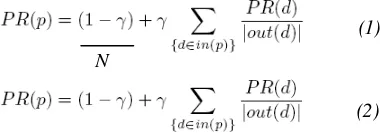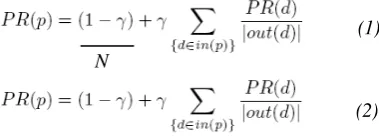EVALUASI ALGORITME
BREADTH FIRST
,
BEST FIRST
,
DAN
PAGE RANK
PADA
WEB CRAWLER
ADE OFIK HIDAYAT
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
1
ABSTRACT
ADE OFIK HIDAYAT. The evaluation of Breadth First, Best First, and Page Rank algorithms on
Web Crawler. Under the guidance of SONY HARTONO WIJAYA, M.Kom.
Web crawling is a process by which we gather pages from the web, in order to index them and
support a search engine. The objective of crawling is to quickly and efficiently gather as many useful
web pages as possible, together with the link structure that interconnects them.
The objective of this research is to evaluate Breadth First, Breadth First with Time Constraint,
Best First and Page Rank algorithms. The process of collecting web pages consists of the initialization
process (keywords and starting URL), inserting a link to the frontier, stoping crawling, take\ing the
link from frontier, fetch, parsing and indexing. The focus of web crawler algorithm is determines the
next link that will be visited.
Based on the precision and opportunity of keywords per algorithm, the result of the evaluation
indicates that the page rank algorithm is better than three other algorithms. While based on the
complexity of algorithm, the result of the evaluation indicates that the page rank algorithm has higher
complexity as compared to three other algorithms. In addition, based on the average fetch time, the
result of the evaluation indicates that the best first algorithm is more stable than three other
algorithms.
1
EVALUASI ALGORITME
BREADTH FIRST
,
BEST FIRST
,
DAN
PAGE RANK
PADA
WEB CRAWLER
ADE OFIK HIDAYAT
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
i
Judul :
Evaluasi
Algoritme
Breadth First
,
Best First
, dan
Page Rank
pada
Web Crawler
Nama : Ade Ofik Hidayat
NRP : G64086014
Menyetujui :
Pembimbing
Sony Hartono Wijaya, M.Kom
NIP 19810809 200812 1 002
Mengetahui :
Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc
NIP
19601126 198601 2 001
ii
PRAKATA
Alhamdulilahirobbil’alamin,
segala puji syukur penulis panjatkan kehadirat Allah SWT atas
segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Topik tugas akhir yang dipilih
dalam penelitian adalah Evaluasi Algoritme
Breadth First
,
Best First
, dan
Page Rank
pada
Web
Crawler
.
Penulis sadar bahwa tugas akhir ini tidak akan terwujud tanpa bantuan dari berbagai pihak. Pada
kesempatan ini penulis ingin mengucapkan terima kasih kepada :
1.
Ibunda tercinta, serta segenap keluarga besar, terima kasih atas doa dan dukungan yang tiada
henti.
2.
Bapak Sony Hartono Wijaya, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih
atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3.
Bapak Firman Ardiansyah, S. Kom, M.Si., dan Bapak Ahmad Ridha, S. Kom, MS., selaku
dosen penguji.
4.
Teman-teman HIMAXILKOM angkatan 3. Terima kasih atas semangat dan kebersamaannya
selama penyelesaian tugas akhir ini.
5.
Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam
pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan
kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya
masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas
akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Juli 2011
iii
RIWAYAT HIDUP
Penulis dilahirkan di Kuningan Jawa Barat pada tanggal 18 Desember 1984 dari ayah (Alm) Edi
Heryadi dan ibu Usih. Penulis merupakan putra ketiga dari empat bersaudara.
Riwayat pendidikan :
2000 – 2003
SMU Negeri 3 Kuningan
2004 – 2006
D3 Program Studi Informatika Sub Program Teknik Informatika,
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian
Bogor.
2008 – 2011
S1 Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor.
Pengalaman Organisasi :
2002 – 2003
Ketua Umum OSIS SMU Negeri 3 Kuningan
2004 – 2005
Anggota Departemen Kewirausahaan BEM FMIPA IPB
iv
DAFTAR ISI
Halaman
DAFTAR ISI ... iv
DAFTAR GAMBAR ... v
DAFTAR TABEL ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN ... 1
Latar Belakang... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat ... 1
TINJAUAN PUSTAKA ... 2
Temu Kembali Informasi ... 2
Web Crawling
... 2
Algoritme
Web Crawler
... 2
Analisis Algoritme ... 4
Cosine Similarity
... 5
Stop Words
... 5
Pembobotan
Term Frequency
(TF) ... 5
Evaluasi Algoritme ... 5
METODE PENELITIAN ... 5
Kajian Literatur ... 5
Analisis dan Implementasi
Crawling
... 5
Evaluasi Algoritme ... 6
HASIL DAN PEMBAHASAN... 6
Penggunaan
Cronjob
... 6
Memasukkan
Link
ke
Frontier
... 6
Pemberhentian
Crawling
... 6
Mengambil
Link
dari
Frontier
Berdasarkan Algoritme
Crawler
... 7
Fetch
... 7
Parsing
... 7
Pengideksan ... 8
Evaluasi Algoritme ... 9
KESIMPULAN DAN SARAN ... 12
Kesimpulan ... 12
Saran ... 12
DAFTAR PUSTAKA ... 12
v
DAFTAR GAMBAR
Halaman
1 Komponen mesin pencari. ... 2
2
Breadth First Crawler
. ... 2
3 Algoritme
Breadth First
. ... 2
4 Algoritme
Breadth First
with Time Constraint
... 2
5
Best First Crawler
. ... 3
6 Algoritme
Best First
. ... 3
7 Ilustrasi
link
. ... 4
8 Algoritme
Page Rank
. ... 4
9 Tahapan implementasi. ... 5
10 Grafik nilai
cosine similarity
algoritme
breadth first
... 9
11 Grafik nilai
cosine similarity
algoritme
breadth first with time constraint
... 9
12 Grafik nilai
cosine similarity
algoritme
best first
... 9
13 Grafik nilai
cosine similarity
algoritme
page rank
... 9
14 Grafik rata-rata
fetch time
. ... 12
DAFTAR TABEL
Halaman
1 Proses perhitungan
page rank
sampai iterasi ke empat... 4
2 Rekapitulasi lima kata atau frase paling banyak terdapat pada halaman
web
. ... 8
3 Rekapitulasi kata atau frase sesuai dengan kata kunci. ... 8
4 Peluang kata kunci per algoritme. ... 9
5 Perbandingan nilai
precision
. ... 9
6 Perbandingan kompleksitas. ... 11
7 Rata-rata
fetch time.
... 11
DAFTAR LAMPIRAN
Halaman
1 Rancangan Tabel... 14
2 Daftar
Stop List
. ... 15
3 Algoritme
Cosine Similarity
dan Perhitungan Nilai
Cosine Similarity
. ... 16
4 Algoritme
Page Rank
dan Implementasi
Page Rank
Menggunakan PHP. ... 18
5 Karakter-karakter Khusus. ... 19
6 Data Mentah untuk Evaluasi. ... 21
1
PENDAHULUAN
Latar Belakang
Sekitar tahun 1990-an hasil penelitian
menunjukkan bahwa orang lebih banyak
mencari dan mendapatkan informasi melalui
media cetak atau media lain, bukan dari sistem
temu kambali informasi. Dalam satu dekade
terakhir, optimasi dan efektivitas sistem temu
kembali informasi mencapai kualitas yang lebih
baik, sehingga membuat sebagian besar
pengguna internet lebih percaya mencari dan
mendapatkan informasi, menggunakan sistem
temu kembali informasi. Tahun 2004 survey
Pew Internet
(Follow 2004, diacu dalam
Manning
et al
. 2009) menunjukkan bahwa 92%
pengguna internet menyatakan internet
merupakan tempat yang baik untuk mencari dan
mendapatkan informasi.
Jumlah halaman
web
pada akhir Januari
2005 diperkirakan mencapai 11,5 miliar
halaman (Romero 2006), dengan jumlah
halaman
web
yang sangat banyak, maka dapat
digunakan oleh sistem pencarian
web
untuk
menemukembalikan informasi sesuai dengan
keinginan pengguna. Google yang merupakan
mesin pencari terbesar saat ini diperkirakan
telah melakukan pengindeksan halaman
web
mencapai delapan miliar.
Salah satu strategi untuk mengumpulkan
halaman
web
yang tersebar di internet pada
domain berbeda, dan disesuaikan dengan kata
kunci yang diinginkan oleh pengguna yaitu
dengan membangun pengindeksaan halaman
web
. Sejak akhir tahun 1990, banyak penelitian
yang membahas tentang strategi pengumpulan
halaman
web
, strategi yang paling populer
adalah
web crawling
.
Pada tahun 2006, Rafael Romero Trujillo
(
Department of Information Technology Lund
University
, Swedia) melakukan penelitian
tentang
web crawling
yang berjudul
Simulation
Tool to Study Focused Web Crawling
Strategies
. Hasil penelitian ini menunjukkan
nilai
precision
terhadap 100.000 dokumen yang
dikumpulkan, untuk algoritme
breadth first
,
best first
,
page rank
, dan
breadth first with time
constraint
yaitu masing-masing 28,797%,
33,930%, 35,090%, dan 37,691%.
Web crawling
adalah suatu proses untuk
mengumpulkan halaman
web
, kemudian
dilakukan pengindeksan halaman
web
yang
bertujuan untuk mendukung sistem pencarian
web
. Aplikasi untuk
web crawling
biasa disebut
dengan
web crawler
.
Tujuan
Tujuan penelitian ini adalah
mengimplementasikan beberapa algoritme
web
crawling
. Kemudian melakukan evaluasi
terhadap beberapa algoritme
web crawling
tersebut.
Ruang Lingkup
Ruang lingkup penelitian ini yaitu :
1.
Web crawler
yang dibangun hanya
menjelajahi format standar halaman
web
,
dan tidak menjelajahi :
a.
file
dengan ekstensi .jpg, .png, .gif, .swf,
.doc, .docx, .ppt, .pptx, .xls, xlsx, .pdf,
.zip, .tar, .gz, dan .tar.gz.
b.
sebuah halaman
web
yang menerapkan
Robot Exclusion Protocol,
yaitu
protocol
yang menyediakan mekanisme untuk
mengatur akses terhadap
file
.
Protocol
ini menyebabkan
file
tidak bisa diambil
oleh
web crawler
.
2.
Web crawler
yang dibangun dikhususkan
untuk dokumen
web
berbahasa Indonesia.
3.
Web crawler
yang dibangun tidak
melakukan proses
stemming
terhadap kata
atau frase yang didapatkan.
Manfaat
Manfaat dari penelitian ini yaitu :
1.
Web crawler
yang dibangun mampu
mengumpulkan halaman
web
dan
melakukan pengindeksan halaman
web
.
2.
Mampu melakukan evaluasi terhadap
beberapa algoritme
web crawling
.
2
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi (
information
retrieval
) yaitu mencari bahan (biasanya
dokumen) yang bersifat tidak terstruktur
(biasanya teks) untuk memenuhi kebutuhan
informasi dari dalam koleksi dokumen yang
besar (tersimpan dalam komputer) (Manning
et
al
. 2009).
Web Crawling
Web crawling
adalah suatu proses untuk
mengumpulkan halaman
web
, kemudian
dilakukan pengindeksan untuk mendukung
sebuah mesin pencari. Tujuan dari
web
crawling
adalah mengumpulkan halaman
web
dengan cepat dan efisien, bersamaan dengan
struktur
link
yang terhubung antar halaman
web
tersebut (Manning
et al
. 2009).
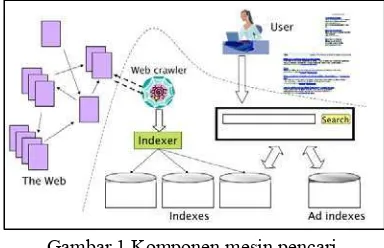
Komponen pendukung mesin pencari salah
satunya yaitu
web crawler
dapat dilihat pada
Gambar 1.
Gambar 1 Komponen mesin pencari.
Algoritme
Web Crawler
Algoritme
web crawler
yang dianalisis dan
dievaluasi yaitu :
1.
Breadth First
Algoritme
breadth first
merupakan strategi
sederhana untuk mengumpulkan halaman
web
.
Algoritme ini tidak menggunakan pendekatan
heuristik untuk menentukan
Uniform Resource
Locator
(URL) berikutnya yang akan
dikunjungi. Proses pengambilan URL dari
frontier
hanya menggunakan
First In First Out
(FIFO)
Queue
(Romero 2006).
Ilustrasi
breadth first crawler
dapat dilihat
pada Gambar 2.
Sedangkan untuk algoritme
breadth first
dapat dilihat pada Gambar 3.
Gambar 3 Algoritme
Breadth First
.
2.
Breadth First with Time Constraint
Breadth first with time constraint
merupakan perluasan dari algoritme
breadth
first
. Algoritme ini didasarkan pada gagasan
tidak mengakses
server
yang sama selama
jangka waktu tertentu dengan tujuan agar tidak
membebani
server
. Dengan demikian, halaman
diambil jika dan hanya jika batas waktu tertentu
telah berlalu sejak terakhir akses ke
server
(Romero 2006).
Algoritme
breadth first with time constraint
dapat dilihat pada Gambar 4.
Gambar 2
Breadth First Crawler
.
Gambar 4 Algoritme B
readth First
with Time Constraint
.
1 Breadth-First(starting_urls) { 2 for each link (starting_urls){ 3 enqueue(frontier, link);4 }
5 while (visited < MAX_PAGES ){ 6 start_time;
7 link = dequeue_link(frontier); 8 page = fetch(link);
9 visited = visited + 1; 10 enqueue(frontier, extract_links(page)); 11 end_time;
12 } 13 }
1 Breadth-First(starting_urls) { 2 for each link (starting_urls){ 3 enqueue(frontier, link); 4 }
5 url = first(frontier); 6 while (visited < MAX_PAGES){
7 if(Now()-timeLastAccessToServer(url) > timeThereshld){
8 start_time; 9 page = fetch(url); 10 visited = visited + 1; 11 enqueue(frontier,
extract_links(page)); 12 url = first(frontier);
13 end_time;
14 }else{
15 url = nextElement(frontier); 16 }
3
3.
Best First
Ide dasar dari algoritme ini memberikan
nilai estimasi pada setiap
link
di
frontier
,
dimana nilai estimasi terbaik akan digunakan
sebagai dasar untuk menjelajahi setiap
link
pada
frontier.
Untuk mendapatkan nilai estimasi
tersebut dengan cara menghitung kesamaan
antara halaman
web
dengan kata kunci yang
diinginkan (Romero 2006).
Ilustrasi
best first crawler
dapat dilihat pada
Gambar 5.
Gambar 5
Best First Crawler
.
Sedangkan untuk Algoritme
best first
dapat
dilihat pada Gambar 6.
Gambar 6 Algoritme
Best First
.
4.
Page Rank
Page rank
diperkenalkan oleh Sergey Brin
dan Larry Page, merupakan model probabilitas
dari prilaku
surfing
pengguna. Skor halaman
web
tergantung secara rekursif dari skor
halaman
web
yang mengarah ke halaman
web
tersebut (Romero 2006).
Page rank
menggunakan konsep
random
surfer model
, merupakan pendekatan yang
menggambarkan seorang pengunjung di depan
sebuah halaman
web
. Hal ini berarti peluang
seseorang mengklik sebuah
link
sebanding
dengan jumlah
link
yang
ada
pada
halaman tersebut. Pendekatan tersebut
digunakan, sehingga
page rank
dari
link
masuk
(
inbound link
) tidak langsung didistribusikan ke
halaman yang dituju, melainkan dibagi dengan
jumlah
link
keluar (
outbound link
) yang ada
pada halaman tersebut.
Sebuah halaman
web
akan semakin populer,
jika semakin banyak halaman
web
lain yang
meletakan
link
yang mengarah ke halaman
web
tersebut. Sedangkan sebuah halaman
web
akan
semakin penting jika halaman lain yang
memiliki nilai
page rank
tinggi mengacu ke
halaman
web
tersebut, dengan asumsi isi dari
halaman
web
tersebut lebih penting dari
halaman
web
yang lain.
Proses perhitungan nilai
page rank
dilakukan secara rekursif sampai konvergen.
Sebuah
rangking
halaman
web
akan ditentukan
oleh
rangking
halaman
web
lain yang memiliki
link
ke halaman
web
tersebut.
Terdapat dua persamaan
page rank
yaitu:
dengan PR(p) adalah
page rank
halaman
p
,
PR(d) adalah
page rank
halaman
d
yang
mengacu ke p,
in(p)
adalah kumpulan halaman
yang menunjuk ke
p
,
out(d)
adalah kumpulan
link
yang keluar dari
d
, dan N adalah jumlah
dokumen. Nilai
γ
(
damping factor
) merupakan
peluang bahwa
random surfer
meminta
halaman lain secara acak, nilai konstanta
γ
kurang dari satu (umumnya digunakan nilai
0.85).
Penentuan nilai
page rank
halaman
p
tidak
langsung diberikan, tetapi sebelumnya dibagi
dengan jumlah
link
yang ada pada halaman
d
(
outbound link
), nilai
page rank
tersebut akan
dibagi rata ke setiap
link
yang ada pada halaman
tersebut. Setelah semua nilai
page rank
didapat
dari halaman lain yang mengacu ke halaman
p
dijumlahkan, nilai itu kemudian dikalikan
dengan konstanta
γ
. Hal ini dilakukan agar tidak
keseluruhan nilai
page rank
halaman
d
didistribusikan ke halaman
p
.
Perbedaan antara kedua persamaan tersebut
yaitu persamaan pertama jumlah
page rank
sama dengan satu, sedangkan persamaan ke dua
jumlah
page rank
sama dengan jumlah halaman
web
. Menurut Brin dan Page (1998)
mengatakan bahwa
page rank
membentuk
N
(1)
(2)
1 Best-First(keyword,starting_urls){ 2 for each link (starting_urls){ 3 enqueue(frontier,link, 1);
4 }
5 while (visited < MAX_PAGES){ 6 start_time;
7 link=dequeue_top_link(frontier); 8 page = fetch(link);
9 score = sim(keyword, page); 10 visited = visited + 1; 11 enqueue(frontier,
extract_links(page),score); 12 end_time;
4
distribusi peluang, jadi jumlah semua nilai
page
rank
halaman
web
sama dengan satu.
Berdasarkan penjelasan tersebut maka
persamaan satu lebih direkomendasikan, karena
page rank
berbasis peluang. Berdasarkan dua
persamaan tersebut dapat dilihat bahwa
page
rank
ditentukan untuk setiap halaman, bukan
keseluruhan
website
.
Ilustrasi
link
antar halaman dapat dilihat
pada Gambar 7.
Proses perhitungan
page rank
dari ilustrasi
pada Gambar 7 sebagai berikut :
misal nilai
γ
= 0.5
PR (A) = 0.5/3 + 0.5 PR(C)
PR (B) = 0.5/3 + 0.5 ( PR(A) / 2 )
PR (C) = 0.5/3 + 0.5 ( PR(A) / 2 + PR(B))
Tabel 1 menujukkan proses iterasi
perhitungan nilai
page rank
sampai dengan
iterasi ke empat, terlihat bahwa halaman C lebih
populer dibandingkan dengan halaman A dan
halaman B, karena memiliki
page rank
yang
lebih besar. Halaman A lebih populer
dibandingkan dengan halaman B walaupun
jumlah
inbound link
sama, karena halaman A
diacu oleh halaman C yang memiliki
page rank
yang besar.
Tabel 1 Proses perhitungan
page rank
sampai
iterasi ke empat.
Iterasi PR(A) PR(B) PR
(C)
0 0 0 0
1 0,167
0,167
0,167
2 0,250
0,208
0,292
3 0,313
0,229
0,333
4 0,333
0,245
0,359
Algoritme
web crawler
menggunakan
page
rank
dapat dilihat pada Gambar 8.
Gambar 8 Algoritme
Page Rank
.
Web crawler
dengan menggunakan
page
rank
merupakan varian dari
best first crawler
.
Berbeda pada evaluasi
link
yang dikunjungi
berikutnya menggunakan dua pendekatan, yaitu
nilai
page rank
dan
cosine similarity
(Menczer
et al
. 2004).
Analisis Algoritme
Secara informal, algoritme adalah prosedur
komputasional yang didefinisikan dengan jelas
untuk mengambil beberapa nilai atau satu set
nilai sebagai
input
, dan menghasilkan beberapa
nilai atau satu set nilai sebagai
output
.
Algoritme adalah urutan langkah komputasi
yang mengubah
input
menjadi
output
(Cormen
et al
. 2002).
Analisis algoritme dibutuhkan untuk
memprediksi sumber daya yang dibutuhkan
oleh suatu algoritme. Sumber daya komputer
seperti memori,
bandwidth
, atau perangkat
keras komputer lainnya menjadi perhatian
utama dalam menganalisis algoritme, tetapi
umumnya yang diukur adalah waktu komputasi
suatu algoritme. Metode matematika secara
efektif dapat digunakan, untuk memprediksi
banyaknya ruang dan waktu yang diperlukan
oleh suatu algoritme, tanpa harus
mengimplementasikan dalam bahasa
pemrograman tertentu (Cormen
et al
. 2002).
A
B
C
Gambar 7 Ilustrasi
link
.
1 PageRank (keyword,starting_url){
2 for each link (starting_urls){ 3 enqueue(frontier, link, 1); 4 }
5 while (visited < MAX_PAGES){ 6 start_time;
7 if(multiplies-X (visited)){ 8 for each link (frontier){ 9 PR(link) = compute_score_PR; 10 }
11 }
12 link = dequeue_max_PR(frontier);
13 if(link not found){
14 link = dequeue_top_link(frontier); 15 }
16 page = fetch(link);
17 score = sim(keyword, page); 18 visited = visited + 1; 19 enqueue(frontier,
extract_links(page),score); 20 end_time;
5
Cosine Similarity
Cosine Similiarity
digunakan oleh
web
crawler
untuk mendapatkan nilai estimasi
antara kata kunci dengan setiap halaman
web
yang dikunjungi. Nilai estimasi ini akan
dijadikan nilai kesamaan untuk setiap
link
yang
didapat dari
web
yang dikunjungi.
Perhitungan
cosine similarity
dapat dilihat
pada persamaan :
dengan
q
merupakan topik,
p
adalah halaman,
Vq
dan
Vp
merupakan vektor
term frequency
dari
p
dan
q
, dan || Vq || & || Vp || merupakan
panjang vektor
Vp
dan
Vq
.
Stop Words
Terkadang kata-kata yang sering muncul dan
umum merupakan kata-kata yang kurang
bermakna jika dijadikan penciri sebuah
dokumen. Kata-kata tersebut akan dibuang dari
himpunan kata yang akan diindeks dan
kata-kata tersebut termasuk dalam
stop words
(Manning
et al
. 2009).
Kata-kata yang akan dibuang akan disimpan
dalam sebuah daftar kata yang disebut
stop list
.
Stop list
akan berbeda-beda tergantung bahasa
yang digunakan, dalam konteks bahasa
indonesia beberapa kata yang termasuk dalam
stop list
di antaranya ‘yang’, ‘sehingga’ dan
‘dengan’.
Pembobotan
Term Frequency
(TF)
Menurut
Manning
(2009)
term frequency
adalah frekuensi kemunculan kata pada
dokumen. Untuk menghitung skor antar kueri
dengan dokumen, pendekatan sederhana dengan
menghitung frekuensi kata pada kueri dengan
dokumen. Nilai frekuensi tersebut adalah bobot
dari dokumen, yang memiliki bobot terbesar
merupakan dokumen yang paling dekat dengan
kueri.
Evaluasi Algoritme
Romero (2006) menjelaskan bahwa untuk
mengukur kinerja algoritme
web crawler
menggunakan nilai
precision
,
yaitu
membandingkan antara jumlah halaman relevan
yang dikunjungi dengan total halaman yang
dikunjungi. Persamaan untuk menghitung nilai
precision
yaitu :
precision =
Jumlah halaman relevan dikunjungi
Total halaman dikunjungi
METODE PENELITIAN
Kajian Literatur
Kajian literatur pada penelitian ini yaitu
mengkaji beberapa algoritme
web crawler
,
strategi
web crawler
, serta teknik yang
berkaitan dengan
web crawler
. Literatur yang
digunakan diambil dari buku, jurnal, dan
artikel-artikel dari internet.
Analisis dan Implementasi
Crawling
Hasil dari kajian literatur didapat beberapa
algoritme seperti yang telah dijelaskan pada
tinjauan pustaka. Beberapa algoritme
web
crawler
tersebut dianalisis kemudian
diimplementasikan.
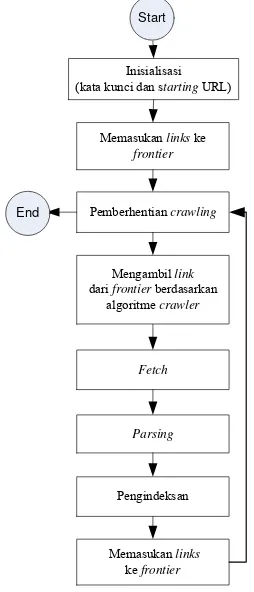
Tahapan implementasi dapat dilihat pada
Gambar 9.
Inisialisasi (kata kunci dan startingURL)
Fetch
Parsing
Pemberhentian crawling
Memasukanlinkske
frontier
Memasukan links
ke frontier
Mengambillink
dari frontierberdasarkan algoritme crawler
Pengindeksan
Start
End
Berikut ini penjelasan untuk setiap tahapan
dari Gambar 9 :
1.
Inisialisasi (kata kunci dan
starting
URL)
Starting
URL adalah
link
yang pertama kali
menjadi acuan untuk dikunjungi,
link
ini
dianggap sebagai
link
yang paling mewakili
isi halaman
web
yang diinginkan untuk
dikumpulkan. Penentuan
starting
URL
sangat penting karena menentukan
links
6
selanjutanya yang akan dikunjungi. Pada
kajian kali ini
starting
URL yang digunakan
yaitu http://www.deptan.go.id/news/.
Kata kunci pada kajian kali ini adalah
“pertanian agriculture tani petani padi
jagung agri agribisnis”, dengan tujuan untuk
mendapatkan halaman
web
yang
berhubungan dengan pertanian.
2.
Memasukkan
link
ke
frontier
Frontier
adalah daftar URL yang belum
dikunjungi oleh
web crawler
(
unvisited
pages
). Berdasarkan terminologi graf,
frontier
adalah sebuah
node
yang belum
diekspan (
unexpanded nodes
). Aturan pada
frontier
tidak boleh ada duplikasi URL,
untuk memastikannya digunakan
pengecekan secara kueri basis data.
Memasukkan
link
ke
frontier
adalah proses
memasukkan setiap
link
yang didapat dari
starting
URL atau
link
dari sebuah halaman
web
. Implementasi
frontier
pada kajian ini
yaitu menggunakan basis data, rancangan
struktur tabel pada basis data dapat dilihat di
Lampiran 1.
3.
Pengecekan pemberhentian
crawling
Pemberhentian
crawling
dilakukan jika total
halaman
web
yang dikunjungi mencapai
total maksimum yang ditentukan, atau jika
frontier
telah mencapai batas maksimum
dalam sebuah penyimpanan.
4.
Mengambil
link
dari
frontier
berdasarkan
algoritme
crawler
Mengambil
link
dari
frontier
berdasarkan
aturan dari setiap algoritme yaitu algoritme
breadth first, breadth first with time
constraint, best first, dan page rank
.
5.
Fetch
Fetch
adalah proses mengunjungi dan
mengambil isi halaman
web
.
6.
Parsing
Parsing
adalah proses mengekstrak
link
dan
kata atau frase dari sebuah halaman
web
.
Pada tahapan ini dilakukan pengecekan
apakah sebuah kata atau frase
termasuk
stop
list
, jika
stop list
maka tidak dimasukkan
dalam penyimpanan.
Pada penelian ini menggunakan
stop list
Bahasa Indonesia dan Bahasa Inggris, alasan
menggunakan
stop list
Bahasa Inggris
dikarenakan beberapa dokumen
web
berbahasa Indonesia menggunakan istilah
Bahasa Inggris. Daftar
stop list
Bahasa
Indonesia dan Bahasa Inggris dapat dilihat
pada Lampiran 2.
7.
Pengindeksan
Hasil dari tahapan
fetch
, dihitung bobot
setiap kata atau frase yang didapat dengan
term frequency
(tf), kata atau frase dan
bobotnya disimpan dalam basis data.
Evaluasi Algoritme
Evaluasi algoritme merupakan proses
evaluasi terhadap algoritme
web crawer
yang
telah diimplementasikan. Evaluasi dilakukan
dengan tiga cara yaitu :
1.
Menghitung nilai
precision
untuk setiap
algoritme.
2.
Menghitung kompleksitas untuk setiap
algoritme.
3.
Menghitung rata-rata
fetch time
sebanyak
dua puluh iterasi untuk setiap algoritme.
HASIL DAN PEMBAHASAN
Penggunaan
Cronjob
Cronjob
adalah aplikasi yang digunakan
untuk penjadwalan, sehingga memungkinkan
pengguna melakukan eksekusi aplikasi atau
script
program sesuai dengan waktu yang telah
ditentukan. Pada penelitan ini digunakan
aplikasi
cronjob
yang sudah terkonfigurasi
langsung dengan Cpanel pada sebuah
hosting
.
Tujuan dari penggunaan
cronjob
adalah untuk
mengatur proses
crawling
sesuai dengan waktu
yang ditentukan.
Memasukkan
Link
ke
Frontier
Untuk mendapatkan
link
dari dokumen
HTML yaitu dengan mengambil semua
tag
hyperlinks.
Link
yang benar (
valid
) harus
memenuhi aturan sebagai berikut :
1.
Sebuah
link
dengan nilai atribut href tidak
boleh bernilai #.
2.
Atribut href dari tidak mengandung
ekstensi
file
yang telah dijelaskan pada
ruang lingkup.
Pemberhentian
Crawling
7
algoritme
crawling
tidak jalan terus menerus
yang akan menyebabkan membebani
server
.
Mengambil
Link
dari
Frontier
Berdasarkan
Algoritme
Crawler
Proses ini merupakan pokok dari algoritme
crawler
yang digunakan untuk menentukan
link
mana saja yang didahulukan untuk dikunjungi.
Berikut ini penjelasan proses pengambilan
link
dari
frontier
berdasarkan algoritme :
1.
Breadth first
Proses penentuan
link
yang didahulukan
untuk dikunjungi sangat sederhana yaitu
menggunakan konsep FIFO, jika
link
yang
terlebih dahulu masuk ke
frontier
maka
akan dikunjungi terlebih dahulu.
2.
Breadth first with time constraint
Proses penentuan
link
yang didahulukan
pada algoritme ini sama persis dengan
algoritme
breadth first
. Pada algoritme ini
terdapat pengecualian dengan melakukan
pengecekan, yaitu selisih antar waktu
sekarang (
now
) dengan waktu terakhir
sebuah
link
dikunjungi, selisih waktu
tersebut harus memenuhi
time threshold
yang ditentukan.
Pada penelitian ini
time threshold
yang
digunakan yaitu 24 jam (86400 detik),
dengan alasan karena rata-rata sebuah
halaman
web
diperbaharui dalam waktu
sehari semalam.
3.
Best first
Proses penentuan
link
yang didahulukan
untuk dikunjungi dengan menggunakan nilai
cosine similarity
. Nilai
cosine similarity
sebuah halaman
web
dihitung berdasarkan
kata kunci yang diberikan, nilai yang
didapat akan diberikan pada setiap
link
yang
ada pada halaman
web
tersebut. Untuk
melihat algoritme
cosine similarity
dan
perhitungan nilai
cosine similarity
secara
manual pada sebuah halaman
web
dapat
dilihat pada Lampiran 3.
4.
Page rank
Proses penentuan
link
yang didahulukan
untuk dikunjungi menggunakan dua
pendekatan, yaitu nilai
cosine similarity
atau
nilai
page rank
dari sebuah halaman
web
.
Pertimbangan nilai
cosine similarity
digunakan hanya pada iterasi satu sampai
lima, karena pada iterasi tersebut nilai
page
rank
belum dihitung.
Ketentuan proses algoritme
page rank
pada
web crawler
yaitu sebagai berikut :
a)
Jika jumlah halaman
web
kelipatan dari
lima, maka dilakukan perhitungan nilai
page rank
untuk setiap
link
yang didapat
dari
frontier
.
b)
Untuk menentukan
links
yang akan
dihitung nilai
page rank
-nya, yaitu
dengan mengambil beberapa
link
dari
frontier
yang memiliki nilai
cosine
similarity
tertinggi.
c)
Jumlah
links
yang diambil dari
frontier
yaitu sepuluh, dengan pertimbangan
jumlah MAX_PAGES sama dengan
sepuluh, jadi penentuan
link
yang
didahulukan untuk dikunjungi pada
iterasi berikutnya tetap menggunakan
nilai
page rank
.
d)
Proses selanjutnya yaitu mendapatkan
link
keluar (
out link
) dari setiap
link
yang
diambil dari
frontier
. Setelah diperoleh
link
keluar, maka dilakukan proses
perhitungan nilai
page rank
.
Algoritme
page rank
dan implementasi
page
rank
menggunakan bahasa pemrograman
PHP dapat dilihat pada Lampiran 4.
Fetch
Implementasi
fetch
menggunakan
library
PHP (
Client URL
) merupakan sebuah
library
yang memungkinkan untuk terhubung dan
berkomunikasi antar berbagai macam tipe
server
dengan berbagai macam protokol, salah
satunya adalah HTTP. Halaman HTML yang
didapat disimpan ke dalam basis data, kemudian
akan digunakan untuk proses
parsing
.
Parsing
Untuk mendapatkan kata atau frase pada
halaman
web
dilakukan pemrosesan HTML.
Tujuan pemrosesan HTML yaitu agar
karakter-karakter khusus serta nilai di dalam tag
style
dan tag
script
tidak dihitung sebagai kata atau
frase.
8
Pengideksan
Setelah proses
parsing
selesai, maka proses
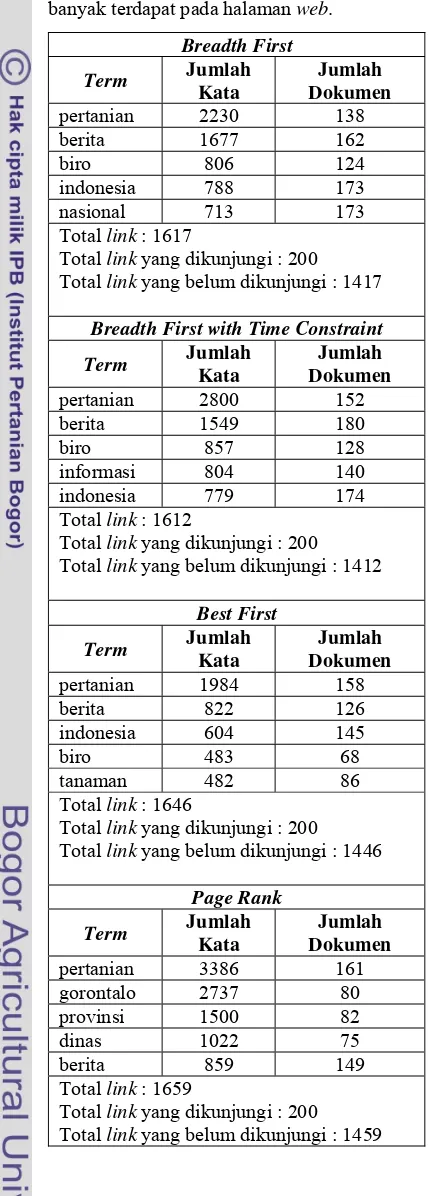
selanjutnya yaitu pengindeksan. Tabel 2
menunjukkan rekapitulasi lima kata atau frase
paling banyak terdapat pada halaman
web
, yang
didapat dari proses pengindeksan.
Tabel 2 Rekapitulasi lima kata atau frase paling
banyak terdapat pada halaman
web
.
Breadth First
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 2230
138
berita 1677 162
biro 806
124
indonesia 788
173
nasional 713
173
Total
link
: 1617
Total
link
yang dikunjungi : 200
Total
link
yang belum dikunjungi : 1417
Breadth First with Time Constraint
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 2800
152
berita 1549 180
biro 857
128
informasi 804
140
indonesia 779
174
Total
link
: 1612
Total
link
yang dikunjungi : 200
Total
link
yang belum dikunjungi : 1412
Best First
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 1984
158
berita 822 126
indonesia 604
145
biro 483 68
tanaman 482
86
Total
link
: 1646
Total
link
yang dikunjungi : 200
Total
link
yang belum dikunjungi : 1446
Page Rank
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 3386
161
gorontalo 2737
80
provinsi 1500
82
dinas 1022 75
berita 859 149
Total
link
: 1659
Total
link
yang dikunjungi : 200
Total
link
yang belum dikunjungi : 1459
Tabel 3 menunjukkan rekapitulasi kata atau
frase sesuai dengan kata kunci. Pada Tabel 3
terlihat bahwa kata “Pertanian” mempunyai
jumlah dokumen paling banyak untuk setiap
algoritme.
Tabel 3 Rekapitulasi kata atau frase sesuai
dengan kata kunci.
Breadth First
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 2230
138
agriculture
43 35
tani 130
87
petani 161 58
padi 105
41
jagung 40 21
agri 7
6
agribisnis 113
90
Breadth First with Time Constraint
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 2800
152
agriculture
64 50
tani 156
96
petani 193 76
padi 143
60
jagung 46 27
agri 7
6
agribisnis 152
124
Best First
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 1984
158
agriculture
36 30
tani 165
98
petani 164 57
padi 318
70
jagung 55 26
agri 3
3
agribisnis 98
73
Page Rank
Term
Jumlah
Kata
Jumlah
Dokumen
pertanian 3386
161
agriculture
97 78
tani 210
128
petani 633 97
padi 400
77
jagung 773 84
agri 1
1
9
Tabel 4 menunjukkan peluang kata kunci
per algoritme. Peluang dihitung dengan
membagi antara jumlah dokumen kata atau
frase dengan total dokumen yang didapat. Pada
Tabel 4 terlihat bahwa rata-rata peluang
algoritme
page rank
lebih baik dibanding
dengan ketiga algoritme lainnya yaitu 0,437.
Tabel 4 Peluang kata kunci per algoritme.
Term
Peluang Algoritma ke-
1 2 3 4
pertanian 0,690
0,760
0,790
0,805
agriculture
0,175 0,250 0,150 0,390
tani 0,435
0,480
0,490
0,640
petani 0,290
0,380
0,285
0,485
padi 0,205
0,300
0,350
0,385
jagung 0,105
0,135
0,130
0,420
agri 0,030
0,030
0,015
0,005
agribisnis 0,450
0,620
0,365
0,365
Rata-rata 0,298 0,369
0,322
0,437
Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank.Evaluasi Algoritme
Evaluasi algoritme menggunakan beberapa
pendekatan yaitu :
1.
Nilai
Precision
Untuk mendapatkan halaman
web
yang
relevan sesuai dengan kata kunci dilakukan
secara manual, yaitu dengan membuka
setiap halaman
web
yang didapat,
kemudian dilihat apakah relevan atau tidak
dengan kata kunci.
Tabel 5 menunjukkan nilai
precision
untuk
setiap algoritme, data mentah setiap
algoritme untuk menghasilkan nilai
precision
dapat dilihat pada Lampiran 6.
Berdasarkan evaluasi nilai
precision,
terlihat bahwa algoritme yang
mempertimbangkan nilai estimasi antara
kata kunci dengan halaman
web
lebih baik
dibandingkan dengan algoritme yang tidak
mempertimbangkan nilai estimasi.
Tabel 5 Perbandingan nilai
precision
.
Algoritme Halaman Relevan Precision
1 200
51
0,255
2 200
59
0,295
3 200
74
0,370
4 200
79
0,395
Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank.
Gambar 10 sampai dengan Gambar 13
menunjukkan grafik hubungan antara nilai
cosine similarity
dengan urutan halaman
web
yang dikunjungi. Algoritme
breadth first
yang
tidak menggunakan nilai estimasi menunjukkan
semakin besar iterasi maka nilai
cosine
similarity
menuju ke nol.
Gambar 10 Grafik nilai
cosine similarity
algoritme
breadth first
.
Gambar 11 Grafik nilai
cosine similarity
algoritme
breadth first with time constraint
.
Gambar 12 Grafik nilai
cosine similarity
algoritme
best first
.
10
Pada penelitian ini dihitung juga nilai
rata-rata
cosine similarty
terhadap dua ratus
dokumen yang dikumpulkan. Hasil yang
didapat untuk algoritme
page rank, breadth first
with time constraint, best first
dan
breadth first
dan yaitu masing-masing 0,175, 0,146, 0,143
dan 0,110.
2.
Kompleksitas Algoritme
a.
Breadth first
Perhitungan kompleksitas algoritme
breadth first
sebagai berikut :
T(n) = 4n
2+ 11n = O(n
2)
Jadi, kompleksitas algoritme
breadth first
yaitu O(n
2).
b.
Breadth first with time constraint
Perhitungan kompleksitas algoritme
breadth first with time constraint
sebagai
berikut :
T1(n) = 4n
2+ 13n + 1 = O(n
2)
T2(n) = 8n + 1 = O(n)
Jadi, kompleksitas algoritme
breadth first
with time constraint
yaitu O(n
2) atau O(n).
O(n
2) yaitu
worst case
, terjadi saat
pengecekan
time threshold
terpenuhi. O(n)
yaitu
best case
, terjadi saat pengecekan
time threshold
tidak terpenuhi.
c.
Best first
Perhitungan kompleksitas algoritme
best
first
sebagai berikut :
T(n) = 4n
2+ 11n + (F(n)) n
dengan F(n) merupakan fungsi
kompleksitas untuk algoritme
cosine
similarity
. Perhitungan kompleksitas
algoritme
cosine similarity
dapat dilihat
pada Lampiran 3, dengan hasil sebagai
berikut :
F(n) = 18n + 11, maka
T(n) = 4n
2+ 11n + (18n + 11) n
T(n) = 22n
2+ 22n = O(n
2)
Jadi, kompleksitas algoritme
best first
yaitu O(n
2).
Breadth-First(starting_urls) {
for each link (starting_urls)
{
enqueue(frontier, link);
}
while (visited < MAX_PAGES ){
start_time;
link=dequeue_link(frontier);
page=fetch(link);
visited = visited + 1;
enqueue(frontier, extract_links(page)); end_time; } } Time 3n n n n n n 2n 4n2 n BestFirst(keyword,starting_urls){
for each link (starting_urls)
{
enqueue(frontier,link, 1);
}
while (visited < MAX_PAGES){
start_time;
link=dequeue_top_link(
frontier);
page = fetch(link);
score = sim(keyword, page);
visited = visited + 1;
enqueue(frontier, extract_links(page), score); end_time; } } Time 3n n n n n n (F(n)) n 2n 4n2 n Breadth-First(starting_urls) {
for each link (starting_urls)
{
enqueue(frontier, link);
}
url = first(frontier);
while (visited < MAX_PAGES){
if(Now()-
timeLastAccessToServer(url)
> timeThereshld){
start_time;
page = fetch(url);
visited = visited + 1;
enqueue(frontier,
extract_links(page));
url = first(frontier);
end_time;
}else{
url = nextElement(frontier);
11
d.
Page rank
Perhitungan kompleksitas algoritme
Page
Rank
sebagai berikut :
T1(n) = 4n
2+ 16n + (F(n)) n
dengan F(n) merupakan fungsi
kompleksitas untuk algoritme
cosine
similarity
. Perhitungan kompleksitas
algoritme
cosine similarity
dapat dilihat
pada Lampiran 3, dengan hasil sebagai
berikut :
F(n) = 18n + 11, maka
T1(n) = 4n
2+ 16n + (18n + 11) n
T1(n) = 22n
2+ 27n = O(n
2)
T2(n) = T1 (n) + 3n
2+ (G(n)) n
2dengan G(n) merupakan fungsi
kompleksitas untuk algoritme
page rank
.
Perhitungan kompleksitas algoritme
page
rank
dapat dilihat pada Lampiran 4, dengan
hasil sebagai berikut :
G(n) = 6n
3+ 22n
2+ 9n + 2
T2(n) = 25n
2+ 27n + (G(n)) n
2T2(n) = 6n
5+ 22n
4+ 9n
3+ 27n
2+ 27n
Jadi, kompleksitas algoritme
page rank
adalah O(n
2) atau O(n
5). O(n
2) yaitu
best
case
, terjadi saat algoritme
page rank
tidak
dijalankan. O(n
5) adalah
worst case
, terjadi
saat algoritme
page rank
dijalankan.
Tabel 6 menunjukkan perbandingan
kompleksitas algoritme
crawler
. Algoritme
page rank
menunjukkan nilai kompleksitas
lebih tinggi dibandingkan dengan algoritme
lainnya, sehingga algoritme
page rank
membutuhkan sumber daya komputer yang
lebih baik.
Tabel 6 Perbandingan kompleksitas.
Algoritme Kompleksitas
Breadth First
O(n
2)
Breadth First with Time
Constraint
O(n
2)
Best First
O(n
2)
Page Rank
O(n
5)
3.
Fetch Time
Fetch time
adalah waktu yang dibutuhkan
suatu algoritme
crawler
untuk mengunjungi dan
mengambil suatu halaman
web
. Setiap itarasi
yang menghasilkan sepuluh halaman web,
kemudian dihitung nilai rata-rata
fetch time
.
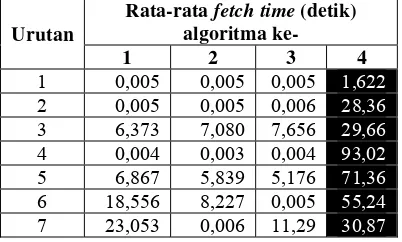
Tabel 7 menunjukkan rata-rata
fetch time
berdasarkan urutan pengulangan untuk setiap
algoritme
web
crawler
dijalankan. Untuk setiap
urutan pengulangan, terlihat bahwa algoritme
page rank
sebelas kali mencapai nilai terbesar
dibandingkan dengan algoritme lain. Hal ini
terjadi dikarenakan proses perhitungan nilai
page rank
membutuhkan waktu.
Selain itu, terlihat bahwa algoritme
best first
lebih stabil dibanding dengan algoritme lain,
karena tidak mencapai
fetch time
maksimum
pada setiap iterasi. Pada iterasi ke sebelas
sampai ke delapan belas, terlihat bahwa
peningkatan
fetch time
yang tinggi untuk
algoritme
breadth first
dan
breadth
first with
time constraint
. Hal ini terjadi karena akses ke
server
mulai melambat, atau akses ke halaman
web
tersebut memang lambat. Setelah dilakukan
pengecekan ulang dengan data mentah, yang
menyebabkan
fetch time
tinggi yaitu adanya
komponen
flash
dalam halaman
web
tersebut.
Tabel 7 Rata-rata
fetch time.
Urutan
Rata-rata
fetch time
(detik)
algoritma ke-
1 2 3
4
1 0,005
0,005
0,005
1,622
2 0,005
0,005
0,006
28,36
3 6,373
7,080
7,656
29,66
4 0,004
0,003
0,004
93,02
5 6,867
5,839
5,176
71,36
6 18,556
8,227
0,005
55,24
7 23,053
0,006
11,29
30,87
PageRank (keyword,starting_url){for each link (starting_urls) {
enqueue(frontier, link, 1);
}
while (visited < MAX_PAGES){
start_time;
if(multiplies-X (visited)){
for each link (frontier){
PR(link) = compute_score_PR;
}
}
link = dequeue_max_PR(frontier);
if(link not found){
link = dequeuetoplink(frontier);
}
page = fetch(link);
score = sim(topic, page);
visited = visited + 1;
enqueue(frontier, extract_links(page),score); end_time; } } Time 3n n n n 3n 3n2
(G(n)) n2
12
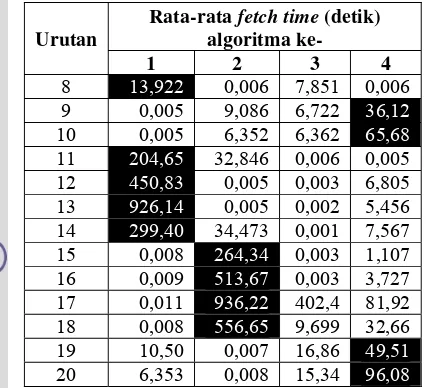
Urutan
Rata-rata
fetch time
(detik)
algoritma
ke-1 2 3
4
8
13,922
0,006 7,851 0,006
9 0,005
9,086
6,722
36,12
10 0,005
6,352
6,362
65,68
11
204,65
32,846 0,006 0,005
12
450,83
0,005 0,003 6,805
13
926,14
0,005 0,002 5,456
14
299,40
34,473 0,001 7,567
15 0,008
264,34
0,003 1,107
16 0,009
513,67
0,003 3,727
17 0,011
936,22
402,4 81,92
18 0,008
556,65
9,699 32,66
19 10,50
0,007
16,86
49,51
20 6,353
0,008
15,34
96,08
Keterangan : (1) Breadth First, (2) Breadth First with Time Constraint, (3) Best First, dan (4) Page Rank. Cell dengan latar hitam menunjukkan nilai terbesar untuk setiap iterasi per algoritme.Gambar 14 menunjukkan grafik hubungan
antara urutan pengulangan
web crawler
dengan
rata-rata
fetch time
, dengan data diambil dari
Table 7.
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian berdasarkan nilai
precision
dan peluang kata kunci per algoritme
menunjukkan bahwa algoritme
page rank
lebih
baik dibanding dengan algoritme lainnya. Hasil
penelitian berdasarkan kompleksitas algoritme,
menunjukkan bahwa algoritme
page rank
memiliki kompleksitas lebih tinggi
dibandingkan dengan algoritme lainnya. Selain
itu, berdasarkan rata-rata
fetch time
menunjukkan bahwa algoritme
best first
lebih
stabil dibanding dengan algoritme lainnya.
Saran
1.
Implementasi pada penelitian ini
menggunakan
share hosting
, sehingga tidak
leluasa dalam menggunakan
resources
server
. Perlu adanya
server
tersendiri untuk
web crawler
agar pengambilan halaman
web
lebih cepat.
2.
Masih terdapat algoritme
web
crawler
lain
selain ke-4 algoritme yang telah dikaji pada
penelitian ini, sehingga pada penelitian
selanjutnya diharapkan dapat mengkaji
algoritme
web
crawler
yang lain.
3.
Proses pengindeksan masih menggunakan
metode sederhana yaitu
term frequency
(tf),
diharapkan pada penelitian selanjutnya
menggunakan metode pengindeksan lain
yang lebih baik.
DAFTAR PUSTAKA
Brin, Page. 1998.
The Anatomy of a
Large-Scale Hypertextual Web Search Engine
.
http://infolab.stanford.edu/~backrub/google.
htm.
Cormen
et al
. 2002.
Introduction to Algorithms
Second Edition
. England. The MIT Press
Cambridge.
Manning
et al
. 2009.
Introduction to
Information Retrieval
. England. Cambridge
University Press.
Menczer
et al
. 2004.
Topical Web Crawlers:
Evaluating Adaptive Algorithms. ACM
Transactions on Internet Technology
.
http://dollar.biz.uiowa.edu/~pant/Papers/TO
IT.pdf.
Romero T, Rafael. 2006.
Simulation tool to
study focused web crawling strategies
.
http://combine.it.lth.se/CrawlSim/CrawlSim.
pdf.
Srinivasan. 2004.
Target Seeking Crawlers and
their Topical Performance
.
http://citeseerx.ist.psu.edu/viewdoc/downloa
d?doi=10.1.1.23.6092.
13
LAMPIRAN
14
Lampiran 1 Rancangan Tabel.
tbl_term
Nama
field
Tipe
data
Keterangan
id int(11)
primary key, auto increment
term varchar(200)
unique
tbl_tf
Nama
field
Tipe
data
Keterangan
id int(11)
primary key, auto increment
id_term int(11)
unique
id_url int(11)
tf int(11)
tbl_webpage
Nama
field
Tipe
data
Keterangan
id int(11)
primary key, auto increment
topic text
link
varchar(250)
unique
link
_teks varchar(250)
html longtext
status
int(1)
0 = belum dikunjungi, 1 = sudah dikunjungi
score double
Menyimpan
nilai
cosing similarity
algorithm int(1)
Jenis
algoritme
fetch_time float
access_time int(11)
15
Lampiran 2 Daftar
Stop List
.
Stop List
Bahasa Indonesia
Sumber : http://fpmipa.upi.edu/staff/yudi/stop_words_list.txt
Stop List
Bahasa Inggris
Sumber : http://www.textfixer.com/resources/common-english-words.txt
yang di dan itu dengan untuk tidak ini dari dalam akan pada juga saya ke karena tersebut bisa
ada mereka lebih kata tahun sudah atau saat oleh menjadi orang ia telah adalah seperti sebagai
bahwa dapat para harus namun kita dua satu masih hari hanya mengatakan kepada kami setelah
melakukan lalu belum lain dia kalau terjadi banyak menurut anda hingga tak baru beberapa
ketika saja jalan sekitar secara dilakukan sementara tapi sangat hal sehingga seorang bagi besar
lagi selama antara waktu sebuah jika sampai jadi terhadap tiga serta pun salah merupakan atas
sejak membuat baik memiliki kembali selain tetapi pertama kedua memang pernah apa mulai
sama tentang bukan agar semua sedang kali kemudian hasil sejumlah juta persen sendiri
katanya demikian masalah mungkin umum setiap bulan bagian bila lainnya terus luar cukup
termasuk sebelumnya bahkan wib tempat perlu menggunakan memberikan rabu sedangkan
kamis langsung apakah pihak melalui diri mencapai minggu aku berada tinggi ingin sebelum
tengah kini the tahu bersama depan selasa begitu merasa berbagai mengenai maka jumlah
masuk katanya mengalami sering ujar kondisi akibat hubungan empat paling mendapatkan
selalu lima meminta melihat sekarang mengaku mau kerja acara menyatakan masa proses
tanpa selatan sempat adanya hidup datang senin rasa maupun seluruh mantan lama jenis segera
misalnya mendapat bawah jangan meski terlihat akhirnya jumat punya yakni terakhir kecil
panjang badan juni of jelas jauh tentu semakin tinggal kurang mampu posisi asal sekali
sesuai sebesar berat dirinya memberi pagi sabtu ternyata mencari sumber ruang menunjukkan
biasanya nama sebanyak utara berlangsung barat kemungkinan yaitu berdasarkan sebenarnya
cara utama pekan terlalu membawa kebutuhan suatu menerima penting tanggal bagaimana
terutama tingkat awal sedikit nanti pasti muncul dekat lanjut ketiga biasa dulu kesempatan
ribu akhir membantu terkait sebab menyebabkan khusus bentuk ditemukan diduga mana ya
kegiatan sebagian tampil hampir bertemu usai berarti keluar pula digunakan justru padahal
menyebutkan gedung apalagi program milik teman menjalani keputusan sumber a upaya
mengetahui mempunyai berjalan menjelaskan b mengambil benar lewat belakang ikut barang
meningkatkan kejadian kehidupan keterangan penggunaan masing-masing menghadapi
16
Lampiran 3 Algoritme
Cosine Similarity
dan Perhitungan Nilai
Cosine Similarity
.
T(n) = 18n + 11 = O(n)
Kompleksitas algoritme
cosine similarity
yaitu O(n).
Sim(topic, doc) {
cosine = 0;
vector_length_doc = 0;
for each term in doc{
vector_length_doc += count_term * count_term;
}
vector_length_topic = 0;
for each term in topic{
vector_length_topic += count_term * count_term;
}
dot_product = 0;
for each term in topic{
dot_product += count_term_topic * count_term_doc;
}
div = SQRT(vector_length_doc) * SQRT(vector_length_topic);
if(div > 0){
cosine = dot_product / div;
}
}
Time
1
1
3n
3n
1
3n
3n
1
3n
3n
17
Contoh perhitungan manual
cosine similarity
pada sebuah halaman
web
Topik atau kueri = pertanian agriculture tani petani padi jagung agri agribisnis
No
Term
Jumlah Term
(D)
Kueri
(Q)
1
agriculture
0
1
2
tani
0
1
3
padi
0
1
4
jagung
0
1
5
agri
0
1
6 account
1
0
7 acs
2
0
8 aduhai
1
0
9 aeki
4
0
10 agenda
3
0
11
agribisnis
1
1
12
agribusiness
2
1
13 agro
1
0
14 akut
1
0
15 alumni
2
0
16 pergaulan
1
0
17 permukaan
1
0
18 pernyataan
2
0
19 pers
1
0
20
pertanian
6
1
21 pertemuan
4
0
22
petani
1
1
23 pilih
1
0
24 pilihan
1
0
25 piper
1
0
26 polling
3
0
27 portal
4
0
28 pphp
1
0
29 visits
1
0
30 wadah
1
0
31
web
1
0
32
web
site 2
0
33 wisata
2
0
34 workshop
1
0
35 yet
1
0
|| D || = SQRT [
∑
D ]
2= 12
|| Q || = SQRT [
∑
Q ]
2=
3
D.Q
=
10
SIM(D,Q) =
0,278
18
Lampiran 4 Algoritme
Page Rank
dan Implementasi
Page Rank
Menggunakan PHP.
T(n) = 6n
3+ 22n
2+ 9n + 2 = O(n
3)
Kompleksitas algoritme
page rank
adalah O(n
3).
calculatePageRank(linkGraph, dampingFactor = 0.85) {
N = count(
link
Graph);
for each node in
link
Graph{
pageRank_each_node = 1/N;
tempRank_each_node = 0;
}
while(pageRank not convergen) {
for each node in linkGraph{
M = count(outbound_each_node);
for each outbound in node {
tempRank_each_node += pageRank_each_node / M;
}
}
total = 0;
for each node in
link
Graph {
tempRank_each_node = (dampingFactor / N)
+ (1-dampingFactor) * tempRank_each_node;
pageRank_each_node = tempRank_each_node;
tempRank_each_node = 0;
total += pageRank_each_node;
}
for each pageRank_each_node{
pageRank_each_node /= total;
}
}
}
Time
2
3n
2n
n
2n
3n
22n
23n
33n
3n
3n
25n
2n
2n
22n
23n
219
Implementasi
Page Rank
Menggunakan PHP.
Penggunan :
$data = array(
1=> array(2, 3),
2=> array(3),
3=> array(1),
);
print_r(calculatePageRank($data));
Output :
Array
(
[1] => 0.35896809895833
[2] => 0.25640869140625
[3] => 0.38462320963542
)
1 function calculatePageRank($
link
Graph, $dampingFactor = 0.85) {
2 $pageRank = array();
3 $tempRank = array();
4 $nodeCount = count($
link
Graph);
5 foreach($
link
Graph as $node => $outbound) {
6 $pageRank[$node] = 1/$nodeCount;
7 $tempRank[$node] = 0;
8 }
9 $change = 1;
10 $i = 0;
11 while($change > 0.005 && $i < 5) {
12 $change = 0;
13 $i++;
14 foreach($
link
Graph as $node => $outbound) {
15 $outboundCount = count($outbound);
16 foreach($outbound as $
link
) {
17 $tempRank[$
link
] += $pageRank[$node] / $outboundCount;
18 }
19 }
20 $total = 0;
21 foreach($
link
Graph as $node => $outbound) {
22 $tempRank[$node] = ($dampingFactor / $nodeCount)
+ (1-$dampingFactor) * $tempRank[$node];
23 $change += abs($pageRank[$node] - $tempRank[$node]);
24 $pageRank[$node] = $tempRank[$node];
25 $tempRank[$node] = 0;
26 $total += $pageRank[$node];
27 }
28 foreach($pageRank as $node => $score) {
29 $pageRank[$node] /= $total;
30 }
31 }
20
Lampiran 5 Karakter-karakter Khusus.
Sumber : www.lookuptables.com
Regular expression
dengan PHP.
preg_replace("'<style[^>]*>.*</style>'",'', [halaman web]);
preg_replace("'<script[^>]*>.*</script>'",'', [halaman web]);
preg_replace("/[~`!#$%^*()+={}\[\]|\"';:<>?,]/", " ",[halaman web])
21
Lampiran 6 Data Mentah untuk Evaluasi.
Hasil Algoritme
Breadth First
.
No Relevan Link Fetch Time Similarity
1 1 http://www.deptan.go.id/news/ 0,00845385 0,283713
2 1 http://www.deptan.go.id/news/detail.php?id=841; 0,00459695 0,357691
3 1 http://www.deptan.go.id/news/detail.php?id=840; 0,00457096 0,247345
4 1 http://www.deptan.go.id/news/detail.php?id=839; 0,005018 0,271648
5 1 http://www.deptan.go.id/news/detail.php?id=838; 0,00459909 0,2553
6 1 http://www.deptan.go.id/news/detail.php?id=837; 0,00539804 0,259711
7 0 http://www.deptan.go.id/news/arsipberita.php?page=1 0,00540686 0,236952
8 0 http://www.deptan.go.id/news/detail.php?id=815; 0,00483918 0,152208
9 1 http://www.deptan.go.id/news/detail.php?id=813; 0,0046351 0,256796
10 0 http://www.deptan.go.id/news/detail.php?id=812; 0,00445318 0,214397
11 0 http://www.deptan.go.id/news/detail.php?id=811; 0,005584 0,208208
12 0 http://www.deptan.go.id/news/detail.php?id=810; 0,004812 0,196614
13 0 http://www.deptan.go.id/news/arsipberita_2.php?page=1 0,0059998 0,201254
14 1 http://www.antara-sumbar.com/id/berita/nusantara/d/22/131129/... 0,00536799 0,206559
15 1 http://www.metrotvnews.com/index.php/metromain/... 0,0037818 0,00826813
16 1 http://www.metrotvnews.com/index.php/metromain/news/... 0,00370789 0,00413803
17 1 http://www.metrotvnews.com/index.php/metromain/news/... 0,00360298 0,0041369
18 0 http://www.kpk.go.id/modules/news/article.php?storyid=1107 0,00434685 0,0149344
19 1 http://www.detikfinance.com/read/2009/... 0,00648689 0,0693375
20 0 http://www.agrina-online.com/redesign2.php?rid=19&aid=1579 0,00513887 0,15795
21 1 http://www.detikfinance.com/read/2008/... 0,00698709 0,00793151
22 0 http://www.deptan.go.id/news/arsipberita_lain.php?page=1 0,00691295 0,27377
23 0 http://www.depkominfo.go.id 0,00381994 0
24 1 http://www.deptan.go.id/news/detail.php?id=845 38,0044 0,287554
25 0 http://www.deptan.go.id/news/detail.php?id=844&awal=0&page=&kunci= 0,00542498 0,250183
26 1 http://www.deptan.go.id/news/detail.php?id=843&awal=0&page=&kunci= 0,00539303 0,295865
27 0 http://www.deptan.go.id/news/detail.php?id=842&awal=0&page=&kunci= 25,6848 0,275459
28 0 http://www.deptan.go.id/news/detailevent.php?id=149 0,0046041 0,223607
29 0 http://www.deptan.go.id/news/detailevent.php?id=148 0,00457788 0,191511
30 0 http://www.deptan.go.id/news/detailevent.php?id=147 0,00565791 0,20781
31 0 http://www.deptan.go.id/news/arsipevent.php 0,00736499 0,211148
32 0 http://www.deptan.go.id/news/pub_stat.php 0,000165939 0,158114
33 0 http://www.deptan.go.id/news/pub_newsletter.php 0,000196934 0,0668153
34 0 http://www.deptan.go.id/news/pub_journal.php 0,000192881 0,188982
35 0 http://www.deptan.go.id/news/pub_bulletin.php 0,00019908 0,2
36 0 http://www.deptan.go.id/news/detail.php?id=836 0,00548005 0,213708
37 0 http://www.deptan.go.id/news/detail.php?id=824 0,00655317 0,0927056
38 1 http://www.deptan.go.id/news/detail.php?id=821 0,00599098 0,0999735
39 1 http://www.deptan.go.id/news/detail.php?id=818 0,00557303 0,247013
22
No Relevan Link Fetch Time Similarity
41 0 http://twitter.com/kementan/ 11,5767 0,0711969
42 0 http://www.deptan.go.id/news/admin/info/ 0,000821829 0,0214768
43 1 http://www.deptan.go.id/news/detail.php?id=845&awal=&page=&kunci= 0,00542402 0,279654
44 1 http://www.deptan.go.id/news/detail.php?id=843&awal=&pag