MELLING VPS. Pencocokan Pola Sfring pa& Berkas Teks Temampatkan (String Pattern Matching on Compressed Text). Dib'ib'ig oleh JULIO ADISANTOSO dan UTAH WIJAYANTI.
Pencocokan pola stringmerupakan bagian tqxnting dari pemrosesan teks. Pemampatan data dibuat un& menghernat media payimpanan
dan
biaya dalam komunikasi data. Telah banyak dilakukan penelitian terhadap berbagai metode pemampatan dan metode pencwdan pola agar operasi pencocokan pola langsung pada berkas hasil pemampatan dapat dilakukan.Algoritme pencocokan pola stringpadabdcis tidak dimampatkan dapat digunakan pada berkas hasil pemampatan derigan menambah proses awal terhadap kueri yang akan dicari. Proses awal ini kmpa pengambilan kode kueri dari head berkas hasil pemampatan. Kode kueri dapat berupa infmasi bit atau byte.
Pada penelitian ini dilakukan pencccokan pola pada berkas teks tidak dimampatkan dan pada berkas hasil pemampatan. Algoritme pencocokan pola string yang digunakan adalah Knuth Morris Pratt (KhP)
sedangkan algoritme pemampatannya adalah Huffban bif dan &£ban byte oriented.
Hasil percobaan yang dipexoleh adalah waktu pencocokan pola pa& berkas hasil pemampatan Huffban byte leb'i cepat dibanding dmgan waktu pencodcan pada berkas yang tidak dimampatkan dengan persenmi keakuratan hasil pencocokan unttk semua kueri percobaan sebesar 1, sedangkan waktu
pencocokan pola pada berkas hasil panampatan Huthan bit lebih lama &banding dengan waktu pencocokan pola pada berkas tidak dimampatkan dan pmmtasi keakuratan antara 0
sam@
1.G/ro/.i
2002
003-
PENCOCOKAN
POLA
STRING
PADA
BERKAS
TEKS
TERMAMPATKAN
JURUSAN
ILMU
KOMPUTER
FAKULTAS MATEMATIKA DAN IIMX
PENGETAEUAN
ALAbfINSTlTUT
PERTANIAN BOGOR
BOGOR
G/ro/.i
2002
003-
PENCOCOKAN
POLA
STRING
PADA
BERKAS
TEKS
TERMAMPATKAN
JURUSAN
ILMU
KOMPUTER
FAKULTAS MATEMATIKA DAN IIMX
PENGETAEUAN
ALAbfINSTlTUT
PERTANIAN BOGOR
BOGOR
MELLING VPS. Pencocokan Pola Sfring pa& Berkas Teks Temampatkan (String Pattern Matching on Compressed Text). Dib'ib'ig oleh JULIO ADISANTOSO dan UTAH WIJAYANTI.
Pencocokan pola stringmerupakan bagian tqxnting dari pemrosesan teks. Pemampatan data dibuat un& menghernat media payimpanan
dan
biaya dalam komunikasi data. Telah banyak dilakukan penelitian terhadap berbagai metode pemampatan dan metode pencwdan pola agar operasi pencocokan pola langsung pada berkas hasil pemampatan dapat dilakukan.Algoritme pencocokan pola stringpadabdcis tidak dimampatkan dapat digunakan pada berkas hasil pemampatan derigan menambah proses awal terhadap kueri yang akan dicari. Proses awal ini kmpa pengambilan kode kueri dari head berkas hasil pemampatan. Kode kueri dapat berupa infmasi bit atau byte.
Pada penelitian ini dilakukan pencccokan pola pada berkas teks tidak dimampatkan dan pada berkas hasil pemampatan. Algoritme pencocokan pola string yang digunakan adalah Knuth Morris Pratt (KhP)
sedangkan algoritme pemampatannya adalah Huffban bif dan &£ban byte oriented.
Hasil percobaan yang dipexoleh adalah waktu pencocokan pola pa& berkas hasil pemampatan Huffban byte leb'i cepat dibanding dmgan waktu pencodcan pada berkas yang tidak dimampatkan dengan persenmi keakuratan hasil pencocokan unttk semua kueri percobaan sebesar 1, sedangkan waktu
pencocokan pola pada berkas hasil panampatan Huthan bit lebih lama &banding dengan waktu pencocokan pola pada berkas tidak dimampatkan dan pmmtasi keakuratan antara 0
sam@
1.PENCOCOKAN POLA
STRISG
PADA BERKAS TEKS TERMAMPATKAN
MELLING VP SITUMORANG
Skripsi
sebagai salah satu s p r a t untuk memperoleh gelar Sarjana Komputer
pada
Program Studi Ilmu Komputer
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Pe~icocoka~i Pola String pada Berkas Teks Termampatkan Natiia : Melliny VP S i t ~ ~ n i o r a ~ i y
Penulis lahir di Palipi - Pulau Samosir pa& tanggal 11 Februari 1979 sebagai anak pertama dari enam bersaudara, anak dari pasangan Mangasi Situmorang dan Eli%& Sitanggang.
- , Tahun 1997 penulis lulus dari SMUN I Pangururan dan pada tahun yang sama diterima di Jurusan
.
Ilmu Komputa, Fakultas Matematika dan Ilmu Pengetahuan Alam IPB melalui jalur USMI.
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Kuasa atas segala berkat dan karunia-
Nya sehimgga karya ilmiah ini dapat diselesaikan. Penelitian ini d i i a i pada a w l bulan Oktober 2001 den@ tema "pencccokan pola string pada berkas teks termampatkan".
Terima kasii penulis ucapkan kepada berbagai pihak yang telah mendukung dan membantu penyelesaian karya ilmiah ini, yang m a m a kepada Ayah, Ibu, Oppmg, semua adik-adik dan segenap keluarga atas doa, dorongan, motivasi dan semangat. Bapak Ir. Julio Adisantoso, M.Komp. dan Ibu Utari wjayanti, S.Komp. selaku pembiibimg slaipsi, Mr. Takuya Kida dari Universitas Kyushu
-
Jepang atas tulisan dan penjelasan Pattern Matching Machine serta kepada Bapak Ir. M Syamsun, MSc. atas bi~~~bingandan
penjelasan automaton. Disamping itu penulis juga magucapkan terimakasii kepada rekan-rekan ilkomen'34 (Nyoman, Adi, Apit, Ridho, Ines), Gibbon, Dedidan
Ivan atas bahasanseminamya, rekan-rekan alumni SMUN I
Pangururan
(Poi, Manris, Evi, Marisi, Lasiama, Hendra), rekan-rekan C-2 (Iwan, Luhut, Mario) dan khususnya kepada D a i s Barus atas smua dukungan, pagertian, motivasi dan kasii sayanpya.Penulis menyadari bahwd karya ilmiah ini masih memiliki banyak kekurangan, tetapi meskipun dernikian penulis berharap semoga tulisan ini dapat bermanfaat.
Bogor, Mei 2002
...
DAFTAR TABEL
DAFTAR LAMPIRAN
...
PENDAHULUANLatar Belakang
...
Tujuan
...
TINJAUAN PUSTAKAPemampatan Data
...
Kode Huffman Bit Oriented...
Kode Huffman Byte Oriented...
Algoritme Pencocokan Pola Shing...
Algoritme Brute Force
...
Algoritme Knuth Morris Pratt...
Deterministic Finite State Acceptor
...
KMP Automaton...
METODE PENELITIAN
Bahan Percobaan
...
Pembuatan Program...
...
Percobaan13ASIL DAN PEMBAHASAN
Pemampatan Berkas
...
Pencocokan Pola String ... Keakuratan Pencccokan Pola String...
Wakhl Pencccokan Pola String...
PENUTUP...
Kesimpdan
...
Saran
...
DAFTAR PUSTAKA
1
.
Nilai ASCII. biner dan frekuensi kemunculan karakter teks T...
22
.
~ c d 6 bit karakter teks T berdasarh oho on ~u5inan bit...
33
.
F'rm transisi state kueri P...
44
.
Ukuran dan rasio pemampatan...
55
.
Rataan wakhl pencocokan pola kueri jenis vokal(10 ms)...
76
.
Rataan waktu penmkan pola kueri jenis konsonan (10ms)
...
7DAFIAR GAMBAR
Halaman
1
.
Pohon HuBnan bit teks T...
2...
...
2
.
Pohon W a n byte tmtuk contoh kata wrId .:: 2 3.
Automaton kueri P ... 4 4.
Pohon Huftinan bit dengan KMP automaton...
65
.
Alut p e n m k a n pola berkas hasil p a m p a t a n HUkkan bit dan byte...
6...
6
.
Gra& rataan waktu pencocokan pola kueri jenis vokal 7 7.
Graiik rataan waktu pencmakan pola kueri jenis konsonan...
7...
1
.
Daflar kueri...
...
2.
Jumlah asli dan basil pencocokan pola kueri jenis vokal...
3
.
Jumlah asli dan h a i l pencocokan pola kueri jenis konsonan4
.
Jumlah asli dan hasil pencocokan pola kueri jenis campuran...
...
5
.
TS
untuk jenis karakter vokal (10 ms)6
.
TS untuk jenis karakter konsonan (10 ms)...
7
.
TS untuk jenis karakter campuran (10 ms)...
8
.
TbifS untuk jenis karakter vokal (10 ms)...
9
.
TbifS untuk jenis karakter konsonan (10 ms)...
10.
TbitS untuk jenis karakter campuran (10 ms)...
...
11
.
TbyteS untuk jenis karakter vokal (10 ms)12
.
TbyteS untuk jenis karakter koasonan (10 ms)...
...
Latar Belakaug
Pencocokan pola string (string pattern matching) merupakan salah satu bagian terpenting dari pemrosesan teks (Shibata et al., 1996). Operasi yang dilakukan adalah menyesuaikan istilah dalam kueri dengan istilah yang terdapat &lam suatu dokumen.
Pemampatan dokumen pada dasarnya dibuat untuk menghemat media penyimpanan dan juga biaya komunikasi (Manber, 1997). Pemampatan suatu dokumen seperti berkas teks dapat dilakukan dengan berbagai algoribne seperti H f f i a n , Lempel Ziv Welch, Byte Pair E n d m g dan lainnya.
Perkembangan teknologi media penyimpanan memberikan kemudahan bagi pemakai komputer untuk mendapatkan ukuran media penyimpanan yang besar dengan kualitas yang bagus serta harga yang relatif menurun dari
tahun ke tahun. Tetapi dokumen yang disimpan
&lam media penyimpanan akan selalu bxtambah.
Umumnya perusaham-perusaham selalu membuclhrp dokumen
secara
berkala clan &lam format yang telah dimampatkan. Jiia pa& suatu saat dibutuhkan informasi yang terdapat &lam dokumen yang telah diiampatkan, hiasanya ddcumen tersebut terlebii dahulu didecompress sebelum dioperasikan. Pendekatan ini tidak masalah bagi komputer yang memiliki sumber daya yang tinggi, tetapi bermasalah pa& komputer yang sumber dayanya sangat terbatas (Klein & Shapira, 2001).Salah satu cara untuk mengatasinya adalah dengan melakukan operasi langsung terhadap dokumen yang sudah diiampatkan, &lam ha1 ini operasi pencocokan pola string. Berbagai algoritme pencocokan pola string yaug digunakan pada dokumen yang tidak dimampatkan dapat digunakan pada dokumen yang sudah diiampatkan dengan menambah proses a w l terhadap kueri yang diberikan. Dengan mengurangi ukuran suatu dokumen maka akan mengurangi waktu yang dibutuhkan untuk pencocokan pola (Manber, 1997).
Tujuan
Penelitian ini bertujuan untuk menelaah pencocokan pola string pada berkas teks yang sudah dimampatkan.
TINJAUAN PUSTAKA
Pemampatan Data
Pemampatan dokumen merupakan representasi dokumen dengan menggunakan kode-kode yang lebii efisien sehingga ukuran berkas yang diiasilkan lebih kecil dibanding aslinya. Keuntungan yang diperoleh dari proses ini adalah penghematan media penyimpanan dan biaya dalam komunikasi data (Chrochemore &
Lecroq, 1996).
Pemampatan data terdiii dari dua kelompok utama, yaitu pemampatan yang lossless dan lossy. Pemampatan data yang lossless dapat mengembalikan data ke dalam bentuk aslinya, xdangkan pemampatan data yang lossy tidak &pat meogembalikan data ke dalam bentuk semula karena adanya data yang hilang pa& saat encoding. Chrochemore & Lwoq (1996) menyebutkan bahwd rasio rata-rata berkas hasil pemampatan berbagai algoritme adalah antara 30% sampai dengan 50% dari ukuran berkas asal. Ada dua model utama dalam pemampatan data lossless, yaitu model statistik dan model kamus. Pada model statistik, pemampatan dilakukan dengan menghitung fiekuensi kemunculan simbol dalam berkas, lalu menggantikannya dengan simbol yang lebii sederhana. Pada model kamus, terdapat tabel yang berisi kumpulan string serta simbol yang merepresentasikannya.
Di dalam American Standard Code for Information Interchange (ASCII), masing-masing karakter memiliki panjang 8 bit (1 byte). Dengan nilai ini maka ada sebanyak 2* atau 256 jenis karakter yang berbeda.
Kode Huffman
Bit
OrientedMetode ini termasuk ke dalam model statistik karena dasar pengkodeannya adalah frekuensi kemunculan karakter pada berkas. Karakter yang memiliki frekuensi paling tinggi akan memiliki panjang kode paling kecil dan begitu juga sebaliknya.
fiekuensi dari karakter node anak yang bersesuaian.
Algoritme H f f i a n bit adalah :
1. Urutkan simbol-simbol berdasarkan fiekuensi kemunculan.
.
2. Buat pohon Huflinan berdasarkan hasil 13. Lakukan penyandian karakter sesuai
dengan pohon Hu£han bit yang sudah terbentuk ( I :
kiri
, 0 : kanan ).Misalkan teks yang
akan
dimampatkan adalah T = ABRACADABRA. Jika menggunakan pengkodean sistem ASCII, teks Takan
memilii panjang bit sebesar1q
x 8 = 88 bit. Karakter teks T dalam ASCII dan biner serta fiekuensi kemnnculan masing-masing karakter dicantumkan pada Tabel 1 dan pohon Hn5inan bjtnya seperti terlihat pada Gamhar 1.Tabel 1. Niiai ASCII, biner dan fiekuensi kernnnculan karakter teks T.
Gambar 1. Pohon Hutlman bit teks T
Badasarkan pohon H f f i a n bit pada Gambar 1, diperoleh kode masing-masing karakter teks T
sqerti terlihat pada Tabel 2. Encode teks T adalah T' = OlllllOOlOlOlOOOllll1OO dan
I
T
1
= 23.T i
hasil ini dibandingkan dengan nilai bit sebelum diencode maka proses encodingini menghemat 65 bit.
Tabel 2. Kode bit karakter teks T berdasarkan pohon H f f i a n bit
Kode Huffman Byte Oriented
Metode ini termasuk ke dalam model statistik karena dasar pengkodeannya adalah firebemi kata dalam ddcumen. Pohon Huf3nan
pada metode
ini
berderajat 128 dan setiap edgemengind&sikan 1 byte, berbeda dengan HufEnan bit yang hanya memilii derajat pohon 2 dan setiap edge mengin-kan 1 bit (De
Moura et al., 1998a). Algoritmenya hampir sama dengan HufEnan bit tetapi karakter diganti dengan kata Kata didefenisikan sebagai
rangkaian karakter ydng dipisahkan oleh tan& baca atau spasi.
Nilai rasio pemampatan yang diperoleh dengan metcde ini tidak terlalu jauh berbeda dengan nilai yang diperoleh dengan metcde
Huf6nan bit. Dengan proses byte, waktn yang
diburuhkao untuk decompress dan pencocokan pola lebih kecil dibandingkan dengan proses bit
(De Moura et al., 1998h). Untnk maghasilkan kale yang unik pada berkas hasil pemampatan maka setiap byte awal kode ditambah dengan 128 pada saat p r m encoding. Gambar 2.
menunjukkan @on Hufiinan bfle untuk contoh kata worlddengan kode 29 121 99.
Gambar 2. Pohon Huflinan byte untuk kata world
Algoritme Pencocokan PoIa W n g
[image:14.582.68.291.70.755.2] [image:14.582.297.496.118.182.2]Kueri dan teks tersusun dari rangkaian alfabet (finite symbols).
Kueri dinotasikan dengan P = P [0
...
M-I] dan lPl= M, teks dinotasikan dengan T = T [0...
N-1] dan IT1 = N. Proses pencocokan biasanya dimulai dari awal kueri dan teks, kemudian membandingkan kesesuaian karakter kueri dan teks sampai pada akhir teks. Proses ini disehut scan and shifl mechanism.Algoritme Brute Force
Algoritme ini merupakan algoritme
pencocdtan pola sning yang sederhana. AlgorLpne ini tidak melakukan suatu proses awal bai terhadap kueri yang akan dicari dan jnga pada teks. Prinsipnya adalah membandiigkan karakter per karakter dari teks dan kueri. Jiia terdapat p g a n karakter yang tidak sama pada posisi tgtentu maka kueri akan digeser satu kali ke kanan teks dan proses pembandingan dilakukan mulai dari karakter awal kueri dengan posisi karakter teks yang baru
int BruteForce(char *T,char *P)( int match = 0 ;
for (int i=O ; i<N-M ; I++) 1 int j = 0;
while (j<M & & T[i+jl == P[jl) j++; if (i>=M) match++;
1 retu;n match ;
Contoh :
T=GCATCGCAGAGAGTATACAGTACG
P = GCAGAGAG
N= IT1 = 24
,
M=IPI = 8Proses pencocokan :
GCATCGCAGAGAGTATACAGTACG
--
- - f
GCAGAGAG
Tiga karakter pertama dari kueri dan teks sesuai tetapi pada karakter ke-4 tidak, maka kueri digeser ke kanan sebesar 1. Bentuk barunya adalah :
GCATCGCAGAGAGTATACAGTACG
f
GCAGAGAG
Ketidaksesuaian terjadi pada karakter pertama sehingga kueri digeser lagi ke kanan sebesar 1. Demikian dilakukan selama i <N-M.
Algoritme Knuth Morris Pratt
Algwitme ini ditemukan oleh Knuth, Moms dan F'ratt pada tahun 1976 (Abel, 2001). Algoritme ini dibuat untuk mengatasi masalah ketidakefisienan yang ditemukan pada algoritme Brute Force. Proses pencocokan pada algoritme Brute Force tidak menyimpan i n f m a s i penyesuaian yang diperoleh sehimgga satu karakter mungkii dibandiigkan heberapa kali yang seharusnya tidak perlu.
Priisip algwitme Knuth Morris Pratt
m)
adalah menganalisa kueri yang akan diproses dan menyimpan informasi hasil proses tersebut ke &lam suatu tabel yang biasa diwhut tabel m t . Tahel ini digunakan sehagai p a t h untuk menenluhn sejauh mana pergesaan kueri jika ditemukan pasangan karakter kueridan
teks yang tidak sama. Analisa ini dilakukan dengan membandiigkan kueri tersehut dengan diiinya sendin'.Proses
ini disebutpreprocessingKMF'.
Algoritme preprocessing Knuth Morris Pratt :
void P r e m P (char *P) I
int i
-
0 ; int j-
nextL0l-
-1 ;while (i<M)
while (j > -1 and P[il != P[jl) j = nextcjl
i++ ; j++ ;
if (P[i]==P[jl) nextcil = next[jl; else nextcil = j ; 11
Setelah diperoleh tahel next maka langkah selanjutnya adalah membandiigkan kesesuaian karakter yang dimulai dari kiii kueri dan teks. Jiia pasangan karakter kueri dan teks sesuai maka i dan j bertambah, jika tidak maka kueri akan digeser ke kanan sebesar i-nexf[i] kemudian memhandimgkan T[i] dengan P[i] yang baru. Jumlah hasil pencocokan pola adalah semua potongan teks yang sama dengan kueri.
int i=j-mtch-0 ;
while (i < N) I
while (j >-1 and P[jl != T[il) j = next [jl ;
j++ ; i++ ;
if ( j >= M)
( m a t c h ; j = next(j1))
Contoh :
T=GCATCGCAGAGAGTATACAGTACG
Pembuatan Program Pemampatan Berkas
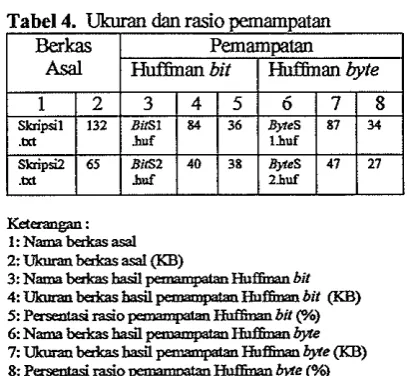
Program aplikasi pemampatan dan Proses pemampatan berkas bahan percobaan pencccokan p l a string dibangm dengan m e n g h a s i i berkas baru yang ukurannya lebii menggunakan perangkat lunak Turbo C++ dan kecil dari aslinya. Ukuran dan rasio basii perangkat keras berupa processor Intel Pentium pmampatan berkas bahan pacobaan dapat
200 MMx, memori 32
ME?
dan kapasitas dilihatpadaTabe1 4.harddisk sebesar 7.5 GB.
ini adalah :
Pemampatanberkas
Percotaan ini dilakukan untuk memampatkan berkas
bahan
pacobaan.Pemamptan dilakukan dengan aplikasi pmampatan Hutfiman bit dan byte yang telah dibuat
Rasio berkas hasid panampatan dihitung untuk mengetahui berapa bgar
kapasitas media penyimpanan yang &pat dihanat oleh kedua a p l i i i PanamPam
Tabel 4. Ukuran dan rasio pemampatan
Pencocokan Pola String
Pada percobaan ini dilakukan penyesuaian kueri terhadap k k a s
asal
danberkashasiipemamm
P m t a s i keakuratan basii pencocokan pola string dihitung dengan membandingkan jumlah kueri hasil pencccokan dengan jumlah kueri asli. Pada percobaan
ini
-ti juga waktu pencocokan pola pa&take
asli berkas h i 1 pemampatan H&an bit dan pada berkas basii p a m p a t a n Huffinan byte. Hal ini dilakukan untuk melihat bagahma waktu penc0w)kan pola pada berkas hasil p a m p a t a n algoritme H&an bit dan byte.Percobaan
Percobaan yang dilakukan pada peneiitian
HASIL DAN PEMBAHASAN
Pencocokan Pola String
Pencocokan pola d a p t langsung d i l m pada berkas yang sudah dimamptkan dengan menggunakan berbagai algoritme pencocokan pola string. Midkan
E(T)
sebagai encwringdari
berkas teks T, &T) sebagai decoding dari E(T) dan E(P) sebagai encoding kueri P. Proses pencocokan pola pada berkas yang sudah d i i p a t k a n adalah mencari E(P) di dalam E(T), bukan mencari P di dalam ~(E(T)) dan E(P) sendhi harm diencode sama seperti EQ.
Proses pencccokan pola pada k k a s yang dimampatkan adalah dengan membandingkan kesesuaian masing-masing bit atau byte. Kcde kueri diambil dari pustaka berkas basii pemampatan yang berada pada bagian head berkas. Head berkas hasil pemampatan berisi
Berkas
Asal
informasi masing-masing
i$r&d
atau kata Penelitian ini mavpakan ujicoba dari dengan kdenya,penelitian yang telah dilakukan oleh Shibata et Pencocokan p l a pada berkas hasil al., (1996) dan De Moura et al., (1998a). pemampatan ~ u f f r n ~ bit rnemerlukan proses
dari penelitian ini menunjukkan ~ a h m s i & ~ s a s i agar r n a s a s i kesalahan
p e n c ~ o k a n pola sMng langs~ng dilakukan pendeteksian bit. proses ini dengan pada berkas yang sudah dimampatkan. menggabungkan pohon HufEnan bit dari berkas
Pemampatan HufEnanbit
I
H&inanbyte [image:17.577.294.498.162.350.2]kueri yang akan dicari seperti terlihat pada Gamhar 4.
Pencocokan pola pada herkas hasil pemampatan Hnffian byte tidak memerlukan pohon Huffman byte tetapi menambah nilai 128 ke a w l byte kode kueri yang diperoleh. Hal ini dilakukan agar basil yang diperoleh pada pencocdtan adalah valid. Contoh pencocokan pada h e r b yang diiampatkan dengan H u f i a n byte adalah :
Kata Kode real 85 32 w r l d 29 121 99
ghosr 32 29 121
Jika pada berkas asli terdapat potongan kalimat berikut :
...
real w r l d..
.
maka kode yang akan terbentuk adalah 85 32 29 121 99. 3 i a kueri yang akan dicari adalah P = ghost diiana kode P adalah 32 29 121, dari susunan kode potongan k a l i a t di atas memungkiian ditemukannya kueri P ymg tidak valid. Unhlk mengatasinya maka byte patama dari kode kueri ditambah dengan 128. Sehimgga kode kueri P yang akan dicari adalah 160 29 121. Dengan demikian akan diperoleh nilai pen& yang valid.Gambar 4. Pohon Huffman bit dengan KMP
automaton
Diagram alur proses pencocokan pola string pada herkas yang telah dimampatkan dengan Huffman bit dan Huffman byte yang terhentuk seperti terlihat pada Gambar 5.
baca bnkas yang dirnamptkan
[image:18.585.297.498.79.336.2] [image:18.585.301.494.603.684.2]buat KMP nutomoton
Gambar 5. Alur proses pencodcan pols pa& herkas hasil pemampatan Huffian bit dan byte
Keakuratan Pencocoksn Pola String
Keakuratan yang diperoleh dari hasil percobaan terhadap semua contoh kueri jenis vokal dan konsonan adalah valid diiana jumlah yang ditemukan sama dengan jumlah aslinya. Untuk kueri jenis campuran, ketidakvalidan diperoleh pada hasil pencocokan pola pada h k a s hasil pemampatan Huffman bit sedangkan pada berkas hasil pemampatan Huffman byte adalah valid. Detil hasil penwokan karakter jenis vokal, konsonan dan campuran dapat dilihat
pada Lampiran 2 sampai dengan 4.
Contoh pendeteksian yang tidak akurat pada berkas hasil pemampatan Huffinan bit. Misalkan dari pohon H u h a n diperoleh kode karakter sehagai herikut : A:ll
,
B:101, C:100, D:01, E:OO. Kueri P = CD, maka P'=10001. StateKMP
automaton kueriP'
:State g(0) d l ) f oufuut 0
-
1 root pohon Huanan1 2 1
2 3
-
13 4 1
4 5 1 5 (CD)
Bagian pohon Hu£linan bit State ~ ( 0 ) ~ ( 1 )
Misalkan teks T = ACDAEDCCD maka T' =
1110001110001100100. Pada teks T terdapat 2 kueri CD tetapi pada T' terdapat 3 kcde kueri P'.
J i i tanpa s M s a s i maka transisi state untuk
T' adalah : 1-1-1-2-345(CD) 1-1-2-345(final state tetapi fdse) 1-2-3-1-2-345(CD)
J i
dengan shkxnisasi maka prcrses transisi sialenya adalah :1-1-1 -2-345(CD) 1-0-94-9-0 1-2-3-0-9-0- 9-0 (CD tidak ditemukan, false).
Waktu Pencocokan Pola M n g
MisaUran TS
sebagai waktu yang dibutuhkaa untuk penmcokan pola pada berkas yang Mum dimampatkan, TbitS adalah waktu penoocokan @a pada berkas hasid paampatan H W a n bit clan TbyteS adalah waktu pencocdtan pola pada berkas hasil panampatanHutsoan byte. Detil nilai rataan waktu
pencocdian pola string kedua berkas
bahan
p e r d m n dapat d i l i i t pada Tabel 5 sampai dengan 7.
Tabel 5. Rataan waktu pencocdtan pola kueri
TbitS 30.72 31.28 30.4 30.9
Tabel 6. Rataan waktu pencocokan pola kueri jenis konsonan (10 mS)
Dari hasil percobaan diperoleh bahwa TbyteS < TbitS. Nilai ini disebabkan oleh proses byte yang memungkinkan pembandingan lebih sedikit karena kale kueri umumnya lebih sedikit dibanding dengan karakter kueri asliiya, ditmbah juga dengan proses pergeseran kcde byte yang efektif Sedangkan pada proses bit, jumlah kode kueri umumnya lebih panjang dari karakter kueri asli sehingga lebii banyak jumlah yang
barus
dibandingkan, ditambah juga dengan pergeseran pada bit yang tidak efisien. Grafik rataan waktu penmcokan pola kedua k k a spercobaan seperti terliiat pada Gambar 6 sampai
8.
Detil
waktu pen& pola string semua kueri percotaan &pat diliiat pada Lampiran 5 sampai 13.4 5 6 7 8
P nnjangkueri t T S--Tbii --t-TbVteS
[image:19.577.72.506.74.703.2]Tabel 7. Rataan waktu pencocokan pola kueri jenis campuran (10 mS)
Gambar 6. Grafik rataan waktupenc~mkan pola kueri jenis vokal
PanjangKar TS TbitS TbyleS
4
Pan.ing kucri t T S --m-TLGi +TbyteS
Gambar 7. Grafik rataan waktn penwokan pola kueri jenis konsonan
7
4.93 31.3
0.54
5
20i
10i::L
0 4 5 P anjmg 6 kueri 7 88 5.5 32 0.6 4 5.39 31.41 0.73 7 4.98 31.5 0.93 6 5.31 31.3 2.04 Panjang Kar TS TbitS TbyteS
Gambar 8. Grafik rataan waktn pencocokan pola kueri jenis campuran
PENUTUP DAlTAR PUSTAKA Kesimpulan
Rasio pemampatan metode Huffman bit
secara mum lebii besar dibandingkan hasil metode Huffman byte.
Persentasi keakuratan yang diperoleh dari pencocdtan pola pada berkas hasil pemampatan Huffman bit adalah antara 0 sampai 1. Nilai ini disebabkan adanya kesalahan pendeteksian bit.
Sedangkan pencodan pola pa& berkas hasil pemampatan Huffman byte diperoleh persentasi keakuratan sebesar 1.
Dari hasil percobaan diperoleh
TbyfeS < TbitS. Nilai ini disebabkan karena kode kueri pada berkas hasil pemampatan Huffman byte rata-rata lebii kecil dibandiig dengan karakter kueri asli dan proses pergesaran pada kcde byte yang efisien. Sedangkan kode kueri pa& berkas hasil pemampatan Hufhan bit
rata-rata lebih panjang dibandiig dengan karakter kueri asli, ditambah dengan proses pergeseran pada kode bit yang tidak efisien.
Tidak ditemukan pola antara mktu pencocokan pola string dengan panjang kueri karena kinerja pencocdcan pola sendiri tergantung pada pola kueri dan teks.
Pada berkas I, TbyteS &pat mempercepat waktu pencoookan s e k 2-25 kali TS sedangkan pada berkas I1 diperoleh percepatan sebesar 1 - 14 kali TS.
Saran
Perlu dicari algoritme pencocokan' pola
string yang tepat digunakan pada berkas pemampatan HufEnan bit sehiigga h a i l pencocokannya valid.
Pencocokan pola string pada penelitian ini dapat dikembangkan menjadi temu kembali dengan menambah proses awai pada algoritme pemampatan seperti pengelompokan kata-kata yang bersamaan arti, bunyi atau aturan temu kembali lainnya serta menghilangkan sifat key sensitive.
Abel, U. 2001. Shing Matching. Proseminar "Algorithmen". hof. Brandenburg.
Chochemore, M. & T. Lecroq. 1996. Pattern Marching And Tsrt Compression Algorithm.
ACM Comput. Swveys
De Moura, ES Navarm, G. Ziviani, N. & R B. Yates. 1996. Compressed Pattern Matching
-
Approximate Compressed Patern Matching-
Direct Compressed Pattern Marching. Depto.De
Ciencia da Computecao, Univ. Federal de M i a s Gerais. Brasil.,1998a. Direct Pattern Matching on Compressed Text.
Tech.
Report03-98, Dept. of Computer Science, Univ. Federal de Minas Gerais, Brazil.
,1998b.
Fart
Searching on Compressed Text Allowing Errors.In Proc. of the ACM Sigir'98.
Klein, ST. & D. Saphim, 2001. Pattern Matching in H m a n Encoded T a t . Data Compression Conference 2001.
Manber, U d i 1997. A Text Compression Scheme that Allow Fast Searching Directly in The Compressed File. ACM Trans. Information Systems, 15(2):124-136, 1997.
Shibata, Y. Kida, T. Fukamachi, S. Takeda, M. Shinohara, A. & T. Shinohara. 1996.
Spedding Up Pattern Matching by Text Compression. Department of Informatics Kyushu University, Fukuoka. Regular Paper.Vol.37 No. 6
Sedgewick, R 1988. Algorithms. Addison Wesley. Bonn.
Treamblay, J.P. & G. Sorenson. 1985. The
Theow and Practice of Compiler Writing.
13
14
Lampiran 7. TS untuk jenis karakter campuran (1Oms)
16
17
18
20
13
14
Lampiran 7. TS untuk jenis karakter campuran (1Oms)
16
17
18
20
Latar Belakaug
Pencocokan pola string (string pattern matching) merupakan salah satu bagian terpenting dari pemrosesan teks (Shibata et al., 1996). Operasi yang dilakukan adalah menyesuaikan istilah dalam kueri dengan istilah yang terdapat &lam suatu dokumen.
Pemampatan dokumen pada dasarnya dibuat untuk menghemat media penyimpanan dan juga biaya komunikasi (Manber, 1997). Pemampatan suatu dokumen seperti berkas teks dapat dilakukan dengan berbagai algoribne seperti H f f i a n , Lempel Ziv Welch, Byte Pair E n d m g dan lainnya.
Perkembangan teknologi media penyimpanan memberikan kemudahan bagi pemakai komputer untuk mendapatkan ukuran media penyimpanan yang besar dengan kualitas yang bagus serta harga yang relatif menurun dari
tahun ke tahun. Tetapi dokumen yang disimpan
&lam media penyimpanan akan selalu bxtambah.
Umumnya perusaham-perusaham selalu membuclhrp dokumen
secara
berkala clan &lam format yang telah dimampatkan. Jiia pa& suatu saat dibutuhkan informasi yang terdapat &lam dokumen yang telah diiampatkan, hiasanya ddcumen tersebut terlebii dahulu didecompress sebelum dioperasikan. Pendekatan ini tidak masalah bagi komputer yang memiliki sumber daya yang tinggi, tetapi bermasalah pa& komputer yang sumber dayanya sangat terbatas (Klein & Shapira, 2001).Salah satu cara untuk mengatasinya adalah dengan melakukan operasi langsung terhadap dokumen yang sudah diiampatkan, &lam ha1 ini operasi pencocokan pola string. Berbagai algoritme pencocokan pola string yaug digunakan pada dokumen yang tidak dimampatkan dapat digunakan pada dokumen yang sudah diiampatkan dengan menambah proses a w l terhadap kueri yang diberikan. Dengan mengurangi ukuran suatu dokumen maka akan mengurangi waktu yang dibutuhkan untuk pencocokan pola (Manber, 1997).
Tujuan
Penelitian ini bertujuan untuk menelaah pencocokan pola string pada berkas teks yang sudah dimampatkan.
TINJAUAN PUSTAKA
Pemampatan Data
Pemampatan dokumen merupakan representasi dokumen dengan menggunakan kode-kode yang lebii efisien sehingga ukuran berkas yang diiasilkan lebih kecil dibanding aslinya. Keuntungan yang diperoleh dari proses ini adalah penghematan media penyimpanan dan biaya dalam komunikasi data (Chrochemore &
Lecroq, 1996).
Pemampatan data terdiii dari dua kelompok utama, yaitu pemampatan yang lossless dan lossy. Pemampatan data yang lossless dapat mengembalikan data ke dalam bentuk aslinya, xdangkan pemampatan data yang lossy tidak &pat meogembalikan data ke dalam bentuk semula karena adanya data yang hilang pa& saat encoding. Chrochemore & Lwoq (1996) menyebutkan bahwd rasio rata-rata berkas hasil pemampatan berbagai algoritme adalah antara 30% sampai dengan 50% dari ukuran berkas asal. Ada dua model utama dalam pemampatan data lossless, yaitu model statistik dan model kamus. Pada model statistik, pemampatan dilakukan dengan menghitung fiekuensi kemunculan simbol dalam berkas, lalu menggantikannya dengan simbol yang lebii sederhana. Pada model kamus, terdapat tabel yang berisi kumpulan string serta simbol yang merepresentasikannya.
Di dalam American Standard Code for Information Interchange (ASCII), masing-masing karakter memiliki panjang 8 bit (1 byte). Dengan nilai ini maka ada sebanyak 2* atau 256 jenis karakter yang berbeda.
Kode Huffman
Bit
OrientedMetode ini termasuk ke dalam model statistik karena dasar pengkodeannya adalah frekuensi kemunculan karakter pada berkas. Karakter yang memiliki frekuensi paling tinggi akan memiliki panjang kode paling kecil dan begitu juga sebaliknya.
Latar Belakaug
Pencocokan pola string (string pattern matching) merupakan salah satu bagian terpenting dari pemrosesan teks (Shibata et al., 1996). Operasi yang dilakukan adalah menyesuaikan istilah dalam kueri dengan istilah yang terdapat &lam suatu dokumen.
Pemampatan dokumen pada dasarnya dibuat untuk menghemat media penyimpanan dan juga biaya komunikasi (Manber, 1997). Pemampatan suatu dokumen seperti berkas teks dapat dilakukan dengan berbagai algoribne seperti H f f i a n , Lempel Ziv Welch, Byte Pair E n d m g dan lainnya.
Perkembangan teknologi media penyimpanan memberikan kemudahan bagi pemakai komputer untuk mendapatkan ukuran media penyimpanan yang besar dengan kualitas yang bagus serta harga yang relatif menurun dari
tahun ke tahun. Tetapi dokumen yang disimpan
&lam media penyimpanan akan selalu bxtambah.
Umumnya perusaham-perusaham selalu membuclhrp dokumen
secara
berkala clan &lam format yang telah dimampatkan. Jiia pa& suatu saat dibutuhkan informasi yang terdapat &lam dokumen yang telah diiampatkan, hiasanya ddcumen tersebut terlebii dahulu didecompress sebelum dioperasikan. Pendekatan ini tidak masalah bagi komputer yang memiliki sumber daya yang tinggi, tetapi bermasalah pa& komputer yang sumber dayanya sangat terbatas (Klein & Shapira, 2001).Salah satu cara untuk mengatasinya adalah dengan melakukan operasi langsung terhadap dokumen yang sudah diiampatkan, &lam ha1 ini operasi pencocokan pola string. Berbagai algoritme pencocokan pola string yaug digunakan pada dokumen yang tidak dimampatkan dapat digunakan pada dokumen yang sudah diiampatkan dengan menambah proses a w l terhadap kueri yang diberikan. Dengan mengurangi ukuran suatu dokumen maka akan mengurangi waktu yang dibutuhkan untuk pencocokan pola (Manber, 1997).
Tujuan
Penelitian ini bertujuan untuk menelaah pencocokan pola string pada berkas teks yang sudah dimampatkan.
TINJAUAN PUSTAKA
Pemampatan Data
Pemampatan dokumen merupakan representasi dokumen dengan menggunakan kode-kode yang lebii efisien sehingga ukuran berkas yang diiasilkan lebih kecil dibanding aslinya. Keuntungan yang diperoleh dari proses ini adalah penghematan media penyimpanan dan biaya dalam komunikasi data (Chrochemore &
Lecroq, 1996).
Pemampatan data terdiii dari dua kelompok utama, yaitu pemampatan yang lossless dan lossy. Pemampatan data yang lossless dapat mengembalikan data ke dalam bentuk aslinya, xdangkan pemampatan data yang lossy tidak &pat meogembalikan data ke dalam bentuk semula karena adanya data yang hilang pa& saat encoding. Chrochemore & Lwoq (1996) menyebutkan bahwd rasio rata-rata berkas hasil pemampatan berbagai algoritme adalah antara 30% sampai dengan 50% dari ukuran berkas asal. Ada dua model utama dalam pemampatan data lossless, yaitu model statistik dan model kamus. Pada model statistik, pemampatan dilakukan dengan menghitung fiekuensi kemunculan simbol dalam berkas, lalu menggantikannya dengan simbol yang lebii sederhana. Pada model kamus, terdapat tabel yang berisi kumpulan string serta simbol yang merepresentasikannya.
Di dalam American Standard Code for Information Interchange (ASCII), masing-masing karakter memiliki panjang 8 bit (1 byte). Dengan nilai ini maka ada sebanyak 2* atau 256 jenis karakter yang berbeda.
Kode Huffman
Bit
OrientedMetode ini termasuk ke dalam model statistik karena dasar pengkodeannya adalah frekuensi kemunculan karakter pada berkas. Karakter yang memiliki frekuensi paling tinggi akan memiliki panjang kode paling kecil dan begitu juga sebaliknya.
fiekuensi dari karakter node anak yang bersesuaian.
Algoritme H f f i a n bit adalah :
1. Urutkan simbol-simbol berdasarkan fiekuensi kemunculan.
.
2. Buat pohon Huflinan berdasarkan hasil 13. Lakukan penyandian karakter sesuai
dengan pohon Hu£han bit yang sudah terbentuk ( I :
kiri
, 0 : kanan ).Misalkan teks yang
akan
dimampatkan adalah T = ABRACADABRA. Jika menggunakan pengkodean sistem ASCII, teks Takan
memilii panjang bit sebesar1q
x 8 = 88 bit. Karakter teks T dalam ASCII dan biner serta fiekuensi kemnnculan masing-masing karakter dicantumkan pada Tabel 1 dan pohon Hn5inan bjtnya seperti terlihat pada Gamhar 1.Tabel 1. Niiai ASCII, biner dan fiekuensi kernnnculan karakter teks T.
Gambar 1. Pohon Hutlman bit teks T
Badasarkan pohon H f f i a n bit pada Gambar 1, diperoleh kode masing-masing karakter teks T
sqerti terlihat pada Tabel 2. Encode teks T adalah T' = OlllllOOlOlOlOOOllll1OO dan
I
T
1
= 23.T i
hasil ini dibandingkan dengan nilai bit sebelum diencode maka proses encodingini menghemat 65 bit.
Tabel 2. Kode bit karakter teks T berdasarkan pohon H f f i a n bit
Kode Huffman Byte Oriented
Metode ini termasuk ke dalam model statistik karena dasar pengkodeannya adalah firebemi kata dalam ddcumen. Pohon Huf3nan
pada metode
ini
berderajat 128 dan setiap edgemengind&sikan 1 byte, berbeda dengan HufEnan bit yang hanya memilii derajat pohon 2 dan setiap edge mengin-kan 1 bit (De
Moura et al., 1998a). Algoritmenya hampir sama dengan HufEnan bit tetapi karakter diganti dengan kata Kata didefenisikan sebagai
rangkaian karakter ydng dipisahkan oleh tan& baca atau spasi.
Nilai rasio pemampatan yang diperoleh dengan metcde ini tidak terlalu jauh berbeda dengan nilai yang diperoleh dengan metcde
Huf6nan bit. Dengan proses byte, waktn yang
diburuhkao untuk decompress dan pencocokan pola lebih kecil dibandingkan dengan proses bit
(De Moura et al., 1998h). Untnk maghasilkan kale yang unik pada berkas hasil pemampatan maka setiap byte awal kode ditambah dengan 128 pada saat p r m encoding. Gambar 2.
menunjukkan @on Hufiinan bfle untuk contoh kata worlddengan kode 29 121 99.
Gambar 2. Pohon Huflinan byte untuk kata world
Algoritme Pencocokan PoIa W n g
[image:49.582.68.291.70.755.2] [image:49.582.297.496.118.182.2]Kueri dan teks tersusun dari rangkaian alfabet (finite symbols).
Kueri dinotasikan dengan P = P [0
...
M-I] dan lPl= M, teks dinotasikan dengan T = T [0...
N-1] dan IT1 = N. Proses pencocokan biasanya dimulai dari awal kueri dan teks, kemudian membandingkan kesesuaian karakter kueri dan teks sampai pada akhir teks. Proses ini disehut scan and shifl mechanism.Algoritme Brute Force
Algoritme ini merupakan algoritme
pencocdtan pola sning yang sederhana. AlgorLpne ini tidak melakukan suatu proses awal bai terhadap kueri yang akan dicari dan jnga pada teks. Prinsipnya adalah membandiigkan karakter per karakter dari teks dan kueri. Jiia terdapat p g a n karakter yang tidak sama pada posisi tgtentu maka kueri akan digeser satu kali ke kanan teks dan proses pembandingan dilakukan mulai dari karakter awal kueri dengan posisi karakter teks yang baru
int BruteForce(char *T,char *P)( int match = 0 ;
for (int i=O ; i<N-M ; I++) 1 int j = 0;
while (j<M & & T[i+jl == P[jl) j++; if (i>=M) match++;
1 retu;n match ;
Contoh :
T=GCATCGCAGAGAGTATACAGTACG
P = GCAGAGAG
N= IT1 = 24
,
M=IPI = 8Proses pencocokan :
GCATCGCAGAGAGTATACAGTACG
--
- - f
GCAGAGAG
Tiga karakter pertama dari kueri dan teks sesuai tetapi pada karakter ke-4 tidak, maka kueri digeser ke kanan sebesar 1. Bentuk barunya adalah :
GCATCGCAGAGAGTATACAGTACG
f
GCAGAGAG
Ketidaksesuaian terjadi pada karakter pertama sehingga kueri digeser lagi ke kanan sebesar 1. Demikian dilakukan selama i <N-M.
Algoritme Knuth Morris Pratt
Algwitme ini ditemukan oleh Knuth, Moms dan F'ratt pada tahun 1976 (Abel, 2001). Algoritme ini dibuat untuk mengatasi masalah ketidakefisienan yang ditemukan pada algoritme Brute Force. Proses pencocokan pada algoritme Brute Force tidak menyimpan i n f m a s i penyesuaian yang diperoleh sehimgga satu karakter mungkii dibandiigkan heberapa kali yang seharusnya tidak perlu.
Priisip algwitme Knuth Morris Pratt
m)
adalah menganalisa kueri yang akan diproses dan menyimpan informasi hasil proses tersebut ke &lam suatu tabel yang biasa diwhut tabel m t . Tahel ini digunakan sehagai p a t h untuk menenluhn sejauh mana pergesaan kueri jika ditemukan pasangan karakter kueridan
teks yang tidak sama. Analisa ini dilakukan dengan membandiigkan kueri tersehut dengan diiinya sendin'.Proses
ini disebutpreprocessingKMF'.
Algoritme preprocessing Knuth Morris Pratt :
void P r e m P (char *P) I
int i
-
0 ; int j-
nextL0l-
-1 ;while (i<M)
while (j > -1 and P[il != P[jl) j = nextcjl
i++ ; j++ ;
if (P[i]==P[jl) nextcil = next[jl; else nextcil = j ; 11
Setelah diperoleh tahel next maka langkah selanjutnya adalah membandiigkan kesesuaian karakter yang dimulai dari kiii kueri dan teks. Jiia pasangan karakter kueri dan teks sesuai maka i dan j bertambah, jika tidak maka kueri akan digeser ke kanan sebesar i-nexf[i] kemudian memhandimgkan T[i] dengan P[i] yang baru. Jumlah hasil pencocokan pola adalah semua potongan teks yang sama dengan kueri.
int i=j-mtch-0 ;
while (i < N) I
while (j >-1 and P[jl != T[il) j = next [jl ;
j++ ; i++ ;
if ( j >= M)
( m a t c h ; j = next(j1))
Contoh :
T=GCATCGCAGAGAGTATACAGTACG
Pembuatan Program Pemampatan Berkas
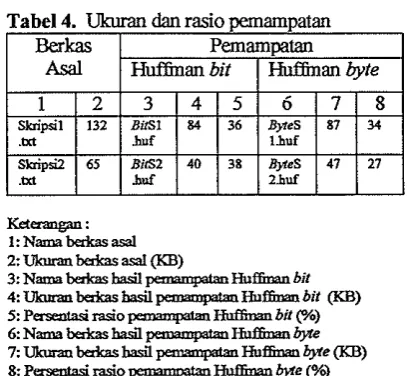
Program aplikasi pemampatan dan Proses pemampatan berkas bahan percobaan pencccokan p l a string dibangm dengan m e n g h a s i i berkas baru yang ukurannya lebii menggunakan perangkat lunak Turbo C++ dan kecil dari aslinya. Ukuran dan rasio basii perangkat keras berupa processor Intel Pentium pmampatan berkas bahan pacobaan dapat
200 MMx, memori 32
ME?
dan kapasitas dilihatpadaTabe1 4.harddisk sebesar 7.5 GB.
ini adalah :
Pemampatanberkas
Percotaan ini dilakukan untuk memampatkan berkas
bahan
pacobaan.Pemamptan dilakukan dengan aplikasi pmampatan Hutfiman bit dan byte yang telah dibuat
Rasio berkas hasid panampatan dihitung untuk mengetahui berapa bgar
kapasitas media penyimpanan yang &pat dihanat oleh kedua a p l i i i PanamPam
Tabel 4. Ukuran dan rasio pemampatan
Pencocokan Pola String
Pada percobaan ini dilakukan penyesuaian kueri terhadap k k a s
asal
danberkashasiipemamm
P m t a s i keakuratan basii pencocokan pola string dihitung dengan membandingkan jumlah kueri hasil pencccokan dengan jumlah kueri asli. Pada percobaan
ini
-ti juga waktu pencocokan pola pa&take
asli berkas h i 1 pemampatan H&an bit dan pada berkas basii p a m p a t a n Huffinan byte. Hal ini dilakukan untuk melihat bagahma waktu penc0w)kan pola pada berkas hasil p a m p a t a n algoritme H&an bit dan byte.Percobaan
Percobaan yang dilakukan pada peneiitian
HASIL DAN PEMBAHASAN
Pencocokan Pola String
Pencocokan pola d a p t langsung d i l m pada berkas yang sudah dimamptkan dengan menggunakan berbagai algoritme pencocokan pola string. Midkan
E(T)
sebagai encwringdari
berkas teks T, &T) sebagai decoding dari E(T) dan E(P) sebagai encoding kueri P. Proses pencocokan pola pada berkas yang sudah d i i p a t k a n adalah mencari E(P) di dalam E(T), bukan mencari P di dalam ~(E(T)) dan E(P) sendhi harm diencode sama seperti EQ.
Proses pencccokan pola pada k k a s yang dimampatkan adalah dengan membandingkan kesesuaian masing-masing bit atau byte. Kcde kueri diambil dari pustaka berkas basii pemampatan yang berada pada bagian head berkas. Head berkas hasil pemampatan berisi
Berkas
Asal
informasi masing-masing
i$r&d
atau kata Penelitian ini mavpakan ujicoba dari dengan kdenya,penelitian yang telah dilakukan oleh Shibata et Pencocokan p l a pada berkas hasil al., (1996) dan De Moura et al., (1998a). pemampatan ~ u f f r n ~ bit rnemerlukan proses
dari penelitian ini menunjukkan ~ a h m s i & ~ s a s i agar r n a s a s i kesalahan
p e n c ~ o k a n pola sMng langs~ng dilakukan pendeteksian bit. proses ini dengan pada berkas yang sudah dimampatkan. menggabungkan pohon HufEnan bit dari berkas
Pemampatan HufEnanbit
I
H&inanbyte [image:53.577.294.498.162.350.2]kueri yang akan dicari seperti terlihat pada Gamhar 4.
Pencocokan pola pada herkas hasil pemampatan Hnffian byte tidak memerlukan pohon Huffman byte tetapi menambah nilai 128 ke a w l byte kode kueri yang diperoleh. Hal ini dilakukan agar basil yang diperoleh pada pencocdtan adalah valid. Contoh pencocokan pada h e r b yang diiampatkan dengan H u f i a n byte adalah :
Kata Kode real 85 32 w r l d 29 121 99
ghosr 32 29 121
Jika pada berkas asli terdapat potongan kalimat berikut :
...
real w r l d..
.
maka kode yang akan terbentuk adalah 85 32 29 121 99. 3 i a kueri yang akan dicari adalah P = ghost diiana kode P adalah 32 29 121, dari susunan kode potongan k a l i a t di atas memungkiian ditemukannya kueri P ymg tidak valid. Unhlk mengatasinya maka byte patama dari kode kueri ditambah dengan 128. Sehimgga kode kueri P yang akan dicari adalah 160 29 121. Dengan demikian akan diperoleh nilai pen& yang valid.Gambar 4. Pohon Huffman bit dengan KMP
automaton
Diagram alur proses pencocokan pola string pada herkas yang telah dimampatkan dengan Huffman bit dan Huffman byte yang terhentuk seperti terlihat pada Gambar 5.
baca bnkas yang dirnamptkan
[image:54.585.297.498.79.336.2] [image:54.585.301.494.603.684.2]buat KMP nutomoton
Gambar 5. Alur proses pencodcan pols pa& herkas hasil pemampatan Huffian bit dan byte
Keakuratan Pencocoksn Pola String
Keakuratan yang diperoleh dari hasil percobaan terhadap semua contoh kueri jenis vokal dan konsonan adalah valid diiana jumlah yang ditemukan sama dengan jumlah aslinya. Untuk kueri jenis campuran, ketidakvalidan diperoleh pada hasil pencocokan pola pada h k a s hasil pemampatan Huffman bit sedangkan pada berkas hasil pemampatan Huffman byte adalah valid. Detil hasil penwokan karakter jenis vokal, konsonan dan campuran dapat dilihat
pada Lampiran 2 sampai dengan 4.
Contoh pendeteksian yang tidak akurat pada berkas hasil pemampatan Huffinan bit. Misalkan dari pohon H u h a n diperoleh kode karakter sehagai herikut : A:ll
,
B:101, C:100, D:01, E:OO. Kueri P = CD, maka P'=10001. StateKMP
automaton kueriP'
:State g(0) d l ) f oufuut 0
-
1 root pohon Huanan1 2 1
2 3
-
13 4 1
4 5 1 5 (CD)
Bagian pohon Hu£linan bit State ~ ( 0 ) ~ ( 1 )
Misalkan teks T = ACDAEDCCD maka T' =
1110001110001100100. Pada teks T terdapat 2 kueri CD tetapi pada T' terdapat 3 kcde kueri P'.
J i i tanpa s M s a s i maka transisi state untuk
T' adalah : 1-1-1-2-345(CD) 1-1-2-345(final state tetapi fdse) 1-2-3-1-2-345(CD)
J i
dengan shkxnisasi maka prcrses transisi sialenya adalah :1-1-1 -2-345(CD) 1-0-94-9-0 1-2-3-0-9-0- 9-0 (CD tidak ditemukan, false).
Waktu Pencocokan Pola M n g
MisaUran TS
sebagai waktu yang dibutuhkaa untuk penmcokan pola pada berkas yang Mum dimampatkan, TbitS adalah waktu penoocokan @a pada berkas hasid paampatan H W a n bit clan TbyteS adalah waktu pencocdtan pola pada berkas hasil panampatanHutsoan byte. Detil nilai rataan waktu
pencocdian pola string kedua berkas
bahan
p e r d m n dapat d i l i i t pada Tabel 5 sampai dengan 7.
Tabel 5. Rataan waktu pencocdtan pola kueri
TbitS 30.72 31.28 30.4 30.9
Tabel 6. Rataan waktu pencocokan pola kueri jenis konsonan (10 mS)
Dari hasil percobaan diperoleh bahwa TbyteS < TbitS. Nilai ini disebabkan oleh proses byte yang memungkinkan pembandingan lebih sedikit karena kale kueri umumnya lebih sedikit dibanding dengan karakter kueri asliiya, ditmbah juga dengan proses pergeseran kcde byte yang efektif Sedangkan pada proses bit, jumlah kode kueri umumnya lebih panjang dari karakter kueri asli sehingga lebii banyak jumlah yang
barus
dibandingkan, ditambah juga dengan pergeseran pada bit yang tidak efisien. Grafik rataan waktu penmcokan pola kedua k k a spercobaan seperti terliiat pada Gambar 6 sampai
8.
Detil
waktu pen& pola string semua kueri percotaan &pat diliiat pada Lampiran 5 sampai 13.4 5 6 7 8
P nnjangkueri t T S--Tbii --t-TbVteS
[image:55.577.72.506.74.703.2]Tabel 7. Rataan waktu pencocokan pola kueri jenis campuran (10 mS)
Gambar 6. Grafik rataan waktupenc~mkan pola kueri jenis vokal
PanjangKar TS TbitS TbyleS
4
Pan.ing kucri t T S --m-TLGi +TbyteS
Gambar 7. Grafik rataan waktn penwokan pola kueri jenis konsonan
7
4.93 31.3
0.54
5
20i
10i::L
0 4 5 P anjmg 6 kueri 7 88 5.5 32 0.6 4 5.39 31.41 0.73 7 4.98 31.5 0.93 6 5.31 31.3 2.04 Panjang Kar TS TbitS TbyteS
Gambar 8. Grafik rataan waktn pencocokan pola kueri jenis campuran
PENUTUP DAlTAR PUSTAKA Kesimpulan
Rasio pemampatan metode Huffman bit
secara mum lebii besar dibandingkan hasil metode Huffman byte.
Persentasi keakuratan yang diperoleh dari pencocdtan pola pada berkas hasil pemampatan Huffman bit adalah antara 0 sampai 1. Nilai ini disebabkan adanya kesalahan pendeteksian bit.
Sedangkan pencodan pola pa& berkas hasil pemampatan Huffman byte diperoleh persentasi keakuratan sebesar 1.
Dari hasil percobaan diperoleh
TbyfeS < TbitS. Nilai ini disebabkan karena kode kueri pada berkas hasil pemampatan Huffman byte rata-rata lebii kecil dibandiig dengan karakter kueri asli dan proses pergesaran pada kcde byte yang efisien. Sedangkan kode kueri pa& berkas hasil pemampatan Hufhan bit
rata-rata lebih panjang dibandiig dengan karakter kueri asli, ditambah dengan proses pergeseran pada kode bit yang tidak efisien.
Tidak ditemukan pola antara mktu pencocokan pola string dengan panjang kueri karena kinerja pencocdcan pola sendiri tergantung pada pola kueri dan teks.
Pada berkas I, TbyteS &pat mempercepat waktu pencoookan s e k 2-25 kali TS sedangkan pada berkas I1 diperoleh percepatan sebesar 1 - 14 kali TS.
Saran
Perlu dicari algoritme pencocokan' pola
string yang tepat digunakan pada berkas pemampatan HufEnan bit sehiigga h a i l pencocokannya valid.
Pencocokan pola string pada penelitian ini dapat dikembangkan menjadi temu kembali dengan menambah proses awai pada algoritme pemampatan seperti pengelompokan kata-kata yang bersamaan arti, bunyi atau aturan temu kembali lainnya serta menghilangkan sifat key sensitive.
Abel, U. 2001. Shing Matching. Proseminar "Algorithmen". hof. Brandenburg.
Chochemore, M. & T. Lecroq. 1996. Pattern Marching And Tsrt Compression Algorithm.
ACM Comput. Swveys
De Moura, ES Navarm, G. Ziviani, N. & R B. Yates. 1996. Compressed Pattern Matching
-
Approximate Compressed Patern Matching-
Direct Compressed Pattern Marching. Depto.De
Ciencia da Computecao, Univ. Federal de M i a s Gerais. Brasil.,1998a. Direct Pattern Matching on Compressed Text.
Tech.
Report03-98, Dept. of Computer Science, Univ. Federal de Minas Gerais, Brazil.
,1998b.
Fart
Searching on Compressed Text Allowing Errors.In Proc. of the ACM Sigir'98.
Klein, ST. & D. Saphim, 2001. Pattern Matching in H m a n Encoded T a t . Data Compression Conference 2001.
Manber, U d i 1997. A Text Compression Scheme that Allow Fast Searching Directly in The Compressed File. ACM Trans. Information Systems, 15(2):124-136, 1997.
Shibata, Y. Kida, T. Fukamachi, S. Takeda, M. Shinohara, A. & T. Shinohara. 1996.
Spedding Up Pattern Matching by Text Compression. Department of Informatics Kyushu University, Fukuoka. Regular Paper.Vol.37 No. 6
Sedgewick, R 1988. Algorithms. Addison Wesley. Bonn.
Treamblay, J.P. & G. Sorenson. 1985. The