TESIS
DENNI APRILSYAH LUBIS 117038002
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
DENNI APRILSYAH LUBIS 117038002
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Judul : PENGEMBANGAN ALGORITMA PENGURUTAN SMS (SCAN, MOVE, AND SORT)
Kategori : TESIS
Nama Mahasiswa : DENNI APRILSYAH LUBIS Nomor Induk Mahasiswa : 117038002
Program Studi : S2 TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Marwan Ramli, M. Si Prof. Dr. Opim Salim Sitompul
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
PENGEMBANGAN ALGORITMA PENGURUTAN SMS (SCAN, MOVE AND SORT
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 20 Juni 2013
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Denni Aprilsyah Lubis
NIM : 117038002
Program Studi : S2 Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak bebas Royalti Non-Eksklusif (non-Exlusive Royalty Free Right) atas tesis saya yang berjudul
PENGEMBANGAN ALGORITMA PENGURUTAN SMS (SCAN, MOVE, AND SORT)
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 20 Juni 2013
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Opim Salim Sitompul Anggota : 1. Prof. Dr. Muhammad Zarlis
DATA PRIBADI
Nama lengkap berikut gelar : Denni Aprilsyah Lubis, ST, M. Kom Tempat dan Tanggal Lahir : Sibolga, 06 April 1982
Alamat Rumah : Jl. Diponegoro No. 15 Sibolga
HP : 085270690202
e-mail : [email protected]
Instansi Tempat Bekerja : SMK Negeri 1 Sibolga
Alamat Kantor : Jl. FL. Tobing No.33 Kota Sibolga
DATA PENDIDIKAN
SD : SD Muhammadiyah 3 Sibolga Tamat : 1993
SMP : SMP Negeri 3 Sibolga Tamat : 1996
SMA : SMKTI Negeri 1 Sibolga Tamat : 1999
S-1 : Teknik Informatika STTH Medan Tamat : 2008
UCAPAN TERIMA KASIH
Pertama-tama kami panjatkan puji syukur kehadirat Allah SWT, atas segala limpahan rahmat dan karunia-Nya sehingga tesis ini dapat diselesaikan tepat pada waktunya. Dengan selesainya tesis ini, perkenanlah saya mengucapkan terima kasih yang sebesar-besarnya kepada :
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc (CTM), Sp. A(K) atas kesempatan yang diberikan kepada saya untuk mengikuti dan menyelesaikan pendidikan Program Magister.
Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Prof. Dr. Muhammad Zarlis atas kesempatan yang diberikan kepada saya menjadi mahasiswa Program Magister pada Program Pascasarjana FASILKOM-TI Universitas Sumatera Utara.
Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr. Muhammad Zarlis dan sekretaris Program Studi Magister (S2) Teknik Informatika M. Andri Budiman, S.T, M.Comp, M.E.M beserta seluruh staff pengajar pada Program Studi Magister (S2) Teknik Informatika Program Pascasarjana FASILKOM-TI Universitas Sumatera Utara.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya saya ucapkan kepada Prof. Dr. Opim Salim Sitompul, selaku pembimbing utama dan kepada Dr. Marwan Ramli, M. Si, selaku pembimbing lapangan yang dengan penuh kesabaran membimbing saya hingga selesainya tesis ini dengan baik.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya saya ucapkan kepada Prof. Dr. Muhammad Zarlis, Prof. Dr. Herman Mawengkang dan Dr. Zakarias Situmorang, sebagai pembanding yang telah memberikan saran dan masukan serta arahan yang baik demi penyelesaian tesisi ini.
Staff Pegawai dan Administrasi pada Program Studi Magister (S2) Teknik Informatika Program Pascasarjana FASILKOM-TI Universitas Sumatera Utara yang
telah memberikan bantuan dan pelayanan terbaik kapada penulis selama mengikuti perkuliahan hingga saat ini.
Kepada Ayahanda Amrilsyah P. Tagor Lubis, Bunda Sensualita Pasaribu selaku orang tua, serta kepada seluruh keluarga besar yang tidak dapat saya sebutkan
satu persatu, terimakasih atas segala pengorbanannya, baik moril maupun materil budi baik ini tidak dapat dibalas hanya diserahkan kepada Allah SWT.
Rekan mahasiswa/i angkatan ketiga tahun 2011 pada Program Pascasarjana Fasilkom-TI Universitas Sumatera Utara yang telah banyak membantu penulis baik berupa dorongan semangat dan doa selama mengikuti perkuliahan.
Seluruh pihak yang tidak dapat penulis sebutkan satu persatu dalam tesis ini, terimakasih atas segala bantuan dan doa yang diberikan. Dengan segala kekurangan dan kerendahan hati, sekali lagi penulis mengucapkan terimakasih. Semoga kiranya Allah SWT membalas segala bantuan dan kebaikan yang telah kalian berikan.
Medan, 20 Juni 2013
ABSTRAK
ENHANCED SMS (SCAN, MOVE AND SORT) ALGORITHM
ABSTRACT
DAFTAR ISI
Hal
UCAPAN TERIMA KASIH i
ABSTRAK iii
ABSTRACT iv
DAFTAR ISI v
DAFTAR TABEL vii
DAFTAR GAMBAR viii
BAB I PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Penelitian Sebelumnya 3
1.3. Rumusan Masalah 4
1.4. Batasan Masalah 4
1.5. Tujuan Penelitian 4
1.6. Manfaat Penelitian 4
BAB II TINJAUAN PUSTAKA 6
2.1. Algoritma 6
2.2. Kompleksitas Algoritma 7
2.3. Kompleksitas Waktu 7
2.4. Kompleksitas Waktu Asimptotik 8
2.5. Kompleksitas Ruang Memori 9
2.6. Algoritma Pengurutan 9
2.7. Klasifikasi Algoritma Pengurutan 9
2.8. Algoritma SMS (Scan, Move, and Sort) 10
2.9. Konsep Algoritma SMS 11
2.10. Langkah-Langkah Algoritma SMS 11
2.11. Pseudocode Algoritma SMS 12
2.12. Kompleksitas Waktu Algoritma SMS 15
2.12.1. Kompleksitas Waktu Prosedur Scan 15
2.12.1. Kompleksitas Waktu Prosedur Sort 16
2.13. Kompleksitas Ruang Memori Algoritma SMS 17
BAB III METODOLOGI PENELITIAN 18
3.1. Lingkungan Penelitian 18
3.2. Teknik Pengembangan 18
3.2.1. Pengembangan Prosedur Scan 18
3.2.2. Pengembangan Prosedur Move 20
3.2.3. Pengembangan Prosedur Sort 22
3.3. Proses Analisis 25
3.3.1. Analisis Kompleksitas Waktu Pengembangan Prosedur Scan 25 3.3.2. Analisis Kompleksitas Waktu Pengembangan Prosedur Move 25 3.3.3. Analisis Kompleksitas Waktu Pengembangan Prosedur Sort 26 3.3.4. Analisis Kompleksitas Ruang Pengembangan Algoritma SMS 27
3.4. Perancangan Program 28
3.5. Instrumen Penelitian 30
BAB IV HASIL DAN PEMBAHASAN 31
4.1. Pengantar 31
4.2. Data Uji 33
4.3. Hasil Pengujian 35
4.3.1. Hasil Pengujian Untuk 50.000 (Lima Puluh Ribu) Data 35 4.3.2. Hasil Pengujian Untuk 50.000 (Lima Puluh Ribu) Data 36
4.4. Pembahasan 38
4.4.1. Pembahasan hasil pengujian untuk 50.000 (lima puluh ribu) data 39
4.4.1. Pembahasan hasil pengujian untuk 100.000 (seratus ribu) data 39
BAB V KESIMPULAN DAN SARAN 40
5.1. Kesimpulan 40
5.2. Saran 41
DAFTAR KEPUSTAKAAN 42
LAMPIRAN LISTING PROGRAM ALGORITMA SMS 43
DAFTAR TABEL
Hal
Tabel 1.1. Riset Terkait 3
Tabel 2.1. Perbandingan pertumbuhan T(n)dengan n2 8
DAFTAR GAMBAR
Hal Gambar 3.1. Flowchart Perancangan Program Algoritma SMS 28 Gambar 3.2. Flowchart Perancangan Program Pengembangan Algoritma SMS 29 Gambar 4.1. Tampilan Output Program Pengurutan Data Menggunakan Algoritma
SMS 31
Gambar 4.2. Tampilan Output Program Pengurutan Data Menggunakan
Pengembangan Algoritma SMS 32
ABSTRAK
Pengurutan data telah menjadi bidang penelitian yang sangat besar bagi para peneliti
algoritma. Banyak sumber daya yang diinvestasikan untuk membuat algoritma
pengurutan data bekerja lebih baik. Untuk tujuan ini banyak algoritma pengurutan
yang diamati dalam hal efisiensi kompleksitas algoritma. Algoritma pengurutan data
yang efisien sangat penting untuk mengoptimalkan penggunaan algoritma lain yang
memerlukan daftar data yang sudah diurutkan untuk dapat bekerja dengan benar.
Pengurutan data telah dianggap sebagai masalah mendasar dalam bidang ilmu
algoritma, dikarenakan berbagai alasan yakni, kebutuhan untuk pengurutan informasi
yang terdapat dalam banyak aplikasi, algoritma lain banyak menggunakan pengurutan
data sebagai subrutin kunci, dalam mendesain algoritma banyak teknik penting
direpresentasikan dalam tubuh algoritma pengurutan dan banyak isu rekayasa yang
timbul ketika menerapkan algoritma pengurutan. Banyak algoritma yang sangat
terkenal untuk pengurutan data, dan salah satu dari algoritma yang terkenal tersebut
yang menjadikan proses pengurutan data menjadi lebih ekonomis dan efisien adalah
algoritma Quicksort yang ditemukan Hoare R pada tahun 1962. Kemudian pada tahun
2010, Rami Mansi menemukan algoritma SMS (Scan, Move and Sort), yang
merupakan peningkatan algoritma Quicksort. Pada penelitian ini penulis membangun
ENHANCED SMS (SCAN, MOVE AND SORT) ALGORITHM
ABSTRACT
BAB I
PENDAHULUAN
1.1. Latar Belakang
Teknologi informasi sudah berkembang sangat pesat pada masa ini. Pencarian informasi yang berjumlah besar dalam waktu yang singkat sangat dibutuhkan sebagai upaya efisiensi waktu. Pencarian sebuah dokumen akan lebih efektif apabila informasi-informasi mengenai dokumen yang dicari tersebut diurutkan terlebih dahulu, dibandingkan pencarian dokumen tanpa pengurutan. Sehingga proses pengurutan data (sorting) merupakan salah satu bagian penting dalam proses pencarian informasi.
Pengurutan data telah menjadi bidang penelitian yang sangat besar bagi para peneliti algoritma, banyak sumber daya yang diinvestasikan untuk membuat algoritma pengurutan data bekerja lebih baik. Untuk tujuan ini banyak algoritma pengurutan yang diamati dalam hal efisiensi kompleksitas algoritma (Friend, 1956). Algoritma pengurutan data yang efisien sangat penting untuk mengoptimalkan penggunaan algoritma lain yang memerlukan daftar data yang sudah diurutkan untuk dapat bekerja
dengan benar (Deitel & Deitel, 2001).
Sejak awal digunakannya teknologi komputer, masalah pengurutan data telah menarik minat banyak peneliti, untuk menciptakan algoritma yang memiliki kompleksitas waktu penyelesaian paling efisien (Kruse & Ryba, 1999). Menurut Cormen et al (2001), pengurutan data telah dianggap sebagai masalah mendasar dalam bidang ilmu algoritma, dikarenakan alasan-alasan berikut :
(a) Kebutuhan untuk pengurutan informasi yang terdapat dalam banyak aplikasi. (b) Algoritma lain banyak menggunakan pengurutan data sebagai subrutin kunci. (c) Dalam mendesain algoritma banyak teknik penting direpresentasikan dalam tubuh
(d) Banyak isu rekayasa yang timbul ketika menerapkan algoritma pengurutan.
Banyak algoritma yang sangat terkenal untuk pengurutan data, dan salah satu dari
algoritma yang terkenal tersebut yang menjadikan proses pengurutan data menjadi lebih ekonomis dan efisien adalah algoritma Quicksort yang ditemukan Hoare R pada tahun 1962. Algoritma Quicksort menggunakan teknik pendekatan divide-and-conquer, pada algoritma yang menggunakan teknik divide-and-conquer, suatu masalah dibagi menjadi beberapa masalah kecil, kemudian memecahkan masalah-masalah kecil tersebut secara rekursi (conquer), dan kemudian mengumpulkan semua solusi untuk mendapatkan solusi utama untuk input awal (combine). Prinsip desain algoritma yang menggunakan teknik divide-and-conquer adalah bahwa lebih mudah untuk memecahkan beberapa kasus masalah kecil daripada satu masalah besar (Dean, 2006).
Kemudian pada tahun 2010, Rami Mansi menggagas algoritma SMS (Scan, Move and Sort), yang merupakan pengembangan dari algoritma Quicksort (Mansi, 2010). Algoritma SMS meningkatkan algoritma Quicksort dalam membagi array masukan. Quicksort menggerakkan pivot untuk berada di tempat yang benar dan kemudian membagi array menjadi dua bagian, dan secara rekursif membuat prosedur yang sama untuk kedua bagian array tersebut, hingga mencapai hasil pengurutan yang benar. Algoritma SMS membagi array menjadi tiga bagian (array), yakni array yang menampung nilai positif, menampung nilai negatif, dan menampung nilai yang sering muncul, lalu kemudian memindahkan setiap elemen ke tempat yang benar sesuai urutan. Dalam kasus terbaik, algoritma quicksort membutuhkan kompleksitas waktu O(n log n), sementara algoritma SMS membutuhkan kompleksitas waktu O(n). Dalam
ini, Penulis akan membangun suatu algoritma baru yang merupakan pengembangan dari algoritma SMS.
1.2. Penelitian Sebelumnya
Terdapat beberapa riset yang telah dilakukan oleh peneliti sebelumnya yang berkaitan dengan penelitian ini. Pada tabel 1.1 berikut akan terlihat beberapa riset tersebut.
Tabel 1.1. Riset Terkait
Nama Peneliti dan Tahun Judul Pembahasan
Hoare (1962) Quicksort Menyajikan algoritma Quicksort
dan cara kerjanya. algoritma Quicksort, berikut cara kerjanya dan membandingkan kompleksitas waktu yang dicapai dengan algoritma quicksort. menggunakan metode divide and conquer
Memberikan beberapa kasus data yang akan diurutkan dan memberikan solusi algoritma yang terbaik untuk masalah tersebut
serta melakukan pengujian untuk jumlah data 50.000 (lima puluh ribu) dan 100.000 (seratus ribu) data integer, dimana masing-masing jumlah data tersebut akan diuji
untuk 20 set data.
1.3. Rumusan Masalah
Algoritma SMS sebenarnya telah berhasil melakukan pengurutan data dengan baik, namun melihat kompleksitas waktu yang dibutuhkan algoritma SMS pada kasus rata-rata dan kasus terburuk yang masih sangat besar, maka dalam penelitian ini penulis membangun algoritma pengurutan yang merupakan pengembangan dari algoritma SMS, dengan kompleksitas waktu yang lebih efisian dibandingkan algoritma SMS untuk kasus rata-rata dan kasus terburuk.
1.4. Batasan Masalah
Agar pembahasan penelitian ini tidak menyimpang dari apa yang telah ditetapkan dalam rumusan masalah, maka dibentuk batasan terhadap permasalahan yaitu :
1. Pengurutan yang dilakukan untuk bilangan integer
2. Perbandingan yang dilakukan berdasarkan efisiensi kompleksitas waktu
1.5. Tujuan Penelitian
Tujuan penelitian tesis ini adalah membangun algoritma pengurutan yang merupakan pengembangan dari algoritma SMS, dengan kompleksitas waktu yang lebih efisien dibandingkan algoritma SMS untuk kasus rata-rata dan terburuk.
1.6. Manfaat Penelitian
acuan dalam pengembangan ilmu pengetahuan bidang informatika, khususnya mengenai algoritma pengurutan. Aplikasi dari penelitian ini diharapkan dapat
BAB II
TINJAUAN PUSTAKA
2.1. Algoritma
Algortima adalah jantung ilmu komputer atau informatika. Banyak cabang dari ilmu komputer yang diacu dalam terminologi algoritma, misalnya algoritma perutean (routing) pesan di dalam jaringan komputer, algoritma berensenham untuk menggambar garis lurus (bidang grafik kumputer), algoritma Knuth-Morris-Pratt untuk mencari suatu pola di dalam teks (bidang information retrievel), dan lain sebagainya.
Algoritma dalam pengertian modern mempunyai kemiripan dengan istilah resep, proses, metode, teknik, prosedur, rutin. Algoritma adalah sekumpulan aturan-aturan berhingga yang memberikan sederetan operasi-operasi untuk menyelesaikan suatu jenis masalah yang khusus (Knuth, 1973). Berdasarkan pengertian algoritma di atas, dapat disimpulkan bahwa algoritma merupakan suatu istilah yang luas, yang tidak hanya berkaitan dengan dunia komputer.
Kriteria Algoritma (Knuth, 1973) adalah:
1. Input: algoritma dapat memiliki nol atau lebih masukan dari luar. 2. Output: algoritma harus memiliki minimal satu buah hasil keluaran.
3. Definiteness (pasti): algoritma memiliki instruksi-instruksi yang jelas dan tidak ambigu.
4. Finiteness (ada batas): algoritma harus memiliki titik berhenti (stopping role). 5. Effectiveness (tepat dan efisien): algoritma sebisa mungkin harus dapat
2.2. Kompleksitas Algoritma
Sebuah permasalahan dapat diselesaikan dengan berbagai algoritma. Sebagai contoh masalah pengurutan data, ada banyak algoritma pengurutan data (sortir) yang dapat digunakan untuk masalah pengurutan data tersebut. Sebuah algoritma yang baik tidak saja harus benar, tetapi juga harus efisien. Tingkat keefisienan sebuah algoritma diukur dari waktu eksekusi algoritma (time complexity/komplesitas waktu) dan kebutuhan ruang (space) memori. Algoritma yang efisien adalah algoritma yang meminimalkan kebutuhan waktu ekseskusi program dan kebutuhan ruang memori (Cormen et al, 2001).
Kebutuhan waktu dan ruang suatu algoritma bergantung pada ukuran masukan (n), yang menyatakan jumlah data yang diproses. Keefisienan algoritma dapat digunakan untuk menilai algoritma yang paling baik dari sejumlah algoritma penyelesaian masalah yang ada. Dengan menggunakan besaran kompleksitas waktu/ruang algoritma, kita dapat menentukan laju peningkatan waktu/ruang yang diperlukan algoritma dengan meningkatnya ukuran masukan (n).
Menghitung kebutuhan waktu algoritma dengan mengukur waktu sesungguhnya (dalam satuan detik) ketika algoritma dieksekusi oleh komputer bukan cara yang tepat, dikarenakan alasan sebagai berikut :
1. Setiap komputer dengan arsitektur berbeda mempunyai bahasa mesin yang berbeda yang berarti waktu setiap operasi antara satu komputer dengan komputer lain tidak sama.
2. Kompiler bahasa pemrograman yang berbeda menghasilkan kode mesin yang
berbeda yang berarti waktu setiap operasi antara satu kompiler dengan kompiler lain tidak sama.
2.3. Kompleksitas Waktu
(a) Operasi baca/tulis
(b) Operasi aritmetika (+, -, *, /)
(c) Operasi pengisian nilai (assignment) (d) Operasi pengakasesan elemen larik (e) Operasi pemanggilan fungsi/prosedur (f) Dan lain-lain.
Dalam hal kompleksitas waktu yang dihitung adalah jumlah operasi khas (tipikal) yang mendasari suatu algoritma. Untuk algoritma pengurutan, operasi khas yang dimaksud adalah perbandingan elemen dan pertukaran elemen. Kompleksitas waktu dibedakan atas tiga jenis, yakni :
1. Tmax(n) : kompleksitas waktu untuk kasus terburuk (worst case), kebutuhan waktu maksimum. lebih penting adalah laju peningkatan T(n) ketika n membesar, pada tabel 2.1 berikut
akan menunjukkan contoh perbandingan pertumbuhan untuk T(n)2n26n1,
Untuk n yang besar, pertumbuhan T(n) sebanding dengan n, T(n) tumbuh seperti n tumbuh. T(n) tumbuh seperti n tumbuh saat n bertambah ditulis T(n) = O(n2). Notasi
“O” berguna untuk membandingkan beberapa algoritma dari dan untuk masalah yang
sama dalam hal menentukan yang terbaik. Semakin kecil nilai O dari suatu algoritma,
maka berarti semakin baik kompleksitas waktu algoritma tersebut (Cormen et al, 2001).
2.5. Kompleksitas Ruang Memori
Kompleksitas ruang memori S(n), diekspresikan sebagai jumlah memori yang digunakan oleh struktur data yang terdapat di dalam algoritma sebagai fungsi dari ukuran masukan n, dan kompleksitas ruang memori S(n) diukur berdasarkan memori yang digunakan oleh struktur data tersebut (Cormen et al, 2001).
2.6. Algotima Pengurutan
Dalam ilmu komputer, algoritma pengurutan (sorting) adalah algoritma yang meletakkan elemen-elemen suatu kumpulan data dalam urutan tertentu atau proses pengurutan data yg sebelumnya disusun secara acak sehingga menjadi tersusun secara teratur menurut suatu aturan, yang pada kenyataannya urutan tertentu yang umum digunakan adalah terurut secara numerikal ataupun secara leksikografi (urutan secara abjad sesuai kamus). Ada 2 (dua) jenis pengurutan, yakni secara ascending (naik) dan descending (turun).
2.7. Klasifikasi Algoritma Pengurutan
Algoritma pengurutan diklasifikasikan menjadi beberapa jenis, yakni : 1. Exchange Sort
2. Selection Sort
Algoritma yang dikategorikan dalam Selection Sort jika cara kerja algoritma tersebut mencari elemen yang tepat untuk diletakkan pada posisi yang telah diketahui, dan meletakkannya di posisi tersebut setelah data tersebut ditemukan. Contohnya Selection sort, Heap sort, Smooth sort, Strand sort.
3. Insertion Sort
Algoritma yang dikategorikan dalam Insertion Sort jika cara kerja algoritma tersebut mencari tempat yang tepat untuk suatu elemen data yang telah diketahui ke dalam subkumpulan data yang telah terurut, kemudian melakukan penyisipan (insertion) data di tempat yang tepat tersebut. Contohnya adalah Insertion sort, Shell sort, Tree sort, Library sort, Patience sort.
4. Merge Sort
Algoritma yang dikategorikan dalam Merge Sort jika cara kerja algoritma tersebut membagi data menjadi subkumpulan-subkumpulan yang kemudian subkumpulan tersebut diurutkan secara terpisah, dan kemudian digabungkan kembali dengan metode merging. algoritma ini melakukan metode pengurutan merge sort juga untuk mengurutkan subkumpulandata tersebut, atau dengan kata lain, pengurutan dilakukan secara rekursif. Contohnya adalah Merge sort.
5. Non Comparison Sort
Algoritma yang dikategorikan dalam Non Comparison Sort jika proses pengurutan data yang dilakukan algoritma tersebut tidak terdapat pembandingan antardata, data diurutkan sesuai dengan pigeon hole principle. Contohnya adalah Radix sort, Bucket
sort, Counting sort, Pigeonhole sort, Tally sort.
2.8. Algoritma SMS (Scan, Move and Sort)
sering muncul. Peningkatan pada kasus rata-rata terjadi ketika n adalah jauh lebih besar dari pada nilai maksimum dan |nilai minimum|, di mana kompleksitas waktu
mendekati O(n). Ketika berurusan dengan berbagai elemen yang berbeda, algoritma SMS lebih efisien dari pada algoritma quicksort. Dalam kasus terburuk, algoritma SMS membutuhkan kompleksitas waktu O(n + f * (nilai maksimum + |nilai minimum|)) (Mansi, 2010).
2.9. Konsep Algoritma SMS
Konsep utama dari algoritma SMS mendistribusikan elemen dari array masukan pada tiga array tambahan sementara. Ukuran dari array ditentukan dan tergantung pada nilai maksimum dan nilai minimum dari array masukan. Array tambahan pertama disebut PosArray yang menampung elemen-elemen yang bernilai positif dari array masukan
dan menggunakan nilai dari elemen itu sendiri sebagai indeks dalam array.
Array kedua adalah NegArray yang menampung elemen-elemen yang bernilai
negatif dari array masukan dan menggunakan nilai absolut dari elemen itu sendiri sebagai indeks dalam array. Array ketiga adalah FreqArray dan digunakan untuk menyimpan elemen yang muncul lebih dari 1 (satu) kali (sering muncul) dari array masukan (Mansi, 2010).
2.10. Langkah-Langkah Algoritma SMS.
Algoritma SMS terdiri dari tiga prosedur, yakni Scan, Move, dan Sort. Prosedur pertama adalah Scan (kenal), yang mengenali array dan berguna untuk mendapatkan nilai minimum, nilai maksimum, jumlah elemen positif, dan jumlah elemen negatif dari array masukan. Selain itu, prosedur ini memeriksa apakah nilai minimum sama dengan nilai maksimum, jika sama berarti array input sudah adalah array yang sudah terurut, jika tidak sama maka dilanjutkan ke prosedur move.
minimum dikurang 1 (satu) untuk yang menunjukkan indeks yang akan dilewati di fase berikutnya. Kemudian, prosedur ini mendistribusikan elemen pada tiga array,
elemen positif disimpan dalam PosArray menggunakan elemen itu sendiri sebagai indeks, elemen-elemen negatif disimpan dalam NegArray menggunakan nilai absolut dari elemen itu sendiri sebagai indeks, dan elemen yang sering muncul disimpan dalam FreqArray menggunakan variabel i sebagai indeks dimulai dari nol dan seterusnya bertambah satu.
if array(a) >= 0 then (13)
Move(array, size, NOP, NON, max, min) (20)
end if (21)
end if (22)
Akhir prosedur Scan
Prosedur Move(array, size, NOP, NON, max, min)
var b,c,d,i (1)
i:=0 (2)
create a new array: FreqArray[size] and initialize by the value (min-1) (3)
if NOP > 0 then (4)
create a new array:PosArray[max+1] (5)
for b:=0 to max do (6)
PosArray(b):= min-1 (7)
end for (8)
end if (9)
if NON>0 then (10)
create a new array: NegArray[|min|+1] (11)
FreqArray(i):=array(d) (21)
Sort(array, NegArray, PosArray, FreqArray, NON, NOP, max, min, i) (33) Akhir prosedur Move
Prosedur Sort(array, NegArray, PosArray, FreqArray, NON, NOP, max, min, i)
for x:= 0 to max do (18)
if PosArray(x) ≠ min-1 then (19)
array(index):= PosArray(x) (20)
index:= index+1 (21)
for y:= 0 to i do (22)
if FreqArray(y)== array(index-1) then (23)
array(index):=FreqArray(y) (24)
index:= index+1 (25)
end if (26)
end for (27)
end if (28)
end for (29)
end if (30)
Akhir prosedur Sort
2.12. Kompleksitas Waktu Algortima SMS
Algoritma SMS terdiri dari tiga prosedur, yakni Scan, Move, dan Sort, berikut akan terlihat kompleksitas waktu dari ketiga prosedur tersebut yang akan menghasilkan kompleksitas waktu keseluruhan dari algoritma SMS
2.12.1. Kompleksitas waktu prosedur scan
2.12.2. Kompleksitas waktu prosedur move
Kasus terbaik prosedur move adalah ketika semua elemen dari array masukan adalah bilangan positif dan nilai maksimumnya kecil, atau ketika semua elemen dari array masukan adalah bilangan negatif dan nilai minimumnya kecil. Jika semua elemen array adalah bilangan positif dan tidak ada yang negatif, maka untuk perulangan (baris 6-8 dari prosedur move) membutuhkan kompleksitas waktu O(max) untuk menginisialisasi PosArray, dan untuk perulangan (baris 16-32 dari prosedur move) membutuhkan kompleksitas waktu O(n). Berdasarkan penjelasan diatas, jika seluruh elemen array masukan merupakan bilangan positif, kompleksitas waktu keseluruhan prosedur move adalah O(n + max). Di sisi lain, jika semua elemen dari array masukan adalah bilangan negatif, maka untuk perulangan (baris 12 -14 prosedur move) membutuhkan kompleksitas waktu O(|min|) menginisialisasi NegArray, dan untuk perulangan (baris 16 -32 prosedur move) membutuhkan kompleksitas waktu O(n). Dalam hal ini berarti, kompleksitas waktu keseluruhan prosedur move jika seluruh elemen array masukan merupakan bilangan negatif adalah O(n + |min|). Dapat dikatakan bahwa dalam kasus rata-rata dan terburuk, jika terdapat elemen positif dan negatif dalam array masukan, maka kompleksitas waktu keseluruhan prosedur move adalah O(n + max + |min|)) (Mansi, 2010).
2.12.3. Kompleksitas waktu prosedur sort
Kasus terbaik prosedur sort adalah ketika semua elemen array masukan merupakan bilangan positif dan semua elemen berbeda serta bilangan maksimum bernilai kecil, atau ketika semua elemen array masukan adalah bilangan negatif dan semua elemen berbeda serta bilangan minimum bernilai kecil. Jika semua elemen array masukan adalah bilangan positif dan berbeda, maka perulangan (baris 18-29 dari prosedur sort) membutuhkan kompleksitas waktu O(max), karena perulangan (baris 22-27 dari prosedur sort) membutuhkan kompleksitas waktu O(1) dalam kasus ini. Jika semua
kompleksitas waktu O(1) dalam kasus ini. Dapat dikatakan, pada kasus rata-rata, dan terburuk prosedur sort, prosedur Sort membutuhkan kompleksitas waktu O(max * f)
+ O(|min| * f), di mana f adalah jumlah elemen yang sama. Dengan kata lain, kompleksitas waktu prosedur sort adalah O(f * (max + |min|)).
Kompleksitas waktu kasus terbaik dari algoritma SMS adalah O(n), ketika array masukan sudah terurut. Ini berarti, ketika nilai max sama dengan min (baris 19-21 prosedur scan) maka array input sudah diurutkan. Dalam kasus rata-rata dan terburuk, prosedur scan memerlukan kompleksitas waktu O(n), prosedur move membutuhkan kompleksitas waktu O(n + max + |min|), dan prosedur sort memerlukan kompleksitas waktu O(f * (max + |min|)). Jika dianggap distribusi data adalah normal, frekuensi elemen harus sedikit, dan karena sebagian besar aplikasi nyata memiliki n jauh lebih besar dari nilai max dan |min|, dapat dipertimbangkan max dan min sebagai konstanta dan menghilangkannya. Kompleksitas waktu keseluruhan dari algoritma SMS dalam kasus rata-rata dan terburuk adalah O(n + f * (max + | min |)), di mana f adalah jumlah elemen yang sama (Mansi, 2010).
2.13. Kompleksitas Ruang Memori Algortima SMS
BAB III
METODOLOGI PENELITIAN
3.1. Lingkungan Penelitian
Dalam penelitian ini penulis membangun algoritma pengurutan yang merupakan pengembangan dari algoritma SMS, terkait hal tersebut maka penulis akan menganalisa langkah-langkah kerja algoritma SMS dan melakukan pengembangan pada beberapa tahapan di dalam algoritma SMS tersebut, sehingga nantinya algoritma yang penulis bangun akan memiliki efisiensi kompleksitas waktu yang lebih baik dibandingkan algoritma SMS pada kasus rata-rata dan terburuk yang terjadi pada algoritma SMS.
3.2. Teknik Pengembangan
Pengembangan yang dilakukan terhadap algoritma SMS adalah pada ketiga prosedur yang terdapat pada algoritma SMS tersebut (prosedur Scan, Move, dan Sort). Pada sub bab berikut ini akan terlihat pengembangan yang terjadi pada masing-masing prosedur tersebut.
3.2.1. Pengembangan prosedur scan
Pada algoritma SMS tujuan dari prosedur scan hanya untuk mendapatkan nilai maksimum, nilai minimum, jumlah elemen positif, dan jumlah elemen negatif dari
array masukan. Adapun kegunaan nilai maksimum positif, nilai minimum positif, nilai maksimum negatif dan nilai minimum negatif tersebut nantinya adalah untuk
meminimalkan jumlah perulangan yang terjadi pada prosedur Move dan prosedur Sort. Untuk mendapatkan nilai maksimum positif, nilai minimum positif, nilai maksimum negatif, nilai minimum negatif, jumlah elemen positif, dan jumlah elemen negatif dari array masukan tersebut, pseudocode prosedur Scan dikembangkan menjadi sebagai berikut:
Prosedur Scan(array, size)
if size > 1 then (1)
var a, maxpos, minpos, maxneg, minneg, NOP, NON (2)
maxpos:= 0 (3)
if array(a) > maxpos then (12)
maxpos := array(a) (13)
end if (14)
if array(a) < minpos then (15)
minpos:=array(a) (16)
end if (17)
else (18)
NON:= NON+1 (19)
if array(a) < minneg then (20)
minneg := array(a) (21)
end if (22)
if array(a) > maxneg then (23)
end if (25) Move(array, size, NOP, NON, maxpos, minpos, maxneg, minneg) (33)
end if (34) NegArray berukuran absolut dari nilai minimum ditambah 1 (satu). Pengembangan yang dilakukan menjadikan prosedur Move bertujuan untuk menciptakan 4 (empat) array sementara, yakni FreqPosArray berukuran jumlah bilangan positif (NOP), FreqNegArray berukuran jumlah bilangan negatif (NON), PosArray berukuran nilai maksimum positif tambah 1 (satu), dan NegArray berukuran absolut dari nilai minimum negatif tambah 1 (satu), kemudian menginisialisasi PosArray, NegArray, FreqPosArray dan FreqNegArray dengan nilai minimum negatif dikurang 1 (satu) untuk yang menunjukkan indeks yang akan dilewati di fase berikutnya. Kemudian prosedur ini mendistribusikan elemen dari array masukan kepada keempat array tersebut, elemen-elemen positif disimpan dalam PosArray menggunakan elemen itu sendiri sebagai indeks, elemen-elemen negatif disimpan dalam NegArray menggunakan nilai absolut dari elemen itu sendiri sebagai indeks, elemen-elemen positif yang sering muncul disimpan dalam FreqPosArray dan elemen-elemen negatif yang sering muncul disimpan dalam FreqNegArray.
dengan batas nilai maksimum, dan perulangan untuk menginisialisasi NegArray dimulai dari 0 dengan step ditambah 1 (satu) hingga batas absolut nilai minimum,
maka pada pengembangan algoritma SMS yang dilakukan penulis jumlah perulangan tersebut diminimalkan, dimana untuk menginisialisasi PosArray dimulai dari nilai minimum positif dengan step ditambah 1 (satu) sampai dengan batas nilai maksimum positif, dan perulangan untuk menginisialisasi NegArray dimulai dari absolut nilai maksimum negatif dengan step ditambahi 1 (satu) hingga batas absolut nilai minimum negatif.
FreqPosArray dan FreqNegArray merupakan array penyederhanaan dari FreqArray pada algoritma SMS sebelumnya, jika pada algoritma SMS sebelumnya seluruh elemen yang muncul lebih dari 1 (satu) kali (sering muncul) baik elemen positif maupun negatif disimpan dalam FreqArray, maka pada pengembangan algoritma SMS yang dilakukan penulis, elemen negatif yang sering muncul disimpan dalam FreqNegArray dengan menggunakan variabel j sebagai indeks dimulai dari nol dan seterusnya bertambah satu, dan elemen positif yang sering muncul disimpan dalam FreqPosArray dengan menggunakan variabel i sebagai indeks, dimulai dari nol dan seterusnya bertambah satu. Hal ini bertujuan nantinya untuk meminimalkan perulangan yang terjadi pada prosedur Sort. Untuk mencapai berbagai tujuan pengembangan diatas, pseudocode prosedur Move dikembangkan menjadi sebagai berikut:
Prosedur Move(array, size, NOP, NON, maxpos, minpos, maxneg, minneg)
var b,c,d,i,j (1)
i:=0 (2)
j:=0 (3)
create a new array: FreqPosArray[NOP] and initialize by the value (minneg-1) (4) create a new array: FreqNegArray[NON] and initialize by the value (minneg-1) (5)
if NOP > 0 then (6)
create a new array:PosArray[maxpos+1] (7)
for b:=minpos to maxpos do (8)
PosArray(b):= minneg-1 (9)
end for (10)
if NON>0 then (12)
create a new array: NegArray[|minneg|+1] (13)
for c:= |maxneg| to |minneg| do (14)
Sort (array, NegArray, PosArray, FreqPosArray, FreqNegArray, NON, NOP,
maxpos, minpos, maxneg, minneg, i, j) (35)
Akhir prosedur Move
3.2.3. Pengembangan prosedur sort
berisi nilai nilai minimum dikurang 1 (satu). Pada prosedur Sort algoritma SMS sebelumnya, perulangan untuk penyalinan elemen-elemen negatif dari NegArray
dimulai dari nilai absolut dari elemen minimum negatif dikurang 1 (satu) sampai batas 0 (nol) dan perulangan untuk penyalinan elemen-elemen positif dari PosArray dimulai dari 0 (nol) ditambah 1 (satu) sampai batas nilai maksimum. Kemudian penulis melakukan pengembangan untuk meminimalkan perulangan tersebut dengan cara perulangan untuk penyalinan elemen-elemen negatif dari NegArray dimulai dari nilai absolut elemen minimum negatif dikurang 1 (satu) sampai batas nilai absolut dari elemen maksimum negatif dan perulangan untuk penyalinan elemen-elemen positif dari PosArray dimulai dari nilai minimum positif ditambah 1 (satu) sampai batas nilai maksimum positif. Penyalinan dilakukan pada array input asli dengan menimpa nilai-nilai asli dengan nilai-nilai-nilai-nilai yang telah diurutkan.
Pada prosedur Sort algoritma SMS sebelumnya, setelah menyalin setiap elemen dari NegArray dan PosArray ke array yang asli, kemudian dilanjutkan prosedur pencarian FreqArray dan menyalin semua elemen yang sama dengan elemen yang disalin dalam operasi penyalinan terakhir (elemen saat ini), yang mengakibatkan akan dilakukan perulangan sejumlah banyaknya elemen pada FreqArray setiap kali ditemukan elemen yang tidak sama dengan nilai minimum kurang 1 (satu). Pengembangan yang dilakukan penulis pada prosedur Sort ini adalah meminimalkan jumlah perulangan tersebut, dengan cara jika elemen saat ini adalah positif maka pencarian akan dilakukan pada FreqPosArray dan jika elemen saat ini adalah negatif maka pencarian akan dilakukan pada FreqNegArray, banyaknya elemen pada FreqPosArray dan FreqNegArray lebih kecil dari banyaknya elemen pada FreqArray,
karena FreqPosArray dan FreqNegArray adalah penyederhanaan dari FreqArray, dimana FreqPosArray menampung elemen positif dari FreqArray dan FreqNegArray menampung elemen negatif dari FreqArray. Untuk mencapai tujuan-tujuan pengembangan diatas, pseudocode prosedur Sort dikembangkan menjadi sebagai berikut :
Prosedur Sort(array, NegArray, PosArray, FreqPosArray, FreqNegArray, NON, NOP,
maxpos, minpos, maxneg, minneg, i, j)
var index,x,y (1)
if NON > 0 then (3)
for x:= |minneg| downto |maxneg| do (4)
if NegArray(x) ≠ minneg-1 then (5)
array(index):= NegArray(x) (6)
index:= index+1 (7)
for y:= 0 to j do (8)
if FreqNegArray(y)==array(index-1) then (9)
array(index):= FreqNegArray(y) (10)
index:= index+1 (11)
end if (12)
end for (13)
end if (14)
end for (15)
end if (16)
if NOP > 0 then (17)
for x:= minpos to maxpos do (18)
if PosArray(x) ≠ minneg-1 then (19)
array(index):= PosArray(x) (20)
index:= index+1 (21)
for y:= 0 to i do (22)
if FreqPosArray(y)== array(index-1) then (23)
array(index):=FreqPosArray(y) (24)
index:= index+1 (25)
end if (26)
end for (27)
end if (28)
end for (29)
end if (30)
3.3. Proses Analisis
Proses analisis merupakan salah satu bagian terpenting dalam penelitian ini, karena dalam proses analisis ini akan terlihat kompleksitas waktu dan kompleksitas ruang yang dicapai berdasarkan pengembangan yang dilakukan terhadap algoritma SMS, Pada sub bab berikut akan dianalisa kompleksitas ruang dari pengembangan algoritma SMS yang dilakukan penulis dan kompleksitas waktu masing-masing pengembangan prosedur (Scan, Move dan Sort) yang nantinya penggabungan kompleksitas waktu ketiga prosedur tersebut akan menghasilkan kompleksitas waktu keseluruhan dari pengembangan yang dilakukan terhadap algortima SMS.
3.3.1. Analisis kompleksitas waktu pengembangan prosedur scan
Tujuan dari pengembangan prosedur scan adalah untuk mendapatkan nilai maksimum positif, nilai minimum positif, nilai maksimum negatif, nilai minimum negatif, jumlah
elemen positif, dan jumlah elemen negatif dari array masukan. Hal ini memerlukan pengenalan array dimana setiap elemen harus dikunjungi 1 (satu) kali. Untuk perulangan (baris 9-27 prosedur scan) memerlukan kompleksitas waktu O(n), sehingga dapat dinyatakan untuk pengembangan yang dilakukan terhadap prosedur Scan, kompleksitas waktu tidak berubah.
3.3.2. Analisis kompleksitas waktu pengembangan prosedur move
Jika semua elemen array adalah bilangan positif dan tidak ada yang negatif, maka untuk perulangan (baris 8-10 dari pengembangan prosedur move) membutuhkan kompleksitas waktu O(maxpos - minpos) untuk menginisialisasi PosArray, dan untuk perulangan (baris 18-34 dari pengembangan prosedur move) membutuhkan kompleksitas waktu O(n). Berdasarkan penjelasan diatas, jika seluruh elemen array masukan merupakan bilangan positif, kompleksitas waktu keseluruhan prosedur move
menginisialisasi NegArray, dan untuk perulangan (baris 18-34 dari pengembangan prosedur move) membutuhkan kompleksitas waktu O(n). Dalam hal ini berarti,
kompleksitas waktu keseluruhan pengembangan prosedur move jika seluruh elemen array masukan merupakan bilangan negatif adalah O(n + |minneg| - |maxneg|). Dapat dikatakan bahwa dalam kasus rata-rata dan terburuk, jika terdapat elemen positif dan negatif dalam array masukan, maka kompleksitas waktu keseluruhan pengembangan prosedur move adalah O(n + (maxpos – minpos) + (|minneg| - |maxneg|)).
Prosedur move pada algoritma SMS sebelumnya untuk kasus rata-rata dan terburuk membutuhkan kompleksitas waktu O(n + max + |min|)), dan setelah dilakukan pengembangan pada penelitian ini, kompleksitas waktu prosedur move untuk kasus rata-rata dan terburuk menjadi lebih efisien.
3.3.3. Analisis kompleksitas waktu pengembangan prosedur sort
Jika semua elemen array masukan adalah bilangan positif dan berbeda, maka
perulangan (baris 18-29 dari pengembangan prosedur sort) membutuhkan kompleksitas waktu O(maxpos - minpos), karena perulangan (baris 22-27 dari pengembangan prosedur sort) membutuhkan kompleksitas waktu O(1) dalam kasus ini. Jika semua elemen array masukan adalah bilangan negatif dan setiap elemen berbeda, maka untuk perulangan (baris 4-15 dari pengembangan prosedur sort) membutuhkan kompleksitas waktu O(|minneg| - |maxneg|), karena perulangan (baris 8-13 dari prosedur sort) membutuhkan kompleksitas waktu O(1) dalam kasus ini. Dapat dikatakan, kasus-kasus terbaik, rata-rata, dan terburuk dari prosedur sort memiliki O(fpos * (maxpos – minpos)) + O(fneg * (|minneg| - |maxneg|)), di mana fpos adalah jumlah elemen positif yang sama dan fneg adalah jumlah elemen negatif yang sama. Dengan kata lain, kompleksitas waktu pengembangan prosedur sort adalah O((fpos * (maxpos – minpos)) + (fneg * (|minneg| - |maxneg|))).
Prosedur sort pada algoritma SMS sebelumnya membutuhkan kompleksitas waktu O(f (max + |min|)), dimana f adalah jumlah elemen yang sering muncul (positif dan negatif) dan setelah dilakukan pengembangan pada penelitian ini, kompleksitas waktu pengembangan prosedur sort menjadi lebih efisien.
waktu O(n + (maxpos – minpos) + (|minneg| - |maxneg|)), dan pengembangan prosedur sort memerlukan kompleksitas waktu O((fpos * (maxpos – minpos)) + (fneg
* (|minneg| - |maxneg|))). Jika dianggap distribusi data adalah normal, frekuensi elemen harus sedikit, dan karena sebagian besar aplikasi nyata memiliki n jauh lebih besar dari nilai maxpos, minpos, maxneg dan |minneg|, dapat dipertimbangkan maxpos, minpos, maxneg dan minneg sebagai konstanta dan menghilangkannya, sehingga kompleksitas waktu keseluruhan dari pengembangan algoritma SMS dalam kasus rata-rata dan terburuk adalah O(n + (fpos * (maxpos – minpos)) + (fneg * (|minneg| - |maxneg|))), di mana fpos adalah jumlah elemen positif yang sama dan fneg adalah jumlah elemen negatif yang sama.
Jika pada algoritma SMS sebelumnya kompleksitas waktu yang dibutuhkan untuk kasus rata-rata dan terburuk adalah O(n + f * (max + | min |)) dan setelah dilakukan pengembangan pada penelitian ini kompleksitas waktu yang dibutuhkan untuk kasus rata-rata dan terburuk adalah O(n + (fpos * (maxpos – minpos)) + (fneg * (|minneg| - |maxneg|))), maka dapat dinyatakan kompleksitas waktu yang dibutuhkan menjadi lebih efisien setelah dilakukan pengembangan algoritma SMS pada penelitian ini.
3.3.4. Analisis kompleksitas ruang memori pengembangan algoritma SMS
3.4. Perancangan Program
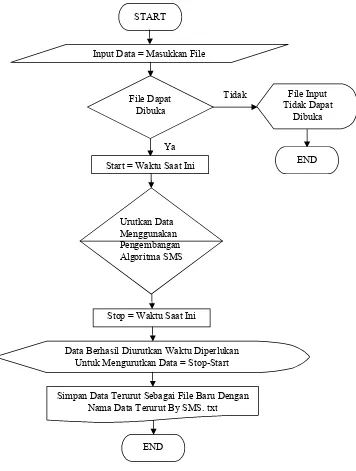
Perancangan program pada penelitian ini menggunakan dua algoritma yaitu algoritma SMS dan pengembangan algoritma SMS yang dilakukan penulis, dimana nantinya akan dilakukan pengurutan terhadap file data-data integer yang diinput menggunakan kedua algoritma tersebut, dimana masing-masing algoritma nantinya akan menghasilkan file baru yang merupakan file yang berisi data-data integer yang diinput dalam keadaan sudah terurut dan akan terlihat besaran waktu yang di butuhkan masing-masing algoritma tersebut untuk mengurutkan data yang sama, sehingga terlihat bahwasanya pengembangan yang dilakukan penulis terhadap algoritma SMS mampu meningkatkan efisiensi kompleksitas waktu algoritma SMS dalam kasus rata-rata dan terburuk dalam melakukan pengurutan data. Untuk lebih jelasnya, perancangan program yang dimaksud dapat dilihat pada gambar 3.1 dan 3.2 berikut.
START
Input Data = Masukkan File
Urutkan Data Menggunakan Algoritma SMS Start = Waktu Saat Ini
File Dapat Dibuka
Tidak
Ya
File Input Tidak Dapat
Dibuka
END
Stop = Waktu Saat Ini
A
Gambar 3.1. Flowchart Perancangan Program Algoritma SMS
Gambar 3.2. Flowchart Perancangan Program Pengembangan Algoritma SMS Simpan Data Terurut Sebagai File Baru Dengan
Nama Data Terurut By SMS. txt
END A
Simpan Data Terurut Sebagai File Baru Dengan Nama Data Terurut By SMS. txt
END START
Input Data = Masukkan File
File Dapat Dibuka
Tidak
Ya
File Input Tidak Dapat
Dibuka
END
Urutkan Data Menggunakan Pengembangan Algoritma SMS Start = Waktu Saat Ini
Stop = Waktu Saat Ini
3.5. Instrumen Penelitian
Adapun instrumen penelitian yang digunakan adalah sebagai berikut :
(a) Data bilangan integer yang digenerate secara acak dan disimpan dalam format txt, yang terdiri dari 50.000 (lima puluh ribu), dan 100.000 (seratus ribu) data integer, dimana masing masing jumlah data tersebut akan diuji untuk 20 set data
(b) Hardware (Processor : Intel(R) Core(TM) 2 Duo T5870 @2,00 GHz, Memory : 1016MB, Hardisk : 320 GB, etc)
BAB IV
HASIL DAN PEMBAHASAN
4.1. Pengantar
Pada bab ini akan dijelaskan mengenai hasil pengujian yang dilakukan penulis dalam melakukan pengurutan data integer yang berjumlah 50.000 (lima puluh ribu) dan 100.000 (seratus ribu) data, dimana untuk masing-masing jumlah data tersebut diuji untuk 20 set data. Data tersebut akan diurutkan menggunakan dua program yang
penulis bangun menggunakan Software (Bloodshed Dev-C++ versi 4.9.9.2 GNU General Public License), dimana kedua program tersebut dibangun masing-masing
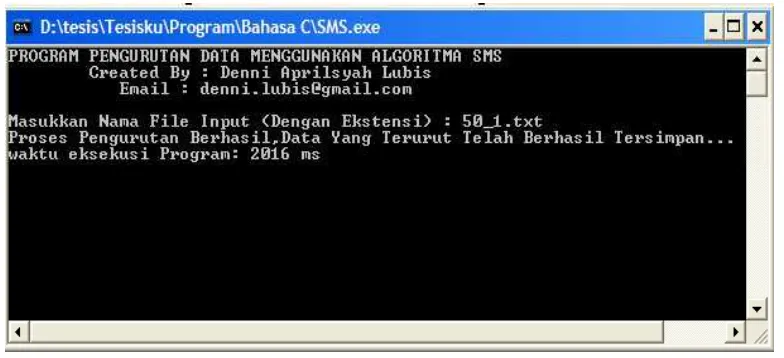
menggunakan algoritma SMS dan pengembangan algoritma SMS yang dilakukan penulis. Untuk mengukur waktu eksekusi kedua algoritma tersebut digunakan fungsi clock () bawaan bahasa C yang diimplementasikan di dalam masing-masing program tersebut. Berdasarkan hasil hasil pengujian tersebut nantinya dapat ditarik kesimpulan, apakah pengembangan algoritma SMS yang dilakukan penulis mampu meningkatkan efisiensi kompleksitas waktu yang lebih baik dibandingkan algoritma SMS sebelumnya dalam melakukan pengurutan data. Pada gambar 4.1 dan 4.2 akan terlihat tampilan output program yang penulis bangun tersebut.
Gambar 4.2. Tampilan Output Program Pengurutan Data Menggunakan Pengembangan Algoritma SMS
Untuk menggunakan kedua program tersebut, masukkan nama file yang berekstensi txt yang berisi data integer yang akan diurutkan diakhiri penekanan tombol enter. File yang dimaksud harus berada dalam 1 folder dengan program tersebut. Selanjutnya program akan melakukan eksekusi terhadap file yang diinput selama rentang waktu tertentu, setelah selesai melakukan proses pengurutan terhadap data yang diinput, kemudian program akan menampilkan pesan hasil eksekusi dan waktu yang dibutuhkan untuk proses eksekusi. Hasil eksekusi menggunakan algoritma SMS disimpan dalam bentuk file dengan nama file adalah Data Terurut By SMS (berekstensi txt) dan hasil eksekusi menggunakan algoritma pengembangan SMS yang dilakukan penulis disimpan dalam juga bentuk file dengan nama file adalah Data Terurut By SMS Plus (juga berekstensi txt). Pada gambar 4.3 dan 4.4 berikut akan terlihat contoh cara penggunaan kedua program tersebut.
Gambar 4.4. Contoh Tampilan Hasil Output Program Untuk Pengembangan Algoritma SMS
4.2. Data Uji
Data integer yang diuji pada penelitian ini seperti dijelaskan pada bab-bab sebelumnya bersumber dari hasil generate secara acak menggunakan program yang dibangun menggunakan Software (Bloodshed Dev-C++ versi 4.9.9.2 GNU General Public License). Fungsi rand() bawaan bahasa C digunakan untuk mengenerate bilangan acak
tersebut. Pada sub bab ini dijelaskan karakteristik 50.000 (lima puluh ribu) dan 100.000 (seratus ribu) data integer untuk 20 set data yang yang akan diuji. Pada tabel 4.1 dan 4.2 berikut akan terlihat karakteristik masing-masing set data tersebut.
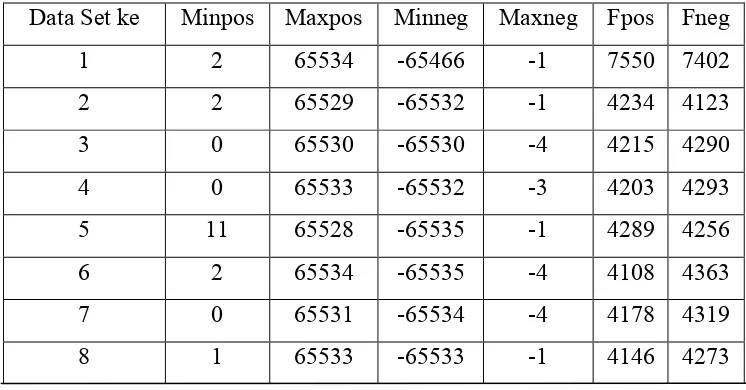
Tabel 4.1. Karakteristik 20 Set Data Integer Untuk 50.000 (lima puluh ribu) Data/Set
Data Set ke Minpos Maxpos Minneg Maxneg Fpos Fneg
1 2 65534 -65466 -1 7550 7402
2 2 65529 -65532 -1 4234 4123
3 0 65530 -65530 -4 4215 4290
4 0 65533 -65532 -3 4203 4293
5 11 65528 -65535 -1 4289 4256
6 2 65534 -65535 -4 4108 4363
7 0 65531 -65534 -4 4178 4319
Lanjutan Tabel 4.1
9 1 65534 -65534 -2 4211 4169
10 2 65533 -65529 -2 4226 4235
11 0 65528 -65535 -1 4216 4120
12 7 65534 -65533 -6 4243 4289
13 2 65529 -65535 -1 4171 4179
14 2 65534 -65535 -1 4215 4216
15 7 65532 -65526 -1 4231 4242
16 2 65533 -65532 -3 4243 4185
17 6 65534 -65534 -4 4217 4208
18 0 65534 -65534 -2 4290 4173
19 0 65530 -65532 -2 4252 4169
20 0 65530 -65535 -4 4164 4224
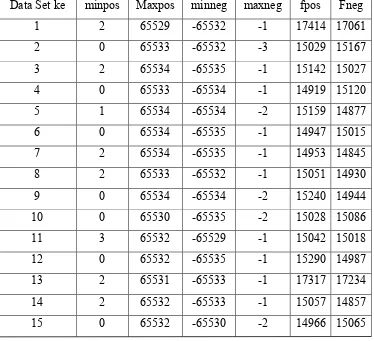
Tabel 4.2. Karakteristik 20 Set Data Integer Untuk 100.000 (seratus ribu) Data/Set
Data Set ke minpos Maxpos minneg maxneg fpos Fneg
1 2 65529 -65532 -1 17414 17061
2 0 65533 -65532 -3 15029 15167
3 2 65534 -65535 -1 15142 15027
4 0 65533 -65534 -1 14919 15120
5 1 65534 -65534 -2 15159 14877
6 0 65534 -65535 -1 14947 15015
7 2 65534 -65535 -1 14953 14845
8 2 65533 -65532 -1 15051 14930
9 0 65534 -65534 -2 15240 14944
10 0 65530 -65535 -2 15028 15086
11 3 65532 -65529 -1 15042 15018
12 0 65532 -65535 -1 15290 14987
13 2 65531 -65533 -1 17317 17234
14 2 65532 -65533 -1 15057 14857
Lanjutan Tabel 4.2
16 0 65530 -65535 -1 15054 14970
17 0 65534 -65534 -2 15143 14978
18 1 65534 -65534 -2 15101 14914
19 0 65534 -65535 -1 14988 14918
20 1 65534 -65535 -1 15184 15018
4.3. Hasil Pengujian
Seluruh data yang dijelaskan pada sub bab sebelumnya yang diuji dalam penelitian ini akan diurutkan menggunakan program yang dibangun oleh penulis, dimana program
tersebut dibangun berdasarkan pseudocode algoritma SMS dan pseudocode pengembangan algoritma SMS yang dilakukan penulis, sehingga kompleksitas waktu yang diperlukan masing-masing algoritma tersebut dalam melakukan pengurutan data untuk masing-masing jumlah data yang dimaksud dapat terlihat hasilnya. Pada sub bab berikut ini akan terlihat kompleksitas waktu berdasarkan hasil pengujian yang dilakukan.
4.3.1. Hasil pengujian untuk 50.000 (lima puluh ribu) data
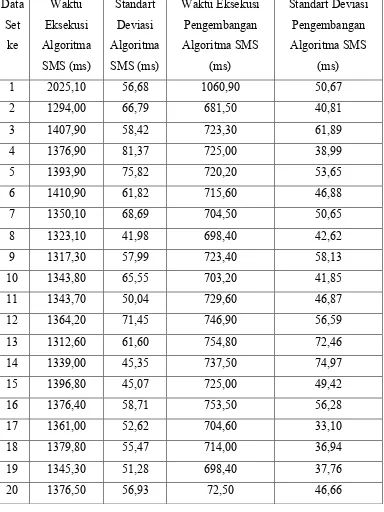
Tabel 4.3. Hasil Pengujian Untuk 50.000 (lima puluh ribu) Data
4.3.2. Hasil pengujian untuk 100.000 (seratus ribu) data
setiap set data dilakukan pengujian sebanyak 10 (sepuluh) kali. Pada tabel 4.4 berikut terlihat hasil pengujian tersebut.
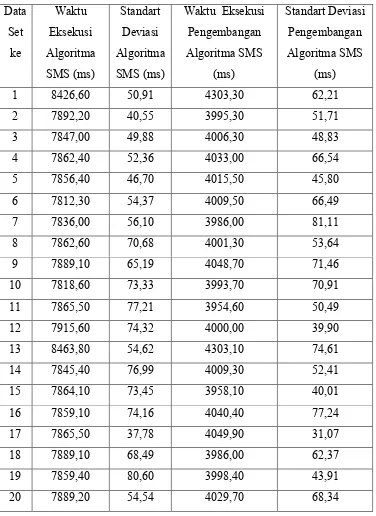
Tabel 4.4. Hasil Pengujian Untuk 100.000 (seratus ribu) Data
4.4. Pembahasan
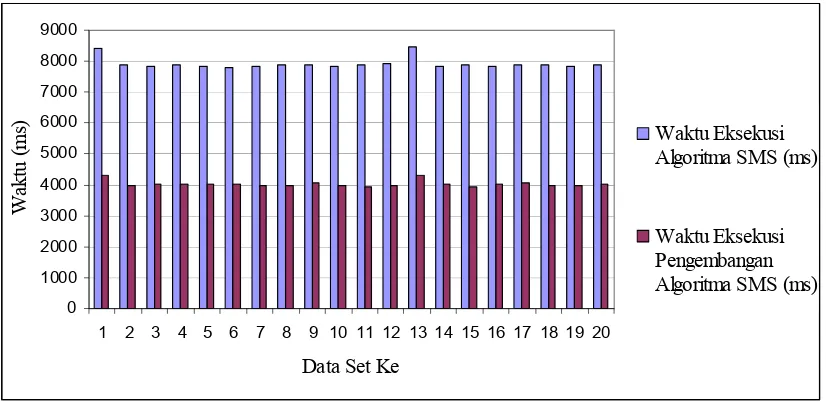
Berdasarkan hasil pengujian pada sub bab sebelumnya yang dilakukan terhadap 50.000 (lima puluh ribu) dan 100.000 (seratus ribu) data integer dimana untuk masing-masing jumlah data tersebut diuji sebanyak 20 set data, maka dapat digambarkan grafik dari hasil pengujian tersebut seperti pada gambar 4.5 dan 4.6 berikut.
Gambar 4.5. Grafik Hasil Pengujian Untuk 50.000 (lima puluh ribu) Data
4.4.1. Pembahasan hasil pengujian untuk 50.000 (lima puluh ribu) data
Berdasarkan gambar 4.5 terlihat bahwasanya untuk pengujian dengan jumlah data sebanyak 50.000 (lima puluh ribu) data, waktu eksekusi yang dibutuhkan pengembangan algoritma SMS yang dilakukan penulis dalam mengurutkan data lebih efisien dibandingkan dengan algoritma SMS sebelumnya. Namun khusus untuk set data ke-1, terlihat perbedaan waktu eksekusi yang sangat signifikan dengan set data yang lainnya. Jika diperhatikan karakteristik data set ke-1 tersebut pada tabel 4.1, perbedaan karakteristik yang sangat signifikan antara data set ke-1 dengan data set yang lainnya adalah pada pada jumlah bilangan positif yang sering muncul (fpos) dan jumlah bilangan negatif yang sering muncul (fneg). Dimana untuk set data ke-1 tersebut nilai fpos adalah sebesar 7.550 dan nilai fneg sebesar 7.402, sedangkan untuk sebaran data yang lain, nilai fpos dan fneg lebih kecil dari 4.300
4.4.2. Pembahasan hasil pengujian untuk 100.000 (seratus ribu) data
Berdasarkan grafik pada gambar 4.6 terlihat bahwasanya untuk pengujian dengan jumlah data sebanyak 100.000 (seratus ribu) data, waktu eksekusi yang dibutuhkan pengembangan algoritma SMS yang dilakukan penulis dalam mengurutkan data lebih efisien dibandingkan dengan algoritma SMS sebelumnya. Namun khusus untuk set data ke-1 dan set data ke-13, terlihat perbedaan waktu eksekusi yang cukup signifikan dengan set data yang lainnya. Jika diperhatikan karakteristik data set ke-1 dan ke-13 tersebut pada tabel 4.2, perbedaan karakteristik yang cukup signifikan antara data set ke-1 dan data set ke-13 dengan data set yang lainnya adalah pada pada jumlah fpos
dan fneg. Dimana untuk set data ke-1 nilai fpos adalah sebesar 17.414 dan nilai fneg sebesar 17.061, untuk set data ke-13 nilai fpos adalah sebesar 17.317 dan nilai fneg sebesar 17.234, sedangkan untuk sebaran data yang lain, nilai fpos dan fneg lebih kecil dari 15.200
BAB V
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Kesimpulan yang dapat diambil dari penelitian ini adalah sebagai berikut :
1. Pengembangan algoritma SMS yang dilakukan penulis dalam penelitian ini bertujuan untuk meningkatkan efisiensi kompleksitas waktu algoritma SMS, yakni dengan cara meminimalkan jumlah iterasi yang terjadi pada algoritma SMS (pada
prosedur Move dan prosedur Sort).
2. Algoritma SMS dan pengembangan algoritma SMS yang dilakukan penulis dalam
kasus terbaik sama-sama membutuhkan kompleksitas waktu sebesar O(n) untuk mengurutkan n buah elemen.
3. Dalam kasus rata-rata dan kasus terburuk, pengembangan algoritma SMS yang dilakukan penulis membutuhkan kompoleksitas waktu lebih efisien dibandingkan algoritma SMS untuk mengurutkan n buah elemen, dimana dalam kasus rata-rata dan kasus terburuk algoritma SMS membutuhkan kompleksitas waktu sebesar O(n + f * (max + |min|)), dengan f adalah jumlah elemen yang sering muncul, sementara pada pengembangan algoritma SMS yang dilakukan penulis, untuk kasus rata-rata dan kasus terburuk tersebut algoritma membutuhkan kompleksitas waktu sebesar O(n + (fpos * (maxpos-minpos)) + (fneg * (|minneg| - |maxneg|))), dengan fpos adalah jumlah elemen positif yang sering muncul dan fneg adalah jumlah elemen negatif yang sering muncul.
5.2. Saran
DAFTAR KEPUSTAKAAN
Alnihoud, J. & Mansi, R. Januari 2010. An Enhancement of Major Sorting Algorithms. The International Arab Journal of Information Technology. vol. 7. No. 1.
Cormen, T., Leiserson, C., Rivest R. & Stein, C. 2001. Introduction to Algorithms. McGraw Hill.
Dean, C. 2006. A Simple Expected Running Time Analysis for Randomized Divide and Conquer Algorithms. Computer Journal of Discrete Applied Mathematics. vol. 154. no. 1. pp. 1-5.
Deitel, H. & Deitel, P. 2001. C# How to Program, Prentice Hall.
Deependra, Kr. Dwivedi. 2011. Comparison Analysis of Best Sorting Algorithms. VSRD-JCSIT. vol. 1 (4). Pp. 261-267.
Friend, E. 1956. Sorting on Electronic Computer Systems. Computer Journal of ACM. pp. 134-168.
Hoare, R. 1962. Quicksort. The Computer Journal. pp. 10-15.
Kruse, R. & Ryba, A. 1999. Data Structures and Program Design in C++, Prentice Hall.
Knuth, E. 1973.The Art of Computer Programming Second Edition Volume I. Addison-Wesley.
Knuth, E. 1998. The Art of Computer Programming Sorting and Searching, 2nd edition. Addison-Wesley.
Levitin, A. 2007. Introduction to the Design and Analysis of Algorithms. Addison Wesley.
Mansi, R. April 2010. Enhanced Quicksort Algorithm. The International Arab Journal of Information Technology. vol. 7 no. 2.
Moller, F. 2001. Analysis of Quicksort, McGraw Hill.
LAMPIRAN LISTING PROGRAM ALGORITMA SMS
int data_bil[100000], PosArray[100000], NegArray[100000]; int FreqArray[100000],size,NOP,NON;
int maks,minim,a,b,c,d,i,x,y,indeks,angka; char kalimat[8],data_text[7],nama[20]; double start,stop; printf("Masukkan Nama File Input (Dengan Ekstensi) : ");
{
printf("Proses Pengurutan Berhasil,Data Yang Terurut Telah Berhasil Tersimpan...\n");
printf("waktu eksekusi Program: %.0f ms", (stop-start)); getch();
LAMPIRAN LISTING PROGRAM PENGEMBANGAN ALGORITMA SMS
int data_bil[100000], PosArray[100000], NegArray[100000]; int FreqPosArray[100000],FreqNegArray[100000],size,NOP,NON; printf("Masukkan Nama File Input (Dengan Ekstensi) : ");
maxpos=0;
indeks++;
if ((qf = fopen("Data Terurut By SMS Plus.txt","w")) == NULL) {
printf("Proses Pengurutan Berhasil,Data Yang Terurut Telah Berhasil Tersimpan...\n");
printf("Data Tidak Mencukupi Untuk di Urutkan,Array Hanya Berisi 1 (Satu) Data...\n");
getch(); }