SISTEM PERINGKAS BERITA ONLINE OTOMATIS
MENGGUNAKAN ALGORITMA TEXTTEASER
SKRIPSI
ANWAR PASARIBU 111402008
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
SISTEM PERINGKAS BERITA ONLINE OTOMATIS MENGGUNAKAN ALGORITMA TEXTTEASER
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
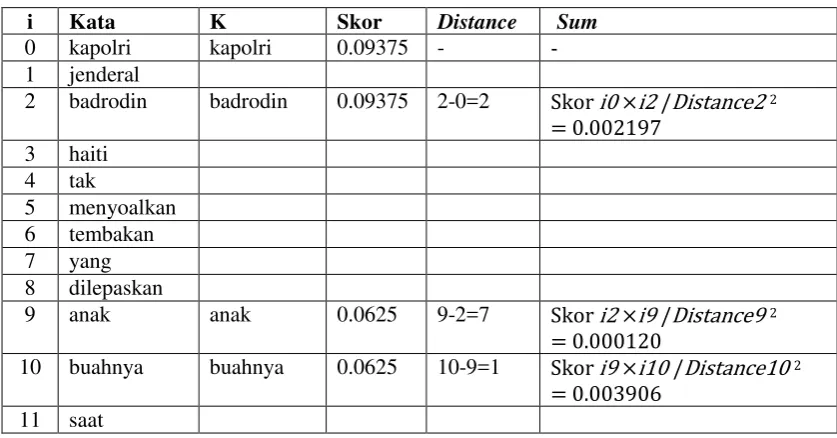
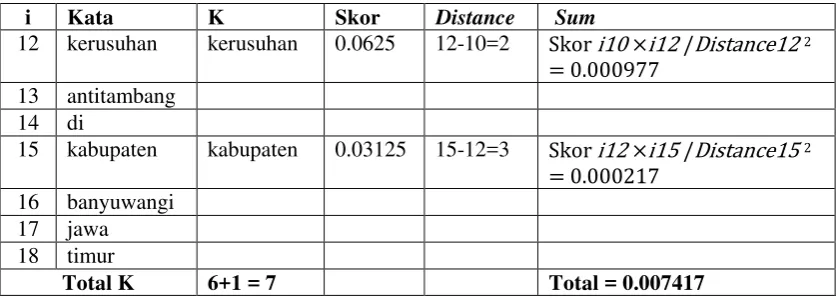
ANWAR PASARIBU 111402008
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : SISTEM PERINGKAS BERITA ONLINE
OTOMATIS MENGGUNAKAN ALGORITMA TEXTTEASER
Kategori : SKRIPSI
Nama : ANWAR PASARIBU
Nomor Induk Mahasiswa : 111402008
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI (FASILKOM-TI)
UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Januari 2016 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Seniman, S.Kom., M.Kom. Dani Gunawan, S.T., M.T. NIP 19870525 201404 1 001 NIP 19820915 201212 1 002
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
SISTEM PRINGKASAN BERITA ONLINE MENGGUNAKAN ALGORTIMA TEXTTEASER
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Januari 2016
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan ke hadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
Ucapan terima kasih penulisan sampaikan kepada Bapak Dani Gunawan, S.T., M.T. selaku pembimbing pertama dan Bapak Seniman, S.Kom., M.Kom. selaku pembimbing kedua yang telah banyak meluangkan waktu untuk memberikan kritik dan saran dalam penelitian dan penulisan skripsi ini. Selanjutnya, terima kasih juga kepada Bapak Muhammad Anggia Muchtar, ST., M.M.IT sebagai dosen penguji pertama serta Ibu Dr. Erna Budhiarti Nababan, M. IT sebagai dosen penguji kedua. Penulis juga mengucapkan terima kasih kepada Bapak dan Ibu dosen S1 Teknologi Informasi yang telah mengajar dan memberikan masukan serta saran yang bermanfaat selama proses perkuliahan hingga dalam penulisan skripsi ini. Ucapan terima kasih juga ditujukan kepada semua pegawai dan staf tata usaha Teknologi Informasi dan Fasilkom-TI, yang telah membantu proses administrasi selama perkuliahan.
Penulis juga berterima kasih kepada kedua orang tua penulis, Bapak Asmar Pasaribu dan Ibu Agonna Siregar yang telah membesarkan penulis dengan penuh cinta dan kasih.
ABSTRAK
Peringkas teks otomatis menjadi salah satu solusi untuk menghadapi pesatnya arus informasi sekarang ini khususnya berita online. Solusi ini memberikan versi teks yang lebih singkat namun tetap mewakili bagian penting dari teks asli. Penelitian ini mengambil data dari tiga situs berita online yaitu kompas.com, detik.com, dan liputan6.com. Kemudian data yang diperoleh diringkas menggunakan metode ekstraktif yang bekerja dengan cara mengambil kalimat-kalimat penting dari teks asli tanpa memodifikasinya. Untuk itu digunakan algoritma TextTeaser yang memanfaatkan empat elemen yang terdiri dari judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword untuk menentukan apakah kalimat termasuk ringkasan atau tidak. Selanjutnya teks juga akan diringkas menggunakan algoritma TextRank yang bekerja dengan memberikan peringkat pada graf representasi objek (kalimat) dalam teks untuk menentukan apakah kalimat termasuk dalam ringkasan. Hasil ringkasan TextTeaser kemudian diuji dengan mengevaluasi menggunakan metode evaluasi intrinsic termasuk metode recall (R), precision (P), dan F-Score (F) dengan hasil ringkasan TextRank pada 3075 data berita. Sehingga 60,11% dari total data memiliki nilai F-Score ≥ 0,5 yang berarti algoritma TextTeaser memiliki tingkat presisi yang cukup baik untuk mengambil kalimat-kalimat penting dalam teks berita. Selanjutnya dari data tersebut, terdapat nilai F-Score > 0,7 untuk 31,36% atau sekitar 884 berita yang memiliki presisi ringkasan yang lebih baik untuk menggambarkan isi teks berita.
ONLINE NEWS SUMMARIZATION SYSTEM USING TEXTTEASER ALGORITHM
ABSTRACT
Automatic text summarization become one of the solutions to deal with the rapid flow of information today, especially online news. This solution provides a shorter version but still represents important parts of the original text so that the general description of the contents of the entire text can be understood in a relatively shorter time. This research took data from three online news sites which are kompas.com, detik.com, and liputan6.com. Furthermore summarize the data using extractive methods by taking the main idea from the original text without any modification. For that purpose, used TextTeaser algorithm which utilizes the four elements consisting of text title, sentence position, sentence length, and keywords frequency. The four elements of this text will produce a score of each sentence to determine whether the sentence include in summary or not. Generated summary was tested with intrinsic evaluation methods, including recall (R), precision (P), and F-Score (F). The evaluation method then used to evaluates the summary by TextTeaser with summary by TextRank for 3075 news articles. So that 60.11% of the total news has a value of F-Score ≥ 0.5 which means that the TextTeaser algorithm is good enough in case to collect important sentences from news article. Furthermore, from the data contained F-Score values > 0.7 at 31.36%, or about 884 news data that have a better summary to describe the whole contents of the news article.
DAFTAR ISI
Hal.
Persetujuan ... i
Pernyataan ... ii
Ucapan Terima Kasih... iii
Abstrak ... iv
Abstract ... v
Daftar Isi ... vi
Daftar Tabel ... viii
Daftar Gambar... ix
BAB 1 Pendahuluan ... 1
Latar Belakang ... 1
Rumusan Masalah ... 2
Batasan Masalah ... 3
Tujuan Penelitian... 3
Manfaat Penelitian ... 3
Metodologi Penelitian ... 3
Sistematika Penulisan ... 4
BAB 2 Landasan Teori ... 6
Berita ... 6
Karakteristik berita ... 6
Peringkasan Teks Otomatis ... 7
Algoritma TextTeaser ... 9
Algoritma TextRank ... 12
Periodic Tasks ... 15
Web Data Extraction ... 17
Python content extraction ... 18
Android ... 21
Library pendukung ... 22
Natural Language Toolkit (NLTK) ... 24
REST... 25
Evaluasi Hasil Ringkasan ... 26
Penelitian Terdahulu ... 27
BAB 3 Analisis dan Perancangan Sistem ... 29
Arsitektur Umum... 29
Analisis Data ... 30
Data Berita ... 31
Data stopword ... 34
Analisis Sistem ... 35
Ekstraksi isi berita ... 35
Pembersihan teks berita ... 36
Menentukan frekuensi keyword ... 38
Menentukan skor judul teks ... 43
Menentukan skor panjang kalimat ... 44
Menentukan skor posisi kalimat ... 44
Menentukan skor total ... 44
Perancangan Sistem ... 45
Perancangan antarmuka sistem ... 45
BAB 4 Implementasi dan Pengujian Sistem ... 50
Implementasi Sistem ... 50
Spesifikasi perangkat keras yang digunakan ... 50
Spesifikasi perangkat lunak yang digunakan ... 51
Implementasi Perancangan Antarmuka ... 51
Tampilan halaman sign in ... 51
Tampilan halaman sign up ... 51
Tampilan halaman home ... 52
Tampilan halaman news details ... 53
Tampilan halaman settings ... 53
Tampilan halaman choose news source ... 54
Hasil Ringkasan ... 54
Pengujian Hasil Ringkasan ... 57
BAB 5 Kesimpulan dan Saran ... 62
Kesimpulan ... 62
Saran ... 62
DAFTAR TABEL
Hal.
Tabel 2.1 Nilai berdasarkan skor posisi kalimat (Balbin, 2011) ... 10
Tabel 2.2 TextRank dibandingkan dengan sistem lain (Mihalcea & Tarau, 2004) ... 14
Tabel 2.3 Contoh penggunaan crontab (Solem, 2015) ... 17
Tabel 2.4 Penelitian terdahulu ... 28
Tabel 3.1 Contoh URL situs berita ... 31
Tabel 3.2 Contoh stopword ... 35
Tabel 3.3 Contoh top keyword ... 39
Tabel 3.4 Skor keyword ... 40
Tabel 3.5 Menghitung nilai variabel DBS ... 40
Tabel 3.6 Skor total SBS ... 42
Tabel 3.7 Hitung fitur judul berita ... 43
Tabel 3.8 Keterangan bagian-bagian tampilan server ... 46
Tabel 4.1 Contoh hasil evaluasi sistem ... 57
Tabel 4.2 Frekuensi nilai F-Score pada seluruh data ... 58
Tabel 4.3 Frekuensi nilai F-Score berita kompas.com ... 59
Tabel 4.4 Frekuensi nilai F-Score berita detik.com ... 60
DAFTAR GAMBAR
Hal.
Gambar 2.1 Alur proses Celery (Smith, 2014) ... 16
Gambar 2.2 Contoh penggunaan Celery periodic tasks (Solem, 2015) ... 17
Gambar 2.3 Goose menentukan bagian yang bukan isi berita (Pfeiffer, 2014) ... 19
Gambar 2.4 Goose Menentukan Lokasi Isi Berita (Pfeiffer, 2014) ... 19
Gambar 2.5 Goose Menandai Gambar Utama untuk Berita (Pfeiffer, 2014) ... 20
Gambar 2.6 Contoh indikasi halaman bersambung ... 20
Gambar 2.7. Arsitektur PushBots (Google Developers, 2015) ... 24
Gambar 3.1 Arsitektur umum sistem peringkas berita ... 30
Gambar 3.2 Indikasi berita bersambung tekno.kompas.com ... 32
Gambar 3.3 Indikasi berita bersambung health.liputan6.com ... 33
Gambar 3.4 Indikasi berita bersambung health.detik.com ... 34
Gambar 3.5 Flowchart text preprocessing ... 37
Gambar 3.6 Contoh input teks ... 37
Gambar 3.7 Teks setelah menghilangkan tanda baca ... 37
Gambar 3.8 Hasil penguraian kata dari teks dan huruf kecil ... 38
Gambar 3.9 Kata-kata setelah penghapusan stopword ... 38
Gambar 3.10 Input judul dan teks berita ... 38
Gambar 3.11 Tampilan console server sistem peringkas ... 45
Gambar 3.12 Rancangan (1) halaman sign in dan (2) halaman sign up ... 46
Gambar 3.13 Rancangan halaman home ... 47
Gambar 3.14 Rancangan halaman news details ... 48
Gambar 3.15 Rancangan halaman Settings ... 48
Gambar 3.16 Rancangan halaman Choose News Source ... 49
Gambar 4.1 Tampilan halaman sign in ... 51
Gambar 4.2 Tampilan halaman sign up ... 52
Gambar 4.3 Tampilan halaman home ... 52
Gambar 4.4 Tampilan halaman news details ... 53
Gambar 4.5 Tampilan halaman settings ... 53
ABSTRAK
Peringkas teks otomatis menjadi salah satu solusi untuk menghadapi pesatnya arus informasi sekarang ini khususnya berita online. Solusi ini memberikan versi teks yang lebih singkat namun tetap mewakili bagian penting dari teks asli. Penelitian ini mengambil data dari tiga situs berita online yaitu kompas.com, detik.com, dan liputan6.com. Kemudian data yang diperoleh diringkas menggunakan metode ekstraktif yang bekerja dengan cara mengambil kalimat-kalimat penting dari teks asli tanpa memodifikasinya. Untuk itu digunakan algoritma TextTeaser yang memanfaatkan empat elemen yang terdiri dari judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword untuk menentukan apakah kalimat termasuk ringkasan atau tidak. Selanjutnya teks juga akan diringkas menggunakan algoritma TextRank yang bekerja dengan memberikan peringkat pada graf representasi objek (kalimat) dalam teks untuk menentukan apakah kalimat termasuk dalam ringkasan. Hasil ringkasan TextTeaser kemudian diuji dengan mengevaluasi menggunakan metode evaluasi intrinsic termasuk metode recall (R), precision (P), dan F-Score (F) dengan hasil ringkasan TextRank pada 3075 data berita. Sehingga 60,11% dari total data memiliki nilai F-Score ≥ 0,5 yang berarti algoritma TextTeaser memiliki tingkat presisi yang cukup baik untuk mengambil kalimat-kalimat penting dalam teks berita. Selanjutnya dari data tersebut, terdapat nilai F-Score > 0,7 untuk 31,36% atau sekitar 884 berita yang memiliki presisi ringkasan yang lebih baik untuk menggambarkan isi teks berita.
ONLINE NEWS SUMMARIZATION SYSTEM USING TEXTTEASER ALGORITHM
ABSTRACT
Automatic text summarization become one of the solutions to deal with the rapid flow of information today, especially online news. This solution provides a shorter version but still represents important parts of the original text so that the general description of the contents of the entire text can be understood in a relatively shorter time. This research took data from three online news sites which are kompas.com, detik.com, and liputan6.com. Furthermore summarize the data using extractive methods by taking the main idea from the original text without any modification. For that purpose, used TextTeaser algorithm which utilizes the four elements consisting of text title, sentence position, sentence length, and keywords frequency. The four elements of this text will produce a score of each sentence to determine whether the sentence include in summary or not. Generated summary was tested with intrinsic evaluation methods, including recall (R), precision (P), and F-Score (F). The evaluation method then used to evaluates the summary by TextTeaser with summary by TextRank for 3075 news articles. So that 60.11% of the total news has a value of F-Score ≥ 0.5 which means that the TextTeaser algorithm is good enough in case to collect important sentences from news article. Furthermore, from the data contained F-Score values > 0.7 at 31.36%, or about 884 news data that have a better summary to describe the whole contents of the news article.
BAB 1
PENDAHULUAN
Latar Belakang
Berita pada media massa online bertambah banyak setiap waktu karena selalu ada sesuatu yang patut untuk diberitakan kepada khalayak. Hal ini membuat pembaca harus menyiapkan waktu untuk mengakses penyedia berita baik melalui situs website atau aplikasi kemudian membaca setiap pembaruan berita yang diminatinya. Memahami isi teks berita keseluruhan memerlukan waktu yang relatif lama dibandingkan dengan teks yang sudah diringkas. Sehingga berita yang sudah diringkas akan mempermudah pembaca untuk memahami isi berita tersebut.
Menurut Aristoteles (2011) yang merujuk kepada (Radev et al. 2002; Blake et al. 2001) peringkasan teks merupakan proses untuk menghasilkan teks yang lebih sedikit (<50%) dari teks asli namun tetap mengandung bagian-bagian penting dan selaras dengan sistematika penulisan teks asli dengan bertujuan untuk mempersingkat waktu untuk memahami isi dokumen. Peringkasan teks otomatis atau automatic text summarization (ATS) yaitu peringkasan teks yang dilakukan oleh mesin dengan algoritma atau metode tertentu. Pada umumnya peringkasan teks terbagi menjadi dua teknik yaitu ekstraktif dan abstraktif. Teknik ekstraktif mengambil kalimat-kalimat yang penting dalam teks kemudian menyatukannya dalam ringkasan yang dihasilkan, kemudian teknik abstraktif adalah teknik yang yang memparafrasakan isi teks asli dalam bentuk yang lebih singkat.
Bobot fitur teks yang didapatkan kemudian diolah dengan model metode regresi logistik. Penelitian yang dilakukan Aristoteles (2014) menggunakan sumber data korpus statis dari penelitian yang dilakukan oleh Ridha (2002). Artinya sumber data yang akan disingkat disimpan terlebih dahulu dalam media penyimpan komputer tanpa memperhatikan adanya pembaruan berita pada media massa online.
Kemudian penelitian yang dilakukan oleh Fachrurrozi et al. (2013) menggunakan metode frequent term based dengan cara mengidentifikasi kemudian mengekstraksi informasi penting dari teks. Pada sistem yang dibuat seluruh kata benda dan kata kerja dihitung, karena menurut Fachrurrozi et al. (2013) kedua kata ini merepresentasikan isi teks. Dengan pendekatan statistik, judul teks dan lokasi kalimat tersebut dalam teks juga digunakan karena ini merupakan konsep dasar dari tingkat kepentingan kalimat dalam teks.
Berbeda dengan penelitian Fachrurrozi et al. (2013), penelitian yang dilakukan Riandayani et al. (2014) membandingkan metode fuzzy logic dan fuzzy c-means (FCM). Peringkasan pada penelitian ini memanfaat 7 fitur kalimat yaitu sentence position, sentence length feature, title feature, term weight, entity word or term, numerical data, thematic word. Skor masing-masing kalimat dalam teks akan dioptimasi oleh metode-metode yang digunakan. Kemudian hasil dari fuzzy logic dan fuzzy c-means dibandingkan dengan ringkasan manual yang dihasilkan oleh manusia.
Pada penelitian ini data diperoleh dari beberapa situs berita online seperti kompas.com, detik.com, liputan6.com menggunakan teknik web data extraction. Kemudian data yang dapatkan diringkas menggunakan algoritma TextTeaser yang memang dioptimalkan untuk meringkas teks berita (Balbin, 2011). Algoritma ini menghasilkan ringkasan secara ekstraktif yang menggunakan elemen dalam teks sebagai acuan peringkasan. Elemen teks yang digunakan TextTeaser ada empat yaitu judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword. Elemen-elemen ini akan menghasilkan skor untuk setiap kalimat yang mana skor ini akan menentukan suatu kalimat masuk dalam ringkasan atau tidak.
Rumusan Masalah
Sehingga akan ada kemungkinan perbedaan informasi yang disampaikan antara satu sumber berita dengan yang lain. Tidak jarang orang akan melakukan cross-check dari berbagai sumber yang ada untuk memeriksa variasi kelengkapan isi berita yang akan menguras waktu dan tenaga. Namun setiap orang memiliki waktu yang berbeda dan terbatas untuk melakukan hal tersebut. Untuk mengatasinya, aplikasi peringkasan isi berita dari berbagai sumber disajikan dalam sebuah aplikasi Android dapat dijadikan solusi untuk meningkatkan efisiensi membaca.
Batasan Masalah
Sistem peringkasan teks yang akan dikembangkan memiliki batasan atau ruang lingkup yang mencakup:
1. Masukan data berupa teks berita bahasa Indonesia.
2. Asumsi teks berita menggunakan pola bahasa yang mengacu pada ejaan yang disempurnakan (EYD).
3. Tidak menangani kesalahan penulisan kata.
4. Kohesi dan koherensi antar kalimat kalimat tidak ditangani.
Tujuan Penelitian
Tujuan penelitian yang dilakukan adalah untuk meringkas teks berita online berbahasa Indonesia menggunakan algoritma TextTeaser.
Manfaat Penelitian
Manfaat yang diperoleh dari penelitian ini adalah:
1. Mempersingkat waktu baca berita menggunakan smartphone Android. 2. Mempermudah pemahaman isi berita.
Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan dalam pelaksanaan penelitian ini adalah sebagai berikut :
1. Studi Literatur
yang berkaitan dengan penelitian seperti automatic text summarization (ATS), algoritma TextTeaser, dan algoritma TextRank.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap berbagai informasi yang telah diperoleh dari berbagai sumber yang terkait dengan penelitian agar didapatkan metode yang tepat untuk menyelesaikan masalah dalam penelitian ini.
3. Perancangan Sistem
Tahap ini dilakukan perancangan sistem mulai dari perancangan arsitektur, perancangan data, dan perancangan user interface (UI) untuk menyelesaikan permasalahan yang terdapat di dalam tahap analisis. Kemudian dilanjutkan dengan mengimplementasikan hasil analisis dan perancangan ke dalam sistem. 4. Implementasi Sistem
Pada tahap ini dilakukan proses implementasi kode program sistem aplikasi yang mencakup aplikasi server dan aplikasi untuk end-user menggunakan bahasa pemrograman yang telah dipilih sesuai dengan analisis dan perancangan yang telah dilakukan.
5. Pengujian
Pada tahap ini dilakukan pengujian sistem untuk mencari kesalahan yang mungkin ada sehingga dapat diperbaiki. Kemudian akan dilakukan analisis terhadap fokus permasalahan penelitian, apakah sudah sesuai dengan yang diinginkan.
Sistematika Penulisan
Penulisan skripsi ini terdiri dari lima bab dengan masing-masing bab secara singkat dijelaskan sebagai berikut:
Bab 1: Pendahuluan
Bab ini berisikan latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian, dan sistematika penulisan. Bab 2: Landasan Teori
Bab 3: Analisis dan Perancangan Sistem
Di dalam bab ini terdapat pemaparan mengenai analisis penelitian dan dasar-dasar perancangan yang digunakan untuk membangun suatu sistem. Seperti arsitektur umum, cara kerja proses peringkasan menggunakan algoritma TextTeaser dan lain-lain.
Bab 4: Implementasi dan Pengujian Sistem
Bab ini berisi implementasi perancangan sistem dari hasil analisis dan perancangan yang sudah dibuat, serta menguji sistem untuk menemukan kelebihan dan kekurangan pada sistem rekomendasi yang dibuat.
Bab 5: Kesimpulan dan Saran
BAB 2
LANDASAN TEORI
Berita
Berita merupakan informasi yang baru saja terjadi dan berguna untuk publikasikan terhadap khalayak melalui berbagai media baik cetak maupun digital atau bahkan dari mulut ke mulut. Kata berita sendiri berasal dari Sanskerta yaitu “vṛtta” yang berarti terjadi atau ada.
Berita tertulis pertama kali dibuat pada abad ke-8 SM di Cina (Zhang, 2007). Pada abad ke-21 gaya penyampaian berita mengalami perubahan yang dramatis, yang membuat setiap kejadian yang baru saja terjadi secara instan akan diketahui oleh semua orang yang terhubung ke Internet.
Karakteristik berita
Setiap berita memiliki perbedaan satu sama lain, namun menurut Saxena (2013) minimal setiap berita harus memiliki beberapa karakteristik berikut :
1. Adil dan seimbang maksudnya berita disampaikan dari berbagai sudut pandang dan tidak mengacu hanya pada satu sudut pandang saja.
2. Akurat, informasi dalam berita ditulis dengan informasi seakurat mungkin. Sehingga berita yang ditulis semestinya sudah melalui proses cross-check atau proses peninjauan kembali.
3. Sumber, berita memiliki sumber informasi yang jelas. Walaupun pada beberapa jenis berita tertentu yang mewajibkan sumber anonim.
4. Ringkas, penulisan berita tidak boleh bertele-tele. Berita harus ditulis singkat namun tetap berisi fakta-fakta penting.
Penyampaian berita tentu harus memperhatikan nilai-nilai yang terkandung di dalamnya. Sehingga kualitas berita dapat ditingkatkan. Menurut Setiawan (2014) yang merujuk kepada (Djuroto, 2004) bahwa berita harus mengandung sepuluh nilai yaitu:
1. Magnitude, pengaruh yang ditimbulkan dengan menyebar luaskan berita pada khalayak.
2. Significant, tingkat kepentingan berita sehingga layak untuk dipublikasikan. 3. Actuality, kejadian yang benar-benar terjadi baru-baru ini.
4. Proximity, jarak kejadian yang semakin dekat dengan khalayak semakin perlu untuk diberitakan.
5. Prominence, kejadian yang menonjol untuk diberitakan.
6. Surprise, unsur kejutan dan isi berita yang tidak mudah ditebak.
7. Clarity, peristiwa harus benar-benar terjadi dan informasi yang akan disampaikan harus jelas dan tidak terlalu banyak opini.
8. Impact, kejadian yang akan diberikan memberikan dampak yang terasa untuk khalayak.
9. Conflict, suatu masalah yang terjadi perlu untuk diberitakan sehingga masalah tersebut diketahui.
10.Human Interest, berita yang mencakup setiap ketertarikan seperti bidang olah raga, teknologi, dan sebagainya.
Berita yang akan dipublikasikan akan lebih berarti jika berita paling tidak memuat sepuluh nilai tersebut.
Peringkasan Teks Otomatis
Ringkasan teks dapat diperoleh melalui peringkasan secara manual dan peringkasan secara otomatis. Peringkasan teks yang dilakukan secara manual oleh manusia melibatkan pemahamannya tentang topik yang akan diringkas, penafsiran dan proses lainnya. Sehingga akan menghasilkan sesuatu yang baru, yang tidak terdapat dalam teks asli karena dalam proses peringkasan telah dipadukan dengan pengetahuan orang yang meringkas.
Peringkasan teks otomatis atau automatic text summarizaton (ATS) adalah program komputer berisi perintah atau algoritma yang mampu memilih kalimat-kalimat penting dalam suatu teks dan menghimpunnya dalam teks baru yang lebih ringkas sehingga bisa langsung digunakan. Peringkasan ini akan menggunakan pendekatan selection-based yang mengekstraksi dan menganalisis fitur-fitur dalam teks.
ATS terbagi menjadi dua tipe yaitu generic summary (text-driven) dan user-focused (query-driven). Tipe yang pertama, generic summary berisi kalimat ringkasan yang berasal dari teks asli. Kalimat yang termasuk dalam ringkasan ditentukan dengan menghitung bobot feature penting dalam teks. Tipe yang kedua, query driven menghasilkan ringkasan sesuai dengan kriteria informasi yang dibutuhkan oleh user seperti query atau topik.
Keuntungan ATS dibandingkan dengan peringkasan manual adalah kecepatan dalam meringkas dokumen yang banyak, distribusi hasil ringkasan yang cepat dan mudah serta biaya yang relatif rendah (Torres-Moreno, 2014).
ATS memiliki tiga tahapan pengerjaan yaitu yang pertama pembuatan tafsiran dari teks sumber untuk mendapatkan perwakilannya (interpretation), kedua mengubah teks dari tahap pertama menjadi representasi hasil ringkasan (tranformation), terakhir yang ketiga pembuatan ringkasan dari representasi teks (generation).
Secara umum peringkasan teks terbagi dua yaitu:
1. Abstraktif
2. Ekstraktif
Hasil ringkasan dengan menggunakan teknik ekstraktif merupakan hasil seleksi kalimat-kalimat yang penting dari teks asli tanpa ada modifikasi pada kalimat tersebut (Kalita, Saharia, & Sharma, 2012). Teknik ekstraktif menggunakan beberapa metode seperti statistik, linguistik, heuristik, graph-based (Ridok, 2014). Di mana semua metode yang digunakan memanfaatkan fitur-fitur yang ada dalam teks untuk menentukan tingkat kepentingan suatu kalimat dalam keseluruhan teks. Kebanyakan yang digunakan dalam penelitian adalah ekstraktif karena memberikan hasil yang relatif lebih baik dari teknik abstraktif berdasarkan perkembangan teknologi peringkas teks otomatis yang ada sekarang ini (Erkan & Radev, 2004).
Algoritma TextTeaser
Algoritma TextTeaser pertama kali dipublikasikan pada Tahun (2011) dalam penelitian Juan Paolo Balbin. Algoritma tidak ditujukan untuk mengganti teks asli yang ada melainkan untuk memberikan gambaran isi teks. Seperti teaser pada film yang tidak berisi keseluruhan isi cerita film tersebut. Algoritma TextTeaser juga ditujukan untuk memberikan gambaran singkat (teaser) tentang isi teks.
TextTeaser meringkas teks secara ekstraktif sehingga kalimat-kalimat ringkasan yang dihasilkan merupakan bagian dari teks asli tanpa ada modifikasi. Untuk menentukan kalimat mana yang termasuk dalam ringkasan, algoritma bekerja dengan menghitung empat elemen dalam teks yang terdiri dari judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword (Balbin, 2011).
1. Judul teks berita
Penghitungan skor kalimat ditentukan dengan menghitung setiap kalimat dalam teks berita yang memiliki kesamaan dengan judul berita. Untuk menghitung skor berdasarkan judul teks, terlebih dahulu stopword pada kalimat dalam teks dan judul teks dihilangkan. Hal ini bertujuan untuk menghindari penghitungan kata yang tidak perlu sehingga proses kalkulasi skor lebih efisien. Selanjutnya bobot dihitung menggunakan persamaan (1).
� = | ∩ |
Metode penghitungan skor memperoleh kalimat dalam teks , adalah kata-kata dalam kalimat , adalah kata-kata-kata-kata dalam judul , kemudian dihitung jumlah kata dalam kalimat dan juga kata yang berada dalam judul. Jumlah kata yang didapatkan selanjutnya dibagi jumlah kata dalam judul dikali 1 (satu).
2. Posisi kalimat
Menentukan skor kalimat berdasarkan posisinya dalam teks. Dari penelitian yang dilakukan oleh Balbin (2011) mendapatkan bahwa skor posisi kalimat pada teks berita memiliki nilai yang lebih tinggi pada kalimat pembukaan atau kesimpulan daripada kalimat-kalimat lainnya .
� � � , = ∙ (2)
Dari persamaan (2) diketahui adalah posisi kalimat dalam teks, adalah jumlah semua kalimat. Kemudian nilai � � � , ditentukan berdasarkan tabel 2.1.
Tabel 2.1 Nilai berdasarkan skor posisi kalimat (Balbin, 2011)
Sentence
position 0. < x ≤ 0.1 . < x ≤ 0.2 . < x ≤ 0.3 0.3 < x ≤ 0.4 0.4 < x ≤ 0.5 Distributed
Probability 0.17 0.23 0.14 0.08 0.05
Sentence
position 0.5 < x ≤ 0.6 0.6 < x ≤ 0.7 0.7 < x ≤ 0.8 0.8 < x ≤ 0.9 0.9 < x ≤ 1.0 Distributed
Probability 0.04 0.06 0.04 0.04 0.15
3. Panjang kalimat
Skor elemen ini ditentukan dengan menghitung banyak kata dalam kalimat. Untuk menghitung nilai panjang setiap kalimat dalam teks digunakan persamaan (3).
� ℎ = − − | | (3)
4. Frekuensi keyword
Frekuensi kemunculan kata pada keseluruhan teks berita. Untuk skor frekuensi keyword digunakan fitur teks (text feature) yang dihitung dengan dua metode yaitu density-based selection (DBS) dan summation-based selection (SBS).
Sebelum menghitung DBS dan SBS, keyword teks dan skornya ditentukan dengan mencari kata-kata unik (tanpa duplikat dan bukan stopword). Kemudian menghitung frekuensi setiap kata unik. Sampai tahap ini keyword dan frekuensi kemunculannya sudah diperoleh.
Langkah selanjutnya keyword beserta frekuensi yang diperoleh diurutkan dari bobot yang terbesar ke bobot yang terkecil. Untuk mendapatkan keyword paling sering muncul (top keyword), sepuluh data terurut diambil kemudian diproses untuk memperoleh skor masing-masing keyword. Skor setiap keyword dapat hitung dengan menggunakan persamaan (4).
= ∙ | | ÷ |�| ∙ . (4)
Dari persamaan (4), diketahui merupakan keyword yang akan dihitung, | | merupakan frekuensi kemunculan keyword dalam teks, dan |�| adalah jumlah semua kata-kata unik dalam teks. Setelah skor masing-masing keyword diperoleh, barulah DBS dan SBS bisa dihitung.
Metode pertama, DBS adalah metode untuk menentukan peringkat (rank) pada teks berdasarkan beberapa parameter antara lain kumpulan keyword yang sudah diberi skor (Hu, Sun, & Lim, 2007), kata-kata pada kalimat yang akan dihitung, kata-kata pada kumpulan keyword. Kemudian kumpulan parameter tersebut dihitung dengan menggunakan persamaan (5).
= ∙ + ∙ ∑ � ( ) ∙ , ++
�−
=
(5)
Metode kedua adalah SBS. Metode ini berfungsi untuk memberikan bobot kalimat yang lebih tinggi apabila kalimat mengandung kata-kata yang mewakili teks keseluruhan (atau disebut dengan top keyword). Untuk menghitung bobot yang dimaksud digunakan persamaan (6).
= | | ∙ ∑ �
��∈��
� (6)
Pada persamaan (6) adalah kalimat dalam teks, | | adalah jumlah kata-kata yang terkandung dalam , kemudian parameter untuk mengambil bobot kata ( ) yang merepresentasikan isi teks dengan � � > .
Langkah selanjutnya untuk memperoleh nilai frekuensi keyword adalah dengan menjumlahkan nilai dan kemudian dibagi 2.0 * 10.0 seperti persamaan (7).
� = . ∙ .+ (7)
Setelah memperoleh skor judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword. Semua nilai tersebut ditotalkan menggunakan persamaan (8).
= + . + � ∙ . +. ∙ . + � ∙ . (8)
Pada persamaan (8), adalah title score atau skor judul teks, � adalah keyword frequency atau frekuensi keyword, adalah sentence length atau skor panjang kalimat, dan � adalah sentence position atau skor posisi kalimat.
Algoritma TextRank
Ketika sebuah simpul menuju pada simpul yang lain, berarti simpul tersebut sudah memilih simpul yang lain tersebut. Semakin tinggi nilai vote yang diperoleh, semakin tinggi tingkat kepentingan suatu simpul. Selain itu, tingkat kepentingan simpul yang menuju simpul lain juga berperan penting untuk menentukan tingkat kepentingan simpul yang dituju. Alhasil bobot sebuah sebuah simpul ditentukan berdasarkan banyak simpul yang menujunya.
Pada peringkasan teks otomatis secara ekstraktif, TextRank memiliki beberapa keunggulan antara lain:
Unsupervised, atau dengan kata lain TextRank dapat bekerja tanpa data training untuk memproses data sesungguhnya.
Language independent, yang berarti TextRank tidak bergantung pada bahasa
tertentu atau pemahaman tentang suatu bahasa seperti grammar. Hal ini karena TextRank bekerja hanya menggunakan kata-kata dalam teks. Keterbatasan TextRank hanya pada saat pemisahan kalimat, kata yang berbeda pada bahasa tertentu.
Simpul-simpul graf dalam algoritma TextRank selain berisi kalimat juga mencakup unit teks seperti kata-kata, collocations (lokasi kalimat), dan sebagainya. Kemudian sisi (edge) pada graf merepresentasikan hubungan antara kalimat yang berelasi (similarity). Tanpa mengacu pada tipe elemen yang dimasukkan dalam graf, menurut Mihalcea & Tarau (2004), implementasi algoritma berbasis graf pada pemrosesan teks bahasa alami (contoh, bahasa Indonesia, bahasa Inggris, dan lain-lain) mencakup empat tahap antara lain:
1. Identifikasi unit teks yang paling cocok untuk dijadikan simpul dalam graf. 2. Pemberian sisi antar simpul unit teks baik dengan bobot atau tidak, berarah atau
tidak berarah.
3. Proses menggunakan algoritma hingga objek graf bertemu satu sama lain (convergence).
4. Urutkan simpul berdasarkan skornya. Nilai skor dimasukkan dalam simpul pada saat proses algoritma.
peringkasan teks otomatis, algoritma ini bekerja dengan memberikan peringkat unit teks berdasarkan teks yang diberikan. Menurut Mihalcea & Tarau (2004), algoritma ini memiliki proses yaitu pertama membuat graf dari teks, untuk simpul berisi kalimat-kalimat dalam teks. Kemudian untuk menentukan hubungan antar simpul digunakan similarity content overlap yang dapat diperoleh dengan menghitung token yang ada pada kalimat-kalimat tersebut. Misalkan pada dua kalimat dan yang akan dihitung, kemudian kumpulan kata-kata � perwakilan dari kedua kalimat misalnya:
= , , … , �� dan begitu juga untuk kalimat . Selain itu panjang masing-masing kalimat log | | atau log | | selanjutnya dihitung menggunakan persamaan (9).
� � � ( , ) =|{ | ∈ & ∈ }|
log | | + log | | (9)
Tingkat keberhasilan yang diperoleh dalam penelitian Mihalcea & Tarau (2004) adalah mendapatkan peringkat lima besar dari 15 sistem peringkas lainnya. Hal ini diperoleh dengan cara meringkas 567 data berita, kemudian hasil ringkasan diuji dengan metode recall-oriented understudy for gisting evaluation (ROUGE). Metode ROUGE bekerja dengan membandingkan teks asli berita dengan ringkasan manual yang dibuat oleh manusia. Hasil peringkasan menggunakan TextRank seperti pada tabel 2.2, berada pada posisi ke tiga. Posisi tersebut sudah cukup bagus dan berhasil untuk menentukan kalimat-kalimat penting dalam sebuah teks mengingat TextRank tidak memerlukan supervisi dari manusia atau pemahaman tentang bahasa teks yang akan diringkas.
Tabel 2.2 TextRank dibandingkan dengan sistem lain (Mihalcea & Tarau, 2004)
Sistem ROUGE score – Ngram(1,1)
basic (a) stemmed (b) stemmed no-stopwords (c)
S27 0,4814 0,5011 0,4405
S31 0,4715 0,4914 0,4160
TextRank 0,4708 0,4904 0,4229
S28 0,4703 0,4890 0,4346
S21 0,4683 0,4869 0,4222
S29 0,4502 0,4681 0,4019
beberapa metode untuk meringkas teks baik yang bersumber dari dokumen HMTL atau teks biasa (Belica, 2015).
PeriodicTasks
Pada sistem operasi unix-like seperti Linux memiliki sebuah fitur yang disebut cron yang berguna untuk menjalankan tugas tertentu secara berkala pada waktu tertentu. Cron merupakan sistem yang menjalankan instruksi tertentu pada satuan waktu yang ditentukan. Pada umumnya cron mengerjakan daftar perintah pada crontab (cron table). File ini berisi daftar perintah yang akan dijalankan oleh cron daemon pada jangka waktu yang ditentukan. Setiap perintah dalam crontab dipisahkan dengan pembatas carriage return atau garis baru.
Seperti cron, Python celery juga memiliki kemampuan untuk menjalankan sebuah instruksi secara berkala. Pada penelitian ini, sistem cron yang digunakan berbasis Python celery.
Python celery pertama kali diperkenalkan pada April 2009 dengan nama “crunchy”. Celery berfungsi untuk menjalankan fungsi Python (atau dalam hal ini disebut task) pada sistem secara asynchronous atau dengan kata lain beberapa task bisa berjalan secara bersamaan. Kemudian celery akan menjalankan proses di luar proses proses utama sistem atau proses yang berjalan di background atau di luar proses utama. Artinya user tetap bisa menjalankan sistem tanpa harus menunggu setiap setiap proses yang tidak memerlukan umpan balik seperti mengirim email atau mengolah gambar untuk disimpan di server.
Producers 4 3 2 1
Celery
Consumer
Worker Pool
*Result Pending
Started
Success/Failure
Message broker
Gambar 2.1 Alur proses Celery (Smith, 2014)
Pada gambar terdapat lima objek yang akan diproses Producers, Celery Queue, Consumer, Worker Pool, Result.
1. Producers menghasilkan task yang akan dijalankan misalnya web request atau fungsi yang dijalankan secara berkala (periodic task).
2. Celery queue yang termasuk dalam message broker akan menghimpun semua task yang masuk kemudian meneruskan terlebih dahulu task yang baru masuk, first in first out (FIFO).
3. Consumer pada celery bertindak untuk memproses task dari celery queue dan bersiap-siap untuk ke tahap selanjutnya. Secara default konsumer akan memproses empat task pada satuan waktu tertentu. Pada tahap ini seluruh task akan berubah status pending, siap untuk dijalankan.
4. Worker pool akan menjalankan semua task yang diberikan serta memberikan status started, task sedang berjalan. Status ini akan memberikan sinyal ke message broker untuk mengirim task selanjutnya.
5. Result adalah hasil dari task yang selesai dijalankan.
berkala (periodic task) yaitu dalam setting objek Python dan dalam database SQL (Solem, 2015).
[image:30.595.141.493.398.510.2]Contoh penggunaan perintah crontab untuk periodic tasks pada celery dapat dilihat pada tabel 2.3.
Tabel 2.3 Contoh penggunaan crontab (Solem, 2015)
Contoh Kegunaan
crontab() Menjalankan perintah setiap menit.
crontab(minute=0, hour=0) Menjalankan perintah setiap hari pada pukul 00.00 (tengah malam).
crontab(minute=0, hour='*/3') Perintah dijalankan setiap tiga jam. crontab(minute='*/15') Setiap 15 menit perintah akan dijalankan.
crontab(day_of_week='sunday') Setiap menit pada hari Minggu perintah akan dijalankan.
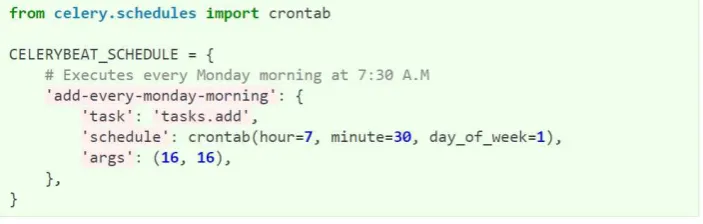
Contoh perintah dalam objek Python seperti pada gambar 2.2, perintah “add-every-monday-morning” akan dijalankan setiap hari senin pagi pukul 7.30. Dalam perintah tersebut fungsi yang akan dikerjakan adalah “task.add”, untuk menjumlahkan data pada “args” yaitu 16 dan 16.
Gambar 2.2 Contoh penggunaan Celery periodic tasks (Solem, 2015)
Celery beat juga secara terus-menerus akan memeriksa daftar perintah yang terdapat di database sehingga jika ditemukan daftar perintah baru, celery beat akan menjalankannya sesuai waktu yang ditetapkan.
WebDataExtraction
Web data extraction bertindak sebagai layaknya web browser yang membuka halaman web, namun tidak menampilkan halaman web seperti biasa melainkan langsung mengambil data. Kriteria pengambilan data bisa saja mengambil langsung dari tag yang ditentukan dalam dokumen HTML. Namun hal tersebut tentu tidak akan bekerja pada website yang berbeda. Karena struktur dokumen HTML setiap website relatif berbeda.
Python content extraction
Secara manual teks berita dapat ditemukan dengan menelusuri tag HTML awal teks berita dimulai. Namun cara tersebut akan menguras waktu apabila banyak situs berita yang akan di ekstrak isinya. Walaupun setiap halaman berita memiliki bentuk layout yang berbeda-beda namun memiliki ciri lokasi teks berita yang sama yaitu banyaknya teks dalam tag HTML tertentu.
Pada penelitian ini penulis menggunakan Python Goose dan Python Newspaper sebagai ekstraktor teks berita.
1. Python Goose
Goose merupakan proyek open source yang dibuat oleh Jim Plush dan Robbie Coleman yang bekerja di gravity.com. Nama proyek diambil dari tokoh karakter film Top Gun pada Tahun 1986. Saat URL berita pertama kali di unduh, goose akan membersihkan dokumen supaya lebih mudah untuk diolah. Selanjutnya adalah menghilangkan bagian sosial media, bagian kolom komentar, mengubah tag HTML dari dalam teks, serta bagian-bagian lainnya yang bukan merupakan isi berita (Pfeiffer, 2014). Goose menghasilkan beberapa data dari halaman web seperti judul artikel, isi artikel, gambar utama, dan data lainnya.
seperti terlihat pada gambar 2.4. Langkah terakhir adalah menentukan gambar utama halaman yang diilustrasikan seperti pada gambar 2.5.
Gambar 2.3 Goose menentukan bagian yang bukan isi berita (Pfeiffer, 2014)
Langkah pertama seperti gambar 2.3 adalah menentukan bagian halaman yang bukan merupakan isi halaman. Pada umumnya halaman web memiliki bagian-bagian pembantu seperti bagian navigasi untuk navigasi halaman yang hanya berisi URL, sidebar yang juga berisi URL untuk konten website lainnya, kemudian bagian lainnya adalah bagian footer berisi informasi seputar website atau link-link utama website. Tahapan selanjutnya goose menentukan bagian yang merupakan konten halaman web. Pada tahap ini goose akan menghitung bobot setiap tag (objek dalam dokumen HTML) dalam bagian konten pada halaman web berdasarkan teks yang ada di dalamnya. Hasil dari tahap ini dapat diilustrasikan seperti pada gambar 2.4 ditandai dengan penambahan kotak merah pada bagian teks.
[image:32.595.258.373.549.725.2]Terakhir goose akan menentukan gambar utama halaman web. Untuk menentukan gambar utama halaman dari gambar-gambar yang ada, goose terlebih dahulu mempersempit ruang lingkup dokumen yang akan periksa. Karena sebelumnya yaitu pada langkah pertama dan langkah kedua bagian non-konten sudah dihilangkan, maka goose akan memfokuskan pencarian dimulai pada tag di mana teks didapatkan. Secara terus-menerus goose akan melakukan pencarian gambar tag-demi-tag keluar dari tag konten ditemukan. Penentuan gambar pada halaman diilustrasikan pada gambar 2.5 yang ditandai dengan kotak hijau.
Gambar 2.5 Goose Menandai Gambar Utama untuk Berita (Pfeiffer, 2014)
Goose selesai menentukan isi berita sehingga terakhir menyimpan URL gambar dan teks berita yang didapatkan.
[image:33.595.229.405.590.698.2]Kemudian untuk menangani berita bersambung, dokumen HTML yang didapatkan oleh goose diperiksa terlebih dahulu apakah terdapat tag yang menandakan berita tersebut bersambung. Salah satu contoh dokumen berita bersambung yaitu seperti gambar 2.6, pada dokumen HTML halaman berita terdapat kelas (CSS class) dengan nilai “kcm-read-paging mt2” yang menandakan sebuah halaman berita bersambung. Setiap halaman berita memiliki indikasi berita bersambung yang berbeda, sehingga masing-masing halaman diproses dengan cara yang berbeda-beda.
2. Python Newspaper
Tidak seperti Python Goose, Python Newspaper memiliki fungsi untuk mendapatkan semua alamat URL dari halaman website yang tuju. Hal tersebut dilakukan dengan beberapa tahap yaitu pertama dimulai dari mengakses halaman website dengan hyper text transfer protocol (HTTP). Halaman website yang diakses tidak ditampilkan dalam web browser melainkan Newspaper akan menelusuri source code dokumen hyper text markup language (HTML) website tersebut. Kemudian setiap tag “a” yang didapatkan akan diambil nilai property “href” di mana alamat URL berada. Dari semua URL yang didapatkan seterusnya akan diseleksi berdasarkan domain website yang diakses sebelumnya.
Android
Sistem operasi dari Google yang dikembangkan dari kernel Linux mempunyai penggunaan yang sangat pesat. Android merupakan perangkat lunak open source dengan dukungan komunitas yang besar sehingga dapat dimodifikasi sesuai kebutuhan. Seiring perkembangannya Android sekarang tidak hanya digunakan pada perangkat handheld seperti Smartphone dan Smart Watch, namun dengan cepat telah memasuki ranah otomotif, hingga perangkat elektronik pada rumah tangga seperti kulkas, mesin cuci dan lainnya. Sehingga tidak bisa dihindari fragmentasi perangkat yang menggunakan Android membuat pengembang aplikasi akan mengalami kesulitan untuk mendukung semua perangkat. Di sisi lain hal ini tentu juga merupakan tantangan dengan profit yang menggiurkan karena pangsa pasar yang didominasi perangkat Android. Harga perangkat yang relatif murah membuat penjualan melonjak tinggi yang mengakibatkan meningkatnya kebutuhan akan aplikasi Android. Pada Juli 2013, terdapat lebih dari 50 miliar download aplikasi yang disediakan di pasar aplikasi Google, Play Store (PhoneArena, 2013).
(XML). Namun tidak menutup kemungkinan untuk menggunakan bahasa pemrograman yang lain, beberapa di antaranya adalah:
Basic4Android atau B4A menggunakan Visual Basic. B4A dikembangkan oleh Anywhere Software Ltd.
Corona SDK, dibuat oleh Walter Luh dari Corona Labs Inc. Pengembangan dengan Corona SDK menggunakan bahasa pemrograman Lua, yang berjalan di atas C++/OpenGL.
Delphi pengembangan menggunakan Object Pascal yang dikembangkan oleh Embarcadero.
Kivy, pengembangan aplikasi menggunakan Python. RubyMotion, pengembangan aplikasi menggunakan Ruby. Xamarin, menggunakan C# untuk membuat aplikasi Android.
PhoneGap, menggunakan pemrograman web seperti HTML atau CSS.
Pada penelitian ini lingkungan pengembangan yang digunakan adalah berbasis Java dan XML, yang merupakan lingkungan pengembangan asli yang disediakan Google untuk pembuatan aplikasi Android.
Library pendukung
Dalam penelitian, pengembangan aplikasi Android menggunakan beberapa library untuk mendukung proses pengembangan yaitu Google Volley, OkHttp, Google Gson, dan PushBots.
1. Google Volley
ke server untuk data yang sudah di request sebelumnya sehingga akan meningkatkan performa aplikasi serta efisiensi penggunaan jaringan.
2. OkHttp
Alternatif untuk melakukan request jaringan atau mengombinasikan dengan Volley adalah menggunakan OkHttp. Library ini digunakan untuk request jaringan dengan metode PATCH. Metode yang berfungsi untuk memperbarui sebagian data yang ada pada server melalui API yang disediakan.
OkHttp akan melakukan request kembali jika terdapat masalah pada jaringan, secara otomatis masalah-masalah umum seperti jaringan yang melambat dan waktu request yang habis akan ditangani. Kemudian OkHttp juga mendukung koneksi dengan menggunakan beberapa alamat IP, sehingga jika koneksi dengan salah satu alamat IP gagal maka alamat IP yang lain akan dicoba.
3. Google Gson
Data yang diperoleh dari API berupa javascript object notation (JSON) akan diubah menjadi objek Java dengan menggunakan Gson. Begitu juga sebaliknya untuk mengirim data ke server objek Java yang dibuat diubah ke string sebelum mengirim melalui jaringan.
4. PushBots
Gambar 2.7. Arsitektur PushBots (Google Developers, 2015)
Pada gambar 2.7, App Server adalah posisi PushBots untuk mengirim pesan ke GCM, kemudian GCM Connection Server akan meneruskan pesan ke perangkat (client app) dan untuk menghasilkan notifikasi.
Kemudian dari sistem yang dibangun digunakan modul Python PushBots berguna untuk mengakses API yang disediakan PushBots seperti mengirimkan pesan ke GCM server atau memperoleh informasi aplikasi klien terdaftar yang sedang aktif.
Natural Language Toolkit (NLTK)
Bahasa pemrograman yang dibuat oleh Guido van Rossum yaitu Python pertama kali muncul pada Tahun 1991. Bahasa pemrograman ini lebih dipilih dibandingkan dengan yang lainnya antara lain relatif mudah dipelajari, sintaks yang mudah dibaca, dan fungsi penanganan string yang bagus (Bird, Loper, & Klien, 2009). Python telah digunakan secara luas pada ranah pengolah data baik tekstual, image, multimedia, dan masih banyak lagi. Dalam bidang pengolahan teks, Python memiliki tools yang relatif banyak dan lengkap di antaranya natural language toolkit (NLTK).
REST
Representational state transfer (REST) merupakan arsitektur sebuah sistem aplikasi perangkat lunak yang menyediakan antarmuka (interface) untuk pendistribusian data atau proses. REST pertama kali diperkenalkan oleh Roy Fielding pada Tahun 2000 dalam disertasinya. Hingga sekarang REST banyak digunakan untuk mendistribusikan data yang pada umumnya melalui hypertext transfer protocol (HTTP).
Sistem yang menggunakan REST disebut RESTful API. Sistem ini menyediakan fitur untuk mengakses server baik untuk menambah, mengubah, atau menghapus data menggunakan uniform resource locator (URL) untuk merepresentasikan objek database di server.
Untuk menggunakannya, client akan memakai beberapa metode HTTP tertentu berdasarkan aktivitas yang akan dilakukan. Beberapa metode HTTP RESTful API yaitu GET, POST, PUT, PATCH, DELETE.
GET, metode yang digunakan untuk memperoleh data.
POST, request ke server untuk menerima data yang dikirim. Data ini kemudian disimpan di database.
PUT, seperti POST, namun data yang diterima diperiksa terlebih dahulu apakah sudah ada dalam database.
PATCH, request dengan metode ini ditujukan untuk memodifikasi sebagian data yang ada.
DELETE, metode untuk menghapus data tertentu pada database.
Setiap aplikasi client melakukan request ke server, data akan dikemas dalam beberapa format seperti extensible markup language (XML), javascript object notation (JSON), atau teks biasa (plain text).
controller (MVC) untuk memudahkan dalam membangun dan mengembangkan aplikasi.
Melalui aplikasi web yang dibuat menggunakan Django, terdapat modul pembantu pada Django yang disebut dengan Django REST framework. Modul ini berfungsi untuk mendaftarkan model-model database dalam bentuk URL sehingga bisa diakses oleh aplikasi client atau bahkan aplikasi di luar sistem yang mengetahui alamat URL API tersebut.
Evaluasi Hasil Ringkasan
Evaluasi hasil ringkasan merupakan bagian penting dalam sebuah sistem peringkasan. Sehingga hasil ringkasan yang dibuat dapat diketahui tingkat keberhasilannya walaupun tidak semua hasil dari teknik evaluasi bisa diterima oleh peneliti peringkas teks otomatis. Secara umum metode evaluasi pada peringkasan teks otomatis dapat dibagi menjadi dua kategori yaitu evaluasi intrinsic dan evaluasi extrinsic (Steinberger & Ježek, 2012). Metode evaluasi instrinsic merupakan metode evaluasi pada hasil sistem itu sendiri, atau dalam kata lain evaluasi dilakukan dengan menganalisis hasil ringkasan yang diperoleh. Kemudian metode evaluasi extrinsic, hasil dinilai berdasarkan tingkat kegunaan fungsi sistem.
Penelitian ini menggunakan metode evaluasi intrinsic dengan penggabungan metode recall (R), precision (P), dan F-Score (F). Dalam konteks peringkasan teks otomatis, recall merupakan jumlah bagian teks (kalimat) relevan dari teks asli berdasarkan jumlah semua kalimat dalam teks referensi, precision merupakan jumlah kalimat relevan dari semua kalimat yang didapatkan dari teks asli, dan F-Score adalah bobot nilai rata-rata dari nilai recall dan precision. Nilai F-Score yang paling baik adalah 1 dan paling buruk adalah 0. Kemudian metode-metode tersebut dibandingkan dengan hasil ringkasan menggunakan algoritma TextRank yang dilakukan oleh (Mihalcea & Tarau, 2004). Pada persamaan (10) berikut perhitungan F-Score, precision, dan recall.
� = � +� ; � =| ∩ || | ; = | ∩ || | (10)
Penelitian Terdahulu
Berdasarkan kenyataan bahwa arus informasi yang kian pesat tidak terkecuali data teks. Membuat ilmuwan komputer tertantang untuk mengurangi dampak information overload tersebut salah satunya dengan menekan porsi teks yang ada dengan jalan meringkasnya. Beberapa penelitian yang penulis rujuk dalam penelitian ini dapat dilihat pada tabel 2.4.
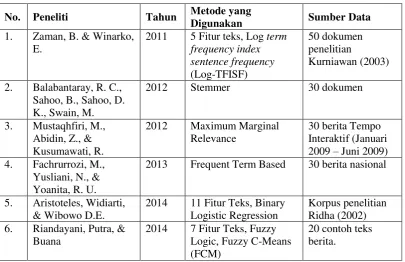
Penelitian peringkasan teks otomatis pertama kali dilakukan oleh Luhn pada Tahun 1956. Hingga saat ini peringkasan teks otomatis dalam bahasa Indonesia merupakan bidang riset yang sedang banyak dilakukan oleh peneliti. Pada umumnya penelitian peringkasan teks otomatis menggunakan metode yang beragam namun memiliki satu tujuan yang sama yaitu meningkatkan presisi hasil ringkasan dan performa komputasi algoritma yang digunakan. Tingkat presisi hasil ringkasan diperoleh dari membandingkan hasil ringkasan yang dihasilkan oleh mesin dengan hasil ringkasan secara manual oleh ahli di dalamnya.
Salah satu peneliti yaitu (Aristoteles, 2014), memanfaatkan 11 fitur teks kemudian diolah dengan metode regresi logistik biner. Penelitian ini memanfaatkan sumber data korpus statis dari penelitian yang dilakukan oleh (Ridha, 2002).
Penelitian yang dilakukan Riandayani et al. (2014) membandingkan metode Fuzzy Logic dan fuzzy c-means (FCM). Peringkasan pada penelitian ini memanfaat 7 fitur kalimat yaitu sentence position, sentence length feature, title feature, term weight, entity word or term, numerical data, thematic word. Skor masing-masing kalimat dalam teks akan dioptimalkan oleh metode-metode yang digunakan. Kemudian hasil dari fuzzy logic dan fuzzy c-means dibandingkan dengan ringkasan manual yang dihasilkan oleh manusia.
Fachrurrozi et al. (2013) menggunakan metode frequent term based dengan cara mengidentifikasi kemudian mengekstraksi informasi penting dari teks. Pada sistem yang dibuat seluruh kata benda dan kata kerja dihitung, karena menurut Fachrurrozi et al. (2013) kedua kata ini merepresentasikan isi teks. Dengan pendekatan statistik, judul teks dan lokasi kalimat tersebut dalam teks juga digunakan karena ini merupakan konsep dasar dari tingkat kepentingan kalimat dalam teks.
kalimat tersebut masuk dalam teks ringkasan atau tidak. Kalimat dalam teks ringkasan tetap mengikuti posisi sistematis penulisan pada teks asli.
Penelitian yang dilakukan oleh Mustaqhfiri et al. (2012) menggunakan metode maximum marginal relevance. Melalui lima tahap preprocessing yaitu pemecahan kalimat, case folding, tokenizing, filtering, dan stemming. Proses selanjutnya menghitung bobot TF-IDF, bobot query relevance dan bobot similarity. Metode maximum marginal relevance berfungsi untuk mengurangi redundansi dalam menentukan peringkat kalimat. Data yang digunakan dalam penelitian ini berasal dari berita online berbahasa Indonesia sebanyak 30 berita yang disimpan di media penyimpan komputer.
[image:41.595.109.515.480.742.2]Penelitian yang dilakukan oleh (Zaman & Winarko, 2011) memanfaatkan bobot fitur kalimat kemudian menganalisisnya. Terdapat lima fitur kalimat yang digunakan dalam penelitian ini yaitu Log-TFISF (term frequency index sentence frequency), posisi kalimat, sentence overlap, title overlap, dan panjang kalimat. Kelima fitur ini akan menentukan hasil ringkasan dengan kalimat yang koheren. Dokumen yang digunakan dalam penelitian ini berasal dari dokumen penelitian Kurniawan (2003) sebanyak 50 dokumen, di mana dokumen tersebut berasal dari situs harian duta masyarakat online.
Tabel 2.4 Penelitian terdahulu
No. Peneliti Tahun Metode yang
Digunakan Sumber Data
1. Zaman, B. & Winarko, E.
2011 5 Fitur teks, Log term frequency index sentence frequency (Log-TFISF) 50 dokumen penelitian Kurniawan (2003)
2. Balabantaray, R. C., Sahoo, B., Sahoo, D. K., Swain, M.
2012 Stemmer 30 dokumen
3. Mustaqhfiri, M., Abidin, Z., & Kusumawati, R.
2012 Maximum Marginal Relevance
30 berita Tempo Interaktif (Januari 2009 – Juni 2009) 4. Fachrurrozi, M.,
Yusliani, N., & Yoanita, R. U.
2013 Frequent Term Based 30 berita nasional
5. Aristoteles, Widiarti, & Wibowo D.E.
2014 11 Fitur Teks, Binary Logistic Regression
Korpus penelitian Ridha (2002) 6. Riandayani, Putra, &
Buana
2014 7 Fitur Teks, Fuzzy Logic, Fuzzy C-Means (FCM)
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
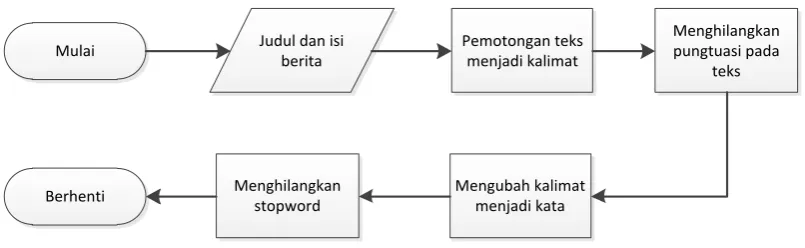
Bab ini akan menjelaskan beberapa hal di antaranya arsitektur umum sistem, sumber data yang digunakan, tampilan aplikasi serta analisis perancangan yang bertujuan untuk mengidentifikasi permasalahan yang ada pada sistem tersebut. Analisis ini diperlukan sebagai dasar perancangan sistem untuk mengimplementasikan algoritma TextTeaser dalam meringkas teks berita.
Arsitektur Umum
Pada awalnya sistem menyediakan konten (teks utuh berita, teks ringkasan, URL berita asli, URL gambar berita) dengan mengambil data berita dari situs berita (di internet) secara berkala menggunakan celery periodic tasks. Pada proses tersebut terdapat beberapa tahap antara lain yang pertama web data extraction untuk mengambil URL dari sebuah halaman yang diberikan, selanjutnya menggunakan URL berita yang didapatkan diproses lagi menggunakan web data extraction untuk mengambil isi berita (teks isi berita dan URL gambar terkait untuk keperluan penyajian aplikasi Android). Kemudian tahap yang kedua adalah melakukan pembersihan teks berita sehingga teks berita siap untuk memulai proses algoritma (TextTeaser dan TextRank). Seterusnya tahap ketiga setelah ringkasan teks baik menggunakan TextTeaser maupun TextRank diperoleh adalah mengevaluasi hasil ringkasan kedua algoritma, dan yang terakhir menyimpan data dalam database.
Aplikasi yang terpasang pada perangkat Android berguna membaca konten yang sudah disediakan oleh sistem. Pengguna aplikasi dapat memilih dan mendapatkan berita melalui kategori default yang sudah ada. Kategori default yang diberikan merupakan kategori umum yang biasa ada pada situs berita online misalnya kategori Economy, National, Technology, dan sebagainya. Kemudian pengguna bisa
server akan dicari judul berita berdasarkan query yang dikirim. Berita yang didapatkan kemudian diubah dalam bentuk string JSON. Terakhir aplikasi akan mengolah data JSON dari server untuk ditampilkan. Berikut pada gambar 3.1 arsitektur umum sistem peringkas berita online yang akan dibuat.
Gambar 3.1 Arsitektur umum sistem peringkas berita
Analisis Data
Data Berita
Data berita seperti judul, berita dan teks berita diperoleh dari situs berita online. Data berita diambil menggunakan teknik web data extraction halaman berita. Beberapa contoh daftar halaman berita yang akan diproses dapat dilihat pada tabel 3.1. Terdapat dua kriteria data yang akan diambil melalui teknik web data extraction seperti data URL berita dan data berita.
Tabel 3.1 Contoh URL situs berita
No. Kategori Berita Sumber Berita URL
1. Gaya Hidup Liputan6.com http://lifestyle.liputan6.com 2. Teknologi Liputan6.com http://tekno.liputan6.com
3. Ekonomi Kompas http://ekonomi.kompas.com
4. Internasional Kompas http://internasional.kompas.com
5 Otomotif Kompas http://otomotif.kompas.com
Web data extraction merupakan teknik untuk mengambil data tertentu dari sebuah halaman website di internet untuk kemudian disimpan pada media penyimpan lokal atau database. Pada penelitian ini, web data extraction bekerja dengan dua tujuan yaitu yang pertama mengambil semua URL pada halaman target seperti “http://otomotif.kompas.com”. Pada halaman tersebut akan diambil semua URL dengan domain yang sama untuk menghindari pengambilan URL yang tidak relevan dengan halaman seperti URL iklan atau media sosial. Kemudian tujuan kedua adalah untuk mengambil isi berita baik teks berita maupun gambar berita.
Kemudian hasil dari pengambilan data melalui web data extraction berupa URL berita. Diproses lagi untuk untuk memperoleh judul dan teks berita. Namun masalah terjadi ketika sebuah URL berita yang berisi hanya sebagian isi berita keseluruhan. Untuk itu dokumen HTML yang diperoleh dari Python Goose terlebih dahulu ditentukan lokasi indikator berita bersambung. Pada berita kompas.com ditemukan lokasi indikator berita bersambung dengan tampilan seperti gambar 3.2. Kemudian pada dokumen HTML, secara manual lokasi indikator tersebut dicari sehingga ditemukan pada tag "div" dengan class "kcm-read-paging mt2". Berita bersambung pada kompas.com memiliki opsi untuk membuka halaman berita utuh berdasarkan berita bersambung yang dideteksi.
Misalnya pada halaman berita bersambung kompas.com:
jika ditelusuri halaman satu per satu diperoleh URL:
“http://tekno.kompas.com/read/2015/07/26/11120087/Ini.5.Aplikasi.yang.Wajib.Diha pus.dari.Android?page=2”
untuk menuju halaman kedua berita (ditandai dengan akhiran “?page=nomor_halaman”). Karena berita kompas.com menyediakan URL untuk menuju halaman utuh berita tersebut yaitu:
“http://tekno.kompas.com/read/2015/07/26/11120087/Ini.5.Aplikasi.yang.Wajib.Diha pus.dari.Android?page=all”.
[image:45.595.115.518.279.552.2]Maka selanjutnya dari URL berita utuh (dengan akhiran “?page=all”) yang didapatkan diproses sehingga isi berita utuh berhasil didapatkan.
Gambar 3.2 Indikasi berita bersambung tekno.kompas.com
Gambar 3.3 Indikasi berita bersambung health.liputan6.com
Berbeda dengan berita kompas.com, berita liputan6.com tidak menyediakan opsi untuk membuka berita utuh. Sehingga, tahapan yang dilakukan setelah URL dideteksi sebagai berita bersambung adalah mengambil URL dari indikator. Misalnya untuk berita bersambung dengan URL:
“http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung”
Pada indikator akan ditemukan URL untuk menuju halaman selanjutnya seperti: “http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung?p=0”, “http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung?p=1”,
dan seterusnya dengan indikator halaman berupa akhiran “?p=nomor_halaman”. Selanjutnya semua URL diproses dengan dengan menggunakan web data extraction, kemudian hasil dari masing-masing URL disatukan.
Untuk berita detik.com, proses yang dilakukan sedikit berbeda. Pada indikator berita bersambung yang dideteksi, detik.com tidak menyediakan daftar URL berita lainnya. Sehingga URL akan dibuat sendiri pada sistem. URL yang dibuat berjumlah sesuai jumlah halaman berita yang ada. Misalnya dideteksi sebuah URL berita detik.com bersambung:
“http://health.detik.com/read/2 015/12/23/201611/3103649/766/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”.
Alamat URL kemudian dipotong menjadi dua bagian:
Setelah lokasi indikator pada tampilan ditemukan terlebih dahulu, kemudian mencari lokasi kode program tampilan tersebut. Sehingga dari indikator yang ditemukan tag “div” per-class “multipage multipage2” seperti gambar 3.4. Di dalam kode tersebut terdapat tag “span” dengan nilai jumlah berita keseluruhan. Misalnya pada gambar 3.4, tag “span” terdapat teks “1 dari 6”, berarti halaman berita terdiri dari 6 halaman. Selanjutnya pada sistem kedua URL hasil pemotongan sebelumnya disatukan dengan penambahan indikasi halaman berita selanjutnya di tengah, misalnya dengan potongan pertama:
“http://health.detik.com/read/2015/12/23/201611/3103649/766”,
kemudian disambung dengan nomor_halaman misalnya “/2/”, seterusnya disambung dengan potongan kedua sehingga akan diperoleh beberapa alamat URL seperti:
“ http://health.detik.com/read/2015/12/23/201611/3103649/766/2/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”
“
http://health.detik.com/read/2015/12/23/201611/3103649/766/3/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”, dan seterusnya.
Dari URL yang dibuat terdapat indikasi halaman berita (cetak tebal, miring, dan garis bawah).
Gambar 3.4 Indikasi berita bersambung health.detik.com
Setelah semua alamat URL berhasil dibuat, langkah selanjutnya memproses alamat URL untuk memperoleh isi berita kemudian isi berita dari masing-masing alamat URL disatukan untuk disimpan ke dalam database.
Data stopword
Kata-kata umum (common word) yang yang tidak bermakna (stopword) berguna untuk mengurangi kompleksitas kalkulasi penghitungan skor fitur teks (text feature).. Stopword yang digunakan berasal dari penelitian (Tala, 2003). Pada penelitian tersebut daftar stopword ditentukan berdasarkan hasil analisis frekuensi kata pada total 3160 dokumen berita berbahasa Indonesia. Dari dokumen tersebut, setelah nama orang, nama
<div class="multipage multipage2"> <span class="fl">... </span> <span>1 dari 6</span>
kota, nama organisasi, nama negara, dan sebagainya dihilangkan, diperoleh 50000 (lima puluh ribu) kata unik.
Pada penelitian yang dilakukan Tala (2003), terbukti dengan menghilangkan stopword dari dokumen yang akan diteliti akan meningkatkan nilai Precision dan R-Precision (indikator pengukuran kualitas hasil). Contoh kata-kata tersebut dapat dilihat pada tabel 3.2. Daftar kata stopword disimpan dalam file teks (*.txt).
Tabel 3.2 Contoh stopword
No. Kata
1 akan 2 di 3 dengan 4 pada 5 yang
Analisis Sistem
Setiap pembangunan sebuah sistem aplikasi diperlukan perancangan tahap-tahap (alur) bagaimana sistem bekerja. Salah satunya adalah identifikasi masalah. Identifikasi permasalahan yang ada pada sistem mencakup software, user, hingga output yang dihasilkan sistem (Setiawan, 2014).
Penelitian ini memiliki tiga proses utama yaitu ekstraksi isi berita, pembersihan isi berita, peringkasan isi berita.
Ekstraksi isi berita
URL berita yang diperoleh akan diproses lagi untuk mendapatkan teks berita. Untuk mendapatkannya digunakan Python Newspaper dan Python Goose yang secara otomatis menentukan bagian halaman berita yang merupakan teks berita. Karena pada umumnya halaman berita memiliki bagian-bagian yang bukan isi berita seperti navigasi halaman, kumpulan link berita terkait, hingga banner iklan. Kemudian pada tahap ini berita berpotong-potong juga akan ditangani.
Pembersihan teks berita
Untuk menghindari mengolah data yang bukan merupakan isi berita. Hasil ekstraksi isi berita terlebih dahulu dibersihkan. Beberapa data yang perlu dibersihkan meliputi judul atau keterangan di bawah gambar (caption gambar), selipan link berita terkait, inisial penulis, inisial sumber berita yang biasanya berada pada awal kalimat, hingga penyelipan inisial sumber berita pada judul berita. Karena setiap sumber berita memiliki kriteria data yang berbeda, maka masing-masing sumber berita akan dibersihkan cara yang berbeda pula.
Persiapan proses peringkasan
Setelah isi berita dibersihkan tahap selanjutnya adalah mempersiapkan teks untuk proses peringkasan (text preprocessing).
Pada tahap text preprocessing, teks berita terlebih dahulu dipotong menjadi kalimat. Pemotongan ini disebut sentence tokenizing yang menggunakan NLTK sentence tokenizer. Tujuan menggunakan NLTK sentence tokenizer adalah untuk memastikan deteksi pembatas kalimat yang lebih baik. Hal ini tentu jauh lebih efektif daripada memotong kalimat hanya berdasarkan pembatas (delimiter) seperti titik, tanda seru, tanda tanya. Contoh sentence tokenizing ini adalah:
“Saya bertemu dengan Prof. Robert, MD, dan Dr. Abdullah tadi pagi di laboratorium” Kalimat tersebut jika menggunakan pemotongan menggunakan tanda baca (contohnya tanda titik) sebagai indikator pemotongan, maka hasilnya terdapat tiga kalimat: “Saya bertemu dengan Prof”, “Robert, MD, dan Dr”, “Abdullah tadi pagi di laboratorium”. Berbeda jika menggunakan NTLK sentence tokenizer, hasil yang didapatkan hanya ada satu kalimat: “Saya bertemu dengan Prof.