IMPLEMENTASI ALGORITMA EM
PADA METODE KEMUNGKINAN MAKSIMUM UNTUK
PEMODELAN REGRESI LINEAR GEROMBOL
RIZKY ARDINSYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Implementasi Algoritma EM pada Metode Kemungkinan Maksimum untuk Pemodelan Regresi Linear Gerombol adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2014
Rizky Ardinsyah
ABSTRAK
RIZKY ARDINSYAH. Implementasi Algoritma EM pada Metode Kemungkinan Maksimum untuk Pemodelan Regresi Linear Gerombol. Dibimbing oleh BAGUS SARTONO dan AJI HAMIM WIGENA.
Pemodelan dengan menggunakan regresi gerombol mempertimbangkan keberadaan gerombol dari suatu gugus data yang masing-masing memiliki fungsi regresi yang berbeda. Regresi gerombol dalam penelitian ini digunakan untuk menentukan jumlah gerombol optimal, menentukan anggota setiap gerombol, dan menduga model regresinya. Pendugaan parameter dilakukan dengan metode kemungkinan maksimum yang diimplementasikan melalui Algoritma Expectation-Maximization (EM). Algoritma EM terdiri atas dua tahapan, yaitu tahapan E
(Expectation) yang merupakan proses perhitungan nilai log kemungkinan dan
tahapan M (Maximization) yang merupakan tahapan penentuan parameter yang baru dan proses penentuan nilai log kemungkinan yang maksimum. Dugaan parameter regresi terbaik dan jumlah gerombol yang optimal diperoleh ketika nilai
log kemungkinan yang maksimum dan nilai Akaike’s Information Criterion (AIC) yang minimum. Data yang digunakan dalam penelitian ini merupakan data hasil simulasi dengan beberapa kriteria yang dikombinasikan dengan rancangan faktorial pecahan (fractional factorial design).
Kata kunci: AIC, algoritma EM, fungsi kemungkinan maksimum, rancangan faktorial pecahan, regresi gerombol.
ABSTRACT
RIZKY ARDINSYAH. Implementation of EM Algorithm in Maximum Likelihood Methodology for Clusterwise Linear Regression Modelling. Supervised by BAGUS SARTONO and AJI HAMIM WIGENA.
Clusterwise regression modelling consider the several hidden clusters from a data set which have different regression functions. This method is used simultaneously to determine the number of clusters, to separate membership into specified cluster K, and to estimate each regression function. Maximum likelihood methodology implemented by Expectation-Maximization (EM) algorithm is used for parameter estimation. EM algorithm consists of two steps. The first step is expectation (E-step), to count log-likelihood function, and the second step is maximization (M-step), to determine the new parameter value which maximizes log-likelihood function. The best regression coefficients estimation and the number of optimal clusters are obtained when log-likelihood value is maximum and Akaike’s Information Criterion (AIC) value is minimum. Some simulation data sets in this research are provided with some criteria that combined with fractional factorial design.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
IMPLEMENTASI ALGORITMA EM
PADA METODE KEMUNGKINAN MAKSIMUM UNTUK
PEMODELAN REGRESI LINEAR GEROMBOL
RIZKY ARDINSYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN INSTITUT PERTANIAN BOGOR
Judul Skripsi : Implementasi Algoritma EM pada Metode Kemungkinan Maksimum untuk Pemodelan Regresi Linear Gerombol
Nama : Rizky Ardinsyah NIM : G14100078
Disetujui oleh
Dr Bagus Sartono, MSi Dr Ir Aji Hamim Wigena, MSc Pembimbing I Pembimbing II
Diketahui oleh
Dr Anang Kurnia, Msi Ketua Departemen
PRAKATA
Puji syukur dipanjatkan ke hadirat Tuhan Yang Maha Esa yang telah memberikan rahmat dan karunia-Nya sehingga karya ilmiah ini dapat diselesaikan. Tema yang dipilih dalam penelitian ini ialah Regresi Gerombol dengan judul Implementasi Algoritma EM pada Metode Kemungkinan Maksimum untuk Pemodelan Regresi Linear Gerombol. Karya ilmiah ini merupakan salah satu syarat untuk mendapatkan gelar Sarjana Statistika pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Penulis mengucapkan terima kasih kepada semua pihak yang telah membantu dalam menyelesaikan karya ilmiah ini, antara lain:
1. Bapak Dr Bagus Sartono, MSi dan Bapak Dr Ir Aji Hamim Wigena, MSc selaku pembimbing yang telah memberikan banyak saran pada penelitian ini. 2. Dosen pengajar Departemen Statistika atas ilmu yang telah diberikan. 3. Ibu Markonah, Ibu Tri, dan staf Tata Usaha Departemen Statistika yang ulet
dan tak pernah lelah mengurusi administrasi kelengkapan mulai dari kolokium hingga sidang mahasiswa Statistika.
4. Orang tua, kakek-nenek, dan adik-adik atas kesabaran, kasih sayang, dan dorongan batin yang begitu besar kepada penulis.
5. Pihak Goodwill International Scholarship Program atas bantuan beasiswa dan training yang diberikan. Serta teman-teman Goodwill yang telah banyak memberikan inspirasi dan motivasi bagi penulis.
6. Dewi Lestari, Amri Najih, Hariz, Benny, Raedi, Nanda Puspita, dan Frisca sebagai teman satu perjuangan satu dosen bimbingan yang selalu memberikan dukungan dan masukannya.
7. Guntur, Azizah, Tusi, Nia, Meta, dan Fathmah sebagai teman-teman terbaik yang selalu memberikan dukungan dan membantu proses belajar selama studi di Statistika.
8. Teman-teman Statistika 47 atas motivasi dan dukungannya selama ini. Semoga karya ilmiah ini dapat bermanfaat bagi semua pihak. Penulis mohon maaf atas segala kekurangan dan kesalahan yang terdapat dalam pembuatan karya ilmiah ini.
Bogor, Agustus 2014
DAFTAR ISI
DAFTAR TABEL x
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
TINJAUAN PUSTAKA 2
Regresi Linear Gerombol 2
Penduga Kemungkinan Maksimum 2
Algoritma EM 4
METODOLOGI 5
Data 5
Metode 6
HASIL DAN PEMBAHASAN 7
Regresi Linear Gerombol 7
Pendugaan Parameter 8
Evaluasi Model 10
Uji Performa Algoritma EM 11
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 13
LAMPIRAN 15
RIWAYAT HIDUP 16
DAFTAR TABEL
Faktor dan taraf untuk pembangkitan gugus data simulasi 6 Kombinasi gugus data melalui rancangan faktorial pecahan 24-1 8
Hasil regresi linear gerombol pada gugus data nomor 8 9 Hasil dugaan parameter λk, σk, & bjk gugus data nomor 8 pada K = 4 9
Nilai MAPE untuk evaluasi pilihan model pada gugus data
simulasi 10
Waktu komputasi (detik) pada gugus data simulasi 10
RMSE bjk pada gugus data simulasi 12
RMSE σk pada gugus data simulasi 12
PENDAHULUAN
Latar Belakang
Regresi gerombol adalah salah satu solusi metode pemodelan dalam menghadapi kasus keheterogenan subjek atau amatan. Metode pemodelan ini bekerja dengan mempertimbangkan keberadaan gerombol dalam suatu populasi untuk mendapatkan model yang tepat sesuai dengan kesamaan karakteristik subjek. Berdasarkan model tersebut, selanjutnya dapat diketahui hubungan fungsional antara peubah bebas dan peubah responnya. Regresi telah banyak diimplementasikan pada berbagai jenis data, baik data pemasaran, ekonomi, kependudukan, pertanian, maupun sosial politik (Chatterjee & Hadi 2006). Demikian halnya dengan regresi gerombol yang dapat dimanfaatkan dalam berbagai bidang, salah satunya dalam bidang pemasaran (Wedel 1990).
Smith (1956) memperkenalkan eksistensi segmentasi dalam bidang pemasaran. Hal ini didasarkan atas pandangan Smith terhadap konsumen yang memiliki karakteristik yang beragam, sehingga pasar dianggap sebagai suatu instrumen yang bersifat heterogen. Ini berarti bahwa dalam suatu pasar tidak menutup kemungkinan terdapat pasar-pasar kecil yang sifatnya lebih homogen. Pasar-pasar kecil itulah yang menggambarkan perbedaan karakter antar kelompok konsumen. Dengan demikian, segmentasi menjadi hal yang cukup penting dalam penentuan kebijakan atau strategi pemasaran karena setiap gerombol memiliki fungsi regresi yang berbeda dan tidak dapat dipaksakan dengan nilai parameter yang sama (Kang & Ghosal 2008). Gerombol yang terbentuk pada metode ini didasarkan pada tingkat kemiripan parameter regresinya (Qian & Wu 2011).
Ada beberapa cara pendugaan parameter yang dapat digunakan dalam regresi, diantaranya metode pendugaan kemungkinan maksimum, metode kuadrat terkecil dan metode Bayes. Penelitian ini merujuk pada penelitian DeSarbo & Cron (1988) yang menggunakan metode kemungkinan maksimum (Maximum Likelihood
Estimation/MKM). Prinsip kerja MKM adalah mencari nilai dugaan parameter
yang memaksimumkan fungsi kemungkinan. Kemudian dalam menentukan jumlah gerombol yang optimal, banyaknya gerombol dipilih saat Akaike’s Information
Criterion (AIC) bernilai minimum. Untuk memudahkan komputasi, algoritma EM
digunakan dalam penelitian ini. Algoritma EM (Expectation-Maximization
Algorithm) diperkenalkan oleh Dempster, Laird, dan Rubin pada tahun 1977 untuk
2
Tujuan Penelitian Tujuan dari penelitian ini adalah sebagai berikut:
1. Mengimplementasikan algoritma EM untuk pemodelan pada regresi gerombol dengan metode pendugaan kemungkinan maksimum agar mendapatkan jumlah gerombol yang optimal dan ketepatan menempatkan anggota gerombol. 2. Menguji performa algoritma EM berdasarkan waktu komputasi serta kebaikan
nilai dugaan parameter.
TINJAUAN PUSTAKA
Regresi Linear Gerombol
Regresi gerombol pertama kali digunakan oleh Spath (1979) sebagai pengembangan dari pemodelan regresi klasik yang hanya membentuk satu model. Regresi gerombol mempertimbangkan keberadaan subgrup pada populasi sehingga model yang terbentuk akan memiliki nilai parameter yang berbeda pada setiap X. Hal ini masuk akal karena X diambil dari populasi yang heterogen.
De Sarbo & Cron (1988) mengaplikasikan regresi gerombol pada data bidang pemasaran untuk mengidentifikasi gerombol dan memisahkan sampel pada populasi tersebut hingga tahap pemodelan pada masing-masing gerombolnya. Metode pendugaan parameter yang digunakan adalah metode kemungkinan maksimum yang diimplementasikan dengan algoritma EM.
Model regresi linear gerombol secara umum (DeSarbo et al. 1989) adalah:
= ∑ ∑ +
Pemodelan pada regresi gerombol dengan menggunakan metode pendugaan kemungkinan maksimum telah dilakukan oleh DeSarbo dan Cron (1988). Dalam MKM, nilai dugaan parameter dicari yang nilai harapannya sama dengan nilai
jika amatan ke-i ditetapkan ke gerombol ke-k
3 parameternya (tak bias). Selain itu, penduga dalam MKM dinilai konsisten dan efisien (Ramachandran 2009).
Penduga �̂�dikatakan penduga yang konsisten jika, untuk � > , lim
�→∞�[|�̂�− �| ≤ �] =
atau ekuivalen dengan,
lim
�→∞�[|�̂�− �| > �] =
Penduga yang konsisten seharusnya semakin mendekati nilai parameternya untuk ukuran sampel yang besar. Oleh karena itu dalam literatur dikatakan bahwa berdasarkan beberapa kasus, performa metode MKM akan lebih optimal untuk ukuran data yang besar (Ramachandran 2009). Kemudian apabila penduga �̂� adalah penduga yang tak bias, artinya nilai harapan dari penduga sama dengan parameternya, maka penduga tersebut dikatakan sebagai penduga konsisten jika
lim
�→∞� �(�̂�) = .
Penduga yang tak bias akan mungkin didapatkan lebih dari satu, dengan demikian penduga yang paling baik nanti dipilih satu penduga yang memiliki ragam paling kecil.
Berikut ini adalah log fungsi kemungkinan untuk ukuran contoh sebesar n: � = ∑ � [∑ �� − / exp [− − ��′�
dengan asumsi galat contoh diambil secara acak dari fungsi kepekatan normal dari setiap gerombol yang belum diketahui proporsinya , , … , . Fungsi tersebut akan dimaksimumkan untuk mendapatkan nilai dugaan λk, σk, dan bjk, dengan
kendala 0 ≤λk ≤ 1, ∑ = λ = ,d�n � > 0, untuk semua nilai k = 1,2,…,K. Kemudian
untuk menempatkan amatan ke-i ke dalam gerombol ke-k dilakukan dengan memilih nilai peluang posterior Bayesian di setiap gerombol k yang paling besar. Dugaan peluang posterior Bayesian-nya adalah sebagai berikut:
�̂ = λ̂ ( | , �̂ , ̂ ) ∑ = λ̂ ( | , �̂ , ̂ ).
dengan ( | , �̂ , ̂ ) = ��̂ − / exp [−(��−��′�̂�)2
�̂�2 ]
Oleh karena dalam metode penelitian ini terdapat kendala ∑ = λ = , fungsi yang akan dimaksimumkan akan diselesaikan menggunakan metode pengganda Lagrange. Fungsi Lagrange merupakan selisih (atau dapat juga sebagai penjumlahan) antara fungsi yang dioptimumkan (fungsi objektif) dengan hasil perkalian antara pengganda Lagrange( ) dan fungsi kendalanya. Dengan demikian, fungsi Lagrange yang akan dimaksimumkan untuk mendapatkan dugaan parameter
4
Untuk mengoptimumkan fungsi Lagrange tersebut maka menurut teori optimasi dalam kalkulus, turunan parsial pertamanya harus sama dengan nol. Secara geometris, hal ini berhubungan dengan titik saat kurvanya memiliki kemiringan nol.
dengan � adalah vektor kolom yang berisi parameter regresi pada kolom ke-k. Sedangkan untuk mencari dugaan bk adalah melalui regresi kuadrat terkecil terboboti (DeSarbo & Cron 1988):
Proses iterasi dari algoritma EM terdiri atas dua tahap, yaitu tahap-E (tahap ekspektasi) dan tahap-M (tahap maksimisasi). Tahap-E bertujuan menemukan log
fungsi kemungkinan dari nilai dugaan parameter k, � , dan bjk,. Nilai parameter k,
� , dan bjk pada iterasi pertama didapat dari nilai inisialisasi. Kemudian tahap selanjutnya adalah tahap-M yang bertujuan mencari nilai dugaan parameter baru k*,
� ∗, dan bjk*. Sebelum penghitungan nilai dugaan parameter yang baru, nilai
peluang posterior Bayesian pik dihitung dengan menggunakan nilai parameter pada tahap-E (McLachlan & Krishnan 2008).
Proses iterasi dikatakan konvergen jika selisih nilai log fungsi kemungkinan dengan nilai log fungsi kemungkinan sebelumnya telah mencapai batas konvergen (10-5):
| ( ∗, � ∗, ∗ ) − ( , � , )| < −5
Nilai tersebut ditentukan berdasarkan referensi dengan pertimbangan bahwa nilai tersebut sudah cukup kecil sebagai batas kekonvergenan (McLachlan & Krishnan 2008).
Berikut ini adalah beberapa keuntungan lainnya dari penggunaan algoritma EM (McLachlan & Krishnan 2008):
(1) Algoritma EM cukup stabil dan mudah dibuat programnya;
(2) Secara umum, algoritma EM memiliki kekonvergenan yang handal, artinya selalu konvergen hampir ke titik maksimum lokalnya;
(3) Membutuhkan kapasitas penyimpanan yang kecil pada komputer; dan
5
METODOLOGI
Terdapat beberapa jurnal yang membahas regresi gerombol. Salah satunya adalah jurnal DeSarbo dan Cron yang membahas pemodelan regresi gerombol dengan pendugaan parameter melalui metode kemungkinan maksimum. Dalam jurnal tersebut DeSarbo dan Cron mengimplementasikan algoritma EM dalam proses komputasinya.
Data
Data yang digunakan adalah data hasil simulasi. Banyaknya gugus data simulasi didasarkan atas beberapa faktor yang digunakan sebagai kriteria gugus data tersebut. Hal ini pun dilakukan oleh DeSarbo dan Cron pada penelitiannya. Untuk mengurangi banyaknya gugus data yang dicobakan dalam penelitian ini, rancangan faktorial pecahan (fractional factorial design) 24-1 digunakan, sehingga banyak gugus data yang digunakan adalah sebanyak setengah dari total kombinasi faktor. Rancangan ini membantu dalam pemilihan kombinasi faktor yang digunakan.
Proses pembangkitan gugus data dilakukan sebagai berikut:
1. Menentukan faktor-faktor dan masing-masing tarafnya yang digunakan sebagai kriteria pembangkitan data. Faktor-faktor dan taraf tersebut ditampilkan dalam Tabel 1.
2. Membangkitkan peubah bebas dan peubah respon yang masing-masing terdiri atas n total amatan. Peubah bebas dibangkitkan dari sebaran seragam diskret dengan batas minimum dan maksimum yang berbeda-beda. Jika peubah bebas yang digunakan pada penelitian ini lebih dari satu, maka antar peubah bebas tersebut tidak boleh terjadi kasus multikolinearitas.
3. Membangkitkan galat (ε) sebanyak n dari sebaran normal dengan rataan = 0 dan ragam = σ2.
4. Menentukan parameter regresi (bjk).
a. Untuk J = 2 dan K = 2 c. Untuk J = 2 dan K = 4 5. Menentukan proporsi ( ) amatan di setiap gerombol:
a. Untuk K = 2, maka 1 = 0.5; 2 = 0.5.
b. Untuk K =4, maka 1 = 0.4; 2 = 0.1; 3 = 0.2; 4 = 0.3.
6
Metode
Analisis yang digunakan dalam penelitian ini adalah regresi gerombol dengan pendugaan parameter melalui metode kemungkinan maksimum. Algoritma EM digunakan untuk mempermudah proses penentuan log fungsi kemungkinan. Algoritma ini digunakan untuk mengatasi kesulitan dalam memaksimumkan log
fungsi kemungkinan dengan menyediakan prosedur iteratif yang mudah diimplementasikan (McLachlan dan Krishnan 2008). Penelitian ini dibantu dengan perangkat lunak R.
Algoritma dalam penelitian ini ditampilkan dalam diagram alir pada Lampiran 1 dengan penjelasan lebih rinci sebagai berikut:
1. Membangkitkan delapan gugus data dengan empat faktor yang masing-masing terdiri atas dua taraf. Pemilihan gugus data ditentukan oleh rancangan faktorial pecahan 24-1.
2. Menentukan model regresi terbaik terhadap gugus data terpilih. Tahap E (Expectation Step):
a. Memberikan inisialisasi awal untuk jumlah gerombol k (dengan k ≥ 1), k, σk,
dan bjk.
b. Menduga nilai peluang posterior Bayesian pik dari inisialisasi k, σk, dan bjk.
c. Menghitung nilai log fungsi kemungkinan sebanyak r kali untuk mendapatkan nilai yang maksimum.
Tahap M (Maximization Step):
d. Menghitung nilai dugaan k,σk, dan bjk yang baru dengan menggunakan hasil
perhitungan pik pada langkah 2b.
e. Mengulang langkah 2a sampai 2d sebanyak m kali untuk mendapatkan nilai
log fungsi kemungkinan di titik global maksimum.
f. Memilih penduga parameter saat log fungsi kemungkinan yang maksimum di titik global.
g. Menghitung nilai AIC (Akaike’s Information Criterion). AIC dihitung dengan rumus berikut:
��� = − × m�x � + × �
dengan n(K) = J x K + 2K – 1 adalah jumlah dugaan parameter efektif untuk hasil regresi gerombol K.
h. Mengulang langkah 2a sampai 2g untuk nilai k yang berbeda.
i. Menentukan banyaknya gerombol yang memiliki nilai AIC minimum.
7 3. Menempatkan amatan ke dalam gerombolnya dengan peluang posterior
Bayesian. Amatan ke-i berada di gerombol ke-k jika �̂ > �̂ .
4. Menguji performa algoritma EM berdasarkan waktu komputasi (detik), RMSE
bjk, dan RMSE σk. RMSE atau Root Mean Square Error dihitung dengan
menghitung akar dari jumlah kuadrat selisih nilai dugaan dan parameternya yang dibagi dengan banyaknya tes ulangan. Nilai ini biasa digunakan sebagai alat ukur untuk kebaikan nilai dugaan.
HASIL DAN PEMBAHASAN
Hasil pembangkitan data, pemodelan, dan pengujian performa algoritma akan dijelaskan pada bab ini. Banyaknya gugus data dalam penelitian ini adalah sebanyak 24-1 atau 8 gugus data dengan beberapa kriteria yang dikombinasikan
melalui rancangan faktorial pecahan. Informasi gugus data diberikan pada Tabel 2. Kemudian dalam menampilkan hasil pendugaan parameter regresi untuk pemodelan, hanya satu gugus data saja yang digunakan. Gugus data yang dipilih adalah gugus data simulasi nomor 8. Pemilihan gugus data nomor 8 adalah secara subjektif oleh peneliti tanpa ada syarat tertentu, gugus data nomor 8 dipilih karena banyaknya peubah bebas dan banyaknya gerombol yang tidak sedikit, sehingga hal-hal yang ingin ditunjukkan dapat dilihat dengan jelas, seperti kekonsistenan nilai
log fungsi kemungkinan dan AIC.
Keberadaan gerombol yang belum diketahui dalam suatu gugus data dapat dideteksi melalui plot diagram pencar antara peubah respon (Y) dengan peubah bebasnya (X). Diagram pencar antara peubah Y dan peubah X1 (Gambar 1) pada gugus data simulasi nomor 8 memberikan ilustrasi bahwa amatan membentuk empat gerombol. Untuk kasus tertentu gerombol dapat mudah diketahui, namun seringkali ditemukan kasus yang lebih kompleks sehingga sulit untuk menentukan banyak gerombol. Oleh karena itu, regresi gerombol menjadi salah satu metode yang bermanfaat dalam menangani kasus seperti ini.
Regresi Linear Gerombol
Pemodelan umumnya dilakukan pada gugus data tanpa memperhatikan keberadaan gerombol. Namun model yang dihasilkan menjadi tidak baik saat amatan membentuk gerombol seperti yang ditampilkan pada Gambar 1. Penggunaan regresi linear gerombol (CLR) pada penelitian ini diharapkan dapat memberikan hasil penggerombolan yang tepat dan hasil pemodelan yang baik karena regresi gerombol dapat mengurangi risiko kesalahan penggambaran data dan meningkatkan kebaikan dugaan model (DeSarbo & Cron 1988).
8
Tabel 2 Kombinasi gugus data melalui rancangan faktorial pecahan 24-1
100
Algoritma EM digunakan dalam penelitian ini sebagai prosedur penentuan penduga parameter yang dapat mengoptimumkan log fungsi kemungkinan. Inisialisasi terhadap k, σk, bjk, r, dan m diperlukan untuk memulai proses pada
algoritma EM.
Inisialisasi k, σk, dan bjk tidak memiliki kriteria tertentu karena besar kecilnya
nilai inisial tidak mempengaruhi nilai pendugaan. Oleh karena itu, inisialisasi terhadap ketiga parameter tersebut di dalam program pada penelitian ini dibuat secara otomatis, misalnya inisial bjk dibangkitkan melalui bilangan acak yang menyebar seragam diskret (bjk ~ U(-1,1)). Penentuan seragam diskret ini merujuk pada penelitian yang dilakukan oleh DeSarbo & Cron (1988), namun tentu sebaran ini dapat diubah menjadi sebaran lain karena tidak akan mempengaruhi hasil nilai dugaan parameter barunya. Kemudian σk diinisialisasi sebesar 10 untuk setiap
gerombol dan λk diinisialisasi 1/k untuk setiap k sehingga ∑ = = . Namun perlu
diketahui bahwa semakin dekat nilai inisialisasi dengan nilai aslinya iterasi akan semakin cepat.
9
yang maksimum pada titik globalnya. Oleh karena itu, perlu dilakukan ulangan terhadap iterasi r sebanyak m kali, m dipilih sebesar 20. Penentuan r dan m dalam penelitian ini ditentukan berdasarkan percobaan beberapa kali untuk mendapatkan nilai yang konsisten. Jika pada r = 20 hasil nilai log fungsi kemungkinan berubah-ubah dengan percobaan komputasi yang diulang beberapa kali, maka nilai tersebut belum tentu nilai yang maksimum. Oleh karena itu perlu dilakukan peningkatan nilai r hingga pada saat komputasi diulang-ulang, nilai log fungsi kemungkinan selalu menghasilkan hal yang sama. Hal ini pun berlaku pada ulangan m dalam mencari nilai log fungsi kemungkinan di titik maksimum global.
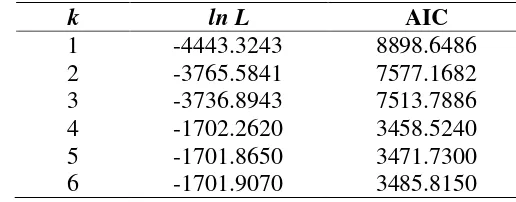
Tabel 3 memberikan informasi hasil komputasi CLR pada gugus data simulasi nomor 8 untuk nilai k = 1 hingga 6, ulangan r = 60, dan ulangan m = 20. Dalam Tabel 3, nilai ln L yang ditampilkan adalah nilai yang sudah konvergen dan maksimum di titik globalnya. Selanjutnya yang perlu diperhatikan adalah perubahan nilai AIC sebagai penentu banyaknya gerombol optimal yang akan dipilih. Model dengan nilai AIC yang paling kecil adalah model yang terbaik atau dengan kata lain, jika ada beberapa pilihan model, maka pilih model dengan nilai AIC yang paling kecil (Latif et al. 2008). Berdasarkan Tabel 3 dapat dilihat bahwa nilai AIC terus menurun seiring dengan bertambahnya k, namun terus meningkat ketika k > 5. Dengan demikian, proses iterasi k dapat dipotong pada k = 6. Kemudian gerombol yang optimal ditentukan saat nilai AIC minimum, yaitu 3458.5240. Dengan demikian, model terbaik yang direkomendasikan adalah model dengan empat gerombol.
Selanjutnya nilai dugaan parameter k, σk, dan bjk yang diperoleh pada saat k
= 4 ditampilkan pada Tabel 4. Nilai dugaan proporsi amatan di setiap gerombol tepat dengan nilai parameternya, yaitu 0.4, 0.3, 0.2, dan 0.1. Artinya bahwa pada penelitian ini amatan ditempatkan sesuai dengan gerombol aslinya. Kemudian nilai dugaan simpangan baku galat, yaitu 2.0141, 2.3782, 2.4306, dan 2.2362, cukup
10
memberikan pengaruh positif terhadap gerombol 1 dan 4, hal ini berlawanan dengan pengaruh pada X1 gerombol 2 dan 3 yang negatif. Ini membuktikan bahwa terdapat sejumlah amatan yang memberikan pengaruh yang berbeda terhadap X1. Pengaruh amatan akan dilihat untuk peubah-peubah bebas lainnya sehingga sedimikian rupa terbentuklah gerombol-gerombol yang mewakili karakteristik sejumlah amatan yang paling mirip.
Evaluasi Model
Dugaan model untuk gugus data simulasi nomor 8 adalah sebagai berikut: ̂ = 4.6886ai1 – 10.1433ai2 – 4.5044ai3 + 10.3081ai4 + 10.002ai1xi1 – 25.0065ai2xi1
– 10.0118ai3xi1 + 24.9733ai4xi1 + 1.9605ai1xi2 + 4.0693ai2xi2 – 1.9135ai3xi2 – 4.0316ai4xi2 – 4.9939ai1xi3 – 12.0017ai2xi3 + 4.9885ai3xi3 + 12.0301ai4xi3 + 7.0025ai1xi4 – 7.9677ai2xi4 – 6.9858ai3xi4 + 8.0737ai4xi4
Peubah a pada model di atas adalah peubah boneka untuk menunjukkan gerombol yang dimaksud. Contohnya, untuk gerombol 1 maka nilai ai1 = 1, sedangkan ai2, ai3, dan ai4 masing-masing bernilai 0.
Hasil evaluasi model dengan nilai Mean Absolute Percentage Error (MAPE) ditampilkan dalam Tabel 5. Nilai MAPE yang baik adalah kurang dari 10%, nilai ini menunjukkan bahwa model tersebut memiliki keakuratan yang sangat baik. Sebaliknya, model dikatakan kurang akurat jika nilai MAPE yang diperoleh lebih dari 30% (Mukhopadhyay 2007). Pada Tabel 5 nilai MAPE yang dicetak tebal adalah presentase nilai kebaikan model untuk setiap gugus data hasil simulasi. Seluruh nilai MAPE tersebut kurang dari 10%. Oleh karena itu, secara keseluruhan seluruh dugaan model pada penelitian ini, dapat dikatakan cukup baik.
Tabel 5 Nilai MAPE untuk evaluasi pilihan model pada gugus data simulasi
k MAPE (%) Gugus Data Ke-
Tabel 6 Waktu komputasi (detik) pada gugus data simulasi
11 Uji Performa Algoritma EM
Pengujian performa algoritma EM dilakukan dengan melihat pengaruh banyak amatan (n), banyak parameter regresi (J), simpangan baku galat (σ), dan banyak gerombol (K) terhadap faktor-faktor berikut:
1. Waktu komputasi (detik). Saat mengukur peubah ini, program sudah dibuat homogen dalam spesifikasi komputer dan jumlah ulangan.
2. RMSE bjk. Peubah ini didapat dengan menghitung akar dari rataan jumlah kuadrat sisaan antara nilai bjk aktual dengan bjk dugaan yang diulang sebanyak 100 kali. Nilai ini menunjukkan kebaikan dugaan bjk.
3. RMSE σk. Peubah ini didapat dengan menghitung akar dari rataan jumlah kuadrat sisaan antara nilai σk aktual dengan σk dugaan yang diulang sebanyak
100 kali. Nilai ini menunjukkan kebaikan dugaan σk.
Hasil perhitungan ketiga faktor tersebut pada delapan gugus data disajikan dalam Tabel 6, Tabel 7, dan Tabel 8. Berdasarkan Tabel 6 dapat dilihat pengaruh n, J, dan K terhadap waktu komputasi. Semakin banyak gerombol maka waktu komputasi semakin meningkat. Hal lainnya yang dapat dilihat adalah waktu komputasi pada gugus data yang memiliki n = 500 lebih lama daripada waktu komputasi pada gugus data yang memiliki n = 100 dan waktu komputasi lebih lama pada gugus data yang memiliki peubah bebas lebih banyak. Pengaruh jumlah amatan, banyaknya gerombol, dan banyaknya peubah bebas memang memberikan pengaruh terhadap banyaknya iterasi di dalam program, sehingga waktu yang dibutuhkan akan meningkat pula. Hasil waktu komputasi pada Tabel 6 akan berbeda jika program dijalankan pada jenis komputer yang memiliki spesifikasi yang berbeda. Kecepatan processor dan besarnya Random Access Memory (RAM) sangat menentukan lama atau lambatnya komputasi program. Pada penelitian ini, spesifikasi komputer yang digunakan adalah processor Intel Atom dan RAM 1 Gb. Waktu komputasi tentu akan lebih cepat jika processor yang digunakan lebih banyak dan ukuran RAM lebih besar daripada komputer yang digunakan pada penelitian ini.
Selanjutnya akan dibahas pengaruh n, J, dan K terhadap nilai kebaikan dugaan bjk (RMSE bjk). Pada penelitian ini, koefisien regresi yang digunakan untuk perbandingan adalah b0 dan b1. Ada dua pertimbangan yang mendasari pemilihan kedua koefisien regresi tersebut, yaitu keduanya dimiliki oleh semua gugus data dan terdapat kecenderungan pola yang sama antara semua koefisien regresi pada satu gugus data dan gugus data yang lainnya. Oleh karena itu, koefisien regresi b2, b3, dan b4 dapat diwakilkan oleh b0 dan b1. Berdasarkan Tabel 7, jika gugus data nomor 1 dan 2, 3 dan 4, 5 dan 6, atau 7 dan 8, dibandingkan maka dapat diketahui pengaruh n terhadap kebaikan dugaan bjk.Hasilnya adalah semakin besar jumlah amatan maka nilai dugaan terhadap bjk akan semakin baik. Jika gugus data nomor 1 dan 3, 2 dan 4, 5 dan 7, atau 6 dan 8, dibandingkan maka dapat diketahui pengaruh
12
dalam data akan berpengaruh pada besar kecilnya RMSE, semakin besar σ maka RMSE akan semakin besar.
Terakhir, berdasarkan Tabel 8 hanya dapat dilihat bahwa banyaknya gerombol (K) mempengaruhi nilai dugaan kebaikan σk jika dibandingkan hasil
antara gugus data 1-4 dan 5-8. Semakin banyak gerombolnya, maka RMSE σk justru
akan semakin besar. Kemudian pada bagian ini, pengaruh faktor lainnya belum dapat dilihat disebabkan pola yang berbeda-beda, sehingga kesimpulan tidak dapat ditentukan berdasarkan hasil pada Tabel 8. Diperlukan gugus data yang lebih banyak untuk menangkap pengaruh faktor lainnya terhadap RMSE σk ini. Hal ini
13
SIMPULAN DAN SARAN
Simpulan
Regresi gerombol dapat melakukan pemodelan dengan memisahkan data populasi berdasarkan kemiripan parameternya dengan tepat. Hasil pendugaan parameter pada gugus data simulasi dengan ukuran amatan 500, banyaknya parameter 5, banyaknya gerombol 4, dan simpangan baku error sebesar 2, memberikan hasil pendugaan parameter yang mendekati nilai aktualnya. Ini menunjukkan bahwa melalui algoritma EM, pemodelan regresi dengan metode pendugaan kemungkinan maksimum memberikan hasil model yang cukup baik. Evaluasi model dengan nilai MAPE menujukkan hasil model yang akurat.
Berdasarkan pengujian performa algoritma EM terhadap dua peubah respon, yaitu waktu komputasi, RMSE bjk, dan RMSE σk, algoritma ini cukup baik digunakan untuk ukuran data yang besar dan jumlah peubah bebas yang banyak. Namun semakin besar simpangan baku galat akan mempengaruhi RMSE bjk serta banyaknya jumlah amatan dan gerombol dalam data dapat meningkatkan waktu komputasi.
Saran
Pemodelan yang dilakukan oleh program CLR yang dibuat terbatas pada data yang peubah bebasnya tidak mengalami kasus multikolinearitas. Program dapat dikembangkan untuk penanganan kasus multikolinearitas dan penelitian dilanjutkan untuk tahap pengujian pengaruh peubah bebas terhadap peubah responnya.
DAFTAR PUSTAKA
Chatterjee S, Hadi AS. 2006. Regression Analysis by Example 4th Ed. New Jersey
(US): John Wiley & Sons Inc.
DeSarbo WS, Cron WL. 1988. A maximum likelihood methodology for clusterwise linear regression. J Classification. 5:249-282.
DeSarbo WS, Oliver RL, Rangaswamy A. 1989. A simulated annealing methodology for clusterwise linear regression. Psychometrika. 54(4):707-736. Kang C, Ghosal S. 2008. Clusterwise regression using Dirichlet mixtures. World
Sci. 9:301-322.
Latif AHMM, Hossain MZ, Islam MA. 2008. Model selection using modified Akaike’s Information Criterion: an application to maternal morbidity data.
Austrian J Statistics. 37(2):175-184.
McLachlan GI, Krishnan T. 2008. The EM Algorithm and Extensions 2nd Ed. New Jersey (US): J Wiley.
Mukhopadhyay SK. 2007. Production Planning and Control Text and Cases2nd Ed. New Delhi (IN): Prentice Hall of India Private Limited.
Qian G, Wu Y. 2011. Estimation and selection in regression clustering. European
14
Ramachandran KM, Tsokos CP. 2009. Mathematical Statistics with Applications. New York (US): Elsevier Academic Press.
Smith WR. 1956. Product differentiation and market segmentation as alternative strategies. Journal of Marketting. 21(7):3-8.
Spath H. 1979. Algorithm 39: Clusterwise Linear Regression. Computing. 22: 367-373.
Wedel M. 1990. Clusterwise Regression and Market Segmentation. Development
15 Lampiran 1 Diagram alir metode penelitian
Data Simulasi Dibangkitkan
Inisialisasi Awal k , k, σk, dan bjk.
Tahap E
Menghitung nilai peluang posterior Bayesian pik
Menghitung nilai log fungsi kemungkinan (ln L)
diulang r kali
Mendapatkan nilai Ln L yang maksimum di titik global Menghitung nilai dugaan k, σk, dan bjk baru.
Tahap M
diulang m kali
ulang dengan nilai k yang berbeda
Mendapatkan model regresi terbaik dengan gerombol yang optimal Mendapatkan penduga parameter
16
RIWAYAT HIDUP
Penulis dilahirkan di Bogor tanggal 22 Februari 1992, sebagai anak pertama dari tujuh bersaudara pasangan Risman Melanoviarsyah dan Selly Sulaeha. Penulis lulus dari SMA Negeri 6 Bogor pada tahun 2010 dan pada tahun yang sama diterima di Institut Pertanian Bogor melalui jalur Ujian Talenta Masuk IPB (UTMI). Penulis diberikan kesempatan untuk belajar menempuh pendidikan sarjananya di Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam IPB dengan minor Ekonomi Studi Pembangunan. Pada semester 6, penulis juga berkesempatan melaksanakan kegiatan praktik lapang di perusahaan Survey and
Research Lingkaran Survei Indonesia di Jakarta Utara. Penulis selama
melaksanakan studi di IPB tidak hanya aktif dalam bidang akademik, tetapi juga dalam bidang non-akademik di dalam kampus.
Selama menempuh pendidikan di Institut Pertanian Bogor penulis berpengalaman menjadi asisten dosen untuk mata kuliah Metode Statistika. Penulis juga aktif baik dalam kegiatan Himpro, UKM, dan kepanitian-kepanitiaan. Pada tahun 2010-2011 penulis bergabung dalam Paduan Suara Mahasiswa IPB Agria Swara dan tahun 2011-2012 bergabung dalam staf Manajemen Leadership and
Entrepreneurship School (LES) IPB. Pada dua periode masa bakti Himpunan
Profesi Mahasiswa Statistika Gamma Sigma Beta (GSB) pada tahun 2012-2013, penulis aktif dalam Badan Pengawas Himpunan Profesi GSB.