Dokumen diterima pada Hari Bulan, Tahun Dipublikasikan pada Hari Bulan, Tahun
Jurnal Politeknik Caltex Riau
http://jurnal.pcr.ac.id
Analisis Sentimen Terhadap ISP Pada Twitter Dengan Klasifikasi Naive Bayes
Abraham Koroh1, Kartina Diah2 dan Meilany Dewi3
Program Studi Sistem Informasi Politeknik Caltex Riau, Pekanbaru 28265,
1[email protected], 2[email protected], 3[email protected]
Abstrak
Twitter merupakan salah satu microblog dimana pengguna bisa melakukan publikasi opini dalam bentuk status Twitter. Salah satu informasi yang bisa diperoleh adalah ISP. Status Twitter disimpan dalam jumlah yang besar dan memiliki informasi bernilai di dalamnya. Untuk memperoleh informasi tersebut diperlukan sistem yang mampu mengambil informasi otomatis yaitu sentimen analysis dengan metode klasifikasi Naive Bayes. Sistem mengklasifikasikan opini ke dalam kategori sentimen positif dan negatif kemudian dari hasil klasifikasi diketahui ISP dinilai positif atau negatif oleh pengguna Twitter. Akurasi pengklasifkasian data diuji dengan confusion matrix. Hasil analisis sentimen menunjukkan bahwa Telkomsel dinilai positif sedangkan Indosat dan XL dinilai negatif. Akurasi klasifikasi data status opini ISP pada Twitter adalah 91% dan akurasi pengujian menggunakan data latih adalah 86%.
Kata kunci : Naive Bayes, confusion matrix, ISP, analisis sentimen, Twitter.
Abstract
Twitter is a microblog where users can express their opinion in form of Tweet. Internet Service Provider’s opinions are one of Tweets that we can find. Huge amount of Tweet stored in database and by processing those Tweets we can find informations and patterns on it. Sistem classified opinion into positive or negative sentiment and the result of classification show the review of ISP. Classification accuration checked by using confusion matrix. Telkomsel get the highest positive review followed by Indosat and XL. XL and Indosat get the least positive review respectively. System accurately classified data at 91% and 86% while using training sets.
Keywords: Naive bayes, confusion matrix, ISP, sentiment analysis, Twitter
2 Abraham Koroh 1. Pendahuluan
Dalam tiga tahun terakhir, pengguna internet semakin bertambah tidak terkecuali Indonesia. Hal ini terlihat dari catatan statistik oleh perusahaan komputasi awan Akamai, yaitu tahun 2012 pengguna internet Indonesia mencapai 63 juta. Di tahun 2014 menurut situs keminfo, pengguna internet Indonesia mencapai 85 juta pengguna. 95 persen pengguna internet mengakses situs jejaring sosial atau microblog. Dalam menggunakan internet, dibutuhkan penyedia jasa layanan internet atau ISP. Contoh perusahaan ISP yang ada di Indonesia adalah Telkomsel, XL dan Indosat.
Microblog merupakan gabungan antara pesan singkat dan blogging. Pengguna microblog bisa mempublikasikan pesan tentang apa yang mereka lakukan melalui microblog[1].
Pengguna internet tertarik mengakses microblogging karena microblog bebas diisi dengan pesan apapun dan dapat diakses dengan berbagai platform (multiplatform)[2]. Contoh situs microblog adalah Facebook, Twitter dan Plurk.
Pada proyek akhir ini akan dikembangkan aplikasi yang dapat menganalisis sentimen status Twitter yang berkaitan dengan ISP di Indonesia, yaitu “Telkomsel, XL, Indosat”. Teknik yang digunakan adalah teknik klasifikasi. Klasifikasi adalah bentuk analisis data yang dapat digunakan untuk menggambarkan kelas data atau untuk memprediksi tren data masa depan[3].
Dengan teknik Naive Bayes data yang merupakan opini akan diklasifikasi ke dalam klasifikasi positif dan negatif. Dari data yang sudah diklasifikasi dicek jumlah data positif dan negatif untuk dianalisa sentimen yang ada pada data.
2. Tinjauan Pustaka 2.1 Text Mining
Text mining (penambangan teks) adalah penambangan yang dilakukan oleh komputer untuk mendapatkan sesuatu yang baru, sesuatu yang tidak diketahui sebelumnya atau menemukan kembali informasi yang tersirat secara implisit, yang berasal dari informasi yang diekstrak secara otomatis dari sumber-sumber data teks yang berbeda-beda[4].
Text mining berusaha untuk menemukan pola baru dari sekumpulan text yang berjumlah besar. Adapun proses pokok pada text mining adalah text preprocessing, transformasi teks atau feature generation, feature selection, pattern discovery [3].
2.1 Frequent Item-Set
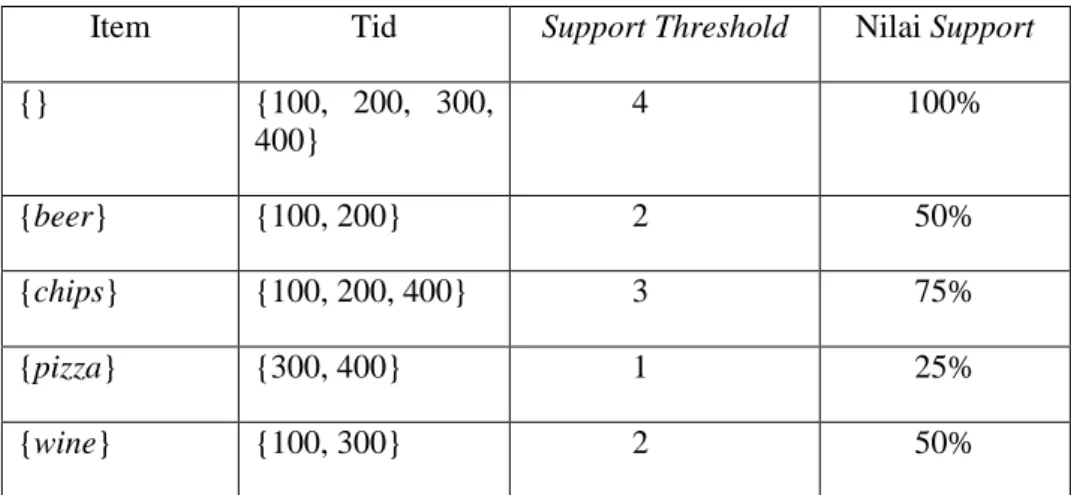
Frequent Item-Set dapat digambarkan sebagai proses pencarian set item yang sering muncul (frequent) dengan nilai support yang diinputkan ke dalam sistem. Untuk menentukan data frequent adalah dengan melihat jumlah kemunculan data. Nilai support ditentukan melalui nilai perbandingan antara jumlah kemunculan data dan jumlah data keseluruhan[3].
Tid Item-Set
100 {beer, chips, wine}
200 {beer, chips}
300 {pizza, wine}
400 {chips, pizza}
Tabel 1 Tabel Item-Set
Item Tid Support Threshold Nilai Support
{} {100, 200, 300,
400}
4 100%
{beer} {100, 200} 2 50%
{chips} {100, 200, 400} 3 75%
{pizza} {300, 400} 1 25%
{wine} {100, 300} 2 50%
Tabel 2 Tabel Nilai Support
Nilai support yang digunakan untuk klasifikasi adalah 0.032 dengan keyword yang dihasilkan adalah 10 keyword. 10 keyword tersebut adalah selamat, sukses, baik, lambat, jaya, aktif, tidak stabil, cepat, super dan suka.
2.2 Klasifikasi Naive Bayes
Teknik klasifikasi Naïve Bayes merupakan teknik klasifikasi dengan metode probabilistic dengan menerapkan aturan Bayes[5]. Pada aplikasi ini, metode Naive Bayes yang digunakan adalah Naive Bayes model Bernoulli, dimana model Bernoulli mengamsumsikan bahwa peluang klasifikasi diukur berdasarkan banyaknya klasifikasi terhadap data. Langkah – langkah metode klasifikasi :
1. Tentukan Peluang Tiap Klasifikasi
2. Hitung peluang masing – masing kata yang telah dilakukan fitur seleksi.
3. Lakukan perhitungan masing – masing klasifikasi dengan rumus :
Keterangan :
Tct = banyaknya kemunculan kata t dalam dokumen training pada kelas c V = Kamus kata (vocabulary)
Untuk menghindari angka 0, maka nilai Tct akan ditambah 1 sehingga tidak ada peluang yang bernilai 0. Proses ini disebut dengan Laplace Smoothing[5]. Karena aplikasi menggunakan Naive Bayes model Bernoulli, maka penyebut ditambah dengan banyak kategori, yaitu 2 (positif dan negatif). Jadi rumus yang digunakan adalah :
4 Abraham Koroh 2.3 Pemrograman PHP dan MySQL
PHP (Hypertext Preprocessor) adalah bahasa komputer yang dibuat untuk pengembangan web dinamis. Pada umumnya PHP digunakan di server namun juga dapat berdiri sendiri sebagai aplikasi graphical[6].
Sedangkan MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL (bahasa Inggris: database management system) atau DBMS yang multi-user dan multithread[6].. DBMS (Database Management System) merupakan suatu sistem perangkat lunak yang memungkinkan user (pengguna) untuk mengakses, mengontrol, memelihara, dan membuat database secara efektif dan efisien. Dengan DBMS, pengguna akan lebih efektif dalam memanipulasi dan mengontrol data.
Dokumen diterima pada Hari Bulan, Tahun Dipublikasikan pada Hari Bulan, Tahun
3. Pembahasan dan Perancangan 3.1 Pembahasan Sistem
Sistem yang dibangun menggunakan API yang disediakan Twitter untuk mengambil data. Aplikasi yang dibangun menggunakan link untuk mencari data yang diminta oleh admin.
Data status akan dipisahkan ke dalam kelompok data opini dan non opini. Selain memisahkan data opini, data juga di-preprocessing secara otomatis oleh sistem. Setelah memisahkan data opini, maka data opini dapat dilatih oleh admin. Admin kemudian dapat menguji data yang belum memiliki kategori. Halaman tamu tidak menggunakan API Twitter, namun halaman tamu menggunakan komentar yang diinputkan oleh tamu. Data tersebut dikategorikan dan data latih yang digunakan adalah data latih yang diinputkan admin.
Gambar 1 Halaman Pengambilan Data
Gambar 2 Halaman Hasil Kategori
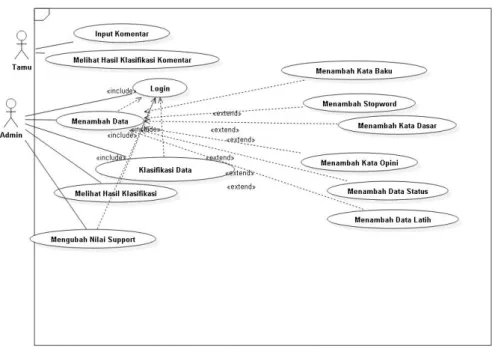
6 Abraham Koroh 3.2 Use Case Diagram
Gambar 3 Use Case Diagram
4. Pengujian dan Analisa 4.1 Pengujian Sistem
Setelah sistem berhasil dibangun, dibuatlah pengujian untuk memastikan apakah sistem sudah berjalan dengan baik. Berikut ini adalah hasil pengujian menggunakan 196 data uji yang belum dikategori dan 100 data uji menggunakan data latih:
Positif Negatif
Positif 137 15
Negatif 1 43
Tabel 3 Confusion Matrix Data Uji 1
Positif Negatif
Positif 13 5
Negatif 9 73
Tabel 4 Confusion Matrix Data Uji 2
4.2 Analisa
Dari penelitian yang dilakukan, terlihat bahwa data latih mempengaruhi hasil dari klasifikasi Naive Bayes. Pengaruh data latih pada penelitian adalah data latih yang tepat menghasilkan keyword yang tepat. Keyword - keyword yang diperoleh digunakan pada penghitungan peluang klasifikasi Naive Bayes. Pengujian manual menggunakan 196 data uji dan menghasilkan 180 data yang benar dan 16 data yang salah diklasifikasi oleh sistem dengan akurasi klasifikasi sebesar 91%. Sementara itu pengujian otomatis yang menggunakan 100 data latih menghasilkan 86 data benar dan 14 data yang salah.
Selain pemilihan data latih yang tepat, kemunculan keyword berpengaruh pada hasil klasifikasi. Jika seluruh keyword penentu klasifikasi data uji tidak muncul, maka yang dilihat adalah besarnya perkalian kemunculan keyword dan peluang positif atau negatif. Jika hasil perkalian menunjukkan peluang positif lebih besar, maka peluang data adalah positif dan berlaku tetap untuk data lainnya jika keyword penentu klasifikasi tidak muncul.
5. Kesimpulan dan Saran 5.1 Kesimpulan
Kesimpulan yang diperoleh dari penelitian adalah :
1. Algoritma Naive Bayes dapat digunakan untuk mengklasifikasi status opini pada Twitter dengan akurasi sebesar 91% pada data uji manual dan pada data uji menggunakan data latih sebesar 86%.
2. Akurasi klasifikasi Naive Bayes dipengaruhi oleh pemilihan data latih dan kemunculan keyword pada data uji.
3. Data dengan hashtag #yangmerahyangterbaek memiliki data positif terbanyak sementara data negatif terbanyak adalah data dengan hashtag #xl pada tanggal 15 Juni 2016 hingga 28 Juni 2016.
5.2 Saran
Adapun saran yang dapat diberikan untuk pengembangan aplikasi ini adalah sebagai berikut:
1. Menambah label data untuk mengukur tingkat positif dan tingkat negatif status Twitter.
2. Mengambil data Twitter tanpa data retweet.
3. Menganalisa sentimen menggunakan data Twitter berbahasa Inggris.
6. Daftar Pustaka
[1] Passant, Alexandre., Hastrup, Tuukka., Bojars, Uldis., dan Breslin, John. 2008.
Microblogging: A Semantic and Distributed Approach.
[2] Agarwal, A., Xie, B., Vovsha, I., Rambow, O., dan Passonneau, R. 2011. Sentiment Analysis of Twitter Data.
[3] Han, Jiawei dan Kamber, Micheline. 2006. Data Mining: Concepts and Techniques. San Francisco: Elsevier Inc
8 Abraham Koroh [4] Feldman, Ronen dan Sanger, James. 2007. The Text Mining Handbook Advanced
Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.
[5] Manning, C.D., Raghavan, Prabakhar., Schütze, Hinrich. 2008. An Introduction to Information Retrieval. Cambridge (UK): Cambridge University Press.
[6] Solichin, Achmad. (2009). Pemograman Web dengan PHP dan MySQL. Jakarta : Universitas Budi Luhur.