MULTIDIMENSIONAL ASSOCIATION RULES MINING
UNTUK DATA KEBAKARAN HUTAN MENGGUNAKAN
ALGORITME FP-GROWTH DAN ECLAT
NUKE ARINCY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Multidimensional Association Rules Mining untuk Data Kebakaran Hutan Menggunakan Algoritme FP-Growth dan ECLAT benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2014
Nuke Arincy
ABSTRAK
NUKE ARINCY.
Multidimensional Association Rules Mining untuk Data Kebakaran Hutan Menggunakan Algoritme FP-Growth dan ECLAT. Dibimbing oleh IMAS SUKAESIH SITANGGANG.Bencana kebakaran hutan dan lahan merupakan permasalahan serius yang harus dihadapi bangsa Indonesia khususnya Provinsi Riau. Salah satu upaya pencegahan kebakaran hutan yaitu dengan mempelajari pola keterkaitan antar kejadian titik panas (hotspot) dengan karakteristik objek geografis terdekat titik panas. Tujuan penelitian ini adalah menerapkan metode aturan asosiasi multidimensi dengan algoritme Frequent Pattern Growth (FP-Growth) dan algoritme Equivalence Class Transformation (ECLAT) untuk menentukan pola keterkaitan antara kemunculan titik panas dan faktor-faktor pendukungnya. Sebagai bahan penentuan faktor kemunculan titik panas penelitian ini menggunakan minimum support 30% dan minimum confidence 80% dengan variabel target yaitu terjadinya titik panas. Hasil penelitian menunjukkan bahwa hubungan yang kuat antara terjadinya titik panas dan pengaruh faktor yang ditemukan dengan support terbesar 44.49%, confidence 100%, dan lift 1.02. Titik panas terjadi umumnya pada daerah yang memiliki curah hujan lebih besar atau sama dengan 3 mm/hari.
Kata Kunci: ECLAT , FP-Growth, hotspot, multidimensional association rules
ABSTRACT
NUKE ARINCY. Multidimensional Association Rules Mining for Forest Fires Data Using FP-Growth and ECLAT Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
Forest fires and land are a serious problem that must be solved by the Indonesian government including Riau Province.One of forest fires prevention effort is learning relationship patterns of hotspot occurences as fire indicators with characteristics of geographic objects where the hotspots occur. The objective of this research is to apply the multidimensional association rule mining method with Frequent Pattern Growth algorithm (FP-Growth) and Equivalence Class Transformation algorithm (ECLAT) to determine association patterns between hotspot occurrences and its supporting factors. The factors that influence hotspot occurrences were discovered on minimum support of 30% and minimum confidence of 80% with hotspot occurrence as the target attribute. The result of this research shows that strong relationships between hotspot occurrences and its influence factor were found with the the highest support of 44.49%, confidence of 100%, and lift of 1.02, where hotspot are mostly occurred in areas which has precipitation greater than or equal to 3 mm/day.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
MULTIDIMENSIONAL ASSOCIATION RULES MINING
UNTUK DATA KEBAKARAN HUTAN MENGGUNAKAN
ALGORITME FP-GROWTH DAN ECLAT
NUKE ARINCY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji: 1 Toto Haryanto, SKom MSi 2 Hari Agung Adrianto, SKom
Judul Skripsi : Multidimensional Association Rules Mining untuk Data Kebakaran Hutan Menggunakan Algoritme FP-Growth dan ECLAT
Nama : Nuke Arincy NIM : G64124054
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wa Ta'ala atas rahmat dan segala karunia-Nya sehingga skripsi ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juli 2014 ini adalah
data mining, dengan judul Multidimensional Association Rules Mining untuk Data Kebakaran Hutan Menggunakan Algoritme FP-Growth dan ECLAT.
Penyelesaian penelitian ini tidak lepas dari dukungan dan bantuan berbagai pihak. Penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya kepada kedua orang tua tercinta Warsono dan Ibunda Diyan Sudiana, kaka Nesya Wardhiani, adik Adha Indrayoga dan segenap keluarga besar penulis atas do’a serta dukungan yang diberikan. Kepada Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing, Bapak Hari Agung Adrianto, SKom MSi dan Bapak Toto Haryanto, SKom MSi selaku penguji. Kepada seluruh teman-teman penulis di Program S1 Ilmu Komputer Alih Jenis Angkatan 7.
Semoga karya ilmiah ini bermanfaat.
Bogor, November 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Data Penelitian 3
Association Rule Mining 3
Aturan Asosiasi Multidimensi 4
Algoritme FP-Growth 4
Algoritme ECLAT 6
Tahapan Penelitian 6
Lingkungan Pengembangan 7
HASIL DAN PEMBAHASAN 8
Data Penelitian 8
Pembentukan Aturan Asosiasi 10
Perbandingan Aturan Asosiasi Algoritme Apriori, FP-Growth, dan ECLAT 16
Visualisasi Aturan Asosiasi Algoritme FP-Growth 16
Penentuan Faktor Pendukung Kemunculan Titik Panas 17
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 19
DAFTAR PUSTAKA 19
DAFTAR TABEL
1 Interval jarak pusat kota ke titik panas (dist_city) 8 2 Interval jarak sungai ke titik panas (dist_river) 8 3 Interval jarak jalan besar ke titik panas (dist_road) 8
4 Interval jumlah penduduk km² (population) 8
5 Interval curah hujan (precipitation) 9
6 Interval jumlah sekolah per km² (school) 9
7 Interval suhu (screen_temp) 9
8 Nilai interval kecepatan angin 10 m (wind_speed) 9 9 Data terjadinya titik panas (hotspot_occurrence) 9
10 Data sumber pendapatan (income_source) 9
11 Data penutupan lahan (land_cover) 10
12 Data tipe lahan gambut (peatland_type) 10
13 Data kedalaman lahan gambut (peatland_depth) 10 14 Jumlah frequent itemset dari algoritme FP-Growth dan ECLAT 11 15 Jumlah aturan asosiasi algoritme Apriori, FP-Growth, dan ECLAT 12 16 Aturan asosiasi dari algoritme Apriori minimum support 30% dan
minimum confidence 80% 13 17 Aturan asosiasi dari algoritme FP-Growth minimum support 30% dan
minimum confidence 80% 14 18 Aturan asosiasi dari algoritme ECLAT minimum support 30% dan
minimum confidence 80% 15
DAFTAR GAMBAR
1 Algoritme FP-Growth 5
2 Tahapan penelitian 6
3 Scatter plot 17 aturan asosiasi yang mengandung
PENDAHULUAN
Latar Belakang
Bencana kebakaran hutan dan lahan merupakan permasalahan serius yang harus dihadapi bangsa Indonesia khususnya Provinsi Riau karena kerugian ekonomi yang ditimbulkan sangat tinggi. Selain kerusakan ekosistem, dampak dari kebakaran hutan tidak hanya secara nasional tetapi juga berpengaruh secara global. Hal ini disebabkan asap yang ditimbulkan dari kebakaran hutan sudah menjalar ke negara-negara tetangga. Untuk menyelesaikan masalah ini maka manajemen penanggulangan bahaya kebakaran harus berdasarkan hasil penelitian dan tidak lagi hanya mengandalkan dari terjemahan textbook atau pengalaman dari negara lain tanpa menyesuaikan dengan keadaan lahan di Indonesia (Saharjo 2000).
Salah satu upaya pencegahan kebakaran hutan yaitu dengan mempelajari pola keterkaitan antar kejadian titik panas (hotspot) dengan karakteristik objek geografis terdekat titik panas, sehingga faktor-faktor yang mungkin mempengaruhi kebakaran dapat ditentukan untuk memprediksi terjadinya titik panas. Konsep data mining sangat sesuai diterapkan untuk pencarian pola tersebut.
Data mining adalah proses menemukan hubungan yang menarik atau pola yang penting dalam dataset berukuran besar (Han et al. 2011). Teknik data mining
yang digunakan pada penelitian ini adalah multidimensional association rule mining.
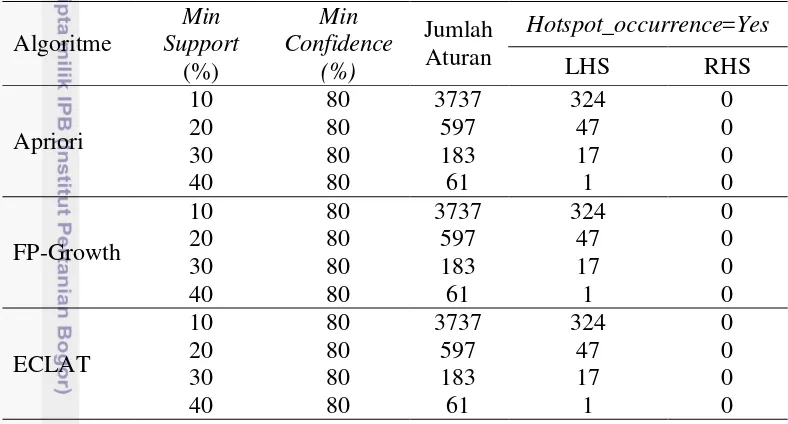
Penelitian mengenai pencarian pola keterkaitan antarlokasi kejadian titik panas sebagai indikator terjadinya kebakaran hutan dan karakteristik wilayah tempat titik panas terjadi sebelumnya telah dilakukan oleh Sitanggang (2013). Penelitian sebelumnya menggunakan teknik multidimensional association rules mining dengan algoritme Apriori. Algoritme Apriori pertama kali diperkenalkan oleh Agrawal dan Srikant (1994). Kelebihan algoritme Apriori yaitu setiap pola dengan panjang pola k yang tidak frequent atau tidak sering muncul dalam sebuah kumpulan data, maka pola dengan panjang (k+1) yang mengandung sub pola k
tersebut tidak frequent pula. Namun di sisi lain, algoritme Apriori harus melakukan scandataset setiap kali iterasi, sehingga meningkatkan waktu eksekusi algoritme. Penelitian sebelumnya oleh Sitanggang (2013) menghasilkan 324 aturan asosiasi multidimensi yang menunjukkan hubungan antara kejadian titik panas dengan faktor-faktor lainnya. Hubungan tersebut didapat pada nilai
minimumsupport 10% dan minimum confidence 80%.
2
yang dimiliki algoritme FP-Growth dan ECLAT, diharapkan pola keterkaitan titik panas dengan karakteristik wilayah yang dihasilkan akan lebih menarik berdasarkan nilai support, confidence, dan lift yang lebih tinggi. Selain itu jumlah aturan asosiasi yang dihasilkan lebih sedikit dibandingkan hasil dari penelitian sebelumnya karena algoritme FP-Growth (Han et al. 2011) dan algoritme ECLAT (Zaki 2000) pada saat pencarian frequent itemset lebih cepat dibandingkan algoritme Apriori.
Perumusan Masalah
Berdasarkan latar belakang di atas, perumusan masalah dalam penelitian ini adalah bagaimana menerapkan algoritme FP-Growth dan ECLAT untuk mencari pola keterkaitan antar lokasi kejadian titik panas dengan karakteristik wilayah tempat titik panas terjadi.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan metode multidimensional association rules mining dengan algoritme FP-Growth dan ECLAT pada dataset kebakaran hutan di Kabupaten Rokan Hilir Provinsi Riau Indonesia untuk menemukan pola keterkaitan antar lokasi kejadian titik panas dengan karakteristik wilayah tempat titik panas terjadi.
2 Menentukan faktor-faktor yang mempengaruhi terjadinya titik panas berdasarkan aturan asosiasi yang dihasilkan.
Manfaat Penelitian
Faktor-faktor yang mempengaruhi terjadinya titik panas yang dihasilkan dapat digunakan untuk memprediksi terjadinya titik panas di masa depan.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1 Data yang akan digunakan pada penelitian ini diperoleh dari peneliti sebelumnya yang dilakukan oleh Sitanggang (2013) dan data telah melalui tahap praproses.
2 Data kebakaran hutan yang digunakan adalah data untuk Kabupaten Rokan Hilir Provinsi Riau Indonesia. Data yang digunakan yaitu kemunculan titik panas tahun2008, penutupan lahan, jarak pusat kota ke titik panas, jarak sungai ke titik panas, jarak jalan besar ke titik panas, sumber pendapatan, jumlah penduduk per km², jumlah sekolah per km², curah hujan, kecepatan angin, suhu, jenis lahan gambut, dan kedalaman lahan gambut.
3
METODE
Data Penelitian
Data dan sumber data yang digunakan dalam penelitian ini sebagai berikut: 1 Data penyebaran dan koordinat titik panas tahun2008. Data diperoleh
dari Fire Information for Resource Management System(FIRMS), University of Maryland, NASA, Conservation International.
2 Peta digital untuk penutupan lahan, jalan besar, sungai, dan pusat kota. Data diperoleh dari Badan Koordinasi Survei dan Pemetaan Nasional (BAKOSURTANAL) Indonesia.
3 Data sosial ekonomi meliputi sumber pendapatan penduduk, jumlah penduduk per km², dan jumlah sekolah per km². Data diperoleh dari Badan Pusat Statistik (BPS) Indonesia.
4 Data Cuaca (dalam format netCDF) tahun 2008 meliputi curah hujan, kecepatan angin, dan suhu. Data diperoleh dari Badan Meteorologi Klimatologi dan Geofisika Badan (BMKG) Indonesia.
5 Peta digital untuk kedalaman lahan gambut dan jenis lahan gambut. Data disediakan oleh Wetland International.
Seluruh data telah melalui tahap praproses dalam penelitian sebelumnya oleh Sitanggang (2013).
Association Rule Mining
Association rule mining digunakan untuk mencari hubungan yang menarik antar item-item yang tersembunyi dalam sebuah dataset yang berukuran besar. Ukuran kemenarikan dalam menentukan suatu association rule mining yaitu (Han
et al. 2011):
a Support, perbandingan terjadinya sebuah itemset terhadap jumlah seluruh transaksidalam dataset. Persamaannya sebagai berikut:
b Confidence, menunjukkan kekuatan hubungan antar-itemset pada sebuah aturan asosiasi. Persamaannya sebagai berikut:
c Correlation, alternatif lain dalam menemukan hubungan kemenarikan antar
itemset. Hubungan kemenarikan dapat ditentukan dengan cara menghitung nilai lift. Persamaannya sebagai berikut:
4
Jika nilai lift (A, B) lebih besar dari 1 maka A dan B berkorelasi positif artinya bahwa kejadian A menunjukan adanya saling keterkaitan dengan kejadian B. Jika nilai lift (A, B) kurang dari 1 maka A dan B berkorelasi negatif artinya bahwa kejadian A tidak menunjukkan adanya saling keterkaitan dengan kejadian B.
Aturan Asosiasi Multidimensi
Aturan asosiasi multidimensi merupakan aturan yang ditemukan dari dataset
yang berisi lebih dari satu variabel. Ada dua macam model untuk aturan asosiasi multidimensi, yaitu (Han et al. 2011):
a Interdimensional association rule, contoh:
Aturan tersebut mengandung tiga variabel (age, occupation dan buys).
Interdimensional association rule adalah aturan dalam aturan asosiasi multidimensi dengan tanpa perulangan predikat.
b Hybrid-dimensional association rule, contoh:
Aturan tersebut mengandung dua variabel (age dan buys). Model hybrid-dimensional association rule memperbolehkan terjadinya pengulangan predikat pada sebuah aturan.
Kedua model tersebut yang membedakan adalah model interdimensional association rule tidak diperbolehkan adanya pengulangan predikat yang sama pada sebuah aturan, sementara hybrid-dimensional association rule
memperbolehkan terjadinya pengulangan predikat pada sebuah aturan.
Algoritme FP-Growth
Algoritme FP-Growth merupakan perluasan dari algoritme Apriori yang telah ada sebelumnya. Struktur data yang digunakan untuk mencari frequent itemset dengan algoritme FP-Growth yaitu menggunakan sebuah pohon prefix
(disebut juga FP-tree). Dengan menggunakan FP-Tree, algoritme FP-Growth dapat langsung mengekstrak frequent itemset dari FP-Tree yang telah terbentuk (Han et al. 2011).
1 Pembentukan FP-Tree
FP-tree adalah sebuah tree yang terdiri dari satu header table, satu
root, dan satu himpunan item prefix subtree sebagai node dari anak root. Algoritme pembentukan FP-Tree secara garis besar sebagai berikut (Han et al. 2000):
a Telusuri transaksi dataset (D) untuk menemukan semua item yang terdapat dalam dataset. Setiap item sesuai diurutkan dengan frekuensi dan jumlah support setiap item terbesar sampai terkecil.
5 ada dalam daftar transaksi. Kemudian fungsi insert_tree ([p|P],T) dijalankan.
Jika root (T) memiliki anak atau child (N) dengan N.nama-child = p.nama-node yang baru maka tambah N dengan nilai 1. Selainnya buat
node baru dengan nilai 1, jika ada node yang sama dengan
N.nama-child hubungkan dengan sebuah node link. Jika P tidak kosong panggil
insert_tree (P,N) secara rekursif.
2 Pembentukan frequent itemset dengan algoritme FP-Growth
Setelah tahap pembentukan FP-tree dari sekumpulan data transaksi, akan diterapkan algoritme FP-Growth untuk mencari frequent itemset yang signifikan. Algoritme FP-growth dibagi menjadi tiga langkah utama, yaitu: a Tahap pembangkitan conditional pattern base
Pembangkitan conditional pattern base didapatkan melalui FP-Tree yang telah dibangun sebelumnya.
b Pembangkitan conditional FP-Tree
Pada tahap ini support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah
support count lebih besar sama dengan minimum support count akan dibangkitkan dengan conditional FP-Tree.
c Pencarian frequent itemset
Berikut algoritme FP-Growth yang digunakan untuk mendapatkan
frequent itemset dapat dilihat pada Gambar 1 (Han et al. 2000).
Gambar 1 Algoritme FP-Growth
Pada algoritme FP-Growth apabila conditional FP-Tree merupakan
single path (P), maka akan didapatkan frequent itemsets dengan melakukan kombinasi item untuk setiap conditional FP-Tree. Selain itu dilakukan pembangkitan FP-Growth secara rekursif.
Input: FP-tree Tree, minimum support
Output:Sekumpulan lengkap frequent pattern
Method: FP-growth(Tree,null)
minimum support dari node-node dalam β;
6
Algoritme ECLAT
Algoritme ECLAT membangkitkan kandidatnya dengan pencarian depth-first dan menggunakan interseksi (titik potong) tid-list antar item-nya (Borgelt 2003). Dalam prosesnya algoritme ECLAT didefinisikan secara rekursif, artinya proses pencarian itemset yang diinginkan akan terjadi secara berkesinambungan sepanjang masih ada itemset yang tersisa. Metode pembentukan itemset pada algoritme ECLAT (Zaki 1997) yaitu:
1 Nyatakan setiap item dalam tabel tid-list secara vertikal
2 Menentukan nilai minimum support dari setiap k-itemset dengan interseksi tid-list dari kedua (k-1) subset. Pendekatan interseksinya adalah bottom-up. Keuntungan dari algoritme ECLAT ialah proses perhitungan frequent itemset lebih cepat dibandingkan dengan algoritme Apriori (Zaki et al. 2000). Hal ini disebabkan proses pencarian itemset-nya secara mendalam dan ketika telah ditemukan itemset yang sering dikunjungi maka proses berakhir. Berbeda pada algoritme Apriori yang proses pencariannya secara melebar sehingga hal ini membutuhkan waktu yang cukup lama untuk menentukan frequent itemset.
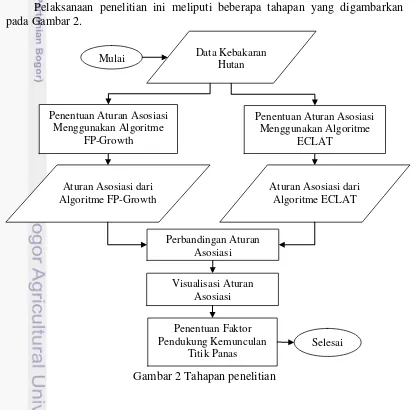
Tahapan Penelitian
7 Penentuan Aturan Asosiasi Menggunakan Algoritme FP-Growth
Pada tahapan ini dilakukan proses pencarian frequent itemset dengan menggunakan algoritme FP-Growth. Pada algoritme FP-Growth penentuan
frequent itemset dilakukan melalui 2 tahap proses yaitu: pembuatan FP-Tree dan penerapan algoritme FP-Growth untuk menemukan frequent itemset. Ketika
frequent itemset telah didapatkan maka akan dibentuk aturan asosiasi yang memenuhi minimum support dan minimum confidence.
Penentuan Aturan Asosiasi Menggunakan Algoritme ECLAT
Pada tahapan ini proses yang dilakukan sama seperti tahapan sebelumnya yaitu pencarian frequent itemsets, tetapi menggunakan algoritme yang berbeda yaitu algoritme ECLAT. Algoritme ECLAT direpresentasikan secara vertikal dalam dataset (Borgelt 2003). Ketika frequent itemset telah didapatkan maka akan dibentuk aturan asosiasi yang memenuhi minimum support dan minimum confidence.
Perbandingan Aturan Asosiasi
Pada tahapan ini dilakukan perbandingan aturan asosiasi yang telah dihasilkan oleh algoritme FP-Growth dan ECLAT. Dari aturan asosiasi kedua algoritme tersebut dipilih pola keterkaitan titik panas dengan karakteristik wilayah yang paling menarik berdasarkan nilai support dan confidence.
Visualisasi Aturan Asosiasi
Pada tahapan ini proses yang dilakukan adalah visualisasi aturan asosiasi. Teknik visualisasi digunakan untuk penggambaran aturan asosiasi yang telah dihasilkan. Ada beberapa macam visualisasi untuk aturan asosiasi seperti scatter plot, balloon plot, graph, dan parallel coordinates plot. Penelitian ini hasil aturan asosiasi digambarkan dengan menggunakan scatter plot.
Penentuan Faktor Pendukung Kemunculan Titik Panas
Pada tahapan ini aturan asosiasi yang telah dipilih dari salah satu algoritme dianalisis untuk mencari faktor-faktor yang mempengaruhi terjadinya titik panas.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi
Intel Core 2 Duo CPU 2.13 GHz.
RAM 2 GB.
Harddisk 360 GB. 2 Perangkat lunak
Sistem operasi Windows 7 Ultimate.
Tool komputasi statistik R versi 3.0.3.
Microsoft Excel 2007 untuk mengolah data.
8
HASIL DAN PEMBAHASAN
Data Penelitian
Data yang digunakan pada penelitian ini diperoleh dari peneliti sebelumnya yaitu oleh Sitanggang (2013). Data telah melalui tahap praproses dan sudah dalam format (.csv). Dataset berisi 490 transaksi dan 12 variabel dengan 1 variabel menyatakan kelas target. Beberapa data telah melalui tahap transformasi yaitu data numerik dikonversi menjadi sebuah interval. Data yang dikonversi adalah data lingkungan fisik pada variabel jarak pusat kota ke titik panas (dist_city), jarak sungai ke titik panas (dist_river), dan jarak jalan besar ke titik panas (dist_road). Untuk data sosial ekonomi pada variabel jumlah penduduk per km² (population), dan jumlah sekolah per km² (school). Kemudian untuk data cuaca pada variabel curah hujan (precipitation), suhu (screen_temp), dan kecepatan angin 10 m (wind_speed). Interval dan jumlah data yang dibentuk dapat dilihat pada Tabel 1 sampai Tabel 8.
Tabel 1 Interval jarak pusat kota ke titik panas (dist_city)
Dist_city Jumlah data
<=7 km 134
(7 km,14 km] 230
>14 km 126
Tabel 2 Interval jarak sungai ke titik panas (dist_river)
Dist_river Jumlah data
<=1.5 km 219
(1.5 km, 3 km] 120
>3 km 151
Tabel 3 Interval jarak jalan besar ke titik panas (dist_road)
Dist_road Jumlah data
<=2.5 km 275
(2.5 km,5 km] 100
>5 km 115
Tabel 4 Interval jumlah penduduk km² (population)
Population Jumlah data
<= 50 332
(50, 100] 115
9
Tabel 5 Interval curah hujan (precipitation)
Precipitation Jumlah data [2 mm/day, 3 mm/day) 12
>=3 mm/day 478
Tabel 6 Interval jumlah sekolah per km² (school)
School Jumlah data <= 0.1 405 (0.1, 0.2] 60
> 0.2 25
Tabel 7 Interval suhu (screen_temp)
Screen_temp Jumlah data [297 K, 298 K) 372 [298 K, 299 K) 118
Tabel 8 Nilai interval kecepatan angin 10 m (wind_speed)
Wind_speed Jumlah data [0 m/s, 1 m/s) 149 [1 m/s, 2 m/s) 341
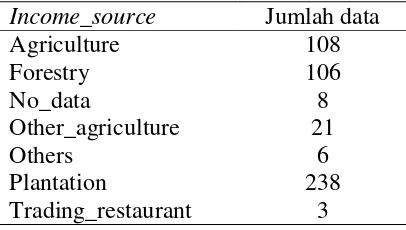
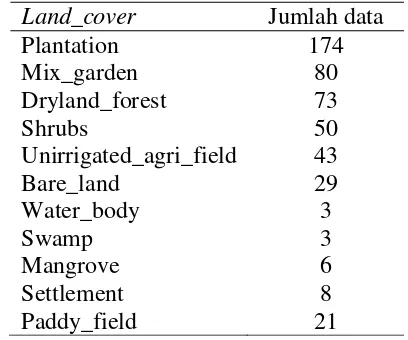
Selain data pada Tabel 1 sampai Tabel 8 data lain yang digunakan pada penelitian ini, seperti data sosial ekonomi yaitu sumber pendapatan (income_source), data lingkungan fisik yaitu penutupan lahan (land_cover), tipe lahan gambut (peatland_type), kedalaman lahan gambut (peatland_depth), dan terjadinya titik panas (hotspot_occurrence). Variabel terjadinya titik panas (hotspot_occurrence) digunakan sebagai kelas target. Tabel 9 sampai Tabel 13 beberapa data yang digunakan pada penelitian.
Tabel 9 Data terjadinya titik panas (hotspot_occurrence)
Hotspot_occurrence Jumlah data
No 272
Yes 218
Tabel 10 Data sumber pendapatan (income_source)
10
Tabel 11 Data penutupan lahan (land_cover)
Land_cover Jumlah data
Tabel 12 Data tipe lahan gambut (peatland_type)
Peatland_type Jumlah data
Tabel 13Data kedalaman lahan gambut (peatland_depth)
Peatland_depth Jumlah data
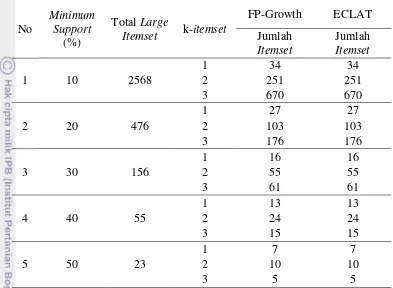
1 Frequent itemset menggunakan algoritmeFP-Growth dan ECLAT Pembentukan frequent itemset digunakan untuk melihat seberapa sering kemunculan itemset dalam dataset. Algoritme FP-Growth frequent itemset
dihasilkan menggunakan aplikasi pemrograman C dalam format .exe yang dijalankan pada command prompt (CMD). Program FP-Growth tersebut diperoleh dari (http://www.borgelt.net/fpgrowth.html). Untuk algoritme ECLAT frequent itemset yang dihasilkan menggunakan aplikasi statistika R dengan menggunakan
11 40%, dan 50%. Tabel 14 merupakan jumlah frequent itemset yang terbentuk untuk setiap minimum support yang diperolehalgoritme FP-Growth dan ECLAT.
Tabel 14 Jumlah frequent itemset dari algoritme FP-Growth dan ECLAT
No
Berdasarkan Tabel 14 pengujian frequent itemset dilakukan sampai dengan
minimum support 50% karena dalam pengujian minimum support 60% pada
3-itemset jumlah yang dihasilkan hanya 2, sehingga tidak dilakukan penentuan
frequent itemset pada minimum support di atas 60%. Hasil tersebut menunjukan jumlah frequent itemset kedua algoritme sama dan semakin kecil nilai minimum support-nya maka semakin banyak frequent itemset yang dihasilkan.
2 Aturan asosiasi algoritme Apriori, FP-Growth, dan ECLAT
Pada penelitian sebelumnya oleh Sitanggang (2013), aturan asosiasi dihasilkan dengan menggunakan algoritme Apriori. Aplikasi statistika R telah menyediakan algoritme Apriori dengan menggunakan package arules langsung membentuk aturan asosiasinya dan penelitian sebelumnya menghasilkan 2981 aturan. Tujuan dari penelitian adalah menemukan faktor-faktor yang sangat mungkin mempengaruhi terjadinya titik panas. Oleh karena itu, analisis aturan asosiasi hanya mencakup terjadinya titik panas (hotspot_occurrence=Yes). Ada 324 aturan atau sekitar 10.87% mengandung terjadinya titik panas yang dihasilkan dari dataset dengan nilai default minimum support 10% dan minimum confidence
80%.
12
tersedia package-nya, maka frequent itemset dihasilkan menggunakan aplikasi pemrograman C dalam format .exe yang dijalankan pada command prompt
(CMD). Untuk algoritme ECLAT aplikasi R hanya dapat menghasilkan frequent itemset meggunakan package arules. Oleh karena itu, pada saat pembentukan aturan asosiasi berdasarkan frequent itemset yang diperoleh dari algoritme FP-Growth dan ECLAT menggunakan aplikasi sederhana yang dibuat dengan bahasa pemrograman PHP. Tabel 15 merupakan jumlah aturan asosiasi yang dihasilkan algoritme Apriori, FP-Growth, dan ECLAT dengan minimum support 10%, 20%, 30%, 40%, dan minimum confidence 80%. Pada Tabel 15 Left Hand Side (LHS) sebagai antecedent dan Right Hand Side (RHS) sebagai consequent.
Tabel 15 Jumlah aturan asosiasi algoritme Apriori, FP-Growth, dan ECLAT Algoritme
Berdasarkan Tabel 15 pengujian dilakukan sampai dengan minimum support
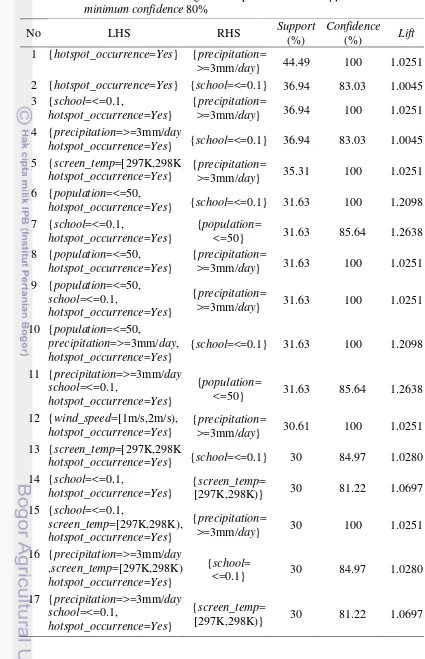
13 Tabel 16 Aturan asosiasi dari algoritme Apriori minimum support 30% dan
14
1 hotspot_occurrence=Yes precipitation=
>=3mm/day 44.49 100 1.0251
2 school=<=0.1,
hotspot_occurrence=Yes
precipitation=
>=3mm/day 36.94 100 1.0251
3 hotspot_occurrence=Yes,
precipitation=>=3mm/day school=<=0.1 36.94 83.03 1.0045
4 hotspot_occurrence=Yes school=<=0.1 36.94 83.03 1.0045
5 screen_temp=[297K;298K),
hotspot_occurrence=Yes
precipitation=
>=3mm/day 35.31 100 1.0251
6 hotspot_occurrence=Yes,
school=<=0.1,
8 precipitation=>=3mm/day,
population=<=50,
hotspot_occurrence=Yes
school=<=0.1 31.63 100 1.2098
9 population=<=50,
hotspot_occurrence=Yes school=<=0.1 31.63 100 1.2098
10 population=<=50,
13 hotspot_occurrence=Yes,
precipitation=>=3mm/day,
school=<=0.1
screen_temp=
[297K;298K) 30 81.22 1.0697
14 hotspot_occurrence=Yes,
school=<=0.1
hotspot_occurrence=Yes school=<=0.1 30 84.97 1.0280
17 school=<=0.1,
screen_temp=[297K;298K),
hotspot_occurrence=Yes
precipitation=
15
1 hotspot_occurrence=Yes precipitation=>=
3mm/day 44.49 100 1.0251
2 school=<=0.1,
hotspot_occurrence=Yes
precipitation=>=
3mm/day 36.94 100 1.0251
3 hotspot_occurrence=Yes,
precipitation=>=3mm/day school=<=0.1 36.94 83.03 1.0045
4 hotspot_occurrence=Yes school=<=0.1 36.94 83.03 1.0045
5 screen_temp=[297K;298K),
hotspot_occurrence=Yes
precipitation=>=
3mm/day 35.31 100 1.0251
6 precipitation=>=3mm/day,
school=<=0.1,
8 hotspot_occurrence=Yes,
population=<=50,
precipitation=>=3mm/day
school=<=0.1 31.63 100 1.2098
9 hotspot_occurrence=Yes,
population=<=50 school=<=0.1 31.63 100 1.2098
10 school=<=0.1,
hotspot_occurrence=Yes,
population=<=50
precipitation=
>=3mm/day 31.63 100 1.0251
11 hotspot_occurrence=Yes,
population=<=50
13 hotspot_occurrence=Yes,
precipitation=>=3mm/day,
school=<=0.1
screen_temp=
[297K;298K) 30 81.22 1.0697
14 hotspot_occurrence=Yes,
16
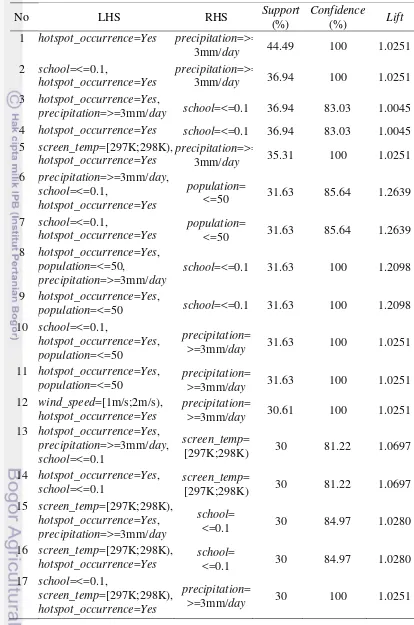
Berdasarkan Tabel 16 sampai Tabel 18, aturan asosiasi yang dihasilkan algoritme Apriori, FP-Growth, dan ECLAT pada setiap aturannya memiliki nilai
support, confidence, dan lift yang sama. Urutan aturan asosiasi yang dihasilkan berdasarkan nilai support tertinggi sampai terendah. Untuk setiap aturan Left Hand Side (LHS) sebagai antecedent dan Right Hand Side (RHS) sebagai
consequent. Dengan nilai minimum support 30%, berarti 147 transaksi dari 490 transaksi mendukung aturan asosiasi yang dihasilkan. Dari ketiga algoritme tersebut, 17 aturan dengan nilai minimum support 30% dan minimum confidence
80% hanya terdapat data sosial ekonomi dan cuaca yang muncul bersama terjadinya titik panas (hotspot_occurrence=Yes). Data sosial ekonomi yang muncul dalam aturan yaitu school=≤0.1 dan population=≤50. Data cuaca yang muncul dalam aturan yaitu precipitation=>=3 mm/hari, screen_temp=[297 K, 298 K), dan wind_speed=[1 m/s, 2 m/s). Aturan yang muncul pada urutan pertama adalah aturan terkuat yang dihasilkan dari dataset kebakaran hutan. Aturan pertama mendapat nilai support 44.49%, confidence 100%, dan lift 1.02. Dengan aturan tersebut dinyatakan bahwa sekitar 44.49% dari transaksi dalam dataset
yang berisi hotspot_occurrence=Yes mengandung juga data cuaca yaitu curah hujan lebih besar atau sama dengan 3 mm/hari. Nilai lift dari aturan tersebut lebih besar dari 1 berarti bahwa terjadinya titik panas dengan curah hujan lebih besar atau sama dengan 3 mm/hari berkorelasi positif.
Perbandingan Aturan Asosiasi Algoritme Apriori, FP-Growth, dan ECLAT
Dari hasil pengujian algoritme Apriori, FP-Growth, dan ECLAT pada penelitian ini dihasilkan aturan asosiasi yang sama, baik jumlah frequent itemset -nya maupun jumlah aturan asosiasi yang dihasilkan. Urutan aturan yang dihasilkan ada beberapa yang berbeda tetapi masih dalam nilai support,
confidence, dan lift yang sama. Walaupun proses membangkitkan frequent itemset ketiga algoritme ini berbeda, jumlah frequent itemset yang dihasilkan tetap sama. Hal ini dapat disebabkan jumlah transaksi yang belum terlalu banyak dan perbedaan pada ketiga algoritme ini yaitu hanya pada waktu pencarian frequent itemset saja. Pada penelitian ini waktu pemrosesan tidak diperhatikan karena proses membangkitkan frequent itemset menggunakan aplikasi yang berbeda-beda.
Visualisasi Aturan Asosiasi Algoritme FP-Growth
17
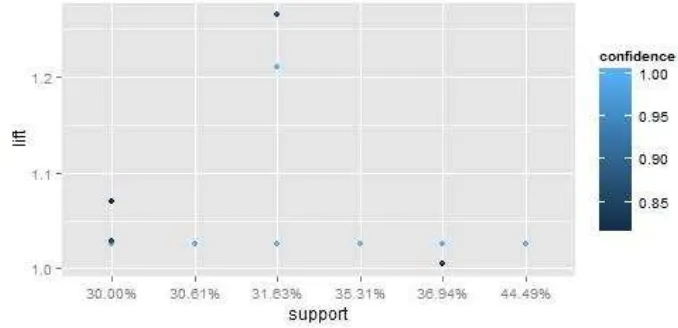
Gambar 3 Scatter plot 17 aturan asosiasi yang mengandung
hotspot_occurrence =Yes
Setiap titik yang terdapat pada plot merupakan aturan. Nilai support dan lift
digunakan pada sumbu x dan y, selain itu warna pada titik menunjukan nilai
confidence dari aturan. Pada bagian kanan bawah pada Gambar 3 ada satu titik dengan nilai support tertinggi yaitu 44.49%. Untuk bagian kiri atas ada dua titik dengan nilai lift tertinggi yaitu 1.26. Nilai confidence tertinggi dengan warna biru paling muda yaitu 1 terdapat pada 9 titik.
Penentuan Faktor Pendukung Kemunculan Titik Panas
Penelitian sebelumnya oleh Sitanggang (2013) menggunakan minimum support 10% dan minimum confidence 80%. Hasil penelitian menunjukkan bahwa hubungan yang kuat antara terjadinya titik panas dan pengaruh faktor yang ditemukan dengan support 12.42%, confidence 100%, dan lift 2.26. Faktor curah hujan lebih besar dari atau sama dengan 3 mm/hari, kecepatan angin 10 m dalam interval [1 m/s, 2 m/s), di daerah non gambut, dengan suhu dalam interval [297 K, 298 K), jumlah sekolah dalam 1 km² kurang dari atau sama dengan 0.1, dan jarak masing-masing titik panas dari jalan terdekat kurang dari atau sama dengan 2.5 km.
Aturan asosiasi yang dihasilkan penelitian ini dengan minimum support 30% dan minimum confidence 80% pada algoritme FP-Growth mengasilkan 17 aturan. Aturan pertama dalam Tabel 17 dengan support 44.49%, confidence 100%, dan
18
dengan 3mm/hari, jumlah sekolah km² kurang dari atau sama dengan 0.1, dan suhu dalam interval [297K, 298K]. Aturan keenam dalam Tabel 17 menyatakan bahwa titik panas terjadi di daerah yang memiliki curah hujan lebih besar dari atau sama dengan 3mm/hari, memiliki jumlah penduduk per km² kurang atau sama dengan 50, dan jumlah sekolah 1 km² kurang dari atau sama dengan 0.1. Aturan keduabelas dalam Tabel 17 titik panas terjadi di daerah dengan kisaran kecepatan angin 10 m dalam interval [1 m/s, 2 m/s) dan memiliki curah hujan lebih besar dari atau sama dengan 3 mm/hari.
Berdasarkan data cuaca yang muncul pada aturan asosiasi seperti variabel curah hujan, menurut penelitian Hadi (2008) bahwa curah hujan merupakan salah satu faktor yang paling menetukan terjadinya kebakaran hutan atau curah hujan menunjukan korelasinya terhadap terjadinya kebakaran hutan. Untuk data faktor sosial ekonomi pada aturan asosiasi seperti titik panas terjadi pada daerah yang memiliki jumlah sekolah dalam 1 km² kurang atau sama dengan 0.1 dan jumlah penduduk kurang atau sama dengan 50. Menurut penelitian Mangandar (2000) tentang keterkaitan sosial masyarakat di sekitar hutan dengan kebakaran hutan daerah penelitian Kabupaten Kampar dan Bengkalis Provinsi Riau, bahwa jumlah sekolah yang sedikit dan sulitnya masyarakat memperoleh pendidikan formal yang tinggi disebabkan lokasi tempat bermukim masyarakat jauh dari kota. Hal ini menyebabkan 70% tingkat pendidikan masyarakat hanya mengecap Sekolah Dasar (SD). Hubungan rendahnya tingkat pendidikan formal dengan kebakaran hutan disebabkan karena kurangnya pengetahuan manfaat hutan sebagai areal konservasi dan bahaya kebakaran hutan sehingga masyarakat tetap melakukan tindakan-tindakan yang merusak hutan seperti membakar hutan.
SIMPULAN DAN SARAN
Simpulan
Struktur data yang berbeda antar algoritme Apriori, FP-Growth, dan ECLAT tidak mempengaruhi frequent itemset dan aturan asosiasi yang dihasilkan. Penelitian ini tidak dilakukan perbandingan waktu eksekusi pada algoritme FP-Growth dan ECLAT karena lingkungan implementasi pencarian frequent itemset
berbeda-beda. Algoritme FP-Growth pencarian frequent itemset menggunakan pemrograman C yang dijalankan pada command promt (CMD), untuk algoritme ECLAT pencarian frequent itemset menggunakan aplikasi R dengan menggunakan package arules.
Pada penelitian ini, sebagai faktor penentu terjadinya titik panas digunakan nilai minimum support 30% dan minimum confidence 80% dengan variabel target terjadinya titik panas (hotspot_occurrence). Hasil penelitian menunjukkan bahwa hubungan yang kuat antara terjadinya titik panas dengan karakeristik wilayah tempat titik panas terjadi yang ditemukan dengan support terbesar 44.49%,
19 kurang sama dengan 50, suhu dalam interval [297 K, 298 K), dan kecepatan angin 10 m dalam interval [1 m/s, 2 m/s).
Saran
Saran untuk penelitian selanjutnya adalah dilakukan perbandingan waktu eksekusi algoritme untuk menentukan frequent itemset pada algoritme Apriori, FP-Growth, dan ECLAT.
DAFTAR PUSTAKA
Agrawal R, Srikant R. 1994. Fast algorithms for mining association rules.
Proceedings of 20th International Conference on Very Large Data Bases
[Internet]. [diunduh 2014 Juni 7]. San Fransisco (US): Morgan Kaufmann Publisher. hlm 487-499. Tersedia pada: http://rakesh.agrawal-family.com/papers/vldb94apriori.pdf.
Borgelt C. 2003. Efficient implementations of Apriori and Eclat. Workshop Proceedings 90 of Frequent Item Set Mining Implementations [Internet]. [diunduh 2014 Mei 5]. Melbourne, FL (US) : IEEE. Tersedia pada: http://www.intsci.ac.cn/shizz/fimi.pdf.
Han J, Kamber M, Pei J. 2011. Data Mining Concepts and Techniques third Edition. San Fransisco (US): Elsevier.
Han J, Pie J, Yin Y. 2000. Mining frequent patterns without candidate generation.
Proceedings of the 2000 ACM SIGMOD international conference on Management of data [Internet]. [diunduh 2014 Juni 30]; 29 (2): 1-12. Tersedia pada: www.cs.uiuc.edu/~hanj/pdf/sigmod00.pdf.
Hadi DP. 2008. A RS/GIS–based multi-criteria approaches to assess forest fire hazard in Indonesia. [tesis]. Bogor (ID): Institut Pertanian Bogor.
Mangandar. 2000. Keterkaitan sosial masyarakat di sekitar hutan dengan kebakaran hutan. [tesis]. Bogor (ID): Institut Pertanian Bogor.
Saharjo BH. 2000. Penyiapan Lahan untuk Pembangunan Hutan Tanaman Industri (HTI). Bogor (ID): Fakultas Kehutanan, Institut Pertanian Bogor. Sitanggang IS. 2013. Spatial multidimensional association rules mining in forest
fire data. Journal of Data Analysis and Information Processing. 1(4): 90-96. Zaki MJ. 1997, Parthasarathy S, Ogihara M, Li W. New algorithms for fast discovery of association rules. 3rd International Conference on Knowledge and Data Engineering [Internet]. [diunduh 2014 Mei 5]. 283-286. Tersedia pada: http://www.aaai.org/Papers/KDD/1997/KDD97-060.pdf.
20
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 11 Januari 1991 dari ayah Warsono dan ibu Diyan Sudiana. Penulis adalah putri kedua dari tiga bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 1 Bogor dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) Program Diploma 3 Teknik Komputer melalui jalur Undangan Seleksi Masuk IPB. Penulis menyelesaikan pendidikan Program Diploma 3 selama tiga tahun dan lulus pada tahun 2012. Kemudian penulis melanjutkan pendidikan Program Sarjana Ilmu Komputer Alih Jenis Departemen Ilmu Komputer FMIPA IPB.