Analisis Sentimen Pengguna Twitter Pada Akun Resmi Samsung Indonesia Dengan Menggunakan Naive Bayes
Teks penuh
Gambar
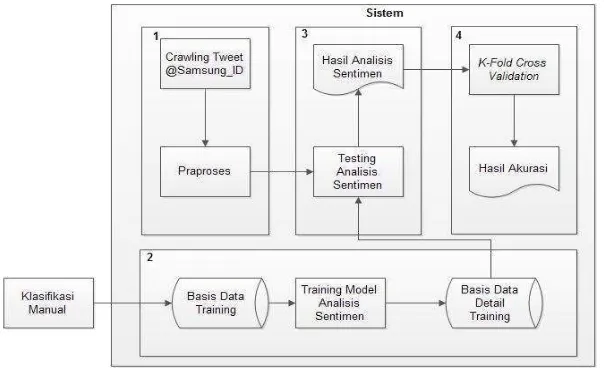


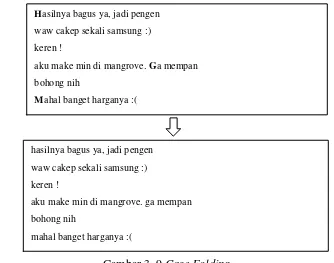
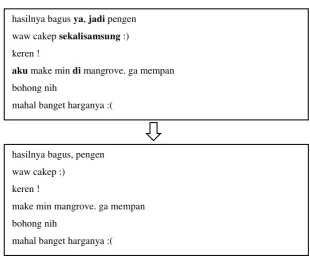
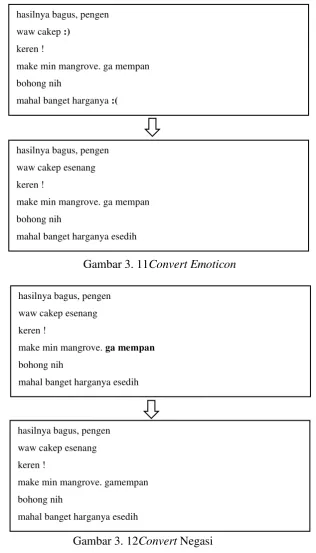


Dokumen terkait
Berdasarkan permasalahan yang ada, maka maksud dari penelitian yang dilakukan adalah menerapkan metode Naive Bayes untuk mengklasifikasikan kalimat sentimen ke
Metode yang digunakan dalam penelitian ini yaitu metode Naive bayes dengan Tools RapidMiner untuk pengklasifikasian sentimen opini positif atau negatif terhadap
Adapun tujuan dalam melakukan penelitian ini yaitu menghasilkan sistem yang dapat mengklasifikasikan sentimen positif dan sentimen negatif pada survei kepuasan
Pada penelitian ini dibuat sistem dengan tujuan untuk menghasilkan informasi sentimen mengenai opini masyarakat terhadap Toko Online Lazada dan Tokopedia yang
Data training dengan prosentase kebenaran 100% digunakan pada sistem analisis sentimen sebagai data training dan data testing berupa data tweet dari responden pada
Hasil dari analisis sentimen dengan menggunakan Naive Bayes Classifier untuk mengklasifikasikan data tweet film “Parasite” dan “Parasitemovie” didapatkan dua sentimen yaitu sentimen
Berdasarkan hasil penelitian yang dilakukan pada sentimen analisis MBKM, penelitian ini menghasilkan akurasi sebesar 86%, presisi sebesar 87% dan recall sebesar 80% dengan data testing
Ada beberapa metode yang digunakan untuk melakukan analisis sentiment, Salah satunya dengan metode Naïve Bayes Classifier Berdasarkan Hasil pengujian algoritma Naive Classifier yang
