“Lecturing Scheduling System at Informatic Engineering Major
Islamic University Syarif Hidayatullah Jakarta
Using Genetic Algorithm”
THESIS WRITING
Created by:
Dewi Aisyah Rahayuningsih
Matric No. : 106091105097
INTERNATIONAL CLASS
INFORMATIC ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
ISLAMIC UNIVERSITY SYARIF HIDAYATULLAH
“Lecturing Scheduling System at Informatic Engineering
Major Islamic University Syarif Hidayatullah Jakarta
Using Genetic Algorithm”
Thesis Writing
As a Requirement for Achieving Bachelor Degree of Computer Science
Faculty of Science and Technology Islamic University Syarif Hidayatullah
Jakarta
Created by :
DEWI AISYAH RAHAYUNINGSIH
Matric No. : 106091105097
INTERNATIONAL CLASS
INFORMATIC ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
ISLAMIC UNIVERSITY SYARIF HIDAYATULLAH
LECTURING SCHEDULING SYSTEM AT INFORMATIC ENGINEERING
MAJOR ISLAMIC UNIVERSITY SYARIF HIDAYATULLAH JAKARTA
USING GENETIC ALGORITHM
Thesis Writing
As a Requirement to Achieve a Bachelor Degree of Computer Science Faculty of Science and Technology
State Islamic University Syarif Hidayatullah Jakarta
Created By
DEWI AISYAH RAHAYUNINGSIH
Matrix No. : 106091105097
Approving,
Supervisor
NIP. 197105222006041002
Yusuf Durrachman, M.Sc, M.IT
Co-Supervisor
NIP. 198208172009122002
Ria Hari Gusmita, ST, M.Kom
Knowing,
Head of InformaticEngineering
NIP. 197105222006041002
iv VALIDATION TEST
Thesis writing which title is “LECTURING SCHEDULING SYSTEM AT INFORMATIC ENGINEERING MAJOR ISLAMIC UNIVERSITY SYARIF HIDAYATULLAH JAKARTA USING GENETIC ALGORITHM”, it has been tested and has passed in Munaqosah Test Faculty of Science and Technology Islamic University Syarif Hidayatullah Jakarta on September 2010. This thesis writing as a requirement for achieving a bachelor degree of computer science at informatic engineering major.
Husni Teja Sukmana. Ph.D NIP. 19771030200112 1 003
Co-Supervisor
Ria Hari Gusmita, ST, M.Kom NIP. 198208172009122002 Supervisor
Yusuf Durrachman, M.Sc, M.IT NIP. 197105222006041002
Examiner II
Imam M Shofi, MT NIP. 19720205 20080 1 010
Dean of
Faculty Science and Technology
DR. Syopiansyah Jaya Putra, M.Sis NIP. 19680 117 200 112 1001
Head of Informatic Engineering Major
v
DECLARATION
I hereby declare that the work in this thesis writing was carried out in accordance
with the Regulations of Islamic University Syarif Hidayatullah Jakarta. The work
presented in this thesis is the result of original research carried out by myself,
whilst enrolled in the Informatic Engineering Major, Faculty of Science and
Technology, Islamic University Syarif Hidayatullah Jakarta as a candidate for the
Bachelor degree. This work has not been submitted for any other degree or award
in any other university or educational establishment.
Jakarta, September 2010
vi
ABSTRACT
DEWI AISYAH RAHAYUNINGSIH, Lecturing Scheduling System at
Informatic Engineering Major Islamic University Syarif Hidayatullah Jakarta
Using Genetic Algorithm was supervised by Mr. YUSUF DURRACHMAN and
Mrs. RIA HARI GUSMITA.
Informatic Engineering Major Islamic University Syarif Hidayatullah
Jakarta is a major under auspices of Science and Technology Faculty. One of the
academic activity at Informatic Engineering Office is providing a lecturing
schedule. Unfortunately the lecturing scheduling system at Informatic engineering
is still using manual way. This thing gives a bad effect for scheduling because
sometime clash of using room is occurred. Based on the problem above, the writer
will design a lecturing scheduling system which could achieve optimization and
efficiency. A new proposed lecturing scheduling system is using waterfall
development system. The steps of waterfall development system are
communication, planning, modelling, construction and deployment. The writer is
using Data Flow Diagram (DFD) to explain the process model and genetic
algorithm method to achieve the optimization. The Results of this thesis is (1)
Genetic Algorithm can is more effective than using manual way because it can
achieve the optimization.(2) Genetic Algorithm is easier in use if we compared to
the manual way. (3) It is very helpful to find the empty room and to match
between the empty room and the course subject. (4)The parameters can be
adjusted as needed.
Keywords :Genetic Algorithms, Class Scheduling.
VI Chapter + xx Pages + 121 Pages + 21 References (1989-2010) + Appendix,
vii
1.1 Background Research Problem ……….
1.2 Objective of the Study ………...………...
1.3 Context of the Study …………..………...………...
1.4 The Purpose of the Research………..
1.5 The Advantage ………...
1.5.1 For The Writer ………...…
1.5.2 For The Academic ………
1.6 The Research Methodology ………
1.6.1 The Collecting Data Method ……….
1.6.2 The System Development Method ………..………….
1.7 Organization of the Study ………..
1
PART II LITERATURE REVIEW
2.1 Introduction ………
2.2 The Concept of Lecturing Scheduling System …………...
2.2.1 Lecturing ………...
16
16
16
viii
2.2.2 Scheduling ………
2.2.3 System ………...
2.3 Software ………..…...
2.3.1 Software Engineering..………...………...
2.4 System Engineering ………...
2.5 System Modeling ...……….
2.6 Computer Engineering …...………
2.7 The Waterfall Process Model ……….
2.7.1 Communication ……….
2.7.2 Planning ………
2.7.3 Modelling………...
2.7.4 Construction ………...………...
2.7.5 Deployment ………...………
2.8 Type of Algorithms ………....………...
2.9 The Concept of Genetic Algorithms ...………....
2.9.1 The Origins of Artificial Species ………
2.9.2 Encoding of chromosomes ……….
2.9.3 Population Size ………...
2.9.4 Evaluating a Chromosomes ………....
2.9.5 Initialising a Population ………..
2.9.6 Methods of Selecting for Extinction or for Breeding..
2.9.7 Crossover ………
2.9.8 Mutation ……….
2.9.9 Inversion ……….
2.9.10 Optimising Genetic Algorithm Performance……....
2.10 Applications of Genetic Algorithms……….
2.11 The Concept of Programming Language ……….
2.11.1 PHP ………..
2.11.2 History of PHP ……….
2.12 MySQL ………....
2.13 Feasibility Study ………..
ix
2.13.1 Economic Feasibility ...……….
2.13.2 Technical Feasibility ………
2.13.3 Operational Feasibility ……….
2.13.4 Schedule Feasibility ……….
2.14 XAMPP ………
2.15 Related Works ………..
2.16 Summary ………..
PART III RESEARCH METHODOLOGY
3.1 Introduction ………..
3.2 Research Method ………
3.3 The System Developing Method ……….
3.3.1 Communication ………..
3.3.1.1 Problem Identification ………...
3.3.1.2 Initiating The Project ...
3.3.1.3 Proposing New System ………...
3.3.1.4 The Scope of System ………...……...
3.3.1.5 Feasibility Study ………....
3.3.2 Planning ………..
3.3.3 Modelling ………...
3.3.3.1 Requirement Models ………..
3.3.3.2 Design Model ……….
3.3.4 Construction .………..
3.3.4.1 Coding ………..………....
3.3.4.2 Testing ………..………
3.3.5 Deployment ...………...
3.4 Fact Finding Technique ………...
3.4.1 Literature Study ………..
3.4.2 Interview method ………
3.4.3 Observation method ………
x
3.6 The Time and Allocation in Research ………... 73
PART IV ANALYSIS AND DESIGN
4.1Overview at Science and Technology Faculty State Islamic
University Syarif Hidayatullah Jakarta ………...
4.1.1 Science and Technology Profile ……….
4.1.2 Vision and Mission of Science and Technology
Faculty ...
4.1.3 Organization Structure ...………
4.2Developing Lecturing Scheduling System at Informatic
Engineering Major State Islamic University Syarif
Hidayatullah Jakarta ……...….
4.2.1 Analysis ………....………..
4.2.1.1 Problem Identification ...
4.2.1.2 Initiate the Project ………...
4.2.1.3 Proposing New System ………...
4.2.1.4 The Scope of the System ………...
4.2.1.5 Feasibility Study ………...
4.2.2 Planning ...
4.2.3 Modeling ...
4.2.3.1 Requirement Model …………...
4.2.3.1.1 Data Flow Diagram (DFD) ...
4.2.3.1.2 Entity Relationship Diagram
(ERD) ...
4.2.3.2 Design Model ... 74
PART V IMPLEMENTATION
5.1System Requirement ...
xi
5.2.2.1Black Box Testing ……….
5.2.2.2White Box Testing ……….
5.3Implementing Lecturing Schedule ………...
111
112
116
PART VI CONCLUSION
6.1The Advantange of This System ...
6.2The Disadvantange of This System ...
6.3The Suggestion for the future ... 119
119
119
APPENDIXES
xii
LIST OF FIGURE
Figure 1.1: Overview of the research process and corresponding chapters ... 13
Figure 2.1: Software Engineering Layers ... 20
Figure 2.2: The Waterfall Model ... 22
Figure 2.3: Top Level description of GA ... 30
Figure 2.4: An Example of Crossover with Fully Encoded Genes ... 37
Figure 2.5: The Inversion Operator ... 39
Figure 2.6: The Genetic Algorithm Process ... 41
Figure 3.1: The writer’s Mind Map (part 1) ... 69
Figure 3.2: The writer’s Mind Map (part 2) ... 70
Figure 4.1: Organization Structure at Science and Technology Faculty ... 73
Figure 4.2: The Flowchart System of Lecturing Scheduling ... 80
Figure 4.3: The Flowchart Process of Genetic Algorithm ... 81
Figure 4.4: The Data Flow Diagram (DFD) of Lecturing Scheduling System .... 95
Figure 4.5: Design Input 1 ... 96
Figure 4.12: Inputing The Time Session ... 109
Figure 4.13: Inputing The Total of The Room (local) ... 110
Figure 4.14: Inputing The Room’s name ... 111
Figure 4.15: Inputing The Total of The Lecturers ... 112
Figure 4.16: Inputing The Name of The Lecturer ... 113
Figure 4.17: Inputing The Total of The Course Subject ... 114
Figure 4.18: Inputing The Course Subject ... 115
LIST OF TABLE
Table 2.1: The List of Algorithm ... 27
Table 4.1: The day in a week ... 87
Table 4.2: The Session in a day ... 87
Table 4.3: The Room Class at Computer engineering Major ... 88
Table 4.4: The Limitation and Priority Value for Scheduling ... 94
Table 4.5: Influential Factor for Calculating Fitness at Computer Engineering Major State Islamic University Syarif Hidayatullah Jakarta ... 95
Table 4.6: The table of the day ... 104
Table 4.7: The table of local ... 105
Table 4.8: The table of lecturer ... 106
Table 4.9: The table of course ... 106
Table 4.10: The table of session ... 100
Table 4.11: The table of schedule ... 107
1
PART I
INTRODUCTION
1.1. Background Research Problem
Information Technology has traversed all aspects of human life today.
The dependence on electronic information exchange infrastructure is
growing exponentially, with each passing millisecond. The society has
emerged into age which has been described using many terms: “The
Computer Revolution”, “The Information Revolution”, “The Binary Age” –
into a society that is called “The Information Society” (Williams et. al.
1999).
Based on Gates (1999), Information Technology is going to change in
every year. It produced many technologies and goals, in every change from
information technology are helping people to run bussiness smoothly,
transforming business and making people easier in doing their job.
If the 1980s were about quality,and the 1990s were about
reengineering then 2000s were about developing technology (Gates, 1999).
How about quickly the nature of information technology will change? How
about information technology access will alter the lifestyle of people and
their expectation of technology?.
After reading some previous thesis writing and article, the writer’s
assumes that using a lecturing scheduling system is very helpful because it
2
lecturing scheduling betwen the lecturers and the student about the time and
the location.
Based on the interviewed with a secretary of Informatic Engineering
Major Islamic University Syarif Hidayatullah Jakarta, the writer found some
problems in lecturing schedule, they are : the clash in using the room
between Informatic Engineering major and other majors in faculty of
science and technology and the clash in using the laboratory room between
Informatic Engineering major and other majors in faculty of science and
technology. There were some important elements that they made influence
in lecturing scheduling system, the writer identified such as: the total credit
of course subject, the course subject, the class, the lecturer (day and time in
giving lesson) and the room.
Today the Lecturing Scheduling System at Informatic Engineering
Major Islamic University Syarif Hidayatullah Jakarta is still using manual
system in processing and managing. The processes of the manual system
3
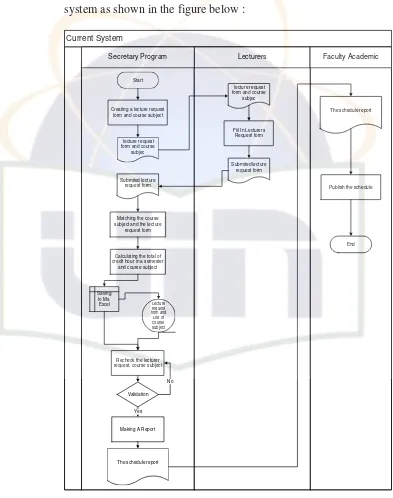
Figure 1.1 : Flowchart of the current system Start
Creating a lecture request form and course
subject
Read course subject and a lecture request
form
Matching the course subject and the lecture
request form
Saving the data into Mic.
Excel Calculating the total of
4
The explanation of the flowchart above is :
1. The secretary of Informatic Engineering is creating the course subject
that will be offered in a semester,
2. The secretary of Informatic Engineering will make a form for lecture,
3. The secretary of Informatic Engineering will make duplicate for the
offered schedule in a semester including with the information about
the due date of submiting the form for lecture then the secretary of
Informatic Engineering will distribute it to the lecture,
4. The lecture of Informatic Engineering will read the course subject list,
5. The lectures of Informatic Engineering will choose the course subject
based on their expectation and fill the form then they give back the
form that already fullfill to the secretary of Informatic Engineering,
6. The secretary of Informatic Engineering will receive and gather the
form from the lecture,
7. The secretary of Informatic Engineering checks the form and insert it
into Microsoft Excel software and leave a space to used as a studying
process in a session,
8. The secretary of Informatic Engineering calculate the number of credit
semester based on the structural position of a lecturer and the course
subject,
9. The secretary of Informatic Engineering will inform the validation
5
10. The secretary of Informatic Engineering will recheck the lecturing
scheduling (in which already made in Microsoft Excel) and will print
the schedule,
11. The secretary of Informatic Engineering gives the schedule printed to
the academic in science and technology faculty for publishing it to the
student,
12. The academic will publish the schedule on the board.
The problems was occuring when the Informatic Engineering Major
uses current system. The problems are identify such:
1. It is less efficient system because of using paper as form.
2. Difficulty in making a lecturing schedule based on agreement form
(which already filled by lecturer)
3. The secretary at Informatic Engineering must work hard to match the
room and the lecturer based on the paper agreement form.
4. Difficult in check the info about the lecturer’s name, the course
subject, the code of course subject, the time and the room for
lecturing.
5. Difficulty in managing schedule for laboratory room between
Informatic Engineering major and other major.
To overcome the problems that occured above, the secretary of
Informatic Engineering did some actions such as : rescheduling and
6
Rescheduling will produce not efficient in time (it spends long time) and
changing the lecturer with other lecturer will give a bad performance for
new lecturer (might be the new lecturer is not ready to teach because of the
short time).
Based on observation, a previous research: Annisa (2009) had not
overcome the problem and she did not use any specific optimization method
to find the best solution in scheduling problem and other previous
researches, they are: Ivan (2008) and Aria (2008) had overcome the problem
by implementing genetic algorithm method.
Based on the explanation above, the writer decides the genetic
algorithm for developing an application which the writer called it
“Lecturing Scheduling System at Informatic Engineering Major Islamic
University Syarif Hidayatullah Jakarta Using Genetic Algorithm”.
1.2. Objective of the Study
The main theme of this thesis centres on a few fundamental questions,
such as: What is Lecturing Scheduling System data and what are the
characteristics of a system that caters to this data? Who are the users of this
system and what is the range of its usage? What factors influence the
adoption of the solutions that have been provided by Information
Technology to the problem of effective use of the lecturing scheduling
system? What would be an ideal system that would enable the users to make
7
More specifically the aims of this study are defined and explained below.
1. To optimize the lecturing scheduling at Informatic Engineering major
so it will avoid the clash of the room between Informatic Engineering
major and other major.
2. To produce the best value for fitness value as genetic algorithm using
fitness value and find the population of solution.
1.3. Context of the Study
In this thesis writing, the writer gives the scope of “Lecturing
Scheduling System at Informatic Engineering Major Islamic University
Syarif Hidayatullah Jakarta Using Genetic Algorithm”.
The area that will be include:
1. This system will work only for searching the room for process study.
The application:
a. The system will give input from the secretary: the day, the
session, the room (local), the course subject, the lecturer’s name.
b. After the secretary giving the input, the genetic algorithm will
process the table of lecturer, room and class then it will produce
the output.
c. The system will give the output:
Lecturer’s name, course subject, day, session, time for lecturing,
8
2. This system processes the data only in the even semester in year
2009/2010. If the user wants to process other semester, the user
must giving input about the elements needed for that semester, they
are : course subject and lecturer.
3. Each session is only for meetings that have weight two credits
hour.
4. The writer uses waterfall as the methodology research.
5. This system is using MySQL as the database server.
1.4. The Purpose of The Research
The purpose of this thesis writing is :
1. Helping Informatic Engineering Major Islamic University Syarif
Hidayatullah in processing data by making a system which it called
“Lecturing Scheduling System at Informatic Engineering Major
Islamic University Sysrif Hidayatullah Jakarta Using Genetic
Algorithm”.
2. Developing a system that it can give advantage to the staff in
9
1.5. The Advantage
1.5.1. For The Writer
1. Understanding the development of the system by using PHP
programming language and analyzing the system by using
genetic algorithm.
2. The writer could implemented the knowledge that the writer
got in university, such: System Design Analysis, Software
Engineering, Web Programming, Artificial Intelligence,
Programming and Algorithm, Research Methodology in ICT,
Database System and Data Structure.
3. This thesis writing is the requirement for achieving a bachelor
degree from university.
1.5.2. For The Academic
1. Knowing the student ability in implementing the university
Into the real.
2. Evaluating the student capability.
1.6. The Research Methodology
1.6.1. The Collecting Data Method
Based on Hasibuan (2007: 155), data used in the research
must be qualified good data, such as: (1) data must be accurate; (2)
10
research method conducted by interview, observation and
ethnography.
Based on Hasibuan (2007: 155), in qualitative research, data
sources can be both human actions and words, materials such as
document libraries, archives, newspapers, magazines, scientific
journals, books, annual reports, etc. Techniques used for qualitative
research data is interviews, participatory research, observation and
literature study.
1. Literature study:
According to Keraf (1994: 164), Literature study is
collecting the data and the information by reading the book as
a reference material for the research.
2. Interview method:
According to Hasibuan (2007: 157), the interview, in
which researchers ask questions with the interviewees, both
the status of the informant as an informant or respondent. The
interview is a conversation with a purpose. The conversations
conducted two parties, namely interviewer that ask questions
and interviewee which provides answers to questions.
3. Observation method:
Based on Hasibuan (2007: 157), the observation is a
study conducted to understand a phenomenon that is based on
11
Based on Jogiyanto (2008: 89), the observation is an
approach to obtain primary data by directly observing the
data object. The observations were divided into two types,
they were: behavioral observation and non behavioral
observation.
Based on Jogiyanto (2008: 90), the behavioural
observation is an oobservation that carried out on everything
except the data and the non behavioral observation is an
analysis of observational data could be collected data from
the current record or historical data.
1.6.2. The System Development Method
The system development method that the writer uses in this
thesis writing is Waterfall model. The waterfall model discovered
by Winston W. Royce in 1970. According to Pressman (2010), The
waterfall model is suggest a systematic, sequential approach to
software development that begins with customer specification of
requirements and progresses through planning, modelling,
construction, and deployment, culminating in on-going support of
the completed software.
Based on Pressman (2010), The steps in waterfall model
12
1. Communication
In this stage, the writer shall try to find the problem that was
occurred, try to identify the problem, collect the data and map
the problem into project scope.
2. Planning
In this stage the writer will summarize the result of analysis
then the writer will make a plan to build something which is
suitable with the user’s request.
3. Modeling
The writer shall design the project according to the
requirement that already collected. Modelling divides into two
types and the writer identified them such as: requirement
model and design model.
4. Construction
In construction stage, the writer will do some activities, such as
coding and testing. The writer shall transform the genetic
algorithm method into the coding and after finishing, the writer
shall test it whether use white box testing or black box testing.
5. Deployment
After finishing and the project ready to be a package or bound
it, the writer shall to deliver it to the user then the user will
give the feedback to the writer. In this stage, the writer shall
13
1.7. Organization of the Study
In this thesis writing, the writer divides the paper into five chapters with
some explanation in each chapter. The writing scheme:
PART I INTRODUCTION
Chapter one gives an overview of the thesis, the identification of
research problems, the reason for undertaking this research and
the purpose of the study.
PART II LITERATURE REVIEW
Chapter two is reviewing lecturing scheduling system using
genetic algorithm literature to bring together various
descriptions of genetic algorithm into a working definition,
concept underlying genetic algorithm. From the review of the
literature, characteristics and capabilities of Information
Technology are identified and summarized into dimensions
which make up lecturing scheduling system using genetic
algorithm.
PART III RESEARCH METHODOLOGY
Chapter three outlines the research methods used in collecting
data for analysis. Various research methods are explored before
a particular method is chosen. As this study is survey based, the
14
PART IV ANALYSIS AND DESIGN
Chapter four explains how the research variables were
operationalised and incorporated. Furthermore, the methods by
which the research instrument was comprehensively validated
are described and evaluated.
PART V IMPLEMENTATION
This part is showing the implementation and the contribution of
genetic algorithm inside the lecturing scheduling system.
PART VI CONCLUSION
This part, summarizes the study’s findings, outlines implications
for both research and practice, and qualifies the result within the
frame of theoretical and statistical limitation. The study
concludes with suggestion for future avenues of research and
15
Figure 1.2: Overview of the research process and corresponding parts
PART 1 - Background research problem - Objective of the study - Context of the study
PART 2
- Literature Review
- Understanding of the concept that relate to the study
PART 3
- Research methodology - Fact finding tools and mechanisms - Case profiles
PART 4
- Discussion of the data collected - Analysis and Design
PART 5
It’s about implementing the genetic algorithm to the lecturing scheduling system
PART 6
16
PART II
LITERATURE REVIEW
2.1. Introduction
The first part of this chapter looks at how Information Technology has
led to the creation of an Information Society, which realises and utilizes the
data available to form information and knowledge. The chapter thus
establishes the importance and influence that IT has on our lives today,
focusing on the scheduling domain. The chapter then looks into the
emergence of lecturing scheduling systems, and then the main areas of
research at current times, from the technological perspective. There is a
brief description of the systems developed and research being carried out in
the world today – thus highlighting the importance it is receiving from both
the science as well as computing field. Finally, the chapter critically reviews
the existing research done in the area of adoption of such systems in real life
scenario and in doing so highlights the areas that warrant further
exploration.
2.2. The Concept of Lecturing Scheduling System
2.2.1. Lecturing
Based on The Oxford Pocket Dictionary (2003), The meaning
of lecture: talk given for the purpose of teaching, give a lecture on a
17
Based on Mifflin (2009), Lecturing is delivering a lecture or
series of lectures or teaching by giving a discourse on some subject
(typically to a class).
2.2.2. Scheduling
According to The Oxford Dictionary (2003), schedule is
arranging for something to happen at a particular time.
Based on business dictionary, Scheduling is determining when
an activity should start or end, depending on its (1)
predecessor activity (or
Based on elook dictionary, scheduling is [noun] setting an
order and time for planned events.
2.2.3. System
There are many understanding of system, the writer explain
them such as:
1. System is a group of parts that are connected or work together,
based on Oxford Dictionary (2003).
2. The IEEE standards define a system as: A collection of
components organized to accomplish a specific function or set
18
3. According to the Pressman (2005), a system is a collection of
related elements related in a way that allows the
accomplishment of some tangible objective.
4. Webster‘s Dictionary defines system in the following way:
a. A set or arrangement of things so related as to form a unity
or organic whole;
b. A set of facts, principles, rules. Classified and arranged in
an orderly form so as to show a logical plan linking in the
various parts;
c. A method or plan of classification or arrangement;
d. An established way of doing something
5. Hartono stated that system is a collection of element or
variable that related each other, organized and did activity to
get some purpose (Hartono: 1999, p.2).
6. Davis (1985), stated that system is a part which has related
each other whic is operate together to get some purpose.
7. Lucas (1989), identified system as an organized component
which related each other.
2.3. Software
Based on Pressman (2010), software is (1) instructions (computer
program) that when executed provide desired features, function, and
19
manipulate information, and (3) descriptive information in both hard copy
and virtual forms that describes the operation and use of the programs.
Today, Software applications divided into seven types. The writer will
explain them, such as:
1. System Software.
This software is a collection of programs written to service other
programs. Some system software (e.g., compilers, editors, and file
management utilities) processes complex, but determine, information
structures.
2. Application Software
This is a stand alone programs that solve a specific business need.
Application software is used to control business functions in real time
(e.g., point of sale transaction processing, real time manufacturing
process control).
3. Engineering / Scientific Software
Scientific Software has been characterized by “number crunching”
algorithm. Application range from astronomy to volcanology, from
automotive stress analysis to space shuttle orbital dynamics, and from
molecular biology to automated manufacturing.
4. Embedded Software
It resides within a product or system and is used to implement and
control features and functions for the end user and for the system
20
5. Product Line Software
It designed to provide a specific capability for use by many different
customers. Product line software can focus on a limited marketplace
(e.g., inventory control product) or address mass consumer markets
(e.g., word processing, spreadsheets, computer graphics, multimedia,
entertainment, database management, and personal and business
financial applications).
6. Web Application
Web application evolving into sophisticated computing environments
that not only provide stand alone features, computing functions, and
content to the end user, but also are integrated with corporate
databases and business applications.
7. Artificial Intelegence Software
It makes use of non numerical algorithms to solve complex problems
that are not amenable to computation or straightforward analysis.
Application within this area include robotics, expert system, pattern
recognition ( image and voice ), artificial neural networks, theorem
proving, and game playing according to Pressman (2010).
Based on the explanation above, the writer states that “Lecturing
Scheduling System at Informatic Engineering Islamic University Jakarta
21
is it use genetic algorithm to translate the problem occured to the
programming language then it proceed into software.
2.3.1. Software Engineering
Based on Pressman (2010), The IEEE [IEE93A] has developed
a more comprehensive definition when it states: Software
Engineering: (1) The application of a systematic, disciplined,
quantifiable, approach to the development, operation, and
maintenance of software; that is, the application of engineering to
software. (2) The study of approaches as in (1).
Based on Pressman (2010), There are many layers in software
engineering. The writer try to explain the layers one by one and the
writer provides the figure of the layer. The layers in software
engineering identified as:
1. Process
Process layer is the foundation in software engineering. It is the
glue that holds the technology layers together and enables
rational and timely development of computer software. Process
defines a framework that must be established for effective
delivery of software engineering technology.
2. Method
It provides the technical how to’s for building software. Method
22
requirement analysis, design modeling, program construction,
testing, and support.
3. Tools
It provides automated or semiautomated support for the process
and the methods.
Figure 2.1: Software Engineering Layers
2.4. System Engineering
According to Pressman (2005), “Software Engineering occurs as a
consequence of a process called system engineering. Instead of
concentrating solely on software, system engineering focuses on a variety of
elements, analyzing, designing, and organizing those elements into a system
that can be a product, a sevice, or a technology for the transformation of
information or control.”
Based on Kevin Forsberg and Harold Mooz (1995), System
Engineering is responsible for involving key personnel (to address human
factors, safety, producibility, inspectibility, reliability, maintainability,
Tools Methods Process
23
logistics, etc.) at each step, starting with risk analyses and feasibility studies
in the Concept Definition phase.
2.5. System Modeling
According to Pressman (2005), As a software engineer, it is very
important to pay attention in system modeling. System modeling is an
important element of the system engineering process. The focus is on the
world view or the detailed view, the engineer creates models that: define the
processes that serve the needs of the view under consideration and represent
the behavior of the processes and the assumptions on which the behavior is
based.
2.6. Computer Engineering
The witer major is Informatic Engineering and specified in software
engineering. There are many meanings of Informatic Engineering in the
world. The writer will explain them one by one which related with the field
study and the project title.
The writer classified them, such as:
1. According to Sommerville (2009), “Software engineering is an
engineering discipline which is concerned with all aspect of software
production.
2. According to Pressman (2010), “Software Engineering is a people who
24
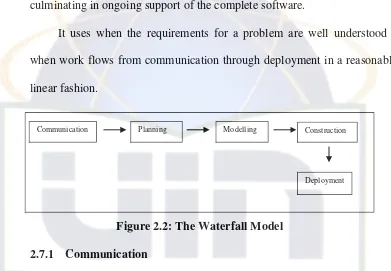
2.7. The Waterfall Process Model
Based on Pressman (2010), the waterfall model, sometimes called the
classic life cycle, suggests a systematic, sequential approach to software
development that begins with customer specification of requirements and
progresses through planning, modeling, construction, and deployment,
culminating in ongoing support of the complete software.
It uses when the requirements for a problem are well understood –
when work flows from communication through deployment in a reasonably
linear fashion.
Figure 2.2: The Waterfall Model
2.7.1 Communication
Communication was begun when the writer responded to the
user request for help. The bridge in communicating step understands
the request even it’s hard to do.
Before customer requirement can be analyzed, modeled, or
specified they must be gathered through the communication activity.
Effective communication among developer, stakeholders and users is
very needed, its important to achive the purpose. In communication
Communication Planning Modelling Construction
25
steps, there are many principles in which very helpfull to do
communication.
The principles in communication are:
1. Listening the user’s words. By listening, the writer could
identify the problem occurred and the writer can ask the
question when she felt unclear with the user’s words.
2. The writer is preparing the equipment before interviewing the
user. The equipments are needed such as: agenda for writing
some note and write down all the important things and a
recorder to record the conversation. Understanding the problem
before continuing to another topic and do some research to
understand the business domain.
3. Face to face communication will work better when some
representation of the relevant information is present.
4. The writer tried to describe to the user what product, feature and
function that she wants to build.
5. The writer focused in one topic. After resolving that topic, the
writer will move to another topic.
6. The writer does negotiation with the user. The project runs
26
2.7.2. Planning
According to Pressman (2010), planning activity encompasses
a set of management and technical practices that enable the software
team to define a road as it travels toward its strategic goal and
tactical objectives.
In planning stage, the writer will do some activities, such as:
1. Understand the scope of the project.
2. Estimating based on the writer knowing.
3. Track the plan frequently and make adjusments as required
2.7.3. Modelling
In building the system, the writer needs to create a model to
make better understanding. A model must be capable of representing
the information that software transform, the architecture and
functions that enable the transformation to occur, the features that
user desire, and the behaviour of the system as the transformation is
taking place.
In software engineering work, two classes of models can be created:
1. Requirement Models
It can be called as analysis model. It represents customer request
by depicting the software in three different domains:
27
The writer uses requirement models to translate what the user
needs such as flow chart and data flow diagram. Using them is
very useful because the user can have well understanding in
system’s flow and the writer can work easier based on the data
flow and flow chart.
2. Design Model
It represents characteristic of the software that help practitioners
to construct it effectively: the architecture, the user interface and
component level detail.
Design model is very helpful because it not only could
communicate information to user who will test the software and
to other who may maintain the software in the future but also it
helps to simplify program flow.
In this writing thesis, the writer provides Entity Relationship
Diagram (ERD), Genetic Algorithm (GA) model and the
interface of the system.
2.7.4. Construction
Construction is a set of coding and testing tasks that lead to
operational software engineering work.
1. Coding
The writer will transform the modelling design into a set of
28
that she is trying to solve. The writer also understand the
concept of programming then the writer select a programming
language that provides tools that will make the writer’s work
easier. In coding, it was divided into two kinds of activities,
such as: installing the software needed and coding for the
interface and for the system. After finishing coding in the first
line, the writer will perform unit test and correct error that the
writer has uncovered.
2. Testing
Testing is a process of executing a program with the intent
of finding an error. It was divided into two types of testing, such
as white box testing and black box testing.
White-box test design allows one to peek inside the "box",
and it focuses specifically on using internal knowledge of the
software to guide the selection of test data. Synonyms for
white-box include: structural, glass-white-box and clear-white-box.
Black-box test design is usually described as focusing on
testing functional requirements. Synonyms for black-box
29
2.7.5. Deployment
Deployment is performing delivery, support and feedback. It
occurs as each software increment is presented to the customer.
2.8. Type of Algorithms
Based on the previous research (Steven : 2008) and (Ivan : 2008), now
a day, using genetic algorithm can solve the optimization problem in
scheduling. Many problems occur when some institutions have a large data
and too many entity inside because, it gives a bad effect in the processing.
As we know, when we do some activities in processing random data, the
important thing that we want to achieve is optimization in all aspect (ex:
search process). The problems were : How to create population which is
needed in genetic algorithm ? How to code in each gen or cromossom ?.
Beside Genetic Algorithm, the writer found some searching algorithm
methods such as the binary search, the depth-first search and the branch and
bound.
This below is a table about the strength and the weakness of using the
genetic algorithm, the binary search, the depth-first search and the branch
and bound.
Table 2.1. The List of Algorithm
No Name of the Algorithm The Strength The Weakness
1. The Binary Search • Its used to search for
stored data
• Its used to efficiently
• The biggest
30
retrieve information stored in computer memory ( if a user has a large database of name stored)
convergence rate.
2. The Depth – First Search • Its used to efficiently
find a set of action that will move from a given initial state to a given goal problem is of limited size and enumeration can be done in reasonable time).
• Extremely
time-consuming: the number of nodes in a branching tree can be too large.
4. The Genetic Algorithm • Its a kind of general
class of search
• The idea is to
efficiently find a solution to a problem in a large space of works by using code (this type is very suitable with
scheduling problem)
• The GA behavoiur
can be complicated
• It feels difficult for
31
2.9. The Concept of Genetic Algorithms
2.9.1. The Origins of Artificial Species
John Holland’s book “Adaptation in natural and artificial
systems” as well as De Jong’s “Adaptation of the behavior of a class
of genetic adaptive systems,” both published in 1975, are seen as the
foundation of Genetic Algorithms (Gas) (Davis, 1991).
Holland’s original schema was a method of classifying objects,
then selectively “breeding” those objects with each other to produce
new objects to be classified (Buckles and Petry, 1994). Created for
the direct purpose of modelling Darwinian natural selection, the
programs followed a simple pattern of the birth, mating and death of
life forms. A top level description of this process is given in figure
below (Gen and Cheng, 1997; Buckles and Petry, 1992; Davis, 1991;
Shaffer, 1996; NovaGenetica, 1997; Heitkoetter, 1993; Hoener,
1996).
32
The creatures upon which the genetic algorithm acts are
composed of a series of units of information- referred to as genes.
The genes which make up each creature are known as the
chromosome. Each creature has its own chromosome.
A GA, as shown in Figure 2.3 requires a process of initialising,
breeding, mutating, choosing and killing. The order and method of
performing each of these gives rise to many variations on Holland’s
original schema.
2.9.2. Encoding of chromosomes
“A certain amount of art is involved in selecting a good
decoding technique when a problem is being attacked” (Davis 1991,
p 4).
The first place one starts when implementing a computer
program is often in choosing data types. And that is where the first
major variation between Holland’s original schema and many other
types of GA arises (Buckles and Petry, 1997).
Holland encoded chromosomes as a string of binary digits. A
number of properties of binary encoding work to provide simple,
effective and elegant GAs. There are, however, many other ways to
represent a creature’s genes, which can have their own implicit
33
2.9.3. Population Size
The first step in a GA is to initialise an entire population of
chromosomes. The size of this population must be chosen.
Depending on the available computing techniques, different sizes are
optimal. If the population size chosen is too small then there is not
enough exploration of the global search space, although convergence
is quicker. If the population size is too large then time will be wasted
by dealing with more data than is required and convergence times
will become considerably larger (Goldberg, 1989).
2.9.4. Evaluating a Chromosomes
Random populations are almost always extremely unfit (Davis,
1991). In order to determine which are fitter than others, each
creature must be evaluated. In order to evaluate a creature, some
knowledge must be known about the environment in which it
survives. This environment is the partially encoded (or partially
decoded) description of the problem (Gen and Cheng). In our
budgeting example we might describe the characteristics of a good
budget as a collection of rules. One rule might be “Caviar is
expensive and not very nourishing- any budget which spends a lot on
caviar will not rate very well.” One by one each piece of knowledge
relating to the problem is converted to another rule used in
34
evaluating a chromosome. Where there are a number of rules (i.e., in
a multi-objective problem), each rule can be given a relative
importance- a weighting (Rich, 1995).
Depending on the way, we structure the method of evaluating a
chromosome we can either aim to generate the least costly
population or the fit; it is a question of minimising cost or
maximising fitness. In the budgeting example, the heuristic
concerning caviar can be represented with a cost. In optimisation
problems cost is not a measure of money, but a unit of efficiency
(Gen and Cheng, 1997; Davis, 1991). In this case it is simpler to say
that caviar is costly, than that a lack of caviar is healthy. Of course,
fitness can be seen as inversely related to cost and vice versa, so one
can be easily transformed to the other (Gen and Cheng, 1997).
When discussing optimisation techniques, the range of possible
solutions is often referred to as the solution space and the cost/fitness
of each point in the solution space is referred to as the altitude in the
landscape of the problem. To looking for the global minimum of the
cost is also to look for the lowest point in the lowest valley of the
cost landscape. Similarly, to look for the global maximum fitness is
to look for the highest point of the highest mountain in the fitness
landscape. Terminology that assumes an understanding of the
35
With any non trivial optimisation problem it would take an
unreasonably long amount of time to exhaustively search the
solution space for the global minimum of cost. As such optimisation
techniques are employed which utilise two techniques to hasten the
search, referred to as exploitation and exploration. Exploitation is
when information about the explored region of the landscape is used
to direct the search. Exploration is where new, unexplored regions of
the landscape are ventured into (Gen and Cheng, 1997). Finding a
suitable medium between these two concepts is essential for fast
optimisation (Gen and Cheng, 1997).
2.9.5. Initialising a Population
There are two general techniques for initialising a population.
A population of creatures (all of the genetic information about all of
the creatures in the colony) can be loaded from secondary storage.
This data will then provide a starting point for the directed evolution.
More commonly the GA can start with a random population. This is
a full sized population of creatures whose genetic make up is
determined by a random process (Davis, 1991).
2.9.6. Methods of Selecting for Extinction or for Breeding
Once a full population of creatures is established, each with a
36
overall fitness is not yet as high as is desired a portion of the least fit
creatures in the population can be selected for extinction. This can be
referred to as an elitist natural selection operator (Davis, 1991).
Alternatively, an overcrowding strategy can be employed.
Early Gas used a replacement strategy, which maintained a constant
population by replacing two parents with their two offspring in each
generation (Gen and Cheng, 1997). Soon afterward a “crowding
strategy” was invented which had a single offspring replacing which
ever of its parents it most resembled. This can require a gene by gene
comparison of the child to each of its parents, and as such is quite
expensive, computationally (Gen and Cheng, 1997).
Tournament selection is another technique for deciding which
creatures to eradicate. In this scheme, two creatures are chosen and
played off against each other- the winner is allowed to reproduce
and/or the loser is selected for extinction (Rich, 1995). This is said to
mimic behaviour exhibited by stags in large deer populations and
occasionally seen amongst humans (Heitkoetter, 1993).
Exactly how many creatures are wiped out at each generation
is a question of some importance. The proportion of premature
termination in the population creates what is termed the selection
pressure (Gen and Cheng, 1997; Gell-Mann, 1994). For example, in
37
ice ages represent periods in which selection pressures are quite
high, in varying directions in each case.
In various GAs, the method of selecting creatures for breeding
is handled in different ways. Holland’s original model uses a method
where the healthiest are most likely to breed (Gen and Cheng, 1997).
Other methods select any two creatures at random for breeding.
Selective breeding can be used in conjunction with or in the absence
of an Elitist Natural Selection Operator- in either case the GA can
perform evolution (Gen and Cheng, 1997).
In highly evolved populations of creatures, the process of
speciation begins. This is where the intra-mating of some groups
(termed “species”) causes high fitness offspring of that species,
while the mating of the species members with members of the
population who are not of that species produces extremely low
fitness offspring, termed “lethal.” Lethal rarely survive into the next
generation (Heitkoetter, 1993).
The purpose of selective breeding is both to promote high
fitness chromosomes (Gen and Cheng, 1997) and to avoid the over
production of lethal (Heitkoetter, 1993).
2.9.7. Crossover
Once parents have been chosen, breeding itself can then take
38
chromosome, an allele from either the mother or the father. The
process of combining the genes can be performed in a number of
ways. The simplest method of combination is called single point
cross-over (Gen and Cheng, 1997; Buckles and Petry, 1997; Davis,
1991). This can be best demonstrated using genes encoded in binary,
though the process is translatable to almost any gene representation
(Davis, 1991).
A child chromosome can be produced using single point
crossover, as shown in the figure below. A crossover point is
randomly chosen to occur somewhere in the string of genes. All
genetic material from before the crossover point is taken from one
parent, and all material after the crossover point is taken from the
other (Davis, 1991).
The process of crossover can be performed with more than one
crossover point (Gen and Cheng, 1997). Indeed, every point can be
chosen for crossover if preferred (Heitkoetter, 1993). One method of
crossover, often used in multi-objective systems, is unity order based
crossover (Heitkoetter, 1993). In this scheme, each gene has an equal
probability of coming from either parent- there may be a crossover
39
Figure 2.4: An Example of Crossover with Fully Encoded Genes
2.9.8. Mutation
After crossover is performed and before the child is released
into the wild, there is a chance that it will undergo mutation. The
chance of this occurring is referred to as the mutation rate. This is
usually kept quite small (Davis, 1991). The purpose of mutation is to
inject noise, and, in particular, new alleles, into the population. This
is useful in escaping local minima as it helps explore new regions of
the multi dimensional solution space (Gen and Cheng, 1997). If a
mutation rate is too high it can cause well bred genes to be lost and
40
solution space. Some systems do not use mutation operators at all
(Heitkoetter, 1993). Instead, they rely on the noisy (i.e., diverse)
random populations created at initialisation to provide enough genes
that recombination alone will yield an effective search (Heitkoetter,
1993).
Once a gene has been selected for mutation, the mutation itself
can take on a number of forms (Davis, 1991). This, again, depends
on the implementation of the GA. In the case of a binary string
representation, simple mutation of a single gene causes that genes
value to be complemented- a 1 becomes a 0 and vice versa. This is
analogous to the effect of stray ultra violet light upon genes in nature
(Gen and Cheng, 1997). The genetic sensitivity which allows light to
cause various forms of cancer also helps life on this planet to search
the solution space of the ultimate question.
In the case of non binary gene representations, more
cumbersome methods of mutation are required. For integer or real
number representations, a common method is to add a zero mean
Gaussian number to the original value. In more complex data types a
value can be randomly selected from a library of possible values. In
any case, all that is required is that the method of mutation is general
enough that it can cause the appearance of any possible allele within
the population (Davis, 1991). It seems that in more highly decoded
41
2.9.9. Inversion
In Holland’s founding work on GAs he made mention of
another operator, besides selection, breeding, crossover and mutation
which takes place in biological reproduction. This is known as the
inversion operator (Davis, 1991). An inversion is where a portion of
chromosomes detaches from the rest of the chromosome, then
changes direction and recombines with the chromosome. This is
demonstrated in the figure below.
Figure 2.5: The Inversion Operator
2.9.10.Optimising Genetic Algorithm Performance
“The problem of tuning the primary algorithm presents a
secondary, or metalevel, optimisation problem.” (Grefenstette 1986,
p 5)
It can be seen that in any implementation there are a number of
variables the value of which will change the speed and effectiveness
42
selection pressure, number of crossovers, constraint weightings and
so on. In more complex implementations there are a greater number
of these variables. For each of these variables there is a range of
values which provide a working GA. But various combinations of
values, at different times, will provide better performance
(Grefenstette, 1986). There are many techniques which can be used
for determining optimum values for these variables (Ravise, Sebag
and Schoenauer, 1995). GAs themselves are of one of these methods
(Heitkoetter, 1993). It is theoretically possible to have GAs driven
by GAs, ad infinitum.
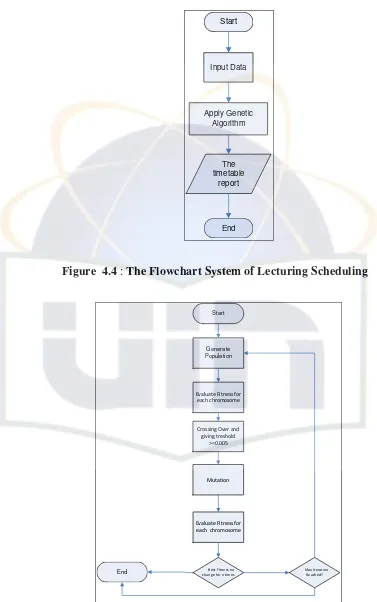
Genetic Algorithm Flowchart
Based on Mehrdad, this figure below is the basic cycle in
genetic algorithm:
Figure 2.6: The Genetic Algorithm Process
Present Generation
Selected Parent New Generation
Selection
43
2.10. Applications of Genetic Algorithms
Unlike most methods of combinatorial optimisation, GAs did not
initially have an underlying mathematical model. As such, they spent some
time demonstrating themselves on a number of famous mathematical
problems (such as the travelling salesperson problem and the k-armed
bandit problem) before tackling more practical issues (Davis, 1991).
By 1989 when David E Goldberg released the seminal “Genetic
algorithms in search, optimisation and machine learning”, the field had
begun the brightest phase of its career- that of Being Applicable to Real
World Problems (Davis, 1991).
Any problem which can be phrased so as to require the minimising or
maximising of some function can be addressed by GAs (Davis, 1991). In
particular, where this function is dependent upon a great many variables,
such that more conventional methods are out of their depth, evolutionary
methods become attractive (Corne and Ross, 1995).
Particularly noteworthy applications of GA include the solving of pipe
network optimisation problems (Anderson and Simpson, 1996)
transportation problems (Gen and Cheng, 1997) conformational analysis of
DNA (Davis, 1991) image processing and machine learning (Buckles and
Petry, 1992) and, of course, scheduling problems (Burke and Ross 1996;
Buckles and Petry, 1992).
GAs are by their very nature, easily translated to parallel systems
44
creature and related, to some degree. At the moment of breeding and death,
there must be some interaction between one creature and the colony (or
some portion of the colony). Tournament selection is a method of choosing
for extinction (or for selecting for breeding) which is most effectively
executed on a parallel system. In this case, it is not necessary for any one
machine to know the average fitness of the entire population, only for the
machines possessing the combatants to briefly communicate. The
application of GAs to parallel architectures has seen a large improvement in
their performance, and has created a large amount of interest (Davis, 1991;
Buckles and Petry, 1997). This appears to be the major direction in which
GA is heading.
GAs are advancing by containing less of a close metaphor with natural
evolution instead conforming only to that essence of evolution, which
allows it to work. For example, data structures are replacing binary numbers
as the most common form of representing genetic material. In modern GAs,
chromosomes are rarely fully encoded (Davis, 1991).
2.11. The Concept of Programming Language
2.11.1. PHP
Based on Quingley(2007), Today PHP is the most popular
script programming language. PHP generally is used to create a
dynamic web even it still can use to another task. The sample of
45
Wikipedia). PHP also can be seen as another chosen from
ASP.NET/C#/ VB.NET Microsoft, ColdFusion Macromedia,
JSP/Java Sun Microsystem and CGI/Perl.
2.11.2. History of PHP
Based on Quingley (2007), At the first time, PHP was made
by Rasmus Lerdorf in 1995. In that time, PHP looks like a script
collect in which its use to process a form of data from web then
Rasmus named the Source code which we called PHP/FI. PHP
stands for Personal Home Page/ Form Interpreter.
After being an open source product, many programmers from
all nations in the world interested to develop PHP. On November
1997, PHP released PHP/FI 2.0 version, in this chance the
interpreter already implemented in C language. In the same year, a
company which the name is Zend, rewritten the PHP interpreter
become more quick and better than before. On June 1998, that
company produced new interpreter for PHP and created name for
new PHP with PHP 3.0.
In the middle on 1999, Zend released new interpreter and
known by PHP 4.0. Many programmers and developers use this
version because PHP 4.0 has a capability to build a complex web
application with high stability and fast process. The enhancer
46
support add on module and consistent syntax. The language that its
use was Perl and C language.
On June 2004, Zend Company released PHP 5.0. This
version is the latest technology from PHP. This version introduced
the latest object oriented model programming to answer the
development of object language. PHP 5.0 version based on Zend
Engine 2.0. It also improved performance and capabilities and
downward compatible.
PHP is very popular because it is a kind of open source
product in which the programmers can read, redistribute, and
modify the source code for a piece of software, the software
evolves. People can improve it, people can adapt it and people can
fix bugs.Using PHP can simplify the dynamic website.
The Comparison between Using PHP Script and Using Perl Script :
1. Using Perl Script :
HTTP CGI
2. Using PHP :
47
The advantages of using PHP :
1. High Performance:
a. It can handle million of transaction without any problem
b. Zend engine which is highly efficient
c. Incorporate business trend as part of future enhancement
to cater Business need.
2. Built in libraries:
a. Contain many built in functions to cater every
development need
b. Every bug exist handle and solve by PHP community
c. API and function implementation examples exist at
3. Extensibility:
a. Developers around the world contribute add on modules to
extend existing functionality
b. Extend the power of PHP programming language
c. Source code of PHP is available for modification and
enhancement
4. Relatively Low Cost:
a. No license required for PHP
b. It runs on any platform (operating system)
c. Source Code of PHP is available for modification and
48
d. Lower the total cost of ownership
5. Portability:
a. It runs almost every platform (operating system)
b. Well written codes can be deployed in every platform with
minor adjustment.
c. Expect the same result even though the application runs on
different platform.
6. Developer Community:
a. Surrounded by huge development community
b. Any problem arise get fixed quickly by the community
c. Programmer problem solved by other programmers
d. Contribution from community make sure PHP is up to
date
7. Ease of Learning:
a. Most of PHP constructs are similar to other languages,
specifically C and Perl
b. Concept of web development is the same for any web
technology
2.12. MySQL
Based on Quingley (2007), Today many organizations face the double
threat of increasing volumes of data and transactions coinciding with a need