PENELUSURAN DAN VISUALISASI
PENCARIAN RUJUKAN PADA
DOKUMEN PENELITIAN
FIRNAS NADIRMAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Penelusuran dan Visualisasi Pencarian Rujukan pada Dokumen Penelitian adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2014
Dokumen Penelitian. Dibimbing oleh AHMAD RIDHA dan WISNU ANANTA KUSUMA.
Daftar pustaka adalah bagian penting dari dokumen penelitian. Daftar pustaka berisi daftar dokumen yang diacu dalam dokumen. Daftar ini berguna bagi pembaca, biasanya sesama ilmuwan, untuk mencari dokumen-dokumen terkait dan mengetahui penelitian ilmuwan lain pada sebuah bidang ilmu. Dokumen penting pada sebuah bidang ilmu tertentu akan lebih sering diacu oleh dokumen lain, maka sangat penting untuk menelusuri dan mendapatkan jumlah dokumen yang menggunakan sebuah rujukan sebagai acuan.
Penelitian ini dimaksudkan untuk membuat sebuah modul yang dapat menelusuri acuan pada daftar pustaka dan menggambarkan hubungan antar-pengarang untuk mempermudah penelusuran dokumen penelitian. Modul yang dibuat merupakan bagian dari sistem temu kembali dokumen penelitian. Hasil dari pembuatan modul ini, selain dapat menelusuri entri daftar pustaka pada dokumen penelitian juga dapat menampilkan visualisasi grafik hubungan antar-pengarang yang bertujuan untuk mempermudah mencari hubungan antara dokumen hasil penelitian dan dokumen yang digunakan sebagai rujukan.
Penelitian dimulai dengan pengumpulan dokumen penelitian dalam bentuk file PDF sebanyak 246 dari Departemen Ilmu Komputer IPB. Setiap dokumen penelitian dalam bentuk file PDF dikonversi menjadi teks dan disimpan pada basis data dokumen penelitian. Setelah itu, teks dokumen penelitian diekstrak dan diidentifikasi entri daftar pustakanya. Hasil ekstraksi entri daftar pustaka disimpan pada basis data lalu digunakan untuk membangun sistem temu kembali dokumen penelitian
Pengembangan sistem pada penelitian ini menggunakan beberapa modul. Modul pdftotext digunakan untuk melakukan konversi file PDF menjadi teks. Proses ekstraksi dan identifikasi entri daftar pustaka menggunakan modul ParaTools. Sphinx digunakan untuk membuat sistem temu kembali informasi. Pada penelitian ini juga dibuat visualisasi hasil pencarian berbasis web serta visualisasi hubungan antar-pengarang menggunakan Javascript Infovis Toolkit.
Sistem yang dikembangkan pada penelitian ini sudah dapat melakukan ekstrak dan identifikasi entri daftar pustaka dengan cukup baik. Hal ini dapat dilihat pada pengujian ekstraksi dan identifikasi atribut entri daftar pustaka, yang menghasilkan 94.63% entri daftar pustaka yang tepat, dan 91.54% entri daftar pustaka dapat diidentifikasi atributnya dengan tepat. Selain pengujian ekstraksi dan identifikasi atribut entri daftar pustaka juga dilakukan pengujian untuk mengukur keberhasilan sistem dalam menghubungkan entri daftar pustaka dengan dokumen. Pengujian ini menghasilkan sebanyak 90.31% entri daftar pustaka berhasil dihubungkan secara tepat dengan dokumen.
Documents. Supervised by AHMAD RIDHA and WISNU ANANTA KUSUMA. Bibliography is an important part of a research document as it lists references cited in the document. The list is useful for readers, usually fellow scientists, to locate other related documents and to know other scientists working on the topic. An important document in a field would be more likely to be cited, so it is also desirable to know the number of citations that a document has.
This study aims to create a module that can extract references from the bibliography entries of research documents. A method is created to recognize the bibliography entries from the research documents. Once identified, the bibliography entries are stored into a database. The database is used to build an information retrieval system for searching research documents along with their references and to visualize the relationship between the authors.
This study began with collecting 246 research documents as PDF files. Each file was converted into plaintext file and stored in a research document database. The text was extracted and identified to get the bibliography entries. The bibliography entries were stored into the database. The database was used to build an information retrieval system of research documents. A visualization module was created to display the relationships between the authors of the documents from bibliographic entries in the database.
The development of the system in this study are using multiple modules. Pdftotext module is used for converting PDF files into text. The process of extraction and identification bibliographic entry is using a ParaTools module. Sphinx is used to make the information retrieval system. In this study also created a web-based visualization of search results as well as the visualization of relationships between author uses Javascript Infovis Toolkit.
The system developed in this study has been able to extract and identification of a bibliography entry. In the measurement of extraction and attributes identification of the bibliography entries, 94.63% of bibliography entries are extracted accurately and 91.54% of the attributes of bibliography entries can be identified accurately. In addition to the measurement of extraction and attributes identification of the bibliography entries, assessment to measure the success of relating the bibliography entries to the documents through the system is also conducted. It indicates that 90.31% of the bibliography entries are successfully and accurately connected with the documents.
© Hak Cipta milik IPB, tahun 2014
Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar bagi IPB.
PENELUSURAN DAN VISUALISASI
PENCARIAN RUJUKAN PADA
DOKUMEN PENELITIAN
FIRNAS NADIRMAN
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Disetujui oleh Komisi Pembimbing
Diketahui oleh Ahmad Ridha, SKom MS
Ketua
Dr Eng Wisnu Ananta Kusuma, ST MT Anggota
Ketua Program Studi Ilmu Komputer
Dr Eng Wisnu Ananta Kusuma, ST MT
Tanggal Ujian : 3 Mei 2014
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Penelitian ini disusun sebagai salah satu syarat meraih gelar master pada Program Studi Magister Ilmu Komputer, Sekolah Pascasarjana, Institut Pertanian Bogor. Tema yang dipilih dalam penelitian ini ialah Temu Kembali Informasi, dengan judul Penelusuran dan Visualisasi Pencarian Rujukan pada Dokumen Penelitian.
Penulis mengucapkan terima kasih kepada Bapak Ahmad Ridha, SKom MS selaku ketua komisi pembimbing yang telah memberikan segenap bantuan dan bimbingan kepada penulis selama proses penelitian dan penyusunan penelitian ini, serta Bapak Dr Eng Wisnu Ananta Kusuma, ST MT selaku anggota komisi pembimbing yang telah memberikan saran, koreksi dan masukan kepada penulis. Terima kasih pula penulis ucapkan kepada Bapak Dr Irman Hermadi, SKom MS selaku penguji. Tak lupa penulis mengucapkan banyak terima kasih kepada kepada Ibu Annisa, SKom MKom yang pernah turut membimbing, memberikan masukan serta saran pada penelitian ini. Penulis juga mengucapkan terima kasih kepada teman-teman Pascasarjana Magister Ilmu Komputer, staf dan dosen Ilmu Komputer IPB atas pertemanan dan bantuannya selama penulis mengikuti perkuliahan.
Penulis juga mengucapkan terima kasih kepada orang tua beserta keluarga yang telah memberikan dukungan moril dan doanya. Terkhusus terima kasih penulis sampaikan kepada istri tercinta Wida Lesmanawati dan anak-anakku tersayang (Reina dan Najib). Penulis juga mengucapkan terima kasih kepada Badan Pengkajian dan Penerapan Teknologi (BPPT) yang sudah memberikan kesempatan kepada penulis untuk melaksanakan pendidikan di IPB. Akhirnya kepada semua pihak yang telah memberikan kontribusi yang besar selama perkuliahan dan pengerjaan penelitian ini yang tidak dapat disebutkan satu per satu, penulis ucapkan terima kasih.
Semoga penelitian ini dapat memberikan manfaat sebesar-besarnya.
Bogor, Juni 2014
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
2 TINJAUAN PUSTAKA 3
Temu Kembali Informasi 3
Sistem Temu Kembali Dokumen Penelitian 3
Visualisasi Informasi 3
Rujukan 4
Perancangan Basis Data 4
Penelitian Sebelumnya 4
Metode Pengukuran Sistem Temu Kembali Informasi 7
Sistem Temu Kembali Informasi Dokumen Penelitian yang Telah Ada 8
3 METODOLOGI PENELITIAN 9
Kerangka Pemikiran 9
Pengumpulan dan Pembuatan Basis Data Dokumen Penelitian 10
Ekstraksi dan Identifikasi Atribut Entri Daftar Pustaka 11
Pembangunan Sistem Temu Kembali Dokumen Penelitian 11
Pembuatan Visualiasasi Hubungan Antar-Pengarang 12
Pengujian Sistem 13
Pengukuran Kinerja Ekstraksi dan Identifikasi Atribut Entri Daftar
Pustaka pada Setiap Dokumen Penelitian 13
Pengukuran Kinerja Hubungan Entri Daftar Pustaka dengan Dokumen 14
4 HASIL DAN PEMBAHASAN 15
Pengumpulan Data 15
Karakteristik Dokumen Skripsi 15
Format Entri Daftar Pustaka 16
Perancangan Basis Data Dokumen Penelitian 16
Pengolahan Data 19
Pengubahan File Dokumen Skripsi dalam Bentuk PDF Menjadi Teks 20
Ekstraksi Entri Daftar Pustaka 20
Identifikasi Atribut Entri Daftar Pustaka 22
Penyimpanan Entri Daftar Pustaka ke Basis Data 25
Visualisasi Hasil Pencarian 31
Pengujian 31
Waktu Proses Entri Dokumen Skripsi 32
Kesalahan pada Hasil Konversi File PDF 32
Kesalahan pada Hasil Identifikasi Atribut Entri Daftar Pustaka 33
Pengujian Ekstraksi Entri Daftar Pustaka 36
Pengujian Identifikasi Atribut Entri Daftar Pustaka 36
Pengujian Hubungan Entri Daftar Pustaka dengan Dokumen 37
5 KESIMPULAN DAN SARAN 38
Kesimpulan 38
Saran 39
2 Kata-kata identifikasi entri daftar pustaka yang digunakan 24 3 Tabel penyimpanan kolom spesifik dari entri daftar pustaka 26 4 Kondisi entri daftar pustaka1 dan entri daftar pustaka2 yang dianggap
sama 26
5 Proses pengujian ekstraksi entri daftar pustaka 36 6 Proses pengujian identifikasi atribut entri daftar pustaka 37
DAFTAR GAMBAR
1 Contoh tampilan BIRS (Ding et al. 2000). 5
2 Framework DBL Browser (Klink et al. 2004). 5
3 Sebuah visualisasi pengarang untuk peraih Nobel Herbert Simon,
ditampilkan dalam format Kohonen (Lin et al. 2003) 7 4 Pengarang bersama (kiri) dan pengarang bersama yang telah menulis
setidaknya 2 dokumen (kanan) (Murray et al. 2006) 7
5 Google Scholar Citations 8
6 Ilustrasi Micorosoft Academic Search 9
7 Metodologi penelitian 10
8 Pembuatan basis data dokumen penelitian 11
9 Arsitektur sistem temu kembali informasi dokumen penelitian 12 10 Model proses sistem temu kembali informasi dokumen penelitian 12
11 Visualisasi dokumen penelitian 13
12 Entri daftar pustaka pada dokumen skripsi 16
13 Perancangan konseptual basis data dokumen penelitian 17
14 Supertype dan subtype pada dokumen 18
15 Supertype dan subtype pada pengarang 18
16 Perancangan logikal basis data dokumen penelitian 19 17 Perancangan fisik basis data dokumen penelitian 19 18 Konsep pengubahan file PDF menjadi format raw text 21 19 Hasil pengubahan file PDF menjadi teks dengan format raw text 21
20 Tahapan esktrak entri daftar pustaka 23
21 Kolom entri daftar pustaka 23
22 Form modul entri data dokumen skripsi 27
23 Penyimpanan dokumen skripsi ke dalam basis data 28 24 Hasil pengolahan entri daftar pustaka dari dokumen skripsi 28
25 Proses pembuatan indeks dengan Sphinx 30
26 Antarmuka pencarian 30
27 Halaman hasil pencarian 31
28 Visualisasi hasil pencarian 32
29 Hasil konversi file PDF diubah menjadi teks yang bercampur (ditandai)
1 Contoh text layout pengubahan file PDF 41 2 Proses membandingkan posisi entri daftar pustaka 42
3 Format metadata entri daftar pustaka 44
4 Model kalimat daftar pustaka yang digunakan untuk mengidentifikasi
atribut entri daftar pustaka 45
5 Hasil dari proses identifikasi atribut entri daftar pustaka 52
6 Penyimpanan dokumen skripsi ke basis data 53
7 Proses identifikasi kesamaan nama pengarang 54
8 Stop words bahasa Indonesia 55
9 Stop words bahasa Inggris 58
10 Hasil recall dan precision pada pengujian ekstraksi entri daftar pustaka
di semua dokuman 61
11 Hasil recall dan precision pada pengujian identifikasi atribut entri
daftar pustaka di semua dokuman 68
12 Hasil pengujian hubungan dokumen dalam koleksi dengan entri daftar
1
PENDAHULUAN
Latar Belakang
Daftar pustaka adalah bagian penting dari dokumen penelitian. Daftar pustaka berisi daftar dokumen yang diacu dalam dokumen. Daftar ini berguna bagi pembaca, biasanya sesama ilmuwan, untuk mencari dokumen-dokumen terkait dan mengetahui penelitian ilmuwan lain pada sebuah bidang ilmu. Dokumen penting pada sebuah bidang ilmu tertentu akan lebih sering diacu oleh dokumen lain, maka sangat penting untuk menelusuri dan mendapatkan jumlah dokumen yang menggunakan sebuah rujukan sebagai acuan.
Penelusuran dokumen hasil penelitian merupakan kegiatan penting bagi peneliti dan ilmuwan. Pada bidang temu kembali informasi, penelusuran dokumen hasil penelitian dianggap sebagai domain tersendiri karena dokumen penelitian berbeda fomatnya dengan jenis dokumen lain (Ding et al. 2001). Metode khusus diperlukan untuk mengekstrak isi dari dokumen penelitian agar informasi yang diinginkan dapat diperoleh.
Dokumen penelitian acapkali memiliki pengacuan ke dokumen penelitian lain. Bagi seorang peneliti atau ilmuwan, pengacuan merupakan informasi yang bermanfaat karena yang diacu adalah rujukan yang digunakan oleh dokumen penelitian. Pada saat melakukan penelitian, mencari rujukan yang terkait dengan sebuah dokumen penelitian dapat menjadi tugas yang sulit.
Untuk mencari rujukan yang relevan dengan sebuah dokumen penelitian, para peneliti atau ilmuwan harus membaca pada bagian daftar pustaka dari dokumen penelitian tersebut. Selanjutnya bila peneliti atau ilmuwan menemukan rujukan yang dibutuhkannya, pencarian dilanjutkan pada dokumen yang didapat dari daftar pustaka. Apabila sebuah dokumen rujukan memiliki isi yang bermanfaat, dokumen rujukan tersebut disimpan, lalu pencarian dilanjutkan untuk mendapatkan dokumen rujukan lainnya dan begitu seterusnya. Sebuah rujukan bisa dianggap sangat bermanfaat ketika dijadikan rujukan oleh banyak dokumen penelitian. Selain itu, bermanfaatnya sebuah dokumen rujukan juga disebabkan karena faktor pengarang. Dokumen rujukan yang ditulis oleh seseorang yang ahli pada tema (bidang) tertentu banyak digunakan oleh dokumen lainnya sebagai acuan pada bidang tersebut.
Saat ini sudah dikembangkan sistem yang dapat menelusuri rujukan dari dokumen penelitian. Salah satu dari sistem tersebut juga sudah dapat menerima masukan berupa dokumen penelitian dari pengguna dan mengekstrak rujukan secara otomatis untuk ditelusuri. Akan tetapi, sistem yang sudah ada saat ini masih belum dapat mengekstrak rujukan dari dokumen penelitian yang memiliki format tertentu, seperti format dokumen penelitian yang digunakan di Institut Pertanian Bogor.
yang bertujuan untuk mempermudah mencari hubungan antara dokumen hasil penelitian dan dokumen yang digunakan sebagai rujukan. Anegón et al. (2004) menyebutkan bahwa representasi dari informasi dalam bentuk grafik dapat dengan mudah direkam oleh otak manusia dibandingkan dengan representasi dalam bentuk teks. Dari hal itu, penelitian ini juga akan membuat grafik hubungan pengarang agar dapat memvisualisasikan hubungan antar-pengarang untuk membantu pencarian dokumen penelitian.
Tujuan Penelitian
Penelitian ini bertujuan untuk membuat sebuah modul di dalam sistem temu kembali dokumen penelitian yang dapat mengidentifikasi entri daftar pustaka dan mengekstraknya secara otomatis. Penelitian ini juga mengembangkan modul untuk menampilkan visualisasi dalam bentuk grafik yang berisi hubungan antara pengarang sebuah dokumen penelitian dan pengarang dokumen lainnya berdasarkan entri daftar pustaka.
Manfaat Penelitian
Penelitian ini menerapkan metode untuk mengenali entri daftar pustaka yang terdapat pada sebuah dokumen penelitian. Setelah dikenali, entri daftar pustaka tersebut disimpan ke dalam basis data. Entri daftar pustaka yang berhasil dikenali, selanjutnya divisualisasikan dalam bentuk grafik untuk menghubungkan antara pengarang dan pengarang lainnya. Hasil dari grafik hubungan pengarang dapat digunakan untuk mempermudah penelusuran dokumen lainnya yang memiliki kesamaan pada tema.
Ruang Lingkup Penelitian
Penelitian ini akan mengembangkan sebuah modul pada sistem temu kembali informasi dokumen penelitian yang memiliki batasan atau ruang lingkup yang harus dikerjakan dengan cakupan sebagai berikut:
• Dokumen yang digunakan sebagai input berbentuk file PDF. Sistem tidak dapat memproses dokumen dalam bentuk citra.
• Dokumen yang digunakan adalah dokumen skripsi Departemen Ilmu Komputer IPB 5 tahun terakhir (2007 s.d 2012).
• Penelusuran rujukan hanya dibatasi pada bagian Daftar Pustaka setiap dokumen skripsi.
• Format daftar pustaka yang digunakan pada penelitian ini mengikuti format yang digunakan pada Pedoman Penulisan Karya Ilmiah di Institut Pertanian Bogor edisi ke 1, 2, dan 3.
2
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi adalah menemukan bahan (dokumen) yang bersifat tidak terstruktur yang memenuhi kebutuhan informasi dari koleksi yang besar. Pada awalnya, temu kembali informasi merupakan kegiatan yang dilakukan beberapa orang yang hanya bergerak di bidang pustakawan. Pada saat ini ratusan juta orang terlibat dalam pengambilan informasi setiap hari menggunakan mesin pencari melalui internet. Temu kembali informasi menjadi bentuk dominan dari akses informasi, meninggalkan pencarian secara tradisional pada bidang pencarian informasi (Manning et al. 2008).
Sistem temu kembali informasi merupakan sistem yang dapat menyimpan, mencari dan mengelola informasi. Informasi yang dimaksud dapat merupakan teks, gambar, audio, video, dan objek multimedia lainnya. Tujuan utama sebuah sistem temu kembali informasi adalah menemukembalikan informasi yang mungkin berguna atau relevan bagi pengguna sesuai dengan kata pencarian yang telah dimasukkannya, penekanannya adalah pada penemukembalian informasi, bukan data (Baeza-Yates dan Ribeiro-Neto 2011). Sebuah sistem temu kembali informasi adalah sebuah program perangkat lunak yang memfasilitasi pengguna dalam mencari informasi sesuai dengan kebutuhan pengguna. Tujuan sebuah sistem temu kembali informasi adalah meminimalkan overhead dari pengguna dalam mencari informasi yang dibutuhkan (Kowalski 1997).
Sistem Temu Kembali Dokumen Penelitian
Sistem temu kembali dokumen penelitian dirancang untuk membantu pengguna merumuskan dan memperluas permintaan untuk mencari informasi pada sejumlah media mulai dari basis data perpustakaan dan World Wide Web (WWW). Antarmuka sistem telah dirancang dan dibuat dengan fasilitas untuk membantu pengguna mendapatkan pemahaman, merumuskan, dan memperluas permintaan pencarian serta memvisualisasikan dokumen penelitian. Sebuah evaluasi terdahulu pada pengguna sistem temu kembali dokumen penelitian mengungkapkan bahwa pengguna umumnya merasa mudah untuk membentuk dan memperluas permintaan mereka. Sistem temu kembali dokumen penelitian juga dapat membantu pengguna memperoleh informasi latar belakang yang berguna tentang domain pencarian. Sistem juga dapat menunjukkan aspek visualisasi informasi, browsing, dan antarmuka pengguna sebagai karakteristik unik (Ding et al. 2000).
Visualisasi Informasi
Ribeiro-Neto 2011). Percobaan visualisasi untuk hasil pencarian telah diterapkan dalam cara berikut:
• Visualisasi pada sintaks boolean
• Visualisasi pada kata query dalam hasil pencarian
• Visualisasi pada hubungan antara kata-kata dan dokumen
• Visualisasi untuk text mining
Pada penelitian ini, jenis visualisasi yang digunakan pada hasil pencarian adalah visualisasi pada hubungan antara kata-kata dan dokumen.
Rujukan
Rujukan atau referensi menurut Kamus Besar Bahasa Indonesia tahun 2008 merupakan bahan sumber yang dipakai untuk mendapatkan keterangan lebih lanjut; acuan. Pada sebuah dokumen penelitian terdapat beberapa sumber yang dijadikan rujukan. Sumber dari rujukan akan dituliskan pada bagian daftar pustaka yang merupakan daftar tulisan baik itu berupa buku, artikel, jurnal atau karangan dari seorang pengarang atau tentang suatu subjek (ilmu) (DEPDIKNAS 2008).
Perancangan Basis Data
Merancang basis data adalah dasar untuk membangun basis data yang memenuhi kebutuhan pengguna. Efektivitas dan efisiensi dari basis data secara langsung berhubungan dengan struktur basis data. Perancangan basis data dimulai dari tahap perancangan konseptual lalu dilanjutkan dengan perancangan logikal dan diakhiri dengan perancangan fisik (Hoffer et al. 2011).
Perancangan konseptual menggambarkan basis data menjadi bentuk entitas-entitas tunggal yang berhubungan, bertujuan untuk mewakili dari model data yang akan dirancang dalam bentuk diagram Entity Relationship (ER). Perancangan logikal dari basis data adalah mengubah rancangan konseptual menjadi rancangan yang menggambarkan data pada teknologi manajemen data yang akan digunakan untuk menerapkan basis data. Perancangan fisik menerjemahkan deskripsi logikal data ke dalam spesifikasi teknis untuk menyimpan dan mengambil data. Tujuannya adalah untuk membuat rancangan penyimpan data yang akan memberikan kinerja yang memadai dan menjamin integritas data.
Penelitian Sebelumnya
Penelitian mengenai pencarian dokumen penelitian sudah banyak dilakukan. Ding et al. (2000) mengembangkan Bibliometric Information Retrieval System (BIRS) yaitu sebuah sistem temu kembali informasi dokumen penelitian dengan antarmuka web. BIRS dirancang dan diimplementasikan sebagai sebuah perangkat lunak untuk memperluas dan memperbaiki pertanyaan pengguna dengan cara yang efisien, mudah, dan dapat diakses secara global. BIRS dihubungkan pada 3 jenis mesin pencari: mesin pencari di internet, perpustakaan, dan basis data yang dapat diakses secara online (lihat Gambar 1).
Gambar 1 Contoh tampilan BIRS (Ding et al. 2000).
Gambar 2 Framework DBL Browser (Klink et al. 2004).
Visualisasi dalam bentuk teks yang diterapkan menggunakan HTML dalam bentuk tabel yang berisi informasi dokumen dan pengarang. Sedangkan untuk visualisasi dalam bentuk grafik, dibuat 2 buah grafik. Grafik pertama menggambarkan hubungan antara seorang pengarang dan pengarang lainnya yang
Web Client GUI Layer
Visualization Layer
textual:
- authors - publications - conferences
graphical:
- authors maps - coauthor nets - ...
Information Retrieval Support
Memory-Database
Compressed Data-File
sama-sama menulis pada dokumen yang sama (Coauthor Relationship Graph). Grafik kedua menggambarkan hubungan antar-jurnal dengan tujuan mendapatkan jurnal yang banyak dijadikan referensi oleh jurnal lainnya. Penelitian Klink et al. (2004) mengasumsikan bahwa jurnal yang banyak diminati merupakan jurnal yang menjadi dasar pengembangan ilmu pada sebuah tema tertentu.
Penelitian yang berkaitan mengenai entri daftar pustaka sudah banyak dilakukan (Gardfield 1972, Day et al. 2005, Hetzner 2008). Algoritme sudah dikembangkan untuk mengenali pola kalimat daftar pustaka. Salah satunya adalah ParaTools yang merupakan sekumpulan koleksi fungsi berbasis bahasa pemrograman Perl yang menggunakan template untuk mengekstrak metadata dari entri daftar pustaka (Jewell 2011). Gupta et al. (2009) juga mengembangkan metode untuk mengekstrak dokumen penelitian yang menggunakan kombinasi dari ekspresi regular berdasarkan heuristik dan sistem pengetahuan untuk mencari entri daftar pustaka.
Metode ekstraksi dokumen penelitian lainnya juga pernah dikembangkan oleh Huang et al. (2004) menggunakan Basic Local Alignment Search Tool (BLAST). BLAST adalah aplikasi pencarian kesamaan yang menggunakan pemrograman dinamik. Basis data digunakan untuk menyimpan format entri daftar pustaka. Basis data yang dibuat dapat memisahkan field dari entri daftar pustaka dengan baik.
Penelitian lainnya yang berkaitan dengan penelitian ini ialah penelitian mengenai visualisasi dari hasil pencarian dokumen penelitian. Anegón et al. (2004) mengembangkan metode untuk membuat klasifikasi dari dokumen rujukan terhadap sebuah dokumen penelitian berdasarkan kelas dan kategori dari dokumen penelitian. Penelitian tersebut mengusulkan sebuah teknik baru yang menggunakan klasifikasi tematik (kelas dan kategori) sebagai entitas pengarang bersama.
Lin et al. (2003) juga membuat prototipe sistem visualisasi hasil pencarian dokumen penelitian berdasarkan analisis co-author dan memvisualisasikan dalam bentuk peta dengan algoritme visualisasi seperti Kohonen's feature maps dan pathfinder network. Sistem yang dikembangkan disebut AuthorLink dan dapat menghasilkan grafik interaktif pengarang dari basis data. Visualisasi menunjukkan pengelompokan subjek dan hubungan antar-pengarang berdasarkan kesamaan bidang ilmu. Melalui antarmuka interaktif pengguna dapat memanfaatkan informasi tersebut untuk memperbaiki query dan mengambil dokumen (lihat Gambar 3).
Gambar 3 Sebuah visualisasi pengarang untuk peraih Nobel Herbert Simon, ditampilkan dalam format Kohonen (Lin et al. 2003)
Gambar 4 Pengarang bersama (kiri) dan pengarang bersama yang telah menulis setidaknya 2 dokumen (kanan) (Murray et al. 2006)
Metode Pengukuran Sistem Temu Kembali Informasi
Recall= jumlah dokumen relevan ∩ jumlah dokumen terambil jumlah dokumen relevan
Precision merupakan rasio dari jumlah dokumen yang relevan yang berhasil ditemukembalikan oleh sistem dibandingkan dengan jumlah dokumen yang ditemukembalikan. Precision dapat dirumuskan sebagai berikut:
Precision= jumlah dokumen relevan ∩ jumlah dokumen terambil jumlah dokumen terambil
Sistem Temu Kembali Informasi Dokumen Penelitian yang Telah Ada
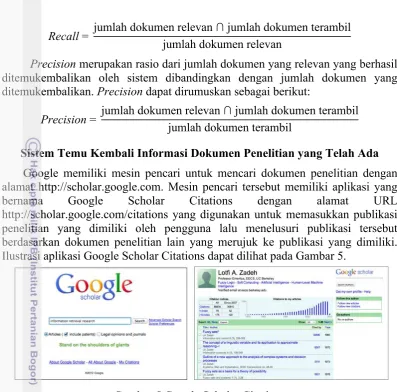
Google memiliki mesin pencari untuk mencari dokumen penelitian dengan alamat http://scholar.google.com. Mesin pencari tersebut memiliki aplikasi yang bernama Google Scholar Citations dengan alamat URL http://scholar.google.com/citations yang digunakan untuk memasukkan publikasi penelitian yang dimiliki oleh pengguna lalu menelusuri publikasi tersebut berdasarkan dokumen penelitian lain yang merujuk ke publikasi yang dimiliki. Ilustrasi aplikasi Google Scholar Citations dapat dilihat pada Gambar 5.
Gambar 5 Google Scholar Citations
Selain Google, Microsoft juga membuat sebuah mesin pencari yang diberi nama Microsoft Academic Search untuk mencari dokumen penelitian dengan alamat URL http://academic.research.microsoft.com. Mesin pencari tersebut memiliki fasilitas untuk menampilkan Co-Author Graph, Co-Author Path, Citation Graph, dan Genealogy Graph yang dapat memvisualisasikan hubungan seorang pengarang dengan pengarang lainnya. Fasilitas tersebut dapat menyajikan hubungan antara seorang pengarang dan pengarang lainnya dari rujukan yang dimiliki pada setiap dokumen penelitian. Ilustrasi visualisasi Microsoft Academic Search dapat dilihat pada Gambar 6.
Gambar 6 Ilustrasi Micorosoft Academic Search
3
METODOLOGI PENELITIAN
Penelitian ini akan membuat sebuah modul di dalam sistem temu kembali informasi dokumen penelitian. Modul yang dibuat nantinya akan mengambil masukan berupa informasi dari dokumen penelitian yaitu dokumen skripsi secara manual disertai dengan file PDF. File PDF akan diubah menjadi teks yang selanjutnya diidentifikasi untuk mendapatkan bagian entri daftar pustaka. Bagian entri daftar pustaka tersebut diekstrak untuk mendapatkan metadata yang diinginkan yang selanjutnya disimpan ke dalam basis data. Basis data yang menyimpan informasi entri daftar pustaka tersebut digunakan untuk menampilkan visualisasi dari hasil pencarian dokumen penelitian.
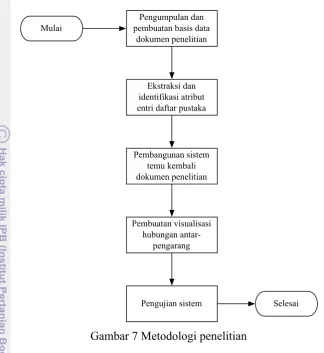
Kerangka Pemikiran
Gambar 7 Metodologi penelitian
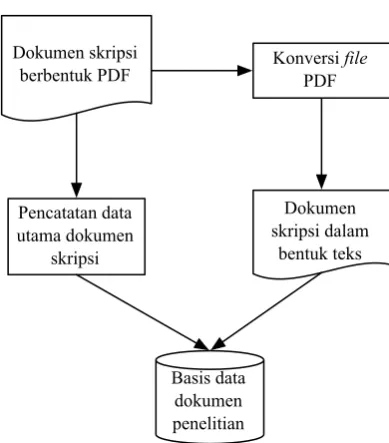
Pengumpulan dan Pembuatan Basis Data Dokumen Penelitian
Proses pembuatan basis data dokumen penelitian dimulai dari proses pengumpulan dokumen penelitian yang merupakan dokumen skripsi dalam bentuk file PDF. Setiap file PDF dibaca dan dicatat secara manual untuk mendapatkan data utama dari dokumen. Data utama dari dokumen terdiri atas judul dokumen, pengarang, pembimbing, tahun, dan penerbit. Selanjutnya file PDF akan dikonversi menjadi teks, lalu data utama dokumen yang sudah dicatat beserta teks hasil konversi file PDF disimpan ke dalam basis data. Hal ini dilakukan pada setiap dokumen skripsi. Data yang sudah tersimpan pada basis data selanjutnya digunakan untuk proses ekstraksi dan identifikasi atribut entri daftar pustaka. Ilustrasi pembuatan basis data dokumen penelitian dapat dilihat pada Gambar 8.
Setelah membuat basis data dokumen penelitian, proses selanjutnya adalah ekstraksi dan identifikasi atribut entri daftar pustaka pada dokumen penelitian. Setiap teks pada dokumen penelitian dibaca oleh sistem untuk mengekstrak kumpulan entri daftar pustaka yang terletak pada bab daftar pustaka. Kumpulan entri daftar pustaka selanjutnya disimpan ke dalam tabel pada basis data untuk dilanjutkan pada proses pengidentifikasian atribut entri daftar pustaka. Proses identifikasi atribut entri daftar pustaka dilakukan oleh sebuah modul pada sistem yang berfungsi mengenali model dari sebuah entri daftar pustaka serta setiap atributnya.
Mulai
Pengumpulan dan pembuatan basis data
dokumen penelitian
Ekstraksi dan identifikasi atribut entri daftar pustaka
Pembangunan sistem temu kembali dokumen penelitian
Pembuatan visualisasi hubungan
antar-pengarang
Gambar 8 Pembuatan basis data dokumen penelitian
Ekstraksi dan Identifikasi Atribut Entri Daftar Pustaka
Atribut yang berhasil dikenali oleh sistem dari sebuah entri daftar pustaka disimpan ke dalam tabel dokumen. Sebelum proses penyimpanan dilakukan, setiap atribut entri daftar pustaka diperiksa untuk mendapatkan kemungkinan adanya entri daftar pustaka yang sama sudah tersimpan pada tabel dokumen. Hal ini bertujuan untuk menghindari adanya dokumen yang sama tersimpan beberapa kali pada tabel dokumen.
Proses ekstraksi dan identifikasi atribut entri daftar pustaka untuk mendapatkan dilakukan dengan menggunakan aplikasi Perl bernama ParaTools (Jewell 2011). ParaTools memiliki 2 buah modul, yang pertama bernama Biblio Document Parser untuk melakukan ekstraksi entri daftar pustaka dan yang kedua bernama Biblio Citation Parser yang digunakan untuk mengindentifikasi atribut entri daftar pustaka. Kedua modul ParaTools tersebut dimodifikasi agar dapat melakukan ekstraksi dan identifikasi atribut entri daftar pustaka pada dokumen skripsi.
Pembangunan Sistem Temu Kembali Dokumen Penelitian
Sistem temu kembali yang dikembangkan terdiri atas 3 buah komponen yaitu backend, mesin pencari, dan antarmuka pengguna. Backend merupakan bagian dari sistem temu kembali yang digunakan untuk memasukkan dan memproses file dokumen penelitian menjadi basis data dokumen penelitian dan basis data entri daftar pustaka. Pada backend, dokumen penelitian dalam bentuk file PDF dibaca, diekstrak, dan diidentifikasi oleh sistem untuk mendapatkan data yang selanjutnya disimpan ke dalam basis data. Basis data digunakan oleh komponen mesin pencari untuk pembuatan kumpulan indeks yang digunakan untuk pencarian dokumen peneltian.
Komponen mesin pencari merupakan sub sistem untuk melakukan proses pencarian dokumen. Mesin pencari melakukan proses pencarian dokumen
Dokumen skripsi berbentuk PDF
Konversi file
Pencatatan data utama dokumen
skripsi
Basis data dokumen penelitian
Dokumen skripsi dalam
berdasarkan kata pencarian yang diperoleh dari pengguna yang dimasukkan pada komponen antarmuka. Komponen yang ketiga yaitu antarmuka pengguna merupakan sub sistem yang berhadapan langsung dengan pengguna dalam melakukan pencarian. Komponen antarmuka pengguna memiliki proses pembuatan visualisasi hasil pencarian dalam bentuk grafik. Arsitektur dari sistem temu kembali informasi dokumen penelitian dapat dilihat pada Gambar 9.
Gambar 9 Arsitektur sistem temu kembali informasi dokumen penelitian
Gambar 10 Model proses sistem temu kembali informasi dokumen penelitian Sistem temu kembali informasi yang dikembangkan memiliki 5 proses utama. Pada bagian antarmuka backend terdapat 2 proses yaitu entri dokumen PDF dan Pencarian kesamaan nama pengarang. Sedangkan, antarmuka frontend memiliki 3
Basis data
Sistem temu kembali dokumen penelitian
proses yaitu pencarian dokumen penelitian, visualisasi hasil pencarian, dan visualisasi hubungan pengarang. Untuk lebih jelasnya dapat dilihat pada Gambar 10.
Pembuatan Visualiasasi Hubungan Antar-Pengarang
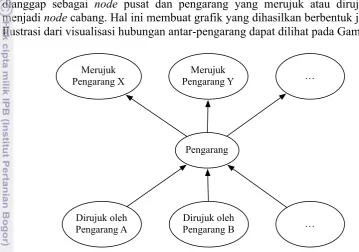
Data hasil ekstraksi dan identifikasi atribut entri daftar pustaka dari dokumen skripsi yang sudah tersimpan pada basis data dapat digunakan untuk menghasilkan grafik hubungan antar-pengarang. Seorang pengarang dapat dianggap sebagai node pusat dan pengarang yang merujuk atau dirujuk oleh menjadi node cabang. Hal ini membuat grafik yang dihasilkan berbentuk jaringan. Ilustrasi dari visualisasi hubungan antar-pengarang dapat dilihat pada Gambar 11.
Gambar 11 Visualisasi dokumen penelitian
Pengujian Sistem
Pengukuran Kinerja Ekstraksi dan Identifikasi Atribut Entri Daftar Pustaka pada Setiap Dokumen Penelitian
Pengukuran ekstraksi dan identifikasi atribut entri daftar pustaka pada setiap dokumen dilakukan dengan mengukur recall dan precision dari setiap entri daftar pustaka yang dihasilkan oleh sistem. Selanjutnya setiap nilai recall dan precision digunakan untuk menghitung presentase recall dan precision. Pengukuran dari ekstraksi dan identifikasi atribut entri daftar pustaka dapat dinotasikan sebagai berikut:
• Set entri daftar pustaka pada sebuah dokumen penelitian ke-i diberi notasi Bi • Set entri daftar pustaka yang berhasil diekstrak dan diidentifikasi dari
dokumen penelitian ke-i oleh sistem diberi notasi Ei
• Recall dari ekstraksi dan identifikasi atribut entri daftar pustaka pada dokumen penelitian ke-i diberi notasi Rbi
• Precision dari ekstraksi dan identifikasi atribut entri daftar pustaka pada dokumen penelitian ke-i diberi notasi Pbi
Dengan notasi tersebut dapat dibuat fungsi recall dan precision pada setiap dokumen menjadi:
Pengarang
Dirujuk oleh Pengarang A
Dirujuk oleh
Pengarang B …
Merujuk Pengarang X
Merujuk
Rbi = Bi∩ Ei Bi
Rbi merupakan pengukuran rasio antara jumlah hasil ekstraksi dan identifikasi
atribut entri daftar pustaka dengan jumlah entri daftar pustaka pada dokumen penelitian ke-i. Rbi akan bernilai 1 jika sistem dapat mengekstrak dan
mengidentifikasi dengan benar seluruh entri daftar pustaka pada dokumen penelitian ke-i.
Pbi = Bi∩ Ei
Ei
Pbi mengukur rasio antara jumlah entri daftar pustaka yang terekstrak dan
teridentifikasi oleh sistem dengan jumlah entri daftar pustaka pada dokumen penelitian ke-i. Pbi akan bernilai 1 jika jumlah hasil ekstraksi dan identifikasi
atribut entri daftar pustaka sama dengan jumlah entri daftar pustaka yang terdapat pada dokumen penelitian ke-i. Dari kedua persamaan tersebut, maka dapat dihitung persentase recall dan precision dari hasil ekstraksi dan identifikasi atribut entri daftar pustaka pada seluruh dokumen dengan rumus sebagai berikut:
PRb = Rbi diekstrak dan diidentifkasi pada seluruh dokumen penelitian
• PPb merupakan persentase precision dari entri daftar pustaka yang berhasil diekstrak dan diidentifikasi pada seluruh dokumen penelitian
• n merupakan jumlah dari dokumen penelitian
Pengukuran Kinerja Hubungan Entri Daftar Pustaka dengan Dokumen
Pengukuran kinerja hubungan entri daftar pustaka dengan dokumen dilakukan dengan mengukur recall dan precision dari jumlah dokumen penelitian yang memiliki entri daftar pustaka tertentu pada sistem. Pengukurannya dapat dinotasikan sebagai berikut:
• Set dokumen penelitian yang memiliki entri daftar pustaka ke-i diberi notasi Ci
• Set dokumen penelitian yang memiliki entri daftar pustaka ke-i yang dihasilkan oleh sistem diberi notasi Fi
• Recall dari dokumen penelitian yang memiliki entri daftar pustaka ke-i diberi notasi Rci
• Precision dari dokumen penelitian yang memiliki entri daftar pustaka ke-i diberi notasi Pci
Dengan notasi tersebut dapat dibuat fungsi recall dan precision menjadi:
Rci =
Ci ∩ Fi
Ci
Rci merupakan pengukuran rasio dari jumlah dokumen yang memiliki entri
ke-i yang dihasilkan oleh sistem. Rci akan bernilai 1 jika seluruh anggota Ci
merupakan anggota Fi.
Pci =
Ci∩ Fi
Fi
Pci akan bernilai 1 jika seluruh anggota Fi merupakan anggota Ci. Dari kedua
persamaan tersebut, maka dapat dicari persentase recall dan precision dari seluruh jumlah entri daftar pustaka yang terhubung ke dokumen dengan rumus sebagai
• PRc merupakan persentase recall dari dokumen penelitian yang memiliki entri daftar pustaka
• PPc merupakan persentase precision dari dokumen penelitian yang memiliki entri daftar pustaka
• n merupakan jumlah dari dokumen penelitian
4
HASIL DAN PEMBAHASAN
Pengumpulan Data
Data yang digunakan pada penelitian ini adalah dokumen hasil penelitian mahasiswa sarjana (dokumen skripsi) Departemen Ilmu Komputer Institut Pertanian Bogor dalam bentuk file PDF. Dokumen skripsi diperoleh dari Perpustakaan Departemen Ilmu Komputer sebanyak 246. Seluruh dokumen skripsi yang diperoleh digunakan sebagai sumber data utama serta sebagai bahan pengujian pada sistem temu kembali dokumen penelitian yang dikembangkan pada penelitian ini.
Karakteristik Dokumen Skripsi
Dokumen skripsi yang diperoleh memiliki karakteristik yang harus dipelajari terlebih dahulu sebelum melakukan proses ekstraksi entri daftar pustaka. Secara umum karakteristik dokumen skripsi yang berkaitan dengan entri daftar pustaka adalah sebagai berikut:
1 Isi tulisan sebagian besar memiliki format dua kolom, kecuali halaman judul, halaman pengesahan, halaman kata pengantar, halaman riwayat penulis, halaman daftar isi, halaman daftar gambar, halaman daftar tabel, halaman daftar lampiran, dan halaman lampiran.
2 Pergantian bab tidak menggunakan halaman baru. Hal ini memungkinkan terdapatnya 2 bab pada halaman yang sama.
3 Kumpulan entri daftar pustaka terletak diantara bab daftar pustaka dan sebuah halaman yang bertuliskan kata Lampiran.
Format Entri Daftar Pustaka
Penulisan skripsi pada Institut Pertanian Bogor menggunakan aturan dari buku Pedoman Penulisan Karya Ilmiah yang diterbitkan oleh IPB Press. Buku Pedoman Penulisan Karya Ilmiah digunakan sebagai panduan setiap mahasiswa dalam menulis dokumen ilmiah seperti laporan, skripsi, tesis, disertasi, dan dokumen ilmiah lainnya di lingkungan IPB. Entri daftar pustaka pada dokumen skrispsi yang diperoleh seharusnya menggunakan format daftar pustaka yang terdapat pada buku Pedoman Penulisan Karya Ilmiah. Buku Pedoman Penulisan Karya Ilmiah yang digunakan sebagai acuan untuk melakukan ekstraksi entri daftar pustaka pada penelitian ini menggunakan Pedoman Penulisan Karya Ilmiah edisi ke 1, 2, dan 3 (IPB 2001, IPB 2004, IPB 2012).
Entri daftar pustaka pada dokumen skripsi Departemen Ilmu Komputer memiliki format dua kolom. Sebuah entri daftar pustaka dapat menjadi beberapa baris. Baris kedua dan seterusnya pada sebuah entri daftar pustaka memiliki posisi lebih menjorok ke kanan dibandingkan dengan baris pertama. Gambar 12 merupakan contoh tampilan dari entri daftar pustaka pada dokumen skripsi.
Gambar 12 Entri daftar pustaka pada dokumen skripsi
Perancangan Basis Data Dokumen Penelitian
Tahap selanjutnya dari penelitian ini adalah perancangan basis data dokumen penelitian. Perancangan basis data dimulai dari perancangan konseptual yang merupakan proses identifikasi entitas yang ada pada sistem temu kembali dokumen penelitian. Entitas utama dari sistem adalah dokumen skripsi yang memiliki pengarang, pembimbing, dan entri daftar pustaka. Identifikasi dari entitas sistem temu kembali dokumen penelitian adalah sebagai berikut:
1 Skripsi memiliki seorang pengarang, pengarang hanya dapat menulis sebuah skripsi.
2 Skripsi memiliki seorang pembimbing.
3 Skripsi memiliki 1 atau beberapa entri daftar pustaka. 4 Entri daftar pustaka merupakan dokumen.
6 Jenis dokumen entri daftar pustaka dapat berupa buku, jurnal, prosiding, dan dokumen web.
7 Setiap dokumen dapat memiliki beberapa pengarang, dan seorang pengarang dapat menulis beberapa dokumen.
8 Seorang pengarang dapat menjadi pembimbing skripsi dan mahasiswa atau bukan keduanya.
Berdasarkan hasil identifikasi entitas pada perancangan basis data dokumen penelitian, rancangan konseptual disajikan pada Gambar 13.
Gambar 13 Perancangan konseptual basis data dokumen penelitian
Dari perancangan konseptual basis data dokumen penelitian diketahui bahwa dokumen dapat digolongkan menjadi beberapa jenis. Dari hal ini, basis data dokumen penelitian yang dibuat dapat menerapkan teknik Enhanced Entity Relationship (EER). EER digunakan untuk mengidentifikasi model yang telah dihasilkan dengan memperluas model ER asli. Teknik ini membuat model EER mirip dengan pemodelan data berorientasi objek (Hoffer et al. 2011).
Pada perancangan konseptual, entitas dokumen dapat dibuat menjadi relasi supertype dan subtype. Relasi ini membuat model umum (supertype) dari dokumen dan membuat dokumen tersebut menjadi beberapa jenis yang lebih spesifik (supertype). Setiap subtype memiliki atribut yang diwarisi dari supertype-nya. Entitas dokumen dapat dijadikan supertype dengan mengambil atribut yang dimiliki oleh setiap atribut subtype-nya. Ilustrasi dari supertype dan subtype dokumen dapat dilihat pada Gambar 14.
Pada perancangan konseptual, entitas pengarang dapat dibuat menjadi relasi supertype dan subtype. Relasi ini membuat model umum (supertype) dari pengarang dan membuat pengarang tersebut menjadi beberapa jenis yang lebih
Dokumen Pengarang Skripsi
Jurnal
Prosiding
Website
d
Membimbing Dibimbing
Ditulis
Menulis
o
spesifik (supertype). Ilustrasi dari supertype dan subtype pengarang dapat dilihat pada Gambar 15.
Perancangan logikal dari basis data dokumen penelitian menambahkan informasi data sebagai penghubung antar-entitas pada rancangan konseptual untuk disimpan pada aplikasi basis data. Rancangan logikal dari basis data dokumen penelitian dapat dilihat pada Gambar 16 serta perancangan fisik basis data dokumen penelitian dapat dilihat pada Gambar 17.
Gambar 14 Supertype dan subtype pada dokumen
Gambar 15 Supertype dan subtype pada pengarang
d
"jurnal" "skripsi" "prosiding" "website"
Gambar 16 Perancangan logikal basis data dokumen penelitian
Gambar 17 Perancangan fisik basis data dokumen penelitian
Pengolahan Data
Setelah mengumpulkan dan mempelajari dokumen skripsi serta merancang basis data, hal yang dilakukan adalah membangun modul pada sistem yang dapat
mengenali kumpulan entri daftar pustaka dari setiap dokumen skripsi dan menyimpan entri daftar pustaka pada basis data. Kumpulan entri daftar pustaka pada dokumen skripsi terletak pada bab Daftar Pustaka dengan format penulisan 2 kolom. Sebuah entri daftar pustaka dapat seluruh barisnya terletak pada sebuah kolom dan dapat sebagian barisnya terletak pada kolom yang berbeda. Modul yang dibuat harus dapat mengenali setiap entri daftar pustaka dengan kondisi tersebut. Agar dapat melakukan hal tersebut, maka pada proses pengolahan data pada modul yang dibuat meliputi 3 tahap yaitu pengubahan file dokumen skripsi dari bentuk file PDF menjadi teks, ekstraksi entri daftar pustaka, dan identifikasi atribut entri daftar pustaka.
Pengubahan File Dokumen Skripsi dalam Bentuk PDF Menjadi Teks
Proses mengubah file dokumen skripsi dalam bentuk PDF menjadi teks menggunakan aplikasi pdftotext. Proses ini hanya dapat dilakukan untuk file PDF yang tidak dibatasi pada proses penyalinan isi. Sebuah file PDF dokumen skripsi diubah menjadi 2 bentuk teks dengan format berbeda. Pengubahan yang pertama menghasilkan format raw text dan pengubahan yang kedua menghasilkan format layout text. Aplikasi pdftotext akan membaca setiap baris kalimat pada file PDF lalu menyimpan setiap baris kalimat tersebut ke dalam file teks.
Pengubahan file PDF menjadi format raw text dilakukan untuk mendapatkan teks dalam bentuk berurut dengan format satu kolom. Pada file PDF dokumen skripsi yang memiliki 2 kolom, pdftotext akan membaca dan memindahkan setiap baris pada halaman pertama kolom pertama, halaman pertama kolom kedua, halaman kedua kolom pertama, halaman kedua kolom kedua, dan begitu seterusnya hingga halaman terakhir dari file PDF (lihat Gambar 18). Format raw text juga mengubah 2 atau lebih spasi yang berdekatan pada tulisan menjadi sebuah spasi. Hasil dari pengubahan file PDF menjadi teks dengan format raw text dapat dilihat pada Gambar 19.
Pengubahan file PDF yang menghasilkan format layout text digunakan untuk mendapatkan posisi dari teks pada dokumen skripsi yang digunakan untuk mengidentifikasi sebuah entri daftar pustaka. Hasil konversi aplikasi pdftotext dengan menerapkan format layout text akan menghasilkan file teks yang berisi tulisan yang sama bentuknya dengan file PDF. Pada file PDF dokumen skripsi yang memiliki dua kolom, maka akan dihasilkan file teks dengan bentuk dua kolom (lihat Lampiran 1).
Ekstraksi Entri Daftar Pustaka
Setelah dokumen skripsi dalam bentuk PDF diubah menjadi teks, tahap selanjutnya adalah melakukan ekstraksi entri daftar pustaka. File teks berformat raw text hasil konversi dokumen skripsi digunakan untuk memisahkan kumpulan baris entri daftar pustaka dengan baris lainnya. Pada dokumen skripsi, baris kumpulan entri daftar pustaka terletak di antara baris yang berisi kata Daftar Pustaka dan Lampiran. Proses pemisahan kumpulan entri daftar pustaka menggunakan modul dari ParaTools yang bernama Biblio Document Parser.
Parser dimodifikasi untuk mendapatkan setiap baris yang terletak di antara baris yang hanya berisi kata Daftar Pustaka dan kata Lampiran karena baris-baris yang terletak di antara kedua baris tersebut dianggap sebagai kumpulan entri daftar pustaka. Modul ini selanjutnya menyimpan setiap baris yang dianggap sebagai kumpulan entri daftar pustaka.
Gambar 18 Konsep pengubahan file PDF menjadi format raw text
Gambar 19 Hasil pengubahan file PDF menjadi teks dengan format raw text
Baris-baris kumpulan entri daftar pustaka yang berhasil didapatkan oleh sistem selanjutnya diidentifikasi untuk mendapatkan setiap kalimat entri daftar pustaka. Proses ekstraksi entri daftar pustaka dilakukan dengan menggunakan bantuan file teks berformat layout text hasil konversi file PDF. Setiap baris kumpulan entri daftar pustaka dibandingkan posisinya dengan baris file teks berformat layout text. Pada dokumen skripsi yang memiliki 2 kolom, sistem yang dibuat harus mengenali entri daftar pustaka dengan kondisi sebagai berikut: 1 Entri daftar pustaka seluruhnya terletak pada kolom pertama
2 Entri daftar pustaka seluruhnya terletak pada kolom kedua Text Box Columns
div.text-col-1 div.text-col-introh3
Benefits
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla:
h3
Good value for money
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien.
div.text-col-2 div.text-col-introh3
Features
p
Nam turpis massa, congue ac, aliquam et. Quisque sed tellus quis nunc ultricies ultricies congue ac, aliquam et.:
h3
Transactional activation
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien.
div.text-col-1 div.text-col-introh3
Benefits
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla:
h3
Good value for money
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien.
Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla.
h3
Scheduled backups
p
Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Text Box Columns
div.text-col-1 h3
Unlimited support
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla.
h3
Product liability and guarantees
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus.
div.text-col-2 h3
Advanced cache strategies
p
Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla.
h3
Scheduled backups
p
Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi.
div.text-col-1 h3
Unlimited support
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. Ut mi. Fusce quis sapien. Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla.
h3
Product liability and guarantees
p
Aliquam consequat nulla sed mauris. Nam turpis massa, congue ac, aliquam et, dapibus eget, nulla. Quisque sed tellus quis nunc ultricies ultricies. Donec lectus lorem, laoreet vel, venenatis id, pellentesque eget, leo. Sed tortor purus, consequat id, placerat id, lacinia id, purus. div.text-col-2 div.text-col-introh3
Features
p
Nam turpis massa, congue ac, aliquam et. Quisque sed tellus quis nunc ultricies ultricies congue ac, aliquam et.:
h3
Transactional activation
p
3 Entri daftar pustaka bagian awalnya terletak pada kolom pertama dan bagian lainnya terletak pada kolom kedua
4 Entri daftar pustaka bagian awalnya terletak pada kolom kedua dan bagian lainnya terletak pada kolom pertama
Dari kondisi posisi entri daftar pustaka tersebut, maka proses mengenali entri daftar pustaka menggunakan proses yang digambarkan pada Lampiran 2.
Setelah diperoleh entri daftar pustaka dari kumpulan entri daftar pustaka, setiap entri daftar pustaka diproses untuk penyeragaman kalimat. Proses penyeragaman dilakukan karena terdapat beberapa karakter, kata, serta kalimat pada entri daftar pustaka memiliki kesalahan yang sudah ada pada penulisan entri daftar pustaka atau kesalahan dapat terjadi pada saat proses memisahkan entri daftar pustaka dari kumpulan entri daftar pustaka. Penyeragaman entri daftar pustaka bertujuan untuk mempermudah proses identifikasi atribut entri daftar pustaka pada tahap berikutnya. Proses penyeragaman entri daftar pustaka adalah sebagai berikut:
1 Menghilangkan karakter spasi di awal dan akhir entri daftar pustaka.
2 Mengubah 2 karakter spasi atau lebih yang berdekatan menjadi sebuah karakter spasi.
3 Memberikan titik (.) pada setiap akhir entri daftar pustaka.
4 Mengubah kata/karakter “hlm”, “halaman”, “pp”, “h”, “pages” yang diikuti dengan nomor halaman menjadi hlm.
5 Mengubah kata Vol, Volume yang diikuti dengan digit menjadi vol.
6 Mengubah kalimat “proceedings of”, “Proc. of”, “proceeding of” menjadi “Proceedings of”.
7 Mengubah kata-kata format skripsi, tesis, disertasi, thesis, dissertation menjadi [skripsi], [tesis], [disertasi].
8 Mengubah kata “dalam:”, “di dalam:”, “in:” menjadi “Di dalam:”. 9 Mengubah kata Editor, (editor), (eds) menjadi editor.
10 Menyeragamkan format versi dari nama aplikasi (contoh: oracle 9. 0. 1 menjadi oracle 9.0.1 )
Identifikasi Atribut Entri Daftar Pustaka
Modul identifikasi atribut entri daftar pustaka dibuat untuk mendapatkan kolom-kolom dari sebuah entri daftar pustaka. Kolom-kolom hasil idetifikasi atribut entri daftar pustaka terdiri atas 2 kategori yaitu umum dan spesifik. Kolom-kolom yang dihasilkan oleh proses ini selanjutnya disimpan ke dalam basis data. Tahapan ekstrak entri daftar pustaka dapat dilihat pada Gambar 20.
Pada sebuah entri daftar pustaka akan berisi kolom-kolom yang merupakan metadata. Kolom-kolom akan dibatasi oleh tanda titik dilanjutkan dengan spasi (. ), koma dilanjutkan dengan spasi (, ), titik dua (:), titik koma (;), terletak di dalam kurung, dan lain sebagainya. Contoh kolom pada entri daftar pustaka dapat dilihat pada Gambar 21.
sesuai dengan entri daftar pustaka yang dibandingkan. Proses pemilihan model yang paling sesuai oleh sistem akan dibahas selanjutnya.
Gambar 20 Tahapan esktrak entri daftar pustaka
Gambar 21 Kolom entri daftar pustaka
Hasil identifikasi atribut entri daftar pustaka adalah kolom-kolom yang terdiri atas 2 jenis yaitu umum dan spesifik. Kolom-kolom berjenis umum yang dihasilkan oleh proses ini adalah kolom yang terdapat pada hampir setiap entri daftar pustaka. Kolom berkategori spesifik merupakan kolom entri daftar pustaka yang hanya dimiliki oleh jenis entri daftar pustaka tertentu. Kolom-kolom spesifik juga digunakan untuk mengklasifikasikan entri daftar pustaka. Klasifikasi entri daftar pustaka yang terdapat pada dokumen skripsi terdiri atas buku,
Mulai
Perbandingan entri daftar pustaka dengan
model entri daftar pustaka Entri daftar
pustaka
Model entri daftar pustaka
Model-model entri daftar pustaka yang
cocok
Pemilihan model entri daftar pustaka yang
paling sesuai
Ekstrak kolom entri daftar pustaka
Penyimpanan kolom entri daftar pustaka ke
basis data
Selesai
Setiawan, D. 2003. Teknologi Selular dan CDMA. Jakarta: PT Elex Media Komputindo.
Kolom 1 : Setiawan, D Kolom 2 : 2003
Kolom 3 : Teknologi Selular dan CDMA Kolom 4 : Jakarta
skripsi/tesis/disertasi, jurnal, prosiding, dan website. Kolom umum dan spesifik dari entri daftar pustaka dapat dilihat pada Tabel 1.
Tabel 1 Kolom umum dan spesifik entri daftar pustaka Jenis Kolom Nama Kolom
Umum Nama pengarang, Judul, Penerbit, Tahun terbit
Spesifik Nama Jurnal, Volume, Halaman, Nama Prosiding (Publikasi), Lokasi, URL
Proses identifikasi atribut entri daftar pustaka dilakukan dengan menggunakan modul Biblio Citation Parser dari aplikasi ParaTools. Modul ini dapat mengidentifikasi setiap entri daftar pustaka dan menghasilkan atribut dari entri daftar pustaka pada dokumen-dokumen yang banyak digunakan di luar negeri. Pada penelitian ini, karena menggunakan format entri daftar pustaka dari Pedoman Penulisan Karya Ilmiah IPB, maka modul Biblio Citation Parser harus dimodifikasi agar dapat digunakan. Pada buku Pedoman Penulisan Karya Ilmiah IPB, setiap kolom entri daftar pustaka dipisahkan oleh tanda titik dilanjutkan dengan spasi (. ), kecuali untuk kolom volume, issue, dan halaman. Penjelasan dari setiap format Metadata entri daftar pustaka dapat dilihat pada Lampiran 3.
Proses identifikasi atribut pada entri daftar pustaka dilakukan dengan cara membandingkan entri daftar pustaka dengan model entri daftar pustaka. Sebuah model entri daftar pustaka akan berisi beberapa kata identifikasi kolom entri daftar pustaka. Kata-kata identifikasi kolom entri daftar pustaka yang digunakan pada penelitian ini dapat dilihat pada Tabel 2.
Tabel 2 Kata-kata identifikasi entri daftar pustaka yang digunakan
Kata Identifikasi Kolom Bobot
_AUTHORS_ Pengarang dokumen 0.65
_YEAR_ Tahun terbit 0.65
_TITLE_ Judul dokumen 0.65
_PUBLISHER_ Penerbit 0.65
_PUBLICATION_ Publikasi 0.9
_PUBLOC_ Lokasi 0.65
_VOLUME_ Nomor volume 0.9
_ISSUE_ Nomor isu 0.9
_PAGES_ Nomor halaman 0.9
_EDITOR_ Nama Editor 0.9
_URL_ Alamat situs di internet 0.9
_EDITORTITLE_ Judul buku dari editor 0.65
_EDISI_ Edisi 0.65
_ANY_ Sembarang kata 0.1
sebuah entri daftar pustaka dengan model kalimat daftar pustaka. Sebuah entri daftar pustaka dapat memiliki kesamaan format dengan beberapa model kalimat daftar pustaka yang sudah dibuat karena beberapa kolom entri daftar pustaka memiliki format yang sama. Kolom judul, penerbit, dan lokasi memiliki format berupa kalimat. Selain itu, kolom nomor volume, isu, dan halaman sama-sama memiliki format berupa nomor.
Kata identifikasi dari model entri daftar pustaka memiliki bobot. Kata-kata identifikasi yang dianggap membedakan kategori sebuah entri daftar pustaka akan diberi bobot lebih tinggi, sedangkan kata identifikasi yang tidak membedakan kategori entri daftar pustaka diberi bobot lebih rendah. Pada Tabel 2, bobot sebesar 0.65 diberikan pada pengarang, tahun terbit, judul dokumen, penerbit, lokasi, judul buku dari editor, dan edisi. Bobot sebesar 0.9 diberikan kepada publikasi, volume, isu, halaman, nama editor, dan alamat situs di internet. Kata-kata identifikasi yang memiliki bobot 0.65 merupakan Kata-kata identifikasi yang tidak membedakan kategori dari sebuah entri daftar pustaka, sedangkan kata identifikasi yang memiliki bobot 0.9 adalah kata-kata identifikasi yang mengkategorikan entri daftar pustaka.
Modul Biblio Citation Parser menggunakan bobot dari kata-kata identifikasi untuk memilih model yang paling sesuai dengan entri daftar pustaka jika terdapat beberapa model yang dianggap sama dengan entri daftar pustaka. Kata-kata identifikasi yang dihasilkan dari beberapa model yang dianggap sama dengan entri daftar pustaka dijumlahkan bobotnya. Model yang memiliki bobot paling besar dianggap sebagai model yang paling sesuai dengan entri daftar pustaka. Sebagai contoh bila pada sistem mendapatkan entri daftar pustaka sebagai berikut:
Purnama PB. 2004. Kiat Praktis Menjadi Desainer Web Profesional. Jakarta: PT Elex Media Komputindo.
Dari entri daftar pustaka tersebut, sistem menghasilkan beberapa model entri daftar pustaka yang cocok, yaitu:
1 buku=>_AUTHORS_. _YEAR_. _TITLE_.
2 buku=>_AUTHORS_. _YEAR_. _TITLE_. _PUBLISHER_.
3 buku=>_AUTHORS_. _YEAR_. _TITLE_. _PUBLOC_: _PUBLISHER_. Model 1 memiliki jumlah bobot sebesar 1.95, model 2 memiliki jumlah bobot sebesar 2.6 dan model 3 memiliki jumlah bobot sebesar 3.25. Sistem akan memilih model 3 sebagai model yang digunakan mengidentifikasi atribut dari entri daftar pustaka. Contoh hasil dari identifkasi atribut entri daftar pustaka dapat dilihat pada Lampiran 5.
Saat ini model entri daftar pustaka yang terdapat pada sistem berjumlah sebanyak 45255. Model format entri daftar pustaka untuk mengidentifikasi atribut entri daftar pustaka dapat disesuaikan dengan kebutuhan. Model-model ini disimpan pada sebuah file pada sistem sehingga model entri daftar pustaka yang baru dapat ditambahkan secara manual.
Penyimpanan Entri Daftar Pustaka ke Basis Data
kolom-kolom entri daftar pustaka yang merupakan subtype menggunakan nama tabel yang dapat dilihat pada Tabel 3.
Tabel 3 Tabel penyimpanan kolom spesifik dari entri daftar pustaka
Nama Tabel Kolom
Jurnal Nama Jurnal
Volume Halaman
Prosiding Nama Prosiding
Lokasi
Website URL
Proses lainnya sebelum melakukan penyimpanan entri daftar pustaka ke basis data adalah melakukan pemeriksaan kesamaan entri daftar pustaka dengan entri daftar pustaka yang sudah tersimpan pada basis data. Hal ini dilakukan agar tidak ada entri daftar pustaka yang sama disimpan beberapa kali pada basis data. Pemeriksaan kesamaan dokumen dilakukan pada kolom nama pengarang, judul, dan tahun dokumen. Proses pemeriksaan kesamaan dokumen dilakukan dengan fungsi jarak levensthein pada kolom judul dan nama pengarang entri daftar pustaka dengan seluruh entri daftar pustaka yang sudah tersimpan pada basis data. Kondisi 2 entri daftar pustaka yang dianggap sama dapat dilihat pada Tabel 4. Tabel 4 Kondisi entri daftar pustaka1 dan entri daftar pustaka2 yang dianggap
sama
Kolom Kondisi
Tahun tahun
1= tahun2
Judul levensthein(judul
1,judul2)
panjang karakter (judul1) ×100% ≤ 10%
Nama Pengarang levensthein(nama pengarang
1, nama pengarang2) ≤ 2
Sebelum memproses fungsi levensthein, dilakukan proses penyeragaman setiap kolom pada entri daftar pustaka yang sudah disimpan pada basis data. Penghilangan spasi di awal dan di akhir pada setiap isi kolom dilakukan. Isi setiap kolom dibuat menjadi huruf kecil semua dan apabila terdapat 2 karakter spasi maka dijadikan sebuah karakter spasi. Pada kolom nama pengarang dilakukan hal berikut:
1 Apabila terdapat nama gelar pada pengarang, gelar awal dan akhir dari nama pengarang dihilangkan.
2 Nama pengarang dibuat menjadi format “[Nama akhir ] ([Huruf awal nama pertama] [Huruf awal nama kedua] [Huruf awal nama ketiga] …)”, contoh:
• Ir. Julio Adisantoso, M.Kom menjadi Adisantoso J
• Abdul Kadir Hakim menjadi Hakim AK