KAJIAN MODEL REGRESI LOGISTIK PADA DATA
KASUS-KONTROL DENGAN TIGA TAHAP PENGAMBILAN
CONTOH
RATNA CHRISTIANINGRUM
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Kajian Model Regresi Logistik pada Data Kasus-Kontrol dengan Tiga Tahap Pengambilan Contoh adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2011
Ratna Christianingrum
ABSTRACT
RATNA CHRISTIANINGRUM. Logistic Regression Model Studies on Case-Control Data with Three-Stage Sampling . Under direction of BUDI SUSETYO, and KUSMAN SADIK
If the sample is taken by using multistage random sampling, through reducing sample size in the next stage, then the ordinary logistic models can’t be used. This data will be analyzed using logistic models with the additional intercept. This research studied the application of addition intercept terms in logistic regression for case control study used multi stage random sampling. Furthermore, this research compared between the model which was formed and the model of the frame sampling data. The addition intercept in logistic models was able to describe the pattern of relationship explanatory variable with response variable. Missing information decreases with increasing number of samples that observed. Average of missing information in the third stage tends to be smaller than in the second stage, because the third stage has more homogeneous sample units than the second stage. The average of missing information is smaller than the average reduction in the number of samples when using multi-stage random sampling, so this sampling technique is also suitable for use in research aimed at predicting the probability of case. Moreover the use of the sampling technique can reduce the sampling cost.
RINGKASAN
RATNA CHRISTIANINGRUM. Kajian Model Regresi Logistik pada Data Kasus-Kontrol dengan Tiga Tahap Pengambilan Contoh. Dibimbing oleh BUDI SUSETYO dan KUSMAN SADIK
Rancangan penelitian yang banyak digunakan dalam bidang epidemiologi adalah rancangan penelitian kasus-kontrol. Dalam penelitian kasus-kontrol, contoh kasus dan contoh kontrol diambil secara terpisah. Kasus merupakan unit contoh yang memiliki karakteristik tertentu yang diamati, sedangkan kontrol merupakan unit contoh yang tidak memiliki karakteristik tertentu yang diamati. Teknik pengambilan contoh dengan beberapa tahap dapat digunakan untuk mengambil contoh kasus dan kontrol.
Manfaat lain dari penggunaan teknik pengambilan contoh dengan beberapa tahap yaitu dapat mengurangi biaya pengambilan contoh. Hal ini mungkin terjadi apabila penelitian memiliki biaya pengamatan suatu peubah lebih mahal dari peubah yang lain. Dengan menggunakan teknik pengambilan contoh dengan beberapa tahap, peubah yang memiliki biaya pengamatan yang mahal diamati di tahap terakhir pengambilan contoh dan hanya sebagian yang diamati.
Konsekuensi dari penggunaan teknik pengambilan contoh dengan beberapa tahap adalah proses analisa data yang lebih komplek. Penelitian ini mengkaji penerapan regresi logistik dengan penambahan konstanta pada penelitian kasus-kontrol yang menggunakan teknik pengambilan contoh dengan beberapa tahap. Selain itu akan membandingkan model yang terbentuk dengan model dari data hasil pembangkitan.
Data yang digunakan merupakan data berpasangan yang diperoleh dari proses pembangkitan. Terdapat tida peubah penjelas yang digunakan, yaitu X1,
X2, dan X3. Peubah X1 memiliki dua nilai yang mungkin (0, 1) dan dibangkitkan
secara acak dari distribusi binomial dengan n=1 dan p=0.3. Peubah X2 memiliki
tiga nilai yang mungkin (0, 1, 2) yang dibangkitkan secara acak dari distribusi multinomial dengan nilai peluang yang digunakan adalah 0.3, 0.2, dan 0,5 untuk masing-masing nilai kategori secara berurutan. Peubah X3
Model regresi logistik dengan penambahan konstanta dibangun dari data contoh. Terdapat 2 macam model yang dibentuk, yaitu model regresi logistik dengan satu konstanta tambahan dan model regresi logistik dengan dua konstanta tambahan. Model regresi logistik dengan satu konstanta tambahan dibangun dari data dengan dua tahap pengambilan contoh, sedangkan model lainnya dibangun dari data dengan tiga tahap pengambilan contoh. Konstanta tambahan (α
memiliki empat nilai yang mungkin yaitu 0, 1, 2, dan 3. Peubah ini dibangkitkan secara acak dari distribusi multinomial dengan nilai peluang yang digunakan adalah 0.1, 0.2, 0.3, dan 0.4 untuk masing-masing nilai kategori secara berurutan. Peubah Y akan bernilai 1 apabila nilai probabilitas > z dan bernilai 0 untuk lainnya. Nilai z dibangkitkan secara acak dari distribusi uniform.
i) tidak hanya berfungsi untuk mengkoreksi β0, namun juga βi
Hasil pengujian terhadap parameter dari model regresi logistik dengan penambahan konstanta, hampir semua parameter yang dimiliki memberikan hasil yang sama dengan parameter dari model untuk data hasil pembangkitan. Selain itu, parameter ini memiliki tanda yang sama dengan parameter dari model untuk
data hasil pembangkitan. Jadi dapat disimpulkan bahwa regresi logistik dengan penambahan konstanta mampu menggambarkan pola hubungan antara peubah respon dengan peubah penjelas.
Informasi yang hilang akan menurun seiring dengan bertambahnya jumlah contoh yang diamati. Rata-rata informasi yang hilang pada tahap ke-3 cenderung lebih kecil dari rata-rata informasi yang hilang pada tahap ke-2. Hal ini dikarenakan tahap ke-3 memiliki unit contoh yang lebih homogen dari tahap ke-2.
© Hak Cipta milik IPB, tahun 2011
Hak Cipta dilindungi Undang-undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar bagi IPB
KAJIAN MODEL REGRESI LOGISTIK PADA DATA
KASUS-KONTROL DENGAN TIGA TAHAP PENGAMBILAN
CONTOH
RATNA CHRISTIANINGRUM
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Penelitian : Kajian Model Regresi Logistik pada Data Kasus-Kontrol dengan Tiga Tahap Pengambilan Contoh
Nama : Ratna Christianingrum
NRP : G151090191
Program Studi : Statistika
Disetujui
Komisi Pembimbing
Ketua
Dr. Ir. Budi Susetyo, MS Dr. Kusman Sadik, MSi Anggota
Diketahui,
Ketua Program Studi S2 Statistika
Dr. Ir. Erfiani, MSi
Dekan Sekolah Pascasarjana IPB
Dr. Ir. Dahrul Syah, M.Sc. Agr.
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan atas segala rahmat dan karunia-Nya sehingga karya ilmiah ini dapat diselesaikan. Judul karya ilmiah ini adalah “Kajian Model Regresi Logistik pada Data Kasus-Kontrol dengan Tiga Tahap Pengambilan Contoh”.
Terima kasih penulis ucapkan kepada Dr. Ir. Budi Susetyo, M.S selaku pembimbing I dan Dr. Kusman Sadik, M.Si selaku pembimbing II, terima kasih atas bimbingan, saran dan waktunya. Disamping itu penulis juga mengucapkan terima kasih kepada Dr. Ir. Aji Hamim Wigena, M.Sc. selaku penguji luar komisi pada ujian tesis dan seluruh staf Program Studi Statistika.
Ungkapan terima kasih juga disampaikan kepada Bapak, Ibu dan adik serta seluruh keluarga atas doa, dukungan dan kasih sayangnya. Terima kasih kepada teman-teman Statistika angkatan 2009 atas bantuan dan kebersamaannya.
Semoga karya ilmiah ini dapat bermanfaat.
Bogor, Agustus 2011
RIWAYAT HIDUP
Penulis dilahirkan di Semarang, pada tanggal 30 Juni 1987 sebagai anak pertama dari pasangan Bapak Suparman, S.Pd dan Ibu Amini, S.Pd.
DAFTAR ISI
Halaman
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiv
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 2
TINJAUAN PUSTAKA Pengertian ... 3
Teknik Pengambilan Contoh ... 4
Teknik Analisis ... 6
METODOLOGI Sumber Data ... 13
Metode Analisis ... 13
HASIL DAN PEMBAHASAN Model Regresi Logistik Biner untuk Data Hasil Pembangkitan ... 17
Model Regresi Logistik Biner dengan Penambahan Konstanta ... 19
Pengujian Parameter ... 24
Informasi yang Hilang ... 26
SIMPULAN DAN SARAN Simpulan ... 31
Saran ... 31
DAFTAR PUSTAKA ... 33
DAFTAR TABEL
Halaman 1 Proses pengambilan contoh dengan tiga tahap ... 5
2 Nilai parameter model Y terhadap X1 dan X2
3 Nilai parameter model Y terhadap X
untuk N=300 ... 18
1, X2, dan X3
4 Nilai rata-rata persentase jumlah parameter yang memberikan kesimpulan yang berbeda dari model data hasil pembangkitan untuk N=300... 24
untuk N=300 ... 19
5 Rata-rata persentase informasi hilang pada tahap kedua pengambilan contoh untuk N=300 ... 25
DAFTAR GAMBAR
Halaman 1 Skema proses pengambilan contoh ... 20
2 Rata-rata informasi hilang pada tahap kedua proses pengambilan
contoh ... 26
3 Rata-rata persentase total informasi hilang………... 28
4 Rata-rata persentase informasi hilang pada tahap kedua dan ketiga
DAFTAR LAMPIRAN
Halaman 1 Program di SAS 6.2 ... 37
2 Program di Matlab ... 39
3 Nilai parameter model Y terhadap X1 dan X2 untuk data hasil
pembangkitan
………... 44
4 Nilai parameter model Y terhadap X1, X2, dan X3 untuk data hasil 46
pembangkitan ………...
5 Rata-rata persentase informasi hilang pada tahap kedua pengambilan contoh ………...
48
PENDAHULUAN
Latar Belakang
Rancangan penelitian kasus-kontrol merupakan rancangan penelitian yang
banyak digunakan dalam bidang epidemiologi. Rancangan ini digunakan untuk
menelusuri faktor resiko dari suatu penyakit. Rancangan ini memiliki hubungan
sebab-akibat yang lebih kuat daripada cross section. Breslow (1996) dalam Scott
(2006) menyatakan bahwa penelitian kasus-kontrol merupakan tulang belakang
dari epidemiologi.
Contoh kasus dan kontrol diambil secara terpisah dalam penelitian
kasus-kontrol. Kasus merupakan kumpulan unit contoh yang memiliki karakteristik
tertentu yang akan diamati, misalnya orang yang terjangkit penyakit tertentu.
Adapun kontrol merupakan kumpulan unit contoh yang tidak memiliki
karakteristik yang akan diamati. Proses pengambilan contoh, baik dalam kasus
maupun kontrol menggunakan teknik pengambilan contoh yang sederhana.
Teknik pengambilan contoh tersebut antara lain menggunakan teknik
pengambilan contoh acak sederhana (simple random sampling) atau teknik pengambilan contoh acak bersrata (stratified random sampling). Scott (2006) lebih menyarankan penggunaan teknik pengambilan contoh yang lebih kompleks
daripada yang sederhana, yaitu teknik pengambilan contoh acak dengan beberapa
tahap.
Manfaat lain dari penggunaan teknik pengambilan contoh dengan beberapa
tahap yaitu dapat mengurangi biaya pengambilan contoh. Hal ini mungkin terjadi
apabila penelitian memiliki biaya pengamatan suatu peubah lebih mahal dari
peubah yang lain. Dengan menggunakan teknik pengambilan contoh dengan
beberapa tahap, peubah yang memiliki biaya pengamatan yang mahal diamati di
tahap terakhir pengambilan contoh dan hanya sebagian yang diamati.
Terdapat beberapa metode yang dapat digunakan untuk menganalisis data
kasus-kontrol, salah satunya dengan menggunakan regresi logistik. Regresi
logistik merupakan metode yang digunakan untuk menggambarkan hubungan
responnya diskrit yang mempunyai dua atau lebih nilai yang mungkin (Hosmer &
Lemeshow 2000). Apabila peubah respon yang digunakan merupakan data biner
maka disebut regresi logistik biner. Dalam regresi logistik terdapat asumsi yang
harus dipenuhi (Meyers, et al. 2006) yaitu: 1. Tidak ada multikolinearitas yang sempurna
2. Tidak terdapat kesalahan spesifikasi (semua prediktor yang relevan harus
disertakan, sedangkan prediktor yang tidak relevan dapat dihilangkan).
3. Peubah bebas harus diukur pada tingkat skala respon sumatif, interval atau
rasio, meskipun peubah dikotomus diperbolehkan.
Data kasus-kontrol dapat dianalisis dengan regresi logisitik biner apabila
proses pengambilan contoh dilakukan dengan satu tahap pengambilan contoh.
Data kasus-kontrol yang diperoleh dengan menggunakan teknik pengambilan
contoh dengan beberapa tahap tidak dapat dianalisis menggunakan regresi logistik
biner. Contoh tersebut diambil dari distribusi bersyarat Y dan X yang telah
diamati di tahap sebelumnya. Akibatnya konstanta yang dihasilkan akan berbias.
Penambahan konstanta pada model regresi logistik dilakukan untuk mengatasi
permasalahan tersebut (Lee, et al. 2010)
Penelitian ini mengkaji penerapan regresi logistik dengan penambahan
konstanta pada penelitian kasus-kontrol yang menggunakan teknik penarikan
contoh acak dengan beberapa tahap. Selain itu akan membandingkan model yang
terbentuk dengan model dari data hasil pembangkitan.
Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk
1. Mengkaji penerapan regresi logistik dengan penambahan konstanta pada
penelitian kasus-kontrol yang menggunakan teknik pengambilan contoh acak
dengan beberapa tahap.
2. Membandingkan model yang terbentuk dari data contoh dengan model dari
TINJAUAN PUSTAKA
Pengertian
Rancangan penelitian kasus-kontrol di bidang epidemiologi didefinisikan
sebagai rancangan epidemiologi yang mempelajari hubungan antara faktor
penelitian dengan penyakit, dengan cara membandingkan kelompok kasus dan
kelompok kontrol berdasarkan faktor penelitian yang diamati (Warti 2010). Kasus
merupakan unit pengamatan yang memiliki karakteristik tertentu, biasanya unit
pengamatan yang mengidap penyakit tertentu. Kontrol merupakan unit
pengamatan yang tidak memiliki karakteristik tertentu (Lee et al. 2010). Scott dan Wild (1991) menyatakan bahwa epidemiologi digunakan untuk memprediksi
hubungan antara peubah penjelas, misalnya faktor-faktor resiko dari suatu
penyakit dan peubah respon yang diskrit.
Langkah awal dari penelitian kasus-kontrol yaitu pengidentifikasian
kelompok orang yang mengidap penyakit tertentu dan yang tidak untuk melihat
faktor resiko keduanya (Woodward 2005 dalam Warti 2010). Langkah selanjutnya
dilakukan penelusuran riwayat penyakit tersebut dengan rancangan penelitian
kasus-kontrol. Rancangan ini memberikan cara yang efisien dalam
mengumpulkan faktor-faktor penelitian dari penyakit yang jarang terjadi.
Misalkan ada seorang peneliti yang akan mengidentifikasi faktor-faktor
yang dapat meningkatkan resiko seseorang terkena penyakit jantung pada usia
produktif, untuk pasien rumah sakit A yang datang dalam kurun waktu setahun
terakhir. Setelah mendapatkan kerangka contoh yang berupa daftar pasien
dilakukan identifikasi pasien yang mengindap penyakit jantung dan yang tidak.
Orang yang mengindap penyakit jantung dimasukkan dalam kelompok kasus,
sedangkan sisanya sebagai kontrol.
Contoh kasus dan kontrol diperoleh dengan menggunakan teknik
pengambilan contoh di masing-masing kelompok kasus dan kelompok kontrol.
Dalam penelitian tersebut, peubah yang diamati tahap pertama adalah jenis
kelamin, tekanan darah dan berat badan. Peubah-peubah ini diamati pada tahap
ini hampir tidak memerlukan biaya. Untuk mendapatkan nilai dari peubah,
peneliti hanya perlu mengunjungi rumah sakit. Peubah yang diamati di tahap
terakhir pengambilan contoh merupakan peubah yang berhubungan dengan
tingkah laku dan kebiasaan, misalkan kebiasaan merokok, kebiasaan
mengkonsumsi alkohol, dan pola konsumsi makanan. Peubah-peubah ini
diletakkan di tahap terakhir proses pengambilan contoh, karena biaya memperoleh
nilai peubah-peubah tersebut relatif mahal. Peneliti harus mengunjungi langsung
orang yang terpilih sebagai contoh untuk mendapatkan nilai peubahnya.
Teknik Pengambilan Contoh
Teknik pengambilan contoh digunakan untuk memperoleh contoh yang
mampu menggambarkan keadaan sebenarnya dari populasi yang diamati.
Penelitian kasus-kontrol menggunakan teknik pengambilan contoh yang biasa
digunakan. Namun dalam penelitian ini, contoh untuk kasus dan kontrol diambil
secara terpisah. Teknik pengambilan contoh yang digunakan merupakan teknik
pengambilan contoh acak sederhana dan teknik pengambilan contoh acak bersrata.
Scott (2006) menyatakan bahwa lebih baik menggunakan rancangan pengambilan
contoh yang lebih kompleks yaitu rancangan pengambilan contoh yang terbagi
dalam beberapa tahap. Teknik pengambilan contoh tersebut dapat menurunkan
biaya pengambilan contoh dan mampu mengatasi data hilang.
Langkah awal proses pengambilan contoh dalam penelitian kasus-kontrol
adalah membagi populasi ke dalam dua kelompok berdasarkan status karakteristik
yang diamati. Kelompok pertama adalah kumpulan unit pengamatan yang
memiliki karakteristik tertentu dan kelompok ini disebut kasus. Kelompok kedua
adalah kumpulan unit pengamatan yang tidak memiliki karakteristik tertentu.
Kelompok ini disebut kontrol. Contoh kasus dan kontrol diambil secara terpisah di
masing-masing kelompok kasus dan kontrol. Teknik pengambilan contoh acak
sederhana digunakan untuk memperoleh contoh kasus ataupun kontrol.
Pada tahap pertama pengambilan contoh, unit contoh terbagi dalam
beberapa kelompok berdasarkan jumlah faktor penelitian dan taraf dari
masing-masing faktor penelitian yang diamati. Misalkan pada tahap pertama terdapat dua
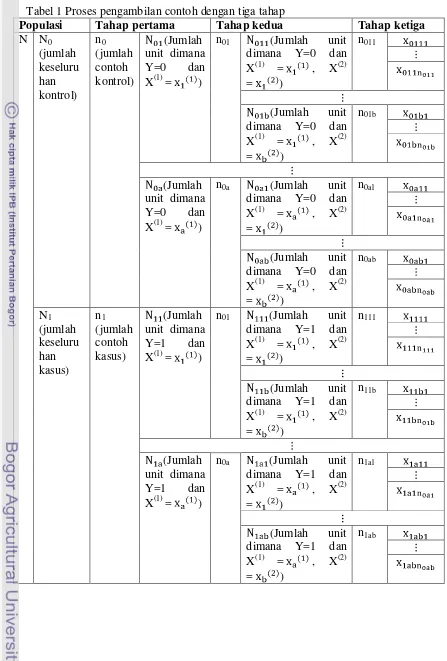
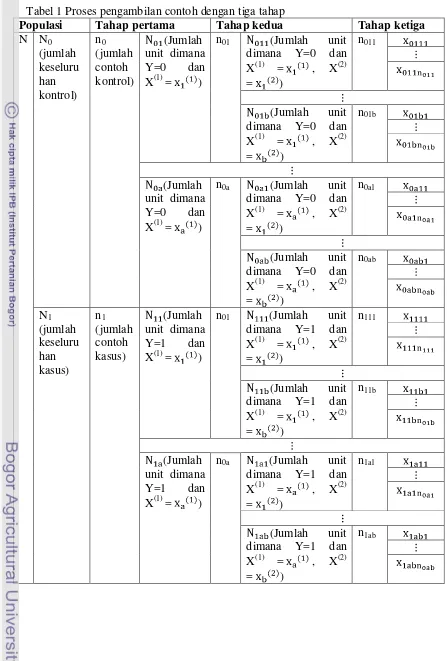
Tabel 1 Proses pengambilan contoh dengan tiga tahap
Populasi Tahap pertama Tahap kedua Tahap ketiga
faktor kedua mempunyai dua taraf. Jumlah kelompok yang ada pada tahap
pertama ini adalah 2 x 3= 6 kelompok. Pada tahap pertama, faktor penelitian yang
diamati biasanya berupa data kategori.
Tahap kedua dimulai setelah unit pengamatan terbagi ke dalam beberapa
kelompok. Dari masing-masing kelompok diamati seluruh anggota kelompok atau
hanya sub-contohnya. Jika hanya diambil sub-contoh, maka proses pengambilan
contohnya menggunakan teknik pengambilan contoh acak sederhana. Selanjutnya
dilakukan pengukuran faktor penelitian yang akan diamati pada tahap ini.
Tahap ketiga pengambilan contoh dilakukan setelah tahap kedua. Cara
memperoleh contoh pada tahap ketiga dan tahap-tahap selanjutnya sama dengan
cara memperoleh contoh pada tahap kedua. Pada tahap terakhir pengambilan
contoh, data yang diamati dapat berupa data diskrit atau kontinu. Tabel proses
pengambilan contoh dengan menggunakan tiga tahap dapat dilihat pada Tabel 1.
Teknik Analisis
Metode yang banyak digunakan untuk menganalisis data kasus-kontrol
adalah regresi logistik. Regresi logistik merupakan suatu metode yang digunakan
untuk menggambarkan hubungan antara peubah respon yang berupa data kategori
dengan satu atau lebih peubah penjelas.
Model
Respon yang diamati dalam penelitian kasus-kontrol adalah status dari
karakteristik yang akan diamati, misalnya status penyakit. Unit yang berasal dari
kelompok kasus diberi nilai peubah respon Y=1. Unit yang berasal dari kelompok
kontrol diberi nilai peubah respon Y=0. Peubah penjelas yang dinyatakan dalam
bentuk vektor penjelas dituliskan dengan notasi X. Nilai peluang untuk kasus
dengan X = x adalah
(1)
Sedangkan nilai peluang untuk kontrol adalah
Model ini merupakan model regresi logistik biner. Namun model ini hanya dapat
digunakan pada rancangan penelitian kasus-kontrol dengan satu tahap.
Model regresi logistik biner yang biasa tidak dapat digunakan pada
rancangan kasus-kontrol dengan menggunakan dua tahap atau lebih dalam proses
pengambilan contoh. Hal ini dikarenakan konstanta dari model regresi logistik
biasa berbias. Untuk mengatasi permasalahan tersebut maka dilakukan modifikasi
terhadap model regresi logistik. Modifikasi yang dilakukan adalah dengan menambahkan konstanta tambahan yang dinotasikan dengan α. Nilai α muncul sebagai akibat penggunaan skema pengambilan contoh kasus kontrol yang dapat
dilihat di Tabel 1 (Scott & Wild 1997). Model baru yang terbentuk adalah sebagai
berikut: • Dua tahap
(3)
(4)
• Tiga tahap
(5)
(6)
dengan
merupakan konstanta tambahan untuk strata ke-i yang terbentuk pada tahap
kedua (i = 1, 2, ..., a)
merupakan konstanta tambahan untuk strata ke-i yang terbentuk di tahap kedua
dan strata ke-j yang terbentuk dari tahap ke-3 (i = 1, 2, ..., a dan j=1, 2, ..., b)
merupakan vektor contoh acak bagi peubah penjelas
merupakan vektor parameter
Pendugaan Parameter
(7)
Sedangkan fungsi likelihood bagi model dengan tiga tahap pengambilan contoh adalah sebagai berikut:
(8)
dengan
C =
D =
dengan
Y merupakan peubah respon
h merupakan nilai dari peubah respon (h=0,1)
merupakan peubah penjelas yang diamati pada tahap pertama proses
pengambilan contoh
merupakan nilai dari peubah penjelas ke-i yang diamati pada tahap pertama
proses pengambilan contoh (i = 1, 2, ..., a)
merupakan peubah penjelas yang diamati pada tahap kedua proses
pengambilan contoh
merupakan nilai dari peubah penjelas ke-j yang diamati pada tahap kedua
proses pengambilan contoh (j = 1, 2, ..., b)
merupakan nilai dari peubah penjelas ke-k yang diamati pada tahap ketiga
proses pengambilan contoh dan berasal dari kelompok peubah respon ke-h,
kelompok peubah penjelas ke-i dan ke-j (i = 1, 2, ..., a dan j=1, 2, ..., b)
merupakan jumlah seluruh anggota kelompok yang memiliki nilai peubah
respon h dan nilai peubah penjelas yang diamati pada tahap pertama proses
pengambilan contoh
merupakan jumlah contoh yang diambil dari kelompok yang memiliki nilai
peubah respon h dan nilai peubah penjelas yang diamati pada tahap pertama
proses pengambilan contoh
merupakan jumlah seluruh anggota kelompok yang memiliki nilai peubah
pengambilan contoh , dan nilai peubah penjelas yang diamati pada
tahap kedua proses pengambilan contoh
merupakan jumlah contoh yang diambil dari kelompok yang memiliki nilai
peubah respon h, nilai peubah penjelas yang diamati pada tahap pertama
proses pengambilan contoh , dan nilai peubah penjelas yang diamati
pada tahap kedua proses pengambilan contoh
Secara umum proses pengambilan contoh dalam penelitian kasus kontrol,
contoh berukuran ni
(9)
diambil dari untuk setiap kategori respon i=1, 2, ...,
a. Peluang Y terpilih sebagai contoh adalah sebesar dan peluang x terpilih
sebesar . Sehingga persamaan (1) dapat ditulis kembali menjadi (Scot dan
Wild 1997):
dengan
merupakan perbandingan antara peluang individu terpilih sebagai contoh
pada kelompok ke-i dengan peluang individu terpilih dari populasi
merupakan jumlah anggota kelompok ke-i
n merupakan jumlah keseluruhan data
Dalam penelitian kasus kontrol, respon yang diamati adalah ada atau
tidaknya karakteristik yang diamati, misalnya status penyakit. Sehingga peubah
responnya merupakan data biner. Apabila dilakukan pengambilan contoh dengan
tiga tahap pengambilan contoh, maka persamaan (9) dapat ditulis kembali
menjadi:
(10)
dengan merupakan nilai pobabilitas contoh terpilih jika Y=h,
. t merupakan indek yang menunjukkan kelompok
yang terbentuk pada setiap tahap pengambilan contoh. Jika dilakukan dua tahap
pengambilan contoh, maka t dapat digantikan dengan i. Jika dilakukan tiga tahap
pengambilan contoh, maka t dapat digantikan dengan kombinasi i dan j (ij).
(11)
dengan =
Persamaan (11) disebut juga sebagai pseudo-likelihood.
Pendugaan konstanta tambahan ( ) dari persamaan (3) dan (5) dapat dicari
dengan menggunakan metode Conditional Maximum Likelihood (CML). CML memperlakukan α sebagai konstanta yang fix. Penduga yang konsisten dapat diperoleh dengan memaksimalkan persamaan (11) dan menggantikan pada
persamaan (9) dengan penduga yang konsisten. Wild (1991) menyatakan bahwa
P(Y=h) dapat digantikan dengan dan pada persamaan (9) dapat digantikan
dengan sampling fraksional .
Sehingga dapat diduga dengan:
Berdasarkan model di persamaan (3) dan (5), maka t dapat digantikan dengan i
dan ij.Penduga dengan menggunakan CML merupakan penduga yang konsisten.
Evaluasi Model
Pengujian parameter secara parsial menggunakan uji Wald dengan
merasionalkan nilai dugaan parameter dengan simpangan bakunya. Hipotesis yang
akan diuji adalah:
H0
H
:
1
Statistik uji yang digunakan adalah : , i=1, 2, ..., p
Jika H0
Proses pengambilan contoh dikatakan efisien apabila biaya yang diperlukan
untuk memperoleh contoh sekecil mungkin, namun contoh yang terambil mampu
memberikan informasi semaksimal mungkin. Besarnya informasi yang hilang
dapat dilihat dari besarnya simpangan.
dengan
P : nilai estimasi peluang dari model untuk data populasi
: nilai estimasi peluang dari model untuk data contoh
Apabila yang dilakukan adalah simulasi, maka ukuran kebaikan model tidak
cukup dengan menggunakan rataan simpangan, namun menggunakan rataan dari
METODOLOGI
Sumber Data
Sumber data yang digunakan dalam penelitian ini adalah data hasil simulasi.
Data yang dibangkitkan merupakan data berpasangan, yaitu Y, X1, X2, dan X3. Y
merupakan peubah respon yang berdistibusi binomial dan bersifat acak. Peubah
X1, X2, dan X3 merupakan peubah penjelas yang berperan sebagai faktor
penelitian. Peubah X1 merupakan faktor penelitian yang berupa data kategori
yang terdiri atas dua kategori. Peubah X2 merupakan faktor penelitian yang
berupa data kategori yang terdiri atas tiga kategori, sedangkan X3
Jumlah data yang dibangkitkan adalah 300, 500, 700, 900 dan 1000. Tiap
jumlah data diulang sebanyak 10 kali. Proses pembangkitan data dan estimasi parameter β menggunakan SAS 9.2, dengan program yang terlampir di Lampiran 1. Proses pengambilan contoh, pendugaan nilai konstanta tambahan (α), dan perhitungan besar informasi yang hilang menggunakan Matlab R2009a dengan
program yang terlampir di Lampiran 2. Asumsi yang digunakan dalam penelitian
ini yaitu peubah X
merupakan
faktor penelitian yang berupa data kategori yang terdiri atas empat kategori.
1 memiliki biaya pengamatan yang paling murah, peubah X2
memiliki biaya pengamatan yang lebih mahal daripada peubah X1, namun masih
lebih murah daripada biaya pengamatan peubah X3 dan peubah X3 memiliki biaya
pengamatan peubah yang paling mahal.
Metode Analisis
Langkah-langkah analisis data yang dilakukan berkaitan dengan tujuan
penelitian terbagi menjadi lima tahap. Tahap-tahap tersebut yaitu:
Tahap Pertama
Langkah awal yang dilakukan adalah membangkitkan data secara acak.
Proses pembangkitan data sebagai berikut:
2. Membangkitkan nilai yang berdistribusi binomial secara acak dengan n=1
dan p=0.3
3. Membangkitkan nilai yang berdistribusi multinomial dengan tiga kategori
secara acak dengan nilai peluang yang digunakan adalah 0.3, 0.2, dan 0,5
untuk masing-masing nilai kategori secara berurutan
4. Membangkitkan nilai yang berdistribusi berdistribusi multinomial dengan
empat kategori secara acak dengan nilai peluang yang digunakan adalah 0.1,
0.2, 0.3, dan 0.4 untuk masing-masing nilai kategori secara berurutan.
5. Membangkitkan nilai z yang berdistribusi uniform secara acak
6. Menghitung nilai probabilitas dengan menggunakan persamaan regresi
logisitik, yaitu:
= dimana
7. Mencari nilai Y dengan kriteria sebagai berikut:
• Y = 1 apabila > z • Y = 0 apabila ≤ z
Tahap Kedua
1. Memodelkan peubah Y terhadap peubah X1, X2, dan X3
2. Menghitung nilai peluang dengan menggunakan model yang terbentuk untuk
nilai-nilai peubah X
dengan regresi
logistik biner pada data hasil pembangkitan
1, X2, dan X3
3. Memodelkan peubah Y terhadap peubah X yang mungkin
1 dan X2
4. Menghitung nilai peluang dengan menggunakan model yang terbentuk untuk
nilai-nilai peubah X
dengan regresi logistik
biner pada data hasil pembangkitan
1 dan X2
5. Melakukan uji signifikansi parameter dengan menggunakan uji Wald pada
model yang terbentuk di nomor 1
yang mungkin
Tahap Ketiga
1. Mengelompokkan data hasil pembangkitan berdasarkan nilai peubah Y dan
2. Melakukan pengambilan contoh dengan menggunakan teknik pengambilan
contoh acak sederhana di tiap kelompok yang terbentuk di nomor 1 dengan
kriteria pengambilan contoh sebagai berikut:
• Apabila jumlah anggota kelompok kurang dari atau sama dengan 5,
maka seluruh anggota kelompok diambil sebagai contoh
• Apabila jumlah anggota kelompok lebih dari 5, maka jumlah contoh
yang diambil adalah sebesar 70 %, 75%, 80%, 85%, 90%, dan 95%
dari jumlah anggota kelompok
Proses pengambilan contoh ini akan diulang sebanyak 10 kali untuk setiap
persentase pengambilan contoh
3. Mengamati nilai peubah X
4. Mengelompokkan contoh yang terambil pada proses pengambilan contoh di
nomor 2 berdasarkan nilai peubah Y, X
2
1, dan X
5. Melakukan pengambilan contoh dengan menggunakan teknik pengambilan
contoh acak sederhana di tiap kelompok yang terbentuk di nomor 4 dengan
kriteria pengambilan contoh dan besar presentase jumlah contoh yang diambil
sama dengan yang digunakan di nomor 2
2
6. Mengamati nilai peubah X3
Tahap Keempat
1. Melakukan estimasi parameter menggunakan regresi logistik biner dengan
penambahan satu konstanta untuk contoh yang terambil pada proses
pengambilan contoh di tahap ketiga nomor 2
2. Mengestimasi nilai peluang untuk nilai peubah X1 dan X2
3. Mencari nilai estimasi parameter dengan menggunakan regresi logistik
dengan penambahan dua konstanta untuk contoh yang diperoleh dari proses
pengambilan contoh pada tahap ketiga nomor 5
yang mungkin
dengan menggunakan model yang terbentuk pada nomor 1
4. Mengestimasi nilai peluang untuk nilai peubah X1, X2, dan X3
5. Melakukan uji signifikansi parameter dengan menggunakan uji Wald untuk
model yang terbentuk di nomor 3
yang mungkin
Tahap Kelima
1. Menghitung besar informasi yang hilang pada tahap kedua proses
pengambilan contoh dengan cara membandingkan nilai peluang yang
diperoleh di tahap kedua nomor 4 dan nilai peluang yang diperoleh pada
tahap keempat nomor 2
2. Menghitung besar informasi yang hilang pada tahap ketiga proses
pengambilan contoh dengan cara membandingkan nilai peluang yang
diperoleh di tahap kedua nomor 2 dan nilai peluang yang diperoleh pada
tahap keempat nomor 4
3. Membandingkan hasil uji signifikansi parameter pada tahap kedua nomor 5
dengan hasil uji signifikansi parameter pada tahap keempat nomor 5
HASIL DAN PEMBAHASAN
Model Regresi Logistik Biner untuk data Hasil Pembangkitan
Model regresi logistik digunakan untuk menggambarkan hubungan antara
peubah respon dan peubah penjelas pada data hasil pembangkitan. Model regresi
logistik biner yang dibangun ada dua macam, yaitu model regresi logistik Y
terhadap dua peubah (X1 dan X2) dan model regresi logistik Y terhadap tiga
peubah (X1, X2, dan X3
Proses pembangkitan data diawali dengan menentukan model regresi yang
akan dibangkitkan. Model tersebut adalah sebagai berikut:
). Kedua model ini digunakan sebagai model pembanding
bagi model-model yang terbentuk dari data hasil pengambilan contoh.
Data hasil pembangkitan dianggap sebagai kerangka contoh.
Model Y terhadap X1 dan X
Model untuk peubah respon, X 2
1 dan X2 yang terbentuk adalah sebagai
berikut:
dengan
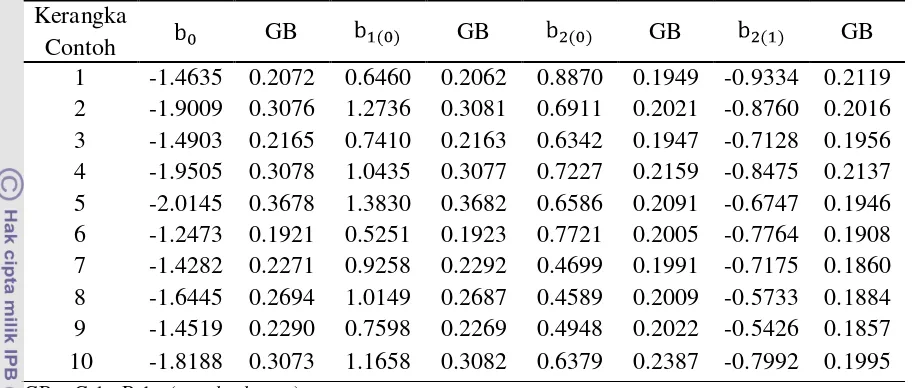
Nilai parameter dari model peubah Y terhadap peubah X1 dan X2
Model dari data hasil pembangkitanpertama menunjukkan semua parameter dalam model tersebut signifikan pada α = 5%. Hal ini berarti bahwa semua peubah penjelas memberikan pengaruh yang nyata terhadap peubah respon. Setiap
parameter dari peubah X
untuk
masing-masing kerangka contoh dapat dilihat di tabel 2.
2 yang bernilai 1 memiliki tanda negatif. Hal ini
menunjukkan bahwa peubah X2 apabila bernilai 1 maka memiliki kecenderungan
untuk menghasilkan respon kasus yang lebih kecil daripada peubah
pembandingnya. Sedangkan peubah lainnya memberikan kecenderungan untuk
Tabel 2 Nilai parameter model Y terhadap X1 dan X2 untuk N=300
Model Y terhadap X1, X2, dan X
Model regresi logistik biner Y terhadap X 3
1, X2, dan X3 yang diperoleh
adalah sebagai berikut:
dengan
.
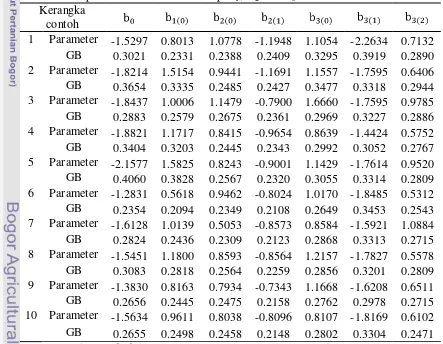
Nilai parameter dari model peubah Y terhadap peubah X1, X2 dan X3
Semua nilai parameter dalam di kesepuluh model tersebut signifikan pada taraf α = 5%. Model dari data hasil pembangkitan pertama menunjukkan semua parameter dalam model tersebut signifikan pada α = 5%. Hal ini berarti bahwa semua peubah penjelas memberikan pengaruh yang nyata terhadap peubah respon.
Setiap parameter dari peubah X
untuk
masing-masing kerangka contoh dapat dilihat di Tabel 3.
2 dan X3 yang bernilai 1 memiliki tanda negatif.
Hal ini menunjukkan bahwa apabila nilai dari peubah X2 dan X3 adalah 1, maka
peubah X2 dan X3
Nilai parameter model regresi logistik biner untuk Y terhadap X
memiliki kecenderungan untuk menghasilkan respon kasus
yang lebih kecil daripada peubah pembandingnya. Sedangkan peubah lainnya
memberikan kecenderungan untuk menghasilkan respon kasus yang lebih besar
daripada peubah pembandingnya.
1 dan X2
parameter model regresi logistik biner untuk Y terhadap X1, X2, dan X3
Apabila nilai parameter dari model Y terhadap X
dari data
hasil pembangkitan secara keseluruhan dapat dilihat di Lampiran 4.
1, X2, dan X3
dibandingkan dengan parameter model yang dibangkitkan, terlihat bahwa
nilai-nilai parameter dari model Y terhadap X1, X2, dan X3 berada di sekitar parameter
model yang dibangkitkan. Misalkan dilakukan perbandingan nilai . Nilai
dari parameter model yang dibangkitkan adalah 1, sedangkan nilai dari
model Y terhadap X1, X2, dan X3 berada dalam rentang 0.5618 sampai 1.5154.
Nilai rata-rata dari parameter-parameter ini sebesar 1.0605 dengan ragam sebesar
0.0897.
Pada sub-bab ini akan dilakukan pembahasan tentang model regresi
logistik dengan penambahan konstanta sebagai akibat penggunaan teknik
Gambar 1 Skema proses pengambilan contoh
pengambilan contoh dengan tiga tahap. Sebagai contoh pada kerangka contoh
pertama untuk jumlah data sebesar 300 data dengan jumlah contoh yang diambil
pada setiap proses pengambilan contoh sebesar 70% dari jumlah data yang ada.
Gambar 1 merupakan skema pengambilan contoh pada salah satu kasus
simulasi. Kasus simulasi yang digunakan adalah data pada kerangka contoh
pertama dengan jumlah contoh yang diambil adalah sebesar 70% pada setiap
pengambilan contoh pada ulangan pertama.
Model regresi logistik dengan konstanta berdasarkan skema pengambilan
contoh (Gambar 1) sebagai berikut:
Model 1 (Y terhadap X1 dan X2)
dengan i = 0,1
Nilai untuk masing-masing αiadalah α0 = -0.03198 dan α1
Model 2 (Y terhadap X
= -0.03953.
1, X2 dan X2)
dengan
i = 0,1
j = 0, 1, 2
Nilai untuk masing-masing αidan αij
= 0.0168 = -0.0395
adalah sebagai berikut:
= 0.0083 = 0.0295 = -0.06899
= 0.3102 = 0.3365 = 0.3365
Model peubah Y terhadap peubah X1 dan X2 dari kerangka contoh
Nilai αi merupakan konstanta untuk mengkoreksi nilai β0 dan β1(0). Berdasarkan
skema pengambilan contoh yang digunakan, pembagian kelompok (i)
menggunakan nilai peubah X1. Misalkan pada saat X1
Dari contoh diatas dapat dilihat bahwa dengan menggunakan , maka
nilai lebih mendekati nilai dari model untuk
data hasil pembangkitan. Nilai parameter dan dari model 1 mendekati
nilai parameter dan dari model model untuk data hasil pembangkitan.
Hal ini menunjukkan bahwa penambahan α mampu mengkoreksi model regresi logistik yang biasa.
= 0, maka nilai
untuk model dari data hasil pembangkitan adalah -0.8175. Sedangkan
nilai untuk model 1 adalah -0.82478. Apabila dengan
menggunakan model 1 namun tanpa memasukkan nilai , maka nilai
yang diperoleh sebesar -0.7928.
Selanjutnya dibandingkan tanda dari parameter model 1 dengan tanda dari
parameter model data hasil pembangkitan. Dari kedua model tersebut, tanda yang
dimiliki oleh parameternya sama. Misalkan untuk tanda dari dan untuk
model data hasil pembangkitan adalah positif dan negatif. Tanda dari dan
dari model 1 juga positif dan negatif.
Apabila dilakukan uji Wald pada setiap parameter di model yang terbentuk
dari data hasil pembangkitan, maka semua parameternya signifikan pada tingkat α = 5%, yang berarti bahwa semua peubah penjelas memberikan pengaruh yang nyata terhadap peubah respon. Setiap parameter dari model 1 dilakukan uji Wald, maka diperoleh bahwa semua parameter signifikan pada tingkat α = 5%, sehingga dapat disimpulkan bahwa dengan menggunakan model 1 semua peubah bebas
memberikan pengaruh yang nyata terhadap peubah respon. Kesimpulan yang
dihasilkan oleh model 1 sama dengan kesimpulan yang dihasilkan oleh model dari
data hasil pembangkitan. Hal ini menunjukkan bahwa model 1 mampu
menggambarkan pola hubungan antara peubah respon dan peubah penjelas dengan
baik.
Model Y terhadap X1, X2, dan X3 dari sampling frame pertama adalah
dengan
Nilai merupakan konstanta untuk mengkoreksi nilai dan , sedangkan
berfungsi untuk mengkoreksi nilai , , dan . Hal ini terjadi
sebagai akibat dari penggunaan teknik pengambilan contoh dengan tiga tahap.
Misalkan pada saat nilai x1= 0 dan x2= 0, maka nilai
untuk model untuk data hasil pembangkitan adalah
0.3494. Nilai adalah
0.3276. Apabila dengan menggunakan model 2, namun tanpa memasukkan nilai
, maka nilai sebesar
0.3024. Terlihat bahwa dengan menggunakan penambahan konstanta nilai
estimasi dari model 2 lebih
mendekati nilai dari model untuk data
hasil pembangkitan. Selain itu nilai juga menunjukkan pengaruh interaksi
antara i dan j. Berdasarkan skema pengambilan contoh yang digunakan, i
terbentuk berdasarkan nilai X1 sedangkan j terbentuk berdasarkan nilai X2.
Sehingga dapat dikatakan bahwa nilai-nilai menggambarkan pengaruh
interaksi antara peubah X1 dan X2
Perbandingan tanda dari nilai estimasi parameter model 2 dengan model
dari data hasil pembangkitan, maka diperoleh bahwa tanda dari parameter di
kedua model sama. Tanda pada parameter dari model untuk
data hasil pembangkitan dan model 2 adalah positif, negatif, dan positif.
Kemudian dilakukan uji Wald untuk masing-masing parameter dari model 2.
Hasil uji Wald menunjukkan bahwa semua parameter dari model 2 signifikan pada tingkat α = 5%, yang berarti bahwa pengaruh yang diberikan oleh peubah penjelas terhadap varibel respon nyata pada α = 5%. Jadi, dapat disimpulkan bahwa model 2 mampu menggambarkan pola hubungan antara peubah penjelas
Pengujian Parameter
Pada setiap model yang terbentuk dari proses simulasi pengambilan
contoh dilakukan uji Wald untuk mengetahui parameter model signifikan atau
tidak. Hipotesis yang digunakan yaitu H0 : lawan H1
Tabel 2 menunjukkan nilai rata-rata persentase jumlah parameter yang
memberikan kesimpulan yang berbeda dengan parameter dari model populasi pada taraf α = 5%. Model yang digunakan adalah model variabel Y terhadap peubah X
: , i=1, 2, ..., p
Kemudian dihitung jumlah parameter yang memberikan hasil uji Wald yang
berbeda dengan hasil uji Wald bagi parameter model dari data hasil
pembangkitan. Setelah jumlah diketahui maka dihitung persentase jumlah
parameter yang memberikan kesimpulan yang berbeda dengan model untuk data
hasil pembangkitan. Selama proses simulasi dilakukan pengulangan, maka
diperoleh nilai rata-rata persentase jumlah parameter yang memberikan
kesimpulan yang berbeda denganmodel untuk data hasil pembangkitan.
1, X2, dan X3, karena pada saat dilakukan survei dengan beberapa tahap
pengambilan contoh model yang digunakan hanyalah model Y terhadap seluruh
peubah penjelas yang diamati (X1, X2, dan X3).
Tabel 4 Nilai rata-rata persentase jumlah parameter yang memberikan kesimpulan yang berbeda dari model data hasil pembangkitan untuk N=300
Kerangka contoh
Saat terjadi pengurangan jumlah contoh sebesar 30 % di masing-masing
tahap pengambilan contoh, maka persentase rata-rata jumlah parameter yang
berbeda dengan parameter model populasi sebesar 24.56 % (Tabel 4). Hal ini
berarti bahwa pada saat diambil contoh sebesar 49% dari jumlah keseluruhan
populasi, maka terdapat 24.56% parameter yang tidak menggambarkan hubungan
antar peubah yang sebenarnya. Apabila terjadi pengurangan jumlah contoh
sebesar 20% dan 25% di masing-masing tahap pengambilan contoh, maka
rata-rata persentase jumlah parameter yang tidak menggambarkan hubungan peubah
respon dengan peubah penjelas berkisar 15%. Nilai rata-rata persentase jumlah
parameter yang tidak mennggambarkan hubungan yang sebenarnya akan menurun
seiring dengan bertambahnya jumlah contoh yang digunakan.
Tanda positif atau negatif dari parameter memiliki peranan yang penting
dalam menggambarkan pola hubungan antara peubah respon dan peubah penjelas.
Tanda positif pada parameter menunjukkan kecenderungan yang lebih besar
daripada peubah pembandingnya. Tanda negatif menunjukkan kecenderungan
yang lebih kecil dari peubah pembandingnya. Hampir semua model yang
dibangun dari data hasil pengambilan contoh memberikan tanda positif atau
negatif yang sama dengan model dari data hasil pembangkitan. Tanda positif dan
negatif dari 600 model yang terbentuk, hanya 13 parameter dalam 13 model yang
berbeda dari model pembanding.
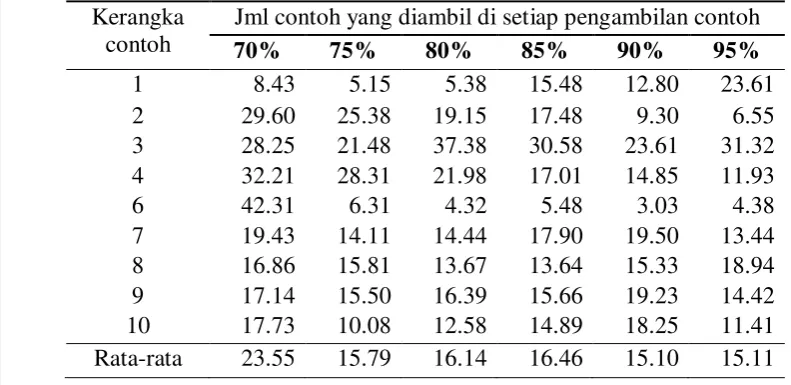
Tabel 5 Rata-rata persentase informasi hilang pada tahap kedua pengambilan contoh untuk N=300
Kerangka contoh
Informasi yang Hilang
Model yang baik merupakan model yang mampu menggambarkan
keadaan populasi yang sebenarnya. Informasi akan hilang dalam setiap
pengurangan jumlah data. Pengurangan jumlah data pertama kali terjadi pada
tahap kedua proses pengambilan contoh. Besar rata-rata persentase informasi yang
hilang dapat dilihat pada Tabel 5.
Pengurangan contoh sebesar 30% mengakibatkan kehilangan informasi
rata-rata sebesar 23.55% (Tabel 5). Pengurangan jumlah contoh sebesar 5% sampai
25% maka akan kehilangan informasi sebesar 15% sampai 16%.
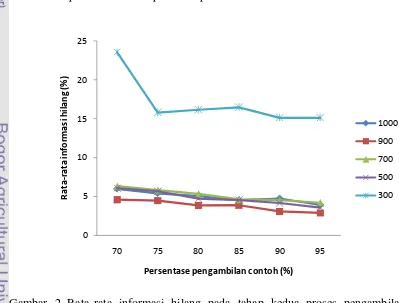
Gambar 2 menunjukkan rata-rata persentase informasi yang hilang pada
tahap kedua proses pengambilan contoh untuk semua data yang dibangkitkan.
Gambar 2 diperoleh dari data pada Lampiran 5.
Gambar 2 Rata-rata informasi hilang pada tahap kedua proses pengambilan contoh
Persentase pengambilan contoh (%)
Penurunan jumlah informasi yang hilang terjadi seiring dengan
bertambahnya jumlah contoh yang diambil (Gambar 2). Jumlah data hasil
pembangkitan 500, 700, dan 1000 menghasilkan rata-rata persentase informasi
yang hilang cenderung sama. Jumlah data hasil pembangkitan sebesar 900
mengakibatkan informasi yang hilang selalu lebih rendah dari jumlah yang lain.
Hal ini mungkin terjadi apabila data hasil pembangkitan dengan jumlah 900 data
lebih homogen dari data hasil pembangkitan yang lainnya. Rata-rata informasi
yang hilang paling banyak ditunjukkan saat jumlah data hasil pembangkitan
sebesar 300, karena jumlah contoh yang terambil lebih kecil dari yanglainnya.
Pengurangan jumlah data yang kedua terjadi pada awal tahap ketiga proses
pengambilan contoh. Besar rata-rata persentase informasi yang hilang dapat
dilihat pada Tabel 6.
Pengurangan jumlah contoh sebesar 30% di masing-masing tahap
pengambilan contoh atau sebesar 51% dari jumlah total populasi, maka nilai
rata-rata informasi yang hilang sebesar 41%. Pengurangan jumlah data sebesar 43.75%
dan 36% dari jumlah total populasi mengakibatkan informasi yang hilang sebesar
33% dan 32%. Persentase kehilangan informasi ini akan menurun seiring dengan
bertambahnya jumlah contoh yang diamati.
Tabel 6 Rata-rata persentase total informasi hilang untuk N=300 Kerangka
contoh
Jml contoh yang diambil di setiap pengambilan contoh
70% 75% 80% 85% 90% 95%
1 29.52 16.82 18.95 12.80 19.07 17.52 2 57.76 41.63 41.63 28.48 17.62 7.59 3 59.86 42.68 52.47 39.55 30.32 31.28 4 70.20 56.26 49.26 32.22 24.43 19.40 6 22.20 18.35 24.39 12.41 21.89 8.66 7 29.13 32.55 24.79 21.92 21.68 18.92 8 49.07 37.39 31.12 21.00 16.26 16.02 9 31.72 29.09 28.09 18.00 17.45 16.66 10 20.43 21.83 17.14 13.79 14.99 12.56 Rata-rata 41.10 32.95 31.98 22.24 20.41 16.51
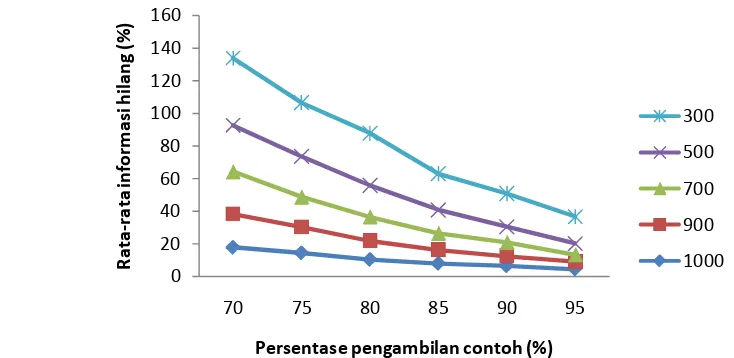
Gambar 3 diperoleh dari data di Lampiran 6, dimana terjadi penurunan
jumlah informasi yang hilang seiring dengan bertambahnya jumlah contoh yang
semakin banyak dan informasi yang hilang semakin kecil. Besar informasi yang
hilang sebagai akibat dari pengurangan jumlah contoh yang diambil selalu lebih
kecil daripada besar pengurangan contoh. Penghematan biaya akan menjadi
berarti apabila biaya untuk memperoleh contoh sangat mahal.
Gambar 3 Rata-rata persentase total informasi hilang
Besarnya informasi yang hilang pada tahap kedua dan ketiga sebanding
dengan jumlah pengurangan contoh. Informasi yang hilang sebesar 23.55%
apabila terjadi pengurangan contoh sebesar 30% pada tahap kedua. Total
informasi yang hilang pada tahap ketiga sebesar 41.11% apabila terjadi
pengurangan jumlah contoh sebesar 51%. Jumlah informasi yang hilang pada
tahap ini sebesar 17.56%, apabila terjadi pengurangan jumlah contoh sebesar 30%
di tahap tiga.
Persentase pengambilan contoh (%)
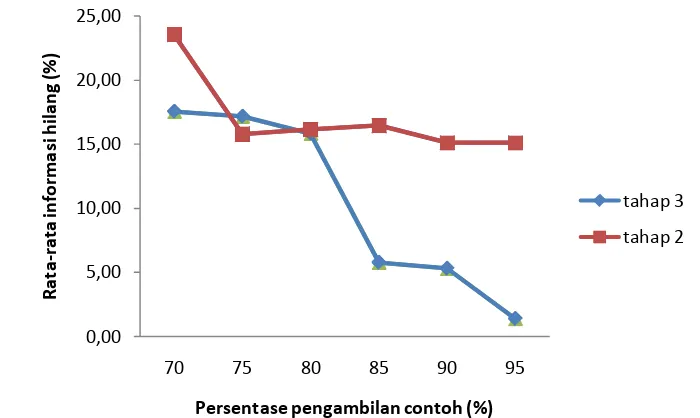
Gambar 4 Rata-rata persentase informasi hilang pada tahap kedua dan ketiga dengan N=300
Penurunan rata-rata informasi yang hilang seiring dengan bertambahnya
jumlah contoh yang diambil pada tahap ketiga (Gambar 4). Rata-rata informasi
yang hilang pada tahap ketiga proses pengambilan contoh hampir semua lebih
kecil dari rata-rata informasi yang hilang di tahap kedua pengambilan contoh. Hal
ini terjadi karena pada tahap ketiga, unit contoh yang ada lebih homogen dari unit
contoh pada tahap kedua. Kehomogenan dari unit contoh terjadi sebagai akibat
dari proses pengelompokan yang dilakukan pada akhir tahap kedua pengambilan
contoh.
Persentase pengambilan contoh (%)
SIMPULAN DAN SARAN
Simpulan
Penggunaan regresi logistik biner dengan penambahan konstanta pada data
kasus-kontrol yang diperoleh dengan menggunakan teknik pengambilan contoh
acak dengan beberapa tahap mampu menggambarkan pola hubungan antara
peubah penjelas dan peubah respon. Teknik pengambilan contoh dengan beberapa
tahap dapat digunakan pada penelitian yang bertujuan untuk melihat pola
hubungan antara peubah respon dengan peubah penjelas.
Informasi yang hilang akan menurun seiring dengan bertambahnya jumlah
contoh yang diamati. Rata-rata informasi yang hilang pada tahap ke-j cenderung
lebih kecil dari rata-rata informasi yang hilang pada tahap sebelumnya. Unit
contoh pada tahap ke-j lebih homogen daripada unit contoh di tahap ke-(j – 1).
Penggunaan teknik pengambilan contoh dengan beberapa tahap memberikan
rata-rata informasi yang lebih kecil dari rata-rata-rata-rata pengurangan contoh, sehingga teknik
pengambilan contoh ini juga cocok digunakan pada penelitian yang bertujuan
memprediksi nilai peluang suatu kasus.
Saran
Penelitian ini menggunakan metode Conditional Maksimum Likelihood
(CML), yang memiliki bound information yang belum mencapai nilai variannya dalam proses estimasi parameter. Penelitian selanjutnya sebaiknya menggunakan
metode Profile Likelihood yang memiliki nilai bound information yang sama dengan nilai variannya. Selain itu, perlu adanya kajian lebih lanjut mengenai sifat
DAFTAR PUTAKA
Breslow NE, Cain KN. 1988. Logistic Regression for tow-stage case-control data. Biometrika 75;1: 11-20.
Chatterjee N, Carroll RJ. 2005. Semiparametric Maximum Likelihood Estimation Exploiting gene-Environment Independence in Case-Control Studies. Biometrika 92; 2: 399-418.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. Canada: John Wiley & Sons, Inc.
Lee AJ, Scott AJ, Wild CJ. 2010. Efficient Estimation in Multi-Phase Case-Control Studies. Biometrika97; 2: 361-374.
Meyers LS, Gamst G, Guarino AJ. 2006. Applied Multivariate Research Desaign and Interpretation. California: SAGE Publication.
Rose S, van der Laan MJ. 2008. Why Match? Investigating Matched Case-Control Study Design with Causal Effect Estimation. UC Berkeley Division of Biostatistic Working; Paper Series 240.
Scott AJ, Wild CJ. 1991. Fitting Logistic Regression Models in Stratified Case-Control Studies. Biometrics; 47: 497-510.
Scott AJ, Wild CJ. 1997. Fitting regression models to case-control data by Maximum Likelihood. Biometrika84; 1: 57-71.
Scott A. 2006. Population-Based Case Control Studies. Statistics Canada, CatalogueNo. 12-001: 32 No 2: 123-132.
Warti R. 2010. Analisis Regresi Dummy pada Hasil Belajar Siswa SMA di Kota Jambi Berdasarkan Pendekatan Matched Case-Control [tesis]. Bogor: Sekolah Pascasarjana, Institut Pertanian Bogor.
Lampiran 1 Program di SAS 6.2
Proses Pembangkitan Data
proc iml;
end;
print y x; dataall=y||x;
varnames={y x1 x2 x3};
create datareg from dataall(|colnames=varnames|); append from dataall;
quit;
Estimasi nilai β
proc logistic data=datareg; class x1 x2 x3;
model y(event='1')=x1 x2 x3/rsquare lackfit;
Lampiran 2 Program di Matlab
Proses pengambilan contoh
function sampelakhir(yx,persen) for(i=1:10)
filename = strcat('data/',int2str(i),'.txt'); m1 = sammpel1tahap(yx,persen);
dlmwrite(filename,m1,'delimiter','\t');
filename = strcat('data/',int2str(i),int2str(i),'.txt');
end
% fungsi tahap 2
[nb,r]=size(b);
Menghitung nilai α
%menghitung jumlah populasi & contoh (matrix N & n) function [N,n]=rekapn(yx,tahap1,tahap2,tahap)
RN0(i,:)=ones(1,12)*N0([1+12*(i-1) 2+12*(i-1) 3+12*(i-1) 4+12*(i-1) 5+12*(i-1) 6+12*(i-1) 7+12*(i-1) 8+12*(i-1) 9+12*(i-1) 10+12*(i-1) 11+12*(i-1) 12+12*(i-1)],:);
RN1(i,:)=ones(1,12)*N1([1+12*(i-1) 2+12*(i-1) 3+12*(i-1) 4+12*(i-1) 5+12*(i-1) 6+12*(i-1) 7+12*(i-1) 8+12*(i-1) 9+12*(i-1) 10+12*(i-1) 11+12*(i-1) 12+12*(i-1)],:);
Rn0(i,:)=ones(1,12)*n0([1+12*(i-1) 2+12*(i-1) 3+12*(i-1) 4+12*(i-1) 5+12*(i-1) 6+12*(i-1) 7+12*(i-1) 8+12*(i-1) 9+12*(i-1) 10+12*(i-1) 11+12*(i-1) 12+12*(i-1)],:);
Rn1(i,:)=ones(1,12)*n1([1+12*(i-1) 2+12*(i-1) 3+12*(i-1) 4+12*(i-1) 5+12*(i-1) 6+12*(i-1) 7+12*(i-1) 8+12*(i-1) 9+12*(i-1) 10+12*(i-1) 11+12*(i-1) 12+12*(i-1)],:);
[n00,n10]=matrikn(tahap2) for i=1:6
else
alpha(i,:)=log((n(i,2))/(N(i,2)))-log((n(i,1))/(N(i,1)))
end end
pj=length(alpha);gNaN=isnan(alpha); for i=1:pj
if gNaN(i)==1 alpha(i)=0; end
end
awal=[alpha;ones(4,1)]; else
pj=length(alpha);gNaN=isnan(alpha); for i=1:pj
if gNaN(i)==1 alpha(i)=0; end
end
awal=[alpha;ones(7,1)]; end
awal;
]; end x;
[b,r]=size(x); [z]=matrikz(x,tahap) [dumx]=dummyx(x,tahap) xdum=[ones(b,1) dumx] lf=z*delta;
pop=xdum*bpop; for i=1:b
ppop(i,:)=exp(pop(i,:))/(1+exp(pop(i,:))) P1(i,:)=exp(lf(i,:))/(1+exp(lf(i,:))) end
ppop; P1;
for i=1:b
sim(i,:)=abs(ppop(i,:)-P1(i,1))/ppop(i,:) end
sim;
Lampiran 3 Nilai parameter model Y terhadap X1, dan X2 untuk data hasil
1 -1,4635 0,646 0,887 -0,9334
2 -1,9009 1,2736 0,6911 -0,876
3 -1,4903 0,741 0,6342 -0,7128
4 -1,9505 1,0435 0,7227 -0,8475
5 -2,0145 1,383 0,6586 -0,6747
6 -1,2473 0,5251 0,7721 -0,7764 7 -1,4282 0,9258 0,4699 -0,7175 8 -1,6445 1,0149 0,4589 -0,5733 9 -1,4519 0,7598 0,4948 -0,5426 10 -1,8188 1,1658 0,6379 -0,7992
N=500
1 -1,8589 1,0393 0,7293 -0,814
2 -1,8463 0,7706 0,4655 -0,7937 3 -1,6602 0,9199 0,3374 -0,5284 4 -1,5895 0,9513 0,7393 -0,9116 5 -1,3306 0,6424 0,6004 -0,7868 6 -1,4985 0,7542 0,5531 -0,7594 7 -1,5052 0,8102 0,4939 -0,7223 8 -1,3623 0,5647 0,7051 -0,9257
9 -1,366 0,6698 0,3277 -0,6077
10 -1,8188 1,1658 0,6379 -0,7992 N=700
1 -1,8452 0,983 0,6888 -0,7314
2 -1,6265 0,8488 0,5007 -0,6917 3 -1,8307 0,9374 0,4102 -0,5878 4 -1,3307 0,7931 0,6631 -0,7146
5 -1,8258 0,8955 0,7836 -0,652
6 -1,4575 0,9746 0,4673 -0,7115 7 -1,6455 0,8931 0,6791 -0,5413 8 -1,4259 0,8509 0,5598 -0,7383 9 -1,6382 0,8258 0,4797 -0,6962 10 -1,8188 1,1658 0,6379 -0,7992
N=900
1 -1,5389 0,8406 0,7615 -0,8
2 -1,5976 0,9799 0,5263 -0,5509
3 -1,57 0,7735 0,4898 -0,5794
5 -1,6773 0,9254 0,4082 -0,3671
6 -1,88 1,2275 0,6561 -0,7197
7 -1,5256 0,7522 0,7169 -0,8436
8 -1,6848 0,8839 0,6037 -0,688
9 -1,6698 1,0289 0,5649 -0,5791 10 -1,8188 1,1658 0,6379 -0,7992
n=1000
1 -1,5635 0,7735 0,5799 -0,6349 2 -1,5431 0,8989 0,6712 -0,9316 3 -1,5429 0,7837 0,6065 -0,4285 4 -1,7373 1,0873 0,8067 -0,8229 5 -1,7983 1,0545 0,4213 -0,7003 6 -1,6111 0,8462 0,5224 -0,7153
7 -1,7221 1,0292 0,5549 0,7316
Lampiran 4 Nilai parameter model Y terhadap X1, X2, dan X3 untuk data hasil
1 -1,5297 0,8013 1,0778 -1,1948 1,1054 -2,2634 0,7132 2 -1,8214 1,5154 0,9441 -1,1691 1,1557 -1,7595 0,6406 3 -1,8437 1,0006 1,1479 -0,79 1,666 -1,7595 0,9785 4 -1,8821 1,1717 0,8415 -0,9654 0,8639 -1,4424 0,5752 5 -2,1577 1,5825 0,8243 -0,9001 1,1429 -1,7614 0,952 6 -1,2831 0,5618 0,9462 -0,8024 1,017 -1,8485 0,5312 7 -1,6128 1,0139 0,5053 -0,8573 0,8584 -1,5921 1,0884 8 -1,5451 1,18 0,8593 -0,8564 1,2157 -1,7827 0,5578 9 -1,383 0,8163 0,7934 -0,7343 1,1668 -1,6208 0,6511 10 -1,5634 0,9611 0,8038 -0,8096 0,8107 -1,8169 0,6102
N=500
1 -2,2438 1,246 0,8446 -1,0065 1,3965 -1,8059 1,0827 2 -2,421 0,9764 0,5439 -0,9263 1,7422 -1,2976 1,1739 3 -1,8401 0,9947 0,3827 -0,6552 1,1302 -1,3451 0,6932 4 -1,7542 1,1088 0,909 -1,0926 0,9712 -1,2971 0,8683 5 -1,6847 0,7067 0,6891 -0,9401 1,3918 -1,6621 1,0607 6 -1,6671 0,9538 0,8198 -0,9574 0,7084 -1,4118 1,2155 7 -1,7347 0,9609 0,5841 -0,9355 1,1902 -1,388 0,6832 8 -1,4328 0,7014 0,8776 -1,1064 0,9051 -1,5832 0,8499 9 -1,3085 0,6899 0,4798 -0,667 0,8085 -1,7326 0,6824 10 -2,2872 1,2893 0,6877 -0,7172 1,2306 -1,2941 0,9193
N=700
1 -2,1145 1,1879 0,9494 -0,97 1,4502 -1,7635 0,9352 2 -1,849 1,0538 0,641 -0,9166 1,2962 -1,5319 0,7631 3 -1,8948 1,0377 0,7928 -0,7756 1,1235 -1,3855 0,6321 4 -1,3138 0,8992 0,8614 -1,0219 1,2658 -1,6967 0,4814 5 -2,2478 1,1643 1,0514 -0,8969 1,4024 -1,6261 1,2683 6 -1,7193 1,1216 0,462 -0,8301 1,1915 -1,5647 1,072 7 -1,7292 1,0537 0,8733 -0,6704 0,9451 -1,7899 0,6333 8 -1,7422 1,0429 0,7835 -0,9204 1,3635 -1,7649 0,9621 9 -1,6834 0,8643 0,5593 -0,8016 1,0611 -1,3806 0,5529 10 -1,9548 0,9114 0,3668 -0,8361 1,7092 -1,4383 1,0101
N=900
6 -2,0598 1,3592 0,8155 -0,8243 1,0273 -1,513 0,7952 7 -1,8091 0,8481 0,9064 -1,0136 1,2801 -1,6119 0,9981 8 -1,7117 1,0386 0,8411 -0,88 1,3824 -1,6681 0,4544 9 -1,7792 1,1758 0,6294 -0,7427 0,8367 -1,4426 0,7826 10 -1,672 1,1245 0,7635 -0,9929 1,2398 -1,9038 0,6343
n=1000
Lampiran 5 Rata-rata persentase informasi hilang pada tahap kedua pengambilan contoh
Sampling frame
Jumlah sampel yg diambil
70% 75% 80% 85% 0,9 0,95 N=300
1 0,08430 0,05151 0,05378 0,15477 0,12803 0,23614
2 0,29603 0,25375 0,19153 0,17480 0,09295 0,06553
3 0,28249 0,21477 0,37380 0,30578 0,23612 0,31318
4 0,32208 0,28309 0,21984 0,17008 0,14848 0,11934
6 0,42305 0,06312 0,04316 0,05484 0,03034 0,04379
7 0,19430 0,14105 0,14439 0,17900 0,19503 0,13441
8 0,16862 0,15806 0,13669 0,13643 0,15328 0,18937
9 0,17143 0,15496 0,16393 0,15663 0,19225 0,14416
10 0,17725 0,10081 0,12581 0,14890 0,18249 0,11409
Rata-rata 0,23551 0,15790 0,16144 0,16458 0,150997 0,151112 N=500
1 0,04089 0,04892 0,03679 0,07002 0,06186 0,05471
2 0,04431 0,03451 0,05214 0,04143 0,06247 0,06318
3 0,03963 0,02481 0,05005 0,03498 0,05211 0,05876
4 0,03614 0,02286 0,04295 0,03354 0,06148 0,03643
5 0,01743 0,02827 0,03357 0,03424 0,04883 0,06578
6 0,02674 0,03147 0,03507 0,04816 0,03708 0,0462
7 0,03418 0,02906 0,03983 0,03397 0,05296 0,05081
8 0,01680 0,02194 0,03805 0,03621 0,04503 0,04508
9 0,02297 0,03901 0,03226 0,04086 0,04203 0,04186
10 0,07626 0,13282 0,09238 0,09730 0,10368 0,14424
Rata-rata 0,03554 0,04137 0,04531 0,04707 0,056753 0,060705 N=700
1 0,04055 0,05574 0,03212 0,03943 0,02212 0,03428
2 0,04861 0,04176 0,04530 0,02140 0,03377 0,01664
3 0,04738 0,04624 0,03792 0,03455 0,02713 0,03598
4 0,03767 0,02966 0,02566 0,01655 0,0143 0,0126
5 0,06837 0,04993 0,04888 0,03358 0,0229 0,03338
6 0,06207 0,02879 0,03307 0,02800 0,03195 0,01512
7 0,04106 0,04755 0,03130 0,02314 0,0314 0,01923
8 0,04066 0,03502 0,03204 0,03109 0,02578 0,01667
9 0,04945 0,03591 0,03876 0,02633 0,0326 0,02219
10 0,19666 0,20824 0,20747 0,20747 0,20892 0,21164
Rata-rata 0,06325 0,05788 0,05325 0,04615 0,045087 0,041773 N=900
1 0,02683 0,03003 0,02820 0,02328 0,01716 0,01815
3 0,04603 0,03412 0,03579 0,02409 0,01985 0,01553
4 0,04892 0,04592 0,02525 0,02177 0,02819 0,02069
5 0,03560 0,04014 0,02969 0,03153 0,02551 0,01332
6 0,03834 0,05792 0,02685 0,04729 0,01347 0,03796
7 0,03969 0,03441 0,02500 0,03232 0,01731 0,01657
8 0,04948 0,02864 0,03525 0,02161 0,01532 0,01165
9 0,02786 0,02808 0,02836 0,02798 0,02953 0,01545
10 0,11862 0,11220 0,11210 0,12337 0,12071 0,12767
Rata-rata 0,04580 0,04466 0,03829 0,03870 0,030607 0,028752 N=1000
1 0,03313 0,02545 0,0294 0,02361 0,01936 0,01309
2 0,03746 0,03363 0,03196 0,02712 0,02773 0,01314
3 0,03955 0,03498 0,02361 0,02213 0,02147 0,0139
4 0,04188 0,03091 0,03469 0,02529 0,02107 0,01512
5 0,04687 0,04579 0,03219 0,02253 0,02579 0,01696
6 0,03724 0,02749 0,03078 0,02037 0,02038 0,01314
7 0,08275 0,06841 0,07494 0,07806 0,07236 0,06481
8 0,03703 0,02721 0,02284 0,02697 0,02446 0,00992
9 0,02588 0,03068 0,02435 0,01949 0,01771 0,01437
10 0,21669 0,21609 0,20023 0,18749 0,22338 0,21535
Lampiran 6 Rata-rata persentase total informasi hilang
Sampling frame
Jumlah sampel yg diambil
70% 75% 80% 85% 90% 95% N=300
1 0,29516 0,16817 0,18949 0,12795 0,19072 0,17523
2 0,57761 0,41634 0,41634 0,28479 0,1762 0,0759
3 0,59864 0,42678 0,52467 0,3955 0,30317 0,31279
4 0,70201 0,56264 0,49264 0,32218 0,24434 0,19395
6 0,22198 0,18348 0,24393 0,12406 0,2189 0,08658
7 0,29134 0,32552 0,2479 0,21922 0,21678 0,18915
8 0,49065 0,37387 0,31121 0,20997 0,16259 0,16021
9 0,31719 0,29085 0,28086 0,18 0,17448 0,16662
10 0,20434 0,21828 0,17144 0,13791 0,14993 0,12563
Rata-rata 0,410991 0,329548 0,319831 0,222398 0,204123 0,165118 N=500
1 0,08656 0,09481 0,16448 0,28704 0,26135 0,33126
2 0,12165 0,14276 0,29728 0,321 0,33319 0,36054
3 0,09351 0,08175 0,19867 0,1737 0,27618 0,27764
4 0,07423 0,08788 0,14772 0,17534 0,27665 0,28071
5 0,05118 0,08957 0,10846 0,1505 0,1593 0,27418
6 0,03653 0,09914 0,10928 0,1262 0,20134 0,20087
7 0,04364 0,09909 0,10891 0,21894 0,22734 0,32409
8 0,04744 0,08547 0,09431 0,14883 0,18265 0,23398
9 0,04853 0,09272 0,08132 0,13339 0,1889 0,24808
10 0,08669 0,09103 0,12442 0,19611 0,38552 0,31412
Rata-rata 0,068996 0,096422 0,143485 0,193105 0,249242 0,284547 N=700
1 0,29675 0,19106 0,15936 0,09158 0,08981 0,03607
2 0,33536 0,16598 0,17967 0,1062 0,09942 0,04495
3 0,27305 0,21427 0,16847 0,09742 0,08879 0,03842
4 0,19884 0,1254 0,10742 0,08329 0,06046 0,03954
5 0,2661 0,23911 0,17491 0,0957 0,07519 0,04545
6 0,29218 0,19454 0,16748 0,09653 0,10315 0,04338
7 0,21279 0,19554 0,13264 0,10994 0,07863 0,03727
8 0,19104 0,1708 0,13145 0,09637 0,06368 0,04083
9 0,23123 0,15999 0,13505 0,1086 0,07647 0,034
10 0,30212 0,18407 0,12263 0,12263 0,09844 0,05661
Rata-rata 0,259946 0,184076 0,147908 0,100826 0,083404 0,041652 N=900
1 0,22459 0,14656 0,1223 0,08785 0,06439 0,0435
3 0,14285 0,10897 0,10863 0,0683 0,05633 0,05671
4 0,14283 0,11466 0,08045 0,05208 0,04536 0,03013
5 0,25386 0,15035 0,13382 0,08311 0,05637 0,04151
6 0,29019 0,30984 0,18745 0,17915 0,0902 0,08142
7 0,16133 0,14407 0,09053 0,07505 0,06535 0,04914
8 0,22399 0,1648 0,10997 0,07179 0,06517 0,04272
9 0,19801 0,16956 0,10874 0,08128 0,05671 0,03477
10 0,2035 0,13244 0,07781 0,07242 0,04908 0,04758
Rata-rata 0,205281 0,158901 0,11486 0,084036 0,061083 0,046876 N=1000
1 0,12307 0,07815 0,07866 0,06295 0,04293 0,0507
2 0,1499 0,12201 0,09642 0,07688 0,05733 0,04111
3 0,12861 0,12103 0,06666 0,05857 0,04914 0,04723
4 0,15291 0,1379 0,11421 0,05868 0,06159 0,03301
5 0,30758 0,25182 0,14406 0,12526 0,11032 0,04071
6 0,1781 0,12665 0,09527 0,06261 0,05464 0,04982
7 0,24122 0,19812 0,13154 0,12672 0,06356 0,03839
8 0,13829 0,13586 0,09788 0,05918 0,05922 0,04634
9 0,19847 0,13992 0,11191 0,09218 0,06016 0,04511
10 0,15478 0,12278 0,08529 0,06319 0,07326 0,04412
Rata-rata 0,177293 0,143424 0,10219 0,078622 0,063215 0,043654
ABSTRACT
RATNA CHRISTIANINGRUM. Logistic Regression Model Studies on Case-Control Data with Three-Stage Sampling . Under direction of BUDI SUSETYO, and KUSMAN SADIK
If the sample is taken by using multistage random sampling, through reducing sample size in the next stage, then the ordinary logistic models can’t be used. This data will be analyzed using logistic models with the additional intercept. This research studied the application of addition intercept terms in logistic regression for case control study used multi stage random sampling. Furthermore, this research compared between the model which was formed and the model of the frame sampling data. The addition intercept in logistic models was able to describe the pattern of relationship explanatory variable with response variable. Missing information decreases with increasing number of samples that observed. Average of missing information in the third stage tends to be smaller than in the second stage, because the third stage has more homogeneous sample units than the second stage. The average of missing information is smaller than the average reduction in the number of samples when using multi-stage random sampling, so this sampling technique is also suitable for use in research aimed at predicting the probability of case. Moreover the use of the sampling technique can reduce the sampling cost.
PENDAHULUAN
Latar Belakang
Rancangan penelitian kasus-kontrol merupakan rancangan penelitian yang
banyak digunakan dalam bidang epidemiologi. Rancangan ini digunakan untuk
menelusuri faktor resiko dari suatu penyakit. Rancangan ini memiliki hubungan
sebab-akibat yang lebih kuat daripada cross section. Breslow (1996) dalam Scott
(2006) menyatakan bahwa penelitian kasus-kontrol merupakan tulang belakang
dari epidemiologi.
Contoh kasus dan kontrol diambil secara terpisah dalam penelitian
kasus-kontrol. Kasus merupakan kumpulan unit contoh yang memiliki karakteristik
tertentu yang akan diamati, misalnya orang yang terjangkit penyakit tertentu.
Adapun kontrol merupakan kumpulan unit contoh yang tidak memiliki
karakteristik yang akan diamati. Proses pengambilan contoh, baik dalam kasus
maupun kontrol menggunakan teknik pengambilan contoh yang sederhana.
Teknik pengambilan contoh tersebut antara lain menggunakan teknik
pengambilan contoh acak sederhana (simple random sampling) atau teknik pengambilan contoh acak bersrata (stratified random sampling). Scott (2006) lebih menyarankan penggunaan teknik pengambilan contoh yang lebih kompleks
daripada yang sederhana, yaitu teknik pengambilan contoh acak dengan beberapa
tahap.
Manfaat lain dari penggunaan teknik pengambilan contoh dengan beberapa
tahap yaitu dapat mengurangi biaya pengambilan contoh. Hal ini mungkin terjadi
apabila penelitian memiliki biaya pengamatan suatu peubah lebih mahal dari
peubah yang lain. Dengan menggunakan teknik pengambilan contoh dengan
beberapa tahap, peubah yang memiliki biaya pengamatan yang mahal diamati di
tahap terakhir pengambilan contoh dan hanya sebagian yang diamati.
Terdapat beberapa metode yang dapat digunakan untuk menganalisis data
kasus-kontrol, salah satunya dengan menggunakan regresi logistik. Regresi
logistik merupakan metode yang digunakan untuk menggambarkan hubungan