ABSTRACT
IGNATIUS EDO PUTRA YANUAR. Graphics Card Utilization as a Computing Tool in Information Retrieval Vector Space Model. Supervised by JULIO ADISANTOSO and ENDANG PURNAMA GIRI.
In recent years, the ability of the graphics card or GPU increase dramatically. This condition allows the GPU to do other than computing or graphics processing is known as the General Purpose GPU (GPGPU). With hundreds to thousands of processors inside GPU, hardware is expected to improve the performance of most applications. Unluckly, the price to be able to implement GPU GPGPU could not be reached by the majority of the community.
This research tried to emulate GPGPU on GPU with Shader Model 2.0a support which is a standard GPU. Vector Space Model is used as a case study because it is easy to implement. Information retrieval computation done in parallel by the CPU and GPU. Process in the GPU is divided into three, namely: multiplication, addition, and sorting. Odd-even transition sort algorithms used to sort the most relevant documents.
The results showed that the emulation GPGPU on GPU with Shader Model 2.0a support able to retrieve the same results with the results retrieved by the CPU. However, this emulation can not produce the expected performance, even the GPU requires more memory than the CPU.
PEMANFAATAN KARTU GRAFIS SEBAGAI ALAT BANTU
DALAM KOMPUTASI TEMU KEMBALI INFORMASI
MODEL RUANG VEKTOR
IGNATIUS EDO PUTRA YANUAR
G64104075
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PEMANFAATAN KARTU GRAFIS SEBAGAI ALAT BANTU
DALAM KOMPUTASI TEMU KEMBALI INFORMASI
MODEL RUANG VEKTOR
IGNATIUS EDO PUTRA YANUAR
G64104075
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PEMANFAATAN KARTU GRAFIS SEBAGAI ALAT BANTU
DALAM KOMPUTASI TEMU KEMBALI INFORMASI
MODEL RUANG VEKTOR
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
IGNATIUS EDO PUTRA YANUAR
G64104075
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
ABSTRACT
IGNATIUS EDO PUTRA YANUAR. Graphics Card Utilization as a Computing Tool in Information Retrieval Vector Space Model. Supervised by JULIO ADISANTOSO and ENDANG PURNAMA GIRI.
In recent years, the ability of the graphics card or GPU increase dramatically. This condition allows the GPU to do other than computing or graphics processing is known as the General Purpose GPU (GPGPU). With hundreds to thousands of processors inside GPU, hardware is expected to improve the performance of most applications. Unluckly, the price to be able to implement GPU GPGPU could not be reached by the majority of the community.
This research tried to emulate GPGPU on GPU with Shader Model 2.0a support which is a standard GPU. Vector Space Model is used as a case study because it is easy to implement. Information retrieval computation done in parallel by the CPU and GPU. Process in the GPU is divided into three, namely: multiplication, addition, and sorting. Odd-even transition sort algorithms used to sort the most relevant documents.
The results showed that the emulation GPGPU on GPU with Shader Model 2.0a support able to retrieve the same results with the results retrieved by the CPU. However, this emulation can not produce the expected performance, even the GPU requires more memory than the CPU.
Judul : Pemanfaatan Kartu Grafis sebagai Alat Bantu dalam Komputasi Temu Kembali Informasi Model Ruang Vektor
Nama : Ignatius Edo Putra Yanuar NRP : G64104075
Menyetujui:
Pembimbing I, Pembimbing II,
Ir. Julio Adisantoso, M.Kom. NIP 196207141986011002
Endang Purnama Giri, S.Kom, M.Kom. NIP 198210102006041027
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. drh. Hasim, DEA NIP 196103281986011002
RIWAYAT HIDUP
Penulis dilahirkan di Malang pada tanggal 7 Januari 1987 dari pasangan Timoteus Marwoto dan Anna Eka Herminayu. Penulis merupakan anak kedua dari dua bersaudara.
PRAKATA
Puji syukur kepada Tuhan Yang Maha Esa atas berkat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Pemanfaatan Kartu Grafis sebagai Alat Bantu dalam Komputasi Temu Kembali Informasi Model Ruang Vektor. Tugas akhir ini merupakan salah satu syarat untuk menyelesaikan jenjang pendidikan Strata Satu Program Studi Ilmu Komputer di Institut Pertanian Bogor.
Penulis mengucapkan terima kasih kepada papa, mama, dan kakak tercinta atas doa, kasih dan dukungan yang selalu diberikan. Penulis juga mengucapkan terima kasih kepada Bapak Ir. Julio Adisantoso, M.Kom. dan Bapak Endang Purnama Giri, S.Kom., M.Kom. selaku pembimbing yang telah membimbing penulis dalam menyelesaikan tugas akhir. Penulis juga mengucapkan terima kasih kepada Bapak Ahmad Ridha, S.Kom, M.S., yang bersedia menjadi penguji pada tugas akhir penulis.
Penyelesaian karya ilmiah ini tidak lepas dari bantuan beberapa pihak, oleh karena itu penulis mengucapkan terima kasih kepada Hani, Yohan, dan William, atas bantuannya dalam penulisan karya ilmiah ini, David, Nanao, Dodo, Ayu, Maul, Indri, dan Popi atas kebersamaannya salama ini, teman-teman Ilkomerz’41 dan Ilkomerz’42 atas semangat yang diberikan, Martin, Afris, Jefry, Mada, Sandro, Sammy, dan teman-teman satu kos lainnya serta semua pihak lain yang telah membantu penulis dan tidak dapat disebutkan satu persatu.
Akhir kata, semoga penelitian ini dapat bermanfaat.
Bogor, Agustus 2009
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Arsitektur CPU dan GPU ... 1
Tekstur ... 2
Tokenisasi ... 2
Vector Space Model ... 2
METODE PENELITIAN CPU Processing ... 3
GPU Processing ... 3
Lingkungan Pengembangan ... 3
HASIL DAN PEMBAHASAN Deskripsi Dokumen Uji ... 3
Algoritme yang Digunakan ... 3
Penggunaan Memori ... 5
Kecepatan Proses ... 5
Proporsi Optimal antara CPU dan GPU ... 6
KESIMPULAN DAN SARAN Kesimpulan ... 7
Saran ... 7
DAFTAR PUSTAKA ... 7
DAFTAR GAMBAR
Halaman
1 Operasi floating-point untuk CPU dan GPU.………... 1
2 Memory bandwidth untuk CPU dan GPU... 1
3 Pembagian transistor di CPU... 2
4 Pembagian transistor di GPU...……….. 2
5 Proses temu kembali informasi ………..………..……….………… 3
6 Scoring pada GPU ……….….…….………. 4
7 Algoritme odd-even transition sort………..………..………...…….… 4
8 Grafik Perbandingan Rata-rata Waktu Proses antara CPU dan GPU …….………...…….…6
DAFTAR LAMPIRAN
Halaman 1 Hasil Pengujian Kecepatan untuk GPU ………...92 Hasil Pengujian Kecepatan untuk CPU ………...……….….... ..……9
3 Grafik Perbandingan Waktu Proses antara CPU dan GPU ………..……… 10
4 Hasil Percobaan dengan Menggunakan GPU Hanya untuk Perkalian………..…… 11
5 Hasil Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU……….………..11
6 Grafik Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU..…….…..……11
7 Tampilan antar Muka Program hanya dengan Menggunakan CPU………..…….…..…… 12
PENDAHULUAN
Latar Belakang
Graphical Processing Unit (GPU) modern dapat ditemukan hampir di setiap komputer. Dalam beberapa tahun terakhir, kemampuan GPU meningkat drastis. Sayangnya, potensi yang tersimpan di dalam GPU tidak digunakan secara optimal pada sebagian besar aplikasi. Umumnya GPU hanya digunakan untuk aplikasi yang membutuhkan komputasi grafis yang tinggi, seperti perangkat lunak Computer Aided Design (CAD) dan games.
GPU computing, atau disebut juga
General Purpose GPU (GPGPU), merupakan konsep pemrograman paralel yang menggunakan GPU sebagai media komputasi untuk memroses komputasi yang umumnya dikerjakan oleh CPU. Konsep ini menghasilkan kecepatan proses yang jauh lebih baik dibanding kecepatan CPU untuk kasus-kasus tertentu. Keunggulan ini tidak berarti GPU dapat menggantikan CPU, namum justru membantu CPU lebih spesifik menangani permasalahan logika dan memberikan permasalahan komputasi pada GPU.
Vector Space Model (VSM), sebagai salah satu model temu kembali informasi, memiliki algoritme yang sederhana sehingga relatif mudah untuk dikembangkan dengan GPU
computing. Bantuan tenaga dari GPU
diharapkan dapat menambah kecepatan eksekusi pada temu kembali informasi.
Abual-Rub (2007) melakukan penelitian menggunakan sejumlah dokumen berisi rangkaian protein. Abual-Rub membuktikan bahwa VSM mampu menemu-kembalikan dokumen relevan dengan hasil yang baik. Govindaraju (2004) melakukan penelitian mengenai operasi database menggunakan GPU sebagai media komputasi. Govindaraju membuktikan bahwa komputasi pada GPU sepuluh kali lebih cepat dibanding komputasi CPU dalam SQL query sederhana. Oleh karena itu, pada penelitian ini digunakan GPU untuk temu kembali informasi menggunakan model VSM.
Tujuan
Tujuan utama dari penelitian ini adalah temu kembali informasi menggunakan GPGPU. Selain itu juga membandingkan kinerja GPU dengan CPU dari sisi memory usage dan kecepatan komputasi.
Ruang Lingkup
GPGPU idealnya membutuhkan kartu grafis yang mendukung Shader Model 4.0 yang harganya belum dapat dijangkau sebagian besar masyarakat. Ruang lingkup penelitian ini difokuskan pada penerapan GPGPU pada kartu grafis yang mendukung Shader Model 2.0a yang merupakan kartu grafis standar.
TINJAUAN PUSTAKA
Arsitektur CPU dan GPU
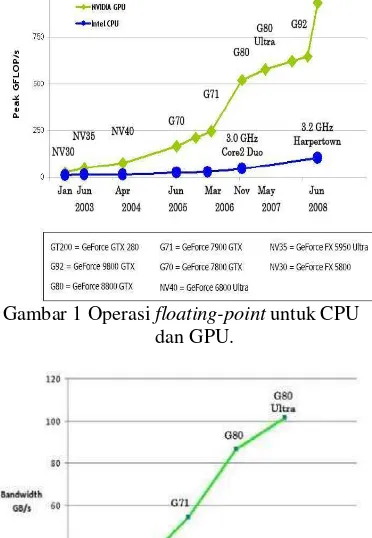
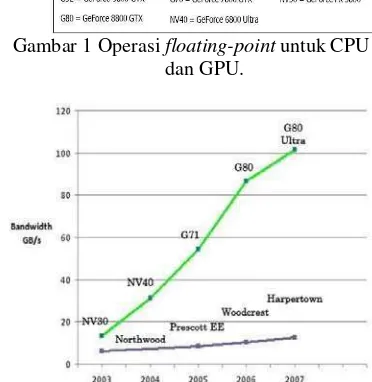
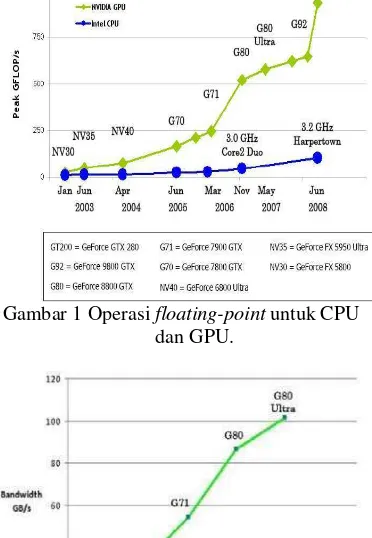
GPU berevolusi menjadi sebuah manycore processor dengan kemampuan komputasi dan memory bandwidth yang tinggi (Gambar 1 dan 2).
Gambar 1 Operasi floating-point untuk CPU dan GPU.
Gambar 2 Memory bandwidth untuk CPU dan GPU.
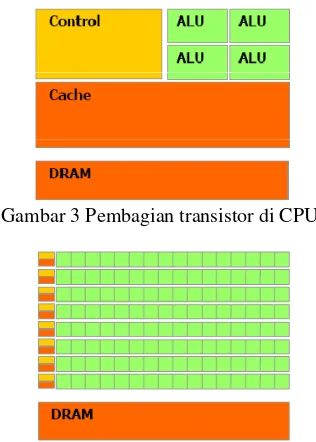
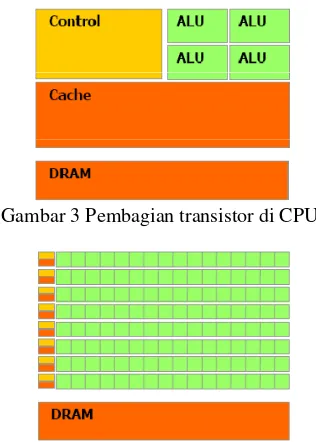
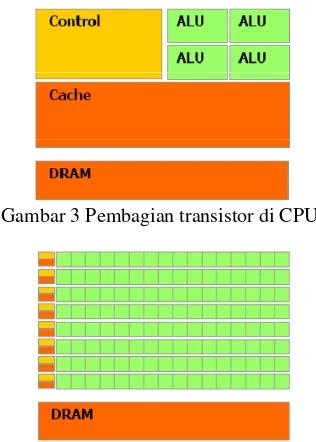
mengolah data daripada data caching dan flow control (Gambar 3 dan 4).
Gambar 3 Pembagian transistor di CPU.
Gambar 4 Pembagian transistor di GPU.
Secara spesifik, GPU cocok untuk mengatasi masalah yang dapat dikategorikan sebagai data-parallel computations (program yang sama dieksekusi pada banyak data elemen secara paralel) dengan intensitas aritmatika yang tinggi (rasio operasi aritmatika dibandingkan operasi pada memori). Oleh karena program dieksekusi pada banyak elemen data dan mempunyai intesitas aritmatika yang tinggi, kalkulasi lebih baik dilakukan secara langsung daripada disimpan di memori.
Tekstur
Data disimpan dalam GPU sebagai tekstur yang merupakan suatu array dua dimensi dan biasanya digunakan sebagai image dan mempunyai kanal-kanal. Sebagai contoh, sebuah texture RGBA mempunyai empat buah kanal – red, green, blue, dan alpha. Data format yang berbeda dapat digunakan di dalam texture, seperti 8-bit bytes, 16-bit integers, dan floating-points. Dalam GPGPU data disimpan di tekstur menggunakan format floating-points, sehingga suatu pixel tidak lagi merepresentasikan suatu warna, melainkan suatu nilai numerik. Pada GPU Shader Model 2.0a terdapat keterbatasan bahwa ukuran texture yang digunakan harus power of two. GPU mampu memroses tekstur dengan dimensi 4096x4096, sehingga satu tekstur mampu menampung lebih dari 16 juta data.
Tokenisasi
Tokenisasi adalah proses memotong dokumen menjadi bagian-bagian kecil (token) dengan cara membuang imbuhan dan kata sambung yang ada. Token yang dihasilkan merupakan kata dasar sehingga token yang dihasilkan lebih sedikit.
Vector Space Model
Vektor Space Model (VSM) menurut
Manning (2008) merupakan metode yang paling populer dalam temu kembali informasi. VSM terdiri atas tiga perhitungan, yaitu:
1. Pembobotan untuk setiap kata indeks di seluruh dokumen. Semakin sering term tersebut muncul dalam setiap dokumen,
maka term tersebut semakin tidak
penting.
2. Pembobotan untuk setiap kata indeks dalam sebuah dokumen. Semakin sering suatu term muncul dalam sebuah dokumen, maka term tersebut semakin penting.
3. Untuk setiap kueri, vektor kueri dibandingkan kemiripannya dengan setiap vektor dokumen. Proses ini bertujuan untuk mengurutkan setiap dokumen berdasarkan kemiripannya dengan kueri. Pembobotan da t dihitung dengan:
pa
dengan:
= frekuensi term i dalam dokumen,
=frekuensi dokumen yang memuat term i,
=jumlah dokumen dalam corpus.
Bobot ini kemudian akan digunakan untuk menghitung cosine im la ty s i ri dengan rumus:
.
,
∑ , · ,∑ , , .
Semakin besar nilai cosine similarity berarti semakin relevan (Manning, 2008).
METODE PENELITIAN
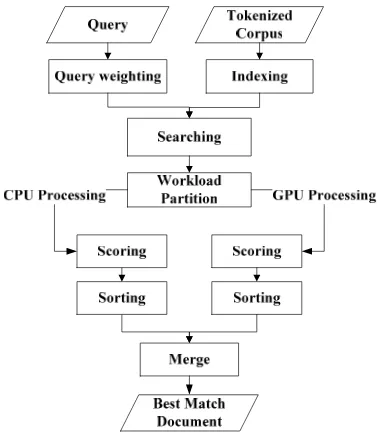
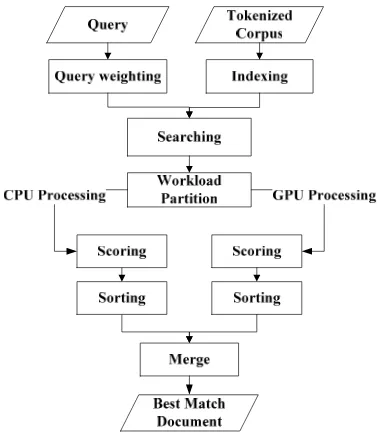
dapat dipecah ke dalam tiga proses yaitu query weighting, scoring, dan sorting. Proses pertama, query weighting adalah pemboboton setiap term pada query yang akan ditemukembalikan. Proses selanjutnya, scoring adalah penghitungan skor kemiripan antara kueri dan seluruh dokumen pada corpus. Proses terakhir, sorting adalah pengurutan seluruh skor kemiripan kueri dengan dokumen (hasil proses scoring), sehingga diperoleh skor kemiripan terbesar. Pada penelitian ini scoring dan sorting dipartisi dan diproses secara paralel oleh CPU dan GPU. Cara memartisinya dengan memecah dokumen-dokumen dalam corpus, sebagian dikerjakan oleh CPU dan sebagian dikerjakan oleh GPU. Untuk penelitian ini, proses dalam CPU dilakukan secara sekuensial. Apabila digambarkan dalam suatu bagan maka proses temu kembali informasi pada penelitian ini terlihat seperti Gambar 5.
Gambar 5 Proses temu kembali informasi.
CPU Processing
Scoring diru uskan sm ebagai berikut :
score (d) =
∑
·
.Apabila d adalah dokumen, t adalah term, n adalah jumlah term pada dokumen, dan q adalah kueri, maka nilai kemiripan dokumen d terhadap kueri q (skor q-d) adalah penjumlahan dari seluruh dot produk term pada dokumen dan term pada kueri. Perhitungan skor q-d pada CPU dilakukan secara sekuensial. Sorting pada CPU menggunakan algoritme quick sort.
GPU Processing
Secara umum tahapan komputasi melalui GPU dapat dijabarkan sebagai berikut:
1. Membuat input buffer di dalam GPU. 2. Membuat output buffer di dalam GPU. 3. Menyalin data masukan dari CPU ke
dalam input buffer.
4. Inisialisasi konstanta yang akan digunakan dalam kernel function.
5. Mengeksekusi kernel function.
6. Menyalin data keluaran ke CPU dari output buffer.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut :
• Mircrosoft Windows Vista Ultimate Edition 32-bit
• Microsoft DirectX 9.0c • NVidia CG 2.0
Perangkat keras yang digunakan adalah sebagai berikut :
• PC Intel Core2Duo 1.8 GHz • RAM 2 GB
• VGA GeForce 7600GT 256 MB
HASIL DAN PEMBAHASAN
Deskripsi Dokumen Uji
Dokumen yang dilakukan untuk pengujian menggunakan corpus IPB yang terdiri dari 1000 dokumen. Dokumen-dokumen tersebut kemudian ditokenisasi sehingga menghasilkan 26.575 term. Term yang dihasilkan dalam proses tokenisasi adalah term tanpa menggunakan stoplist dan stemming. setelah itu term-term tersebut disimpan ke dalam bentuk file.
Algoritme yang Digunakan
Kernel function diemulasi menggunakan pixel shader atau disebut juga fragment shader. Kernel function mempunyai parameter berupa indeks matriks dari output buffer. Indeks inilah yang akan digunakan untuk mengakses data terkait pada input buffer.
Kernel digambarkan sebagai body of
loops. Sebagai contoh jika kita ingin
TRANSFORM-CPU(x,y,in,out)
for x Å 0 to 10000 for y Å 0 to 10000 out[x][y] Å
do_some_work(in[x,y])
Di dalam GPU pendistribusian data terjadi secara otomatis sehingga kita tidak perlu memaralelkan data secara manual. Kita hanya perlu menentukan body of loops.
TRANSFORM-GPU(x,y,in)
return do_some_work(in[x,y])
Perhitungan skor q-d pada GPU dilakukan melalui dua tahap. Tahap pertama, GPU melakukan operasi perkalian secara paralel, setiap nilai bobot term dari dokumen dikalikan dengan nilai bobot term dari kueri. Tahap berikutnya, hasil perkalian tersebut dijumlahkan secara paralel. Hasil keluaran pada tahap perkalian akan digunakan sebagai masukan pada tahap penjumlahan.
Penjumlahan dilakukan dengan cara menjumlahkan suatu elemen dengan elemen setelahnya. Proses yang sama diulang tetapi menjumlahkan dengan elemen ke-2i-1 setelahnya, dengan i adalah banyaknya iterasi. Proses ini berhenti pada iterasi ke-log . Prosesnya terlihat pada Gambar 6. Pada gambar tersebut, elemen yang tidak dihitamkan tidak lagi digunakan dalam algoritme ini karena nilai elemen tersebut sudah tersimpan dalam elemen yang dihitamkan.
Gambar 6 Scoring pada GPU.
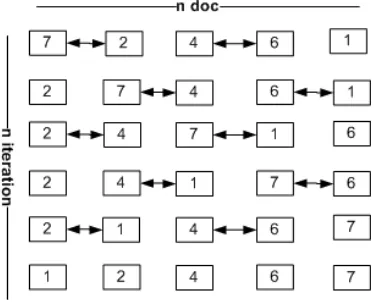
Sorting pada GPU menggunakan algoritme odd-even transition sort. Algoritme ini melakukan proses compare and swap dengan
pasangan indeks ganjil-genap, kemudian dengan pasangan indeks genap-ganjil, lalu kembali lagi dengan pasangan indeks ganjil-genap, dan begitu seterusnya, sehingga untuk mengurutkan data membutuhkan /2 compare and swap untuk pasangan indeks ganjil-genap dan /2 compare and swap untuk pasangan indeks genap-ganjil. Ilustrasi algoritma odd-even transition sort terlihat pada gambar 7.
Gambar 7 Algoritme odd-even transition sort.
Algoritme yang digunakan dalam penelitian berbeda untuk CPU dan GPU. Untuk CPU digunakan algoritme scoring dan
quick sort. Algoritme SCORING-CPU
digunakan untuk menghitung nilai kemiripan antara dokumen dan kueri. Algoritme ini menggunakan W yang merupakan bobot term dalam suatu dokumen, n jumlah dokumen,
dan m jumlah term. Hasil dari algoritme ini
adalah Score yaitu nilai kemiripan antara dokumen dan kueri.
SCORING-CPU (Score,W,n,m) for i Å 1 to n
Score[i] Å 0 for j Å 1 to m
Score[i]ÅScore[i]+W[i,j]xW[q,j]
Algoritme quick sort menggunakan
std::sort dari C++ Standart Template
Library (STL). Algoritme ini digunakan untuk mengurutkan hasil scoring pada algoritme SCORING-CPU secara descending.
MULTIPLY-GPU(
termIndex,DocTerm,QueryTerm)
return DocTerm[termIndex] . QueryTerm[termIndex]
Algoritme MULTIPLY-GPU menerima input termIndex, DocTerm, dan
indeks term pada dokumen dan kueri sedangkan DocTerm adalah matriks yang berisi bobot term pada dokumen yang akan diberi skor. QueryTerm adalah matriks yang berisi bobot term pada kueri.
SUMMATION-GPU(
termIndex,iteration,DocTerm)
partner Å termIndex
+ pow(2,iteration-1) return DocTerm[termIndex]+DocTerm[]
Algoritme SUMMATION-GPU menerima input termIndex, iteration, dan
DocTerm. termIndex merupakan indeks
term pada dokumen dan kueri sedangkan DocTerm adalah matriks yang berisi bobot term pada dokumen yang akan diberi skor. CPU memanggil fungsi SUMMATION-GPU diiterasi mulai dari satu sampai dengan log(n) dengan n adalah jumlah term.
SORT-GPU(
termIndex,transition,DocScore)
if docIndex mod 2 = transition compare Å 1
else
compare Å -1
partner Å termIndex + compare
if DocScore[termIndex] . compare > DocScore[partner] . compare return DocScore[termIndex]
else
return DocScore[partner]
Algoritme SORT-GPU diiterasi mulai dari satu sampai dengan jumlah dokumen yang ada. Algoritme ini menerima input
termIndex, transition, dan
docScore. termIndex merupakan indeks
term pada dokumen dan kueri sedangkan DocScore adalah matriks yang berisi skor
setiap dokumen. transition digunakan untuk memilih model genap-ganjil atau ganjil-genap. Bila menggunakan model genap-ganjil, maka transition bernilai 0, dan bila menggunakan model ganjil-genap, maka transition bernilai 1.
Penggunaan Memori
Pada penelitian ini dicobakan temu kembali suatu kueri dari 1000 dokumen. Setelah melalui proses tokenisasi, diperoleh 26575 term dari 1000 dokumen tersebut. Apabila satu term membutuhkan alokasi 4 byte memori, maka pada CPU, memori yang dibutuhkan untuk memroses 26575 term adalah sebanyak 1000 x 26575 x 4 byte = 101 MB. Pada GPU, memori yang dibutuhkan adalah sebanyak 1000 x 32768 x 4 = 128 MB. Nilai 32768 berasal dari 256x128 ukuran tekstur. Untuk dapat menampung 26575 term, GPU tidak bisa menyediakan ruang yang tepat sama, karena data disimpan dalam GPU sebagai tekstur dengan dimensi 2 (power of two). Dalam kasus ini, apabila dibandingkan penggunaan memori pada GPU lebih besar dari pada penggunaan memori pada CPU.
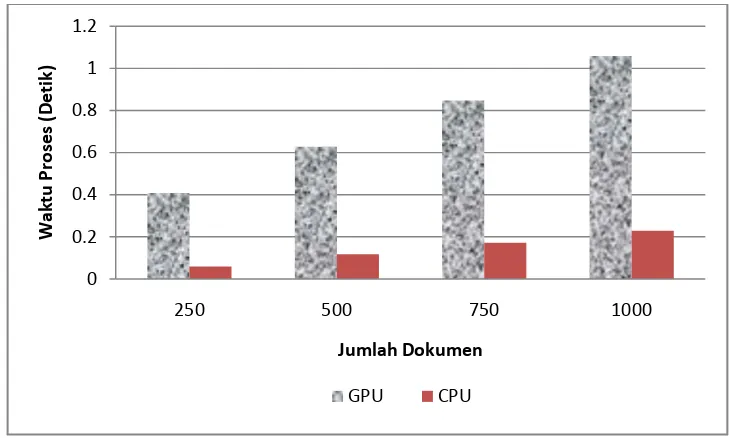
Kecepatan Proses
Gambar 8. Grafik Perbandingan Rata-rata Waktu Proses antara CPU dan GPU
Pada kondisi ideal kecepatan GPU lebih baik daripada CPU. Hal ini terbukti pada saat proses komputasi hanya melibatkan proses perkalian, tanpa ada penjumlahan dan sorting, GPU sanggup melakukan perkalian hingga tiga kali lebih cepat dibandingkan CPU. Untuk operasi penjumlahan dan sorting CPU jauh mengungguli GPU. Untuk hasil percobaannya dapat dilihat pada Tabel 1.
Tabel 1 Perbandingan Operasi Utama pada CPU dan GPU
Perkalian (detik) Penjumlahan (detik) Sorting (detik)
GPU 0.079993 0.968640 0.360896
CPU 0.214159 0.143024 0.002568
Hasil percobaan pada GPU untuk penjumlahandan sorting membutuhkan waktu proses yang lebih lama daripada CPU. Hal ini dikarenakan kompleksitas algoritme GPU untuk operasi tersebut lebih besar daripada CPU.
Kompleksitas penjumlahan pada GPU adalah N log(N) dan kompleksitas sorting-nya adalah N2. Meskipun sorting pada GPU memiliki kompleksitas yang lebih tinggi dari pada kompleksitas penjumlahan tetapi proses sorting lebih cepat daripada penjumlahan. Hal ini disebabkan N dalam sorting merupakan jumlah dokumen yaitu 1000 dokumen dan N dalam penjumlahan merupakan jumlah term yang memiliki jumlah 26575 term dan diiterasi sebanyak jumlah dokumen (1000
kali). Perbedaan nilai N yang jauh menyebabkan kompleksitas pada operasi penjumlahan menjadi lebih besar daripada sorting.
Seperti yang terlihat pada Tabel 1, GPU memiliki keunggulan dalam melakukan proses perkalian sedangkan CPU unggul dalam proses penjumlahan dan sorting. Dengan fakta tersebut timbul ide untuk memanfaatkan keunggulan pada CPU dan GPU. GPU unggul dalam proses perkalian maka GPU hanya akan melakukan proses perkalian sedangkan operasi sisanya (penjumlahan dan sorting) dilakukan oleh CPU.
Hasil pengujian ini dapat dilihat pada Lampiran 4. Rata-rata waktu proses yang dihasilkan dalam percobaan ini adalah 16.53731 detik. Percobaan ini menghasilkan waktu proses yang lebih lama dari pengujian pertama. Hal ini dikarenakan pada pengujian yang pertama output dari GPU ke CPU hanya merupakan satu buah matriks yang berisi 1.000 data berupa indeks descending. Lain halnya dengan pengujian kedua yang mengirimkan data dari GPU ke CPU berupa 1.000 buah matriks yang masing-masing berisi 26.575 data yang berupa hasil perkalian antara bobot term dokumen dengan kueri sehingga waktu transfer yang dibutuhkan akan jauh lebih lama.
Proporsi Optimal antara CPU dan GPU Pada kedua pengujian sebelumnya dapat dilihat bahwa percobaan pertama memberikan hasil yang lebih memuaskan oleh karena itu dilakukan pengujian ketiga yang merupakan 0 0.2 0.4 0.6 0.8 1 1.2
250 500 750 1000
Waktu
Proses
(Detik)
Jumlah Dokumen
pengembangan dari pengujian pertama. Pengujian pada tahap ini menggunakan algoritme yang sama dengan algoritme pada percobaan pertama. Yang membedakan adalah cara pengujiannya.
Pada pengujian tahap ini dicari proporsi optimal pendistribusian dokumen pada CPU dan GPU. Hal ini dilakukan karena adanya kemungkinan bahwa GPU masih dapat membantu CPU dalam mempercepat proses. Pada pengujian tahap ini diperoleh proporsi optimal yaitu 960 dokumen untuk diproses CPU dan sisanya yaitu 40 dokumen diproses GPU. Proporsi ini membutuhkan waktu proses selama 0.233671 detik untuk CPU dan 0.2244426 detik untuk GPU, sehingga waktu proses keseluruhan menjadi 0.2244426 karena CPU dan GPU bekerja secara paralel. Tabel pengujian selengkapnya dapat dilihat pada Lampiran 5.
Tampilan antar muka program dan contoh penggunaannya dapat dilihat pada lampiran 7. Semakin slider digeser ke arah CPU maka semakin banyak dokumen yang didistribusikan ke CPU. Demikian juga sebaliknya pada lampiran 8, semakin slider digeser ke arah GPU maka semakin banyak dokumen yang didistribusikan ke GPU.
KESIMPULAN DAN SARAN
Kesimpulan
Dari implementasi Vector Space Model menggunakan GPU ini, diperoleh beberapa kesimpulan, yaitu:
1. GPU mampu digunakan untuk temu kembali menggunakan metode Vector Space Model. Hasil temu kembali antara dan GPU tepat sama. Hanya berbeda urutan pada dokumen yang mempunyai nilai similarity yang sama.
2. GPU yang digunakan pada penelitian ini tidak mampu mengimbangi kecepatan CPU. Hal ini disebabkan oleh keterbatasan perangkat keras dan pustaka yang digunakan.
3. GPU membutuhkan alokasi memori dengan ukuran power of two, sehingga tidak mampu mengalokasikan memori yang dibutuhkan secara tepat. Hal ini menyebabkan penggunaan memori pada GPU lebih besar daripada CPU.
4. Proporsi optimal didapat dengan mendistribusikan 960 dokumen ke CPU dan 40 dokumen ke GPU. Proporsi ini membutuhkan waktu proses selama 0.2336710 detik untuk CPU dan 0.2244426 detik untuk GPU.
Saran
Saran untuk penelitian selanjutnya adalah:
1. Penggunaan pustaka khusus GPGPU seperti OpenCL. Pada saat penelitian ini ditulis, pustaka ini masih dalam tahap pengembangan.
2. Analisis perbandingan algoritme sorting pada GPU (even transition sort, odd-even merge sort, dan bitonic merge sort).
DAFTAR PUSTAKA
Abual-Rub MS, Abdullah R, Rashid NA. 2007. A Modified Vector Space Model for Protein Retrieval. IJCSNS International Journal of Computer Science and Network Security, VOL.7 No 9, September 2007. Cormen TH, Leiserson CE, Rivest RL, Stein
C. 2003. Introduction to Algorithms. England : MIT Press.
Govindaraju NK, et al. 2004. Fast Computation of Database Operations using Graphics Processors. Proceedings of the 2004 ACM SIGMOD international conference on Management of data; 2004. New York, NY : ACM, hlm 215-256.
Grama A, Gupta A, Karypsi G, Kumar V. 2003. Introduction to Parallel Computing. England : Pearson Education.
Manning CD, Raghavan P., Schütze H. 2008. Introduction to Information Retrieval. Cambridge : Cambridge University Press.
NVidia CUDA Programming Guide.
http://developer.download.nvidia.com/com pute/cuda/2_0/docs/NVIDIA_CUDA_Pro gramming_Guide_2.0.pdf
[14 Desember 2008].
Ujaldon M, Saltz J. 2005. The GPU as an Indirection Engine for a Fast Information Retrieval.
Lampiran 1 Hasil Pengujian Kecepatan untuk GPU dengan NVidia GeForce 7600GT 256 MB
Jumlah
Dokumen
Percobaan
250 500 750 1000
I 0.408731 0.629764 0.848080 1.058242
II 0.408514 0.627643 0.849722 1.059130
III 0.407703 0.627410 0.849204 1.058855
IV 0.410138 0.625872 0.846324 1.059262
V 0.408039 0.625708 0.846568 1.057303
Min 0.407703 0.625708 0.846324 1.057303
Max 0.410138 0.629764 0.849722 1.059262
Mean 0.408625 0.627279 0.847980 1.058558
Deviasi 0.000936 0.001641 0.001523 0.000804
Lampiran 2 Hasil Pengujian Kecepatan untuk CPU dengan Core2Duo @1,8 GHz 2 GB
Jumlah
Dokumen
Percobaan
250 500 750 1000
I 0.057096 0.113787 0.172135 0.229296
II 0.058416 0.122536 0.171951 0.228380
III 0.057263 0.116249 0.171371 0.228768
IV 0.057095 0.120622 0.170481 0.228040
V 0.064641 0.113423 0.171372 0.227793
Min 0.057095 0.113423 0.170481 0.227793
Max 0.064641 0.122536 0.172135 0.229296
Mean 0.058902 0.117323 0.171462 0.228455
Lampiran 3 Grafik Perbandingan Waktu Proses antara CPU dan GPU
0 0.2 0.4 0.6 0.8 1 1.2
250 500 750 1000
Waktu
Proses
(detik)
Jumlah Dokumen
Lampiran 4 Tabel Hasil Percobaan dengan Menggunakan GPU Hanya untuk Perkalian
Percobaan Waktu Proses (Detik)
1 16.287366 2 16.421183 3 16.875864
4 16.523233 5 16.578902
Min 16.287366
Max 16.875864
Median 16.523230
Mean 16.537310
Deviasi 0.2193770
Lampiran 5 Hasil Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU
Proporsi Dokumen Rata-rata Waktu Proses
CPU GPU CPU GPU
980 20 0.206467 0.235119
970 30 0.214151 0.241237
960 40 0.224443 0.233671
950 50 0.237622 0.229072
940 60 0.242955 0.226976
Lampiran 6 Grafik Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU
0.18 0.19 0.2 0.21 0.22 0.23 0.24 0.25
20:980 30:970 40:960 50:950 60:940
Waktu
Proses
(detik)
Perbandingan jumlah dokumen (GPU : CPU)
Lampiran 7 Tampilan antar Muka Program hanya dengan Menggunakan CPU
Lampiran 1 Hasil Pengujian Kecepatan untuk GPU dengan NVidia GeForce 7600GT 256 MB
Jumlah
Dokumen
Percobaan
250 500 750 1000
I 0.408731 0.629764 0.848080 1.058242
II 0.408514 0.627643 0.849722 1.059130
III 0.407703 0.627410 0.849204 1.058855
IV 0.410138 0.625872 0.846324 1.059262
V 0.408039 0.625708 0.846568 1.057303
Min 0.407703 0.625708 0.846324 1.057303
Max 0.410138 0.629764 0.849722 1.059262
Mean 0.408625 0.627279 0.847980 1.058558
Deviasi 0.000936 0.001641 0.001523 0.000804
Lampiran 2 Hasil Pengujian Kecepatan untuk CPU dengan Core2Duo @1,8 GHz 2 GB
Jumlah
Dokumen
Percobaan
250 500 750 1000
I 0.057096 0.113787 0.172135 0.229296
II 0.058416 0.122536 0.171951 0.228380
III 0.057263 0.116249 0.171371 0.228768
IV 0.057095 0.120622 0.170481 0.228040
V 0.064641 0.113423 0.171372 0.227793
Min 0.057095 0.113423 0.170481 0.227793
Max 0.064641 0.122536 0.172135 0.229296
Mean 0.058902 0.117323 0.171462 0.228455
Lampiran 3 Grafik Perbandingan Waktu Proses antara CPU dan GPU
0 0.2 0.4 0.6 0.8 1 1.2
250 500 750 1000
Waktu
Proses
(detik)
Jumlah Dokumen
Lampiran 4 Tabel Hasil Percobaan dengan Menggunakan GPU Hanya untuk Perkalian
Percobaan Waktu Proses (Detik)
1 16.287366 2 16.421183 3 16.875864
4 16.523233 5 16.578902
Min 16.287366
Max 16.875864
Median 16.523230
Mean 16.537310
Deviasi 0.2193770
Lampiran 5 Hasil Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU
Proporsi Dokumen Rata-rata Waktu Proses
CPU GPU CPU GPU
980 20 0.206467 0.235119
970 30 0.214151 0.241237
960 40 0.224443 0.233671
950 50 0.237622 0.229072
940 60 0.242955 0.226976
Lampiran 6 Grafik Percobaan Penentuan Proporsi Optimal Dokuman antara CPU dan GPU
0.18 0.19 0.2 0.21 0.22 0.23 0.24 0.25
20:980 30:970 40:960 50:950 60:940
Waktu
Proses
(detik)
Perbandingan jumlah dokumen (GPU : CPU)
Lampiran 7 Tampilan antar Muka Program hanya dengan Menggunakan CPU
PENDAHULUAN
Latar Belakang
Graphical Processing Unit (GPU) modern dapat ditemukan hampir di setiap komputer. Dalam beberapa tahun terakhir, kemampuan GPU meningkat drastis. Sayangnya, potensi yang tersimpan di dalam GPU tidak digunakan secara optimal pada sebagian besar aplikasi. Umumnya GPU hanya digunakan untuk aplikasi yang membutuhkan komputasi grafis yang tinggi, seperti perangkat lunak Computer Aided Design (CAD) dan games.
GPU computing, atau disebut juga
General Purpose GPU (GPGPU), merupakan konsep pemrograman paralel yang menggunakan GPU sebagai media komputasi untuk memroses komputasi yang umumnya dikerjakan oleh CPU. Konsep ini menghasilkan kecepatan proses yang jauh lebih baik dibanding kecepatan CPU untuk kasus-kasus tertentu. Keunggulan ini tidak berarti GPU dapat menggantikan CPU, namum justru membantu CPU lebih spesifik menangani permasalahan logika dan memberikan permasalahan komputasi pada GPU.
Vector Space Model (VSM), sebagai salah satu model temu kembali informasi, memiliki algoritme yang sederhana sehingga relatif mudah untuk dikembangkan dengan GPU
computing. Bantuan tenaga dari GPU
diharapkan dapat menambah kecepatan eksekusi pada temu kembali informasi.
Abual-Rub (2007) melakukan penelitian menggunakan sejumlah dokumen berisi rangkaian protein. Abual-Rub membuktikan bahwa VSM mampu menemu-kembalikan dokumen relevan dengan hasil yang baik. Govindaraju (2004) melakukan penelitian mengenai operasi database menggunakan GPU sebagai media komputasi. Govindaraju membuktikan bahwa komputasi pada GPU sepuluh kali lebih cepat dibanding komputasi CPU dalam SQL query sederhana. Oleh karena itu, pada penelitian ini digunakan GPU untuk temu kembali informasi menggunakan model VSM.
Tujuan
Tujuan utama dari penelitian ini adalah temu kembali informasi menggunakan GPGPU. Selain itu juga membandingkan kinerja GPU dengan CPU dari sisi memory usage dan kecepatan komputasi.
Ruang Lingkup
GPGPU idealnya membutuhkan kartu grafis yang mendukung Shader Model 4.0 yang harganya belum dapat dijangkau sebagian besar masyarakat. Ruang lingkup penelitian ini difokuskan pada penerapan GPGPU pada kartu grafis yang mendukung Shader Model 2.0a yang merupakan kartu grafis standar.
TINJAUAN PUSTAKA
Arsitektur CPU dan GPU
GPU berevolusi menjadi sebuah manycore processor dengan kemampuan komputasi dan memory bandwidth yang tinggi (Gambar 1 dan 2).
Gambar 1 Operasi floating-point untuk CPU dan GPU.
Gambar 2 Memory bandwidth untuk CPU dan GPU.
PENDAHULUAN
Latar Belakang
Graphical Processing Unit (GPU) modern dapat ditemukan hampir di setiap komputer. Dalam beberapa tahun terakhir, kemampuan GPU meningkat drastis. Sayangnya, potensi yang tersimpan di dalam GPU tidak digunakan secara optimal pada sebagian besar aplikasi. Umumnya GPU hanya digunakan untuk aplikasi yang membutuhkan komputasi grafis yang tinggi, seperti perangkat lunak Computer Aided Design (CAD) dan games.
GPU computing, atau disebut juga
General Purpose GPU (GPGPU), merupakan konsep pemrograman paralel yang menggunakan GPU sebagai media komputasi untuk memroses komputasi yang umumnya dikerjakan oleh CPU. Konsep ini menghasilkan kecepatan proses yang jauh lebih baik dibanding kecepatan CPU untuk kasus-kasus tertentu. Keunggulan ini tidak berarti GPU dapat menggantikan CPU, namum justru membantu CPU lebih spesifik menangani permasalahan logika dan memberikan permasalahan komputasi pada GPU.
Vector Space Model (VSM), sebagai salah satu model temu kembali informasi, memiliki algoritme yang sederhana sehingga relatif mudah untuk dikembangkan dengan GPU
computing. Bantuan tenaga dari GPU
diharapkan dapat menambah kecepatan eksekusi pada temu kembali informasi.
Abual-Rub (2007) melakukan penelitian menggunakan sejumlah dokumen berisi rangkaian protein. Abual-Rub membuktikan bahwa VSM mampu menemu-kembalikan dokumen relevan dengan hasil yang baik. Govindaraju (2004) melakukan penelitian mengenai operasi database menggunakan GPU sebagai media komputasi. Govindaraju membuktikan bahwa komputasi pada GPU sepuluh kali lebih cepat dibanding komputasi CPU dalam SQL query sederhana. Oleh karena itu, pada penelitian ini digunakan GPU untuk temu kembali informasi menggunakan model VSM.
Tujuan
Tujuan utama dari penelitian ini adalah temu kembali informasi menggunakan GPGPU. Selain itu juga membandingkan kinerja GPU dengan CPU dari sisi memory usage dan kecepatan komputasi.
Ruang Lingkup
GPGPU idealnya membutuhkan kartu grafis yang mendukung Shader Model 4.0 yang harganya belum dapat dijangkau sebagian besar masyarakat. Ruang lingkup penelitian ini difokuskan pada penerapan GPGPU pada kartu grafis yang mendukung Shader Model 2.0a yang merupakan kartu grafis standar.
TINJAUAN PUSTAKA
Arsitektur CPU dan GPU
GPU berevolusi menjadi sebuah manycore processor dengan kemampuan komputasi dan memory bandwidth yang tinggi (Gambar 1 dan 2).
Gambar 1 Operasi floating-point untuk CPU dan GPU.
Gambar 2 Memory bandwidth untuk CPU dan GPU.
mengolah data daripada data caching dan flow control (Gambar 3 dan 4).
Gambar 3 Pembagian transistor di CPU.
Gambar 4 Pembagian transistor di GPU.
Secara spesifik, GPU cocok untuk mengatasi masalah yang dapat dikategorikan sebagai data-parallel computations (program yang sama dieksekusi pada banyak data elemen secara paralel) dengan intensitas aritmatika yang tinggi (rasio operasi aritmatika dibandingkan operasi pada memori). Oleh karena program dieksekusi pada banyak elemen data dan mempunyai intesitas aritmatika yang tinggi, kalkulasi lebih baik dilakukan secara langsung daripada disimpan di memori.
Tekstur
Data disimpan dalam GPU sebagai tekstur yang merupakan suatu array dua dimensi dan biasanya digunakan sebagai image dan mempunyai kanal-kanal. Sebagai contoh, sebuah texture RGBA mempunyai empat buah kanal – red, green, blue, dan alpha. Data format yang berbeda dapat digunakan di dalam texture, seperti 8-bit bytes, 16-bit integers, dan floating-points. Dalam GPGPU data disimpan di tekstur menggunakan format floating-points, sehingga suatu pixel tidak lagi merepresentasikan suatu warna, melainkan suatu nilai numerik. Pada GPU Shader Model 2.0a terdapat keterbatasan bahwa ukuran texture yang digunakan harus power of two. GPU mampu memroses tekstur dengan dimensi 4096x4096, sehingga satu tekstur mampu menampung lebih dari 16 juta data.
Tokenisasi
Tokenisasi adalah proses memotong dokumen menjadi bagian-bagian kecil (token) dengan cara membuang imbuhan dan kata sambung yang ada. Token yang dihasilkan merupakan kata dasar sehingga token yang dihasilkan lebih sedikit.
Vector Space Model
Vektor Space Model (VSM) menurut
Manning (2008) merupakan metode yang paling populer dalam temu kembali informasi. VSM terdiri atas tiga perhitungan, yaitu:
1. Pembobotan untuk setiap kata indeks di seluruh dokumen. Semakin sering term tersebut muncul dalam setiap dokumen,
maka term tersebut semakin tidak
penting.
2. Pembobotan untuk setiap kata indeks dalam sebuah dokumen. Semakin sering suatu term muncul dalam sebuah dokumen, maka term tersebut semakin penting.
3. Untuk setiap kueri, vektor kueri dibandingkan kemiripannya dengan setiap vektor dokumen. Proses ini bertujuan untuk mengurutkan setiap dokumen berdasarkan kemiripannya dengan kueri. Pembobotan da t dihitung dengan:
pa
dengan:
= frekuensi term i dalam dokumen,
=frekuensi dokumen yang memuat term i,
=jumlah dokumen dalam corpus.
Bobot ini kemudian akan digunakan untuk menghitung cosine im la ty s i ri dengan rumus:
.
,
∑ , · ,∑ , , .
Semakin besar nilai cosine similarity berarti semakin relevan (Manning, 2008).
METODE PENELITIAN
mengolah data daripada data caching dan flow control (Gambar 3 dan 4).
Gambar 3 Pembagian transistor di CPU.
Gambar 4 Pembagian transistor di GPU.
Secara spesifik, GPU cocok untuk mengatasi masalah yang dapat dikategorikan sebagai data-parallel computations (program yang sama dieksekusi pada banyak data elemen secara paralel) dengan intensitas aritmatika yang tinggi (rasio operasi aritmatika dibandingkan operasi pada memori). Oleh karena program dieksekusi pada banyak elemen data dan mempunyai intesitas aritmatika yang tinggi, kalkulasi lebih baik dilakukan secara langsung daripada disimpan di memori.
Tekstur
Data disimpan dalam GPU sebagai tekstur yang merupakan suatu array dua dimensi dan biasanya digunakan sebagai image dan mempunyai kanal-kanal. Sebagai contoh, sebuah texture RGBA mempunyai empat buah kanal – red, green, blue, dan alpha. Data format yang berbeda dapat digunakan di dalam texture, seperti 8-bit bytes, 16-bit integers, dan floating-points. Dalam GPGPU data disimpan di tekstur menggunakan format floating-points, sehingga suatu pixel tidak lagi merepresentasikan suatu warna, melainkan suatu nilai numerik. Pada GPU Shader Model 2.0a terdapat keterbatasan bahwa ukuran texture yang digunakan harus power of two. GPU mampu memroses tekstur dengan dimensi 4096x4096, sehingga satu tekstur mampu menampung lebih dari 16 juta data.
Tokenisasi
Tokenisasi adalah proses memotong dokumen menjadi bagian-bagian kecil (token) dengan cara membuang imbuhan dan kata sambung yang ada. Token yang dihasilkan merupakan kata dasar sehingga token yang dihasilkan lebih sedikit.
Vector Space Model
Vektor Space Model (VSM) menurut
Manning (2008) merupakan metode yang paling populer dalam temu kembali informasi. VSM terdiri atas tiga perhitungan, yaitu:
1. Pembobotan untuk setiap kata indeks di seluruh dokumen. Semakin sering term tersebut muncul dalam setiap dokumen,
maka term tersebut semakin tidak
penting.
2. Pembobotan untuk setiap kata indeks dalam sebuah dokumen. Semakin sering suatu term muncul dalam sebuah dokumen, maka term tersebut semakin penting.
3. Untuk setiap kueri, vektor kueri dibandingkan kemiripannya dengan setiap vektor dokumen. Proses ini bertujuan untuk mengurutkan setiap dokumen berdasarkan kemiripannya dengan kueri. Pembobotan da t dihitung dengan:
pa
dengan:
= frekuensi term i dalam dokumen,
=frekuensi dokumen yang memuat term i,
=jumlah dokumen dalam corpus.
Bobot ini kemudian akan digunakan untuk menghitung cosine im la ty s i ri dengan rumus:
.
,
∑ , · ,∑ , , .
Semakin besar nilai cosine similarity berarti semakin relevan (Manning, 2008).
METODE PENELITIAN
dapat dipecah ke dalam tiga proses yaitu query weighting, scoring, dan sorting. Proses pertama, query weighting adalah pemboboton setiap term pada query yang akan ditemukembalikan. Proses selanjutnya, scoring adalah penghitungan skor kemiripan antara kueri dan seluruh dokumen pada corpus. Proses terakhir, sorting adalah pengurutan seluruh skor kemiripan kueri dengan dokumen (hasil proses scoring), sehingga diperoleh skor kemiripan terbesar. Pada penelitian ini scoring dan sorting dipartisi dan diproses secara paralel oleh CPU dan GPU. Cara memartisinya dengan memecah dokumen-dokumen dalam corpus, sebagian dikerjakan oleh CPU dan sebagian dikerjakan oleh GPU. Untuk penelitian ini, proses dalam CPU dilakukan secara sekuensial. Apabila digambarkan dalam suatu bagan maka proses temu kembali informasi pada penelitian ini terlihat seperti Gambar 5.
Gambar 5 Proses temu kembali informasi.
CPU Processing
Scoring diru uskan sm ebagai berikut :
score (d) =
∑
·
.Apabila d adalah dokumen, t adalah term, n adalah jumlah term pada dokumen, dan q adalah kueri, maka nilai kemiripan dokumen d terhadap kueri q (skor q-d) adalah penjumlahan dari seluruh dot produk term pada dokumen dan term pada kueri. Perhitungan skor q-d pada CPU dilakukan secara sekuensial. Sorting pada CPU menggunakan algoritme quick sort.
GPU Processing
Secara umum tahapan komputasi melalui GPU dapat dijabarkan sebagai berikut:
1. Membuat input buffer di dalam GPU. 2. Membuat output buffer di dalam GPU. 3. Menyalin data masukan dari CPU ke
dalam input buffer.
4. Inisialisasi konstanta yang akan digunakan dalam kernel function.
5. Mengeksekusi kernel function.
6. Menyalin data keluaran ke CPU dari output buffer.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut :
• Mircrosoft Windows Vista Ultimate Edition 32-bit
• Microsoft DirectX 9.0c • NVidia CG 2.0
Perangkat keras yang digunakan adalah sebagai berikut :
• PC Intel Core2Duo 1.8 GHz • RAM 2 GB
• VGA GeForce 7600GT 256 MB
HASIL DAN PEMBAHASAN
Deskripsi Dokumen Uji
Dokumen yang dilakukan untuk pengujian menggunakan corpus IPB yang terdiri dari 1000 dokumen. Dokumen-dokumen tersebut kemudian ditokenisasi sehingga menghasilkan 26.575 term. Term yang dihasilkan dalam proses tokenisasi adalah term tanpa menggunakan stoplist dan stemming. setelah itu term-term tersebut disimpan ke dalam bentuk file.
Algoritme yang Digunakan
Kernel function diemulasi menggunakan pixel shader atau disebut juga fragment shader. Kernel function mempunyai parameter berupa indeks matriks dari output buffer. Indeks inilah yang akan digunakan untuk mengakses data terkait pada input buffer.
Kernel digambarkan sebagai body of
loops. Sebagai contoh jika kita ingin
dapat dipecah ke dalam tiga proses yaitu query weighting, scoring, dan sorting. Proses pertama, query weighting adalah pemboboton setiap term pada query yang akan ditemukembalikan. Proses selanjutnya, scoring adalah penghitungan skor kemiripan antara kueri dan seluruh dokumen pada corpus. Proses terakhir, sorting adalah pengurutan seluruh skor kemiripan kueri dengan dokumen (hasil proses scoring), sehingga diperoleh skor kemiripan terbesar. Pada penelitian ini scoring dan sorting dipartisi dan diproses secara paralel oleh CPU dan GPU. Cara memartisinya dengan memecah dokumen-dokumen dalam corpus, sebagian dikerjakan oleh CPU dan sebagian dikerjakan oleh GPU. Untuk penelitian ini, proses dalam CPU dilakukan secara sekuensial. Apabila digambarkan dalam suatu bagan maka proses temu kembali informasi pada penelitian ini terlihat seperti Gambar 5.
Gambar 5 Proses temu kembali informasi.
CPU Processing
Scoring diru uskan sm ebagai berikut :
score (d) =
∑
·
.Apabila d adalah dokumen, t adalah term, n adalah jumlah term pada dokumen, dan q adalah kueri, maka nilai kemiripan dokumen d terhadap kueri q (skor q-d) adalah penjumlahan dari seluruh dot produk term pada dokumen dan term pada kueri. Perhitungan skor q-d pada CPU dilakukan secara sekuensial. Sorting pada CPU menggunakan algoritme quick sort.
GPU Processing
Secara umum tahapan komputasi melalui GPU dapat dijabarkan sebagai berikut:
1. Membuat input buffer di dalam GPU. 2. Membuat output buffer di dalam GPU. 3. Menyalin data masukan dari CPU ke
dalam input buffer.
4. Inisialisasi konstanta yang akan digunakan dalam kernel function.
5. Mengeksekusi kernel function.
6. Menyalin data keluaran ke CPU dari output buffer.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut :
• Mircrosoft Windows Vista Ultimate Edition 32-bit
• Microsoft DirectX 9.0c • NVidia CG 2.0
Perangkat keras yang digunakan adalah sebagai berikut :
• PC Intel Core2Duo 1.8 GHz • RAM 2 GB
• VGA GeForce 7600GT 256 MB
HASIL DAN PEMBAHASAN
Deskripsi Dokumen Uji
Dokumen yang dilakukan untuk pengujian menggunakan corpus IPB yang terdiri dari 1000 dokumen. Dokumen-dokumen tersebut kemudian ditokenisasi sehingga menghasilkan 26.575 term. Term yang dihasilkan dalam proses tokenisasi adalah term tanpa menggunakan stoplist dan stemming. setelah itu term-term tersebut disimpan ke dalam bentuk file.
Algoritme yang Digunakan
Kernel function diemulasi menggunakan pixel shader atau disebut juga fragment shader. Kernel function mempunyai parameter berupa indeks matriks dari output buffer. Indeks inilah yang akan digunakan untuk mengakses data terkait pada input buffer.
Kernel digambarkan sebagai body of
loops. Sebagai contoh jika kita ingin
TRANSFORM-CPU(x,y,in,out)
for x Å 0 to 10000 for y Å 0 to 10000 out[x][y] Å
do_some_work(in[x,y])
Di dalam GPU pendistribusian data terjadi secara otomatis sehingga kita tidak perlu memaralelkan data secara manual. Kita hanya perlu menentukan body of loops.
TRANSFORM-GPU(x,y,in)
return do_some_work(in[x,y])
Perhitungan skor q-d pada GPU dilakukan melalui dua tahap. Tahap pertama, GPU melakukan operasi perkalian secara paralel, setiap nilai bobot term dari dokumen dikalikan dengan nilai bobot term dari kueri. Tahap berikutnya, hasil perkalian tersebut dijumlahkan secara paralel. Hasil keluaran pada tahap perkalian akan digunakan sebagai masukan pada tahap penjumlahan.
[image:34.595.326.513.227.379.2]Penjumlahan dilakukan dengan cara menjumlahkan suatu elemen dengan elemen setelahnya. Proses yang sama diulang tetapi menjumlahkan dengan elemen ke-2i-1 setelahnya, dengan i adalah banyaknya iterasi. Proses ini berhenti pada iterasi ke-log . Prosesnya terlihat pada Gambar 6. Pada gambar tersebut, elemen yang tidak dihitamkan tidak lagi digunakan dalam algoritme ini karena nilai elemen tersebut sudah tersimpan dalam elemen yang dihitamkan.
Gambar 6 Scoring pada GPU.
Sorting pada GPU menggunakan algoritme odd-even transition sort. Algoritme ini melakukan proses compare and swap dengan
pasangan indeks ganjil-genap, kemudian dengan pasangan indeks genap-ganjil, lalu kembali lagi dengan pasangan indeks ganjil-genap, dan begitu seterusnya, sehingga untuk mengurutkan data membutuhkan /2 compare and swap untuk pasangan indeks ganjil-genap dan /2 compare and swap untuk pasangan indeks genap-ganjil. Ilustrasi algoritma odd-even transition sort terlihat pada gambar 7.
Gambar 7 Algoritme odd-even transition sort.
Algoritme yang digunakan dalam penelitian berbeda untuk CPU dan GPU. Untuk CPU digunakan algoritme scoring dan
quick sort. Algoritme SCORING-CPU
digunakan untuk menghitung nilai kemiripan antara dokumen dan kueri. Algoritme ini menggunakan W yang merupakan bobot term dalam suatu dokumen, n jumlah dokumen,
dan m jumlah term. Hasil dari algoritme ini
adalah Score yaitu nilai kemiripan antara dokumen dan kueri.
SCORING-CPU (Score,W,n,m) for i Å 1 to n
Score[i] Å 0 for j Å 1 to m
Score[i]ÅScore[i]+W[i,j]xW[q,j]
Algoritme quick sort menggunakan
std::sort dari C++ Standart Template
Library (STL). Algoritme ini digunakan untuk mengurutkan hasil scoring pada algoritme SCORING-CPU secara descending.
MULTIPLY-GPU(
termIndex,DocTerm,QueryTerm)
return DocTerm[termIndex] . QueryTerm[termIndex]
Algoritme MULTIPLY-GPU menerima input termIndex, DocTerm, dan
[image:34.595.114.305.510.673.2]indeks term pada dokumen dan kueri sedangkan DocTerm adalah matriks yang berisi bobot term pada dokumen yang akan diberi skor. QueryTerm adalah matriks yang berisi bobot term pada kueri.
SUMMATION-GPU(
termIndex,iteration,DocTerm)
partner Å termIndex
+ pow(2,iteration-1) return DocTerm[termIndex]+DocTerm[]
Algoritme SUMMATION-GPU menerima input termIndex, iteration, dan
DocTerm. termIndex merupakan indeks
term pada dokumen dan kueri sedangkan DocTerm adalah matriks yang berisi bobot term pada dokumen yang akan diberi skor. CPU memanggil fungsi SUMMATION-GPU diiterasi mulai dari satu sampai dengan log(n) dengan n adalah jumlah term.
SORT-GPU(
termIndex,transition,DocScore)
if docIndex mod 2 = transition compare Å 1
else
compare Å -1
partner Å termIndex + compare
if DocScore[termIndex] . compare > DocScore[partner] . compare return DocScore[termIndex]
else
return DocScore[partner]
Algoritme SORT-GPU diiterasi mulai dari satu sampai dengan jumlah dokumen yang ada. Algoritme ini menerima input
termIndex, transition, dan
docScore. termIndex merupakan indeks
term pada dokumen dan kueri sedangkan DocScore adalah matriks yang berisi skor
setiap dokumen. transition digunakan untuk memilih model genap-ganjil atau ganjil-genap. Bila menggunakan model genap-ganjil, maka transition bernilai 0, dan bila menggunakan model ganjil-genap, maka transition bernilai 1.
Penggunaan Memori
Pada penelitian ini dicobakan temu kembali suatu kueri dari 1000 dokumen. Setelah melalui proses tokenisasi, diperoleh 26575 term dari 1000 dokumen tersebut. Apabila satu term membutuhkan alokasi 4 byte memori, maka pada CPU, memori yang dibutuhkan untuk memroses 26575 term adalah sebanyak 1000 x 26575 x 4 byte = 101 MB. Pada GPU, memori yang dibutuhkan adalah sebanyak 1000 x 32768 x 4 = 128 MB. Nilai 32768 berasal dari 256x128 ukuran tekstur. Untuk dapat menampung 26575 term, GPU tidak bisa menyediakan ruang yang tepat sama, karena data disimpan dalam GPU sebagai tekstur dengan dimensi 2 (power of two). Dalam kasus ini, apabila dibandingkan penggunaan memori pada GPU lebih besar dari pada penggunaan memori pada CPU.
Kecepatan Proses
Gambar 8. Grafik Perbandingan Rata-rata Waktu Proses antara CPU dan GPU
Pada kondisi ideal kecepatan GPU lebih baik daripada CPU. Hal ini terbukti pada saat proses komputasi hanya melibatkan proses perkalian, tanpa ada penjumlahan dan sorting, GPU sanggup melakukan perkalian hingga tiga kali lebih cepat dibandingkan CPU. Untuk operasi penjumlahan dan sorting CPU jauh mengungguli GPU. Untuk hasil percobaannya dapat dilihat pada Tabel 1.
Tabel 1 Perbandingan Operasi Utama pada CPU dan GPU
Perkalian (detik) Penjumlahan (detik) Sorting (detik)
GPU 0.079993 0.968640 0.360896
CPU 0.214159 0.143024 0.002568
Hasil percobaan pada GPU untuk penjumlahandan sorting membutuhkan waktu proses yang lebih lama daripada CPU. Hal ini dikarenakan kompleksitas algoritme GPU untuk operasi tersebut lebih besar daripada CPU.
Kompleksitas penjumlahan pada GPU adalah N log(N) dan kompleksitas sorting-nya adalah N2. Meskipun sorting pada GPU memiliki kompleksitas yang lebih tinggi dari pada kompleksitas penjumlahan tetapi proses sorting lebih cepat daripada penjumlahan. Hal ini disebabkan N dalam sorting merupakan jumlah dokumen yaitu 1000 dokumen dan N dalam penjumlahan merupakan jumlah term yang memiliki jumlah 26575 term dan diiterasi sebanyak jumlah dokumen (1000
kali). Perbedaan nilai N yang jauh menyebabkan kompleksitas pada operasi penjumlahan menjadi lebih besar daripada sorting.
Seperti yang terlihat pada Tabel 1, GPU memiliki keunggulan dalam melakukan proses perkalian sedangkan CPU unggul dalam proses penjumlahan dan sorting. Dengan fakta tersebut timbul ide untuk memanfaatkan keunggulan pada CPU dan GPU. GPU unggul dalam proses perkalian maka GPU hanya akan melakukan proses perkalian sedangkan operasi sisanya (penjumlahan dan sorting) dilakukan oleh CPU.
Hasil pengujian ini dapat dilihat pada Lampiran 4. Rata-rata waktu proses yang dihasilkan dalam percobaan ini adalah 16.53731 detik. Percobaan ini menghasilkan waktu proses yang lebih lama dari pengujian pertama. Hal ini dikarenakan pada pengujian yang pertama output dari GPU ke CPU hanya merupakan satu buah matriks yang berisi 1.000 data berupa indeks descending. Lain halnya dengan pengujian kedua yang mengirimkan data dari GPU ke CPU berupa 1.000 buah matriks yang masing-masing berisi 26.575 data yang berupa hasil perkalian antara bobot term dokumen dengan kueri sehingga waktu transfer yang dibutuhkan akan jauh lebih lama.
Proporsi Optimal antara CPU dan GPU Pada kedua pengujian sebelumnya dapat dilihat bahwa percobaan pertama memberikan hasil yang lebih memuaskan oleh karena itu dilakukan pengujian ketiga yang merupakan 0 0.2 0.4 0.6 0.8 1 1.2
250 500 750 1000
Waktu
Proses
(Detik)
Jumlah Dokumen
pengembangan dari pengujian pertama. Pengujian pada tahap ini menggunakan algoritme yang sama dengan algoritme pada percobaan pertama. Yang membedakan adalah cara pengujiannya.
Pada pengujian tahap ini dicari proporsi optimal pendistribusian dokumen pada CPU dan GPU. Hal ini dilakukan karena adanya kemungkinan bahwa GPU masih dapat membantu CPU dalam mempercepat proses. Pada pengujian tahap ini diperoleh proporsi optimal yaitu 960 dokumen untuk diproses CPU dan sisanya yaitu 40 dokumen diproses GPU. Proporsi ini membutuhkan waktu proses selama 0.233671 detik untuk CPU dan 0.2244426 detik untuk GPU, sehingga waktu proses keseluruhan menjadi 0.2244426 karena CPU dan GPU bekerja secara paralel. Tabel pengujian selengkapnya dapat dilihat pada Lampiran 5.
Tampilan antar muka program dan contoh penggunaannya dapat dilihat pada lampiran 7. Semakin slider digeser ke arah CPU maka semakin banyak dokumen yang didistribusikan ke CPU. Demikian juga sebaliknya pada lampiran 8, semakin slider digeser ke arah GPU maka semakin banyak dokumen yang didistribusikan ke GPU.
KESIMPULAN DAN SARAN
Kesimpulan
Dari implementasi Vector Space Model menggunakan GPU ini, diperoleh beberapa kesimpulan, yaitu:
1. GPU mampu digunakan untuk temu kembali menggunakan metode Vector Space Model. Hasil temu kembali antara dan GPU tepat sama. Hanya berbeda urutan pada dokumen yang mempunyai nilai similarity yang sama.
2. GPU yang digunakan pada penelitian ini tidak mampu mengimbangi kecepatan CPU. Hal ini disebabkan oleh keterbatasan perangkat keras dan pustaka yang digunakan.
3. GPU membutuhkan alokasi memori dengan ukuran power of two, sehingga tidak mampu mengalokasikan memori yang dibutuhkan secara tepat. Hal ini menyebabkan penggunaan memori pada GPU lebih besar daripada CPU.
4. Proporsi optimal didapat dengan mendistribusikan 960 dokumen ke CPU dan 40 dokumen ke GPU. Proporsi ini membutuhkan waktu proses selama 0.2336710 detik untuk CPU dan 0.2244426 detik untuk GPU.
Saran
Saran untuk penelitian selanjutnya adalah:
1. Penggunaan pustaka khusus GPGPU seperti OpenCL. Pada saat penelitian ini ditulis, pustaka ini masih dalam tahap pengembangan.
2. Analisis perbandingan algoritme sorting pada GPU (even transition sort, odd-even merge sort, dan bitonic merge sort).
DAFTAR PUSTAKA
Abual-Rub MS, Abdullah R, Rashid NA. 2007. A Modified Vector Space Model for Protein Retrieval. IJCSNS International Journal of Computer Science and Network Security, VOL.7 No 9, September 2007. Cormen TH, Leiserson CE, Rivest RL, Stein
C. 2003. Introduction to Algorithms. England : MIT Press.
Govindaraju NK, et al. 2004. Fast Computation of Database Operations using Graphics Processors. Proceedings of the 2004 ACM SIGMOD international conference on Management of data; 2004. New York, NY : ACM, hlm 215-256.
Grama A, Gupta A, Karypsi G, Kumar V. 2003. Introduction to Parallel Computing. England : Pearson Education.
Manning CD, Raghavan P., Schütze H. 2008. Introduction to Information Retrieval. Cambridge : Cambridge University Press.
NVidia CUDA Programming Guide.
http://developer.download.nvidia.com/com pute/cuda/2_0/docs/NVIDIA_CUDA_Pro gramming_Guide_2.0.pdf
[14 Desember 2008].
Ujaldon M, Saltz J. 2005. The GPU as an Indirection Engine for a Fast Information Retrieval.
pengembangan dari pengujian pertama. Pengujian pada tahap ini menggunakan algoritme yang sama dengan algoritme pada percobaan pertama. Yang membedakan adalah cara pengujiannya.
Pada pengujian tahap ini dicari proporsi optimal pendistribusian dokumen pada CPU dan GPU. Hal ini dilakukan karena adanya kemungkinan bahwa GPU masih dapat membantu CPU dalam mempercepat proses. Pada pengujian tahap ini diperoleh proporsi optimal yaitu 960 dokumen untuk diproses CPU dan sisanya yaitu 40 dokumen diproses GPU. Proporsi ini membutuhkan waktu proses selama 0.233671 detik untuk CPU dan 0.2244426 detik untuk GPU, sehingga waktu proses keseluruhan menjadi 0.2244426 karena CPU dan GPU bekerja secara paralel. Tabel pengujian selengkapnya dapat dilihat pada Lampiran 5.
Tampilan antar muka program dan contoh penggunaannya dapat dilihat pada lampiran 7. Semakin slider digeser ke arah CPU maka semakin banyak dokumen yang didistribusikan ke CPU. Demikian juga sebaliknya pada lampiran 8, semakin slider digeser ke arah GPU maka semakin banyak dokumen yang didistribusikan ke GPU.
KESIMPULAN DAN SARAN
Kesimpulan
Dari implementasi Vector Space Model menggunakan GPU ini, diperoleh beberapa kesimpulan, yaitu:
1. GPU mampu digunakan untuk temu kembali menggunakan metode Vector Space Model. Hasil temu kembali antara dan GPU tepat sama. Hanya berbeda urutan pada dokumen yang mempunyai nilai similarity yang sama.
2. GPU yang digunakan pada penelitian ini tidak mampu mengimbangi kecepatan CPU. Hal ini disebabkan oleh keterbatasan perangkat keras dan pustaka yang digunakan.
3. GPU membutuhkan alokasi memori dengan ukuran power of two, sehingga tidak mampu mengalokasikan memori yang dibutuhkan secara tepat. Hal ini menyebabkan penggunaan memori pada GPU lebih besar daripada CPU.
4. Proporsi optimal didapat dengan mendistribusikan 960 dokumen ke CPU dan 40 dokumen ke GPU. Proporsi ini membutuhkan waktu proses selama 0.2336710 detik untuk CPU dan 0.2244426 detik untuk GPU.
Saran
Saran untuk penelitian selanjutnya adalah:
1. Penggunaan pustaka khusus GPGPU seperti OpenCL. Pada saat penelitian ini ditulis, pustaka ini masih dalam tahap pengembangan.
2. Analisis perbandingan algoritme sorting pada GPU (even transition sort, odd-even merge sort, dan bitonic merge sort).
DAFTAR PUSTAKA
Abual-Rub MS, Abdullah R, Rashid NA. 2007. A Modified Vector Space Model for Protein Retrieval. IJCSNS International Journal of Computer Science and Network Security, VOL.7 No 9, September 2007. Cormen TH, Leiserson CE, Rivest RL, Stein
C. 2003. Introduction to Algorithms. England : MIT Press.
Govindaraju NK, et al. 2004. Fast Computation of Database Operations using Graphics Processors. Proceedings of the 2004 ACM SIGMOD international conference on Management of data; 2004. New York, NY : ACM, hlm 215-256.
Grama A, Gupta A, Karypsi G, Kumar V. 2003. Introduction to Parallel Computing. England : Pearson Education.
Manning CD, Raghavan P., Schütze H. 2008. Introduction to Information Retrieval. Cambridge : Cambridge University Press.
NVidia CUDA Programming Guide.
http://developer.download.nvidia.com/com pute/cuda/2_0/docs/NVIDIA_CUDA_Pro gramming_Guide_2.0.pdf
[14 Desember 2008].
Ujaldon M, Saltz J. 2005. The GPU as an Indirection Engine for a Fast Information Retrieval.