PENGELOMPOKAN DATA INDEKS PEMBANGUNAN
MANUSIA DI PULAU JAWA DENGAN ALGORITME
ST-DBSCAN DAN BAHASA PEMROGRAMAN PYTHON
AJENG TRISNANINGTYAS
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pengelompokan Data Indeks Pembangunan Manusia di Pulau Jawa dengan Algoritme ST-DBSCAN dan Bahasa Pemograman Python adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, September 2014
Ajeng Trisnaningtyas
ABSTRAK
AJENG TRISNANINGTYAS. Pengelompokan Data Indeks Pembangunan Manusia di Pulau Jawa dengan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python. Dibimbing oleh HARI AGUNG ADRIANTO.
Indeks Pembangunan Manusia (IPM) merupakan indikator yang biasa digunakan oleh United Nations Development Programme (UNDP) untuk menilai keberhasilan pembangunan. Tiga unsur pembentuk IPM adalah tingkat kesehatan, pendidikan dan ekonomi. Data IPM per kabupaten yang digunakan pada penelitian ini hanya mencakup wilayah Jawa tahun 2012 yang diperoleh dari Badan Pusat Statistik meliputi data spasial (koordinat wilayah), temporal (tahun) dan non-spasial (IPM). Teknik data mining yang diaplikasikan adalah teknik clustering dengan ST-DBSCAN menggunakan bahasa pemrograman Python. Clustering digunakan untuk menemukan pengelompokan berdasarkan tingkat kemiripan IPM di tiap wilayah. Visualisasi dari objek data IPM menghasilkan peta wilayah persebaran cluster. Dengan menggunakan parameter jarak spasial (Eps1)=0.4, jarak temporal (Eps2)=0, ukuran selisih nilai atribut non-spasial yang ditoleransi (∆)=2, dan minimum anggota dalam cluster (MinPts)=5 menghasilkan 4 cluster dan 18 titik
noise dengan silhouette coefficient bernilai 0.020.
Kata kunci: clustering, indeks pembangunan manusia, Python, ST-DBSCAN
ABSTRACT
AJENG TRISNANINGTYAS. Clustering on Human Development Index Data in Java with ST-DBSCAN Algorithm and Python Programming Language. Supervised by HARI AGUNG ADRIANTO.
Human Development Index (HDI) is an indicator commonly used by the United Nations Development Programme (UNDP) to assess the success of development. Three elements forming the HDI value are the level of health, education, and economics. The HDI data per district used in this research only cover Java region in 2012, obtained from the Central Bureau of Statistics including spatial data (area coordinates), temporal data (years), and non-spatial data (HDI). Data mining technique applied in this research is clustering with ST-DBSCAN using Python programming language. Clustering can be used to found similar grouping based on HDI in each region. Visualization of HDI data objects produces a map of the cluster spread. By using spatial distance parameter (Eps1)=0.4, temporal distance (Eps2)=0, size of the tolerated difference in value of non-spatial atributes (∆)=2, and minimum number of members in each cluster (MinPts)=5 resulted in 4 clusters and 18 point of noise with silhouette coefficient worth 0.020.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
PENGELOMPOKAN DATA INDEKS PEMBANGUNAN
MANUSIA DI PULAU JAWA DENGAN ALGORITME
ST-DBSCAN DAN BAHASA PEMROGRAMAN PYTHON
AJENG TRISNANINGTYAS
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pengelompokan Data Indeks Pembangunan Manusia di Pulau Jawa dengan Algoritme ST-DBSCAN dan Bahasa Pemrograman Python Nama : Ajeng Trisnaningtyas
NIM : G64100094
Disetujui oleh
Hari Agung Adrianto, SKom MSi Pembimbing I
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Maret 2014 ini ialah data
mining, dengan judul Pengelompokan DataIndeks Pembangunan Manusia di Pulau Jawa dengan Algoritme ST-DBSCAN dan Bahasa Pemograman Python.
Terima kasih penulis ucapkan kepada Ayah dan Ibu serta seluruh keluarga atas segala doa dan kasih sayangnya. Ungkapan terima kasih juga disampaikan kepada Bapak Hari Agung Adrianto selaku pembimbing, serta teman-teman Program Studi S1 Ilmu Komputer yang telah banyak memberi saran.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2014
DAFTAR ISI
DAFTAR TABEL ix
DAFTAR GAMBAR ix
DAFTAR LAMPIRAN ix
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 3
Data Spasial Temporal 3
ST-DBSCAN (Spatio Temporal-Density Based Spatial Clustering) 3
Indeks Pembangunan Manusia (IPM) 4
Praproses Data 4
Penentuan Koordinat Centroid (Titik Tengah) pada Poligon 5 Perhitungan Jarak menggunakan Metrik Euclidean 5
METODE PENELITIAN 5
Data Penelitian 5
Tahapan Penelitian 6
Lingkupan Pengembangan 8
HASIL DAN PEMBAHASAN 8
Sumber Data dan Karakteristik Data 8
Praproses Data 9
Penentuan Nilai Parameter 10
Implementasi Algoritme ST-DBSCAN menggunakan Python 11
Hasil Clustering menggunakan ST-DBSCAN 14
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR TABEL
1 Kriteria indeks pembangunan manusia (BPS 2013) 4
2 Contoh nilai atribut dalam shapefile 9
3 Nilai koefisien Silhouette cluster 11
4 Karakteristik wilayah tiap cluster 15
DAFTAR GAMBAR
1 Data spasial dalam bentuk poligon 3
2 Core point, border point, dan noise (Birant dan Kut 2007) 3
3 Diagram alir penelitian 6
4 Grafik observasi k-dist (Purwanto 2012) 7
5 Ilustrasi titik i dalam koefisien Silhouette (Rousseeuw 1987) 7
6 Peta wilayah Pulau Jawa 9
7 Pergeseran nilai ambang pada k-dist 10
8 Hubungan titik noise dengan Eps1 10
9 Diagram jumlah cluster 11
10 Implementasi ST-DBSCAN menggunakan Python 13 11 Pengelompokan di Pulau Jawa berdasarkan IPM tahun 2012 14 12 Hasil cluster dengan Eps1=0.4, Eps2=0, MinPts=5, dan ∆=2 14
DAFTAR LAMPIRAN
1 Antar muka implementasi ST-DBSCAN menggunakan Python 18
2 Hasil cluster menggunakan Python 18
PENDAHULUAN
Latar Belakang
Pada tahun 2013, perekonomian Indonesia tumbuh sebesar 5.78% dibanding tahun 2012, dimana semua sektor ekonomi mengalami pertumbuhan. Perkembangan Indeks Pembangunan Manusia (IPM) Provinsi di Indonesia juga menunjukkan peningkatan pada tahun 2012 sebesar 0.52 poin dibanding tahun 2011 yaitu dari 72.77 menjadi 73.29 (BPS 2013). Meningkatnya indikator-indikator tersebut diharapkan dapat memberikan dampak positif terhadap penyelesaian permasalahan yang terjadi di Indonesia. Menurut Badan Pusat Statistik, pertumbuhan ekonomi dan IPM merupakan indikator yang biasa digunakan untuk menilai sampai seberapa jauh pembangunan suatu daerah tersebut berjalan. Secara spesifik United Nations Development Programme (UNDP) menetapkan indeks komposit yang sangat berpengaruh dalam melakukan pembangunan pada umumnya. Tiga unsur pembentuk IPM tersebut adalah tingkat kesehatan, pendidikan dan ekonomi.
Pada tahun 2012, rata-rata IPM di Pulau Jawa meningkat dibanding tahun-tahun sebelumnya yaitu sebesar 74.33 (BPS 2013). Dengan meningkatnya nilai IPM dari tahun ke tahun di Pulau Jawa, maka data IPM di Pulau Jawa menarik untuk diteliti apakah persebarannya merata. Data IPM yang diperoleh dari Badan Pusat Statistik meliputi data spasial (koordinat wilayah), temporal (tahun) dan non-spasial (indeks pembangunan manusia), dapat digolongkan sebagai data non-spasial temporal. Penggunaan data spasial dalam beberapa tahun ini mengalami peningkatan, contohnya adalah pemanfaatan Sistem Informasi Geografis (SIG) dalam memperoleh, menyimpan, dan merepresentasikan data yang bersifat geografis. Keunggulan dari SIG adalah mempermudah pengguna dalam memperoleh data yang dibutuhkan serta mempermudah dalam mendigitalisasi objek-objek di lapangan yang umumnya tidak nampak pada peta. Data spasial yang digunakan pada penelitian ini direpresentasikan dalam bentuk poligon. Perancangan mekanisme untuk pengelompokan objek spasial penting dilakukan, karena sebagian besar objek dalam ruang geografis adalah dua dimensi. Hasilnya pun akan lebih akurat untuk direpresentasikan sebagai poligon dua dimensi dibandingkan dengan titik satu dimensi (Joshi 2011).
Salah satu sarana untuk mendapatkan suatu pola persebaran kondisi sosial ekonomi di Pulau Jawa adalah dengan melakukan pengelompokan. Pada penelitian ini, teknik data mining yang akan diaplikasikan adalah teknik clustering. Teknik
clustering bertujuan untuk menemukan pengelompokan dan mengidentifikasi pendistribusian dan pola yang menarik dari data yang digunakan (Halkidi et al.
2
interpreternya. Hal ini didukung dengan tersedianya beberapa modul di Python yang dapat diunduh, sehingga akan mendukung pengerjaan pembangunan geo-spasial di Python. Visualisasi dari objek data IPM di Pulau Jawa, berupa peta wilayah persebaran per cluster berdasarkan pengaruh indikator IPM di Pulau Jawa. Hasil visualisasi bisa dibedakan dengan memberi warna area tiap-tiap cluster
dengan deskripsi simbol area.
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah bagaimana cara mengimplementasi algoritme ST-DBSCAN dalam bahasa pemrograman Python dan menemukan informasi pola persebaran kesejahteraan penduduk di Pulau Jawa.
Tujuan Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah menerapkan teknik
clustering dengan metode ST-DBSCAN terhadap data IPM Pulau Jawa tahun 2012. Hasil dari cluster-cluster tersebut akan divisualisasikan dalam peta wilayah penyebaran per cluster sehingga didapatkan informasi yang lebih berguna dan lebih mudah untuk dipahami. Persebaran tersebut bisa dibedakan dengan memberi warna area tiap-tiap cluster dengan disertai deskripsi area tersebut.
Manfaat Penelitian
Penelitian ini diharapkan dapat mengetahui persebaran kondisi pembangunan manusia, khususnya masyarakat di Pulau Jawa sehingga bisa menentukan daerah mana yang harus diprioritaskan, merujuk pada hasil clustering data yang dilakukan. Hasil dari penelitian ini diharapkan dapat digunakan oleh pihak-pihak yang berkepentingan untuk mendapatkan informasi pengetahuan yang bermanfaat dan akurat terkait dengan perkembangan kependudukan di Pulau Jawa serta menjadi pendukung dalam proses pengambilan keputusan.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah:
1 Penelitian ini menerapkan proses data mining dengan menggunakan teknik
clustering dengan algoritme ST-DBSCAN.
3
TINJAUAN PUSTAKA
Data Spasial Temporal
Data spasial temporal terdiri atas data spasial dan data temporal. Data spasial merupakan sebuah data yang berorientasi geografis, memiliki sistem koordinat tertentu sebagai dasar referensinya dan mempunyai dua bagian utama yaitu informasi lokasi (spasial) dan informasi deskriptif (atribut). Informasi lokasi (spasial) berkaitan dengan suatu koordinat baik koordinat geografi meliputi lintang dan bujur. Informasi lokasi dari suatu objek spasial terbagi ke dalam tiga kategori yaitu titik, garis, dan poligon(dua dimensi). Informasi deskriptif merupakan uraian atribut data spasial (hasil pengukuran, kategori objek, dan penjelasan hasil analisis). Atribut yang terdapat dalam data temporal memiliki faktor waktu yang mempengaruhi sebuah analisis yang dapat direpresentasikan secara berbeda-beda (Tork 2012). Contoh data spasial berupa area (poligon) ditunjukkan pada Gambar 1.
Gambar 1 Data spasial dalam bentuk poligon
ST-DBSCAN (Spatio Temporal-Density Based Spatial Clustering)
Metode Density Based digunakan ketika cluster-cluster tidak beraturan dan ketika terdapat noise dan outlier dalam data. Konsep dasar ST-DBSCAN yaitu untuk setiap dari hasil clustering sekitar radius Eps tertentu harus memiliki setidaknya minimum jumlah titik. Neighboorhood dengan radius ɛ dari suatu objek dikatakan sebagai Eps-neighboorhood. Berdasarkan pendekatan tersebut, terdapat tiga macam titik (Gambar 2) yaitu core point, border point dan noise. Suatu titik disebut sebagai core point jika jumlah Eps-neighboorhood≥ MinPts. Seperti yang dijelaskan pada Gambar 2 bahwa nilai minimum dari MinPts yaitu berjumlah 5.
Border point merupakan titik yang bukan core point tetapi density reachable dari
core point lainnya. Density reachable merupakan objek yang terjangkau oleh tetangga dari objek. Noise point merupakan titik yang tidak menjadi anggota manapun dari suatu cluster (Birant dan Kut 2007).
4
Algoritme ST-DBSCAN merupakan perluasan dari algoritme DBSCAN. Terdapat empat parameter input dalam ST-DBSCAN yaitu Eps1, Eps2, MinPts dan ∆. Eps1 digunakan untuk mengukur parameter jarak untuk atribut spasial seperti lintang dan bujur. Eps2 digunakan untuk mengukur parameter jarak untuk atribut non-spasial. MinPts merupakan jumlah minimum titik dalam Eps-neighboorhood
dari suatu titik. ∆ digunakan untuk mencegah penemuan cluster gabungan karena perbedaan kecil nilai non-spasial dari lokasi neighboorhood. Algoritme ini mampu menemukan clustering yang berkaitan dengan nilai-nilai spasial, non-spasial dan temporal dari objek (Lopez et al. 2011).
Indeks Pembangunan Manusia (IPM)
Indeks Pembangunan Manusia (IPM) merupakan indeks komposit untuk mengukur tiga dimensi pokok pembangunan manusia yang dinilai mampu mencerminkan kemampuan dasar (basic capabilities) penduduk. Ketiga kemampuan dasar itu adalah umur panjang dan sehat, berpengetahuan dan berketerampilan, serta akses terhadap sumber daya yang dibutuhkan untuk mencapai standar hidup layak (Setiawan dan Hakim 2013).
Metode perhitungan untuk menyusun indeks pembangunan manusia telah diterapkan oleh Badan Pusat Statistik berdasarkan ketetapan United Nations Development Programme (UNDP) pada tahun 1994. Kriteria untuk setiap tingkat status nilai IPM tiap wilayah ditunjukkan pada Tabel 1.
Tabel 1 Kriteria indeks pembangunan manusia (BPS 2013) Tingkat Status Kriteria
Praproses data merupakan proses yang dilakukan sebelum melakukan analisis terhadap data yang digunakan. Hal ini dilakukan untuk mengatasi data yang seringkali bersifat incomplete (kurangnya nilai dari suatu atribut), noisy
(mengandung kesalahan atau mengandung nilai outlier yang menyimpang dari analisis yang diharapkan), dan inconsistent (mengandung data yang tidak konsisten). Tahapan praproses data meliputi (Han et al. 2012):
1 Pembersihan data
Pembersihan data dilakukan untuk mengatasi nilai-nilai atribut yang hilang, mengidentifikasi atau membuang data pencilan serta memperbaiki data yang tidak konsisten.
2 Integrasi dan Transformasi data
5 dalam proses analisis. Proses transformasi data dilakukan dengan mengubah data menjadi format yang dapat digunakan untuk proses analisis.
3 Reduksi data
Teknik reduksi data diterapkan untuk memperoleh representasi kumpulan data dengan ukuran yang lebih kecil, namun tetap mempertahankan integritas keaslian data. Walaupun ukuran dataset berkurang namun tetap menghasilkan hasil analisis yang lebih efisien.
Penentuan Koordinat Centroid (Titik Tengah) pada Poligon
Centroid merupakan titik tengah dari suatu wilayah geografis. Misalnya,
centroid dari wilayah di suatu kabupaten/kota letaknya tepat berada di tengah-tengah wilayah kabupaten/kota tersebut. Menentukan titik centroid dapat dilakukan menggunakan software QuantumGIS yang menyediakan plugin fTools geometri.
Tools polygon_centroids ini akan memberikan koordinat centroid yang terletak di setiap poligon pada lapisan poligon data yang diberikan. Dengan demikian, hasilnya akan didapatkan suatu koordinat centroid_longitude dan centroid_latitude
di tiap wilayah kabupaten/kota tersebut.
Perhitungan Jarak menggunakan Metrik Euclidean
Terdapat beberapa langkah yang mudah untuk menentukan jarak antar objek. Pada penelitian ini, perhitungan jarak antar objek spasial dan objek temporal menggunakan euclidean metric. Metode ini digunakan untuk mengukur kesamaan antara data item dalam cluster. Berikut merupakan perhitungan jarak menggunakan metrik Euclidean antara titik i dan j:
� , = √ � − � + � − � … + ��− ��
dimana d(i,j) adalah jarak antar objek i dan j, dengan i= (� , � , ... , ��) dan j= (� , � , ... , ��) adalah n-dimensi objek (Han et al. 2012). Perhitungan jarak dengan metrik euclidean sering digunakan dalam algoritme clustering. Berdasarkan analisis dan hasil eksperimen menunjukkan bahwa metrik euclidean menghasilkan performa yang lebih baik dibandingkan dengan metode lainnya seperti Manhattan metric dalam hal jumlah iterasi yang dilakukan selama proses perhitungan (Sinwar dan Kaushik 2014).
METODE PENELITIAN
Data Penelitian
6
Tahapan Penelitian
Penelitian ini mengacu pada langkah-langkah dalam proses Knowledge Discovery in Database (Han et al. 2012). Proses tersebut dilaksanakan dalam beberapa tahapan. Tahapan-tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 3.
Gambar 3 Diagram alir penelitian a Pengumpulan data
Data yang digunakan adalah data IPM di Pulau Jawa tahun 2012. Data tersebut diperoleh dari Badan Pusat Statistik dan http://data.ukp.go.id yang merupakan portal resmi data Indonesia yang berisi data Kementrian, lembaga pemerintahan, pemerintah daerah dari semua instansi lain yang terkait dengan Indonesia. Data IPM yang digunakan berupa data spasial (koordinat wilayah), data non-spasial (indeks pembangunan manusia) dan data temporal (tahun). b Praproses data
Tahap praproses data meliputi seleksi data, reduksi data serta integrasi dan transformasi data.
c Clustering menggunakan ST-DBSCAN
Clustering data IPM tersebut menggunakan algoritme ST-DBSCAN dan bahasa pemrograman Python dengan memodifikasi fungsi DBSCAN pada
package Scikit-learn. Algoritme ST-DBSCAN mampu menemukan cluster
yang berkaitan dengan nilai-nilai spasial, non-spasial dan temporal dari objek (Lopez et al. 2011). Apabila pada teknik DBSCAN hanya diperlukan satu nilai Eps, maka pada teknik ST-DBSCAN diperlukan dua nilai Eps untuk mengukur persamaan data temporal yaitu atribut waktu dan persamaan untuk mengukur jarak data spasial. Penentuan nilai parameter tersebut dapat dilakukan menggunakan observasi k-dist yang mengacu pada penelitian Purwanto (2012). Berikut merupakan langkah-langkah penentuan nilai Eps
dan MinPts melalui observasi k-dist yang ditunjukkan pada Gambar 4:
Mulai Pengumpulan data Praproses data
7
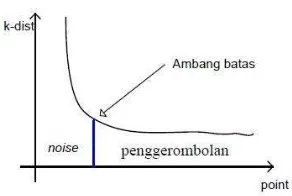
Gambar 4 Grafik observasi k-dist (Purwanto 2012)
1 Komputasikan k-dist untuk seluruh titik pada beberapa k. Urutkan dalam urutan menurun dan plot nilai yang telah diurutkan.
2 Perubahan tajam pada nilai k-dist yang berhubungan dengan nilai Eps
dan nilai k digunakan sebagai MinPts yang sesuai.
3 Poin yang k-dist lebih kecil dari Eps akan disebut sebagai core point (titik inti), sementara titik lain akan dilabeli sebagai titik noise atau titik border. 4 Jika k terlalu besar maka penggerombolan kecil (ukuran kurang dari k)
cenderung diberi label sebagai titik noise. Jika k terlalu kecil maka titik
noise atau outlier akan salah diberi label sebagai penggerombolan. d Evaluasi cluster
Hasil cluster yang telah diperoleh akan dievaluasi seberapa bagus cluster
tersebut menggunakan koefisien Silhouette. Berikut merupakan formula perhitungan koefisien Silhouette (Sklearn 2014) untuk satu titik sampel i:
s(i) = b(i) – a(i) max { a(i), b(i) }
dimana a(i) merupakan rata-rata jarak intra-cluster dan b(i) merupakan rata-rata jarak nearest-cluster. Penjelasan tentang intra-cluster dan nearest-cluster
ditunjukkan pada Gambar 5.
Gambar 5 Ilustrasi titik i dalam koefisien Silhouette (Rousseeuw 1987) Misalkan, titik sampel i berada di dalam cluster A (Gambar 5), sehingga a(i) merupakan rata-rata jarak titik i ke titik-titik lain yang berada di dalam cluster A. Kemudian, b(i) merupakan rata-rata jarak titik i ke titik-titik lain yang berada di
cluster terdekat dengan cluster A, yaitu cluster B.
Setelah mendapatkan nilai koefisien Silhouette untuk satu titik i, nilai koefisien Silhouette (Rousseeuw 1987) untuk N jumlah titik dapat dihitung menggunakan:
SC =
�∑ s
8
Nilai koefisien Silhouette yang diperoleh berada pada rentang -1 hingga 1. Nilai terbaik diperoleh adalah 1 dan nilai terburuk adalah -1. Jika nilai yang diperoleh bernilai negatif, hal ini bisa disebabkan karena terdapat sampel titik yang telah ditetapkan masuk ke dalam cluster yang salah serta dapat disimpulkan juga bahwa rata-rata jarak titik i dengan titik-titik lain di cluster B (nearest-cluster) lebih dekat daripada rata-rata jarak titik i dengan titik-titik lain yang berada di cluster itu sendiri (cluster A).
e Representasi pengetahuan
Tahap representasi pengetahuan merupakan tahap untuk memperlihatkan kepada pengguna hasil visualisasi terhadap cluster yang telah divalidasi menggunakan koefisien Silhouette. Pada tahap ini hasil visualisasi berbentuk peta wilayah cluster yang didasarkan pada berbagai sektor yang bisa dibedakan dengan memberi warna berbeda tiap-tiap cluster.
Lingkupan Pengembangan
Pembuatan model clustering dengan menggunakan metode ST-DBSCAN pada penelitian ini menggunakan beberapa perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
1 Perangkat Keras
Processor: Intel(R) Core(TM) i3 CPU M 2348 @ 2.30GHz Memori: 4 GB RAM
2 Perangkat Lunak
Sistem operasi Windows 7 Enterprise 32-bit Bahasa Pemograman Python 2.7.2
Quantum GIS
Microsoft Excel 2013 Notepad++
LibreOffice 4.2
Package di Python yang digunakan: Scikit-learn 0.14.1, Numpy-MKL 1.8.1, Matplotlib 1.3.1, Scipy, dan Osgeo.
HASIL DAN PEMBAHASAN
Sumber Data dan Karakteristik Data
9
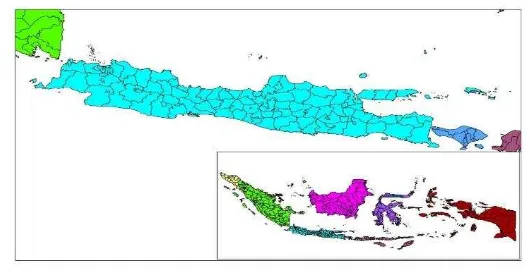
Gambar 6 Peta wilayah Pulau Jawa Praproses Data
Tahapan-tahapan praproses data dilakukan terhadap semua data yang digunakan dalam penelitian ini meliputi:
1 Seleksi Data
Pada tahapan ini dilakukan pemilihan data di Pulau Jawa yang terdiri atas pemilihan data poligondan data IPM. Data poligon dengan format shapefile (.shp) dan data IPM dengan format comma delimited (.csv) berisi seluruh wilayah di Indonesia, dipilih hanya yang mencakup Pulau Jawa saja.
2 Reduksi Data
Dataset yang diperoleh berisi data IPM dan komponen-komponen terkait per Kabupaten dan Kota di Pulau Jawa dalam bentuk csv file. Reduksi data dilakukan dengan cara memilih 3 atribut dari 11 atribut. Atribut yang terdapat dalam dataset
awal yaitu: nama_provinsi, kode_kabkota, nama_kabkota, koordinat_kabkota, tahun, angka_harapan_hidup, angka_melek_huruf, lama_sekolah, pengeluaran_perkapita, ipm, dan jumlah_penduduk. Atribut yang dipilih yaitu nama_kabkota, ipm, dan tahun.
3 Integrasi dan Transformasi data
Integrasi data dilakukan dengan menggabungkan atribut-atribut yang menarik dari tabel ke dalam format shapefile (.shp). Koordinat titik centroid dari data poligon diperoleh dari software QuantumGIS digabungkan ke dalam shapefile
menggunakan software LibreOffice. Atribut-atribut IPM yang terdapat dalam csv file yang telah direduksi, juga digabungkan ke dalam shapefile. Transformasi ke dalam bentuk data shapefile, dilakukan agar data shapefile tersebutdapat digunakan sebagai input dalam implementasi ST-DBSCAN menggunakan Python. Contoh nilai atribut yang terdapat dalam shapefile, ditunjukkan dalam Tabel 2.
Tabel 2 Contoh nilai atribut dalam shapefile
Nama_Kab Centroid_Longitude Centroid_Latitude IPM Tahun
Pemalang 109,39612 -7,03542 70,66 2012
10 hasil cluster yang diperoleh. Parameter Eps1 diperlukan untuk mengukur persamaan jarak data spasial (koordinat posisi suatu geometri) dan Eps2 digunakan untuk mengukur persamaan jarak data temporal. Parameter ∆ diperlukan untuk mengukur selisih nilai atribut non-spasial yang masih berada dalam batas toleransi yang telah ditentukan, sedangkan MinPts merupakan jumlah minimum titik yang terdapat dalam Eps1 dan Eps2. Penentuan keempat parameter tersebut merujuk pada penelitian Purwanto (2012) yang dapat dilakukan melalui observasi k-dist. Grafik k-dist dari data IPM tahun 2012 terdapat pada Gambar 7.
Gambar 7 Pergeseran nilai ambang pada k-dist
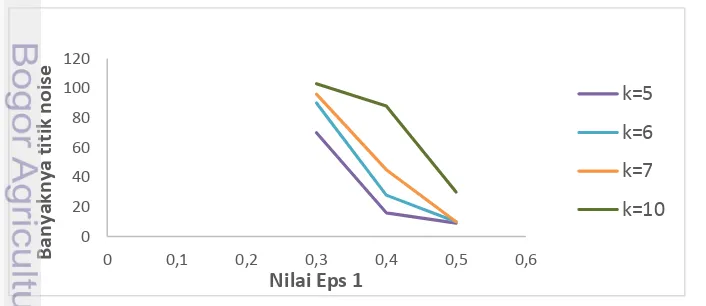
Untuk mendapatkan nilai Eps dan MinPts yang optimal, dipilih garis yang mendekati garis menaik kemudian dipotong secara vertikal pada plot k tetangga terdekat untuk menjadi batas titik ambang. Tujuan diberikannya titik ambang ini adalah untuk mendapatkan penggerombolan dengan jumlah noise yang sedikit. Nilai Eps yang dipilih kurang dari jarak yang ditentukan oleh lembah pertama yaitu berkisar dari 0.3-0.5. Pergeseran nilai Eps1 (Gambar 7) dilakukan pada nilai k=5,
k=6, k=7, dan k=10. Berdasarkan nilai Eps1 tersebut diperoleh jumlah titik noise
paling sedikit pada k=0.5 seperti yang ditunjukkan pada Gambar 8.
11 Pada Gambar 8 terlihat bahwa titik noise paling sedikit diperoleh pada k=5 dengan nilai Eps1=0.3, Eps1=0.4, dan Eps1=0.5. Berdasarkan nilai Eps1=0.3 didapatkan jumlah cluster sebanyak 4 cluster ditunjukkan pada Gambar 9. Jika menggunakan nilai Eps1=0.4 didapatkan jumlah cluster sebanyak 4 cluster. Tetapi, jika menggunakan nilai Eps1=0.5 hanya didapatkan 1 cluster saja.
Gambar 9 Diagram jumlah cluster
Berdasarkan jumlah hasil cluster yang diperoleh dari nilai Eps1 yang digunakan dari rentang 0.3 - 0.5, akan dievaluasi hasil cluster tersebut menggunakan koefisien Silhouette. Berikut merupakan nilai koefisien Silhouette yang diperoleh dari tiap cluster yang terdapat dalam Tabel 3.
Tabel 3 Nilai koefisien Silhouette cluster
Nilai Eps1 Koefisien Silhouette
0.3 - 0.158 dikarenakan data non-spasial yang digunakan hanya data IPM tahun 2012.
Implementasi Algoritme ST-DBSCAN menggunakan Python
Implementasi ST-DBSCAN di Python dapat dilihat pada Gambar 10 yang dilakukan dengan mengubah beberapa fungsi DBSCAN yang ada dalam package Scikit-learn. Pada modul DBSCAN, perhitungan jarak titik hanya dilakukan dengan menggunakan aspek spasial, sedangkan pada modul ST-DBSCAN dilakukan perhitungan jarak dari aspek spasial dan aspek temporal yang dilakukan pada baris 21-22.
Perhitungan jarak menggunakan metrik Euclidean yang terdapat dalam modul
pairwise dengan fungsi pairwise_distance(S, metric=’euclidean’), dimana S merupakan data spasial yang berisi koordinat centroid longitude dan centroid
12
latitude. Hasil perhitungan jarak akan disimpan dalam DistS dan DistT yang merupakan matriks jarak spasial dan matriks jarak temporal(baris 21-22).
Melalui perhitungan matriks jarak spasial dan jarak temporal, dilakukan pencarian tetangga terdekat yang berada dalam rentang nilai Eps. Pencarian tetangga dilakukan dengan mencari irisan antara aspek spasial dan juga temporal. Tetangga terdekat yang berada dalam rentang nilai Eps1 merupakan anggota tetangga spasial yang disimpan dalam spat_neighbor (baris 23), sedangkan tetangga terdekat yang berada dalam rentang nilai Eps2 merupakan anggota tetangga temporal yang disimpan dalam temp_neighbor (baris 24). Irisan antara aspek spasial dan juga aspek temporal disimpan dalam neigh (baris 28) yang merupakan anggota tetangga secara aspek spasial dan temporal.
Baris 1-42 menunjukkan proses clustering dengan melibatkan dua aspek yaitu aspek spasial dan aspek temporal (Gambar 10). Untuk proses clustering yang melibatkan aspek non-spasial (IPM) dijelaskan pada baris 43-62 (Gambar 10).
Variabel non-spasial yang merupakan nilai IPM tiap kabupaten/kota akan disimpan dalam variabel global NS (baris 43). Parameter ∆ dihitung menggunakan formula perhitungan Zscore untuk setiap objek x di dalam cluster
(Han et al. 2012):
� =
|x −
�
x̄
|
dimana x merupakan nilai IPM objek dalam cluster, x̄ merupakan mean dari IPM satu cluster, dan σ merupakan standar deviasi untuk data populasi. Nilai Zscore
berisi atribut non-spasial yaitu nilai IPM tahun 2012. Variabel NS disimpan ke dalam variabel numpy array yaitu ave_cluster (baris 46). Variabel tersebut didefinisikan sebagai fungsi Zscore yang menghitung nilai IPM tiap kabupaten/kota. Jika suatu objek tidak ditandai sebagai noise atau tidak berada dalam cluster
manapun, objek tersebut akan dievaluasi menggunakan Zscore. Jika nilai Zscore
dari titik objek tersebut >= ∆ (baris 55), maka titik tersebut akan dilabeli dengan label -1 atau noise, sebaliknya jika nilai Zscoredari titik tersebut <∆ maka titik tersebut akan dilabeli sebagai cluster yang sedang diproses. Hasil akhir dari proses
13
1 S = np.array(object_spatial) # Mengubah array ke bentuk numpy 2 T = np.array(object_temporal) # Numpy digunakan untuk mengolah matrix 3 NS = np.array(object_nonspatial)
4 O = np.array(object) # terdiri dari objek spasial, nonspasial dan temporal 5
6 eps1 = 0.5 # Parameter input yang dibutuhkan 7 eps2 = 0
8 min_samples = 4
9 de = 2
10 metric = 'euclidean' # Menghitung matrix jarak dengan metric euclidean 11 random_state= None # Jenis random_state yang diinginkan, dibuat default=none 12
13 n = O.shape[0] # Menghitung panjang array O (banyaknya data di obj) 14 random_state = check_random_state(random_state) # Memeriksa random_state 15 index_order = np.arange(n) # Membuat array sepanjang n, dijadikan index 16 random_state.shuffle(index_order) # Mengacak urutan dari index_order 17 labels = -np.ones(n) # Semua titik dijadikan noise dulu, dilabeli dgn -1 18 core_samples = [] # List untuk menyimpan core_sample
19 label_num = 0 # Label jika ditemukan cluster baru 20
21 DistS = pairwise_distances(S, metric=metric) # Mengukur jarak spatial 22 DistT = pairwise_distances(T, metric=metric) # Mengukur jarak temporal 23 spat_neighbor = [np.where(s <= eps1)[0] for s in DistS] # Tetangga spasial 24 temp_neighbor = [np.where(t <= eps2)[0] for t in DistT] # Tetangga temporal 25
26 neighborhoods = [] # Mencari tetangga di setiap baris (X1-Xn) 27 for i in range(n):
28 neigh = list( set(spat_neighbor[i]) & set(temp_neighbor[i]) ) 29 # Mencari irisan (intersection) antara tetangga spasial degan temporalnya 30 array_neigh = np.array(neigh, dtype=np.int64) # Ubah ke numpy array 31 neighborhoods.append(array_neigh) # Append ke var neighborhoods 32
33 for index in index_order:
34 if labels[index] != -1 or len(neighborhoods[index]) < min_samples: 35 continue # Jika objek sudah dilabeli/bukan core, maka tdk diproses 36 core_samples.append(index) # jika objek=core msk ke dlm core_samples 37 labels[index] = label_num # labeli dgn label cluster yg sdg diproses 38 candidates = [index]
39
40 while len(candidates) > 0: # Ekspansi cluster ke seluruh objek 41 new_candidates = []
42
43 global NS # Dijadikan global variabel
44 NS=np.array(object_nonspatial)
45 stats.zscore(NS, axis=0, ddof=0) # Fungsi Zscore dengan objek non-spasial 46 global ave_cluster
47 ave_cluster=np.array(stats.zscore) # Zscore disimpan dalam numpy ave_cluster 48
49 for c in candidates:
50 noise = np.where(labels[neighborhoods[c]] == -1)[0] 51 noise = neighborhoods[c][noise]
52 labels[noise] = label_num # Tetangga dari kandidat yg 53 mempunyai nilai -1 akan dijadikan noise
54 for neighbor in noise: 55 if ave_cluster >= de: 56 labels[neighbor] = label_num
57 if len(neighborhoods[neighbor]) >= min_samples: 58 # Jika tetangga memenuhi min-pts, ditemukan core_point baru 59 new_candidates.append(neighbor) 60 core_samples.append(neighbor) 61 candidates = new_candidates # core_point yg baru didapat, 62 label_num += 1 akan dimulai dengan cluster baru
14
SampangS
Yogyakarta
Sampang
Hasil Clustering menggunakan ST-DBSCAN
Proses clustering data IPM dilakukan menggunakan aplikasi yang telah dibuat menggunakan bahasa pemrograman Python. Tampilan utama dari aplikasi tersebut dapat dilihat pada Lampiran 1. Gambar 11 menunjukkan bahwa wilayah-wilayah di Pulau Jawa terkelompokkan berdasarkan nilai IPM yang diperoleh di tiap wilayahnya. Nilai IPM yang digunakan adalah nilai IPM pada tahun 2012. Intensitas warna yang diberikan, digunakan untuk membedakan tinggi rendahnya nilai IPM di suatu wilayah. Semakin tinggi intensitas warnanya maka nilai IPM di wilayah tersebut semakin tinggi. Yogyakarta merupakan wilayah yang memiliki nilai IPM tertinggi di tahun 2012 yaitu sebesar 80.24, sedangkan Sampang memiliki nilai IPM terendah yaitu sebesar 61.67.
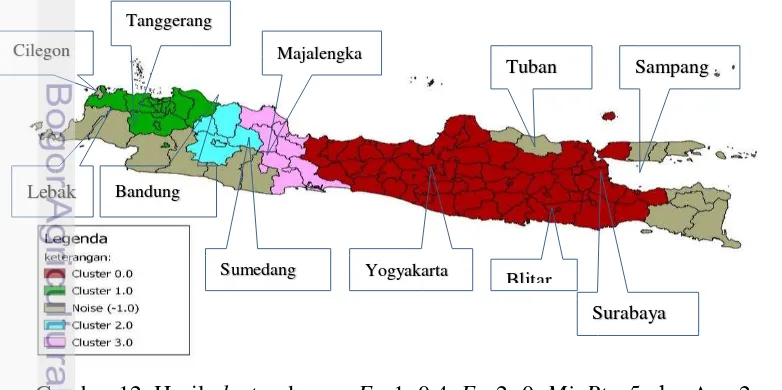
Gambar 11 Pengelompokan di Pulau Jawa berdasarkan IPM tahun 2012 Proses clustering menggunakan algoritme ST-DBSCAN pada data IPM di Pulau Jawa tahun 2012 menghasilkan 4 cluster dan 18 titik noise dengan menggunakan parameter Eps1=0.4 (≈ 44 km), Eps2=0, MinPts=5, dan ∆=2.
Hasil clustering menggunakan Python menghasilkan data berupa titik (poin) seperti yang ditunjukkan pada Lampiran 2. Kemudian, poin tersebut ditransformasikan ke dalam peta wilayah menggunakan software QuantumGIS. Hasil transformasi tersebut dapat dilihat pada Gambar 12.
15 Hasil cluster yang telah terbentuk dianalisis persebarannya berdasarkan aspek spasial, aspek non-spasial dan juga aspek temporalnya. Setiap cluster memiliki karakteristik wilayah yang berbeda-beda seperti yang ditunjukkan pada Tabel 4.
Tabel 4 Karakteristik wilayah tiap cluster Cluster ke- Karakteristik wilayah
0 Memiliki rata-rata IPM=72.49, anggota cluster 0 terdiri dari wilayah-wilayah di sekitar timur Jawa seperti Blitar dan Kediri. 1 Memiliki rata-rata IPM=76.57, anggota cluster 1 sebagian besar
wilayah di sekitar JABODETABEK yang memiliki nilai IPM cenderung tinggi.
2 Memiliki rata-rata IPM=73.70, anggota cluster 2 terdiri dari wilayah Bandung, Sumedang, dan sekitarnya.
3 Memiliki rata-rata IPM=72.15, wilayah yang berada di dalam
cluster 3 sebagian besar memiliki nilai IPM yang rendah seperti Indramayu dan Cirebon
Gambar 12 menunjukkan bahwa wilayah yang berada di cluster 1 terdiri atas wilayah yang berada di sekitar JABODETABEK seperti yang ditunjukkan pada Lampiran 3. Secara umum, nilai IPM DKI Jakarta berada di atas angka IPM Nasional. Selama kurun waktu 2004-2012, kinerja pembangunan manusia di DKI Jakarta menunjukkan peningkatan. Tingginya nilai IPM di wilayah ini dikarenakan tingginya akses masyarakat terhadap layanan di bidang pendidikan dan kesehatan. Namun, wilayah Cilegon dan Lebak yang secara spasial berdekatan dengan Tanggerang tidak termasuk ke dalam cluster 1. Hal ini disebabkan karena nilai IPM di Cilegon dan Lebak berbeda jauh dengan nilai IPM di sekitarnya. Kenyataannya, Lebak yang secara spasial berdekatan dengan Bogor, memiliki nilai IPM yang rendah yaitu 68.42 hal ini dilihat dari akses jalan dan transportasi yang sangat buruk.
Cluster 3 beranggotakan Indramayu, Majalengka dan Kabupaten Cirebon memiliki rata-rata IPM terendah yaitu sebesar 72.15. Hal ini disebabkan karena masih tingginya kesenjangan kualitas sumber daya manusia antara gender. Pada bidang pendidikan misalnya, kualitas angka melek huruf penduduk perempuan dewasa jauh tertinggal dibandingkan dengan penduduk laki-laki.
Cluster 2 merupakan cluster yang memiliki rata-rata IPM sebesar 73.70. Anggota dari cluster 2 yaitu wilayah Bandung dan sekitarnya, sedangkan cluster 0 memiliki rata-rata IPM tertinggi ketiga yaitu sebesar 72.49 yang terdiri dari wilayah-wilayah di sekitar timur Jawa yaitu seperti Kediri, Blitar, dan Surabaya.
Sebagian besar wilayah yang masuk ke dalam kategori noise terletak di wilayah Jawa Barat dan Provinsi Banten. Hal ini dikarenakan wilayah-wilayah di daerah barat luasnya lebih besar secara spasial dibandingkan wilayah-wilayah di bagian timur dan tengah.
16
SIMPULAN DAN SARAN
Simpulan
Pengimplementasian ST-DBSCAN menggunakan bahasa pemrograman Python pada data indeks pembangunan manusia tahun 2012 menghasilkan 4 cluster
dan 18 titik noise, dengan menggunakan parameter jarak spasial (Eps1) = 0.4 (≈ 44 km), parameter jarak temporal (Eps2) = 0, parameter untuk mengukur selisih nilai atribut non-spasial yang masih berada dalam batas toleransi yang telah ditentukan (∆) = 2, dan minimum anggota dalam cluster (MinPts) = 5. Cluster 1 memiliki rata-rata nilai IPM tertinggi pertama di Pulau Jawa yaitu sebesar 76.57 yang sebagian besar wilayahnya berada di JABODETABEK. Tingginya nilai IPM di wilayah ini dikarenakan tingginya akses masyarakat terhadap layanan di bidang pendidikan maupun kesehatan. Hal ini berlawanan dengan cluster 3 yang berangotakan wilayah di sekitar Indramayu dan Cirebon, memiliki nilai rata-rata IPM terendah di Pulau Jawa yaitu sebesar 72.15. Hal ini disebabkan oleh masih tingginya kesenjangan kualitas sumber daya manusia antar gender. Oleh karena itu, pemerintah harus memberikan perhatian yang lebih besar bagi kabupaten/kota yang pembangunannya masih lambat.
Saran
Berikut merupakan saran-saran yang diberikan untuk penelitian selanjutnya: 1 Pada penelitian selanjutnya dapat menambahkan aspek temporal dari
beberapa tahun, tidak hanya satu tahun saja.
2 Menentukan parameter Eps1, Eps2, MinPts, dan ∆ secara otomatis untuk membentuk suatu cluster yang optimal.
DAFTAR PUSTAKA
Birant D, Kut A. 2007. ST-DBSCAN: An algorithm for clustering spatialtemporal data. Data and Knowledge Engineering. 60:208-221. doi:10.1016/j.datak.2006.01.013.
[BPS] Badan Pusat Statistik. 2013. Publikasi Indeks Pembangunan Manusia 2012 [internet]. [diacu 2014 Juni 12]. Tersedia pada: http://www.bps.go.id/publications/publikasi2013.php?key=indeks+pembangun an+manusia.
Cai X, Langtangen HP, Moe H. 2005. On the performance of the python programming language for serial and parallel scientific computations. Scientific Programming. 13(2005): 31-56.
Halkidi M, Batistakis Y, Vazirgiannis M. 2001. On clustering validation techniques.
Journal of Intelligent Information Systems. 17: 2/3: 107-145.
17 Joshi D. 2011. Polygonal spatial clustering[disertasi]. Nebraska (NE): University
of Nebraska.
Lopez D, Parimala M, Senthilkumar NC. 2011. A survey on density based clustering algorithms for mining large spatial databases.International Journal of Advanced Science and Technology. 31: 59-66.
Purwanto UY. 2012. Penggerombolan spasial hotspot kebakaran hutan dan lahan menggunakan DBSCAN dan ST-DBSCAN [tesis]. Bogor (ID): Institut Pertanian Bogor.
Rousseeuw PJ. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics. 20(1987): 53-65. doi: 10.1016/0377-0427(87)90125-7.
Setiawan MB, Hakim A. 2013. Indeks pembangunan manusia. Jurnal Economia. 9(1).2013.
Sinwar D, Kaushik R. 2014. Study of euclidean and manhattan distances metrics using simple K-Means clustering. International Journal for Research in Applied Science and Engineering Technology. 2(5): 1-5. doi: 2321-9653/ijraset.2014.2.5 [Sklearn] Scikit-learn. 2014. sklearn.metrics.silhouette_score [internet]. [diacu
2014 Agustus 11]. Tersedia dari: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.silhouette_score.html. Tork HF. 2012. Spatio-temporal clustering methods classification. Di dalam: -,
18
Lampiran 1 Antar muka implementasi ST-DBSCAN menggunakan Python
19 Lampiran 3 Anggota cluster
Cluster 0
Nama kabupaten/kota Ipm tahun 2012
20
Cluster 0 (lanjutan)
Nama kabupaten/kota Ipm tahun 2012 Yogyakarta(kota) 80.238544
Nama kabupaten/kota Ipm tahun 2012
Bogor 73.077391
Jakarta selatan (kota) 80.165068 Jakarta pusat (kota) 79.123632 Jakarta timur (kota) 79.797018 Jakarta barat (kota) 79.429627 Jakarta utara (kota) 78.254531
Tangerang 72.361690
21
Cluster 2
Nama kabupaten/kota Ipm tahun 2012
Bandung 74.731844
Nama kabupaten/kota Ipm tahun 2012
Ciamis 72.140920
Nama kabupaten/kota Ipm tahun 2012
22
RIWAYAT HIDUP
Penulis dilahirkan di Samarinda pada tanggal 23 Januari 1994, dari pasangan Bapak Ir Agus Darmono, MM dan Ibu Ir Irma Haerastiati sebagai anak terakhir dari empat bersaudara. Pada tahun 2010 penulis lulus dari SMA Negeri 3 Bogor dan lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Program Studi S1 Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis pernah aktif menjadi anggota dalam Himpunan Mahasiswa Ilmu Komputer (HIMALKOM). Pada tahun 2013, penulis mengikuti kegiatan Praktik Kerja Lapangan di PT Industri Telekomunikasi Indonesia (Persero).