10
BAB 2
LANDASAN TEORI
Dalam bab ini akan membahas tentang teori-teori yang akan di gunakan sebagai landasan atau acuan untuk mengerjakan makalah ini. Adapaun teori-teori yang digunakan adalah SPSS (Statistical Package for Social Science), Analisis Cluster dan tahap-tahap penggunaan Analisis Cluster dalam program SPSS.
2.1
SPSS (
Statistikal Product and Service Solutions
)
SPSS adalah sebuah program aplikasi yang memiliki kemampuan analisis statistik cukup tinggi serta sistem manajemen data pada lingkungan grafis dengan menggunakan menu-menu deskriptif dan kotak-kotak dialog yang sederhana sehingga mudah untuk dipahami cara pengoperasiannya.
Pada tahun 1984, muncul SPSS dalam versi PC (bisa dipakai untuk komputer desktop) dengan nama SPSS/PC+ dan sejalan dengan populernya sistem operasi Windows maka SPSS pada tahun 1992 mengeluarkan versi Windows. Selain itu, SPSS juga menjalin aliansi strategis dengan software house lainnya, seperti Oracle Corp, Business Object, serta Ceres Integrated Solution untuk memperkuat market dalam bidang business intelligence.
Pada awalnya SPSS dibuat untuk keperluan pengolahan data statistik untuk ilmu-ilmu sosial, sehingga SPSS merupakan singkatan dari statistical package for social science. Sekarang kemampuan SPSS diperluas untuk melayani berbagai jenis pengguna (user), seperti untuk proses produksi di pabrik, riset ilmu sains dan lainnya. Dengan demikian, sekarang kepanjangan dari SPSS Statistikal Product and Service Solutions.
[email protected] Beberapa kemudahan yang lain yang dimiliki SPSS dalam pengoperasiannya adalah karena SPSS menyediakan beberapa fasilitas seperti berikut ini:
a. Data Editor
Digunakan untuk pengolahan data. Data editor dirancang sedemikian rupa seperti pada aplikasi-aplikasi spreadsheet untuk mendefinisikan, memasukkan, mengedit, dan menampilkan data.
b. Viewer
Untuk mempermudah pemakai untuk melihat hasil pemrosesan, menunjukkan atau menghilangkan bagian-bagian tertentu dari output, serta memudahkan distribusi hasil pengolahan dari SPSS ke aplikasi-aplikasi yang lain.
c. Multidimensional Pivot Tables.
Digunakan untuk melihat hasil pengolahan data. Pengguna SPSS dapat dengan mudah melakukan pengaturan kelompok data dengan melakukan splitting tabel sehingga hanya satu grup tertentu saja yang ditampilkan pada satu waktu.
d. High-Resolution Graphics
Dengan kemampuan grafikal beresolusi tinggi, baik untuk menampilkan pie charts, bar charts, histogram, scatterplots, 3-D graphics, dan yang lainnya, akan membuat SPSS tidak hanya mudah dioperasikan tetapi juga membuat pengguna merasa nyaman dalam pekerjaannya.
e. Database Access
Pengguna program ini dapat memperoleh informasi sebuah database dengan menggunakan database wizard yang disediakannya.
f. Data Transformations
Transformasi data akan membantu pemakai memperoleh data yang siap untuk dianalisis. Pemakai dapat dengan mudah melakukan subset data, mengkombinasikan kategori, add, aggregat, merge, split, dan beberapa perintah transpose files, serta yang lainnya.
g. Electronic Distribution
[email protected] h. Online Help
SPSS menyediakan fasilitas online help yang akan selalu siap membantu pemakai dalam melakukan pekerjaannya. Bantuan yang diberikan dapat berupa petunjuk pengoperasian secara detail, kemudahan pencarian prosedur yang diinginkan sampai pada contoh-contoh kasus dalam pengoperasian program ini.
i. Interface dengan Database Relasional
Fasilitas ini akan menambah efisiensi dan memudahkan pekerjaan untuk mengekstrak data dan menganalisnya dari database relasional.
j. Analisis Distribusi
Fasilitas ini diperoleh pada pemakaian SPSS for Server atau untuk aplikasi multiuser. Kegunaan dari analisis ini adalah apabila peneliti akan menganalisis file-file data yang sangat besar dapat langsung me-remote dari server dan memprosesnya sekaligus tanpa harus memindahkan ke komputer user.
k. Multiple Sesi
SPSS memberikan kemampuan untuk melakukan analisis lebih dari satu file data pada waktu yang bersamaan, misalnya dengan menggunakan tipe bar, pie atau jangkauan nilai, simbol gradual, dan chart.
l. Mapping
Visualisasi data dapat dibuat dengan berbagai macam tipe baik secara konvensional atau interaktif, misalnya dengan menggunakan tipe bar, pie atau jangkauan nilai, simbol gradual, dan chart.
2.2
Metode Analisis Cluster
2.2.1 Pengertian Analisis Cluster
Analisis Cluster adalah teknik statistik multivariat untuk mengindentifikasi sekelompok obyek yang memiliki karakteristik tertentu, yang dapat dipisahkan dengan kelompok obyek lainnya. Tujuan dari analisis ini yaitu mengelompokkan sekelompok obyek ke dalam beberapa kelompok berdasarkan kesamaan karakteristik.
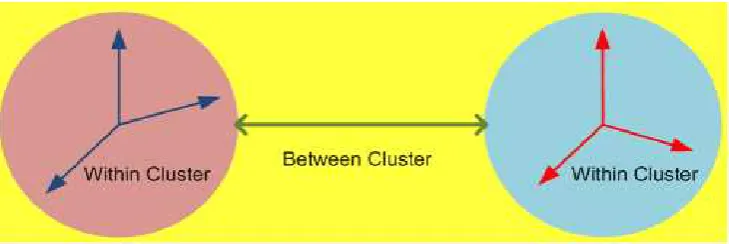
[email protected] Homogenitas internal (within cluster);
yaitu kesamaan antar anggota dalam satu cluster.
Heterogenitas external (between cluster); yaitu perbedaan antara cluster yang satu dengan
cluster yang lain. Gambar 2.1
Grup Objek Within Cluster Dan Between Cluster
Sumber : Modul Praktikum MAP 2015
Langkah pengelompokan dalam analisis cluster mencakup 3 hal berikut : 1. Mengukur kesamaan jarak
2. Membentuk cluster secara hirarkis 3. Menentukan jumlah cluster.
2.2.2 Metode Pendukung
Perhitungan analisis cluster adalah dengan teknik pengukuran jarak similaritas dengan berbagai metode:
1. Interval
1. Euclidian distance
2. Square euclidian distance
3. Cosine
4. Peason Correlation
5. Chebychev
6. Block
7. Minkowski
8. Customized
b. Frekuensi
1. Chi-square
2. Phi-square
c. Biner :
1. Square Euclidian Distance
2. Euclidian distance
3. Size Difference
4. Pattern Difference
5. Variance
6. Shape
7. Lance and Williams
8. Present and Absent
[email protected] Tahapan Analisis Cluster (Gambar 2.2):
Tahap 1 Tahap 2
Proximity Distance Measure of Similarity Pattern: Correlation
Measure of Similarity
TAHAP 5
TAHAP 6
Masalah Penelitian Tentukan Tujuan
Desain Penelitian Outlier
Pengukuran Similaritas Apakah Variabel Matrik atau Non Matrik
Data Non Matrik Association of Similarity
Data Matrik
Fokus pada pola Proximity
Standarisasi Standarisasi Variabel
Asumsi
Pemenuhan Asumsi Dasar
Algoritma Clustering Hirarki, Non Hirarki, Kombinasi
Validasi Interpretasi Periksa Cluster Centroid
Hirarki Non Hirarki kombinasi
1. Penentuan tujuan
Tentukan tujuan analisis cluster yang akan lakukan. Secara umum
tujuan utama analisis cluster adalah mempartisi suatu set objek menjadi dua grup atau lebih berdasarkan kesamaan objek tersebut. Dengan membentuk grup yang homogen, dapat dilihat 2 hal:
a. Deskripsi taksonomi b. Identifikasi relationship
Dalam penentuan tujuan ini variabel yang akan dipakai telah dipilih dan
ditentukan (sesuaikan dengan tujuan analisis).
Data yang digunakan untuk tiap variabel dapat berupa data interval,
ratio, nominal, atau ordinal.
2. Desain penelitian
Terdapat data mentah berupa matriks dengan n objek dan p veriabel
(sebaiknya jumlah objek > jumlah variable).
Menstransformasikan matriks data mentah (n x p) menjadi matriks
jarak antar objek (nxn) dengan menggunakan metode perhitungan jarak.
Dalam tahap ini harus dideteksi terdapat data yang outlier atau tidak.
outlier / pencilan adalah objek yang memiliki nilai ekstrim dibandingkan objek-objek lain. outlier ini dapat mengganggu pengelompokan. Jika terdapat data outlier, maka harus dilakukan standarisasi data.
Standarisasi data dapat dilakukan dengan 2 metode:
a. Standarisasi variabel (dengan Z score)
Z = Skor standar Xi = Skor data mentah M = rata-rata σ = standar deviasi
b. Standarisasi dengan observasi
3. Asumsi model
[email protected] 2. Tidak terjadi multikolinearitas (artinya variabel yang satu bebas dari
variabel lainnya).
4. Pengelompokan
Pembentukan Cluster dilakukan dengan menggunakan metode tertentu Hierarchical Cluster atau Mutually Exclusive Cluster.
a. Metode Hirarki
Memulai pengelompokan dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat. Kemudian diteruskan pada obyek yang lain dan
seterusnya hingga cluster akan membentuk semacam ‘struktur pohon’
dimana terdapat tingkatan (hirarki) yang jelas antar obyek, dari yang paling mirip hingga yang paling tidak mirip. Alat yang membantu untuk
memperjelas proses hirarki ini disebut “dendogram”.
I. Metode Agglomerative
1. Single Lingkage (Nearest Neigbor Methods) / Pautan Tunggal Metode ini didasarkan pada jarak minimum. Dimulai dengan dua objek yang dipisahkan dengan jarak paling pendek maka keduanya akan ditempatkan pada cluster pertama. Keduanya membentuk kelompok yang pertama. Pada langkah selanjutnya, terdapat dua kemungkinan:
a. Objek ketiga akan bergabung dengan kelompok yang ada b. Dua objek lainnya akan membentuk kelompok baru
Metode ini dikenal pula dengan nama pendekatan tetangga terdekat.
2. Complete Lingkage (Futhest Neigbor Methods) / Pautan Lengkap Metode ini disebut juga pendekatan tetangga terjauh, dasarnya adalah jarak maksimum. Dalam metode ini seluruh objek dalam suatu cluster dikaitkan satu sama lain pada suatu jarak maksimum atau dengan kesamaan minimum.
3. Average Lingkage methods (Between Groups Methods) / Pautan Rata-rata
[email protected] 4. Ward’s error sum of squares methods
Dalam metode ini jarak antara dua cluster adalah jumlah kuadrat antara dua cluster untuk seluruh variabel. Metode ini cenderung digunakan untuk mengkombinasi cluster-cluster dengan jumlah kecil.
5. Centroid entry and enter methods
Jarak antara dua cluster adalah jarak antar centroid cluster tersebut. Centroid cluster adalah nilai tengah observasi pada variabel dalam suatu set variabel cluster. Keuntungannya adalah outlier hanya sedikit berpengaruh jika dibandingkan dengan metode lain.
II. Metode Divisive
Metode ini berlawanan dengan metode aglomerasi, pertama-tama mulai dengan satu kelompok besar mencakup semua objek. Selanjutnya objek yang memiliki ketidakmiripan besar dipisahkan sehingga membentuk kelompok yang lebih kecil. Pemisahan ini dilanjutkan hingga mencapai sejumlah kelompok yang diinginkan.
b. Metode Non-Hirarki
memulai pengelompokkan dengan menentukan terlebih dahulu jumlah cluster yang diinginkan (dua, tiga, atau yang lain). Setelah jumlah cluster ditentukan, maka proses cluster dilakukan dengan tanpa mengikuti proses
hirarki. Metode ini biasa disebut “K-Means Cluster”.
1. Sequential Threshold Procedure
Metode pengelompokan ini terlebih dahulu memilih satu objek dasar yang akan menjadi nilai awal kelompok, lalu semua objek yang ada didalam jarak terdekat dengan kelompok ini akan bergabung, kemudian dipilih kelompok kedua dengan prosedur yang sama. 2. Paralel Threshold Procedure
Prinsipnya sama dengan prosedur sekunsial, hanya saja dilakukan pemilihan terhadap beberapa objek sekaligus lalu melakukan penggabungan objek ke dalamnya secara bersamaan.
3. Optimizing
5. Interpretasi
Mendeskripsikan profil cluster yang terbentuk
Pada tahap ini perlu diperhatikan karakteristik apa yang
membedakan masing-masing kelompok yang disesuaiakan dengan tujuan awal analisis. Dimana perlu spesifikasi kriteria.
6. Validasi
Pengujian dapat dilakukan dengan membandingkan hasil yang diperoleh dengan algoritma yang berbeda. Misalnya yang pertama menggunakan teknik hirarki, maka tahap selanjutnya coba gunakan teknik non hirarki. Bila hasilnya berbeda, maka kelompok yang terbentuk tersebut belum valid dan tidak dapat diterapkan secara umum, begitu sebaliknya.
2.3
Proses Input Data
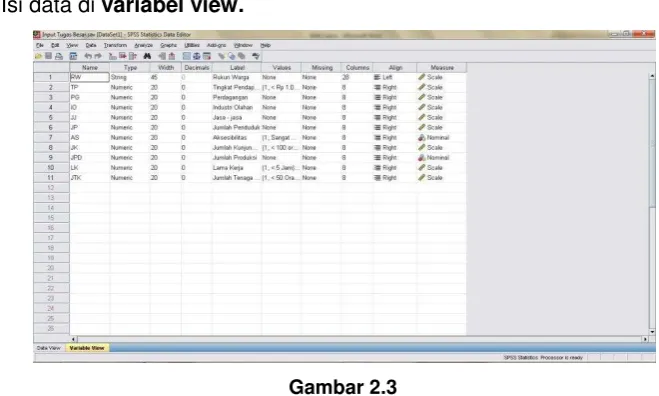
Tahapan pengolahan analisis cluster dengan SPSS : 1. Isi data di variabel view.
Gambar 2.3
Input Variabel Analisis Cluster
[email protected] 2. Masukan Value.
Gambar 2.4
Pengisian Data Pada Value
Sumber: Hasil Analisis Kelompok, 2016.
3. Isi data pada Data View.
Gambar 2.5
Input Data Analisis Cluster
4. Dari menu utama SPSS, pilih “Analyze” lalu pilih sub menu “Classify”
kemudian “Hierarchical Cluster…
Gambar 2.6
Sub Menu Analisis Cluster
Sumber: Hasil Analisis Kelompok, 2016.
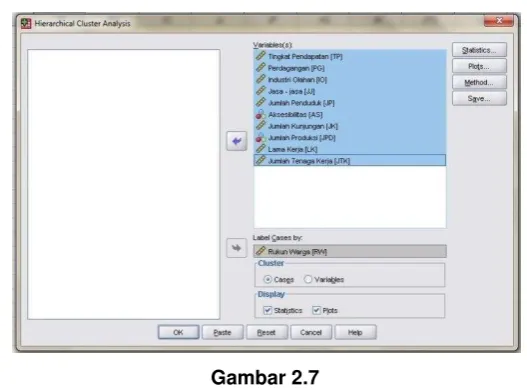
5. Tampak di layar :
Gambar 2.7
Penentuan Variabel dan Label Cases
Sumber: Hasil Analisis Kelompok, 2016.
[email protected] 6. Pilih menu Statistics, akan tampak pada layar :
Gambar 2.8
Statistics
Sumber: Hasil Analisis Kelompok, 2016.
Klik pada kolom Proximity matrix. Untuk Cluster Membership, pilih none, lalu klik tombol Continue.
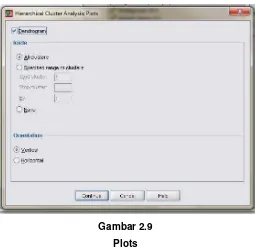
7. Kemudian klik icon Plots, akan tampak pada layar :
Gambar 2.9
Plots
Sumber: Hasil Analisis Kelompok, 2016.
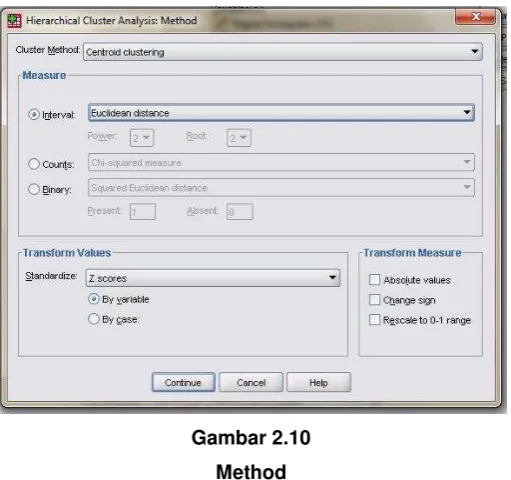
[email protected] 8. Klik icon Methods, akan tampak pada layar :
Gambar 2.10
Method
Sumber: Hasil Analisis Kelompok, 2016.
[email protected] 9. Klik icon Save, akan tampak pada layar :
Gambar 2.11
Save
Sumber: Hasil Analisis Kelompok, 2016.
Pada kolom Cluster Membership, pilih none. Kemudian klik Continue. 10. Terakhir, tekan tombol OK. SPSS akan menampilkan output analisis
cluster.
Gambar 2.12
Hasil Output Analisis Cluster