Informasi Dokumen
- Penulis:
- Styfanda Pangestika
- Pengajar:
- Dr. Scolastika Mariani, M.Si.
- Prof. Dr. Zaenuri, S.E, M.Si,Akt.
- Sekolah: Universitas Negeri Semarang
- Mata Pelajaran: Matematika
- Topik: Analisis Estimasi Model Regresi Data Panel Dengan Pendekatan Common Effect Model (CEM), Fixed Effect Model (FEM), Dan Random Effect Model (REM)
- Tipe: Skripsi
- Tahun: 2015
- Kota: Semarang
Ringkasan Dokumen
I. PENDAHULUAN
Bab ini menjelaskan mengenai latar belakang, tujuan, dan manfaat dari penelitian mengenai estimasi model regresi data panel. Penelitian ini penting untuk memahami bagaimana berbagai pendekatan model dapat mempengaruhi hasil analisis data yang kompleks, seperti yang terjadi dalam konteks pembangunan manusia di Jawa Tengah. Dengan menggunakan data panel, peneliti dapat menganalisis hubungan antara variabel independen, seperti angka melek huruf, rata-rata lama sekolah, dan pengeluaran riil per kapita terhadap Indeks Pembangunan Manusia (IPM). Hal ini memberikan wawasan yang lebih dalam tentang dinamika sosial dan ekonomi yang dapat digunakan untuk pengambilan keputusan dalam kebijakan pendidikan dan pembangunan.
1.1 Latar Belakang
Analisis regresi merupakan metode penting dalam statistika untuk menentukan hubungan antara variabel. Data panel, yang menggabungkan data runtun waktu dan data silang, memberikan keunggulan dalam analisis karena memungkinkan observasi yang lebih banyak dan lebih beragam. Penelitian ini berfokus pada estimasi parameter model regresi data panel dengan menggunakan pendekatan Common Effect Model (CEM), Fixed Effect Model (FEM), dan Random Effect Model (REM). Dengan pendekatan ini, peneliti dapat mengidentifikasi model terbaik yang menjelaskan pengaruh variabel-variabel tersebut terhadap IPM.
1.2 Batasan Masalah
Ruang lingkup penelitian ini terbatas pada analisis estimasi parameter model regresi data panel yang mengkaji pengaruh angka melek huruf, rata-rata lama sekolah, dan pengeluaran riil per kapita terhadap IPM di Jawa Tengah selama periode 2008 hingga 2012. Fokus ini penting untuk memahami faktor-faktor yang berkontribusi terhadap pembangunan manusia di daerah tersebut dan memberikan rekomendasi kebijakan yang relevan.
1.3 Rumusan Masalah
Rumusan masalah dalam penelitian ini mencakup tiga pertanyaan utama: (1) Bagaimana estimasi parameter model regresi data panel dengan pendekatan CEM, FEM, dan REM? (2) Model estimasi mana yang terbaik untuk digunakan? (3) Bagaimana analisis hasil estimasi dengan menggunakan kriteria uji diagnostik? Pertanyaan-pertanyaan ini akan mengarahkan penelitian untuk mengeksplorasi dan memahami dinamika yang ada dalam data yang dianalisis.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menjelaskan estimasi parameter model regresi data panel dengan pendekatan CEM, FEM, dan REM. Selain itu, penelitian ini bertujuan untuk menentukan model estimasi terbaik dan menganalisis hasil estimasi tersebut dengan menggunakan kriteria uji diagnostik. Tujuan ini penting untuk memberikan panduan yang jelas bagi peneliti dan pembuat kebijakan dalam memahami dan mengimplementasikan analisis regresi dalam konteks pembangunan manusia.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini diharapkan dapat memberikan kontribusi bagi penulis dalam mengembangkan pengetahuan di bidang matematika, serta memberikan informasi yang berguna bagi pembaca dan lembaga terkait. Penelitian ini dapat menjadi referensi bagi penelitian selanjutnya dan memberikan wawasan tentang model estimasi regresi data panel yang dapat diterapkan dalam konteks pembangunan manusia.
1.6 Sistematika Penulisan
Sistematika penulisan skripsi ini terdiri dari lima bab. Bab pertama adalah pendahuluan yang mencakup latar belakang, rumusan masalah, batasan masalah, tujuan, manfaat, dan sistematika penulisan. Bab kedua adalah tinjauan pustaka yang menguraikan teori-teori yang mendasari penelitian. Bab ketiga membahas metode penelitian, bab keempat menyajikan hasil dan pembahasan, dan bab kelima berisi kesimpulan serta saran.
II. TINJAUAN PUSTAKA
Bab ini membahas teori-teori yang relevan dengan analisis regresi data panel dan model-model yang digunakan dalam penelitian. Tinjauan pustaka ini memberikan dasar teoritis yang kuat untuk memahami berbagai pendekatan dalam analisis regresi, serta pentingnya pemilihan model yang tepat dalam pengolahan data panel. Teori-teori ini juga membantu peneliti untuk memahami karakteristik data dan bagaimana model yang berbeda dapat memberikan hasil yang berbeda dalam analisis.
2.1 Model Regresi Linear
Model regresi linear adalah metode yang digunakan untuk memahami hubungan antara variabel dependen dan independen. Dalam konteks analisis ini, pemahaman tentang model regresi linear sederhana dan ganda sangat penting untuk membangun fondasi bagi analisis data panel. Model ini memungkinkan peneliti untuk menguji hipotesis dan membuat prediksi berdasarkan data yang ada. Dengan menggunakan model regresi linear, peneliti dapat menilai seberapa besar pengaruh variabel independen terhadap variabel dependen dalam konteks yang lebih luas.
2.2 Model Regresi Data Panel
Data panel merupakan kombinasi dari data cross-sectional dan time series, yang memberikan kelebihan dalam analisis karena memungkinkan peneliti untuk mengamati perubahan dari waktu ke waktu. Model regresi data panel dapat dipecah menjadi beberapa pendekatan, termasuk Common Effect Model (CEM), Fixed Effect Model (FEM), dan Random Effect Model (REM). Pemilihan model yang tepat sangat penting untuk mendapatkan estimasi yang akurat dan relevan. Dengan memahami perbedaan antara model-model ini, peneliti dapat memilih pendekatan yang paling sesuai dengan data yang dianalisis.
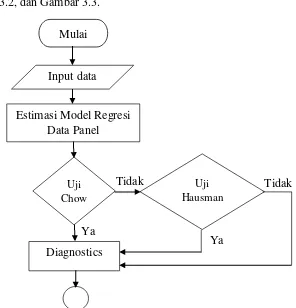
2.3 Pemilihan Model Estimasi Regresi Data Panel
Pemilihan model estimasi yang tepat dalam analisis regresi data panel sangat penting untuk memastikan hasil yang akurat. Uji Chow, Hausman, dan Breusch-Pagan adalah beberapa metode yang digunakan untuk menentukan model mana yang paling sesuai untuk data yang dianalisis. Melalui pemilihan model yang tepat, peneliti dapat menghindari kesalahan dalam estimasi yang dapat mempengaruhi kesimpulan penelitian. Uji-uji ini membantu dalam menilai apakah efek individu atau waktu perlu dipertimbangkan dalam model yang digunakan.
III. METODE PENELITIAN
Metode penelitian menjelaskan langkah-langkah yang diambil dalam penelitian ini, mulai dari pengumpulan data hingga analisis. Metode yang digunakan penting untuk memastikan bahwa penelitian dilakukan secara sistematis dan hasil yang diperoleh dapat dipercaya. Dalam konteks ini, pengumpulan data dilakukan dengan mendokumentasikan informasi dari Badan Pusat Statistik (BPS) dan analisis dilakukan menggunakan software R. Metodologi yang jelas dan tepat akan memberikan hasil yang lebih valid dan dapat diandalkan.
3.1 Fokus Penelitian
Fokus penelitian ini adalah untuk menganalisis pengaruh angka melek huruf, rata-rata lama sekolah, dan pengeluaran riil per kapita terhadap Indeks Pembangunan Manusia (IPM) di Jawa Tengah. Dengan menggunakan data panel, penelitian ini bertujuan untuk memberikan wawasan yang lebih dalam mengenai faktor-faktor yang mempengaruhi pembangunan manusia di daerah tersebut. Penelitian ini juga berusaha untuk mengeksplorasi model regresi yang paling tepat untuk analisis data panel.
3.2 Klasifikasi Penelitian Berdasarkan Tujuan dan Pendekatan
Penelitian ini termasuk dalam kategori penelitian kuantitatif yang menggunakan pendekatan analisis regresi. Dengan menggunakan data panel, peneliti dapat mengeksplorasi hubungan antara variabel-variabel secara lebih komprehensif. Klasifikasi ini membantu dalam menentukan metode analisis yang tepat dan teknik statistik yang sesuai untuk digunakan dalam penelitian ini.
3.3 Pengumpulan Data
Pengumpulan data dilakukan dengan mendokumentasikan informasi dari Badan Pusat Statistik (BPS) Jawa Tengah. Data yang dikumpulkan mencakup angka melek huruf, rata-rata lama sekolah, pengeluaran riil per kapita, dan Indeks Pembangunan Manusia (IPM) dari tahun 2008 hingga 2012. Proses pengumpulan data yang sistematis dan terencana sangat penting untuk memastikan bahwa data yang diperoleh akurat dan relevan dengan tujuan penelitian.
IV. HASIL DAN PEMBAHASAN
Bab ini menyajikan hasil analisis dan pembahasan mengenai estimasi model regresi data panel. Hasil analisis memberikan wawasan tentang pengaruh variabel independen terhadap IPM dan membandingkan efektivitas model-model yang digunakan. Pembahasan ini penting untuk memahami bagaimana hasil penelitian dapat diterapkan dalam kebijakan pendidikan dan pembangunan manusia. Dengan membandingkan hasil dari berbagai model, peneliti dapat memberikan rekomendasi yang lebih baik untuk kebijakan yang mendukung pembangunan manusia.
4.1 Estimasi Model Regresi Data Panel
Estimasi model regresi data panel dilakukan dengan menggunakan pendekatan CEM, FEM, dan REM. Hasil estimasi menunjukkan perbedaan yang signifikan antara model-model tersebut, dengan FEM memberikan hasil yang paling baik dalam menjelaskan variasi IPM. Pemilihan model yang tepat sangat penting untuk memastikan bahwa analisis yang dilakukan dapat memberikan informasi yang relevan dan akurat tentang pengaruh variabel independen terhadap IPM.
4.2 Pemilihan Model Estimasi Regresi Data Panel
Pemilihan model estimasi yang tepat dilakukan dengan menggunakan uji Chow, Hausman, dan Breusch-Pagan. Hasil dari uji-uji ini menunjukkan bahwa FEM adalah model yang paling sesuai untuk data yang dianalisis. Pemilihan model yang tepat tidak hanya mempengaruhi hasil analisis tetapi juga memberikan dasar yang kuat untuk pengambilan keputusan dalam kebijakan pendidikan dan pembangunan manusia.
V. PENUTUP
Bab penutup menyajikan kesimpulan dari penelitian serta saran untuk penelitian selanjutnya. Kesimpulan merangkum temuan utama dari analisis dan memberikan rekomendasi berdasarkan hasil yang diperoleh. Saran yang diberikan bertujuan untuk mendorong penelitian lebih lanjut dalam bidang ini, serta memberikan panduan bagi peneliti dan pembuat kebijakan dalam mengimplementasikan hasil penelitian. Dengan demikian, penelitian ini diharapkan dapat memberikan kontribusi yang berarti bagi pengembangan ilmu pengetahuan dan kebijakan publik.
5.1 Kesimpulan
Kesimpulan dari penelitian ini menunjukkan bahwa model FEM adalah model yang paling tepat untuk menganalisis pengaruh angka melek huruf, rata-rata lama sekolah, dan pengeluaran riil per kapita terhadap IPM. Hasil ini memberikan wawasan yang penting bagi pengambilan keputusan dalam kebijakan pendidikan dan pembangunan manusia di Jawa Tengah.
5.2 Saran
Saran bagi penelitian selanjutnya adalah untuk mengeksplorasi lebih lanjut faktor-faktor lain yang dapat mempengaruhi IPM, serta menggunakan data panel dari daerah lain untuk perbandingan. Penelitian ini juga dapat dikembangkan dengan mempertimbangkan variabel-variabel tambahan yang mungkin berpengaruh terhadap pembangunan manusia.