibandingkan dengan pasangan paragraf similaritas rendah dan sedang, query dua kata memperlihatkan hasil query juga mirip dengan hasil query satu kata, dan untuk query tiga kata memperlihatkan bahwa pasangan dengan similaritas tinggi dapat dideteksi dengan baik, dan untuk persentase nilai similaritas rendah sebesar 50-65,99%, sedang 66-80,99%, dan tinggi 81-100%.
Pada penelitian ini dilakukan tahap stemming dalam mendeteksi plagiarisme,
“Penentuan Tingkat Plagiarisme Dokumen Penelitian Menggunakan Centroid Linkage Hierarchical Method (CLHM)” mampu membandingkan kemiripan dokumen terhadap sekelompok dokumen dan penelitian tersebut melalui tahapan stemming dimana pemotongan kata secara secara random berpengaruh pada nilai similarity, serta hasil akurasi sistem menghasilkan rata-rata f-measure sebesar 0,984%. Penggunaan stemming bertujuan untuk memperkecil tindakan penjiplakan tanpa mengabaikan perubahan posisi kalimat, pemotongan kata ataupun perubahan kata aktif menjadi kata pasif atau sebaliknya. Penelitian yang dilakukan oleh Milani Winangga (Winangga, 2012) dengan judul “Deteksi Plagiarisme Pada Dokumen Teks Bahasa Indonesia Menggunakan Algoritma Winnowing Dengan Stemming” penggunaan stemming menghasilkan persentase kemiripan yang lebih baik pada kasus pengubahan jenis kata kerja berimbuhan dari aktif ke pasif ataupun sebaliknya tanpa mengubah susunan objek, predikat, ataupun objeknya, dari dua penelitian tersebut penggunaan stemming berpengaruh pada persentase kemiripan dan perubahan kata dari aktif ke pasif. Dalam penelitian yang dilakukan tersebut masih diperlukan pengembangan dari batasan yang telah ada sebelumnya dalam
mendeteksi kemiripan atau plagiarisme suatu dokumen.
Berdasarkan permasalahan tersebut maka akan dirancang dan dibangun suatu aplikasi untuk pendeteksi plagiarisme, dan penggunaan metode vector space model diharapkan bisa membantu aplikasi ini dalam mendeteksi plagiarisme dengan baik dan memberikan persentase tingkat kemiripan dokumen lebih baik. Oleh karena itu, penulis tertarik mengambil pokok bahasan skripsi dengan judul “Pendeteksian
Plagiarisme Abstrak Paper Menggunakan Metode Vector Space Model”.
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang telah dijelaskan di atas, maka dapat ditarik identifikasi dan masalah yang timbul, yaitu : mengetahui tingkat kemiripan atau
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang ada, maksud dari penelitian tugas akhir ini adalah untuk membangun aplikasi pendeteksi plagiarisme menggunakan metode Vector Space Model.
Sedangkan tujuan dari penelitian tugas akhir ini adalah untuk mengetahui tingkat akurasi pendeteksian kemiripan atau plagiarisme suatu dokumen dengan penggunaan stemming pada proses preprocessing.
1.4 Batasan Masalah
Adapun batasan masalah yang diberikan pada penelitian ini sebagai berikut : 1. Data Input :
a. Bentuk teks paper masukan dalam Bahasa Indonesia. b. Format dokumen : *.pdf dengan 30 data.
c. Bila terdapat rumus, gambar dalam teks maka tidak akan dimasukkan,
hanya huruf saja yang diambil.
d. Aplikasi ini tidak memperhatikan kesalahan penulisan (typo) pada
dokumen input.
2. Data Output yang ditampilkan berupa status persentase plagiarisme.
1.5 Metodologi Penelitian
Untuk mempermudah dalam pengumpulan dan pencarian informasi dalam pengerjaan penelitian ini, ada beberapa metode penelitian yang dilakukan diantaranya:
1.5.1 Metode Pengumpulan Data
Metode yang dilakukan dalam pengumpulan data adalah Studi Literatur. Tahapan ini melakukan studi kepustakaan dari hasil penelitian yang telah dilakukan sebelumnya oleh orang lain, artikel–artikel yang terkait dengan pembuatan pendeteksi plagiarisme, membaca paper dan jurnal mengenai plagiarisme, serta mempelajari teknik dan algoritma yang tepat untuk dapat
1.5.2 Metode Pembangunan Perangkat Lunak
Metode pembangunan perangkat lunak yang digunakan adalah dengan menggunakan metode prototype yang dapat dilihat pada Gambar 1.1.
Gambar 1.1 Metode Pembangunan Perangkat Lunak (Roger, 2001)
1. Definisi Kebutuhan
Tahap ini memperoleh informasi melalui paper, jurnal, dan buku. Informasi tersebut dianalisis untuk mendapatkan dokumentasi kebutuhan pengguna untuk digunakan pada tahap selanjutnya.
2. Desain Sistem dan Software
Tahap ini dilakukan sebelum melakukan coding. Dalam tahap ini membuat gambaran yang dikerjakan dan bagaimana tampilan dari software yang dibangun.
3. Implementasi Sistem
Tahap ini dilakukan pemrograman (coding). Pembuatan software dipecah menjadi modul-modul kecil yang nantinya akan digabungkan dalam sistem.
4. Pengujian
Tahap ini dilakukan pengujian terhadap sistem melakukan
pemeriksaaan terhadap modul yang dibuat, apakah sudah memenuhi fungsi yang diinginkan atau belum.
1.6 Sistematika Penulisan
Sistematika dalam penulisan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan laporan ini adalah sebagai berikut.
BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, identifikasi masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, sistematika penulisan dari
pembangunan aplikasi deteksi plagiarisme. BAB II LANDASAN TEORI
Bab ini berisikan teori-teori mengenai plagiarisme, pembobotan dengan algoritma TF/IDF, metode Vector Space Model(VSM), Software, Model Perangkat Lunak. BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisikan tentang menganalisis masalah dari model penelitian untuk memperlihatkan keterkaitan antar variabel yang diteliti serta model matematis untuk analisisnya. Serta dalam bab ini akan dibahas tentang analisis sistem, analisis masalah, gambaran umum mengenai sistem yang akan dibangun, pemodelan analisis terstruktur dan desain antarmuka.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Bab ini berisikan tahapan yang dilakukan dalam penelitian secara garis besar sejak dari tahap persiapan sampai penarikan kesimpulan, metode dan kaidah yang diterapkan dalam penelitian. perancangan aplikasi untuk mengetahui keberhasilan algoritma dalam menyelesaikan aplikasi pendeteksi plagiarisme. Pengujian terhadap aplikasi deteksi plagiarisme dilakukan dengan menggunakan metode Black Box.
BAB V KESIMPULAN DAN SARAN
7
Pengertian plagiarisme menurut Kamus Besar Bahasa Indonesia (KBBI) “Plagiarisme adalah penjiplakan yang melanggar hak cipta” (dikutip dari [KBBI], 2014).
Pengertian plagiarisme dari kata dasar dan sumber lain. Plagiarisme berasal dari kata plagiat yang berarti pengambilan karangan (pendapat dan sebagainya) orang lain dan menjadikannya seolah-olah karangan (pendapat dan sebagainya) sendiri, misal menerbitkan karya tulis orang lain atas nama dirinya sendiri (KBBI, 2014). “Plagiarisme adalah bentuk penyalahgunaan hak kekayaan intelektual milik orang lain, yang mana karya tersebut dipresentasikan dan diakui secara tidak sah sebagai hasil karya pribadi” (Sulianta, 2007).
Pengertian Plagiarisme menurut para ahli. Neville mengemukakan bahwa Plagiarisme sebagai tindakan mengambil tulisan orang lain tanpa menyebutkan rujukan dan diklaim sebagai miliknya sendiri.
Pengertian Plagiarisme menurut hukum menurut pasal 1 Peraturan Mentri, plagiat adalah perbuatan secara sengaja atau tidak sengaja dalam memperoleh atau mencoba memperoleh kredit atau nilai untuk suatu karya ilmiah, dengan mengutip
sebagian atau seluruh karya dan/ atau karya ilmiah pihak lain yang diakui sebagai karya ilmiahnya, tanpa menyatakan sumber secara tepat dan memadai (Mentri
Pendidikan Nasional, 2010).
Sejalan dengan definisi yang bermacam-macam. Maka banyak orang membuat “klasifikasi” atau jenis-jenis plagiarisme dengan dasar yang berbeda. Menurut Sudigdo Sastroasmoro (2007, h.5), klasifikasi proporsi atau persentasi kata kalimat, paragraf yang dibajak dibagi menjadi beberapa klasifikasi, yaitu : a) Plagiarisme ringan : <30%
Plagiarisme mempunyai beberapa jenis, yaitu: (a) plagiarisme ide :
mengambil ide yang sudah ada tanpa menyebut sumber dengan jelas, (b)
plagiarisme isi (data penelitian) : mengambil data penelitian orang lain, (c)
plagiarisme kata, kalimat, paragraf, (d) plagiarisme total” (Herqutanto, 2013).
Ketiga jenis tindakan plagiarisme ini sering terjadi di kalangan mahasiswa. Penulis
mengambil penelitian terhadap jenis plagiarisme pada kata, kalimat, paragraf.
2.2 Preprocessing
Preprocessing merupakan tahapan awal dalam mengolah data input sebelum
memasuki proses tahapan utama. Preprocessing terdiri dari beberapa tahapan. Adapun tahapan preprocessing berdasarkan (Triawati, 2009) , yaitu: case folding, tokenizing / parsing, filtering, stemming. Berikut penjelasan empat tahapan dalam proses preprocessing adalah sebagai berikut.
2.2.1 Tokenizing
Gambar 2.1 Tokenizing
2.2.2 Filtering
Tahap filtering adalah tahap mengambil kata - kata penting dari hasil tokenizing. Proses filtering dapat menggunakan algoritma stoplist(membuang kata
yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh stopwordadalah “yang”, “dan”, “di”, “dari” dan lain – lain.(Triawati, 2009).
Gambar 2.2 Filtering
2.2.3 Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR yang
menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (prefixes), sisipan (infixes), akhiran (suffixes) dan confixes (kombinasi dari awalan dan akhiran) pada kata turunan. Stemming digunakan untuk mengganti bentuk dari suatu kata menjadi kata dasar dari kata tersebut yang sesuai dengan struktur morfologi bahasa Indonesia yang benar (Tala, 2003). Algoritma stemming untuk teks berbahasa Indonesia, diantaranya: Algoritma Porter, Algoritma Nazief & Adriani. Berdasarkan hasil penelitian yang dilakukan(Agusta, 2009).
Pada proses stemming menggunakan Algoritma Nazief & Adriani yang
membutuhkan waktu lebih lama, tetapi memiliki presentase keakuratan (presisi) lebih besar dibandingkan Algoritma Porter. Kamus yang digunakan juga sangat mempengaruhi hasil stemming. Semakin lengkap kamus yang digunakan maka semakin akurat pula hasil stemming dan perhitungan presisi.
Gambar 2.3 Stemming
2.3 Pembobotan TF-IDF
Term Frequency-Inversed Document Frequency (TF/IDF) merupakan suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Hasil
dengan menggunakan metode tf-idf adalah nilai atau bobot terhadap kata kunci yang dimasukan. TF-IDF menggambarkan dua konsep untuk perhitungan bobot yaitu, frekunsi kemunculan sebuah kata didalam dokumen tertentu dan inverse frekuensi dokumen yang mengandung kata tersebut (Robertson, 2004).
Untuk mengetahui nilai dari tf, dapat dicari dari jumlah kata pada dokumen yang mengandung kata kunci dari masukan. Dokumen yang mengandung kata kunci akan diambil kemudian akan melalui pre-processing yang akan menghasilkan kata dasar dan setiap kemunculannya akan dihitung sebagai nilai tf.
Dimana: t = kata d = dokumen
Untuk mencari nilai dari df, dapat dicari banyaknya dokumen yang mengandung kata kunci yang dimasukan. Setiap kata akan dicari keberadaannya pada dokumen, kemudian akan dihitung jumlah dokumen yang mengandung kata tersebut sebagai nilai dari df.
Perhitungan inverse document frequency (idf) menggunakan persamaan 2.2 IDFt = log (D/dft)...Persamaan 2.2
Dimana:
` t = kata ke-t dari kata kunci
df = Jumlah dokumen yang mengandung kata ke-t dari kata kunci D = Jumlah semua dokumen yang ada di dalam database
Idf = Rasio frekuensi dokumen pada kata ke-t dari kata kunci
Perhitungan term frequency-inverse document frequency (tf-idf) menggunakan persamaan 2.3
Wd,t = t fd,t * IDFt...Persamaan 2.3
Dimana:
d = dokumen ke-d
t = kata ke-t dari kata kunci
tf = frekuensi banyaknya kata ke-t dari kata kunci pada dpkumen ke-d W = bobot dokumen ke-d terhadap kata kunci ke-t
IDF = rasio frekunsi dokumen pada kata ke-t dari kata kunci
2.4 Vector Space Model
Vector Space Model (VSM) adalah metode untuk melihat tingkat kedekatan atau kesamaan (similarity) term dengan cara pembobotan term. Dokumen
dipandang sebagai sebuah vektor yang memiliki magnitude (jarak) dan direction (arah). Model ruang vektor sering digunakan untuk mempresentasikan sebuah dokumen dalam ruang vektor (Baeza, 1999).
1. Adanya peringkat pengambilan informasi
2. Menampilkan referensi yang sesuai kebutuhan
3. Penyocokan secara partial.
Pada VSM, setiap dokumen dan query dari pengguna direpresentasikan sebagai ruang vektor berdimensi n. Biasanya digunakan nilai bobot istilah (term weigthing) sebagai nilai dari vektor pada dokumen nilai 1 untuk setiap istilah yang muncul pada vektor query.
Pada model ini, bobot dari query dan dokumen dinyatakan dalam bentuk vektor, seperti: Q = (wq1, wq2, wq3, . . . ,wqt) dan Di= (wi1, wi2, wi3, . . . , wit) Dengan wqj dan wij sebagai bobot istilah Tj dalam query Q dan dokumen Di. Dengan demikian dokumen yang lebih panjang dengan jumlah istilah yang lebih banyak memiliki kemungkinan lebih besar untuk dianggap relevan dengan istilah-istilah query tertentu dibandingkan dokumen-dokumen yang lebih pendek. Sehingga pada kebanyakan lingkungan penemu-kembalian, vektor dokumen ternormalisasi lebih disukai namun proses normalisasi vektor querytidak diperlukan karena ukurannya yang umumnya pendek dan perbedaan panjang antar-query relatif kecil.
Gambar 2.4 Vector Space Model
Gambar 2.4 memperlihatkan tiga buah vektor pada ruang dimensi 3, nilai kosinus digunakan untuk mengukur tingkat kesamaan antar dua vektor. Pada Gambar 2.4, Qadalah vektor dari paragraf pembanding, sementara D1 dan D2
adalah vektor dari paragraf yang dibandingkan.
Sim (q,dj) = q.dj = Wiq.Wij
2.5 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) merupakan diagram yang menggunakan notasi
notasi atau symbol
simbol untuk mengambarkan sistem jaringan kerja antar fungsi-fungsi yang berhubungan satu sama lain dengan aliran dan penyimpanan data (Adi Nugroho, 2011).
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau
sistem baru yang akan dikembangkan secara logika tanpa mempertimba ngkan
lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan. Salah satu keuntungan menggunakan diagram aliran data adalah memudahkan pemakai (user) yang kurang menguasai bidang komputer untuk mengerti sistem yang akan dikerjakan.
DFD terdiri dari diagram konteks (context diagram) dan diagram rinci (level diagram). Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level
ada store dalam diagram konteks. Diagram rinci adalah diagram yang menguraikan proses apa yang ada dalam diagram level di atasnya.
2.6 Kamus Data
Kamus data atau data dictionary adalah katalog fakta tentang data dan kebutuhan-kebutuhan informasi dari suatu sistem informasi. Dengan kamus data analis sistem dapat mendefinisikan data yang mengalir di sistem dengan lengkap. Pada tahap analisis sistem, kamusdata digunakan sebagai alat komunikasi antara analis sitem dengan pemakai sistem tentang datayang mengalir ke sistem, yaitu
tentang data yang masuk ke sistem dan tentang informasi yang dibutuhkan oleh pemakai sistem. Pada tahap perancangan sistem, kamus data digunakan untuk merancang input, merancang laporan-laporan dan database (Jogiyanto, 2005)..
Kamus data dibuat berdasarkan arus data yang ada di Data Flow Diagram (DFD). Arus data di DFD sifatnya adalah global, hanya di tunjukkan nama arus datanya saja. Keterangan lebih lanjut tentang struktur dari suatu arus datadi DFD secara lebih terinci dapat di lihat di kamus data. DD tidak menggunakan notasi grafik sebagaimana halnya DFD. DD berfungsi membantu pelaku sistem untuk mengerti aplikasi secara detil, dan mereorganisasi semua elemen data yang digunakan dalam sistem secara presisi sehingga pemakai dan penganalisa sistem punya dasar pengertian yang sama tentang masukan, keluaran, penyimpanan dan proses. DD mendefinisikan elemen data dengan fungsi sebagai berikut:
1. Menjelaskan arti aliran data dan penyimpanan dalam DFD
2. Mendeskripsikan komposisi paket data yang bergerak melalui aliran,misalnya
alamat di uraikan menjadi kota, kodepos, propinsi, dan negara. 3. Mendeskripsikan komposisi penyimpanan data.
4. Menspesifikasikan nilai dan satuan yang relevan bagi penyimpanan dan aliran. 5. Mendeskripsikan hubungan detil antara penyimpanan yang akan menjadi titik
perhatian dalam entity relationship diagram.
2.7 ERD (Entity Relationship Diagram)
relasi. ERD untuk memodelkan struktur data dan hubungan antar data, untuk menggambarkannya digunakan beberapa notasi dan simbol (Jogiyanto, 2005). Pada dasarnya ada tiga simbol yang digunakan, yaitu :
a. Entitas
Entiti merupakan objek yang mewakili sesuatu yang nyata dan dapat dibedakan dari sesuatu yang lain. Simbol dari entiti ini biasanya digambarkan dengan persegi panjang.
b. Atribut
Setiap entitas pasti mempunyai elemen yang disebut atribut yang berfungsi untuk mendeskripsikan karakteristik dari entitas tersebut. Isi dari atribut mempunyai sesuatu yang dapat mengidentifikasikan isi elemen satu dengan yang lain. Gambar atribut diwakili oleh simbol elips.
c. Hubungan / Relasi
Hubungan antara sejumlah entitas yang berasal dari himpunan entitas yang berbeda. Relasi dapat digambarkan sebagai berikut :
Relasi yang terjadi diantara dua himpunan entitas (misalnya A dan B) dalam
satu basis data yaitu:
1). Satu ke satu (One to one)
Hubungan relasi satu ke satu yaitu setiap entitas pada himpunan entitas A berhubungan paling banyak dengan satu entitas pada himpunan entitas B. 2). Satu ke banyak (One to many)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B, tetapi setiap entitas pada entitas B dapat berhubungan dengan satu entitas pada himpunan entitas A.
3). Banyak ke banyak (Many to many)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B.
2.8 PHP (Personal Home Page)
Rasmus Lerdorf (dengan dikeluarkannya PHP versi 1) yang digunakan untuk membuat home page pribadinya. Versi pertama ini berupa kumpulan script PERL. Untuk versi keduanya, Rasmus menulis ulang script - script PERL tersebut menggunakan bahasa C, kemudian menambahkan fasilitas untuk form html dan koneksi MYSQL.
PHP merupakan bahasa script yang digunakan untuk membuat halaman web yang dinamis. Dinamis berarti halaman yang ditampilkan dibuat saat halaman itu diminta oleh client. Mekanisme ini menyebabkan informasi yang diterima client
selalu yang terbaru. Semua script PHP dieksekusi pada server di mana script tersebut di jalankan. Oleh karena itu, spesifikasi server lebih berpengaruh pada eksekusi dari script PHP daripada spesifikasi client. Namun tetap diperhatikan bahwa halaman web yang dihasilkan tentunya harus dapat dibuka oleh browser pada client. PHP masuk kedalam kategori server-side scripting dimana browser pada client tidak lagi bertanggung jawab dalam menjalankan kode- kode PHP, melainkan web server proses ini diilustrasikan kedalam gambar berikut .
Pertama-tama web browser pada client me-request sebuah file (1). Dalam kasus ini bagaimanapun juga file yang di-request berekstensi/berakhiran .php (contoh: File.php), tanda bahwa didalam file tersebut terkandung kode-kode PHP yang perlu diproses oleh server. Web server mengenali file ini dan tidak mengirim file tersebut langsung ke browser, tetapi dikirim ke PHP scripting engine (2) (mesin pengolah kode-kode PHP). PHP engine merupakan komponen perangkat lunak dari server yang mampu mengartikan kode-kode PHP dan memberikan output dalam kode HTML. Setiap kode PHP dapat memberikan output kode HTML yang berbeda, tergantung pada jenis request dari client (browser). Proses tersebut membangkitkan halaman HTML secara dinamis lalu dikirimkan kembali ke client (browser) untuk merespon terhadap request yang sebelumnya telah dikirimkan.
2.9 HTML (Hyper Text Markup Language)
HyperText Markup Language, sering disebut sebagai HTML, merupakan standar bahasa markup yang digunakan untuk membuat halaman web. Web browser dapat membaca file HTML dan membuat mereka ke dalam halaman web terlihat atau terdengar. HTML menggambarkan struktur dari situs semantik bersama dengan isyarat untuk presentasi, membuatnya menjadi bahasa markup, daripada bahasa pemrograman.
Elemen HTML membentuk blok bangunan dari semua website. HTML
memungkinkan gambar dan objek yang akan tertanam dan dapat digunakan untuk membuat bentuk-bentuk interaktif. Menyediakan sarana untuk membuat dokumen terstruktur oleh struktural menunjukkan semantik untuk teks seperti judul, paragraf, daftar, link, kutipan dan item lainnya.
Bahasa ini ditulis dalam bentuk elemen HTML terdiri dari tag diapit kurung sudut (seperti <html>). Browser tidak menampilkan tag HTML dan script, tetapi menggunakannya untuk menafsirkan isi halaman.
HTML dapat menanamkan script yang ditulis dalam bahasa seperti JavaScript yang mempengaruhi perilaku halaman web HTML. Web browser juga dapat merujuk ke Cascading Style Sheets (CSS) untuk menentukan tampilan dan tata letak teks dan bahan lainnya. The World Wide Web Consortium (W3C), pengelola dari kedua HTML dan CSS standar, mendorong penggunaan CSS lebih eksplisit HTML presentasi sejak tahun 1997.
2.10 MySQL
MySQL adalah Relational Database Managemen System (RDBMS) yang didistribusikan secara gratis di bawah lisensi GPL (General Public Licence). Dimana setiap orang bebas untuk menggunakannya, tapi tidak boleh dijadikan produk turunan yang bersifat Closed Source atau komersial.
MySQL sebenarnya merupakan turunan salah satu konsep utama dalam database sejak lama, yaitu SQL (Structur Query Language). SQL adalah sebuah
pemasukan data, yang memungkinkan pengoperasian data dikerjakan dengan mudah secara otomatis.
19
BAB 3
ANALISIS DAN PERANCANGAN
3.1 Analisis Masalah
Permasalahan yang terjadi pada penelitian ini yaitu mengetahui tingkat kemiripan dokumen untuk menangani masalah plagiarisme setiap informasi yang didapatkan oleh pengguna bisa menjadi bentuk dari plagiat dikarenakan adanya perlakuan copy-paste dari suatu dokumen tanpa mencantumkan sumber dari kutipan yang diambil tersebut.
Pembangunan sistem ini diperlukan untuk menangani plagiarisme dengan ketentuan file yang sudah terintegrasi sebelumnya. Sistem ini dapat mengolah dokumen dengan tahap awal preprocessing, perhitungan TF-IDF, dan perhitungan vsm. Keluaran dari sistem ini memberikan informasi berupa persentase plagiarisme pada dokumen.
3.2 Analisis Sistem
Analisis sistem digunakan dengan tujuan untuk mengidentifikasi dan mengevaluasi seluruh komponen yang terkait dengan sistem yang dibangun. Sistem ini memiliki tahap proses di mulai dengan input dokumen, preprocessing hingga perhitungan similaritas, dan output berupa hasil persentase plagiarisme.
3.2.1 Analisis Metode
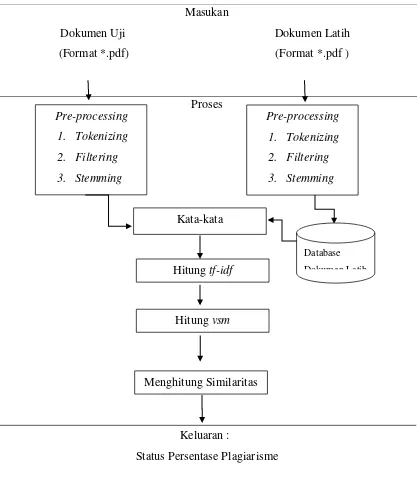
Pada sistem yang akan dibangun terdapat 3 tahapan yang akan dilakukan yaitu masukan, proses yang dilakukan oleh sistem, dan yang terakhir yaitu keluaran yang dihasilkan oleh sistem. berikut merupakan penjelasan dari masing-masing tahapan:
Masukan
Dokumen Uji Dokumen Latih
(Format *.pdf) (Format *.pdf )
Proses
Keluaran :
Status Persentase Plagiarisme
Gambar 3.1 Gambaran Umum Sistem Pre-processing
1. Tokenizing
2. Filtering
3. Stemming Pre-processing
1. Tokenizing
2. Filtering
3. Stemming
Hitung tf-idf
Menghitung Similaritas Kata-kata
Hitung vsm
Database
3.2.2 Analisis Masukan
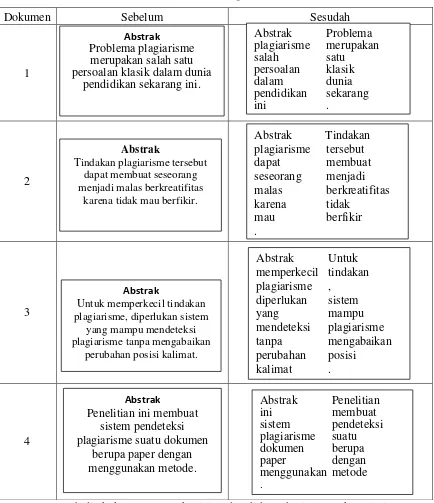
Masukan dalam aplikasi pendeteksi plagiarisme disini menjelaskan tentang data yang digunakan. Masukan yang digunakan yaitu berupa dokumen teks Bahasa Indonesia dengan format *.pdf dimana file dalam bentuk tersebut akan diubah menjadi file .txt yang berisi teks dan sudah terintegrasi, nantinya teks tersebut dipecah menjadi kata-kata untuk menjadi pembanding dengan teks lainnya yang sudah tersimpan didalam sistem. Contoh dokumen masukan.
Abstrak
Problema plagiarisme merupakan salah satu persoalan klasik dalam dunia pendidikan sekarang ini karena seorang bisa dengan mudah mendapatkan
informasi secara mudah. Tindakan plagiarisme tersebut dapat membuat seseorang menjadi malas berkreatifitas karena tidak mau berfikir.
3.2.3 Proses
Pada tahap ini dokumen yang dimasukkan oleh pengguna mengalami
beberapa tahap proses. Tahap pertama yaitu preprocessing, menghitung bobot dengan tf-idf, dan metode Vector Space Model, dan yang terakhir yaitu menghitung
nilai similarity.
3.2.3.1 Preprocessing
Tahapan preprocessing adalah proses untuk mendapatkan pengetahuan dari data, dalam tahap preprocessing pengetahuan tersebut berarti diambil dari dokumen dengan mencari keterkaitan kata-kata yang terdapat pada isi setiap dokumen, tujuannya adalah untuk menganalisa informasi setiap kata yang saling berhubungan pada sebuah dokumen. Proses temu informasi pada preprocessing pada setiap dokumen melalui tahapan tokenizing, filtering, dan stemming.
3.2.3.1.1 Tokenizing
Tabel 3.1 Tabel Tokenizing Dokumen Latih
Dokumen Sebelum Sesudah
1
2
3
4
Setelah dilakukan proses Tokenizing dan didapat hasilnya maka selanjutnya akan masuk pada tahap Filtering.
3.2.3.1.2 Filtering
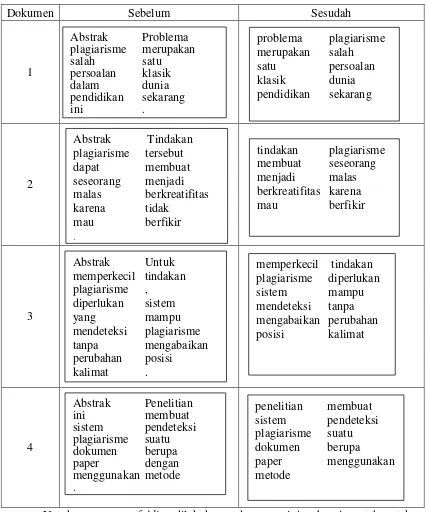
Pada tahap filtering berfungsi untuk menghilangkan tanda baca, angka, serta menghilangkan kata-kata yang tidak penting seperti: abstrak, ada, yang, ke, dengan, kepada, oleh, dll. Lebih lengkapnya dapat dilihat pada tabel 3.2 berikut.
Abstrak
Problema plagiarisme merupakan salah satu persoalan klasik dalam dunia
pendidikan sekarang ini.
Abstrak Problema plagiarisme merupakan
karena tidak mau berfikir.
Tabel 3.2 Tabel Filtering Dokumen Latih
Dokumen Sebelum Sesudah
1
2
3
4
Untuk proses case folding dilakukan pada proses ini, sebagai contoh untuk kata ”Sering” dengan huruf kapital diubah menjadi “sering”. Setelah dilakukan proses Filtering dan didapat hasilnya maka selanjutnya akan masuk pada tahap Stemming.
memperkecil tindakan plagiarisme diperlukan
3.2.3.1.3 Stemming
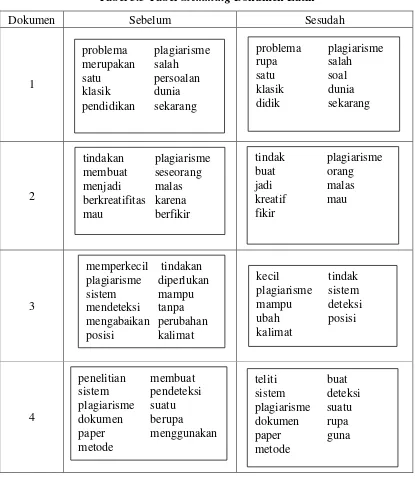
Tahap stemming berfungsi untuk menghilangkan semua imbuhan, baik imbuhan yang berada diawal, diakhir, atau berada diawal dan diakhir. Lebih lengkapnya dapat dilihat pada tabel 3.3 berikut.
Tabel 3.3 Tabel Stemming Dokumen Latih
Dokumen Sebelum Sesudah
1
2
3
4
Setelah dilakukan proses Stemming maka didapatkan kata-kata dari masing-masing dokumen latih.
3.2.3.1.4 Tokenizing Dokumen Uji
Pada tahap tokenizing dokumen Uji ini menghilangkan spasi pada dokumen, atau memisahkan sebuah kalimat menjadi token-token. Sebuah kalimat dipisahkan dan dibuat menjadi bagian-bagian kata yang dapat dilihat pada tabel 3.4 berikut.
Tabel 3.4 Proses Tokenizing Dokumen Uji
Sebelum Sesudah
3.2.3.1.5 Filtering Dokumen Uji
Pada tahap filtering dokumen Uji ini, menghilangkan tanda baca “,”, menghilangkan kata “pada” dan kata “di” karena termasuk kata yang tidak penting. Untuk proses case folding dilakukan pada proses ini, sebagai contoh untuk huruf “M” pada kata “Mendeteksi” diubah menjadi huruf kecil.
Tabel 3.5 Proses Filtering Dokumen Uji
Sebelum Sesudah
3.2.3.1.6 Stemming Dokumen Uji
Pada tahap stemming dokumen uji ini kata “mendeteksi” dihilangkan imbuhannya sehingga menjadi kata “deteksi”, kata “dilakukan” menjadi “laku”, dan kata “berbagai” menjadi “bagai”.
Tabel 3.6 Proses Stemming Dokumen Uji
Sebelum Sesudah
3.2.3.2 Proses Perhitungan Term Frequency-Inverse Document Frequency (TF-IDF)
Dari tabel 3.3 didapat kata-kata dari hasil stemming dokumen latih dan tabel 3.6 didapat kata-kata dari hasil stemming dokumen uji, kemudian kata-kata tersebut diambil dan dihitung bobot setiap katanya menggunakan tf-idf . Tahap perhitungan tf-idf yaitu sebagai berikut.
a) Menghitung nilai IDF dari query:
D = jumlah data latih yang terdapat dalam database, DF = jumlah query
D = 4 DF = 2
Maka nilai IDF dari query berdasarkan persamaan 2.2 adalah:
��� = ����� → ��� = ��� = ,�
b) Menghitung nilai TF-IDF dari query berdasarkan persamaan 2.3 adalah:
Wi = nilai perkalian dari Tf dan Idf setiap dokumen
W1 = 0 x 0,3010 = 0 W3 = 0 x 0,3010 = 0
W2 = 1 x 0,3010 = 0,3010 W4 = 1 x 0,3010 = 0,3010
Tabel 3.7 Perhitungan TF-IDF
3.2.3.3 Proses Perhitungan Vector Space Model (VSM)
Dari tabel 3.7 didapatkan bobot tf-idf dari masing-masing dokumen, maka dapat dilanjutkan dengan menghitung menggunakan metode vector space model (vsm). Tahap perhitungan metode vsm yaitu sebagai berikut.
a) Menghitung nilai panjang vektordari query sebagai berikut.
Nilai dari |Q| merupakan hasil dari penjumlahan seluruh query lalu diakarkan.
|Q| = √∑ � �,�
=√ + + + + = √ = 2,24
Nilai dari Wi2 merupakan hasil dari pembobotan yang dikuadratkan
W12 = 0
W22 = 0,0906
W32 = 0
W42 = 0,0906
b) Menghitung nilai vector space model dari query berdasarkan persamaan
2.4 adalah:
Q x W1 = 0
Q x W2 = 0,0906
Q x W3 = 0
Q x W4 = 0,0906
Tabel 3.8 Perhitungan Vector Space Model
N
O Kata-kata Q(Wiq)
TF-IDF VECTOR SPACE MODEL
3.2.3.4 Proses Perhitungan Cosine Similarity
Selanjutnya menghitung nilai kemiripan similarity dengan menggunakan nilai cosine antara vector kata kunci pada setiap dokumen berdasarkan persamaan 2.4 sebagai berikut.
1. Dokumen Latih ke-1
Q.W1 = jumlah nilai perkalian antara query dengan bobot dokumen 1
|Q| = nilai akar dari jumlah query , |W1| = nilai akar dari jumlah bobot dokumen 1
Similaritas (Q,W1)= �.�
|�|.|� |
=
, × ,
=
,
= 0
2. Dokumen Latih ke-2
Q.W2 = jumlah nilai perkalian antara query dengan bobot dokumen 2
|Q| = nilai akar dari jumlah query , |W2| = nilai akar dari jumlah bobot dokumen 2
Similaritas(Q,W2)= �.�
|�|.|� |
= ,
, × ,
= ,
,
3. Dokumen Latih ke-3
Q.W3 = jumlah nilai perkalian antara query dengan bobot dokumen 3 |Q| = nilai akar dari jumlah query , |W3| = nilai akar dari jumlah bobot dokumen 3
Similaritas (Q,W3)= �.�
|�|.|� |
= ,
, × ,
= ,
,
= 0,1405
4. Dokumen Latih ke-4
Q.W4 = jumlah nilai perkalian antara query dengan bobot dokumen 4 |Q| = nilai akar dari jumlah query , |W4| = nilai akar dari jumlah bobot dokumen 4
Similaritas (Q,W4)= �.�
|�|.|� |
= ,
, × ,
= ,
,
3.2.4 Keluaran
Keluaran dalam aplikasi pendeteksi plagiarisme ini berupa status persentase plagiarisme. Sesuai perhitungan di atas maka nilai cosinus setiap dokumen telah didapat, seperti tabel di bawah ini.
Tabel 3.9 Tabel Perhitungan Similarity
D1 D2 D3 D4
Similaritas x 100 %
Nilai
Setelah diurutkan menjadi:
D4 D3 D2 D1
Similaritas x 100 % Nilai
Berdasarkan hasil perhitungan vector space model dan nilai similarity diatas dapat diketahui bahwa solusi yang terdapat pada D4 memiliki tingkat similaritas tertinggi terhadap dokumen uji (DU) yaitu 19,62%, disusul dengan D3 yaitu 14,05%, dan D2 yaitu 2,59%.
3.3 Analisis Pengguna
Tabel 3.10 Deskripsi Pengguna
No Aktor Deskripsi
1 User(Pengguna) Merupakan aktor yang berperan melakukan input dokumen dalam bentuk *.pdf dan melihat hasil persentase similaritas dokumen, dan serta melakukan pengelolaan data pelatihan dan stopword.
3.4 Perancangan Sistem
Perancangan sistem ini bertujuan untuk menggambarkan bagaimana sistem yang akan dibangun sebagai bentuk penyempurnaan dari sistem yang sedang berjalan, maka dibangunlah aplikasi plagiarisme yang dapat membantu pengguna dalam mencari solusi yang tepat. Tahapan pemodelan untuk pembuatan sistem pada penelitian ini menggunakan diagram perancangan yang terdapat pada Pemodelan Analisis Terstruktur.
3.4.1 Entity Relationship Diagram (ERD)
ERD merupakan suatu model untuk menjelaskan hubungan antar data dalam basis data berdasarkan objek-objek dasar data yang mempunyai hubungan antar relasi. ERD untuk memodelkan struktur data dan hubungan antar data, untuk menggambarkannya digunakan beberapa notasi dan simbol.
3.4.2 Diagram Konteks
Diagram yang terdiri dari suatu proses saja dan biasa diberi nomor proses 0. Proses ini mewakili dari dari seluruh sistem. Diagram konteks menggambarkan input atau output suatu sistem dengan dunia luar atau dunia kesatuan luar. Proses yang terjadi dalam aplikasi pendeteksian plagiarisme ini dapat dilihat pada gambar berikut.
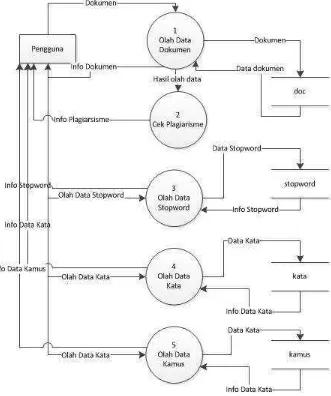
Gambar 3.3 Diagram Konteks
3.4.3 Data Flow Diagram (DFD)
3.4.3.1 DFD level 1 Pengolahan Data
3.4.3.2 DFD level 2 Proses
Gambar 3.5 DFD level 2
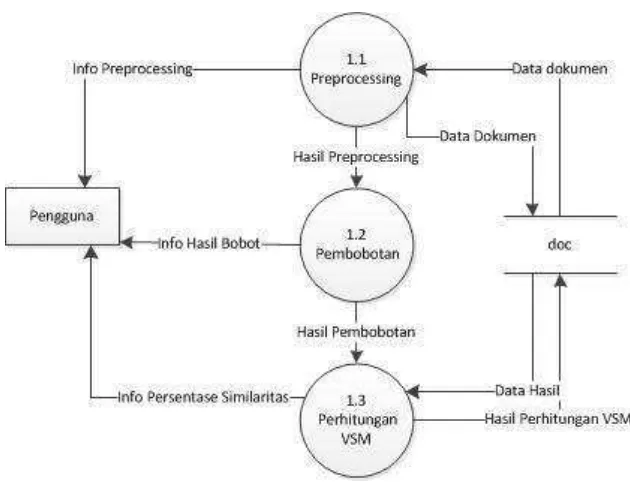
3.4.3.3 DFD level 3 Preprocessing Dokumen
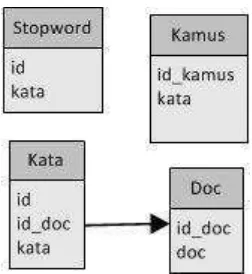
3.4.4 Kamus Data
Kamus data merupakan Katalog Fakta tentang data dan kebutuhan informasi dari suatu sistem dengan mendefinisikan data yang mengalir pada sistem secara lengkap. Dan berikut merupakan kamus data dari data yang mengalir pada sistem.
3.4.4.1 Kamus Data Data Dokumen
Tabel 3.11 Kamus Data Data Dokumen Nama Arus Data Data Dokumen
Alias -
Bentuk Data Dokumen
Arus Data Proses 1
Penjelasan Data Dokumen diinputkan kedalam aplikasi
Periode Setiap ada inputan
Volume volume rata-rata adalah 1 dan volume puncak adalah 2
Struktur Data Id_doc = [0-9]
Doc = [A-Z | a-z | 0-9]
3.4.4.2 Kamus Data Data Stopword
Tabel 3.12 Kamus Data Data Dokumen
Nama Arus Data Data Stopword
Alias -
Bentuk Data Label
Arus Data Proses 4
Penjelasan Admin memasukkan kata tambahan pada stopword
Periode Saat login aplikasi dan mengolah stopword
Volume Volume rata-rata adalah 1 dan volume puncak adalah 2
Struktur Data Id = [0-9]
3.4.4.3 Kamus Data Data Kata
Tabel 3.13 Kamus Data Data Kata Nama Arus Data Data Kata
Alias -
Bentuk Data Kata
Arus Data Proses 6
Penjelasan Kata kunci yang terdapat pada dokumen uji
Periode Saat login admin dari aplikasi
Volume Volume rata-rata adalah 1 dan volume puncak adalah 2
Struktur Data Id = [0-9] Id_doc = [0-9] Kata = [A-Z | a-z]
3.4.5 Spesifikasi Proses
Spesifikasi proses merupakan gambaran deskripsi dan spesifikasi dari setiap proses pada pemodelan DFD sesuai kebutuhan sistem.
Tabel 3.14 Spesifikasi Proses
No Proses Keterangan
1
No. Proses 1
Nama Proses Olah Data Dokumen
Sumber -
Masukan Data Dokumen
Keluaran Info Dokumen
Tujuan Pengguna
Logika Proses Begin
- Pengguna memasukkan dokumen. - Jika data valid maka data akan proses.
-Menampilkan info persentase plagiat dokumen, info tabel perhitungan.
No Proses Keterangan
2
No. Proses 2
Nama Proses Cek Plagiarisme
Sumber -
Masukan Hasil olah data
Keluaran Info plagiarisme
Tujuan Pengguna
Logika Proses Begin
- Sistem mengambil hasil olah data dokumen. - Jika data valid, data akan diproses.
- Menampilkan info plagiarisme. End.
No Proses Keterangan
3
No. Proses 3
Nama Proses Olah Data Stopword
Sumber -
Masukan Data Stopword
Keluaran Info Data Stopword
Tujuan Pengguna
Logika Proses Begin
- Sistem menampilkan fitur Halaman depan. - Pengguna memilih fitur stopword.
- Masukan data yang sesuai. - Data disimpan dalam data store. - Menampilkan info data stopword.
End.
No Proses Keterangan
4
No. Proses 4
Input Data Kata
Output Info Data Kata
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem menampilkan fitur Halaman depan. - Pengguna memilih fitur Pelatihan.
- Masukan dokumen yang sudah terintegrasi. - Jika valid maka sistem akan menyimpan data
dalam data store
- Menampilkan info data kata. End.
No Proses Keterangan
5
No. Proses 5
Nama Proses Olah Data Kamus
Sumber -
Masukan Data Kamus
Keluaran Info Data Kamus
Tujuan Pengguna
Logika Proses Begin
- Sistem menampilkan fitur Halaman depan. - Pengguna memilih fitur kamus.
- Masukan data yang sesuai. - Data disimpan dalam data store. - Menampilkan info data kamus.
End.
No Proses Keterangan
6
No. Proses 1.1
Nama Proses Preprocessing Source (Sumber) Olah Data Dokumen
Output Info Preprocessing
Destination (Tujuan) Pengguna Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
- Melakukan proses preprocessing dengan tahapan tokenizing, filtering, dan stemming. - Jika data valid maka data disimpan dalam data store.
- Menghasilkan info data preprocessing. End.
No Proses Keterangan
7
No. Proses 1.2
Nama Proses Pembobotan
Source (Sumber) Olah Data Dokumen
Input Hasil dari preprocessing
Output Info Hasil Bobot
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
- Melakukan proses dari hasil preprocessing.
- Sistem melakukan perhitungan bobot.
- Jika data valid maka data disimpan dalam data store.
- Menghasilkan info data bobot. End.
No Proses Keterangan
8 No. Proses 1.3
Source (Sumber) Olah Data Dokumen
Input Hasil dari pembobotan
Output Info persentase similaritas
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
- Melakukan proses dari hasil bobot.
- Sistem melakukan perhitungan vector space model (vsm).
- Jika data valid maka data akan disimpan dalam data store.
-Menghasilkan info data persentase plagiarisme. End.
No Proses Keterangan
9
No. Proses 1.1.1
Nama Proses Tokenizing
Source (Sumber) Preprocessing
Input Data Dokumen
Output Info Tokenizing
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
-Melakukan proses tokenizing, membuat kalimat-kalimat menjadi token-token.
- Menghasilkan info data tokenizing.
End.
No Proses Keterangan
Nama Proses Filtering
Source (Sumber) Preprocessing Input Hasil dari tokenizing
Output Info Hasil Filtering
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
-Melakukan proses filtering dengan menghilangkan stopword.
- Menghasilkan info data filtering. End.
No Proses Keterangan
11
No. Proses 1.1.3
Nama Proses Stemming
Source (Sumber) Preprocessing
Input Hasil dari filtering
Output Kata-kata
Destination (Tujuan) Pengguna
Logika Proses Begin
- Sistem mengolah data dokumen yang sudah dimasukkan sebelumnya.
- Melakukan proses stemming dengan membuat kata-kata yang ada menjadi kata dasar.
- Menghasilkan info data stemming. End.
3.4.6 Perancangan Basis Data
Gambar 3.7 Perancangan Basis Data
3.4.7 Perancangan Struktur Menu
Struktur menu adalah bentuk umum dari suatu rancangan sistem untuk memudahkan pemakai dalam menjalankan sistem. Sehingga saat menjalankan sistem, pengguna tidak mengalami kesulitan dalam memilih menu yang diinginkan. Pada perancangan perangkat lunak ini dibuat menu seperti dibawah ini.
Gambar 3.8 Struktur Menu
3.4.8 Perancangan Antarmuka Sistem
Tahap perancangan antarmuka dilakukan untuk merancang antarmuka agar dapat digunakan oleh pengguna. Berikut ini adalah tampilan antarmuka yang
3.4.8.1 Tampilan Halaman Utama
Gambar 3.9 Antarmuka Halaman Utama
3.4.8.2 Tampilan Halaman Stopword
3.4.8.3 Tampilan Halaman Tabel Proses
Gambar 3.11 Antarmuka Halaman Tabel Proses
3.4.8.4 Tampilan Halaman Input Data Pelatihan
3.4.9 Perancangan Semantik
Jaringan Semantik merupakan gambaran pengetahuan grafis yang menunjukkan hubungan antar berbagai objek. Jaringan semantik terdiri dari lingkaran-lingkaran yang menunjukkan objek dan informasi tentang objek-objek tertentu. Jaringan semantik untuk sistem klasifikasi ini adalah sebagai berikut.
T01
T03 T02
T04
T05
Gambar 3.13 Jaringan Semantik Keterangan:
T01: Antarmuka Halaman Utama T02: Antarmuka Stopword T03: Antarmuka Pelatihan T04: Antarmuka Perhitungan T05: Antarmuka Kamus
3.4.10 Perancangan Prosedural
Perancangan prosedural adalah tata cara atau urutan langkah-langkah untuk
melakukan suatu proses. Prosedural ini dugunakan sebagai algoritma dasar dalam mengkodekan prosedur yang ada. Alat yang digunakan adalah flowchart. Membuat
3.4.10.1Prosedur Preprocessing
Pada prosedur ini dilakukan proses preprocessing dimana tahapan tersebut dilakukan oleh sistem sebelum masuk pada tahap proses utama.
3.4.10.2 Prosedur Perhitungan TF-IDF
Pada prosedur ini dilakukan proses perhitungan TF-IDF dimana tahapan tersebut dilakukan oleh sistem setelah melakukan proses preprocessing.
Gambar 3.15 Flowchart Perhitungan Bobot
3.4.10.3 Prosedur Perhitungan VSM
Pada prosedur ini dilakukan proses perhitungan vsm dimana tahapan tersebut dilakukan oleh sistem setelah melakukan proses perhitungan TF-IDF.
3.4.10.4Prosedur Tokenizing
Pada prosedur ini dilakukan proses tokenizing dimana dalam proses ini dokumen dibuat menjadi token-token, tahapan tersebut dilakukan oleh sistem dan terjadi dalam proses preprocessing.
Gambar 3.17 Flowchart Tokenizing
3.4.10.5Prosedur Filtering
Gambar 3.18 Flowchart Filtering
3.4.10.6 Prosedur Stemming
Pada prosedur ini dilakukan proses tokenizing dimana dalam proses ini didapat kata-kata kuncinya, tahapan tersebut dilakukan oleh sistem dan terjadi dalam proses preprocessing.
53
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Implementasi
Implementasi merupakan tahap menerjemahkan perancangan berdasarkan hasil analisis. Implementasi Aplikasi Pendeteksi Plagiarisme berbasis Web dilakukan dengan menggunakan PHP, HTML, Javascript, framework Codeignitier, dan MySQL.
Implementasi Perangkat Keras
Perangkat keras yang digunakan untuk mengimplementasikan sistem ini dijelaskan pada tabel 4.1.
Tabel 4.1 Perangkat Keras yang digunakan
No. Perangkat Keras
Spesifikasi Minimum
Eksistensi Keterangan
1 Processor Intel Pentium Intel Core 2 duo Memenuhi
2 RAM 512 MB 1 GB Memenuhi
3 Hardisk 40 GB 128 GB Memenuhi
Implementasi Perangkat Lunak
Perangkat Lunak yang digunakan dalam mengimplementasikan sistem ini dijelaskan pada tabel 4.2.
Tabel 4.2 Perangkat Lunak yang digunakan
No. Perangkat Lunak Keterangan
1 Windows 7 Sistem Operasi
2 XAMPP/WAMP Web Server
3 MySQL DBMS
4 Mozilla Firefox, Google Chrome, Internet Explorer Web Browser
Implementasi Basis Data (Sintak SQL)
1 Nama Basis Data : ta_plagiarisme
2 Tabel User
Tabel 4.3 Tabel User
CREATE TABLE `tb_user` (
`id_user` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(30) NOT NULL,
`password` varchar(30) NOT NULL,
`level` enum('Administrator','Pengguna') NOT NULL, PRIMARY KEY (`id_user`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1
3 Tabel Stopword
Tabel 4.4 Tabel Stopword
CREATE TABLE `stopword` (
`id` int(11) NOT NULL AUTO_INCREMENT, `kata` varchar(30) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1310 DEFAULT CHARSET=latin1
4 Tabel Doc
Tabel 4.5 Tabel Doc
CREATE TABLE `doc` (
`id_doc` int(11) NOT NULL AUTO_INCREMENT,
`doc` varchar(1000) NOT NULL, PRIMARY KEY (`id_doc`)
5 Tabel Kata
CREATE TABLE `kata` (
`id` int(11) NOT NULL AUTO_INCREMENT, `id_doc` int(11) NOT NULL,
`kata` varchar(50) NOT NULL, PRIMARY KEY (`id`),
KEY `id_doc` (`id_doc`),
CONSTRAINT `kata_ibfk_1` FOREIGN KEY (`id_doc`) REFERENCES `doc` (`id_doc`) ) ENGINE=InnoDB AUTO_INCREMENT=1191 DEFAULT CHARSET=latin1
6 Tabel Kamus
CREATE TABLE `kamus` (
`id_kamus` int(11) NOT NULL AUTO_INCREMENT, `makna` varchar(30) NOT NULL,
`kata` varchar(30) NOT NULL, PRIMARY KEY (`id_kamus`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=latin1
Implementasi Antarmuka
Halaman Utama
Implementasi halaman utama pada pengguna Aplikasi dapat dilihat pada gambar di bawah ini.
Gambar 4.1 Halaman Utama
Halaman Stopword
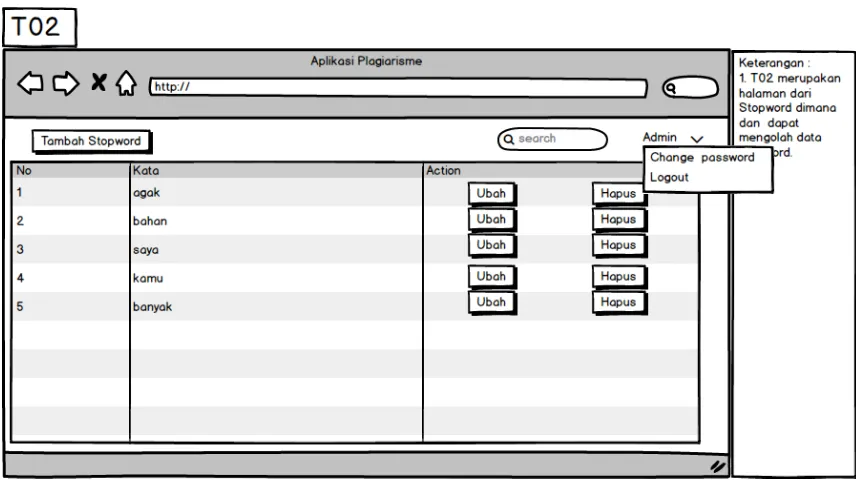
Implementasi halaman pengolahan stopword dapat dilihat pada gambar di bawah ini.
Gambar 4.2 Halaman Stopword
Pada Halaman Stopword, Admin bisa melakukan pengolahan data yang ada pada stopword.
Halaman Tabel Proses
Gambar 4.3 Halaman Tabel Proses
Pada Halaman Tabel Proses, Pengguna Aplikasi bisa melihat pemrosesan yang dilakukan sistem terhadap dokumen yang telah diinputkan.
Halaman Data Pelatihan
Gambar 4.4 Halaman Pelatihan
Halaman Kamus Dasar
Implementasi halaman data pelatihan dapat dilihat pada gambar di bawah ini.
Pengujian
Pengujian merupakan tahapan penting dalam pembangunan perangkat lunak. Pengujian dilakukan untuk mengetahui kelayakan suatu perangkat lunak sehingga perangkat lunak tersebut dapat berjalan sesuai dengan yang diharapkan dan
4.2.1 Rencana Pengujian
Dalam melakukan rencana pengujian pembangunan aplikasi ini menggunakan metode black box. Pengujian black box berfokus pada persyaratan fungsional perangkat lunak yang dibuat. Daftar pengujian yang dilakukan dapat dilihat pada tabel berikut.
Daftar Pengujian
Item Uji Detail Pengujian Jenis Pengujian
Dokumen Input data dokumen
Black box
Dokumen Latih Input data latih
Selain itu dilakukan pula pengujian terhadap tingkat similaritas antar dokumen. Pengujian similarity dan waktu ekseskusi ialah membandingkan hasil persentase similarity dan lama waktu antara sistem dengan stemming. Dokumen latih merupakan dokumen uji yang telah diberikan delapan perlakuan yaitu : 100% sama, 80% sama, 60% sama, 40% sama, 20 % sama, tukar 20%, tukar 60%, dan ubah 10%. Perlakuan tersebut merupakan pemotongan kata sebesar persentase yang disebutkan terhadap dokumen uji. Daftar pengujian yang dilakukan dapat dilihat sebagai berikut.
1. 100% sama artinya tidak mengubah sedikitpun kata yang ada dalam
2. 80% sama artinya memiliki kemiripan dengan melakukan
pemotongan dari dokumen asli secara random.
3. 60% sama artinya memiliki kemiripan dengan melakukan
pemotongan dari dokumen asli secara random.
80%
4. 40% sama artinya memiliki kemiripan dengan melakukan
pemotongan dari dokumen asli secara random.
5. 20% sama artinya memiliki kemiripan dengan melakukan
pemotongan dari dokumen asli secara random.
40% 60%
40%
6. Tukar 20% artinya dengan melakukan penukaran posisi kata dari
dokumen asli secara random.
7. Tukar 60% artinya dengan melakukan penukaran posisi kata secara random.
Menukar posisi kata yang sebelumnya berada dibawah
Menukar posisi kata yang sebelumnya berada diatas
20%
8. Ubah 10% artinya dengan melakukan ubah kata secara random.
4.2.2 Kasus dan Hasil Pengujian
Kasus dan hasil pengujian dibuat untuk mengetahui apakah Aplikasi Pendeteksi Plagiarisme dapat berjalan dengan baik atau tidak. Berdasarkan rencana pengujian, maka dapat dilakukan pengujian adalah sebagai berikut:
4.2.2.1Pengujian Proses Dokumen
Dalam pengujian ini dilakukan pengujian terhadap inputan file dokumen yang dimasukkan ke dalam aplikasi.
Menukar posisi kata yang sebelumnya berada diatas menjadi ke bawah dan sebaliknya
Tabel 4.6 Pengujian Dokumen Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- klik tombol
4.2.2.2Pengujian Proses Pengolahan Data Stopword
Dalam pengujian ini dilakukan pengujian terhadap halaman stopword dimana pengguna akan melakukan pengolahan data di dalamnya.
Tabel 4.7 Pengujian Tambah Data Stopword Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- Kata : saya Data tersebut di
Tabel 4.8 Pengujian Ubah Data Stopword Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- Memilih data
Data masukkan Yang diharapkan Pengamatan Kesimpulan
4.2.2.3Pengujian Proses Pengolahan Data Stopword
Dalam pengujian ini dilakukan pengujian terhadap halaman kamus dasar dimana pengguna akan melakukan pengolahan data di dalamnya.
Tabel 4.10 Pengujian Tambah Data Kamus Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- Kata : saya Data tersebut di
Tabel 4.11 Pengujian Ubah Data Kamus Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- Memilih data
Tabel 4.12 Pengujian Hapus Data Kamus Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
4.2.2.4Pengujian Proses Dokumen Latih
Dalam pengujian ini dilakukan pengujian terhadap halaman inputan dokumen latih dimana pengguna akan melakukan pengolahan data di dalamnya.
Tabel 4.13 Pengujian Data Latih Kasus dan hasil uji ( data benar )
Data masukkan Yang diharapkan Pengamatan Kesimpulan
- klik tombol
4.2.3 Kesimpulan Hasil Pengujian Black Box
Berdasarkan hasil pengujian dengan kasus uji di atas, dapat ditarik kesimpulan bahwa perangkat lunak bebas dari kesalahan sintaks dan secara
fungsional mengeluarkan hasil yang sesuai dengan yang diharapkan.
4.2.4 Pengujian Penghitungan Tingkat Similaritas
Pada pengujian tingkat similaritas akan dihitung nilai similaritas dari dokumen yang diupload oleh dokumen secara lengkap dapat dilihat pada halaman lampiran A-1. Dari dokumen tersebut dapat diambil hasil sebagai berikut. pengguna dan nantinya akan dibandingkan dengan dokumen latih yang ada dalam database. Setelah hasil similarity didapatkan selanjutnya akan diurutkan berdasarkan tingkat similaritas dokumen dari yang terbesar ke terkecil. Daftar dari
- Total Dokumen : 3
Dokumen Uji : jurnal_13423.pdf
a. Dokumen Latih 1 : 21tudesmanJurnal1.pdf b. Dokumen Latih 2 : DR00098201306_FIN_(1).pdf c. Dokumen Latih 3 : SNETE-2013.pdf
- Nilai Persentase Similarity = (Similaritas x 100 %) - Nilai Persentase Similarity :
a. Dokumen Latih 1 : 0,156 x 100 % = 15,6 % b. Dokumen Latih 2 : 0,146 x 100 % = 14,6 % c. Dokumen Latih 3 : 0,152 x 100 % = 15,2 %
Setelah dilakukan pengujian, nilai similaritas yang mendekati dengan dokumen uji adalah sokumen latih 1 sebesar 15,6 %.
4.2.5 Hasil Pengujian Similarity dan Waktu Eksekusi
Hasil pengujian dibawah ini adalah hasil yang sudah dilakukan dengan melakukan tahapan seperti pada rencana pengujian tingkat similaritas.
Tabel 4.14 Hasil Pengujian Similarity dan Waktu Eksekusi
Dokumen Rata-rata Persentase Similarity (%)