PENERAPAN ALGORITME PREFIXSPAN DAN CLOSPAN
UNTUK MENCARI POLA SEKUENSIAL PADA DATA
PEMINJAMAN BUKU DI PERPUSTAKAAN IPB
DEVI MEISITA KHAIRUNNISA
DEPARTEMEN ILMU KOMPUTER FAKULTAS ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan Algoritme Prefixspan dan Clospan untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB benar karya saya denganarahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
DEVI MEISITA KHAIRUNNISA. Penerapan Algoritme Prefixspan dan Clospan untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB. Dibimbingoleh IMAS SUKAESIH SITANGGANG dan BADOLLAHI MUSTAFA.
Perpustakaan merupakan suatu fasilitas yang memiliki peranan penting dalam pendidikan. Dari data perpustakaan didapatkan berbagai informasi, salah satunya pola peminjaman buku oleh pengguna perpustakaan. Penelitian ini bertujuan untuk menentukan pola sekuensial pada data peminjaman buku di perpustakaan IPB dengan menggunakan algoritme Prefixspan dan Clospan. Penelitian ini menggunakandataset berukuran mulai dari 50 sampai 4,140 dengan minimum support mulai dari 5% sampai 15%. Hasil percobaan menunjukkan bahwa semakin besar dataset dan minimum support yang dipakai, algoritme Clospan memiliki kinerja lebih baik daripada Prefixspan. Selain itu, pola sekuensial yang dihasilkan kedua algoritme menunjukkan keterkaitan antar item yaitu kode 027 (kategori perpustakaan) dengan kode 820 (kategori sastra), buku dengan kode 631 (kategori manajemen pertanian) dengan kode 636 (kategori buku peternakan dan manajamen peternakan), buku dengan kode 631 dengan kode 658 (kategori manajemen, administrasi bisnis dan organisasi bisnis).
Kata kunci: pola sekuensial, data transaksi sirkulasi perpustakaan, Prefixspan, Clospan
ABSTRACT
DEVI MEISITA KHAIRUNNISA. Application of Prefixspan Algorithm and Clospan Algorithm for Searching Sequential Pattern Mining on Data of Books Loan in IPB’s Library. Supervised by IMAS SUKAESIH SITANGGANG dan BADOLLAHI MUSTAFA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENERAPAN ALGORITME PREFIXSPAN DAN CLOSPAN
UNTUK MENCARI POLA SEKUENSIAL PADA DATA
PEMINJAMAN BUKU DI PERPUSTAKAAN IPB
DEVI MEISITA KHAIRUNNISA
DEPARTEMEN ILMU KOMPUTER FAKULTAS ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
Judul Skripsi : Penerapan Algoritme Prefixspan dan Clospan untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB Nama : Devi Meisita Khairunnisa
NIM : G64114040
Disetujui oleh
Dr Imas S. Sitanggang, SSi, MKom. Pembimbing I
Drs Badollahi Mustafa, MLib Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juli 2013 ini ialah data mining, dengan judul Penerapan Algoritme Prefixspan dan Clospan untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB.
Terima kasih penulis ucapkan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi, MKom dan Bapak Drs Badollahi Mustafa, MLib selaku pembimbing. Serta, Bapak Hari Agung Adrianto, SKom,MSi sebagai penguji. Selain itu, penulis ucapkan terima kasih kepada Bapak Feri yang telah membantu dalam pengumpulan data. Penghargaan penulis sampaikan kepada Bapak Philippe Fournier Viger yang telah membuat perangkat lunak Sequential Pattern Mining Framework (SPMF) dan Bapak Agus Anang, SKom yang telah membantu selama praproses data dan penulisan karya tulis ini. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, Arina Pramudita, serta seluruh keluarga dan teman-teman Ilmu Komputer Angkatan 6, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
HASIL DAN PEMBAHASAN 5
Praproses 5
Penentuan pola sekuensial 7
Perbandingan kinerja Algoritme Prefixspan dan Clospan 9
Analisis Pola Sekuensial 17
SIMPULAN DAN SARAN 19
Simpulan 19
Saran 19
DAFTAR PUSTAKA 19
LAMPIRAN 18
DAFTAR TABEL
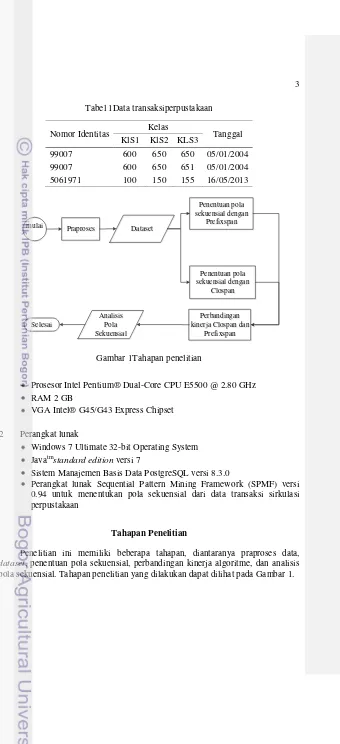
1 Data transaksi perpustakaan 3
2 Jumlah pola sekuensial dan waktu eksekusi algoritme Prefixspan dan Clospan berdasarkan dataset dan minimum support 10 3 Pola sekuensial dengan urutan pola berbeda untuk dataset 50 pada
minimum support 5% 18
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Tahapan praproses data 4
3 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum support dengan waktu eksekusi untuk dataset 50 12 4 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk dataset 100 12 5 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk dataset 500 12 6 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk dataset 1,000 12 7 Perbandingan Clospan (■) dan Prefixspan (♦) minimum support dengan
waktu eksekusi untuk dataset 2,000 12
8 Perbandingan Clospan (■) dan Prefixspan (♦) minimum support dengan
waktu eksekusi untuk dataset 4,140 12
9 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah
dataset dengan waktu eksekusi untuk minimum support 5%Error! Bookmark not defined. 10 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah
dataset dengan waktu eksekusi untuk minimum support 6%Error! Bookmark not defined. 11 Perbandingan Clospan (■) dan Prefixspan (♦) jumlah dataset dengan
waktu eksekusi untuk minimum support 7% 16
12 Perbandingan Clospan (■) dan Prefixspan (♦) jumlah dataset dengan
waktu eksekusi untuk minimum support 8% 16
13 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah dataset dengan waktu eksekusi untuk minimum support 10% 16 14 Perbandingan Clospan (■) dan Prefixspan (♦) jumlah dataset dengan
PENDAHULUAN
Latar Belakang
Perpustakaanmempunyai peranan penting dalam dunia pendidikan. Pengelolaan yang baik untuk memperbaiki layanan menjadi sebuah keharusan untuk menunjang proses belajar dan mengajar di lingkungan akademik. Salah satu proses dalam pengelolaan yang baik adalah pengambilan keputusan atau kebijakan yang tepat yang didasari dari informasi yang baik dan tepat pula. Informasi yang baik dapat digali dari data yang benar dan teknik pengggalian yang teruji. Salah satu data yang dapat digali dari perpustakaan adalah transaksi peminjaman buku pada perpustakaan.
Teknologi penggalian informasi dari data dengan basis besar yang tersimpan atau yang lebih sering di kenal dengan data mining sudah mulai marak dikembangkan, didalami dan digunakan diberbagai bidang. Berbagai teknik/metode diajukan untuk mendapatkan hasil yang lebih akurat dan cepat. Analisis perbandingan kinerja algoritme dilakukan untuk mengetahui perbedaan kecepatan dan akurasi dari algoritme yang dibandingkan, sehingga dapat diperoleh kesimpulan dalam pemilihan algoritme untuk mendapatkan informasi yang lebih baik dan akurat.
Teknik sequential pattern mining merupakan salah satu teknik data mining yang banyak diterapkan. Algoritme yang telah dikembangkandalamtekniktersebut, antara lain Prefixspan dan Clospan. Menurut Gregoriuset al. (2013) algoritme Clospan memiliki waktu eksekusi yang cepat pada data transaksi perpustakaan sehinggapada penelitian ini algoritme tersebut akan diterapkan. Pada penelitian inialgoritmePrefixspan dan Clospan akan diterapkan padadata transaksipeminjaman buku di perpustakaan IPB dari tahun 2003 hingga 2013. Kedua algoritme tersebut akan dibandingkan kinerja dan pola sekuensial yang dihasilkan.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah bagaimana pola sekuensial pada data transaksi peminjaman buku perpustakaan ditentukan menggunakan algoritme Prefixspan dan Clospan dan algoritme manakah yang memberikan hasil terbaik.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menentukan pola sekuensial pada data transaksi perpustakaan menggunakan algoritme Prefixspan dan Clospan.
2 Membandingkan kinerja dari algoritme Prefixspan dan Clospan dalam menemukanpola sekuensialpada data transaksi sirkulasi perpustakaan. 3 Menganalisis pola sekuensial yang dihasilkan oleh algoritme Prefixspan dan
2
Manfaat Penelitian
1 Penelitian ini diharapkan dapat memberikan manfaat sebagaiberikut: 2 Sebagai referensi bagi pihak perpustakaan terkait algoritme terbaik yang
dapat digunakan dalam mengolah data transaksi sirkulasi perpustakaan. 3 Pihak perpustakaan dapat mengetahui pola peminjaman yang dilakukan
anggota perpustakaan.
4 Memudahkan pihak perpustakaan dalam penambahan stok buku. 5 Memberikan rekomendasibukukepada pemustaka.
Ruang Lingkup Penelitian
Penelitian ini memiliki ruang lingkup sebagai berikut:
1 Data yang digunakan dalam penelitian ini merupakan data transaksi peminjaman buku perpustakaan IPB tahun 2003 sampai dengan 2013. 2 Pola sekuensial dihasilkan dengan menggunakan perangkatlunak Sequential
Pattern Mining Framework (SPMF) (Viger 2013).
METODE
Data Perpustakaan
Penelitian ini menggunakan data transaksi peminjaman buku di perpustakaan IPB tahun 2003 sampai dengan 2013 sebanyak 18,669 data. Data transaksi perpustakaan terdiri atas beberapa atribut, diantaranya nomor identitas, nama peminjam, kelas buku, judul buku, kondisi buku yang dipinjam, tanggal peminjaman, kode peminjaman, tanggal buku harus kembali, jenis buku,jenis peminjaman, operator transaksi buku, dan nomor registrasi buku.
Pada penelitian ini atribut data yang digunakan adalah nomor identitas, kelas buku, dan tanggal peminjaman.Nomor identitas merupakan nomor unik yang dimiliki oleh pengunjung perpustakaan dan dapat berupa nomor induk mahasiswa. Kelas buku merupakan kategori buku. Pengelompokkan kelas buku pada perpustakaan IPB didasarkan pada bagan klasifikasi UDC (Universal Decimal Classification) seperti 630 yang menyatakan klasifikasi pertanian. UDC terdiri atas dua jenis angka, yaitu angka utama yang menyatakan subjek utama dan angka bantu yang merupakan angka khusus (dinyatakan dengan tanda atau symbol seperti .(titik) dan - (dash)). Tanggal peminjaman merupakan berupa tanggal transaksi peminjaman buku. Contoh data transaksiperpustakaanyang digunakandapatdilihatpadaTabel 1.
Peralatan Penelitian
3
Prosesor Intel Pentium® Dual-Core CPU E5500 @ 2.80 GHz RAM 2 GB
VGA Intel® G45/G43 Express Chipset 2 Perangkat lunak
Windows 7 Ultimate 32-bit Operating System Javatmstandard edition versi 7
Sistem Manajemen Basis Data PostgreSQL versi 8.3.0
Perangkat lunak Sequential Pattern Mining Framework (SPMF) versi 0.94 untuk menentukan pola sekuensial dari data transaksi sirkulasi perpustakaan
Tahapan Penelitian
Penelitian ini memiliki beberapa tahapan, diantaranya praproses data, dataset, penentuan pola sekuensial, perbandingan kinerja algoritme, dan analisis pola sekuensial. Tahapan penelitian yang dilakukan dapat dilihat pada Gambar 1.
Tabel 1Data transaksiperpustakaan
Nomor Identitas Kelas Tanggal
4
1 Praproses
Praproses dilakukan untuk membersihkan data dan membuat data yang ada menjadi pola sekuensial. Praproses terbagi ke dalam empat tahapan, yaitu transformasi data, seleksi data, pembersihan data, dan pembuatan data sekuensial yang dapat dilihat pada Gambar 2. Transformasi data merupakan suatu proses konversi perubahan data untuk diolah pada tahapan selanjutnya. Pembersihan data merupakan tahapan membuang data dari noise dan menyesuaikan data dengan format klasifikasi yang ada. Pembuatan data sekuensial merupakan tahapan pengurutan data berdasarkan nomor identitas dan waktu.
Gambar 2Tahapan praproses data
2 Dataset
Dataset merupakan data hasil praproses yang telah diurutkan berdasarkan waktu atau lebih dikenal dengan data sekuensial. Dataset dihasilkan dari praproses kemudian disesuaikan kembali menjadi data sekuensial yang sesuai dengan format perangkat lunak SPMF. Pembuatan dataset dilakukan dengan sebuah program PHP sederhana yang menghasilkan pola sekuensial sebanyak 4,110 data.
3 Penentuan pola sekuensial dengan Prefixspan dan Clospan
Pola sekuensial merupakan pola keterkaitan antar objek. Dalam penelitian ini pola untuk data perpustakaan dihasilkan menggunakan perangkatlunak Sequential Pattern Minning Framework (SPMF) (Viger2013). SPMF tidak hanya menghasilkan pola sekuensial, tetapi juga jumlah pola yang dihasilkan dan waktu eksekusi.
4 Perbandingan kinerja Algoritme Prefixspan dan Clospan
Perbandingan kinerja diukur dengan membandingkan jumlah pola dan waktu eksekusi dari algoritme Prefixspan dan Clospan. Pada tahapan ini akan dianalisis hasil dari pengujian dan keterkaitan antara jumlah pola atau waktu eksekusi terhadap minimum support dan dataset.
5 Analisis pola sekuensial
Analisis pola sekuensial merupakan tahap analisis faktor-faktor yang menjadi perbedaan dari pola sekuensial antara algoritme Prefixspan dan Clospan.
5
HASIL DAN PEMBAHASAN
Praproses
Praproses dilakukan melalui beberapa tahapan, yaitu transformasi data, seleksi data, pembersihan data, dan pembuatan data sekuensial.
1 Transformasi data
Data perpustakaan yang didapatkan dari basis data CDS/ISIS memiliki format CIRC sedangkan untuk dapat diolah data tersebut harus ditransformasi ke dalam format xlsxuntuk dilakukan proses seleksi data dan pembersihan data terlebih dulu. Proses transformasi data dilakukan dengan dua tahapan, yaitu: a. Data diubah ke dalam format XML dengan menggunakan fasilitas konversi
yang telah tersedia aplikasi CDS/ISIS.
b. Data yang telah ditransformasi ke dalam format XML, kemudian ditransformasi kembali menjadi format xlsx dengan menggunakan Microsoft Excel.
2 Seleksi data
Seleksi data merupakan suatu proses pemilihan atribut yang akan digunakan dalam percobaan. Pemilihan atribut didasarkan oleh kebutuhan dari algoritme Prefixspan dan Clospan. Algoritme Prefixspan dan Clospan membutuhkan masukan berupa data sekuensial. Data sekuensial dapat dibentuk oleh tiga atribut, yaitu nomor identitas, kelas buku, dan tanggal peminjaman. Kelas buku terdiri atas tiga tingkatan yaitu KLS1 (umum), KLS2 (sedang), dan KLS3 (khusus). Pada penelitian ini tingkatan yang akandigunakan adalah KLS3. KLS3 merupakan tingkatan yang paling khusus diantara tingkatan kelas yang lain sehingga diharapkan akan terbentuk pola sekuensial yang lebih spesifik dari segi tipe dan jenis buku.
3 Pembersihan data
Atribut-atribut yang telah terpilih pada proses sebelumnya, kemudian dimasukkan ke dalam DBMS PostgreSQL untuk dilakukan proses pembersihan data. Pada proses pembersihan data awal, ditemukan 3,000 data invalid sehingga data mengandung noisedan perlu dilakukan praproses. Data invalid pada data tersebut mengandung tanda selain angka seperti . (titik), ‘ (kutip), dan – (strip). Proses pembersihan noise dilakukan dengan melakukan sebuah querydengan mengasumsikannoisesebagai angka ‘0’.
6
Kekeliruan tersebut kemudian didiskusikan dengan pakar dari Perpustakaan IPB. Hasil diskusi menunjukkan bahwa memang terjadi kekeliruan pada kelas tersebut sehingga perlu dilakukan proses perbandingan antara KLS1 dan KLS3.
Selanjutnya, proses query diterapkan kembali untuk menukar KLS3 dengan KLS1 dengan aturan jika KLS1 berisi kategori khusus dan KLS3 berisi kategori proses penyesuaian data secara manual. Proses penyesuaian dilakukan dengan mencocokkan antara kelas data beserta judul buku dengan format pengklasifikasian UDC.
4 Pembuatan data sekuensial
Sequential pattern miningmerupakan penambangan data yang telah diurutkan berdasarkan waktu (Han dan Kamber 2006). Dalam penelitian ini, pembuatan data sekuensial dilakukan dengan menggunakan sebuah program PHP. Program tersebut bekerja dengan dua tahapan, yaitu:
a. Menggabungkan kategori kelas yang memiliki nomor identitas dan tanggal yang sama.
Program ini bekerja dengan membandingkan kategori yang memiliki nomor identitas dan tanggal yang sama dan menuliskannya ke dalam sebuah file teks. Berikut potongan program tersebut.
$cekquery=" SELECT DISTINCT k.nrp, k.tanggal,
ORDER BY k.nrp, k.tanggal ";
7
c. Membuat sesuai dengan format masukan SPMF
Program ini bekerja dengan membandingkan panjang dari setiap item. Jika panjang item lebih dari 3 item tersebut akan ditambahkan -1 pada akhir item tersebut dan ketika suatu transaksi pada setiap item telah selesai dibandingkan pada setiap akhir transaksi akan diberi akhiran -2. Berikut potongan program tersebut.
$str.=wordwrap($awal[$i],3,' ', true).' -1 '; }
} $str.='-2';
Ketiga program tersebut menghasilkan data sekuensial sebanyak 4.104 dalam format teks dengan masukan seperti 630 -1 -2. Angka 630 merepresentasikan tingkatan buku,-1 menunjukkan spasi, dan -2 menunjukkan akhir dari setiap data sekuensial.
Penentuan pola sekuensial
Penentuan pola sekuensial dilakukan dengan mencari frequent sequence. Frequent sequence merupakan kumpulan transaksi yang memiliki jumlah minimum support sama atau melebihi minimum support yang telah ditentukan sebelumnya (Han dan Kamber 2006). Pada penelitian ini algoritme Prefixspan dan Clospan akan diterapkan untuk menghasilkan pola sekuensial tersebut.
1 Algoritme Prefixspan
8
al.2000). Prefixspan menerapkan konsep depth first search yang bekerja dengan tiga tahapan, yaitu (Saputra dan Sulaiman 2006):
a. Hitung panjang prefix data sekuensial dengan panjang 1.
b. Bagi ruang pencarian berdasarkan prefixnya (pisahkan antara prefix dan postfix).
c. Cari pola yang memenuhi minimum support berdasarkan ruang pencarian. Prefixspan akan memproyeksikan prefix dari item yang dimiliki sehingga ukuran proyeksi data akan semakin menyusut dan redundansi menjadi tereduksi (Hanet al. 2000).Berikut algoritme dari Prefixspan tersebut (Yan et al. 2003):
Input : A sequence s, projected DB Ds, and min_sup, α item, i new item Output: The frequent sequence set F.
1: insert s to F;
2: scan Ds once, find every frequent item α such that (a)s can be extended to (s <>i α)
8: Call Prefixspan(s <>s α, D s <>sα, min_sup, F); 9: return;
2 Algoritme Clospan
Clospan merupakan suatu algoritme penghasil pola sekuensial dengan metode efisiensi basis data (Yanet al. 2003). Clospan bekerja dengan dua tahapan, yaitu:
a. Membangkitkanpola sekuensial dengan algoritme Prefixspan. b. Melakukan post-pruning.
Pruning merupakan suatu proses efisiensi pola pada basis data. Pada Clospan pruning dilakukan dengan menggabungkan nodeyang memiliki prefix yang sama menjadi satu kesatuan. Clospan memiliki dua teknik pruning, yaitu backward sub-patterndan backward super-pattern(Yan et al.2003). Berikut algoritme dari Clospan:
Input : A sequence s, a projected DB Ds, and min_sup, α item, i new item Output: The prefix search lattice L.
1: Check whether a discover sequence s’ exist s.t. either s [ s’ or s’ [ s, and I(Ds)
2: if such super-pattern or sub-pattern exist then 3: modify the link in L, return;
4: else insert s into L;
5: Scan Ds once, find every frequent item α such that
Comment [U1]: Numbering tidak perlu pakai titik
a Hitung b Bagi
9
3 Penggunaan algoritme Prefixspan dan Clospan pada data peminjaman buku perpustakaan
Sebelum dilakukan penerapan algoritme Prefixspan dan Clospan pada data transaksi perpustakaan,perlu dilakukan penentuan minimum supportdan datasetterlebih dulu. Penentuan minimum supportdan datasetakan berpengaruh terrhadap kinerja dari kedua algoritme nantinya.
a. Pemilihan minimum support
Penentuan minimum support dipilih dengan melakukan percobaan berulang-ulang dengan minimum support secara progresif dimulai dari 0% sampai 100% dengan menggunakan perangkat lunak SPMF. Pemilihan minimum support dipilih dengan dasar terdapat perbedaan jumlah pola sekuensial yang dihasilkan oleh setiap dataset untuk setiap minimum support yang berbeda.
Dari hasil beberapa kali percobaan didapatkan bahwa pada data dengan minimum supportdiatas 15% tidak ditemukan lagi pola sekuensial dan pola sekuensial yang dihasilkan oleh data dengan minimum support dibawah 5% tidak akurat karena pola sekuensial yang dihasilkan sangat banyak sehingga tidak ditemukan keterkaitan antar item. Oleh karena itu, minimum support di bawah 5% dan di atas 15% tidak dapat digunakan dalam pengujian. Minimum support yang digunakan adalah 5%, 6%, 7%, 8%, 10%, dan 15% untuk setiap dataset. Pada minimum support tersebut terlihat terdapat minimum support yang jaraknya signifikan nilainya, yaitu dari minimum support 10% ke 15%. Hal tersebut disebabkan olehminimum support tersebut tidak ditemukan perubahan jumlah pola sekuensial (jumlah pola sekuensial tetap).
b. Pemilihan dataset
Penentuan dataset dilakukan secara acak dengan mengelompokkan dataset menjadi beberapa jumlah dataset yaitu dataset 50, 100, 200, 300, 400, 500, 1,000, 1,500, 2,000, 2,500, 3,000, 3,500, dan 4,140. Pada penelitian ini yang akan dianalisis adalah dataset dengan jumlah 50, 100, 500, 1,000, 2,000, dan 4,140. Pemilihan dataset ini didasarkan oleh kemiripan minimum support pada setiap dataset.
Perbandingan kinerja Algoritme Prefixspan dan Clospan
Pada penelitian ini kinerja dari algoritme Prefixspan dan Clospan akan diuji berdasarkan kriteria dataset, minimum support, jumlah pola sekuensial, dan waktu eksekusi. Penelitian ini dilakukan dalam dua bentuk percobaan, yaitu:
10
1 Hubungan antara dataset, minimum support, dan jumlah pola sekuensial
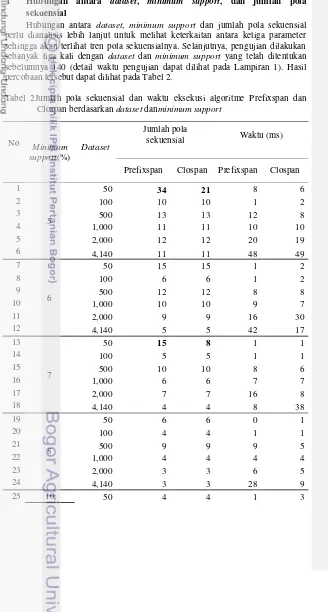
Hubungan antara dataset, minimum support dan jumlah pola sekuensial perlu dianalisis lebih lanjut untuk melihat keterkaitan antara ketiga parameter sehingga akan terlihat tren pola sekuensialnya. Selanjutnya, pengujian dilakukan sebanyak tiga kali dengan dataset dan minimum support yang telah ditentukan sebelumnya 140 (detail waktu pengujian dapat dilihat pada Lampiran 1). Hasil percobaan tersebut dapat dilihat pada Tabel 2.
Tabel 2Jumlah pola sekuensial dan waktu eksekusi algoritme Prefixspan dan Clospan berdasarkan dataset danminimum support
No Minimum support(%)
Dataset
Jumlah pola
sekuensial Waktu (ms)
11
Prefixspan Clospan Prefixspan Clospan
26 100 4 4 1 1
Hasil percobaan pada Tabel 2 menunjukkan bahwa kedua algoritme menghasilkan pola sekuensial dengan jumlah yang sama yaitu 34 dari 36 percobaan. Perbedaan jumlah pola kedua algoritme hanya didapatkan 2 percobaan. Perbedaan tersebut ditemukan untuk dataset 50 dengan minimum support 5% dan 7%. Pada dataset tersebut jumlah pola sekuensial Prefixspan lebih banyak daripada Clospan.
Pada pengujian ini kedua algoritme menghasilkan pola sekuensial dengan presentase kemiripan yang sangattinggi. Hal tersebut diperkirakan karena setiap item pada dataset yang digunakan tidak memiliki keterkaitan yang kuat antara satu item dengan item yang lain sehingga dapat dikatakan setiap item berbeda satu sama lain.
2 Hubungan antara dataset, minimum support, dan waktu eksekusi Hubungan antara dataset, minimum support dan waktu eksekusi perlu dianalisis lebih lanjut untuk melihat keterkaitan antara ketiga parameter sehingga akanterlihat algoritme mana yang lebih cepat dalam menghasilkan pola sekuensial. Hasil percobaan dapat dilihat pada Tabel 2.
Pada Tabel 2terlihat bahwa pada 11 data pengujian (nomor percobaan 4, 6, 9, 13, 14, 16, 20, 22, 26, 31, dan 34 ) Prefixspan memiliki waktu eksekusi yang sama dengan Clospan dan Prefixspan jauh lebih cepat dibandingkan Clospan pada 12 data pengujian (nomor percobaan 7, 8, 11, 18, 19, 25, 32, dan 33). Clospan terlihat lebih cepat dibandingkan dengan Prefixspan pada 13 data pengujian (nomor percobaan 1, 2, 3, 5, 10, 12, 15, 17, 21, 23, 24, 27, 29, 30, 35, dan 36).
12
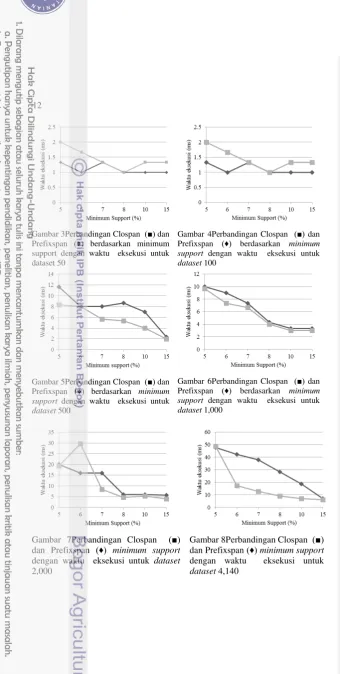
Gambar 3Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum support dengan waktu eksekusi untuk dataset 50
Gambar 4Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk
dataset 100
Gambar 5Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk
dataset 500
Gambar 6Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan minimum
support dengan waktu eksekusi untuk
dataset 1,000
Gambar 7Perbandingan Clospan (■) dan Prefixspan (♦) minimum support dengan waktu eksekusi untuk dataset 2,000
14
16
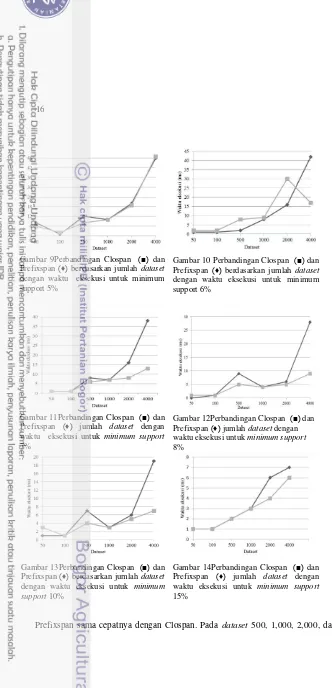
Gambar 9Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah dataset dengan waktu eksekusi untuk minimum support 5%
Gambar 10 Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah dataset dengan waktu eksekusi untuk minimum support 6%
Gambar 11Perbandingan Clospan (■) dan Prefixspan (♦) jumlah dataset dengan waktu eksekusi untuk minimum support 7%
Gambar 12Perbandingan Clospan (■) dan Prefixspan (♦) jumlah dataset dengan waktu eksekusi untuk minimum support 8%
Gambar 13Perbandingan Clospan (■) dan Prefixspan (♦) berdasarkan jumlah dataset dengan waktu eksekusi untuk minimum
support 10%
17 4,140 waktu eksekusi Clospan lebih cepat jika dibandingkan dengan Prefixspan. Selanjutnya dilakukan perbandingan antara jumlah datasetdan waktu eksekusi yang digambarkan pada Gambar 9 sampai dengan Gambar 14.
Pada Gambar 9 sampai dengan Gambar 14 terlihat jika dataset semakin besar dan minimum support semakin tinggi baik algoritme Prefixspan maupun Clospan memiliki waktu eksekusi yang semakin cepat. Namun, algoritme Clospan terlihat lebih baik jika dibandingkan dengan Prefixspan. Selain itu, dari Gambar 9 sampai 14 didapatkan fakta-fakta sebagai berikut:
- Pada minimum support 5% Prefixspan dan Clospan memiliki waktu eksekusi yang sama, kecuali untuk dataset 50 dan 500. Pada minimum support tersebut Clospan jauh lebih cepat dibandingkan dengan Prefixspan. - Pada minimum support 6% Prefixspan lebih cepat dibandingkan dengan
Clospan, kecuali untuk dataset di atas 2,000.
- Pada minimum support 7%, 8%, 10%, dan 15% Clospan memiliki waktu eksekusi yang sama atau lebih cepat jika dibandingkan dengan Prefixspan, kecuali untuk dataset di bawah 100. Pada dataset tersebut waktu eksekusi Prefixspan jauh lebih cepat dibandingkan dengan Clospan.
-Analisis Pola Sekuensial
Pada pengujian sebelumnya, yaitu hubungan antara dataset, minimum support, dan jumlah pola sekuensial didapatkan fakta bahwa pada 34 percobaan dari seluruh percobaan yang telah dilakukan, algoritme Prefixspan dan Clospan memiliki jumlah pola sekuensial yang sama untuk dataset serta minimum support yang sama (lihat Tabel 2).
Pada sub bab ini akan dianalisis pola sekuensial yang dihasilkan bersertaketerkaitan Antara pola sekuensial dengan koleksi buku perpustakaan. a. Pola sekuensial
Dari percobaan yang telah dilakukan sebelumnya terlihat bahwa dataset yang menghasilkan jumlah pola sekuensial yang samaternyata memiliki pola sekuensial yang sama, namun pola yang dihasilkan memiliki perbedaan urutan. Perbedaan tersebut ditemukan untuk dataset dengan jumlah pola sekuensial di atas 4 pola dan sebaliknya untuk pola sekuensial dengan jumlah di bawah 4 tidak memiliki perbedaan urutan.Dataset yang menghasilkan perbedaan jumlah dan urutan pola dapat dilihat pada Tabel 3.
Pada Tabel 3 terlihat bahwa pola sekuensial yang dihasilkan Clospan berurutan, sedangkan Prefixspan menghasilkan pola sekuensial secara acak. Hal tersebut menunjukkan perbedaan cara kerja dari kedua algoritme.Clospan mengurutkan itemset setelah membangkitkan semua kandidat, sedangkan Prefixspan tidak memperhatikan urutan pola ketika membangkitkankandidat.
18
Tabel 3Pola sekuensial dengan urutan pola berbeda untuk dataset50 pada minimum support 5%
b. Keterkaitan antara pola sekuensial dengan item buku
Pada pengujian yang telah dilakukan sebelumnya diperoleh pola sekuensial yang secara umum tidak memiliki keterkaitan antar item atau hanya memiliki keterkaitan dengan item itu sendiri. Pola sekuensial yang menarik ditemukan pada dataset 50, 100, 500, 1,000, 2,000 dan 4,140 dengan minimum support 10%. Pada dataset tersebut terlihat bahwa buku dengan jenis 631, 639, dan 658 merupakan buku yang paling banyak dipinjam, tetapi pada pengujian tersebut tidak dihasilkan pola sekuensial yang memiliki keterkaitan yang kuat antaraitem satu dengan item lain. Hal tersebut dikarenakan hanya terdapat satuitem untuk setiap pola sekuensial.
Keterkaitan yang kuat antar item hanya ditemukan pada dataset 50 dengan minimum support5%.Item027 memiliki keterkaitan dengan item 820, 631 dan 636, dan 631 dan 638 dengan jumlah support 2 pada masing-masing pola. Kode buku 027 merupakan kode buku dengan kategori perpustakaan, 631 termasuk buku dengan kategori manajemen pertanian, 636 merupakan peternakan dan manajemen peternakan, 658 termasuk kategori manajemen, administrasi bisnis, dan organisasi komersial, dan 820 termasuk kategori sastra.
19 dataset50 dengan minimum support maksimal 15% dan dataset4,140 dengan minimum support 11%.
SIMPULAN DAN SARAN
Simpulan
Dari penelitian yang telah dilakukan dapat disimpulkan sebagai berikut: 1 Secara umum waktu eksekusi algoritme Clospan lebih cepat dibandingkan
dengan Prefixspan untuk dataset yang berukuran besar.
2 Secara umum algoritme Clospan dan Prefixspan memiliki jumlah pola sekuensial yang sama yaitu 34 data dari 36 data percobaan.
3 Pola menarik ditemukan pada dataset 50 dengan minimum support 5%. 4 Buku dengan kategori perpustakaan (kode 027) akan dipinjam secara
bersamaan dengan buku kategori sastra (kode 820), buku dengan kategori manajemen pertanian (kode 631) akan dipinjam secara bersamaan dengan buku peternakan dan manajemen peternakan (kode 636).
5 Buku dengan kategori manajemen, administrasi bisnis, dan organisasi komersialbisnis (kode 658) memiliki keterkaitan yang kuat dengan manajemen pertanian (kode 631).
Saran
Penelitian selanjutnya dapat dilakukan pada data transaksi peminjaman buku perpustakaan lintas disiplin ilmu sehingga didapatkan pola menarik yang lebih beragam.
DAFTAR PUSTAKA
Gregorius SB, Gunawan, Yulia. 2013. CloSpan Sequential Pattern Mining for Books Recommendation System in Petra Christian University Library. International Conference on Computer Networks and Information Technology (ICCNIT- 2013); Bangkok, Thailand.
Han J, Kamber M. 2006. Data Mining Concepts and Techniques Second Edition. San Fransisco (US): Morgan Kaufmann Publ.
Han J, Mortazavi-Asi B, Pei J, Pinto H. 2000. Prefixspan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth. Prefixspan [Internet]. ([diunduh 2013 Agustus 26]).
Han J, Pei J, Yan X. 2003. Sequential Pattern Mining by Pattern Growth. Sequential Pattern Mining [internet].([diunduh 2013 Juli 25]).
20
Saputra D,Solaeman R. 2006. Analisis kinerja algoritma prefixspan dan aprioriall pada penggalian pola sekuensial. Di dalam: Fasholli Daswir, editorProsiding SNATI 2006 [internet].Seminar Nasional Aplikasi Teknologi Informasi 2006;2006 Juni 17; Yogyakarta, Indonesia. Yogyakarta (ID): UII. hlm F7-F12.
Viger PF. 2013. Sequential pattern mining framework versi 0.94. SPMF [internet]. (2013 Agustus 12 [diunduh 2013 Agustus 20]). Tersedia pada:
21 Lampiran 1Pengujian terhadap beberapa datasetdenganminimum support
1 Dataset 50
Minimum Support (%)
Jumlah sekuen Waktu (ms)
Prefixspan Clospan Prefixspan Clospan 1 2 3 R* 1 2 3 R*
Jumlah sekuen Waktu (ms)
Prefixspan Clospan Prefixspan Clospan 1 2 3 R* 1 2 3 R*
Jumlah sekuen Waktu (ms)
22
4 Dataset 1,000 Minimum
Support (%)
Jumlah sekuen Waktu (ms)
Prefixspan Clospan Prefixspan Clospan 1 2 3 R* 1 2 3 R*
Jumlah sekuen Waktu (ms)
Prefixspan Clospan Prefixspan Clospan 1 2 3 R* 1 2 3 R*
Jumlah sekuen Waktu (ms)
23
RIWAYAT HIDUP
Penulis bernama Devi Meisita Khairunnisa yang lahir di Bandung tanggal 30 Mei 1991. Penulis merupakan putri pertama dari pasangan Drs H. Herlambang Sitompul, MM dan Natin Karyatin. Penulis bersekolah di SMA N 66 Jakarta dan melanjutkan pendidikan di Diploma IPB dengan jurusan Teknik Komputer pada tahun 2008 dan lulus tahun 2011. Kemudian, penulis melanjutkan pendidikan Sarjana melalui program alih jenis pada program studi Ilmu Komputer IPB pada tahun yang sama.