PENYELESAIAN MASALAH MANAJERIAL DENGAN
METODE ITERASI KEBIJAKAN PADA DISCOUNTED
MARKOV DECISION PROCESSES
NURUL HIDAYAH
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penyelesaian Masalah Manajerial dengan Metode Iterasi Kebijakan pada Discounted Markov Decision Processes adalah benar karya saya dengan arahan dari dosen pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Mei 2013
Nurul Hidayah
ABSTRAK
NURUL HIDAYAH. Penyelesaian Masalah Manajerial dengan Metode Iterasi Kebijakan pada Discounted Markov Decision Processes. Dibimbing oleh I WAYAN MANGKU dan HADI SUMARNO.
Tujuan karya ilmiah ini adalah menyelesaikan suatu permasalahan manajemen yakni di bidang periklanan dan produksi yang telah dirumuskan menjadi suatu model stokastik dengan sistem pengambilan keputusan. Teknik pengambilan keputusan yang digunakan adalah proses keputusan Markov dengan metode iterasi kebijakan. Penentuan kebijakan optimal menggunakan algoritme
Discounted-Return Policy-Improvement sehingga pada perhitungan setiap
kasusnya menggunakan faktor diskon yaitu sebesar 0.9. Pada kasus periklanan, produsen akan menggunakan RCTI sebagai media promosi saat penjualan produknya berkurang dan saat penjualannya baik produsen menggunakan Indosiar. Sementara saat penjualan produknya sangat memuaskan, produsen menggunakan SCTV sebagai media promosi produknya. Pada kasus manajemen produksi, petani harus menyisakan ikannya sebanyak 2 ton dalam kolam setiap masa panen, dan jika belum memenuhi kriteria tersebut maka petani tidak akan memanen ikannya. Kata kunci: model stokastik, proses keputusan Markov, algoritme discounted-return policy-imrovement, faktor diskon
ABSTRACT
NURUL HIDAYAH. Solution of Managerial Problems Using the Policy Iteration Method in Discounted Markov Decision Processes. Supervised by I WAYAN MANGKU and HADI SUMARNO.
The aim of this paper is to solve a management problem in advertising and production that have been formulated into a stochastic model of the decision-making system. The Decision-decision-making technique used in this paper is the Markov decision process with policy iteration method. To determine the optimal policy, it is employed the discounted-return policy improvement algorithm that uses a discount factor equal to 0.9 for each case. In the case of advertising, the manufacturers will use RCTI as a promotion media when their product sales are low and Indosiar when they have a good sales. When they have satisfied sales, they use SCTV as media promotion. In the case of production management, farmers must keep the fishes in the pond at least 2 tons when they harvest their fishes.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada
Departemen Matematika
PENYELESAIAN MASALAH MANAJERIAL DENGAN
METODE ITERASI KEBIJAKAN PADA DISCOUNTED
MARKOV DECISION PROCESSES
NURUL HIDAYAH
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Penyelesaian Masalah Manajerial dengan Metode Iterasi Kebijakan pada Discounted Markov Decision Processes.
Na
ma : Nurul HidayahNIM : G54090023
Disetujui oleh
Dr Ir I Wayan Mangku, MSc Pembimbing I
Dr Ir Hadi Sumarno, MS Pembimbing II
Diketahui oleh
Dr Berlian Setiawaty, MS Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga skripsi dengan judul Penyelesaian Masalah Manajerial dengan Metode Iterasi Kebijakan pada Discounted Markov Decision Processes berhasil diselesaikan. Skripsi ini merupakan syarat bagi penulis untuk dapat meraih gelar Sarjana Sains pada Mayor Matematika. Terima kasih penulis ucapkan kepada Bapak Dr Ir I Wayan Mangku, MSc dan Bapak Dr Ir Hadi Sumarno, MS selaku dosen pembimbing serta Bapak Dr Paian Sianturi selaku dosen penguji yang telah memberi masukan dalam penulisan skripsi. Selain itu, penulis juga mengucapkan terima kasih kepada bapak, ibu, adik-adik, Jemi atas doa dan kasih sayangnya serta teman-teman matematika 46. Selain itu, ungkapan terima kasih juga disampaikan kepada Syifa, Novi, Hani, dan teman-teman Andhika.
Penulis menyadari bahwa penulisan skripsi ini kurang sempurna. Oleh karena itu, kritik dan saran yang membangun sangat penulis harapkan. Penulis juga berharap skripsi ini dapat memberikan pengetahuan dan manfaat bagi semua.
Bogor, Mei 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan 2
METODE 2
PROSES KEPUTUSAN MARKOV 2
Unsur-unsur Pembangun Proses Keputusan Markov 2
Policy Improvement 5
APLIKASI PROSES KEPUTUSAN MARKOV 7
Aplikasi pada Manajemen Pemasaran 7
Aplikasi pada Manajemen Produksi 10
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Sebaran peluang dan reward kasus manajemen pemasaran 8 2 Hasil perhitungan ys pada iterasi pertama (kasus manajemen
pemasaran) 9
3 Hasil perhitungan ys pada iterasi kedua (kasus manajemen pemasaran) 10
4 Sebaran peluang kasus manajemen produksi 11
5 Keuntungan hasil pemanenan ikan 11
6 Hasil perhitungan ys pada iterasi pertama (kasus manajemen produksi) 12
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Dalam kehidupan setiap harinya manusia dituntut untuk mengambil keputusan atau tindakan, baik keputusan kecil maupun besar. Setiap pengambilan keputusan akan ada risiko yang harus ditanggung. Risiko inilah yang menjadi pertimbangan dalam pengambilan keputusan. Pertimbangan yang sederhana mungkin hanya akan berpengaruh pada keputusan-keputusan yang sederhana pula, sedangkan untuk keputusan besar akan berakibat besar pula, sehingga perlu perhitungan yang matang. Dalam praktiknya, adanya banyak alternatif pilihan keputusan, menyebabkan diperlukan teknik-teknik dalam pemilihannya agar memperoleh hasil yang optimal. Alternatif keputusan tersebut memiliki unsur probabilitas karena dalam pembuatan keputusan dihadapkan pada ketidakpastian. Proses keputusan Markov (Markov Decision Process) menjelaskan model dinamika dari pengambilan keputusan yang mengandung unsur ketidakpastian.
Pada proses keputusan Markov setiap langkah dipilih tindakan tertentu dan tindakan tersebut akan menghasilkan keuntungan (reward) yang sesuai. Untuk mendapatkan keuntungan yang optimal, diperlukan kebijakan yang optimal pula. Kebijakan optimal dapat diperoleh dengan menggunakan tiga metode yaitu metode iterasi nilai (value iteration method), metode iterasi kebijakan (policy iteration method), dan metode solusi program linier (linear program solution method).
Pembahasan utama dalam skripsi ini yakni metode iterasi kebijakan pada
Discounted Markov Decision Processes. Metode iterasi kebijakan ini diawali dengan mengambil sebuah kebijakan dan menghitung nilainya yang dalam perhitungannya terdapat faktor diskon. Setelah itu, memperbaiki kebijakan secara iteratif sesuai algoritme yang ada hingga kebijakan tersebut tidak dapat diperbaiki, dengan kata lain telah mencapai kondisi optimal. Dalam karya ilmiah ini diberikan contoh aplikasinya pada bidang manajemen terutama manajemen produksi dan pemasaran.
Manajemen produksi menjadi faktor utama dalam pencapaian keberhasilan suatu usaha. Berbagai kebijakan dalam proses produksi diharuskan memiliki pengaruh yang baik bagi perusahaan, dalam hal ini perolehan keuntungan yang optimal. Proses keputusan Markov adalah salah satu konsep matematika yang mampu menyelesaikan permasalahan optimalitas termasuk pada proses produksi.
2
Tujuan
Tujuan karya ilmiah ini adalah menyelesaikan suatu permasalahan manajemen yakni di bidang periklanan dan produksi yang telah dirumuskan menjadi suatu model stokastik dengan sistem pengambilan keputusan dan menunjukkan bagaimana menggunakan metode pengiterasian kebijakan untuk mengambil keputusan optimal.
METODE
Penelitian ini berupa kajian teori yang disertai penerapannya, yang disusun berdasarkan rujukan pustaka dengan langkah-langkah sebagai berikut:
1 Memaparkan tentang proses keputusan Markov berkenaan dengan definisi dan unsur pembangun.
2 Memaparkan lema dan teorema yang merupakan konsep dasar dari algoritme penentuan kebijakan optimal.
3 Menerapkan metode pengiterasian dengan algoritme Discounted-Return
Policy-Improvement pada permasalahan manajerial.
PROSES KEPUTUSAN MARKOV
Unsur-Unsur Pembangun Proses Keputusan Markov
Proses keputusan Markov (Markov Decision Process/ MDP) awalnya diperkenalkan oleh Andrey Markov, seorang matematikawan Rusia pada awal abad ke-20 (Tijms 1994). Proses keputusan Markov berguna untuk mempelajari berbagai masalah optimasi yang dipecahkan melalui dynamic programming.
Proses keputusan Markov adalah sebuah sistem yang dapat memindahkan satu keadaan yang khusus ke keadaan lainnya yang mungkin. Proses keputusan Markov pada dasarnya merupakan perluasan dari rantai Markov sehingga harus memenuhi syarat Markov. Menurut Grimmet dan Stirzaker (1992) suatu proses S disebut sebagai rantai Markov jika memenuhi syarat Markov, yaitu
P St=s | S0= s0, S1= s1,…, St-1= st-1 =P St= s | St-1 =st-1 .
Dalam proses keputusan Markov memungkinkan adanya pilihan tindakan (action) yang menghasilkan keuntungan. Oleh karena itu, dapat dikatakan proses keputusan Markov merupakan kerangka matematika untuk memodelkan pembuatan keputusan di situasi yang hasilnya bersifat acak dan berada di bawah kontrol dari pembuat keputusan. Proses keputusan Markov memiliki unsur-unsur pembangun sebagai berikut.
1 State
3
2 Tindakan
Tindakan adalah suatu bagian dari aksi atau strategi yang mungkin dipilih oleh seorang pengambil keputusan di setiap state. Tindakan dilambangkan a dengan a = 1, 2,..., N. Setiap a�As dengan As himpunan
tindakan(Rosadi 2000). 3 Fungsi transisi
Menurut Taylor dan Karlin (1998), fungsi transisi disebutkan sebagai peluang n-step pij(n), yaitu peluang bahwa suatu proses yang mula-mula berada pada statei akan berada pada statej setelah n tambahan transisi.
Menurut Heymen dan Sobel (2004), fungsi transisi adalah suatu fungsi yang menyatakan peluang perpindahan dari suatu state ke state lainnya, notasinya sebagai berikut :
���,�+1 =P sn+1∈ J|Hn, an .
Notasi J melambangkan himpunan state dan Hnmenyatakan kejadian lampau hingga waktu pengambilan keputusan ke-n diambil. Bentuk notasinya sebagai berikut Hn= s1,a1,s2,a2,…,sn-1,an-1,sn . Fungsi transisi pada proses
keputusan Markov harus memenuhi asumsi sifat Markov seperti yang dijelaskan sebelumnya yakni ketika tindakan an diambil di state sn, maka state sn+1 telah ditentukan dengan sebuah cara yang hanya bergantung pada sn dan an.
Sehingga berlaku persamaan berikut :
P sn+1∈ J|Hn, an =P sn+1∈J|sn= s, an=a .
Pengambilan keputusan masa yang akan datang biasanya didasarkan pada keadaan sekarang, bukan berdasarkan pada keadaan di masa lalu. Hal ini dikarenakan keadaan di masa lalu dianggap bebas dengan keadaan di masa yang akan datang. Dalam prosesnya, pembuat keputusan harus mengambil suatu tindakan dari alternatif-alternatif yang ditetapkan. Tindakan sekarang mempengaruhi peluang transisi pada perpindahan yang akan datang dan mendatangkan sebuah keuntungan atau kerugian setelah itu.
Nilai peluang adalah tak negatif dan karena proses tersebut harus mengalami transisi ke suatu state maka
pija ≥0, untuk semua i, j∈{1,2,…, N },
pija =1 N
j=1 untuk semua i, j∈{1,2,…, N }. 4 Fungsi single-stage reward
Fungsi single stage reward yaitu berkenaan dengan pendapatan yang diperoleh sebagai implikasi terjadinya transisi antar state pada alternatif keputusan. Bentuk fungsi single-stage reward adalah
r(s,a) = E(Xn|sn = s, an = a).
Domain dari r(. , .) dan p(J|. , .) adalah himpunan pasangan state dan tindakan yang mungkin, disimbolkan dengan ϐ= s,a :a∈ As, s∈S .
5 Single-stage decision rule
4
tindakandari As. Jika δ∈∆ digunakan untuk memilih tindakan an untuk periode
ke-n, maka an = δ sn .
6 Kebijakan Markov
Kebijakan Markov adalah serangkaian dari single-stage decision rule δ1,δ2,… . Sebuah kebijakan Markov an= δ sn yakni tindakan dipilih
oleh suatu prosedur δn yang bergantung pada state sekarang berlaku untuk semua periode. Namun demikian dimungkinkan adanya perbedaan prosedur terjadi di setiap waktu karena δi ≠ δj untuk i ≠j.
Pembahasan karya ilmiah ini berkenaan dengan Discounted Markov Decision Processes, sehingga pada proses keputusan Markov ada algoritme
Discounted-Return Policy-Improvement sebagai algoritme mencapai kebijakan
optimal yang menggunakan faktor diskon � . Faktor diskon adalah pengali untuk menghitung nilai uang yang akan datang bila dinilai dalam waktu sekarang.
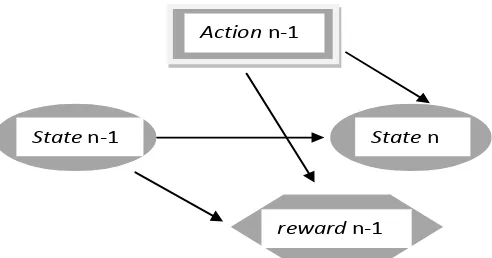
Berikut gambaran sistem proses keputusan Markov :
5 Materi pendukung dalam pembahasan lema di atas yakni relasi biner pada
Y. Misalkan D adalah himpunan tak kosong dan L D×D. Maka (L,D) adalah transitif jika (a,b) L dan (b,c) L menyebabkan (a,c) L. Pasangan terurut (L,D) adalah refleksif jika (b,b) L untuk semua b D. Himpunan L adalah sebuah preorder dan (L,D) adalah himpunan preordered jika L adalah transitif dan refleksif. Sebuah pemetaan f dari D ke D adalah isoton jika (a,b) L
Policy improvement merupakan usaha memperbaiki keputusan yang
diambil dengan algoritme tertentu sehingga tercipta keputusan yang bersifat
6
dengan G s, adalah kumpulan tindakan yang digunakan di state untuk menunda ∞ satu periode karena lebih disukai daripada menggunakannya langsung. Andaikan sebuah MDP memiliki banyak state tercacah dan 0≤ <1 sehingga
7
Proses pencapaian keputusan atau kebijakan yang optimal dalam karya ilmiah ini menggunakan algoritme Discounted-Return Policy-Improvement. Berikut adalah langkah algoritme tersebut.
Salah satu masalah yang dapat diselesaikan dengan proses keputusan Markov adalah permasalahan manajemen pemasaran yakni menentukan media iklan yang tepat sehingga mampu memberikan keuntungan (reward) optimum kepada produsen. Formulasi masalah di atas dibatasi dengan asumsi-asumsi sebagai berikut.
1 Pemilihan media iklan didasarkan pada tingkat penjualan.
2 Produsen hanya menggunakan satu jenis media untuk setiap keadaan penjualan produknya.
3 Alternatif media iklan pada setiap keadaan tidak harus sama.
Langkah awal yang harus dilakukan adalah memformulasikan masalah periklanan dalam sebuah rantai Markov yang disesuaikan dengan jenis keputusan yang ingin diambil. Misalkan keadaan atau state digolongkan menjadi tiga yakni
state 1 menunjukkan penjualan kurang, state 2 menunjukkan penjualan baik, dan
state 3 menunjukkan penjualan sangat memuaskan.
Pendefinisian tindakan untuk kasus ini adalah media iklan yang digunakan di setiap state. Media iklan RCTI didefinisikan sebagai tindakan 1, SCTV sebagai tindakan 2, Indosiar sebagai tindakan 3, dan Kompas sebagai tindakan 4.
8
tindakan di setiap state, kemudian mencari penyelesaian tunggal g(a), vi(a) pada
sistem persamaan linier vi=qi ai –g+ j∈S pij(ai)vj dengan q(a) menunjukkan
ekspektasi keuntungan, dan g(a) menunjukkan nilai ekspektasi keuntungan per unit waktu jika sistem telah berjalan sampai dengan waktu tak berhingga. Setelah itu, menentukan keputusan yang memberi nilai maksimum {qi ai + j∈S pij(ai)vj- g }. Nilai maksimum untuk setiap state inilah yang
digunakan untuk mendefinisikan kebijakan baru. Jika kebijakan baru sama dengan kebijakan sebelumnya maka iterasi dihentikan atau dapat dikatakan telah mencapai kebijakan yang optimal. Sedangkan pada karya ilmiah ini menggunakan algoritme Discounted-Return Policy-Improvement. Berikut adalah penentuan kebijakan optimal dengan algoritme Discounted-Return Policy-Improvement
9
v3=6645.992. Langkah berikutnya adalah menghitung nilai
ys=r s,b(s) + j∈Spsjb(s)vj-vs sehingga dapat mengetahui ada tidaknya tindakan lain yang menjadi anggota G(s,b(s)). Berikut adalah perhitungan nilai ys pada state
1 dengan menggunakan tindakan 2, hasil perhitungan lainnya disajikan pada Tabel 2 (proses perhitungan terdapat pada Lampiran 2).
y1= r 1,2 + p12j
10
Tabel 3 Hasil perhitungan ys pada iterasi kedua v2= r 2,3 + 0.9 p213 v
1+p223 v2+p233 v3 =1300 + 0.9 (0.1v1 +0.5v2+0.4v3).
v3 = r 3,2 +0.9 p312 v1+p322 v2+p332 v3
= 1069.6 + 0.9 (0.01v1+0.1v2+0.89v3).
Penyelesaian persamaan di atas adalah v1 = 11595.21 , v2= 11537.89 ,
v3 = 11117.42. Langkah selanjutnya adalah menghitung nilai ys untuk mengetahui
keanggotanaan G(s,a) pada state 2 dan state 3 karena tindakan pada state 1 telah optimal.
Berdasarkan Tabel 3 diperoleh G(s,a) =∅ ∀ s=1,2,3 sehingga a∞
optimal. Pada state 1 menggunakan tindakan 1, state 2 menggunakan tindakan 3, dan state 3 menggunakan tindakan 2, kesimpulannya produsen akan memilih menggunakan RCTI sebagai media promosi saat penjualan produknya kurang dan menggunakan Indosiar saat penjualannya baik. Sementara saat penjualan produknya sangat memuaskan, produsen menggunakan SCTV sebagai media promosi produknya.
Aplikasi pada Manajemen Produksi
Sebuah perusahaan baik skala kecil maupun besar pastinya memiliki tujuan memperoleh keuntungan yang tinggi dari usahanya. Misalnya pada kasus berikut. Sebuah perusahaan pembudidayaan ikan menginginkan keuntungan yang tinggi dari penjualan ikan di setiap periode pemanenannya. Oleh karena itu, perusahaan tersebut harus memiliki sistem manajemen pemanenan yang baik. Petani dapat menduga secara akurat jumlah ikan di kolam dan kemudian memutuskan jumlah ikan yang dipanen. Pendefinisian state s pada kasus ini yakni jumlah ikan (ton) di kolam sebelum pemanenan, sedangkan yang disebut tindakan adalah jumlah ikan (ton) sisa setelah pemanenan. Hal penting yang perlu dipikirkan oleh petani yakni berapa jumlah ikan (ton) yang harus disisakan dalam kolam untuk pemanenan periode berikutnya. Berdasarkan pengalaman petani dan data dari Departemen Pertanian Amerika Serikat diperoleh peluang transisi yang disajikan pada Tabel 4.
state tindakan ys G(s,b(s))
2 1 -2.684 -
2 -4.183
3 1 -4.55685 -
11
Penyelesaian proses keputusan Markov pada kasus ini menggunakan faktor diskonsebesar 0.9 dan keuntungannya diberikan pada Tabel 5.
Misalkan petani menggunakan sistem pemilihan tindakan sebagai berikut:
b(1) = b(3) = 1, b(2) = b(5) = 2, b(4) = 3.
12
Hasil penyelesaikan persamaan di atas adalah v1=5.566414, v2=11.75132,
v3 =15.566411 , v4 =20.99324 , v5 =26.75132 . Langkah berikutnya adalah menghitung nilai ys=r s,b(s) + j∈Spb(s)sj vj-vs sehingga dapat mengetahui ada
tidaknya tindakan lain yang menjadi anggota G(s,b). Berikut adalah perhitungan nilai ys pada state 2 dengan menggunakan tindakan 1. Hasil perhitungan lainnya
disajikan pada Tabel 6 (proses perhitungan terdapat pada Lampiran 3).
13 menyebabkan a∞ > b∞ dengan susunan kebijakan baru yaitu
a(1)=1, a(2) = a(3) = a(4) = a(5) = 2. Iterasi kedua adalah sebagai berikut.
vs a∞ = rs,a s + psjas j∈S
vj a∞
v1 = r 1,1 + 0.9 p111v1 +p121 v2+p131 v3+p114v4 +p151 v5 = 0 + 0.9(0.9v1+0.1v2).
v2 = r 2,2 + 0.9 p212 v
1 +p222 v2+p232 v3+p242 v4+p252 v5
= 0 + 0.9(0.8v2+0.1v3+0.1v4).
v3 = r 3,2 + 0.9 p312 v
1 +p322 v2+p332 v3+p342 v4+p352 v5
= 5 + 0.9(0.8v2 +0.1v3+0.1v4).
v4 = r 4,2 + 0.9 p241v1 +p422 v2+p432 v3+p244v4+p452 v5
= 10+ 0.9(0.8v2 +0.1v3+0.1v4).
v5 = r 5,2 + 0.9 p251v1 +p522 v2+p532 v3+p254v4+p552 v5 = 15 + 0.9(0.8v2 +0.1v3+0.1v4).
Hasil penyelesaian persamaan di atas yaitu v1=6.394737 , v2=13.5 ,
v3=18.5, v4=23.5, v5 =28.5. Kemudian langkah berikutnya adalah memeriksa keanggotaan G(s,a(s)) pada state 3 dengan tindakan 3. Sedangkan untuk state 1,
state 2, dan state 5 telah optimal. Sementara state 4 tidak memiliki alternatif state
lain sehingga telah optimal pula.
y3=r 3,3 + p33j j∈S
vj - v3
= 0 + 0.9 0.7v3 + 0.2 v4+ 0.1 v5 - v3
=-0.05 <0 3
G
3,a .14
SIMPULAN DAN SARAN
Simpulan
Hasil iterasi dengan menggunakan algoritme Discounted-Return
Policy-Improvement dalam karya ilmiah ini menghasilkan suatu kesimpulan bahwa pada
kasus periklanan, produsen akan menggunakan RCTI sebagai media promosi saat penjualan produknya berkurang dan saat penjualannya baik produsen menggunakan Indosiar. Sementara saat penjualan produknya sangat memuaskan, produsen menggunakan SCTV sebagai media promosi produknya.
Selain itu, pada kasus manajemen produksi disimpulkan bahwa petani harus menyisakan ikannya sebanyak 2 ton dalam kolam setiap masa panen, dan jika belum memenuhi kriteria tersebut maka petani tidak akan memanen ikannya.
Solusi dari kedua permasalahan tersebut memberikan keuntungan yang optimal sehingga konsep proses keputusan Markov cocok digunakan untuk menyelesaikan masalah pemillihan keputusan terutama pada permasalahan manajerial.
Saran
Penulisan karya ilmiah ini menggunakan faktor diskon hipotetik dan data yang digunakan pun telah dibuat menjadi sederhana maka karya ilmiah ini mungkin dapat dikembangkan dengan menyesuaikan antara data dengan faktor diskonyang berlaku pada saat tersebut. Selain itu, alternatif keputusan dapat lebih bervariasi sehingga lebih dekat dalam menggambarkan permasalahan yang sebenarnya.
DAFTAR PUSTAKA
Grimmet GR, Stirzaker DR.. 1992. Probability and Random Processes. Ed ke-2. Oxford (GB): Clarendon Press.
Heymen DP, Sobel MJ. 2004. Stochastic Models in Operation Research. Volume ke-2. New York (US): Publications.inc.Mineola.
Rosadi D. 2000. Pengambilan Keputusan Markov dan Aplikasinya di Bidang Periklanan. Integral. 5(2): 75-82.
Taylor HM, Karlin S. 1998. An Introduction to Stochastic Modeling. Ed ke-3. USA: Academic Press.
15 Lampiran 1 Lema 2 (syarat optimal suatu kebijakan Markov)
Andaikan 0≤ <1 dan S terdiri atas banyak state tercacah. Jika �∗ adalah sebuah kebijakan Markov yang memenuhi
π* T
δπ* maka π*optimal.
16
Lampiran 2 Proses perhitungan pada aplikasi manajemen pemasaran. Iterasi pertama
v1 = r 1,1 + 0.9 p111 v1 + p121 v2+p131 v3
v1 = 1390 + 0.9 0.2v1 +0.3v2+0.5v3
0.82v1- 0.27v2- 0.45v3 = 1390 (4)
v2 = r 2,4 + 0.9 p214 v1+ p224 v2+p234 v3
v2 = 430.5+0.9 0.4v1 + 0.55v2 + 0.05v3
-0.36v1 + 0.505v2- 0.045v3 = 430.5 (5)
v3 = r 3,4 + 0.9 p314 v
1 + p324 v2 + p334 v3
v3 = 539.5 + 0.9 0.07v1+0.33v2+0.6v3
-0.063v1 - 0.297v2+ 0.46v3 = 539.5 (6) Eliminasi persamaan (4) dan (5)
0.82v1- 0.27v2 - 0.45v3 = 1390 ×1 -0.36v1 + 0.505v2 - 0.045v3 = 430.5 ×10 0.82v1- 0.27v2 - 0.45v3 = 1390
-3.6v1 + 5.05v2- 0.45v3 = 4305 -
4.42v1- 5.32v2 = -2915 (7) Eliminasi persamaan (5) dan (6)
-0.36v1 + 0.505v2- 0.045v3 = 430.5 × 0.46 -0.063v1- 0.297v2 + 0.46v3 = 539.5 × 0.045 -0.1656v1+ 0.2323v2 - 0.0207v3 = 198.03
-0.002835v
1- 0.013365v2 + 0.0207v3 = 24.2775 + -0.168435v1+0.218935v2= 222.3075 (8) Eliminasi persamaan (7) dan (8)
4.42v1- 5.32v2 = -2915 × 0.218935 -0.168435v1+0.218935v2= 222.3075 × 5.32 0.9676927v1– 1.1647342v2 = -638.195525
-0.8960742v1+ 1.1647342v3= 1182.6759 + 0.0716185v1 = 544.480375
v1=7602.51
sehingga dengan subtitusi diperoleh
v2 = 6864.304
18 menyebabkan a∞ > b∞ dengan susunan kebijakan baru sebagai berikut:
19
y2= r 2,1 + p21j j∈S
vj- v2
= 1373 + 0.9 p211 v1+p122v2 +p231 v3 - v2
= 1373 + 0.9 0.1v1+0.3v2+0.6v3 - v2
= -2.684 < 0 1G(2,a).
y2=r 2,2 + p22j j∈S
vj- v2
= 1350 + 0.9 p212 v1 + p222v2+ p232 v3 - v2 = 1350 + 0.9 0.15v1+0.3v2+0.55v3 - v2
= -4.183< 0 2G 2,a .
y3= r 3,1 + p31j j∈S
vj- v3
= 1010 + 0.9 p311 v1+p132v2 +p331 v3 - v3 = 1010 + 0.9 0.05v1+0.2v2+0.75v3 - v3 = -4.55685 < 0 1G 3,a .
y3= r 3,3 + p33j
j∈S
vj- v3
= 894.5 + 0.9 p313 v1+p323 v2+p333 v3 - v3 = 894.5 + 0.9 0.08v1+0.4v2+0.52v3 - v3 = -31.472 < 0 3G 3,a .
20
Lampiran 3 Proses perhitungan pada aplikasi manajemen produksi Iterasi pertama
21 dapat menyebabkan a∞ > b∞ dengan susunan kebijakan baru seperti berikut.
22
Iterasi kedua
vs a∞ = r s,a s + psja s j∈S
vj a∞
v1 = r 1,1 + 0.9 p111v1 +p121 v2+p131 v3 +p114v4+p151 v5
=0 + 0.9(0.9v1+0.1v2).
v2 = r 2,2 + 0.9 p221v1 +p222 v2+p232 v3+p224v4+p252 v5 = 0 + 0.9(0.8v2+0.1v3+0.1v4).
v3 = r 3,2 + 0.9 p312 v
1 +p322 v2+p332 v3 +p342 v4+p352 v5
= 5 + 0.9(0.8v2+0.1v3+0.1v4).
v4 = r 4,2 + 0.9 p241v1 +p422 v2+p432 v3 +p244v4+p452 v5
= 10+ 0.9(0.8v2+0.1v3+0.1v4).
v5 = r 5,2 + 0.9 p251v1 +p522 v2+p532 v3 +p254v4+p552 v5
= 15 + 0.9(0.8v2+0.1v3+0.1v4).
Kemudian dilakukan cara yang sama untuk mencari nilai harapan dari lima persamaan di atas, sehingga diperoleh v1 = 6.394737, v2 = 13.5, v3 = 18.5, v4 = 23.5,
v5 = 28.5. Langkah selanjutnya hanya memeriksa G(s,a(s)) pada state 3 dengan
tindakan 3.
y3= r 3,3 + p33j
j∈S
vj - v3
= 0 + 0.9 0.7v3 + 0.2 v4+ 0.1 v5 - v3
= -0.05 < 0 3G 3,a .
23
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 4 Februari 1991 dari ayah Abdul Mugeni dan ibu Wadiningsih. Penulis adalah putri pertama dari empat bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 1 Cilegon dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam.