PERBANDINGAN METODE KLASIFIKASI REGRESI LOGISTIK
DAN JARINGAN SARAF TIRUAN PADA KASUS
PENGKLASIFIKASIAN DATA DEMOGRAFI
SKRIPSI
SITI HARDIANTI
070803022
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERBANDINGAN METODE KLASIFIKASI REGRESI LOGISTIK DAN JARINGAN SARAF TIRUAN PADA KASUS PENGKLASIFIKASIAN
DATA DEMOGRAFI
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
SITI HARDIANTI 070803022
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PERBANDINGAN METODE KLASIFIKASI
REGRESI LOGISTIK DAN JARINGAN SARAF TIRUAN PADA KASUS PENGKLASIFIKASIAN DATA DEMOGRAFI
Kategori : SKRIPSI
Nama : SITI HARDIANTI
Nomor Induk Mahasiswa : 070803022
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juni 2011
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dra. Elly Rosmaini, M.Si Dr. Sutarman, M. Sc
NIP. 19600520198503 2 002 NIP. 19631026199103 1 001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
Prof. Dr. Tulus, M.Si
PERNYATAAN
PERBANDINGAN METODE KLASIFIKASI REGRESI LOGISTIK DAN JARINGAN SARAF TIRUAN PADA KASUS PENGKLASIFIKASIAN
DATA DEMOGRAFI
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya
Medan, Juni 2011
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa yang telah memberikan rahmat dan hidayah-Nya sehingga skripsi ini dapat diselesaikan dalam waktu telah ditetapkan.
Ucapan terima kasih penulis sampaikan kepada Bapak Dr. Sutarman, M.Sc selaku Dekan FMIPA USU sekaligus pembimbing dan Ibu Dra. Elly Rosmaini, M. Si selaku pembimbing yang telah memberikan panduan dan penuh kepercayaan kepada penulis untuk menyempurnakan skripsi ini.
Penulis juga mengucapkan terima kasih kepada Bapak Prof. Dr. Tulus, M.Si, selaku ketua Departemen Matematika Ibu Dra. Mardiningsih, M.Si selaku sekretasis Departemen Matematika, Bapak Drs. Suyanto, M.Kom dan Bapak Syahriol Sitorus, S.Si, M.IT selaku penguji skripsi, dan staf pengajar Matematika di FMIPA USU, beserta pegawai Administrasi.
Penulis juga mengucapkan terima kasih kepada kedua orang tua yang tercinta Ibunda Suparmi dan Ayahanda Suwondo yang telah memberikan dorongan dan semua bantuan yang diperlukan. Adik penulis yang penulis sayangi Raji Mahadi Sudarjat dan Ridho Dharma Satria terima kasih atas dorongan dan bantuan yang diberikan. Dan penulis mengucapkan terima kasih kepada Ibu Nasrah. Akhirnya penulis juga mengucapkan terima kasih kepada Siti F. Sihotang, Rina Yanti Lubis, Yazeni Diana Putri, Novita Sari, Evi Mulyanti, Annida Wijaya Yusuf, Harizahayu, Hikmah dan teman-teman lain yang tidak dapat disebutkan satu persatu atas bantuannya dalam menyelesaikan skripsi ini.
Semoga segala bentuk bantuan yang telah diberikan mendapat balasan yang jauh lebih baik dari Tuhan Yang Maha Esa.
Sebagai seorang mahasiswa, penulis menyadari bahwa masih banyak kekurangan di dalam menyelesaikan skripsi ini. Untuk itu, kritik dan saran yang membangun sangat diharapkan demi perbaikan tulisan ini.
Medan, Juni 2011 Penulis
ABSTRAK
COMPARISON OF CLASSIFICATION METHODS LOGISTIC REGRESSION AND ARTIFICIAL NEURAL NETWORK IN CASE CLASSIFICATION OF DATA DEMOGRAPHY
ABSTRACT
DAFTAR ISI
Daftar Gambar viii
Bab 1 Pendahuluan
1.1. Latar Belakang 1
1.2. Perumusan Masalah 4
1.3. Pembatasan Masalah 5
1.4. Tujuan Penelitian 5
1.5. Metodologi Penelitian 5
1.6. Tinjauan Pustaka 6
1.6.1. Regresi logistik 6
1.6.2. Jaringan Saraf Tiruan 7
Bab 2 Landasan Teori
2.7. Aturan Pembelajaran Jaringan Saraf Tiruan 19
2.8. Jaringan Saraf Back Propagation 20
2.9. Prosedur Klasifikasi 21
2.10. Demografi 22
Bab 3 Pembahasan
3.1. Evaluasi Fungsi Klasifikasi Regresi Logistik 23 3.2. Analisis Data Dengan Regresi Logistik 23
3.3. Klasifikasi Dengan Regresi Logistik 24
3.4. Algoritma Pelatihan Jaringan Saraf Tiruan Back Propagation 28
3.5. Klasifikasi Jaringan Saraf Tiruan 28
3.6. Perbandingan Klasifikasi Regresi Logistik Dan Jaringan Saraf
Tiruan 35
Bab 4 Penutup
4.1. Kesimpulan 37
Daftar Pustaka 38
Lampiran A 40
DAFTAR TABEL
Halaman
Tabel 1: Klasifikasi Actual dan Predicted Group 2
Tabel 2: Data Demografi Indonesia Pada Data Proyeksi Penduduk
Indonesia Tahun 2000-2010 (x 1000) 25
Tabel 3: Data Demografi Indonesia Pada Data Proyeksi Penduduk
Indonesia Tahun 2000-2010 (Setelah Diberi Pengkodean) 26
Tabel 4: Tabel Uji Chi Square 27
Tabel 5: Tabel Klasifikasi 27
Tabel 6: Tabel Informasi Jaringan Saraf Tiruan 32
Tabel 7: Bobot Lapisan Input Ke Lapisan Tersembunyi 33 Tabel 8: Tabel Kesalahan klasifikasi Jaringan Saraf Tiruan 34 Tabel 9: Tabel Nilai Misclassified Pada Regresi Logistik Dan
DAFTAR GAMBAR
Halaman
Gambar 1.1 : Arsitektur Jaringan Saraf Tiruan Dengan Satu Jaringan Lapis
Tunggal 8
Gambar 1.2 : Arsitektur Jaringan Saraf Tiruan Dengan Jaringan Multilapis 9 Gambar 1.3 : Arsitektur Jaringan Saraf Tiruan Dengan Jaringan Kompetitif 9
Gambar 2.1 : Struktur Neuron Jaringan Saraf 18
ABSTRAK
COMPARISON OF CLASSIFICATION METHODS LOGISTIC REGRESSION AND ARTIFICIAL NEURAL NETWORK IN CASE CLASSIFICATION OF DATA DEMOGRAPHY
ABSTRACT
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Pengklasifikasian merupakan salah satu metode statistika untuk mengelompok atau menglasifikasi suatu data yang disusun secara sistematis. Masalah klasifikasi sering dijumpai dalam kehidupan sehari-hari. Baik itu pengklasifikasian data pada bidang akademik, sosial, pemerintahan, maupun pada bidang lainnya. Masalah klasifikasi ini muncul ketika terdapat sejumlah ukuran yang terdiri dari satu atau beberapa kategori yang tidak dapat diidentifikasikan secara langsung tetapi harus menggunakan suatu ukuran.
Dalam banyak kasus pengklasifikasian dapat diasumsikan sebagai banyaknya kategori atau populasi dari suatu individu yang ada dan setiap populasi dikarakteristikkan dengan ukuran distribusi probabilitasnya (Anderson,1984). Sebagai contoh yakni: pengklasifikasian siswa yang akan mengikuti ujian masuk di suatu universitas. pengklasifikasian didasarkan atas jurusan yang akan dipilih. Dalam hal ini yang menjadi ukuran ialah jurusan yang dipilih. Pengklasifikasian yang ada terdiri dari tiga klasifikasi yakni IPA, IPS, dan IPC yang memilih IPA dan IPS. Bisa saja siswa tersebut masuk ke dalam kelompok IPA, IPS, ataupun IPC.
dengan analisis diskriminan, regresi logistik merupakan metode klasifikasi yang cukup baik, setidaknya pada saat ada variabel independen berskala kuantitatif maupun kualitatif ataupun keduanya (Kurt et al, 2006).
Dalam penelitian ini yang akan dibahas ialah metode klasifikasi regresi logistik dan jaringan saraf tiruan (Artificial Neural Network). Regresi logistik adalah salah satu pendekatan model matematis yang digunakan untuk menganalisis hubungan antara satu atau beberapa variabel independen yang bersifat kontinu maupun biner dengan satu variabel dependen yang bersifat dikotomus (biner). Misalkan variabel dependen adalah Y dan variabel independen adalah X. Dalam hal ini regresi logistik tidak memodelkan secara langsung variabel dependen Y dengan variabel independen
X, melainkan melalui transformasi variabel dependen ke variabel logit yang merupakan natural log dari odds rasio.
Satu hal penting untuk menghasilkan prosedur klasifikasi ialah dengan menghitung tingkat error atau probabilitas misklasifikasi. Salah satu ukuran yang dapat digunakan adalah APER. Ukuran ini disebut dengan apparent error rate
(APER) yang didefenisikan sebagai fraksi observasi dalam sampel yang salah diklasifikasikan pada fungsi klasifikasi (Johnson et al,2007). APER digunakan dalam perhitungan ini karena mudah untuk dihitung, dan untuk sampel yang lebih sedikit APER dapat dipergunakan. Disamping itu hasil pengukuran dengan APER tidak bergantung pada distribusi populasi dan dapat dihitung untuk setiap prosedur klasifikasi. Perhitungan APER dapat dilakukan dengan terlebih dahulu membuat tabel klasifikasi, observasi dari dan observasi dari .
Tabel 1: Klasifikasi Actual dan Predicted Group Predicted group
Actual Group
Dari tabel diperoleh:
Dengan:
n1A : Jumlah pengamatan dari π1tepat diklasifikasikan sebagai π1.
n1B : Jumlah pengamatan dari π1 salah diklasifikasikan sebagai π2.
n2B : Jumlah pengamatan dari π2 salah diklasifikasikan sebagai π1.
n2A : Jumlah pengamatan dari π2 tepat diklasifikasikan sebagai π2.
Dalam evaluasi fungsi klasifikasi, khususnya pada regresi logistik ialah dengan terlebih dahulu membuat tabulasi antara actual group dan predicted group yang diperoleh dari fungsi logistik. Kemudian dihitung proporsi pengamatan yang salah diklasifikasikan. Diharapkan proporsi pengamatan misklasifikasi tersebut bisa minimum.
Selain regresi logistik, klasifikasi juga dapat dilakukan menggunakan jaringan saraf tiruan (artificial neural network). Jaringan saraf tiruan merupakan suatu sistem pemrosesan data yang memiliki karakteristik mirip dengan jaringan biologis, baik cara kerjanya maupun susunannya juga meniru jaringan saraf biologis.
Masalah yang umum dijumpai pada sistem klasifikasi pola adalah cara menemukan data ciri yang tepat bisa membedakan satu objek dengan objek lainnya. Cara membedakan atau dikenal dengan metode klasifikasi pola juga harus dipertimbangkan. Algoritma artificial neural network banyak digunakan untuk mengatasi masalah-masalah penyimpangan dan pemanggilan data, klasifikasi dan identifikasi pola, pemetaan pola input dan output, pengelompokan pola, hingga pada pencarian nilai-nilai optimasi.
Dalam hal melakukan perbandingan metode yang dinyatakan terbaik ialah metode yang memiliki tingkat error lebih kecil. Error dapat diketahui dari hasil akhir perhitungan masing-masing metode klasifikasi.
Untuk lebih jelasnya bagaimana regresi logistik dan jaringan saraf tiruan bekerja dan metode klasifikasi yang manakah lebih baik dalam proses pengklasifikasian maka penulis mengambil contoh pada data demografi. Data demografi yang diambil merupakan data tentang kependudukan Indonesia pada 30 provinsi yang diambil secara garis besarnya saja atau secara umum.
1.2. Perumusan Masalah
1.3. Pembatasan Masalah
Ruang lingkup penelitian ini dibatasi pada data demografi jumlah penduduk 30 provinsi di Indonesia secara umum yang diklasifikasikan dengan menggunakan metode klasifikasi regresi logistik dan jaringan saraf tiruan (artificial neural network).
1.4. Tujuan Penelitian
Tujuan penelitian ini ialah untuk membandingkan hasil metode klasifikasi regresi logistik dengan jaringan saraf tiruan (artificial neural network) pada data demografi kemudian memilih metode klasifikasi yang manakah lebih baik dalam pengklasifikasian.
1.5. Metodologi Penelitian
Dalam penelitian ini penulis melakukan studi literatur dan mencari bahan dari internet yang membahas mengenai regresi logistik dan artificial neural network (jaringan saraf tiruan). Kemudian mengambil sampel data demografi di 30 provinsi di Indonesia dari internet. Adapun langkah-langkahnya adalah sebagai berikut:
a. Menguraikan penyelesaian pengklasifikasian dengan menggunakan metode klasifikasi regresi logistik dan artificial neural network (jaringan saraf tiruan). b. Melakukan pengklasifikasian data demografi dengan bantuan komputer
spss17
c. Membandingkan kedua metode klasifikasi regresi logistik dan artificial neural network (jaringan saraf tiruan).
1.6. Tinjauan Pustaka
Berikut diberikan tinjauan pustaka tentang pengklasifikasian dengan metode regresi logistik dan neural artificial network (jaringan saraf tiruan). Untuk itu dalam hal pengklasifikasian di ambil sampel data demografi jumlah penduduk Indonesia dari 30 provinsi secara umum.
1.6.1. Regresi Logistik
Regresi logistik merupakan salah satu metode klasifikasi yang sering digunakan. Regresi logistik biner digunakan saat variabel dependen merupakan variabel dikotomus. Regresi logistik multinomial digunakan pada saat variabel dependen adalah variabel kategorik dengan lebih dari 2 kategori. Secara umum model regresi logistik multivariate adalah:
(Hosmer et al, 1989)
dimana merupakan nilai probabilitas sehingga , yang berarti bahwa regresi logistik menggambarkan suatu probabilitas. Dengan mentransformasikan pada persamaan di atas dengan transformasi logit , dimana:
(Hosmer et al, 1989)
maka diperoleh bentuk logit:
(Hosmer et al, 1989)
Pada dasarnya metode maximum likelihood memberikan nilai estimasi dengan memaximumkan fungsi likelihoodnya.
Dalam melakukan evaluasi fungsi klasifikasi dilakukan dengan membagi data menjadi 2 bagian. Bagian pertama akan dipergunakan sebagai training set, yang diperlukan untuk membentuk model klasifikasi regresi logistik. Berikutnya, bagian kedua akan dipergunakan sebagai validasi set, yang berfungsi sebagai cross-validasi fungsi klasifikasi regresi logistik.
Dalam melakukan pengklasifikasian diharapkan untuk meminimalkan kesalahan klasifikasi atau meminimalkan rata-rata efek buruk dari kesalahan klasifikasi.
1.6.2. Jaringan Saraf Tiruan
Jaringan saraf tiruan merupakan model tiruan bagaimana makhluk hidup memahami dan mengenali informasi disekitarnya (eka et al, 2006). Secara sederhana, jaringan saraf tiruan adalah sebuah alat pemodelan tiruan dapat digunakan untuk memodelkan hubungan yang kompleks antara input dan output untuk menemukan pola-pola pada data (Wikipedia, 2010).
Jaringan saraf tiruan ini disusun oleh elemen-elemen pemroses yang berada pada lapisan-lapisan yang berhubungan dan diberi bobot. Dengan serangkaian inputan diluar sistem yang diberikan kepadanya jaringan ini dapat memodifikasi bobot yang akan dihasilkannya, sehingga akan menghasilkan output yang konsisten sesuai dengan input yang diberikan kepadanya.
Ada pun langkah-langkah klasifikasi data pada jaringan saraf tiruan diantaranya ialah :
b. Penggunaan model untuk mengklasifikasikan data baru. Dalam hal ini, sebuah record “diumpankan” ke model, dan model akan memberikan jawaban “kelas” hasil perhitungannya.
Jaringan Saraf Tiruan dibagi ke dalam 3 macam arsitektur, yaitu: a. Jaringan Lapis Tunggal
Jaringan yang memiliki arsitektur jenis ini hanya memiliki satu buah lapisan bobot koneksi. Jaringan lapisan tunggal terdiri dari unit-unit input yang menerima sinyal dari dunia luar, dan unit-unit output dimana kita bisa membaca respons dari jaringan saraf tiruan tersebut.
Lapisan input w2m
w1m w21 wn1 wnm
w11 bobot
Lapisan output
Gambar 1.1: Arsitektur Jaringan Saraf Tiruan Dengan Satu Jaringan Lapis Tunggal
b. Jaringan Multilapis
Lapisan input
Gambar 1.2: Arsitektur Jaringan Saraf Tiruan Dengan Jaringan Multilapis
c. Jaringan Kompetitif
Pada jaringan ini sekumpulan neuron bersaing untuk mendapatkan hak menjadi aktif.
Gambar 1.3: Arsitektur Jaringan Saraf Tiruan Dengan Jaringan Kompetitif
Y1 Yn
A1
Ai A
BAB 2
LANDASAN TEORI
2.1. Regresi Logistik Biner
Regresi logistik biner merupakan salah satu pendekatan model matematis yang digunakan untuk menganalisis hubungan beberapa faktor dengan sebuah variabel yang bersifat dikotomus (biner). Pada regresi logistik jika variabel responnya terdiri dari dua kategori misalnya Y = 1 menyatakan hasil yang diperoleh “sukses” dan Y = 0 menyatakan hasil yang diperoleh “gagal” maka regresi logistik tersebut menggunakan regresi logistik biner. Menurut Agresti variabel y yang demikian lebih tepat dikatakan sebagai variabel indikator dan memenuhi distribusi Bernoulli. Fungsi distribusi peluang untuk y dengan parameter πi adalah
dengan . Dari fungsi distribusi tersebut diperoleh rata-rata :
Misalkan probabilitas ini dinotasikan sebagai yang bergantung dengan variabel
penjelas dengan dan , sehingga diperoleh
Secara umum model probabilitas regresi logistik dengan melibatkan beberapa variabel prediktor dapat diformulasikan sebagai berikut:
Dimana merupakan penjumlahan dari . Fungsi merupakan fungsi non linear sehingga perlu dilakukan transformasi logit untuk memperoleh fungsi yang linier agar dapat dilihat hubungan antara variabel respon dengan variabel prediktornya . Bentuk logit dari dinyatakan sebagai , yaitu:
Persamaan (1) dan persamaan (2) disubtitusikan sehingga diperoleh:
Untuk memperoleh estimasi dari parameter regresi logistik dapat dilakukan dengan dua cara yakni dengan cara Maximum Likelihood Estimation (MLE) dan iterasi Newton Raphson.
a. Maximum Likelihood Estimation (MLE)
Metode MLE digunakan untuk mengestimasi parameter-parameter dalam regresi logistik dan pada dasarnya metode maksimum likelihood memberikan nilai estimasi β dengan memaksimumkan fungsi likelihoodnya. (Hosmer dan Lemeshow, 1989). Secara matematis fungsi likelihood dapat dinyatakan:
dan logaritma likelihoodnya dinyatakan sebagai:
Untuk memperoleh nilai β maka dengan memaksimumkan nilai dan mendiferensialkan terhadap dan menyamakannya dengan nol. Persamaan ini dapat ditulis dalam bentuk sebagai berikut:
dan persamaan likelihood:
b. Metode Newton Rhapson
Metode Newton Rhapson merupakan metode untuk menyelesaikan persamaan nonlinear seperti menyelesaikan persamaan likelihood dalam model regresi logistik (Agresti, A. 1990). Metode newton rhapson memerlukan taksiran awal untuk nilai fungsi maksimumnya, yang mana fungsi tersebut merupakan taksiran yang menggunakan pendekatan polinomial berderajat dua. Dalam hal ini untuk menentukan
nilai dari β yang merupakan fungsi maksimum dari . Andaikan:
, dan andaikan H dinotasikan sebagai matriks yang mempunyai
anggota . Andaikan dan merupakan bentuk evaluasi dari ,
taksiran ke t pada . Pada langkah t dalam proses iterasi (t = 0, 1, 2, ...), ialah
pendekatan yang merupakan bentuk orde kedua dari ekspansi deret Taylor,
dengan mengasumsikan sebagai matriks nonsingular.
2.2. Fungsi Klasifikasi Regresi Logistik
Dalam regresi logistik penglasifikasian dilakukan dengan menghitung “error rates”
atau probabilitas kesalahan klasifikasi (Johnson et al, 2007). Misalkan dan merupakan fungsi kepadatan peluang dengan p x 1 variabel acak X. Dan misalkan Ω ialah ruang sampel yang merupakan semua observasi x yang mungkin. Andaikan R1 merupakan nilai x sebagai objek klasifikasi dan sebagai
objek klasifikasi . Jika setiap objek disimbolkan dengan 1 atau hanya 1 dari 2 populasi maka himpunan dan merupakan mutually exclusive dan exhaustive. Sehingga probabbilitas kondisional ialah
Sama halnya dengan
Andaikan merupakan probabilitas dari dan merupakan probabilitas dari . Total probabilitas misklasifikasi (TPM) ialah:
Dalam hal ini untuk menentukan kesalahan klasifikasi dapat digunakan prosedur klasifikasi optimal yang disebut optimum error rate (OER) yaitu:
Dimana dan ,
Dalam hal lain OER dapat dihitung jika fungsi densitas populasi diketahui. Namun , dalam kasus lain populasi parameter harus di estimasikan terlebih dahulu sehingga evaluasi error ratenya menjadi tidak seimbang. Untuk itu sampel fungsi klasifikasinya dapat dihitung dengan menghitung actual error rate (AER).
AER akan mengindikasikan bagaimana fungsi klasifikasi yang akan diperlihatkan pada sampel berikutnya seperti OER namun tidak dapat menghitung secara umum karena tergantung pada fungsi densitas yang tidak diketahui yaitu dan . Sehingga untuk mempermudah perhitungan dalam proses klasifikasi dan tidak bergantung pada distribusi populasi dengan menghitung error rate atau probabilitas kesalahan klasifikasi pada APER (apperent error rate) yang merupakan fraksi observasi dalam sampel yang salah diklasifikasikan atau misclassified pada fungsi klasifikasi (Johson et al, 2007). Perhitungan APER terlebih dahulu dibuat matriks konfusinya yang diperlihatkan dalam tabel 1 sebelumnya. Sehingga diperoleh:
2.3. Model Logit
Pada umumnya variabel respon data kategorik hanya mempunyai 2 kategorik yaitu sukses dan gagal, ya atau tidak, hidup atau mati dan sebagainya. Hasil observasi untuk setiap objek diklasifikasikan sebagai sukses dan gagal. Untuk sukses dinyatakan dengan 1, gagal dinyatakan dengan 0. Seperti halnya distribusi Bernaulli/Binomial untuk variabel random dengan probabilitas sukses dan gagal
Distribusi ini termasuk dalam exponensial sejati dengan parameter sejatinya ialah
dan
Dalam regresi logistik untuk variable biner model natural odds rasio disebut logit sehingga
Fungsi logit merupakan fungsi probabilitas , jika diasumsikan ke dalam variabel predictor variable Z maka
Dengan kata lain log odds merupakan variabel prediktor linear. Jika dimasukkan bentuk logit atau log odds ke dalam probabilitas diperoleh:
Sehingga dapat ditentukan:
2.4. Distribusi Binomial
tersebut bersifat bebas dan peluang keberhasilan setiap ulangan tetap sama,yaitu sebasar 0,5 ( Cyber-learn, 2011).
Secara umum bentuk distribusi binomial yaitu
Dengan probabilitas sukses p (atau probabilitas gagal q=1-p).
2.5. Deret Taylor
Deret taylor dapat memberikan nilai hampiran bagi suatu fungsi pada suatu titik, berdasarkan nilai fungsi dan turunannya pada titik yang lain.(Kholijah, S. 2008). Andaikan suatu fungsi dan turunannya, yaitu
kontinu dalam selang , dan , maka untuk nilai x disekitar , dapat diekspansikan (diperluas) ke dalam deret Taylor sebagai:
Aproksimasi orde nol pada deret taylor merupakan suku pertama dari deret taylor tersebut. Bila dalam deret taylor terdapat penambahan suku maka akan berkembang menjadi aproksimasi orde 2 dan seterusnya. Misalkan merupakan suku tambahan dalam deret taylor setelah bentuk ke n dalam deret dan , maka diperoleh deret taylor secara umum:
Dengan
2.6. Konsep Dasar Jaringan Saraf Tiruan
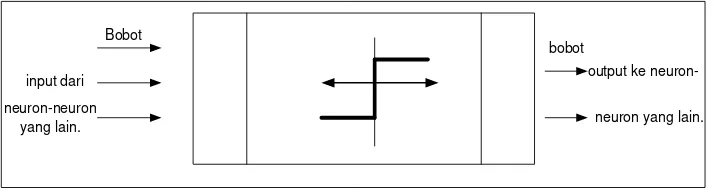
Jaringan saraf ini diimplementasikan dengan menggunakan program komputer yang mampu menyelesaikan sejumlah proses perhitungan selama proses pembelajaran. Ada beberapa tipe jaringan saraf yang sebagian besar memiliki komponen-komponen yang sama. Sama halnya otak manusia, jaringan saraf juga terdiri dari beberapa neuron dan memiliki hubungan antara neuron-neuron tersebut. Neuron-neuron tersebut akan menstranformasikan informasi yang diterima melalui sambungan keluarnya menuju ke neuron yang lain. Pada jaringan saraf, hubungan ini dikenal dengan nama bobot. Informasi tersebut disimpan pada suatu nilai tertentu pada bobot tersebut. Gambar 2.1 berikut menunjukkan struktur neuron pada jaringan saraf tiruan:
Bobot
Gambar 2.1: Struktur Neuron Jaringan Saraf. (Kusumadewi, 2004)
Adapun lapisan-lapisan penyusun jaringan saraf tiruan dapat dibagi menjadi tiga, yaitu:
1. Lapisan Input
Node-node di dalam lapisan input disebut unit-unit input. Unit-unit input menerima input dari dunia luar. Input yang dimasukkan merupakan penggambaran dari suatu masalah.
2. Lapisan Tersembunyi
Node-node di dalam lapisan tersembunyi disebut unit-unit tersembunyi. Output dari lapisan ini tidak secara langsung dapat diamati.
3. Lapisan Output
Node-node pada lapisan output disebut unit-unit output. Keluaran atau output dari lapisan ini merupakan output jaringan saraf tiruan terhadap suatu permasalahan.
2.7. Aturan Pembelajaran Jaringan Saraf Tiruan
Aturan kerja atau aturan pembelajaran jaringan saraf tiruan secara umum terdiri dari 4 tipe dasar (Diyah, 2006), yaitu:
1. Aturan Pengoreksian Error (Error Correcting)
Prinsip dasar dari aturan pembelajaran pengoreksian error ialah memodifikasi bobot-bobot koneksi dengan menggunakan sinyal kesalahan (output target– output aktual) untuk mengurangi besarnya kesalahan secara bertahap.
2. Aturan Pembelajaran Boltzmann
neuron yang visible, sedangkan neuron-neuron yang tidak berinteraksi dengan lingkungan disebut neuron tersembunyi (hidden neurons).
3. Aturan Hebbian
Pada aturan hebbian kekuatan koneksi antara 2 buah neuron akan meningkat jika kedua neuron memilik tingkah laku yang sama (keduanya memiliki aktivasi positif atau keduanya memiliki aktivasi negatif).
4. Aturan Pembelajaran Kompetitif (competitive Learning)
Unit-unit output pada aturan pembelajaran kompetitif ini harus saling bersaing untuk beraktivasi. Jadi hanya satu unit output yang aktif pada satu waktu. Bobot-bobotnya diatur setelah satu node pemenang terpilih.
Adapun hal yang ingin dicapai dalam pembelajaran jaringan saraf tiruan ialah untuk mencapai keseimbangan antara kemampuan memorisasi dan generalisasi. Yang dimaksud dengan kemampuan memorisasi ialah kemampuan jaringan saraf tiruan untuk memanggil kembali secara sempurna sebuah pola yang telah dipelajari. Kemampuan generalisasi ialah kemampuan jaringan saraf tiruan untuk menghasilkan respons yang bisa diterima terhadap pola-pola input yang serupa (tidak identik) dengan pola-pola yang sebelumnya telah dipelajari. Hal ini sangat bermanfaat bila pada suatu saat ke dalam jaringan saraf tiruan itu diinputkan informasi baru yang belum pernah dipelajari, maka jaringan saraf tiruan itu masih akan tetap dapat memberikan tanggapan yang baik, memberikan keluaran yang paling mendekati.
2.8. Jaringan Saraf Back Propagation
2.9. Prosedur Klasifikasi
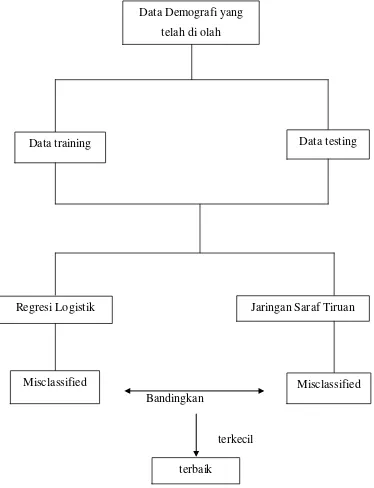
Untuk dapat menyatakan metode klasifikasi yang terbaik dari perbandingan metode klasifikasi regresi logistik dan jaringan saraf tiruan yaitu dengan menghitung
misclassified pada kedua metode tersebut. Atau dengan kata lain misclassified
digunakan sebagai indikator dalam melakukan proses klasifikasi. Prosesdur pengklasifikasian dapat dilihat pada Gambar 2.2 berikut:
Bandingkan
terkecil
Gambar 2.2: Diagram Proses Pengklasifikasian Data Demografi yang
telah di olah
Data training Data testing
Regresi Logistik Jaringan Saraf Tiruan
Misclassified Misclassified
Dalam melakukan klasifikasi, digunakan data training yang berfungsi untuk membentuk model, baik untuk regesi logistik maupun pada jariangan saraf tiruan. Sedangkan data testing digunakan untuk menguji ketepatan klasifikasi dari model yang telah terbentuk. Misclassified kedua model nantinya akan dibandingkan. Pemilihan data training dan data testing di pilih secara acak.
2.9. Demografi
Berdasarkan Multilingual Demographic Dictionary (IUSSP, 1982) defenisi demografi ialah: Demography is the scientific study of human populations in primarily with the respect to their structure (composition) and their development (change).
Menurut Donald J. Bogue mengatakan bahwa demografi ialah ilmu yang mempelajari secara statistik dan matematik tentang besar, komposisi, dan distribusi penduduk dan perubahan-perubahannya sepanjang masa melalui bekerjanya lima komponen demografi yaitu kelahiran (fertilitas), kematian (mortalitas), perkawinan, migrasi, dan mobilitas sosial.
BAB 3
PEMBAHASAN
3.1. Evaluasi Fungsi Klasifikasi Regresi Logistik
Hal penting dalam melakukan evaluasi fungsi klasifikasi untuk mengetahui seberapa tepat klasifikasi yang dilakukan yaitu dengan menggunakan APER (Apparent Error Rate) sebagaimana telah di jelaskan pada Bab 2. Sebelum menggunakan APER hal pertama yang dilkukan ialah dengan membuat tabel klasifikasinya terlebih dahulu (lihat Tabel 1). Dalam melakukan klasifikasi dengan regresi logistic terlebih dahulu dibuat tabulasi antara actual group dan predicted group yang diperoleh dari fungsi logistik (persamaan 2).
Selanjutnya dihitung proporsi pengamatan yang salah diklasifikasikan. Diharapkan proporsi pengamatan yang salah diklasifikasikan tersebut bias sekecil mungkin. Dalam regresi logistik tidak memilih asumsi normalitas atas variabel bebas yang digunakan dalam model variable bebas tersebut dapat berupa variabel kontinu, diskrit, dan dikotomus (Kuncoro, 2000).
3.2. Analisis Data Dengan Regresi Logistik
Tahap kedua ialah menguji apakah asumsi multivariate normal dan homogenitas varian terpenuhi oleh data pada masing-masing kelompok respon. Asumsi multivariate normal diuji dengan Chi Square plot, sedangkan asumsi homogenitas varians diuji dengan Box’s. Tahap ketiga ialah dengan membentuk model klasifikasi dengan regresi logistik menggunakan data pada training set. Model klasifikasi yang telah diperoleh ini selanjutnya divalidasi dengan data pada validasi set, akan diketahui besarnya APER atau tingkat ketepatan klasifikasi (Wibowo, 2002). Proporsi kesalahan (misclassified) atau ketepatan klasifikasi ini yang akan digunakan sebagai pembanding antara regresi logistik dan jaringan saraf tiruan.
3.3. Klasifikasi Dengan Regresi Logistik
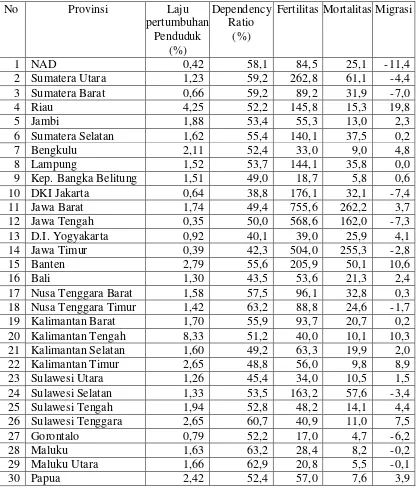
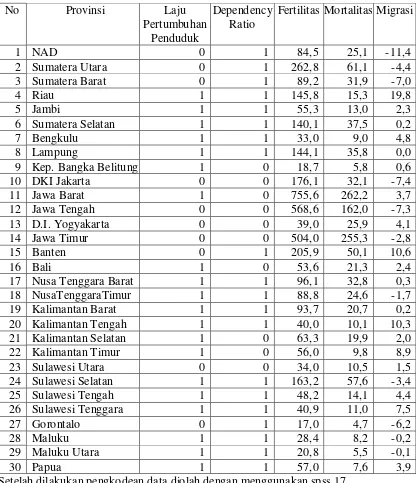
Pengklasifikasian yang dilakukan yaitu dengan menggunakan data demografi penduduk Indonesia pada 30 provinsi yang diambil dari tahun 2000 sampai tahun 2010. Dengan variabel responnya ialah persentasi laju pertumbuhan penduduk. variabel ini dikode 0 jika persentasi perubahannya di bawah persentasi seluruh laju pertumbuhan penduduk di Indonesia dan dikode 1 jika persentasi laju pertumbuhan penduduk setiap provinsi di atas persentasi laju pertumbuhan penduduk seluruh Indonesia.
Variabel prediktornya ialah komposisi umur (dependency ratio), fertilitas, mortalitas, dan migrasi penduduk di masing-masing provinsi.. Untuk dependency ratio
akan dikode 0 jika di bawah rata-rata tingkat dependency ratio penduduk Indonesia dan akan dikode 1 jika berada di atas rata-rata tingkat dependency ratio penduduk Indonesia. Berdasarkan hasil pengujian asumsi, untuk nilai data ini yang skala datanya campuran, asumsi kesamaan matrik kovarian dapat terpenuhi, sedangkan asumsi multivariate normal tidak terpenuhi karena menghsilkan kesimpulan yang berbeda.
Proses Klasifikasi:
1. Tahap pertama ialah melakukan pengkodean pada data demografi di atas, perubahan yang terjadi dapat dilihat pada Tabel 3 berikut ini:
Tabel 3: Data Demografi Indonesia Pada Data Proyeksi Penduduk Indonesia Tahun 2000-2010 (Setelah Diberi Pengkodean).
No Provinsi Laju
Setelah dilakukan pengkodean data diolah dengan menggunakan spss 17.
multivariate normal diuji dengan Chi Square plot, sedangkan asumsi homogenitas varians diuji dengan Box’s.
Tabel 4: Tabel Uji Chi Square
Dari Chi Square pada derajat kebebasan 5% dengan nilai 11,135 artinya model dengan hanya intercept, berbeda secara statistik dibandingkan dengan model yang memasukkan semua variabel. Hal ini dapat dilihat dari taraf signifikannya yakni 0,025 < 0,05.
3. Tahap 3 yaitu dengan menggunakan spss 17 dapat diperoleh tabel klasifikasi actual group dan predicted group dari Tabel 3 di atas, antara lain:
Tabel 5: Tabel Klasifikasi Predicted group
Actual Group
Sehingga proporsi pengamatan yang salah diklasifikasikan dapat diperoleh dengan menghitung APER, yakni:
Model Fitting Information
Model
Model
Fitting
Criteria Likelihood Ratio Tests
-2 Log
Likelihood
Chi-Square df Sig.
Intercept Only 38.191
3.4. Algoritma Pelatihan Jaringan Saraf Tiruan Back Propagation
Algoritma pelatihan jaringan saraf tiruan back propagation pada dasarnya terbagi menjadi 2 langkah yaitu langkah maju (feed forward) dan propagasi balik. Pada langkah maju, perhitungan bobot-bobot neuron hanya didasarkan pada vektor masukan, Sedangkan pada propagasi balik, bobot-bobot diperhalus dengan memperhitungkan nilai target atau keluaran.
Dalam melakukan klasifikasi hal yang dilakukan ialah dengan mencari nilai MSE (Mean Square Error). Nilai mean square error (MSE) pada satu siklus pelatihan (langkah 2 – 10, dimana seluruh record dipresentasikan satu kali) ialah nilai kesalahan (error = nilai keluaran – nilai masukan) rata-rata dari seluruh record yang dipresentasikan ke jaringan saraf tiruan dan dirumuskan sebagai:
Semakin kecil MSE, jaringan saraf tiruan semakin kecil kesalahannya dalam memprediksikelas dari record yang baru. Maka, pelatihan jaringan saraf tiruan ditujukan untuk memperkecil MSE dari satu siklus ke siklus berikutnya sampai selisih nilai MSE dari satu siklus ini dengan siklus sebelumnya lebih kecil atau sama dengan batas minimal yang diberikan (Dhaneswara et al, 2004).
3.5. Klasifikasi Jaringan Saraf Tiruan
Setelah dilakukan klasifikasi dengan regresi logistik maka akan dilakukan klasifikasi dengan menggunakan jaringan saraf tiruan. Pada tahap awal yaitu dengan melakukan pelatihan pada jaringan saraf back propagation. Pelatihan ini dilakukan dengan penggunaan momentum pada perhitungan perubahan bobot-bobot, yang bertujuan untuk melancarkan pelatihan dan mencegah agar bobot tidak “berhenti “ di sebuah nilai yang belum optimal. Perubahan bobot pada Algoritma 1 diubah menjadi:
Namun terkadang dalam melakukan pelatihan muncul masalah dalam sistem yang terlalu berlebihan hal ini dikarenakan kapasitas jaringan melebihi parameter bebas yang diperlukan secara signifikan. Untuk menghindari masalah ini hal yang dilakukan ialah dengan menggunakan cross validasi untuk meminimalkan kesalahan dan menggunakan beberapa bentuk regularisasi yang merupakan konsep yang muncul secara alami dalam probabilitas Bayesian, dimana regularisasi tersebut dapat dilakukan dengan memilih model sederhana yang lebih utama, tetapi dalam statistik tujuannya untuk meminimalkan resiko empiris dan resiko struktural yang sesuai dengan kesalahan selama training set dan kesalahan prediksi pada data yang tak terlihat karena overfitting (Wikipedia, 2011).
Setelah pelatihan selesai diakukan, maka model jaringan saraf tiruan akan digunakan untuk menglasifikasikan record baru. Klasifikasi ini cukup dilakukan dengan langkah feed forward dan hasilnya berupa kelas yang diprediksi jaringan saraf tiruan untuk rekord yang baru ini. Langkah-langkah dalam melakukan klasifikasi jaringan saraf tiruan dilakukan dengan (Dhaneswara et al, 2004):
Algoritma :
1. Menginisialisasi bobot awal dengan nilai acak yang sangat kecil, hitung mean square error (MSE) dan MSE inisialisasi.
2. Selama MSE , dengan lakukan: 3. Untuk setiap rekord pada set data pelatihan lakukan:
Feedforward:
4. Setiap unit masukan menerima vektor masukan dan mengirimkan vektor ini ke seluruh unit pada lapis diatasnya (hidden layer).
5. Setiap unit hidden menjumlahkan bobot dari vektor
masukan:
hitung keluaran fungsi aktivasi: kirimkan vektor ini ke
6. Setiap unit keluaran menjumlahkan vektor masukan:
hitung keluaran dari fungsi aktivasi:
Propagasi balik dari error:
7. Setiap unit keluaran menerima vektor hasil yang diinginkan untuk data masukan tersebut, hitung error-nya
Hitung nilai koreksi bobotnya dengan sebagai learning ratenya:
, hitung nilai koreksi biasnya: kirimkan ke unit
pada lapis dibawahnya.
8. Setiap unit hidden menjumlahkan delta masukannya (dari
unit-unit pada lapis diatasnya):
Kalikan dengan turunan dari fungsi aktivasinya untuk menghitung errornya: hitung nilai koreksi bobotnya:
.
Perbaharui bobot dan bias:
9. Setiap unit keluaran memperbaharui bias dan bobotnya .
Setiap unit tersembunyi memperbaharui bias dan
bobotnya .
. MSElama=MSE.
Hitung
Keterangan notasi untuk algoritma 1:
x = vektor masukan = (x1, …, xi, …, xn),
t = vektor keluaran= (t1, …, tk, …, tm)
δk = nilai koreksi bobot error untuk wjk yang disebabkan oleh error pada unit
keluaranYk .
δj = nilai koreksi bobot error untuk yang disebabkan oleh informasi propagasi
balik dari error pada lapis keluaran ke unit tersembunyi Zj . α = konstanta laju pembelajaran (learning rate).
Xi = unit masukan i.
v0j = bias pada unit tersembunyi j.
Zj = unit tersembunyi j.
w0k = bias pada unit keluaran k.
Yk = unit keluaran k.
Fungsi aktivasi yang dapat digunakan pada propagasi balik ialah:
Binary sigmoid: mempunyai rentang diantara 0 dan 1, fungsi identitas
merupakan fungsi aktivasi untuk semua unit input, fungsi sigmoid
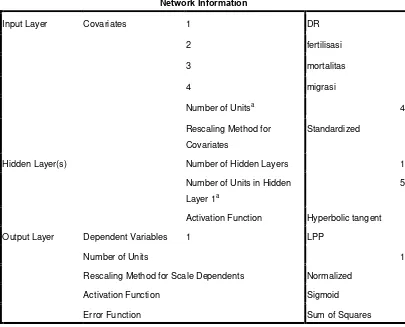
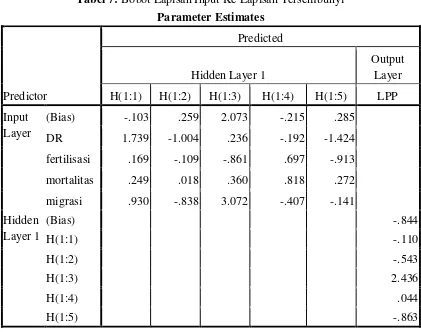
Analisis dan arsitektur pada jaringan saraf tiruan dalam hal pengklasifikasian data demografi ialah dengan menggunakan jaringan saraf tiruan jumlah hidden layer yang digunakan 1 dengan 5 unit hidden layer, dengan learning rate 0,4. Dan fungsi aktivasi yang digunakan ialah fungsi aktivasi binary sigmoid. Untuk lebih jelasnya dapat di lihat pada tabel di bawah ini (Lampiran B):
Tabel 6: Tabel Informasi Jaringan Saraf Tiruan
Network Information
Hidden Layer(s) Number of Hidden Layers 1
Number of Units in Hidden
Layer 1a
5
Activation Function Hyperbolic tangent
Output Layer Dependent Variables 1 LPP
Number of Units 1
Rescaling Method for Scale Dependents Normalized
Activation Function Sigmoid
Error Function Sum of Squares
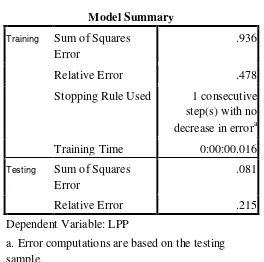
Sehingga diperoleh hasil penglasifikasian data demografi Indonesia dengan menggunakan jaringan saraf tiruan yang diproses dengan menggunakan spss 17 dapat dilihat pada tabel di bawah ini (Lampiran B):
Tabel 8:
Dari tabel terlihat bahwa berdasarkan data training kesalahan klasifikasi pada jaringan saraf tiruan ialah sebesar 0,936. Hal ini terlihat pada nilai sum of square error.. Sedangkan pada data Testing kesalahan klasifikasi ialah sebesar 0,081 atau dengan kata lain tingkat errornya sebesar 8,1 %.
Model Summary
Training Sum of Squares Error
.936
Relative Error .478
Stopping Rule Used 1 consecutive step(s) with no decrease in errora Training Time 0:00:00.016
Testing Sum of Squares
Error
.081
Relative Error .215
Dependent Variable: LPP
Gambar 3.1 : Arsitektur Jaringan Saraf Dengan 1 Hidden Layer
3.6. Perbandingan Klasifikasi Regresi Logistik Dan Jaringan Saraf Tiruan
Tabel 9: Nilai Misclassified Pada Regresi Logistik Dan Jaringan Saraf Tiruan Misclassified Regresi Logistik Jaringan Saraf Tiruan
Data Training 0,3 0,936
Data Testing 0,1 0,081
Dari hasil perhitungan dapat diperoleh bahwa misclassified pada regresi logistik yaitu dapat dilihat pada data training sebesar 0,3 yang diperoleh dari tabel klasifikasi antara predicted dan actual group. Sedangkan pada jaringan saraf tiruan diperoleh misclassifiednya sebesar 0,936. Sehingga jika dilihat dari data trainingnya regresi logistik lebih baik dibandingkan jaringan saraf tiruan dalam hal pengklasifikasian data demografi. Namun, jika dilihat dari data testing diperoleh hasil bahwa jaringan saraf memiliki misclassified yang lebih kecil dibandingkan regresi logistik yakni pada regresi sebesar 0,1 dan pada jaringan saraf sebesar 0,081. Sehingga jaringan saraf merupakan metode klasifikasi yang lebih baik dalam hal pengklasifikasian data demografi.
BAB 4
PENUTUP
4.1. Kesimpulan
Kesimpulan yang diperoleh dari hasil perbandingan metode klasifikasi antara regresi logistik dan jaringan saraf tiruan ialah jaringan saraf tiruan merupakan metode klasifikasi yang lebih baik dibandingkan regresi logistik dalam hal menglasifikasikan data demografi. Hal ini dapat dilihat dari misclassified pada data testing antara regresi logistik dan jaringan saraf tiruan. Nilai dari data testing kedua metode klasifikasi tersebut yakni: regresi logistik 0,1 dan jaringan saraf tiruan 0,081.
4.2. Saran
1. Pada penglasifikasian data demografi Indonesia menggunakan sampel data yang sedikit karena diambil data secara keseluruhan pada masing-masing provinsi. Untuk mengetahui hasil klasifikasi yang lebih jelas dapat digunakan data dengan jumlah yang lebih besar.
DAFTAR PUSTAKA
Anderson, T. W. 1984. An Introduction to Multivariate Statistical Analysis. New York: John Wiley & Sons, Inc.
Daneswara, G., dan Moertini, S. V. 2004. Jaringan Saraf Tiruan Propagasi Balik Untuk Klasifikasi Data. Integral. 9(3): hal. 117-131.
Hosmer, D. W., dan Lemeshow, S. 1989. Applied Logistic Regression. New York: John Wiley.
Johnson, R. A., dan Wichern, D. W. 2007. Applied Multivariate Statistical Analysis.
6th edition. United Stated of America: Pearson Education International
Kuncoro, M. 2000. Regresi Logistik dan Diskriminan. Yogyakarta: UGM.
Kurt, I., Ture, M., dan Kurum, A. T. 2006. Comparing Performances of Logistic Regression Classification and Regression Tree, and Neural Network for Predicting Coronary Artery Disease, Expert Systems with Applications. 34(1): hal.366-374.
Kholija, S. 2008. Perbandingan Metode Gauss Newton Dan Metode Stepest Descent Dalam Penaksiran Parameter RegresiNonlinier. Medan: USU.
Manel, S., Dias, J. M., dan Ormerod, S. J. 1999. Comparing Discriminant Analysis, Neural Networks And Logistic Regression For Predicting Species Distributions: A Case Study With A Himalayan River Bird. Ecological Modelling. 120 (2-3): hal.337-347.
Mantra, I., B. 2003. Demografi Umum.Yogyakarta: Pustaka Belajar Offset. Yogyakarta: UGM.
Puspitaningrum, Diyah. 2006. Pengantar Jaringan Saraf Tiruan. Yogyakarta: Andi.
Wibowo, W. 2002. Perbandingan hasil klasifikasi analisis diskriminan dan regresi logistik pada pengklasifikasian data respon biner. Kappa: 3(1): hal. 36-45.
Negnevitsky dan Michael (dalam Pujiati, S. A). 2002. Artificial Intelligence: A Guide To Intelligent System. Boston: PWS-KENT.
2010.
LAMPIRAN A
Out Put Klasifikasi Regresi Logistik Dengan Menggunakan Spss 17
Case Processing Summary
a. The dependent variable has only one value observed in 30 (100.0%) subpopulations.
Model Fitting Information
Model
Model Fitting
Iteration History
Intercept DR fertilisasi mortalitas migrasi 0 0 38.191 -.693147 .000000 .000000 .000000 .000000 a. The parameter estimates converge. Last absolute change in -2 Log Likelihood is .000, and last maximum absolute change in parameters is 7.58323E-008.
Classification
Observed
Predicted
.00 1.00
Percent Correct
.00 7 3 70.0%
1.00 0 20 100.0%
Overall Percentage
LAMPIRAN B
Out Put Klasifikasi Jaringan Saraf Tiruan Dengan Menggunakan Spss 17
Case Processing Summary
Hidden Layer(s) Number of Hidden Layers 1
Number of Units in Hidden
Layer 1a
5
Activation Function Hyperbolic tangent
Output Layer Dependent Variables 1 LPP
Number of Units 1
Rescaling Method for Scale Dependents Normalized
Activation Function Sigmoid
Error Function Sum of Squares
Lanjutan:
Model Summary
Training Sum of Squares Error .936
Relative Error .478
Stopping Rule Used 1 consecutive step(s)
with no decrease in
errora
Training Time 0:00:00.016
Testing Sum of Squares Error .081
Relative Error .215
Dependent Variable: LPP
a. Error computations are based on the testing sample.
Parameter Estimates
Predictor
Predicted
Hidden Layer 1 Output Layer