Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
i
SUSUNAN DEWAN REDAKSI JELIKU
KETUA
AGUS MULIANTARA, S.KOM, M.KOM
PENYUNTING
DRA. LUH GEDE ASTUTI, M.KOM
NGURAH AGUS SANJAYA E.R., S.KOM, M.KOM
IDA BAGUS MAHENDRA, S.KOM, M.KOM
IDA BAGUS GEDE DWIDASMARA, S.KOM, M.CS
PELAKSANA
I KETUT GEDE SUHARTANA, S.KOM., M.KOM
I GEDE SANTI ASTAWA, S.T., M.CS
I MADE WIDIARTHA, S.SI., M.KOM
ALAMAT REDAKSI
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS UDAYANA
KAMPUS BUKIT JIMBARAN – BADUNG
TELEPON : 0361 – 701805
EMAIL : [email protected]
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
iii
DAFTAR ISI
SUSUNAN DEWAN REDAKSI JELIKU ... i DAFTAR ISI ... iii
IMPLEMENTASI GAMMU SEBAGAI MESIN SMS GATEWAY DI IPHONE BALI
Putu Suma Arthajaya, Agus Muliantara, Ngurah Agus Sanjaya ER ... 1
PERANCANGAN DAN IMPLEMENTASI SISTEM PENDETEKSIAN PLAGIARISME PADA DOKUMEN DIGITAL DENGAN MENGGUNAKAN ALGORITMA WINNOWING
Ade Harya Satriya ... 6
PERANCANGAN DAN IMPLEMENTASI SISTEM INTERAKTIF JURNAL PADA SISTEM AKUNTASI (AISO) DENGAN KONSEP OBJECT ORIENTED PROGRAMING (OOP)
Anak Agung Gde Surya Bhuwana ... 13
IMPLEMENTASI SISTEM INTEGRASI MESIN ABSENSI (FINGER PRINT) DENGAN HARISMA (HUMAN RESOURCE MANAGEMENT SYSTEM) PT. DIMATA SORA JAYATE Obie Rahman ... 19
SISTEM PENGENALAN EKSPRESI WAJAH TERSENYUM DENGAN ALGORITMA JARINGAN SYARAF TIRUAN LEVENBERG-MARQUARDT
Tikha Prasatya Nugraha, I Made Widiartha, I Gede Santi Astawa ... 25
PENGIRIMAN REPORT OTOMATIS KE EMAIL MENGGUNAKAN IMPLEMENTASI MUTT DAN CRONTAB DI FAKULTAS HUKUM UNIVERSITAS UDAYANA
I Gede Hardi Surya Budiana, Cokorda Rai Adi Pramartha ... 31
PERANCANGAN DAN IMPLEMENTASI TEXT MINING MENGGUNAKAN ALGORITMA RABIN-KARP PADA APLIKASI PENCARIAN DOKUMEN REFERENSI TUGAS AKHIR I Gusti Ngurah Lanang Septiadi Putra, Ngurah Agus Sanjaya ER, I B Made Mahendra
... 35
PERANCANGAN SISTEM REGISTRASI KONFERENSI DENGAN MS. VISUAL BASIC PT. OPTIONS - DENPASAR
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
iv SISTEM INFORMASI ADMINISTRASI SURAT
Ida Bagus Ngurah Indraswara, Agus Muliantara, Ngurah Agus Sanjaya ER ... 49
PENYISIPAN CITRA RAHASIA MENGGUNAKAN ALGORITMA GIFSHUFFLE
I Gede Ngurah Aryawan ... 56
IMPLEMENTASI ALGORITMA GENETIK DALAM PENYELESAIAN PERMAINAN SUDOKU
Gede Dita Aditya Elanda ... 61
PEMODELAN DAN SIMULASI SISTEM ANTRIAN DENGAN METODE PRIORITAS STUDI KASUS : STUDIO FOTO
Sahmanbanta.S. ... 65
SISTEM INFORMASI GEOGRAFIS KEAMANAN PARIWISATA PANTAI
Ida Bagus Gede Arsa Wedhana ... 71
ANALISIS PERBANDINGAN KINERJA ANTARA NETWORK FILE SYSTEM (NFS) DAN PRIMARY DOMAIN CONTROLLER (PDC) SAMBA
Gede Wahyudi,Trisna Hanggara ... 77
ANALISIS PADA IKEE.B IPHONE BOTNET
I Putu Arich Arthawan, I Dewa Made Bayu Atmaja Darmawan ... 84
IMPLEMENTASI BANDWIDTH MANAGEMENT DI DISCOVERY KARTIKA PLAZA HOTEL
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
35
PERANCANGAN DAN IMPLEMENTASI TEXT MINING MENGGUNAKAN ALGORITMA RABIN-KARP PADA APLIKASI PENCARIAN DOKUMEN REFERENSI TUGAS AKHIR
I Gusti Ngurah Lanang Septiadi Putra, Ngurah Agus Sanjaya ER, I B Made Mahendra Program Studi Teknik Informatika, Jurusan Ilmu Komputer,
Fakultas Matematika Dan Ilmu Pengetahuan Alam, Universitas Udayana
Email : [email protected], [email protected], [email protected]
ABSTRAK
Text Mining merupakan metode yang digunakan untuk menemukan informasi yang relevan dengan kebutuhan dari penggunanya secara otomatis. Penelitian ini bertujuan untuk mengimplementasikan text mining menggunakan algoritma Rabin-Karp dan dice similarity coefficient pada aplikasi pencarian dokumen referensi tugas akhir. Jumlah substring K-Grams yang ditemukan pada algoritma Rabin-Karp akan menjadi variabel dalam perhitungan dice similarity. Hasil dari dice similarity pada masing-masing dokumen terhadap query akan diurutkan secara descending, sehingga hasil pencarian akan menampilkan dokumen yang paling mendekati kata kunci. Sistem ini dikembangkan menggunakan bahasa pemrograman PHP dan dokumen yang digunakan sebagai data uji sebanyak 20 abstrak yang penulis kutip dari jurnal ilmu Komputer edisi online. Penelitian ini telah berhasil mengimplementasikan algoritma Rabin-Karp dalam aplikasi pencarian dokumen. Hasil dari penelitian ini menunjukkan bahwa tiap nilai K-Grams menghasilkan urutan dokumen relevan yang berbeda.
Kata kunci: Text Mining, K-Grams, Hashing, Rabin-Karp, Dice Similarity Coeficients
ABSTRACT
Text Mining is the method used to locate information relevant to the needs of the users automatically. This study aims to implement text mining using Rabin-Karp algorithm and dice similarity coefficient at a reference document search application thesis. Number of K-Grams substring found in Rabin-Karp algorithm will become a variable in the calculation of similarity dice. Results of dice similarity to each document to the query will be sorted in descending order, so the search results will show you the closest document keywords. This system was developed using the PHP programming language and documents that are used as test data of 20 abstract author quotes from the online edition of the journal Computer science. This study has successfully implemented the Rabin-Karp algorithm in document search application. The results of this study indicate that each value of K-Grams produce a different sequence of the relevant documents.
Keywords:Text Mining, K-Grams, Hashing, Rabin-Karp, Dice Similarity Coeficients
PENDAHULUAN
Kebutuhan untuk pencarian informasi secara otomatis dari kumpulan dokumen tekstual sangat diperlukan untuk mempercepat pencarian informasi yang sesuai dengan kebutuhan kita. Keadaan tersebut dapat diatasi menggunakan metode text mining. Dalam memberikan solusi, text mining mengadopsi dan mengembangkan banyak teknik dari
bidang lain, seperti Data mining, Information Retrieval, Statistik dan Matematik, Machine Learning, Linguistic, Natural Languange Processing, dan Visualization.
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
36 topik yang dibutuhkan oleh pengguna dengan tahapan preprocessing meliputi tokenizing, filtering, dan stemming serta dilakukan processing meliputi pencocokan string menggunakan Rabin-Karp dan perankingan dokumen.
Diharapkan aplikasi ini dapat menjawab permasalahan-permasalahan pembaca dan pencari informasi seperti lamanya proses membaca secara manual dan pencarian informasi yang lebih relevan bagi pembaca.
MATERI
1. Text Mining
Text mining memiliki definisi menambang data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen.
Didalam proses text mining dilakukan beberapa tahapan umum diantaranya adalah tokenizing dan case folding, filtering, dan stemming. Tahap tokenizing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Setelah teks input dilakukan proses tokenizing, maka tahap selanjutnya dilakukan tahap filtering. yaitu tahap mengambil kata-kata penting dari hasil token. Tahap selanjutnya adalah tahap stemming adalah tahap mencari dasar kata dari tiap kata hasil filtering. Setiap kata yang memiliki imbuhan seperti imbuhan awalan dan akhiran maka akan diambil kata dasarnya. Tahap yang terakhir dalam text mining adalah tahap analyzing yaitu tahap penentuan seberapa jauh keterhubungan antar kata-kata antar dokumen yang ada. Untuk melakukan analisa pada tahap analyzing dapat digunakan algoritma Rabin-Karp dan dice coefficient.
2. Algoritma Rabin-Karp
Algoritma Karp-Rabin diciptakan oleh Michael O. Rabin dan Richard M. Karp pada tahun 1987. Algoritma ini lebih berguna pada pencarian multiple pattern daripada pencarian single pattern. Karena algoritma ini tidak memperdulikan huruf besar atau kecil, dan
tanda baca yang digunakan. Algoritma Rabin-Karp ini menggunakan fungsi hash. Fungsi hash adalah fungsi yang digunakan untuk mengubah string menjadi untaian integer. Pada algoritma ini untaian string akan diubah menjadi integer berdasarkan bilangan ASCII nya. Karena menggunakan bilangan ASCII, proses komputasi menjadi lebih “dekat” ke bahasa mesin. Pendekatan utamanya adalah, string yang sama akan memiliki nilai hash yang sama.
3. K-Grams
K-Grams adalah rangkaian terms dengan panjang K. Kebanyakan yang digunakan sebagai terms adalah kata. K-Grams merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Metode K-Grams ini digunakan untuk mengambil potongan-potongan karakter huruf sejumlah k dari sebuah kata yang secara kontinuitas dibaca dari teks sumber hingga akhir dari dokumen. Dalam Markov Model nilai K-Grams yang sering digunakan yaitu, 2-gram (bigram), 3-gram (trigram) dan seterusnya disebut K-Grams (4-gram, 5-gram dan seterusnya). Dalam natural language processing, penggunaan K-Grams (atau lebih dikenal dengan n-gram), proses parsing token (tokenisasi) lebih sering menggunakan 3-gram dan 4-gram, sedangkan 2-gram digunakan dalam parsing sentence, misal dalam part-of-speech (POS). Penggunaan 2-gram dalam tokenisasi akan menyebabkan tingkat perbandingan antar karakter akan semakin besar.
4. Dice Coeficient
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
37 Similarity Coefficient dalam penghitungan nilai similarity yang menggunakan pendekatan k-gram.
- S adalah nilai similarity
- A dan B adalah jumlah K-Grams dalam teks 1 dan teks 2
- C adalah jumlah k-grams yang sama dari kedua teks
Perankingan dokumen akan dilakukan dengan mengurutkan nilai similarity antar dokumen dari yang terbesar sampai terkecil sehinggga didapatkan urutan dokumen sesuai dengan keterkaitannya dengan query pengguna.
5. Batasan Masalah
Dalam penelitian ini ada beberapa hal yang dibatasi agar permasalahan tidak meluas dari atau tidak sesuai dengan tujuan awal. Adapun batasan masalah dalam penelitian ini adalah sebagai berikut :
x Hanya menguji data berupa teks, tidak menguji data berupa gambar maupun suara.
x Sistem tidak memperhatikan kesalahaan ejaan / penulisan pada dokumen.
x Sistem tidak memperhatikan sinonim / persamaan kata.
x file yang yang digunakan sebagai dokumen sumber bertipe .pdf lalu dirubah ke dalam bentuk .txt untuk memudahkan proses membaca file.
x Data yang diuji menggunakan bahasa Indonesia.
6. Metodelogi Penelitian
Pemodelan sistem dilakukan untuk dapat terlebih dahulu mengidentifikasi masalah beserta seluruh proses bisnis yang berlangsung sebelum memulai tahapan pembangunan perangkat lunak yang akan diimplementasikan ke dalam sistem. Pemodelan juga ditujukan agar saat pembangunan perangkat lunak berlangsung sudah tidak terdapat kebutuhan-kebutuhan tambahan pada implementasi sistem yang dapat menghambat proses pembangunan perangkat lunak itu sendiri.
Pemodelan aplikasi pencarian dokumen terdiri dari beberapa tahapan sebagai berikut :
1. Tahap analisa kebutuhan sistem 2. Tahap pemodelan sistem 3. Tahap pembuatan sistem 4. Tahap pengujian
HASIL DAN PEMBAHASAN
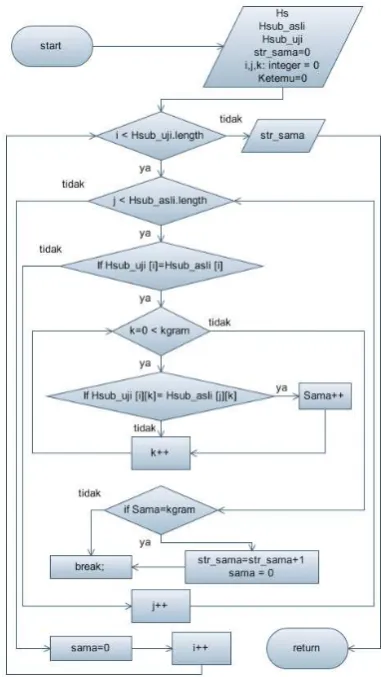
1. Flowchart Program
Gambar 1. Preprocessing dokumen uji dan query
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
38 hanya pada saat pengguna ingin melakukan pencarian dokumen.
Gambar 2. Proses similarity dokumen
Pengujian pertama adalah pengujian dengan 5 dokumen menggunakan dokumen yang sama hanya saja dokumen 2, 3, 4, dan 5 dilakukan pemotongan kata hingga berjumlah masing-masing 80%, 60%, 40%, dan 20% dari dokumen 1. Tujuannya adalah untuk mengetahui perankingan yang didapatkan oleh sistem setelah memasukkan kelima dokumen tersebut. Jenis dokumen uji dengan pemotongan adalah dokumen yang telah dirubah sedemikian rupa dengan cara memotong kata secara acak pada dokumen untuk menguji apakah sistem yang telah dibuat dapat memberikan hasil yang sesuai. Perkiraan awal dari pengujian ini adalah hasil dari pengujian didapatkan hasil dokumen berurut dari yang memiliki similaritas tertinggi hingga terendah yaitu dokumen 1 hingga 5.
Pengujian kedua adalah pengujian dengan 15 dokumen acak menggunakan dokumen yang memiliki topik yang berbeda dengan query.
Tujuannya adalah untuk mengetahui
perankingan yang didapatkan oleh sistem
menggunakan dokumen yang memang
berbeda dengan query. 15 dokumen acak yang bersumber dari abstrak tugas akhir mahasiswa ilmu computer. Pengolahan data pada kedua pengujian dilakukan proses preprocessing dan processing. Preprocessing akan dilakukan dikedua sisi query dan dokumen.
Penentuan stoword pada penelitian ini dilakukan dengan mencari kata yang paling sering muncul dari beberapa dokumen yang diujikan dan mengambil 10% dari atas sehingga didapatkan kata-kata yang memang dapat dihilangkan dari dokumen. Jumlah stopword yang digunakan adalah 63 kata. Penentuan kata dasar yang diperlukan dalam proses stemming digunakan KBBI (Kamus Besar Bahasa Indonesia) edisi online. Jumlah kata dasar yang digunakan adalah 28562 kata. Processing dilakukan dengan menggunakan Rabin-Karp dan dice coefficient. Variable yang digunakan dalam analisis ini adalah waktu proses dan nilai similaritas dokumen terhadap query. Waktu proses didapatkan dari selisih waktu antara proses akhir dan proses awal. Sedangkan nilai similaritas didapatkan dengan menggunakan dice coefficient yang akan menghitung jumlah substring K-Grams yang ditemukan dengan jumlah substring K-Grams pada masing-masing dokumen.
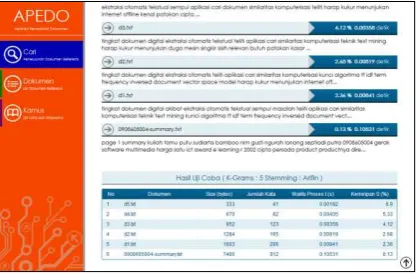
Gambar 3. Pencarian Dokumen
2. User Interface
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
39
preprocessing dan membandingkan hasilnya dengan beberapa dokumen yang ada pada
database.
Gambar 4. Hasil Pencarian
Setelah proses selesai maka akan diperoleh
nilai kemiripan dan waktu prosesnya.
Ditampilkan juga data dalam bentuk table dan grafik agar lebih mudah memahami hasil proses pencarian dokumen.
Gambar 5. Tabel Hasil Pencarian
Ditampilkan juga data dalam bentuk grafik agar lebih menarik dan lebih mudah saat menganalisa hasil pencarian dokumen. Grafik pada aplikasi ini menggunakan library highchart.
3. Penjelasan Program
Aplikasi ini dibuat dengan bahasa pemrograman PHP dikombinasikan dengan
penggunaan CSS3 untuk mempercantik
tampilan antar mukanya. Design sistem ini terinspirasi dari design metro dari Windows 8 yang simple dan elegant. Aplikasi ini juga menggunakan ajax dimana setiap proses yang
memerlukan fungsi server akan dilakukan dibelakang layar sehingga pengguna tidak akan perlu lagi mereload halaman web mereka. Semua proses akan berlangsung seperti halnya pengguna melakukan atau
menjalankan aplikasi desktop. Proses – proses
utama seperti tokenizing, filtering, stemming, dll akan dibuat sebagai fungsi agar terlihat rapi dan mudah dipahami dalam penggunaannya. Aplikasi ini dibuat sedemikian rupa agar mudah dalam penggunaannya serta dapat menghasilkan dokumen yang sesuai dengan kebutuhan pengguna.
Pada halaman pencarian terdapat beberapa isian, yaitu query, jumlah k-grams dan algoritma stemming yang ingin digunakan. Setelah menekan tombol submit system akan melakukan pencarian dokumen sesuai dengan query dan menampilkannya ke layar tanpa perlu meroload halaman web kembali.
Gambar 6. Grafik Hasil Pencarian
4. Hasil
Dari hasil percobaan yang dilakukan, pada tabel 3 algoritma Rabin-Karp dengan menggunakan stemming arifin dan pengujian
beberapa K-Grams menghasilkan nilai
similarity sesuai dengan yang diinginkan yaitu berurut dari dokumen 1 dengan similarity paling tinggi diikuti oleh dokumen lainnya yang memiliki similarity lebih rendah. Setelah dilakukan percobaan pada dokumen yang dimodifikasi dengan melakukan pemotongan kata secara acak dapat diketahui bahwa
pemilihan kgram yang semakin besar
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
40 menggunakan K-Grams yang lebih besar. Hal ini karena pada kgram yang lebih sedikit, string yang dipotong lebih kecil sehingga kemungkinan untuk ditemukannya string yang sama semakin besar tetapi dengan semakin
besarnya K-Grams, maka potongan string
mengandung huruf yang lebih banyak
sehingga menyebabkan string yang ditemukan pun semakin berkurang.
Tabel 1 Hasil Dengan Pemotongan Dokumen
Dokumen K-Grams Jumlah Kata Waktu (s) Similarity (%)
document1.txt 2 191 0.01381 100
document2.txt 2 153 0.01291 97.44
document3.txt 2 114 0.01255 94.43
document4.txt 2 76 0.00964 85.71
document5.txt 2 38 0.00711 75
document1.txt 3 191 0.05228 100
document2.txt 3 153 0.04821 91.91
document3.txt 3 114 0.03988 83.51
document4.txt 3 76 0.02985 70.81
document5.txt 3 38 0.01971 55.34
document1.txt 4 191 0.07448 100
document2.txt 4 153 0.06387 89.29
document3.txt 4 114 0.05186 76.72
document4.txt 4 76 0.03847 63.48
document5.txt 4 38 0.02529 48.68
document1.txt 5 191 0.08004 100
document2.txt 5 153 0.06831 87.02
document3.txt 5 114 0.05583 71.54
document4.txt 5 76 0.04389 57.06
document5.txt 5 38 0.02651 44.52
KESIMPULAN DAN SARAN
1. Kesimpulan
Berdasarkan hasil analisis dan pengujian terhadap aplikasi pencarian referensi tugas akhit dengan mengimplementasikan text mining menggunakan aloritma rabin-karp ini maka dapat disimpulkan bahwa persentase similarity cenderung menurun jika jumlah K-Grams yang digunakan semakin besar. Dengan
semakin besarnya K-Grams, maka potongan string akan mengandung huruf yang lebih banyak dibandingkan dengan K-Grams yang lebih sedikit sehingga menyebabkan string yang ditemukan pun semakin berkurang. Waktu proses mengalami peningkatan jika nilai K-Grams semakin besar karena akan
membandingkan jumlah karakter yang
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
41
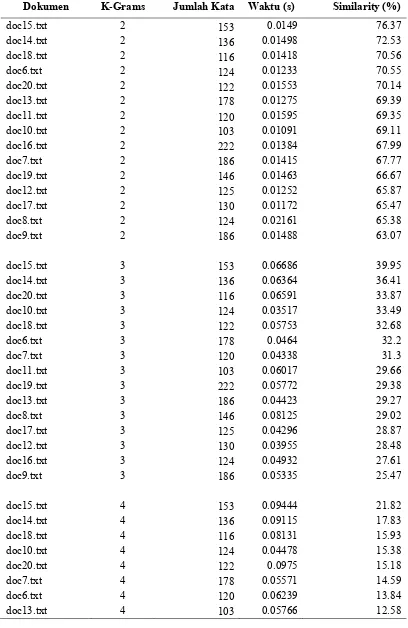
Tabel 2 Hasil Dengan Dokumen Yang Berbeda
Dokumen K-Grams Jumlah Kata Waktu (s) Similarity (%)
doc15.txt 2 153 0.0149 76.37
doc14.txt 2 136 0.01498 72.53
doc18.txt 2 116 0.01418 70.56
doc6.txt 2 124 0.01233 70.55
doc20.txt 2 122 0.01553 70.14
doc13.txt 2 178 0.01275 69.39
doc11.txt 2 120 0.01595 69.35
doc10.txt 2 103 0.01091 69.11
doc16.txt 2 222 0.01384 67.99
doc7.txt 2 186 0.01415 67.77
doc19.txt 2 146 0.01463 66.67
doc12.txt 2 125 0.01252 65.87
doc17.txt 2 130 0.01172 65.47
doc8.txt 2 124 0.02161 65.38
doc9.txt 2 186 0.01488 63.07
doc15.txt 3 153 0.06686 39.95
doc14.txt 3 136 0.06364 36.41
doc20.txt 3 116 0.06591 33.87
doc10.txt 3 124 0.03517 33.49
doc18.txt 3 122 0.05753 32.68
doc6.txt 3 178 0.0464 32.2
doc7.txt 3 120 0.04338 31.3
doc11.txt 3 103 0.06017 29.66
doc19.txt 3 222 0.05772 29.38
doc13.txt 3 186 0.04423 29.27
doc8.txt 3 146 0.08125 29.02
doc17.txt 3 125 0.04296 28.87
doc12.txt 3 130 0.03955 28.48
doc16.txt 3 124 0.04932 27.61
doc9.txt 3 186 0.05335 25.47
doc15.txt 4 153 0.09444 21.82
doc14.txt 4 136 0.09115 17.83
doc18.txt 4 116 0.08131 15.93
doc10.txt 4 124 0.04478 15.38
doc20.txt 4 122 0.0975 15.18
doc7.txt 4 178 0.05571 14.59
doc6.txt 4 120 0.06239 13.84
Jurnal Elektronik Ilmu Komputer - Universitas Udayana JELIKU Vol 2 No. 1 Pebruari 2013
42
doc12.txt 4 222 0.05251 12.37
doc8.txt 4 186 0.11696 11.51
doc19.txt 4 146 0.08006 11.02
doc16.txt 4 125 0.0711 9.81
doc9.txt 4 130 0.0676 9.71
doc11.txt 4 124 0.084 7.86
doc17.txt 4 186 0.05916 7.79
doc15.txt 5 153 0.10723 14.38
doc14.txt 5 136 0.10357 11.83
doc10.txt 5 116 0.05021 9.88
doc18.txt 5 124 0.0919 9.87
doc7.txt 5 122 0.06246 8.51
doc6.txt 5 178 0.0697 8.07
doc20.txt 5 120 0.10828 7.99
doc12.txt 5 103 0.05932 7.49
doc13.txt 5 222 0.06538 7.41
doc16.txt 5 186 0.07833 5.81
doc9.txt 5 146 0.07815 5.14
doc8.txt 5 125 0.14598 5.03
doc19.txt 5 130 0.08874 4.6
doc11.txt 5 124 0.09532 2.87
doc17.txt 5 186 0.06356 2.66
2. Saran
Untuk penelitian lebih lanjut, disarankan penggunaan data uji yang lebih bervariasi seperti pengubahan bentuk kalimat yang lebih
banyak sehingga pengaruh penggunaan
stemming dapat lebih akurat. Penggunaan stopword yang lebih disesuaikan dengan
penelitian yang dilakukan. Pemilihan
algoritma stemming Bahasa Indonesia yang lebih baik dapat meningkatkan akurasi. Format dokumen input agar lebih beragam untuk meningkatkan kemampuan sistem dalam mengolah beberapa dokumen yang berbeda.
DAFTAR PUSTAKA
[1]
Arifin, Agus Zainal dan Ari Setiono,Novan. Klasifikasi Dokumen Berita
Kejadian Berbahasa Indonesia dengan Algoritma Single Pass Clustering. Institut
Teknologi Sepuluh November (ITS). Surabaya
[2]
Berry, M.W., Kogan, J. (2010). TextMining: Application and Theory.
Chichester: John Wiley & Sons, Ltd.
[3]
Feldman, R., Sanger, J. (2007). The TextMining Handbook: Advanced Approaches in Analyzing Unstructured Data. New York: Cambridge University Press.