SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
IWAN MUHAMAD RIDWANNULOH
10110413
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xiv
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang Masalah ... 1
I.2 Perumusan Masalah ... 2
I.3 Maksud dan Tujuan... 2
I.4 Batasan Masalah ... 3
I.5 Metodologi Penelitian ... 3
I.5.1 Metode Pengumpulan Data ... 3
I.5.2 Metode Pembangunan Perangkat Lunak ... 4
I.5.3 Metode Pembangunan Sistem Analisis Sentimen ... 5
I.6 Sistematika Penulisan ... 6
BAB II TINJAUAN PUSTAKA ... 7
II.1 Tentang Telkom Speedy ... 7
II.1.1 Struktur Organisasi Perusahaan ... 8
II.1.2 Visi dan Misi ... 9
II.2 Landasan Teori... 9
II.3 Analisis Sentimen ... 9
II.4 Text Mining ... 10
II.4.1 Preprocessing ... 10
II.4.2 Pembobotan (Term Weighting) ... 14
II.4.2.1 TF-IDF (Term Frequency – Inverse Document Frequency) ... 14
II.5 Klasifikasi ... 15
vi
II.5.2 Naïve Bayes Classifier ... 16
II.5.3 Confusion Matrix ... 17
II.6 Object Oriented Programming (OOP) ... 18
II.7 Unified Modeling Language (UML) ... 20
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 21
III.1 Analisis Sistem... 21
III.1.1 Analisis Masalah ... 21
III.1.2 Analisis Sumber Data ... 22
III.1.3 Analisis Preprocessing ... 24
III.1.4 Analisis Penerapan Algoritma Naive Bayes Classifier ... 29
III.1.5 Analisis Pembobotan Kata (TF-IDF) ... 33
III.2 Spesifikasi Kebutuhan Perangkat Lunak ... 35
III.3 Analisis Kebutuhan Non Fungsional ... 36
III.3.1 Analisis Kebutuhan Perangkat Keras ... 36
III.3.2 Analisis Kebutuhan Perangkat Lunak ... 37
III.3.3 Analisis Kebutuhan Perangkat Pikir ... 38
III.4 Analisis Kebutuhan Fungsional ... 38
III.4.1 Identifikasi Aktor ... 38
III.4.2 Use Case Diagram... 38
III.4.2.1 Identifikasi Use Case ... 39
III.4.2.2 Skenario Use Case Diagram ... 40
III.4.3 Activity Diagram ... 47
III.4.4 Sequence Diagram ... 53
III.4.5 Class Diagram ... 58
III.5 Perancangan Arsitektur Sistem ... 59
III.5.1 Perancangan Struktur Menu ... 59
III.5.2 Perancangan Antarmuka ... 59
III.5.3 Perancangan Pesan ... 62
III.5.4 Jaringan Semantik ... 62
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 63
vii
IV.1.1. Implementasi Data ... 63
IV.1.2. Implementasi Antarmuka ... 64
IV.2. Pengujian Perangkat Lunak ... 65
IV.2.1. Pengujian Black Box... 65
IV.2.2. Pengujian Confusion Matrix ... 68
IV.2.3. Pengujian Beta ... 70
BAB V KESIMPULAN DAN SARAN... 73
V.1. Kesimpulan ... 73
V.2. Saran ... 73
75
DAFTAR PUSTAKA
[1] A. R. Noor, "detik inet," 10 Mei 2013. [Online]. Available: http://inet.detik.com/read/2013/05/10/091915/2242239/328/. [Accessed 24 Maret 2014].
[2] "statisticbrain," [Online]. Available: http://www.statisticbrain.com/twitter-statistics/. [Accessed 9 February 2014].
[3] R. P. Hestya, "tempo," 17 Desember 2013. [Online]. Available:
http://www.tempo.co/read/news/2013/12/17/072538043/Indonesia-Pengguna-Twitter-Nomor-3-di-Dunia. [Accessed 9 February 2014].
[4] B. Liu, Sentiment Analysis and Opinion Mining, Morgan & Claypool Publisher, 2012.
[5] I. Sommerville, Software Engineering, Jakarta: Erlangga, 2003.
[6] J. M. C, "slideshare," 2011. [Online]. Available: http://www.slideshare.net/mcjenkins/how-sentiment-analysisworks/.
[Accessed 16 Maret 2014].
[7] B. Pang and L. Lee, "Opinion Mining and Sentiment Analysis," Foundations and Trends in Information Retrieval, vol. II, no. 1-2, pp. 1-135.
[8] B. Pang, L. Lee and S. Vaithyanathan, "Thumbs up? Sentiment Classification using Machine Learning," in Proceedings of the ACL-02 conference on Empirical Methods in natural language processing, Morristown, 2002.
[9] B. Liu, "Sentiment Analysis and Subjectivity," Handbook of Natural Language Processing, 2010.
[10] B. Liu, "Sentiment Analysis: A Multi-Faceted Problem," IEEE Intelligent Systems.
76
[13] H. and Y. Wibisono, "Sistem Analisis Opini Microblogging Berbahasa Indonesia," Bandung, 2012.
[14] V. Narayanan, I. Arora and A. Bhatia, "Fast and accurate sentiment classification using an enhanced Naive Bayes model," Department of Electronics Engineering, Indian Institute of Technology (BHU), Varanasi, India.
iii
KATA PENGANTAR
Assalaamu’alaikum wr. wb,
Alhamdulillahi Rabbil alamiin, segala puji dan syukur penulis panjatkan kepada Allah SWT atas rahmat dan karunia-Nya yang telah dilimpahkan, shalawat dan salam tidak lupa dicurahkan kepada Nabi Muhammad SAW, penulis dapat menyelesaikan skripsi ini dengan judul “ANALISIS SENTIMEN PADA
POSTING OFFICIAL AKUN TWITTER TELKOM SPEEDY
MENGGUNAKAN NAÏVE BAYES CLASSIFIER”.
Adapun tujuan dari penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Dalam penyusunan skripsi ini banyak sekali bantuan yang penulis terima. Karena itu, penulis ingin menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada:
1. Allah SWT yang telah mencurahkan rahmat dan hidayahnya hingga detik ini. 2. Bapak Adam Mukharil Bachtiar, S.Kom., M.T. selaku dosen pembimbing yang
telah meluangkan waktu, tenaga dan pikirannya untuk membimbing dan memberikan saran serta ilmu pengetahuannya kepada penulis dalam penyusunan skripsi ini.
3. Ibu Ednawati Rainarli, S.Si., M.Si. selaku dosen penguji I yang telah memberikan saran serta kritiknya dalam penyempurnaan skripsi ini.
4. Ibu Utami Dewi W, S.Kom., M.Kom. selaku dosen penguji III yang telah memberikan saran serta kritiknya dalam penyempurnaan skripsi ini.
iv
Selain itu tidak lupa juga penulis ucapkan terima kasih yang sebesar-besarnya dan penghargaan yang setinggi-tingginya kepada:
1. Kedua orang tua dan kedua saudara yang dengan tulus selalu mendoakan, memberikan dorongan moril dan materil, masukan, perhatian, dukungan sepenuhnya, dan kasih sayang yang tidak ternilai dan tanpa batas yang telah kalian berikan.
2. Kepada teman-teman kelas IF-10 angkatan 2010 atas dukungan dan kebersamaannya, terutama untuk Wildan, Reynoldo, Taupik dan Gilar yang telah bersedia meminjamkan laptopnya untuk membantu penulis dalam menyelesaikan skripsi ini.
Keterbatasan kemampuan, pengetahuan dan pengalaman penulis dalam pembuatan skripsi ini masih jauh dari kesempurnaan. Untuk itu penulis akan selalu menerima segala masukkan yang ditujukan untuk menyempurnakan skripsi ini. Akhir kata penulis mengharapkan semoga skripsi ini dapat bermanfaat serta menambah wawasan pengetahuan baik bagi penulis sendiri maupun bagi pembaca pada umumnya.
Bandung, 19 Agustus 2014
NIM : 10110413
Tempat/Tanggal Lahir : Bandung/05 Mei 1992
Jenis Kelamin : Laki-laki
Agama : Islam
Alamat : Kp. Sukajaya 2 RT 01 RW 11 No. 76 Lembang
Kota : Bandung Kode POS:40391
Telepon : 02291280627
Email : [email protected]
PENDIDIKAN
1. 1998 – 2004 : SD Negeri Lembang VII 2. 2004 – 2007 : SMPN 1 Lembang 3. 2007 – 2010 : SMAN 1 Lembang
4. 2010 – 2014 : Program Studi S1 Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer
Universitas Komputer Indonesia, Bandung
Dengan ini Penulis menyatakan bahwa semua informasi yang diberikan dalam dokumen ini adalah benar
Bandung, 19 Agustus 2014 Penulis
1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
Telkom Speedy adalah layanan broadband akses internet dari PT. Telekomunikasi Indonesia Tbk. yang berkualitas tinggi bagi perumahan serta SME (Small Medium Enterprise). Telkom Speedy menggunakan teknologi ADSL (Asymmetric Digital Line Subsriber), MSAN (Multi Service Access Node), dan GPON (Gigabit Passive Optical Network), yang menghantarkan sinyal digital berkecepatan tinggi melalui jaringan telepon secara optimal bagi keperluan konsumsi konten internet, dengan kecepatan data dari 384 kpbs hingga 100 Mbps. Pada tahun 2013, jumlah pengguna Telkom Speedy mencapai 2,4 juta orang [1]. Banyaknya jumlah pengguna ini membuat Telkom Speedy harus menyediakan layanan berupa feedback untuk penggunanya agar memudahkan dalam meninjau kembali produknya. Salah satu media yang digunakan sebagai layanan feedback adalah Twitter.
Pada jaman sekarang, mikroblogging menjadi sarana komunikasi online yang sangat popular di tengah masyarakat. Terlihat sangat jelas dari salah satu mikroblogging yang sangat popular yaitu Twitter, dengan jumlah pengguna aktif mencapai lebih dari 231,7 juta dengan rata-rata jumlah tweets perharinya mencapai 58 juta tweets [2]. Indonesia sendiri memiliki pengguna aktif Twitter sebanyak 19,5 juta [3]. Jumlah tweets berkembang dengan cepat karena kesederhanaan dan kemudahan dalam penggunaannya merupakan beberapa alasan mengapa Twitter lebih digemari masyarakat Indonesia dalam berkomunikasi. Tentu saja, informasi yang terkandung dalam tweets ini sangat berharga sebagai alat penentu kebijakan dan ini bisa dilakukan dengan menggunakan analisis sentimen.
yang termasuk opini positif dan mana yang termasuk opini negatif [4]. Salah satu contoh dari pengaplikasian analisis sentimen adalah ketika suatu perusahaan mengeluarkan suatu produk dan perusahaan tersebut menyediakan layanan untuk menerima opini dari konsumen mengenai produk tersebut. Analisis sentimen digunakan untuk mengelompokkan opini-opini positif dan negatif dari konsumen yang menggunakan produk tersebut sehingga mempercepat dan mempermudah tugas perusahaan untuk meninjau kembali kekurangan produknya.
Berdasarkan gambaran penjelasan di atas, disini penulis tertarik untuk mengaplikasikan sistem analisis sentimenterhadap official akun Twitter Telkom Speedy dengan menggunakan Naïve Bayes Classifier (NBC).
I.2 Perumusan Masalah
Berdasarkan uraian latar belakang diatas dapat dirumuskan masalahnya adalah bagaimana membangun suatu sistem yang dapat melakukan analisis sentimen pada official akun Twitter Telkom Speedy dengan menggunakan Naïve Bayes Classifier (NBC)?
I.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penelitian ini adalah untuk menerapkan metode Naïve Bayes Classifier (NBC) dalam membangun sebuah aplikasi yang mampu mengklasifikasikan opini sebagai opini positif ataupun opini negatif sebagai salah fungsi utama analisis sentimen.
Tujuan yang akan dicapai dalam penelitian ini yaitu:
1. Membangun suatu sistem analisis sentimen pada official akun Twitter Telkom Speedy dengan menggunakan Naïve Bayes Classifier (NBC), yang dapat membantu Telkom Speedy dalam menganalisis sentimen para penggunanya.
I.4 Batasan Masalah
Adapun batasan masalah dari penelitian ini adalah:
1. Dataset yang digunakan berasal dari tweets yang menggunakan bahasa Indonesia yang ditujukan kepada akun @TelkomSpeedy.
2. Metode pengklasifikasiannya menggunakan Naïve Bayes Classifier (NBC).
3. Metode pembobotan yang digunakan adalah Term Frequency – Inverse Document Frequency (TF-IDF).
4. Tweets yang diklasifikasi, diharapkan berupa tweets yang mengandung opini.
5. Tweets diklasifikasikan berdasarkan 2 kelas, yaitu kelas sentimen positif dan kelas sentimen negatif.
I.5 Metodologi Penelitian
Metodologi penelitian merupakan suatu proses untuk memecahkan suatu masalah yang logis, dan memerlukan data-data untuk mendukung terlaksananya suatu penelitian. Metode yang digunakan dalam penelitian ini adalah metode deskriptif. Metode deskriptif merupakan sebuah metode yang menggambarkan fakta-fakta dan informasi secara sistematis, faktual dan akurat.
I.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut:
a. Studi Literatur
Pengumpulan data dengan cara mengumpulkan referensi seperti jurnal, paper dan bacaan-bacaan yang ada kaitannya dengan judul penelitian. Mempelajari literatur dan teori pendukung penelitian mengenai klasifikasi, khususnya naïve bayes classifier.
b. Observasi
I.5.2 Metode Pembangunan Perangkat Lunak
Metode pembangunan dalam pembuatan perangkat lunak ini menggunakan paradigma waterfall. Fase-fase dalam model waterfall menurut referensi Ian Sommerville terdapat pada Gambar I.1 berikut :
Requirements definition
System and software design
Implementation and unit testing
Integration and system testing
Operation and maintenance
Gambar I.1 Skema Waterfall [5]
Yang meliputi beberapa proses diantaranya : a. Requirements Analysis and Definition
Tahap ini merupakan kegiatan pengumpulan kebutuhan secara lengkap kemudian dianalisis dan didefinisikan kebutuhan yang harus dipenuhi oleh program yang akan dibangun. Fase ini harus dikerjakan secara lengkap untuk bisa menghasilkan desain sistem yang lengkap.
b. System and Software Design
Merupakan tahap menganalisis hal-hal yang diperlukan dalam pelaksanaan proyek pembuatan perangkat lunak.
c. Implementation and Unit Testing
Desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan. Program yang dibangun langsung diuji secara unit.
d. Integration and System Testing
e. Operation and Maintenance
Mengoperasikan program dilingkungannya dan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi dengan situasi sebenarnya.
I.5.3 Metode Pembangunan Sistem Analisis Sentimen
Sistem analisis sentimen yang akan dibangun akan melewati tahapan-tahapan pada Gambar I.2.
Analisis Sumber Data
Data Preprocessing
Klasifikasi Sentimen
Pembobotan
Kata Visualisasi
Gambar I.2 Alur Pembangunan Sistem Analisis Sentimen Tahapannya terdiri dari:
a. Analisis Sumber Data
Data yang digunakan adalah kumpulan tweets bahasa Indonesia yang diambil dari official akun Twitter Telkom Speedy (@TelkomSpeedy). Data tweets ini diperoleh dengan membuat program crawling yang secara otomatis akan mengambil data tweets yang mengandung kata
“TelkomSpeedy”, “speedy reguler”, “speedy instant”, dan “speedy gold”.
b. Data Preprocessing
Pada tahap ini, tweets yang terkumpul akan diproses sehingga data yang didapat menjadi lebih terstruktur dan mudah untuk diolah. Langkah-langkah preprocessing terdiri dari tokenizing, normalisasi fitur, case folding, convert emoticon, convert negation, stemming dan stopword removal.
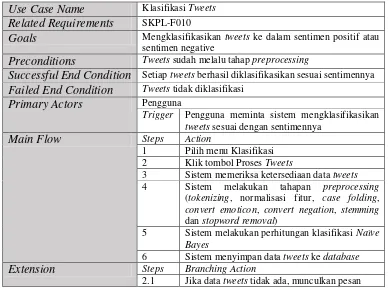
c. Klasifikasi Sentimen
Langkah selanjutnya adalah proses pengklasifikasian yang akan diproses menggunakan metode Naïve Bayes Classifier untuk menentukan mana yang termasuk opini positif dan mana yang termasuk opini negatif.
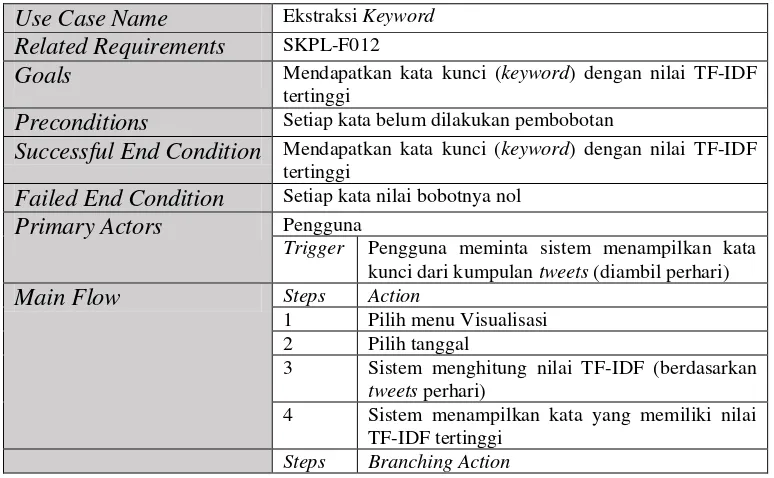
d. Pembobotan Kata
(kata) yang memiliki bobot TF-IDF terbesarlah yang akan merepresentasikan topik pemicu nilai sentimen di selang waktu tersebut (diambil perhari).
e. Visualisasi
Hasil dari tahap klasifikasi sentimen akan digambarkan dalam bentuk diagram pie. Data diambil dari jumlah opini positif dan opini negatif lalu ditampilkan dalam bentuk persentase pada diagram.
I.6 Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum tentang kasus yang akan dipecahkan. Sistematika penulisan penelitian ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini menjelaskan mengenai latar belakang masalah, perumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, serta sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Menganalisis masalah dari model penelitian untuk memperlihatkan keterkaitan antar variabel yang diteliti serta model matematis untuk analisisnya. BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini membahas tentang implementasi dari hasil tahapan analisis dan perancangan aplikasi yang dibangun. Serta berisi uji coba dan hasil pengujian sistem.
BAB V KESIMPULAN DAN SARAN
7
BAB II
TINJAUAN PUSTAKA
II.1 Tentang Telkom Speedy
Telkom Speedy adalah layanan broadband akses internet dari Telkom Indonesia yang berkualitas tinggi bagi perumahan serta SME (Small Medium Enterprise). Speedy menggunakan teknologi ADSL (Asymmetric Digital Line Subscriber), MSAN (Multi Service Access Node), dan GPON (Gigabit Passive Optical Network), yang menghantarkan sinyal digital berkecepatan tinggi melalui jaringan telepon secara optimal bagi keperluan konsumsi konten internet, dengan kecepatan data dari 384 kbps hingga 100 Mbps. Tetapi tidak menutup kemungkinan penggunaan teknologi baru lain yang lebih baik/terbaru. Sebagai perusahaan telekomunikasi dengan jaringan kabel terluas di tanah air, Telkom melalui Speedy menawarkan solusi akses internet kecepatan tinggi atau broadband via teknologi ADSL (Assymmetric Digital Subscriber Line) yang memungkinkan komunikasi data dan suara bisa dilakukan secara bersamaan di sebuah saluran kabel telepon. Berbeda dengan layanan koneksi internet dial up dari Telkom sebelumnya yaitu TelkomNet Instan, Speedy memiliki beberapa keunggulan. Speedy lebih cepat dan memungkinkan telepon dan internet dapat digunakan secara bersamaan, tidak seperti TelkomNet Instan yang mengharuskan pelanggan memakai saluran telepon secara bergantian. Jika dibandingkan dengan teknologi koneksi broadband lain yang berbasis wireless seperti yang banyak ditawarkan beberapa operator seluler, Speedy juga lebih stabil karena menggunakan media kabel yang tidak terkondisi oleh gangguan cuaca dan letak geografis.
termurah biasanya sudah mencukupi, namun untuk kebutuhan bisnis dan perkantoran, paket langganan unlimited adalah pilihan yang lebih tepat.
II.1.1 Struktur Organisasi Perusahaan
Struktur organisasi perusahaan adalah gambar bagan yang menjelaskan posisi dan hierarki struktur kerja pegawai di dalam perusahaan. Struktur organisasi perusahaan dari PT. Telekomunikasi Indonesia, Tbk dapat dilihat pada Gambar II.1.
SVP Public Phone SVP CPE
Asman TOS Asman CPE
Asman Daman Asman MFRAN
Asman CAM Asman CCA
Manager Gudang Manager
Optimalisasi Manager
Outsourching Manager Operation
Manager Access Area
General Manager
Gambar II.1 Struktur Organisasi PT. Telekomunikasi Indonesia, Tbk
Uraian tugas dan wewenang dari Manager Operation adalah sebagai berikut:
a. Merencanakan sasaran dan ruang lingkup project serta merinci aktivitas project dan penjadwalannya. Mampu melakukan monitoring dan reporting pelaksanaan project.
c. Menganalisis statistik gangguan dan menyusun program penanganan gangguan layanan pelanggan secara efisien dan efektif.
d. Menganalisis statistik performansi layanan secara menyeluruh dan membuat rekomendasi solusi peningkatan performansi layanan.
II.1.2 Visi dan Misi
Visi dari Telkom Group adalah “To become a leading Telecommunication, Information, Media, Edutainment and Services (“TIMES”) player in the
region”. Sedangkan misi perusahaan ini adalah : a. Menyediakan layanan “more for less”TIMES.
b. Menjadi model pengelolaan korporasi terbaik di Indonesia.
II.2 Landasan Teori
Landasan teori ini merupakan penjelasan berbagai konsep dasar dan teori-teori yang berkaitan dalam pembangunan sistem analisis sentimen dengan menggunakan metode Naïve Bayes Classifier.
II.3 Analisis Sentimen
Analisis sentimen atau disebut juga opinion mining, adalah bidang studi dalam menganalisis pendapat orang, evaluasi, penilaian, sikap dan emosi terhadap suatu entitas seperti produk, jasa, organisasi, individu, isu-isu, peristiwa dan topik. Fokus utama dari analisis sentimen adalah untuk menyatakan mana yang termasuk opini positif dan mana yang termasuk opini negatif. Salah satu contoh penggunaan analisis sentimen dalam dunia nyata adalah identifikasi kecenderungan pasar dan opini pasar terhadap suatu objek barang.
menghindari kejadian serupa untuk meningkatkan sentimen. Kebutuhan-kebutuhan tersebut biasanya muncul ketika suatu pihak ingin mendapatkan sentimen publik yang baik atau melakukan pencitraan. Kebutuhan seperti ini biasa dimiliki oleh tokoh-tokoh publik, atau lebih khusus lagi tokoh politik seperti calon gubernur, calon presiden, menteri, atau ketua partai.
Kita dapat melacak tentang produk, merek dan orang untuk menentukan apakah mereka dilihat sebagai hal positif atau negatif. Dalam dunia bisnis, hal ini memungkinkan untuk melacak :
a. Persepsi produk baru. b. Persepsi Merek. c. Manajemen reputasi.
Hal ini juga memungkinkan individu untuk mendapatkan sebuah pandangan tentang sesuatu (review) pada skala global [6].
II.4 Text Mining
Text mining merupakan salah satu aplikasi dari data mining. Text mining juga sering disebut sebagai Text Data Mining (TDM) dan Knowledge Discovery in Textual Databases (KDT). Text mining merupakan proses mengesktrak pengetahuan atau informasi yang bersifat menarik dan penting dari dokumen-dokumen teks. Pada intinya proses kerja text mining sama dengan proses kerja data mining pada umumnya, hanya saja data yang di mining merupakan text databases. Data teks akan diproses menjadi data numerik agar dapat dilakukan proses lebih lanjut. Sehingga dalam text mining ada istilah preprocessing data, yaitu proses pendahulu yang diterapkan terhadap data teks yang bertujuan untuk menghasilkan data numerik.
II.4.1 Preprocessing
yang memudahkan untuk kebutuhan pemakai. Proses ini disebut preprocessing dokumen. Setelah dalam bentuk yang lebih terstruktur dengan adanya proses diatas data dapat dijadikan sumber data yang dapat diolah lebih lanjut. Sama halnya preprocessing pada Information Retrieval (IR), tahapannya terdiri dari tokenizing, normalisasi fitur, case folding, stopword removal dan stemming. Namun pada preprocessing analisis sentimen, ada tambahan tahapan seperti convert emoticon dan convert negation.
1. Tokenizing
Tokenizing merupakan sebuah proses yang dilakukan untuk menjadikan sebuah kalimat menjadi lebih bermakna dengan cara memecah kalimat tersebut menjadi kata. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat berisi kata-kata dan tanda pemisah antara kata seperti titik(.), koma(,), spasi dan tanda pemisah lain menjadi kata-kata saja, baik itu berupa kata-kata penting maupun kata-kata tak penting. Secara sederhana proses tokenizing ini terlihat sebagai proses pengambilan kata jika ketemu tanda delimiter namun pada kenyataannya tidak sesederhana itu. Contoh dari tokenizing dapat dilihat pada Gambar II.2.
Input
Output 2. Normalisasi Fitur
Ada beberapa komponen khas yang biasa ada di tweet yakni, username,
URL, dan “RT” (tanda retweet). Karena username, URL, dan “RT” tidak memiliki pengaruh apapun terhadap nilai sentimen, maka ketiga komponen di
Kebakaran ini terjadi akibat adanya kebocoran gas pada salah satu rumah
Kebakaran
atas akan dibuang. Komponen username diidentifikasi dengan kemunculan
karakter ‘@’, sedangkan komponen URL dikenali melalui ekspresi regular
(http). Contoh dari normalisasi fitur dapat dilihat pada Gambar II.3.
3. Case Folding
Pada tahap ini, semua huruf akan diubah menjadi lowercase atau huruf kecil. Contohnya ada pada Gambar II.4.
4. Convert Emoticon
Emoticon (emotion icon) merupakan salah satu cara pengungkapan perasaan secara tekstual. Hal ini tentu akan membantu dalam menentukan sentimen dari suatu kalimat. Setiap emoticon akan dikonversikan ke dalam string yang bersesuaian. Salah satu emoticon style yang sering digunakan saat ini ialah Western Style.
Min @telkomcare @telkomspeedy gabisa connect nih wifi-nya padahal signal banyak. Error mulu hih.
Min gabisa connect nih wifi-nya padahal signal banyak. Error mulu hih.
Min gabisa connect nih wifi-nya padahal signal banyak. Error mulu hih.
min gabisa connect nih wifi-nya padahal signal banyak. error mulu hih.
Gambar II.3 Contoh Normalisasi Fitur
Tabel II.1 Konversi Emoticon kalimat. Convert negation dilakukan jika terdapat kata negasi sebelum kata yang bernilai positif, maka kata tersebut akan diubah nilainya menjadi negatif dan begitupun sebaliknya. Kata yang bersifat negasi adalah “bukan”, “tidak”,
“enggak”, “ga”, “jangan”, “nggak”, “tak”, dan “gak”.
6. Stemming
Stemming merupakan suatu proses yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Algoritma Nazief & Adriani sebagai algoritma stemming untuk teks berbahasa Indonesia yang memiliki kemampuan presentase keakuratan (presisi) lebih baik dari algoritma lainnya. Sebagai contoh, kata menyebutkan, tersebut, disebut dapat dikatakan serupa atau satu kelompok dan dapat diwakili oleh satu kata umum sebut. Contohnya ada pada Gambar II.5.
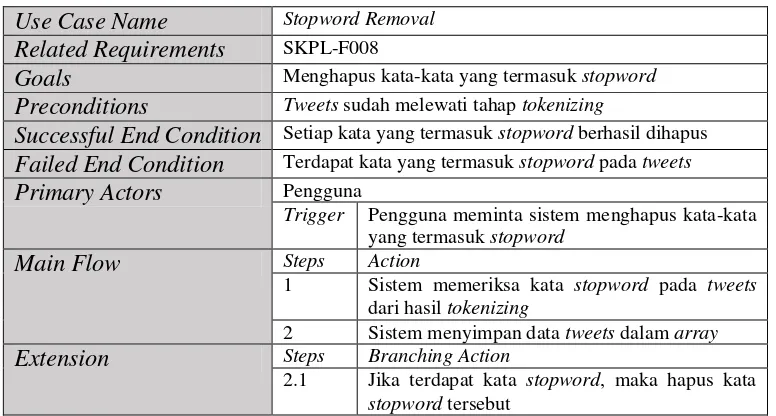
7. Stopword Removal
Stopword didefinisikan sebagai term yang tidak berhubungan (irrelevant) dengan subyek utama dari database meskipun kata tersebut sering kali hadir di dalam dokumen. Jika termasuk di dalam stoplist maka kata-kata tersebut akan di-remove dari deskripsi sehingga kata-kata yang tersisa di dalam deskripsi di anggap sebagai kata-kata penting atau keywords.
II.4.2 Pembobotan (Term Weighting)
Pembobotan dilakukan untuk mendapatkan nilai dari kata/term yang berhasil diekstrak. Metode yang paling umum digunakan untuk melakukan pembobotan terhadap term adalah pembobotan TF-IDF. Metode ini banyak diterapkan dalam pencarian teks (text retrieval) dan pemrosesan teks (text preprocessing).
II.4.2.1 TF-IDF (Term Frequency – Inverse Document Frequency)
Metode TF-IDF ini merupakan metode pembobotan dalam bentuk sebuah metode yang merupakan integrasi antar term frequency (TF), dan inverse document frequency (IDF). Metode TF-IDF dapat dirumuskan sebagai berikut:
tf.idf(d,t) = tf(d,t) * log (|�|
�) (II.1)
Kebakaran ini
terjadi akibat adanya kebocoran gas pada salah satu rumah
Kebakaran kebocoran gas rumah
Dimana tf(d,t) adalah frekuensi kemunculan kata t pada dokumen d. |N| adalah jumlah semua dokumen pada koleksi, dan df adalah jumlah dokumen yang mengandung kata t. Metode pembobotan TF-IDF digunakan karena metode pembobotan ini paling baik dalam task information retrieval. Nilai bobot suatu term menyatakan kepentingan bobot tersebut dalam merepresentasikan dokumen. Pada pembobotan TF-IDF, bobot akan semakin besar jika frekuensi kemunculan term semakin tinggi, tetapi bobot akan berkurang jika term tersebut semakin sering muncul pada dokumen lainnya.
II.5 Klasifikasi
Klasifikasi adalah proses pencarian sekumpulan model atau fungsi yang menggambarkan dan membedakan kelas data. Tujuan dari klasifikasi adalah untuk memprediksi kelas dari suatu obyek yang belum diketahui kelasnya.
Klasifikasi memiliki dua proses yaitu membangun model klasifikasi dari sekumpulan kelas data yang sudah didefinisikan sebelumnya (training data set) dan menggunakan model tersebut untuk klasifikasi tes data serta mengukur akurasi dari model. Klasifikasi dapat dimanfaatkan dalam berbagai aplikasi seperti diagnosa medis, selective marketing, pengajuan kredit perbankan, email dan analisis sentimen. Model klasifikasi dapat disajikan dalam berbagai macam model klasifikasi seperti decision trees, naïve bayes classifier, k-nearest-neighbourhood classifier, neural network dan lain-lain.
Teorema Bayes
Teorema Bayes adalah pendekatan statistik yang fundamental dalam pengenalan pola (pattern recognation). Metode Bayes juga merupakan metode yang baik di dalam machine learning berdasarkan data training, dengan menggunakan probabilitas bersyarat sebagai dasarnya.
Pada teorema Bayes, bila terdapat dua kejadian yang terpisah (misalkan X dan Y ), maka teorema Bayes dirumuskan sebagai berikut:
P(Y | X) = � | �
Keterangan:
X = data sampel dengan kelas (label) yang tidak diketahui
Y = hipotesa bahwa X adalah data dengan kelas C (kelas yang sudah diketahui) P(Y) = peluang dari hipotesa Y
P(X) = peluang data sampel yang diamati
P(X | Y) = peluang data sampel X, bila diasumsikan bahwa hipotesa benar (valid)
Naïve Bayes Classifier
Naïve Bayes Classifier (NBC) merupakan sebuah metode klasifikasi yang berakar pada teorema Bayes. Ciri utama dari Naïve Bayes Classifier ini adalah asumsi yang sangat kuat (naif) akan independensi dari masing-masing variabel. Dengan kata lain, Naïve Bayes Classifier mengasumsikan bahwa keberadaan sebuah atribut (variabel) tidak ada kaitannya dengan keberadaan atribut (variabel) yang lain. Algoritma Naïve Bayes Classifier terdiri dari dua tahap. Tahap pertama adalah pelatihan terhadap himpunan dokumen contoh (data latih) dan tahap kedua adalah proses klasifikasi dokumen yang belum diketahui kategorinya (kelas).
Algoritma ini memanfaatkan teori probabilitas yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya. Karena asumsi atribut tidak saling terkait (conditionally independent), maka :
Vmap = ������ �
� � � P(Vj) П P(wk | Vj) (II.3) Setelah diperoleh perhitungan untuk masing-masing kategori, maka kategori yang dipilih adalah yang memiliki nilai Vmap terbesar. Nilai P(Vj) ditentukan pada saat pelatihan, yang nilainya berdasarkan persamaan:
P(Vj) =
| o s j|
| ℎ|
(II.4)
Keterangan:
|contoh|: banyaknya dokumen dalam contoh yang digunakan saat pelatihan.
P(wk | Vj) : probabilitas kemunculan kata wk pada suatu dokumen dengan kategori Vj.
nk :frekuensi munculnya kata wk dalam dokumen yang berkategori Vj. n : banyaknya seluruh kata dalam dokumen berkategori Vj.
|kosakata| : banyaknya kata dalam contoh pelatihan.
Secara garis besar, tahapan pada algoritma Naïve Bayes Classifier dapat dilihat pada Gambar II.7 berikut:
Pembelajaran
1. Bentuk kosakata pada setiap dokumen data pelatihan.
2. Untuk setiap kategori Vj:
a. Tentukan docs j (himpunan dokumen dalam kategori Vj).
b. Hitung probabilitas pada setiap kategori P(Vj).
2. Tentukan kategori berdasarkan nilai P(Vj) П P(wk| Vj) terbesar. Data Latihan
Model Probabilistik
Kategori Dokumen
Gambar II.7 Tahapan Algoritma Naive Bayes Classifier
Confusion Matrix
Tabel II.2 Confusion Matrix
Predicted Class
Positif Negatif
Actual Class Positif True Positives
True positives adalah jumlah record positif yang diklasifikasikan sebagai positif, falsepositives adalah jumlah record positif yang diklasifikasikan sebagai negatif, false negatives adalah jumlah record negatif yang diklasifikasikan sebagai positif, true negatives adalah jumlah record negatif yang diklasifikasikan sebagai negatif. Setiap kolom dari confusion matrix merupakan contoh di kelas yang telah diprediksi, sedangkan setiap baris mewakili contoh di kelas yang sebenarnya. Setelah didapat true positives, false positives, true negatives dan false negatives, selanjutnya hitung nilai precision dan akurasinya. Precision adalah ukuran terhadap suatu kelas yang telah diprediksi. Berikut persamaan dari precision dan akurasi.
Akurasi = TP+TN
TP+FP+TN+FN (II.6)
Precision = TP
TP+FP (II.7)
Keterangan:
TP = True Positives FP = False Positives TN = True Negatives FN = False Negatives
II.6 Object Oriented Programming (OOP)
1. Object
Object adalah sebuah struktur yang menggabungkan data dan prosedur untuk bekerja bersama-sama.
2. Abstraction
Ketika membangun objects dalam aplikasi OOP, adalah penting untuk menggabungkan konsep abstraction ini. Jika membangun aplikasi shipping, maka harus membangun object produk dengan atribut seperti ukuran dan berat. Warna adalah contoh informasi yang tidak ada hubungannya dan harus dibuang. Tetapi ketika akan membangun order-entry application, warna menjadi penting dan harus termasuk atribut object produk.
3. Enkapsulasi
Sebuah proses dimana tidak ada akses langsung ke data yang diberikan, bahkan hidden. Jika ingin mendapat data, harus berinteraksi dengan object yang bertanggung jawab atas data tersebut.
4. Polymorphisms
Kemampuan dua buah object yang berbeda untuk merespon pesan permintaan yang sama dalam suatu cara yang unik. Contohnya, dapat mengirim pesan print ke object printer yang akan mencetak pada printer, dan juga dapat mengirim pesan yang sama ke object screen yang akan menuliskan pada screen monitor. Dalam OOP, diterapkan tipe polymorphism melalui proses yang disebut overloading. Dapat dilakukan dalam implementasi metode yang berbeda pada sebuah object yang mempunyai nama yang sama.
5. Inheritance
II.7 Unified Modeling Language (UML)
UML adalah bahasa pemodelan untuk sistem atau perangkat lunak berorientasi objek. Pemodelan sesungguhnya digunakan untuk penyederhanaan permasalahan-permasalahan yang kompleks sehingga lebih mudah dipelajari dan dipahami. UML digunakan untuk melakukan analisis dan perancangan sistem/perangkat lunak. UML merupakan bahasa standar untuk merancang dan mendokumentasikan perangkat lunak yang berorientasi objek.
1. Use Case Diagram
Use case diagram digunakan untuk memodelkan bisnis proses berdasarkan perspektif pengguna sistem. Use case diagram terdiri atas diagram untuk use case dan actor. Actor merepresentasikan orang yang akan mengoperasikan atau orang yang berinteraksi dengan sistem aplikasi.
2. Activity Diagram
Activity diagram adalah representasi grafis dari alur kerja tahapan aktifitas. Diagram ini mendukung pilihan tindakan, iterasi dan concurrency. Pada pemodelan UML, activity diagram dapat digunakan untuk menjelaskan bisnis dan alur kerja operasional secara step-by-step dari komponen suatu sistem. Activity diagram menunjukkan keseluruhan dari aliran kontrol.
3. Sequence Diagram
Sequence diagram menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari use case. Interaksi yang terjadi antar class, operasi apa saja yang terlibat, urutan antar operasi, dan informasi yang diperlukan oleh masing-masing operasi
4. Class Diagram
21
III.1 Analisis Sistem
Pada bab ini akan membahas tentang analisis dan perancangan sistem analisis sentimen dengan menggunakan algoritma naïve bayes classifier. Langkah-langkah yang dilakukan dalam analisis sistem ini yaitu:
1. Analisis masalah. 2. Analisis sumber data. 3. Analisis preprocessing.
4. Analisis penerapan algoritma naïve bayes classifier. 5. Analisis pembobotan kata (TF-IDF).
III.1.1 Analisis Masalah
Twitter adalah salah satu microblogging yang sangat popular di tengah masyarakat. Hal ini terlihat dari banyaknya jumlah pengguna Twitter yang mencapai 231,7 juta [5]. Biasanya Twitter digunakan sebagai sarana untuk menyampaikan pendapat. Informasi yang terkandung dalam tweets ini sangat berharga sebagai alat penentu kebijakan. Salah satunya adalah untuk menilai suatu produk yang dikeluarkan oleh perusahaan atau yang sering disebut dengan analisis sentimen.
harus dilakukan preprocessing pada data tweets yang akan digunakan. Hal ini berguna untuk mengatasi model bahasa yang tidak formal yang sering digunakan pada Twitter.
Selain itu, pengklasifikasian sentimen saat ini dilakukan secara manual oleh manusia. Permasalahan ini berdampak pada kualitas dan kecepatan dalam menganalisis sentimen yang sangat banyak. Maka dari itu, penggunaan aplikasi yang dapat melakukan analisis sentimen secara otomatis merupakan salah satu solusi untuk mengatasi masalah ini.
III.1.2 Analisis Sumber Data
Data yang digunakan pada penelitian ini diambil dari kumpulan tweets bahasa Indonesia yang diambil dari official akun Twitter Telkom Speedy. Data tweets ini diperoleh dengan membuat program crawling yang menggunakan Tweetinvi API. Dalam proses crawling,secara otomatis akan mengambil data tweets yang mengandung kata “TelkomSpeedy”, “speedy reguler”, “speedy
instant”, dan “speedy gold”. Data tweets yang terkumpul nantinya akan melewati tahap preprocessing dan selanjutnya akan diklasifikasikan. Dalam sistem analisis sentimen ini, tweets akan diklasifikasikan ke dalam dua kelas (kategori), yaitu kelas sentimen positif dan kelas sentimen negatif. Contoh dari tweets yang termasuk sentimen positif dapat dilihat pada Gambar III.1, sedangkan tweets yang termasuk sentimen negatif dapat dilihat pada Gambar III.2.
Gambar III.2 Contoh Sentimen Negatif
Data yang dibutuhkan dalam penelitian ini terdiri dari dua jenis, yaitu data latih dan data uji. Data latih yang digunakan ini diambil dari kumpulan tweets yang telah dilabeli dengan kelas sentimennya secara manual. Data inilah yang digunakan sebagai data latih untuk membentuk model analisis sentimen. Model ini nantinya akan digunakan untuk mengklasifikasikan tweets pada kelas sentimennya. Pada penelitian ini, metode klasifikasi yang digunakan adalah naïve bayes classifier. Sebagian dari hasil crawling, nantinya akan digunakan sebagai data uji. Data uji ini menggunakan kumpulan tweets yang belum memiliki label.
Setiap orang memiliki ciri khas dalam penulisan tweets. Dari hasil observasi yang dilakukan pada official akun Twitter Telkom Speedy, terdapat beberapa karakteristik dalam penulisan tweets, seperti:
1. Penulisan kata yang disingkat.
Keterbatasan karakter yang dapat ditulis dalam suatu tweets (maksimal 140 karakter) membuat banyak kata dalam tweets disingkat. Contohnya dapat dilihat pada Gambar III.3.
2. Penggunaan titik (.) atau koma (,) pada akhiran tweets.
Ada beberapa orang yang biasa menggunakan dua sampai empat titik (.) atau koma (,) pada akhiran tweets. Contohnya seperti pada Gambar III.4.
Gambar III.4 Contoh Tweets 3. Penggunaan emoticon.
Ada beberapa orang yang menyatakan sentimennya dalam tweets dengan menggunakan emoticon. Contohnya seperti berikut:
Gambar III.5 Contoh Tweets
III.1.3 Analisis Preprocessing
Pemrosesan teks merupakan proses menggali, mengolah, mengatur informasi dengan cara menganalisis hubungannya, aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur. Untuk lebih efektif dalam proses pemrosesan dilakukan langkah transformasi data ke dalam suatu format yang memudahkan untuk kebutuhan pemakai. Preprocessing merupakan salah satu langkah yang penting dalam analisis sentimen. Sama halnya preprocessing pada Information Retrieval (IR), tahapannya terdiri dari tokenizing, normalisasi fitur, case folding, stopword removal dan stemming. Namun pada preprocessing analisis sentimen, ada tambahan tahapan seperti convert emoticon dan convert negation. Tahapan dari preprocessing adalah sebagai berikut:
1. Case Folding
konek @wifi_id lg di rumah. Makasih atas bantuan maintenancenya yang cepat
:)”.
1. Memeriksa ukuran setiap karakter dari awal sampai akhir karakter. 2. Jika ditemukan karakter yang menggunakan huruf kapital (uppercase),
maka huruf tersebut akan diubah menjadi huruf kecil (lowercase). Gambaran tahap case folding dapat dilihat pada Gambar III.6.
Input:
Puas dgn layanan primanya @TelkomSpeedy, akhirnya bisa konek @wifi_id lg di rumah. Makasih atas
bantuan maintenancenya yang cepat :)
Output:
puas dgn layanan primanya @telkomspeedy, akhirnya bisa konek @wifi_id lg di rumah. makasih atas bantuan maintenancenya yang cepat :)
Gambar III.6 Contoh Case Folding 2. Normalisasi Fitur
Ada beberapa komponen khas yang biasa ada di tweet yakni, username, URL (Uniform Resource Locator), dan “RT” (tanda retweet). Karena username,
URL, dan “RT” tidak memiliki pengaruh apapun terhadap nilai sentimen, maka
ketiga komponen di atas akan dibuang. Komponen username diidentifikasi
dengan kemunculan karakter ‘@’. Selain username, karakter ‘@’ biasa juga digunakan untuk pemanggilan suatu tempat seperti @FloatingMarket. Namun nama tempat tersebut tidak memiliki pengaruh pada analisis sentimen sehingga nama tempat pun harus dihapus. Pada komponen URL dikenali melalui ekspresi regular (seperti http, www). Berikut langkah-langkah pada tahap normalisasi fitur:
1. Kata yang digunakan hasil dari case folding.
2. Hasil dari case folding akan diperiksa apakah terdapat username, URL, dan RT.
Output:
puas dgn layanan primanya , akhirnya bisa konek lg di rumah. makasih atas bantuan maintenancenya yang cepat :)
Input:
puas dgn layanan primanya @telkomspeedy, akhirnya bisa konek @wifi_id lg di rumah. makasih atas bantuan maintenancenya yang cepat :)
Gambar III.7 Contoh Normalisasi Fitur
3. Convert Emoticon
Pada tahap ini, kumpulan tweets yang terdapat emoticon (emotion icon) akan dikonversikan ke dalam string yang bersesuaian. Namun, tidak semua akan diimplementasikan, karena tidak semua emoticon sering digunakan oleh pengguna Twitter. Emoticon yang digunakan berdasarkan Western Style, dapat dilihat pada Tabel II.1.
Berikut merupakan langkah-langkah dalam tahap convert emoticon: 1. Kata yang digunakan berasal dari hasil normalisasi fitur.
2. Membandingkan setiap karakter dengan tabel list emoticon pada 3. Jika terdapat emoticon, maka emoticon tersebut akan diubah ke dalam
bentuk string.
Gambaran tahap convert emoticon dapat dilihat pada Gambar III.8.
Output:
puas dgn layanan primanya , akhirnya bisa konek lg di rumah. makasih atas bantuan maintenancenya yang cepat Esenang
Input:
puas dgn layanan primanya , akhirnya bisa konek lg di rumah. makasih atas bantuan maintenancenya yang cepat :)
Gambar III.8 Contoh Convert Emoticon 4. Convert Negation
“bukan”, “tidak”, “enggak”, “ga”, “jangan”, “nggak”, “tak”, dan “gak”.Convert negation dilakukan jika terdapat kata negasi sebelum kata yang bernilai positif, maka kata tersebut akan diubah nilainya menjadi negatif dan begitupun sebaliknya. Langkah-langkah pada tahap convert negation adalah sebagai berikut:
1. Kata yang digunakan adalah hasil dari convert emoticon.
2. Setiap kata akan diperiksa dan dibandingkan dengan kumpulan kata-kata yang bersifat negasi pada database.
3. Jika setelah kata yang bersifat negasi terdapat kata yang termasuk sentimen positif, maka sentimen tersebut akan diubah menjadi negatif. 4. Jika setelah kata yang bersifat negasi terdapat kata yang termasuk sentimen negatif, maka sentimen tersebut akan diubah menjadi positif.
tidak menyesal saya berlangganan internet
dari terutama untuk cs yang
ramah dan cepat tanggap
Gambar III.9 Contoh Tweets yang mengandung kata negasi
Dalam contoh Gambar III.9, terdapat kata “menyesal” yang merupakan sentimen
negatif. Namun, didepan kata “menyesal” terdapat kata yang bersifat negasi
yaitu “tidak”, sehingga sentimennya menjadi positif.
5. Tokenizing
Pada tahap ini akan dilakukan pengecekan tweets dari karakter pertama sampai karakter terakhir. Apabila karakter ke-i bukan tanda pemisah kata seperti titik(.), koma(,), spasi dan tanda pemisah lainnya, maka akan digabungkan dengan karakter selanjutnya. Langkah-langkah pada tahap tokenizing adalah sebagai berikut:
1. Kata yang digunakan adalah hasil dari convert negation.
2. Memotong setiap kata dalam teks berdasarkan pemisah kata seperti titik(.), koma(,), dan spasi.
4. Bagian yang hanya memiliki satu karakter non alfabet dan angka akan dibuang.
Gambaran tahap tokenizing dapat dilihat pada Gambar III.10. Input:
puas dgn layanan primanya , akhirnya bisa konek lg di rumah. ma kasih atas bantuan maintenancenya yang cepat Esenang
Output:
puas dgn layanan primanya akhirnya bisa
konek lg di rumah makasi h atas
bantuan maintenancenya yang cepat Esenang
Gambar III.10 Contoh Tokenizing 6. Stopword Removal
Pada tahap ini, kumpulan tweets yang telah melewati tahap tokenzing akan melalui tahap stopword removal. Setiap kata pada tweets akan diperiksa. Jika terdapat kata sambung, kata depan, kata ganti atau kata yang tidak ada hubungannya dalam analisis sentimen, maka kata tersebut akan dihilangkan. Langkah-langkah pada stopword removal adalah sebagai berikut:
1. Kata hasil tokenizing akan dibandingkan dengan daftar stopword. 2. Dilakukan pengecekan apakah kata sama dengan daftar stopword atau
tidak.
3. Jika kata sama dengan yang ada pada daftar stopword, maka akan dihilangkan.
Contoh dari tahap stopword removal dapat dilihat pada Gambar III.11.
Input:
puas dgn layanan primanya akhirnya bisa
konek lg di rumah makasi h atas
bantuan maintenancenya yang cepat Esenang
Output:
puas layanan primanya konek rumah bantuan cepat Esenang
7. Stemming
Kata-kata yang muncul di dalam tweets sering mempunyai banyak varian morfologik. Oleh karena itu, setiap kata-kata direduksi ke bentuk stemmedword (term) yang cocok. Kata-kata tersebut akan diambil bentuk kata dasarnya dengan cara menghilangkan awalan atau akhiran. Langkah-langkah pada tahap stemming adalah sebagai berikut:
1. Kata yang digunakan adalah dari hasil stopword removal.
2. Setiap kata dalam tweets akan diperiksa dari awal hingga akhir kata. 3. Jika terdapat kata yang mengandung imbuhan, maka imbuhan pada
kata tersebut akan dihilangkan.
Input:
puas layanan primanya konek
rumah bantuan cepat e_senang
Output:
puas layan prima konek
rumah bantu cepat e_senang
Gambar III.12 Contoh Stemming III.1.4 Analisis Penerapan Algoritma Naive Bayes Classifier
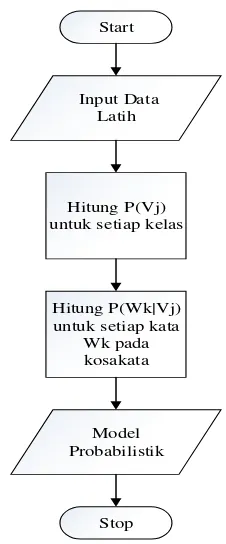
Pada tahap ini, metode yang digunakan dalam pengklasifikasian sentimen adalah naïve bayes classifier (NBC). Metode ini terdiri dari dua proses, yaitu sebagai berikut:
1. Proses Pelatihan Naive Bayes Classifier
Start
Input Data Latih
Hitung P(Vj) untuk setiap kelas
Hitung P(Wk|Vj) untuk setiap kata
Wk pada kosakata
Model Probabilistik
Stop
Gambar III.13 Flowchart Proses Pelatihan Naive Bayes Classifier
Untuk proses pembelajaran naïve bayes classifier, maka sebelumnya harus diperhatikan hal-hal berikut:
a. Kosakata
|kosakata| adalah jumlah kata unik pada semua data latih. Data latih disini berarti kumpulan tweets yang sudah diklasifikasikan. Pada analisis sentimen, kata dibagi menjadi dua kelas (kategori) yaitu: 1. Data 1 (D1) = kelas sentimen positif.
2. Data 2 (D2) = kelas sentimen negatif.
Contoh himpunan data latih terdapat pada Tabel III.1.
Tabel III.1 Contoh Himpunan Data Latih
Data Keyword (kemunculan) Kelas Sentimen
D1 Bagus (2), cepat (3), ramah (1) Positif D2 Kecewa (5), Lambat (2), rugi (3) Negatif
|kosakata| yang dihasilkan dari data latih berjumlah 6 kata.
Tabel III.2 Nilai P(Vj) untuk setiap kelas
Data Keyword (kemunculan) Kelas Sentimen (V) P(Vj)
D1 Bagus (2), cepat (3), ramah (1) Positif = 0.5 D2 Kecewa (5), Lambat (2), rugi (3) Negatif = 0.5
Untuk setiap kata wk pada kelas Vj diterapkan perhitungan berdasarkan persamaan II.5. Sebagai contoh untuk menampilkan perhitungannya, akan diambil satu kata pada masing-masing kelas, yaitu perhitungan terhadap kata
“lambat”.
Tabel III.3 Nilai P(lambat) untuk setiap kelas
Vj Sentimen Positif Sentimen Negatif
nk n nk n
0 6 2 10
P(wk | Vj)
6
Hal yang sama diterapkan pada setiap kata wk sehingga diperoleh nilai P(wk) untuk setiap kelas Vj dan didapatkan model probabilistik seperti pada Tabel III.4.
Tabel III.4 Model Probabilistik
V P(Vj) P(wk | Vj)
bagus cepat ramah kecewa lambat rugi Positif
Negatif
6 6 6
6
6 6 6
2. Proses Klasifikasi Naïve Bayes Classifier
Start
Input Data Uji
Hitung P(Vj)П P(wk| Vj) untuk
setiap kelas
Tentukan kelas dengan nilai P(Vj)П P(wk| Vj)
maksimal
Kategori dokumen
Stop
Gambar III.14 Flowchart Proses Klasifikasi Naive Bayes Classifier Data uji adalah data tweets yang belum diklasifikasikan. Data uji ini adalah hasil dari tahap preprocessing.
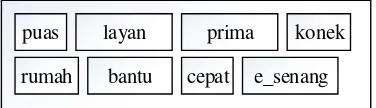
puas layan prima konek
rumah bantu cepat e_senang
Gambar III.10 Hasil Preprocessing Contoh:
Data uji (D4): puas (1), layan (1), prima (1), konek (1), rumah (1), bantu (1), cepat (1), Esenang (1).
Pada tahap klasifikasi, dimulai dengan menghitung nilai Vmap untuk tiap kelas dengan persamaan II.3.
Vmap = Vj{Positif�� ���, "Negatif"}P Vj П P wk | Vj
Vmap = Vj{Positif�� ���, "Negatif"}P Vj P "puas"|Vj P "layan"|Vj P "prima"|Vj
P "konek"|Vj P "rumah"|Vj P "bantu"|Vj P "cepat"|Vj P "Esenang"|Vj
Nilai Vmap untuk Sentimen Positif
Vmap(“Positif) = P(“Positif”) P(“puas”|“Positif”) P(“layan”|“Positif”) P(“prima”|“Positif”) P(“konek”|“Positif”)
P(“rumah”|“Positif”) P(“bantu”|“Positif”) P(“cepat”|“Positif”) P(“Esenang”|“Positif”)
= x x x x x x x x
= 0.000000002
Nilai Vmap untuk Sentimen Negatif
Vmap(“Negatif) = P(“Negatif”) P(“puas”|“Negatif”) P(“layan”|“Negatif”) P(“prima”|“Negatif”) P(“konek”|“Negatif”)
P(“rumah”|“Negatif”) P(“bantu”|“Negatif”) P(“cepat”|“Negatif”) P(“Esenang”|“Negatif”)
= x
6 x 6 x 6 x 6 x 6 x 6 x 6 x 6
= 0.0000000001
Kelas suatu tweets ditentukan berdasarkan nilai Vmap terbesar. Pada perhitungan diatas, didapat bahwa nilai Vmap untuk kelas sentimen positif memiliki nilai tertinggi dibandingkan dengan kelas sentimen negatif sehingga tweets tersebut termasuk kelas sentimen positif. Jika nilai Vmap untuk sentimen positif dan sentimen negatif sama, maka akan dianggap sebagai sentimen negatif karena dengan menganggap sentimen negatif, setidaknya perusahaan akan meninjau kembali kekurangan produknya.
III.1.5 Analisis Pembobotan Kata (TF-IDF)
Nilai bobot suatu kata (term) menyatakan kepentingan bobot tersebut dalam merepresentasikan tweets. Pada pembobotan TF-IDF, bobot akan semakin besar jika frekuensi kemunculan kata semakin tinggi, tetapi bobot akan berkurang jika kata tersebut semakin sering muncul pada tweets lainnya
Contoh: Terdapat 3 tweets (sudah melewati preprocessing) seperti berikut: D1 : puas layan prima Esenang internet bantu cepat Esenang
D2 : internet lambat kecewa Esedih D3 : internet lancar video stabil salut Dari persamaan II.1, diketahui:
Idf = log( �
�� ) (III.5)
N = 3 (jumlah tweets)
df = Banyaknya tweets dimana suatu kata (term) muncul
Tabel III.5 Tabel Pembobotan Kata
Kata tf D1 tf D2 tf D3 df � �
Idf W D1 W D2 W D3
puas 1 0 0 1 = 3 0.48 0.48 0 0
layan 1 0 0 1 = 3 0.48 0.48 0 0
prima 1 0 0 1 = 3 0.48 0.48 0 0
internet 1 1 1 3 = 1 0 0 0 0
bantu 1 0 0 1 = 3 0.48 0.48 0 0
cepat 1 0 0 1 = 3 0.48 0.48 0 0
Esenang 2 0 0 2 = 1.5 0.18 0.36 0 0
lambat 0 1 0 1 = 3 0.48 0 0.48 0
kecewa 0 1 0 1 = 3 0.48 0 0.48 0
Esedih 0 1 0 1 = 3 0.48 0 0.48 0
lancar 0 0 1 1 = 3 0.48 0 0 0.48
video 0 0 1 1 = 3 0.48 0 0 0.48
stabil 0 0 1 1 = 3 0.48 0 0 0.48
Keterangan: merepresentasikan ketiga tweets diatas adalah puas, layan, prima, bantu, cepat, lambat, kecewa, e_sedih, lancar, video, stabil, dan salut.
III.2 Spesifikasi Kebutuhan Perangkat Lunak
Spesifikasi kebutuhan perangkat lunak dilakukan berdasarkan kebutuhan perangkat lunak analisis sentimen berdasarkan hasil observasi. Spesifikasi kebutuhan perangkat lunak akan dibagi kedalam dua bagian yaitu SKPL-F (Spesifikasi Kebutuhan Perangkat Lunak Fungsional) dan SKPL-NF (Spesifikasi Kebutuhan Perangkat Lunak Non Fungsional). Berikut ini adalah tabel spesifikasi kebutuhan perangkat lunak fungsional dan non fungsional pada tabel Tabel III.6 dan Tabel III.7.
Tabel III.6 Spesifikasi Kebutuhan Perangkat Lunak Fungsional
Kode Kebutuhan
SKPL-F001 Perangkat lunak dapat melakukan crawling tweets pada akun Twitter @TelkomSpeedy
SKPL-F002 Perangkat lunak dapat melakukan request tweets pada Tweetinvi API SKPL-F003 Perangkat lunak dapat melakukan case folding pada tweets.
SKPL-F004 Perangkat lunak dapat melakukan normalisasi fitur pada tweets.
SKPL-F005 Perangkat lunak dapat melakukan convert emoticon pada tweets.
SKPL-F006 Perangkat lunak dapat melakukan convert negation pada tweets.
SKPL-F007 Perangkat lunak dapat melakukan tokenizing pada tweets.
SKPL-F008 Perangkat lunak dapat melakukan stopword removal pada tweets.
SKPL-F009 Perangkat lunak dapat melakukan stemming pada tweets.
SKPL-F010 Perangkat lunak dapat melakukan klasifikasi tweets berdasarkan sentimennya.
SKPL-F011 Perangkat lunak dapat menggambarkan persentasi dari hasil klasifikasi
tweets dalam bentuk diagram pie.
Tabel III.7 Spesifikasi Kebutuhan Perangkat Lunak Non Fungsional
Kode Kebutuhan
SKPL-NF001 Pengguna yang menggunakan perangkat lunak ini adalah orang yang memiliki jabatan manager operation.
SKPL-NF002 Terhubung dengan akses internet.
SKPL-NF003 Perangkat keras yang digunakan adalah komputer dengan spesifikasi minimal processor 2.0 GHz, RAM 1 GB, hard disk 40 GB, monitor,
keyboard dan mouse.
SKPL-NF004 Bahasa pemrograman yang digunakan adalah C#.
III.3 Analisis Kebutuhan Non Fungsional
Analisis kebutuhan non fungsional adalah langkah dalam menganalisis sumber daya yang akan digunakan, yang direkomendasikan oleh pembangun perangkat lunak (software developer) kepada pengguna agar perangkat lunak yang dibangun menjadi user friendly dan perangkat keras yang mendukung secara maksimal terhadap kinerja perangkat lunak. Perangkat keras dan perangkat lunak yang digunakan harus sesuai dengan kebutuhan, sehingga sistem yang dibangun akan berjalan dengan baik.
Analisis kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahap, yaitu:
1. Analisis kebutuhan perangkat keras. 2. Analisis kebutuhan perangkat lunak. 3. Analisis kebutuhan perangkat pikir.
III.3.1 Analisis Kebutuhan Perangkat Keras
Perangkat keras adalah seluruh komponen atau unsur peralatan yang digunakan untuk menunjang pembangunan aplikasi. Spesifikasi perangkat keras yang digunakan di PT. Telekomunikasi Indonesia, Tbk adalah sebagai berikut:
6. Keyboard 7. Mouse
Spesifikasi perangkat keras minimum untuk aplikasi yang akan dibangun pada unit personal komputer agar dapat menjalankan aplikasi secara optimal adalah sebagai berikut:
1. Processor 1.5 GHz 2. VGA On-Board 3. Hard disk 40 GB 4. RAM 1 GB 5. Monitor 6. Keyboard 7. Mouse
Berdasarkan analisis spesifikasi perangkat keras yang ada di PT. Telekomunikasi Indonesia, Tbk, spesifikasi perangkat keras yang digunakan sudah memenuhi syarat untuk menerapkan sistem yang akan dibangun.
III.3.2 Analisis Kebutuhan Perangkat Lunak
Sistem operasi yang digunakan saat ini di PT. Telekomunikasi Indonesia, Tbk menggunakan Windows 8, sedangkan perangkat lunak yang dibutuhkan untuk membangun dan menerapkan aplikasi ini adalah sebagai berikut:
1. Sistem operasi Windows 7.
2. XAMPP
3. Visual Studio 2012
III.3.3 Analisis Kebutuhan Perangkat Pikir
Sistem yang akan dibangun ini nantinya akan digunakan oleh manager operation PT. Telekomunikasi Indonesia, Tbk. Adapun karakteristik dari pengguna adalah sebagai berikut:
1. Mampu menggunakan komputer. 2. Mampu mengoperasikan internet.
3. Mampu memahami maksud dari suatu diagram.
Berdasarkan hasil dari analisis pengguna, dapat diambil kesimpulan bahwa pengguna yang ada sudah memenuhi syarat sebagai pengguna sistem ini.
III.4 Analisis Kebutuhan Fungsional
Analisis kebutuhan fungsional menggambarkan proses kegiatan yang akan diterapkan dalam sebuah sistem dan menjelaskan kebutuhan yang diperlukan sistem agar berjalan dengan baik. Kebutuhan fungsional dalam pembangunan aplikasi ini dimodelkan dengan menggunakan UML (Unified Modeling Language). Tahapan pemodelan dalam analisis ini antara lain melakukan identifikasi aktor, pembuatan use case diagram, activity diagram, sequence diagram, dan class diagram.
III.4.1 Identifikasi Aktor
Identifikasi aktor dimaksudkan untuk mengetahui siapa saja aktor yang terlibat di dalam sistem ini. Aktor pada sistem ini adalah pengguna (user) yang yang memiliki jabatan sebagai Manager Operation.
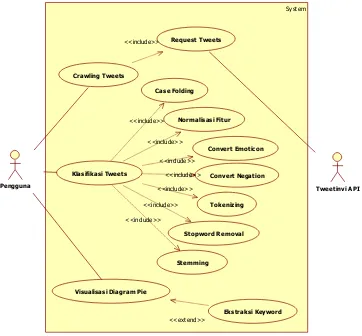
III.4.2 Use Case Diagram
Gambar III.15 Use Case Diagram Analisis Sentimen III.4.2.1 Identifikasi Use Case
Identifikasi use case berfungsi untuk menjelaskan proses yang terdapat pada setiap use case. Hasil dari identifikasi use case dijelaskan pada Tabel III.8.
Tabel III.8 Identifikasi Use Case Analisis Sentimen
No. Use Case Deskripsi
1. Crawling Tweets Proses untuk melakukan pengambilan tweets dari Twitter. 2. Request Tweets Proses untuk meminta tweets pada Tweetinvi API. 3. Case Folding Proses untuk mengubah kata ke dalam huruf kecil
(lowercase).
4. Normalisasi Fitur Proses yang digunakan untuk menghilang username, URL dan RT pada tweets.
5. Convert Emoticon Proses untuk mengganti setiap emoticon menjadi kata. 6. Convert Negation Proses untuk mengubah nilai sentimen jika terdapat kata
negasi
7. Tokenizing Proses untuk memecah tweets menjadi potongan kata-kata.
8. Stopword Removal Proses yang digunakan untuk menghapus setiap kata yang tidak ada kaitannya dengan analisis sentimen.
9. Stemming Proses untuk mereduksi setiap kata pada tweets sehingga mendapatkan bentuk kata dasar.
10. Klasifikasi Tweets Proses yang digunakan untuk mengklasifikasikan tweets
menjadi sentimen positif atau sentimen negatif.
11. Visualisasi Diagram Pie Proses untuk menggambarkan persentasi dari sentimen positif dan sentimen negatif dalam bentuk diagram pie. 12. Ekstraksi Keyword Proses untuk mendapatkan kata kunci (keyword) yang
menjadi topik dari kumpulan sentimen.
III.4.2.2 Skenario Use Case Diagram
Setiap urutan langkah-langkah dalam sistem dideskripsikan dengan skenario use case diagram. Berikut adalah skenario dari masing-masing use case analisis sentimen:
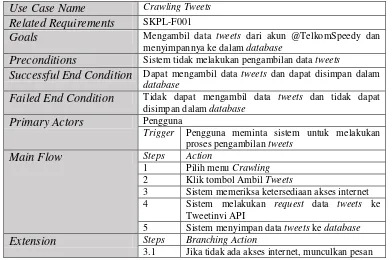
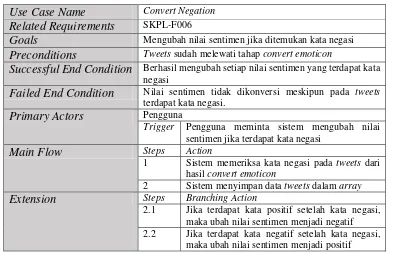
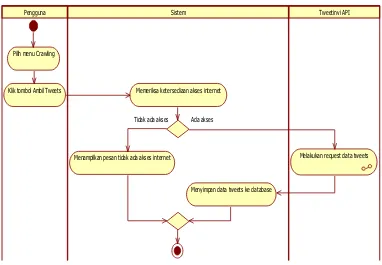
a. Use Case Crawling Tweets
Proses ini dilakukan untuk mengambil data tweets dari official akun Twitter Telkom Speedy (@TelkomSpeedy). Proses crawling secara otomatis akan mengambil data tweetsyang mengandung kata “TelkomSpeedy”, “speedy
reguler”, “speedy instant”, dan “speedy gold” dan akan disimpan dalam database. Skenario untuk use case crawling dapat dilihat pada Tabel III.9.
Tabel III.9 Skenario Use Case Crawling
Use Case Name Crawling Tweets
Related Requirements SKPL-F001
Goals Mengambil data tweets dari akun @TelkomSpeedy dan menyimpannya ke dalam database
Preconditions Sistem tidak melakukan pengambilan data tweets
Successful End Condition Dapat mengambil data tweets dan dapat disimpan dalam
database
Failed End Condition Tidak dapat mengambil data tweets dan tidak dapat disimpan dalam database
Primary Actors Pengguna
Trigger Pengguna meminta sistem untuk melakukan proses pengambilan tweets
Main Flow Steps Action
1 Pilih menu Crawling
2 Klik tombol Ambil Tweets
3 Sistem memeriksa ketersediaan akses internet 4 Sistem melakukan request data tweets ke
Tweetinvi API
5 Sistem menyimpan data tweets ke database
Extension Steps Branching Action
b. Use Case Request Tweets
Proses ini digunakan untuk meminta tweets pada Tweetinvi API. Skenario untuk use case request tweets dapat dilihat pada Tabel III.10.
Tabel III.10 Skenario Use Case Request Tweets
Use Case Name Requst Tweets
Related Requirements SKPL-F002
Goals Melakukan request data tweets ke Tweetinvi API
Preconditions Sistem terhubung dengan jaringan internet
Successful End Condition Tweetinvi API mengirimkan data tweets pada sistem
Failed End Condition Tweetinvi API tidak mengirimkan data tweets pada sistem
Primary Actors Tweetinvi API
Trigger Request tweets pada Tweetinvi API
Main Flow Steps Action
1 Sistem melakukan request data tweets ke Tweetinvi API
2 Tweetinvi API mengirimkan data tweets ke sistem
c. Use Case Case Folding
Proses ini digunakan untuk mengubah kata ke dalam huruf kecil (lowercase). Skenario use case ekstraksi keyword dapat dilihat pada Tabel III.11.
Tabel III.11 Skenario Use Case Case Folding
Use Case Name Case Folding
Related Requirements SKPL-F003
Goals Mengubah kata ke dalam huruf kecil (lowercase)
Preconditions Sistem sudah melakukan proses crawling
Successful End Condition Berhasil mengubah kata menjadi lowercase
Failed End Condition Masih terdapat huruf capital pada tweets
Primary Actors Pengguna
Trigger Pengguna meminta sistem mengubah setiap kata menjadi lowercase
Main Flow Steps Action
1 Pilih menu Klasifikasi 2 Klik tombol Proses Tweets
3 Sistem memeriksa huruf kapital pada tweets
4 Sistem menyimpan data tweets dalam array
Extension Steps Branching Action