SPATIO
-
TEMPORAL
CLUSTERING
HOTSPOT
DI SUMATERA
SELATAN TAHUN 2002-2003 MENGGUNAKAN
ALGORITME ST-DBSCAN DAN BAHASA
PEMROGRAMAN PYTHON
COLIN SABATINI LUMBAN TOBING
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Spatio-temporal Clustering Hotspot di Sumatera Selatan Tahun 2002-2003 Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Colin Sabatini Lumban Tobing
ABSTRAK
COLIN SABATINI LUMBAN TOBING. Spatio-temporal Clustering Hotspot di Sumatera Selatan Tahun 2002-2003 Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python. Dibimbing oleh HARI AGUNG ADRIANTO.
Beberapa tahun terakhir ini isu kebakaran hutan di Sumatera meningkat secara dramatis sehingga menarik perhatian dunia internasional. Data hotspot
yang dipantau menggunakan satelit dapat dijadikan indikator terjadinya kebakaran di permukaan bumi. Salah satu pendekatan untuk menganalisis dataset hotspot
adalah spatio-temporal clustering yang dapat mengenali pola kejadian hotspot
berdasarkan ruang dan waktu. Penelitian ini menerapkan clustering menggunakan ST-DBSCAN pada data hotspot di Sumatera Selatan tahun 2002-2003. Sebagai bahasa pemrograman yang multiparadigma, Python dipilih agar algoritme ST-DBSCAN dapat bekerja dengan cepat. Dengan menggunakan parameter jarak spasial (Eps1) 22 km, jarak temporal (Eps2) 7 hari, dan kepadatan cluster (MinPts)
7 didapat 41 cluster dengan banyak pola stationary pada kabupaten Musi Banyu Asin. Rata-rata runtime eksekusi ST-DBSCAN menggunakan Python berdurasi 4.934 detik.
Kata kunci: kebakaran hutan, Python, spatio-temporalclustering, ST-DBSCAN
ABSTRACT
COLIN SABATINI LUMBAN TOBING. Spatio-temporal Clustering on South Sumatera Hotspot in Year 2002-2003 Using ST-DBSCAN Algorithm and Python Programming Language. Supervised by HARI AGUNG ADRIANTO.
These last few years the issues of forest fire in Sumatera increase dramatically, attracting international attention. Hotspot data which are monitored using satellites can be used as an indicator of the occurrence of fire on the Earth's surface. One approach to analyze hotspot dataset is spatio-temporal clustering which can recognize patterns of hotspot event based on space and time. This study applies ST-DBSCAN clustering using hotspot data in South Sumatera 2002-2003. As multi-paradigm programming language, Python is chosen so that ST-DBSCAN algorithm can work fast. By using spatial distance (Eps1) 22 km, temporal distance (Eps2) 7 days, and density of cluster (MinPts) 7, 41 clusters were found to have many stationary patterns in Musi Banyu Asin. The average ST-DBSCAN execution runtime using Python was 4.934 seconds.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
SPATIO
-
TEMPORAL
CLUSTERING
HOTSPOT
DI SUMATERA
SELATAN TAHUN 2002-2003 MENGGUNAKAN
ALGORITME ST-DBSCAN DAN BAHASA
PEMROGRAMAN PYTHON
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji:
Judul Skripsi : Spatio-temporalClusteringHotspot di Sumatera Selatan Tahun 2002-2003 Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python
Nama : Colin Sabatini Lumban Tobing NRP : G64100065
Disetujui oleh
Hari Agung Adrianto, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Judul yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2014 ini ialah Spatio
-temporal Clustering Hotspot di Sumatera Selatan Tahun 2002-2003 Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python.
Terima kasih penulis ucapkan kepada seluruh keluarga atas segala doa dan kasih sayangnya. Ungkapan terima kasih juga disampaikan kepada Bapak Hari Agung Adrianto, SKom MSi selaku pembimbing yang telah membina dan membantu dalam penelitian ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2014
DAFTAR ISI
Penghitungan Jarak Menggunakan Metrik Euclidean 5
Pola Penyebaran Hotspot 5
Sumber Data dan Karakteristik Data 9
Praproses Data 10
Penentuan Nilai Parameter 10
Implementasi ST-DBSCAN Menggunakan Python 11
Hasil Clustering ST-DBSCAN 12
Saran 17
DAFTAR PUSTAKA 18
LAMPIRAN 20
DAFTAR TABEL
1 Jarak derajat lintang dan bujur (Kirvan 1997) 9
2 Contoh transformasi tanggal ke format number 10
3 Atribut hotspot 10
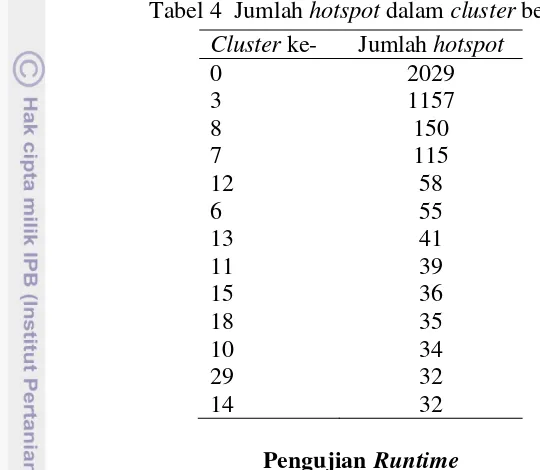
4 Jumlah hotspot dalam cluster besar 12
5 Pola hotspot yang ditemukan di Sumatera Selatan 14
DAFTAR GAMBAR
1 Core-point, border-point, dan noise (Verma 2009) 3 2 Directly density-reachable, density-reachable, dan density-connected
(Cassisi 2011) 3
3 Algoritme ST-DBSCAN (Birant dan Kut 2007) 4
4 Ilustrasi pola stationary 5
5 Ilustrasi pola reappearingregular 6
6 Ilustrasi pola reappearingirregular 6
7 Ilustrasi pola occasional 6
8 Ilustrasi pola tracks 6
9 Diagram alir penelitian 7
10 Ilustrasi koefisien Silhouette (Rousseeuw 1987) 8
11 Sumatera Selatan (Purwanto 2012) 9
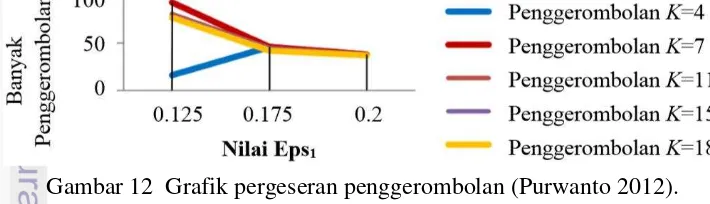
12 Grafik pergeseran penggerombolan (Purwanto 2012) 10 13 Hubungan titik noise dengan Eps1 (Purwanto 2012) 11
14 Grafik persebaran hotspot di Sumatera Selatan tahun 2002-2003 12
15 Hotspot di Sumatera Selatan tahun 2002-2003 13
16 Cluster 18 pada periode 1 (paling kiri), 2, 3 dan 4 (paling kanan) 13 17 Visualisasi cluster secara tiga dimensi (1) 15 18 Visualisasi cluster secara tiga dimensi (2) 16
19 Visualisasi cluster secara dua dimensi 16
DAFTAR LAMPIRAN
1 Implementasi ST-DBSCAN menggunakan Python 20
2 Antarmuka aplikasi ST-DBSCAN 21
PENDAHULUAN
Latar Belakang
Pada musim kemarau, Indonesia sering mengalami kebakaran hutan. Intensitas kebakaran hutan akan semakin meningkat seiring terjadinya peristiwa
El-Niño. Kebakaran hutan di Indonesia tidak hanya terjadi pada lahan kering tetapi juga lahan basah seperti gambut yang akan menghasilkan sangat banyak asap. Beberapa tahun terakhir ini isu kebakaran hutan di Sumatera meningkat secara dramatis sehingga menarik perhatian dunia internasional dikarenakan arus angin serta pola pergerakan udara dari Sumatera telah membawa sebagian besar asap kebakaran ke Singapura dan Malaysia (WRI 2013).
Titik panas (hotspot) di permukaan bumi dapat dipantau dengan metode penginderaan jarak jauh menggunakan satelit. Pemantauan kebakaran hutan dengan satelit ini sering disebut sebagai penentuan hotspot (Thoha 2008). Melihat data NASA tahun 2001-2012, penentuan hotspot di Sumatera berjumlah sekitar 20000 setiap tahun. Dataset hotspot yang diperoleh melalui satelit meliputi data spasial (latitude dan longitude), temporal (waktu/tanggal) dan nonspasial (seperti temperatur), sehingga dapat dikategorikan sebagai datasetspatio-temporal (Rao et al. 2012).
Datasethotspot dapat dijadikan salah satu indikator kemungkinan terjadinya kebakaran di permukaan bumi (Adinugroho et al. 2005). Salah satu pendekatan untuk menganalisis datasethotspot adalah clustering, seperti yang dilakukan pada penelitian Purwanto (2012) menggunakan algoritme DBSCAN dan ST-DBSCAN
– pengembangan dari DBSCAN. Pengelompokkan penyebaran hotspot dengan
clustering dapat dijadikan acuan prediksi kejadian kebakaran hutan berdasarkan pola yang ditemukan pada setiap cluster.
DBSCAN yang termasuk ke dalam kategori density-based clustering algorithm memanfaatkan kepekatan titik-titik dalam suatu wilayah untuk menemukan sebuah cluster. Untuk menghitung kepekatan suatu wilayah, DBSCAN membutuhkan dua parameter, yaitu Eps dan MinPts. Hal ini menyebabkan DBSCAN sangat sensitif terhadap perubahan nilai parameter yang diambil (Han et al. 2001). Sebagai perkembangan DBSCAN, ST-DBSCAN menambahkan satu Eps untuk atribut temporal dan untuk atribut nonspasial (Birant dan Kut 2007).
Pada penilitian ini, algoritme ST-DBSCAN akan diimplementasikan menggunakan Python dengan memodifikasi modul DBSCAN pada package
Scikit-learn. Python sangat unggul dalam mengatur penggunaan memory sehingga diyakinkan dapat mengolah data besar (Ewing 2014). Pada penulisan programnya pun, Python lebih ringkas dibanding bahasa pemrograman lainnya sehingga mudah untuk dimengerti (Pyzo 2013). Python juga merupakan salah satu fasilitas perangkat lunak yang sangat efektif dalam visualisasi cluster menggunakan
package Matplotlib. Terlebih lagi, Python dapat digunakan secara gratis.
Pada penelitian ini akan dilakukan proses data mining pada datasethotspot
2
dapat menghasilkan pola penyebaran hotspot yang dapat dijadikan acuan untuk mengendalikan kebakaran hutan di Indonesia.
Perumusan Masalah
Perumusan masalah dalam penelitian ini ialah bagaimana cara mengimplementasikan algoritme ST-DBSCAN menggunakan Python dan menganalisis pola pada setiap cluster yang dihasilkan.
Tujuan Penelitian
Tujuan dari penelitian ini ialah mengimplementasikan algoritme ST-DBSCAN menggunakan Python dan menemukan pola penyebaran hotspot di Sumatera Selatan.
Manfaat Penelitian
Pola penyebaran hotspot pada hasil penelitian ini diharapkan dapat menjadi acuan prediksi kejadian kebakaran hutan di Sumatera Selatan dan dapat digunakan oleh pihak terkait, di antaranya peneliti di bidang kehutanan, pemerintah, maupun masyarakat.
Ruang Lingkup Penelitian
Dataset hotspot pada penelitian ini dibatasi pada provinsi Sumatera Selatan tahun 2002-2003. Algoritme clustering yang akan digunakan untuk pengolahan
dataset hotspot adalah ST-DBSCAN. Parameter yang digunakan pada penilitan ini hanya mencakup Eps1 (parameter jarak spasial), Eps2 (parameter jarak
temporal), dan MinPts (parameter kepadatan cluster). Implementasi algoritme ST-DBSCAN dilakukan menggunakan bahasa pemrograman Python.
TINJAUAN PUSTAKA
Praproses Data
Praproses diperlukan untuk meningkatkan kualitas data yang selanjutnya akan membantu meningkatkan akurasi dan efisiensi pada proses mining. Tindakan yang dapat dilakukan adalah pembersihan data (mengisi missing value, menghilangkan noisy, membuang pencilan, dan memisahkan data yang
inconsistent), integrasi data (penggabungan data dari berbagai sumber), transformasi, dan reduksi data.
3 Reduksi data dilakukan untuk mengurangi ukuran data tanpa merubah hasil
mining. Reduksi data menghasilkan representasi dataset tereduksi yang berukuran lebih kecil namun memperlihatkan hasil analisis yang sama atau hampir sama. Strategi reduksi data meliputi agregrasi, seleksi subset atribut, reduksi dimensional, dan reduksi jumlah (Han etal. 2012).
Algoritme ST-DBSCAN
Algoritme ST-DBSCAN membutuhkan empat parameter, yaitu Eps1 (ɛ1),
Eps2 (ɛ2), MinPts, dan . Eps1 dan Eps2 adalah parameter jarak untuk atribut
spasial dan temporal yang dapat dihitung dengan metrik Euclidean, Manhattan, Minkowski, dsb. MinPts adalah jumlah minimum objek yang berada dalam jarak Eps1 dan Eps2. Suatu wilayah dinyatakan tinggi kepadatannya jika memiliki
jumlah objek lebih banyak dari nilai MinPts. Parameter digunakan untuk mencegah ditemukannya kombinasi cluster akibat kecilnya perbedaan atribut nonspasial.
Algoritme ST-DBSCAN dimulai dari objek pertama p di D. Jika p
merupakan core-object – suatu objek yang memiliki tetangga minimal sejumlah MinPts dalam radius Eps1 dan Eps2 (dapat dilihat pada Gambar 1), maka
terbentuklah suatu cluster. Algoritme mengembalikan semua objek yang berada dalam jangkauan Eps1 dan Eps2 (directly density-reachable, dapat dilihat pada
Gambar 2) dari p. Jika p adalah border-object – bukan core-object tetapi density-reachable dari core-object lainnya, tidak ada objek-objek lain yang density-reachable dari p, maka algoritme akan mengunjungi objek berikutnya di D. Proses berulang sampai semua objek diproses.
Gambar 1 Core-point, border-point, dan noise (Verma 2009).
(a) (b) (c)
Gambar 2 Directlydensity-reachable, density-reachable, dan density-connected
4
Pada Gambar 3, algoritme dimulai dari objek pertama o1 di D (poin i).
Setelah memproses objek o1, dipilih objek selanjutnya (o2) di D. Jika objek o2
belum termasuk ke dalam cluster manapun (poin ii), fungsi Retrieve_Neighbours dipanggil pada (poin iii). Pemanggilan fungsi Retrieve_Neighbours(o2, Eps1,
Eps2) mengembalikan objek yang berada pada jarak kurang dari parameter Eps1
dan Eps2 dari objek o2.
Gambar 3 Algoritme ST-DBSCAN (Birant dan Kut 2007).
Retrieve_Neighbours(oi, Eps1, Eps2) sama dengan mencari irisan dari
Retrieve_Neighbours(oi, Eps1) dan Retrieve_Neighbours(oi, Eps2). Jika jumlah
objek yang dikembalikan dalam Eps-Neighborhood kurang dari MinPts, maka objek ditetapkan sebagai noise – oi tidak memiliki cukup tetangga untuk
5 dapat berubah pada proses selanjutnya jika density-reachable dari objek-objek lain di D. Kejadian seperti ini sering terjadi pada border-object di cluster.
Jika oi adalah core-object, cluster baru dibuat (poin v). Semua objek yang directly density-reachable dari core-object tersebut juga ditandai sebagai label
cluster baru. Lalu algoritme mengumpulkan objek yang density-reachable secara iteratif menggunakan stack (poin vi). Stack yang dimaksud berguna untuk mencari objek lain yang density-reachable dari objek directly density-reachable – ekspansi
cluster. Jika suatu objek tidak ditandai sebagai noise atau tidak dalam cluster
manapun, dan perbedaan antara nilai rataan cluster dengan nilai objek tersebut kurang dari , maka objek tersebut dilabeli sebagai cluster yang sedang diproses (poin vii). Setelah memproses objek tersebut, algoritme memilih objek selanjutnya di D dan berlanjut sampai semua objek diproses.
Jika dua cluster C1 dan C2 berhimpitan satu sama lain, ketika objek p dapat
menjadi anggota cluster kedua-duanya (border-object antara C1 dan C2).
Algoritme ST-DBSCAN akan menetapkan objek p ke cluster yang terlebih dahulu ditemukan.
Penghitungan Jarak Menggunakan Metrik Euclidean
Banyak pilihan metrik yang dapat digunakan untuk penghitungan jarak. Pada penelitian ini metrik Euclidean dipilih untuk menghitung jarak spasial dan temporal objek. Berikut adalah penghitungan jarak menggunakan Euclidean antara titik i dan j:
d i,j = √(xi1-xj1)2+(xi2-xj2)2+…+(xin-xjn)2
dengan i = (xi1, xi2, … , xin) dan j = (xj1, xj2, … , xjn) adalah n-dimensi objek (Han
etal. 2012).
Pola Penyebaran Hotspot
Dengan menggunakan berbagai macam algoritme clustering, hasil cluster
yang diperoleh pasti memiliki kesamaan baik secara spasial maupun temporal. Kita dapat mendeteksi tipe-tipe cluster (stationary, reappearing, occasional, dan
tracks) berdasarkan Pöelitz dan Andrienko (2010). Tipe-tipe cluster dapat dikelompokkan sebagai berikut:
1 Stationary
Cluster dibatasi secara spasial dan diperluas secara temporal pada rentang waktu penelitian. Sebagai contoh, kejadian pada lokasi x di rentang t1, t2, t3, …,
tn dengan t1-tn masih dalam rentang waktu penelitian yang diilustrasikan pada Gambar 4.
6
2 Reappearing
Beberapa cluster temporal terjadi dalam lokasi yang sama dan dipisahkan oleh interval waktu. Tipe clusterreappearing dibagi menjadi dua:
a Regular (periodik)
Cluster dipisahkan pada interval yang kira-kira hampir sama pada setiap kemunculan objek. Sebagai contoh, kejadian pada lokasi x dan waktu t1, t3,
t5, …, tn dengan perbedaan waktu t1-t3= 2 minggu, t3-t5 = 2 minggu, begitu seterusnya hingga tn yang diilustrasikan pada Gambar 5.
t1 t2 t3 t4 t5 t6 Gambar 5 Ilustrasi pola reappearingregular. b Irregular
Cluster dipisahkan pada interval waktu yang berbeda-beda. Sebagai contoh, kejadianpada lokasi x dan waktu t1, t3, t4, t5 dengan perbedaan waktu t1-t3= 2 minggu, t3-t4 = 1 minggu, dan t4-t6 = 2 minggu yang diilustrasikan pada Gambar 6.
t1 t2 t3 t4 t5 t6 Gambar 6 Ilustrasi pola reappearingirregular. 3 Occasional
Cluster ini berpindah-pindah tempat seiring dengan perubahan waktu. Sebagai contoh adalah kejadian kecelakaan lalu lintas yang diilustrasikan pada Gambar 7.
t1 t2 t3 t4 tn Gambar 7 Ilustrasi pola occasional.
4 Tracks
Pola cluster terbentuk saat kejadian setelahnya bergerak secara spasial setelah kejadian sebelumnya terjadi. Contohnya adalah serangkaian foto yang diambil oleh Flickr user dalam perjalanan yang diilustrasikan pada Gambar 8.
7
METODE
Data Penelitian
Data yang digunakan pada penelitian ini adalah data hotspot kebakaran hutan di Sumatera Selatan pada tahun 2002-2003.
Tahapan Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 9.
Gambar 9 Diagram alir penelitian. a Pengumpulan data
Data hotspot diperoleh dari FIRMS (https://earthdata.nasa.gov/data/near-real-time-data/firms/active-fire-data).
b Praproses data
Tahap praproses data meliputi transformasi dan reduksi data. c Implementasi ST-DBSCAN menggunakan Python
Implementasi algoritme ST-DBSCAN menggunakan Python dilakukan dengan cara memodifikasi modul DBSCAN pada package Scikit-learn.
d Pengujian runtime
Setelah implementasi ST-DBSCAN berhasil dilakukan akan diuji runtime
algoritme ST-DBSCAN menggunakan Python selama sepuluh kali. e Clustering dengan ST-DBSCAN
8
f Analisis dan evaluasi cluster
Hasil cluster yang diperoleh pasti memiliki persamaan spasial dan temporal. Oleh karena itu, akan dianalisis pola yang dimiliki pada setiap cluster. Cluster
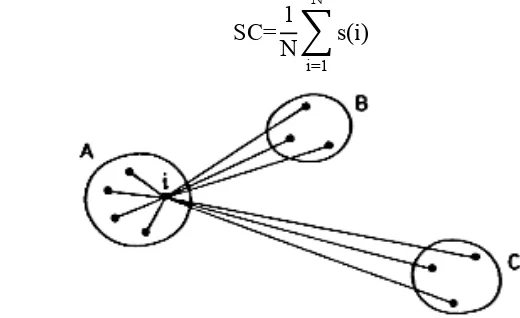
yang ditemukan akan dievaluasi seberapa bagus cluster yang telah terbentuk menggunakan koefisien Silhouette. Berikut formula koefisien Silhouette untuk satu titik i:
i ke semua titik dalam cluster B. Nilai koefisien Silhouette secara keseluruhan pada N jumlah titik dapat dihitung dengan:
SC=N1∑s(i)
N
i=1
Gambar 10 Ilustrasi koefisien Silhouette (Rousseeuw 1987). g Visualisasi cluster
Setelah cluster ditemukan, maka akan divisualisasikan secara tiga dan dua dimensi guna melihat penyebaran hotspot. Matplotlib menyediakan fitur visualisasi tiga dimensi yang akan digunakan untuk melihat perbedaan hasil
cluster dari atribut temporalnya. Untuk visualisasi dua dimensi, digunakan
package Basemap sehingga hotspot dapat divisualisasikan di atas layer peta. Lingkungan Pengembangan
Spesifikasi yang digunakan untuk penelitian ini adalah sebagai berikut. 1 Perangkat lunak:
Sistem operasi: Windows 8.1 Pro 64-bit Praproses: Microsoft Excel 2013
Penulisan script: Notepad++ v6.6 Bahasa pemrograman: Python 2.7.6
Package Python: Scikit-learn 0.14.1, Numpy-MKL 1.8.1, Matplotlib 1.3.1, dan Basemap 1.0.7
9 2 Perangkat keras:
Processor: Intel® CoreTM i3-330M 2.13 GHz Memori (RAM): 2.00 GB DDR3 1066 MHz
HASIL DAN PEMBAHASAN
Sumber Data dan Karakteristik Data
Dataset hotspot diperoleh dari Fire Information for Resource Management System (FIRMS) yang disediakan oleh National Aeronautics and Space Administration (NASA). Hotspot dipantau menggunakan satelit Terra dan Aqua dengan sensor bernama Moderate Resolution Imaging Spectroradiometer (MODIS). Wilayah dari pengumpulan data penelitian dapat dilihat pada Gambar 11.
Gambar 11 Sumatera Selatan (Purwanto 2012).
Data yang diteliti adalah data hotspot di Sumatera Selatan yang terletak antara 5o10’ sampai 1o20’ Lintang Selatan dan 101o40’ sampai 106o30’ Bujur Timur. Setiap 1o akan mewakili jarak sekitar 110 km (Tabel 1).
Tabel 1 Jarak derajat lintang dan bujur (Kirvan 1997) Derajat ∆LAT1 ∆LONG1
0o 110.574 km 111.320 km
15o 110.649 km 107.551 km
30o 110.852 km 96.486 km
45o 111.132 km 78.847 km
60o 111.412 km 55.800 km
75o 111.618 km 28.902 km
10
Praproses Data
Tahapan praproses data yang dilakukan adalah sebagai berikut: 1 Tranformasi Tanggal
Data tanggal akan diubah ke dalam format number dengan hari pertama dimulai dari 1 Januari 1900 seperti contoh pada Tabel 2.
Tabel 2 Contoh transformasi tanggal ke format number
Tanggal (mm/dd/yyyy) Tanggal (number)
01/01/2002 37257
01/02/2002 37258
01/03/2002 37259
01/04/2002 37260
2 Reduksi Data
Reduksi data dilakukan dengan cara memilihatribut yang akan digunakan saja, yaitu latitude, longitude, dan acq_time pada Tabel 3.
Tabel 3 Atribut hotspot
Atribut Keterangan
confidence kualitas hotspot (0-100%) version sumber sensor
bright_t31 temperatur channel-31 (K)
frp fireradiativepower (MegaWatts) Penentuan Nilai Parameter
Penentuan nilai Eps bertujuan untuk mendapatkan total cluster dalam jumlah sedikit, sedangkan penentuan MinPts bertujuan untuk memperkecil jumlah
noise. Pada Purwanto (2012), hasil cluster paling sedikit didapatkan pada Eps1=0.2 (≈ 22 km) seperti pada Gambar 12.
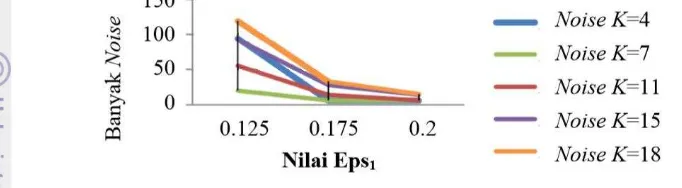
11 Berdasarkan nilai Eps1 diperoleh titik noise paling sedikit pada k=4, k=7,
dan k=11. Pada penelitian ini akan digunakan k=7 –k merupakan representasi dari MinPts. Pemilihan k=7 disebabkan jumlah noise yang cenderung stabil seiring dengan penambahan nilai Eps1 yang dapat dilihat pada Gambar 13. Nilai Eps2=7
dipilih dengan tujuan untuk mendapatkan pola penyebaran hotspot dalam rentang waktu yang cenderung singkat.
Gambar 13 Hubungan titik noise dengan Eps1 (Purwanto 2012).
Implementasi ST-DBSCAN Menggunakan Python
Implementasi ST-DBSCAN menggunakan Python dapat dilihat pada Lampiran 1 dengan nilai Eps1=0.2, Eps2=7, dan MinPts=7. Modifikasi modul
DBSCAN pada Scikit-learn menjadi ST-DBSCAN dilakukan pada baris 19-29. Modifikasi dilakukan pada penghitungan jarak dan pencarian tetangga secara spasial dan temporal.
Berdasarkan modul DBSCAN, penghitungan jarak hanya dilakukan pada aspek spasial. Untuk memenuhi keperluan parameter temporalnya, penghitungan jarak juga dilakukan pada aspek temporal. Penghitungan jarak menggunakan metrik Euclidean dilakukan dengan memanggil fungsi pairwise_distance()
pada modul pairwise. Hasil penghitungan jarak disimpan dalam DS dan DT yang
merupakan matriks jarak spasial dan matriks jarak temporal (baris 19 dan 20). Matriks jarak yang didapat akan digunakan selanjutnya untuk mencari tetangga. Pencarian tetangga dilakukan terhadap kedua aspek. Tetangga didapat melalui pencarian nilai yang lebih kecil sama dengan epsilon dalam matriks jarak atau dengan kata lain masih dalam radius epsilon.
Daftar tetangga spasial tersimpan dalam spat_neighbor (baris 21),
sedangkan daftar tetangga temporal tersimpan dalam temp_neighbor (baris 22). Tetangga spasial dan tetangga temporal harus diiris (baris 26) guna mendapatkan tetangga akhir secara spatio-temporal.
Parameter diduga dapat meningkatkan cohesion intra-cluster dan
separation antar-cluster, karena parameter tersebut mencakup aspek nonspasial. Ketidakikutsertaan parameter pada penelitian ini dapat membuat hasil cluster
tidak optimal. Selain itu, diharapkan pada penelitian selanjutnya dapat mencari nilai parameter (Eps1, Eps2, dan MinPts) secara otomatis berdasarkan Gaonkar
12
Hasil Clustering ST-DBSCAN
Pada data hotspot di Sumatera Selatan tahun 2002-2003 ditemukan 41
cluster dan 712 noise. Terdapat 13 cluster besar dan 28 cluster kecil. Suatu cluster
dikatakan cluster besar jika memiliki lebih dari 30 titik. Jumlah hotspot pada setiap cluster besar dapat dilihat pada Tabel 4.
Tabel 4 Jumlah hotspot dalam cluster besar
Cluster ke- Jumlah hotspot
0 2029
Pengujian runtime dilakukan sebanyak sepuluh kali. Rata-rata runtime berdurasi 4.934 detik. Salah satu faktor yang mempengaruhi kecepatan komputasi Python adalah penggunaan Numpy yang efisien dalam pengolahan array n-dimensi (Numpy developers 2013). Selain itu, tidak diikutsertakannya parameter juga menjadi penyebab cepatnya runtime eksekusi algoritme ST-DBSCAN.
Analisis Pola
Pada provinsi Sumatera Selatan hotspot banyak terjadi antara bulan Agustus-November saat musim kemarau berlangsung (Gambar 14) dan terdapat 4822 hotspot di tahun 2002-2003 yang dapat dilihat persebarannya pada Gambar 15.
Gambar 14 Grafik persebaran hotspot di Sumatera Selatan tahun 2002-2003. 0
Nov-01 Feb-02 May-02 Sep-02 Dec-02 Mar-03 Jun-03 Oct-03 Jan-04 Apr-04
13
Sumatera Selatan
Hotspot
Gambar 15 Hotspot di Sumatera Selatan tahun 2002-2003.
Setelah data hotspot dikelompokkan dengan ST-DBSCAN, terbentuklah 13
cluster besar seperti pada Tabel 4 yang akan dianalisis polanya berdasarkan Pöelitz dan Andrienko (2010). Setiap cluster besar akan dibagi per periode (tujuh hari) untuk perbandingan lokasi persebaran hotspot antar-periode. Penentuan lokasi persebaran hotspot hanya dibatasi pada cakupan kabupaten saja.
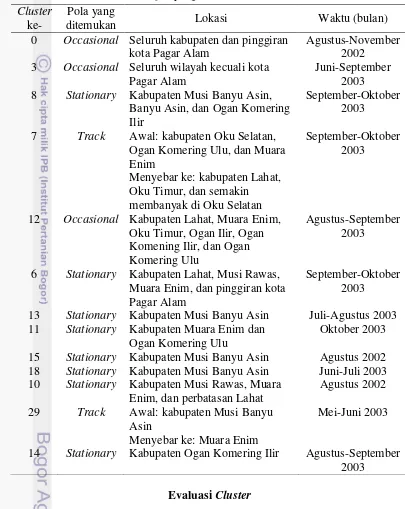
Pola hotspot yang ditemukan pada provinsi Sumatera Selatan dapat dilihat pada Tabel 5. Berdasarkan Tabel 5, pola hotspot yang paling banyak ditemukan adalah pola stationary yang berlokasi di Musi Banyu Asin dan Muara Enim serta berlangsung pada Agustus 2002 dan Juni-Oktober 2003.
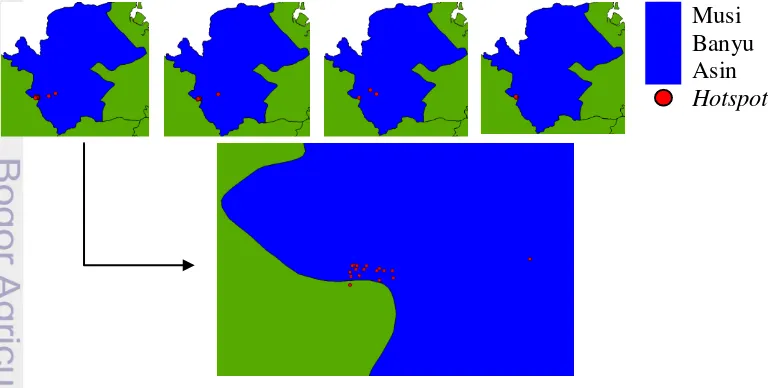
Sebagai contoh, pada cluster 18 (Gambar 16) terlihat bahwa hotspot berada pada kabupaten yang sama, yaitu Musi Banyu Asin, di keempat periode. Jika
cluster 18 pada periode 1 diperbesar, maka terlihat bahwa hanya sau titik pencilan saja yang tidak berada di Musi Banyu Asin. Oleh karena itu, pola stationary telah ditemukan pada cluster 18 di kabupaten Musi Banyu Asin. Gambar pola
occasional pada cluster 0 dan track pada cluster 29 per periode dicantumkan dalam Lampiran 3 dan 4.
Musi Banyu Asin
Hotspot
Gambar 16 Cluster 18 pada periode 1 (paling kiri), 2, 3 dan 4 (paling kanan). Pola reappearing regular dan irregular tidak ditemukan pada 13 cluster
14
rentang periode dibuat lebih pendek (dua/tiga hari), pola regular dan irregular
akan terlihat. Namun pemilihan rentang periode yang pendek akan menyebabkan kesulitan pada proses analisis karena masih dilakukan secara manual.
Tabel 5 Pola hotspot yang ditemukan di Sumatera Selatan
Cluster
ke-
Pola yang
ditemukan Lokasi Waktu (bulan)
0 Occasional Seluruh kabupaten dan pinggiran kota Pagar Alam
Agustus-November 2002
3 Occasional Seluruh wilayah kecuali kota Pagar Alam
Juni-September 2003 8 Stationary Kabupaten Musi Banyu Asin,
Banyu Asin, dan Ogan Komering Ilir
September-Oktober 2003
7 Track Awal: kabupaten Oku Selatan, Ogan Komering Ulu, dan Muara Enim
12 Occasional Kabupaten Lahat, Muara Enim, Oku Timur, Ogan Ilir, Ogan Komening Ilir, dan Ogan Komering Ulu
Agustus-September 2003
6 Stationary Kabupaten Lahat, Musi Rawas, Muara Enim, dan pinggiran kota Pagar Alam
September-Oktober 2003
13 Stationary Kabupaten Musi Banyu Asin Juli-Agustus 2003 11 Stationary Kabupaten Muara Enim dan
Ogan Komering Ulu
Oktober 2003 15 Stationary Kabupaten Musi Banyu Asin Agustus 2002 18 Stationary Kabupaten Musi Banyu Asin Juni-Juli 2003 10 Stationary Kabupaten Musi Rawas, Muara
Enim, dan perbatasan Lahat
Agustus 2002 29 Track Awal: kabupaten Musi Banyu
Asin
Menyebar ke: Muara Enim
Mei-Juni 2003
14 Stationary Kabupaten Ogan Komering Ilir Agustus-September 2003
Evaluasi Cluster
Evaluasi cluster dilakukan secara spasial dan temporal setelah hasil cluster
didapatkan. Evaluasi cluster dilakukan dengan cara pemanggilan modul koefisien Sillhouette pada Scikit-learn.
metrics.silhouette_score(X, labels) # Evaluasi cluster secara spasial
15 Hasil evaluasi cluster menggunakan koefisien Sillhouette berkisar antara nilai -1 hingga 1, dengan -1 merupakan nilai terburuk dan 1 merupakan nilai terbaik (Sklearn 2014). Pada penelitian ini, evaluasi cluster secara spasial bernilai -0.638 dan -0.745 secara temporal.
Evaluasi cluster yang tidak bagus disebabkan kesalahan pemilihan nilai parameter. Evaluasi DBSCAN dengan Eps1=0.2 dan MinPts=7 yang diambil dari
hasil penelitian Purwanto (2012) menghasilkan koefisien Sillhouette dengan nilai 0.197. Sedangkan nilai Eps2=7 hanya ditujukan untuk mengambil rentang waktu
yang cukup pendek. Baik ST-DBSCAN maupun DBSCAN sangat sensitif terhadap pemilihan nilai parameternya. Jika terjadi kesalahan pada pemilihan nilai parameter, cluster yang dihasilkan pun tidak bagus. Oleh karena itu, diharapkan penelitian selanjutnya dapat menghasilkan nilai Eps1, Eps2, dan MinPts secara
otomatis berdasarkan Gaonkar dan Sawant (2013) sehingga cluster yang terbentuk memiliki nilai evaluasi yang bagus.
Visualisasi Cluster
Untuk visualisasi, kode program dimodifikasi dari contoh pemanggilan modul DBSCAN dalam file plot_dbscan.py. Setiap objek yang berlabel -1 adalah
noise yang akan diberi warna hitam. Pada visualisasi hasil cluster pada Gambar 17 dan Gambar 18 terlihat dua cluster yang memiliki banyak sekali hotspot– disebut sebagai cluster besar. Kedua cluster besar tersebut terpisah secara temporal yang dapat dilihat pada rongga antar-cluster.
16
Gambar 18 Visualisasi cluster secara tiga dimensi (2).
Hampir setiap titik hotspot yang berada di antara dua cluster besar tersebut merupakan noise. Noise terjadi antara hari ke-37582 (22 November 2002) sampai hari ke-37797 (25 Juni 2003) saat musim penghujan berlangsung. Hotspot pada
cluster besar pertama terjadi pada hari 37474 (6 Agustus 2002) sampai hari ke-37581 (21 November 2002) dan hotspot pada cluster besar kedua terjadi pada hari ke-37798 (26 Juni 2003) sampai hari ke-37890 (26 September 2003) saat musim kemarau berlangsung.
Persebaran cluster di atas layer peta Sumatera dapat dilihat pada Gambar 19 yang menunjukkan dua cluster terbesar berwarna jingga dan magenta. Contoh visualisasi per cluster dapat dilihat Lampiran 5 dan 6.
17
SIMPULAN DAN SARAN
Simpulan
Implementasi ST-DBSCAN menggunakan Python berhasil dilakukan. Ditemukan 41 cluster data hotspot di Sumatera Selatan dengan 13 cluster besar. Pola yang paling banyak ditemukan adalah pola stationary pada kabupaten Musi Banyu Asin dan Muara Enim yang berlangsung pada Agustus 2002 dan Juni-Oktober 2003. Rata-rata runtime ST-DBSCAN menggunakan Python adalah 4.934 detik.
Saran
Berikut saran-saran yang diberikan untuk penelitian selanjutnya:
1 Kekurangan pada penelitian ini adalah belum diimplementasikannya parameter . Pada penelitian selanjutnya diharapkan dapat menambahkan parameter tersebut karena parameter nonspasial dapat membuat cohesion dan
separationcluster semakin optimum.
2 Pada penelitian ini nilai parameter ditentukan manual sehingga belum menghasilkan cluster yang optimal, diharapkan pada penelitian selanjutnya dapat menentukan nilai Eps1, Eps2, dan Minpts secara otomatis.
3 Diharapkan pada penelitian selanjutnya dapat menggunakan Dunn Index (DI) untuk evaluasi cluster.
4 Antarmuka sistem dapat dibuat lebih menarik.
5 Pada sistem ini layer peta yang digunakan adalah peta dunia sehingga proses visualisasi memakan waktu lama. Diharapkan pada penelitian selanjutnya dapat menggunakan peta Indonesia saja.
6 Pada penelitian ini data disimpan di dalam memory. Penggunaan basis data untuk penyimpanan telah dicoba, tetapi masih terkendala pada saat penggunaan data dalam jumlah yang sangat besar dikarenakan terlalu banyak proses overwrite. Diharapkan pada penelitian selanjutnya dapat memanfaatkan basis data dengan memilih variabel apa saja yang akan disimpan.
18
DAFTAR PUSTAKA
Adinugroho WC, Suryadiputra INN, Saharjo BH, Siboro L. 2005. Panduan Pengendalian Kebakaran Hutan dan Lahan Gambut. Bogor (ID): Wetlands International.
Birant D, Kut A. 2007. ST-DBSCAN: an algorithm for clustering spatialtemporal data. Data and Knowledge Engineering. 60:208-221. doi:10.1016/j.datak.2006.01.013.
Cassisi C. 2011. Implemented methods [internet]. [diacu 2014 Apr 20]. Tersedia pada: http://www.dmi.unict.it/~cassisi/DBStrata/help/methods.html
Ewing C. 2014. 5 Reasons why Python is powerful enough for Google [internet]. [diacu 2014 Jun 09]. Tersedia pada: https://www.codefellows.org/blogs/5-reasons-why-python-is-powerful-enough-for-google.
Gaonkar MN, Sawant K. 2013. AutoEpsDBSCAN: DBSCAN with Eps automatic for large dataset. International Journal on Advanced Computer Theory and Engineering. 2:2319-2526.
Kirvan AP. 1997. Unit 014 - latitude and longitude [internet]. [diacu 2014 Jun 06]. Tersedia pada http://www.ncgia.ucsb.edu/giscc/units/u014/u014_f.html.
Purwanto UY. 2012. Penggerombolan spasial Hotspot kebakaran hutan dan lahan menggunakan DBSCAN dan ST-DBSCAN [tesis]. Bogor (ID): Institut Pertanian Bogor.
[Pyzo]. 2013. Why Python [internet]. [diacu 2014 Jun 09]. Tersedia pada: http://www.pyzo.org/whypython.html.
Rao KV, Govardhan A, Rao KVC. 2012. Spatiotemporal data mining: issues, tasks and applications. International Journal of Computer Science & Engineering Survey. 3:39-52. doi:10.5121/ijcses.2012.3104.
Rousseeuw PJ. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics. 20(1987): 53-65. doi: 10.1016/0377-0427(87)90125-7.
[Sklearn] Scikit-learn. 2014. sklearn.metrics.silhouette_score [internet]. [diacu 2014 Mei 29]. Tersedia pada: http://scikit-learn.org/stable/modules/generated/ sklearn.metrics.silhouette_score.html.
Thoha AS. 2008. Penggunaandata Hotspot untukmonitoringkebakaranhutandan lahandiIndonesia [skripsi]. Medan (ID): Universitas Sumatera Utara.
Verma R. 2009. Section 4 DBSCAN [internet]. [diacu 2014 Apr 20]. Tersedia pada: http://www.hypertextbookshop.com/dataminingbook/public_
20
LAMPIRAN
22
Lampiran 3 Pola occasional pada cluster 0 (periode = 7 hari) Palembang (Kota)
Prabumulih (Kota) Pagar Alam (Kota) Lubuklinggau (Kota)
Hotspot
Periode 1 Periode 2
Periode 3 Periode 4
23 Lanjutan
Periode 7 Periode 8
Periode 9 Periode 10
24 Lanjutan
Periode 13 Periode 14
25 Lampiran 4 Pola track pada cluster 29 (periode = 7 hari)
Musi Banyu Asin Muara Enim
Hotspot
Periode 1 Periode 2
Periode 3 Periode 4
26
Lampiran 5 Contoh visualisasi per cluster secara tiga dimensi
Hotspot
Cluster 0 Cluster 3
Cluster 6 Cluster 7
27 Lampiran 6 Contoh visualisasi per cluster secara dua dimensi
Hotspot
Cluster 0 Cluster 3
Cluster 6 Cluster 7
28
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 28 Agustus 1993, dari pasangan Bapak Bennet Parsaoran Lumban Tobing dan Ibu Bina Nainggolan, SPd sebagai anak kedua dari dua bersaudara. Pada tahun 2010 penulis lulus dari SMA Negeri 12 Jakarta dan lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.