ABSTRACT
APRILIA RAMADHINA. Indonesian Language Document Classification Using Semantic Smoothing. Supervised by JULIO ADISANTOSO.
The first supervised learning method for document classification is Naive Bayes classifier. A common problem that often occurs on simple methods like Naive Bayes is data sparsity. This problem especially occurs when the size of training and testing data is too small. Smoothing technique is a method for handling the sparsity problem, one method from smoothing technique is Semantic Smoothing.
Document Agricultural Research Journal of holticulture domain is used for this research, this document contains of three classes. The average for accuracy of document classification on Semantic Smoothing is 92.88%. Results of the classification with Semantic Smoothing has been
KLASIFIKASI DOKUMEN BAHASA INDONESIA MENGGUNAKAN
METODE SEMANTIC SMOOTHING
APRILIA RAMADHINA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
APRILIA RAMADHINA. Indonesian Language Document Classification Using Semantic Smoothing. Supervised by JULIO ADISANTOSO.
The first supervised learning method for document classification is Naive Bayes classifier. A common problem that often occurs on simple methods like Naive Bayes is data sparsity. This problem especially occurs when the size of training and testing data is too small. Smoothing technique is a method for handling the sparsity problem, one method from smoothing technique is Semantic Smoothing.
Document Agricultural Research Journal of holticulture domain is used for this research, this document contains of three classes. The average for accuracy of document classification on Semantic Smoothing is 92.88%. Results of the classification with Semantic Smoothing has been
KLASIFIKASI DOKUMEN BAHASA INDONESIA MENGGUNAKAN
METODE SEMANTIC SMOOTHING
APRILIA RAMADHINA
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada Departemen Ilmu komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji :
Judul : Klasifikasi Dokumen Bahasa Indonesia Menggunakan Metode Semantic Smoothing Nama : Aprilia Ramadhina
NRP : G64070083
Menyetujui, Pembimbing
Ir. Julio Adisantoso, M.Kom NIP. 19620714 198601 1 002
Mengetahui,
Ketua Departemen Ilmu Komputer
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
PRAKATA
Puji syukur kehadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya sehingga tugas akhir dengan judul Klasifikasi Dokumen Bahasa Indonesia Menggunakan Metode Semantic Smoothing ini dapat terselesaikan. Laporan ini merupakan hasil penelitian yang bertempat di Departemen Ilmu Komputer yang berlangsung mulai Desember 2010 sampai dengan Juli 2011.
Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Orang tua tersayang, Ayahanda Rizki Mirhadi dan Ibunda Marianti, juga kakak Soraya Rizfathanty. Keluarga yang selalu memberikan doa, nasihat, semangat, dukungan dan kasih sayang yang luar biasa kepada penulis.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir, dengan bantuan dan bimbingan disertai kesabaran dalam penyelesaian tugas akhir. Dr. Yeni Herdiyeni, S.Si, M.Kom dan Soni Hartono Wijaya, S.Kom, M.Kom selaku dosen pembimbing akademik. 3. Bapak Andi Pramurjadi yang telah memberi informasi dan mengajarkan penulis saat memulai
dan mengerjakan tugas akhir.
4. Muhamad Rofi Hidayat yang selalu ada dan membantu, memberi ketenangan juga kesabaran dalam menghadapi permasalahan saat mengerjakan tugas akhir ini.
5. Teman-teman satu bimbingan Devi Dian P, Agus Umruadi, Isna Mariam, Nova Maulizar, Nutri Rahayuni, Fandi Rahmawan dan Woro Indriani telah bersama berjuang dalam proses mengerjakan tugas mengenai Temu Kembali Informasi.
6. Teman sekumpulan ilkomerz44 rumpz Yoga Permana, Fani Wulandari, Trie Setiowati, Ira Nurazizah, Laras Mutiara, Yuridhis Kurniawan, Fadly Hilman, Fanny Risnuraini, Arif, Tito Heyzi, Teguh Cipta, Anggit, Dian Sulma, Ria Astriratma dan seluruh ilkomerz yang senantiasa memberikan semangat dan doa kepada penulis.
7. Teman setempat tinggal di Wisma Flora yang menemani penulis, Nie Sukma, Indi Husnul dan Winda Ristiani. Dan kakak-kakak di Flora mba Ayu, mba Pipit, mba Ijup, mba I’i, mba Dian dan mba Marsel.
8. Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun perkuliahan.
Dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis menerima adanya masukan berupa saran atau kritik yang bersifat membangun mengenai tugas akhir ini. Semoga tulisan ini bermanfaat baik sekarang maupun di masa mendatang. Amin.
Bogor, Agustus 2011
RIWAYAT HIDUP
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vii
DAFTAR TABEL ... vii
DAFTAR LAMPIRAN ... vii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Temu Kembali Informasi ... 1
Klasifikasi ... 2
Naive Bayes Classifier (NBC) ... 2
Language Model ... 3
Background dan Semantic Smoothing ... 3
Confusion Matrix ... 4
METODE PENELITIAN Gambaran Umum Sistem ... 4
Data Penelitian ... 5
Praproses ... 5
Ekstraksi Topic Signature ... 5
Background dan Semantic Smoothing ... 6
Evaluasi Hasil Klasifikasi ... 6
HASIL DAN PEMBAHASAN Uji Coba Klasifikasi Dokumen ... 6
Hasil Semantic Smoothing ... 6
Hasil Background & Semantic Smoothing ... 7
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
vii
DAFTAR TABEL
Halaman
1 Confusion Matrix (Hammel 2008) ... 4
2 Confusion Matrix Semantic Smoothing ... 6
3 Hasil Kinerja Semantic Smoothing ... 7
4 Hasil Long Document dan Short Document ... 7
5 Confusion Matrix Background dan Semantic Smoothing (Short Document) ... 7
6 Perbandingan Hasil Background dan Semantic Smoothing (Short Document) ... 8
7 Confusion Matrix Background dan Semantic Smoothing (Long Document) ... 8
8 Perbandingan Hasil Background dan Semantic Smoothing (Long Document) ... 8
DAFTAR GAMBAR
Halaman
1 Proses Sistem Temu Kembali Informasi (Hiemstra 2001) ... 22 Gambaran Umum Sistem ... 5
3 Tingkat Kinerja Semantic Smoothing pada Long Document dan Short Document ... 7
4 Tingkat Kinerja Background dan Semantic Smoothing (Short Document)) ... 8
5 Tingkat Kinerja Background dan Semantic Smoothing (Long Document) ... 9
DAFTAR LAMPIRAN
Halaman
1 Antarmuka Sistem Klasifikasi Semantic Smoothing ... 112 Antarmuka Hasil Sistem Klasifikasi Semantic Smoothing ... 11
3 Hasil Klasifikasi Dokumen Uji pada Short Document ... 12
1
PENDAHULUAN Latar Belakang
Saat ini jumlah dokumen semakin banyak dan beragam sejalan dengan bertambahnya waktu dan teknologi. Jika jumlah dokumen semakin bertambah banyak maka proses pencarian dan penyajian dokumen semakin sukar, sehingga akan lebih mudah jika dokumen tersebut sudah tersedia sesuai dengan kategorinya masing-masing. Salah satu metode yang dapat membantu mengorganisasikan dokumen sesuai dengan ketegorinya adalah klasifikasi. Klasifikasi dokumen adalah proses menggolongkan suatu dokumen ke dalam suatu kategori tertentu (Manning et al 2008). Terdapat beberapa metode klasifikasi dokumen, yaitu Naïve bayes, k-nearest neighbor, decision trees, neural network dan support vector machine. Naïve bayes classifier (NBC) merupakan algoritme klasifikasi yang mudah diimplementasikan jika dibandingkan dengan algoritme lain dan disebut sebagai simple bayesian classification. Masalah umum yang sering terjadi pada metode tersebut adalah saat kata atau terms yang merupakan penciri dari data uji (testing) tidak ditemukan pada penciri pada dokumen latih (training) yang biasa disebut sparsity data. Salah satu penyebab yang bisa mengakibatkan sparsity data adalah saat ukuran data latih (training) yang digunakan terlalu kecil, sehingga peluang penciri dokumen uji ada pada dokumen latih juga sedikit. Untuk membantu menghindari masalah tersebut, dapat digunakan metode smoothing.
Metode smoothing memberikan nilai pada term yang tersembunyi untuk menambah tingkat keakurasian dari penduga peluang kata yang terdapat pada dokumen latih. Beberapa metode smoothing yang telah dihasilkan yaitu dirichlet prior, witten-bell, jelinek-mercer, kneiser-ney, katz, good turing estimation, background smoothing dan semantic smoothing dengan pendekatan language modeling (Zhou et al 2008).
Proses klasifikasi dokumen umumnya memiliki kesalahan makna kata, sehingga terjadi ketidakcocokan antara dokumen testing dengan dokumen training. Kesalahan makna kata terjadi saat kata yang ada pada dokumen memiliki banyak makna. Semantik merupakan pasangan kata yang terdiri atas dua kata atau lebih. Keterkaitan kata yang
ada pada semantik akan berubah makna jika hanya memperhatikan satu kata. Kesalahan makna dalam mengartikan semantik ini yang dapat memicu kekeliruan dalam klasifikasi dokumen, sehingga dibutuhkan metode yang memperhatikan keterkaitan kata untuk klasifikasi dokumen yaitu metode semantic smoothing.
Sebelumnya metode background smoothing telah dilakukan oleh Pramurjadi (2010). Hasil klasifikasi dengan background smoothing belum memuaskan karena metode ini tidak memperhatikan keterkaitan kata yang ada di dalam dokumen. Diharapkan penelitian klasifikasi menggunakan metode semantic smoothing ini dapat lebih meningkatkan tingkat akurasi dan membantu dalam mengelompokkan dokumen.
Tujuan
Tujuan penelitian ini yaitu melihat pengaruh metode semantic smoothing pada klasifikasi dokumen dan membandingkan tingkat akurasi klasifikasi antara hasil metode background smoothing dan semantic smoothing.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada hasil keakurasian klasifikasi dokumen menggunakan metode semantic smoothing pada short document dan long document. Pasangan kata atau semantik yang didapat tergantung dari pasangan kata yang ada pada dokumen latih. Selain itu, dokumen yang digunakan adalah dokumen berbahasa Indonesia mengenai tanaman holtikultura dari bidang pertanian.
Manfaat Penelitian
Manfaat dari hasil penelitian ini diharapkan dapat menambah khazanah metode klasifikasi dokumen dan membantu dalam mengorganisasikan dokumen, sehingga mempermudah dalam menyajikan dan pencarian dokumen.
TINJAUAN PUSTAKA Temu Kembali Informasi
2
komputer (Manning et al 2008). Sistem temu kembali informasi melakukan proses yang secara otomatis menemukan kembali informasi dari sekumpulan informasi yang relevan dengan kebutuhan pengguna.
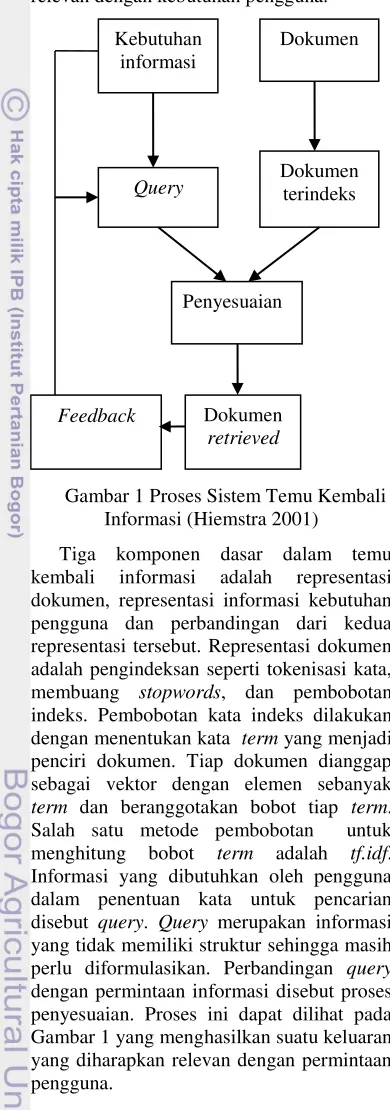
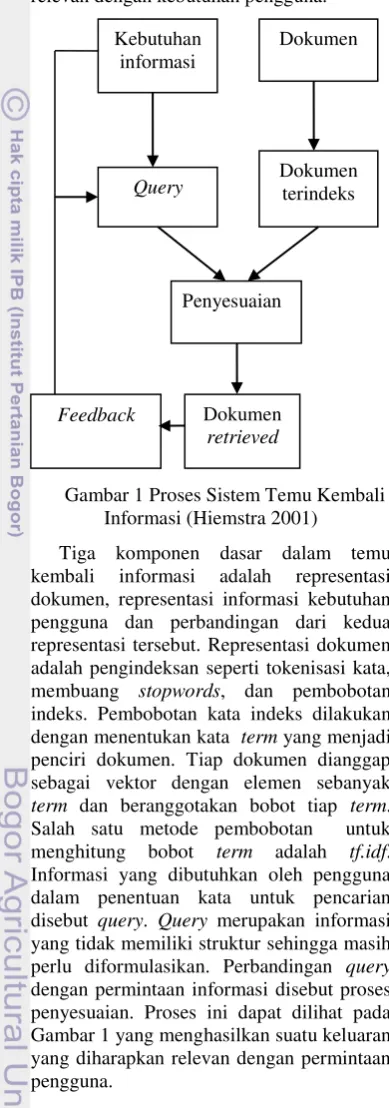
Gambar 1 Proses Sistem Temu Kembali Informasi (Hiemstra 2001)
Tiga komponen dasar dalam temu kembali informasi adalah representasi dokumen, representasi informasi kebutuhan pengguna dan perbandingan dari kedua representasi tersebut. Representasi dokumen adalah pengindeksan seperti tokenisasi kata, membuang stopwords, dan pembobotan indeks. Pembobotan kata indeks dilakukan dengan menentukan kata term yang menjadi penciri dokumen. Tiap dokumen dianggap sebagai vektor dengan elemen sebanyak term dan beranggotakan bobot tiap term. Salah satu metode pembobotan untuk menghitung bobot term adalah tf.idf. Informasi yang dibutuhkan oleh pengguna dalam penentuan kata untuk pencarian disebut query. Query merupakan informasi yang tidak memiliki struktur sehingga masih perlu diformulasikan. Perbandingan query dengan permintaan informasi disebut proses penyesuaian. Proses ini dapat dilihat pada Gambar 1 yang menghasilkan suatu keluaran yang diharapkan relevan dengan permintaan pengguna.
Klasifikasi
Klasifikasi dokumen merupakan proses menemukan sekumpulan model yang mendeskripsikan dan membedakan
kelas-kelas data sesuai dengan kategori yang dimilikinya. Tujuan klasifikasi untuk memprediksikan kelas dari objek yang belum diketahui kelasnya dengan karakteristik tipe data yang bersifat kategorik. Proses klasifikasi dibagi menjadi dua fase, yaitu learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase test, model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk memprediksi kelas data yang belum diketahui.
Metode klasifikasi dokumen secara otomatis memiliki tingkat keakuratan yang cukup tinggi jika aturan dibuat dengan baik. Metode tersebut dibagi menjadi dua, yaitu klasifikasi secara manual dan klasifikasi secara otomatis. Pada klasifikasi manual dilakukan oleh tenaga ahli sehingga cukup akurat, tetapi butuh waktu yang lama, sedangkan klasifikasi dokumen secara otomatis terdiri atas dua kategori, yaitu hand-coded rule-based systems dan supervised learning (Manning et al 2008). Hand-coded rule-based systems tingkat akurasinya tinggi jika rule dibuat dengan sangat baik dan kompleks serta butuh biaya yang mahal. Supervised learning menggunakan data latih untuk memberikan label kategori yang telah terdefinisi sebelumnya. Beberapa model yang digunakan dalam supervised learning adalah naive bayes, bernoulli, vector space model, k-nearest neighbors dan maximum a posteriori.
Naive Bayes Classifier (NBC)
Naive bayes classifier merupakan penyederhanaan dari bayesian classification dan biasa disebut simple bayesian classification. Klasifikasi NBC termasuk dalam multinomial yang mengambil jumlah kata yang muncul pada sebuah dokumen. Pada model ini, sebuah dokumen terdiri atas beberapa kejadian kata dan diasumsikan panjang dokumen tidak bergantung pada kelasnya. Lainnya adalah kemungkinan tiap kejadian kata dalam sebuah dokumen adalah bebas dan tidak terpengaruh dengan konteks kata atau posisi kata dalam dokumen. NBC merupakan metode klasifikasi dengan cara menghitung peluang sebuah dokumen d berada di kelas c (Manning et al 2008). Dokumen
retrieved Feedback
Dokumen
Query Dokumen terindeks
Penyesuaian Kebutuhan
3
Peluang dari suatu dokumen d ada pada kelas c adalah :
P(c|d) ∞ P(c) ∏1 ≤ k ≤ n d P(tk|c)
dengan P(c|d) adalah nilai penduga peluang dokumen d dikelaskan ke dalam kelas c, P(tk|c) merupakan peluang kata atau term ke-k yang muncul pada dokumen kelas c, dengan perkalian k yang merupakan term sebanyak n, dan P(c) merupakan peluang dari dokumen yang ada di dalam kelas c. Pendekatan yang digunakan untuk menduga P(c) dan P(tk|c) adalah :
P(c) =
P(tk|c) = ( )
dimana Ncadalah banyaknya dokumen yang ada di dalam kelas c dan N adalah total seluruh dokumen yang ada. P(tk|c) dimaksudkan sebagai ukuran seberapa banyak term ke-k menunjukkan c merupakan kelas yang tepat untuk dokumen d dan Tctadalah banyaknya t dalam dokumen latih kelas c.
Laplace smoothing (LS) berguna untuk menghilangkan dugaan parameter yang bernilai nol. LS merupakan teknik smoothing yang biasa digunakan dalam perhitungan Maximum Likelihood Estimation (MLE). Maximum Likelihood Estimation atau pengelompokan kemungkinan terbesar adalah algoritme dengan pendekatan supervised classification yang paling sering digunakan. Laplace smoothing disebut add-one karena ada penambahan satu nilai pada notasi tertentu. Formula laplace smoothing adalah:
P(t|c) = ( ) =
( )
notasi B’ merupakan banyaknya term dalam kosa kata dan adalah banyaknya kata unik yang menghitung satu nilai untuk term yang muncul lebih dari satu. Kelas terbaik pada klasifikasi NBC adalah kelas yang paling mirip dengan dokumen yang ingin diklasifikasikan atau yang memiliki nilai posteriori tertinggi (Maximum a Posteriori).
Language Model
Dalam bidang Information Retrieval (IR), Language Model (LM) yang digunakan adalah unigram model karena urutan kata tidak terlalu dipermasalahkan. Penggunaan
LM atau statistical language modeling muncul sebagai probabilistic framework yang baru untuk menangkap ketidakteraturan statistik yang menjadi ciri dari ketidakteraturan penggunaan bahasa. Sebuah LM adalah suatu model mengenai sebaran bersyarat dari identitas kata dalam rangkaian, ditentukan oleh identitas dari semua kata sebelumnya. Salah satu model temu kembali informasi yang menggunakan LM adalah query-likelihood model yang diusulkan Ponte dan Croft (dalam Liu & Croft 2004) yang menganggap query sebagai vektor dari atribut biner, masing-masing atribut untuk sebuah istilah yang unik di dalam kosa kata indeks dan menandakan ada atau tidaknya istilah tersebut di dalam query. Ada dua asumsi yang mendasari model ini, pertama adalah semua atribut biner. Jika sebuah istilah ada di query maka atribut yang mewakili istilah tersebut adalah 1 dan jika sebaliknya adalah 0. Kedua, istilah dianggap tidak berkaitan di dalam sebuah dokumen. Asumsi ini mirip dengan dugaan yang digunakan dalam teori-teori peluang pada temu kembali informasi.
Background dan Semantic Smoothing
Smoothing berfungsi membandingkan peluang kata yang muncul dan tidak muncul dalam suatu dokumen. Smoothing merupakan bagian penting dari LM yang akan menambah keakurasian perkiraan peluang kata yang ada pada dokumen latih dengan cara memberi nilai peluang pada kata yang tidak muncul. Smoothing sebagai pengontrol MLE agar hasilnya lebih akurat (Zhai 2001). Dalam metode semantic smoothing, teknik simple language model atau background collection model disebut background smoothing (Zhou et al 2008). Background smoothing menduga peluang dari kata yang tidak muncul berdasarkan background model atau seluruh dokumen latih. Formula background smoothing yaitu: Pb(t|cj) = (1-λ) Pm l (t|cj) + λP(t|D) ...(1)
Model kelas unigram dengan pendugaan parameter adalah Pml (t|cj), sedangkan Pb(t|cj) merupakan model kelas unigram dengan background smoothing, dan P(t|D) merupakan peluang kata yang ada pada dokumen.
4
Ps(t|ci)=(1-λ)Pb(t|ci)+ λ�P(t|wk)P(wk|ci) ..(2)
dengan Ps(t|ci) adalah model kelas unigram dengan semantic smoothing dan wk merupakan topic signature, P(t|wk) merupakan peluang kata dalam dokumen uji yang terdapat dalam topic signature, sedangkan P(wk|ci) adalah kata dalam kumpulan topic signature dalam dokumen latih, dan Pb(t|ci) merupakan nilai hasil dari formula background smoothing.
Dua metode ini menggunakan koefisien
λ dari collection background model dalam
semantic smoothing. Kriteria tersebut digunakan sebagai komponen pengontrol pada pemetaan topic signature sebagai model campuran atau mixture model (Zhou et al 2007). Koefisien ini dapat mengatur komposisi antara komponen background smoothing dan semantic smoothing.
Semantic smoothing merupakan salah satu teknik dari language model. Metode ini digunakan untuk mendekomposisi sebuah dokumen ke dalam suatu set dari kata atau frase yang terdiri atas beberapa kata, dengan memetakannya menggunakan perhitungan statistika (maximum likelihood estimation) ke dalam kata yang berdiri sendiri.
Confusion Matrix
Confusion matrix disebut juga matriks klasifikasi yang menjadi suatu alat visual dalam supervised learning. Confusion matrix merupakan sebuah tabel (Tabel 1) yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi, digunakan untuk menentukan kinerja suatu model klasifikasi. Tabel 1. Confusion Matrix (Hammel 2008)
Observed
True False
Predicted Class True True Positive (TP) False Positive (FP) False False Negative (FN) True Negative (TN)
Pada kasus yang diklasifikasikan dengan benar muncul pada diagonal, hal ini disebabkan kelompok prediksi dan kelompok aktual adalah sama. Elemen yang selain diagonal menunjukkan kasus yang
salah diklasifikasikan. Jumlah elemen diagonal dibagi total jumlah kasus adalah rasio tingkat akurasi dari klasifikasi. Untuk evaluasi kesamaan dokumen dapat diukur dengan recall, precision dan F-measure.
Recall merupakan evaluasi untuk mengetahui tingkat keberhasilan kinerja user dalam observasi yang telah dilakukan. Recall (R) dinyatakan dalam jumlah pengenalan entitas bernilai benar dibagi jumlah entitas yang dikenali sistem. Precision (P) adalah tingkat ketepatan hasil klasifikasi dan jumlah keseluruhan pengenalan yang dilakukan sistem.
F-measure (F) adalah nilai yang lebih dipengaruhi kinerja sistem dibandingkan dengan user. Formula di atas merupakan recall dan precision dimana [ ] dan
[ ] dengan =1/2 atau =1,
sehingga formula F-measure menjadi :
Akurasi dari klasifikasi dapat diperoleh dari penjumlahan true positif dan true negatif dibagi total untuk melihat kinerja secara keseluruhan.
METODOLOGI PENELITIAN Gambaran Umum Sistem
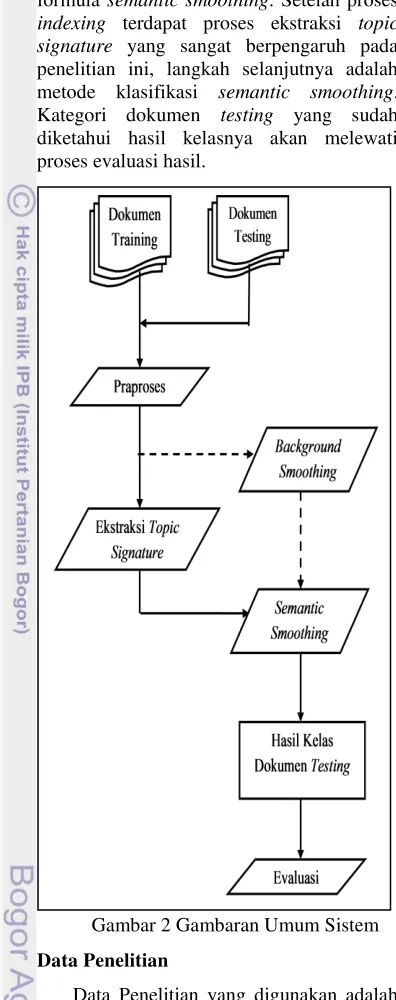
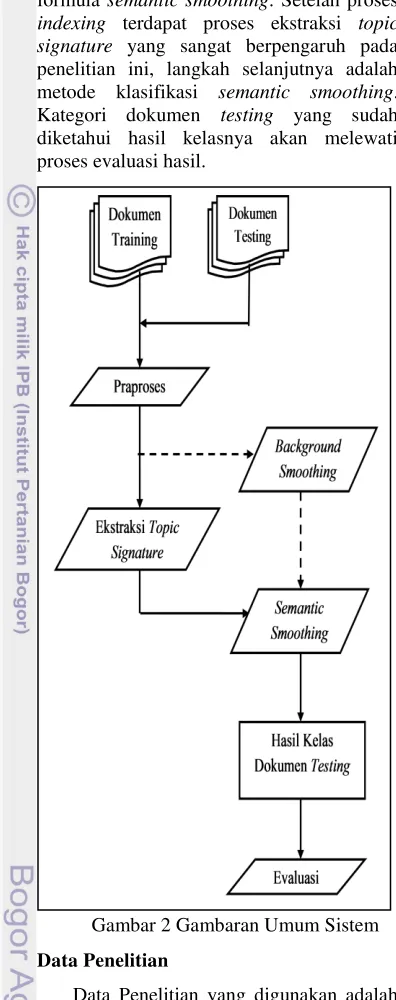
Alur dari penelitian secara garis besar ditunjukkan pada Gambar 2. Beberapa tahap dari sistem yaitu pengumpulan dokumen, praproses, ekstraksi topic signature, semantic smoothing, kategori dokumen testing yang dihasilkan dan evaluasi hasil klasifikasi.
5
formula semantic smoothing. Setelah proses indexing terdapat proses ekstraksi topic signature yang sangat berpengaruh pada penelitian ini, langkah selanjutnya adalah metode klasifikasi semantic smoothing. Kategori dokumen testing yang sudah diketahui hasil kelasnya akan melewati proses evaluasi hasil.
Gambar 2 Gambaran Umum Sistem Data Penelitian
Data Penelitian yang digunakan adalah hasil penelitian dari Jurnal Penelitian Holtikultura tahun 2002 sampai dengan tahun 2009. Adapun pembagian jenis tanaman holtikultura yaitu komoditas buah tropik, buah sub tropik, tanaman hias dan sayuran. Dokumen tersebut terbagi menjadi tiga bidang penelitian yaitu ekofisiologi-agronomi, pemuliaan-teknologi benih dan proteksi. Koleksi dokumen yang digunakan dibagi menjadi 70% dokumen latih dan 30% dokumen uji. Pengujian pada dokumen uji terbagi dua jenis yaitu short document dan long document.
Praproses
Tahapan awal dalam proses klasifikasi setelah dokumen tersedia adalah praproses. Tahap pertama yang dilakukan saat praproses adalah pengelompokan dokumen sesuai dengan kelas atau kategori yang ditentukan. Tahap kedua yaitu proses indexing. Proses ini bertujuan mengekstrak kata dari dokumen. Dalam proses indexing terdapat langkah awal yaitu parsing, memilah dokumen menjadi unit yang lebih kecil berupa kata. Setelah itu membuang kata yang sering muncul dan bukan merupakan penciri dokumen yang biasa disebut stopwords. Selanjutnya dilakukan pembobotan indeks dengan menghitung term frekuensi dari setiap dokumen yang ada di koleksi dokumen dan pembobotan tf.idf pada setiap term. File yang telah didapatkan akan dibagi menjadi data training dan data testing.
Ekstraksi Topic Signature
Topic signature memiliki peranan penting dalam semantic smoothing. Ekstraksi topic signature yang membantu proses pencarian kedekatan semantik berdasarkan frase itu sendiri dan set dari kata yang mengandung frase tersebut. Proses pertama yang dilakukan adalah membuat deretan pasangan kata sesuai dengan keterkaitan kata yang ada. Dalam penelitian ini, list pasangan kata didapatkan dari dokumen latih yang kemudian dijadikan korpus semantik (topic signature).
Topic signature berisi pasangan kata yang telah terpilih. Penelitian ini berfokus pada pasangan kata yang terdiri atas dua kata. Seluruh kata yang terdapat di dokumen latih dijadikan pasangan kata setelah stopwords dibuang. Selanjutnya mencari peluang untuk tiap pasangan kata, kemudian di ekstraksi dengan memilih pasangan kata yang memiliki peluang tinggi dengan batasan tertentu dan membuang pasangan kata yang memiliki nilai peluang kecil. Langkah untuk membuat topic signature adalah :
1. Pasangan kata dicari dengan mendapat kata unik terlebih dahulu, kata unik yang berarti tidak ada stopword dan tidak ada kata yg sama atau berulang.
6
“tanaman hama penyakit wereng”Hasil : “tanaman hama”
“hama penyakit”
“penyakit wereng”
3. Setelah didapatkan deretan pasangan kata, kemudian dihitung peluang kemunculan masing-masing pasangan kata yang terdapat pada dokumen. 4. Peluang pasangan kata yang telah
didapatkan dapat digunakan untuk mengetahui frekuensi kemunculan semantik atau pasangan kata pada dokumen.
5. Jika terdapat pasangan kata yang memiliki peluang kemunculan terlalu kecil, maka lakukan proses pembuangan pada pasangan kata tersebut. Karena pasangan kata yang peluang kemunculannya terlalu kecil bukan merupakan penciri dokumen.
Pasangan kata atau topic signature ini yang mempengaruhi klasifikasi semantic smoothing, karena pasangan kata dokumen yang akan diuji akan mendapatkan nilai peluang yang bergantung pada pasangan kata dari topic signature.
Background dan Semantic Smoothing
Metode semantic smoothing dilakukan untuk memudahkan proses klasifikasi dokumen yang menggunakan metode NBC. Semantic smoothing sebagai parameter kontrol untuk menjadikan hasil klasifikasi menjadi akurat. Proses pertama yang dilakukan adalah menghitung peluang berdasarkan kata yang terdapat pada dokumen uji. Proses yang telah dilakukan oleh Pramurjadi (2010) menggunakan formula (1) dengan pendugaan parameter peluang pada dokumen oleh background smoothing. Proses berikutnya adalah yang dilakukan pada penelitian ini menggunakan semantic smoothing. Metode semantic smoothing sesuai dengan formula (2) dilakukan dengan menambah perhitungan probability, perhitungan tiap kata yang ada di korpus semantik. Metode semantic smoothing memiliki formula yang di dalamnya terdapat formula background smoothing. Teknik semantic smoothing merupakan penambahan parameter pada formula dari background smoothing. Setelah didapatkan peluang tiap kata dari dokumen uji berdasarkan topic signature dan kelas pada dokumen latih, proses dilanjutkan
dengan menghitung peluang tiap kelas terhadap dokumen uji.
Evaluasi Hasil Klasifikasi
Evaluasi hasil klasifikasi dokumen dilakukan untuk mengetahui tingkat keakurasian klasifikasi semantic smoothing. Evaluasi dilakukan pada hasil kelas untuk data testing yang terbagi menjadi short document dan long document. Selanjutnya membandingkan hasil klasifikasi dokumen antara background smoothing dan semantic smoothing. Perbandingan hasil kedua metode tersebut dengan melakukan pengukuran kesamaan menggunakan recall, precision, f-measure atau F-1, tabel confusion matrix dan tingkat akurasi.
HASIL DAN PEMBAHASAN Dokumen yang digunakan terdiri atas 83 dokumen untuk masing-masing kelas, yaitu :
1. Kelas Ekofisiologi dan Agronomi 2. Kelas Pemuliaan dan Teknologi Benih 3. Kelas Proteksi (Hama dan Penyakit)
Keseluruhan kelas yang berjumlah 249 terbagi menjadi 70% dokumen latih dan 30% dokumen uji. Dokumen yang akan diuji terbagi dua jenis yaitu long document dan short document. Dalam praproses dilakukan penentuan kata stopwords yang disesuaikan dengan kebutuhan penelitian. Setelah stopwords dihilangkan maka didapatkan 20415 total jumlah kata unik pada dokumen latih. Penelitian semantik dilanjutkan dengan ekstraksi topic signature. Tahap awal dilakukan proses penghilangan stopwords dan proses pembentukan pasangan kata. Tiap kata yang terdapat pada dokumen latih dibuat menjadi pasangan kata dan dicari peluang pasangan kata yang ada pada seluruh dokumen latih. Setelah dilakukan proses ektraksi maka didapatkan 13040 total jumlah pasangan kata yang menjadi topic signature.
Uji Coba Klasifikasi Dokumen
7
seperti yang terdapat pada formula (2). Semakin besar nilai parameter pengontrol menjadikan nilai peluang yang dihasilkan juga meningkat. Kemudian dilakukan perbandingan hasil klasifikasi dari tingkat keakurasian semantic smoothing dengan background smoothing.
Hasil Semantic Smoothing
Hasil klasifikasi semantic smoothing (SS) untuk kelas Ekofisiologi dan Agronomi (a), kelas Pemuliaan dan Teknologi Benih (b), kelas Proyeksi Hama dan Penyakit (c) berupa confusion matrix.
Tabel 2 merupakan hasil klasifikasi pada short document dan long document. Hasil dokumen uji short document yang benar masuk dalam kelas a,b dan c adalah 64 dan untuk jumlah dokumen yang salah berjumlah 11, sedangkan pada long document yang benar masuk dalam kelas a,b dan c adalah 70 untuk jumlah dokumen yang salah berjumlah 11.
Tabel 2. Confusion Matrix Semantic Smoothing
Short Document
TRUE FALSE
TRUE 64 11
FALSE 11 139
Long Document
TRUE FALSE
TRUE 70 5
FALSE 5 145
Confusion matrix ini didapatkan dari hasil pengujian tiap kelas yang terdapat pada Lampiran 3 dan Lampiran 4. Terlihat bahwa hasil klasifikasi pada long document lebih besar dibandingkan dengan hasil short document.
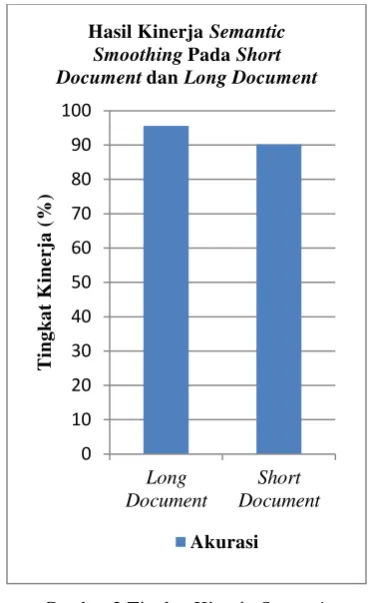
Tabel 3. Hasil Kinerja Semantic Smoothing
Short Document
Rec Prec F-1 Akurasi SS (%) 85,33 85,33 85,33 90,22
Long Document Rec Prec F-1 Akurasi SS (%) 93,33 93,33 93,33 95,55
Gambar 3 Tingkat Kinerja Semantic Smoothing pada Long Document dan Short
Document
Akurasi yang didapatkan untuk dokumen uji short document adalah 90% dan dokumen uji long document adalah 95%. Pada penelitian ini didapatkan hasil short document lebih rendah, karena sedikitnya pasangan kata yang sama dengan topic signature dan mengakibatkan nilai peluang yang kecil. Jika nilai peluang yang didapatkan kecil bisa mengakibatkan kurang maksimalnya pengklasifikasian.
Tabel 4. Hasil Long Document dan Short Document
Akurasi Long Document 95,55% Short Document 90,22%
Terlihat bahwa hasil klasifikasi pada long document lebih baik dibandingkan dengan short document, karena long document memiliki banyaknya pasangan kata yang sama dengan topic signatures dan didapatkan nilai peluang yang cukup tinggi. Rata-rata akurasi kinerja semantic smoothing adalah 92.88% dengan adanya pengukuran pada long document dan short document.
0 10 20 30 40 50 60 70 80 90 100 Long Document Short Document T ing k a t K inerj a ( %)
Hasil Kinerja Semantic Smoothing Pada Short Document dan Long Document
8
Hasil Background & Semantic Smoothing Hasil klasifikasi yang didapatkan dari penggunaan metode background smoothing dan semantic smoothing dapat dilihat pada Tabel 5.
Tabel 5. Confusion Matrix Background dan Semantic Smoothing(Short Document)
Background Smoothing
TRUE FALSE
TRUE 63 12
FALSE 12 138
Semantic Smoothing
TRUE FALSE
TRUE 64 11
FALSE 11 139
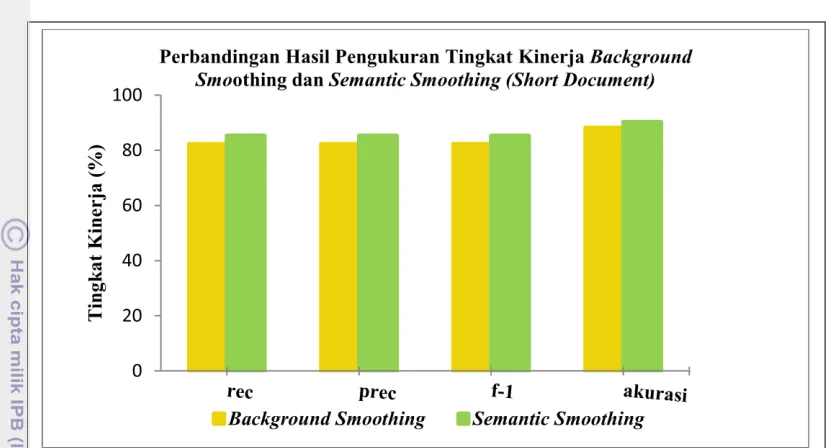
Tabel 6. Perbandingan Hasil Background dan Semantic Smoothing (Short Document)
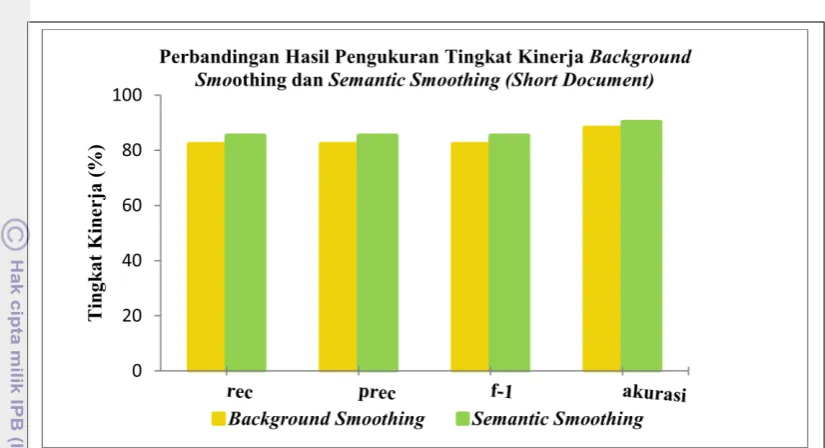
BGS SS
Recall 82,22% 85,33%
Precision 82,22% 85,33%
F-1 82,22% 85,33%
Akurasi 88,15% 90,22%
Perbandingan hasil klasifikasi background smoothing dan semantic smoothing dilihat pada Tabel 6 yaitu pengukuran hasil tingkat kinerja kedua metode tersebut untuk short document. Hasil klasifikasi pada short document menggunakan metode semantic smoothing
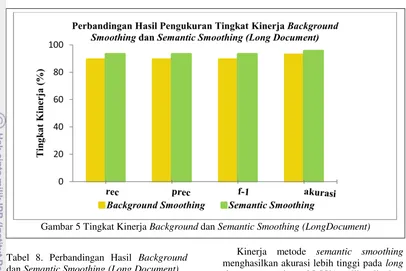
lebih baik, terjadi peningkatan untuk akurasi antara hasil background smoothing dengan metode semantic smoothing. Seperti yang terlihat pada Gambar 4 dan Gambar 5 hasil klasifikasi semantic smoothing lebih baik dibandingkan hasil klasifikasi background smoothing. Hal ini membuktikan bahwa keterkaitan kata yang ada pada dokumen dapat mempengaruhi klasifikasi dokumen. Tabel 7 merupakan perbandingan confusion matrix dari background smoothing dan semantic smoothing pada long document. Hasil klasifikasi background smoothing adalah 67 dokumen uji yang sesuai dengan kelas, sedangkan hasil klasifikasi dari semantic smoothing menghasilkan 70 dokumen uji yang sesuai dengan kelas. Perhitungan confusion matrix tersebut menghasilkan pengukuran kinerja yang diberikan pada Tabel 8. Tingkat akurasi pada semantic smoothing lebih tinggi dengan nilai 95.55% dibandingkan dengan tingkat akurasi background smoothing yaitu 92.88%.
Tabel 7. Confusion Matrix Background dan Semantic Smoothing(Long Document)
Background Smoothing
TRUE FALSE
TRUE 67 8
FALSE 8 142
Semantic Smoothing
TRUE FALSE
TRUE 70 5
FALSE 5 145
9
Tabel 8. Perbandingan Hasil Background dan Semantic Smoothing (Long Document)
BGS SS
Recall 89,33% 93,33%
Precision 89,33% 93,33%
F-1 89,33% 93,33%
Akurasi 92,88% 95,55%
Pertimbangan semantic smoothing dalam klasifikasi salah satunya adalah keterkaitan kata dan topic signature. Hal ini membuat akurasi semantic smoothing menjadi lebih baik dibandingkan dengan background smoothing. Sistem klasifikasi ini bergantung pada dokumen yang digunakan sehingga sistem ini hanya untuk dokumen pertanian.
KESIMPULAN DAN SARAN Kesimpulan
Semantic smoothing merupakan teknik smoothing yang mengandalkan topic signature dan keterkaitan kata. Hasil yang didapatkan dari penelitian ini adalah tingkat akurasi semantic smoothing yang cukup tinggi. Hal ini juga dipengaruhi oleh dokumen pertanian yang masing-masing dokumen memiliki kata yang relatif sama. Akurasi yang didapatkan metode semantic smoothing lebih tinggi dibandingkan dengan hasil yang didapatkan background smoothing.
Kinerja metode semantic smoothing menghasilkan akurasi lebih tinggi pada long document yaitu 95.55% dibandingkan dengan short document dangan nilai akurasi 90.22%, karena banyaknya kata yang terdapat pada dokumen uji cukup mempengaruhi nilai peluang yang akan digunakan untuk klasifikasi. Semantic smoothing menghasilkan akurasi dengan rata-rata 92.88%. Hasil klasifikasi semantic smoothing dipengaruhi oleh keterkaitan kata atau pasangan kata yang ada pada dokumen latih dan dokumen uji..
Saran
Perlu dilakukan penelitian untuk menentukan topic signature yang lebih baik, yaitu dengan mengambil tiga pasangan kata atau lebih. Disamping itu dapat dilakukan analisis lebih dalam untuk topic signature dan pengetahuan mengenai semantik. Klasifikasi selanjutnya dapat menggunakan penggabungan metode Semantic Smoothing dengan metode klasifikasi lainnya.
DAFTAR PUSTAKA
Hamel L. 2008. Model Assessment with ROC Curves. The Encyclopedia of Data Warehousing and Mining. 2nd Edition. Idea Group Publisher.
10
Liu X, Croft WB. 2004. Statistical Language Modeling for Information Retrieval. Annual Review of Information Science and technology, vol.39, pp.3-31.
Manning CD, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval. New York : Cambridge University Press. Pramurjadi A. 2010. Klasifikasi Dokumen Menggunakan Background Smoothing [skripsi]. Bogor. Departemen Ilmu Komputer Institut Pertanian Bogor. Zhai C, Lafferty J. 2001. A study of
Smoothing Methods for Language Models Applied to Ad Hoc Information Retrieval, Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval
(SIGIR’01), hlm 334-342.
Zhou X, Zhang X, Hu X. 2007. Topic Signature Language Model for Ad Hoc Retrieval. J IEEE Trans Knowledge and data Eng(TKDE).19:9: 1276-1287.
12 Lampiran 1 Antarmuka Sistem Klasifikasi Semantic Smoothing
13 Lampiran 3. Hasil Klasifikasi Dokumen Uji pada Short Document
Class a b c
Fisologi dan agronomi a 24 1 0
Pemuliaan dan tek. Benih b 2 23 0
Proteksi c 1 1 23
Fisiologi & Agronomi Pemulian & Tek.Benih Proteksi
a b+c b a+c c a+b
a 21 4 b 20 5 c 23 2
b+c 6 44 a+c 2 48 a+b 3 47
recall a = 88,8% recall b = 90,9% recall c = 92,00% prec a = 96,0% prec b = 80,0% prec c = 100,00% f1 = 92,3% f1 = 85,1% f1 = 95,83% akurasi = 94,6% akurasi = 90,6% akurasi = 97,33%
Lampiran 4. Hasil Klasifikasi Dokumen Uji pada Long Document
Class a b c
Fisologi dan agronomi a 21 1 3
Pemuliaan dan tek. Benih b 5 20 0
Proteksi c 1 1 23
Fisiologi & Agronomi Pemulian & Tek.Benih Proteksi
a b+c b a+c c a+b
a 24 1 b 23 2 c 23 2
b+c 3 47 a+c 2 48 a+b 0 50
1
PENDAHULUAN Latar Belakang
Saat ini jumlah dokumen semakin banyak dan beragam sejalan dengan bertambahnya waktu dan teknologi. Jika jumlah dokumen semakin bertambah banyak maka proses pencarian dan penyajian dokumen semakin sukar, sehingga akan lebih mudah jika dokumen tersebut sudah tersedia sesuai dengan kategorinya masing-masing. Salah satu metode yang dapat membantu mengorganisasikan dokumen sesuai dengan ketegorinya adalah klasifikasi. Klasifikasi dokumen adalah proses menggolongkan suatu dokumen ke dalam suatu kategori tertentu (Manning et al 2008). Terdapat beberapa metode klasifikasi dokumen, yaitu Naïve bayes, k-nearest neighbor, decision trees, neural network dan support vector machine. Naïve bayes classifier (NBC) merupakan algoritme klasifikasi yang mudah diimplementasikan jika dibandingkan dengan algoritme lain dan disebut sebagai simple bayesian classification. Masalah umum yang sering terjadi pada metode tersebut adalah saat kata atau terms yang merupakan penciri dari data uji (testing) tidak ditemukan pada penciri pada dokumen latih (training) yang biasa disebut sparsity data. Salah satu penyebab yang bisa mengakibatkan sparsity data adalah saat ukuran data latih (training) yang digunakan terlalu kecil, sehingga peluang penciri dokumen uji ada pada dokumen latih juga sedikit. Untuk membantu menghindari masalah tersebut, dapat digunakan metode smoothing.
Metode smoothing memberikan nilai pada term yang tersembunyi untuk menambah tingkat keakurasian dari penduga peluang kata yang terdapat pada dokumen latih. Beberapa metode smoothing yang telah dihasilkan yaitu dirichlet prior, witten-bell, jelinek-mercer, kneiser-ney, katz, good turing estimation, background smoothing dan semantic smoothing dengan pendekatan language modeling (Zhou et al 2008).
Proses klasifikasi dokumen umumnya memiliki kesalahan makna kata, sehingga terjadi ketidakcocokan antara dokumen testing dengan dokumen training. Kesalahan makna kata terjadi saat kata yang ada pada dokumen memiliki banyak makna. Semantik merupakan pasangan kata yang terdiri atas dua kata atau lebih. Keterkaitan kata yang
ada pada semantik akan berubah makna jika hanya memperhatikan satu kata. Kesalahan makna dalam mengartikan semantik ini yang dapat memicu kekeliruan dalam klasifikasi dokumen, sehingga dibutuhkan metode yang memperhatikan keterkaitan kata untuk klasifikasi dokumen yaitu metode semantic smoothing.
Sebelumnya metode background smoothing telah dilakukan oleh Pramurjadi (2010). Hasil klasifikasi dengan background smoothing belum memuaskan karena metode ini tidak memperhatikan keterkaitan kata yang ada di dalam dokumen. Diharapkan penelitian klasifikasi menggunakan metode semantic smoothing ini dapat lebih meningkatkan tingkat akurasi dan membantu dalam mengelompokkan dokumen.
Tujuan
Tujuan penelitian ini yaitu melihat pengaruh metode semantic smoothing pada klasifikasi dokumen dan membandingkan tingkat akurasi klasifikasi antara hasil metode background smoothing dan semantic smoothing.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada hasil keakurasian klasifikasi dokumen menggunakan metode semantic smoothing pada short document dan long document. Pasangan kata atau semantik yang didapat tergantung dari pasangan kata yang ada pada dokumen latih. Selain itu, dokumen yang digunakan adalah dokumen berbahasa Indonesia mengenai tanaman holtikultura dari bidang pertanian.
Manfaat Penelitian
Manfaat dari hasil penelitian ini diharapkan dapat menambah khazanah metode klasifikasi dokumen dan membantu dalam mengorganisasikan dokumen, sehingga mempermudah dalam menyajikan dan pencarian dokumen.
TINJAUAN PUSTAKA Temu Kembali Informasi
1
PENDAHULUAN Latar Belakang
Saat ini jumlah dokumen semakin banyak dan beragam sejalan dengan bertambahnya waktu dan teknologi. Jika jumlah dokumen semakin bertambah banyak maka proses pencarian dan penyajian dokumen semakin sukar, sehingga akan lebih mudah jika dokumen tersebut sudah tersedia sesuai dengan kategorinya masing-masing. Salah satu metode yang dapat membantu mengorganisasikan dokumen sesuai dengan ketegorinya adalah klasifikasi. Klasifikasi dokumen adalah proses menggolongkan suatu dokumen ke dalam suatu kategori tertentu (Manning et al 2008). Terdapat beberapa metode klasifikasi dokumen, yaitu Naïve bayes, k-nearest neighbor, decision trees, neural network dan support vector machine. Naïve bayes classifier (NBC) merupakan algoritme klasifikasi yang mudah diimplementasikan jika dibandingkan dengan algoritme lain dan disebut sebagai simple bayesian classification. Masalah umum yang sering terjadi pada metode tersebut adalah saat kata atau terms yang merupakan penciri dari data uji (testing) tidak ditemukan pada penciri pada dokumen latih (training) yang biasa disebut sparsity data. Salah satu penyebab yang bisa mengakibatkan sparsity data adalah saat ukuran data latih (training) yang digunakan terlalu kecil, sehingga peluang penciri dokumen uji ada pada dokumen latih juga sedikit. Untuk membantu menghindari masalah tersebut, dapat digunakan metode smoothing.
Metode smoothing memberikan nilai pada term yang tersembunyi untuk menambah tingkat keakurasian dari penduga peluang kata yang terdapat pada dokumen latih. Beberapa metode smoothing yang telah dihasilkan yaitu dirichlet prior, witten-bell, jelinek-mercer, kneiser-ney, katz, good turing estimation, background smoothing dan semantic smoothing dengan pendekatan language modeling (Zhou et al 2008).
Proses klasifikasi dokumen umumnya memiliki kesalahan makna kata, sehingga terjadi ketidakcocokan antara dokumen testing dengan dokumen training. Kesalahan makna kata terjadi saat kata yang ada pada dokumen memiliki banyak makna. Semantik merupakan pasangan kata yang terdiri atas dua kata atau lebih. Keterkaitan kata yang
ada pada semantik akan berubah makna jika hanya memperhatikan satu kata. Kesalahan makna dalam mengartikan semantik ini yang dapat memicu kekeliruan dalam klasifikasi dokumen, sehingga dibutuhkan metode yang memperhatikan keterkaitan kata untuk klasifikasi dokumen yaitu metode semantic smoothing.
Sebelumnya metode background smoothing telah dilakukan oleh Pramurjadi (2010). Hasil klasifikasi dengan background smoothing belum memuaskan karena metode ini tidak memperhatikan keterkaitan kata yang ada di dalam dokumen. Diharapkan penelitian klasifikasi menggunakan metode semantic smoothing ini dapat lebih meningkatkan tingkat akurasi dan membantu dalam mengelompokkan dokumen.
Tujuan
Tujuan penelitian ini yaitu melihat pengaruh metode semantic smoothing pada klasifikasi dokumen dan membandingkan tingkat akurasi klasifikasi antara hasil metode background smoothing dan semantic smoothing.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada hasil keakurasian klasifikasi dokumen menggunakan metode semantic smoothing pada short document dan long document. Pasangan kata atau semantik yang didapat tergantung dari pasangan kata yang ada pada dokumen latih. Selain itu, dokumen yang digunakan adalah dokumen berbahasa Indonesia mengenai tanaman holtikultura dari bidang pertanian.
Manfaat Penelitian
Manfaat dari hasil penelitian ini diharapkan dapat menambah khazanah metode klasifikasi dokumen dan membantu dalam mengorganisasikan dokumen, sehingga mempermudah dalam menyajikan dan pencarian dokumen.
TINJAUAN PUSTAKA Temu Kembali Informasi
2
komputer (Manning et al 2008). Sistem temu kembali informasi melakukan proses yang secara otomatis menemukan kembali informasi dari sekumpulan informasi yang relevan dengan kebutuhan pengguna.
Gambar 1 Proses Sistem Temu Kembali Informasi (Hiemstra 2001)
Tiga komponen dasar dalam temu kembali informasi adalah representasi dokumen, representasi informasi kebutuhan pengguna dan perbandingan dari kedua representasi tersebut. Representasi dokumen adalah pengindeksan seperti tokenisasi kata, membuang stopwords, dan pembobotan indeks. Pembobotan kata indeks dilakukan dengan menentukan kata term yang menjadi penciri dokumen. Tiap dokumen dianggap sebagai vektor dengan elemen sebanyak term dan beranggotakan bobot tiap term. Salah satu metode pembobotan untuk menghitung bobot term adalah tf.idf. Informasi yang dibutuhkan oleh pengguna dalam penentuan kata untuk pencarian disebut query. Query merupakan informasi yang tidak memiliki struktur sehingga masih perlu diformulasikan. Perbandingan query dengan permintaan informasi disebut proses penyesuaian. Proses ini dapat dilihat pada Gambar 1 yang menghasilkan suatu keluaran yang diharapkan relevan dengan permintaan pengguna.
Klasifikasi
Klasifikasi dokumen merupakan proses menemukan sekumpulan model yang mendeskripsikan dan membedakan
kelas-kelas data sesuai dengan kategori yang dimilikinya. Tujuan klasifikasi untuk memprediksikan kelas dari objek yang belum diketahui kelasnya dengan karakteristik tipe data yang bersifat kategorik. Proses klasifikasi dibagi menjadi dua fase, yaitu learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase test, model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk memprediksi kelas data yang belum diketahui.
Metode klasifikasi dokumen secara otomatis memiliki tingkat keakuratan yang cukup tinggi jika aturan dibuat dengan baik. Metode tersebut dibagi menjadi dua, yaitu klasifikasi secara manual dan klasifikasi secara otomatis. Pada klasifikasi manual dilakukan oleh tenaga ahli sehingga cukup akurat, tetapi butuh waktu yang lama, sedangkan klasifikasi dokumen secara otomatis terdiri atas dua kategori, yaitu hand-coded rule-based systems dan supervised learning (Manning et al 2008). Hand-coded rule-based systems tingkat akurasinya tinggi jika rule dibuat dengan sangat baik dan kompleks serta butuh biaya yang mahal. Supervised learning menggunakan data latih untuk memberikan label kategori yang telah terdefinisi sebelumnya. Beberapa model yang digunakan dalam supervised learning adalah naive bayes, bernoulli, vector space model, k-nearest neighbors dan maximum a posteriori.
Naive Bayes Classifier (NBC)
Naive bayes classifier merupakan penyederhanaan dari bayesian classification dan biasa disebut simple bayesian classification. Klasifikasi NBC termasuk dalam multinomial yang mengambil jumlah kata yang muncul pada sebuah dokumen. Pada model ini, sebuah dokumen terdiri atas beberapa kejadian kata dan diasumsikan panjang dokumen tidak bergantung pada kelasnya. Lainnya adalah kemungkinan tiap kejadian kata dalam sebuah dokumen adalah bebas dan tidak terpengaruh dengan konteks kata atau posisi kata dalam dokumen. NBC merupakan metode klasifikasi dengan cara menghitung peluang sebuah dokumen d berada di kelas c (Manning et al 2008). Dokumen
retrieved Feedback
Dokumen
Query Dokumen terindeks
Penyesuaian Kebutuhan
3
Peluang dari suatu dokumen d ada pada kelas c adalah :
P(c|d) ∞ P(c) ∏1 ≤ k ≤ n d P(tk|c)
dengan P(c|d) adalah nilai penduga peluang dokumen d dikelaskan ke dalam kelas c, P(tk|c) merupakan peluang kata atau term ke-k yang muncul pada dokumen kelas c, dengan perkalian k yang merupakan term sebanyak n, dan P(c) merupakan peluang dari dokumen yang ada di dalam kelas c. Pendekatan yang digunakan untuk menduga P(c) dan P(tk|c) adalah :
P(c) =
P(tk|c) = ( )
dimana Ncadalah banyaknya dokumen yang ada di dalam kelas c dan N adalah total seluruh dokumen yang ada. P(tk|c) dimaksudkan sebagai ukuran seberapa banyak term ke-k menunjukkan c merupakan kelas yang tepat untuk dokumen d dan Tctadalah banyaknya t dalam dokumen latih kelas c.
Laplace smoothing (LS) berguna untuk menghilangkan dugaan parameter yang bernilai nol. LS merupakan teknik smoothing yang biasa digunakan dalam perhitungan Maximum Likelihood Estimation (MLE). Maximum Likelihood Estimation atau pengelompokan kemungkinan terbesar adalah algoritme dengan pendekatan supervised classification yang paling sering digunakan. Laplace smoothing disebut add-one karena ada penambahan satu nilai pada notasi tertentu. Formula laplace smoothing adalah:
P(t|c) = ( ) =
( )
notasi B’ merupakan banyaknya term dalam kosa kata dan adalah banyaknya kata unik yang menghitung satu nilai untuk term yang muncul lebih dari satu. Kelas terbaik pada klasifikasi NBC adalah kelas yang paling mirip dengan dokumen yang ingin diklasifikasikan atau yang memiliki nilai posteriori tertinggi (Maximum a Posteriori).
Language Model
Dalam bidang Information Retrieval (IR), Language Model (LM) yang digunakan adalah unigram model karena urutan kata tidak terlalu dipermasalahkan. Penggunaan
LM atau statistical language modeling muncul sebagai probabilistic framework yang baru untuk menangkap ketidakteraturan statistik yang menjadi ciri dari ketidakteraturan penggunaan bahasa. Sebuah LM adalah suatu model mengenai sebaran bersyarat dari identitas kata dalam rangkaian, ditentukan oleh identitas dari semua kata sebelumnya. Salah satu model temu kembali informasi yang menggunakan LM adalah query-likelihood model yang diusulkan Ponte dan Croft (dalam Liu & Croft 2004) yang menganggap query sebagai vektor dari atribut biner, masing-masing atribut untuk sebuah istilah yang unik di dalam kosa kata indeks dan menandakan ada atau tidaknya istilah tersebut di dalam query. Ada dua asumsi yang mendasari model ini, pertama adalah semua atribut biner. Jika sebuah istilah ada di query maka atribut yang mewakili istilah tersebut adalah 1 dan jika sebaliknya adalah 0. Kedua, istilah dianggap tidak berkaitan di dalam sebuah dokumen. Asumsi ini mirip dengan dugaan yang digunakan dalam teori-teori peluang pada temu kembali informasi.
Background dan Semantic Smoothing
Smoothing berfungsi membandingkan peluang kata yang muncul dan tidak muncul dalam suatu dokumen. Smoothing merupakan bagian penting dari LM yang akan menambah keakurasian perkiraan peluang kata yang ada pada dokumen latih dengan cara memberi nilai peluang pada kata yang tidak muncul. Smoothing sebagai pengontrol MLE agar hasilnya lebih akurat (Zhai 2001). Dalam metode semantic smoothing, teknik simple language model atau background collection model disebut background smoothing (Zhou et al 2008). Background smoothing menduga peluang dari kata yang tidak muncul berdasarkan background model atau seluruh dokumen latih. Formula background smoothing yaitu: Pb(t|cj) = (1-λ) Pm l (t|cj) + λP(t|D) ...(1)
Model kelas unigram dengan pendugaan parameter adalah Pml (t|cj), sedangkan Pb(t|cj) merupakan model kelas unigram dengan background smoothing, dan P(t|D) merupakan peluang kata yang ada pada dokumen.
4
Ps(t|ci)=(1-λ)Pb(t|ci)+ λ�P(t|wk)P(wk|ci) ..(2)
dengan Ps(t|ci) adalah model kelas unigram dengan semantic smoothing dan wk merupakan topic signature, P(t|wk) merupakan peluang kata dalam dokumen uji yang terdapat dalam topic signature, sedangkan P(wk|ci) adalah kata dalam kumpulan topic signature dalam dokumen latih, dan Pb(t|ci) merupakan nilai hasil dari formula background smoothing.
Dua metode ini menggunakan koefisien
λ dari collection background model dalam
semantic smoothing. Kriteria tersebut digunakan sebagai komponen pengontrol pada pemetaan topic signature sebagai model campuran atau mixture model (Zhou et al 2007). Koefisien ini dapat mengatur komposisi antara komponen background smoothing dan semantic smoothing.
Semantic smoothing merupakan salah satu teknik dari language model. Metode ini digunakan untuk mendekomposisi sebuah dokumen ke dalam suatu set dari kata atau frase yang terdiri atas beberapa kata, dengan memetakannya menggunakan perhitungan statistika (maximum likelihood estimation) ke dalam kata yang berdiri sendiri.
Confusion Matrix
Confusion matrix disebut juga matriks klasifikasi yang menjadi suatu alat visual dalam supervised learning. Confusion matrix merupakan sebuah tabel (Tabel 1) yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi, digunakan untuk menentukan kinerja suatu model klasifikasi. Tabel 1. Confusion Matrix (Hammel 2008)
Observed
True False
Predicted Class True True Positive (TP) False Positive (FP) False False Negative (FN) True Negative (TN)
Pada kasus yang diklasifikasikan dengan benar muncul pada diagonal, hal ini disebabkan kelompok prediksi dan kelompok aktual adalah sama. Elemen yang selain diagonal menunjukkan kasus yang
salah diklasifikasikan. Jumlah elemen diagonal dibagi total jumlah kasus adalah rasio tingkat akurasi dari klasifikasi. Untuk evaluasi kesamaan dokumen dapat diukur dengan recall, precision dan F-measure.
Recall merupakan evaluasi untuk mengetahui tingkat keberhasilan kinerja user dalam observasi yang telah dilakukan. Recall (R) dinyatakan dalam jumlah pengenalan entitas bernilai benar dibagi jumlah entitas yang dikenali sistem. Precision (P) adalah tingkat ketepatan hasil klasifikasi dan jumlah keseluruhan pengenalan yang dilakukan sistem.
F-measure (F) adalah nilai yang lebih dipengaruhi kinerja sistem dibandingkan dengan user. Formula di atas merupakan recall dan precision dimana [ ] dan
[ ] dengan =1/2 atau =1,
sehingga formula F-measure menjadi :
Akurasi dari klasifikasi dapat diperoleh dari penjumlahan true positif dan true negatif dibagi total untuk melihat kinerja secara keseluruhan.
METODOLOGI PENELITIAN Gambaran Umum Sistem
Alur dari penelitian secara garis besar ditunjukkan pada Gambar 2. Beberapa tahap dari sistem yaitu pengumpulan dokumen, praproses, ekstraksi topic signature, semantic smoothing, kategori dokumen testing yang dihasilkan dan evaluasi hasil klasifikasi.
4
Ps(t|ci)=(1-λ)Pb(t|ci)+ λ�P(t|wk)P(wk|ci) ..(2)
dengan Ps(t|ci) adalah model kelas unigram dengan semantic smoothing dan wk merupakan topic signature, P(t|wk) merupakan peluang kata dalam dokumen uji yang terdapat dalam topic signature, sedangkan P(wk|ci) adalah kata dalam kumpulan topic signature dalam dokumen latih, dan Pb(t|ci) merupakan nilai hasil dari formula background smoothing.
Dua metode ini menggunakan koefisien
λ dari collection background model dalam
semantic smoothing. Kriteria tersebut digunakan sebagai komponen pengontrol pada pemetaan topic signature sebagai model campuran atau mixture model (Zhou et al 2007). Koefisien ini dapat mengatur komposisi antara komponen background smoothing dan semantic smoothing.
Semantic smoothing merupakan salah satu teknik dari language model. Metode ini digunakan untuk mendekomposisi sebuah dokumen ke dalam suatu set dari kata atau frase yang terdiri atas beberapa kata, dengan memetakannya menggunakan perhitungan statistika (maximum likelihood estimation) ke dalam kata yang berdiri sendiri.
Confusion Matrix
Confusion matrix disebut juga matriks klasifikasi yang menjadi suatu alat visual dalam supervised learning. Confusion matrix merupakan sebuah tabel (Tabel 1) yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi, digunakan untuk menentukan kinerja suatu model klasifikasi. Tabel 1. Confusion Matrix (Hammel 2008)
Observed
True False
Predicted Class True True Positive (TP) False Positive (FP) False False Negative (FN) True Negative (TN)
Pada kasus yang diklasifikasikan dengan benar muncul pada diagonal, hal ini disebabkan kelompok prediksi dan kelompok aktual adalah sama. Elemen yang selain diagonal menunjukkan kasus yang
salah diklasifikasikan. Jumlah elemen diagonal dibagi total jumlah kasus adalah rasio tingkat akurasi dari klasifikasi. Untuk evaluasi kesamaan dokumen dapat diukur dengan recall, precision dan F-measure.
Recall merupakan evaluasi untuk mengetahui tingkat keberhasilan kinerja user dalam observasi yang telah dilakukan. Recall (R) dinyatakan dalam jumlah pengenalan entitas bernilai benar dibagi jumlah entitas yang dikenali sistem. Precision (P) adalah tingkat ketepatan hasil klasifikasi dan jumlah keseluruhan pengenalan yang dilakukan sistem.
F-measure (F) adalah nilai yang lebih dipengaruhi kinerja sistem dibandingkan dengan user. Formula di atas merupakan recall dan precision dimana [ ] dan
[ ] dengan =1/2 atau =1,
sehingga formula F-measure menjadi :
Akurasi dari klasifikasi dapat diperoleh dari penjumlahan true positif dan true negatif dibagi total untuk melihat kinerja secara keseluruhan.
METODOLOGI PENELITIAN Gambaran Umum Sistem
Alur dari penelitian secara garis besar ditunjukkan pada Gambar 2. Beberapa tahap dari sistem yaitu pengumpulan dokumen, praproses, ekstraksi topic signature, semantic smoothing, kategori dokumen testing yang dihasilkan dan evaluasi hasil klasifikasi.
5
[image:30.595.95.293.91.591.2]formula semantic smoothing. Setelah proses indexing terdapat proses ekstraksi topic signature yang sangat berpengaruh pada penelitian ini, langkah selanjutnya adalah metode klasifikasi semantic smoothing. Kategori dokumen testing yang sudah diketahui hasil kelasnya akan melewati proses evaluasi hasil.
Gambar 2 Gambaran Umum Sistem Data Penelitian
Data Penelitian yang digunakan adalah hasil penelitian dari Jurnal Penelitian Holtikultura tahun 2002 sampai dengan tahun 2009. Adapun pembagian jenis tanaman holtikultura yaitu komoditas buah tropik, buah sub tropik, tanaman hias dan sayuran. Dokumen tersebut terbagi menjadi tiga bidang penelitian yaitu ekofisiologi-agronomi, pemuliaan-teknologi benih dan proteksi. Koleksi dokumen yang digunakan dibagi menjadi 70% dokumen latih dan 30% dokumen uji. Pengujian pada dokumen uji terbagi dua jenis yaitu short document dan long document.
Praproses
Tahapan awal dalam proses klasifikasi setelah dokumen tersedia adalah praproses. Tahap pertama yang dilakukan saat praproses adalah pengelompokan dokumen sesuai dengan kelas atau kategori yang ditentukan. Tahap kedua yaitu proses indexing. Proses ini bertujuan mengekstrak kata dari dokumen. Dalam proses indexing terdapat langkah awal yaitu parsing, memilah dokumen menjadi unit yang lebih kecil berupa kata. Setelah itu membuang kata yang sering muncul dan bukan merupakan penciri dokumen yang biasa disebut stopwords. Selanjutnya dilakukan pembobotan indeks dengan menghitung term frekuensi dari setiap dokumen yang ada di koleksi dokumen dan pembobotan tf.idf pada setiap term. File yang telah didapatkan akan dibagi menjadi data training dan data testing.
Ekstraksi Topic Signature
Topic signature memiliki peranan penting dalam semantic smoothing. Ekstraksi topic signature yang membantu proses pencarian kedekatan semantik berdasarkan frase itu sendiri dan set dari kata yang mengandung frase tersebut. Proses pertama yang dilakukan adalah membuat deretan pasangan kata sesuai dengan keterkaitan kata yang ada. Dalam penelitian ini, list pasangan kata didapatkan dari dokumen latih yang kemudian dijadikan korpus semantik (topic signature).
Topic signature berisi pasangan kata yang telah terpilih. Penelitian ini berfokus pada pasangan kata yang terdiri atas dua kata. Seluruh kata yang terdapat di dokumen latih dijadikan pasangan kata setelah stopwords dibuang. Selanjutnya mencari peluang untuk tiap pasangan kata, kemudian di ekstraksi dengan memilih pasangan kata yang memiliki peluang tinggi dengan batasan tertentu dan membuang pasangan kata yang memiliki nilai peluang kecil. Langkah untuk membuat topic signature adalah :
1. Pasangan kata dicari dengan mendapat kata unik terlebih dahulu, kata unik yang berarti tidak ada stopword dan tidak ada kata yg sama atau berulang.
6
“tanaman hama penyakit wereng”Hasil : “tanaman hama”
“hama penyakit”
“penyakit wereng”
3. Setelah didapatkan deretan pasangan kata, kemudian dihitung peluang kemunculan masing-masing pasangan kata yang terdapat pada dokumen. 4. Peluang pasangan kata yang telah
didapatkan dapat digunakan untuk mengetahui frekuensi kemunculan semantik atau pasangan kata pada dokumen.
5. Jika terdapat pasangan kata yang memiliki peluang kemunculan terlalu kecil, maka lakukan proses pembuangan pada pasangan kata tersebut. Karena pasangan kata yang peluang kemunculannya terlalu kecil bukan merupakan penciri dokumen.
Pasangan kata atau topic signature ini yang mempengaruhi klasifikasi semantic smoothing, karena pasangan kata dokumen yang akan diuji akan mendapatkan nilai peluang yang bergantung pada pasangan kata dari topic signature.
Background dan Semantic Smoothing
Metode semantic smoothing dilakukan untuk memudahkan proses klasifikasi dokumen yang menggunakan metode NBC. Semantic smoothing sebagai parameter kontrol untuk menjadikan hasil klasifikasi menjadi akurat. Proses pertama yang dilakukan adalah menghitung peluang berdasarkan kata yang terdapat pada dokumen uji. Proses yang telah dilakukan oleh Pramurjadi (2010) menggunakan formula (1) dengan pendugaan parameter peluang pada dokumen oleh background smoothing. Proses berikutnya adalah yang dilakukan pada penelitian ini menggunakan semantic smoothing. Metode semantic smoothing sesuai dengan formula (2) dilakukan dengan menambah perhitungan probability, perhitungan tiap kata yang ada di korpus semantik. Metode semantic smoothing memiliki formula yang di dalamnya terdapat formula background smoothing. Teknik semantic smoothing merupakan penambahan parameter pada formula dari background smoothing. Setelah didapatkan peluang tiap kata dari dokumen uji berdasarkan topic signature dan kelas pada dokumen latih, proses dilanjutkan
dengan menghitung peluang tiap kelas terhadap dokumen uji.
Evaluasi Hasil Klasifikasi
Evaluasi hasil klasifikasi dokumen dilakukan untuk mengetahui tingkat keakurasian klasifikasi semantic smoothing. Evaluasi dilakukan pada hasil kelas untuk data testing yang terbagi menjadi short document dan long document. Selanjutnya membandingkan hasil klasifikasi dokumen antara background smoothing dan semantic smoothing. Perbandingan hasil kedua metode tersebut dengan melakukan pengukuran kesamaan menggunakan recall, precision, f-measure atau F-1, tabel confusion matrix dan tingkat akurasi.
HASIL DAN PEMBAHASAN Dokumen ya