IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOR DAN METODE TOPSIS
( TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL SOLUTION) DALAM PENENTUAN MUTU BERAS MISKIN
(STUDI KASUS: BULOG ACEH)
SKRIPSI
Sisca Lidhya Sari 111421065
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOR DAN METODE TOPSIS
( TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL SOLUTION) DALAM PENENTUAN MUTU BERAS MISKIN
(STUDI KASUS: BULOG ACEH)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Ilmu Komputer
SISCA LIDHYA SARI 111421065
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
PERSETUJUAN
Judul : IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOR DAN METODE TOPSIS DALAM (TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL SOLUTION)DALAM PENENTUAN MUTU BERAS MISKIN (STUDI KASUS: BULOG ACEH)
Kategori : SKRIPSI
Nama : SISCA LIDHYA SARI
Nomor Induk Mahasiswa : 111421065
Program Studi : EKSTENSI S1 ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan,
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Ade Candra, ST, M.Kom Maya Silvi Lydia, B.Sc, M.Sc
NIP. 19790904 200912 1 002 NIP. 19740127 200212 2 001
Diketahui/disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
PERNYATAAN
IMPLEMENTASI ALGORITMA K-NEAREST NEIGHBOR DAN METODE TOPSIS (TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL
SOLUTION) DALAM PENENTUAN MUTU BERAS MISKIN (STUDI KASUS: BULOG ACEH)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Februari 2014
PENGHARGAAN
Alhamdulillah, puji syukur penulis panjatkan kehadirat Allah SWT, yang telah memberikan rahmat dan hidayah-Nya serta segala sesuatunya dalam hidup. Sehingga penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, Program Studi S1 Ilmu Komputer Universitas Sumatera Utara.
Skripsi ini penulis persembahkan kepada kedua orangtua tercinta, Papa Ansari dan Ibunda Dra. Rosniar yang tiada hentinya memberikan doa dan kasih sayangnya serta semangat dan motivasi selama penulisan skripsi ini.
Selanjutnya ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis selama pengerjaan skripsi ini, antara lain kepada:
1. Bapak Dr. Poltak Sihombing, M.Kom sebagai Ketua Program Studi S1 Ilmu Komputer.
2. Ibu Maya Silvi Lydia, B.Sc, M.Sc selaku Sekretaris Program Studi Ilmu Komputer sekaligus pembimbing saya yang telah membimbing, mengarahkan, menasehati, memotivasi, dan menyemangati penulis agar dapat menyelesaikan skripsi ini.
3. Bapak Ade Candra, ST, M.Kom selaku pembimbing yang telah meluangkan waktu, tenaga, dan pikiran dalam membimbing, mengarahkan, menasehati, memotivasi, dan menyemangati penulis agar dapat menyelesaikan skripsi ini. 4. Bapak Drs. Marihat Situmorang, M.Kom dan Ibu Dian Rachmawati, S.Si,
M.Kom sebagai dosen penguji yang telah memberikan kritik dan saran yang berguna bagi penulis.
6. Kepala UPGB dan karyawan Bulog Aceh yang telah banyak membantu penulis selama penelitian skripsi ini.
7. Cutbang tersayang Randhy Ramadhani dan Adik terkasih Rizky Ramadiana Sari yang telah memberikan semangat kepada penulis.
8. Andria Rezki S.Kom, yang selalu memberikan semangat dan dukungan penuh kepada penulis guna meraih sarjana.
9. Teman-teman seangkatan Ekstensi S1 Ilmu Komputer tahun 2011, Maya, Wita, Zhe, Yuyun, Aim, Della dan Yolan serta teman – teman yang lain yang sama-sama berjuang meraih gelar Sarjana.
10. Teman-teman terbaik penulis FERNANDO: Fidyatunnisa ST, M. Heru A. Junaidi, ST, Fairuzziana S.Psi, dan Cut Lina Keumala Sari, S.Pd yang telah banyak mendukung penulis hingga meraih sarjana.
Semoga Allah SWT memberikan limpahan karunia semua pihak yang membantu penulis dalam menyelesaikan skripsi ini. Akhirnya penulis berharap bahwa skripsi ini bermanfaat terutama kepada penulis maupun para pembaca serta semua pihak akademisi yang tertarik mengembangkannya. Penulis menyadari bahwa skripsi ini masih jauh dari kesempurnaan, oleh karena itu penulis menerima saran dan kritik demi kesempurnaan skripsi ini sehingga bermanfaat bagi semua pihak.
Medan, Februari 2014 Penulis
ABSTRAK
Penyaluran beras kepada masyarakat miskin menjadi salah satu pokok kegiatan operasi utama Perusahaan Bulog guna memajukan kesejahteraan masyarakat Indonesia. Dalam kinerjanya penentuan keputusan terhadap mutu beras untuk penerima beras miskin sering kali menjadi persoalan yang rumit. Untuk mengatasi masalah-masalah tersebut perlu dilakukan langkah yang efektif agar suatu keputusan dapat diambil. Salah satu cara yang dapat dilakukan adalah dengan melakukan proses klasifikasi dan mencari hasil terbaik dari data yang telah ada menggunakan perangkat lunak untuk mendapatkan solusi optimal atas suatu permasalahan dengan menggunakan Algoritma K-Nearest Neighbor dan metode techniuqe for orders preference by similarity to ideal solution (TOPSIS). Dengan adanya aplikasi ini dapat memudahkan pihak perusahaan Bulog dalam menentukan mutu beras terbaik yang akan disalurkan ke masyarakat miskin. Waktu yang dibutuhkan untuk proses mining antara K-Nearest Neighbor dan TOPSIS terlihat algoritma Nearest Neigbor lebih sederhana proses perhitungannya terhadap data beras dibanding dengan Metode Topsis, namun membutuhkan waktu yang lebih lama karena harus dilakukan proses training secara berulang untuk setiap data yang akan diprediksi sedangkan Topsis lebih cepat kinerjanya dibandingkan dengan K-Nearest Neighbor.
IMPLEMENTATION OF K-NEAREST NEIGHBOR ALGORITHM AND TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL SOLUTION (TOPSIS) METHOD IN DETERMINING RICE QUALITY FOR
ECONOMICALLY DISADVANTAGED GROUP OF PEOPLE
ABSTRACT
Rice distribution for economically disadvantaged group of people is one of the main operational activities of Bulog Company to advance Indonesian society welfare. Decision making for rice quality for the addressee often became a complicated problem. Overcoming those problems takes an effective step in order to take a decision. One way to do so is to perform the classification process and search for the best result using the existing data. The use of software can be an optimal solution of the problem by using K- Nearest Neighbor Algorithm and Techniuqe for orders preference by similarity to ideal solution (TOPSIS) method. This application will ease Perum Bulog to determine the best rice quality to be distributed to the economically disadvantaged group of people. The time required data mining process between K- Nearest Neighbor Algorithm and TOPSIS method generated data defined seen that K- Nearest Neighbor simpler than TOPSIS, but it took a lot of time by processing of data training repeatedly for data to be predicted, while TOPSIS faster than K- Nearest Neighbor.
DAFTAR ISI
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metode Penelitian 3
1.7 Sistematika Penulisan 4
Bab 2 Tinjauan Pustaka 6
2.1 Konsep Sistem Pendukung Keputusan 6
2.1.1 Tahap-Tahap dalam Pengambilan Keputusan 8
2.1.2 Kerangka Kerja pengambilan Keputusan 9
2.1.3 Karakteristik Sistem Pendukung Keputusan 11
2.1.4 Sistem Pendukung Keputusan Database 12
2.2. Konsep Algoritma K - Nearest Neighbor 13
2.3. Metode TOPSIS 16
2.3.1.Prosedur dan langkah- langkah metode TOPSIS 17
2.3.2 Ilustrasi Metode TOPSIS 19
2.3 Penelitian Terdahulu 23
Bab 3 Analisis dan Perancangan Sistem 26
3.1 Analisis 26
3.1.1 Analisis Masalah 26
3.2 Analisis Kebutuhan Sistem 27
3.2.1 Analisis Fungsional Sistem 27
3.2.2 Analisis Non- Fungsional Sistem 28
3.3. Perancangan Sistem 29
3.3.1 Use case diagram 30
3.3.3 Flowchart K-nearest Neighbor 34
3.3.4 Flowchart Metode TOPSIS 36
3.4 Rancangan Database 37
3.5 Pembuatan Rancangan Tampilan Aplikasi 38
3.5.1 Rancangan Jendela Utama 38
3.5.2 Rancangan Form Data User 40
3.5.3 Rancangan Form Data Mitra Beras 41
3.5.4 Rancangan Form Parameter 40
3.5.5 Rancangan Form K-Nearest Neighbor 42
3.5.6 Rancangan Form Proses Metode TOPSIS 43
Bab 4 Implementasi Dan Pengujian 46
4.1 Implementasi 46
4.1.1 Implementasi Algoritma K-Nearest Neighbor 46
4.1.2 Implementasi Metode TOPSIS 53
4.1.3 Perbandingan Algoritma K-Nearest Neighbor dan TOPSIS 69
4.2 Pengujian 69
4.2.1 Tampilan Halaman Login 70
4.2.2 Tampilan Jendela Utama 71
4.2.3 Tampilan Form Data User 71
4.2.4 Tampilan Form Data Mitra 72
4.2.5 Tampilan Form Klasifikasi Data K-Nearest Neighbor 74
4.2.6 Tampilan Form Metode TOPSIS 76
Bab 5 Kesimpulan Dan Saran 79
5.1 Kesimpulan 79
5.2 Saran 80
Daftar Pustaka
DAFTAR TABEL
Halaman
2.1 Alternatif kecocokan pada setiap kriteria 20
2.2 Bobot Kriteria 20
3.1 Tabel Mitra 32
3.2 Tabel Parameter 38
3.3 Tabel User 37
4.1 Data Testing dan Data Training 45
4.2 Nilai Hasil Pengujian DataBeras 47
4.3 Cluster Data Training 49
4.4 Perthitungan Data Training dan Data Testing 50
4.5 Hasil perhitungan data testing 51
4.6 Data Beras dan Kriteria 52
4.7 Nilai Normalisasi 1 55
4.8 Nilai Ternormalisasi Terbobot 56
4.9 Nilai Solusi Ideal Positif dan Negatif 58
4.10 Jarak alternatif A+ 60
4.11 Jarak alternatif A- 62
4.12 Jarak solusi ideal positif A- dan A+ 63
DAFTAR GAMBAR
Halaman
2.1 FaseProses Pengambilan Keputusan 9
2.2 Ilustrasi Solusi pada KNN 14
3.1 Diagram Ishikawa 27
3.2 Use Case Diagram pada Sistem 30
3.3 Diagram Activity Sistem 32
3.4 Diagram Activity algortima K-Nearest Neighbor 33
3.5 Diagram Activity Metode TOPSIS 34
3.6 Flowchart Perhitungan K-Nearest Neighbor 35
3.7 Flowchart Perhitungan TOPSIS 36
3.8 Rancangan Jendela Utama 39
3.9 Rancangan Form Data User 40
3.10 Rancangan Form Data Mitra Beras 41
3.11 Rancangan Form Parameter 42
3.12 Rancangan Form Klasifikasi Data K-Nearest Neighbor 43
3.13 Rancangan Form Metode Topsis 44
4.11 Form Pengisian Data Beras dan Kriteria 66
4.1 Tampilan Halaman login 67
4.2 Tampilan Jendela Utama Aplikasi 67
4.3 Tampilan Form DataUser 68
4.4 Tampilan Menambah Data User 68
4.5 Tampilan Form Data Mitra 69
4.6 Tampilan Form Tambah Data Mitra 69
4.7 Tampilan Form Klasifikasi Data K-Nearest Neighbor 70
4.8 Form Tampilan Hasil Nilai Pembagian Kelas 71
4.9 Form Hasil Klasifikasi Data 72
ABSTRAK
Penyaluran beras kepada masyarakat miskin menjadi salah satu pokok kegiatan operasi utama Perusahaan Bulog guna memajukan kesejahteraan masyarakat Indonesia. Dalam kinerjanya penentuan keputusan terhadap mutu beras untuk penerima beras miskin sering kali menjadi persoalan yang rumit. Untuk mengatasi masalah-masalah tersebut perlu dilakukan langkah yang efektif agar suatu keputusan dapat diambil. Salah satu cara yang dapat dilakukan adalah dengan melakukan proses klasifikasi dan mencari hasil terbaik dari data yang telah ada menggunakan perangkat lunak untuk mendapatkan solusi optimal atas suatu permasalahan dengan menggunakan Algoritma K-Nearest Neighbor dan metode techniuqe for orders preference by similarity to ideal solution (TOPSIS). Dengan adanya aplikasi ini dapat memudahkan pihak perusahaan Bulog dalam menentukan mutu beras terbaik yang akan disalurkan ke masyarakat miskin. Waktu yang dibutuhkan untuk proses mining antara K-Nearest Neighbor dan TOPSIS terlihat algoritma Nearest Neigbor lebih sederhana proses perhitungannya terhadap data beras dibanding dengan Metode Topsis, namun membutuhkan waktu yang lebih lama karena harus dilakukan proses training secara berulang untuk setiap data yang akan diprediksi sedangkan Topsis lebih cepat kinerjanya dibandingkan dengan K-Nearest Neighbor.
IMPLEMENTATION OF K-NEAREST NEIGHBOR ALGORITHM AND TECHNIQUE FOR ORDERS PREFERENCE BY SIMILARITY TO IDEAL SOLUTION (TOPSIS) METHOD IN DETERMINING RICE QUALITY FOR
ECONOMICALLY DISADVANTAGED GROUP OF PEOPLE
ABSTRACT
Rice distribution for economically disadvantaged group of people is one of the main operational activities of Bulog Company to advance Indonesian society welfare. Decision making for rice quality for the addressee often became a complicated problem. Overcoming those problems takes an effective step in order to take a decision. One way to do so is to perform the classification process and search for the best result using the existing data. The use of software can be an optimal solution of the problem by using K- Nearest Neighbor Algorithm and Techniuqe for orders preference by similarity to ideal solution (TOPSIS) method. This application will ease Perum Bulog to determine the best rice quality to be distributed to the economically disadvantaged group of people. The time required data mining process between K- Nearest Neighbor Algorithm and TOPSIS method generated data defined seen that K- Nearest Neighbor simpler than TOPSIS, but it took a lot of time by processing of data training repeatedly for data to be predicted, while TOPSIS faster than K- Nearest Neighbor.
BAB 1
PENDAHULUAN
1.1. Latar Belakang
BULOG adalah perusahaan umum milik negara yang bergerak di bidang logistik dan pangan. Ruang lingkup bisnis perusahaan ini meliputi usaha logistik atau pergudangan, perdagangan komoditi pangan dan usaha eceran. Sebagai perusahaan yang tetap mengemban tugas publik dari pemerintah, BULOG tetap melakukan kegiatan menjaga harga dasar pembelian untuk gabah, menyalurkan beras untuk orang miskin dan pengelolaan stok pangan. Dari salah satu kegiatan yang tertera, penyaluran beras untuk orang miskin menjadi salah satu pokok kegiatan utama guna memajukan kesejahteraan masyarakat Indonesia.
Dalam operasinya penentuan keputusan terhadap mutu beras miskin untuk penerima manfaat beras miskin atau raskin sering kali menjadi persoalan yang rumit. Dinamika penentuan keputusan data beras yang berkualitas baik dan tidak baik memerlukan adanya kebijakan lokal melalui operasi langsung ke gudang-gudang beras di tiap-tiap daerah. Pengoperasian langsung tersebut cenderung memerlukan waktu yang tidak efisien dalam pengambilan keputusan, sehingga mengakibatkan penyaluran beras miskin menjadi lambat. Akibat dari keterlambatan pengambilan keputusan ini data yang diterima oleh pemerintah pusat menyebutkan bahwa sering kali penyaluran tidak dilakukan dengan efisien.
Sebagaimana penelitian terdahulu oleh Arif Juanto dengan judul “Perbandingan Performansi Algoritma K-Nearest Neighbor dan SLIQ utuk prediksi kinerja Akademik Mahasiswa Baru” [2] dan Meliya Ningrum dengan judul “Aplikasi Metode TOPSIS FUZZY dalam Menentukan Prioritas Kawasan Perumahan di Kecamatan Percut Sei Tuan”[7].
Dari beberapa penjabaran di atas, Judul penelitian yang diambil adalah Implementasi Algoritma K-Nearest Neighbor dan Metode Topsis dalam Penentuan Mutu Beras Miskin yang di implementasikan di Bulog Aceh.
1.2. Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana menentukan mutu beras miskin untuk pengambilan keputusan dan bagaimana mengimplementasikan Algoritma K- Nearest Neighbor dan TOPSIS dalam penentuan mutu beras miskin.
1.3. Batasan Masalah
Dalam penelitian ini, penulis membuat batasan masalah agar tidak menyimpang dari tujuan penelitian, adapun batasan masalah sebagai berikut:
1. Data diperoleh dari Bulog Aceh.
2. Karakteristik penilaian kriteria mutu beras miskin yang digunakan berdasarkan bebas hama penyakit, butir patah beras, kadar air beras, dan bebas bahan kimia.
3. Pengguna dalam sistem ini yaitu admin dan karyawan Bulog.
4. Publik di luar dari karyawan Bulog tidak dapat mengakses sistem ini.
6. Bahasa pemrograman yang digunakan adalah Hypertext Preprocessor
(PHP) dengan database management system MySQL.
1.4. Tujuan Penelitian
Adapun dari tujuan penelitian ini adalah untuk menghasilkan suatu sistem pengambilan keputusan guna mengetahui mutu beras miskin (Raskin), yang nantinya dapat memudahkan pihak perusahaan dalam mengambil keputusan untuk menyalurkan beras tersebut kepada pihak masyarakat miskin.
1.5. Manfaat Penelitian
Adapun manfaat dari penelitian ini diharapkan memudahkan perusahaan Bulog untuk mengetahui kriteria mutu beras miskin, serta memungkinkan perusahaan mempunyai sistem pendukung keputusan dalam kinerjanya.
1.6. Metodelogi Penelitian
1. Studi Kepustakaan
Metode ini dilaksanakan dengan melakukan studi kepustakaan yang relevan serta buku-buku maupun artikel dan jurnal mengenai algoritma K-nearest Neighbor dan Topsis atau e-book dan juga jurnal yang didapatkan melalui internet.
2. Analisis dan Perancangan Sistem
juga dilakukan perancangan diagram alir proses kerja sistem berupa flowchart serta model antarmuka untuk memudahkan dalam penulisan kode program.
3. Implementasi Sistem dan Pengujian Sistem
Pada tahap ini dilakukan pemasukan data serta memproses data untuk mendapatkan hasil apakah sudah sesuai dengan tujuan serta dilakukan pengujian program dalam melakukan proses pengambilan keputusan pada perusahaan.
4. Dokumentasi
Tahap akhir dari penelitian yang dilakukan, yaitu membuat kesimpulan dan laporan tentang penelitian yang telah dilakukan.
1.7. Sistematika Penulisan
Dalam penulisan penelitian ini ada beberapa sistematika penulisan, yaitu:
BAB 1: PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodelogi penelitian dan sistematika penulisan skripsi.
BAB 2: TINJAUAN PUSTAKA
BAB 3: ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini berisi proses pembuatan algoritma program, flowchart sistem, rancangan aplikasi, dan pembuatan user interface aplikasi.
BAB 4: IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang pengujian program yang telah diimplentasikan dengan menggunakan bahasa pemograman PHP dan MySQL.
BAB 5: KESIMPULAN DAN SARAN
BAB 2
TINJAUAN PUSTAKA
2.1. Konsep Sistem Pendukung Keputusan
Sistem pendukung keputusan merupakan suatu sistem yang berbasis komputer
yang ditujukan untuk mempermudah pengambil keputusan dengan memanfaatkan data
dan model tertentu untuk memecahkan berbagai persoalan yang tidak terstruktur.
Pengambilan keputusan juga merupakan suatu pendekatan sistematis dari suatu
masalah dengan cara mengumpulkan fakta, menentukan alternatif yang akan dihadapi,
dan pengambilan suatu tindakan dimana tindakan tersebut berdasarkan perhitungan
yang tepat.
Dalam mengambil suatu keputusan, kesulitan yang timbul seringkali dari data yang sangat banyak dan bervariasi, maka untuk kepentingan ini, sebagian besar pembuat keputusan diharuskan untuk mengandalkan seperangkat sistem yang dapat memecahkan masalah secara efektif dan efisien [6].
Suatu sistem pendukung keputusan (SPK) memiliki tiga subsistem utama, yaitu: A. Subsistem manajemen basis data yaitu sumber data untuk SPK berasal dari luar
dan dari dalam (basis data). Kemampuan yang dibutuhkan dari manajemen basis data SPK antara lain adalah:
a) Mengkombinasikan berbagai variasi data melalui pengambilan dan ekstraksi data.
b) Menambahkan sumber data secara cepat dan mudah.
c) Menggambarkan struktur data logikal sesuai dengan pengertian pemakai sehingga pemakai mengetahui apa yang tersedia dan dapat menentukan kebutuhan penambahan dan penguruangan.
d) Mengelola berbagai variasi data.
B. Subsistem manajemen basis model yaitu model-model yang banyak digunakan dalam proses pengambilan keputusan yang dibagi dalam dua jenis, yaitu:
a) Model matematika, yang mempresentasikan sistem secara simbolik dengan menggunakan rumus-rumus atau abstrak, selanjutnya akan dijabarkan dalam operasi matriks, algoritma dan model-model keputusan matematika lainnya.
b) Model informasi, yang mempresentasikan sistem dalam format grafik atau tabel. Model informasi akan mendeskripsikan apa dan bagaimana objek secara rinci (bentuk tabel atau daftar), merepresentasikan hubungan antar objek (bentuk grafis), menunjukkan urutan tugas atau proses yang dilakukan objek (peta proses operasi atau diagram alur)
a) Dialog tanya jawab yaitu sistem bertanya pemakai menjawab, seterusnya hingga sistem menghasilkan jawaban yang diperlukan untuk mendukung keputusan.
b) Dialog perintah yaitu adalah perintah untuk menjalankan fungsi-fungsi SPK.
c) Dialog menu yaitu pemakai memilih salah satu dari beberapa menu yang disediakan.
d) Dialog form masukan atau keluaran yaitu sistem menyediakan form input
untuk pemakai memasukkan data atau perintah dan form output sebagai bentuk tanggapan dari sistem.
2.1.1. Tahap - tahap dalam Pengambilan Keputusan
Tahap - tahap dalam pengambilan keputusan antara lain adalah
1. Kegiatan mengamati (intelligence)
2. Kegiatan merancang (design)
3. Kegiatan memilih dan menelaah (choice)
Kegiatan mengamati merupakan kegiatan mengamati lingkungan untuk mengetahui kondisi-kondisi yang perlu diperbaiki. Kegiatan ini merupakan tahapan dalam perkembangan cara berfikir. Untuk melakukan kegiatan intelijen ini diperlukan sebuah sistem informasi, dimana informasi yang diperlukan ini didapatkan dari kondisi internal maupun eksternal sehingga seorang manajer dapat mengambil sebuah keputusan dengan tepat.
Sedangkan kegiatan memilih dan menelaah ini digunakan untuk memilih satu rangkaian tindakan tertentu dari beberapa yang tersedia dan melakukan penilaian terhadap tindakan yang telah dipilih [3].
Gambar 2.1. FaseProses Pengambilan Keputusan [11].
2.1.2. Kerangka Kerja Pengambilan Keputusan
Agar dapat memahami kerangka kerja dan konsep pengambilan keputusan, ada beberapa cara untuk mengklasifikasikan suatu pengambilan keputusan, yaitu:
1. Sistem pengambilan keputusan
Sebuah sistem pengambilan keputusan, yaitu model dari sistem bagaimana keputusan diambil, dapat tertutup atau terbuka.
A. Sistem keputusan tertutup
Sistem iniberanggapan bahwa keputusan harus dipisah dari masukan yang tidak diketahui dari lingkungan. Dalam sistem ini pengambil keputusan dianggap:
a. Mengetahui semua perangkat alternatif dan hasilnya masing masing. Kegiatan mengamati
(intelligence)
Kegiatan merancang (design)
Kegiatan memilih dan menelaah
b. Memiliki metode yang memungkinkan untuk membuat urutan kepentingan semua alternatif.
c. Memilih alternatif untuk memaksimalkan sesuatu, misalnya keuntungan penjualan atau kegunaannya.
B. Sistem keputusan terbuka
Sistem ini memandang suatu keputusan sebagian besar berada dalam suatu keadaan yang tidak diketahui. Keputusan ini sangat dipengaruhi oleh lingkungannya, dan proses pengambilan keputusan tersebut juga mempengaruhi lingkungan.
Dalam sistem ini pengambil keputusan dianggap:
a. Tidak mengetahui semua alternatif dan semua hasil.
b. Melakukan pencarian secara terbatas untuk menemukan beberapa alternatif yang memuaskan [12].
7. Pengetahuan tentang hasil.
Suatu hasil menentukan apa yang akan terjadi bila sebuah keputusan diambil atau arah tindakan yang diambil. Dalam analisis pengambilan keputusan, ada tiga jenis pengetahuan yang berhubungan dengan hasil, yaitu:
a. Kepastian, yaitu pengetahuan yang lengkap dan akurat mengenai hasil tiap pilihan. Hanya ada suatu hasil untuk setiap pilihan.
b. Resiko, yaitu hasil yang mungkin timbul dapat diidentifikasi, dan suatu kemungkinan peristiwa dapat diletakkan pada masing-masing hasil.
c. Ketidakpastian, yaitu beberapa hasil yang mungkin terjadi dan dapat diidentifikasi, tetapi tidak ada ciri-ciri tentang kemungkinan yang dapat dilihat pada masing-masing hasil.
8. Tanggapan keputusan
Keputusan dapat digolongkan sebagai keputusan terprogram atau tidak terprogram berdasarkan kemampuan perusahaan atau individu untuk mengadakan
a. Keputusan terprogram adalah keputusan yang dapat dispesifikasikan sebelumnya sebagai seperangkat aturan atau prosedur keputusan.
b. Keputusan tidak terprogram adalah keputusan yang terjadi hanya satu kali atau berubah setiap saat diperlukan.
9. Model pengambilan keputusan
Sebuah model pengambilan keputusan adalah sebuah model yang memberitahukan pengambil keputusan bagaimana seorang harus mengambil keputusan disebut model normatif atau perspektif. Sebuah model yang menjelaskan bagaimana sesungguhnya pengambil keputusan mengambil keputusan disebut model deskriptif.Model deskriptif berusaha menjelaskan perilaku sebenarnya.
10. Kriteria untuk pengambilan keputusan
Kriteria untuk memilih diantara alternatif-alternatif di dalam model normatif adalah pemaksimalan atau maksimisasi. Tujuannya dinyatakan dalam bentuk kuantitatif, dan digolongkan sebagai fungsi objektif sebuah keputusan. Tujuan umum untuk menetukam kriteria pengambilan keputusan yang memiliki resiko yaitu memaksimalkan nilai yang diharapkan [1].
2.1.3. Karakteristik Sistem Pendukung Keputusan
Dalam mengambil keputusan banyak yang menjadi identitas suatu sistem agar menjadi lebih baik untuk dikemas dalam bentuk sebuah sistem, ada beberapa dukungan-dukungan yang berpengaruh dalam membuat suatu sistem pendukung keputusan. Adapun karakteristik sistem pendukung keputusan tersebut adalah sebagai berikut:
a. Dukungan kepada pengambil keputusan, terutama pada situasi semi terstruktur dan tak terstruktur, dengan menyertakan penilaian manusia dan informasi terkomputerisasi. Masalah-masalah tersebut tidak bisa dipecahkan oleh sistem komputer lain atau oleh metode atau alat kuantitatif.
c. Dukungan untuk semua individu dan kelompok. Masalah yang kurang terstruktur sering memerlukan ketertiban individu dari departemen dan tingkat organisasi yang berbeda atau bahkan dari organisasi lain.
d. Dukungan di semua fase proses pengambilan keputusan: intelegensi, desain, pilihan, dan implementasi.
e. Dukungan di berbagai proses dan gaya pengambilan keputusan.
f. Adaptivitas sepanjang waktu. Pengambil keputusan seharusnya reaktif, bisa menghadapi perubahan kondisi secara cepat, dan mengadaptasi sistem pendukung keputusan untuk memenuhi perubahan tersebut. Sistem pendukung keputusan bersifat fleksibel. Oleh karena itu, pengguna bisa menambahkan, menghapus, menggabungkan, mengubah, atau menyusun kembali elemen-elemen dasar pada sistem.
g. Ramah pengguna, kapabilitas grafis yang sangat kuat, dan antarmuka manusia dan mesin yang interaktif dengan satu bahasa alami bisa sangat meningkatkan efektivitas sistem.
h. Peningkatan efektivitas pengambilan keputusan misalnya seperti akurasi,
timelinnes, kualitas dan efisiensinya (biaya pengambilan keputusan). Ketika Sistem pendukung keputusan disebarkan, pengambilan keputusan sering membutuhkan waktu yang lebih lama, tetapi hasilnya lebih baik.
i. Kontrol penuh oleh pengambil keputusan terhadap semua langkah proses pengambilan keputusan dalam memecahkan suatu masalah. Sistem pendukung keputusan secara khusus menekankan untuk mendukung pengambilan keputusan, bukannya menggantikan.
2.1.4. Sistem Pendukung Keputusan Database
sumber data. Pengguna menggunakan sebuah browser web untuk mengakses
database. Data pada sistem pendukung keputusan diekstrak dari sumber data internal dan eksternal, juga dari data personal milik satu atau lebih pengguna. Hasil ekstraksi ditempatkan pada database khusus atau pada data warehouse perusahaan.
Ada beberapa macam jenis data yang memiliki sumber tersendiri dalam database: a. Data internal
Data yang sumbernya berasal terutama dari sistem pemrosesan transaksi dari dalam organisasi. Contoh umum seperti upah atau gaji bulanan, jadwal pemeliharaan mesin, alokasi anggaran, perkiraan terhadap penjualan yang akan datang, biaya produksi, rencana rekruitmen pegawai baru masa mendatang, dan lain-lain.
b. Data eksternal
Data yang sumbernya dari luar sistem organisasi, seperti data industri, data riset pemasaran, data sensus, data tenaga kerja regional, regulasi pemerintah, jadwal tarif pajak, data ekonomi dalam negeri, dan lain-lain. Data tersebut dapat berasal dari lembaga pemerintah, asosiasi perdagangan, perusahaan riset pasar, dan lain-lain. c. Data privat
Meliputi petunjuk-petunjuk yang digunakan oleh pengambil keputusan khusus dan penilaian terhadap data dan atau situasi spesifik.
d. Data ekstraksi
Data ekstraksi merupakan hasil kombinasi data dari berbagai sumber termasuk sumber internal dan eksternal.
2.2. Konsep Algoritma K - Nearest Neighbor
Algoritma k-nearest neighbor (KNN) merupakan sebuah metode untuk melakukan yang jaraknya paling dekat dengan objek tersebut. KNN termasuk algoritma
k-nearest neighbor menggunakan klasifikasi ketetanggaan (neighbor) sebagai nilai prediksi dari query instance yang baru. Algoritma ini sederhana, bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menentukan ketetanggaannya [9].
Training sample diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi training sample. Sebuah titik pada ruang ini ditandai kelas c, jika kelas c merupakan klasifikasi yang paling banyak ditemui pada k buah tetangga terdekat dari titik tersebut maka dekat atau jauhnya tetangga biasanya dihitung berdasarkan Euclidean Distance. Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise
pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Kasus khusus dimana klasifikasi diprekdisikan berdasarkan training data yang paling dekat dengan kata lain, k=1 disebut algoritma Nearest Neighbor [13].
K- Nearest Neighbor adalah algoritma untuk mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, yaitu berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada. Misalkan diinginkan untuk mencari solusi terhadap pasien baru dengan menggunakan solusi dari data pasien terdahulu. Untuk mencari kasus pasien mana yang akan digunakan maka dihitung kedekatan kasus pasien baru dengan semua kasus pasien lama. Kasus pasien lama dengan kedekatan terbesar yang akan diambil solusinya untuk digunakan pada kasus pasien baru [9].
Seperti tampak pada Gambar 2.1. terdapat dua pasien lama A dan B. Ketika ada pasien baru, maka solusi yang akan diambil adalah solusi dari pasien terdekat dari pasien baru. Seandainya d1 adalah kedekatan antara pasien baru dan pasien A, sedangkan d2 adalah kedekatan antara pasien baru dengan pasien B. Karena d2 lebih dekat dari d1 maka solusi dari pasien B yang akan digunakan untuk memberikan solusi pasien baru.
Algoritma K-Nearest Neighbor bersifat sederhana, bekerja dengan berdasarkan pada jarak terpendek dari sampel uji (testing sample) ke sampel latih (training sample) untuk menentukan K-Nearest Neighbor nya. Setelah mengumpulkan K-Nearest Neighbor, kemudian diambil mayoritas dari K-Nearest Neighbor (KNN) untuk dijadikan prediksi dari sample uji. KNN memiliki beberapa kelebihan yaitu tangguh terhadap training data yang noise dan efektif apabila data latih nya besar. Pada fase
training, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data atau yang klasifikasinya tidak diketahui. Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut..
Ketepatan algoritma K-Nearest Neighbor sangat dipengaruhi oleh ada atau tidaknya fitur-fitur yang tidak relevan atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur agar performa klasifikasi menjadi lebih baik [9].
Langkah-langkah untuk menghitung metode K-Nearest Neighbor antara lain: 1. Tentukan parameter K
2. Hitung jarak antara data yang akan dievaluasi dengan semua pelatihan 3. Urutkan jarak yang terbentuk
4. Tentukan jarak terdekat sampai urutan K
6. Cari jumlah kelas dari tetangga yang terdekat dan tetapkan kelas tersebut sebagai kelas data yang akan dievaluasi
(
)
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k
yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi diprekdisikan berdasarkan training data yang paling dekat (dengan kata lain, k=1) disebut algoritma Nearest Neighbor.
Kelebihan algoritma K-Nearest Neighbor yaitu:
1. Tangguh terhadap training data yang memiliki banyak noise. 2. Efektif apabila training datanya besar.
2.3. Metode TOPSIS
alternatif yang memiliki jarak terpendek dengan solusi ideal positif adalah alternatif yang terbaik. Dengan kata lain, alternatif yang memiliki nilai yang lebih besar itulah yang lebih baik untuk dipilih.
TOPSIS menggunakan prinsip bahwa alternatif yang terpilih harus mempunyai jarak terdekat dari solusi ideal positif dan terjauh dari solusi ideal negatif. Dari sudut pandang geometris dengan menggunakan jarak Euclidean untuk menentukan kedekatan relatif dari suatu alternatif dengan solusi optimal. Solusi ideal positif didefinisikan sebagai jumlah dari seluruh nilai terbaik yang dapat dicapai untuk setiap atribut, sedangkan solusi ideal negatif terdiri dari seluruh nilai terburuk yang dicapai untuk setiap atribut. TOPSIS mempertimbangkan keduanya, jarak terhadap solusi ideal positif dan jarak terhadap solusi ideal negatif dengan mengambil kedekatan relatif terhadap solusi ideal positif. Berdasarkan perbandingan terhadap jarak relatifnya, susunan prioritas alternatif bisa dicapai [4].
2.3.1. Prosedur dan langkah- langkah metode TOPSIS
Metode TOPSIS banyak digunakan untuk menyelesaikan pengambilan keputusan secara praktis. Hal ini disebabkan konsepnya sederhana dan mudah dipahami, komputasinya efisien,dan memiliki kemampuan mengukur kinerja relatif dari alternatif-alternatif keputusan.
Adapun prosedur dari metode TOPSIS yaitu:
1. Menentukan normalisasi matriks keputusan. Nilai ternormalisasi rij
dihitung dengan rumus:
r
ij = ... (2)Keterangan:
Dengan i= 1,2,... m, dan j=1,2,...n. r = matriks ternormalisasi
2. Pembobotan pada matriks yang telah dinormalisasikan. Diberikan bobot W = (w1,w2,…,wn), sehingga weighted normalized matrix V dapat
dihasilkan sebagai berikut:
Y = ………(3)
y
ij= w
jr
ij ... (4)Dimana i= 1,2,...m; sedangkan j= 1,2,...n Keterangan:
yij= matriks normalisasi terbobot [i][j]
wj= vektor bobot [j]
rij = matriks ternormalisasi [i][j]
3. Menentukan solusi ideal positif dan solusi ideal negatif, solusi ideal positif
dinotasikan dengan A+ dan solusi ideal negatif dinotasikan dengan A
-sebagai berikut : Menentukan Solusi Ideal (+) & (-)
A+ = ( )………….…(5)
A- = ( )………….………….……….(6)
4. Menentukan matriks solusi ideal positif dan matriks solusi ideal negatif. S + max dan S – min.
Si+ = 2...(7)
Keterangan:
S = solusi ideal [+] [-]
yij = elemen matriks y baris ke-i dan kolom ke-j
5. Menghitung kedekatan relatif dengan ideal positif dan ideal negatif.
Kedekatan relatif dari alternatif A+ dengan solusi ideal A- direpresentasikan dengan:
Ci+= ………..(6)
Keterangan:
C = kedekatan relatif [+]
S = Solusi ideal [+] [-]
6. Mengurutkan Pilihan yaitu alternatif dapat dirangking berdasarkan urutan Ci, alternatif terbaik adalah salah satu yang berjarak terpendek
terhadap solusi ideal dan berjarak terjauh dengan solusi ideal negatif[7]
2.3.2. Ilustrasi Metode TOPSIS
Dalam melakukan penentuan pencarian solusi terdapat berbagai kriteria yang akan dicari berikut adalah contoh permasalahan yang dapat diisi untuk melakukan pengukuran alternatif.
Suatu perusahaan ingin menentukan mutu beras untuk dibagikan ke masyarakat miskin Ada 3 macam beras yang akan jadi alternatif yaitu:
A1= Beras 1 A2= Beras 2 A3= Beras 3
Ada 4 kriteria yang dijadikan acuan dalam pengambilan keputusan : C1= Bebas hama penyakit
C3= Kadar air (%) C4= Bebas Bahan Kimia
A. Pengurutan kecocokan
Cara mengurutkan kecocokan dapat dibuat berdasarkan kriteria yang ditetapakan, dari 1 sampai 4 yaitu: 4= Sangat Baik, 3= Baik, 2= Cukup, 1= Buruk
Tabel 2.1. Alternatif kecocokan pada setiap kriteria
Alternatif
Kriteria
C1 C2 C3 C4
A1 4 3 2 1
A2 3 2 4 2
A3 3 4 2 2
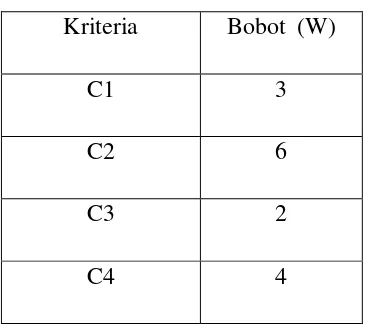
B. Pembobotan kriteria dan matrik Keputusan
Pembobotan untuk setiap kriteria pada beras 1 yaitu C1,C2…C4 = ( 4, 3, 2, 4) Nilai total keseluruhan bobot kepentingan 15.
Matriks keputusan yang dibentuk dapat dilihat dari Tabel 8.2. berikut:
Tabel 2.2. Bobot Kriteria
Kriteria Bobot (W)
C1 3
C2 6
C3 2
Demikian seterusnya sampai didapat matriks keputusan ternormalisasi dan matriks keputusan ternormalisasi terbobot sehingga didapat nilai preferensi tiap alternatif [7].
C. Proses membuat matriks keputusan yang ternormalisasi
Berdasarkan dengan rumus rij = ………(2)
untuk mencari matriks keputusan yang ternormalisasi pada contoh Tabel 8.1 berikut adalah
prosesnya:
|x1| =
|x1| =
= 5.8
r1.1 = = 0,689 r21 = = 0.517 r32 = = 0,517
|x2| =
|x2| =
= 5.38
r12 = = 0,557 r22 = = 0.185 r32 = = 0,743
|x3| =
|x3| =
= 5,6
r13 = = 0,357 r23 = = 0.714 r33 = = 0,357
|x4| =
= 2,8
r14 = = 0,357 r24 = = 0.714 r34 = = 0,714
dari hasil persamaan di atas mata diperoleh matriks ternormalisasi R sebagai berikut:
R=
Kemudian matriks Y dihitung dengan persamaan 3:
y
ij= w
ijr
ij ………(3)y11 = w1 r11 y21 = w1 r21
y11 = 6 x 0,689 = 4,134 y21 = 6 x 0,517 = 3,102
y12 = w2 r12 y22 = w2 r22
y12 = 4 x 0,557 = 2,228 y22 = 4 x 0,185 = 0,74
y13 = w3 r13 y23 = w3 r23
y13 = 3 x 0,357 = 1,071 y23 = 3 x 0,714 = 2,142
y14 = w4 r14 y24 = w4 r24
y14 = 2 x 0,357 = 0,714 y24 = 2 x 0,714 = 1,428
y31 = w1 r31
y31 = 6 x 0,517= 3,102
y32 = w2 r32
y32 = 4 x 0,743 = 2,927
y33 = w3 r33
y33 = 3 x 0,357 = 1,071
y44 = w4 r44
matriks Y=
Kemudian solusi ideal positif A+dihitung berdasarkan persamaan 4
A+ = ( )…………(4)
y+1 = max {4,134, 3,102, 3,102} = 4,134
y+2 = min {2,228, 1,071, 0,714} = 2,228
y+3 = max {1,071, 2,142, 1,071} = 2,142
y+4 = min {0,714, 1,428, 1,428} = 1,428
A+ = {4,134, 2,228, 2,142, 1,428}
Kemudian solusi ideal negatif A- dihitung berdasarkan persamaan 5:
A- = ( )…………(5)
y-1 = max {4,134, 3,102, 3,102} = 3,102
y-2 = min {2,228, 1,071, 0,714} = 0,714
y-3 = max {1,071, 2,142, 1,071} = 1,071
y-4 = min {0,714, 1,428, 1,428} = 0,714
A- = {3,102, 0,714, 1,071, 0,714}..
Jarak alternatif Ai dengan solusi ideal positif dirumuskan dengan persamaan 6 dan 7:
S+i = 2………..(6)
S-i = 2………..(7)
2.4. Penelitian Terdahulu
tinjauan pustaka dari sumber yang terpercaya. Berikut ini adalah beberapa penelitian terdahulu:
1. Penelitian oleh Arief Jananto dengan judul Perbandingan Performansi Algoritma
K- Nearest Neighbor dan SLIQ untuk Prediksi Kinerja Akademik Mahasiswa Baru. Dalam Penelitian ini peneliti membangun aplikasi dengan menerapkan metode k- nearest neighbour dan SLIQ untuk memprediksi kinerja akademik dari mahasiwa baru berdasarkan training mahasiswa lama. Variabel yang digunakan yaitu usia dan asal SMA. Data akademik yang digunakan didapat dari setiap angkatan, setiap angkatan mempunyai pola yang berbeda-beda yang ditunjukkan oleh tingkat akurasi yang berbeda untuk penentuan dari prediksi kinerja akademik dari setiap data testing yang digunakan. Hasil pengujian tingkat akurasi model tiap data tahun angkatan ternyata mempunyai nilai akurasi yang berbeda, dan hal ini dapat disebabkan karena sebaran nilai data yang berbeda-beda. Dari sisi waktu yang dibutuhkan untuk proses mining, maka pada algoritma k-Nearest Neighbor
lebih sederhana dibandingkan SLIQ namun membutuhkan waktu yang lebih lama karena harus dilakukan proses training secara berulang untuk setiap data yang akan diprediksi [2].
2. Penelitian oleh Yeni Kustiyahningsih dengan Sistem Pendukung Keputusan untuk Menentukan Jurusan pada Siswa SMA Menggunakan Metode KNN dan SMART
(Simple Multi Attribute Rating Technique). Penelitian ini bertujuan untuk membantu Guru maupun Siswa SMA dalam menentukan jurusan.Pada penelitian ini bobot dan kriteria rata-rata nilai raport dan hasil tes psikologis adalah 2 acuan untuk menentukan jurusan apa yang cocok bagi siswa tersebut. Dalam menentukan jurusan dilakukan uji coba sebanyak 3 kali, kemudian diperoleh hasil penjurusan yang paling banyak kesamaanya dengan data yang asli (hasil dari penjurusan yang dilakukan oleh guru BP secara manual). Hasil yang didapat bahwa dengan menggunakan metode KNN dan SMART dapat diperoleh hasil yang cukup mendekati keakuratan dari data manual [5].
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis
Menganalisis suatu aplikasi merupakan proses dimana suatu aplikasi yang utuh diuraikan ke dalam komponennya dengan tujuan untuk mengevaluasi kebutuhan-kebutuhan dan permasalahan yang timbul sehingga dapat memudahkan dilakukannya perbaikan-perbaikan terhadap aplikasi. Dalam melakukan implementasi algoritma K-Nearest Neighbor dengan metode TOPSIS pada penentuan mutu beras terlebih dahulu dilakukan analisis masalah terhadap masing-masing metode ini.
3.1.1. Analisis Masalah
adalah alternatif yang terbaik. Dengan kata lain, alternatif yang memiliki nilai yang lebih besar itulah yang lebih baik untuk dipilih.
Analisis masalah pada sistem yang dirancang dapat digambarkan dalam diagram Ishikawa seperti pada Gambar 3.1.
Gambar 3.1. Diagram Ishikawa
3.2. Analisis Kebutuhan Sistem
Dalam membangun sebuah sistem, tahap analisis kebutuhan sistem perlu dilakukan dengan tujuan untuk mempermudah analisis sistem dalam menentukan keseluruhan kebutuhan secara lengkap. Analisis kebutuhan sistem dapat dikelompokkan menjadi 2 bagian yaitu: kebutuhan fungsional dan kebutuhan non-fungsional.
-Beras terlalu banyak -Kualitas tidak bagus -Masalah penanganan
mutu
- Pengawasan tidak bagus
- Kurang konsentrasi - Pelatihan tidak cukup - Salah perhitungan
3.2.1 Analisis Fungsional Sistem
Kebutuhan fungsional adalah kebutuhan yang berisi proses-proses apa saja yang nantinya dilakukan oleh sistem. Adapun kebutuhan fungsional yang harus dipenuhi aplikasi yang dirancang adalah sebagai berikut:
a. Sistem dapat menampilkan fitur sesuai dengan hak akses.
b. Sistem dapat melakukan entri data yang berhubungan dengan pendataan beras. c. Sistem harus dapat menginputkan data beras berupa nama mitra kilang padi,
dan kriteria-kriteria. Sistem dapat menampilkan dan melakukan pencatatan laporan data siswa baru.
d. Sistem dapat melakukan klasifikasi data berdasarkan algortima K-Nearest Neighbor. Pada proses pengklasifikasian sistem harus dapat menentukan kelas-kelas untuk data beras dari hasil penentuan kriteria, serta sistem harus mampu mencari jarak Euclidean Distance terdekat untuk penentuan nilai jarak pada pengujian data testing dan data training.
e. Sistem harus mampu mencari matriks keputusan ternormalisasi dari data beras yang ada menggunakan algoritma Topsis, sistem juga dapat membuat matriks keputusan yang ternormalisasi berdasarkan bobot-bobot kriteria yang ada. Hasil pembobotan yang telah ditentukan harus dapat dilakukan penentuan solusi ideal positif dan solusi ideal negatif oleh sistem serta harus mampu menentukan jarak antara nilai setiap alternatif dengan matriks solusi ideal positif dan solusi ideal negatif dan sistem harus mampu menentukan nilai hasil beras yang terbaik dari algoritma Topsis tersebut.
3.2.2. Analisis Non- Fungsional Sistem
Kebutuhan non-fungsional adalah kebutuhan yang memnfokuskan pada properti perilaku yang dimiliki oleh sistem. Adapun kebutuhan non- fungsional sistem tersebut antara lain:
Sistem harus mampu melukan setiap perintah secara utuh dalam selang waktu yang tidak terlalu lama sesuai dengan ukuran data input yang diberikan.
b. Informasi
Sistem harus mampu menyediakan informasi tentang data-data yang akan digunakan pada sistem.
c. Ekonomi
Sistem harus dapat bekerja dengan baik tanpa harus mengeluarkan biaya tambahan yang tinggi.
d. Kontrol
Sistem yang telah dibangun harus tetap dikontrol setelah selesai dirancang agar fungsi dan kinerja sistem tetap terjaga dan dapat memberikan hasil yang sesuai dengan keinginan pengguna.
e. Efisiensi
Sistem harus dirancang sebaik mungkin agar memudahkan pengguna dalam menggunakan atau menjalankan aplikasi tersebut.
f. Pelayanan
Sistem yang telah dirancang bisa dikembangkan ke tingkat yang lebih kompleks lagi bagi pihak-pihak yang ingin mengembangkan sistem tersebut.
3.3. Perancangan Sistem
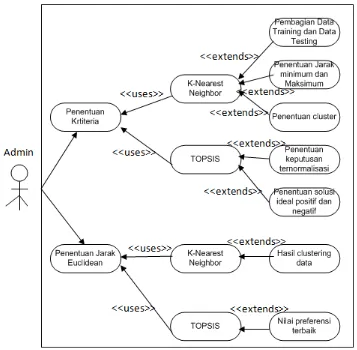
digunakan empat diagram untuk memodelkan sistem, yaitu use case diagram, activity diagram, dan Class Diagram.
3.3.1. Use case diagram
Use-Case diagram pada pemodelan aplikasi seperti yang ditunjukkan pada Gambar 3.2.
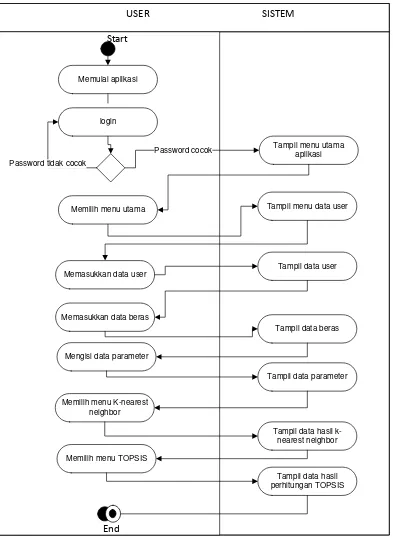
3.3.2. Diagram Activity
Diagram Activity merupakan suatu alir yang menggambarkan berbagai alir aktivitas dalam sistem yang sedang dirancang, tujuannya adalah untuk mengetahui bagaimana
Memulai aplikasi
Memilih menu utama login
Password tidak cocok
Tampil menu utama aplikasi Password cocok
Memasukkan data user
Tampil menu data user
Memasukkan data beras
Tampil data user
Tampil data beras
Mengisi data parameter
Tampil data parameter
Memilih menu K-nearest neighbor
Tampil data hasil k-nearest neighbor Memilih menu TOPSIS
Tampil data hasil perhitungan TOPSIS
Gambar 3.3. Diagram Activity Sistem
Diagram activity untuk Proses Pencarian data beras menggunakan Algoritma K-Nearest Neighbor dapat dilihat pada Gambar 3.4.
USER SISTEM
Start
Memilih menu K-nearest
neighbor Tampilan Data Beras
Memilih menu nilai kelas Tampilan nilai kelas
Memilih hasil pengelompokan beras terbaik
Tampilan hasil pengelompokan beras terbaik
Gambar 3.4. Diagram Activity Algoritma K-Nearest Neighbor
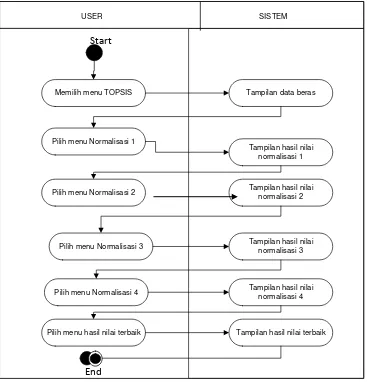
Diagramactivity untuk proses pencarian data beras metode TOPSIS dapat dilihat pada Gambar 3.5.
USER SISTEM
Start
Memilih menu TOPSIS Tampilan data beras
Pilih menu Normalisasi 1
Tampilan hasil nilai normalisasi 1
Pilih menu Normalisasi 2 Tampilan hasil nilai normalisasi 2
Pilih menu Normalisasi 3 Tampilan hasil nilai normalisasi 3
Tampilan hasil nilai normalisasi 4 Pilih menu Normalisasi 4
Pilih menu hasil nilai terbaik Tampilan hasil nilai terbaik
USER SISTEM
Gambar 3.5. Diagram Activity Metode TOPSIS
3.3.3. Flowchart K-nearest Neighbor
Proses perhitungan data beras menggunakan algoritma K-Nearest neighbor agar mendapatakan hasil pengelompokan yang terbaik yaitu dapat dilihat pada alur proses Gambar 3.6.
Start
Gambar 3.6. Flowchart Perhitungan K-Nearest Neighbor
Pada Gambar 3.6. Flowchart K-Nearest Neighbor, data awal berupa data beras di input masuk pada sistem dan selanjutnya di bagi menjadi 2 data training dan data testing dengan persentase 70% dan 30%, hingga akhir dari flowchart berupa tampilan hasil klasifikasi data yang telah diproses.
3.3.4. Flowchart metode TOPSIS
Proses menentukan beras dengan menggunakan metode topsis dapat dilihat pada
3.4. Rancangan Database
Aplikasi database yang digunakan pada penelitian ini adalah menggunakan MySQL. File database yang digunakan yaitu db_sisca. Dalam sistem database yang ada terdapat beberapa tabel-tabel yang digunakan beserta field-field yang ada dalam tabel tersebut. Ada 3 tabel yang dirancang dalam sistem database, yaitu tabel mitra berisi data-data beras yang dimasukkan ke dalam sistem, tabel parameter yaitu tabel yang berisi kriteria-kriteria beras dan tabel user berisi data user yang akan menggunakan aplikasi tersebut. Tabel-tabel yang dirancang dalam sistem database beserta field-field nya terdapat pada Tabel 3.1
Tabel mitra merupakan tabel yang berisi data-data beras yang dimasukkan ke dalam sistem, pada tabel ini terdapat 4 jenis kriteria beras sesuai data yang telah dimasukkan. Pada field id_mitra Rancangan tabel mitra terdapat pada Tabel 3.1.
Tabel 3.1. Tabel Mitra
Field Type
id_mitra Int(4) Primary key nama_mitra Varchar(50)
c1 Varchar(11)
c2 Varchar(11)
c3 Varchar(11)
c4 Varchar(11)
Tabel 3.2. Tabel Parameter
Field Type
id_param Int (4) primary key nama_param Varchar(30) Value Varchar(30)
Tabel user berisi data user yang akan menggunakan aplikasi. Tabel ini berisi
username untuk user mendaftar nama, password untuk keamanan penggunaan sistem oleh user, nama lengkap dan level yaitu pilihan untuk memilih apakah user sebagai admin atau hanya pengguna biasa. Tabel user terdapat pada Tabel 3.3.
Tabel 3.3. Tabel User
Field Type
username Varchar(50) Primary Key password Varchar(50)
nama_lengkap Varchar(100)
level Varchar(20)
3.5. Pembuatan Rancangan Tampilan Aplikasi 3.5.1. Rancangan Jendela Utama
Gambar 3.8. Rancangan Jendela Utama
Keterangan:
1. Menu nomor 1 merupakan menu Home yang berisi utama untuk menampilkan menu-menu yang akan dipilih.
2. Menu nomor 2 merupakan menu Program data user untuk menginput nama user dan password baru, mengubah serta menghapus nama dan password user. 3. Menu nomor 3 merupakan menu Data Mitra, menu untuk menginput,
menampilkan data beras, mengubah dan menghapus data beras.
4. Menu nomor 4 merupakan menu Parameter yang berisi input parameter atau karakteristik pada pendataan beras baru.
5. Menu nomor 5 merupakan menu K-Nearest Neighbor, yaitu menu perhitungan dan hasil pengklasifikasian data beras.
6. Menu nomor 6 merupakan menu TOPSIS, yaitu menu perhitungan data dan hasil penentuan data beras.
7. Menu nomor 7 merupakan menu logout untuk keluar dari menu utama.
8. Kotak nomor 4 merupakan Label, yang berfungsi sebagai tempat menampilkan judul skripsi.
3.5.2. Rancangan Form Data User
Rancangan form data user berfungsi untuk menginput nama user yang baru, pada
menu ini juga dapat menyimpan dan membatalkan pendataan user baru tertera pada
Gambar 3.9.
Gambar 3.9. Rancangan Form Data User
Keterangan :
1. Kotak nomor 1 merupakan label untuk mengisi username 2. Kotak nomor 2 merupakan label untuk mengisi password baru. 3. Kotak nomor 3 merupakan label pengisian nama baru.
4. Kotak nomor 4 merupakan ComboBox dalam memilih level sebagai pengguna atau admin.
5. Kotak nomor 5 merupakan Submit Buttonvalue yang berfungsi untuk menyimpan dan membatalkan pengisian username dan password baru.
Username
Password
Nama
(1)
(2)
(3)
(4)
Level admin user
3.5.3. Rancangan Form Data Mitra Beras
Rancangan form data mitra beras berfungsi untuk menginput beras terdapat pada
Gambar 3.10.
Gambar 3.10. Rancangan Form Data Mitra Beras
Keterangan :
1. Kotak nomor 1 merupakan Label mengisi nama mitra yang menghasilkan beras yang terpilih.
2. Kotak nomor 2 merupakan Label mengisi criteria beras pertama. 3. Kotak nomor 3 merupakan Label mengisi criteria beras pertama. 4. Kotak nomor 4 merupakan Label mengisi criteria beras pertama. 5. Kotak nomor 5 merupakan Label mengisi criteria beras pertama. 6. Kotak nomor 6 merupakan Submit Button Value yang berfungsi untuk
menyimpan dan membatalkan pengisian data beras. Nama Mitra beras
Parameter 1
Parameter 2
Parameter 3
Parameter 4
simpan Batal
(1)
(2)
(3)
(4)
(5)
3.5.4. Rancangan Form Parameter
Rancangan form data parameter berfungsi untuk menginput parameter terdapat pada
Gambar 3.11.
Gambar 3.11. Rancangan Form Parameter Keterangan :
1. Kotak nomor 1 merupakan label untuk mengisi nilai bobot pada kriteria C1. 2. Kotak nomor 2 merupakan label untuk mengisi nilai bobot pada kriteria C2. 3. Kotak nomor 3 merupakan label untuk mengisi nilai bobot pada kriteria C3. 4. Kotak nomor 4 merupakan label untuk mengisi nilai bobot pada kriteria C4. 5. Kotak nomor 5 merupakan label untuk mengisi nama kriteria pertama. 6. Kotak nomor 6 merupakan label untuk mengisi nama kriteria kedua. 7. Kotak nomor 7 merupakan label untuk mengisi nama kriteria ketiga.
8. Kotak nomor 8 merupakan label untuk mengisi nama kriteria keempat. 9. Kotak nomor 9 merupakan label untuk mengisi nilai K ketetanggan. 7. Kotak nomor 10 merupakan CommandButton yang berfungsi untuk menyimpan dan membatalkan pengisian parameter yang akan diisi.
3.5.5. Rancangan Form K-Nearest Neighbor
Rancangan form Form K-Nearest Neighbor tertera pada Gambar 3.12.
Gambar 3.12. Rancangan Form Klasifikasi Data K-Nearest Neighbor Keterangan:
1. Kotak nomor 1 Command Button untuk menampilkan hasil nilai kelas yang sudah didapat dari proses klasifikasi.
2. Kotak nomor 2 adalah tabel yang berfungsi untuk menampilkan hasil nilai kelas-kelas yang telah dibagi.
3. Kotak nomor 3 Command Button untuk menampilkan data beras. 4. Kotak nomor 4 Command Button untuk pengujian nilai K.
3.5.6. Rancangan Form Proses Metode TOPSIS
Rancangan Form metode TOPSIS tertera pada Gambar 3.13.
Gambar 3.13. Rancangan Form Metode Topsis
Keterangan:
1. Kotak nomor 1 command button berfungsi untuk menampilkan data beras. 2. Kotak nomor 2 command button berfungsi untuk menampilkan hasil
normalisasi pertama.
3. Kotak nomor 3 command button berfungsi untuk menampilkan hasil normalisasi kedua.
4. Kotak nomor 3 command button berfungsi untuk menampilkan hasil normalisasi ketiga.
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1Implementasi
Setelah dilakukan perancangan dan analisis terhadap sistem maka tahap selanjutnya adalah mengimplementasikannya ke dalam bentuk program komputer. Implementasi perangkat lunak dilakukan dengan menggunakan bahasa pemrograman terstruktur, yaitu menggunakan bahasa pemrograman PHP dan mengintegrasikannya ke database MySQL dan aplikasi ini berjalan di komputer dengan sistem operasi Windows 7. Implementasi dilakukan bertujuan untuk memudahkan pengambil keputusan dalam menentukan mutu beras. Pada implementasi ini, terdapat 2 implementasi algoritma yang dilakukan, pertama menggunakan algortima K-Nearest Neighbor dan implementasi kedua menggunakan metode TOPSIS.
Proses yang dilakukan pertama kali pada aplikasi adalah menginput data beras yang menjadi data utama dari pengujian menggunakan kedua algoritma, baik itu k-nearest neighbor maupun TOPSIS. Data beras yang didapat berasal dari pihak perusahaan Bulog.
4.1.1. Implementasi Algoritma K-Nearest Neighbor
nilai r1, r2, r3,..., r18 terletak pada data training dan r19, r20,..., r25 terletak pada data
testing.
Pembagian nilai dari semua data beras yang ada dibagi ke daalam 2 kelompok data yaitu data 70% training dan 30% data testing, kode untuk pembentukan nilai pembagian tersebut terlihat pada Tabel 4.1.
Tabel 4.1. Psudocode K-Nearest Neighbor Baris pseducode
Masuk <- untuk membaca kriteria dari file input File_input <- nama file input
File_output <- nama file output C <- nilai kriteria
Count <- jumlah kriteria yang dihitung Last <- kriteria terakhir yang dibaca
C <- masuk.read(); While Not EOF do Write c;
Last := c;
Tabel 4.2. Data Testing dan Data Training
Setelah melakukan pembagian data maka selanjutnya pengujian terhadap data-data yang ada untuk mendapatkan cluster-cluster. Contoh pada data untuk data R1
R1, R2 =
= 30.669365823245
R3, R4 =
= 16.70808188
Seterusnya pencarian nilai dengan data training R3R4,….. R17R18. Hasil pengujian data
beras dapat dilihat pada Tabel 4.3.
Tabel 4.3. Nilai Hasil Pengujian Data Beras
R
kedekatannya dengan mencari nilai dari jarak terkecil dan terbesar. Penentuan cluster-cluster ini menggunakan range dari jarak yang telah dihasilkan yaitu:
Range = ……….(8)
= 9.0438801793863
Dengan menggunakan range tersebut maka terbentuklah 3 cluster yang akan menjadi penentuan nilai status beras yang dicari, 3 cluster tersebut seperti yang tertera berikut ini:
1. Class 1 (C1) buruk: 6.2449979983984 s/d 15.288878177785
2. Class 2 (C2) sedang: 15.288878177785 s/d 24.332758357171
3. Class 3 (C3) baik: 24.332758357171 s/d 33.376638536557
Dasar anggota cluster yang telah didapatkan mengacu dari rentang nilai C1,C2 dan C3
Tabel 4.4. Cluster Data Training
Setelah penempatan cluster-cluster pada data training selesai, selanjutnya dilakukan pengujian data dengan menggunakan data testing. Nilai k yang digunakan adalah k=5. Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k
yang tinggi akan mengurangi efek noise pada klasifikasi, Kemudian dihitung jarak
data testing yang terdekat dengan data training dengan menggunakan rumus
Euclidean distance. Untuk proses penentuan letak cluster dari data testing tersebut,
ditentukan menurut kedekatan nilai jarak euclideannya.
Tabel 4.5. Perthitungan data training dan data testing
Dari gambaran Tabel 4.5. dapat dilakukan pengujian data untuk mendapatkan class-class pada data testing.
Untuk data testing R19 terhadap data training R14,15,16,17,18
R14,19 =
Tabel 4.6. Hasil perhitungan
R Nilai Class
19 6 -
20 12.5299641 C1 21 3.74165739 -
22 6.244998 C1
23 7.14142843 C1 24 5.56776436 - 25 6.8556546 C1
Berdasarkan perhitungan yang telah dilakukan, nilai terkecil adalah 6. Jadi nilai dari R19 adalah 6 dan tidak memiliki nilai terdekat dengan apapun jadi tidak termasuk ke
dalam class manapun. Artinya beras tersebut termasuk tidak layak disalurkan, sebaliknya pengelompokan pada C1 termasuk ke dalam beras mutu baik, maka beras tersebut dapat disalurkan ke masyarakat miskin.
4.1.2. Implementasi Metode TOPSIS
Pada pengujian menggunakan metode TOPSIS, data beras juga berasal dari mitra kerja Bulog yang berasal dari kilang padi mitra kerja. Data yang akan diolah juga harus memiliki nilai-nilai kriteria sebagai penentu suatu nilai yang akan dicari. Sama halnya seperti pengujian dengan algortima K-Nearest Neighbor, data awal berupa data beras yang sudah diisi dengan kriteria-kriteria yang sudah ditetapkan.
Untuk menentukan nilai mutu beras maka parameter-parameter yang digunakan adalah:
1. Bebas Hama Penyakit 2. Butir Patah
3. Kadar Air
Untuk mengubah dan memasukkan parameter atau kriteria yang ada dari data yang lain, maka pada sistem dibuat sebuah form untuk mengubah nama parameter yang akan di masukkan ke dalam sistem, form parameter merupakan form yang berfungsi untuk menambah bobot-bobot kriteria dari beras yang akan dimasukkan ke data mitra beras. Nilai bobot tingkat kepentingan untuk kriteria di atas berdasarkan wawancara dengan pihak terkait adalah: 0.55 untuk nilai bobot bebas hama penyakit , 0.1 untuk nilai bobot butir patah, 0.05 untuk nilai bobot kadar air, dan 0.30 untuk nilai bobot bebas bahan kimia.
Proses selanjutnya menentukan mutu beras terbaik, TOPSIS membutuhkan rating kinerja setiap alternatif pada setiap kriteria yang ternormalisasi yaitu berdasarkan persamaan (2). Berdasarkan data yang ada maka dilakukan perhitungan dengan menggunakan persamaan (2) sehingga didapatkan nilai normalisasi untuk x1. Tabel
data beras dan kriteria dapat dilihat pada Tabel 4.7 dan tabel hasil normalisasi untuk setiap kriteria dapat dilihat pada Tabel 4.8.
Tabel 4.7. Data Beras dan Kriteria
Tabel 4.7. Data Beras dan Kriteria (lanjutan)
Untuk menampilkan tabel normalisasi 1 yaitu kuadrat dari kriteria, jumlah kuadrat seluruh data, akar dari jumlah kuadrat menggunakan persamaan (2)
rij = ……..……….…(2)
|x| =
Untuk memudahkan menerjemahkan kode pada pembentukan program untuk menampilkan halaman tabel, pada Tabel 4.8. tertera kode beserta keterangan pengertian dari kode program tersebut.
Tabel 4.8. Kode Program Untuk Menampilkan Halaman Tabel Baris Kode kode
1 $tampil=mysql_query("SELECT * FROM tb_param WHERE nama_param like 'c%'");
2 $no=1;
3 $bobot = array();
4 while ($r=mysql_fetch_array($tampil)){ 5 echo "<td>$r[value]</td>";
6 $bobot[$no-1]=$r[value];
7 $no++;
8
}
echo " </tr>";
9 $tampil=mysql_query("SELECT * FROM tb_mitra ORDER BY id_mitra");
10 $no=1;
11 while ($r=mysql_fetch_array($tampil)){
Keterangan:
1. Mengambil nilai bobot dari tb_param dalam database
2. Inisialisasi nilai awal untuk perulangan
3. Inisialisasi variabel bobot sebagai array
4. Melakukan perulngan hingga baris terakhir
5. Menampilkan nilai dari r[value]
6. Mengisi nilai bobot ke-(no-1) = r[value]
7. Menambhakan nilai no+1
8. Mengambil data beras dari tb_mitra dalam database
10. Inisialisasi nilai awal untuk perulangan
11. Perulangan hingga baris terakhir
Setelah dilakukan perhitungan, maka hasil nilai normalisasi |x| dapat dilihat pada Tabel 4.9.
Tabel 4.9. Nilai Normalisasi 1
no Nama Mitra Kriteria
Tabel 4.9. Nilai Normalisasi 1 (Lanjutan)
22 KP. ANTARA 6400 121 49 4489
23 KP. LIMA SAUDARA 7225 225 64 4900
24 KP. ANTARA 5929 225 49 4900
25 KP. CiTRA UTAMA 6400 196 64 5776
Jumlah |x| 135844 2804 2877.37 125368
x 368.5702 52.95281 53.64112 354.0734
Setelah mendapatkan nilai x maka selanjutnya membandingkan nilai tersebut dengan x2ij sesuai dengan persamaan 2:
r1.1 = r2.1 =
= 0.20348904464370832 = 0.2832710904751867
r3.1 = r4.1 =
= 0.2442156211867758 = 0.22594182803274018
Perhitungan terus dilakukan hingga nilai r2.1..r.25.1 didapatkan hasilnya. Nilai hasil
bobot yang ternormalisasi dari dapat dilihat pada Tabel 4.10.
Tabel 4.10. Nilai Ternormalisasi Terbobot
no Nama Mitra
Kriteria Bebas Hama
Penyakit Butir Patah Kadar Air
5 KP. LIMA SAUDARA 0.203489 0.169963 0.242351 0.169456
Tabel 4.10. Nilai Ternormalisasi Terbobot (Lanjutan)
no Nama Mitra
W1= 0.55, W2= 0.1, W3= 0.05, dan W4= 0.30
y
ij= w
ijr
ij ………..………(4)maka persamaan (3) dapat dijabarkan ke dalam perhitungan berikut:
y11 = W1 x r11 y12 = W2 x r12
= 0.55 x 0.20348904464370832 = 0.1 x 0.2832710904751867
= 0.11191897455403958 = 0.028327109047518673
y13 = W3 x r13 y14 = W4 x r14
= 0.05 x 0.2442156211867758 = 0.30 x 0.22594182803274018
= 0.012210781059338791 = 0.06778254840982205
Kemudian solusi ideal positif A+ dan solusi ideal negatif A- dihitung berdasarkan persamaan 5 dan 6 :
A+ = ( )…………(5)
A- = ( )………….(6)
Tabel 4.11. Solusi Ideal Positif dan Negatif
Tabel 4.11. Solusi Ideal Positif dan Negatif (Lanjutan)
Jarak alternatif Ai dengan solusi ideal positif dirumuskan dengan persamaan berikut:
S+i = 2………..(6)
S-i = 2………..(7)
Perhitungan jarak alternatif dengan solusi ideal positif
S+1c1 =
= (-0.02089154191675406)2
= 0.00043645652365949196
S+1 c 2 =
= 02
= 0
S+1 c 3 =
= (-0.0017710293139499012)2 = 0.0000031365448308698577
S+1 c 4 =
= 02
= 0
![Gambar 2.1. Fase Proses Pengambilan Keputusan [11].](https://thumb-ap.123doks.com/thumbv2/123dok/89648.7916/23.595.253.375.241.455/gambar-fase-proses-pengambilan-keputusan.webp)
![Gambar 2.2 Ilustrasi Solusi pada KNN [9]](https://thumb-ap.123doks.com/thumbv2/123dok/89648.7916/28.595.255.441.621.739/gambar-ilustrasi-solusi-pada-knn.webp)