CLUSTERING
DATA INDEKS PEMBANGUNAN MANUSIA
(IPM) PULAU JAWA MENGGUNAKAN ALGORITME
ST-DBSCAN DAN BAHASA PEMROGRAMAN R
NURUL AFIFAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Clustering Data Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman R adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
NURUL AFIFAH. Clustering Data Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman R. Dibimbing oleh HARI AGUNG ADRIANTO.
Indeks pembangunan manusia (IPM) dapat digunakan sebagai tolak ukur penentuan derajat kesejahteraan rakyat. Data IPM merupakan data yang terdiri dari data spasial berbentuk poligon dan data temporal. ST-DBSCAN merupakan salah satu algoritme yang mampu mengolah data spatial dan temporal. Tujuan penelitian ini adalah menerapkan algoritme ST-DBSCAN pada data IPM Pulau Jawa tahun 2012. Hasil penelitian memperoleh 9 cluster menggunakan parameter Eps1 (parameter jarak spasial) = 0.4, Eps2 (parameter jarak temporal) = 0, MinPts (jumlah minimal anggota cluster) = 4, dan (parameter ukuran selisih atribut non-spasial yang ditoleransi) = 2. Rata-rata nilai IPM tertinggi terletak di wilayah Jabodetabek yaitu sebesar 77.67. Tingginya nilai IPM di wilayah ini dikarenakan letaknya yang berada di pusat ibukota Indonesia. Hal ini berlawanan dengan wilayah timur Jawa yang memiliki nilai rata-rata IPM terendah yaitu sebesar 72.24. Ukuran yang dapat menunjukkan kualitas suatu cluster dengan perhitungan silhouette index. Pada penelitian ini, nilai koefisien silhouette index adalah 0.1599514. Berdasarkan nilai koefisien silhouette index, kualitas cluster data IPM yang terbentuk belum mendekati nilai terbaik. Implentasi algoritme ST-DBSCAN menggunakan bahasa R. Package dalam bahasa pemrograman R yang digunakan adalah maptools, cluster, dan rgeos.
Kata kunci: clustering, IPM, R, silhouette index, ST-DBSCAN
ABSTRACT
NURUL AFIFAH. Clustering on Human Development Index (HDI) Data on Java in Year 2012 Using ST-DBSCAN Algorithm and R Programming Language. Supervised by HARI AGUNG ADRIANTO.
Human development index (HDI) is an important indicator for regional quality evaluation. HDI data consist of a polygon-shaped spatial and temporal data. ST-DBSCAN can process both spatial and temporal data. The purpose of this research is to apply ST-DBSCAN algorithm on HDI data on Java. Nine clusters are found on Eps1 = 0.4, Eps2 = 0, MinPts = 4 and delta-e equal to 2 local z-score. The highest HDI value is located at Jabodetabek, 77.67. It is caused by its location at capital of Indonesia. This is in contrast with the eastern of Java that has the lowest HDI value, 72.24. The precision of a cluster is calculated using silhouette index. In this research, the cluster evaluation is 0.1599514. Based on this result, it is still not close to the best value. ST-DBSCAN algorithm is implemented using R language, using maptools, cluster and rgeos packages.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
CLUSTERING
DATA INDEKS PEMBANGUNAN MANUSIA
(IPM) PULAU JAWA MENGGUNAKAN ALGORITME
ST-DBSCAN DAN BAHASA PEMROGRAMAN R
NURUL AFIFAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Clustering Data Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman R
Nama : Nurul Afifah NIM : G64100087
Disetujui oleh
Hari Agung Adrianto, SKom MSi Pembimbing I
Diketahui oleh
Dr Ir Agus Buono, MSi MKom
Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2014 ini ialah data mining, dengan judul Clustering Data Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggunakan Algoritme ST-DBSCAN dan Bahasa Pemrograman R.
Terima kasih penulis ucapkan kepada Bapak Hari Agung Adrianto selaku pembimbing, keluarga, serta teman-teman Program Studi S1 Ilmu Komputer yang telah banyak memberi saran. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
TINJAUAN PUSTAKA 3
Praproses Data 3
Algoritme ST-DBSCAN 3
Hausdorff Distance 4
Silhouette Index 5
Indeks Pembangunan Manusia 6
METODE PENELITIAN 7
Data Penelitian 7
Tahapan Penelitian 7
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Sumber Data dan Karakteristik Data 10
Praproses Data 11
Implementasi ST-DBSCAN dengan Bahasa Pemrograman R 11
Clustering Menggunakan ST-DBSCAN 13
Hasil Clustering ST-DBSCAN 16
Evaluasi Cluster 17
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 18
DAFTAR PUSTAKA 18
DAFTAR TABEL
1 Kriteria IPM menurut UNDP (BPS 2013) 6
2 Atribut dalam shapefiles 11
3 Hasil perhitungan nilai silhoutte index untuk MinPts=4 15
DAFTAR GAMBAR
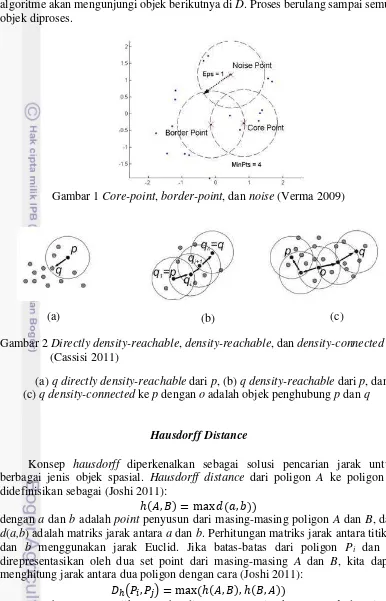
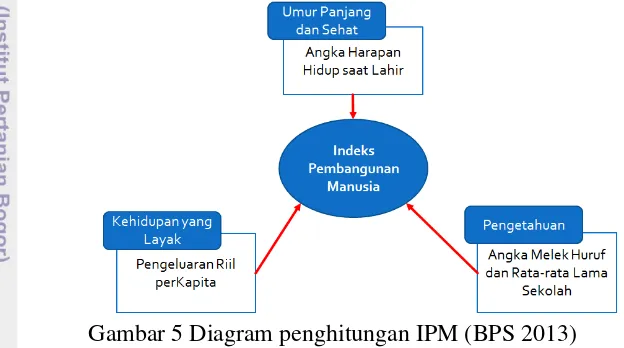
1 Core-point, border-point, dan noise (Verma 2009) 4 2 Directly density-reachable, density-reachable, dan density-
connected (Cassisi 2011) 4
3 Perbedaan hausdorff distance dengan centroid distance (Joshi 2011) 5 4 Ilustrasi silhouette index (Rousseeuw 1987) 5
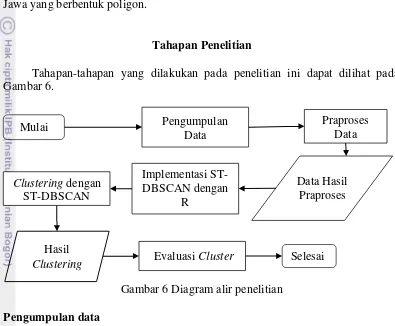
5 Diagram penghitungan IPM (BPS 2013) 6
6 Diagram alir penelitian 7
7 Algoritme ST-DBSCAN (Birant dan Kut 2007) 8
8 Grafik nilai Eps (Purwanto 2012) 9
9 Implementasi menghitung jarak antar kota dan kabupaten 11 10 Implementasi direcly density reachable suatu objek 12
11 Implementasi pembentukan cluster baru 12
12 Implementasi penelusuran aspek non-spasial data IPM 13
13 Pergeseran nilai ambang pada K-Dist 14
14 Hubungan jumlah noise dengan nilai Eps 1 14 15 Hubungan jumlah cluster dengan nilai Eps1 pada MinPts=4 15 16 Hasil clustering data IPM Pulau Jawa tahun 2012 16
17 Boxplot data IPM setiap cluster 17
18 Implementasi evaluasi cluster Silhouette Index 17
DAFTAR LAMPIRAN
1 Hasil implementasi ST-DBSCAN menggunakan bahasa
pemrograman R 20
1
PENDAHULUAN
Latar Belakang
Peningkatan derajat kesejahteraan rakyat merupakan salah satu tujuan dari suatu program perekonomian suatu daerah. Konsep IPM (Indeks Pembangunan Manusia) pertama kali dipublikasikan United Nations Development Programme (UNDP) melalui Human Development Report tahun 1996, yang kemudian berlanjut setiap tahun (UNDP 1996). Dalam publikasi ini pembangunan manusia didefinisikan sebagai “a process of enlarging people’s choices” atau proses yang meningkatkan aspek kehidupan masyarakat. IPM menggabungkan tiga aspek penting, yaitu peningkatan kesehatan, pendidikan, dan kemampuan ekonomi masyarakat dalam kurun waktu tertentu (BPS 2013). Ketiga unsur ini sangat penting dalam menentukan tingkat kesejahteraan suatu wilayah.
Nilai IPM Indonesia terus meningkat dari 67.70 ke 73.29 selama tahun 1996 sampai 2012, sehingga Indonesia dikelompokkan sebagai negara berkembang (121th world rank). Pada tahun 2012, Pulau Jawa memiliki rata-rata IPM yang lebih tinggi jika dibandingkan dengan pulau yang lain, yaitu sebesar 74.33 (BPS 2013). Jadi, menemukan pola nilai IPM di Pulau Jawa dapat bermanfaat untuk mendefinisikan strategi pembangunan daerah.
Pemanfaatan metode data mining untuk data IPM mulai banyak dilakukan pemerintah dalam mengambil kebijakan. Beberapa metode telah digunakan untuk pengelompokan daerah/kecamatan berdasarkan kemiripan IPM, misalnya Fuzzy Cmeans Cluster dan Fuzzy C-Shell Cluster (Widodo dan Purhadi 2012) dan SOM (Santosa et al. 2013) namun tidak satupun dari penelitian tersebut menggunakan dimensi spasial seperti jarak dan topologi. Dengan menggunakan teknik clustering diharapkan akan diketahui pola persebaran nilai IPM pada suatu wilayah.
Data IPM terdiri dari data yang berbentuk spasial, data temporal, dan data non-spasial. Mengekstrak pola data spasial dan temporal pada umumnya lebih kompleks daripada data numerik dan data kategori sehubungan dengan kompleksitas tipe data spasial, ukuran yang lebih besar, dan waktu. Clustering adalah proses pengelompokan data besar sehingga membentuk kelompok-kelompok sehingga pada setiap kelompok-kelompoknya memiliki kesamaan karakteristik yang lebih tinggi dibandingkan dengan kelompok yang lain (Tork 2012).
2
Dengan diterapkannya proses data mining diharapkan dapat menghasilkan informasi atau pengetahuan yang penting dan berguna dari data spasial dan data temporal dengan menggunakan ST-DBSCAN.
Pada penelitian ini, penerapan ST-DBSCAN untuk clustering data spasial kabupaten dan kota di Pulau Jawa berdasarkan nilai IPM pada tahun 2012. Untuk mengukur jarak aspek spasial, digunakan perhitungan jarak haussdorff, karena jarak hausdorff dapat digunakan untuk menghitung jarak antar poligon (Joshii 2011). Selain itu, parameter Eps2 diabaikan karena pada penelitian ini hanya menggunakan data 1 tahun. Parameter terakhir adalah z-score yang digunakan untuk menentukan threshold data non-spasial ().
Salah satu fasilitas perangkat lunak yang sangat efektif untuk implementasi clustering adalah bahasa R (Venables dan Smith 2009). R efektif dalam pengelolaan data dan fasilitas penyimpanan. Ukuran fail yang disimpan jauh lebih kecil dibanding software lainnya. Sehingga, sangat dimungkinkan untuk pengolahan data kependudukan yang sangat besar. Selain itu, R dapat dikembangkan sesuai keperluan dan kebutuhan, sifatnya yang terbuka, dan setiap orang dapat menambahkan fitur-fitur tambahan dalam bentuk paket ke dalam software R yang sifatnya gratis. R bersifat multiplatform, yakni dapat diinstall dan digunakan baik pada sistem operasi Windows dan UNIX/LINUX.
Perumusan Masalah
Data IPM Pulau Jawa berbentuk data spasial, data non-spasial, dan data temporal. Clustering terhadap data spasial, data non-spasial dan data temporal dapat dilakukan dengan algoritme ST-DBSCAN. Perumusan masalah dalam penelitian ini ialah bagaimana cara mengimplementasikan algoritme ST-DBSCAN menggunakan R untuk data spasial berbentuk poligon dan data non-spasial.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan proses spatial data mining dengan menggunakan teknik clustering ST-DBSCAN pada data IPM Pulau Jawa tahun 2012 dengan pengimplementasian menggunakan bahasa pemrograman R.
Manfaat Penelitian
3
Ruang Lingkup Penelitian
Dataset pada penelitian ini adalah data IPM Pulau Jawa tahun 2012. Algoritme clustering yang akan digunakan untuk pengolahan data IPM adalah ST-DBSCAN. Implementasi algoritme ST-DBSCAN dilakukan menggunakan bahasa pemrograman R.
TINJAUAN PUSTAKA
Praproses Data
Praproses diperlukan untuk meningkatkan akurasi dan efisiensi pada proses mining. Pada praproses data, hal yang dapat dilakukan adalah pembersihan data, integrasi data, transformasi data, dan reduksi data. Proses pembersihan data adalah mengisi missing value (nilai yang hilang), menghilangkan noisy, membuang pencilan, dan memisahkan data yang yang tidak konsisten. Integrasi data adalah proses penggabungan data dari berbagai sumber. Pada transformasi data, data diubah atau digabungkan menjadi bentuk yang tepat untuk mining. Transformasi data ini mencakup smoothing (untuk menghilangkan noise), agregasi (operasi peringkasan atau penyatuan), generalisasi (penyamarataan level pada suatu atribut), normalisasi (atribut diskalakan sehingga nilainya berkurang ke rentang yang lebih kecil), dan konstruksi atribut (atribut baru dibuat dan ditambahkan dari sekumpulan atribut lain). Reduksi data bertujuan untuk mengurangi ukuran data tanpa merubah hasil mining. Reduksi data menghasilkan representasi dataset tereduksi yang berukuran lebih kecil namun memperlihatkan hasil analisis yang sama atau hampir sama. Strategi reduksi data meliputi agregrasi, seleksi subset atribut, reduksi dimensional, dan reduksi jumlah (Han et al. 2012).
Algoritme ST-DBSCAN
Algoritme ST-DBSCAN dibangun dengan memodifikasi algoritme DBSCAN (Ester et al. 1996). Algoritme ST-DBSCAN membutuhkan empat parameter, yaitu Eps1, Eps2, MinPts, dan . Eps1 adalah parameter jarak untuk atribut spasial. Eps2 adalah parameter jarak untuk atribut temporal. Eps1 dan Eps2 dapat dihitung dengan matriks Euclidean, Manhattan, Minkowski, Hausdorff, dan sebagainya. MinPts adalah jumlah minimum objek yang berada dalam jarak Eps1 dan Eps2. Parameter digunakan untuk mencegah ditemukannya kombinasi cluster akibat perbedaan nilai yang cukup besar dari atribut non-spasial suatu objek dengan objek lainnya.
core-4
object lainnya, tidak ada objek-objek lain yang density-reachable dari p, maka algoritme akan mengunjungi objek berikutnya di D. Proses berulang sampai semua objek diproses.
Gambar 1 Core-point, border-point, dan noise (Verma 2009)
Gambar 2 Directly density-reachable, density-reachable, dan density-connected (Cassisi 2011)
(a) q directly density-reachable dari p, (b) q density-reachable dari p, dan (c) q density-connected ke p dengan o adalah objek penghubung p dan q
Hausdorff Distance
Konsep hausdorff diperkenalkan sebagai solusi pencarian jarak untuk berbagai jenis objek spasial. Hausdorff distance dari poligon A ke poligon B didefinisikan sebagai (Joshi 2011):
ℎ , = max � ,
dengan a dan b adalah point penyusun dari masing-masing poligon A dan B, dan d(a,b) adalah matriks jarak antara a dan b. Perhitungan matriks jarak antara titik a dan b menggunakan jarak Euclid. Jika batas-batas dari poligon Pi dan Pj
direpresentasikan oleh dua set point dari masing-masing A dan B, kita dapat menghitung jarak antara dua poligon dengan cara (Joshi 2011):
ℎ(� , � ) = max ℎ , , ℎ ,
Gambar 3 menyajikan perbandingan antara jarak Centroid dan jarak Hausdorff antara dua poligon. Pada jarak Centroid Dc memungkinkan terjadinya
underestimate dan overestimate distance ketika centroid jatuh di luar poligon.
5 Sementara itu, dengan jarak Hausdorff, yang didefinisikan dengan Dh, memberikan
pengukuran secara lebih akurat (Joshi 2011).
Gambar 3 Perbedaan hausdorff distance dengan centroid distance (Joshi 2011)
Silhouette Index
Silhouette Index digunakan untuk mengukur kualitas dari cluster yang terbentuk. Nilai Silhouette Index suatu objek i adalah (Rousseeuw 1987):
� � =max{� − �, }
dengan a(i) merupakan jarak rata-rata antara objek i dengan seluruh objek yang berada dalam satu cluster yang sama (intra-cluster). b(i) adalah jarak rata-rata antara objek i dengan seluruh objek yang berada pada cluster terdekat (nearest-cluster) (Sklearn 2014). Sebagai ilustrasi pada Gambar 4, titik i berada dalam cluster A, maka cluster B adalah cluster terdekatnya, dengan a(i) adalah rataan jarak titik i dengan titik lain di dalam cluster A dan b(i) adalah rataan jarak titik i ke semua titik dalam cluster B (Rousseeuw 1987).
Gambar 4 Ilustrasi silhouette index (Rousseeuw 1987)
Nilai koefisien Silhouette (SC) suatu cluster yang terdiri dari N jumlah objek dapat dihitung dengan rata-rata dari seluruh nilai Silhoette Index setiap objek s(i) (Rousseeuw 1987):
� = 1∑ � �
�
6
Indeks Pembangunan Manusia
Indeks Pembangunan Manusia (IPM) mengukur capaian pembangunan manusia berbasis sejumlah komponen dasar kualitas hidup. Sebagai ukuran kualitas hidup, IPM dibangun melalui pendekatan tiga dimensi dasar. Dimensi tersebut mencakup umur panjang dan sehat; pengetahuan, dan kehidupan yang layak. Ketiga dimensi tersebut memiliki pengertian sangat luas karena terkait banyak faktor. Untuk mengukur dimensi kesehatan, digunakan angka harapan hidup waktu lahir. Selanjutnya untuk mengukur dimensi pengetahuan digunakan gabungan indikator angka melek huruf dan rata-rata lama sekolah. Adapun untuk mengukur dimensi hidup layak digunakan indikator kemampuan daya beli masyarakat terhadap sejumlah kebutuhan pokok yang dilihat dari rata-rata besarnya pengeluaran per kapita sebagai pendekatan pendapatan yang mewakili capaian pembangunan untuk hidup layak. Metode perhitungan untuk menyusun indeks pembangunan manusia telah diterapkan oleh BPS berdasarkan ketetapan United Nations Development Programs (UNDP) pada tahun 1994.
Gambar 5 Diagram penghitungan IPM (BPS 2013)
Berdasarkan ketiga indikator IPM, pada Gambar 5 (indeks kesehatan, indeks pendidikan, dan indeks ekonomi), maka nilai IPM dapat dihitungan dengan menggunakan rumus dibawah ini (BPS 2013):
�� =13 �� + �� + �
dengan IPM adalah Indeks Pembangunan Manusia, IK adalah Indeks Kesehatan, dan IE adalah Indeks Ekonomi. Kriteria untuk setiap tingkat status nilai IPM tiap wilayah ditunjukkan pada Tabel 1.
Tabel 1 Kriteria IPM menurut UNDP (BPS 2013) Tingkat Status Kriteria
Rendah IPM < 50
Menengah kebawah 50 ≤ IPM < 66 Menengah keatas 66 ≤ IPM < 80
7
METODE PENELITIAN
Data Penelitian
Data yang digunakan pada penelitian ini adalah data IPM Pulau Jawa pada tahun 2012. Data spasial berupa batas-batas wilayah kota dan kabupaten pada Pulau Jawa yang berbentuk poligon.
Tahapan Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 6.
Gambar 6 Diagram alir penelitian
Pengumpulan data
Data IPM diperoleh dari Badan Pusat Statistik (http://bps.go.id/ipm.php). Peta Pulau Jawa diperoleh dari http://data.ukp.go.id.
Praproses data
Tahap praproses data meliputi seleksi data dan reduksi data. Seleksi data dilakukan dengan memilih peta Pulau Jawa dari peta Indonesia menggunakan QuantumGIS. Reduksi data dilakukan dengan memilih atribut yang dibutuhkan untuk proses clustering.
Implementasi ST-DBSCAN dengan Bahasa Pemrograman R
Implementasi algoritme ST-DBSCAN menggunakan bahasa pemrograman R. Implementasi dilakukan dengan menyesuaikan syntax dengan algoritme dan dibantu dengan package yang dapat memudahkan proses implementasi. Package yang digunakan adalah maptools, rgeos, cluster, dan fpc. Package maptools digunakan untuk membaca peta Pulau Jawa yang berbentuk poligon, sehingga koordinat-koordinat penyusun batas kota dan kabupaten dapat digunakan pada perhitungan jarak spasial. Package rgeos digunakan untuk menghitung jarak antar poligon kota dan kabupaten menggunakan fungsi Hausdorff. Package cluster
8
digunakan untuk menghitung nilai Silhouette Index hasil clustering menggunakan fungsi sihouette. Package fpc digunakan sebagai acuan pengetikan kode ST-DBSCAN, dengan memodifikasi fungsi dbscan di dalam package.
Proses implementasi dimulai dengan memahami algoritme ST-DBSCAN seperti ditujukan pada Gambar 7:
Gambar 7 Algoritme ST-DBSCAN (Birant dan Kut 2007)
Pada Gambar 7, algoritme dimulai dari objek pertama o1 di D – seperti pada baris (i). Setelah memproses objek o1, dipilih objek selanjutnya (o2) di D. Jika objek o2 belum termasuk ke dalam cluster manapun – baris (ii), fungsi Retrieve_Neighbours dipanggil – baris (iii). Pemanggilan fungsi Retrieve_Neighbours(o2, Eps1, Eps2) mengembalikan objek yang berada pada jarak kurang dari parameter Eps1 dan Eps2 dari objek o2.
9 Jika jumlah objek yang dikembalikan dalam Eps-Neighborhood kurang dari MinPts, maka objek ditetapkan sebagai noise – oi tidak memiliki cukup tetangga untuk membentuk suatu cluster – baris (iv). Objek yang telah ditandai sebagai noise dapat berubah pada proses selanjutnya jika density-reachable dari objek-objek lain di D. Kejadian seperti ini sering terjadi pada border-object di cluster.
Jika oi adalah core-object, maka cluster baru dibuat – baris (v). Semua objek yang directly density-reachable dari core-object tersebut juga ditandai sebagai label cluster baru. Lalu algoritme mengumpulkan objek yang density-reachable secara iteratif menggunakan stack – baris (vi). Stack yang dimaksud berguna untuk mencari objek lain yang density-reachable dari objek directly density-reachable – ekspansi cluster. Pada baris (vii), data non-spasial (data IPM) suatu objek akan dibandingkan dengan data non-spasial objek lain dalam satu cluster. Data non-spasial tersebut harus dinormalisasi menggunakan normalisasi zscore, yaitu nilai mutlak dari rataan data non-spasial cluster dikurangi dengan nilai data non-spasial objek tersebut. Normalisasi membantu mencegah munculnya atribut dengan perbedaan nilai rentang yang besar. Berikut adalah normalisasi zscore (z) untuk nilai non-spasial suatu objek (x) (Han et al. 2001):
� =� − �̅�
�
dengan �̅ adalah mean dari seluruh nilai data non-spasial pada satu cluster. �� adalah standar deviasi dari seluruh nilai data non-spasial pada satu cluster. Jika suatu objek tidak ditandai sebagai noise atau tidak dalam cluster manapun, dan nilai zscore objek tersebut kurang dari , maka objek tersebut dilabeli sebagai cluster yang sedang diproses – baris (vii). Sebaliknya jika nilai zscore objek tersebut lebih dari , maka objek tersebut dilabeli sebagai noise. Setelah memproses objek tersebut, algoritme memilih objek selanjutnya di D dan berlanjut sampai semua objek diproses.
Jika dua cluster C1 dan C2 berhimpitan satu sama lain, ketika objek p dapat menjadi anggota cluster kedua-duanya (border-object antara C1 dan C2). Algoritme ST-DBSCAN akan menetapkan objek p ke cluster yang terlebih dahulu di temukan.
Clustering dengan ST-DBSCAN
Data hasil praproses akan diolah menggunakan algoritme clustering ST-DBSCAN yang telah diimplementasikan menggunakan R sehingga menghasilkan cluster. Algoritme ST-DBSCAN membutuhkan empat parameter, yaitu Eps1, Eps2, MinPts, dan . Menentukan parameter Eps dan MinPts dari penggerombolan terkecil pada basis data dapat dilakukan melalui observasi k-dist (Gambar 8) (Purwanto 2012).
10
Berikut langkah-langkah penentuan nilai Eps dan MinPts dari k-dist (Purwanto 2012):
1 Komputasikan k-dist untuk seluruh titik pada beberapa k. Urutkan dalam urutan menurun dan plot nilai yang telah diurutkan.
2 Perubahan tajam pada nilai k-dist yang berhubungan dengan nilai Eps dan nilai k gunakan sebagai MinPts yang sesuai (pada Gambar 8).
3 Poin yang k-dist lebih kecil dari Eps akan disebut sebagai core point (titik inti), sementara titik lain akan dilabeli sebagai titik noise atau titik border. 4 Jika k terlalu besar maka penggerombolan kecil (ukuran kurang dari k)
cenderung diberi label sebagai titik noise. Jika k terlalu kecil maka titik noise atau outlier akan salah diberi label sebagai penggerombolan.
5 Eps dipilih yang kurang dari jarak yang ditentukan oleh lembah pertama. Penentuan threshold data non-spasial ( menggunakan zscore. Setelah diperoleh nilai Eps1, Eps2, MinPts, dan data hasil praproses akan dilakukan clustering dengan menggunakan algoritme ST-DBSCAN.
Evaluasi cluster
Cluster yang ditemukan akan dievaluasi kualitas dari cluster yang telah terbentuk menggunakan koefisien Silhouette. Koefisien Silhouette didapat dari rata-rata nilai koefisien Silhoette semua cluster (Rousseeuw 1987).
Lingkungan Pengembangan
Spesifikasi yang digunakan untuk penelitian ini adalah: 1 Perangkat lunak:
Sistem operasi: Windows 7 Enterprise 32-bit Libre Office, QuantumGIS 2.2.0
R-3.0.2 version of R64, RStudio
Package R: maptools, rgeos, cluster, dan fpc 2 Perangkat keras:
Processor: Intel® CoreTM i5-330M 2.13 GHz Memori (RAM): 4.00 GB DDR3 1066 MHz
HASIL DAN PEMBAHASAN
Sumber Data dan Karakteristik Data
11
Praproses Data
Seleksi data
Pada tahapan ini dilakukan pemilihan peta Pulau Jawa dari peta Indonesia. Peta Pulau Jawa merupakan data dengan format shapefiles (.shp). Kemudian, dari data IPM Indonesia, hanya dipilih data IPM pada Pulau Jawa dengan format comma delimited (.csv).
Reduksi Data
Reduksi data dilakukan dengan memilih atribut yang akan digunakan pada proses clustering, yaitu nama_kabkota, ipm, dan tahun. Contoh nilai atribut yang akan digunakan terdapat dalam Tabel 2.
Tabel 2 Atribut dalam shapefiles Nama_KabKota IPM Tahun
Pemalang 70.66 2012
Magelang 77.26 2012
Implementasi ST-DBSCAN dengan Bahasa Pemrograman R
Implementasi algoritme ST-DBSCAN dilakukan dengan memodifikasi fungsi dbscan yang tersedia pada R 3.02. R packages yang digunakan adalah maptools, rgeos, cluster, dan fpc. Package maptools digunakan R untuk membaca peta Pulau Jawa yang berbentuk poligon, sehingga koordinat-koordinat penyusun batas kota dan kabupaten dapat digunakan pada perhitungan jarak spasial. Package rgeos digunakan R untuk menghitung jarak antar poligon kota dan kabupaten menggunakan fungsi Hausdorff. Package cluster digunakan R untuk menghitung nilai Silhouette Index hasil clustering menggunakan fungsi sihouette. Package fpc digunakan sebagai acuan pengetikan kode ST-DBSCAN, dengan memodifikasi fungsi dbscan di dalam package. Hasil implementasi ST-DBSCAN menggunakan bahasa pemrograman R terdapat pada Lampiran 1.
Perhitungan Jarak
Matriks jarak antar poligon (data spasial) dihitung dengan hausdorff distance. Matriks jarak antar waktu (data temporal) dihitung dengan euclidean distance. Implementasi untuk menghitung jarak antar poligon dan jarak antar waktu terdapat Gambar 9.
12
Implementasi diawali dengan membaca data shapefiles peta Pulau Jawa menggunakan fungsi readShapePoly. Jarak antar kota dan kabupaten berbentuk matriks dengan dimensi sejumlah kota dan kabupaten. Fungsi outer digunakan untuk membentuk matriks jarak antar poligon dengan dimensi sejumlah kota dan kabupaten (115×115). Pada fungsi outer terdapat fungsi gDistance untuk menghitung jarak antar kota dan kabupaten menggunakan metode hausdorff distance. Hasil dari matriks jarak antar kota dan kabupaten terdapat pada variabel data_spasial. Fungsi dist digunakan untuk membentuk matriks jarak antar waktu dengan dimensi sejumlah kota dan kabupaten (115×115). Hasil dari matriks jarak antar waktu terdapat pada variabel data_temporal.
Proses Implementasi Algoritme ST-DBSCAN Menggunakan Bahasa Pemrograman R
Algorime dimulai dari objek pertama (O1) dari data. Setelah memproses objek Oi, dipilih objek selanjutnya (Oi+1) sampai objek terakhir dari data. Jika objek Oi+1 belum termasuk ke dalam cluster manapun, maka akan dicari objek yang berada pada jarak kurang dari parameter Eps1 dan Eps2 dari Oi+1, seperti yang tertera pada Gambar 10.
Gambar 10 Implementasi direcly density reachable suatu objek
Isi dari variabel directly_density_reachables adalah semua objek terdekat dari objek yang sedang dikunjungi dalam jangkauan jarak parameter Eps1 dan Eps2.
Pada Gambar 11, jika jumlah objek yang terdapat pada variabel directly_density_reachables kurang dari MinPts – baris (i), maka objek ditetapkan sebagai noise – baris (ii)– (objek tidak memiliki cukup tetangga untuk membentuk suatu cluster). Jika Oi adalah core object, maka cluster baru dibuat – baris (iv). Semua objek yang directly density-reachable dari core-object tersebut juga ditandai sebagai label cluster baru.
Gambar 11 Implementasi pembentukan cluster baru
13
Gambar 12 Implementasi penelusuran aspek non-spasial data IPM
Pada Gambar 12, algoritme mengumpulkan objek yang density-reachable secara iteratif menggunakan stack – baris (ii). Selanjutnya, dihitung rata-rata – baris
(v) – dan standar deviasi – baris (vii) –dari cluster. Stack yang dimaksud berguna untuk mencari objek lain yang density-reachable dari objek directly density-reachable – ekspansi cluster – baris (x). Jika suatu objek tidak ditandai sebagai noise atau tidak dalam cluster manapun, dan perbedaan antara nilai rataan cluster dengan nilai objek tersebut kurang dari , maka objek tersebut dilabeli sebagai cluster yang sedang diproses – baris (xix). Kemudian menggabungkan seluruh hasil ekspansi cluster – baris (xxiv). Setelah memproses objek tersebut, algoritme memilih objek selanjutnya dan berlanjut sampai semua objek diproses.
Clustering Menggunakan ST-DBSCAN
Penentuan Nilai Eps dan MinPts
14
bervariasi. Untuk mengoptimalkan nilai Eps dan MinPts, dipilih garis yang mendekati garis menaik kemudian dipotong secara vertikal pada plot k tetangga terdekat dengan seluruh titik di sebelah kiri garis vertikal merupakan core point (Gambar 13). Oleh karena itu, semakin jauh digeser ke kiri, core point lebih sedikit dan penggerombolan yang terbentuk semakin sedikit. Sebaliknya jika garis potong vertikal berada di dekat sisi kanan grafik core point lebih banyak dan penggerombolan yang terbentuk semakin banyak. Berdasarkan Gambar 13, pergeseran nilai ambang pada penelitian ini dilakukan pada nilai k=4, k=5, dan k=6 dengan pergeseran nilai Eps 0.3 sampai 0.6. Nilai tersebutlah yang akan dimasukkan pada algoritme ST-DBSCAN untuk menentukan nilai Eps dan MinPts yang tepat.
Gambar 13 Pergeseran nilai ambang pada K-Dist
Berdasarkan Gambar 14, jumlah titik noise terkecil terdapat pada nilai k=4. Nilai k=4 yang ditentukan sebagai nilai MinPts. Selanjutnya, dengan MinPts =4, maka akan dihitung jumlah cluster yang terbentuk.
Gambar 14 Hubungan jumlah noise dengan nilai Eps 1
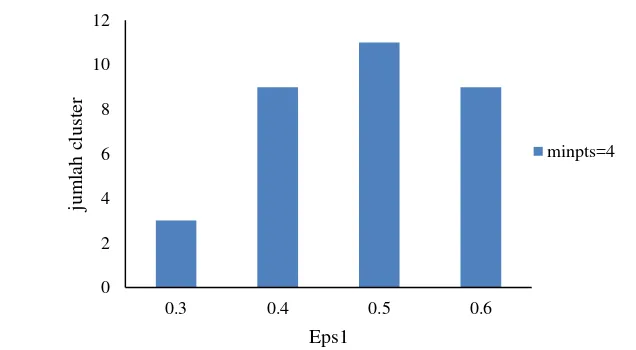
15 Berdasarkan Gambar 15, jumlah cluster yang terbentuk memiliki variasi yang beragam, sehingga, diperlukan perhitungan untuk menentukan kualitas cluster yang baik. Cara menentukan kualitas suatu cluster adalah dengan menghitung nilai Silhouette Index dari masing-masing yang terbentuk.
Gambar 15 Hubungan jumlah cluster dengan nilai Eps1 pada MinPts=4 Hasil perhitungan menggunakan Sillhouette Index berkisar antara nilai -1 hingga 1, dengan -1 merupakan nilai terburuk dan 1 merupakan nilai terbaik (Sklearn 2014). Pada Tabel 3, nilai Silhouette Index yang mendekati nilai 1 adalah pada saat Eps1 = 0.4 (sekitar 45 kilometer jarak di bumi), yaitu bernilai 0.1599514.
Tabel 3 Hasil perhitungan nilai silhoutte index untuk MinPts=4 Eps1 Silhouette Index
0.3 -0.09661161
0.4 0.1599514
0.5 -0.08757854
0.6 -0.00065357
Perhitungan menggunakan algoritme ST-DBSCAN membutuhkan parameter Eps2 untuk mengukur kesamaan pada dimensi temporal, namun parameter ini diabaikan dengan memberi nilai Eps2=0, karena pada penelitian ini hanya menggunakan data 1 tahun. Untuk atribut non-spasial (data IPM), objek yang berdekatan akan terkelompokkan ke dalam sebuah cluster selama IPM kurang dari 2 z-score. Pada penelitian didapatkan nilai Eps1=0.4, Eps2=0, MinPts=4, dan .
16
Hasil Clustering ST-DBSCAN
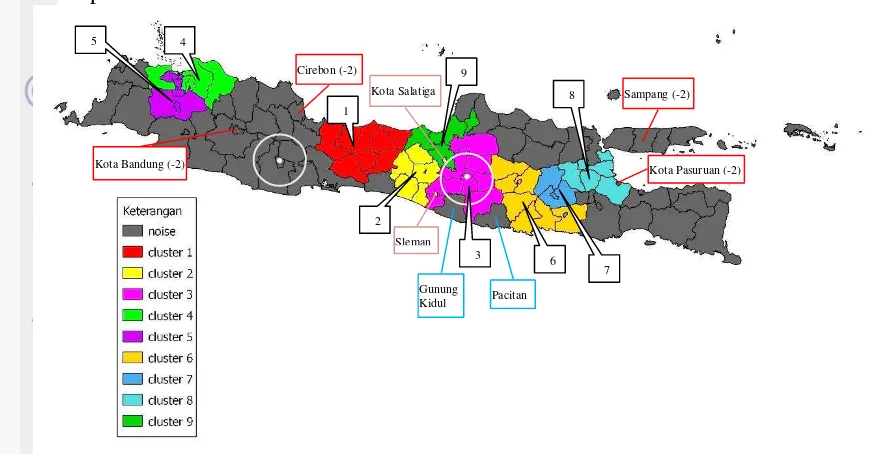
Pada data IPM Pulau Jawa tahun 2012, dari 115 objek data, dengan nilai Eps1=0.4, Eps2=0, MinPts=4, dan ditemukan 9 cluster dan 51 noise. Visualisasi hasil clustering menggunakan QuantumGIS, dapat dilihat pada Gambar 16 dan Lampiran 2.
Gambar 16 Hasil clustering data IPM Pulau Jawa tahun 2012
Pada Gambar 16, Kota Salatiga dan Sleman ditetapkan sebagai cluster 2 meskipun tidak bersebelahan langsung secara wilayah dengan cluster 2. Hal ini disebabkan ketika proses ekspansi cluster 2, Kota Salatiga dan Sleman terdeteksi sebagai objek terdekat dalam jangkauan Eps1 untuk cluster 2. Efek atribut non-spasial terjadi pada Kota Bandung, Cirebon, Sampang, dan Kota Pasuruan, yang dilabeli sebagai outlier (-2) karena IPM keempat kota tersebut sangat berbeda dibandingkan dengan daerah disekitarnya. Kabupaten Gunung Kidul dan Pacitan terdeteksi sebagai noise meskipun memiliki kedekatan wilayah dengan cluster 3. Penyebab kedua kota tersebut dilabeli sebagai noise adalah karena ketika ekspansi cluster 3, jarak Kabupaten Gunung Kidul dan Pacitan dengan cluster 3 lebih besar dari nilai Eps1, meskipun ada kemungkinan kedua kota tersebut adalah anggota cluster 3. Salah satu faktor yang menyebabkan suatu objek dilabeli sebagai cluster atau noise adalah penentuan parameter Eps1, Eps2, MinPts, dan , sehingga penentuan empat parameter tersebut lebih baik secara otomatis. Terdapat 47 noise (berwarna abu-abu) yang disebabkan tetangga mereka berada di bawah parameter yang diperlukan. Sebagian besar noise terletak di Jawa Barat dan Banten karena luas wilayah lebih besar daripada di Pulau Jawa bagian tengah dan timur. Dua lingkaran yang digambar pada Gambar 16 menunjukkan perbedaan kepadatan antara Pulau Jawa bagian barat dan bagian tengah. Rentang nilai IPM pada masing-masing cluster ada pada Gambar 17.
17
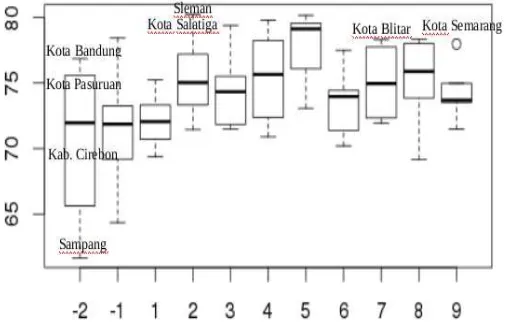
Gambar 17 Boxplot data IPM setiap cluster
Gambar 17 menunjukkan bahwa wilayah JABODETABEK (cluster 5) memiliki nilai IPM tertinggi di Pulau Jawa yaitu sebesar 77.67. Berdasarkan kriteria IPM menurut UNDP, cluster 5 termasuk dalam kriteria kelas menengah ke atas. Tingginya nilai IPM di wilayah ini dikarenakan letaknya yang berada di pusat ibukota Indonesia. Hal ini berlawanan dengan cluster 1 yang memiliki nilai rata-rata IPM terendah yaitu sebesar 72.24.
Evaluasi Cluster
Evaluasi cluster dilakukan setelah hasil cluster didapatkan. Pada Gambar 18, evaluasi cluster dilakukan dengan cara pemanggilan fungsi ‘silhouette’ pada package ‘cluster’. Perhitungan dilakukan menggunakan hasil cluster yang terdapat pada variabel hasil$cluster, menggunakan matriks jarak yang terdapat pada variabel data_spasial. Kemudian dilakukan perhitungan rata-rata dari SI untuk mendapatkan nilai akhir dari koefisien silhouette menggunakan jarak canberra.
Gambar 18 Implementasi evaluasi cluster Silhouette Index
Hasil evaluasi cluster menggunakan Sillhouette Index berkisar antara nilai -1 hingga 1, dengan -1 merupakan nilai terburuk dan 1 merupakan nilai terbaik (Sklearn 2014). Jika nilai Sillhouette Index bernilai negatif, maka jarak objek tersebut lebih dekat dengan objek-objek pada cluster terdekatnya. Pada penelitian ini, evaluasi cluster bernilai 0.01599514. Berdasarkan hasil perhitungan, nilai Silhouette masih belum mendekati nilai terbaik. Evaluasi cluster yang tidak bagus disebabkan kesalahan pemilihan nilai parameter. Oleh karena itu, diharapkan pada penelitian selanjutnya dapat menghasilkan nilai Eps1, Eps2, dan MinPts secara otomatis berdasarkan Gaonkar dan Sawant (2013) sehingga cluster yang terbentuk memiliki nilai evaluasi yang bagus.
> SI<- silhouette(hasil$cluster,dist(data_spasial,”canberra”))
18
SIMPULAN DAN SARAN
Simpulan
Pengimplementasian ST-DBSCAN menggunakan bahasa pemrograman R pada data kependudukan menghasilkan 9 cluster dan 51 titik noise, dengan menggunakan parameter Eps1 (parameter jarak spasial)=0.4 (≈ 45 km), Eps2 (parameter jarak temporal)=0, MinPts (parameter kepadatan cluster)=4, dan (parameter ukuran selisih atribut non-spasial yang ditoleransi)=2. Wilayah JABODETABEK (cluster 5) memiliki nilai IPM tertinggi di Pulau Jawa yaitu sebesar 77.67. Berdasarkan kriteria IPM menurut UNDP, cluster 5 termasuk dalam kriteria kelas menengah ke atas. Tingginya nilai IPM di wilayah ini dikarenakan letaknya yang berada di pusat ibukota Indonesia. Hal ini berlawanan dengan cluster 1 yang memiliki nilai rata-rata IPM terendah yaitu sebesar 72.24.
Saran
Pada penelitian ini, algoritme ST-DBSCAN hanya diimplementasikan pada data 1 tahun dan satu atribut non-spasial (IPM). Untuk penelitian selanjutnya, diharapkan mampu mengimplementasikan pada data lebih dari 1 tahun, dan memasukkan banyak atribut non-spasial. Menentuan nilai MinPts, Eps1, dan Eps2 yang lebih optimal.
DAFTAR PUSTAKA
Birant D, Kut A. 2007. ST-DBSCAN: An Algorithm for Clustering Spatialtemporal Data. Data and Knowledge Engineering. 60:208-221. doi:10.1016/j.datak.2006.01.013.
[BPS] Badan Pusat Statistik (ID). 2013. Publikasi Indeks Pembangunan Manusia 2012 [internet]. [diacu 2014 Juni 12]. Tersedia pada: http://www.bps.go.id/publications/publikasi2013.php?key=indeks+pembangun an+manusia.
Ester M, Kriegel H, Sander J, Xu X. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Di dalam: 2nd International Conference on Knowledge Discovery and Data Mining (KDD-96); 1996 Agustus 2-4; Portland, Amerika Serikat. Portland (US): AAAI Press. hlm 226-231.
Cassisi C. 2011. Implemented Methods [internet]. [diacu 2014 April 20]. Tersedia dari: http://www.dmi.unict.it/~cassisi/DBStrata/help/methods.html
Gaonkar MN, Sawant K. 2013. Autoepsdbscan: dbscan with eps automatic for large dataset. International Journal on Advanced Computer Theory and Engineering. 2:2319-2526.
Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. San Francisco (US): Morgan Kaufmann Publisher.
19 Joshi D. 2011. Polygonal Spatial Clustering. Nebraska (US): University of
Nebraska.
Purwanto UY. 2012. Penggerombolan spasial hotspot kebakaran hutan dan lahan menggunakan DBSCAN dan ST-DBSCAN [tesis]. Bogor (ID): Institut Pertanian Bogor.
Rousseeuw PJ. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics. 20(1987): 53-65. doi: 10.1016/0377-0427(87)90125-7.
[Sklearn] Scikit-learn. 2014. sklearn.metrics.silhouette_score [internet]. [diacu 2014 Mei 29]. Tersedia dari: http://scikit-learn.org/stable/modules/generated/ sklearn.metrics.silhouette_score.html.
Tork, HD. 2012. Spatio-temporal clustering methods classification. Di dalam: -, editor. Doctoral Symposium on Informatics Engineering (DSIE'2012); 2012 Jan 26-27; Porto, Portugal. Porto (PT): Doctoral Symposium on Informatics Engineering. hlm 1-5.
[UNDP] United Nation Development Programme (NY). 1996. Human Developmet Report 1996 [internet]. [diacu 2014 Juni 20]. Tersedia dari: http:// hdr.undp.org/sites/default/files/.../hdr_1996_en_complete_nostats.pdf.
Venables WN, Smith DM. 2009. An Introduction to R. Berlin Heidelberg (US): Springer.
20
LAMPIRAN
Lampiran 1 Hasil implementasi ST-DBSCAN menggunakan bahasa pemrograman R
## Input: Shapefile already loaded into global shape variable ## Determine eps1 value, Determine eps2 value, delta_e ranges to 2-zscore
stdbscan <- function (shape, eps1=0.4, eps2=0, minpts=4, delta_e=2, seeds=TRUE, countmode=NULL)
{
## Calculate spatial distance
shape.split <- split(shape, seq_len(length(shape))) data_spasial<-outer(shape.split,shape.split,
FUN=Vectorize(function(x, y)gDistance(x, y, hausdorff=TRUE)))
## Calculate temporal distance
data_temporal<- dist(cbind(data$date)) data_spasial <- as.matrix(data_spasial) data_temporal <- as.matrix(data_temporal)
n <- nrow(data_spasial) # Counting number of element
data_temporal <- matrix(0,n,n) # set zero distance on temporal
dimension
21
zscore<-((shape$IPM_2012[density_reachables_from_j]-cluster_mean)/cluster_var)<delta_e
cv[density_reachables_from_j[zscore]] <-cn }
density_connected<-union(density_connected,
density_reachables_from_j[cv[density_ reachables_from_j] == 0] )
classn[density_reachables_from_j]<-classn[ density_reachabl
22
Lampiran 2 Tabel hasil clustering data IPM pulau Jawa tahun 2014
Cluster 1
No Nama Kota IPM 2012
1 PEMALANG 70,66238
2 TEGAL 71,74376
3 BREBES 69,36627
4 PEKALONGAN (KOTA) 75,24874
5 TEGAL (KOTA) 74,62955
6 BANYUMAS 73,32884
7 PURBALINGGA 72,9652
8 BANJARNEGARA 70,70124
9 BATANG 71,41448
10 PEKALONGAN 72,36919
Cluster 2
No Nama Kota IPM 2012
1 MAGELANG (KOTA) 77,26195
2 SALATIGA (KOTA) 77,12971
3 KULON PROGO 75,33186
4 YOGYAKARTA (KOTA) 80,23854
5 PURWOREJO 73,52678
6 WONOSOBO 71,44899
7 MAGELANG 73,13523
8 TEMANGGUNG 74,73593
Cluster 3
No Nama Kota IPM 2012
1 SURAKARTA (KOTA) 78,59729
2 BANTUL 75,51432
8 KARANGANYAR 74,62103
9 SRAGEN 71,84736
23
3 TULUNGAGUNG 74,44697
24
3 MOJOKERTO (KOTA) 78,00757
4 SURABAYA (KOTA) 78,32743
5 TASIKMALAYA 72,83585
6 CIAMIS 72,14092
13 PURWAKARTA 72,21296
14 SUKABUMI (KOTA) 75,73038
15 BANDUNG (KOTA) 76,85586
20 KEPULAUAN SERIBU 71,44737
21 LEBAK 68,42803
22 PANDEGLANG 69,22021
23 SERANG 69,83033
24 CILEGON (KOTA) 75,89282
25 PACITAN 72,88149
25
27 BONDOWOSO 64,98052
28 BOJONEGORO 67,74232
29 TUBAN 69,17777
30 LAMONGAN 71,0475
31 BANGKALAN 65,68775
32 PAMEKASAN 66,51011
33 MALANG (KOTA) 78,42962
34 PROBOLINGGO (KOTA) 75,4365
35 PASURUAN (KOTA) 74,32981
36 BATU (KOTA) 75,41659
37 BANYUWANGI 70,53415
38 GRESIK 75,97364
39 JEMBER 65,99298
40 MALANG 71,94313
41 PROBOLINGGO 64,35177
42 SAMPANG 61,66698
43 SITUBONDO 65,06144
44 SUMENEP 66,41009
45 GUNUNG KIDUL 71,11121
46 CILACAP 72,76898
47 KEBUMEN 71,8621
48 BLORA 71,4877
49 REMBANG 72,81291
50 PATI 73,80792
26
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 13 Agustus 1992, dari pasangan Bapak Achmad Ru’yat dan Ibu Triami Sofia sebagai anak pertama dari tujuh bersaudara. Pada tahun 2010 penulis lulus dari MA Pondok Pesantren Husnul Khotimah Kuningan dan lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.