KATA PENGANTAR
Perihal : Permohonan Pengisian Angket Lampiran : 1 (Satu) Berkas
Judul Skripsi : ANALISIS FAKTOR – FAKTOR YANG
MEMPENGARUHI HASIL PRODUKSI KENTANG Dengan hormat,
Dalam rangka penulisan skripsi di Universitas Sumatera Utara (USU), sebagai salah satu syarat mendapatkan gelar Sarjana Sains (S.Si), maka Saya memohon dengan sangat kepada Bapak/Ibu/Saudara/i penduduk Kabupaten karo kecamatan Namanteran untuk mengisi angket yang telah disediakan.
Angket ini bukan test psikologi dari manapun, maka dari itu Bapak/Ibu/Saudara/I tidak perlu takut atau ragu memberikan jawaban yang sejujurnya. Artinya, semua jawaban yang diberikan Bapak/Ibu/Saudara/i adalah benar, dan jawaban yang diminta adalah sesuai dengan yang Bapak/Ibu/Saudara/i rasakan dan ketahui.
Setiap jawaban yang diberikan merupakan bantuan yang tidak ternilai harganya pada penelitian ini. Atas perhatian, bantuan, dan kerja sama yang baik, Saya
mengucapkan terima kasih.
Hormat Saya
Sartika br perangin- angin Petunjuk Pengisian Angket
1. Mohon dengan hormat bantuan dan kesediaan Bapak/Ibu/Saudara/i untuk menjawab seluruh pertanyaan yang ada.
SS = Sangat Setuju
“ ANALISIS FAKTOR – FAKTOR YANG MEMPENGARUHI HASIL PRODUKSI KENTANG”
1. Pengolahaan pupuk kandang pada awal penanaman akan mempengaruhi kesuburan tanah.
2.
Lahan yang luas akan menghasilkan panen kentang yang tinggi.
3.
Setelah umur kentang 30 hari maka penyemprotan pestisida harus dilakukan 2 hari sekali sampai panen.
4.
7. Bibit kentang yang berkualitas adalah bibit yang di impor dari luar
8. Interval pemberiaan pupuk terhadap tanaman kentang mempengaruhi tingginya hasil panen.
80 4 5 5 4 4 4 4 4 4
81 5 3 4 5 4 5 5 4 4
82 5 4 4 4 3 4 5 5 5
83 5 4 2 2 3 3 4 5 5
84 5 4 4 5 3 5 5 5 3
85 5 4 3 3 5 4 4 3 3
86 4 4 3 5 4 5 5 4 3
87 5 4 4 5 5 4 4 3 3
88 5 5 4 5 4 3 4 5 5
89 5 4 4 5 5 4 3 3 3
90 5 5 4 4 3 3 5 4 4
91 5 4 2 2 2 3 3 4 5
92 2 3 4 2 3 1 4 1 3
93 5 5 4 3 5 4 4 5 5
94 5 4 5 4 3 3 4 4 4
95 4 2 2 2 2 4 4 4 4
96 5 4 4 2 4 4 4 4 4
97 5 2 1 2 2 4 4 4 4
98 5 2 1 2 4 2 1 4 5
99 5 1 2 2 2 1 1 4 5
Lampiran 3
Hasil Output SPSS
Case Processing Summary
N %
Cases Valid 100 100.0
Excludeda 0 .0
Total 100 100.0
a. Listwise deletion based on all variables in the
procedure.
Reliability Statistics
Cronbach's Alpha
Cronbach's Alpha
Based on
Standardized Items N of Items
.714 .710 9
Item Statistics
Mean Std. Deviation N
VAR00001 2.9853 .84835 100
VAR00002 3.0627 .94112 100
VAR00003 2.7093 .93990 100
VAR00004 3.0628 .94647 100
VAR00005 3.0629 .94466 100
VAR00006 3.1542 .94623 100
VAR00007 2.4582 .98305 100
VAR00008 3.3828 .93165 100
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .721
Bartlett's Test of Sphericity Approx. Chi-Square 150.262
df 36
Sig. .000
Component Transformation Matrix
Compo
nent 1 2 3
1 .784 .522 .337
2 -.618 .713 .331
3 .067 .467 -.881
Component Matrixa
Component
1 2 3
VAR00001 .294 .578 .319
VAR00002 .519 .131 .012
VAR00003 .457 -.515 -.012
VAR00004 .690 -.121 .168
VAR00005 .597 -.132 .589
VAR00006 .569 -.460 -.180
VAR00007 .742 -.086 -.209
VAR00008 .497 .337 -.668
VAR00009 .540 .590 .051
Total Variance Explained
Compon
ent
Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings
Total % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative %
1 2.810 31.220 31.220 2.810 31.220 31.220 2.237 24.855 24.855
2 1.329 14.770 45.990 1.329 14.770 45.990 1.662 18.462 43.317
3 1.003 11.142 57.132 1.003 11.142 57.132 1.243 13.815 57.132
4 .944 10.489 67.621
5 .781 8.676 76.297
6 .687 7.635 83.932
7 .556 6.180 90.111
8 .496 5.509 95.620
9 .394 4.380 100.000
Inter-Item Correlation Matrix
VAR00001 VAR00002 VAR00003 VAR00004 VAR00005 VAR00006 VAR00007 VAR00008 VAR00009
VAR00001 1.000 .102 -.005 .077 .174 -.005 .135 .154 .278
VAR00002 .102 1.000 .162 .375 .184 .159 .172 .225 .253
VAR00003 -.005 .162 1.000 .288 .214 .276 .295 .094 -.007
VAR00004 .077 .375 .288 1.000 .383 .261 .381 .205 .253
VAR00005 .174 .184 .214 .383 1.000 .314 .328 .010 .268
VAR00006 -.005 .159 .276 .261 .314 1.000 .456 .198 .031
VAR00007 .135 .172 .295 .381 .328 .456 1.000 .351 .347
VAR00008 .154 .225 .094 .205 .010 .198 .351 1.000 .320
Anti-image Matrices
VAR00001 VAR00002 VAR00003 VAR00004 VAR00005 VAR00006 VAR00007 VAR00008 VAR00009
Anti-image Covariance VAR00001 .898 -.024 .021 .033 -.108 .057 -.024 -.074 -.140
VAR00002 -.024 .808 -.060 -.205 -.012 -.053 .063 -.095 -.112
VAR00003 .021 -.060 .832 -.112 -.060 -.076 -.117 -.005 .110
VAR00004 .033 -.205 -.112 .681 -.168 -.011 -.107 -.042 -.040
VAR00005 -.108 -.012 -.060 -.168 .715 -.153 -.060 .162 -.136
VAR00006 .057 -.053 -.076 -.011 -.153 .704 -.225 -.083 .136
VAR00007 -.024 .063 -.117 -.107 -.060 -.225 .592 -.140 -.161
VAR00008 -.074 -.095 -.005 -.042 .162 -.083 -.140 .771 -.159
VAR00009 -.140 -.112 .110 -.040 -.136 .136 -.161 -.159 .701
Anti-image Correlation VAR00001 .713a -.029 .024 .043 -.134 .072 -.033 -.089 -.177
VAR00002 -.029 .742a -.073 -.276 -.015 -.070 .091 -.121 -.149
VAR00003 .024 -.073 .779a -.149 -.078 -.099 -.167 -.006 .144
VAR00004 .043 -.276 -.149 .783a -.240 -.015 -.168 -.058 -.058
VAR00005 -.134 -.015 -.078 -.240 .707a -.215 -.092 .218 -.192
VAR00006 .072 -.070 -.099 -.015 -.215 .685a -.349 -.113 .194
VAR00007 -.033 .091 -.167 -.168 -.092 -.349 .736a -.207 -.250
VAR00008 -.089 -.121 -.006 -.058 .218 -.113 -.207 .690a -.216
VAR00009 -.177 -.149 .144 -.058 -.192 .194 -.250 -.216 .657a
LAMPIRAN 4
A. PERHITUNGAN ANALISIS FAKTOR MENGGUNAKAN MATRIKS
MATRIKS KORELASI SEDERHANA (
1 2 3 4 5 6 7 8 9
1 1 0,102 -0,005 0,077 0,174 -0,005 0,135 0,154 0,278
2 0,102 1 0,162 0,375 0,184 0,159 0,172 0,225 0,253
3 -0,005 0,162 1 0,288 0,214 0,276 0,295 0,094 -0,007
4 0,077 0,375 0,288 1 0,383 0,261 0,381 0,205 0,253
= 5 0,174 0,184 0,214 0,383 1 0,314 0,328 0,01 0,268
6 -0,005 0,159 0,276 0,261 0,314 1 0,456 0,198 0,031
7 0,135 0,172 0,295 0,381 0,328 0,456 1 0,351 0,347
8 0,154 0,225 0,094 0,205 0,01 0,198 0,351 1 0,32
Dengan bantuan software MATLAB (Matrix Laboratory), didapat nilai karakteristik (eigen value) dan vektor karakteristik (eigen vector) dari matrik korelasi sederhana ( .
MATRIKS EIGEN VALUE (L)
1 2 3 4 5 6 7 8 9
1 2,8095 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
2 0,0000 1,3296 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
3 0,0000 0,0000 1,0023 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
4 0,0000 0,0000 0,0000 0,9447 0,0000 0,0000 0,0000 0,0000 0,0000
= 5 0,0000 0,0000 0,0000 0,0000 0,7808 0,0000 0,0000 0,0000 0,0000
6 0,0000 0,0000 0,0000 0,0000 0,0000 0,6870 0,0000 0,0000 0,0000
7 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5563 0,0000 0,0000
8 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,4960 0,0000
MATRIKS EIGEN VEKTOR (V )
1 2 3 4 5 6 7 8 9
1 -0,0340 -0,1322 -0,1696 0,3201 0,5965 0,3327 0,3197 0,5006 0,01753
2 0,2317 -0,0978 -0,3443 0,4299 0,0702 -0,7211 0,0100 0,1125 0,3096
3 -0,1222 0,1002 -0,2702 0,4296 0,6621 -0,0682 -0.0122 -0,4470 0,2729
4 0,2535 -0,1700 0,7341 0,1608 -0,0998 -0,3521 0,1668 -0,1056 0,4113
= 5 0,2711 0,5836 -0,0732 0,0106 -0,2573 0,1675 0,5883 -0,1146 0,3562
6 -0,4835 -0,0639 -0,1336 0,5607 -0,1501 0,3175 -0,1797 -0,3992 0,3390 7 0,5915 -0,5016 -0,0166 -0,1613 -0,1285 0,3330 -0,2078 -0,0741 0,4429
8 0,0762 0,5698 0,2088 0,0049 0,0815 0,0220 0,6674 0,2925 0,2962
9 -0,3226 -0,1141 -0,4022 -0,4022 -0,2810 0,0217 0,0517 0,0513 0,3226
AKAR DARI MATRIKS EIGEN VALUE (√ )
1 2 3 4 5 6 7 8 9
1 1,6761 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
2 0,0000 1,1531 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
3 0,0000 0,0000 1,0011 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
4 0,0000 0,0000 0,0000 0,9720 0,0000 0,0000 0,0000 0,0000 0,0000
√ = 5 0,0000 0,0000 0,0000 0,0000 0,8836 0,0000 0,0000 0,0000 0,0000
6 0,0000 0,0000 0,0000 0,0000 0,0000 0,8299 0,0000 0,0000 0,0000
7 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,7458 0,0000 0,0000
8 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,7043 0,0000
MATRIKS LOADING FACTOR ( )
1 2 3 4 5 6 7 8 9
1 0,2939 0,5773 0,3201 0,3234 0,5271 0,2653 0,1265 -0,0931 -0,0213 2 0,5189 0,1297 0,0101 -0,7008 -0,0620 0,3563 -0,2568 -0,688 0,1454 3 0,4574 -0,5155 -0,0123 -0,0663 0,5851 -0,3561 -0,2015 0,0706 -0,0767
4 0,6894 0,1218 0,1670 -0,3442 -0,0882 -0,1333 0,5475 -0,1197 -0,1591 = 5 0,5970 -0,1322 0,5890 0,1628 -0,2274 0,0088 -0,0546 0,4110 0,1701
Matriks Rotated Factor Loading diperoleh dengan mengalikan matriks factor loading dengan matriks transformasi (Component Transformation Matrix). Atau dalam persamaan matematis ditulis sebagai : .
1 2 3
1 0,7840 0,5220 0,3370
=
2 -0,6180 0,7130 0,33103 0,670 0,4670 -0,8810
0,2939 0,5773 0,3201 -0,105 0,714 0,009
0,5189 0,1297 0,0101 0,327 0,370 0,207
0,4574 -0,5155 -0,0123 0,676 -0,134 -0,006
0,6894 0,1218 0,1670 0,627 0,352 0,044
0,5970 -0,1322 0,5890 0,7840 0,5220 0,3370 0,587 0,493 -0,362
=
0,5683 -0,4603 -0,1799 -0,6180 0,7130 0,3310 0,718 -0,116 0,198B. PERHITUNGAN DAN
Untuk menghitung dan , maka diperlukan matriks korelasi sederhana dan matriks korelasi parsial yang semua entrinya telah dikuadratkan. Berikut ini akan disajikan matriks korelasi sederhana dan matriks korelasi parsial yang semua entrinya telah dikuadratkan
MATRIKS KORELASI PARSIAL
1 2 3 4 5 6 7 8 9
1 -0,029 -0,024 0,043 -0,134 0,072 -0,033 -0,089 -0,177
2 -0,029 -0,073 -0,276 -0,015 -0,070 0,091 -0,121 -0,149 3 -0,024 -0,073 -0.149 -0,078 -0,099 -0,167 -0,006 0,144 4 0,043 -0,276 -0.149 -0,240 -0,015 -0,168 -0,058 -0,058
[ ] 5 -0,134 -0,015 -0,078 -0,240 0,215 -0,092 -0,218 -0,192
6 0,072 -0,070 -0,099 -0,015 -0,215 -0,349 -0,113 -0,194 7 -0,033 0,091 -0,167 -0,168 -0,092 -0,349 -0,207 -0,250
KUADRAT MATRIKS KORELASI PARSIAL
1 2 3 4 5 6 7 8 9 Jumlah
1 0,000841 0,000576 0,001849 0,017956 0,005184 0,001089 0,007921 0,031329 0,066745
2 0,000841 0 0,005329 0,076176 0,000225 0,0049 0,008281 0,014641 0,022201 0,131753 3 0,000576 0,005329 0 0,022201 0,006084 0,009801 0,027889 0,000036 0,020736 0,092076 4 0,001849 0,076176 0,022201 0 0,0576 0,000225 0,028224 0,003364 0,003364 0,191154
[ ] 5 0,017956 0,000225 0,006084 0,0576 0 0,046225 0,008464 0,047524 0,036864 0,202986
6 0,005184 0,0049 0,009801 0,000225 0,046225 0 0,121801 0,012769 0,037636 0,233357 7 0,001089 0,008281 0,027889 0,028224 0,008464 0,121801 0 0,042849 0,0625 0,300008 8 0,007921 0,014641 0,000036 0,003364 0,047524 0,012769 0,042849 0 0,046656 0,167839 9 0,031329 0,022201 0,020736 0,003364 0,036864 0,037636 0,0625 0,046656 0,022201 0,283487
KUADRAT MATRIKS KORELASI SEDERHANA
1 2 3 4 5 6 7 8 9 Jumlah
1 0,010404 0,000025 0,005929 0,030276 0,000025 0,018225 0,023716 0,077284 0,165884
2 0,010404 0,026244 0,140625 0,033856 0,025281 0,029584 0,050625 0,064009 0,380628 3 0,000025 0,026244 0,082944 0,045796 0,076176 0,087025 0,008836 0,000049 0,327095 4 0,005929 0,140625 0,082944 0,146689 0,068121 0,145161 0,042025 0,064009 0,695503
[ ] 5 0,030276 0,033856 0,045796 0,146689 0,098596 0,107584 0,0001 0,071824 0,534721
6 0,000025 0,025281 0,076176 0,068121 0,098596 0,207936 0,039204 0,000961 0,5163 7 0,018225 0,029584 0,087025 0,145161 0,107584 0,207936 0,123201 0,120409 0,839125 8 0,023716 0,050625 0,008836 0,042025 0,0001 0,039204 0,123201 0,1024 0,390107 9 0,077284 0,064009 0,000049 0,064009 0,071824 0,000961 0,120409 0,1024 0,500945
Jumlah 4,350308
∑ ∑
∑ ∑ ∑ ∑
∑
∑ ∑
C. UJI BARTLETT DENGAN PENDEKATAN STATISTIK CHI
SQUARE
Untuk menguji apakah matriks korelasi sederhana bukan merupakan suatu matriks identitas, maka digunakan uji Bartlett dengan pendekatan statistik chi square. Berikut ini diuraikan langkah-langkah pengujiannya.
1. Hipotesis
: Matriks korelasi sederhana merupakan matriks identitas : Matriks korelasi sederhana bukan merupakan matriks identitas 2. Statistik uji
[ ] | |
3. .
;
4. Kriteria pengujian : tolak jika 5. Perhitungan
[ ] [ ]
6. Kesimpulan :
D.PERHITUNGAN KOMUNALITAS
X1 -0,105 0,714 0,009 0,011025 0,509796 0,000081 0,520902
X2 0,327 0,370 0,207 0,106929 0,13690 0,042849 0,286678
X3 0,676 -0,134 -0,006 0,456976 0,017956 0,000036 0,474968
X4 0,627 0,352 0,044 0,393129 0,123904 0,001936 0,518969
X5 0,589 0,493 -0,362 0,346921 0,243049 0,131044 0,721014
X6 0,718 -0,116 0,198 0,515524 0,013456 0,039204 0,568184
X7 0,621 0,228 0,406 0,385641 0,051984 0,164836 0,602461
X8 0,136 0,188 0,868 0,018496 0,035344 0,753424 0,807264
DAFTAR PUSTAKA
Anton Howard . 1988. Penerapan Aljabar Linear. Penerjemah Silaban. P .Penerbit Erlangga.
Badan Pusat Statistik Karo. 2011. Kabupaten Karo dalam Angka 2011, penerbit BPS Kabupaten Karo .
Ghozali, Imam. 2005. Aplikasi Analisis Multivariat dengan Program SPSS. Universitas Diponegoro, Semarang.
Idawati Nurul. 2012. Pedoman Lengkap Bertanam Kentang. Yogyakarta: Pustaka Baru Press.
Lubis, Ade Fatma et al 2007. Aplikasi SPSS (Statistical Product and Service Solutions) untuk penyusunan skripsi & tesis, USU Press, Medan.
Maman dan Sambas. 2011. Dasar-dasar Metode Statistika Untuk Penelitiaan Bandung: CV Pustaka Setia
Riduwan. 2009. Skala Pengukuran Variabel-variabel Penelitian. Alfabeta, Bandung.
Santoso, Singgih. 2010. Statistik Multivariat. PT. Gramedia, Jakarta.
Setiadi dan surya fitri nurulhuda.2007. Kentang Varieta dan Pembudidayaan. Jakarta: Penebar swadaya
Soelarso Bambang 1997. Budi Daya Kentng Bebas Penyakit: Penerbit Kanisius, Yogyakarta.
Singarimbun, Masri dan Sofian effendi. 1987. Metode Penelitian Survai. LP3ES, Jakarta.
Supranto, J. (2004). Analisis Multivariat Arti dan Interpretasi. PT. Rineka Cipta, Jakarta.
BAB 3
PEMBAHASAN DAN HASIL
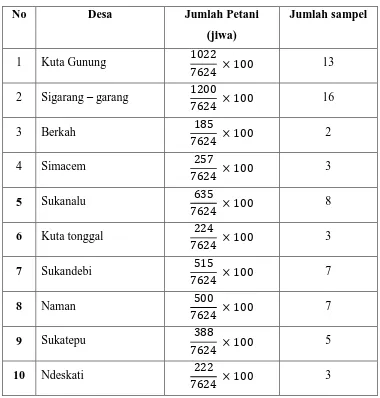
3.1 Populasi, Sampel dan Teknik Pengambilan Sampel
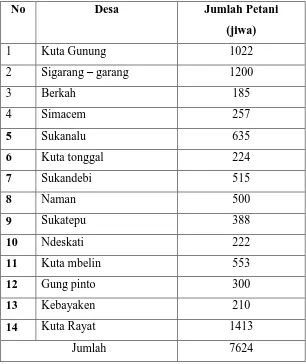
Populasi dalam penelitian ini adalah seluruh petani di kecamatan Naman Teran. Populasi sasaranya adalah petani kentang yang menanam kentang pada saat penelitiaan. Data total jumlah petani di kecamatan Naman Teran pada tahun 2011 yang diproleh dari hasil sensus oleh Badan Pusat Statistika adalah sebagai berikut:
Tabel 3.1 Daftar Jumlah Petani Tahun 2011 di Kecamatan Naman Teran
No Desa Jumlah Petani
11 Kuta mbelin
7
12 Gung pinto
4
13 Kebayaken
3
14 Kuta Rayat
19
Jumlah 100
Sumber: setelah diolah
3.2 Variabel Penelitiaan
Variable yang digunakaan dalam penelitiaan ini adalah:
= Pupuk kandang
= Luas lahan
= Pestisida
= Kesuburan lahan
= Tenaga kerja
= Jarak tanam antara kentang
= Bibit = Pupuk
3.3 Sumber Data
Dalam penelitiaan ini data yang digunakan adalalah data primer dan data sekunder. Data primer bersumber dari hasil wawancara terstruktur terhadap responden denggan menggunakan kuisoner. Kuesioner yang digunakan adalah kuisioner berstruktur dalam bentuk pernyataan yang telah disertai dengan pilihan jawaban dalam bentuk sekala.
Sekala yang digunakan adalah sekala telah dimodifikasi dalam bentuk pernyataan diberi range skor anatara 1 sampai dengan 5, masing - masing adalah: 1 = Sangat tidak setuju
2 = Tidak setuju 3 = Tidak tahu/Netral 4 = Setuju
5 = Sangat setuju
3.4 Pengolahan Data 3.4.1 Input Data Mentah
Tabel 3.3 Data Hasil Kuisioner
Data mentah secara keseluruhan dapat dilihat di dalam lampiran 1 A.
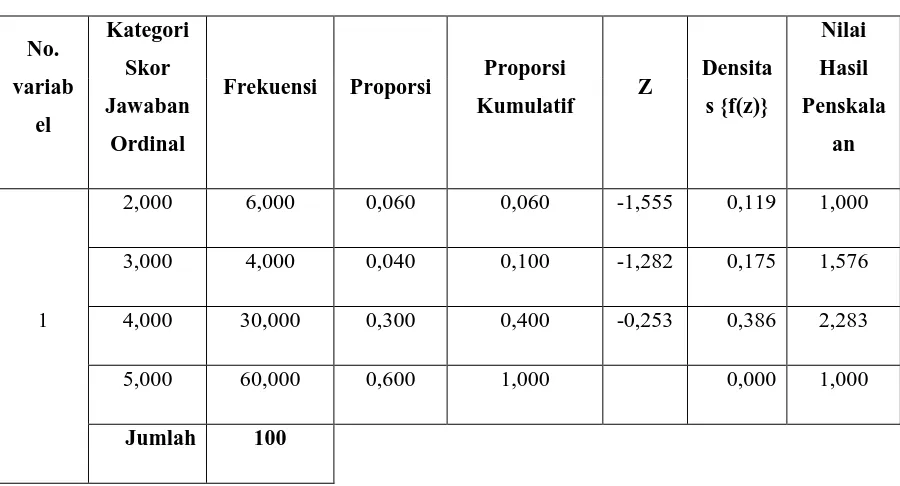
3.4.2 Penskalaan Data Ordinal Menjadi Data Interval
Tabel 3.4 Penskalaan Variabel 1
1. Menghitung frekuensi skor jawaban dalam skala ordinal.
2. Menghitung proporsi dan proporsi kumulatif untuk masing-masing skor jawaban.
6. Menentukan Scale Value min sehingga | | Scale Value terkecil =
| |
| |
7. Mentransformasikan nilai skala dengan menggunakan rumus :
| |
Selanjutnya dengan melakukan cara yang sama, maka semua variabel akan ditransformasikan ke dalam data interval.
Tabel 3.5 Penskalaan Variabel 1
X1 X2 X3 X4 X5 X6 X7 X8 X9
4 2,883 3,352 2,870 3,906 3,600 3,351 3,047 3,417 3,789 5 3,629 4,409 4,028 4,981 4,730 4,450 4,068 4,966 4,784
3.4.3 Uji Validitas
Validitas menunjukkan sejauh mana ketepatan dan kecermatan suatu alat ukur dalam melakukan fungsi ukurnya. Untuk mengetahui valid atau tidak dilihat dari nilai korelasi hitung dibandingkan dengan tabel korelasi product moment untuk N = 100 dan α = 5% adalah 0,195. Dari hasil uji validitas, terlihat bahwa seluruh variabel dinyatakan valid karena nilai r-hitung > r tabel, r-hitung > 0,195. Dari bantuan SPSS diproleh hasil seperti tablel berikut ini
Tabel 3.6 Uji Validitas Variable Penelitian
No. Variabel r hitung r tabel Kesimpulan
1 X1 = Pupuk Kandang 0,197 0,195 Valid
2 X2 = Luas Lahan 0,364 0,195 Valid
3 X3 = Pestisida 0,291 0,195 Valid
4 X4 = Kesuburan Tanah 0,514 0,195 Valid
5 X5 = Tenaga Kerja 0,424 0,195 Valid
6 X6 = Jarak Tanaman antar Kentang 0,381 0,195 Valid
7 X7 = Bibit 0,576 0,195 Valid
8 X8 = Pupuk 0,348 0,195 Valid
9 X9 = Modal 0,388 0,195 Valid
3.7 Contoh Perhitungan Korelasi Product Moment 10 4,784 16,28807 77,9206 22.88574785 265.3014 11 2,518 18,28527 46,0493 6.34225307 334.351 12 2,518 18,69854 47,0901 6.34225307 349.6352 13 4,784 21,77678 104,1780 22.88574785 474.2279
.
100 4,784 16,64635 79,63457 22.88574785 277.1011 JUMLAH 338,304 2387,866 8237,443 1241.071022 58766.2
√
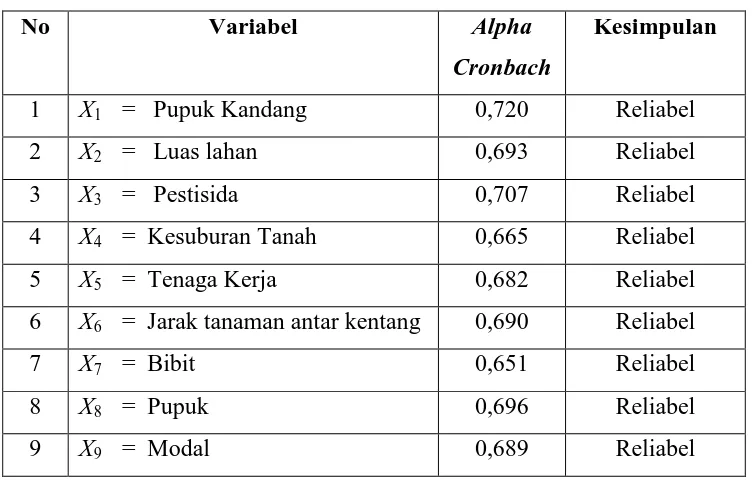
3.4.4 Uji Reliabilitas
Uji Reliabilitas menunjukkan sejauh mana hasil suatu pengukuran dapat dipercaya. Metode yang digunakan untuk menguji reliabilitas adalah metode Alpha Cronbach. Variabel dikatakan reliabel jika memberikan nilai Alpha
Cronbach > 0,6 (Ghozali, 2005). Hasil uji reliabilitas terhadap variabel-variabel
penelitian menunjukkan bahwa data mempunyai tingkat reliabilitas yang tinggi karena nilai Alpha Cronbach untuk ke 9 variabel > 0,6. Dengan demikian, data dapat memberikan hasil pengukuran yang konsisten (reliabel).
Tabel 3.8 Uji Reliabilitas Variabel Penelitian
No Variabel Alpha
Cronbach
Kesimpulan
1 X1 = Pupuk Kandang 0,720 Reliabel
2 X2 = Luas lahan 0,693 Reliabel
3 X3 = Pestisida 0,707 Reliabel
4 X4 = Kesuburan Tanah 0,665 Reliabel
5 X5 = Tenaga Kerja 0,682 Reliabel
6 X6 = Jarak tanaman antar kentang 0,690 Reliabel
7 X7 = Bibit 0,651 Reliabel
8 X8 = Pupuk 0,696 Reliabel
3.5 Analisis Data
Metode analisis data yang digunakan adalah teknik analisis faktor dengan pendekatan komponen utama. Langkah-langkah dalam analisis faktor adalah sebagai berikut :
3.5.1 Membentuk Matriks Korelasi
Proses analisis didasarkan pada suatu matriks korelasi antar variabel. Agar analisis faktor bisa menjadi tepat dipergunakan. Variabel-variabel yang akan dianalisis harus berkorelasi. Apabila koefisien korelasi antar variabel terlalu kecil berarti hubungannya lemah, maka metode analisis faktor kurang tepat untuk dipergunakan. Peneliti mengharapkan selain variabel awal berkorelasi dengan sesama variabel lainnya juga berkorelasi dengan faktor sebagai variabel terakhir yang didapat dari variabel-variabel awal.
Perhitungan nilai korelasi masing-masing variabel diperoleh dengan memakai rumus korelasi product moment :
∑ ∑ ∑
√{ ∑ ∑ }{ ∑ ∑ }
Contoh perhitungan korelasi antara variabel X1 dengan X9. Misalkan X1 adalah X dan X9 adalah Y.
3.9 Perhitungan Korelasi Antara Variabel X1 Dengan X9 No
Responden X Y XY X
2
Y2
4 3,629 1,000 3,629287 13,1717239520275 1,0000000000000 5 3,629 3,789 13,7526 13,1717239520275 14,3590910131709 6 2,283 2,518 5,748382 5,2101200893299 6,3422530729171 7 3,629 4,784 17,36216 13,1717239520275 22,8857478450558 8 2,283 2,518 5,748382 5,2101200893299 6,3422530729171 9 3,629 4,784 17,36216 13,1717239520275 22,8857478450558 10 3,629 4,784 17,36216 13,1717239520275 22,8857478450558 11 3,629 2,518 9,139935 13,1717239520275 6,3422530729171 12 3,629 2,518 9,139935 13,1717239520275 6,3422530729171 13 2,283 4,784 10,91959 5,2101200893299 22,8857478450558
.
100 2,283 4,784 10,91959 5,2101200893299 22,8857478450558 298,538 338,304 1.033,007 962,542 1.241,073
Dengan perhitungan di atas, maka diperoleh nilai korelasi antara variabel X1 dengan X9 adalah 0,278. Hasil tersebut sesuai dengan output SPSS. Dengan melakukan cara yang sama dengan di atas atau dengan menggunakan SPSS maka akan diperoleh korelasi antara variabel.Hasil perhitungannya dapat disajikan dalam bentuk matriks.
Pada penelitian ini matriks korelasi yang dibentuk dari data yang diperoleh untuk mengectahui faktor-faktor yang mempengaruhi hasil produksi kentang memperlihatkan korelasi yang cukup kuat antara variabel X1 dengan X9 sehingga diharapkan nantinya bahwa variabel-variabel ini akan berkorelasi dengan faktor yang sama.
Data mengenai 9 variabel yang berasal dari jawaban 100 orang responden kemudian dianalisa pada anti image correlation. Uji ini dilakukan dengan memperhatikan angka KMO MSA. Angka MSA (Measure of Sampling
MATRIK KORELASI
X1 X2 X3 X4 X5 X6 X7 X8 X9
MSA = 1, variabel dapat diprediksi tanpa kesalahan oleh variabel lain. MSA > 0,5, variabel masih bisa diprediksi dan bisa dianalisis lebih lanjut. MSA < 0,5, variabel tidak bisa diprediksi dan tidak bisa dianalisis lebih lanjut.
Tabel 3.10 Kaiser-Meyer-Olkin (KMO) dan Barlett’s Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. 0,721 Bartlett's Test of Sphericity Approx. Chi-Square 150,262
Df 36
Sig. 0.000
Hasil output SPSS seperti tabel di atas menunjukkan angka KMO dan
Barlett’s test adalah 0,721 lebih besar dari 0,5 dengan signifikansi 0,000 lebih kecil dari 0,05 maka variabel dan sampel sudah layak untuk dianalisis lebih lanjut.Perhitungan secara manual nilai KMO dan Barlett’s test dapat dilihat pada lampiran.
Hipotesis untuk uji diatas adalah :
H0 = sampel belum memadai untuk dianalisis lebih lanjut
H1 = sampel sudah memadai untuk dianalisis lebih lanjut
Kriteria dengan melihat probabilitas (tingkat signifikansi) : Angka Sig. > 0,05, maka H0 diterima
Angka Sig. < 0,05, maka H0 ditolak
Tabel 3.11 Nilai Measure of Sampling Adequecy (MSA)
No Variabel Nilai MSA
6 X6 = Jarak tanam anatar kentang 0,685 variabel masih bisa diprediksi untuk dianalisa lebih lanjut. Dari kedua hasil pengujian di atas, semua variabel mempunyai korelasi yang cukup tinggi dengan variabel lain, sehingga analisis layak untuk dilanjutkan dengan mengikutkan 9 variabel. Perhitungan secara manual dapat dilihat pada lampiran 4.
3.5.2 Ekstraksi Faktor
Dalam penelitian ini metode ekstraksi yang digunakan adalah Principal Component Analysis (Analisis Komponen Utama). Di dalam Principal Component Analysis jumlah varians data dipertimbangkan yaitu diagonal matriks
korelasi, setiap elemennya sebesar satu dan full variance dipergunakan untuk dasar pembentukan faktor, yaitu variabel-variabel lama, yang jumlahnya lebih sedikit dan tidak berkorelasi lagi satu sama lain, seperti variabel-variabel asli yang memang saling berkorelasi.
Tabel 3.12 Komunalitas
No Variabel Initial Extraction
8 X8 = Pupuk 1,000 0.806
9 X9 = Modal 1,000 0,643
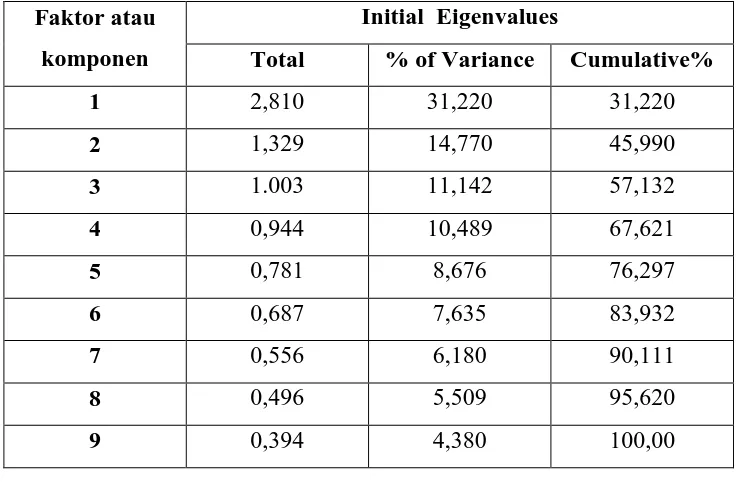
Tabel 3.13 Initial Eigenvalue
Faktor atau komponen
Initial Eigenvalues
Total % of Variance Cumulative%
1 2,810 31,220 31,220
2 1,329 14,770 45,990
3 1.003 11,142 57,132
4 0,944 10,489 67,621
5 0,781 8,676 76,297
6 0,687 7,635 83,932
7 0,556 6,180 90,111
8 0,496 5,509 95,620
9 0,394 4,380 100,00
Sumbangan Masing-Masing Faktor Terhadap Varians Seluruh Variabel Asli
Faktor atau Komponen
Extraction Sums of Squared Loadings Total % of Variance Cumulative %
1 2,810 31,220 31,220
2 1,329 14,770 45,990
a. Untuk variabel pupuk kandang, nilai komunalitasnya adalah 0.522 atau sekitar 52,2% varians dari variabel pupuk kandang bisa dijelaskan oleh faktor yang terbentuk.
b. Untuk variabel luas lahan, nilai komunalitasnya adalah 0,286 atau sekitar 28,6% varians dari variabel luas lahan bisa dijelaskan oleh faktor yang terbentuk.
c. Untuk variabel pestisida, nilai komunalitasnya adalah 0,475 atau sekitar 47,5% varians dari variabel pestisida bisa dijelaskan oleh faktor yang terbentuk. d. Untuk variabel kesuburan tanah, nilai komunalitasnya adalah 0,519 atau sekitar
51,9% varians dari kesuburan tanah bisa dijelaskan oleh faktor yang terbentuk. e. Untuk tenaga kerja, nilai komunalitasnya adalah 0,721 atau sekitar 72,1%
varians dari variabel tenaga kerja bisa dijelaskan oleh faktor yang terbentuk. f. Untuk variabel jarak tanaman antara kentang, nilai komunalitasnya adalah
0,567 atau sekitar 56,7% varians dari variabel jarak tanaman antara kentang bisa dijelaskan oleh faktor yang terbentuk.
g. Untuk variabel bibit, nilai komunalitasnya adalah 0,602 atau sekitar 60,2% varians bibit bisa dijelaskan oleh faktor yang terbentuk.
h. Untuk variabel pupuk, nilai komunalitasnya adalah 0,806 atau sekitar 80,6% varians dari variabel pupuk bisa dijelaskan oleh faktor yang terbentuk.
i. Untuk variabel modal, nilai komunalitasnya adalah 0,643 atau sekitar 64,3% varians dari variabel modal bisa dijelaskan oleh faktor yang terbentuk.
3.5.3 Menentukan Banyaknya Faktor
Penentuan banyaknya faktor yang dilakukan dalam analisis faktor maksudnya adalah mencari variabel terakhir yang disebut faktor yang saling tidak berkorelasi, bebas satu sama lainnya, lebih sedikit jumlahnya daripada variabel awal akan tetapi dapat menyerap sebagian besar informasi yang terkandung dalam variabel awal atau yang dapat memberikan sumbangan terhadap varians seluruh variabel.
Ada beberapa prosedur yang dapat dipergunakan dalam menentukan banyaknya faktor, antara lain adalah sebgai berikut :
1. Dilihat dari Initial Eigen Value Total
Untuk menentukan banyaknya faktor dari initial values dilihat dengan metode pendekatan, hanya faktor dengan eigen value lebih besar dari satu yang dipertahankan, jika lebih kecil dari satu, faktornya tidak diikutsertakan dalam model. Suatu eigen value menunjukkan besarnya sumbangan dari faktor terhadap varians seluruh variabel asli. Hanya faktor dengan varians lebih besar dari satu yang dimasukkan dalam model.
Berdasarkan tabel 3.13 ternyata diperoleh banyaknya faktor yang dapat mempengaruhi hasil produksi kentang menurut persepsi penduduk atau asumsi responden adalah 3, karena ada 3 faktor atau komponen yang eigen value nya lebih dari 1, yaitu Faktor dengan eigen value 2,810 , Faktor 2 dengan eigen value 1,329 , Faktor 3 dengan eigen value dan 1,003.
Perhitungan secara manualnya untuk mencari nilai ini dapat di lihat di lampiran.
2. Menentukan Banyaknya Faktor dengan Scree Plot
Suatu Scree Plot adalah plot dari eigen value melawan banyaknya faktor yang bertujuan untuk melakukan ekstraksi agar diperoleh jumlah faktor. Scree plot berupa suatu kurva yang diperoleh dengan memplot eigen value sebagai sumbu vertikal dan banyaknya faktor sebagai sumbu horizontal. Bentuk kurva atau plotnya dipergunakan untuk menentukan banyaknya faktor.
Jika tabel total varians menjelaskan dasar jumlah faktor yang didapat dengan perhitungan angka, maka scree plot memperlihatkan hal tersebut dengan grafik. Terlihat bahwa dari sutu ke dua faktor (daris dari sumbu Component 1 ke 2), arah garis cukup menurun tajam. Kemudian dari 2 ke 3 garis juga menurun. Pada faktor 4 sudah dibawah angka 1 dari sumbu eigen value. Hal ini menunjukkan bahwa ada 3 faktor yang mempengaruhi hasil produksi kentang, yang dapat diekstraksi berdasarkan scree plot.
3.5.4 Melakukan Rotasi Faktor
Output terpenting dalam analisis faktor adalah Matriks Faktor atau yang disebut juga dengan Komponen Matriks. Matriks faktor memuat koefisien yang dipergunakan untuk mengekspresikan variabel yang dibakukan dinyatakan dalam faktor. Koefisien ini merupakan factor loading, mewakili koefisien korelasi antara faktor dengan variabel. Koefisien dengan nilai mutlak (absolute) yang besar menunjukkan bahwa faktor dan variabel sangat terkait. Koefisien dari matriks faktor dapat dipergunakan untuk menginterpretasi faktor. Matriks faktor atau matriks komponen dapat dilihat sebagai berikut :
Tabel 3.14 Matriks Faktor (a) (Sebelum Dirotasi) Faktor (Komponen)
1 2 3
X1 0,294 0,578 0,319
X2 0,519 0,131 0,012
X3 0,457 -0,515 -0,012
X4 0,690 -0,121 0,168
X5 0,597 -0,132 0,589
X6 0,569 -0,460 -0,180
X7 0,742 -0,086 -0,209
X8 0,497 0,337 -0,668
X9 0,540 0,590 0,051
dianggap cukup kuat jika koefisien korelasi yang diwaliki factor loading mempunyai nilai lebih besar dari 0,30. Juga variabel berkorelasi dengan banyak faktor, seperti variabel X1 berkorelasi dengan faktor 2 dan 3 variabel X8 berkorelasi dengan faktor 1 dan 2 variabel X9 berkorelasi dengan faktor 1 dan 2. Situasi seperti ini membuat kesimpulan mengenai banyaknya faktor yang diekstraksi dari variabel menjadi sulit.
Untuk mengatasi hal tersebut dapat dilakukan proses rotasi pada faktor yang terbentuk agar memperjelas posisi sebuah variabel, akankah dimasukkan pada faktor yang satu ataukah ke faktor lainnya. Beberapa metode rotasi yang bisa digunakan adalah orthogonal rotation, varimax rotation, dan oblique rotation.
Proses rotasi terhadap faktor pada penelitian ini menggunakan metode varimax rotation. Dan hasil rotasi dapat dilihat pada matriks faktor (setelah
dirotasi) dibawah ini :
Tabel 3.15 Matriks Faktor (a) (Setelah Dirotasi) Faktor (Komponen)
3.5.5 Interpretasi Faktor
Setelah rotasi dilakukan langkah selanjutnya adalah interpretasi faktor. Interpretasi faktor dipermudah dengan mengidentifikasi variabel yang loadingnya besar pada faktor yang sama. Faktor tersebut kemudian dapat diinterpretasi menurut variabel-variabel yang memiliki loading tinggi dengan faktor tersebut. Atau penentuan variabel yang dimasukkan ke dalam faktor dengan cara melihat factor loading yang terbesar.
a. Variabel pupuk kandang : Korelasi antara variabel dengan faktor 2 sebelum dirotasi adalah 0,578; dengan rotasi korelasi menjadi 0,714 dengan faktor 2. Jadi variabel ini masuk faktor 2.
b. Variabel luas lahan : Korelasi antara variabel luas lahan dengan faktor 1 sebelum dirotasi adalah 0,519; dengan rotasi korelasi menjadi 0,370 dengan faktor 2. Jadi variabel ini masuk faktor 2.
c. Variabel pestisida : Korelasi antara variabel pestisida dengan faktor 1 sebelum dirotasi adalah 0,457; dengan rotasi korelasi menjadi 0,676 dengan faktor 1. Jadi variabel ini masuk faktor 1.
d. Variabel kesuburan tanah: Korelasi antara variabel kesuburan tanah dengan faktor 1 sebelum dirotasi adalah 0,690; dengan rotasi korelasi menjadi 0,627dengan faktor 1. Jadi variabel ini masuk faktor 1.
e. Variabel tenaga kerja : Korelasi antara variabel tenaga kerja dengan faktor 1 sebelum dirotasi adalah 0,597; dengan rotasi korelasi menjadi 0,589 dengan faktor 1. Jadi variabel ini masuk faktor 1.
h. Variabel pupuk: Korelasi antara variabel pupuk dengan faktor 1 sebelum dirotasi adalah 0,497; dengan rotasi korelasi menjadi 0,868 dengan faktor 3. Jadi variabel ini masuk faktor 3.
i. Variabel modal: Korelasi antara variabel modal dengan faktor 2 sebelum dirotasi adalah 0,590; dengan rotasi korelasi menjadi 0,727 dengan faktor 2. Jadi variabel ini masuk faktor 2.
Dengan demikian ke 9 variabel telah direduksi menjadi tiga faktor yang dapat mempengaruhi hasil produksi kentang di kecamatan Naman Teran yaitu: 1. Faktor 1 (F1) terdiri atas variabel X3 = pestisida, variable X4 = kesuburan
tanah, variable X5 = tenaga kerja, variabel X6 = jarak tanam antar kentang, variabel X7 = bibit. Sehingga faktor ini diberi nama:
FAKTOR CARA PEMELIHARAAN KENTANG.
2. Faktor 2 (F2) terdiri atas variabel X1 = Pupuk kandang, Variabel X2 = luas lahan, Variabel X9= modal. Faktor ini diberi nama :
FAKTOR MODAL DAN LUAS LAHAN.
3. Faktor 3 (F3) terdiri atas variabel X8 = Pemupukan Faktor ini diberi nama FAKTOR PEMUPUKAN.
Interpretasi dipercepat melalui variabel-variabel yang memiliki loading lebih besar pada faktor yang sama yang kemudian dapat diinterpretasikan dalam batasan variabel-variabel yang loadingnya tinggi. Variabel-variabel yang berkorelasi kuat (nilai faktor loadingnya besar) dengan faktor tertentu akan memberikan inspirasi nama faktor bersangkutan.
Faktor Pertama
Tabel 3.16 Variabel yang Mendukung Faktor Pertama No Variabel
Pendukung
Nama Variabel Bobot
Variabel
1 Jarak tanam antar kentang 0,718
2 Pestisida 0,676
3 Kesuburan tanah 0,627
4 Bibit 0,621
5 Tenaga kerja 0,589
Dari tabel 3.16 diatas, faktor pertama didukung oleh variabel-variabel jarak tanam antar kentang, pestisida, kesuburan tanah, bibit dan banyaknya tenaga kerja. Dari data tersebut bahwa X6 = jarak antara tanaman kentanglah yang mempunyai factor loading terbesar yaitu 0,718. Hal ini menunjukan bahwa variable ini berpengaruh paling kuat terhadap hasil produksi kentang di tempat penelitiaan. Faktor pertama yaitu Faktor Cara dan Pemeliharaan kentang menyumbangkan varians yaitu sebesar 31,220 %. Dari hasil factor loading yang paling dominan untuk menghasilkan hasil produksi yang tinggi tergantung pada saat ingin menanam kentang bahwa jarak tanam itu sangat besar pengaruhnya terhadap panen penghasilanya kentang.
Faktor Kedua
Tabel 3.17 Variabel yang Mendukung Faktor Kedua No Variabel
Pendukung
Nama Variabel Bobot
Variabel
Dari tabel dapat dilihat bahwa bobot variable yang paling tinggi adalah variable X9 = Modal sehingga dari beberapa varibel yang berada di faktor 2 maka varibel X9 = Modal yang dominan dimana factor loading sebesar 0,727 . Faktor ke dua merupakan faktor Modal dan luas lahan yang memberikan pengaruh yang cukup besar untuk hasil produksi kentang yaitu memberi sumbangan varian sebesar 14,77 %. Perlu diperhatikan bahwa ketika ingin melakukan penanaman kentang pasti membutuhkan modal, jadi dari hasil penelitiaan yang dilakukan bahwa ketika semakin besar modal yang akan di gunakan maka hasil produksi juga akan meningkat.
Faktor Ketiga
Faktor ketiga hasil rotasi bahwa hanya 1 variabel yang mendukung yaitu variable X8 = pemupukan. Variabel ini mempunyai faktor loding sebesar 0,868. Pada faktor Ketiga interval pemupukan yang mempengaruhi hasil produksi kentang pada saat diadakan penelitian. Faktor pemupukan ini mempengaruhi hasil produksi kentang sesuai asumsi petani yang di dapat oleh peneliti yaitu memberi sumbangan varian sebesar 11,142 %.
3.5.6 Menentukan Ketepatan Model
Proses akhir dari analisis faktor adalah menguji ketepatan model, dengan menggunakan output program SPSS. Perbedaan antara korelasi yang diobservasi (pada matriks korelasi sebelum analisis faktor) dengan korelasi analisis faktor (yang diestimasi dari matriks faktor) yaitu yang disebut dengan residual. Kalau banyak residual yang nilainya lebih besar dari 0,05 (residual > 0,05), berarti model tidak tepat, model dipertimbangkan kembali. Sebaliknya, jika banyak residual yang nilainya lebih kecil dari 0,05 (residual < 0,05), berarti model sudah tepat.
Tabel 3.18 selisih(residual) antara matriks korelasi sebelum analisis faktor dengan analisis setelah analisis factor
x1 x2 x3 x4 x5 x6 x7 x8 x9
x1 -
x2 -0,131 -
x3 0,029 -0,235 -
x4 -0,034 -0,651 -0,437 -
x5 -0,308 -0,199 -0,292 -0,623 -
x6 0,077 -0,229 -0,375 -0,276 -0,529 -
x7 -0,168 -0,081 -0,462 -0,549 -0,42 -0,805 -
x8 -0,243 -0,346 -0,1 -0,263 0,208 -0,311 -0,558 -
x9 -0,455 -0,402 0,151 -0,311 -0,46 0,163 -0,597 -0,536 -
BAB 4
KESIMPULAN DAN SARAN
4.1Kesimpulan
Pengolahan data dengan menggunakan analisis faktor pada penelitian ini adalah untuk mengetahui seberapa besar pengaruh dari faktor faktor yang di pertimbangkan oleh petani untuk meningkatkan hasil produksi kentang di kecamatan Naman Teran. Dari penelitian ini maka penulis dapat membuat kesimpulan-kesimpulan sebagai berikut :
1. Dari hasil penelitiaan 100 responden dan 9 variabel penelitiaan memberikan proporsi keragaman kumulatif sebesar 57,132% dengan tiga faktor ekstraksi yang terbentuk. Ketiga faktor tersebut menurut asumsi/persepsi dari petani kentang yang di teliti di kecamatan Naman Teran bahwa yang mempengaruhi hasil produksi kentang sebesar 57,132 % dan sisanya dapat dipengaruhi faktor-faktor lainnya yang tidak teridentifikasi oleh model penelitian.
2. Faktor yang paling dominan mempengaruhi hasil produksi kentang di kecamatan Naman Teran. Faktor dominan pertama cara dan pemliharaan yaitu memberikan sumbangan variansi sebesar (31,22%), faktor dominan kedua adalah permodalan dan lahan memberikan sumbangan varians sebesar (14,77%), faktor dominan ketiga adalah faktor Pemupukan memberikan sumbangan varians sebesar (11,42%).
4.2 Saran
Menurut hasil penelitian diatas ada dua hal yang disampaikan sebagai saran, yaitu :
1. Pemerintah tanah karo lebih memperhatikan kondisi pertaniaan terutama dalam penyediaan pupuk dan juga butuh penyuluhan kepada petani untuk dapat meningkatkan hasil panen pertaniaan
BAB 2
LANDASAN TEORI
2.1 Faktor - Faktor yang Mempengaruhi Hasil Produksi Kentang
a) Pupuk kandang adalah pada awal penanaman pupuk kandang digunakan untuk mempersiapkan lahan supaya tanahnya subur dan gembur (Hartus,2001). Dalam hal ini tidak semua petani kentang memperhatikan takaran sesuai luas lahan yang akan ditanam untuk menghasilkan hasil produksi.
b) Luas lahan adalah pada dasarnya bahwa luas lahan akan mempengaruhi hasil produksi, tetapi peneliti mengambil landasan tersebut karena tidak semua daerah dalam lokasi penelitian setiap periode penelitian menanam dengan luas yang sama. Lokasi penelitian tidak hanya tanaman kentang saja, tetapi juga hasil dari pertanian, jadi setiap periode akan berbeda beda luas lahan yang akan di tanami.
c) Pestisida adalah pada penanaman kentang penyemprotan pestisida sangat menjamin hasil produksi yang dilakukan tergantung rutinnya penyemprotan sehingga mempengaruhi hasil produksi.
d) Kesuburan lahan adalah tanaman kentang dapat tumbuh baik pada tanah yang mempunyai struktur cukup halus atau gembur (Idawati,2013). Keadaan tanah tergantung terhadap tanaman apa sebelumnya di tanam di lahan tersebut sehingga dapat ditanggulangi dengan cara penyiraman atau penambahan pupuk pada lahan.
cepat memerlukan tenaga kerja yang banyak, semakin banyak tenaga kerja akan mempengaruhi hasil produksi.
f) Jarak antar tanam kentang adalah Jika bibitnya seukuran telur bebek jarak tanamannnya 35 cm. Jika bibitnya seukuran telur ayam jaraknya 25 cm (Idawati, 2013). Dalam pelaksanaannya penanaman kentang tidak mempehatikan ukuran tesebut karena setiap daerah penanaman kentang berbeda – beda.
g) Bibit adalah umbi kentang itu sendiri yang sudah disimpan dalam waktu tertentu (tergantung jenis kentangnya) dan sudah melewati masa dormansi (dorman periode) dan mulai mengeluarkan tunas tanaman baru. Bila bibit dibeliusahakan harus bersertifikat karena bibit ini sangat menentukan hasil yang akan di peroleh dalam hasil panen. Pada dasarnya bibit yang bagus adalah bibit yang diperoleh atau anggap saja generasi pertama (F1), bibit generasi (F2) dan bibit generasi (F3) (Soelarso,1997). Pada kenyataannya di lapangan, bibit yang di gunakan rata – rata hasil tanamnya sendiri, untuk itu peneliti ingin mengetahui berapa besar peranannya dalam meningkatkan hasil produksi.
h) Modal adalah biaya permulaan dasar dalam memulai melakukan usaha. Tapi dalam hal penanaman kentang yang dimaksud bahwa tidak selama penanaman kentang dengan modal yang tinggi menghasilkan hasil produksi yang tinggi. Peneliti ingin mengetahui seberapa besar modal berpengaruh terhadap hasil produksi yang akan di peroleh.
2.2Populasi dan Sampel Penelitiaan
Populasi adalah (population atau universal) adalah keseluruhan elemen, atau unit penelitian, atau unit analisis yang memiliki ciri atau karakteristik tertentu yang dijadikan sebagai objek penelitiaan atau menjadi perhatiaan dalam suatu penelitiaan (Maman Abdurahman, 2011). Dengan demikian populasi tidak terbatas pada sekelompok orang, tetapi apa aja yang menjadi perhatiaan dalam suatu permasalahaan.
Populasi adalah kumpulan lengkap dari elemen - elemen yang sejenis akan tetapi dapat dibedakaan karena karaktristiknya. Misalnya seluruh penduduk Indonesia, seluruh penduduk propinsi, seluruh karyawan suatu depatemen atau perusahaan, seluruh mahasiswa perguruan tinggi, seluruh turis, seluruh langganan, seluruh petani, seluruh desa, seluruh ternak, seluruh kendaraan, seluruh perkebunan, seluruh pasien, seluruh calon haji, seluruh pasar (Supranto, 2004).
Sampel adalah sebagian anggota populasi yang dipilih dengan menggunakan prosedur tertentu sehingga diharapkan dapat mewakili populasinya.
2.3 Teknik Pengumpulan Data 2.3.1 Data
Data merupakan kumpulan fakta atau angka atau segala sesuatu yang dapat dipercaya kebenaranya sehingga dapat digunakan sebagai dasar menarikan kesimpulan. Data dapat digolongkan berdasarkan aspek sifat, dimensi waktu, cara memperoleh dan pengukuranya (Muhidin, 2009).
2.3.2 Data Ditinjau Menurut Sifatnya
Dalam hal ini, data dibagi menjadi dua bagian, yaitu :
Contoh : a. Harga dolar hari ini mengalami kenaikan.
b. Sebagian dari produksi barang “ X “ pada perusahaan “Y”
rusak.
2. Data Kuantitatif adalah data yang berbentuk bilangan Contoh : a. Luas bangunan hotel itu adalah 6000 m2.
b. Tinggi badan Dody mencapai 180 cm.
c. Banyak perguruan tinggi di kota “A” ada 6 buah.
2.3.3 Data Menurut Jenisnya
1. Data Diskrit adalah data yang diperoleh dengan cara menghitung atau membilang.
a. Banyak kursi yang ada di ruangan ini ada 50 buah.
b. Jumlah mahasiswa yang mengikuti mata kuliah ini mencapai 60 orang.
c. Banyak anak pada keluarga Patris ada 4 orang 2. Data Kontinu adalah data yang diperoleh dengan cara mengukur.
a. Jarak antara kota Medan dengan kota Siantar adalah 128 km
b. Berat bayi yang baru lahir adalah 3,2 kg.
2.3.4 Data Menurut Cara Memperolehnya
Dalam hal ini data dibagi menjadi dua bagian, yaitu :
susu “ Segar Jaya “ ingin mengetahui jumlah konsumsi susu yang diminum
oleh masyarakat di Kelurahan Medan Baru, maka petugas dari perusahaan tersebut secara langsung mendatangi rumah tangga- rumah tangga yang ada di Kelurahan Medan Baru.
2. Data Sekunder adalah data yang diperoleh dalam bentuk sudah jadi, sudah dikumpulkan dan diolah oleh pihak lain, biasanya data itu dicatat dalam bentuk publikasi- publikasi Contoh : Misalkan seorang peneliti memerlukan data mengenai jumlah pendududk di sebuah kota dari tahun 1980 sampai 1990, maka data itu dapat diperolehnya di BPS.
2.4 Metode Pengambilan Sampel
Pada dasarnya ada dua macam metode pengambilan sampel yaitu pengambilan sampel secara acak (probability Sampling) dan secara tidak acak (non probability Sampling)
1. Probability sampling, meliputi:
a. Simple random sampling (populasi homogen) yaitu pengambilan sampel dilakukan secara acak tanpa memperhatikan strata yang ada. Teknik ini hanya digunakan jika populasinya homogen.
b. Proportionale stratifiled random sampling (populasi tidak homogen) yaitu pengambilan sampel dilakukan secara acak dengan memperhatikan strata yang ada. Artinya setiap strata terwakili sesuai proporsinya.
c. Disproportionate stratifiled random sampling yaitu teknik ini digunakan untuk menentukan jumlah sampel dengan populasi berstrata tetapi kurang proporsional, artinya ada beberapa kelompok strata yang ukurannya kecil sekali.
2. Non probability sampling, meliputi: sampling sistematis, sampling kuota, sampling incidental, purposive sampling, sampling jenuh, dan snowball sampling.
Pada penelitian ini digunakan Proportionate Stratified Random sampling yaitu responden yang terpilih secara kebetulan dengan peneliti dan dianggap cocok sebagai sumbur data.
Beberapa alasan menggunakan Proportionate Stratified Random sampling adalah (Supranto J,1992):
1. Setiap strata homogen atau relatif homogen,sehingga sampel acak yang diambil dari setiap strata akan memberikan pikiran yang dapat mewakili strata yang bersangkutan. Perkiraan gambaran yang diperoleh berdasarkan perkiraan dari setiap strata akan memberikan perkiraan menyeluruh yang mewakili populasi.
2. Biaya untuk pelaksanaan Proportionate Stratified Random sampling lebih murah dari simple Random Sampling.
3. Perkiraan bias dibuat untuk setiap strata yang dapat dianggap sebagai populasi yang berdiri sendiri dan mungkin bias dilakukan oleh peneliti seorang diri saja.
Alokasi proporsi dalam Proportionate Stratified Random sampling. Ditentukan dengan menggunakan rumus:
∑
Keterangan:
2.5 Teknik Pengukuran dan Sampel
Pada dasarnya proses pengukuran adalah merupakan rangkaian dari empat aktivitas pokok (Singarimbun dan Effendi, 1985). Rangkaian empat aktivitas pokok tersebut antara lain :
1. Menentukan dimensi variabel penelitian.
2. Merumuskan ukuran untuk masing-masing dimensi.
3. Menentukan tingkat ukuran yang akan digunakan dalam pengukuran. 4. Menguji validitas dan reliabilitas alat ukur.
Pada teknik penskalaan, banyak sekali jenis skala pengukuran yang telah dikembangkan, terutama dalam ilmu-ilmu sosial. Namun dalam penelitian ini skala pengukuran yang digunakan adalah skala Likert. Skala ini dikembangkan oleh Rensis Likert (1932) untuk mengukur sikap masyarakat dan skalanya terkenal dengan nama technique of summated rating atau skala Likert. Banyak faktor yang menyebabkan skala Likert banyak digunakan sebagai berikut :
1. Skala ini relatif mudah dibuat.
2. Adanya kebebasan dalam memasukkan item- item pernyataan asal masih relevan dengan masalah.
3. Jawaban atas item dapat berupa beberapa alternaitf, sehigga dapat memberikan informasi yang lebih jelas dan nyata terhadap item tersebut. 4. Dengan jumlah item yang cukup besar, tingkat reliabilitas yang tinggi
dapat dicapai.
5. Mudah untuk diterapkan pada berbagai situasi.
2.6 Uji Dalam Pengolahan Data 2.6.1 Uji Validitas
dikatakan mempunyai validitas yang tinggi apabila alat ukur tersebut menjalankan fungsi ukurnya, atau memberikan hasil ukur yang sesuai dengan maksud dilakukannya pengukuran tersebut. Metode yang yang digunakan untuk menguji validitas adalah dengan korelasi product moment yang rumusnya sebagai berikut :
∑ ∑ ∑
√{ ∑ ∑ }{ ∑ ∑ }
Keterangan :
rxy = koefisien korelasi X = skor pertanyaan Y = skor total n = jumlah sampel
Untuk menentukan valid tidaknya variabel adalah dengan cara mengkonsultasikan hasil perhitungan koefisien korelasi dengan tabel nilai koefisien (r) pada taraf kepercayaan 95 %.(Ade Fatma, 2007).
Apabila rxy ≥ rtabel → valid Apabila rxy < rtabel → tidak valid
2.6.2 Uji Realibilitas
Realibilitas menunjukkan sejauh mana hasil pengukuran dapat dipercaya. Pengukuran yang memiliki realibilitas tinggi disebut sebagai pengukuran yang realibilitas. Metode yang digunakan untuk menguji realibilitas adalah metode Alpha Cronbach. Variabel dikatakan realibel jika memberikan nilai Alpha
Keterangan:
= nilai (koefisien) Alpha Cronbach = banyaknya variabel penelitian ∑ = jumlah varians variabel penelitian
= varians total
2.7 Analisis Faktor
2.7.1 Definisi Analisis faktor
Analisis faktor merupakan salah satu prosedur reduksi data serta salah satu alat untuk menguji alat ukur dalam metode statistic multivariate (Dillon and Goldstein, 1984). Analisis faktor diartikan sebuah analisis yang mensyaratkan adanya keterkaitan antar variabel. Pada prinsipnya analisis faktor menyederhanakan hubungan yang beragam dan kompleks pada variabel yang diamati dengan menyatukan faktor atau dimensi yang saling berhubungan atau mempunyai korelasi pada suatu struktur data yang baru yang mempunyai set faktor lebih kecil. Data-data yang dimasukkan pada umumnya data metrik dan terdiri dari variabel-variabel dengan jumlah yang besar.
Analisis faktor dapat digunakan di dalam situasi sebagai berikut :
1. Mengenali atau mengidentifikasi dimensi yang mendasari (underlying dimensions) atau faktor, yang menjelaskan korelasi antara suatu set variabel.
3. Mengenali atau mengidentifikasi suatu set variabel yang penting dari suatu set variabel yang lebih banyak jumlahnya untuk dipergunakan di dalam analisis multivariat selanjutnya.
Ada tiga fungsi utama analisis faktor, yaitu :
1. Mereduksi banyaknya variabel penelitian dengan tetap mempertahankan sebanyak mungkin informasi data awal. Banyaknya variabel awal dapat dikurangi menjadi beberapa variabel yang jumlahnya lebih sedikit dengan tetap mempertahankan sebagian besar variasi data.
2. Mencari perbedaan kualitatif dan kuantitatif dalam data, dalam situasi dimana terdapat jumlah data yang sangat besar.
3. Data digunakan pula untuk menguji hipotesis tentang perbedaan kualitatif dan kuantitatif dalam data penelitian.
Asumsi dasar dalam menggunakan analisis faktor adalah : 1. Tingginya korelasi antar variabel
Korelasi antar variabel yang kuat dapat diindikasikan oleh nilai determinan matriks korelasi yang mendekati nol. Nilai determinan dari matriks korelasi yang elemen-elemennya menyerupai matriks identitas akan memiliki nilai determinan sama dengan satu. Hal ini dapat diuji dengan Bartlett’s test of sphericity.
nilai measure of sampling adequacy (MSA) berkisar antara 0,5 – 1,0. Apabila ada beberapa variabel memiliki nilai MSA kurang dari 0,5 maka variabel tersebut harus dikeluarkan satu persatu secara bertahap.
2.7.2 Model Analisis Faktor
Secara matematis, analisis faktor agak mirip dengan analisis regresi, yaitu dalam hal bentuk fungsi linier. Jumlah varians yang dikontribusi dari sebuah variabel dengan seluruh variabel lainnya lebih dikelompokkan sebagai komunalitas. Kovarians diantara variabel dijelaskan terbatas dalam sejumlah kecil komponen ditambah sebuah faktor unik untuk setiap variabel. Faktor-faktor tersebut tidak secara eksplisit diamati.
Jika variabel distandarisasi, maka model analisis faktor dapat ditulis sebagai berikut : m = Banyaknya komponen faktor.
Faktor yang unik tidak berkorelasi dengan sesama faktor yang unik dan juga tidak berkorelasi dengan komponen faktor. Komponen faktor sendiri bisa dinyatakan sebagai kombinasi linier dari variabel-variabel yang terlihat/ terobservasi hasil penelitian lapangan.
Dimana :
Fi = Perkiraan faktor ke i (didasarkan pada nilai variabel X dengan
koefisiennya Wi ).
Wi = Koefisien nilai faktor ke i.
k = banyaknya variabel
2.7.3 Statistik yang Berkaitan dengan Analisis Faktor
Statistik yang berkaitan dengan analisis faktor adalah :
a. Barlett’s test of sphericity
Barlett’s test of sphericity adalah uji statistik yang digunakan untuk menguji hipotesis yang menyatakan bahwa variabel-variabel tersebut tidak berkorelasi dalam populasinya. Dengan kata lain, matriks korelasi populasi adalah sebuah matriks identitas, dimana setiap variabel berkorelasi dengan variabel itu sendiri (r = 1), tetapi tidak berkorelasi dengan variabel lainnya (r = 0).
Statistik uji bartlett adalah sebagai berikut :
[ ] | |
dengan derajat kebebasan(degree of freedom) df Keterangan :
= jumlah observasi = jumlah variabel
| | = determinan matriks korelasi
b. Correlation matrix (Matriks Korelasi)
n = 3 →
Komunalitas adalah jumlah varian yang dikontribusi dari sebuah variabel dengan seluruh variabel lainnya dalam analisis. Ini juga merupakan proporsi dari varians yang diterangkan oleh komponen faktor.
Nilai eigen merupakan jumlah varians yang dijelaskan oleh setiap faktor-faktor yang mempunyai nilai eigen value > 1, maka faktor tersebut akan dimasukkan ke dalam model.
e. Factor loadings (Faktor Muatan)
Faktor muatan adalah korelasi sederhana antara variabel dengan faktor.
f. Factor loading plot (Plot Faktor Muatan)
g. Factor matrix (Faktor Matriks)
Matriks faktor mengandung factor loading dari seluruh variabel dalam seluruh faktor yang dikembangkan.
h. Kaiser - Meyer - Olkin (KMO) measure of sampling adequency
Kaiser – Meyer – Olkin (KMO) merupakan suatu indeks yang digunakan untuk menguji ketepatan analisis faktor. Nilai yang tinggi (antara 0,5 – 1,0) mengidentifikasi analisis faktor tepat. Apabila dibawah 0,5 menunjukkan bahwa analisis faktor tidak tepat untuk diaplikasikan.
∑ ∑ ∑ ∑
∑ ∑
Keterangan :
= koefisien korelasi sederhana antara variabel ke- dan = koefisien korelasi parsial antara variabel ke- dan
ke-Measure of Sampling Adequacy (MSA) yaitu suatu indeks perbandingan antara
koefisien korelasi parsial untuk setiap variabel. MSA digunakan untuk mengukur kecukupan sampel.
∑ ∑
∑
i. Percentage of variance (Persentase Varians)
Persentase varians adalah persentase total varians yang disumbangkan oleh setiap faktor.
j. Residuals
k. Scree plot
Scree plot adalah sebuah plot dari eigenvalue untuk menentukan banyaknya
faktor.
2.8.4 Langkah-Langkah Analisis Faktor
Langkah-langkah dalam analisis faktor adalah sebagai berikut : 1. Merumuskan masalah
2. Membentuk matriks korelasi 3. Menentukan metode analisis faktor 4. Menentukan banyaknya faktor 5. Melakukan rotasi terhadap faktor
6. Membuat intrepretasi hasil rotasi terhadap faktor 7. Menentukan ketepatan model (model fit)
Secara skematis langkah-langkah dalam analisis faktor dapat digambarkan sebagai berikut :
Merumuskan masalah
Membentuk matriks korelasi
Menghitung nilai karakteristik (eigen value)
Menghitung vektor karakteristik (eigen vector)
Menentukan banyaknya faktor
Menghitung matriks factor loading
Interpretasi faktor
Menentukan ketepatan model (model fit) Gambar 2.1 Langkah-langkah dalam analisis faktor
1. Merumuskan Masalah
Merumuskan masalah meliputi beberapa kegiatan. Pertama, tujuan analisis faktor harus diidentifikasi. Variabel yang akan digunakan dalam analisis faktor harus dispesifikasi berdasarkan penelitian sebelumnya, teori dan pertimbangan subjektif dari peneliti. Pengukuran variabel berdasarkan skala interval dan rasio. Besarnya sampel harus tepat, sebagai petunjuk umum besarnya sampel paling sedikit empat atau lima kali banyaknya variabel.
2. Membentuk Matriks Korelasi
Proses analisis didasarkan pada suatu matriks korelasi antar variabel. Agar analisis faktor menjadi tepat, variabel-variabel yang dikumpulkan harus berkorelasi. Dilakukan perhitungan matriks korelasi . Matriks korelasi digunakan sebagai input analisis faktor.
Korelasi antar Variabel
3. Menghitung nilai karakteristik (eigen value)
Perhitungan nilai karakteristik (eigen value) , dimana perhitungan ini berdasarkan persamaan karakteristik :
Eigen value adalah jumlah varian yang dijelaskan oleh setiap faktor.
4. Menghitung vektor karakteristik (eigen vector)
Penentuan vektor karakteristik (eigen vector) yang bersesuaian dengan nilai karakteristik (eigen value), yaitu dengan persamaan :
dengan
= eigen vector
5. Menentukan Banyaknya Faktor
Ada beberapa prosedur yang dapat dipergunakan dalam menentukan banyaknya faktor yaitu, penentuan secara a priori, penentuan berdasarkan pada eigen value, penentuan berdasarkan Screen plot, penentuan berdasarkan persentase varians, penentuan berdasarkan Split-Half Reliability, dan penentuan berdasarkan uji signifikan.
a. Penentuan Secara A priori
Kadang-kadang karena adanya dasar teori atau pengalaman sebelumnya, peneliti sudah dapat menentukan banyaknya faktor yang akan diekstraksi. Hampir sebagaian besar program komputer memungkinkan peneliti untuk menentukan banyaknya faktor yang diinginkan dengan pendekatan ini.
b. Penentuan Berdasarkan Eigen value
varians lebih besar dari satu yang dimasukkan dalam model. Faktor dengan varians lebih kecil dari satu tidak lebih dari variabel asli, sebab variabel yang dibakukan (distandarisasi) yang berarti rata-ratanya nol dan variansinya satu. c. Penentuan Berdasarkan Screen Plot
Screen Plot merupakan plot dari nilai eigen value terhadap banyaknya faktor
dalam ekstraksinya. Bentuk plot yang dihasilkan, digunakan untuk menentukan banyaknya faktor. Biasanya plot akan berbeda antara slope tegak faktor, dengan eigen value yang besar dan makin kecil pada sisa faktor yang tidak perlu diekstraksi.
d. Penentuan Berdasarkan Persentase Varians
Dalam pendekatan ini, banyaknya faktor yang diekstraksi ditentukan berdasarkan persentasi kumulatif varians mencapai tingkat yang memuaskan peneliti. Tingkat persentase kumulatif yang memuaskan peneliti tergantung kepada permasalahannya. Sebagai petunjuk umum bahwa ekstraksi faktor dihentikan kalau kumulatif persentase varians sudah mencapai paling sedikit 60% atau 75% dari seluruh varians variabel asli.
e. Penentuan Split-Half Reliability
Sampel dibagi menjadi dua, dan analissi faktor diaplikasikan kepada masing-masing bagian. Hanya faktor yang memiliki faktor loading tinggi antar dua bagian itu yang akan dipertahankan.
f. Penentuan Berdasarkan Uji Signifikan