CLUSTERING DATASET TITIK PANAS DENGAN
ALGORITME RDBC MENGGUNAKAN WEB
FRAMEWORK SHINY PADA BAHASA R
ARIES SANTOSO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Clustering Dataset Titik Panas dengan Algoritme RDBC Menggunakan Web Framework Shiny pada Bahasa R adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2015
Aries Santoso
ABSTRAK
ARIES SANTOSO. Clustering Dataset Titik Panas dengan Algoritme RDBC Menggunakan Web Framework Shiny pada Bahasa R. Dibimbing oleh KARLINA KHIYARIN NISA.
Indonesia memiliki hutan tropis yang cukup luas, namun sering terbakar hingga menimbulkan dampak yang besar bagi Indonesia. Pemantauan titik panas dapat menjadi salah satu penanggulangan bencana kebakaran hutan tersebut. Tiap titik panas akan dicatat pada suatu dataset sehingga dapat diproses untuk mendapatkan informasi. Penelitian ini bertujuan untuk membangun aplikasi web clustering pada data titik panas. Aplikasi ini menggunakan bahasa pemrograman R dengan mengimplementasikan algoritme Recursive Density Based Clustering
(RDBC) serta menggunakan framework Shiny. Clustering dilakukan pada data titik panas Pulau Kalimantan dan Provinsi Sumatera Selatan tahun 2002-2003 untuk menemukan pola penyebaran titik panas. Hasil yang diperoleh dari proses
clustering dievaluasi menggunakan Silhouette Coefficient (SC). Nilai SC yang diperoleh pada penelitian ini sebesar 0.2045354 untuk dataset Pulau Kalimantan dan sebesar 0.2414827 untuk dataset Provinsi Sumatera Selatan. Hasil tersebut ditampilkan dalam bentuk halaman web agar dapat diakses dengan mudah serta dapat menjadi acuan prediksi kejadian kebakaran selanjutnya.
Kata kunci: clustering, RDBC, Shiny, Silhouette Coefficient, titik panas
ABSTRACT
ARIES SANTOSO. Clustering on Hotspots Dataset with RDBC Algorithm using Shiny Web Framework on R Programming Language. Supervised by KARLINA KHIYARIN NISA.
Indonesia has tropical forest that is quite extensive, but forest fires often occur resulting in great impact for Indonesia. Monitoring hotspots can be one of the forest fire disaster mitigation efforts. Each hotspot will be recorded on a dataset that can be processed to obtain information. This study aims to build a clustering web application on the hotspot data. This application uses the R programming language to implement Recursive Density Based Clustering (RDBC) algorithms using Shiny framework. Clustering is performed on hotspot data of the Kalimantan island and province of South Sumatra in 2002-2003 to find the pattern of spread of hotspots. The results obtained from the clustering process are evaluated using the Silhouette Coefficient. The SC value of this research is 0.2045354 for Kalimantan Island dataset and 0.232323 for South Sumatera Province dataset. The result is displayed in the form of web pages that can be accessed easily and can be referred for subsequent fire occurrence prediction.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
CLUSTERING DATASET TITIK PANAS DENGAN
ALGORITME RDBC MENGGUNAKAN WEB
FRAMEWORK SHINY PADA BAHASA R
ARIES SANTOSO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Clustering Dataset Titik Panas dengan Algoritme RDBC Menggunakan Web Framework Shiny pada Bahasa R Nama : Aries Santoso
NIM : G64110071
Disetujui oleh
Karlina Khiyarin Nisa, SKom MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul
Clustering Dataset Titik Panas Dengan Algoritme RDBC Menggunakan Web Framework Shiny Pada Bahasa R. Penelitian ini dilaksanakan di Departemen Ilmu Komputer Institut Pertanian Bogor.
Dalam pelaksanaan penelitian ini, penulis ingin menyampaikan terima kasih kepada:
1 Ayah, ibu dan seluruh anggota keluarga yang selalu memberikan dukungan serta doa dalam penyelesaian penelitian ini.
2 Ibu Karlina Khiyarin Nisa, SKom MT selaku pembimbing yang sudah memberikan banyak bantuan dan bimbingan selama proses penyelesaian penelitian ini.
3 Bapak Dr Ir Agus Buono, MSi Mkom dan Bapak Hari Agung Adrianto, SKom MSi selaku penguji yang telah banyak memberi bantuan perbaikan dalam penelitian ini.
4 Seluruh dosen dan staf Departemen Ilmu Komputer IPB yang sudah membantu proses penyelesaian penelitian ini.
5 Lani Kurnia Sari yang senantiasa memberikan semangat dan motivasinya. 6 Rekan – rekan satu bimbingan yaitu Fitrah dan Ela yang selalu saling
memberikan dukungan satu sama lain dalam menyelesaikan penelitian masing – masing.
7 Rekan – rekan Ilmu Komputer angkatan 48 yang selalu menjadi motivasi dalam menyelesaikan penelitian ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 3
Density Based Clustering 3
Algoritme RDBC 5
Silhouette Coefficient 6
Package Shiny 7
METODE PENELITIAN 8
Data Penelitian 8
Tahapan Penelitian 9
Lingkupan Pengembangan 10
HASIL DAN PEMBAHASAN 11
Praproses Data 11
Implementasi RDBC pada Bahasa R 11
Clustering dengan Algoritme RDBC 12
Evaluasi Cluster 17
Hasil Clustering RDBC 17
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 18
DAFTAR PUSTAKA 19
DAFTAR TABEL
1 Hasil clustering RDBC dan DBSCAN dataset Pulau Kalimantan 12 2 Hasil perhitungan nilai SC dataset Pulau Kalimantan 16 3 Hasil perhitungan nilai SC pada dataset Provinsi Sumatera Selatan 16
DAFTAR GAMBAR
1 Ilustrasi jenis titik dalam Density Based Clustering. 3
2 Ilustrasi beberapa teknik dalam DBSCAN 4
3 Ilustrasi algoritme RDBC 5
4 Ilustrasi (a) Cohesion dan (b) Separation 7
5 Alur sistem aplikasi Shiny 8
6 Skema metode penelitian 9
7 Grafik penentuan nilai Eps (Purwanto 2012) 10
8 Implementasi fungsi RDBC 12
9 Pergeseran nilai ambang pada k-dist dataset Pulau Kalimantan 13 10 Pergeseran nilai ambang pada k-dist dataset Provinsi Sumatera Selatan 13 11 Pengaruh Eps dan MinPts terhadap jumlah cluster pada dataset Pulau
Kalimantan 14
12 Pengaruh Eps dan MinPts terhadap jumlah cluster pada dataset Provinsi
Sumatera Selatan 15
13 Jumlah noise yang terbentuk pada Eps = 0.3 pada dataset Pulau Kalimantan 15 14 Jumlah noise yang terbentuk pada Eps = 0.14 dan Eps = 0.15 pada dataset
Provinsi Sumatera Selatan 16
15 Implementasi fungsi menghitung nilai silhouette coefficient 17
PENDAHULUAN
Latar Belakang
Indonesia memiliki hutan tropis yang cukup luas. Sebagai aset bangsa dan dunia, hutan Indonesia sering terbakar hingga menimbulkan dampak yang besar bagi Indonesia. Hal ini disebabkan oleh alam dan ulah manusia. Pada konteks alam, kebakaran dapat diakibatkan oleh cuaca terik di musim kemarau dan tak jarang pula terkena sambaran petir. Dampak yang ditimbulkan kebakaran hutan cukup luas dan sangat kompleks, tidak hanya kerusakan lingkungan, tetapi juga mencakup bidang lain seperti perekonomian, budaya, hubungan antarnegara dan lainnya. Pada bidang lingkungan, kebakaran hutan menyebabkan kerusakan ekosistem satwa liar, pencemaran kabut asap, peningkatan emisi karbon dan sebagainya. Pada bidang lainnya, kebakaran hutan dapat menghilangkan mata pencaharian masyarakat, meningkatnya penyakit saluran pernapasan (ISPA) hingga berkurangnya pendapatan negara yang berasal dari hasil hutan.
Pemantauan titik panas melalui satelit penginderaan jauh dapat menjadi salah satu bentuk penanggulangan bencana kebakaran hutan. Pemantauan tersebut berfungsi sebagai bahan prediksi munculnya kebakaran hutan berikutnya. Setiap titik panas akan dicatat pada suatu dataset yang meliputi data spasial (latitude dan
longitude), data temporal (waktu dan tanggal pemantauan) dan data nonspasial (suhu udara, curah hujan, dsb). Persebaran titik panas biasanya akan berkumpul atau bergerombol pada suatu area tertentu sehingga dari data tersebut dapat di analisis dengan teknik clustering. Menurut Ester et al. (1996), algoritme DBSCAN efisien untuk menemukan cluster dari data spasial yang besar. Tetapi menurut Rehman dan Mehdi (2005), algoritme DBSCAN masih belum efektif dalam penentuan jumlah titik minimum dan jarak epsilon (Eps) yang tepat. Menurutnya terdapat algoritme yang lebih efektif dalam menentukan cluster yaitu algoritme RDBC. Algoritme Recursive Density Based Clustering (RDBC) merupakan modifikasi dari algoritme DBSCAN dan memiliki runtime lebih cepat serta lebih efektif pada penentuan parameter.
Algoritme RDBC merupakan modifikasi algoritme DBSCAN yang mengelompokkan objek dari database ke dalam cluster berdasarkan kepadatan. Selain itu, algoritme ini tidak memerlukan jumlah cluster yang telah ditetapkan sebelumnya untuk beroperasi (Zhong Su 1999). Dengan demikian, parameter jumlah titik minimum dan Eps akan dipilih yang terbaik dengan cara rekursif sehingga mampu menciptakan cluster dengan kepadatan yang beragam.
Komputasi berbasis dekstop masih banyak dilakukan pada penelitian-penelitian sebelumnya. Data dan komputasi diolah sistem di tempat yang sama menjadikan sistem tersebut semakin lama dan berat. Kebutuhan akan penyimpanan yang lebih besar juga menjadi kendala ketika sistem semakin berkembang. Selain itu, akses terhadap penelitian tersebut terbatas karena hanya dapat diakses pada komputasi lokal. Oleh sebab itu, diperlukan cara baru dalam pengembangan sistem yaitu dengan memanfaatkan komputasi berbasis internet yang disebut sebagai cloud computing.
2
memberikan layanan kepada pengguna dalam mengakses suatu sistem melalui internet. Kemudian dengan adanya teknologi ini, komputasi menjadi lebih ringan dan tidak memerlukan penyimpanan yang besar karena penyimpanan dialihkan ke tempat lain.
Purwanto (2012) telah melakukan clustering data titik panas dengan algoritme DBSCAN dan ST-DBSCAN menggunakan MATLAB. Sedangkan Mardhiyyah (2014) telah melakukan clusteringdataset titik panas dengan algoritme DBSCAN menggunakan web framework Shiny pada bahasa R, tetapi penentuan parameter jumlah titik minimum dan jarak Eps hanya berdasarkan masukan dari pengguna. Pada penelitian ini, algoritme RDBC diimplementasikan menggunakan bahasa R dengan memanfaatkan package fpc dan Shiny. Penentuan parameter dilakukan secara otomatis oleh sistem sehingga menjadi lebih efektif agar menghasilkan cluster yang terbaik dan pola penyebaran titik panas yang akurat untuk dijadikan acuan prediksi kejadian kebakaran hutan. Kemudian hasil dari proses clustering tersebut dapat pula diakses melalui peramban internet.
Perumusan Masalah
Rumusan permasalahan pada penelitian ini adalah bagaimana membangun aplikasi web yang melakukan clustering dengan algoritme RDBC pada dataset titik panas menggunakan bahasa R.
Tujuan Penelitian
Penelitian ini bertujuan untuk mengimplementasikan algoritme clustering
RDBC pada data spasial titik panas dengan menggunakan bahasa R dan package
Shiny untuk menghasilkan cluster yang lebih baik dengan penentuan parameter yang efektif serta dapat ditampilkan pada peramban internet.
Manfaat Penelitian
Penelitian ini diharapkan dapat membangun aplikasi web clustering yang dapat menghasilkan pola penyebaran titik panas dengan hasil yang lebih akurat dan mudah diakses oleh seluruh masyarakat. Dengan demikian, tindakan pencegahan dan evakuasi dapat dilakukan lebih awal.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah:
1 Penelitian ini dibatasi pada data titik panas Pulau Kalimantan dan Provinsi Sumatera Selatan.
2 Algoritme clustering yang digunakan untuk pengolahan dataset titik panas adalah algoritme RDBC.
3
TINJAUAN PUSTAKA
Density Based Clustering
Clustering adalah proses pengelompokan suatu kumpulan data ke dalam beberapa kelompok atau cluster. Clustering memiliki beberapa metode, salah satunya metode Density-Based. Metode Density-Based Clustering lebih banyak digunakan untuk menemukan wilayah yang padat objek dan dikelilingi wilayah dengan kepadatan yang rendah. Kemampuan lain yang dimiliki metode ini ialah mampu menangani data dengan jumlah besar dan membentuk cluster dengan bentuk yang tidak beraturan (arbitrary shape). Selain itu, algoritme ini cukup baik dalam menangani noise. Salah satu algoritme yang terkenal dan termasuk dalam
Density-Based Clustering ialah algoritme DBSCAN.
Menurut Putro (2011), ide dasar dari DBSCAN adalah memanfaatkan jumlah titik minimal yang harus dimiliki untuk menentukan suatu titik digolongkan menjadi core point, border point, atau noise point yang disebut MinPts. Selain itu, juga menggunakan threshold yang harus dipenuhi untuk menentukan titik tersebut menjadi core point, border point, atau noise point yang disebut juga Eps. Tiga jenis titik tersebut diilustrasikan pada Gambar 1.
Core point ditunjukkan oleh titik yang memiliki jarak Eps berwarna merah pada Gambar 1. Titik tersebut memiliki jumlah ketetanggaan yang lebih dari MinPts yaitu sebanyak 6 titik. Sedangkan border point ditunjukkan pada titik yang memiliki jarak Eps berwarna biru. Titik tersebut termasuk anggota ketetanggaan titik lain yang menjadi core point tetapi memiliki jumlah ketetanggaan yang kurang dari MinPts yaitu sebanyak 3 titik yang ditunjukkan pada Gambar 1. Adapun titik lain yaitu noise point yang ditunjukkan pada titik yang memiliki jarak Eps berwarna hijau. Titik tersebut memiliki jumlah ketetanggaan lebih sedikit dari MinPts sebanyak 2 titik pada Gambar 1 serta bukan anggota ketetanggaan core point.
Adapun definisi lainnya yang terdapat dalam DBSCAN dan diilustrasikan pada Gambar 2 yaitu sebagai berikut:
4
1 Directly Density Reachable
Suatu titik p dikatakan directly density reachable dengan titik q apabila titik p merupakan anggota q dalam jarak Eps dan titik q merupakan titik core point yang memiliki anggota himpunan sama atau lebih dari MinPts.
2 Density Reachable
Suatu titik p dikatakan density reachable apabila terdapat titik penghubung antara titik p dan q. Titik p tersebut harus directly density reachable dengan titik penghubung dan titik penghubung juga harus directly density reachable dengan titik q.
3 Density Connected
Suatu titik p dan q dikatakan density connected apabila dihubungkan oleh titik o yang density reachable dari titik p dan q.
Berikut adalah pseudocode DBSCAN (Ester et al. 1996).
1 DBSCAN (SetOfPoints, Eps, MinPts)
2 // SetOfPoints is UNCLASSIFIED
3 ClusterId := nextId(NOISE);
4 FOR i FROM 1 TO SetOfPoints.size DO
5 Point := SetOfPoints.get(i);
6 IF Point.ClId = UNCLASSIFIED THEN
7 IF ExpandCluster(SetOfPoints, Point,
8 ClusterId, Eps, MinPts) THEN
9 ClusterId := nextId(ClusterId)
10 END IF
11 END IF
12 END FOR
13 END; // DBSCAN
Setelah algoritme DBSCAN diberikan parameter tetap Eps dan MinPts, kemudian akan dilakukan penelusuran core point untuk memulai proses clustering.
Hal tersebut dilakukan secara rekursif kepada semua titik hingga menghasilkan
cluster. Berikut adalah tahapan algoritme DBSCAN (Ester et al. 1996) 1 Memilih secara acak sebuah titik p seperti pseudocode baris 5.
2 Mencari seluruh titik yang density reachable dengan titik p sesuai Eps dan MinPts pada fungsi ExpandCluster.
3 Jika p adalah core point , maka akan membentuk cluster dengan mengganti ClusterId yang sebelumnya didefinisikan sebagai noise.
Gambar 2 Ilustrasi beberapa teknik dalam DBSCAN p
5 4 Jika p adalah border point maka dicari kembali titik - titik yang density reachable dari titik p maka proses penelusuran dilanjutkan ke titik selanjutnya.
5 Lakukan proses tersebut hingga seluruh titik dalam database. Algoritme RDBC
Recursive Density-Based Clustering (RDBC) adalah algoritme clustering
yang dikembangkan dari algoritme DBSCAN, sebuah algoritme untuk mengelompokkan objek tetangga ke dalam cluster. Selain itu, algoritme ini tidak memerlukan tetapan jumlah cluster untuk melakukan clustering (Zhong Su 1999). Pada algoritme RDBC, penentuan threshold jarak Eps dan threshold MinPts dilakukan secara rekursif atau berulang hingga menghasilkan jumlah cluster yang tepat. Menurut Rehman dan Mehdi (2005), perbedaan diantara algoritme RDBC dengan DBSCAN ialah pada algoritme RDBC perhitungan core point dilakukan secara terpisah dari proses clustering. Nilai Eps dan MinPts awal digunakan untuk mengidentifikasi himpunan core point. Setelah jumlah anggota himpunan CSET tepat, Eps dan MinPts digunakan untuk melakukan clustering DBSCAN pada
dataset.
Berikut adalah pseudocode algoritme RDBC (Rehman dan Mehdi 2005).
1 Set initial values ε = ε1 and Mpts=Mpts1
2 Dataset = data_set
3 RDBC(ε, Mpts, Dataset)
4 Use ε and Mpts to get the core points set Cset
5 If size(Cset) > size(Dataset)/2
6 DBSCAN(Dataset, ε, Mpts);
7 Else
8 ε = ε/2;
9 Mpts=Mpts/4;
10 RDBC(ε, Mpts, Cset);//collect all points
around cluster
Ilustrasi algoritme RDBC dapat dilihat pada Gambar 3. Proses awal
clustering RDBC ialah identifikasi core point. Core point yang diperoleh lalu dilakukan clustering DBSCAN. Apabila himpunan core point tidak sesuai syarat atau kurang dari setengah jumlah dataset maka akan dilakukan reduksi nilai Eps dan MinPts. Kemudian dilakukan proses selanjutnya yaitu clustering titik-titik selain core point dengan menggunakan nilai parameter yang sudah direduksi.
(a) (b) (c)
6
Untuk lebih jelasnya, berikut tahapan yang dilakukan algoritme RDBC pada Gambar 3:
1 Pada Gambar 3a terdapat dataset awal yang berjumlah 11 titik.
2 Kemudian diberikan parameter awal Eps = 1 dan MinPts = 4. Sesuai
pseudocode pada baris ke 4, dilakukan proses identifikasi core point terlebih dahulu. Pada Gambar 3b diperoleh core point sebanyak 5 titik.
3 Sesuai pseudocode baris 5, jika jumlah core point kurang dari setengah jumlah dataset maka akan dilakukan reduksi nilai Eps dan MinPts. Jika jumlah core point sudah lebih dari setengah jumlah dataset maka dilakukan
clustering DBSCAN. Pada Gambar 3, jumlah core point yang diperoleh sebanyak 5. Karena kurang dari setengah jumlah dataset maka dilakukan reduksi parameter menjadi Eps = 0.5 dan MinPts = 1 sesuai pseudocode
baris ke 8 dan 9.
4 Kemudian dilakukan rekursif kembali algoritme RDBC dengan mengambil titik lainnya yang sebelumnya tidak teridentifikasi sebagai core point dan dengan parameter yang telah direduksi.
5 Dengan nilai Eps dan MinPts yang lebih kecil dari sebelumnya, diperoleh
core point tambahan seperti yang ditunjukkan pada Gambar 3c. Setelah itu dilakukan clustering DBSCAN hingga diperoleh menjadi 3 cluster dengan
noise sebanyak 2 titik.
Dengan proses rekursif tersebut, noise yang terbentuk menjadi lebih sedikit dibandingkan hanya melakukan clustering DBSCAN saja setelah identifikasi core point. Perubahan nilai Eps dan MinPts yang dilakukan berdampak pada hasil yang diperoleh. Algoritme RDBC akan membangkitkan cluster yang lebih banyak dibandingkan algoritme DBSCAN.
Silhouette Coefficient
Validasi sangat diperlukan pada hasil cluster baik itu merupakan hasil klasifikasi maupun hasil clustering. Pada validasi hasil klasifikasi, biasanya dilakukan perhitungan akurasi, precision, dan recall. Hal tersebut dikarenakan label dari setiap kelas yang ada sudah diketahui, sedangkan cluster hasil clustering tidak memiliki label sehingga validasi hasil clustering dilakukan dengan membandingkan hasil dengan algoritme lain atau menentukan jumlah cluster atau menghindari pola pada noise.
Menurut Halkidi et al. (2002), validasi cluster digolongkan ke dalam tiga kategori yaitu internal index, external index, dan relative index. Pada internal index, validasi dilakukan dengan melakukan pengukuran terhadap goodness struktur
clustering tanpa memperhatikan informasi eksternal. Contoh teknik yang termasuk
internal index ialah Sum of Squared Error (SSE), F-ratio, Silhouette Coefficient,
dll. Sedangkan validasi pada external index dilakukan pengukuran tingkat kemiripan antara label cluster dengan label kelas yang diberikan diluar proses
7 yang digunakan sama dengan external index atau internal index, biasanya SSE atau
entropy.
Teknik silhouette coefficient mengkombinasikan ide dari cohesion dan
separation untuk masing-masing titik baik dari beberapa cluster atau clustering. Cohesion mengukur seberapa dekat relasi antar objek di dalam sebuah cluster.
Sedangkan separation mengukur seberapa besar perbedaan cluster dengan cluster
lain. Ilustrasi mengenai cohesion dan separation dijelaskan pada Gambar 4.
Formula untuk menghitung silhouette dari sebuah titik adalah sebagai berikut (Kaufman dan Rousseeuw 1990)
� � = max {a i , b i }b i − a i
Pada Formula 1, terdapat titik i dalam cluster A dan s(i) merupakan
silhouette dari titik i tersebut, sedangkan a(i) merupakan rata-rata tingkat perbedaan (dissimilarity) diantara titik i dengan titik lain dan b(i) sebagai rata-rata tingkat perbedaan antara titik i dengan titik pada cluster yang terdekat dari cluster A. Kemudian hasil rata-rata silhouette keseluruhan titik pada datasetS’(k) digunakan
untuk menemukan angka yang tepat untuk cluster, k, dan memilih k yang memiliki nilai S’(k) yang terbesar .Silhouette coefficient (SC) didefinisikan sebagai berikut:
�� = max {�′ � }
Pada Formula 2, nilai maksimum diambil dari keseluruhan k yang dibentuk dari seluruh silhouette, k = 2,3,…,n-1 (Kaufman dan Rousseeuw 1990).
Package Shiny
Bahasa R merupakan bahasa yang berbasis bahasa S yang dibangun oleh Rick Becker, John Chambers, dan Allan Wilks pada tahun 80-an di Bell Laboratories. Kemudian dibangun menjadi sebuah perangkat lunak oleh Ross Ihaka dan Robert Gentleman yang dinamakan seperti bahasa pemrograman yang digunakan yaitu R. Fasilitas yang dibawa bahasa pemrograman ini ialah kemampuan untuk memanipulasi, menghitung serta menampilkan grafik dan antarmuka pengguna lainnya. Bahasa R termasuk pemrograman yang berorientasi
Gambar 4 Ilustrasi (a) Cohesion dan (b) Separation
Formula 1 Rumus menghitung Silhouette dari sebuah titik
Formula 2 Rumus menghitung Silhouette Coefficient (SC)
8
objek dan memiliki banyak library/package yang dikembangkan oleh kontributornya. Salah satunya ialah package Shiny.
Shiny merupakan sebuah web framework dari RStudio yang mempermudah pembangunan aplikasi web langsung dari bahasa R. Menurut Beeley (2013), Shiny merupakan paket yang sempurna untuk R, mudah dan sederhana untuk menampilkan hasil analisis dan grafik dari R dan pengguna dapat berinteraksi melalui web. Package ini dapat digolongkan ke dalam pemrograman yang reaktif atau mampu menampilkan output dengan mudah sesuai inputnya. Nilai output dapat diperoleh tanpa perlu memuat halaman ulang. Shiny tersusun dari dua komponen yaitu bagian antarmuka dan bagian server. Antarmuka sebagai pengatur tampilan dari aplikasi, sedangkan server sebagai tempat instruksi bagi komputer untuk membangun aplikasi tersebut. Alur sistem aplikasi Shiny dapat dilihat pada Gambar 5.
Mardhiyyah (2014) telah menggunakan Shiny pada penelitiannya yaitu
clustering dataset titik panas dengan algoritme DBSCAN. Pada penelitian tersebut, hasil clustering langsung ditampilkan dalam bentuk halaman web. Penyimpanan data masih berbasis file serta instruksi menggunakan server lokal.
METODE PENELITIAN
Data Penelitian
Data titik panas yang digunakan pada penelitian ini adalah data titik panas di Pulau Kalimantan dan Provinsi Sumatera Selatan tahun 2002-2003. Data ini diperoleh dari Fire Information for Resource Management System (FIRMS) yang disediakan oleh National Aeronautics and Space Administration (NASA). Pada
dataset Pulau Kalimantan terdapat 4999 titik panas, sedangkan dataset Provinsi Sumatera Selatan terdapat 4871. Dataset ini memiliki 11 atribut diantaranya
Track : ukuran piksel citra yang diamati oleh satelit
Acq_date : tanggal kejadian titik panas
Acq_time : waktu kejadian titik panas
Satellite : satelit yang digunakan (Aqua, Terra)
Confidence : kualitas titik panas (0-100%)
Bright_t31 : temperature channel-31 (K)
9
Frp : fire radiative power (MegaWatts)
Versi : 5.0 = MODIS NASA-LANCE, 5.1 = MODIS MODAPS-FIRMS
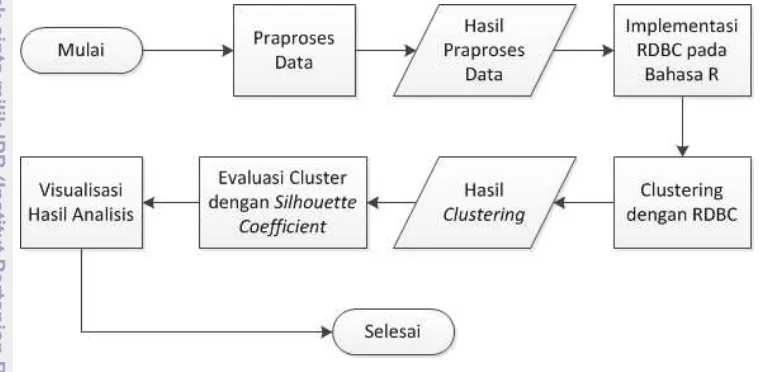
Tahapan Penelitian
Tahapan yang dilakukan pada penelitian ini dimulai dari praproses data, implementasi algoritme RDBC dengan bahasa R, evaluasi atau cluster dengan
Silhouette Coefficient, dan visualisasi dengan Shiny. Ilustrasi tahap pengerjaan penelitian ini dapat dilihat pada Gambar 6.
Praproses Data
Dataset yang diperoleh tidak dapat langsung digunakan untuk proses
clustering. Perlu adanya praproses data untuk mendapatkan data yang dibutuhkan agar memudahkan proses clustering. Praproses ini dapat dilakukan dengan reduksi data atau membuang data yang tidak digunakan hingga hanya berisi data yang diperlukan dalam penelitian ini.
Implementasi Algoritme RDBC
Tahapan selanjutnya ialah implementasi algoritme RDBC pada bahasa R dengan memanfaatkan modul DBSCAN pada package fpc. Algoritme RDBC diimplementasi menjadi sebuah fungsi sehingga untuk melakukan clustering
dilakukan dengan memanggil fungsi tersebut dari server aplikasi Shiny.
Clustering dengan Algoritme RDBC
Algoritme RDBC membutuhkan dua parameter sebagai inisialisasi awal seperti algoritme DBSCAN. Kedua parameter tersebut ialah Eps dan MinPts. Eps ialah parameter jarak pada data spasial. Sedangkan MinPts merupakan jumlah titik minimum pada jarak Eps. Oleh karena itu, sebelum melakukan clustering,
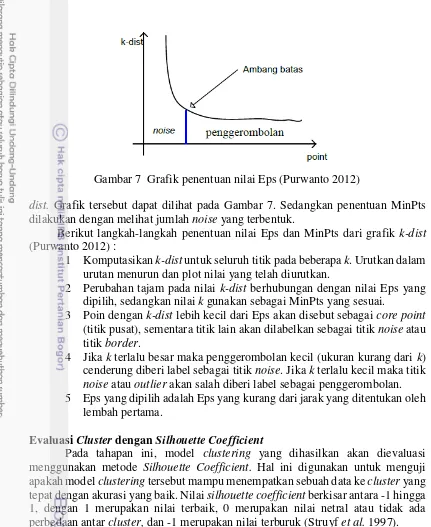
diperlukan penentuan Eps dan MinPts terlebih dahulu agar dapat menghasilkan hasil clustering yang terbaik. Penentuan Eps dilakukan dengan melihat grafik
10
dist. Grafik tersebut dapat dilihat pada Gambar 7. Sedangkan penentuan MinPts dilakukan dengan melihat jumlah noise yang terbentuk.
Berikut langkah-langkah penentuan nilai Eps dan MinPts dari grafik k-dist
(Purwanto 2012) :
1 Komputasikan k-dist untuk seluruh titik pada beberapa k. Urutkan dalam urutan menurun dan plot nilai yang telah diurutkan.
2 Perubahan tajam pada nilai k-dist berhubungan dengan nilai Eps yang dipilih, sedangkan nilai k gunakan sebagai MinPts yang sesuai.
3 Poin dengan k-dist lebih kecil dari Eps akan disebut sebagai core point
(titik pusat), sementara titik lain akan dilabelkan sebagai titik noise atau titik border.
4 Jika k terlalu besar maka penggerombolan kecil (ukuran kurang dari k) cenderung diberi label sebagai titik noise. Jika k terlalu kecil maka titik
noise atau outlier akan salah diberi label sebagai penggerombolan. 5 Eps yang dipilih adalah Eps yang kurang dari jarak yang ditentukan oleh
lembah pertama.
Evaluasi Cluster dengan Silhouette Coefficient
Pada tahapan ini, model clustering yang dihasilkan akan dievaluasi menggunakan metode Silhouette Coefficient. Hal ini digunakan untuk menguji apakah model clustering tersebut mampu menempatkan sebuah data ke cluster yang tepat dengan akurasi yang baik. Nilai silhouette coefficient berkisar antara -1 hingga 1, dengan 1 merupakan nilai terbaik, 0 merupakan nilai netral atau tidak ada perbedaan antar cluster, dan -1 merupakan nilai terburuk (Struyf et al. 1997). Visualisasi Hasil Analisis
Tahap terakhir yaitu visualisasi hasil analisis ke dalam halaman website agar dapat diakses melalui internet. Visualisasi ini memanfaatkan framework Shiny yang tersedia dalam Rstudio. Algoritme RDBC yang diimplementasikan ke dalam sebuah fungsi.
Lingkupan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
11 Perangkat lunak :
Sistem operasi Windows 7
Bahasa pemrograman R versi 3.1.2
RStudio versi 0.98.501 dengan package Shiny, fpc, cluster, dan jpeg
Microsoft Excel 2013
Google Chrome Perangkat keras :
Processor Intel Core i3 2.10 GHz,
Memori 4 GB DDR3
Harddisk berkapasitas 500 GB
HASIL DAN PEMBAHASAN
Praproses Data
Pada tahapan ini dilakukan pemilihan data titik panas yang terjadi di Pulau Kalimantan dan Provinsi Sumatera Selatan pada tahun 2002-2003. Tahapan praproses data yang dilakukan adalah reduksi data atau menghilangkan atribut/field
untuk memperoleh data yang diperlukan dalam perhitungan clustering. Berdasarkan dataset titik panas yang diperoleh dari Fire Information for Resource Management System (FIRMS), terdapat 11 field diantaranya latitude, longitude, brightness, scan, track, acq_date, satellite, confidence, version, bright_t31, dan frp. Kemudian direduksi menjadi 2 field yaitu latitude dan longitude.
Implementasi RDBC pada Bahasa R
Berdasarkan algoritme RDBC, dilakukan implementasi ke dalam bahasa pemrograman R. Implementasi algoritme RDBC dilakukan dengan menyesuaikan sintaks pada R, kemudian dibantu dengan package untuk mempermudah proses implementasi. Algoritme RDBC didefinisikan sebagai fungsi dengan masukan berupa parameter dataset, Eps dan Minpts. Perbedaan yang menonjol dari algoritme DBSCAN ialah penentuan core point dilakukan secara terpisah dari proses
clustering.
Pada RDBC, jumlah core point sangat dipertimbangkan untuk menghasilkan cluster yang minim noise. Oleh karena itu, pada algoritme RDBC diawali dengan perhitungan jumlah core point. Jika jumlah core point kurang dari setengah jumlah titik pada dataset, maka dilakukan pengurangan nilai Eps dan MinPts. Proses tersebut dilakukan secara rekursif hingga jumlah core point
memenuhi syarat yakni lebih dari setengah jumlah dataset. Apabila jumlah titik pusat (core point) sudah memenuhi syarat atau lebih dari setengah jumlah dataset, maka nilai Eps dan MinPts saat itu akan digunakan untuk melakukan clustering
12
Tabel 1 merupakan perbandingan clustering dengan algoritme RDBC dan DBSCAN dari dataset Pulau Kalimantan dengan parameter awal Eps=0.009 dan MinPts=2. Algoritme RDBC menghasilkan cluster yang lebih baik dengan nilai SC yang lebih tinggi karena melakukan perbaikan pada nilai parameter awal. Algoritme RDBC mempertimbangkan jumlah core point, ketika jumlah core point tersebut belum mencapai setengah jumlah dataset maka parameter Eps dan MinPts akan dikurangi. Pada algoritme DBSCAN, tidak dilakukan perbaikan nilai parameter, sehingga menghasilkan cluster yang kurang baik dikarenakan jumlah core point
lebih sedikit dari jumlah non core point.
Clustering dengan Algoritme RDBC
Sebelum melakukan clustering, diperlukan adanya penentuan nilai Epsdan jumlah titik minimum (MinPts). Clustering menggunakan RDBC maupun DBSCAN sama-sama membutuhkan parameter Eps dan MinPts. Penentuan nilai Eps dan MinPts sangat berpengaruh terhadap cluster yang akan dihasilkan. Nilai
RDBC DBSCAN
Silhouette Coefficient 0.3220798 -0.2491384
Algoritme RDBC pada R
# input :
# Memasukkan dataset untuk dilakukan clustering
# Memasukkan nilai eps dan minpts sebagai inisialisasi awal
rdbc <- function(data,eps,minpts){ n <- nrow(data)
# Menghitung core point
cset <- cset(data,eps,minpts)
if (cset > n/2)
result <- dbscan(data,eps,minpts)
# Melakukan rekursif jika core point kurang dari setengah # jumlah dataset
else {
eps <- eps/2
minpts <- minpts/4
result <- rdbc(nocset,eps,minpts)
#rekursif titik selain core point
}
out <- list(result,cset) return(out);}
13 MinPts akan menentukan jumlah noise, semakin besar nilai MinPts yang diberikan akan menghasilkan cluster yang memiliki banyak noise. Sedangkan penentuan nilai Eps akan berpengaruh pada jumlah cluster yang dihasilkan (Purwanto 2012). Untuk mengevaluasi cluster, Silhouette coefficient menjadi tolak ukur tingkat ketepatan suatu cluster.
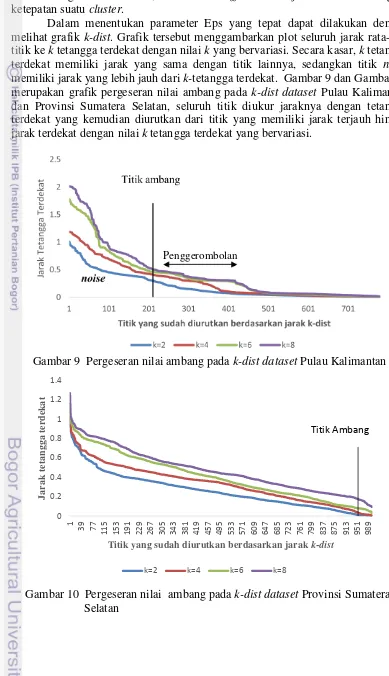
Dalam menentukan parameter Eps yang tepat dapat dilakukan dengan melihat grafik k-dist. Grafik tersebut menggambarkan plot seluruh jarak rata-rata titik ke k tetangga terdekat dengan nilai k yang bervariasi. Secara kasar, k tetangga terdekat memiliki jarak yang sama dengan titik lainnya, sedangkan titik noise
memiliki jarak yang lebih jauh dari k-tetangga terdekat. Gambar 9 dan Gambar 10 merupakan grafik pergeseran nilai ambang pada k-dist dataset Pulau Kalimantan dan Provinsi Sumatera Selatan, seluruh titik diukur jaraknya dengan tetangga terdekat yang kemudian diurutkan dari titik yang memiliki jarak terjauh hingga jarak terdekat dengan nilai k tetangga terdekat yang bervariasi.
Gambar 9 Pergeseran nilai ambang pada k-dist dataset Pulau Kalimantan
Penggerombolan
115 153 191 229 267 305 343 381 419 457 495 533 571 609 647 685 723 761 799 837 875 913 951 989
J
Titik yang sudah diurutkan berdasarkan jarak k-dist
k=2 k=4 k=6 k=8
Titik Ambang
14
Pada grafik tersebut dapat dilihat adanya penggerombolan yang ditandai grafik yang melandai. Untuk memudahkan penentuan batas penggerombolan, dapat menggunakan garis vertikal sebagai titik ambang. Garis vertikal tersebut digeser ke kiri atau ke kanan untuk menemukan lekukan tajam pada plot. Apabila digeser ke kiri maka Eps yang dipilih semakin besar sehingga semakin sedikit penggerombolan yang diperoleh, sebaliknya apabila garis vertikal digeser ke kanan, penggerombolan yang terbentuk semakin banyak. Pada penelitian ini, nilai ambang pergeseran atau nilai k tetangga terdekat yang digunakan yaitu k=2, k=4, k=6, dan
k=8. Berdasarkan Gambar 9, rentang penggerombolan titik terjadi pada jarak terdekat 0.2 – 0.5 untuk dataset Pulau Kalimantan. Sedangkan untuk dataset
Provinsi Sumatera Selatan, jarak masing - masing titik dengan tetangga terdekat memiliki jarak yang hampir berbeda sehingga titik ambang digeser ke kanan untuk mendapatkan garis yang melandai seperti yang ditunjukkan pada Gambar 10. Berdasarkan grafik k-dist yang diperoleh, maka rentang penggerombolan titik terjadi pada jarak terdekat 0.1 – 0.15 untuk dataset Provinsi Sumatera Selatan. Nilai ini merupakan parameter Eps yang kemudian dimasukkan ke dalam algoritme RDBC untuk mendapatkan hasil clustering yang tepat.
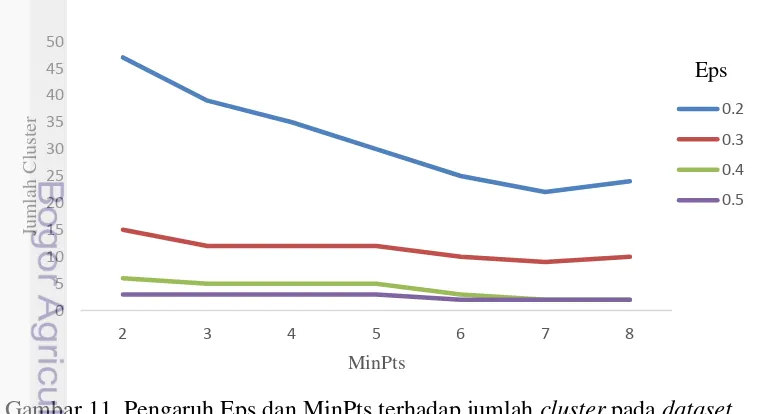
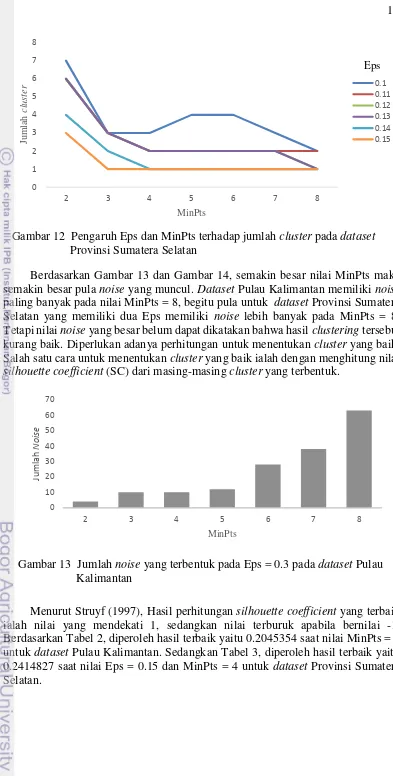
Grafik pengaruh Eps dan MinPts terhadap jumlah cluster ditunjukkan pada Gambar 11 dan Gambar 12. Hasil clustering yang terbaik memiliki grafik melandai yang dapat diartikan kekonsistenan jumlah cluster yang terbentuk. Berdasarkan Gambar 11, nilai Eps = 0.3 menunjukkan grafik yang melandai. Dengan demikian, nilai Eps = 0.3 merupakan nilai yang optimal untuk dataset Pulau Kalimantan. Sedangkan pada Gambar 12, nilai Eps = 0.14 dan nilai Eps = 0.15 merupakan nilai yang optimal untuk dataset Provinsi Sumatera Selatan. Kemudian untuk menentukan nilai MinPts disesuaikan dengan dimensi d dataset yaitu MinPts >=d+1. Nilai MinPts berpengaruh pada jumlah noise yang terbentuk. Semakin kecil nilai MinPts maka akan semakin memungkinkan muncul banyak titik noise yang akan dimasukkan ke dalam cluster.
0
Gambar 11 Pengaruh Eps dan MinPts terhadap jumlah cluster pada dataset
15
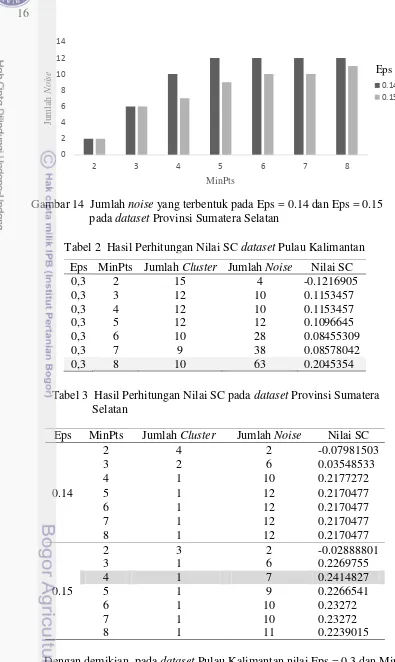
Berdasarkan Gambar 13 dan Gambar 14, semakin besar nilai MinPts maka semakin besar pula noise yang muncul. Dataset Pulau Kalimantan memiliki noise
paling banyak pada nilai MinPts = 8, begitu pula untuk dataset Provinsi Sumatera Selatan yang memiliki dua Eps memiliki noise lebih banyak pada MinPts = 8. Tetapi nilai noise yang besar belum dapat dikatakan bahwa hasil clustering tersebut kurang baik. Diperlukan adanya perhitungan untuk menentukan cluster yang baik. Salah satu cara untuk menentukan cluster yang baik ialah dengan menghitung nilai
silhouette coefficient (SC) dari masing-masing cluster yang terbentuk.
Menurut Struyf (1997), Hasil perhitungan silhouette coefficient yang terbaik ialah nilai yang mendekati 1, sedangkan nilai terburuk apabila bernilai -1. Berdasarkan Tabel 2, diperoleh hasil terbaik yaitu 0.2045354 saat nilai MinPts = 8 untuk dataset Pulau Kalimantan. Sedangkan Tabel 3, diperoleh hasil terbaik yaitu 0.2414827 saat nilai Eps = 0.15 dan MinPts = 4 untuk dataset Provinsi Sumatera Selatan.
Gambar 13 Jumlah noise yang terbentuk pada Eps = 0.3 pada dataset Pulau Kalimantan
Gambar 12 Pengaruh Eps dan MinPts terhadap jumlah cluster pada dataset
16
Dengan demikian, pada dataset Pulau Kalimantan nilai Eps = 0.3 dan MinPts = 8 memiliki ketepatan cluster yang optimal atau lebih baik dengan nilai silhouette coefficient (SC) sebesar 0.2045354, sedangkan untuk dataset Provinsi Sumatera
Eps MinPts Jumlah Cluster Jumlah Noise Nilai SC
Tabel 2 Hasil Perhitungan Nilai SC dataset Pulau Kalimantan 0 pada dataset Provinsi Sumatera Selatan
17 Selatan, nilai Eps = 0.15 dan MinPts = 4 memiliki ketepatan cluster yang optimal atau lebih baik dengan nilai silhouette coefficient (SC) sebesar 0.2414827.
Evaluasi Cluster
Setelah hasil proses clustering diperoleh, kemudian dilakukan evaluasi ketepatan penentuan cluster menggunakan silhouette coefficient (SC). Dengan bantuan package “cluster” pada R, nilai SC dapat diperoleh dengan memanggil
fungsi “silhouette”. Perhitungan nilai silhouette dilakukan pada variabel clusters()[[1]]$cluster dan menggunakan matriks jarak euclidean untuk menghitung jarak antar titik pada variabel selectedData(). Setelah nilai silhouette
diperoleh, lalu dilakukan perhitungan rata-rata nilai silhouette dari setiap titik untuk mendapatkan nilai silhouette coefficient (SC). Implementasi perhitungan nilai SC menggunakan bahasa R dapat dilihat pada Gambar 15.
Nilai silhouette berkisar antara -1 hingga 1. Nilai 1 dapat diartikan bahwa seluruh objek atau titik dimasukkan pada cluster dengan tepat. Kemudian nilai 0 diartikan bahwa seluruh objek atau titik berada di antara dua cluster, sedangkan nilai -1 diartikan bahwa seluruh objek atau titik dimasukkan pada bukan cluster
yang seharusnya (Struyf 1997). Berdasarkan hasil clustering, diperoleh nilai SC terbaik sebesar 0.2045354 untuk dataset Pulau Kalimantan dan sebesar 0.2414827 untuk dataset Provinsi Sumatera Selatan. Hasil perhitungan tersebut belum dapat dikatakan bagus karena nilai SC masih jauh dari nilai terbaik.
Hasil Clustering RDBC
Hasil dari proses clustering dengan RDBC kemudian divisualisasikan ke dalam aplikasi web dengan bantuan package Shiny pada bahasa R. Pada aplikasi ini, pengguna dapat memilih dataset yang akan diproses, yakni Pulau Kalimantan atau Provinsi Sumatera Selatan.
Kemudian sebagai inisialisasi awal, pengguna dapat memasukkan nilai Eps dan jumlah titik minimum (MinPts). Dari nilai inisialisasi parameter awal ini, algoritme RDBC akan mencari Eps dan MinPts yang paling baik, yakni yang menghasilkan core point lebih besar dari setengah dataset. Jika core point yang didapatkan semakin banyak, maka noise yang dihasilkan akan semakin sedikit. Gambar 16 merupakan hasil clustering dari dataset Pulau Kalimantan dengan nilai Eps = 0.3 dan MinPts = 8. Berdasarkan gambar tersebut, clustering menghasilkan 10 cluster dengan nilai silhouette coefficient sebesar 0.2045354.
sil <- silhouette(clusters()[[1]]$cluster, dist(selectedData(),"euclidean")) sc <- mean(sil[,3])
18
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini, algoritme RDBC dapat diimplementasikan ke dalam bahasa R menjadi sebuah aplikasi web clustering dengan bantuan framework Shiny. Nilai Eps berpengaruh terhadap jumlah cluster. Semakin kecil nilai Eps maka jumlah cluster yang terbentuk semakin banyak. Sedangkan nilai MinPts berpengaruh pada jumlah titik noise. Semakin besar nilai MinPts maka semakin banyak pula titik noise yang muncul. Evaluasi cluster membantu dalam menentukan parameter untuk membentuk cluster yang tepat. Parameter yang optimal untuk dataset titik panas Pulau Kalimantan ialah Eps = 0.3 dan MinPts = 8, sedangkan untuk dataset titik panas Provinsi Sumatera Selatan ialah Eps = 0.15 dan MinPts = 4.
Saran
Untuk penelitian selanjutnya, diharapkan clustering dapat dilakukan secara multidimensi tidak berdasarkan data spasial saja. Selain itu, aplikasi dapat diintegrasikan dengan database server yang memiliki kapasitas lebih besar. Kemudian pengembangan sistem dapat dilakukan dengan skala yang lebih luas meliputi 3 layer yaitu database server, web server, dan client.
19
DAFTAR PUSTAKA
Beeley C. 2013. Web Application Development with R Using Shiny. Birmingham (GB) : Packt Publishing.
Ester M, Kriegel H, Sander J, Xu X. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Di dalam: 2nd International Conference on Knowledge Discovery and Data Mining (KDD-96); 1996 Agustus 2-4; Portland, Amerika Serikat. Portland (US): AAAI Press. hlm 226-231.
Halkidi M, Batistakis Y, Vazirgiannis M. 2002. Clustering Validity Checking Methods: Part II. Athena(GR) : Athens University of Economics & Bussiness. Kaufman L, Rousseeuw PJ. 1990. Finding Groups in Data: An Introduction to
Cluster Analysis. London (GB) : John Wiley and Sons.
Mardhiyyah R. 2014. Clustering dataset titik panas dengan algoritme DBSCAN menggunakan web framework Shiny pada bahasa R [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Purwanto UY. 2012. Penggerombolan spasial hotspot kebakaran hutan dan lahan menggunakan DBSCAN dan ST-DBSCAN [tesis]. Bogor (ID): Institut Pertanian Bogor.
Putro BA. 2011. Implementasi Density Based Spatial Clustering Application with Noise (DBSCAN) dalam perkiraan terjadinya banjir di Bandung [Skripsi].
Bandung (ID): Universitas Telkom
Rehman M, Mehdi SA. 2005. Comparison of density-based clustering algorithms [Internet]. [diunduh 2014 Sep 29]. Tersedia pada: https://www.researchgate.net/publication/242219043_COMPARISON_OF_ DENSITY-BASED_CLUSTERING_ALGORITHMS.
Struyf A, Hubert M, Rousseeuw PJ. 1997. Clustering in an object-oriented environment [Internet]. [diunduh 2014 Des 2];1(4). Tersedia pada: http://www.jstatsoft.org/v01/i04.
20
RIWAYAT HIDUP
Aries Santoso dengan panggilan Aries dilahirkan di Jakarta pada tanggal 30 Maret 1994, dari pasangan suami istri Bapak Darsono dan Ibu Kartini. Penulis merupakan anak pertama dari dua bersaudara. Pada tahun 2011, penulis lulus dari SMA Negeri 5 Bekasi lalu diterima di Program Studi Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui seleksi jalur SNMPTN tertulis.