MENENTUKAN BANYAKNYA GEROMBOL POPULASI
KUDSIATI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa tesis Pengkajian Keakuratan TwoStep Cluster
dalam Menentukan Banyaknya Gerombol Populasi adalah karya saya sendiri dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka dibagian akhir tesis ini.
Bogor, September 2006
Kudsiati
KUDSIATI. Pengkajian Keakuratan TwoStep Cluster dalam Menentukan Banyaknya Gerombol Populasi. Dibimbing oleh BAMBANG JUANDA dan ITASIA DINA SULVIANTI.
Algoritma analisis gerombol seperti metode penggerombolan hirarki dan k-rataan tidak dapat menangani peubah (atribut) campuran kategorik dan numerik, serta penentuan banyaknya gerombol. Metode TwoStep Cluster (Chiu et al. 2001) dapat menangani peubah campuran kategorik dan numerik dan penentuan banyaknya gerombol secara objektif (otomatis).
Penelitian ini mengevaluasi keakuratan TwoStep Cluster dalam menghasilkan banyaknya gerombol dan ukuran gerombol yang sama dengan populasi yang sebenarnya. Perbandingan struktur gerombol dalam populasi hipotetik dengan hasil penduga banyaknya gerombol yang dihasilkan dari algoritma TwoStep Cluster dapat diperoleh dengan studi simulasi.
MENENTUKAN BANYAKNYA GEROMBOL POPULASI
KUDSIATI
Tesis
sebagai salah satu syarat memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Nama : Kudsiati NIM : G151020151
Disetujui Komisi Pembimbing
Dr. Ir. Bambang Juanda, M.S. Ir. Itasia Dina Sulvianti, M.Si. Ketua Anggota
Diketahui
Ketua Program Studi Statistika Dekan Sekolah Pascasarjana
Dr. Ir. Aji Hamim Wigena, M.Sc. Prof. Dr. Ir. Khairil A. Notodiputro, M.S.
Puji dan syukur penulis panjatkan kepada Allah SWT atas rahmat dan karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Judul yang dipilih dalam penelitian ini adalah Pengkajian Keakuratan TwoStep Cluster dalam Menentukan Banyaknya Gerombol Populasi.
Terima kasih penulis sampaikan kepada berbagai pihak yang telah membantu penyelesaian karya ilmiah ini, antara lain :
1. Bapak Dr. Ir. Bambang Juanda, M.S. dan Ibu Ir. Itasia Dina Sulvianti, M.Si. atas segala bimbingan dan arahannya.
2. Suami Satrio Wiseno serta anak tercinta Haikal Fadlurrahman, atas doa dan dukungan yang telah memperlancar selesainya karya ilmiah ini.
3. Seluruh Staf Departemen Statistika IPB, atas kesempatan dan ilmu yang diberikan selama penulis menuntut ilmu di Departemen Statistika IPB.
4. Rekan-rekan di GRP, terima kasih atas bantuan yang telah diberikan kepada penulis.
Akhirnya sebagaimana manusia yang tidak pernah luput dari kesalahan, penulis mohon maaf apabila ada kesalahan dalam penulisan ini dan semoga karya ilmiah ini dapat bermanfaat.
Bogor, September 2006
Kudsiati
Penulis dilahirkan di Jakarta pada tanggal 26 Agustus 1964, anak kedelapan dari 11 bersaudara, dari ayah H.Usman (Alm) dan ibu Hj. Tarbiah.
Tahun 1987 penulis lulus dari program sarjana IPB Jurusan Statistika. Pada tahun 2002 penulis diterima pada Program Pascasarjana IPB Program Studi Statistika. Pada tahun 1988 s/d 2000 penulis bekerja di Bank Duta dan sejak bulan Januari 2001 sampai saat ini bekerja pada PT. Grup Riset Potensial.
DAFTAR ISI
Halaman
DAFTAR TABEL... viiii
DAFTAR GAMBAR ...ix
PENDAHULUAN...1
Latar Belakang ...1
Tujuan Penelitian...2
TINJAUAN PUSTAKA...4
Metode Penggerombolan Berhirarki...5
Metode Penggerombolan K-rataan...6
TwoStep Cluster...7
1. Penggerombolan Awal (Pre-Clustering) ...7
2. Penggerombolan Individu Objek ( Step 2 Cluster)...11
3. Konsep Jarak ...11
4. Penentuan Banyaknya Gerombol...12
5. Langkah Penetapan Keanggotaan Gerombol dan Penanganan Pencilan...13
BAHAN DAN METODE ...15
Bahan...15
Model Populasi Hipotetik ...15
Model Komposisi Peubah yang Dianalisis ...16
Data Hipotetik ...17
Metode ...19
Metode Pembangkitan Data ...19
Prosedur Pembangkitan Data ...23
Opsi Penanganan Pencilan dan Tanpa Penanganan Pencilan ...24
Metode Analisis ...25
Halaman
HASIL DAN PEMBAHASAN ...28
Kasus Data Homogen...28
Kasus Data Berasal dari Populasi yang Terbedakan...30
Kasus Populasi yang Saling Tumpang Tindih ...34
Perbandingan dengan Metode Hirarkidan K-rataan...39
SIMPULAN DAN SARAN ...45
Simpulan...45
Saran...45
DAFTAR PUSTAKA ...47
LAMPIRAN ...50
Lampiran 1. Tahapan analisis TwoStep Cluster dengan SPSS...51
DAFTAR TABEL
Halaman
Tabel 1. Kombinasi parameter model data hipotetik yang akan dibangkitkan--- 18 Tabel 2. Persentase ketepatan banyaknya gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya pada kasus
data homogen --- --- 29 Tabel 3. Persentase salah klasifikasi gerombol hasil olahan algoritma TwoStep
Cluster dengan gerombol populasi sebenarnya pada kasus data homogen --- --- -- 30 Tabel 4. Persentase ketepatan banyaknya gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang terbedakan --- 32 Tabell5. Persentase kesesuaian ukuran gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang terbedakan --- 33 Tabel 6. Persentase salah klasifikasi gerombol hasil olahan algoritma TwoStep
Cluster dengan gerombol populasi sebenarnya, pada kasus data
berasal dari populasi yang terbedakan --- 35 Tabel 7. Persentase ketepatan ukuran gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus
data berasal dari populasi yang tumpang tindih --- 36 Tabel 8. Persentase kesesuaian ukuran gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus
data berasal dari populasi yang tumpang tindih --- 37 Tabel 9. Persentase salah klasifikasi gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus
Halaman
Tabel 10. Perbandingan metode penggerombolan hirarki, k-rataan, dan
TwoStep Cluster--- 40
Tabel 11. Perbandingan persentase kesesuaian sebaran ukuran gerombol hasil olahan metode hirarki, k-rataan, dan TwoStep Cluster (hasil 100 kali simulasi)--- 43
Tabel 12. Perbandingan persentase salah klasifikasi individu pada populasi dengan yang dihasilkan oleh metode hirarki, k-rataan, dan TwoStep Cluster (hasil 100 kali simulasi) --- 44
DAFTAR GAMBAR
Halaman Gambar 1. Diagram pembentukan CF tree pada TwoStep Cluster --- 10Gambar 2. Sebaran Populasi Tunggal, N (0,1) --- 19
Gambar 3. Sebaran model 2 populasi dengan pemisahan tidak tegas--- 20
Gambar 4. Sebaran model 2 populasi dengan pemisahan yang tegas--- 20
Gambar 5. Sebaran model 3 populasi dengan pemisahan yang tegas--- 21
PENDAHULUAN
Latar Belakang
Dalam riset pemasaran, segmentasi pelanggan merupakan topik yang paling banyak diterapkan. Pada dasarnya segmentasi pelanggan adalah pengelompokan pelanggan baik atas dasar karakteristik individu (sosio-demografik), gaya hidup (life style), psikografik, atau kebutuhan pelanggan (Kotler 2000 serta Kotabe & Helsen 2001). Segmentasi pelanggan merupakan hal yang sangat penting untuk merancang berbagai strategi pemasaran (Porter 1980 & Aaker 2001), karena pada situasi pasar yang kompetitif, jika mengambil pasar yang umum (mass market) maka akan sulit bersaing atau menjadi tidak fokus, sehingga biaya pemasaran yang dikeluarkan menjadi mahal.
Selama ini khususnya di Indonesia, alat analisis statistika untuk segmentasi pelanggan yang biasa digunakan adalah analisis gerombol (Kasali 1998 ). Permasalahan utama dalam penerapan analisis gerombol pada data-data riset pemasaran adalah peubah kriteria penggerombolan sebagai dasar segmentasi bersifat kategorik maupun campuran kategorik dan numerik (Aaker & Day 1990), sedangkan algoritma -algoritma analisis gerombol konvensional seperti metode penggerombolan berhirarki (aglomeratif) dikembangkan untuk peubah-peubah numerik berskala interval atau ordinal, walaupun telah tersedia pilihan berbagai konsep jarak untuk peubah biner seperti konsep jarak Russel & Rao, Simple Matching, Jaccard, Dice, Sokal & Sneeath dan sebagainya (Dillon and Goldstein, 1984). Sementara itu, metode k-rataan (k-means) mensyaratkan peubah kriteria penggerombolan berskala interval.
dianalisis, sehingga hasil segmentasi sangat tergantung dari pengetahuan, pengalaman, serta subyektivitas peneliti (Garson, 2006).
Untuk mengatasi kedua permasalahan di atas, SPSS telah me ngembangkan algoritma penggerombolan yang memungkinkan untuk mengolah data campuran kategorik dan kontinu (kuantitatif), serta kriteria statistik yang memungkinkan penentuan banyaknya gerombol secara objektif. Algoritma tersebut sudah mulai diimplementasikan pada SPSS versi 11.5 atau yang lebih tinggi dengan nama
TwoStep Cluster (SPSS 2001, 2004). Prosedur ini masih belum banyak digunakan sampai saat ini. Pada algoritma penggerombolan, baik metode berhirarki aglomeratif
maupun metode tak berhirarki (k-rataan) mempunyai beberapa permasalahan yang telah diketahui secara luas (misalnya, Bacher 2000: 223; Everitt et al. 2001: 94-96; Huang 1998: 288), sedangkan TwoStep Cluster dapat menyelesaikan beberapa dari permasalahan yang ditimbulkan pada metode-metode sebelumnya. Lebih tepatnya, atribut tipe campuran dapat ditangani dan banyaknya gerombol dapat ditentukan secara otomatis.
Namun demikian, kemampuan algoritma TwoStep Cluster dalam mengidentifikasi banyaknya gerombol secara akurat dan tingkat salah klasifikasi penggerombolan belum banyak ditelaah oleh para peneliti di Indonesia. Bahkan metode ini belum banyak diterapkan di kalangan peneliti pemasaran di Indonesia.
Tujuan Penelitian
Penelitia n ini bertujuan untuk melakukan evaluasi terhadap keakuratan algoritma TwoStep Cluster dalam mengidentifikasi banyaknya gerombol populasi yang sebenarnya. Secara rinci, penelitian ini bertujuan untuk menjawab hal-hal berikut :
2. Seberapa baik algoritma TwoStep Cluster mampu mengidentifikasi karakteristik gerombol sebenarnya yang terdapat di populasi, pada kasus peubah-peubah yang terlibat semuanya bersifat kategorik.
3. Seberapa baik algoritma TwoStep Cluster mampu mengidentifikasi karakteristik gerombol sebenarnya yang terdapat di populasi, pada kasus peubah-peubah yang terlibat merupakan campuran kategorik dan kontinu.
TINJAUAN PUSTAKA
Analisis gerombol dalam bidang riset pemasaran sering diistilahkan sebagai analisis segmentasi, merupakan alat statistika peubah ganda yang bertujuan untuk mengelompokkan n individu data ke dalam k gerombol, dengan k < n. Individu yang terletak dalam satu gerombol memiliki kemiripan sifat yang lebih besar dibandingkan dengan individu yang terletak dalam gerombol lain (Dillon & Goldstein 1984). Dengan demikian, sasaran analisis gerombol adalah mendapatkan gugus pengelompokkan yang meminimumkan keragaman di dalam gerombol dan sekaligus memaksimumkan keragaman antar gerombol (Garson 2006). Secara umum, metode penggerombolan dapat dibedakan ke dalam 3 kelompok, yaitu (1) metode penggerombolan berhirarki, (2) metode penggerombolan tak-berhirarki, dan (3) penggabungan kedua pendekatan metode penggerombolan, atau dikenal juga sebagai metode hybrid (Putri 2005).
Semakin rumitnya masalah yang dihadapi dalam menggerombolkan gugus data berdimensi besar dan banyaknya individu yang sangat besar, mendorong berkembangnya teknik-teknik penggerombolan baru yang dalam prosesnya dilakukan secara bertahap (pre clustering dan clustering). Metode-metode yang cukup dikenal dikalangan peneliti bidang pemasaran dan data mining diantaranya adalah, TwoStep Cluster (Chiu et al. 2001), Latent Segment Analysis (Vermunt & Magidson 2000; McCutcheon 1999, dan Bernstein et al. 2002), BIRCH (Zhang 1996), CLARANS,
CURE, dan DBscan (Strehl & Gosh 2002), serta Two Stage Clustering
Metode Penggerombolan Berhirarki
Metode penggerombolan berhirarki digunakan apabila banyaknya gerombo l yang akan dibentuk belum diketahui dengan pasti di awal. Menurut Garson (2006), penggerombolan berhirarki cocok untuk ukuran data yang kecil (biasanya<250). Metode penggerombolan berhirarki dapat dibedakan menjadi dua yaitu metode penggabungan (agglomerative) dan metode pemecahan (divisive). Garson (2006) mengistilahkannya sebagai forward dan backward clustering. Pendekatan metode penggabungan berhiraki (agglomerative hierarchical) paling umum digunakan oleh para peneliti.
Metode berhirarki agglomerative dimulai dengan mengasumsikan bahwa setiap objek merupakan satu gerombol, selanjutnya secara bertahap dilakukan penggabungan pada objek-objek yang paling dekat. Proses ini berlanjut sampai semua sub grup bergabung menjadi satu gerombol. Sebaliknya, meto de divisive
diawali dengan asumsi semua objek berada dalam satu gerombol, kemudian objek-objek yang paling jauh dipisah dan membentuk satu gerombol lain. Proses tersebut berlanjut sampai semua objek masing- masing membentuk satu gerombol. Hasil pembentukan gerombol berhirarki beserta jarak penggabungannya dapat digambarkan dalam suatu dendogram.
Secara umum pembentukan dendogram dengan algoritma agglomerative adalah sebagai berikut (Johnson 1967) :
1. Mulai dengan N gerombol yang masing- masing hanya beranggotakan satu individu.
2. Gabungkan dua individu atau sub-gerombol yang memiliki jarak terdekat pada matrik jarak.
3. Hitung kembali jarak antar gerombol yang baru.
Dalam metode penggerombolan berhirarki setiap langkah penggabungan gerombol diikuti dengan perbaikan matrik s jarak. Adenberg (1973), Dillon dan Goldstein (1984), serta Morrison (1990) memaparkan beberapa pilihan metode perbaik an jarak yang dapat digunakan pada langkah (3) di atas, yaitu :
a. Pautan tunggal (single linkage) b. Pautan lengkap (complete linkage)
c. Pautan rataan dalam kelompok (average linkage within the new group) d. Pautan rataan antar kelompok (average linkage between merged group) e. Centroid
f. Median g. Ward
Wijayanti (2002), dengan menggunakan metode simulasi, menunjukkan bahwa metode perbaikan jarak pautan rataan dalam kelompok memberikan nilai salah klasifikasi yang paling rendah diantara metode perbaikan jarak lainnya.
Metode penggerombolan berhirarki memungkinkan untuk digunakan pada gugus peubah kriteria penggerombolan yang semuanya berskala rasio, interval, ordinal, atau biner (Garson 2006). Untuk masing- masing jenis skala terdapat pilihan konsep jarak yang sesuai. Berbagai konsep jarak untuk data biner dibahas pada Digby dan Kempton (1987).
Metode Penggerombolan K-rataan
Titik pusat awal k buah gerombol dipilih secara acak pada pertama kali, selanjutnya dilakukan proses iterasi yang mana pada setiap iterasi dibentuk penggerombolan berdasarkan jarak Euclidian terdekat ke pusat gerombol. Jadi pada setiap iterasi pusat gerombol akan berubah. Proses iterasi akan berhenti bila rata-rata gerombol lebih kecil dari batas perubahan yang ditentukan, atau banyaknya iterasi telah melampaui batasan maksimum (Adenberg 1973). Secara umum, metode k-rataan menghasilkan tepat k gerombol yang memiliki perbedaan keragaman terbesar1). Garson (2006) mengemukakan bahwa metode k-rataan cocok untuk digunakan pada data berukuran besar (misal lebih dari 200 individu).
TwoStep Cluster
Algoritma TwoStep Cluster dikembangkan oleh Chiu, Fang, Chen, Wang, dan Jeris (2001) untuk analisis pada gugus data yang besar. Prosedurnya terdiri dari dua langkah (Chiu et al. 2001, SPSS 2004), yaitu :
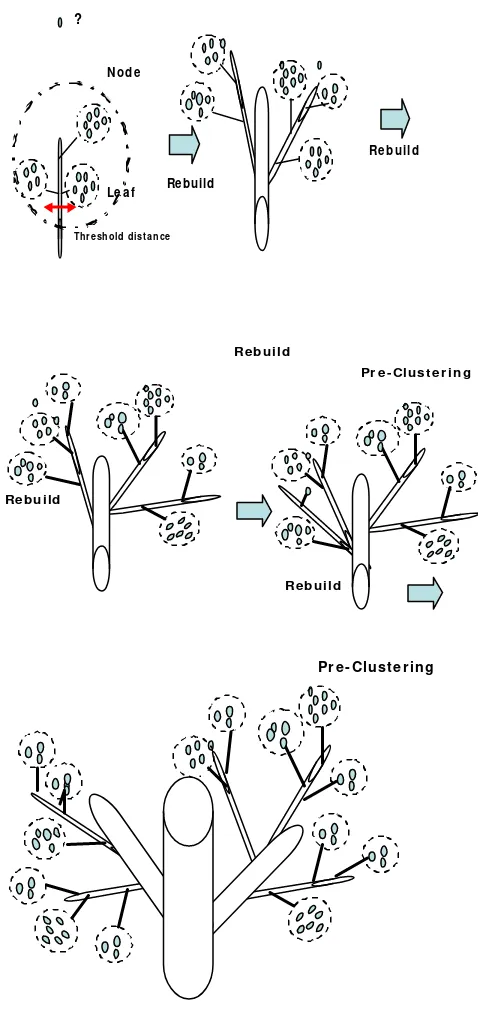
1. Penggerombolan Awal (Pre-Clustering)
Tujuan penggerombolan awal (pre-clustering) adalah untuk memasukkan data matriks baru dengan objek yang lebih sedikit pada langkah selanjutnya. Langkah penggerombolan awal menggunakan pendekatan penggerombolan secara sekuensial (Theodoridis & Koutroumbas 1999). Pendekatan ini menelusuri (scan) vektor data individu (record) satu per satu dan memutuskan apakah vektor data yang bersangkutan akan digabung dengan gerombol yang telah terbentuk sebelumnya atau memulai gerombol yang baru berdasarkan kriteria jarak yang telah ditetapkan.
___________________________________________
1)
Prosedur tersebut diimplementasikan dengan membentuk Cluster Feature tree
(Zhang et al. 1996), pada penulisan ini diterjemahkan sebagai “pohon ciri gerombol”. Pohon ciri gerombol terdiri dari beberapa tingkatan cabang (nodes) dan masing-masing cabang berisikan individu data (entries). Individu yang terdapat pada cabang yang berisikan individu rujukan disebut Leaf Entry, merepresentasikan anak-gerombol (sub-cluster) dari gerombol rujukan awal. Cabang-cabang yang bukan menjadi rujukan (non-leaf nodes) beserta individu di dalamnya akan mengarahkan vektor individu baru ke dalam cabang yang tepat secara cepat. Sebagai contoh, SPSS memberikan nilai default untuk banyaknya tingkat cabang maksimum (maximum levels of nodes)=3 dan banyaknya entries per nodes maksimum 8 sehingga banyaknya leaf entries maksimum sebanyak 83 = 512 anak-gerombol (SPSS Technical Guide 2001).
Jika CF tree berkembang melewati batas ukuran maksimum yang telah ditetapkan, maka CF tree yang telah ada akan dibangun ulang dengan cara meningkatkan kriteria ukuran penerimaan. CF tree yang melewati batas biasanya dikarenakan pada saat proses algoritma CF tree ini dijalankan, terbentuk daun entri yang beranggotakan pencilan (outlier). Pencilan pada analisis TwoStep Cluster
adalah data yang tidak dapat dimasukkan pada gerombol manapun. Pada saat CF tree
akan dibangun ulang, maka akan diperiksa daun entri yang berpote nsi sebagai pencilan. Daun entri yang terdeteksi beranggotakan pencilanmerupakan daun entri yang jumlah anggotanya kurang dari fraksi ukuran gerombol yang memiliki jumlah paling besar yang telah ditetapkan. Pada saat pembangunan ulang, daun entri yang berpotensi sebagai pencilan disimpan. Setelah CF tree dibangun ulang, maka satu per satu data dalam daun entri yang berpotensi sebagai pencilan dimasukkan ke dalam
CF tree yang baru tanpa mengubah ukuran CF tree tersebut. Jika masih ada data yang tidak masuk ke dalam daun entri manapun, maka data tersebut dikatakan sebagai pencilan. Data-data yang dideteksi sebagai pencilan dimasukkan ke dalam satu gerombol.
Pada diagram algoritma CF tree yang disajikan pada Gambar 1, maksimum
depth dan maksimum nodes yang digunakan yaitu masing- masing 3, sehingga daun entri (anak gerombol) yang terbentuk adalah sebanyak 33 atau 27 anak gerombol, sedangkan pada penelitian ini sesuai dengan default dari program SPSS maksimum
depth sama dengan 3 dan maksimum nodes 8.
Menurut Bacher, Wenzig, dan Vogler (2004), hasil penggerombolan awal bergantung pada urutan dari objek/individu yang disusun pada matriks data. Oleh karena itu, SPSS (2001:2) merekomendasikan untuk menggunakan urutan data secara acak.
?
Rebuild
Re bu ild N o d e
Le a f
Thr e shold dist a nce
Pr e - Clu st e r in g
Re b u ild
Re b u ild
Re b u ild
Pr e- Clu st e r in g
2. Penggerombolan Individu Objek ( Step 2 Cluster)
Pada tahap ini diterapkan model berbasiskan teknik hirarki. Sebagaimana halnya dengan teknik hirarki aglomeratif, hasil penggerombolan awal digabungkan dengan menggunakan cara bertatar (stepwise) sampai semua objek berada dalam satu gerombol. Berbeda dengan teknik -teknik hirarki aglomeratif, algoritma TwoStep Cluster didasarkan pada suatu model statistik. Model dilandasi pada asumsi bahwa peubah-peubah kontinu xj (j = 1,2,…,p) pada gerombol ke-i menyebar normal bebas
stokastik dengan nilai tengah µij dan ragam 2
ij
σ , serta peubah-peubah kategorik aj
pada gerombol ke-i mengikuti sebaran multinomial dengan peluang πijl, yang mana (jl) adalah indeks dari kategori ke l (l = 1,2,…,ml) dari peubah aj(j = 1,2,…,q).
3. Konsep Jarak
Terdapat dua konsep pengukuran jarak yang tersedia pada SPSS TwoStep Cluster yaitu jarak Euclidean dan jarak log-likelihood. Bacher, Weinzig, dan Vogler (2004) menyatakan bahwa ukuran jarak log-likelihood dapat diterapkan untuk atribut (peubah-peubah) campuran antara kategorik dan numerik.
Jarak log-likelihood antara dua kelompok i dan s didefinisikan sebagai berikut:
Untuk penyingkatanξi,s dituliskan sebagai εv , yang dapat ditafsirkan sebagai
suatu jenis galat penyimpangan (dispersi) di dalam gerombol v (v = i,s,(i,s)). εv
terdiri dari dua komponen keragaman. Bagian pertama adalah )
−
∑
= yang mengukur total simpangan (keragaman) dari peubahkontinu xj di dalam gerombol v dan bagian kedua 1 1 ˆvjllog( ˆvjl)
(entropy) mengukur dispersi pada peubah kategorik. Seperti halnya dengan teknik hirarki aglomeratif, gerombol- gerombol dengan jarak terkecil d(i,s) digabungkan pada tiap langkah. Fungsi log-likelihood untuk langkah dengan k gerombol dituliskan sebagai:
Fungsi lk bukan merupakan fungsi log-likelihood yang selengkapnya
sebagaimana dituliskan pada persamaan sebelumnya. Fungsi ini dapat ditafsirkan sebagai dispersi di dalam gerombol (keragaman dalam gerombol). Bila hanya diperhatikan pada bagian peubah kategorik, lk adalah entropy dalam gerombol ke k.
4. Penentuan Banyaknya Gerombol
Pada SPSS TwoStep Cluster, banyaknya gerombol dapat diperoleh secara otomatis. Dua tahap pendugaan diterapkan untuk menentukan banyaknya gerombol secara objektif. Tahap pertama menghitung besaran Kriteria Informasi Akaike (AIC) dan Kriteria Informasi Bayes (BIC). Kriteria Informasi Akaike untuk k buah gerombol dirumuskan sebagai :
AICk = −2lk +2rk (6)
yang mana rk adalah banyaknya parameter bebas.
Menurut Chiu et al. (2001: 266) BICk atau AICk menghasilkan penduga awal
yang baik bagi banyaknya gerombol maksimum. Banyaknya gerombol maksimum ditentukan sama dengan banyaknya gerombol yang memiliki rasio BICk/BIC1 yang
pertama kali lebih kecil dari c1 (SPSS menetapkan c1 = 0,04 yang didasarkan atas
studi simulasi) (SPSS Technical Support 2001).
Tahap kedua digunakan kriteria perubahan rasio jarak untuk k buah gerombol,
R(k) , yang didefinisikan sebagai :
Jarak dk dapat diperoleh dari hasil perhitungan sebagai berikut :
k
Menurut Bacher, Wenzig, dan Vogler (2004), menggunakan BIC atau AIC menghasilkan jawaban ya ng berbeda. Sebagai catatan, SPSS menyediakan 2 pilihan kriteria, yaitu menggunakan BIC atau AIC. Banyaknya gerombol diperoleh berdasarkan ketentuan ditemukannya perbedaan yang nyata pada rasio perubahan gerombol. Rasio perubahan gerombol dihitung sebagai berikut
R
( ) ( )
k1 /Rk2 (11)untuk dua nilai terbesar dari R(k) (k=1,2,…,kmax; kmax didapatkan dari langkah
pertama).
Jika rasio perubahan lebih besar daripada nilai batas c2 (SPSS menetapkan nilai
c2 = 1,15 berdasarkan studi simulasi), banyaknya gerombol ditetapkan sama dengan
k1, selainnya banyak gerombol sama dengan maksimum {k1,k2}.
5. Langkah Penetapan Keanggotaan Gerombol dan Penanganan Pencilan
secara deterministik memungkinkan terjadinya penduga yang bias bagi profil gerombol, bila terjadi tumpang tindih (overlap) antar dua gerombol yang saling berdekatan. Kelompok data yang dapat mengakibatkan terjadinya bias dalam penetapan keanggotaan gerombol disebut sebagai pencilan (outlier) atau gangguan (noise). Untuk menanggulangi hal ini, Bacher, Wenzig, dan Vogler (2004) menyarankan agar pengguna SPSS menentukan nilai fraction of noise (opsi penanganan pencilan), misalnya 5 (=5%). Bila diyakini pada data tidak terdapat gangguan (penc ilan), maka pilihan penanganan pencilan dapat diabaikan.
Suatu dahan (pada tahapan penggerombolan awal) dianggap sebagai gerombol yang berpotensi sebagai pencilan bilamana banyaknya individu pada sub gerombol yang bersangkutan lebih sedikit dari persentase (proporsi) fraksi ukuran gerombol maksimum yang ditetapkan.
Pencilan atau gangguan (noise) diasumsikan menyebar mengikuti sebaran seragam. Untuk mendeteksi bahwa suatu individu dapat dinyatakan sebagai pencilan atau bukan, dilakukan perhitungan jarak log-likelihood dari titik yang bersangkutan ke sub gerombol terdekat yang bukan pencilan (closest non-noise cluster), dan jarak
log-likelihood bilamana titik tersebut dimasukkan sebagai pencilan. Langkah berikutnya, memilih jarak log-likelihood terbesar dari kedua perhitungan tersebut. Langkah ini setara dengan memasukkan individu yang diduga sebagai pencilan ke sub gerombol terdekat yang bukan pencilan bilamana jarak log-likelihood lebih kecil dari titik kritis
C=log(V) (12)
L = Banyaknya kategori untuk peubah kategori ke-m
BAHAN DAN METODE
Bahan
Model Populasi Hipotetik
Pada penelitian ini akan digunakan pendekatan simulasi untuk mengevaluasi efektivitas algoritma TwoStep Cluster, sebagai mana dinyatakan pada tujuan penelitian. Data bangkitan yang akan digunakan didasarkan pada 5 model data hipotetik, yang dipandang dapat mewakili situasi yang mungkin muncul atau dapat dijadikan rujukan untuk generalisasi berbagai situasi di populasi.
Kelima model tersebut adalah :
P1 : Populasi yang homogen (1 gerombol), yaitu dapat ditafsirkan bahwa tidak terdapat struktur kelas (gerombol) pada populasi yang dianalisis. Dalam kasus pemasaran, beberapa produk -produk masal (misal minuman ringan/soft drink) tidak tersegmen, karena preferensi atas produk tersebut tidak terkait dengan kelas sosial ekonomi, gaya hidup, atau demografi.
P2 : Populasi yang dibentuk dari 2 gerombol yang memiliki sifat hampir mirip (overlap) atau tidak terpisah secara tegas. Contoh pada kasus pemasaran adalah segmentasi preferensi antara kelompok laki- laki dan perempuan pada kelompok umur muda (15-24 tahun) untuk berbagai jenis produk non kosmetik atau model pakaian.
P3 : Populasi yang dibentuk dari 2 gerombol yang terpisah secara tegas (mutually exclusive). Pada penerapan bidang pemasaran, sangat umum dijumpai pemisahan kelas atas (upper class atau high end) dan kelas bawah (lower class
P4 : Populasi yang dibentuk dari 3 gerombol yang terpisah secara tegas. Sama pada kasus di atas (P3), namun populasi yang dianalisis tersegmen menjadi kelompok kelas atas (upper), menengah (middle), dan kelas bawah (lower).
P5 : Populasi yang dibentuk dari 5 gerombol yang terdiri dari 3 gerombol yang terbedakan secara tegas, dan 2 gerombol lainnya tumpang tindih satu dengan lainnya serta dengan gerombol lain. Pada bidang pemasaran, segmentasi berdasarkan psikografik atau gaya hidup cukup umum dijump ai pemisahan yang tidak nyata pada beberapa kelompok dan pada kelompok lainnya terdapat perbedaan yang nyata.
Model Komposisi Peubah yang Dianalisis
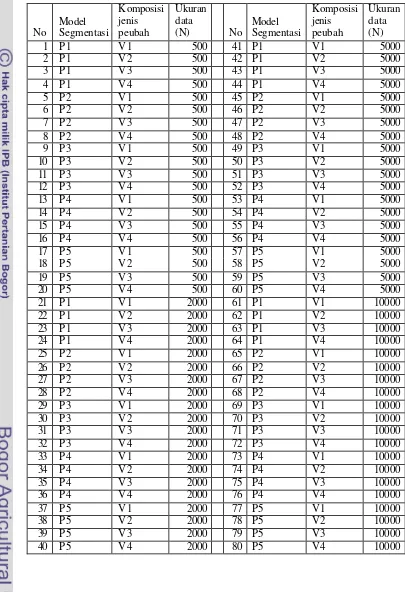
Selain model- model populasi hipotetik di atas, pada penelitian ini akan dievaluasi pengaruh jenis peubah yang terlibat dalam proses penggerombolan. Untuk membatasi lingkup penelitian, ditetapkan banyaknya peubah yang terlibat adalah 14. Dalam prakteknya, berdasarkan pengalaman penulis di bidang riset pemasaran, atribut preferensi produk yang diukur untuk tujuan segmentasi umumnya tidak lebih dari 10. Pada segmentasi konsumen berdasarkan psikografik, sangat umum digunakan 14 dimensi nilai (value), sedangkan pada segmentasi berdasarkan sosio -demografik peubah-peubah yang umum digunakan adalah (1) kelompok umur, (2) pendidikan tertinggi, (3) kelas rata-rata pengeluaran rumah tangga per bulan, (4) kelas rata-rata pendapatan rumah tangga per bulan, (5) status perkawinan, (6) status pekerjaan, (7) gender, (8) ukuran keluarga, dan (9) kepemilikan barang-barang tahan lama di rumah tangga. Kelompok peubah yang akan dievaluasi adalah :
V2: Kumpulan peubah yang semuanya merupakan peubah kategorik (nominal atau ordinal yang diperlakukan sebagai nominal). Kasus ini paling banyak dijumpai pada bidang pemasaran, ilmu- ilmu sosial, manajemen, dan politik.
V3 : Kumpulan peubah yang terdiri dari sebagian kecil (4) peubah kuantitatif, dan sisanya (10) merupakan peubah kategorik. Pada bidang pemasaran dan ilmu-ilmu sosial kasus seperti ini mulai mendapat perhatian.
V4 : Kumpulan peubah yang terdiri dari sebagian besar (10) merupakan peubah kuantitatif, dan sisanya (4) merupakan peubah kategorik. Pada bidang pertanian dan ekonomi keterlibatan peubah-peubah yang tidak dapat dikuantifikasi, saat ini mulai mendapat perhatian.
Data Hipotetik
Faktor lain yang dipandang berpengaruh terhadap data bangkitan yang akan digunakan adalah ukuran contoh secara total (banyaknya data). Pada penelitian ini akan dievaluasi kemungkinan ukuran data relatif kecil (500), sedang (2.000), besar (5.000) dan sangat besar (10.000). Dengan demikian, model data bangkitan yang akan digunakan dalam penelitian ini merupakan fungsi dari :
• 5 Model hipotetik segmentasi di populasi.
• 4 Komposisi jenis peubah yang terlibat dalam analisis.
• 4 Ukuran data.
Metode
Metode Pembangkitan Data
Data hipotetik dibangkitkan dari sebaran normal dengan nilai tengah µ dan ragam=1. Lebih lanjut diasumsikan bahwa antar peubah-peubah yang terlibat dalam analisis saling bebas stokastik, dengan sebaran yang sama. Dengan demikian, peubah-peubah yang terlibat dalam analisis menyebar normal, bebas stokastik, identik (normally independently identically distributed), N(µ,1). Nilai tengah untuk masing-masing model segmentasi yang dievaluasi dinyatakan sebagai berikut :
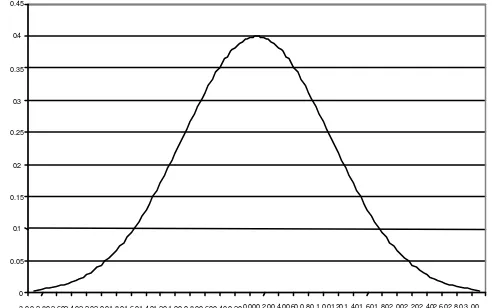
P1 : Tidak terdapat struktur kelas (gerombol), yaitu populasi dengan 1 gerombol.
µ (xi) = 0,00 ; i = 1,2,3,..., N (ukuran data).
Gambar 2. Sebaran populasi tunggal, N (0,1)
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45
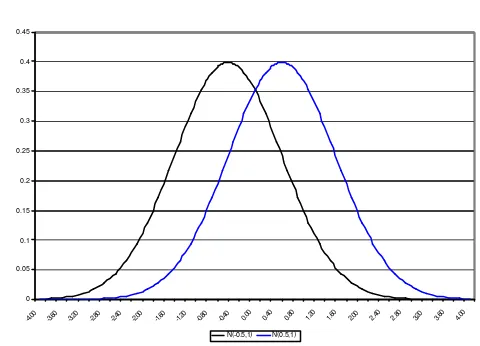
P 2: Populasi yang dibentuk dari 2 gerombol dengan jarak antar gerombol relatif kecil (pemisahan tidak tegas)
Gerombol 1 : µ (x1i) = -0,50 ; i = 1,2,3,..., n1 (catatan : n1=N/2)
Gambar 3. Sebaran model 2 populasi dengan pemisahan tidak tegas
P3 : Populasi yang dibetuk dari 2 gerombol dengan jarak antar gerombol relatif besar (pemisahan antar gerombol tegas)
Gerombol 1 : µ (x1i) = -3 ,00 ; i = 1,2,3,..., n1 (catatan : n1=N/2)
P4 : Populasi yang dibentuk dari 3 gerombol dengan jarak antar gerombol cukup besar (pemisahan secara tegas)
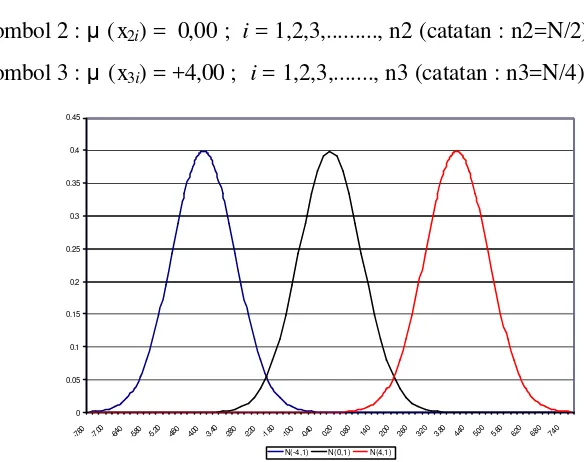
Gerombol 1 : µ (x1i) = -4,00 ; i = 1,2,3,..., n1 (catatan : n1=N/4)
Gerombol 2 : µ (x2i) = 0,00 ; i = 1,2,3,..., n2 (catatan : n2=N/2)
Gerombol 3 : µ (x3i) = +4,00 ; i = 1,2,3,..., n3 (catatan : n3=N/4)
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45
-7.60 -7.00 -6.40 -5.80 -5.20 -4.60 -4.00 -3.40 -2.80 -2.20 -1.60 -1.00 -0.40 0.20 0.80 1.40 2.00 2.60 3.20 3.80 4.40 5.00 5.60 6.20 6.80 7.40
N(-4,1) N(0,1) N(4,1)
Gambar 5. Sebaran model 3 populasi dengan pemisahan yang tegas
Penyebaran banyaknya data pada masing-masing (ukuran gerombol) ditetapkan tidak seimbang, tetapi proporsional dan menyebar secara simetrik. Pada kasus ini, ukuran contoh masing- masing gerombol adalah 25%, 50%, dan 25% dari jumlah keseluruhan data yang dicobakan.
P5 : Populasi yang dibentuk dari 3 gerombol dengan jarak antar gerombol cukup besar dan 2 gerombol lainnya terletak diantara 3 gerombol lain serta tumpang tindih terhadap gerombol lain.
Gerombol 1 : µ (x1i) = -4,00 ; i = 1,2,3,..., n1 (catatan : n1=15% dari N)
Gerombol 2 : µ (x2i) = -1,00 ; i = 1,2,3,..., n2 (catatan : n2= 10% dari N)
Gerombol 3 : µ (x3i) = 0,00 ; i = 1,2,3,..., n3 (catatan : n3= 50% dari N)
Gerombol 4 : µ (x4i) = +1,00 ; i = 1,2,3,..., n4 (catatan : n4= 10% dari N)
-0.05 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45
-10.00 -9.4 0
-8.80 -8.20 -7.60 -7.00-6.40 -5.80 -5.20 -4.60-4.00 -3.40 -2.80 -2.20-1.60-1.00 -0.40 0.20 0.80 1.40 2.00 2.60 3.20 3.80 4.40 5.00 5.60 6.20 6.80 7.40 8.00 8.60 9.20 9.80
N(-4,1) N(0,1) N(4,1) N(-1.0,1) N(1.0,1)
Gambar 6. Sebaran model 5 populasi dengan 3 gerombol terpisah secara tegas dan 2 gerombol saling tumpang tindih dengan lainnya.
Seperti pada kasus sebelumnya, ukuran contoh pada masing-masing gerombol ditetapkan menyebar secara simetrik, sehingga pada kasus ini ukuran contoh masing-masing gerombol adalah 10%, 15%, 50%, 15% dan 10% dari jumlah keseluruhan data yang dicobakan.
Data hipotetik peubah kategorik akan dibentuk dari pembangkitan dengan menggunakan aturan pada peubah kuantitatif. Transformasi peubah kuantitatif menjadi kategorik dilakukan dengan mengikuti aturan sebagai berikut :
• Peubah Biner dengan π1 = 0,5
yi = 1 jika xi < µ(xi)
yi = 0 jika xi > µ(xi) dengan xi adalah data bangkitan pada peubah kuantitatif
Prosedur Pembangkitan Data
Pembangkitan data untuk masing- masing kasus yang dievaluasi, dilakukan dengan menggunakan bantuan paket program statistika MINITAB versi 13. Pada masing-masing kasus, pemba ngkitan 14 peubah kriteria penggerombolan dilakukan secara serentak (bersamaan), karena nilai tengah dan ragam untuk masing- masing peubah sama dan saling bebas stokastik satu dengan lainnya. Proses pembangkitan data dengan menggunakan perintah pada MINITAB, misal untuk kasus populasi P4, V1, dengan ukuran data 500, adalah sebagai berikut :
1. Memasukkan parameter populasi hipotetik MTB> LET K1=125
MTB> LET K2=250 MTB> LET K3=-4.0 MTB> LET K4=0.0 MTB> LET K5=4.0
2. Makro membangkitkan data masing- masing gerombol hipotetik MTB>SET C1
K1 (1) END.
MTB>RANDOM K1 C2-C15; NORMAL K3 1.0. MTB> SET C16
K2 (2) END.
MTB> RANDOM K2 C17-C30; NORMAL K4 1.0. MTB>SET C31
MTB>RANDOM K1 C32-C45; NORMAL K5 1.0.
3. Makro menggabungkan data dari setiap gerombol bangkitan MTB> STACK C1 C16 C31 C1
MTB> STACK C2 C17 C32 C2 MTB> STACK C3 C18 C33 C3 MTB> STACK C4 C19 C34 C4 MTB> STACK C5 C20 C35 C5 MTB> STACK C6 C21 C36 C6 MTB> STACK C7 C22 C37 C7 MTB> STACK C8 C23 C38 C8 MTB> STACK C9 C24 C39 C9 MTB> STACK C10 C25 C40 C10 MTB> STACK C11 C26 C41 C11 MTB> STACK C12 C27 C42 C12 MTB> STACK C13 C28 C43 C13 MTB> STACK C14 C29 C44 C14 MTB> STACK C15 C30 C45 C15
Konversi data kontinu menjadi data biner dilakukan dengan menggunakan paket program SPSS V. 11.5. Hal ini dilakukan karena pengolahan data hasil pembangkitan, konversi, dan analisis TwoStep Cluster dapat dilakukan pada paket program yang sama.
Opsi Penanganan Pencilan dan Tanpa Penanganan Pencilan
tanpa penanganan pencilan ditampilkan pada lampiran 1.gambar 6. Pada penelitian ini, akan dibandingkan hasil penggerombolan TwoStep Cluster antara penggunaan opsi penanganan pencilan dengan tanpa penanganan pencilan.
Metode Analisis
Fokus penelitian ini adalah mengevaluasi keakuratan algoritma TwoStep Cluster dalam mendeteksi banyaknya gerombol dan ukuran masing-masing gerombol pada gugus data dari populasi yang dianalisis. Analisis yang akan dilakukan adalah :
1. Mengukur tingkat keakuratan algoritma TwoStep Cluster dalam mendeteksi banyaknya gerombol sebenarnya. Pada penelitian ini, tingkat keakuratan didefinisikan sebagai persentase jumlah percobaan (run) yang menghasilkan banyaknya gerombol yang sama dengan populasi data hipotetik (dipandang sebagai banyaknya gerombol sebenarnya).
A = Σ Xi / N (14)
dengan Xi bernilai 1 bila banyaknya gerombol yang dihasilkan dari algoritma
TwoStep Cluster sama dengan banyaknya gerombol sebenarnya di dalam populasi (pada penelitian ini diketahui) dan 0 selainnya. N adalah banyaknya ulangan percobaan, pada penelitian ini sama dengan 100.
2. Analisis berikutnya adalah menelusuri kesesuaian sebaran ukuran
gerombol yang dihasilkan dari algoritma TwoStep Cluster dengan sebaran
ukuran gerombol sebenarnya pada populasi. Kesesuaian sebaran ukuran gerombol diuji dengan menggunakan uji khi-kuadrat sebagai berikut :
Ho : Sebaran ukuran gerombol hasil TwoStep Cluster = sebaran gerombol populasi.
Pada taraf nyata (a) sebesar 30%, dapat didefinisikan tingkat kesesuaian sebaran ukuran gerombol hasil algoritma TwoStep Cluster dengan ukuran gerombol sebenarnya, yaitu :
K = Σ Yi / N (15)
dengan Yi bernilai 1 bila hasil uji khi-kuadrat (pada taraf nyata tertentu) menghasilkan kesimpulan “Terima Ho”; dan 0 bila “Tolak Ho”. N adalah banyaknya ulangan percobaan, pada penelitian ini sama dengan 100.
3. Tingkat salah klasifikasi dari anggota gerombol. Salah klasifikasi dari hasil penggerombolan, pada penelitian ini didefinisikan sebagai total persentase semua individu (objek) yang berasal dari suatu gerombol namun teridentifikasi sebagai anggota gerombol lain pada proses penggerombolan, dalam hal ini adalah hasil penggerombolan SPSS TwoStep Cluster.
Keanggotaan pada populasi yang sebenarnya Hasil
Penggerombolan
Populasi 1 Populasi 2
Gerombol 1 n1 n2
Gerombol 2 n3 n4
Salah klasifikasi pada 2 populasi (geromb ol) adalah (n2+n3)/(n1+n2+n3+n4)
Prosedur dan Pelaksanaan Percobaan
1. Membangkitkan gugus data hipotetik untuk setiap kombinasi struktur populasi, komposisi jenis peubah, dan ukuran data yang tercantum pada Tabel 1. Masing- masing kombinasi perlakuan diulang sebanyak 100 kali. Dengan demikian akan dibangkitkan sebanyak 8.000 gugus data untuk dianalisis.
lunak (software) statistika yang tersedia, dalam hal ini peneliti menggunakan Minitab versi 13.2.
Pada setiap gugus data bangkitan yang akan digunakan sebagai bahan simulasi, akan ditambahkan peubah (kolom atau field) yang menunjukkan indeks asal populasi.
2. Setiap gugus data yang terbentuk akan digerombolkan dengan menggunakan prosedur SPSS TwoStep Cluster. Pada SPSS versi 11.5 tersedia pada modul
Analyze -> Clasify. Pilihan menu dasar (basic option) yang digunakan adalah :
Distance Measure : Log-likelihood
Number of clusters : Determined Automatically, Maximum : 15 Clustering Criterion : BIC
Sesuai dengan saran dari Bacher, Wenzig, dan Vogler (2004), pada menu Options, akan dilakukan pilihan pada kotak “Outlier Treatment” dengan memberi check box pada kotak “Use noise handling” dan mengisi pada kotak “Percentage”
bilangan 5 (artinya 5%) dan dicobakan pula tanpa pencilan. Pada menu “Output” akan dipilih Statistik -statistik :
a. Deskripsi setiap gerombol (Descriptives by cluster) untuk data kuantitatif. b. Sebaran frekuensi setiap gerombol (Cluster frequencies) untuk data
kategorik.
c. Informasi BIC , dan
d. Simpan data keanggotaan gerombol (Create cluster membership variable). 3. Hasil penggerombolan TwoStep Clust er, khususnya banyaknya gerombol yang
terbentuk dan profil masing-masing gerombol, termasuk ukuran gerombol, akan dicatat kemudian dimasukkan sebagai data yang akan dianalisis pada pengolahan selanjutnya.
HASIL DAN PEMBAHASAN
Kasus Data Homogen
Data homogen adalah gugus data yang mana setiap individu berasal dari satu sebaran populasi tertentu. Dengan demikian pada populasi sebenarnya tidak terjadi penggerombolan, yaitu hanya terdapat 1 gerombol. Kasus ini jarang dijumpai pada situasi nyata, kecuali pada beberapa masalah segmentasi pelanggan dari produk masal. Berdasarkan percobaan simulasi, hasil analisis keakuratan penggerombolan algoritma
TwoStep Cluster pada kasus ini berbeda dengan kasus-kasus populasi lain yang dicobakan. Oleh karena itu kasus ini dibahas secara terpisah. Disamping itu, metode penggerombolan konvensiona l, baik metode hirarki maupun k-rataan tidak memungkinkan untuk menghasilkan 1 gerombol.
Pada Tabel 2 ditampilkan persentase kesesuaian banyaknya gerombol yang dihasilkan dari algoritma TwoStep Cluster dengan banyaknya gerombol sebenarnya pada populasi. Pada tabel tersebut terlihat bahwa persentase ketepatan TwoStep Cluster dalam mengidentifikasi banyaknya gerombol pada kasus data homogen umumnya sangat rendah, kecuali bila ukuran datanya kecil (dalam penelitian ini yaitu 500). Algoritma TwoStep Cluster cukup akurat bilamana ukuran data relatif kecil dan peubah kriteria penggerombolan bersifat (1) semuanya kuantitatif (V1), (2) semuanya bersifat kategorik (V2) dan mentransfernya menjadi peubah biner yang diperlakukan sebagai data numerik , atau (3) sebagian kecil peubah kriteria bersifat kuantitatif (V3) dan sebagian kecil peubah kategorik (V4), yang ditransformasi ke peubah biner dan diperlakukan sebagai numerik.
Tabel 2 juga menyajikan hasil percobaan simulasi pada kasus data homogen dengan opsi tanpa penanganan pencilan dan dengan penanganan pencilan sebesar 5%. Secara keseluruhan, ketepatan algoritma TwoStep Cluster dalam menduga banyaknya gerombol (pada gugus data homogen) tanpa penanganan terhadap pencilan maupun dengan penanganan terhadap pencilan sebesar 5% memberikan hasil yang tidak berbeda nyata.
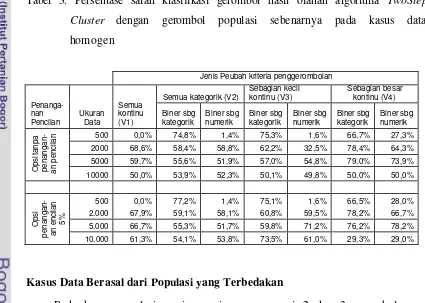
Tabel 2. Persentase ketepatan banyaknya gerombol hasil olahan algoritma
TwoStep Cluster dengan gerombol populasi sebenarnya pada kasus data homogen
Jenis Peubah kriteria penggerombolan
Semua kategorik (V2) Sebagian kecil kontinu (V3)
Ukuran Data Semua kontinu
Pada kasus ini banyaknya gerombol sebenarnya hanya 1, maka untuk setiap hasil banyaknya penggerombolan algoritma TwoStep Cluster yang tepat sama dengan populasi, ukuran gerombolnya juga akan tepat sama, sedangkan bila dugaan banyaknya gerombol berbeda dengan populasi maka ukuran gerombolnya juga berbeda.
secara benar. Sebaliknya bila banyaknya gerombol dugaan lebih dari 1, maka terdapat individu yang salah klas ifikasi. Tabel 3 menampilkan rata-rata persentase salah klasifikasi penggerombolan pada kasus di populasi hanya terdapat 1 gerombol.
Pada Tabel 3 terlihat bahwa bila ketepatan pendugaan banyaknya gerombol tinggi, maka salah klasifikasinya rendah, yaitu untuk kasus-kasus ukuran data 500 dengan semua peubah berjenis kontinu (V1), semua peubah bersifat kategorik (V2) yang ditransformasi ke bentuk biner dan diperlakukan sebagai peubah numerik, dan peubah campuran (V3 dan V4) yang mana peubah kategorik ditransformasi ke biner dan diperlakukan sebagai numerik.
Tabel 3. Persentase salah klasifikasi gerombol hasil olahan algoritma TwoStep
Cluster dengan gerombol populasi sebenarnya pada kasus data homogen
Jenis Peubah kriteria penggerombolan
Semua kategorik (V2)
Kasus Data Berasal dari Populasi yang Terbedakan
semakin besar ukuran data, ketepatan rata-rata banyaknya gerombol cenderung menurun.
Pada kasus data berasal dari populasi yang saling terpisah secara tegas, algoritma TwoStep Cluster sangat akurat, dalam menduga banyaknya gerombol sebenarnya pada populasi, untuk berbagai jenis kumpulan peubah kriteria penggerombolan, baik semua peubahnya berjenis kontinu (V1), semua nya peubah kategorik (V2), ataupun peubah campuran (V3 dan V4). Bilamana kumpulan peubah kriteria penggerombolan semuanya kategorik, transformasi ke peubah biner yang diperlakukan sebagai peubah numerik akan menurunkan tingkat keakuratan pendugaan banyaknya gerombol, sedangkan bilamana kumpulan peubah kriteria berupa campuran peubah kontinu dan kategorik, transformasi peubah kategorik menjadi peubah biner dan diperlakukan sebagai peubah numerik akan meningkatkan ketepatan pendugaan banyaknya gerombol.
Penanganan pencilan (outlier treatment) dengan pilihan sebesar 5% berpengaruh pada keakuratan pendugaan banyaknya gerombol yang terbentuk. Pada semua peubah kriteria penggerombolan berjenis kontinu (V1) keakuratan penduga banyaknya gerombol dari algoritma TwoStep Cluster menurun untuk ukuran data besar (10.000) baik untuk populasi dengan banyaknya gerombol 2 maupun 3. Sementara itu, bila semua peubah kriteria penggerombolan bersifat kategorik, baik tetap dipandang sebagai kategorik atau ditransformasi menjadi peubah biner yang diperlakukan sebagai numerik, memberikan hasil yang lebih buruk dibandingkan tanpa penanganan pencilan; kecuali untuk ukuran data kecil (500) dengan memperlakukan biner sebagai numerik.
dengan sebagian besar kontinu; penanganan pencilan 5% masih cukup akurat untuk ukuran data kecil dan sedang (500 dan 2.000), tetapi untuk ukuran data besar (5.000 dan 10.000) keakuratan pendugaan menurun secara drastis dibandingkan tanpa penanganan pencilan.
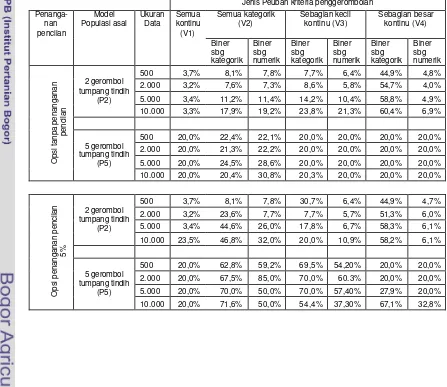
Tabel 4. Persentase ketepatan banyaknya gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang terbedakan.
Jenis Peubah kriteria penggerombolan Semua kategorik
Dengan menggunakan uji suai khi-kuadrat, diperoleh kesimpulan bahwa tanpa penanganan pencilan bila banyaknya gerombol yang dihasilkan dari algoritma
populasi (terima Ho); kecuali pada perlakuan semua peubah kategorik ditransformasi ke biner dan dipandang sebagai peubah numerik untuk kasus 3 populasi. Sebaliknya, dengan menerapkan opsi penanganan pencilan sebesar 5%, sebaran ukuran gerombol yang terbentuk dari algoritma TwoStep Cluster hanya akurat pada kasus 2 populasi yang terpisah secara tegas, sedangkan pada kasus 3 populasi, hanya akurat bilamana peubah kriteria penggerombolan semuanya kontinu atau ukuran datanya relatif kecil (500).
Tabell5. Persentase kesesuaian ukuran gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang terbedakan.
Tabulasi silang antara individu- individu anggota gerombol asal dengan gerombol yang diperoleh dari TwoStep Cluster menunjukkan bahwa algoritma ini akurat dalam menghasilkan gerombol yang sama dengan populasi asal. Secara keseluruhan, terutama pada opsi tanpa penanganan pencilan, salah klasifikasi dari individu- individu gerombol sangat kecil (di bawah 5%); kecuali pada kasus semua peubah kriteria penggerombolan berjenis kategorik yang ditransformasi ke biner dan diperlakukan sebagai numerik. Sebagaimana tampak pada Tabel 6; salah klasifikasi penggerombolan dari TwoStep Cluster sangat kecil bila seluruh peubah kriteria penggerombolan berjenis kontinu, baik dengan penanganan pencilan 5% atau tanpa penanganan pencilan.
Bilamana semua peubah kriteria penggerombolan merupakan peubah kategorik, pilihan penanganan pencilan 5% atau transformasi peubah kategorik menjadi bentuk biner yang diperlakukan sebagai peubah numerik akan memperbesar salah klasifikasi penggerombolan. Bila peubah kriteria penggerombolan merupakan campuran kontinu dan kategorik penanganan pencilan 5% memperbesar salah klasifikasi. Sementara itu, bila tanpa perlakuan penanganan pencilan, salah klasifikasi penggerombolan sangat kecil baik perlakuan peubah biner sebagai kategorik atau sebagai numerik.
Kasus Populasi yang Saling Tumpang Tindih
Tabel 6. Persentase salah klasifikasi gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang terbedakan.
Jenis Peubah kriteria penggerombolan
Semua kategorik
numerik, namun dengan data yang sangat besar (10.000) juga tidak dapat menduga banyaknya gerombol dengan baik. Untuk populasi dengan 5 gerombol yang saling tumpang tindih, TwoStep Cluster tidak dapat mengidentifikasi secara akurat.
Tabel 7. Persentase ketepatan ukuran gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang tumpang tindih
Jenis Peubah kriteria penggerombolan Semua kategorik
Bila ditelusuri lebih lanjut, dapat diketahui bahwa algoritma TwoStep Cluster
gerombol yang tidak terpisah secara tegas, ukuran masing- masing gerombol yang dihasilkan dari algoritma TwoStep Cluster sebagian besar tidak sesuai dengan ukuran gerombol sebenarnya dari populasi bangkitan (Tabel 8 ).
Tabel 8. Persentase kesesuaian ukuran gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang tumpang tindih.
Jenis Peubah kriteria penggerombolan Semua kategorik
terdapat 2 gerombol, algoritma TwoStep Cluster masih akurat dalam menggerombolkan individu untuk kasus semua peubah kriteria berjenis kontinu, sedangkan bilamana peubah kriteria penggerombolan merupakan peubah kategorik atau campuran kontinu dan kategorik, salah klasifikasi penggerombolan relatif kecil bila ukuran data di bawah 5.000 (Tabel 9).
Tabel 9. Persentase salah klasifikasi gerombol hasil olahan algoritma TwoStep Cluster dengan gerombol populasi sebenarnya, pada kasus data berasal dari populasi yang tumpang tindih
Perbandingan dengan Metode Hirarki dan K-rataan
Secara umum, berdasarkan aspek-aspek penggunaannya, perbandingan antar metode penggerombolan hirarki, k-rataan, dan TwoStep Cluster diringkas pada Tabel 10. Ditinjau dari aspek peubah kriteria penggerombolannya, metode hirarki sesuai untuk peubah-peubah yang bersifat kuantitatif yang berskala rasio, interval, ordinal, berupa peubah biner. Metode k-rataan hanya dapat digunakan bilamana peubah kriteria penggerombolan merupakan peubah kuantitatif dengan skala rasio atau interval. TwoStep Cluster memungkinkan peubah kriteria penggerombolan bersifat kuantitatif, kategorik, atau campuran dari kuantitatif dan kategorik. Berdasarkan konsep jarak yang berlaku, metode hirarki memiliki banyak pilihan konsep jarak diantaranya Euclidian, khi-kuadrat atau phi-kuadrat, beda pola (pattern difference), kecocokan sederhana (simple matching), dan sebagainya. Konsep jarak yang berlaku pada metode k-rataan adalah Euclidian. Pada algoritma TwoStep Cluster, pilihan konsep jarak yang dapat digunakan adalah Euclidian (bila semua peubah bersifat kuantitatif atau biner) atau jarak log-likelihood (terutama bila melibatkan peubah campuran atau kategorik). Metode hirarki dan k-rataan tidak mensyaratkan sebaran dari peubah-peubah kriteria penggerombolan; sedangkan TwoStep Cluster
Tabel 10. Perbandingan metode penggerombolan hirarki, k-rataan, dan TwoStep Cluster
Aspek yang dibandingkan
Metode hirarki Metode k-rataan Metode TwoStep Cluster
Pada tabel perbandingan di atas, dipaparkan bahwa metode hirarkihanya sesuai untuk jenis peubah kriteria penggerombolan yang semuanya berjenis kuantitatif atau semuanya peubah biner, selain itu ukuran data yang digerombolkan relatif kecil. Di pihak lain, metode TwoStep Cluster memungkinkan untuk mengolah data yang berukuran besar dan peubah kriteria penggerombolan bersifat semuanya kuantitatif, semuanya kategorik, atau campuran kuantitatif dan kategorik. Dengan demikian, perbandingan hasil penggerombolan antara metode hirarki dan TwoStep Cluster
hanya dapat dilakukan untuk kasus peubah kriteria penggerombolan yang (1) semuanya bersifat kuantitatif dan (2) semuanya peubah biner. Mengingat metode hirarki efektif untuk ukuran data yang kecil, maka untuk tujuan perbandingan digunakan kasus ukuran data relatif kecil ( 500 data). Pada paket program SPSS versi 11.5, penentuan banyaknya gerombol minimum dengan menggunakan metode hirarki adalah 2 gerombol. Dengan demikian, metode ini tidak memungkinkan untuk mengidentifikasi kasus bilamana di dalam populasi hanya terdapat 1 gerombol. Oleh karena itu, dalam perbandingan kasus ini tidak dilibatkan.
Sebagaimana dipaparkan pada Tabel 10, penentuan banyaknya gerombol pada metode hirarki umumnya bersifat subjektif sehingga sangat bervariasi dan sangat tergantung dari pengalaman pe neliti. Salah satu kriteria objektif yang sering digunakan dalam menentukan banyaknya gerombol yang terbentuk adalah dengan menggunakan kriteria jarak penggabungan terbesar (lihat Lampiran 2). Penentuan banyaknya gerombol juga dapat ditelusuri dari pendekatan eksplorasi data dengan mengamati sebaran dari data yang akan digerombolkan, umumnya juga memanfaatkan analisis komponen utama. Dengan situasi tersebut, maka perbandingan keakuratan penentuan banyaknya gerombol yang dihasilkan oleh metode hirarki dan TwoStep Cluster tidak relevan; karena penentuan banyaknya gerombol dengan metode hirarki tergantung dari pengamatan secara visual.
dibandingkan dengan metode TwoStep Cluster. Kasus-kasus yang dibandingkan adalah kasus semua peubah kriteria penggerombolan berjenis kontinu (V1) dan semua peubah kategorik yang ditransformasi ke biner diperlakukan sebagai numerik (V2) dengan ukuran contoh 500. Mempertimbangkan hasil evaluasi yang dilakukan oleh Wijayanti (2002), pada penelitian ini digunakan metode perbaikan jarak pautan rataan dalam kelompok (average linkage within group) dan konsep jarak untuk peubah biner yang digunakan adalah simple matching. Hasil simulasi dan uji kesesuaian sebaran ukuran gerombol sebenarnya dengan yang dihasilkan dari metode hirarkidan TwoStep Cluster ditampilkan pada Tabel 11.
Secara umum, pada kasus-kasus yang dibandingkan dengan ukuran data 500, metode TwoStep Cluster lebih baik dibandingkan dengan metode hirarki. Pada kasus data berasal dari populasi yang terbedakan (P3 dan P4) dan peubah kriteria penggerombolan semuanya berjenis kontinu, persentase kesesuaian ukuran gerombol populasi dengan yang dihasilkan dari metode hirarki sama dengan yang dihasilkan dari TwoStep Cluster (100%), sedangkan bila semua peubah kriteria penggerombolan merupakan peubah biner metode TwoStep Cluster jauh lebih baik dibandingkan dengan metode hirarki pada kasus populasi memiliki 3 gerombol yang terpisah secara tegas. Bila pada populasi terdapat 2 gerombol yang saling tumpang tindih, metode TwoStep Cluster lebih baik dibandingkan dengan metode hirarki, pada kasus peubah kriteria penggerombo lan semuanya berjenis kontinu. Pada kasus yang sama, metode hirarki sedikit lebih baik dibandingkan TwoStep Cluster untuk peubah kriteria berupa peubah biner. Sementara itu, bila pada populasi terdapat 5 gerombol yang saling tumpang tindih, metode hirarki lebih baik dibandingkan TwoStep Cluster untuk peubah kriteria semuanya bersifat kontinu.
Tabel 11. Perbandingan persentase kesesuaian sebaran ukuran gerombol hasil olahan metode hirarki, k-rataan, dan TwoStep Cluster (hasil 100 kali simulasi)
Jenis peubah yang dianalisis Jenis populasi
hirarki k-rataan TwoStep hirarki k-rataan TwoStep
2 gerombol tumpang
Secara keseluruhan persentase salah klasifikasi dari metode TwoStep Cluster
tidak berbeda nyata dengan yang dihasilkan dari metode k-rataan, bilamana semua peubah kriteria penggerombolan merupakan peubah kontinu. Bila peubah kriteria penggerombolan merupakan peubah biner, salah klasifikasi dari metode TwoStep Cluster lebih kecil dibandingkan metode k-rataan.
Tabel 12. Perbandingan persentase salah klasifikasi individu pada populasi dengan yang dihasilkan oleh metode hirarki, k-rataan, dan TwoStep Cluster (hasil 100 kali simulasi)
Jenis Peubah yang dianalisis
Jenis populasi hipotetik
Semua kontinu (V1)
Semua biner (V2) diperlakukan sebagai
numerik
hirarki k-rataan TwoStep hirarki k-rataan TwoStep
2 gerombol tumpang
tindih (P2) 6,7% 3.5% 3.7% 11,1% 7.3% 7.8%
2 gerombol terpisah
tegas (P3) 0% 0% 0% 0,0% 0% 0%
3 gerombol terpisah
tegas (P4) 0% 0% 0% 50,7% 3% 2.1%
5 gerombol tumpang
tindih (P5) 7,1% 12.8% 20% 72,8% 52.0% 22.1%
SIMPULAN DAN SARAN
Simpulan
1. Metode TwoStep Cluster menghasilkan gerombol yang sama dengan populasi sebenarnya apabila semua peubah kriteria penggerombolan bersifat kontinu; kecuali pada situasi data yang saling tumpang tindih dan tidak terbedakan.
2. Metode TwoStep Cluster sangat akurat dalam menghasilkan gerombol yang sama dengan populasi sebenarnya pada kasus-kasus data yang terpisah secara tegas, atau setidaknya terlihat adanya perbedaan penggerombolan pada data yang dianalisis. 3. Transformasi peubah kategorik ke dalam bentuk biner dan memperlakukannya
sebagai peubah numerik akan meningkatkan keakuratan TwoStep Cluster dalam menduga banyaknya gerombol, apabila peubah kriteria penggerombolan merupakan peubah campuran.
4. Apabila pada data tidak terdapat pencilan, penggunaan opsi “Penanganan Pencilan” (outlier treatment) akan menurunkan keakuratan TwoStep Cluster dalam menduga gerombol yang sebenarnya.
5. Pada kasus-kasus populasi dengan 2 dan 3 gerombol dan peubah kriteria penggerombolan semuanya kontinu atau semuanya peubah biner untuk ukuran data kecil (500), metode TwoStep Cluster lebih baik dibandingkan dengan metode hirarki dan tidak berbeda nyata dibandingkan metode k-rataan dalam hal akurasi sebaran ukuran gerombol asal serta salah klasifikasi.
Saran
1. Sebelum melakukan penggerombolan disarankan peneliti memiliki pengetahuan awal terhadap data atau populasi yang akan digerombolkan.
3. Perlu dilakukan studi perbandingan atau evaluasi terhadap keakuratan berbagai metode penggerombolan, khususnya metode hirarki, TwoStep Cluster, dan Latent Segment dalam menduga banyaknya gerombol serta profil gerombol yang sebenarnya di populasi.
DAFTAR PUSTAKA
Aaker, D.A. 2001. Strategic Marketing Management. Ed ke-6. John Wiley & Sons Inc. New York.
Aaker, D. A. And G. S. Day. 1990. Marketing Research. Ed ke-4. John Wiley & Sons, New York.
Adenberg, M.R. 1973, Cluster Analysis For Applications, Academic Press, Inc. New York
Anonimous. 2001. The SPSS TwoStep Cluster Component. A scalable component to segment your customers more effectively. White paper – technical report, SPSS Inc. Chicago.
__________. 2004. TwoStep Cluster Analysis. Technical Report, SPSS Inc. Chicago.
Bacher, J. 2000. A Probabilistic Clustering Model for Variables of Mixed Type.
Quality & Quantity.
Bacher, J., K. Wenzig and M. Vogler. 2004.. SPSS TwoStep Cluster : A First Evaluation. Friedrich-Alexander-Universität Erlangen-Nurnberg.
Bernstein, L. K. Bradley, and S. Zarich. 2002. GOLDminer : Improving Models for Classifying Patients with Chest Pain. Yale Journal of Biology and Medicine 75.
Chiu, T., Fang,D., Chen,J., Wang,Y., and Jeris,C. 2001. A Robust and Scalable Clustering Algorithm for Mixed Type Attributes in Large Database Environment. In Proceedings of the 7th ACM SIGKDD International Confererence on Knowledge Discovery and Data Mining 2001.
Digby, P.G.N. and R.A. Kempton. 1987. Multivariate Analysis of Ecological Communities. Chapman and Hall. New York.
Everitt, B.S., Landan, S. and Leese, M. 2001. Cluster Analysis. Ed ke-4 Arnold, London.
Garson, D.G. 2006. Quantitative Research in Public Administration. Lecture Note. North Carolina State University.
Huang, Z. (1998). Extensions to the k- means Algorithm for Clustering Large Data Sets with Categorical Variables. Data Mining and Knowledge Discovery.
Kasali, R. (1998). Membidik Pasar Indonesia : Segmentasi, Targeting, dan Positioning. Gramedia Pustaka Utama, Jakarta..
Kotabe, M and K. Helsen. 2001. Global Marketing Management . Ed ke-2. John Wiley & Sons, New York.
Kotler, P. 2000. Marketing Management : The Millennium Edition. Prentice Hall International Inc. New Jersey.
Lakshminarayan, C.K. and Q. Yu. 2001. A Novel Two-Stage Clustering Approach for Visitor Segmentation and Prediction Based on Click Stream Attributes. The Indian Institute of Information Technology, Bangalore.
McCutcheon A, Hagenaars J., eds. (1999). Advances in Latent Class Modeling. Cambridge, UK and NY: Cambridge University Press.
Morrison, D.F. 1990. Multivariate Statistical Methods. McGraw-Hill. Inc. New York.
Porter, M. 1980. Competitive Strategy : Techniques for Analyzing Industries and Competitors. The Free Press, New York.
Strehl, A. And J. Gosh. 2002. Relationship -Based Clustering and Visualization for High-Dimensional Data Mining. INFORMS. Journal on Computing. Pp. 1-23.
Theodoridis, S. and K. Koutroumbas. 1999. Pattern Recognition. Academic Press, New York.
Vermunt, J. K. and J. Magidson (2000). "Latent class cluster analysis." Chapter B1 in Hagenaars and McCutcheon, eds., Advances in latent class models. Cambridge, UK: Cambridge University Press. Related to Latent Gold software.
Wijayanti, A. 2002. Evaluasi Konsep Jarak dan Metode Penggerombolan untuk Data Biner. Skripsi. Jurusan Statistika. FMIPA. Institut Pertanian Bogor, Bogor.
Zhang, T, R. Ramakrishnon and M. Livny. (1996). BIRCH: An Efficient data clustering method for very large databases. Proceeding of the ACM SIGMOD Conference on Management of Data, 103-114, Montreal, Canada.
Lampiran 1. Tahapan analisis TwoStep Cluster dengan SPSS
1. Penyiapan data.
2. Pilih Menu : Analyze/Classify/TwoStep Cluster (Gambar 1), maka akan muncul kotak dialog (Gambar 2).
Gambar 1 . Kotak dialog pemilihan metode TwoStep Cluster
3. Pindahkan variabel yang akan digerombolkan ke kotak variabel sesuai dengan perlakuan yang diinginkan.
Gambar 3. Kotak dialog perlakuan variabel
4. Pada kotak DISTANCE MEASURE beri tanda log likelihood untuk pilihan ukuran jarak, karena peubah yang akan dianalisis pada contoh diatas merupakan peubah campuran kategorik dan kontinu.
5. Pada kotak Clustering Criterion beri tanda pada salah satu kriteria penggerombolan yang diinginkan (BIC atau AIC)
7. Selanjutnya klik ADVANCED jika ingin me mgubah Threshold Distance, maksimum Branches dan Tree Depth. Default SPSS adalah seperti tertera pada Gambar 5. Selanjutnya kembali ke CONTINUE.
Gambar 4. Kotak OPTION pada TwoStep Cluster
Gambar 6. Kotak OPTION dengan pilihan penanganan pencilan 5%
8. Klik OUTPUT, maka akan muncul kotak dialog seperti Gambar 7 sesuai dengan pilihan output yang diinginkan.
9. Klik PLOTS, maka akan muncul kotak dialog berikut:
Gambar 8. Kotak dialog PLOT
Lampiran 2. Jarak penggabungan dengan metode hirarki
Kasus 1: Populasi dengan 2 gerombol yang saling tumpang tindih (P2) dan peubah kontinu (V1) Ukuran data = 500, dengan 100 Ulangan
Ulangan Jarak Penggabungan
Kasus 1: Populasi dengan 2 gerombol yang saling tumpang tindih (P2) dan peubah kontinu (V1) Ukuran data = 500, dengan 100 Ulangan
Ulangan Jarak Penggabungan
Kasus 1: Populasi dengan 2 gerombol yang saling tumpang tindih (P2) dan peubah kontinu (V1) Ukuran data = 500, dengan 100 Ulangan
Ulangan Jarak penggabungan
10 to 9 9 to 8 8 to 7 7 to 6 6 to 5 5 to 4 4 to 3 3 to 2 2 to 1
79 3,61 3,33 3,06 3,01 2,74 2,74 2,24 2,24 13,49
80 3,73 3,78 3,55 3,10 3,10 2,76 2,76 3,58 14,00
81 3,56 3,56 3,56 3,34 3,34 3,34 3,87 3,62 12,61
82 3,58 3,58 3,24 3,24 2,69 2,69 3,28 5,28 13,11
83 3,56 3,56 3,53 3,52 2,65 2,65 3,21 2,83 12,64
84 3,33 3,40 3,00 2,60 2,18 2,18 2,64 4,54 13,37
85 3,18 3,18 3,11 3,11 3,11 3,33 3,53 2,65 14,71
86 3,23 3,23 2,98 2,98 2,98 3,09 3,24 2,46 15,15
87 3,87 3,87 3,40 3,40 2,78 2,60 2,60 3,17 13,70
88 4,03 3,64 3,83 3,51 3,51 3,28 3,28 4,06 13,89
89 3,73 3,73 3,73 3,18 3,18 2,79 2,79 4,25 14,37
90 3,32 3,73 3,38 3,38 3,38 2,98 2,73 4,24 13,91
91 3,39 3,21 3,21 3,21 3,08 3,08 2,51 2,51 13,68
92 3,59 3,59 3,61 3,61 3,61 2,95 2,95 3,06 14,55
93 3,44 3,44 2,91 2,78 2,78 3,73 3,94 2,57 13,94
94 3,07 3,07 2,84 2,84 3,80 2,98 2,98 2,56 14,93
95 3,34 3,34 2,45 2,16 2,16 2,16 3,62 2,97 14,21
96 3,28 3,43 3,28 3,28 3,65 3,56 3,56 3,29 14,66
97 3,69 3,69 2,64 2,40 2,40 5,26 5,63 5,18 13,45
98 3,38 3,38 3,69 3,69 3,12 2,73 2,58 2,58 13,78
99 3,86 3,40 3,51 2,73 2,49 2,49 2,99 2,01 14,87
Kasus 2 : Populasi dengan 2 gerombol yang saling terpisah (P3) dan peubah kontinu (V1) Ukuran data = 500, dengan 100 Ulangan
Ulangan Jarak Penggabungan
Kasus 2 : Populasi dengan 2 gerombol yang saling terpisah (P3) dan peubah kontinu (V1) Ukuran data = 500, dengan 100 Ulangan
Ulangan Jarak Penggabungan