CLUSTERING DATASET
TITIK PANAS DENGAN ALGORITME
DBSCAN MENGGUNAKAN
WEB FRAMEWORK
SHINY PADA
BAHASA PEMROGRAMAN R
RAHMAH MARDHIYYAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul
Clustering Dataset
Titik
Panas dengan Algoritme DBSCAN Menggunakan
Web Framework
Shiny pada
Bahasa Pemrograman R adalah benar karya saya dengan arahan dari komisi
pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana
pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun
tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam
Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Agustus 2014
Rahmah Mardhiyyah
ABSTRAK
RAHMAH MARDHIYYAH. Clustering Dataset Titik Panas dengan Algoritme DBSCAN Menggunakan Web Framework Shiny pada Bahasa Pemrograman R. Dibimbing oleh KARLINA KHIYARIN NISA.
Kebakaran hutan merupakan permasalahan serius yang terjadi berulang kali di Indonesia. Salah satu bentuk penanggulangan bencana kebakaran hutan adalah dengan melakukan pemantauan terhadap titik panas melalui satelit penginderaan jauh. Setiap titik panas yang berpotensi sebagai lokasi kebakaran akan dicatat pada suatu dataset. Penelitian ini bertujuan membangun sebuah aplikasi web yang melakukan clustering pada data titik panas. Aplikasi ini dibangun menggunakan framework Shiny dan algoritme DBSCAN pada bahasa pemrograman R. Clustering dilakukan pada dataset titik panas di pulau Kalimantan dan provinsi Sumatera Selatan pada tahun 2002-2003. Clustering menggunakan DBSCAN menghasilkan pola-pola penyebaran hotspot kebakaran hutan. Wilayah yang memiliki cluster hotspot terluas adalah provinsi Kalimantan Barat yang memiliki 3528 hotspot.
Kata kunci: clustering, DBSCAN, kebakaran hutan, R, Shiny, titik panas
ABSTRACT
RAHMAH MARDHIYYAH. Clustering on Hotspot Dataset with DBSCAN Algorithm using Shiny Web Framework on R Programming Language. Supervised by KARLINA KHIYARIN NISA
Forest fire is a very serious and critical problem which occurs repeatedly in Indonesia. One prevention and solution for the forest fire disaster is by monitoring the hotspots through remote sensing satellite. Every hotspot which is likely to be fire location is recorded in a dataset. The purpose of this research is to build a web application that performs clustering on the hotspot dataset. This application implements the DBSCAN algorithm using Shiny web framework on R programming language. Clustering is performed on a dataset of hotspots in Borneo island and South Sumatra province in 2002-2003. Clustering using DBSCAN produces patterns of distributing hotspot forest fire. The widest cluster hotspot is located at West Kalimantan province which has 3528 hotspots.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
CLUSTERING DATASET
TITIK PANAS DENGAN ALGORITME
DBSCAN MENGGUNAKAN
WEB
FRAMEWORK
SHINY PADA
BAHASA PEMROGRAMAN R
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Penguji: 1 Hari Agung Adrianto, SKom, MSi
Judul Skripsi : Clustering Dataset Titik Panas dengan Algoritme DBSCAN Menggunakan Web Framework Shiny pada Bahasa Pemrograman R
Nama : Rahmah Mardhiyyah NIM : G64080037
Disetujui oleh
Karlina Khiyarin Nisa, SKom, MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Clustering Dataset Titik Panas Dengan Algoritme DBSCAN Menggunakan Web Framework Shiny pada Bahasa Pemrograman R. Penelitian ini dilaksanakan di Departemen Ilmu Komputer Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada Ibu Karlina Khiyarin Nisa, SKom, MT selaku pembimbing, serta Bapak Hari Agung SKom, MKom dan Ibu Dr. Imas Sukaesih Sitanggang, SSi MKom selaku penguji yang telah banyak memberi bantuan dalam penyelesaian skripsi ini. Penulis juga menyampaikan terima kasih untuk suami tercinta, Roy Septian Sugiharto dan ananda tersayang, Muhammad Aufa Ghaisan atas semua doa dan kasih sayang yang diberikan. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, seluruh keluarga, dan teman-teman atas segala doa dan dukungannya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Titik Panas (Hotspot) 2
Algoritme DBSCAN 3
Package Shiny 3
METODE 3
Data Penelitian 3
Tahapan Penelitian 4
Lingkupan Pengembangan 5
HASIL DAN PEMBAHASAN 5
Praproses Data 5
Implementasi Aplikasi Web Clustering pada Bahasa R 5
Penentuan Epsilon dan MinPts 8
Hasil Clustering dengan Algoritme DBSCAN 10
SIMPULAN DAN SARAN 12
Simpulan 12
Saran 12
DAFTAR PUSTAKA 12
LAMPIRAN 14
DAFTAR TABEL
1 Atribut pada dataset hotspot 4
2 Spesifikasi perangkat pembuatan aplikasi web clustering 5
3 Perhitungan untuk menentukan ambang batas 9
4 Jumlah titik pada hasil clustering dataset hotspot pulau
Kalimantan 11
DAFTAR GAMBAR
1 Tahapan penelitian 4
2 Fail server.r 6
3 Fail ui.r 7
4 Aplikasi clustering berbasis internet 7
5 Grafik penentuan nilai Eps 8
6 Grafik K-dist pada dataset hotspot pulau Kalimantan 8
7 Pengaruh Epsilon terhadap jumlah cluster 9
8 Jumlah cluster pada beberapa nilai Epsilon dan MinPts 10
9 Jumlah noise pada beberapa nilai Epsilon dan MinPts 10
10 Hasil clustering pada dataset hotspot pulau Kalimantan 11
LAMPIRAN
PENDAHULUAN
Latar Belakang
Kebakaran hutan merupakan salah satu bencana alam yang sering terjadi di Indonesia. Dampak yang ditimbulkan kebakaran hutan sangat kompleks, tidak hanya pada kerusakan ekosistem lingkungan namun juga mencakup bidang lain seperti perekonomian, budaya, hubungan antar negara dan lainnya. Pada bidang lingkungan, kebakaran hutan menyebabkan pencemaran kabut asap, peningkatan emisi karbon, juga hilangnya tempat tinggal bagi sejumlah satwa liar yang mengakibatkan ketidakseimbangan ekosistem.
Salah satu bentuk penanggulangan dan pencegahan bencana kebakaran hutan adalah dengan melakukan pemantauan terhadap hotspot melalui satelit penginderaan jauh. Hotspot merupakan titik-titik panas di permukaan bumi yang dapat digunakan sebagai indikasi terjadinya kebakaran hutan. Setiap titik panas akan dicatat pada suatu dataset yang meliputi data spasial (latitude, longitude), data temporal (waktu dan tanggal pemantauan) dan data nonspasial (suhu udara, curah hujan, dsb). Persebaran titik panas biasanya menggerombol secara alami, sehingga apabila penggerombolan lokasi hotspot diketahui maka dapat digunakan dalam analisis terjadinya kebakaran hutan. Penggerombolan ini dilakukan dengan algoritme DBSCAN yang mampu menemukan cluster dari data spasial yang besar (Gaonkar dan Sawant 2013).
DBSCAN adalah sebuah algoritme yang mengelompokkan objek berdasarkan kepadatan. Algoritme ini memastikan wilayah yang cukup padat menjadi sebuah cluster apabila memenuhi jumlah titik ketetanggaan (MinPts) dalam jarak tertentu (epsilon). Kepadatan suatu objek didapatkan dari jumlah titik yang memenuhi nilai epsilon tersebut sehingga DBSCAN menghasilkan cluster yang memiliki beragam kepadatan dengan bentuk cluster yangtidak beraturan.
R merupakan salah satu bahasa pemrograman yang melakukan pengolahan data. R sangat efektif dalam pengelolaan data, fasilitas penyimpanan dan memvisualisasikan cluster. Selain itu R dapat dikembangkan sesuai kebutuhan dengan menambah fitur-fitur tambahan dalam bentuk paket ke dalam software R yang sifatnya gratis (Venables dan Smith 2009).
Purwanto (2012) telah melakukan clustering data titik panas dengan algoritme DBSCAN dan ST-DBSCAN menggunakan MATLAB. Penelitian tersebut berbasis desktop dengan running time selama 6 jam. Aplikasi berbasis desktop ini memiliki beberapa kekurangan diantaranya perlu instalasi pada komputer untuk menjalankan aplikasi tersebut sehingga tidak bisa diakses oleh banyak orang.
Pada penelitian ini, clustering dilakukan menggunakan algoritme DBSCAN dengan bahasa pemrograman R dan aplikasi clustering dibuat berbasis web agar hasil clustering dapat diakses dengan mudah oleh siapapun.
Perumusan Masalah
2
Tujuan Penelitian
Penelitian ini bertujuan untuk membuat aplikasi clustering berbasis web pada data spasial titik panas menggunakan bahasa pemrograman R.
Manfaat Penelitian
Penelitian ini membangun aplikasi webclustering yang dapat menghasilkan pola penyebaran titik panas yang mudah diakses oleh peneliti bidang kehutanan, pemerintah, maupun masyarakat. Dengan demikian tindakan pencegahan dan evakuasi dapat dilakukan lebih awal.
Ruang Lingkup Penelitian
Lingkup dari penelitian ini antara lain yaitu:
1 Penelitian ini dibatasi pada data titik panas Pulau Kalimantan dan Provinsi Sumatera Selatan.
2 Algoritme clustering yang digunakan untuk pengolahan dataset titik panas adalah algoritme DBSCAN.
3 Aplikasi ini dijalankan pada server lokal.
TINJAUAN PUSTAKA
Titik Panas (Hotspot)
Titik panas (hotspot) menurut Peraturan Menteri Kehutanan Nomor: P.12/Menhut/II/2009 adalah indikator kebakaran hutan yang mendeteksi suatu lokasi yang memiliki suhu relatif lebih tinggi dibandingkan dengan suhu di sekitarnya. Pemantauan hotspot dapat dilakukan dengan menggunakan satelit penginderaan jauh (remote sensing).
Salah satu sensor satelit yang digunakan untuk memantau permukaan bumi adalah Moderate Resolution Imaging Spectroradiometer (MODIS). MODIS merupakan sensor yang terdapat pada satelit Terra (EOS AM-1), yang diluncurkan pada 18 Desember 1999 dan Aqua (EOS PM-1) yang diluncurkan pada 4 Mei 2002. Pendeteksian titik api yang aktif menggunakan MODIS mewakili titik tengah dari piksel berukuran 1 kilometer yang bisa terdiri dari satu titik api atau lebih. Titik api dapat diketahui menggunakan data dari instrumen MODIS yang terdapat pada badan satelit Aqua atau Terra milik NASA (National Aeronautics and Space Administration.)
3
Algoritme DBSCAN
DBSCAN (Density-Based Clustering of Application with Noise) merupakan algoritme clustering yang mengelompokkan titik berdasarkan kepadatan data di suatu wilayah. Algoritme DBSCAN memerlukan masukan parameter jarak epsilon (Eps) dan jumlah titik minimum (MinPts). Epsilon merupakan jarak antar titik yang menandakan kepadatan objek. Ketetanggaan antar titik yang memenuhi jarak epsilon disebut e-neighborhood dan titik yang memiliki e-nighborhood minimal sebanyak jumlah MinPts disebut sebagai titik pusat (core point). Langkah-langkah membangun cluster menggunakan DBSCAN adalah sebagai berikut (Han et al. 2001):
1 Pilih titik p secara acak
2 Dapatkan titik yang e-neighborhood dari titik p.
3 Jika jumlah titik dari langkah 2 memenuhi nilai MinPts, maka p merupakan titik pusat dan sebuah cluster telah terbentuk
4 Jika jumlah titik dari langkah 2 tidak memenuhi nilai MinPts maka titik p merupakan titik batas (border point) dan pilih titik berikutnya.
5 Lanjutkan hingga semua titik telah diproses dan tidak ada titik yang dapat ditambahkan pada cluster.
Package Shiny
Shiny merupakan sebuah package yang mempermudah pembangunan aplikasi web dari bahasa pemrograman R. Shiny mampu menampilkan query dan ringkasan data secara interaktif kepada end user melalui web browser dengan mudah. Shiny menyediakan berbagai macam widget untuk membangun antarmuka pengguna yang interaktif. Selain itu, aplikasi Shiny juga dapat diperluas dan diintegrasikan dengan aplikasi web lain menggunakan HTML dan CSS. Bahkan JavaScript dan jQuery juga dapat digunakan untuk memperluas bidang aplikasi Shiny (Beeley 2013).
Shiny termasuk dalam pemrograman reaktif yang mampu menampilkan output data sesuai dengan inputnya. Perubahan pada nilai input akan menghasilkan nilai output baru tanpa perlu memuat ulang halaman. Aplikasi Shiny tersusun dari dua komponen yaitu bagian antarmuka dan bagian server yang tergabung dalam satu folder. Bagian antarmuka mengatur tampilan dan layout dari aplikasi yang dikembangkan sedangkan bagian server akan berisi instruksi bagi komputer untuk membangun aplikasi tersebut.
METODE
Data Penelitian
4
dataset pulau Kalimantan terdapat 4999 titik panas, sedangkan pada dataset provinsi Sumatera Selatan terdapat 4821 titik panas. Atribut pada dataset hotspot yang diperoleh dari FIRMS dapat dilihat pada Tabel 1.
Tabel 1 Atribut pada dataset hotspot
No. Nama Atribut Keterangan
1 Latitude Koordinat lintang lokasi hotspot (o)
2 Longitude Koordinat bujur lokasi hotspot (o)
3 Brightness temperature temperatur (K)
4 Scan Ukuran lebar piksel citra satelit
5 Track Ukuran panjang piksel citra satelit
6 Acq_date tanggal kejadian titik panas
7 Acq_time waktu kejadian titik panas
8 Satellite satelit yang digunakan (Aqua, Terra)
9 Confidence kualitas titik panas (0-100%)
10 Bright_t31 temperatur channel-31 (K)
11 Frp fire radiative power (MegaWatts)
12 Versi 5.0 = MODIS NASA-LANCE,
5.1 = MODIS MODAPS-FIRMS
Tahapan Penelitian
Tahapan yang dilakukan pada penelitian ini ditunjukkan pada Gambar 1. Praproses Data
Dataset titik panas yang diperoleh dari FIRMS berupa fail CSV yang diolah menggunakan perangkat lunak Microsoft Excel 2007. Terdapat 12 atribut pada setiap data titik panas. Untuk proses clustering, atribut yang digunakan berupa data spasial yaitu koordinat lintang dan bujur dari lokasi titik panas tersebut sehingga atribut lain direduksi.
Implementasi Aplikasi Web Clustering
Pada tahapan ini aplikasi web clustering dibangun menggunakan perangkat lunak RStudio. Aplikasi ini memanfaatkan framework Shiny untuk membangun aplikasi web clustering dari bahasa pemrograman R. Untuk penggunaan algoritme
5 DBSCAN menggunakan bahasa pemograman R dilakukan dengan pemanggilan fungsi DBSCAN yang terdapat pada package FPC.
Lingkupan Pengembangan
Pembuatan aplikasi web clustering algoritme DBSCAN ini menggunakan beberapa perangkat keras dan perangkat lunak dengan spesifikasi yang terdapat pada Tabel 2.
Tabel 2 Spesifikasi perangkat pembuatan aplikasi web clustering
Perangkat Keras Perangkat Lunak
Processor Intel Core 2 Duo 2.10 GHz, RAM 2 GB
Harddisk berkapasitas 160 GB.
Sistem operasi Windows 8
Bahasa pemrograman R versi 3.1.0 RStudio versi 0.98.501 dengan package Shiny dan fpc
Microsoft Excel 2007 Browser Google Chrome
HASIL DAN PEMBAHASAN
Praproses Data
Dataset titik panas pulau Kalimantan dan provinsi Sumatera Selatan yang diperoleh dari FIRMS berupa fail CSV. Contoh dataset titik panas dapat dilihat pada Lampiran 1. Untuk clustering titik panas dilakukan pada data tersebut akan dilakukan pemilihan field data yang diperlukan untuk perhitungan clustering. Dari dataset titik panas yang memiliki 12 field direduksi dengan memilih 2 field saja yaitu koordinat lintang dan bujur.
Implementasi Aplikasi Web Clustering pada Bahasa R
Aplikasi Shiny tersusun atas komponen server dan antarmuka yang terdapat dalam satu folder. Bagian server berisi instruksi yang digunakan pada aplikasi yang disimpan dalam fail server.r. Baris pertama pada fail server.r adalah library yang dibutuhkan untuk membangun aplikasi. Pada aplikasi ini, diperlukan library fpc untuk mengimplementasikan algoritme DBSCAN pada bahasa R.
Input dataset pada aplikasi ini adalah fail csv yang berisi koordinat lintang dan bujur dari titik panas. Dataset ini dijadikan sebuah objek sebagai global environment. Objek ini digabungkan untuk membentuk data frame baru yang akan digunakan sebagai input fungsi DBSCAN. Pengguna dapat memilih data mana yang akan digunakan untuk proses clustering. Objek data ini dibuat reaktif untuk menanggapi setiap perubahan permintaan pengguna. Potongan program pada fail server.r dapat dilihat pada Gambar 2.
6
nilai Epsilon dan jumlah titik minimum (MinPts) dari algoritme DBSCAN didapatkan dari nilai yang dimasukkan oleh pengguna.
Gambar 2 Fail server.r
Instruksi untuk menampilkan hasil clustering dataset titik panas menggunakan fungsi renderPlot. Fungsi ini berisi argument par yang mengatur letak gambar hasil clustering, plot yang mengambil data hasil clustering dan points yang menentukan jenis titik plotting pada gambar hasil clustering.
Bagian antarmuka berisi atribut-atribut yang ditampilkan pada halaman web browser. Antarmuka ini terdiri dari headerPanel, sidebarPanel dan mainPanel. HeaderPanel merupakan judul halaman aplikasi. SidebarPanel berisi berbagai input yang bisa dipilih pengguna. Terdapat 3 pilihan input yaitu : input untuk pilihan dataset, input untuk memasukkan nilai Epsilon dan input untuk nilai MinPts. MainPanel merupakan area untuk menampilkan hasil clustering yang sesuai dengan input . Potongan program yang terdapat pada fail ui.r dapat dilihat pada Gambar 3.
library("fpc")
shinyServer(function(input, output, session) {
#mengambil data koordinat titik panas
selectedData <- reactive({
#Menggabungkan variable terpilih menjadi sebuah data frame baru
assign("data", myobj, envir = .GlobalEnv) return(data[, c(input$ycol, input$xcol)])
#memanggil fungsi dbscan
clusters <- reactive({
dbscan(selectedData(), input$eps,input$minPts)})
#mengatur visualisasi hasil clustering
7
Gambar 3 Fail ui.r
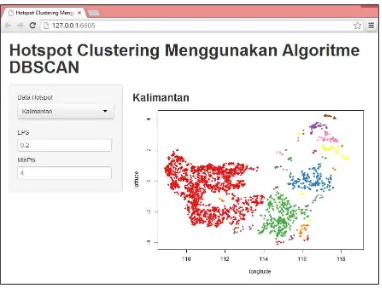
Implementasi aplikasi web clustering pada bahasa R menghasilkan cluster tanpa noise. Pengguna dapat memilih dataset yang tersedia untuk dilakukan proses clustering. Dataset ini terdiri dari dataset hotspot pulau Kalimantan dan dataset hotspot provinsi Sumatera Selatan. Tampilan aplikasi ini dapat dilihat pada Gambar 2.
Gambar 4 Aplikasi clustering berbasis internet
#memilih jenis halaman yang akan ditampilkan
shinyUI(pageWithSidebar(
headerPanel('Hotspot Clustering Menggunakan Algoritme DBSCAN'), sidebarPanel(
#mengambil pilihan dataset
selectInput("daerah", "Data Hotspot", choices = c("Sumatera" = "smt", "Kalimantan" = "klm"), selected="smt")
#masukan nilai epsilon dan minimum points
numericInput('eps', 'EPS', 0.2, min = 0.1, max = 1), numericInput('minPts', 'MinPts', 4, min = 1, max= 7)),
#menampilkan judul dan plot data hasil clustering
mainPanel(
8
Penentuan Epsilon dan MinPts
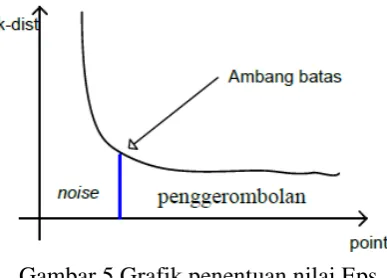
Clustering menggunakan algoritme DBSCAN membutuhkan parameter nilai epsilon (Eps) dan jumlah titik minimum (MinPts). Penentuan nilai Eps dan MinPts sangat berpengaruh terhadap cluster yang akan dihasilkan. Untuk memilih nilai Eps, diperlukan observasi pada grafik k-dist pada semua dataset (Purwanto, 2012). K-dist merupakan jarak k tetangga terdekat dari sebuah titik dalam suatu dataset.
Pada algoritme DBSCAN, antar titik tetangga dalam satu cluster memiliki jarak yang sama, sedangkan titik noise memiliki jarak terjauh dari k-tetangga terdekat. Untuk mengetahui pada epsilon berapa titik noise mulai terdeteksi, yaitu saat jarak titik-titik pada cluster mulai menjauh, dilakukan plot jarak secara terurut pada setiap titik pada k-tetangga terdekat. Plot jarak ini digunakan untuk melihat lekukan sebagai ambang batas pada grafik yang menandakan titik mulai menjauh. Ilustrasi plot k-dist dapat dilihat pada Gambar 5.
Pada dataset hotspot pulau Kalimantan dilakukan perhitungan k-dist pada seluruh titik kemudian diurutkan dalam urutan menurun. Hasil k-dist yang telah diurutkan ini di-plot dalam sebuah grafik k-dist yang dapat dilihat pada Gambar 4. Perhitungan k-dist dilakukan dengan beberapa nilai k. Epsilon dipilih dari nilai yang menjadi ambang batas grafik k-dist. Ambang batas yang terlihat pada grafik dimulai saat nilai Eps= 0.5 sehingga clustering mulai dilakukan dengan nilai Epsilon tersebut.
Gambar 6 Grafik K-dist pada dataset hotspot pulau Kalimantan 0
9
Gambar 5 merupakan grafik yang memperlihatkan pengaruh nilai Epsilon pada jumlah cluster. Nilai Epsilon dipilih dari garis yang mendekati garis melandai kemudian dipotong secara vertikal. Grafik yang semakin melandai menandakan jumlah cluster yang semakin konsisten dimulai pada nilai epsilon 0.2. Dengan demikian, nilai Eps=0.2 merupakan nilai yang optimal.
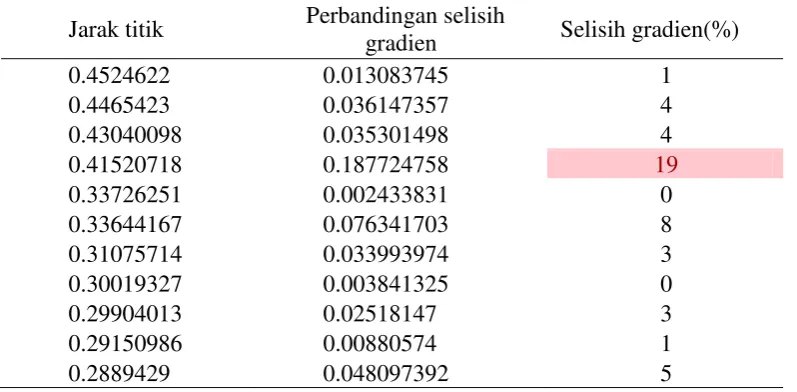
Selain menentukan nilai Eps dari ambang batas yang terlihat secara visual dari grafik k-dist, penentuan ambang batas dapat juga dilakukan secara komputasi yaitu dengan menghitung selisih kemiringan garis. Setiap perbedaan kemiringan sebesar 10% sampai 20% akan menjadi kandidat nilai Eps yang diambil. (Gaonkar&Sawat, 2012). Tabel 1 memperlihatkan contoh perhitungan untuk menentukan ambang batas pada plot k-dist. Selisih gradien yang pertama mencapai nilai antara 10-20% dijadikan sebagai kandidat nilai Epsilon yang optimal.
Tabel 3 Perhitungan untuk menentukan ambang batas Jarak titik Perbandingan selisih
gradien Selisih gradien(%)
0.4524622 0.013083745 1
0.4465423 0.036147357 4
0.43040098 0.035301498 4
0.41520718 0.187724758 19
0.33726251 0.002433831 0
0.33644167 0.076341703 8
0.31075714 0.033993974 3
0.30019327 0.003841325 0
0.29904013 0.02518147 3
0.29150986 0.00880574 1
0.2889429 0.048097392 5
10
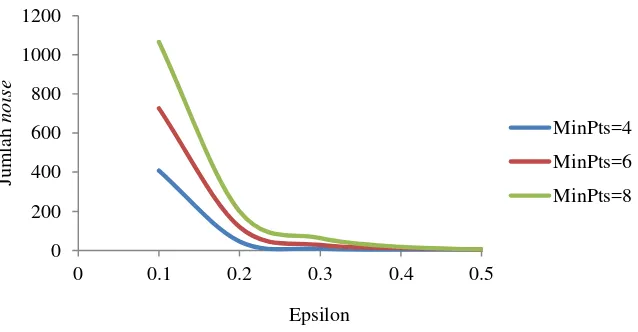
Penentuan nilai jumlah titik minimum (MinPts) akan mempengaruhi jumlah noise pada hasil clustering. Semakin besar nilai MinPts menghasilkan lebih sedikit noise dengan komputasi yang lebih kompleks. Sedangkan apabila nilai MinPts yang dipilih terlalu kecil memungkinkan banyak titik noise yang akan menjadi cluster. Pada data 2-dimensi, clustering dengan nilai MinPts lebih besar dari 4 hasilnya tidak jauh berbeda dari MinPts= 4 (Ester 1996). Hal ini dapat dilihat pada Gambar 8 dan Gambar 9. Gambar 8 menampilkan jumlah cluster yang dihasilkan dengan nilai Epsilon dan MinPts yang beragam pada dataset hotspot pulau Kalimantan sedangkan Gambar 9 menampilkan hasil noise pada variasi nilai MinPts pada dataset hotspot pulau Kalimantan.
Hasil Clustering dengan Algoritme DBSCAN
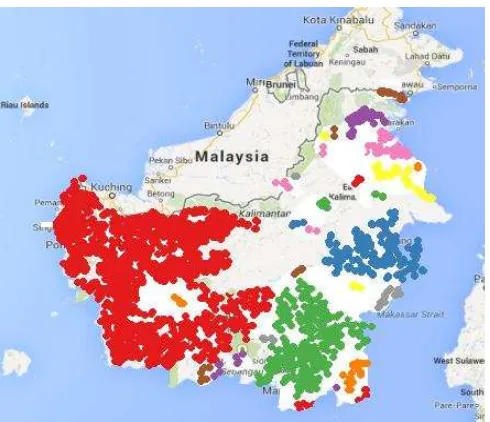
Clustering pada dataset hotspot menggunakan algoritme DBSCAN dilakukan untuk menemukan pola kebakaran hutan. Konsentrasi hotspot akan mengindikasikasikan wilayah yang rawan terjadi kebakaran hutan. Gambar 10 merupakan hasil clustering dengan algoritme DBSCAN pada dataset hotspot pulau Kalimantan, dengan nilai Epsilon= 0.2 dan MinPts= 4. Clustering ini menghasilkan 35 cluster dengan 46 noise.
Gambar 9 Jumlah noise pada beberapa nilai Epsilon dan MinPts 0 Gambar 8 Jumlah cluster pada beberapa nilai Epsilon dan MinPts
11
Tabel 4 memperlihatkan jumlah titik pada setiap cluster yang dihasilkan menggunakan algrotime DBSCAN pada dataset hotspot pulau Kalimantan. Cluster ke-0 merupakan jumlah titik noise. Cluster terbesar memiliki 3528 hotspot yang terletak pada wilayah provinsi Kalimantan Barat. Cluster terbesar kedua memiliki 528 hotspot yang terletak pada provinsi Kalimantan Selatan dan cluster terbesar ketiga memiliki 346 hotspot yang terletak pada provinsi Kalimantan Timur.
Tabel 4 Jumlah titik pada hasil clustering datasethotspot pulau Kalimantan
Cluster
12
SIMPULAN DAN SARAN
Simpulan
Penelitian ini berhasil membuat sebuah aplikasi clustering dengan algoritme DBSCAN berbasis web menggunakan bahasa R dan framework Shiny pada dataset hotspot kebakaran hutan. Clustering menggunakan DBSCAN menghasilkan pola-pola cluster hotspot kebakaran hutan. Pola ini merupakan persebaran lokasi yang memiliki kemunculan yang sering terjadi. Wilayah yang memiliki cluster hotspot terluas adalah provinsi Kalimantan Barat yang memiliki 3528 hotspot.
Saran
Berikut ini adalah saran-saran yang dapat dilakukan untuk penelitian selanjutnya agar menghasilkan pengembangan yang lebih baik:
1 Data yang dipakai dibuat terintegrasi dalam suatu database server yang mampu menyimpan data dalam kapasitas besar.
2 Pengembangan sistem dapat dilakukan dalam skala luas meliputi 3 layer yaitu database server, web server dan client.
3 Clustering DBSCAN juga disarankan untuk dilakukan secara multidimensi tidak hanya pada dimensi spasial latitude dan longitude saja.
DAFTAR PUSTAKA
Adinugroho WC, Suryadiputra INN, Saharjo BH, Siboro L. 2005. Panduan Pengendalian Kebakaran Hutan dan Lahan Gambut. Proyek Climate Change, Forests and Peatlands in Indonesia. Bogor (ID): Wetlands International-Indonesia Programme dan Wildlife Habitat Canada.
Beeley C. 2013. Web Application Development with R Using Shiny. Birmingham (UK): Packt Publishing Ltd.
Ester M, Kriegel HP, Sander J, Xu X. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Di dalam: Simoudis E, editor. Proceedings of 2nd International Conference on Knowledge Discovery and Data Mining (KDD-96); 1996 Agustus 4-6; hlm 226-231. Gaonkar MN, Sawant K. 2013. AutoEPs DBSCAN: DBSCAN with Eps Automatic
for Large Dataset. International Journal on Advanced Computer Theory and Engineering Volume-2, Issue-2 hlm 11-16.
Han J, Kamber M, Tung AKH. 2001. Spatial clustering methods in data mining: a survey. Di dalam: Geographic Data Mining and Knowledge Discovery. New York (USA): CRC Press.
Purwanto UY, Barus B, Adrianto HA. 2013. Penggerombolan spasial hotspot kebakaran hutan dan lahan menggunakan DBSCAN dan ST-DBSCAN [tesis]. Bogor (ID): Institut Pertanian Bogor.
14
LAMPIRAN
Lampiran 1 Contoh dataset titik panas pulau Kalimantan latitude longitude brightness scan track acq_date acq_
15
RIWAYAT HIDUP
Rahmah Mardhiyyah dilahirkan di Bogor pada tanggal 14 Oktober 1990 dan merupakan anak kedua dari empat bersaudara dengan ayah bernama Usman Effendi AS dan ibu bernama Heri Kartini. Pada tahun 2008 penulis lulus dari MA Husnul Khotimah Kuningan dan diterima di Program Studi Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur USMI (Undangan Seleksi Masuk IPB).