KLASIFIKASI LAHAN GAMBUT YANG TERBAKAR DI
KABUPATEN OGAN KOMERING ILIR MENGGUNAKAN
ALGORITME
RANDOM FOREST
DAN ALGORITME C5.0
MELIANA O. MEO
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Klasifikasi Lahan Gambut yang Terbakar di Kabupaten Ogan Komering Ilir Menggunakan Algoritme Random Forest dan Algoritme C5.0 adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
MELIANA O. MEO. Klasifikasi Lahan Gambut yang Terbakar di Kabupaten Ogan Komering Ilir Menggunakan Algoritme Random Forest dan Algoritme C5.0. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan AGUS BUONO.
Kebakaran hutan atau lahan di Indonesia tidak terjadi hanya pada lahan kering saja, tetapi terjadi juga pada lahan basah seperti lahan gambut. Kebakaran di lahan gambut lebih berbahaya dan sulit diatasi dibandingkan dengan kebakaran di daerah non-gambut, selain itu dampak dari kebakaran lahan gambut sangat merugikan masyarakat. Salah satu cara yang memungkinkan kita untuk mengetahui kondisi kebakaran hutan dan lahan gambut adalah dengan memanfaatkan teknologi penginderaan jauh. Citra satelit yang dihasilkan dari penginderaan jauh dapat dianalisis melalui proses klasifikasi.
Tujuan dari penelitian ini adalah membangun model klasifikasi menggunakan algoritme Random Forest (RF) dan algoritme C5.0 untuk mengklasifikasikan area lahan gambut sebelum terbakar, terbakar, dan setelah terbakar pada citra satelit Landsat 7 ETM+ dengan tanggal akusisi citra yaitu 6 September 2015. Area yang digunakan adalah Kabupaten Ogan Komering, Provinsi Sumatera Selatan. Model yang dibangun menggunakan 2 algoritme tersebut akan dianalisis untuk mengetahui algoritme yang terbaik dalam mengklasifikasi lahan gambut yang terbakar sehingga dapat dimanfaatkan untuk mengestimasi luasan lahan gambut yang terbakar.
Penelitian ini terdiri dari tiga pekerjaan utama yaitu praproses citra satelit, proses klasifikasi citra dan analisis hasil klasifikasi. Hasil penelitian ini menunjukan bahwa algoritme RF memiliki akurasi terbaik, yaitu sebesar 97.26% dan nilai koefisien Kappa sebesar 0.97. Algoritme C5.0 memiliki akurasi sebesar 97.10% dan nilai Kappa sebesar 0.96 serta menghasilkan 27 aturan yang dapat digunakan untuk mengetahui karakteristik band dari kelas sebelum terbakar, terbakar, dan setelah terbakar pada citra satelit Landsat 7 ETM+.
Dari aturan yang dihasilkan dapat diketahui bahwa kelas sebelum terbakar memiliki nilai band 7 lebih besar dari 40 dan lebih kecil dari atau sama dengan 101, band 4 memiliki nilai lebih besar dari 73, dan band 2 memiliki nilai lebih kecil dari atau sama dengan 123. Kelas terbakar memiliki nilai band 7 lebih besar dari 78, band 4 memiliki nilai lebih besar dari 94 dan lebih kecil dari atau sama dengan 149 dan band 2 memiliki nilai lebih besar dari 75. Kelas setelah terbakar memiliki nilai band 7 lebih besar dari 40 dan lebih kecil dari atau sama dengan 166, band 4 memiliki nilai lebih kecil atau sama dengan 119 dan band 2 memiliki nilai lebih kecil dari atau sama dengan 82. Kelas awan memiliki nilai band 4 nilai lebih besar 94, dan band 2 memiliki nilai lebih besar 83.
Selain itu, hasil penelitian menunjukan bahwa total estimasi luasan lahan gambut di kabupaten Ogan Komering Ilir, Sumatera Selatan pada tanggal 6 September 2015 dengan menggunakan algoritme C5.0 adalah 7 119.995 km2 pada kelas sebelum terbakar, 689.895 km2 pada kelas terbakar dan 2 155.300 km2 pada kelas setelah terbakar.
SUMMARY
MELIANA O. MEO. Classification of Burned Peatland in Ogan Komering Ilir District using Random Forest Algorithm and C5.0 Algorithm. Supervised by IMAS SUKAESIH SITANGGANG and AGUS BUONO.
Forest or land fires in Indonesia are not only occurred in dry lands but also in peatlands. Peatland fires are more dangerous and more difficult to overcome compared to non-peatland fires and the impacts of peatland fires are very harmful to society. One of the solutions in assessing forest and peatland fires is remote sensing technology. Satellite images obtained from remote sensing technology are usually classified for further analysis.
The main objective of this study is to develop a classification model using Random Forest (RF) algorithm and C5.0 algorithm to classify area in peatland before, during and after being burned on the satellite image Landsat 7 ETM + with the acquisition date September 6th 2015 The study area is Ogan Komering Ilir District, South Sumatera Province. The classification models that built using RF algorithm and C5.0 algorithm were analyzed to determine the best algorithm to classify peat fires.
There are three main steps of this research. These steps include satellite image preprocessing, image classification and classification result analysis. The experimental results showed that the RF algorithm generate the most accurate classifier with the accuracy of 97.26% and a Kappa value of 0.97. In addition, the C5.0 algorithm results a classifier with the accuracy of 97.10% and Kappa value of 0.96. The C5.0 algorithm produces 27 rules that can be used to determine the characteristics of the beforeburned class, burned class, and after burned class on the satellite image Landsat 7 ETM +.
Based on the generatedrules, it can be known that pixels with the before burned class have values of band 7 greater than 40 and less than or equal to 101, band 4 greater than 73, and band 2 less than or equal to 123. Pixels with the burned class have values of band 7 is greater than 78, band 4 greater than 94 and less than or equal to 149 and band 2 greater than 75. Pixels with the after burned class have values of band 7 greater than 40 and less than or equal to 166, band 4 less than or equal to 119 and band 2 less than or equal to 82. Pixels with the cloud class have values of band 4 greater than 94, and band 2 greater than 83.
In addition, this research results the estimated total area of peat based on the C5.0 classifier on September 6th 2015 in Ogan Komering Ilir District, South Sumatera is 7 119.995 km2 at the before burned class, 689.895km2 at the burned class and 2 155.300 km2 at the after burned class.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
KLASIFIKASI LAHAN GAMBUT YANG TERBAKAR DI
KABUPATEN OGAN KOMERING ILIR MENGGUNAKAN
ALGORITME
RANDOM FOREST
DAN ALGORITME C5.0
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Kuasa atas segala karunia-Nya sehingga penulis dapat menyelesaikan tesis ini. Tesis ini disusun sebagai laporan penelitian yang telah dilakukan penulis sejak bulan Agustus 2015 dengan judul Klasifikasi Lahan Gambut yang Terbakar di Kabupaten Ogan Komering Ilir Menggunakan Algoritme Random Forest dan Algoritme C5.0. Keberhasilan penulis menyelesaikan tesis ini tentunya tidak lepas dari bantuan serta dukungan berbagai pihak, baik secara langsung maupun tidak langsung. Oleh karena itu, pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada pihak-pihak yang telah membantu penyelesaian tesis ini, antara lain :
1. Kedua orang tua tercinta Bapak Fransiskus Meo, Mama Tresia Go Ai Tjen, Kak Ika, Kak Ambo, Adik Rina, suamiku Donzilio Antonio Meko dan anakku tercinta Marcello yang selalu memberikan dukungan, semangat serta doa demi kelancaran penyusunan laporan tesis ini.
2. Ibu Dr Imas Sukaesih Sitanggang, SSi MKom dan Bapak Dr. Ir. Agus Buono, MSi MKom selaku dosen pembimbing I dan II yang selalu bersedia memberikan waktu untuk membantu dan membimbing penulis dalam menyelesaikan tugas akhir ini.
3. Dr Eng Wisnu Ananta Kusuma, ST MT selaku dosen penguji yang telah memberikan arahan dan masukan untuk perbaikan tesis ini.
4. Teman-teman mahasiswa Magister Ilmu Komputer angkatan 2014 khususnya Nalar Istiqomah dan Putri Thariqa yang telah membantu dan memberi masukan kepada penulis dalam pengolahan data citra.
5. Direktorat Jenderal Pendidikan Tinggi yang telah memberikan beasiswa melalui program BPP-DN.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 3
Manfaat Penelitian 3
Ruang Lingkup Penelitian 3
2 TINJAUAN PUSTAKA 3
Kebakaran Lahan Gambut 3
Satelit Landsat dan Citra Satelit 4
Klasifikasi Data Citra Satelit 5
Pohon Keputusan 6
Algoritme C5.0 7
Algoritme Random Forest 8
3 METODOLOGI 9
Area Studi 9
Bahan 9
Peralatan Penelitian 10
Tahapan Penelitian 10
4 HASIL DAN PEMBAHASAN 14
Praproses Citra 14
Klasifikasi Citra 16
Klasifikasi Menggunakan Algoritme Random Forest dan C5.0 17
Analisis Perbandingan Model Klasifikasi 19
5 KESIMPULAN 23
Simpulan 23
Saran 23
DAFTAR PUSTAKA 24
LAMPIRAN 26
DAFTAR TABEL
1 Karakteristik sensor Landsat 7 ETM+ 4
2 Confusion matrix 13
3 Jumlah piksel area contoh 16
4 Akurasi rata-rata hasil klasifikasi model Random Forest 17 5 Akurasi rata-rata model berbasis pohon keputusan 18
6 Akurasi rata-rata model berbasis aturan 18
7 Perbandingan akurasi algoritme C5.0 dan RF 19
8 Kesalahan komisi algoritme C5.0 dan RF 19
9 Kesalahan omisi algoritme C5.0 dan RF 20
10 Confusion matrix untuk classifier dari algoritme C5.0 20 11 Confusion matrix untuk classifier dari algoritme RF 20 12 Estimasi luasan lahan gambut dengan algoritme RF 21 13 Estimasi luasan lahan gambut dengan algoritme C5.0 21
DAFTAR GAMBAR
1 Tampilan gelombang spektrum Landsat 7ETM+ (GDSC 2010). 4 2 Tampilan digital number (DN) pada citra (NASA 2006) 5 3 Skema klasifikasi terbimbing (Lillesand at el. 2004) 6
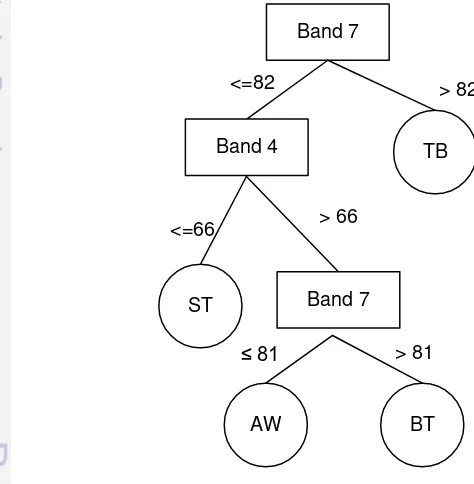
4 Pohon keputusan 6
5 Arsitektur umum Random Forest (Verikas et al. 2011) 8
6 Tahapan penelitian 11
7 Proses pengisian gap 14
8 Proses kombinasi band 15
9 Tahapan penentuan citra 15
10 Contoh kelas tutupan lahan 16
11 Perbandingan citra hasil klasifikasi 21
DAFTAR LAMPIRAN
1 Pembentukan tree dengan algoritme pohon keputusan 27 2 Pembentukan tree dengan algoritme Random Forest 33
3 Contoh hasil ekstraksi nilai DN 40
4 Contoh training area 40
1
PENDAHULUAN
Latar Belakang
Lahan gambut merupakan salah satu tipe lahan basah yang memiliki potensi besar dalam mendukung kehidupan manusia serta alam sekitarnya. Lahan gambut terdiri atas timbunan bahan-bahan organik yang berasal dari sisa-sisa tumbuhan yang telah mati dan membusuk (Wetlands 2011). Lahan gambut dapat tumbuh di berbagai negara, termasuk di Indonesia. Lahan gambut di Indonesia tersebar di beberapa pulau antara lain pulau Sumatera, Kalimantan dan Papua (BB Litbang SDLP 2011). Saat ini luasan lahan gambut di Indonesia khususnya di pulau Sumatera dan Kalimantan mengalami degradasi. Penyebab dari degradasi ini dapat berupa kejadian alamiah dan aktivitas manusia. Salah satu penyebab degradasi hutan adalah kebakaran.
Pada bulan September 2015, Badan Penanggulangan Bencana Daerah (BPBD) Kabupaten Ogan kemering Ilir mendeteksi sebanyak 234 titik panas yang tersebar di 10 kecamatan (Rohali 2015). Menurut analisis Greenpeace (2014) frekuensi titik panas memiliki jumlah lima kali lebih banyak pada lahan gambut dibandingkan dengan tanah mineral (lahan kering). Kebakaran di lahan gambut sangat sulit diatasi dan lebih berbahaya dibandingkan dengan kebakaran pada lahan non gambut hal ini disebabkan karena kebakaran di lahan gambut termasuk dalam tipe kebakaran bawah (ground fire). Kebakaran gambut (ground fire) sulit diketahui sebarannya, karena kebakaran terjadi di bawah permukaan tanah dan tidak terlihat adanya nyala api sehingga sulit untuk diamati selain itu juga lapisan gambut yang terbakar akan bertahan lama dan menghasilkan asap tebal (Syaufina 2008).
Penyebab kebakaran sering kali tidak dapat ditentukan dengan pasti, namun kebakaran-kebakaran yang terjadi hampir selalu disebabkan oleh ulah manusia seperti pembukaan lahan dengan cara membakar. Kebakaran hutan telah memberikan dampak yang cukup serius yaitu adanya akumulasi asap di atas Pulau Sumatera dan Kalimantan yang mengganggu kesehatan, menganggu kelancaran lalu lintas penerbangan, transportasi darat dan air, bahkan adanya keluhan dari negara tetangga (Syaufina 2008). Besarnya angka kerugian akibat kebakaran menuntut kita untuk melakukan usaha pencegahan dan pengendalian kebakaran secara terus menerus.
Upaya pencegahan menjadi prioritas utama dalam penanggulangan kebakaran hutan khususnya untuk daerah-daerah yang menjadi zona kebakaran salah satunya yaitu di Kabupaten Ogan Komering Ilir. Salah satu upaya yang dapat dilakukan adalah dengan memanfaatkan teknologi remote sensing. Pengolahan citra satelit yang dihasilkan dari remote sensing sangat bermanfaat bagi stakeholder terkait dalam menyediakan informasi mengenai sebaran spasial daerah-daerah yang telah mengalami kebakaran hutan dan lahan (area terbakar) terutama informasi luas lahan yang terbakar (Suwarsono et al. 2013).
2
berbagai algoritme dalam pohon keputusan antara lain algoritme Random Forest dan algoritme C5.0.
Beberapa penelitan telah dilakukan dengan menggunakan algoritme pohon keputusan, antara lain Galiano et al. (2012) mengklasifikasikan data citra Landsat-5 Thematic Mapper ke dalam 14 kategori tutupan lahan yang berbeda di selatan Spanyol dengan menggunakan algoritme Random Forest (RF). Penelitian menunjukkan bahwa algoritme Random Forest menghasilkan klasifikasi tutupan lahan yang akurat, dengan nilai akurasi keseluruhan sebesar 92% dan indeks Kappa sebesar 0,92. Liang et al. (2012), mengklasifikasikan dan membandingkan data citra tutupan lahan di wilayah Victoria Australia dengan menggunakan algoritme C5.0 dan maximum likelihood. Hasil penelitian menunjukkan bahwa akurasi terbaik ditemukan pada algoritme C5.0.
Thariqa et al. (2015) melakukan klasifikasi dan membandingkan data citra satelit untuk area gambut yang terbakar di Provinsi Riau menggunakan beberapa algoritme pohon keputusan antara lain algoritme C4.5, algoritme CART, algoritme C5.0 dan algoritme pohon keputusan berbasis autokorelasi spasial. Hasil penelitian yang dilakukan menunjukan bahwa algoritme C5.0 memiliki akurasi terbaik yaitu sebesar 99.79%. Lowe dan Kulkarni (2015) melakukan klasifikasi dan membandingkan citra satelit Landsat-8 Operational Land Imager (OLI) di wilayah Mississippi Bottomland dan Yellowstone National Park dengan menggunakan empat algoritme, yaitu algoritme Random Forest, SVM, maximum likelihood dan Neural Network. Hasil penelitian menunjukkan bahwa algoritme Random Forest memiliki akurasi yang paling baik dibandingkan algoritme lainnya.
Algoritme pohon keputusan dapat digunakan untuk mengklasifikasikan data yang besar, namun hasil klasifikasi pohon keputusan cenderung tidak stabil, karena perubahan-perubahan kecil pada data learning akan mempengaruhi hasil akurasi prediksi (Sutton 2005). Untuk memperbaiki stabilitas dan kekuatan akurasi prediksi pohon klasifikasi dapat digunakan metode boosting. Boosting adalah teknik untuk menghasilkan dan menggabungkan beberapa pengklasifikasi untuk meningkatkan akurasi prediksi (Rulequest 2012). Beberapa algoritme yang telah menerapkan metode ini antara lain algoritme C5.0 dan algoritme Random Forest.
Berdasarkan hal tersebut, maka pada penelitian ini akan dilakukan pengklasifikasian area lahan gambut yang terbakar di kabupaten Ogan Komering Ilir dari data citra Landsat 7. Klasifikasi citra sendiri dilakukan dengan menggunakan algoritme pohon keputusan C5.0 dan algoritme RF. Hasil klasifikasi dari kedua algoritme ini, selanjutnya akan dibandingkan untuk menemukan classifier yang terbaik dengan akurasi tinggi yang nantinya dapat digunakan untuk mengklasifikasikan dan menghitung estimasi luasan lahan atau wilayah yang belum terbakar, terbakar dan telah terbakar.
Perumusan Masalah
3 Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Membangun model pohon keputusan dengan menggunakan algoritme C5.0 dan Random Forest untuk mengklasifikasikan area lahan gambut yang terbakar di kabupaten Ogan Komering Ilir, Sumatera Selatan.
2. Menganalisis hasil perbandingan dari kedua algoritme yang diterapkan untuk mengetahui classifier terbaik dalam mengklasifikasikan lahan gambut yang terbakar.
Manfaat Penelitian
Manfaat dari penelitian ini diharapkan dapat memberikan informasi mengenai karakteristik lahan gambut sebelum terbakar, terbakar, dan setelah terbakar berdasarkan nilai band yang digunakan pada citra satelit. Karakteristik yang dihasilkan dapat digunakan untuk mendeteksi terjadinya kebakaran lahan gambut dari citra satelit. Selain itu hasil klasifikasi citra juga dapat digunakan untuk estimasi luasan lahan gambut yang sudah terbakar, belum terbakar, dan terbakar.
Ruang Lingkup Penelitian
Ruang lingkup penelitian yang dilakukan meliputi:
1. Data yang digunakan adalah citra satelit Landsat 7 ETM+ pada lahan gambut di Kabupaten Ogan Komering Ilir, Provinsi Sumatera Selatan pada tahun 2015 yang diambil dari USGS (United States Geological Survey).
2. Penelitian ini menerapkan algoritme pohon keputusan C5.0 dan Random Forest untuk mengklasifikasikan area gambut yang terbakar.
3. Penelitian ini hanya mengklasifikasikan wilayah lahan gambut yang terbakar pada permukaan lahan.
2
TINJAUAN PUSTAKA
Kebakaran Lahan Gambut
Kebakaran hutan dapat didefinisikan sebagai suatu kejadian di mana api melalap bahan bakar bervegetasi yang terjadi di dalam kawasan hutan yang menjalar secara bebas dan tidak terkendali (Syaufina 2008). Kebakaran hutan tidak terjadi pada lahan kering saja tetapi juga pada lahan basah seperti lahan/hutan gambut. Kebakaran hutan dapat dikelompokkan menjadi 3 tipe yaitu :
1. Kebakaran bawah (Ground fire)
Kebakaran ini terjadi di mana api membakar bahan oganik di bawah permukaan serasah yang pada umumnya berupa humus dan gambut. Penjalaran api berlangsung secara perlahan dan tidak dipengaruhi oleh angin, tanpa nyala sehingga sulit untuk dideteksi dan dikontrol. Selain itu ketika terbakar, api akan bercampur dengan uap air dari dalam gambut dan hasilkan asap yang sangat tebal.
2. Kebakaran permukaan (Surface fire)
4
penjalarannya, api dipengaruhi oleh angin permukaan sehingga dapat membakar tumbuhan yang lebih tinggi hingga ke tajuk pohon. Kebakaran permukaan ini biasanya merupakan langkah awal menuju kebakaran tajuk.
3. Kebakaran Tajuk (Crown fire)
Pada tipe ini, api menjalar dari tajuk pohon satu ke tajuk pohon berikutnya. Arah dan kecepatan penjalaran api sangat dipengaruhi oleh angin sehingga api menjalar sangat cepat dan sulit dikendalikan.
Satelit Landsat dan Citra Satelit
Satelit Landsat merupakan satelit hasil program sumberdaya bumi milik Amerika Serikat yang dikembangkan oleh NASA (the National Aeronautical and Space Administration). Satelit Landsat pertama kali diluncurkan pada tanggal 23 Juli 1972 dengan nama ERTS-I (Earth Resources Technology Satellite) yang kemudian berganti nama menjadi Landsat I. Hingga saat ini, seri Landsat yang diluncurkan telah sampai pada seri Landsat 8. Satelit ini berorbit sirkular dan sunsynchronous (melintasi garis equator setiap hari pada waktu lokal yang sama) serta dapat mencapai lokasi yang sama setiap 16 hari dan beresolusi radiometrik 8-bit (DN) (NASA 2013). Kelebihan sensor pada Landsat ETM+ adalah menggunakan delapan saluran, enam saluran dititikberatkan untuk studi vegetasi, satu saluran untuk studi geologi dan satu saluran untuk sensor pankromatik seperti tampak pada Tabel 1.
Tabel 1 Karakteristik sensor Landsat 7 ETM+
Band Resolusi Keterangan Spektral (μm)
1 30 m Blue 0.441 - 0.514
2 30 m Green 0.519 - 0.601
3 30 m Red 0.631 - 0.692
4 30 m NIR 0.772 - 0.898
5 30 m SWIR-1 1.547 - 1.749
6 60 m Thermal IR 10.31 - 12.36
7 30 m SWIR-2 2.064 – 2.345
8 15 m Pan 0.515 – 0.896
Landsat 7 ETM+ mencatat jumlah interval panjang gelombang kecil dalam spektrum elektromagnetik (cahaya tampak, dekat dan pendek inframerah gelombang) seperti tampak pada Gambar 1.
5 Citra merupakan representasi dua dimensi dari suatu objek di dunia nyata. Menurut Danoedoro (2012), citra dalam bidang remote sensing merupakan gambaran sebagian permukaan bumi yang diperoleh dari sistem perekaman melalui sensor yang dipasang pada pesawat terbang ataupun satelit. Citra digital adalah array angka-angka dalam bentuk dua dimensi. Setiap sel citra digital disebut piksel yang nilainya koordinatnya diketahui dan nilai intensitasnya diwakili oleh suatu angka (digital number [DN]) yang merepsentasikan tingkat kecerahan masing-masing piksel penyusun citra tersebut. Piksel merupakan unit terkecil dari sebuah citra. Masing-masing piksel terkait secara spasial dengan area di permukaan bumi. Gambar 2 merupakan tampilan digital number (DN) dari data citra satelit.
Gambar 2 Tampilan digital number (DN) pada citra (NASA 2006) Klasifikasi Data Citra Satelit
Klasifikasi citra satelit merupakan salah satu teknik yang digunakan untuk mengekstrak informasi dari sejumlah besar gambar satelit. Pada klasifikasi citra dilakukan proses pengelompokan nilai-nilai piksel ke dalam kelas yang berarti (Lillesand at el. 2004). Terdapat dua metode klasifikasi citra satelit yaitu klasifikasi tak terbimbing dan klasifikasi terbimbing.
Klasifikasi tak terbimbing akan mencari kelompok-kelompok piksel dari citra satelit kemudian menandai setiap piksel ke dalam sebuah kelas berdasarkan parameter-parameter pengelompokkan awal yang didefinisikan oleh penggunanya. Algoritme yang biasa digunakan adalah Isodata dan K-means. Sedangkan klasifikasi terbimbing memerlukan inputan atau informasi yang dikenal sebagai data latih untuk memulai klasifikasi. Piksel atau kelompok piksel yang sesuai dijadikan sebagai data latih, piksel-piksel tersebut digunakan untuk melatih dan mengenali piksel serupa lainnya (Lillesand at el. 2004). Algoritme yang biasa digunakan pada klasifikasi terbimbing adalah Maximum Likelihood dan Decision Tree (Abburu dan Golla 2015). Adapun skema dari klasifikasi terbimbing ditunjukkan pada Gambar 3.
6
diketahui”. Hasil dari klasifikasi tersebut kemudian dipetakan ke dalam bentuk tematik.
Gambar 3 Skema klasifikasi terbimbing (Lillesand at el. 2004) Pohon Keputusan
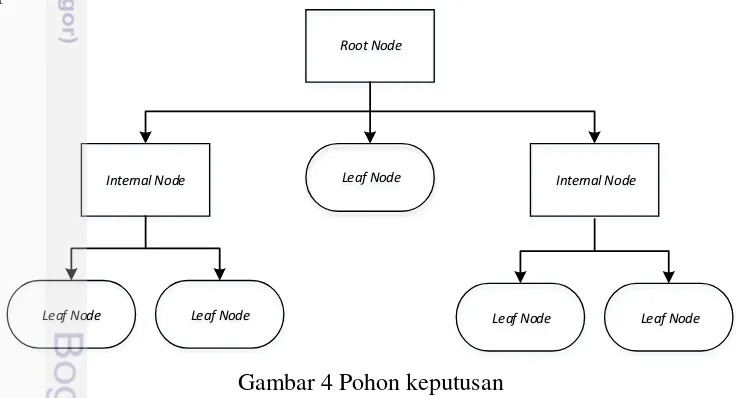
Pohon keputusan atau dikenal dengan decision tree merupakan salah satu metode dalam klasifikasi dan merupakan model prediksi dengan menggunakan struktur pohon atau struktur hirarki (Han et al. 2012). Peranan pohon keputusan ini adalah sebagai decision support tool untuk membantu manusia dalam mengambil suatu keputusan (Tsang et al. 2009). Manfaat dari pohon keputusan adalah melakukan break down proses pengambilan keputusan yang kompleks menjadi lebih simpel sehingga orang yang mengambil keputusan akan lebih mudah menginterpretasikan solusi dari permasalahan. Konsep dasar pohon keputusan adalah mengubah data menjadi pohon (tree) dan aturan keputusan (rule). Proses
Leaf Node Leaf Node Leaf Node Leaf Node
Gambar 4 Pohon keputusan
7 1. Root Node
Node ini merupakan node yang terletak paling atas dari suatu pohon dan tidak memiliki cabang yang masuk.
2. Internal Node
Node ini merupakan node percabangan, hanya terdapat satu input serta mempunyai minimal dua output.
3. Leaf Node
Node ini merupakan node akhir, hanya memiliki satu input, dan tidak memiliki output.
Algoritme C5.0
Algoritme C5.0 adalah pengembangan dari algoritme C4.5 dan juga ID3 (Patil et al. 2012). Algoritme C5.0 memiliki fitur penting yang membuat algoritme ini menjadi lebih unggul dibandingkan dengan algoritme terdahulunya (C4.5) dan mengurangi kelemahan yang ada pada algoritme pohon keputusan sebelumnya. Fitur tersebut (Rulequest 2012) adalah :
1. Boosting: proses yang akan melakukan beberapa kali percobaan dan akan menghasilkan beberapa aturan dan pohon keputusan. Beberapa aturan dan pohon keputusan tersebut dikombinasikan untuk meningkatkan prediksi
2. Winnowing: menyebabkan classifier lebih kecil dan menghasilkan akurasi prediksi yang lebih tinggi
3. Meminimalkan biaya kesalahan: algoritme C5.0 memisahkan biaya kesalahan yang pada masing-masing pasangan kelas prediksi dengan kelas yang sebenarnya. Jika pilihan ini digunakan, algoritme C5.0 akan membangun classifier untuk meminimalkan biaya kesalahan klasifikasi daripada membangun membangun
classifier untuk meminimalkan tingkat kesalahan (error rate).
4. Dari segi akurasi, algoritme C5.0 memiliki tingkat kesalahan yang lebih rendah dibandingkan dengan algoritme sebelumnya. Algoritme C4.5 dan algoritme C5.0 memiliki akurasi prediksi yang sama, tetapi set aturan algoritme C5.0 lebih kecil.
5. Untuk kecepatan, C5.0 jauh lebih cepat, menggunakan algoritme yang berbeda dan sangat dioptimalkan.
6. Penggunaan memori pada algoritme C5.0 umumnya lebih ringan dari C4.5. Menurut Patil et al. (2012) pemilihan atribut dalam algoritme C5.0 diproses dengan menghitung besarnya nilai information gain. Dalam memilih atribut untuk memecahkan objek harus dipilih atribut yang menghasilkan information gain paling besar. Atribut yang memiliki information gain terbesar akan dipilih sebagai parent atau untuk node selanjutnya.
Persamaan entropy dan information gain yang digunakan pada algoritme algoritme C5.0 adalah sebagai berikut (Han et al. 2012) :
� � = − ∑= � � (1)
Di mana info � adalah nilai entropy dari sampel data D, m adalah jumlah kelas yang ada di atribut, sedangkan ��adalah peluang dari kelas i atau rasio dari kelas. Partisi tuple di D pada beberapa atribut A memiliki nilai v yang berbeda
8
v partisi atau sub himpunan {D1, D2, …, Dv}. | | merupakan bobot partisi ke-j. Nilai entropy yang dihasilkan untuk mengklasifikasi tuple dari D berdasarkan partisi oleh A adalah (Han et al. 2012):
� � = ∑� | |
= × � (� ) (2)
Information gain yang diperoleh pada atribut A adalah:
��� = � � − � � (3)
Gain(A) menyatakan bahwa ada berapa banyak cabang yang akan diperoleh pada A. Atribut A dengan information gain tertinggi, maka Gain(A) dipilih sebagai atribut pada node (Han et al. 2012). Contoh pembentukan pohon keputusan dapat dilihat pada Lampiran 1.
Algoritme Random Forest
Algoritme Random Forest (RF) merupakan pengembangan dari metode Classification and Regression Tree (CART) dengan menerapkan metode bootstrap aggregating (bagging) dan random feature selection (Breiman 2001). Metode ini merupakan metode pohon gabungan (ensemble tree). Dalam RF, banyak pohon ditumbuhkan sehingga terbentuk suatu hutan (forest), kemudian analisis dilakukan pada kumpulan pohon tersebut. Penggunaan bagging pada RF berguna dalam mengatasi sifat ketidakstabilan dari metode klasifikasi tunggal.
Pada RF pembentukan tree dilakukan dengan cara melakukan training sampel data. Cara yang digunakan untuk mengambil sampel data adalah dengan Sampling with replacement. Variabel yang digunakan sebagai split dipilih secara acak. Proses klasifikasi dilakukan setelah semua tree terbentuk dan penentuan hasil klasifikasi diambil berdasarkan vote dari masing-masing tree. Vote terbanyak yang akan menjadi pemenangnya. Arsitektur umum dari RF dapat dilihat pada Gambar 4.
Gambar 5 Arsitektur umum Random Forest (Verikas et al. 2011)
Berikut ini adalah prosedur atau algoritme untuk membangun Random Forest pada gugus data yang terdiri dari n amatan dan p peubah penjelas (Breiman 2001; Breiman dan Cutler 2003):
9 2. Dengan menggunakan contoh bootstrap, pohon dibangun sampai mencapai ukuran maksimum yaitu tanpa pemangkasan (pruning). Pembangunan pohon dilakukan dengan menerapkan random feature selection yaitu m peubah penjelas dipilih secara acak dengan m << p, selanjutnya pemilah terbaik dipilih berdasarkan m peubah penjelas.
Langkah 1 dan 2 diulangi sebanyak k kali untuk membuat sebuah forest yang terdiri dari k pohon.
Tahapan pembuatan model klasifikasi menggunakan algoritme Random Forest dilakukan setelah membuat pemodelan data latih menggunakan package randomForest di R. Contoh pembentukan tree dengan algoritme RF dapat dilihat pada Lampiran 2.
Pada Random Forest pembentukan tree dilakukan dengan menerapkan motode CART dimana split yang akan dijadikan root dihitung dengan menggunakan nilai Gini Index. Gini index memiliki persamaan sebagai berikut (Han et al. 2012) :
�� � = − ∑= � (4)
�� � ��� = �� � − �� � , = �� � − ∑= |� ||�| �� � (5)
dengan � adalah probabilitas dari S milik kelas i, sedangkan adalah partisi dari dataset yang memiliki atribut A.
Metode CART menghasilkan suatu pohon klasifikasi jika peubah responnya kategorik, dan menghasilkan pohon regresi jika peubah responnya kontinu. Untuk peubah kontinu � penyekatan yang diperbolehkan adalah � dan � dimana c adalah nilai tengah antara dua nilai amatan peubah � secara berurutan (Breiman et al. 1993).
3
METODOLOGI
Area Studi
Area studi yang akan digunakan dalam penelitian ini adalah lahan gambut di Kabupaten Ogan Komering Ilir, Provinsi Sumatera Selatan yang memiliki luas wilayah 19.023,47 km2. Kabuaten ini terletak pada koordinat 104°.20’ sampai 106°.00’ Bujur Timur (BT) dan 2°.30’ sampai 4°15’ Lintang Selatan (LS), secara geografis Ogan Komering Ilir berbatasan dengan Kabupaten Ogan Ilir, Kabupaten Banyuasin dan Kota Palembang (Utara), Propinsi Lampung (Selatan), Kabupaten Ogan Ilir dan Kabupaten Ogan Komering Ulu Timur (Barat), Selat Bangka dan Laut Jawa (Timur) (Pemerintah Kabupaten Ogan Komering Ilir 2013).
Bahan
10
mewakili luas 30×30 meter di bumi atau di lapangan. Citra satelit tersebut memiliki path 124 dan row 62 dengan tanggal akusisi citra yang digunakan adalah tanggal 6 September 2015.
Data peta lahan gambut di pulau Sumatera tahun 2002 digunakan untuk mengetahui letak tutupan lahan gambut yang terdapat pada citra satelit. Peta lahan gambut berupa poligon yang diperoleh dari Wetlands International Programme Indonesia. Data titik panas tanggal 1 - 6 September 2015 digunakan untuk menentukan kelas sebelum terbakar, terbakar, dan setelah terbakar. Data ini diperoleh dari FIRMS MODIS Fire/Hotspot, NASA/University of Maryland. Keseluruhan data spasial tersebut menggunakan sistem referensi spasial WGS84.
Peralatan Penelitian
Perangkat lunak dan perangkat keras yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Perangkat lunak :
a. Sistem Operasi Windows 8 b. Aplikasi Microsoft Excel 2010
c. R sebagai bahasa pemrograman yang digunakan untuk klasifikasi data d. ILWIS dan Quantum GIS 2.6.0 untuk praproses citra satelit.
e. PostgreSQL 9.1 digunakan untuk mengelola data spasial
2. Perangkat keras yaitu komputer personal dengan spesifikasi sebagai berikut: a. Processor Intel Core2Duo @2.1 GHz,
b. RAM 4 GB DDR2, dan c. Harddisk 1 Terabyte
Tahapan Penelitian
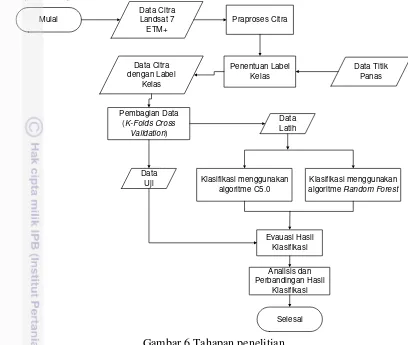
Penelitian ini terdiri dari 3 tahapan utama yaitu praproses citra, klasifikasi citra satelit dan evaluasi serta analisis hasil. Setiap tahap tersebut ditunjukan dalam Gambar 6.
1. Praproses Citra
Tahapan ini merupakan tahapan awal sebelum proses klasifikasi dilakukan, beberapa tahapan yang dilakukan pada praproses citra ini adalah :
a. Pengisian Gap
Pada tanggal 31 Mei 2013, sistem satelit Landsat-7 ETM+ mengalami kerusakan berupa kegagalan pengoreksi baris pemindai pada sensor SLC (Scan Line Corrector). Akibat kegagalan ini, data hasil pemindaian banyak yang hilang. Sejak kerusakan itu, maka seluruh data Landsat-7 ETM+ hasil rekaman pasca kerusakan disebut sebagai data Landsat SLC-Off, sedangkan data hasil rekaman sebelum kerusakan disebut sebagai data Landsat SLC-On.
11 b. Kombinasi band danproses georeferensi
Citra komposit adalah citra hasil kombinasi atau penggabungan tiga saluran (band) yang memiliki resolusi spektral berbeda (Lillesand at el. 2004). Tujuan dari citra komposit ini untuk mendapatkan tampilan visual yang optimal untuk identifikasi kebakaran hutan. Pada penelitian ini digunakan kombinasi band 7, band 4, dan band 2 yang mengacu pada standar dari NASA (GDSC 2010).
Kombinasi band ini cocok untuk menggambarkan daerah sebelum terbakar, terbakar, dan setelah terbakar karena dapat menunjukkan daerah terbakar dengan warna merah yang jelas berbeda dari daerah sekitarnya yang berwarna hijau. Band 7 sangat sensitif terhadap pancaran radiasi sehingga dapat mendeteksi sumber panas (Pennington 2006). Kombinasi band 742 membuat daerah setelah terbakar mudah terlihat dari daerah yang tidak terbakar. Kombinasi 3 band ini akan digunakan dalam membantu penentuan area contoh.
12
menghasilkan peta raster yang sudah memiliki titik georeferensi dan sistem koordinat.
c. Penentuan area studi
Tahap praproses selanjutnya adalah penentuan area studi yang dilakukan dengan cara overlay dan clipping citra satelit dengan peta lahan gambut. Overlay adalah proses yang memungkinkan untuk mengambil dua atau lebih tematik peta dengan wilayah yang sama dan menempelkan peta yang satu di atas peta yang lain sehingga membentuk peta baru (Kumar 2005). Citra satelit Landsat 7 akan dioverlay dengan peta lahan gambut setelah itu akan dilakukan proses clipping untuk memotong bagian citra satelit yang terletak di daerah tutupan lahan gambut. Proses overlay dan clipping dilakukan dengan menggunakan perangkat lunak QGIS.
2. Klasifikasi Citra Satelit
Sebelum dilakukan klasifikasi citra satelit, terdapat beberapa tahapan yang dilakukan yaitu proses penentuan kelas citra satelit, pembagian data latih dan data uji serta proses klasifikasi. Proses penentuan kelas citra satelit dilakukan dengan cara meng-overlay titik panas dengan citra satelit untuk mendapatkan label kelas yang dibutuhkan. Terdapat empat buah kelas label yang akan dihasilkan, yaitu: sebelum terbakar, terbakar, setelah terbakar dan awan. Data titik panas yang digunakan adalah data titik panas taggal 1 - 6 September 2015 yang disesuaikan dengan akusisi citra yang digunakan yaitu tanggal 6 September 2015.
Setelah proses penentuan label kelas, tahapan selanjutnya adalah pembagian data latih dan data uji. Pembagian data dilakukan dengan menggunakan metode K-fold cross validation. Cross-validation adalah pengujian standar yang dilakukan untuk memprediksi error rate. Data training dibagi secara random ke dalam k-subset dengan perbandingan yang sama. Kemudian secara bertahap akan dilakukan pelatihan dan validasi sebanyak k ulangan. Setiap ulangan disisakan satu subset untuk pengujian, dan sisanya digunakan untuk pelatihan.
Pembagian data dengan metode K-fold cross validation ini akan membagi data menjadi K kelompok dan akan mengulang percobaan sebanyak K-kali. Data akan dibagi menjadi 10 kelompok percobaan dengan proporsi 90% data latih dan 10% data uji. Pembagian data dilakukan dengan menggunakan package caret yang terdapat pada perangkat lunak R.
Tahapan akhir setelah pembagian data yaitu proses klasifikasi. Proses klasifikasi dilakukan dengan menerapkan algoritme RF dan algoritme C5.0. Semua proses klasifikasi dilakukan dengan menggunakan perangkat lunak R. Data set yang akan diolah memiliki 3 atribut, yaitu band 7, band 4, dan band 2. Setiap atribut berisi nilai piksel dari setiap band.
3. Analisis Perbandingan Model Klasifikasi
Pada tahap ini dilakukan analisis perbandingan hasil klasifikasi yang telah dilakukan menggunakan algoritme C5.0 dan algoritme Random Forest. Analisis ini dilakukan untuk mengetahui classifier terbaik untuk mengklasifikasikan area terbakar pada lahan gambut.
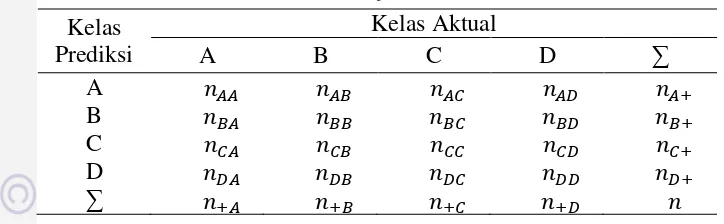
13 berdasarkan Confusion matrix antara lain adalah kesalahan komisi, kesalahan omisi, akurasi keseluruhan. Bentuk Confusion matrix dapat dilihat pada Tabel 2 (Foody 2002).
Kesalahan komisi merupakan kesalahan akibat suatu area diklasifikasikan pada kelas yang salah di lapangan. Nilai ini dapat menunjukkan seberapa baik suatu piksel yang telah diklasifikasi, secara aktual mewakili kelas-kelas tersebut di lapangan. Kesalahan Komisi dapat dirumuskan sebagai berikut (Foody 2002).
Kesalahan Komisi = + +
+ × % (6)
Kesalahan omisi merupakan kesalahan akibat suatu area di lapangan tidak diklasifikasikan pada kelas yang benar. Nilai ini dapat menunjukkan seberapa baik suatu kelas telah dapat diklasifikasikan (Foody 2002).
Kesalahan Omisi = + +
+ × % (7)
Akurasi keseluruhan menunjukkan banyaknya jumlah piksel yang terklasifikasi secara benar pada tiap kelas dibanding jumlah sampel yang digunakan untuk uji akurasi pada semua kelas (Foody 2002).
Akurasi = ∑ �
= × (8)
Nilai akurasi yang paling banyak digunakan adalah akurasi koefisien Kappa. Kappa dapat digunakan untuk mengukur kebenaran antara model dengan kenyataan atau menghitung jumlah nilai yang ada dalam perhitungan Confusion matrix (Foody 2002).
�� � = ∑�= −∑�= +× +
−∑�= +× + (9)
dimana:
= nilai diagonal dari matrik kontingensi baris ke-k dan kolom ke-k + + = jumlah piksel dalam kolom ke-k
14
4
HASIL DAN PEMBAHASAN
Praproses Citra
1. Pengisian Gap
Kerusakan Scan Line Corrector (SLC) pada tanggal 31 Mei 2003,mengakibatkan data citra satelit yang dihasilkan Satelit LANDSAT 7 tidaklah sempurna. Semua citra yang diambil setelah tanggal tersebut memiliki celah/gap. Gap ini menyebabkan hasil klasifikasi menjadi kurang baik. Oleh karena itu dilakukan pengisian gap pada masing-masing band dengan gapmask yang telah dengan disediakan oleh NASA. Pengisian gap dilakukan menggunakan perangkat lunak QGIS. Gambar 7 merupakan contoh citra yang telah diisi gapnya.
(a) (b)
Gambar 7 Proses pengisian gap (a) Citra satelit sebelum pengisian gap (b) Citra satelit setelah pengisian gap
2. Kombinasi Band dan proses georeferensi
Pada tahapan ini akan dilakukan proses kombinasi band dan georeferensi. Proses kombinasi band citra satelit dilakukan pada citra tanggal 6 September 2015. Band yang akan dikombinasikan adalah band 7, band 4, dan band 2. Sebelum proses composit, citra satelit masih berwarna abu-abu dan setiap piksel dalam citra tersebut hanya memiliki 1 nilai digital saja. Setelah proses composite dilakukan, setiap piksel dalam citra memiliki 3 nilai digital yang berasal dari kombinasi band 7, band 4, dan band 2. Tiga band tersebut memiliki nilai digital berbeda yang digunakan sebagai atribut dalam proses klasifikasi. Citra hasil proses composite memiliki warna campuran merah, hijau, dan biru atau dikenal dengan RGB. Setiap piksel memiliki nilai digital dari 0 sampai 255. Gambar 8 (a), (b), dan (c) menunjukan citra sebelum proses kombinasi band dan Gambar 8 (d) menunjukan citra hasil kombinasi band.
15
(a) (b)
(c) (d)
Gambar 8 Proses kombinasi band (a) Citra satelit band 7 sebelum kombinasi band (b) Citra satelit band 4 sebelum kombinasi band (c) Citra satelit band 2 sebelum kombinasi band (d) Citra hasil kombinasi band 7-4-2
3. Penentuan area studi
Pada penelitian ini, citra satelit yang digunakan hanya citra yang memiliki daerah tutupan lahan gambut yang terdapat di kabupaten Ogan Komering Ilir. Untuk memperoleh citra yang memiliki tutupan lahan gambut maka dilakukan proses overlay dan clipping. Overlay dilakukan untuk mengetahui bagian citra satelit yang memiliki tutupan lahan gambut sedangkan proses clipping dilakukan untuk mengambil dan memotong bagian citra yang terdapat lahan gambutnya saja. Gambar 9 (a) menunjukkan proses overlay citra satelit dengan peta lahan gambut kabupaten Ogan Komering Ilir dan Gambar 9 (b) menunjukkan hasil clipping citra satelit dengan peta lahan gambut.
(a) (b)
16
Klasifikasi Citra
Tahapan awal yang dilakukan sebelum proses klasifikasi yaitu tahap penentuan label kelas. Penentuan label kelas sendiri bertujuan untuk memperoleh informasi mengenai kelas-kelas yang akan digunakan dalam klasifikasi. Dalam penelitian ini terdapat empat buah label kelas yang akan digunakan yaitu sebelum terbakar, terbakar, setelah terbakar dan awan. Untuk menentukan label kelas tersebut digunakan data titik panas. Penentuan data titik panas yang digunakan dilihat dari banyaknya jumlah titik panas yang muncul di lahan gambut pada tahun 2015. Jumlah titik panas yang paling banyak muncul di lahan gambut pada tahun 2015 adalah di bulan September. Penggunaan data titik panas disesuaikan dengan tanggal akusisi citra yang digunakan yaitu tanggal 6 September 2015, artinya tidak semua data titik panas di bulan September digunakan dalam penelitian ini. Data titik panas yang digunakan dimulai dari tanggal 1 September 2015 sampai dengan tanggal 6 September 2015.
Penentuan label kelas dilakukan dengan cara tumpang susun data titik panas dengan citra satelit yang digunakan. Setelah proses overlay dilakukan, selanjutnya adalah pengambilan sampel atau area contoh. Sampel piksel yang diambil berdasarkan kenampakan visual pada display monitor, di mana kelas sebelum terbakar ditandai dengan warna hijau, kelas terbakar ditandai dengan merah terang, kelas setelah terbakar ditandai dengan merah kecoklatan dan kelas awan ditandai dengan warna putih. Sampel yang telah dipotong selanjutnya diekstrak ke dalam nilai digital menggunakan perangkat lunak R, contoh dari hasil ekstraksi nilai DN dapat dilihat pada Lampiran 3. Pada data hasil ekstraksi tersebut akan memiliki 3 atribut dengan tipe data numerik. Gambar 10 merupakan contoh kelas untuk kebakaran lahan. Banyaknya jumlah piksel setiap kelas yang menjadi area contoh disajikan pada Tabel 3.
(a) (b) (c) (d)
Gambar 10 Contoh kelas tutupan lahan (a) Kelas sebelum terbakar (b) kelas terbakar (c) Kelas setelah terbakar (d) Kelas awan
Tabel 3 Jumlah piksel area contoh
Kelas tutupan lahan Jumlah sampel Jumlah piksel pada setiap sampel
Sebelum Terbakar 10 2.500
Terbakar 10 2.343
Setelah Terbakar 10 2.502
Awan 10 2.400
17 Data dibagi menjadi 10 kelompok percobaan dengan porsi 9/10 data digunakan sebagai data latih dan 1/10 data digunakan sebagai data uji. Artinya dari 9.745 piksel dataset diambil 8.770 piksel atau 8.771 piksel sebagai data latih dan sisanya sebanyak 975 piksel atau 974 piksel sebagai data uji. K-fold cross validation akan melakukan pengulangan percobaan sebanyak 10 kali, sehingga didapatkan data latih dan data uji yang berbeda. Contoh data latihdapat dilihat pada Lampiran 4.
Pembentukan model klasifikasi dilakukan menggunakan data latih. Sementara itu, hasil akurasi model klasifikasi diperoleh dari data uji. Data latih dari 10 kelompok percobaan akan dilatih menggunakan algoritme Random Forest dan C5.0. Proses klasifikasi sendiri dilakukan dengan menggunakan package yang telah disediakan pada perangkat lunak R.
Klasifikasi Menggunakan Algoritme Random Forest dan C5.0
Tahap selanjutnya setelah proses pembagian data latih dan data uji adalah melakukan klasifikasi dengan algoritme Random Forest dan C5.0. Pelatihan Random Forest dan C5.0 dilakukan dengan menggunakan package yang telah disediakan oleh perangkat lunak R yaitu packagerandomForest untuk klasifikasi menggunakan Random Forest dan package C5.0 untuk klasifikasi menggunakan C5.0.
1. Algoritme Random Forest
Dalam pengklasifikasian menggunakan Random Forest, jumlah tree yang akan dibangun sebanyak 100 dan pembagian untuk setiap node sebanyak 3, berdasarkan jumlah variabel penjelas. Pembangunan model tersebut dilakukan sebanyak 10 kali (10-fold). Pemodelan yang dijalankan di R ini tidak menghasilkan model berupa tree dan vote yang terpilih. Akurasi hasil klasifikasi training area (data uji) daridata citra satelit yang digunakandapat dilihat pada Tabel 4.
Tabel 4 Akurasi rata-rata hasil klasifikasi model Random Forest Fold Koefisien Kappa Akurasi Keseluruhan
(%)
18
2. Algoritme C5.0
Algoritme C5.0 menghasilkan model klasifikasi berupa model pohon keputusan dan model berbasis aturan. Model berbasis aturan memiliki banyak aturan yang dapat disederhanakan dan dipangkas sehingga aturan yang diturunkan dapat berjumlah sedikit dari aturan yang dihasilkan oleh model berbasis pohon keputusan. Dari tahapan implementasi menggunakan algoritme C5.0 dengan menggunakan perangkat lunak R, diperoleh model berbasis pohon keputusan untuk dataset tiap fold. Akurasi model berbasis pohon keputusan dapat dilihat pada Tabel 5 sedangkan akurasi model berbasis aturan dapat dilihat pada Tabel 6.
Tabel 5 Akurasi rata-rata model berbasis pohon keputusan Fold Ukuran
Akurasi rata-rata yang diperoleh dari model pohon keputusan dari 10-fold pada Tabel 5 diatas sebesar 97.14% dan nilai koefisien Kappa sebesar 0.96. Sedangkan akurasi rata-rata model berbasis aturan sebesar 97.10% dan nilai koefisien Kappa sebesar 0.96 seperti diberikan pada Tabel 6.
Tabel 6 Akurasi rata-rata model berbasis aturan Fold Jumlah
19 dan Tabel 6, dapat dilihat bahwa ukuran pohon keputusan dan jumlah aturan yang dihasilkan pada fold ke-10 lebih sedikit dibandingkan dengan fold lainnya yaitu dengan ukuran pohon sebesar 45 pohon dan jumlah aturan sebanyak 27 aturan.
Analisis Perbandingan Model Klasifikasi
Evaluasi hasil klasifikasi dilakukan dengan melihat beberapa ukuran, yaitu akurasi, kesalahan komisi, kesalahan omisi, dan citra hasil klasifikasi. Nilai akurasi didapatkan dengan menggunakan Confusion matrix. Hasil akurasi dengan menggunakan algoritme C5.0 dan algoritme Random Forest terdapat pada Tabel 7. Hasil tersebut merupakan hasil rata-rata yang didapatkan dari 10-fold.
Tabel 7 Perbandingan akurasi algoritme C5.0 dan RF Algoritme Koefisien Kappa Akurasi Keseluruhan (%)
C5.0 0.96 97.10
RF 0.97 97.26
Berdasarkan hasil perbandingan dari algoritme RF dan C5.0 pada Tabel 7 di atas, dapat dilihat bahwa kedua algoritme tersebut memiliki akurasi dan nilai koefisien Kapa yang sangat besar. Dari kedua algoritme tersebut, diketahui bahwa selisih dari nilai akurasi keseluruhan sebesar 0.16 % dan nilai koefisien Kappa sebesar 0.01.
Algoritme RF menggunakan indeks gini untuk membagi kriteria dalam membangun pohon. Algoritme ini mengembangkan pohon dengan cara binary split. Variabel yang digunakan sebagai split dipilih secara acak. Sedangkan algoritme C5.0 biasanya digunakan untuk melakukan klasifikasi dengan data kategorikal dan membuat pohon dengan multi-split, ketika terdapat data numerik algoritme ini akan membuat pohon dengan binary split. Penggunaan binary split pada algoritme tersebut akan membuat atribut yang ada muncul beberapa kali di dalam pohon.
Tabel 8 dan Tabel 9 merupakan kesalahan komisi dan kesalahan omisi dari 2 algoritme yang digunakan berdasarkan pada Confusion matrix yang tertera pada Tabel 10 dan Tabel 11. Confusion matrix yang terdapat pada Tabel 10 dan Tabel 11 diperoleh dari salah satu data uji yang memiliki akurasi yang terbaik dari 10-fold. Untuk Confusion matrix dari masing-masing fold disajikan pada Lampiran 5 dan Lampiran 6. Kesalahan omisi dalam penelitian ini adalah jumlah kesalahan interpretasi dari kelas X dibagi dengan jumlah seluruh kelas yang diinterpretasi, sedangkan kesalahan komisi adalah jumlah kelas lain yang diinterpretasikan sebagai kelas X dibagi jumlah seluruh kelas yang diinterpretasikan.
Tabel 8 Kesalahan komisi algoritme C5.0 dan RF Kelas Kesalahan Komisi dari algoritme
C5.0 RF
20
Tabel 9 Kesalahan omisi algoritme C5.0 dan RF Kelas Kesalahan Omisi dari algoritme
C5.0 RF
Sebelum Terbakar 1.99 1.59
Terbakar 1.36 2.16
Setelah Terbakar 7.52 3.17
Awan 0 0.42
Kesalahan omisi terbesar terdapat pada kelas setelah terbakar untuk algoritme C5.0 maupun algoritme RF. Kesalahan ini terjadi karena piksel-piksel suatu area di lapangan tidak diklasifikasikan pada kelas yang benar.
Tabel 10 Confusion matrix untuk classifier dari algoritme C5.0 Aktual
Tabel 11 Confusion matrix untuk classifier dari algoritme RF Aktual kelas terbakar. Hal ini dikarenakan terdapat kemiripan antara kelas setelah terbakar dan kelas terbakar. Kemiripan antara kelas setelah terbakar dan kelas terbakar menyebabkan kelas setelah terbakar sering diklasifikasikan menjadi kelas terbakar ataupun sebaliknya. Kemiripan antara kelas setelah terbakar dan kelas terbakar terletak pada warna yang di tunjukan pada citra satelit. Lahan bekas terbakar memiliki warna merah kecoklatan dan warna merah identik dengan kelas terbakar.
21
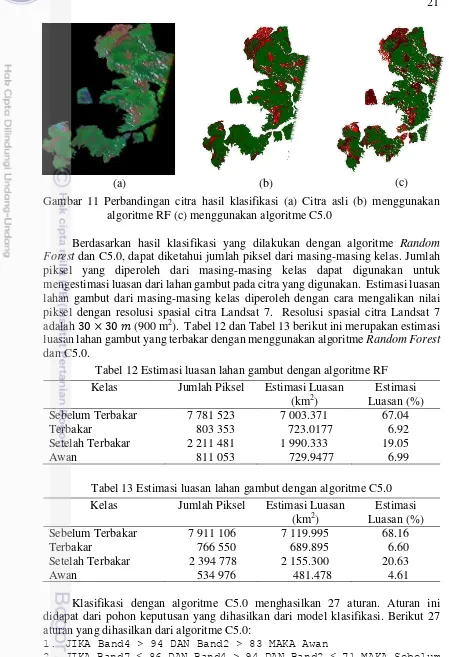
(a) (b) (c)
Gambar 11 Perbandingan citra hasil klasifikasi (a) Citra asli (b) menggunakan algoritme RF (c) menggunakan algoritme C5.0
Berdasarkan hasil klasifikasi yang dilakukan dengan algoritme Random Forest dan C5.0, dapat diketahui jumlah piksel dari masing-masing kelas. Jumlah piksel yang diperoleh dari masing-masing kelas dapat digunakan untuk mengestimasi luasan dari lahan gambut pada citra yang digunakan. Estimasi luasan lahan gambut dari masing-masing kelas diperoleh dengan cara mengalikan nilai piksel dengan resolusi spasial citra Landsat 7. Resolusi spasial citra Landsat 7 adalah × (900 m2). Tabel 12 dan Tabel 13 berikut ini merupakan estimasi luasan lahan gambut yang terbakar dengan menggunakan algoritme Random Forest dan C5.0.
Tabel 12 Estimasi luasan lahan gambut dengan algoritme RF Kelas Jumlah Piksel Estimasi Luasan
(km2)
Estimasi Luasan (%)
Sebelum Terbakar 7 781 523 7 003.371 67.04
Terbakar 803 353 723.0177 6.92
Setelah Terbakar 2 211 481 1 990.333 19.05
Awan 811 053 729.9477 6.99
Tabel 13 Estimasi luasan lahan gambut dengan algoritme C5.0 Kelas Jumlah Piksel Estimasi Luasan
(km2)
Estimasi Luasan (%)
Sebelum Terbakar 7 911 106 7 119.995 68.16
Terbakar 766 550 689.895 6.60
Setelah Terbakar 2 394 778 2 155.300 20.63
Awan 534 976 481.478 4.61
Klasifikasi dengan algoritme C5.0 menghasilkan 27 aturan. Aturan ini didapat dari pohon keputusan yang dihasilkan dari model klasifikasi. Berikut 27 aturan yang dihasilkan dari algoritme C5.0:
1. JIKA Band4 > 94 DAN Band2 > 83 MAKA Awan
2. JIKA Band7 ≤ 86 DAN Band4 > 94 DAN Band2 ≤ 71 MAKA Sebelum Terbakar
22
4. JIKA Band4 > 119 DAN Band2 ≤ 81 MAKA Sebelum Terbakar 5. JIKA 86 < Band7 ≤ 101 DAN Band4 > 94 DAN 69 < Band2 ≤ 83 13.JIKA Band7 > 86 DAN Band2 ≤ 69 MAKA Setelah Terbakar
14.JIKA 101 < Band7 ≤ 166 DAN 94 < Band4 ≤ 119 DAN Band2 ≤ 81 MAKA Setelah Terbakar
15.JIKA Band4 ≤ 94 MAKA Setelah Terbakar
16.JIKA Band7 > 161 DAN Band4 ≤ 94 MAKA Terbakar 17.JIKA Band7 > 166 DAN Band4 ≤ 149 MAKA Terbakar
18.JIKA Band7 > 79 DAN Band4 ≤ 70 DAN Band2 > 82 MAKA Terbakar
23 Dari aturan-aturan yang dihasilkan oleh algoritme C5.0 dapat disimpulkan bahwa kelas sebelum terbakar memiliki nilai band 4 yang lebih besar dari band 7, kelas terbakar memiliki nilai band 7 yang lebih besar dari band 4, kelas setelah terbakar berada di pertengahan nilai band dan kelas awan memiliki nilai band 2 yang lebih besar dari band lainnya.
Aturan yang dihasilkan dari algoritme ini dapat dimanfaatkan untuk mendeteksi adanya kebakaran di lahan gambut pada citra satelit. Aturan ini dapat memberikan kemudahan dalam mendapatkan informasi mengenai area yang terbakar, sebelum terbakar, dan telah terbakar. Kemudahan tersebut berupa waktu yang singkat untuk mendeteksi terjadinya kebakaran lahan gambut pada citra satelit.
5
KESIMPULAN
Simpulan
Penelitian ini berhasil menerapkan algoritme RF dan C5.0untuk klasifikasi area lahan gambut yang terbakar di kabupaten Ogan Komering Ilir, Sumatera Selatan. Nilai akurasi rata-rata dari kedua algoritme sangat besar, namun akurasi rata-rata pada algoritme RF lebih baik dari algoritme C5.0 yaitu sebesar 97.26% dan nilai kappa sebesar 0.97, sedangkan nilai akurasi rata-rata yang dihasilkan algoritme C5.0 sebesar 97.10% dan nilai Kappa sebesar 0.96. Hasil klasifikasi citra dari kedua algoritme tersebut menunjukan bahwa terdapat kemiripan piksel antara lahan setelah terbakar dengan lahan terbakar. Hal ini disebabkan karena lahan bekas terbakar memiliki warna merah kecoklatan dan warna merah identik dengan kelas terbakar.
Selain itu, hasil penelitian menunjukan bahwa estimasi luasan lahan gambut pada kelas terbakar dengan menggunakan algoritme RF mencapai 723.0177 km2 (6.92%) dan mencapai 689.895 km2 (6.60%) dengan menggunakan algoritme C5.0. Sedangkan estimasi luasan lahan gambut untuk kelas setelah terbakar mencapai 1990.333 km2 (19.05%) dengan algoreitme RF dan mencapai 2155.300 km2 (20.63%) dengan menggunakan algoritme C5.0. Perbedaan tersebut terlihat karena adanya piksel-piksel pada kelas terbakar yang terdapat di antara kelas setelah terbakar dan sebaliknya.
Saran
24
DAFTAR PUSTAKA
Abburu U, Golla SB. 2015. Satellite Image Classification Methods and Techniques: A Review. International Journal of Computer Applications (IJCA). 119(8):20-25
Alpaydin E. 2004. Introduction to Machine Learning. Cambridge (MA): The MIT Press.
[BB Litbang SDLP] Balai Besar Penelitian dan Pengembangan Sumberdaya Lahan Pertanian. 2011. Peta Lahan Gambut Indonesia [Internet]. [diunduh 2015 Agustus 30]. Tersedia pada: http://bbsdlp.litbang.pertanian.go.id/phoca download/gambutindonesia_250000/Naskah%20Peta%20Gambut%20Indone si a%202011.pdf
Breiman L. 2001. Random Forests. Machine Learning. 45: 11–13.
Breiman L, Cutler A. 2003. Manual–setting up, using, and understanding Random Forests V4.0. [Internet]. [diunduh tanggal 06/06/2015]. Tersedia pada: https://www.stat.berkeley.edu/forests_V3.1.pdf.
Danoedoro P. 2012. Pengantar Penginderaan Jauh Digital. Yogyakarta (ID) : Penerbit Andi.
Foody GM. 2002. Status of Land Cover Classification Accuracy Assesment. Remote Sensing of Environtment. 8:185-201
Galiano VFR, Ghimire B, Rogan J, Olmo MC, Sanchez JPR. 2012. An assessment of the effectiveness of a Random Forest classifier for land-cover classification. ISPRS Journal of Photogrammetry and Remote Sensing 67: 93–104
[GDSC] Geospatial Data Service Centre. 2010. Band Combination [Internet].
[diunduh 2015 Oktober 2]. Tersedia pada:
http://gdsc.nlr.nl/gdsc/en/information/earth_observation/band_combinations Greenpeace. 2014. Sumatera: akan tertutup dengan asap [ulasan]. Pers
Greenpeace. [diunduh 2015 Des 15]. Tersedia pada: http://www.greenpeace.org/seasia/id/PageFiles/616273/Kabut%20Asap%20S umatera.pdf
Han J, Kamber M, Pei J. 2012. Data Mining Concepts and Techniques Second Edition. San Francisco (US): Morgan Kaufmann Publisher.
Kumar S. 2005. Basics of remote sensing and GIS. New Delhi (IN): Laxmi Publication (P) LTD.
Liang Z, Jinping S, Huiyong S, Gang Y, Yi J. 2012. Large Area Land Cover Classification with Landsat ETM+ Images Based On Decision Tree. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 39 (B7).
Lillesand TM, Kiefer RW, Chipman JW. 2004. Remote Sensing and Image Interpretation, USA: John Wiley & Sons, Inc.
Lowe B, Kulkarni A, 2015. Multispectral Image Analysis Using Random Forest, International Journal on Soft Computing (IJSC). 6(1). DOI: 10.5121/ijsc.2015.6101
25 [NASA] National Aeronautical and Space Administration. 2013. History. [Internet].
[diunduh 2015 Nov 20]. Tersedia pada:
http://landsat.gsfc.nasa.gov/?page_id=2281
Patil N, Lathi R, Chitre V. 2012. Customer card classification based on C5.0 and CART algorithms. International Journal of Enggineering Research and Applications ; 2012 July-August. 2 (4):164-167.
Pemerintah Kabupaten Ogan Komering Ilir. 2013. OKI dalam Geografis. [Internet].
[diunduh 2016 Mei 1]. Tersedia pada:
http://www.kaboki.go.id/index.php/selayang-pandang/kaboki-dalam-geografis.h
Pennington C. 2006. Burn Scar Mapping in the Sabine National Wildlife Refuge using Landsat TM and ETM+ Imagery [tesis]. Los Angeles (US): B.A. Louisiana State University
Rohali D. 2015. Hotspot di OKI Tercatat 234 Titik [Internet]. [diunduh 2015 Des 15]. Tersedia pada: http://daerah.sindonews.com/read/1044643/190/hotspot-di-oki-tercatat-234-titik-1442252742
Rulequest. 2012. C5.0: An Informal Tutorial. [Internet]. [diunduh 2016 Maret 23]. Tersedia pada: https://www.rulequest.com/see5-unix.html.
Sutton CD. 2005. Classification and regression trees, Bagging, and Boosting, Handbook of statistics, 24(1): 303-329.
Suwarsono, Rokhmatuloh, Waryono T. 2013. Pengembangan Model Identifikasi Daerah Bekas Kebakaran Hutan dan Lahan (Burned Area) Menggunakan Citra Modis di Kalimantan. Jurnal Penginderaan Jauh. 10(2) : 93-112
Syaufina L. 2008. Kebakaran Hutan dan Lahan di Indonesia : Perilaku Api, Penyebab dan Dampak Kebakaran. Malang (ID) : Bayumedia Publishing Tan P, Steinbach M, Kumar V. 2006. Introduction to Data Mining. Minneapolis
(US): Addison Wesley.
Thariqa P, Sitanggang IS, Syaufina L. 2016. Comparative Analysis of Spatial Decision Tree Algorithms for Burned Area of Peatland in Rokan Hilir Riau. TELKOMNIKA 14(2):684-691.
Tsang S, Kao B, Yip K, Ho WS, Lee SD, 2009. Decision trees for uncertain data. Data Engineering, 2009. ICDE ‟09. IEEE 25th International Conference on, 2009, pp. 441–444
Verikas A, Gelzinis A, Becausekiene M. 2011. Mining data with Random Forest: a survey and result of new tests. Pattern Recognition. 44(2): 330-349. DOI: 10.1016/j.patcog.2010.08.011.
26
27 Lampiran 1 Pembentukan tree dengan algoritme pohon keputusan
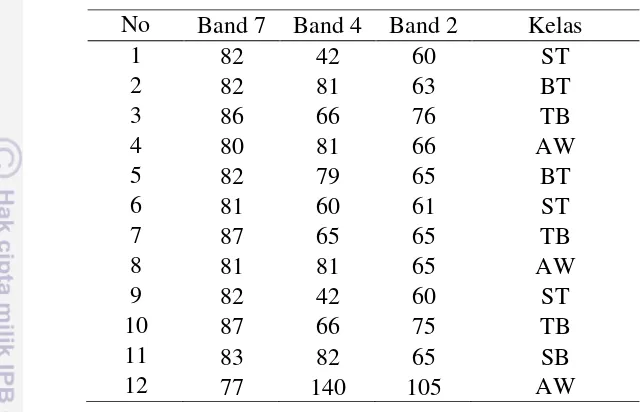
Berikut ini disajikan contoh dataset kebakaran hutan. Kelas T (Terbakar), kelas ST (setelah Terbakar), kelas BT (Belum Terbakar) dan kelas AW (Awan).
Tabel 1.1 Dataset kebakaran hutan
No Band 7 Band 4 Band 2 Kelas
1 82 42 60 ST
2 82 81 63 BT
3 86 66 76 TB
4 80 81 66 AW
5 82 79 65 BT
6 81 60 61 ST
7 87 65 65 TB
8 81 81 65 AW
9 82 42 60 ST
10 87 66 75 TB
11 83 82 65 SB
12 77 140 105 AW
Dari contoh data training pada Tabel 1.1, dapat dilihat bahwa tipe data dari ke tiga atribut yang digunakan termasuk dalam tipe data kontinu. Menurut Han et al. 2012, jika peubah responnya bertipe kontinu maka pohon keputusan yang dihasilkan berupa pohon regresi. Untuk peubah kontinu � split yang diperbolehkan adalah � dan � dimana c adalah nilai tengah antara dua nilai amatan peubah � secara berurutan. Dengan menggunakan data pada Tabel 1.1 data yang digunakan terdiri dari 8 data sebagai data latih (no urut 1 sampai dengan no urut 8) dan 4 data digunakan untuk data uji (no urut 9 sampai dengan no urut 12).
Tahap ini dimulai dengan melakukan seleksi atribut menggunakan formula
information gain yang terdapat pada persamaan (1) pada tinjauan pustaka, sehingga diperoleh nilai information gain untuk masing-masing atribut, atribut dengan nilai gain tertinggi akan menjadi parent bagi node-node selanjutnya. Node-node tersebut didapat dari atribut-atribut yang memiliki nilai information gain yang lebih kecil dari nilai
information gain atribut parent.
Perhitungan Information Gain (Kelas)
� = � =
� = � � =
�� � = − (� � )-(� � )-(� � )-(� � )
28
Lampiran 1 Lanjutan
Perhitungan Information Gain (Atribut)
Band 7
Tabel 1.2 menunjukkan atribut Band 7 dengan jumlah kelas BT, TB, ST dan AW untuk menghitung information gain di setiap atributnya.
Tabel 1.2 Atribut Band 7 dengan jumlah kelas BT, TB, ST dan AW
No Band 7 Kelas
1 82 ST
2 82 BT
3 86 TB
4 80 AW
5 82 BT
6 81 ST
7 87 TB
8 81 AW
� � = dengan jumlah kelas sebagai berikut :
| � ≤ | = , dimana jumlah kelas BT pada tuple Band 7 ≤ 80 = 0
| � ≤ | = ,dimana jumlah kelas TB pada tuple Band =
| � ≤ | = , dimana jumlah kelas ST pada tuple Band =
| � � ≤ | = , dimana jumlah kelas AW pada tuple Band 7 ≤ 80 = 1 � � > = dengan jumlah kelas sebagai berikut :
| � > | = , dimana jumlah kelas BT pada tuple Band 7 > 80 = 2
| � > | = , dimana jumlah kelas TB pada tuple Band 7 > 80 = 2
| � > | = , dimana jumlah kelas ST pada tuple Band 7 > 80 = 2
| � � > | = , dimana jumlah kelas AW pada tuple Band 7 > 80 = 1 � � = dengan jumlah kelas sebagai berikut :
| � ≤ | = , dimana jumlah kelas BT pada tuple Band 7 ≤ 81 = 0
| � ≤ | = ,dimana jumlah kelas TB pada tuple Band 81 = 0
| � ≤ | = , dimana jumlah kelas ST pada tuple Band 81= 1
| � � ≤ | = , dimana jumlah kelas AW pada tuple Band 7 ≤ 81 = 2 � � > = dengan jumlah kelas sebagai berikut :
| � > | = , dimana jumlah kelas BT pada tuple Band 7 > 81 = 2
| � > | = , dimana jumlah kelas TB pada tuple Band 7 > 81 = 2
| � > | = , dimana jumlah kelas ST pada tuple Band 7 > 81 = 1
| � � > | = , dimana jumlah kelas AW pada tuple Band 7 > 81 = 0 � � = dengan jumlah kelas sebagai berikut :
29 Lampiran 1 Lanjutan
| � ≤ | = , dimana jumlah kelas TB pada tuple Band 7 ≤ 82 = 0
| � ≤ | = , dimana jumlah kelas ST pada tuple Band 82 = 2
| � � ≤ | = , dimana jumlah kelas AW pada tuple Band 2 = 2
� � > = dengan jumlah kelas sebagai berikut :
| � > | = , dimana jumlah kelas BT pada tuple Band 7 > 82 = 0
| � > | = , dimana jumlah kelas TB pada tuple Band 7 > 82 = 2
| � > | = , dimana jumlah kelas ST pada tuple Band 7 > 82 = 0
| � � > | = , dimana jumlah kelas AW pada tuple Band 7 > 82 = 0
� � = dengan jumlah kelas sebagai berikut :
| � ≤ | = , dimana jumlah kelas BT pada tuple Band =
| � ≤ | = ,dimana jumlah kelas TB pada tuple Band =
| � ≤ | = , dimana jumlah kelas ST pada tuple Band =
| � � ≤ | = , dimana jumlah kelas AW pada tuple Band =
� � > = dengan jumlah kelas sebagai berikut :
| � > | = , dimana jumlah kelas BT pada tuple Band 7 > 86 = 0
| � > | = , dimana jumlah kelas TB pada tuple Band 7 > 86 = 1
| � > | = , dimana jumlah kelas ST pada tuple Band 7 > 86 = 0
| � � > | = , dimana jumlah kelas AW pada tuple Band 7 > 86 = 0
� � = dengan jumlah kelas sebagai berikut :
| � ≤ | = , dimana jumlah kelas BT pada tuple Band = | � ≤ | = ,dimana jumlah kelas TB pada tuple Band =
| � ≤ | = , dimana jumlah kelas ST pada tuple Band =
| � � ≤ | = , dimana jumlah kelas AW pada tuple Band =
� � > = dengan jumlah kelas sebagai berikut :
| � > | = , dimana jumlah kelas BT pada tuple Band 7 > 87 = 0
| � > | = , dimana jumlah kelas TB pada tuple Band 7 > 87 = 0
| � > | = , dimana jumlah kelas ST pada tuple Band 7 > 87 = 0
| � � > | = , dimana jumlah kelas AW pada tuple Band 7 > 87 = 0
Menghitung information gain pada atribut Band 7 :
� � ≤ = − ( ) − ( ) − ( ) − ( ) =
� � > = − ( ) − ( ) − ( ) − ( ) = .
Nilai information gainyang dihasilkan dari atribut Band 7 ≤ 80, Band 7 >80 yaitu:
30
Lampiran 1 Lanjutan
� � ≤ = − ( ) − ( ) − ( ) − ( ) = .
� � > = − ( ) − ( ) − ( ) − ( ) = .
Nilai information gainyang dihasilkan dari atribut Band 7 ≤ 81, Band 7 >81 yaitu:
�������� ≤ ,���� > = − . − . = ,
� � ≤ = − ( ) − ( ) − ( ) − ( ) = .
� � > = − ( ) − ( ) − ( ) − ( ) =
Nilai information gainyang dihasilkan dari atribut Band 7 ≤ 82, Band 7 >82 yaitu:
�������� ≤ ,���� > = − . − = ,
� � ≤ = − ( ) − ( ) − ( ) − ( ) = .
� � > = − ( ) − ( ) − ( ) − ( ) =
Nilai information gainyang dihasilkan dari atribut Band 7 ≤ 86, Band 7 >86 yaitu:
�������� ≤ ,���� > = − . − = ,
� � ≤ = − ( ) − ( ) − ( ) − ( ) =
� � > = − ( ) − ( ) − ( ) − ( ) =
Nilai information gainyang dihasilkan dari atribut Band 7 ≤ 87, Band 7 >87 yaitu: